
Abstract
Graph Convolutional Networks are able to characterize non-Euclidean spaces effectively compared with traditional Convolutional Neural Networks, which can extract the local features of the point cloud using deep neural networks, but it cannot make full use of the global features of the point cloud for semantic segmentation. To solve this problem, this paper proposes a novel network structure called DeepGCNs-Att that enables deep Graph Convolutional Network to aggregate global context features efficiently. Moreover, to speed up the computation, we add an Attention layer after the Graph Convolutional Network Backbone Block to mutually enhance the connection between the distant points of the non-Euclidean space. Our model is tested on the standard benchmark S3DIS. By comparing with other deep Graph Convolutional Networks, our DeepGCNs-Att’s mIoU has at least two percent higher than that of all other models and even shows excellent results in space complexity and computational complexity under the same number of Graph Convolutional Network layers.
Keywords
Introduction
Deep learning has been applied to various image processing applications recently, such as image classification [4, 17], object detection [15, 27], and semantic segmentation [8, 28–32]. However, due to the lack of depth information, two-dimensional image data collected by single-shot camera has such certain limitations that cannot fully perceive the surrounding environment, which further facilitates the rapid development of three-dimensional sensors [21, 47]. By transforming the real scenes into the three-dimensional point clouds, researchers utilize each single point to represent pixel’s 3D geometric coordinate, RGB color, normal vectors and other information. However, the irregular format of point cloud makes it difficult for convolutional neural networks to work efficiently in the point cloud data, which is the most obvious difference between the 2D and 3D datasets processing. Moreover, Some classic machine learning methods based on manual feature extraction, such as support vector machine (SVM) and random forest (RF), have also achieved relatively successful results in a series of 3D model segmentation tasks [44, 45]. However, the point cloud data collected by these methods need to wait for a long manual extraction of features before performing the scene analysis, which is obviously not feasible. To solve this problem, 3D datasets processing methods can be divided into four mainstream directions as follow: 3D convolution [6, 26], multi-view projection onto images and 2D convolution [12], 1D/2D convolution or Multi-layer Perceptron(MLP) on point cloud [25], and Graph Convolution Network(GCN) [34]. PointNet [25], which is concise and effective due to its MLP and max-pooling layer, is widely used in feature extraction for point cloud detection. However, PointNet will limit the accuracy in more complex scenes because of ignoring local features’ influence. Soon after, PointNet++ [3] put forward improvements that construct local and global features through the sampling and grouping layers. This method designed the Multi-scale grouping and the Multi-resolution grouping to capture details in densely sampled regions to capture different features, but its too much empirical data also leads to limited results. Considering the graphs are able to represent point cloud efficaciously, more and more networks are proposed to use GCN for point cloud processing. However, as the number of GCN layers increased, the problem of vanishing gradient and over-smoothing appeared. DeepGCNs [11] inspired by dilated convolutions [9] and DGCNN [34] construct a dilated graph to solve the problem above. Nevertheless, DeepGCNs only use one max-pooling layer at the end to aggregate global features without considering the connection between each point and global information. In this paper, we propose a novel neural network structure that uses ResGCN [11] as GCN Backbone Block and Multilayer Perceptron(MLP) for dimensionality reduction in the output layer of the network, and utilize the dual attention module [13], including Spatial-wise Attention and Channel-wise Attention, to adaptively aggregates global features. Our contributions can be summarized as follow: We propose a novel neural network model with higher accuracy and faster computational speed than others under the same number of GCN layers. In the output layer of ResGCNs, dimensionality reduction is performed through MLP, and the attention layer is used to directly output the classification of each point instead of the max-pooling layer. The experiments on point cloud segmentation indicate that our model is robust to sampling density variation and has an excellent correct rate, which achieves better performance in OA and mIoU than DeepGCNs under the same number of network layers.
