
Abstract
Purpose:
Reading spinal CT (Computed Tomography) images is very important in the diagnosis of spondylosis, which is time-consuming and prones to make biases. In this paper, we propose a framework based on Faster-RCNN to improve detection performances of three spinal fracture lesions: cfracture (cervical fracture), tfracture (thoracic fracture) and lfracture (lumbar fracture).
Methods:
First, we use ResNet50 to replace VGG16 in backbone network in Faster-RCNN to increase depth of training network. Second, we utilize soft-NMS (Non-Maximum Suppression) instead of NMS to avoid missed detection of overlapped lesions. Third, we simplify RPN (Region Proposal Network) to accelerate training speed and reduce missed detection. Finally, we modify the classifier layer in Faster-RCNN and choose appropriate length-width ratio by changing anchor sizes in sliding window, then adopt multi-scale strategy in training to improve efficiency and accuracy.
Results:
The experimental results show that the proposed scheme has a good performance, mAP (mean average precision) is 90.6%, IOU (Intersection of Union) is 88.5 and detection time is 0.053 second per CT image, which means our proposed method can accurately detect spinal fracture lesions.
Conclusion:
Our proposed method can provide assistance and scientific references for both doctors and patients in clinically.
Introduction
At present, spondylosis has become a common disease and high incidence. Reading spinal CT images is a very effective and common way in the treatment for spondylosis. The traditional way of checking CT images needs doctors to read a series(usually about 200 CT images) of CT images one by one. Due to the low contrast and resolution of CT images and irregular shape of vertebral body, it is difficult to distinguish the body boundary between upper and lower vertebral, so reading CT images is relatively time-consuming. Meanwhile the diagnosis and treatment seriously rely on the doctors’ clinical experiences and subjective diagnosis, which is easy to cause misdiagnosis and make subjective errors.
With the developments of computer technology, many deep learning algorithms are applied in computer-aided diagnoses, which can present relatively objective diagnoses and reduce occurrences of misdiagnoses effectively. In this paper, we propose a novel scheme based on Faster-RCNN [1] to provide objective and accurate detection of spinal fracture lesions. The contributions in this paper are:
a. We use ResNet50 to replace VGG16 in Faster-RCNN to increase the depth of training network for a better lesions detection performance.
b. We simplify the original RPN(Region Proposal Network) to accelerate the training speed.
c. We utilize the soft-NMS(Non-Maximum Suppression) instead of the original NMS to avoid the overlapping of proposal boxes and reduce the missed detection.
d. We modify the classifier layer in Faster-RCNN to reduce parameter number and computation complexity to accelerate spinal lesions detection, meanwhile adopt multi-scale strategy in training for accurate detection.
In part 2, we present a brief introduction of deep learning algorithms applied in medical image processing. In part 3, we describe spinal CT images collected from Xijing Hospital(Military Medical University of Air Force) and other hospitals for training and testing. In part 4, we present the improvements of our proposed scheme, which are mentioned above. In part 5, we make comparative experiments and present discussions. Finally, we summarize our work and present next objective in future.
Related work
Now deep learning algorithms are applied in many fields, which also make great progresses in medical image processing and spinal diseases. Sa, R. et al. [2] presented a method to identify landmark points in lateral lumbar X-ray images by fine tuning Faster-RCNN. Ma, S. et al. [3] implemented a deep neural network for MRI to detect lesions caused by cervical diseases by using the ResNet-50 and VGG-16 networks as backbone network to detect lesions from MRI(Magnetic Resonance Imaging) data. Zeybel M. et al. [4] used a multi-stage deep learning system to detect candidate disc positions and identify human lumbar discs from MRI data based on Faster-RCNN. Shinde J. V. [5] had presented a contemporary semiautomatic feature level fusion approach for the classification of inter-vertebral discs, which was used in MR image modality for grading the discs. Masad I. S. et al. [6] presented a fully-automated measurement of the lumbar spine’s lordotic curve angle in T2-MR images, which was based on texture features for recognizing the lumbar-spine pattern. Sa R. et al. [7] had trained a (Support Vector Machine) classifiers on different layers of CaffeNet features to show that deeper the better concept does not hold for task such as intervertebral disc detection. Pan Q. et al. [8] presented an automatic system to diagnosis of disc bulge and herniation which was time-saving and effective so that can reduce radiologists’ workload by using deep convolutional neural networks from MRI data. Mbarki W. et al. [9] developed an automatic system based on deep convolutional neural network which can detect and diagnose herniated lumbar disc effectively. Kafri As Al et al. [10] addressed the central problem of automatic segmentation of lumbar spine Magnetic Resonance Imaging (MRI) images to delineate boundaries between the anterior arch and posterior arch of the lumbar spine. Lamerigts K [11] presented a deep neural network that automatically localizes the lumbar foramina from MRI scans. Zhou Y. et al. [12] automatically detected lumbar vertebras in MRI images with bounding boxes and their classes, which can