
Abstract
Automatic Text Summarization(ATS) is distinctly beneficial due to a vast amount of textual data and time-consuming manual summarization. In order to enhance ATS for single document in huge datasets, a new extractive graph framework - text extractive SUMmarization framework based on EDge information with COreference resolution EDCOSUM is proposed in this paper that relies on coreference resolution, adding edge information in word-level graph and a sentence-ranking strategy. EDCOSUM combines the graph-based and statistical-based extractive summarization methods. It is a general method for any document (not limited to a specific domain). Moreover, two ranking strategies(sentence and LSA ranking strategy) are proposed for sentence selection. A set of extensive experiments on CNN/Daily Mail and NEWSROOM are conducted for investigating the proposed method. The widely used automatic evaluation tool: Recall-Oriented Understudy for Gisting Evaluation(ROUGE) is utilized to evaluate EDCOSUM. Compared to the state-of-the-art ATS methods, EDCOSUM achieves a competitive result by improvements of over the highest scores in the literature for metrics ROUGE-1, ROUGE-2 and ROUGE-L respectively.
Keywords
Introduction
According to de Kunder, M. [1], the estimated size of web in 2021 is around 4.51 billion pages due to the Internet since its invention three decades. The text grows particularly at a fast pace, such as news articles, electronic books, scientific papers, etc. The purpose of text extractive summarization is to condense the input text and remain the core meaning of the input text.
In [2], Radev et al. also have defined the summary as follows: “A summary can be loosely defined as a text that is produced from one or more texts, that conveys important information in the original text(s), and that is no longer than half of the original text(s) and usually significantly less than that. Text here is used rather loosely and can refer to speech, multimedia documents, hypertext, etc.” As we know, text summarization is a process of creating the compressed or short version from the original document which reduces the invalid information and gets significant parts from the original document.
Automatic Text Summarization(ATS) can be divided into multiple categories depending on the factor that is used for comparison. According to the input size, ATS can be classified into multi-document or single-document summarization. The single-document summarization is to extract several sentences from single document while multi-document summarization is to extract a summary from a group of cluster documents. On the other hand, in light of the output type, ATS can be divided into generic and query methods. Generic methods do not require any query, since the method aims to cover all the information. Query methods aim to answer the query concisely. Moreover, in terms of applied methods, ATS can be categorized into extractive, abstractive and hybrid summarization. In abstractive summarization methods, the summary which consists of concepts taken from document contains the new sentences. By comparison, extractive approaches aim to select a subset of sentences in source document, thereby enjoying better fluency and efficiency [3]. The extractive summarization with the selection of sentences is closer to human-written summary. The hybrid summarization combines the extractive and abstractive approaches. Extractive summarization is more simple than abstractive and hybrid methods. EDCOSUM is the single-document, generic and extractive summarization. The structure of text extractive summarization is shown in Fig. 1.
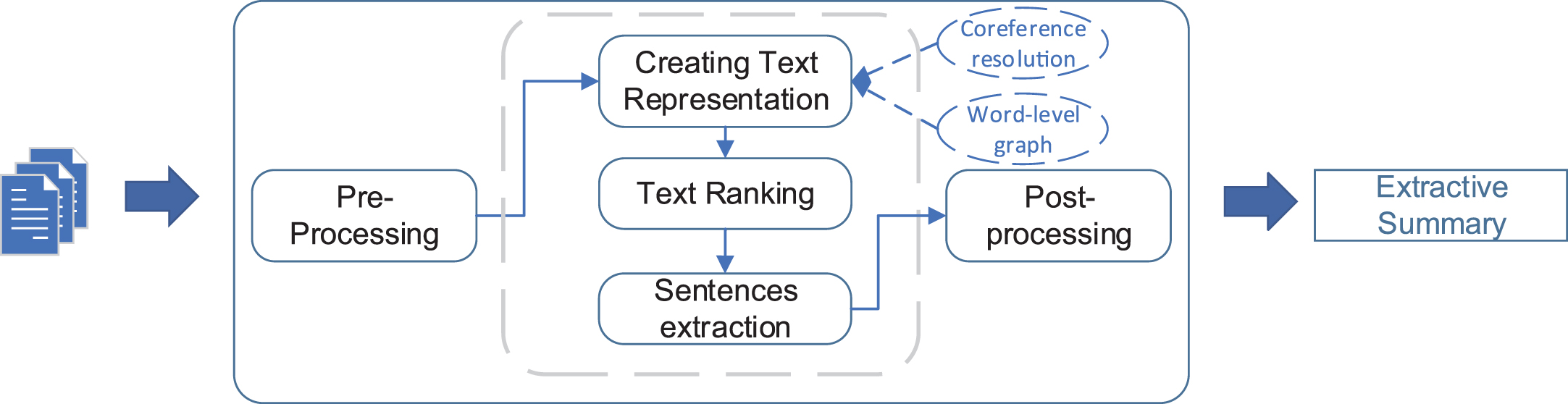
The structure of text extractive summarization.