Our shorter conference version of this paper appeared in [30], which did not address the problem that analyze the effect of hyperparameters on model training results. This manuscript elaborates the structure of the proposed neural network model in more detail and provides additional analysis on the ablation experiment to address the issue above. The second section introduces other related work on point cloud semantic segmentation. The third section systematically expounds the theoretical basis of the designed network model. The fourth section proves the superiority of our model through experiments, and utilizes ablation experiments to discuss the influence of different hyperparameters on the model performance. Finally, the fifth section summarizes the work done in this paper.
Related work
Due to the three-dimensional point cloud belongs to the non-Euclidean space, that is, the point data sorting is irregular and the input dimension is not fixed, which causes the traditional two-dimensional convolutional neural network to be difficult to perform convolution operations on it. The methods to solve the poor performance of two-dimensional convolution in point cloud segmentation can be roughly divided into three categories as follows: pointwise MLP methods, point convolution methods and graph-based methods.
Pointwise MLP methods
PointNet firstly applies deep learning model directly on point cloud data. However, this model only has one max-pooling layer to integrate all sampling points’ features, leading to a weak ability to extract local information. VoxelNet [35] improves the single max-pooling layer and proposes Voxel Feature Encoding(VFE), which divides the point cloud into equally spaced three-dimensional voxels and convertes a set of points in each voxel into unified features through the VFE layer. Inspired by CNN, PointNet++ uses local structure through hierarchical feature extraction and proposes two multi-scale grouping and multi-resolution grouping strategies to ensure better feature extraction. In [36], the absolute coordinates of each point and the relative coordinates of its neighbors are used to represent the point cloud, and Group Shuffle Attention is used to obtain the relationship between points. Then, a Gumbel Subset Sampling layer with displacement invariability, differentiability and end-to-end trainability is used to train hierarchical features. PointWeb [37] is based on PointNet++, which utilizes Adaptive Feature Adjustment and the relationship between local neighbors to improve the features of points. [38] is proposed to use Structural Relational Network to learn the structural relationship characteristics between different local features.
Graph-based methods
Super Points Graph (SPG) [19] is proposed to represent the point cloud as the collection of internal connections of simple shapes, which reduces the input point cloud’s size, and finally uses PointNet to get the classification of each point. DGCNN proposes the EdgeConv [34], which integrates the information of local neighbors. Each layer builds a new K-NN graph to learn the global shape attributes gradually, and captures the potential global similar features after multiple iterations. Inspired by deep CNN, DeepGCNs proposes dilated convolutions to realize deep GCN and proposes GCNs with residual connections [16] inspired by ResNet. [39] regards point clouds as a collection of connected simple shapes and superpoints, and uses directed graphs to obtain structural and environmental information. [40] proposes a supervised framework to oversegment a point cloud into pure superpoints. In order to better obtain local geometric relations in high-dimensional space, [191] proposes Network PyramNet based on Graph Embedding Module(GEM) and Pyramid Attention Network(PAN). GEM module expresses point cloud as directed acyclic graph, and uses covariance matrix to replace Euclidean distance when constructing similarity matrix. In the PAN module, four convolution kernels of different sizes are used to extract features.
Attention-based methods
Attention modules are used to solve the problem that long-distance information will be misdetected, and grasp the key points from a large amount of data without losing features. The work [2] uses self-attention in machine translation for the first time so that each word has global semantic information and captures the long-distance dependency between features. [5] proposes the attention-based score refinement(ASR) module, which concatenates scores of neighboring points with learned weights of attention modules. [13] proposes a Dual Attention Network (DANet) to integrate global and local features, including the Position Attention Module and Channel Attention Module. The results of two attention models are fused through an addition operation, and finally, the convolutional layer outputs the classification of each point. In order to better obtain the spatial distribution of point cloud, [42] proposes the Local Spatial Aware(LSA) layer to learn the weight of spatial perception. [43] proposes the attention-based Score Refinement(ASR) module to conduct post-processing of segmentation results and modify the initial segmentation results by pooling.
