
Abstract
The face is a dominant biometric for recognizing a person. However, face recognition becomes challenging when there are severe changes in lighting conditions, i.e., illumination variations, which have been shown to have a more severe effect on recognition performance than the inherent differences between individuals. Most of the existing methods for tackling the problem of illumination variation assume that illumination lies in the large-scale component of a facial image; as such, the large-scale component is discarded, and features are extracted from small-scale components. Recently, it has been shown that large-scale component is also important; in addition, small-scale component contains detrimental noise features. Keeping this in view, we introduce a method for illumination invariant face recognition that exploits large-scale and small-scale components by discarding the illumination artifacts and detrimental noise using ContourletDS. After discarding the unwanted components, local and global features are extracted using a convolutional neural network (CNN) model; we examined three widely employed CNN models: VGG-16, GoogLeNet, and ResNet152. To reduce the dimensions of local and global features and fuse them, we employ linear discriminant analysis (LDA). Finally, ridge regression is used for recognition. The method was evaluated on three benchmark datasets; it achieved accuracies of 99.7%, 100%, and 79.76% on Extended Yale B, AR, and M-PIE, respectively. The comparison reveals that it outperforms the state-of-the-art methods.
Introduction
Face recognition is a key biometric technology that has attracted the attention of a large research community for decades. The performance of a face recognition system is influenced by many factors [1]; one critical factor among them is the variation in lighting conditions, i.e., illumination variations. As illustrated in Fig. 1, the appearance of facial images for the same person is greatly altered when illumination varies. The variations caused by changing illumination effects have been shown to have a more severe effect on face recognition algorithms than the variations due to facial characteristics of individuals [2]. A great deal of methods has been proposed based on various approaches [3]. Though the existing methods deal with different types of variations, severe illumination variation is still a challenging problem. Many efforts based on several approaches have been made to solve this problem. The methods based on traditional image processing techniques such as histogram equalization (HE) [4, 5] and log transform [6] can account for mild light variations only.
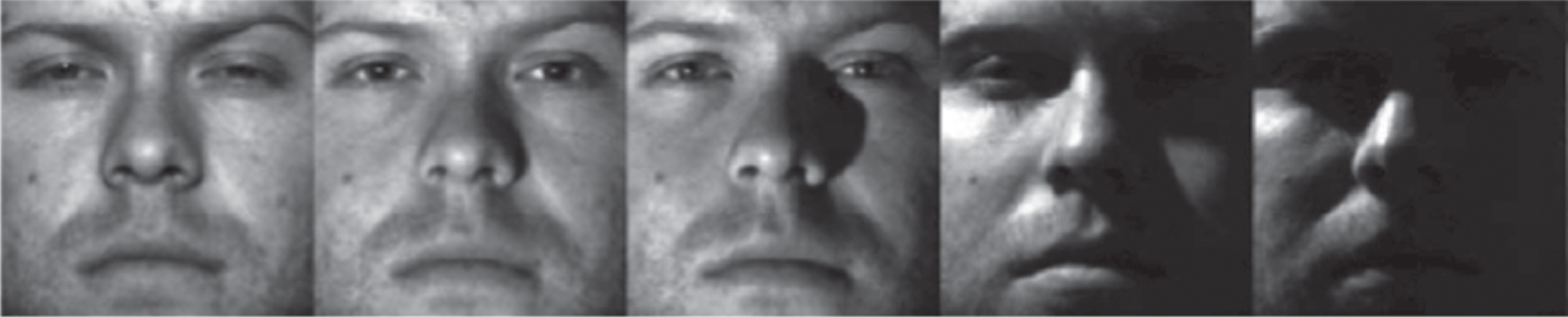
Effect of the varying illumination on facial images of the same person.
The most effective approach to tackle severe lighting conditions is based on Lambertian reflectance model I (x, y) = ρ (x, y) S (x, y), where ρ (x, y) is small scale component (surface albedo), and S (x, y) is large scale component (reflectance component). In this approach, illumination invariant representation is extracted from face images. GradientFaces [7] uses gradient-domain, and WeberFace [8] employs Weber’s law to extract illumination invariant features. Kim et al. [9] introduced SVDFace and Hu et al. [10] proposed HFSVDFace based on SVD decomposition of face images to compensate for illumination variations. Hu et al. [11] and Lia et al. [12] extended the idea of WeberFace to the logarithmic domain to propose illumination invariant descriptors. All these methods offer good tolerance to illumination variations. However, these methods assume that large-scale component contains light intensity and exploit small-scale component; however, this component is sensitive to detrimental noise [13].
