
Abstract
Word representation plays a vital role in most Natural Language Processing systems, especially for Neural Machine Translation. It tends to capture semantic and similarity between individual words well, but struggle to represent the meaning of phrases or multi-word expressions. In this paper, we investigate a method to generate and use phrase information in a translation model. To generate phrase representations, a Primary Phrase Capsule network is first employed, then iteratively enhancing with a Slot Attention mechanism. Experiments on the IWSLT English to Vietnamese, French, and German datasets show that our proposed method consistently outperforms the baseline Transformer, and attains competitive results over the scaled Transformer with two times lower parameters.
Introduction
Word representation is an important component in many Neural Machine Translation (NMT) systems. A model trained over a large amount of unlabeled text corpus is used to map words from a vocabulary to a continuous vector representation. Word representation is capable of learning multiple degrees of similarity between different words [1]. Besides that, it can also capture morphology information and other linguistic phenomena at different layer depths in a translation model [2]. However, this technique is at its limit when encountering complex phrases (e.g., compound words and idioms) in general. The meanings of some compound words and idioms are often lost when we consider each word as a particular semantic unit. Various studies have proved that the word-based translation systems could be augmented with phrase translation capability. Koehn et. al. [3] proposed a framework to evaluate and compare various phrase translation methods. Their study did show that phrase translation gives better performance than traditional word-based methods and has inspired many phrase-based machine translation methods [4–8]. Although these methods were only applied to statistical machine translation, they gave a strong evidence that the word representation is not enough for the complex task like machine translation.
An NMT system usually adopts an encoder-decoder framework [9], in which the encoder is supposed to encode the properties of the source language into useful representations, then the decoder decodes this information to the target language. To improve the performance of NMT systems, we propose a PhraseAttn model that uses phrase information to emphasize contextual awareness. Our work is based on Learning Phrase [10] that integrates phrase information at an encoder side, then they route phrase information of an encoder to a decoder by using Transparent Attention [11]. However, their weakness lies in their decoder [10] which is two times deeper than that of the baseline Transformer leading to a significant increase in the time inference of the NMT system. Moreover, they use Stanford Parser [12] to segment a sentence into phrases, but a semantic parser is often inaccessible in low-resource languages. The proposed method, namely, PhraseAttn eliminates their heavy decoder and uses a simple phrase segmentation, while providing better phrase information and can widely use in different languages by using Capsule Networks. In Section 4, the main experiments show that the better quality of phrase representations results in the better performance of an NMT system. Specifically, a PhraseAttn architecture has three major differences compared with the encoder of the Transformer: A Primary Phrase Capsule (PPC) that is similar to the attentive phrase representation of Learning Phrase [10], but we change the activation function from Sigmoid to ReLU. A Dynamic Slot Attention (DSA) whose architecture is identical to Slot Attention [13], but we change the input from a trainable Gaussian Distribution to the output of PPC. The dense connections of self-attention module whose idea is inspired by DenseNet [14].
PPC and DSA are respectively analogous to the lower-level, and higher-level capsule in CapsNet [15], since we observe that CapsNet and its variance can produce the higher-level phrase information. In this setting, PPC considers primary capsules as a group of lower-level phrase information. Next, DSA can be referred to as an iterative routing-by-agreement module [15] whose lower-level phrase information iteratively competes with each other to produce higher-level one. Out preliminary experimental results show that information that comes out of the self-attention module is non-trivial, thus we apply dense connections on self-attention.