Methodology
Point cloud semantic segmentation is a problem of classifying the categories of three-dimensional points in the point cloud. The model we proposed consists of the following two aspects, namely GCN Backbone Block and Prediction Block, which completes an end-to-end point cloud semantic segmentation network based on GCN. The network process is shown in Fig. 1.
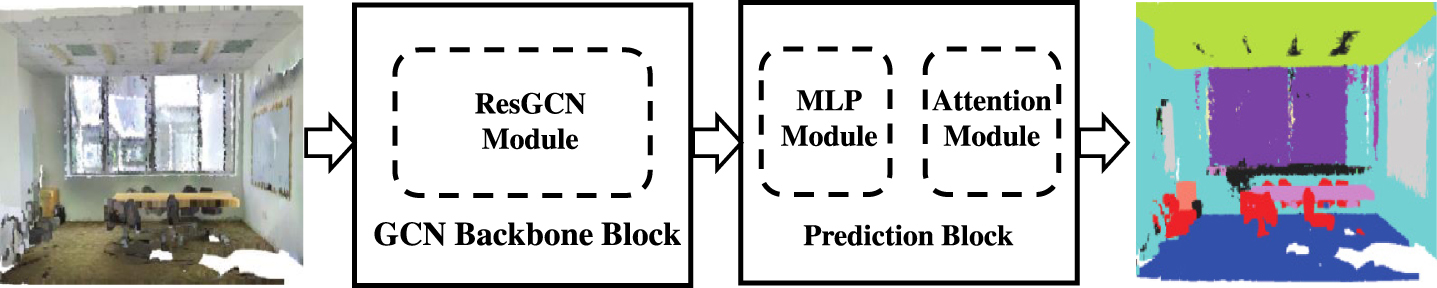
Our proposed model is divided into two components. GCN Backbone Block is composed of ResGCNs, used to learn the correlation of adjacent points in the point cloud. For points that are far apart in the point cloud, we use MLP to fuse high-dimensional features in the prediction block and use a dual attention module to extract global features from both spatial and channel and finally classify each point.
Traditional convolutional neural networks are not suitable for extracting point cloud features, which are spatially disordered. So ResGCNs utilizes GCNs to represent the point cloud as an undirected graph g (ν, ɛ), where ν and ɛ represent the set of n nodes and e edges of each layer respectively. Each layer of graph convolution performs the following update and aggregation operations,
where F () is a fixed function that performs convolution operations in each l - th layer, g
l
and gl+1 represent the input and output of each layer, φ and ρ are the aggregation function and update function.The aggregation function aggregates the features of the neighborhood of each vertex in the point cloud graph, and then uses the update function to update the representation of each node through a nonlinear transformation to learn new features,
where h
ν
l
∈
where N (v l ) is the neighbor set of the vertex h ν l . With the increase in the number of network layers, dilated convolution can help deep GCNs expand the field of view of the convolution kernel without increasing the amount of calculation, so that each vertex can learn the features of farther vertices, so as to obtain global feature information. As shown in Fig. 2, our GCN Attention Backbone set each node to search for the number of neighboring points k = 16, each layer of ResGCN has f = 64 hidden layers or filters, and the dilation convolution parameter d increases layer by layer. Then, ResGCNs utilize MLP as the update function with the batch normalization to speed up gradient descent and use ReLu as the activation function to achieve nonlinear transformation. Since the algorithm using ResGCN as the GCN Backbone Block, it can be stacked in multiple layers through the residual connection, which solves the vanishing gradient and over smothing problem of the graph convolutional neural networks.