Keeping in view the strengths and limitations of the existing methods for illumination robust face recognition under severe variations of lighting conditions, we felt motivated to propose a new method that exploits discriminative information embedded in small-scale and large-scale components. For this purpose, we employed an improvement of contourlet transform (ControuletDS) [14] in the logarithmic domain, which allows decomposing a face image into a fine-grained hierarchy of multi-scale and multi-directional sub-bands and yields perfect reconstruction. It allows to retain the important information from small-scale and large-scale components and remove the detrimental noise and illumination effects. We extract discriminative features using pre-trained CNN models because of the limited amount of labeled data, and finally, we employ ridge regression for identification. The main contributions of this work are as follows: Proposed an illumination-invariant face recognition method that normalizes the illumination effect using ContourletDS and extracts discriminative features from face images using deep learning. The method considers the important information embedded in small-scale and large-scale components, unlike most existing methods. It fuses local and global features using a class discriminative approach. It does not need to solve optimization problems for varying lighting conditions, unlike DMI [15]. The proposed method gives promising results under severe illumination variations. Performed detailed experiments and evaluated the state-of-the-art best CNN models. It has been observed that ResNet152 is the best model for extracting features for illumination invariant face recognition. Evaluated the method thoroughly on three benchmark datasets, and its performance has been compared with the state-of-the-art methods. Our proposed deep learning approach outperforms the other methods.
The rest of this paper is organized as follows: In Section 2, we discuss the literature review. In Section 3, we describe the proposed method for illumination invariant face recognition. In Section 4, we discuss the dataset used for validation and evaluation protocol. In Section 5, we present the detailed experiments and show the results. Then, we discuss the obtained results and compare the performance of the proposed method with the recent works. In Section 6, we conclude our work.
In this section, we discuss the existing state-of-the-art methods for Illumination Invariant Face Recognition. One such approach is the use of texture descriptors which have also been widely used for face recognition. Tan and Triggs [16] employed local ternary patterns (LTP), Lei et al. [17] proposed discriminant face descriptor, Ren et al. [18] used Gabor filters, Hu et al. [19] introduced diagonal symmetric pattern (DSP) to tackle the problem of light variations. These methods also exploit small-scale components and perform well when the lighting condition is not severe. Their performance degrades when the illumination variations become severe.
It is not only a small-scale component but also a large-scale component that contains important information for illumination invariant face recognition [15, 20]. Multilayer decomposition-based method – multi-layer illumination-robust feature extraction (DMI) – was proposed by Yu et al. [15] to exploit both small-scale and large-scale components for dealing with difficult light conditions. In this method, the face image is decomposed into multiple layers using the total variation model (TV-L1), and then the illumination-robust representation is recovered as a weighted linear sum of the layers. The optimization problem is solved to optimize the weights. Though this method gives very good results, the procedure of decomposition and reconstruction can lose some important information, and further improvement is needed.
Kumar et al. [21] presented an assessment of the light source direction from an image. The proposed technique detects the forged images by using the inconsistencies in the light source direction. Their proposed technique works on images that have homogenous illuminated surfaces. CASIA1 dataset was used for evaluation. Kumar et al. [22] presented an image forgery detection method based on using multiple light sources for synthetic images. They estimated the source light vector using pixel patches from the image regions. They used images where more than one light sources were present and were able to detect the forged images by using the angle α, which was obtained from the source of light and surface normal.
Aggarwal et al. [23] proposed a convolutional neural network (CNN) model based on deep learning for the image surface texture analysis and their classification. They designed two sub-models and used customized parameters for the classification of surface textures. Rani et al. [24] presented an image forgery detection system that detected the copy-move and image splicing-based forgeries using a pixel-based forgery detection approach. The authors proposed an enhanced version of the speed-up robust feature (SURF) and template matching for the detection of forged images. CASIA is used for the evaluation of the approach, and overall accuracy of 97.5% is obtained. Aggarwal et al. [25] presented an analysis by using three techniques; HMM’s, ANN, and PCA using eigenfaces. The authors present their findings using these methodologies on the ORL and Yale Face datasets and find that ANN performs the best among other techniques.
Kumar et al. [26] also presented a lighting estimation technique for image forensics where they used a physics-based approach. Their proposed approach is robust as it works for all types of images. Manipulated objects are identified by the lighting parameters, and the incidence angle is returned. Aggarwal et al. [27] discussed the use of segmentation and ROI for the authentication of license plates of cars. They presented a three-phase system for the recognition of the license plate numbers and reported a detection rate of 93.34% and a false positive rate of 6.65%.
Nowadays, it has been shown that deep learning extracts the best features for face recognition [28–31]. However, these features do not exhibit satisfactory performance when the illumination variations are severe [32]. The development of an illumination robust face recognition method needs a huge volume of labeled faces images captured under a variety of severe lighting conditions, but it is not practical.
The overview of the state-of-the-art methods given above indicates that most of the existing methods do not give good results, especially in poor lighting conditions [32]. Thus there is a need for the development of a robust model for illumination robust face recognition.
Proposed method
This section introduces the proposed method for illumination invariant face recognition. First, the overview and motivation for the proposed solution are presented. Then, we give the detail of how features are extracted and how recognition is performed.