Text extractive summarization field still needs extensive research efforts due to the generated summaries which are far away from human-written summaries. Therefore, in this paper, we propose a text extractive SUMmarization framework based on EDge information with COreference resolution(EDCOSUM) which objectively includes: Representation of sentences in the form of a graph. A new methodology based on word-level graph to obtain an extractive summarization.
The rest of this paper is organized as follows: Section 2 presents a literature review of text extractive summarization. Section 3 illustrates the proposed method – EDCOSUM. The used evaluation methods, datasets, experiments and results are discussed in Section 4. Finally, Section 5 concludes the paper.
Various summarization methods are proposed for extractive summarization in literature: linguistic and statistical-based, LSA, graph-based and reinforcement learning methods.

The example of coreference resolution.
Additionally, there are several mentions that refer to the same entity in text. Coreference resolution solves the problem of determining which refers to each real-word entity mentioned in document. Coreference resolution aims to enrich the semantic information and reduce the noun nodes which refer to the same entity. As a preprocessing, coreference resolution with rich semantic information has been successfully applied to plenty of downstream tasks. The process of coreference resolution is depicted in Fig. 2.
In this paper, we try to present an extractive summarization approach based on edge information with coreference resolution. The structure of EDCOSUM is depicted in Fig. 3. The methodology contains text preprocessing, graph construction, the calculation of node weight, the candidate edge selection, the ranking of candidate summary.
Text preprocessing
The document from datasets that contains non-English characters needs to be preprocessed. As illustrated in Fig. 3, preprocessing contains 4 steps: (1) sentence segment. (2) word lemmatization. (3) non-English characters (4) word frequency calculation.

The structure of EDCOSUM.
EDCOSUM models a document as a directed, unweighted graph to capture the sequence between words’ nodes. Given a document D = {S1, S2, . . . , S n }, the directed unweighted graph G (V, E) of input document is built, where V is a set of nouns in D and E is a collection of edges between pair of vertices. The representation of a sentence is a path from beginning token "CLS#" to destination token "SEP#" based on the word sequence. We assume that contextual information can be retained by graph structure. Algorithm 1 illustrates the procedure of graph construction. The process starts with a document and produces a document graph over text spans(nouns) according to coreference resolution, node selection and edge construction. Graph construction of EDCOSUM represents the meaningful relation among words.
Graph Construction
1: Given sentence_dict and G, construct its word graph G _ w
2: beginning node cls _ node = " CLS # "
3: sentence order edge _ order = 0
4: edge information edge _ label = " "
5: ending node sep _ node = " "
6: word graph node sentence _ node = []
7: #Step 1: coreference resolution for sentence _ dict
8: sentence _ dict _ core = coreference _ solution (sentence _ dict)
9: tag = pos _ tagging _ text (sentence _ dict _ core)
10:
11:
12: word _ lemma = get _ word _ lemma (tag [word] [0])
13: sep _ node = word _ lemma
14:
15: add _ node (G, word _ lemma)
16: add _ edge (cls _ node, sep _ node, newlinesentence, edge _ orde)
17: edge _ order + =1
18: cls _ node = word _ lemma
19: edge _ label = " "
20:
21: edge _ label = edge _ label + " " + tag [word] [0]
22:
23:
24:
25:
Due to the simple network of NeuralCoref 1 , we choose it to find coreference chains. Firstly, coreference can be recognized through NeuralCoref. Subsequently, pronouns are replaced with corresponding nouns. It is dedicated to the construction of coreference resolution system without the utilization of complex models.
After coreference resolution, we screen the Part Of Speech(POS) tagging of words which is a feature of the node. This paper utilizes the special feature as a part of graph construction. We classify word tags into 2 types: (1) noun. (2) non-noun. If the tag is [NN, NNS, NNP, NNPS], the lemmatized word will be added to V. Otherwise, the word is regarded as a part of edge in E.