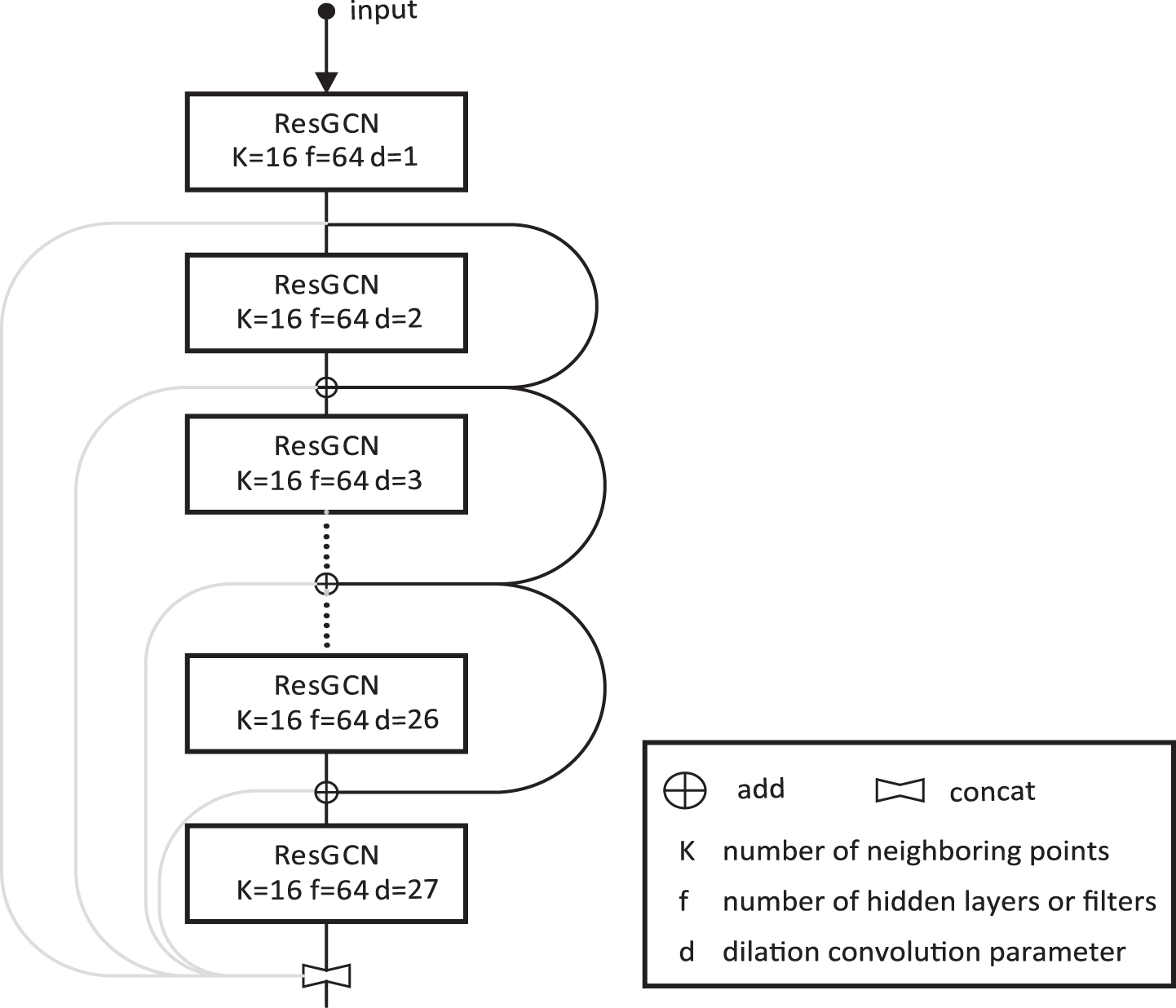
Examples of the ResGCN model which utilize residual connections to alleviate the vanishing gradient problem.
At the prediction block layer, our algorithm uses the fusion of global features and local features to semantically classify the category of each point in the point cloud. As shown in Fig. 1, the prediction block first uses MLP to reduce the dimensionality of the high-dimensional features of the vertices, then uses the attention module to extract the global features, and finally obtains the semantic classification results of each point.
MLP feature aggregation
Our MLP module is inspired by PointNet, which connects each layer’s GCN Backbone Block features to reduce the high-dimensional vertex features’ dimensionality and uses the 1 × 1 convolution kernel to aggregate global and local features.