It is commonly assumed that illumination variations are embedded in large-scale components (i.e., low-frequency components) of an image [33]. In view of this, most of the techniques [8–12] for illumination invariant face recognition decompose a face image into large-scale and small-scale (high-frequency) components using different techniques. The large-scale component is discarded, and features are extracted from the small-scale component. Recently, it has been shown that large-scale component also contains discriminative information and cannot be discarded [15]. On the other hand, small-scale component contains detrimental features [13], such as noise which must be removed. Motivated by this observation, we decompose a face image into a hierarchy of multi-scale and multi-directional sub-bands, discard the highest and the lowest scales to eliminate the effects of illumination and noise and for illumination invariant face recognition, extract discriminative features from the image reconstructed from the remaining large-scale and small-scale components.
Based on this idea, the designs of the training and testing phases of the proposed method are shown in Figs. 2 and 3; the pseudo-codes of the training and testing phases are given in Algorithm-1 and Algorithm-2. First, an image is transformed to a log domain using log transform. Then it is processed using ContourletDS [14], an edge-preserving version of contourlet transform, to remove the illimitation effect and noise and retain the large-scale and small components. After that, we extract discriminative features using a convolutional neural network (CNN) and project them on a low dimensional space using linear discriminant analysis. Finally, the classification is performed using ridge regression. The detail and motivation of each step are given in the following subsections.

Face Recognition System (training phase).

Face Recognition System (testing phase).
The logarithmic domain is more effective in dealing with illumination variations [11, 12]. Because of this, the first step is to transform the image into a logarithmic domain by applying log transform (step 2 in algorithm 1 and step 1 in algorithm 2) shown in Eq 1, which turns the multiplication in the reflectance model into addition, shown in Eq 2 [20]:
Log transform preserves the structures, which means that u has the same characteristics of reflectance R, and v has the same characteristics as luminance L. Another advantage of using log transform is that it reduces the effect of illumination [20].
To keep the large-scale and small-scale components and discard the illumination effect and noise, the image must be decomposed into multi-scale and multi-directional sub-bands so that the illumination effect (the highest scale sub-band, i.e., the lowest frequency sub-band) and noise (the lowest scale sub-band, i.e., the highest frequency sub-band) can be eliminated. There are many possible options to accomplish this task. However, we employ ContourletDS [14] (step 3 in algorithms 1 and step 2 in algorithm 2), a variant of contourlet transform CT), due to the reasons that (i) it decomposes an image into a fine-grained hierarchy of multi-dimensional and multi-scale sub-bands, which allow to remove the illumination effect and noise without losing the discrimination information embedded in large-scale and small components, (ii) it preserves edges by employing basis images in the frequency domain and (iii) significantly outperforms CT in image denoising [34]. As edges play a key role in discrimination and noise deteriorates the discrimination, ContourletDS is a suitable choice for decomposing a face image. It allows to keep edges and other discriminative information and remove detrimental features such as noise.
Though CT has already been used for illumination invariant face recognition [35, 36], it has been employed for a different purpose, i.e., for feature extraction. On the other hand, we do not use CT, but ContourletDS, and our purpose is not to extract features using ContourletDS.
Decimation and reconstruction
Using contourletDS, an image is decomposed into a fine-grained hierarchy of nd decomposition levels, lower levels represent small-scale components, and higher levels encode large-scale components. The lowest-frequency sub-band is at the highest level among the higher levels and embeds illumination variations. To remove the illumination component, the lowest frequency sub-band is eliminated by setting its coefficients to zero. On the other hand, the highest frequency sub-bands are at the lowest scale among lower levels and mainly encode noise. To get rid of detrimental noisy features, the highest frequency sub-bands are eliminated by setting their coefficients to zero. Step 4 in algorithm 1 and step 3 in algorithm 2 accomplish this task. After this, the image is reconstructed, which now contains the discriminative information of large- and small-scale components and is devoid of detrimental illumination and noisy features. It is obtained with step 5 in algorithm 1 and step 4 of algorithm 2. In the case of RGB, images, decomposition and reconstruction are applied on each of the R, G, andB planes.
CNN model
The next important step is to extract discriminative features from the reconstructed image. Motivated by the outstanding performance of deep learning and in particular, convolutional neural networks (CNN) for various computer vision problems, we employ CNN for feature extraction. It has been shown that CNN does not exhibit satisfactory performance when the illumination variations are severe [32] because for developing an illumination invariant face recognition system, the available data is limited, and it is not practical to acquire training data under all possible illumination variation. However, it can be employed as a feature extractor after removing the illumination effects from an image; we use a pre-trained CNN model as a featureextractor.
After preprocessing the image using ContourletDS, it is passed to a CNN model to extract features (step 8 in algorithm 1 and step 5 in algorithm 2). Different CNN models exist in the literature. We examine three widely used CNN pre-trained models, which are VGG-16 [37] (winner of ILSVRC’s localization task in 2014), GoogLeNet [38] (winner of the classification task in ILSVRC 2014), and ResNet-152 [39] (winner of ILSVRC 2015). We extract local features (X L ) from the last convolution (CONV) layers, which preserve the spatial arrangement of features and global features (X G ) from the fully connected (FC) layers, which encode the global information of the input image. We employed pre-trained CNN models available at [40]; these models are pre-trained on challenging ImageNet database.