The proposed method, namely PhraseAttn, shows significant improvements and consistent performances over the baseline Transformer [16], and the scaled Transformer. We conduct our experiments on the IWSLT English to Vietnamese (En-Vi), French (En-Fr), and German (En-De) datasets which are comparatively low-resource pair-language with an average of 200k sentences. In the En-Vi 2015 test set, we improve the baseline and its scaled model by +0.91 and +0.37 BLEU, as well as, +2.12 and +0.45 BLEU in the En-Fr 2014 test set. However, in the En-De 2014, we barely increase the baseline over +0.31 BLEU and observe the negative result against the scaled baseline with -0.19 BLEU. It is noted that the number of parameters in the proposed model is 58%lower than that in the scaled Transformer. Nevertheless, the model can maintain competitive performances, or even better in 5 over 8 test sets. Although we originally reckon that this method will improve the ability to learn phrases, we observe that it rather exploits the phrase representations to improve contextual awareness of NMT systems, as reported in Sections 4.2 and 4.3. The analysis result in Section 4.4 suggests that our model can capture more information from long-dependency distance to improve translation quality.
To the best of our knowledge, our work is the first to model Capsule Network for phrase representations in which the number of capsules is the number of phrases in a sentence
1
. Our contributions in this paper are: We propose a method that generates expressive phrase representation via the capsule network; We employ a dense connection on self-attention to regulate phrase-level information into token-level information; We experiment on three different language-pair datasets to show consistent improvements over the baseline.
Background and related work
In this section, we provide a brief overview of exploiting phrases in NMT and innovative ideas of using Capsule Network.
Phrase utilizations in NMT
To intergrate phrase information into NMT, a collection of some specific phrases to handle domain-specific problems are usually employed. For example, Shardlow & Nawaz [17] built a phrase table that maps medical terminology to a simpler vocabulary to improve the understandability of clinical letters for patients. However, these approaches are not feasible for general uses dataset (i.e., daily conversations dataset), because it is impossible to build every possible phrase. On the other hand, Learning Phrase [10] uses Stanford Parser [12] as a phrase segmentation, revealing a new way to achieve phrase representations for general uses in an NMT system. However, one limmitation of Learning Phrase [10] is that semantic parsers are sometimes inaccessible in low-resource languages, leading to a limitation on wide usages.
Capsule network (CapsNet) and slot attention
CapsNet [15] defines two principal parts of a capsule network: a low-level capsule (or primary capsule) projects vectors into a reasonable number of feature slots, and a high-level capsule iterates a dynamic routing algorithm to encapsulate higher information for each slot.
Two challenges that prevent applying a CapsNet directly to Natural Language Processing (NLP) tasks are the curse of dimensionality and choosing a logical amount of slots in primary capsules. Slot Attention [13] is an attentive mechanism that eliminates heavy 4D vectors to effectively compute primary capsule layers with cross-product attentions. Moreover, Slot Attention can improve the interpretability of the modular CapsNet by attention weights. Zhao et al. [18] suggested an adaptive Kernel Density Estimation routing to help CapsNet become more reliable to NLP tasks. Yang et al. [19] proposed a Query-guided Capsule Network to enhance Document-level NMT performance.
The proposed method
The architecture of our network is depicted in Fig. 1. PhraseAttn is a variance of Capsule Networks for generating phrase representation, which consists of Primary Phrase Capsule and Dynamic Slot Attention for producing lower-level and higher-level phrase information, respectively.

The proposed PhraseAttn structure.
Given a sequence of tokens X = w1, . . . , w
l
, a function F is applied to produce a sequence of phrases R =
Similarlt to [10], our Primary Phrase Capsule is an attentive phrase representation in Learning Phrase. We however change the activation function at the equation 2 from Sigmoid to ReLU, which yields better empirical results.
In practice, the output of self-attention module is first segmented into phrases R as in Section 3.1, then a mean operation is used to primitively summarize all
We name the Dynamic Slot Attention after its variable slots depending on the number of phrases, as well as the implementation technically looks identical to Slot Attention [13]. According to this setting, Slot Attention first samples phrase information slots from a Gaussian distribution, however, this seems inappropriate in NMT. Thus, we replace this representation slots with the output of PPC.