Attention prediction
Compared with the traditional method of directly using softmax on the results of the network output layer to obtain the classification of each vertex, our algorithm uses the dual attention module of the network output layer to enhance the global context information of each vertex. We compared the results of the prediction part with DeepGCNs and found that our model has fewer calculation parameters, which means that the model inference has a faster prediction speed. And we increase the output vertex information of the graph to get better classification results.

The architecture of our proposed Prediction Block, which stacks MLP and dual attention module to operate feature fusion and global feature aggregation.The input feature is the N*1024 feature vector obtained by ResGCN feature extraction of N three-dimensional points in the point cloud.
The role of Spatial-wise Attention is to adaptively aggregate global spatial feature information in the non-Euclidean space, which takes the feature map H ∈
After that, our model performes MLP on the feature vectors H to get a new feature map C
j
∈
where
Channel-wise Attention is similar in form to Spatial-wise Attention. The channel’s high-dimensional feature map in each layer’s output of ResGCN can be regarded as a map of classes, making the self-attention module utilizes the interdependence between channels to learn global feature representation. Given the feature map H ∈
where V
ji
is the impact exerted by each vertex h
i
v
in i - th channel on the vertex h
j
v
in j - th channel. The output of this module is
Experiment setting
Dataset
The S3DIS [1] dataset constructs six different areas by scanning the indoor environment, including 271 rooms and 13 object classes (ceiling, floor, wall, beam, column, window, door, bookcases, board, clutters), 11 Scenes (offices, meeting rooms, corridors, auditoriums, open spaces, lobbies, lounges, pantry, copy rooms, storage and toilets), which has a rich three-dimensional indoor characteristic structure. Compared with other datasets, The S3DIS dataset has more complex spatial semantic information, which makes semantic segmentation more challenging.
Hardware configuration
We use the TensorFlow framework to complete the construction, training and inference of our DeepGCNs-Att model. Our computational device equiped Intel(R) Core(TM) i9-9900k CPU @3.60GHz and two NVIDIA RTX 2080 Ti GPUs.
Implementation
In order to more clearly distinguish the DeepGCNs-Att models trained with different network layers, we named the 7-layer and 14-layer models ResGCN-Att-7 and ResGCN-Att-14, respectively. Adam gradient descent optimizer [33] is used for network training, where the initial learning rate is 0.01. The batch size of the ResGCN-Att-7 and ResGCN-Att-7 is set to 8 and 6, respectively, which depend on the computing power of our hardware equipment. On area5 and over 6 fold of S3DIS, we compared our model with PointNet [25], SEGCloud [20], RSNet [22], MS+CU [8], G+RCU [8], PointNet++ [3], 3DRNN+CF [35]. Due to the limitation of our hardware computing power, the batch size of ResGCN-Att-28 can only be set to 2, which directly cause serious gradient oscillation and training is not easy to converge. So we did not test ResGCN-Att-28, but through the analysis of ResGCN-Att-7 and ResGCN-Att-14, we prove that the proposed neural network architecture can achieve excellent point cloud semantic segmentation results on the deep graph convolutional neural network. The overall accuary(OA) and mean intersection over union(mIoU) are utilized to evaluate the semantic segmentation performance of the network model. The results of semantic segmentation can be divided into the following four categories: true positive(TP), false positive(FP), true negative(TN) and false negative(FN). The mIoU measures the ratio of the intersection and union of the two sets of true and predicted values, that is, mIoU = TP/(FP + FN + TP).
Training and testing process
Firstly, we trained and tested the ResGCN-Att-7 and ResGCN-Att-14 models on area 5 of the S3DIS dataset. The training curves of ResGCN-Att-7 and ResGCN-Att-14 are shown in the Fig. 5. The final accuarcies of two models are both about 0.84. When the number of epochs is about 40, the test accuracy of the model begin to oscillate, indicating that the model has converged and it will be globally optimal. So we tested all models from epoch 40 to 60 and find the final best cloud segmentation model.