Fusion using LDA model
Two issues must be addressed to employ the extracted global (X G ) and local (X L ) features (i) their dimensions are very high, and (ii) the features must be fused. We address these issues using linear discriminant analysis (LDA); it enhances the discriminability of features by projecting the high dimensional features to lower dimensional space by maximizing the inter-class separation and minimizing the intra-class variation [41]. Two approaches can be used to achieve this goal. The first approach is to apply LDA separately on global (X G ) and local (X L ) features, reduce their dimensions and fuse them. The second is to concatenate global and local features [X G , X L ], then apply LDA to reduce the dimension (steps 12–16 in algorithm 1 and steps 6–8 in algorithm 2). We found that the second approach is more effective; see the results. In each case, the transformation matrix M LDA of LDA is learned using training data. The dimensions of features X G andX L are very large. LDA faces the problem of singular within-class scatter matrices when the dimension of the feature space is excessively large as compared to the number of training images. To overcome this problem, first, we apply principal component analysis (PCA) to reduce the dimension of features [42] and the number of principal components (PCs) that preserve the maximum energy is selected for projection.
LDA has already been used to extract class-discriminative features from face images for face recognition [43]. However, we use it to fuse and project deep features.
Classification using ridge regression
The final step is to determine the identity of a subject using the extracted features; we employ ridge regression (RR) for this purpose. RR is very simple, fast, and has been shown to give good performance [44, 45]. Let X ∈ Rd×n, the matrix of n training d-dimensional vectors extracted from the training face images and Y ∈ { 0, 1 }c×n, the matrix of the corresponding labels in on-hot-encoding i.e., in the ith column of Y, Y
ij
= 1 if the ith column of X belongs to the jth subject and 0 otherwise. Ridge regression uses a matrix W ∈ Rd×c to model the linear dependencies between X and Y, and calculates it by solving the optimization problem with the following objective function shown in Eq 3:
where λ is the regularization parameter that is used to balance the bias and variance of the solution. The solution to this problem is shown in Eq 4:
In order to learn the classifier parameters W for all c classes, we only need to invert a d×d matrix once. The matrix of parameters is learned using training data, and the regularization parameter ρ is calculated using cross-validation. Step 17 of algorithm 1 computes W using Eq. 4. After learning the model, the label of an unknown face image x (i.e., the d-dimensional feature vector of the image) is predicted as follows in Eq 5:
In this section, first, we discuss the databases that were used for evaluation and then we present the detail of how the performance of the method is evaluated and which measures are employed.
Datasets
The experiments were conducted on three benchmark face databases: Extended Yale B (EYB) [46], AR [47], and M-PIE [48]. The characteristics of each database are shown in Table 1. The Extended Yale B database is divided into 5 subsets based on the lighting conditions. Among these subsets, subset 1 is the set with the slight lighting variation effects, while subset 5 contains the images with large variations. Figure 4 shows some sample images from the three databases.
AR, Extended Yale B, and M-PIE databases characteristics
AR, Extended Yale B, and M-PIE databases characteristics

Sample images from: a) Extended Yale B b) AR database c) M-PIE database.
To evaluate the proposed method, we used the evaluation protocols of the datasets. The recognition performance of the method is measured in terms of classification accuracy. It is computed as the fraction of correctly classified samples [49]. Given the test set X ={ (x1, y1) , …, (x
N
, y
N
) }, that contains N pairs of test samples where x
i
represents the face image and y
i
is its label, the classification accuracy is computed in Eq 6:
where y
i
and
In this section, we present and discuss the results of the experiments conducted on the three datasets to evaluate the proposed method.
Experimental results on Extended Yale B database
For experiments on the Extended Yale B database (EYB), subset1 is used as a gallery (i.e., for training), and the other subsets are used for testing. The subsets 1–5 contain 263, 454, 521, 456, and 714 images, respectively, of 38 subjects. On this database, four main experiments were conducted. Experiment 1 is performed to test the effect of CT decomposition levels. Experiment 2 is performed to test the effect of the CNN model. Experiment 3 is performed to test the effect of the number of principal components of PCA and the fusion approach of LDA. Finally, experiment 4 is performed to test the effect of the regularization parameter λ of the ridge regression.
Experiment 1
In order to demonstrate the effect of CT decomposition levels, the other parameters are fixed. The POOL5 (#31 and FC-6 (#34) layers of VGG-16 are used to extract local and global features (X G , X L ), respectively. The second approach for fusing features using LDA is applied as mentioned in the system design, and the number of PCs is fixed at 100. The regularization parameter λ of the ridge regression is set equal to 20.
The results of this experiment on EYB datasets are shown in Fig. 5. It is noted that using larger number of decomposition levels achieves better accuracy. The maximum accuracy on each subset is achieved by using 5 levels of decomposition.

Effect of decomposition levels on EYB database.