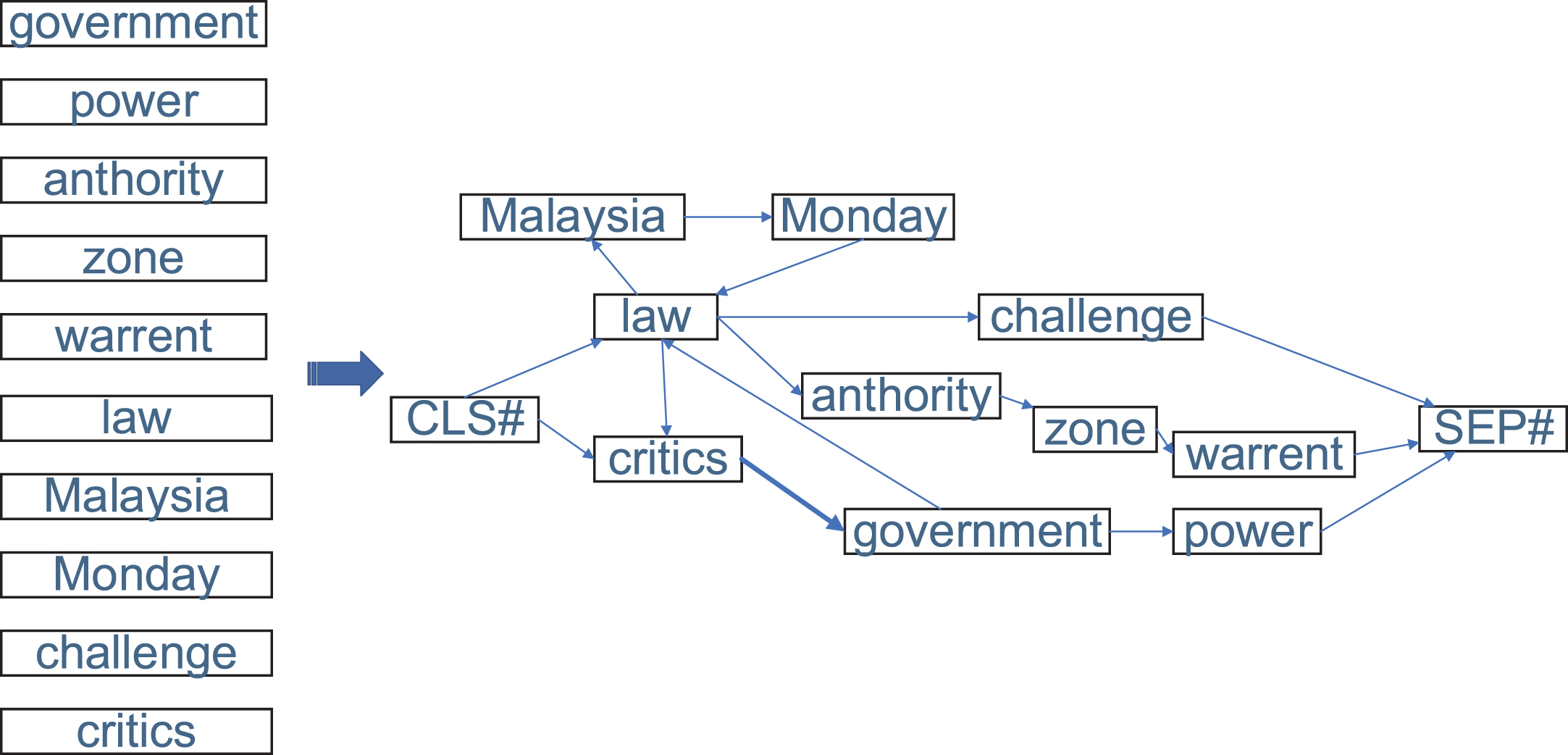
The illustration of constructing graph. Firstly, the noun vertices are selected into V. Subsequently, the noun vertices are connected through the sentence. For example, the sentence “A new security law in Malaysia came into force on Monday one that critics say gives the government broad unchecked powers. ”? contains the words “Malaysia”? and “Monday”?. The edge between “Malaysia”? and “Monday”? is “came into force on”?.
S0: A new security law in Malaysia came into force on Monday one that critics say gives the government broad unchecked powers.
S1: It allows for authorities to create a so-called security zone inside which arrests and seizures can happen without warrants.
S2: Some say the government could use this law to ward off political and legal challenges.
Each word node has a word frequency in the input document. Above the calculation of word frequency, we find that the median word frequency is equal to 1 and represents the minimum word frequency. It is a matter for the selection of candidate node in the next step. To address the problem, we combine the text features with a bias to calculate the node weight. Previously, extractive summarization models incorporate a wide variety of features, such as keywords, proper nouns, bigrams, etc. Indeed, how these features work is not explicit for the node weight calculation. We aim to spot these features and identify the efficient features to adjust the importance of words in sentences. The features contain as follows:
As introduced in text information that contains keywords, bigrams, title and proper words, each word may be as a part of text essential features. Additionally, we define a bias list which is domain-specific for the special text. Each word in bias list can get an additional weight to reflect the importance. The text information with the bias calculation is utilized in node weight calculation, which is computed as:
where word _ frequence (·) represents word frequency as the initial value. W
P
, W
T
, W
K
, W
B
are the word weights that words are in proper nouns, title, keywords and bigrams. However, the constant value of weight is not suitable for all documents. The manual setting value maybe cause bias for the downstream work. To solve the problem, we propose an adjusted value to reduce the bias. The process means that Av
T
, Av
K
, Av
P
, Av
B
are utilized for adjusting constant weight. The calculation of adjusted weight is computed as:
Based on the calculation of node weight, the search algorithm is proposed for the candidate edge selection. We assume that the word node connected more edges is more essential for text summarization since the words frequently appear at the same time in document [29]. In addition, we deem that the long and short sentences are of capital importance. Not only is the weight of words considered, but the number of edges connected with nodes is not neglected as well. We propose an edge selection method which considers the number of edges connected to the node. The Equ(1) is changed into Equ(6).