Algorithm 1 in pseudo-code takes a Gated Recurrent Unit (GRU) [20] to remember the previous information, and the function f (·) indicates a linear transformation. The DSA takes the output of the PPC
The attention scores in line 6 of the algorithm are computed as the softmax function given a batch matrix-matrix product:
Normally, the number of slots in Capsule Networks is a hyper-parameter that is well-specified in prediction tasks, for example, in the recognizing digits task, this number is set to 10 slots. In this setting, however, the number of slots is dynamically variated based on the sequence length.
During practical experiments, we observe two critical things that promote a dense connection on self-attention. First, information that comes out of self-attention module is non-trivial; after that, the phrase information from the Dynamic Slot Attention (DSA) can damage the positional information. Therefore, we repeatedly connect the output of the self-attention to other modules as in the encoder side of Fig. 1. First, we pass it to Primary Phrase Capsule (PPC), then again transfer it DSA as a key-value pair. Next, it is sent to a cross-attention as a query, after that, it is concatenated with the output of the previous cross-attention then transfer to Feedforward Neural Network Combining with a ReLU activation. Finally, in this module only, we combine the outputs of FFNN Combining and Self-attention by a Gating Connection instead of a residual connection as in the Transformer, as follows:
In this section, we first examine the effectiveness of our methods by comparing the performances and parameters with previous works. Second, we retrain the proposed method on two other language datasets to show consistent improvements over previous methods. Finally, to gain further insight into the improvement of translation qualities, we conduct the length analysis.
Settings
We extend our model on the FairSeq framework 2 as well as preprocessing datasets by Byte-Pair Encoding [21] with approximately 8,000 merge operations. The hyper-parameter settings are shown in Table 1, we note that the Transformer Baseline and the proposed method use the language pair base settings. Pattn-drop and Pact-drop are respectively the attention and activation dropout, and h is the number of attention heads.
Hyper-parameter settings for different language pair datasets
Hyper-parameter settings for different language pair datasets
We conduct an ablation study to expose which phrase information generated from other modules will enhance translation qualities most. To this end, we carry out a significance test on the IWSLT15 En-Vi dataset to compare case-insensitive BLEU [22] (a quality metric for machine translation systems) between our models and previous work. The model "Our baseline" shown in the following tables is the sequential modules of “Self-attention” => “Layer X” => “Cross-Attention” => “FFNN Combining” => “FFNN”. “Layer X” can be either “PPC”, “Slot Attention”, or both (i.e., “PPC” and then “DSA”). It is noted that “Our baseline” is quite similar to Learning Phrase [10] without Transparent Attention in the decoder because the Transparent Attention requires huge amount of parameters and slows down the inference speed (as discussed in Section 3.2).
As shown in Table 2, Learning Phrase 3 . outperforms the Transformer Baseline on all four test sets, and gains competitive results with the Transformer Big on the En-Vi 2015 and Vi-En 2013 datasets. We observe that the decoder of Learning Phrase significantly scales up the inference time of NMT systems, thus escalating the training costs on GPU time. Therefore, we decide to eliminate the Transparent Attention, which routes the phrase information of an encoder to a decoder in Learning Phrase, and solely focus on their encoder. Comparing to the Transformer Baseline, “Our baseline” which does not involve any phrase information, simply enlarges parameters by 18.14%, but observing slight performance improvements. After integrating phrase information, “Our baseline + PPC” model gain competitive results to Learning Phrase in the En-Vi 2013 and Vi-En 2013 test sets. However, that performance is still lower than that by Transformer Big.
Ablation Study (We set an iteration number of 3 for both Slot Attn and DSA)
Ablation Study (We set an iteration number of 3 for both Slot Attn and DSA)
When adding “Slot Attention” into the model, we could produce higher performance than the Transformer Big on 3/4 test sets. Athough “PPC” and “Slot Attention” have the same purpose to produce phrase information, the performance by “Slot Attention” is much better than that by ‘PPC”. Thus, we follow the idea of CapsNet [15] (considered “PPC” and “Slot Attention” as lower-level and higher-level representations) to combine them into one module, namely PhraseAttn (“PPC + DSA”). Finally, “Our baseline + PPC + DSA” obtains +0.16, +0.37, and +0.47 BLEU over the Transformer Big in En-Vi 2013, 2015, and Vi-En 2013, respectively, with less than 58%parameters.