This experiment is performed to select the most suitable CNN model. We considered three widely adopted CNN models: VGG-16, GoogLeNet, and ResNet-152. In each model, different combinations of layers are used to extract global and local features. In this experiment, the number of CT decomposition levels is fixed at 5, the number of PCs is fixed at 100 and λ = 20. The fusion of LDA is done using the second approach.
Results of this experiment on the EYB database are shown in Table 2. From the table, we see that the highest accuracy for each subset is achieved using the ResNet-152 model for feature extraction. The FC layer fc1000 is used to extract global features, and the CONV layer res3b7 is used to extract local features. It is important to note that low-level layers (24, Icp3_out, res3b7) of all models give better recognition accuracies than high-level layers (31, icp9_out, res5b). The reason is that the low-level layers encode the low-level features which are not specific to any particular types of images.
Effect of pre-trained CNN models on EYB database
Effect of pre-trained CNN models on EYB database
In this experiment, the effects of two factors are explored: (i) the approach for the fusion of the local and global features using LDA, (ii) the choice of the number of PCs in each fusion approach. In this experiment, we used the best number of decomposition levels, which is 5 levels. The CNN model used in this experiment is ResNet-152 with the layers fc1000 and res3b7. Also, the λ parameter is set equal to 20.
The setup and results of this experiment on EYB are shown in Table 3. In this experiment, the best accuracy for subset2 has reached 100% using all the tested #PCs. For subset3, the maximum reached accuracy is 99.8%, which is achieved using 100, 150, and 200 #PCs for both approaches. Subset4 also reached 100% accuracy using 100, 150 #PCs for the first approach and 150, 200 #PCs for the second approach. On subset5 the maximum accuracy which is 99.01% is achieved only using the second approach with 150 PCs. From that, we can see that the best choice is the second approach with 150 PCs.
Effect of features fusion approach and the number of PCs on EYB
Effect of features fusion approach and the number of PCs on EYB
This experiment is performed to find out the best value of the parameter λ. It is performed using the best choice of decomposition levels, which is 5 on EYB, layers fc1000, and res3b7 of ResNet-152 for feature extraction and 150 PCs. The results are shown in Table 4, which indicate that the best value for λ is 20 because it achieves the best accuracy for all the subsets of the EYB database.
Effect of p parameter on EYB
Effect of p parameter on EYB
From the results of the experiments performed on EYB, the best accuracies achieved for subset2, subset3, subset4, and subset5 are 100%, 99.8%, 100%, and 99.01%, respectively.
The accuracies are achieved using five decomposition levels of CT, ResNet-152 for feature extraction, the second approach to fuse the features employing LDA with 150 PCs, and λ equal to 20. In ResNet-152, FC layer fc1000 extracts global features and CONV layer res3b7 extracts local features. The overall accuracy of the method on EYB is 99.07%. The best accuracies are achieved due to three reasons: (i) the method extracts the discriminative information embedded in small scale and large scale components, (ii) the hierarchical features are extracted using deep learning, (iii) deep local and global features are fused using LDA, a class discriminative approach.
For each subject of the AR database, 3 images are used for training, and 5 images are used for testing. Three experiments were conducted. In Experiment 1, the effect of decomposition levels on the AR database is examined. The second experiment is conducted to demonstrate the impact of a CNN model and its layers for feature extraction. The focus of the third experiment is to test the effect of the LDA fusion method and the number of PCs, along with the effect of the λ parameter of ridge regression.
Experiment 1
This experiment is set up the same way as experiment 1 on EYB. Different levels of decomposition are tested. The CNN model used in this experiment is VGG-16 (layers 34 and 31). The #PCs is fixed at 100, and λ = 20. Figure 6 presents the results of Experiment 1 on the AR database. It shows that decomposing images using 5 levels achieves the best accuracy.