The criterion of edge selection is to choose the maximum weight of nodes connected with more edges. Provided that a sentence at least has a selected edge, the sentence is possibly selected as the candidate summary. The candidate edge selection is achieved using Algorithm 2. Additionally, an example of candidate edge selection processing(the letters represent the noun in each sentence) is following:
S0: E-G-D-A-G-D-B-C
S1: L-G-J-D-B
S2: H-F-J-I-B-I-K
S3: L-J-B
Firstly, node information is added to the node. Specifically, the weight of “CLS#” is set to 0. Secondly, the node that has the maximum weight as the destination node is visited successively and the corresponding edge is selected.
Candidate Edge Selection
1: Given node weight graph _ nodes _ weights and G, obtain candidate summary candidate _ summary
2: candidate edge candidate _ edge _ list = []
3: # add the edge information into nodecandidate summary candidate _ summary
4:
5:
6: graph _ nodes _ weights [node] + = calculate _ edge _ num (node)
7:
8: sorted _ weight _ list = sorted (graph _ nodes _ weights)
9:
10:
11:
12: visted (node)
13: out _ edge = G . edge (node, data = True)
14: out _ edge _ visited = []
15: max _ weight = 0
16:
17:
18: max _ weight = graph _ nodes _ weights [out [1]]
19:
20: out _ weight = graph _ nodes _ weights [out [1]]
21:
22: sent = G . edge [out [0] , out [1]] [′sentence′]
23: tup = (out [0] , out [1] , {′sentence′ : sent, ′order′ : G . edges [out [0] , out [1]] [′order′]})
24: candidate _ edge _ list . add (tuple)
25:
26:
27:
28:
29: candidate _ summary = sentence (candidate _ edge _ list)
30:
The node weight with edge information is shown in Table. 1. The process of candidate edge selection is depicted in Fig. 5. The candidate edges include L-G, G-D, D-B, B-C. Therefore, the candidate summary contains S0 and S1 in this example.
The calculation of node weight
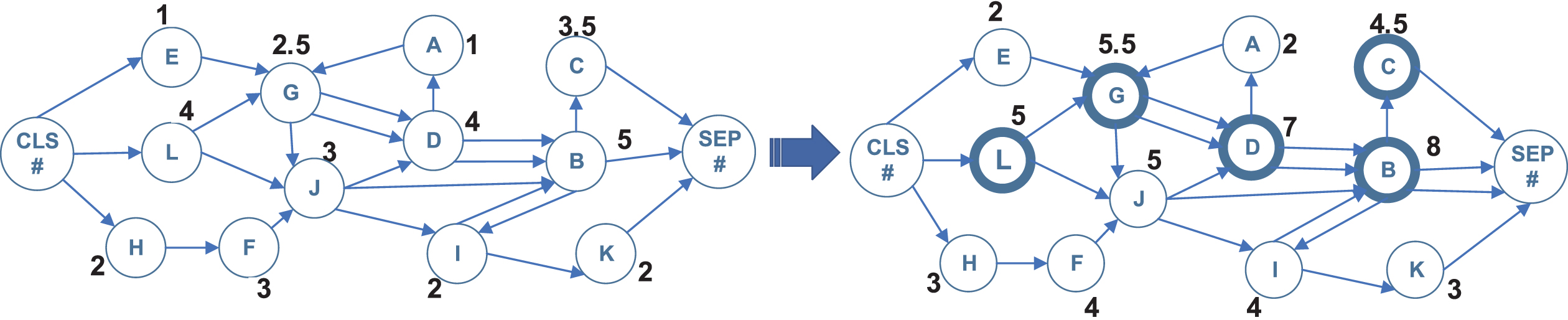
The processing of the candidate edge selection.
The final summary is extracted from candidate summary due to sentence rank strategy, which follows the steps:
Step 1: define the ranking strategy.
Step 2: sort the sentence based on ranking strategy.
Step 3: apply the K-means clustering algorithm to obtain a set of clusters where similar sentences are grouped.
Step 4: select a sentence in each cluster to form the final summary.
The ranking strategy is a vitally essential part to rank candidate summary. As demonstrated in section 3.3, the word weight with edge information has contained the weight of title, proper nouns, keywords, bigrams and bias words. In this section, we propose two ranking strategies to deal with word weight: The value of a sentence consists of the word weight in the sentence. The topic word weight is added to sentence weight.