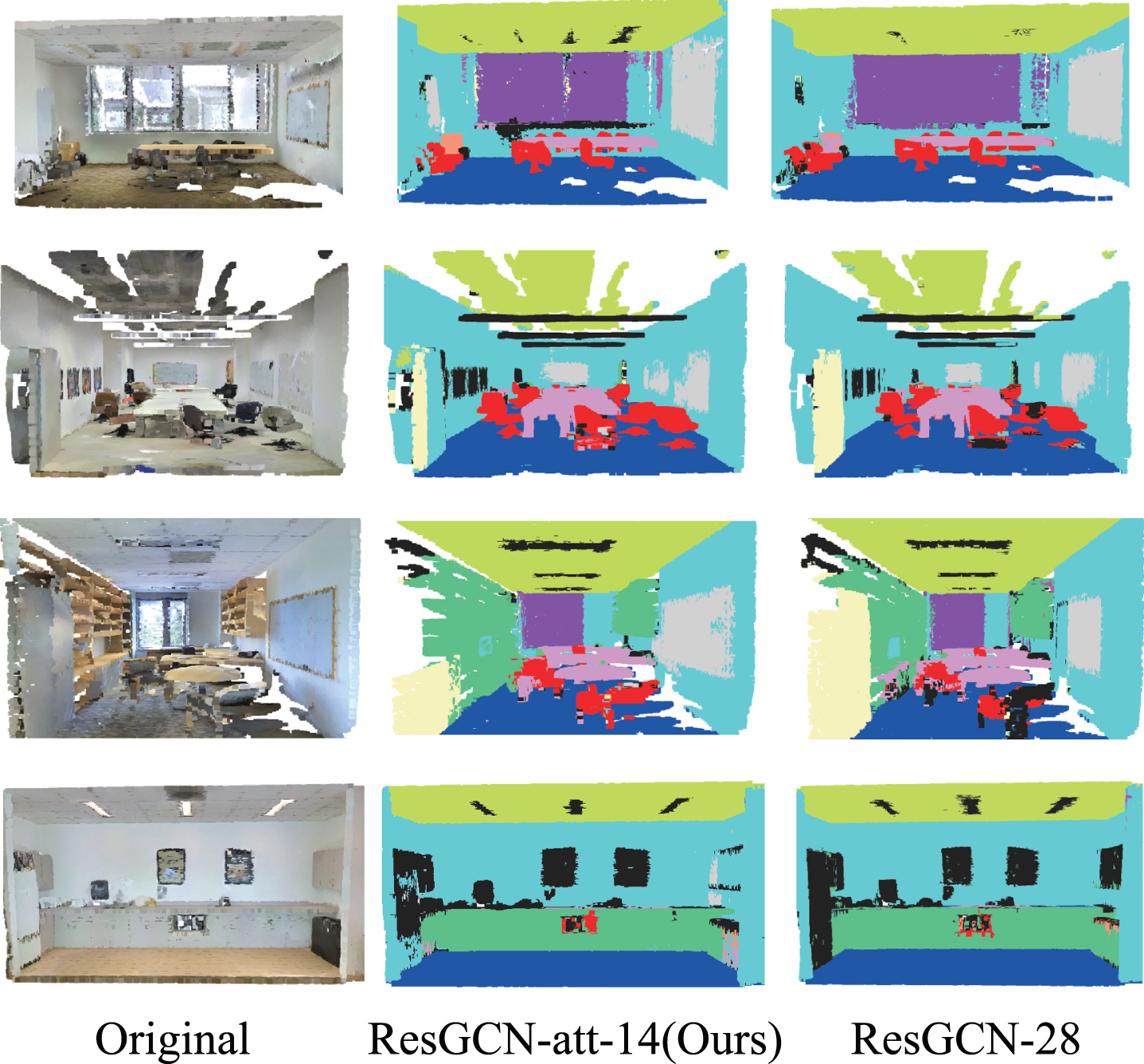
Visualized results of semantic segmentation.