From a high-level view, our baseline does not capture much phrase information. However, adding PPC helps to capture some aspects of phrase representations, thus significantly outperforms the baseline and Transformer baseline. The combination of PPC and DSA provides the higher-level phrase representation to enhance the performance, even better than that of the Transformer Big in 3 over 4 test sets.
In summary, the proposed method not only gains competitive results to Transformer Big, but also reduces the costs of training. While we manually examine the translated results between the Transformer Baseline and our method, we observe that the proposed method slightly helps NMT systems translate phrases, but primarily improving contextual awareness. Thus, we further carry out two following analyses to gain more insight into the proposed method.
To confirm consistent improvements, we carry out a significance test on the IWSLT17 En-Fr, and En-De datasets, which contain 233k, and 209k training pair-sentences, respectively.
Table 3 shows that our method consistently outperforms the baseline, but not the Transformer Big in the En-De translation tasks. In particular, we remarkably gain +2.12, +1.52 BLEU over the baseline in the En-Fr test sets, although a little improvement compares to the big Transformer which is +0.45 and +0.37 BLEU, respectively. In contrast, our method observes the negative results regarding the big Transformer in the En-De test sets, which are -0.19 and -0.53 BLEU, despite the enhancements over the baseline are +0.31, +0.23 BLEU, respectively.
Experiments on English to French, German IWSLT dataset
Experiments on English to French, German IWSLT dataset
In section 4.2, we have claimed that the proposed method improves contextual awareness for NMT systems. In this experiment, we verify this statement by a hypothesis that a longer sentence has a more complicated context, thus, the proposed method should outperform its baseline in long sentences. To this end, we group sentences based on sentence length and compute their BLEU scores in the IWSLT15 En-Vi dataset. The same method can be found in [23, 24].
Figure 2 shows that all of our models outperform the Transformer baseline in most groups, and the number of iterations is a hyper-parameter of a for-loop in Algorithm 1. Moreover, the differences in performances over each group appear in a logical phenomenon. For example, the model with 5 iterations outperforms other models in groups of longest-length sentences (40-60), as well as, the model with 3 iterations outperforms others in groups of short, medium-length sentences (0-30). In conclusion, we suggest two statements: 1. The proposed method improves contextual awareness of NMT systems, 2. The number of iterations should be chosen depending on the average sentence length in datasets (i.e. the IWSLT15 En-Vi dataset has a plethora of sentence lengths from 0 to 30, thus picking 3 iterations will improve the overall performance).