We suppose that the first-K sentences are more important than the following sentences because the lead-3 which selects the first-3 sentences as the final summary is a widely baseline method. The calculation of sentence weight is illustrated as:
To select the sentence as a summary, sentence and LSA ranking strategy are utilized which are shown in Equ(8) and Equ(9).
We conduct several experiments to evaluate the effectiveness of different parts of EDCOSUM. Moreover, a set of comparable experiments are organized in order to assess the efficiency of the proposed framework. This section provides the evaluation of EDCOSUM compared with the state-of-the-art ATS systems.
Dataset
CNN/Daily Mail: The CNN/Daily Mail is the most widely used benchmark dataset for single document summarization. The dataset consists of online CNN and Daily Mail news articles for question/answering systems originally. We follow the dataset [30] which replaces the anonymized entities with their actual values and creates the non-anonymized version.
NEWSROOM [31]: This corpus, a dataset with 1.3 million news articles and human-written summaries, is the most recent large-scale dataset from different domains introduced to text summarization genuinely. We regard sources variety as a diversity of summarization styles.
Evaluation metrics
Following previous works [30, 33], we evaluate CNN/Daily Mail and NEWSROOM on ROUGE which is an extensive-used automatic evaluation tool. It calculates the appropriate n-gram word-overlap between reference summary and system summary. ROUGE-1, ROUGE-2 and ROUGE-L are the most utilized measures in the literature. ROUGE-L calculates the longest common subsequence while ROUGE-N calculates N-gram between the system and reference summaries. For input documents with the summarization model, we use the value which is the average score of all the results as the final score for computing the overall ROUGE scores.