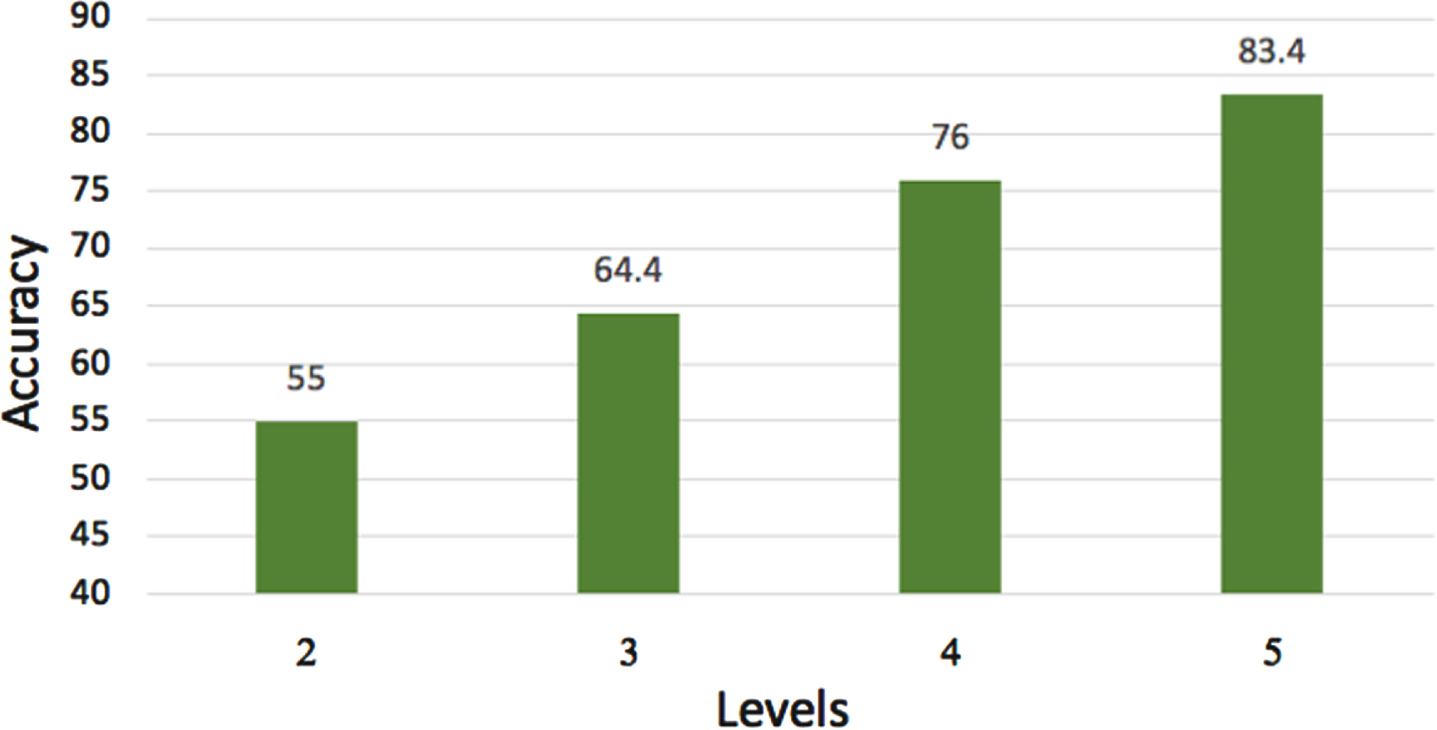
Effect of decomposition levels on AR database.
In this experiment, we test the effect of VGG-16, GoogLeNet, and ResNet-152 models. To do that, decomposition with 5 levels is used. The fusion approach used is the second approach for all the tested models. The #PCs is fixed at 100 and λ = 20. The results of this experiment are shown in Table 5.
Effect of CNN pre-trained models on AR database
Effect of CNN pre-trained models on AR database
From Table 5, we see that using the ResNet-152 model for features extraction achieves the best accuracy by extracting global features from layer fc1000 and local features from layer res3b7. It is in agreement for experiment 2 on the EYB database.
Experiment 3 was performed on AR to demonstrate the effect of the fusion approach of LDA, number of PCs, and λ parameter. The parameters chosen for this experiment are the parameters that result in the best accuracies in experiments 1 and 2, which are 5 decomposition levels, ResNet-152 with fc1000 and res3b7 layers. The accuracy results obtained from this experiment are shown in Table 6. The second approach of fusion achieves the maximum accuracy (100%) with 200 PCs, and the value of λ does not affect the accuracy with this number of PCs, whereas the effect of λ value is different on other #PCs. Averaging the accuracies achieved using the same λ value for all #PCs on both approaches, we can see that p = 1 achieves the maximum average.
Effect of features fusion approach and number of PCs on the accuracy of the method on AR database
Effect of features fusion approach and number of PCs on the accuracy of the method on AR database
From the above experimental results on the AR database, the maximum reached accuracy is 100%. This accuracy is a result of using 5 decomposition levels, fc1000 and res3b7 layers from the ResNet-152 model for feature extraction, second fusion approach with 200 PCs and λ = 1.
For each subject of the M-PIE database, 4 images are used for training, and 11 images are used for testing. Three experiments were conducted like the experiments on the AR database. Experiment 1 is to test the effect of decomposition levels on the M-PIE database. Experiment 2 demonstrates the impact of the CNN model and the layers for feature extraction. Experiment 3 is performed to test the effect of the LDA fusion method and the number of PCs, along with the effect of the λ parameter of ridge regression.
Experiment 1
In this experiment, in order to test the effect of decomposition levels, the VGG-16 model is used to extract global features using layer 34 and local features using layer 31. Fusion of these features is done using the second approach. The number of PCs is fixed at 250 and λ = 20. The results of this experiment are shown in Fig. 7. The best accuracy is achieved using 4 levels, while 2 levels give the worst accuracy.

Effect of decomposition levels on M-PIE database.
This experiment demonstrates the effect of using VGG-16, GoogLeNet, and ResNet-152 CNN models. For each tested model, 4 levels of decomposition are used. The second LDA fusion approach is used. The number of PCs is fixed at 250 and λ = 20. The setup and results are shown in Table 7.