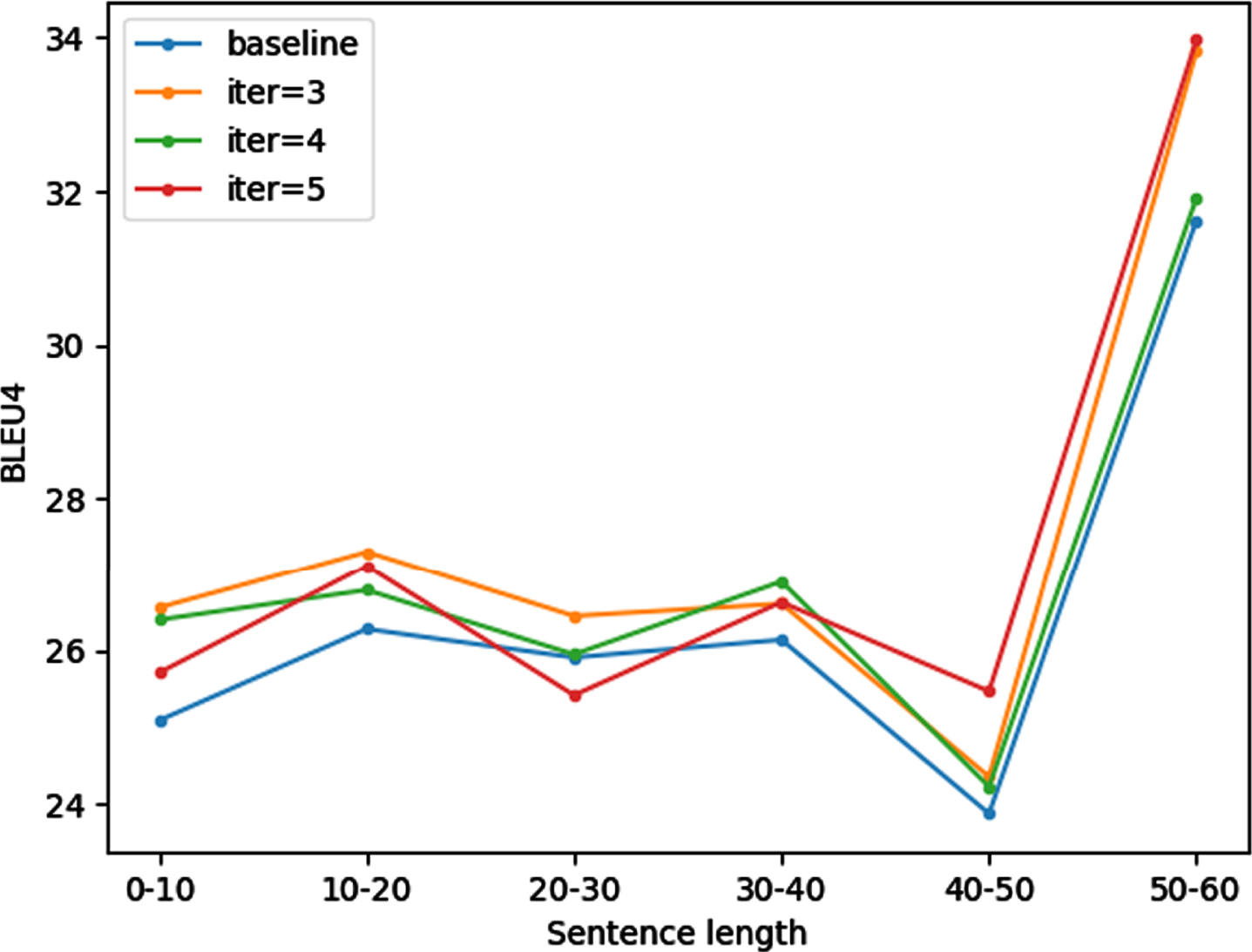
Length analysis on iteration numbers.
The interpretability of a neural network is essential for understanding how it works, thus, it is important to visualize attention scores of DSA in Algorithm 1. In practice, attention scores indicate token-level information attending to each phrase-level information.
For example, in Fig. 3, it lays phrases on the horizontal axis and tokens on the vertical axis with the brighter (red) color meaning more attention than the darker (blue) color. The figure shows that most tokens concentrate on the phrase of “of many people” over each iteration. This suggests that DSA can exploit the feature-rich indicators to improve performance.