Comparison model
A set of classic and well-known summarization methods, such as lead-3, Oracle method, Relevance Measure, LSA, TextRank, LexRank and TextRank variation, is utilized to assess the proposed framework in CNN/Daily Mail and NEWSROOM. Besides, a set of state-of-the-art ATS systems have been selected for comparisons such as SumRunner, NEUSUM, REFRESH, VHTM, Exconsumm, SUMO and LATENT. The existed extractive summarization methods are selected for comparison with the proposed framework because they obtain the best result in the literature on CNN/Daily Mail which is the most common dataset for single-document summarization.
Result
In order to evaluate EDCOSUM fully, we designed two parallel experiments. The first one is conducted with CNN/Daily Mail. We further add the second experiment to assess the performance of the proposed method on NEWSROOM.
Experiment 1: CNN/Daily Mail
We try to find the discipline concerning coreference resolution, edge information and ranking strategy for CNN/Daily Mail. Moreover, to evaluate the effectiveness of EDCOSUM, we compare EDCOSUM to state-of-the-art methods.
Fig. 6 illustrates the effectiveness of edge information. The experiment result demonstrates that adding edge information has a positive influence on extractive summarization. Fig. 7 shows the results of ranking strategy and the importance of coreference resolution. From Fig. 7, the result has an improvement with the coreference resolution compared to the method without the coreference resolution.
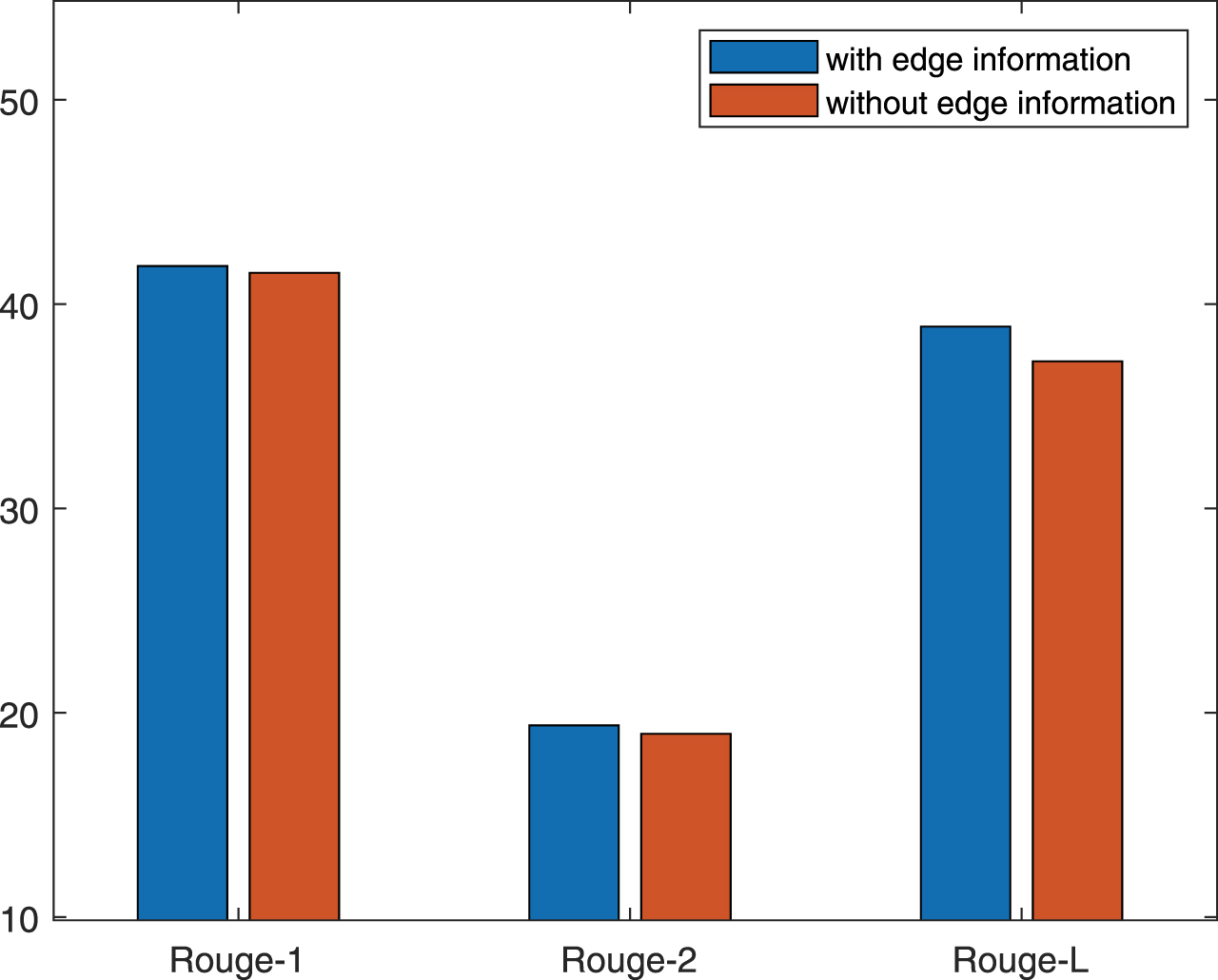
The result of methods by adding edge information on CNN/Daily Mail.
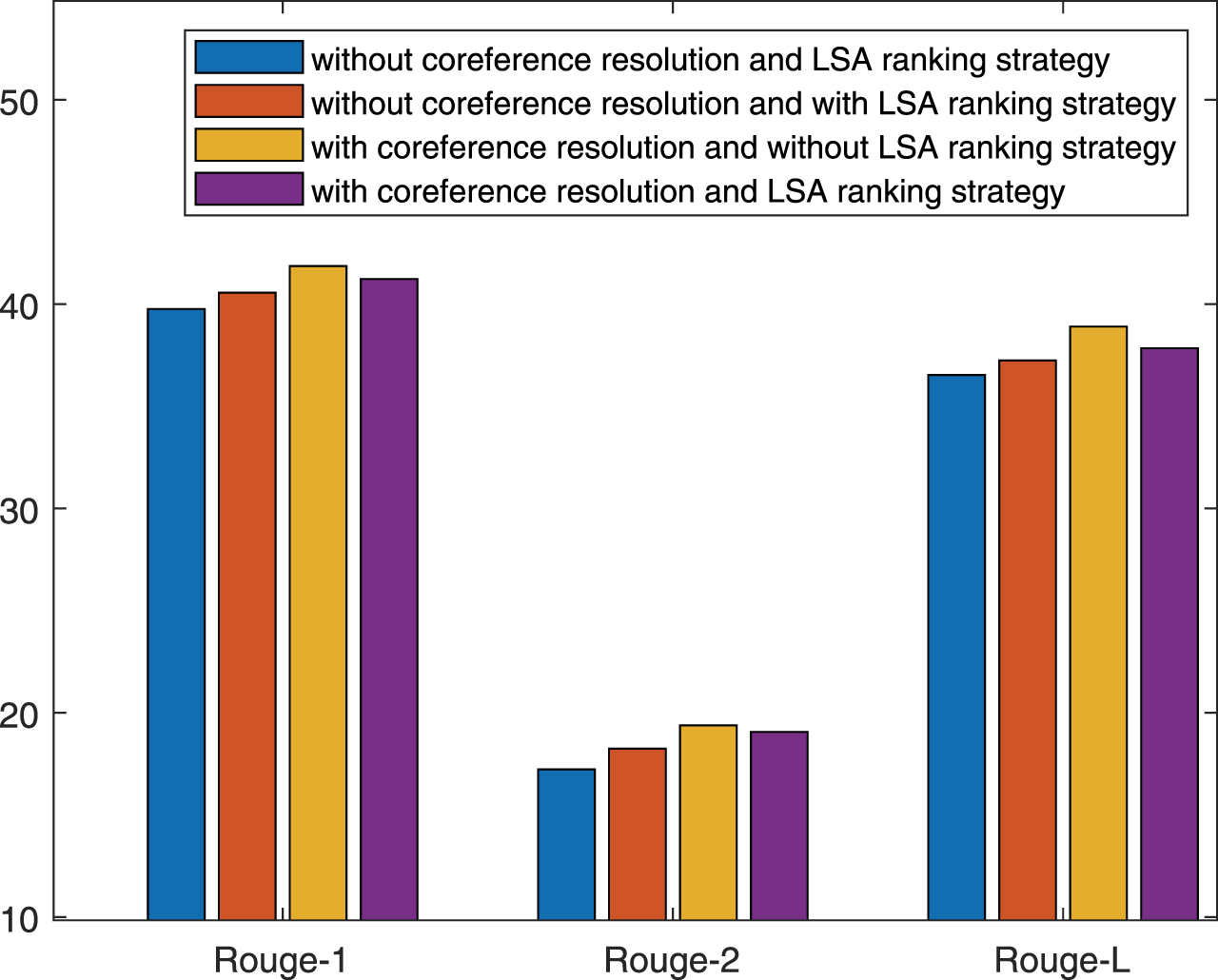
The result of methods by coreference resolution and LSA ranking strategy on CNN/Daily Mail.