The number of Params represents the usage of computer’s memory and the number of Flops is an essential indicator for evaluating the neural network’s overall performance, which corresponds to the algorithm’s computational complexity and space complexity. As shown in Table 1, by calculating the number of Flops and Params of the proposed ResGCN-att model, we found that our ResGCN-att model has fewer Params and Flops than ResGCN model under the same network layer. This means that our ResGCN-att requires less computing resources, and the calculation speed is faster.
Params and Flops of the two network models under the same number of layers
Params and Flops of the two network models under the same number of layers
We analyzed the overall performance of the different number of layers of our DeepGCNs-Att model by conducting tests on the ResGCN-Att-7 and ResGCN-Att-14. Results in Table 2 show that with the number of network layers increasing, ResGCN-Att-7 and ResGCN-Att-14’s mIoU are both approximately two percent higher than that of the DeepGCN. Although we did not test ResGCN-Att-28 due to computational limitation, we are able to make reasonable predictions from mIoU results of ResGCN-Att-7 and ResGCN-Att-14 that our ResGCN-Att-28 model will show better performance than that of ResGCN-28.
Results of S3DIS dataset on Area 5 in different layers of GCN Backbone Block
Results of S3DIS dataset on Area 5 in different layers of GCN Backbone Block
In order to test the overall performance of the model on the entire S3DIS data set, we performed 6-fold cross-validation, which are compared with the state-of-art models on area 5 and over 6 fold respectively. The results of OA and mIoU are shown in Table 3. In Area5, the mIoU of our model is 2.48%higher than that of ResGCN-14, which is even very similar to the results of ResGCN-28, and surpasses other existing network models. In terms of over 6 fold, our model achieves accuracy close to the original network model and surpasses the existing network model on mIoU, but has fewer parameters and faster computational speed.
IoU segmentation results of each category of the S3DIS data set in Area5 and 6-fold
IoU segmentation results of each category of the S3DIS data set in Area5 and 6-fold
We summarized each category’s IoU in Table 4. It can be seen that our proposed model has a similar IoU result to ResGCN-28 in most categories, with only a small decline, which is due to the decrease in the number of GCN layers. We replaced the fusion module of the original network layer with the dual attention module, which made the prediction module have fewer parameters. With the reduction of the GCN Backbone Block’s layers, the network model can still achieve relatively good results in semantic segmentation. Besides, in terms of area5 and over 6 fold, the semantic segmentation performance of our model is better than the state-of-art model in most categories.
IoU segmentation results of each category of the S3DIS data set in Area5
As shown in Fig. 4, the classification results of our ResGCN-Att-14 are almost identical to that of ResGCN-28. Only a few parts of the point cloud misdetected since the algorithm adopted the dual attention module, which enables the model to learn global context information autonomously in the prediction part. So we utilized fewer GCN layers to obtain classification results similar to 28 layers.