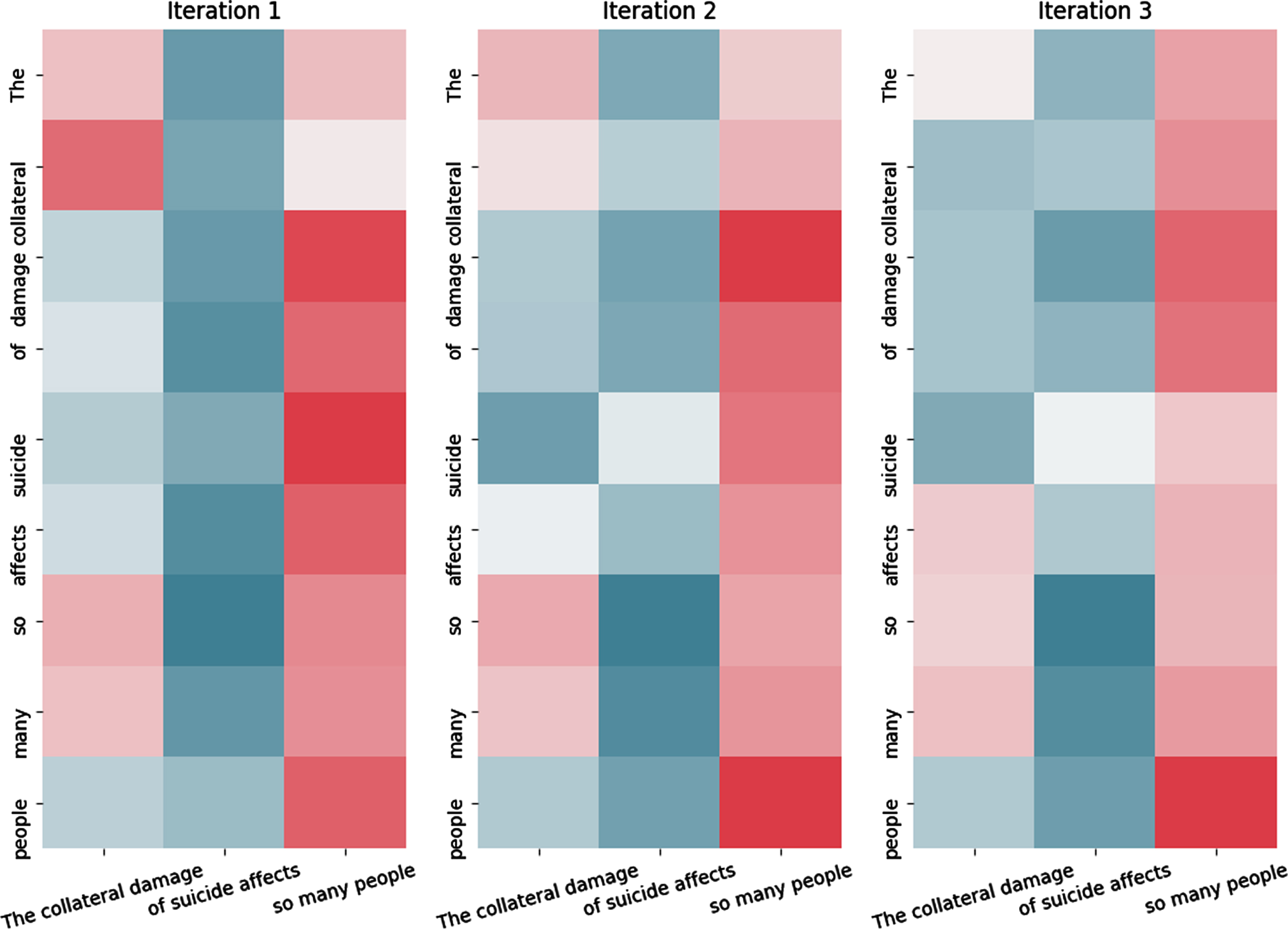
Redistributed information procedures in DSA.
In this work, we propose an architecture called PhraseAttn that creates phrase representation to refine word representation. Empirical results show that our method gains considerable improvement over the baseline Transformer, especially in long sentences. In future work, we plan to explore how different embedding levels such as character embeddings and graph embeddings affect phrase information.
Footnotes
Acknowledgment
This work was funded by the Advanced Program in Computer Science, University of Science, Vietnam National University - Ho Chi Minh City.
The authors would like to thank Nhung T.H. Nguyen for the her comments.
Learning Phrase uses Stanford Parser for Phrase Segmentation as their final result, but we use an n-gram chunker in this experiment.