Effect of CNN pre-trained models on M-PIE database
Effect of CNN pre-trained models on M-PIE database
In this experiment, different numbers of PCs are tested for both LDA fusion approaches, along with different values of λ. The decomposition with 4 levels is used. Features are extracted using ResNet-152 fc1000 and res3b7 layers. The accuracies of this experiment are shown in Table 8. The best accuracy is achieved using the second fusion approach with 600 PCs and λ = 20. It is noticeable that the best accuracy for each #PCs is achieved using different values of λ. Therefore, we show the average accuracies achieved using each value λ. The maximum average is using λ = 20.
Effect of features fusion approaches and number of PCs on M-PIE database
Effect of features fusion approaches and number of PCs on M-PIE database
From experimental results on the M-PIE database, the best-achieved accuracy is 96.54%. This accuracy is a result of using 4 levels of decomposition, and then extracting global and local features using ResNet-152 fc1000 and res3b7 layers respectively. The fusion of these extracted features is done using the second approach with 600 PCs and λ = 20.
To assess the performance of the proposed face recognition method, we conducted different experiments on Extended Yale B (EYB), AR, and M-PIE databases. Different factors affect the performance of the method: the number of decomposition levels of CT, the choice CNN model, the fusion approach, the number of PCs, and the value of the regularization parameter of the RR method. The experiments revealed that 5 levels of decomposition are suitable for EYB and AR, while this number is 4 for the M-PIE database. This difference in the number of decomposition levels is probably due to the reason that the first two databases consist of grayscale images while M-PIE contains RGB images. The results show that larger levels of decomposition produce a fine-grained hierarchy of multi-scale and multi-directional features, which help us to keep the discriminative information at large and small scales. Using two or three decomposition levels implies that the large-scale (low-frequency) sub-band still contains distinctive features that cannot be discarded. As we expected, ContourletDS allows us to separate the multi-directional features of an image at different scales and remove the features which are due to the illumination variation and noise and preserve the large-scale and small-scale features, which are important for discrimination. This is validated by the results on the three databases.
Figure 8 gives a comprehensive view of the performance of different CNN models and their layers on the three datasets. The CNN model which yields the discriminative features from all databases is ResNet152, and the features from CONV layer res3b7 and FC layer fc1000 are the most discriminative. As the CNN models are trained on imageNet database, and the low-level layers learn the features which are independent of the domain of the database, the higher level CONV layer res5b does not give a result in the discriminative features but the lower level CONV layer res3b7.
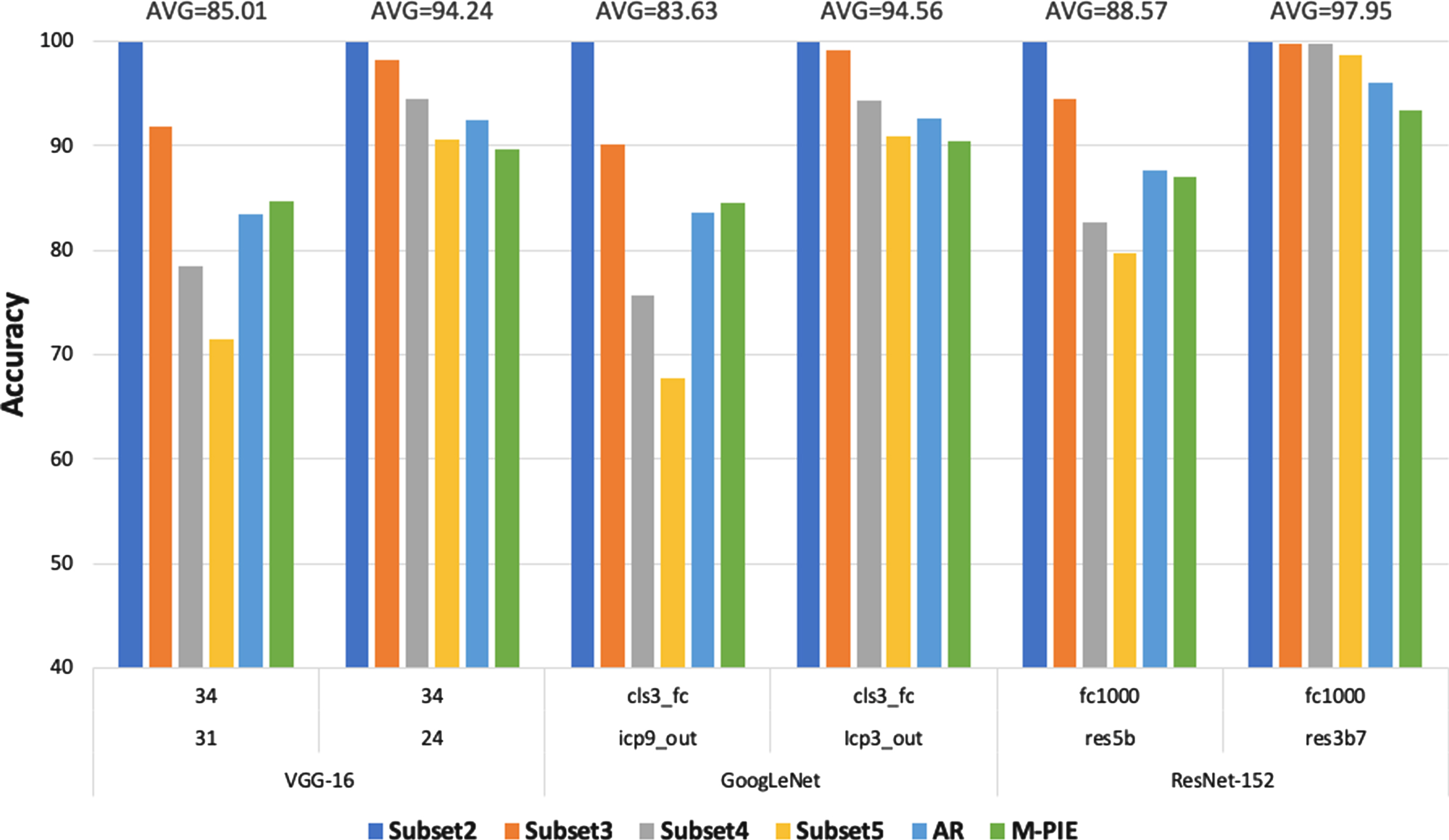
Effect of CNN different models on EYB, AR and M-PIE databases.