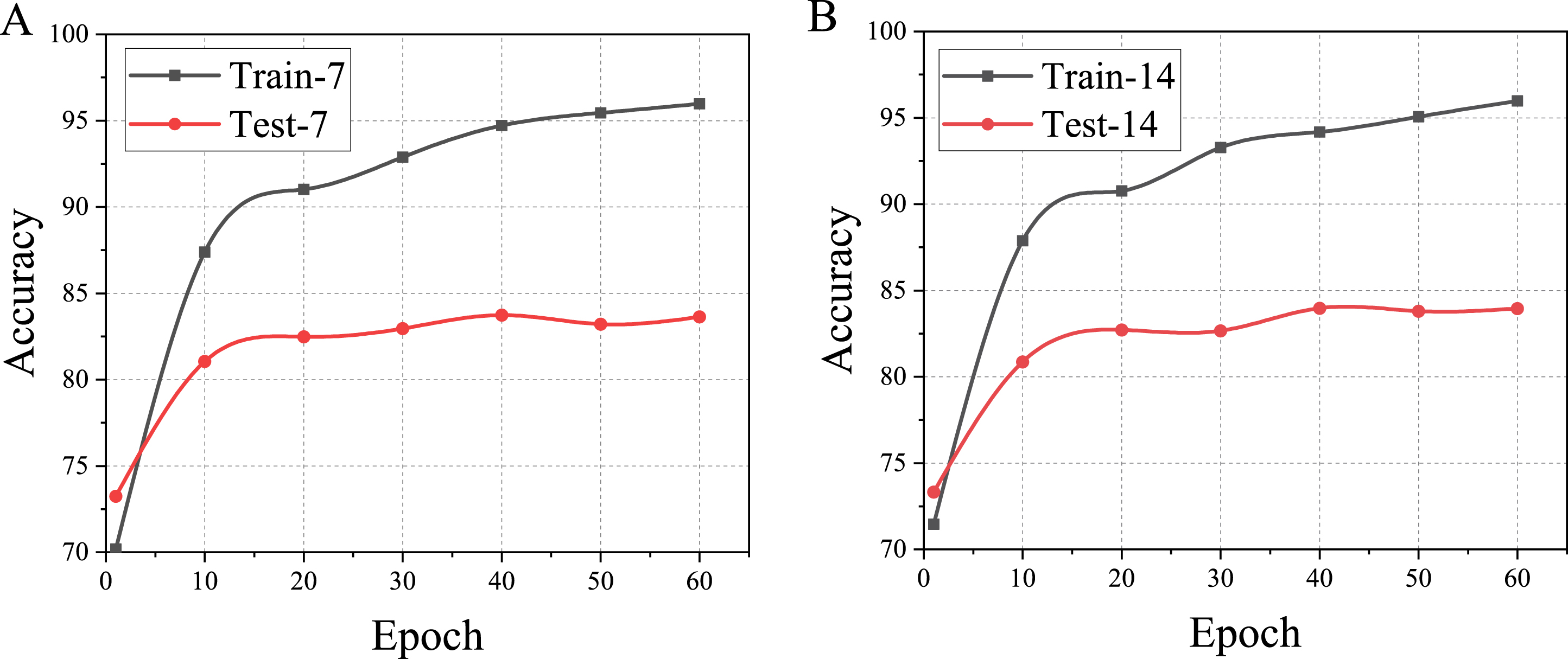
The training process of ResGCN-Att-7 and ResGCN-Att-14.
We conducted ablation experiments on our proposed model using the method of control variables, which change the parameters of dilation, neighbors, depth, width, fixed k-NN, and connection respectively to verify the influence of these parameters on the model results, as shown in Table 5.
Ablation study on area 5 of S3DIS.We compare our reference network (ResGCN-Att-14) with 14 layers, residual graph connections, and dilated graph convolutions to several ablated variants.We denote residual with the ⊕
Ablation study on area 5 of S3DIS.We compare our reference network (ResGCN-Att-14) with 14 layers, residual graph connections, and dilated graph convolutions to several ablated variants.We denote residual with the ⊕
In this paper, we proposed a novel neural network model to improve DeepGCNs performance. After the GCN Backbone Block, we utilized MLP for feature fusion and used the dual attention module, which replaces max-pooling, to actively learn global features in the point cloud. Through a large number of experimental comparisons, we have proved that the proposed neural network model has a better point cloud semantic segmentation effect than existing models, and has fewer model parameters, which is conducive to accelerating model inference. We also conducted ablation experiments on the proposed algorithm to explore the influence of different hyperparameters on the point cloud semantic segmentation results. In the future, we will further improve the neural network framework. Considering that the existing algorithm has high time complexity for the FPS algorithm of point cloud downsampling, we will replace it with a random sampling method to further aggregate the local features of the point cloud to improve the efficiency of the neural network, and it can be applied to more large range of point cloud data.
Footnotes
Acknowledgment
Our project was supported by the National Natural Science Foundation of China (Grant No. 61974073).