According to the above experiments, we configure the proposed method with coreference resolution, edge information and sentence ranking strategy to achieve the best performance. To evaluate the effectiveness of the proposed method, we have compared the results with state-of-the-art text summarization methods. Table 2 represents the comparison among the various methods of text extractive summarization, which are evaluated on CNN/Daily Mail for F-measure. As shown in Table 2, EDCOSUM_LSA represents the proposed method with coreference resolution, edge information in graph and LSA ranking strategy while EDCOSUM is the proposed method with coreference resolution, edge information and sentence ranking strategy. The best results in this set of experiments are in boldface.
Comparison among the state-of-the-art extractive summarization methods for F-measure on CNN/Daily Mail
Overall, empirical results illustrate that the proposed summarization framework achieves the best performance in terms of both ROUGE-1, ROUGE-2 and ROUGE-L on CNN/Dail Mail. Compared to the sentence-level graph(TextRank, LexRank, TextRank Variation), there is also a rise of almost 9% in EDCOSUM. We consider the proposed framework is better than sentence-level graph methods for text summarization due to the word-level graph. Moreover, there is an improvement compared to the SUMO. We reckon on the word-level graph is better than the tree structure. Compared to the simple machine learning methods(REFRESH, LATENT, NEUSUM, Exconsum), the proposed method takes first place with an improvement(nearly 2%). We deem that coreference resolution could yield positive impacts on the proposed method. Therefore, it can be proved that word-level graph construction and coreference resolution has a positive influence on proposed method. We consider the improved result due to the reduction of reference relation.
However, it’s amazing that the best result is the method with coreference resolution and sentence ranking strategy compared to others. Therefore, the sentence ranking strategy has a positive influence on text extractive summarization. Although the proposed method with LSA ranking strategy has a negative result compared to one with sentence ranking strategy, it is better than other state-of-the-art approaches. We guess that the LSA ranking strategy overlapping on the statistical feature reduces the summarization result.
In conclusion, the coreference resolution is beneficial for the text summarization based on word-level graph. Moreover, the ranking strategy positively influences extractive summarization results. Finally, adding edge information in graph is helpful for summarization.
NEWSROOM is a large-scale summarization dataset. We try to evaluate the large-scale dataset by using EDCOSUM. Moreover, to investigate the importance of each part of EDCOSUM, we choose NEWSROOM dataset to conduct experiments.
Fig. 8 shows the comparison of the proposed method with or without edge information. The results of ranking strategy and coreference resolution are depicted in Fig. 9. The experiments prove that the proposed method with coreference resolution, edge information and sentence ranking strategy is the best one than other methods. The conclusion is the same as that of above experiments.

The result of methods by adding edge information on NEWSROOM.