The experiments of all the three databases revealed that the second approach for the fusion of local and global features is more effective, but the number of PCs is different for different datasets; for EYB and AR, it is 150 and 200, respectively, but for M-PIE it is 600. For the first two datasets, the difference is not big, but for M-PIE, the difference is big. This difference can be attributed to the format of images. Also, the experiments have shown that the best value of the regularization parameter λ of RR is 20 for the three datasets. To establish the usefulness of the proposed method, we compare it with state-of-the-art methods. For a fair comparison, we use the EYB database due to two reasons: (i) it involves face images with severe illumination variations and validates the performance of an algorithm to tackle severe lighting conditions, (ii) in this database, the protocol is fixed, whereas in other databases there can be the differences in the choice of gallery and probe samples. The comparison results are shown in Table 9. We have taken the results, which are reported in the original papers, to avoid any bias due to parameter tuning.
Comparison between some related work and proposed method on EYB database w.r.t Accuracy (%)
It is noted that the proposed method outperforms the other state-of-the-art methods on all of the EYB subsets. The reason is that it employs contourletDS to decompose an image into a fine-grained hierarchy of multi-dimensional and multi-scale sub-bands, which allow getting rid of illumination variations and noise without losing the discriminative information, and CNN for discriminative feature extraction.
The fair comparison of the computational complexity of the state-of-the-art methods is possible if they are implemented and run on the same platform. As the implementation of the state-of-the-art methods is not available, it is not possible to compare with them. However, we give an idea of the computational complexity of our method. The main steps of the algorithm are (i) extracting small-scale and large scale components, which takes 0.167284 seconds; (ii) computation of local and global features, which costs 6.193673 seconds with ResNet, (iii) fusion of local and global features, it takes 0.0370 seconds and (iv) finally matching, which consumes 0.007468 seconds. Thus the total cost for a single query is 6.405425 seconds on an ordinary system equipped with an I7 processor. This computational cost with enhanced accuracy is acceptable for real-time applications. The bottleneck is the computation of the local and global features using CNN models. There are two possible avenues to explore to overcome this issue. First, we make two separate forward possesses, which take twice the time. An intelligent implementation can overcome this issue which allows computing local and global features in one pass. Second, to explore the CNN models with less computational cost.
We have proposed an illumination invariant face recognition system using ContourletDS and CNN models. Based on the Lambertian reflectance model, a face image can be decomposed into large-scale and small-scale components. The small-scale component contains the illumination invariant features, while the illumination variations affect the large-scale features. To retain the discriminative information from large-scale and small-scale components, and discard the illumination effect from large-scale components and detrimental noise from small components, the system employs ContourletDS. Then, the discriminative features are extracted from the preprocessed image using a CNN model. Global and local features are extracted using pre-trained models (VGG-16, GoogLeNet, and ResNet-152). After that LDA is used to fuse these features and reduce the dimension using two different approaches. For classification, ridge regression is used. The larger decomposition levels of ContourletDS help in a better way to separate and eliminate illumination variation effects and detrimental noise and lead to better results. The ResNet-152 model with layer CONV layer res3b7 and FC layer fc1000 beats the VGG-16 and GoogLeNet models. The proposed method achieved 99.7%, 100%, and 96.54% accuracies on EYB, AR, and M-PIE databases, respectively, and it outperforms the state-of-the-art methods. The proposed method uses ContourletDS to eliminate the illumination variation and noise. The alternative is to use generative adversarial learning to remove the illumination effects; it is our future work.
Footnotes
Acknowledgments
The research was supported under Researchers Supporting Project number (RSP-2019/109) King Saud University, Riyadh, Saudi Arabia.