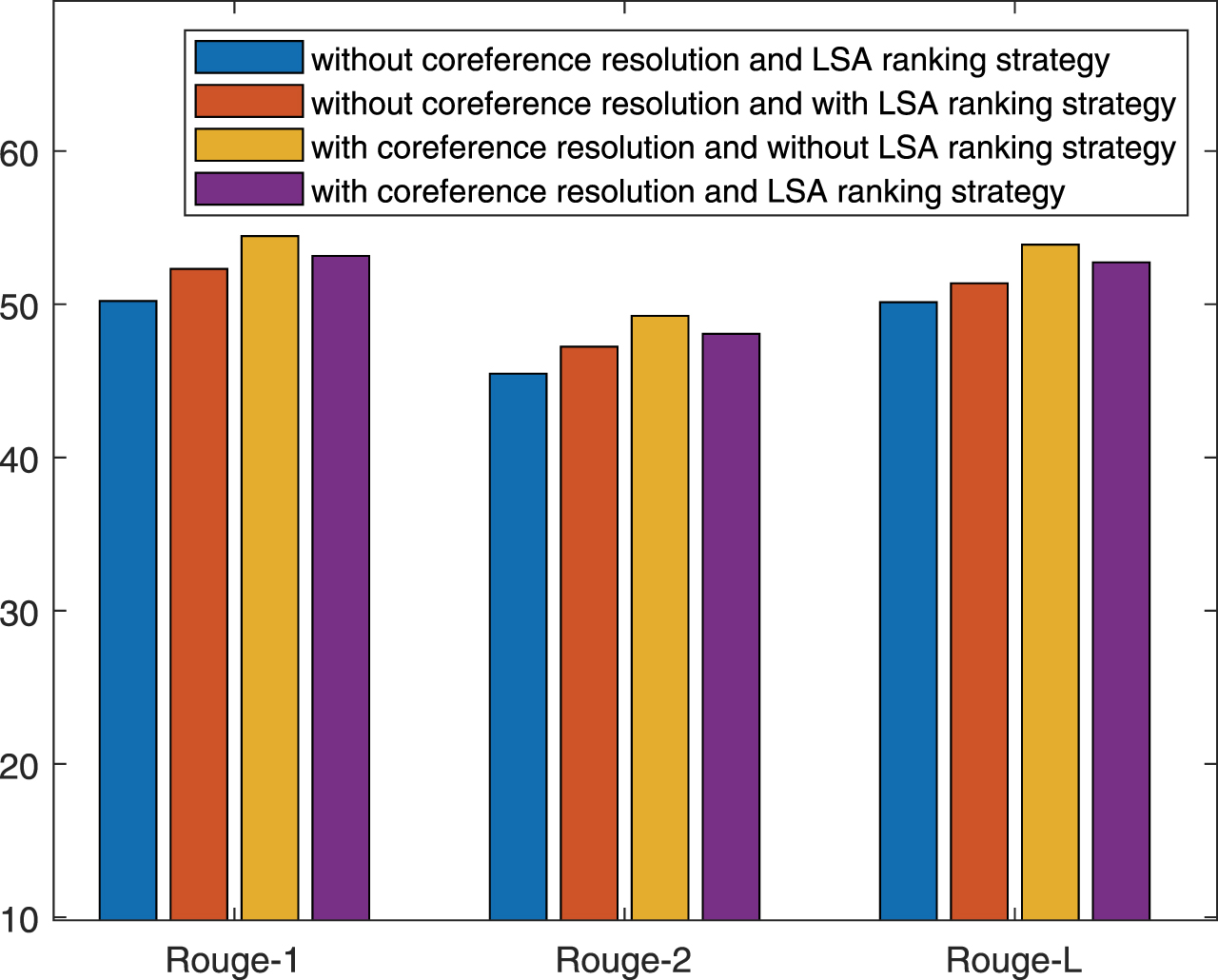
The result of methods by coreference resolution and LSA ranking strategy on NEWSROOM
In addition, we try to prove that the proposed method can be utilized in a large-scale dataset. On the basis of above experiments, Table 3 depicts the comparison among state-of-the-art methods, calculating the average F-measure value evaluated on NEWSROOM. As shown in Table 3, the proposed method still has a positive influence on NEWSROOM which is better than a majority of mentioned methods. We reckon on EDCOSUM which can be utilized in NEWSROOM relies on the word-level graph.
Comparison between the lead-3 and Oracle on NEWSROOM
As a significant and fashionable graph theory implement, text extractive summarization based on graph contributes to a great diversity of work. The main contribution of this paper constructing word-level graph framework addresses the generic single-document extractive summarization problem. In addition, coreference resolution is considered in EDCOSUM. The edge information is added to word-level graph where the elementary unit is a word. The vertices are combined with statistical features as word weight. The two ranking strategies are proposed in EDCOSUM.
The experiments with two datasets(CNN/Daily Mail and NEWSROOM) show that the result of EDCOSUM combining the coreference resolution and edge information has a significantly positive impact compared with the state-of-the-art extractive summarization methods. The comparison experiments show that the method with coreference resolution, edge information and sentence ranking strategy has a better result. Although the proposed method with LSA ranking strategy is not better than one with sentence ranking strategy, its result has an improvement compared to almost state-of-the-art methods. Additionally, experiments exhibit that the proposed method can be utilized in a large-scale dataset. It may be possible to improve result by considering the word-level feature for a document. Both experiments demonstrate that the proposed method EDCOSUM is better than baseline models.
Footnotes
Acknowledgments
This work is partially supported by Joint Fund of Science & Technology Department of Liaoning Province and State Key Laboratory of Robotics, China (2020-KF-12-11), Fundamental Research Funds for the Central Universities N181706001, N2017009, N2017008, N182608003, N181703005), National Natural Science Foundation of China (61902057).