assist clinicians with diagnoses based on large amounts of MRI slices. Li Y. et al. [13] presented a novel CNN (Convolutional Neural Network) model to automatically and accurately detect lumbar vertebrae for C-arm X-ray images. Li Y. et al. [14] proposed an automatic lumbar vertebrae recognition method which was based on hierarchical recurrent neural network, according to the characteristic of mobile C-arm X-ray imaging in image-guided minimally invasive spine surgery. Tran V. L et al. [15] proposed a multi-task deep neural network, MBNet,which was developed based on new multi-path convolutional neural network for semantic segmentation on X-ray images. A, Pabitra Das et al. [16] introduced a novel deep neural network architecture coined as RIMNet, which was a Region-to-Image Matching Network model, capable of performing an automated and simultaneous IVDs(spinal intervertebral disc) identification and segmentation of MRI images. Iriondo, C. [17] proposed a new methodology using MRI (n = 31, across the spectrum of disc degeneration) that combined deep learning-based segmentation, atlas-based registration, and statistical parametric mapping for voxel-based analysis of T1 and T2 relaxation time maps to characterize disc degeneration and its associated disability. Mbarki, W. et al. [18] investigated the segmentation accuracies of different segmentation networks trained on 730 manually annotated lateral lumbar spine X-rays and compared instance segmentation networks with semantic segmentation networks. Zhang, B. et al. [19] developed a DCNN(Deep Convolutional Neural Network) model to classify osteopenia and osteoporosis with the use of lumbar spine X-ray images as compared to DXA(dual-energy X-ray absorptiometry) measures. Huang, J. et al. [20] developed a deep learning based program (Spine Explorer) for automated segmentation and quantification of the vertebrae and intervertebral discs on lumbar spine MRIs. Lessmann, N. et al. [21] proposed an iterative instance segmentation approach that used a fully convolutional neural network to segment and label vertebrae one after the other, independently of the number of visible vertebrae. Rak, M. et al. [22] proposed an automatic approach for fast vertebral body segmentation in three-dimensional magnetic resonance images of the whole spine. Arif, Smmra, K. Knapp et al. [23] proposed a deep learning-based fully automatic framework for segmentation of cervical vertebrae in X-ray images towards building an automatic injury detection system. Lu, J. T. et al. [24] developed an efficient methodology to leverage the subject-matter-expertise stored in large-scale archival reporting and image data for a deep-learning approach to fully-automated lumbar spinal stenosis grading. Lee, S. J. [25] verified the feasibility of a computer-assisted spine stenosis grading system by comparing the diagnostic agreement between two experts and the agreement between the experts and trained artificial CNN classifiers.
There are some problems in these method mentioned above, such as: 1. These method have not a balance between the detection accuracy and detection speed of spinal lesions, which can not satisfy the clinical demands. 2. The size of receptive field is small, which means we can not extract sufficient feautre information of spinal lesions, so as to detect lesions unaccuractely and mis-detect spinal lesions. 3. The model has not a powerful spinal lesions feacture extraction ability, so as to produce many noises in predicted spinal lesions. 4. It is not possible to correctly achieve spinal lesions information of different sizes, so as to unaccurately detect the spinal lesions and tiny lesions. In this paper, we define a novel framework based on Faster-RCNN to detect spinal fracture lesions from CT images.
Materials
In this section, we describe spinal CT images collected from Xijing Hospital and other hospitals. For the spinal CT images are scanned by different CT equipments, there are some errors and interferences inevitably, even the same spinal fracture lesion can be different due to the differences of scanned equipments. So we should preprocess the CT images of spinal fracture lesions for training and testing.
Data preprocess
The format of spinal CT images is DICOM(Digital Imaging and Communications in Medicine), which contains many information about patients and spinal lesions. In data preprocess, we input the original CT images, make equalization firstly due to the pixels are different which are scanned by CT equipments with different thick layer. Then we use HU(Hounsfield Unit) value to process the CT images, which is a measurement unit for measuring the density of local tissue or organ of the human body. Usually the air is - 1000 and the density of dense bone is + 1000. The HU and the pixels of spinal CT images have a linear relationship and can be switched each other.
In this paper, we select HU value above 400 to extract spinal bones from CT images, then make the [400, 2000] normalized as [0,1] to preprocess CT images. Third, we utilize Gauss Filter to remove the noisy in CT images. Finally, we extract spinal fracture lesion ROI(Region of Interest) by binary segmentation and mathematical morphology to get spinal fracture lesions.
Label spinal lesions in CT image
With help of orthopedic residents in Xijing Hospital, we label spinal fracture lesions in every CT image, then classify as cfracture (cervical fracture), tfracture(thoracic fracture), lfracture(lumbar fracture), by the software LabelImg, which is a graphical image annotation tool and save label annotation as XML files in Pascal VOC [26] format. In Fig. 1, there are some samples of labelled fracture lesions.
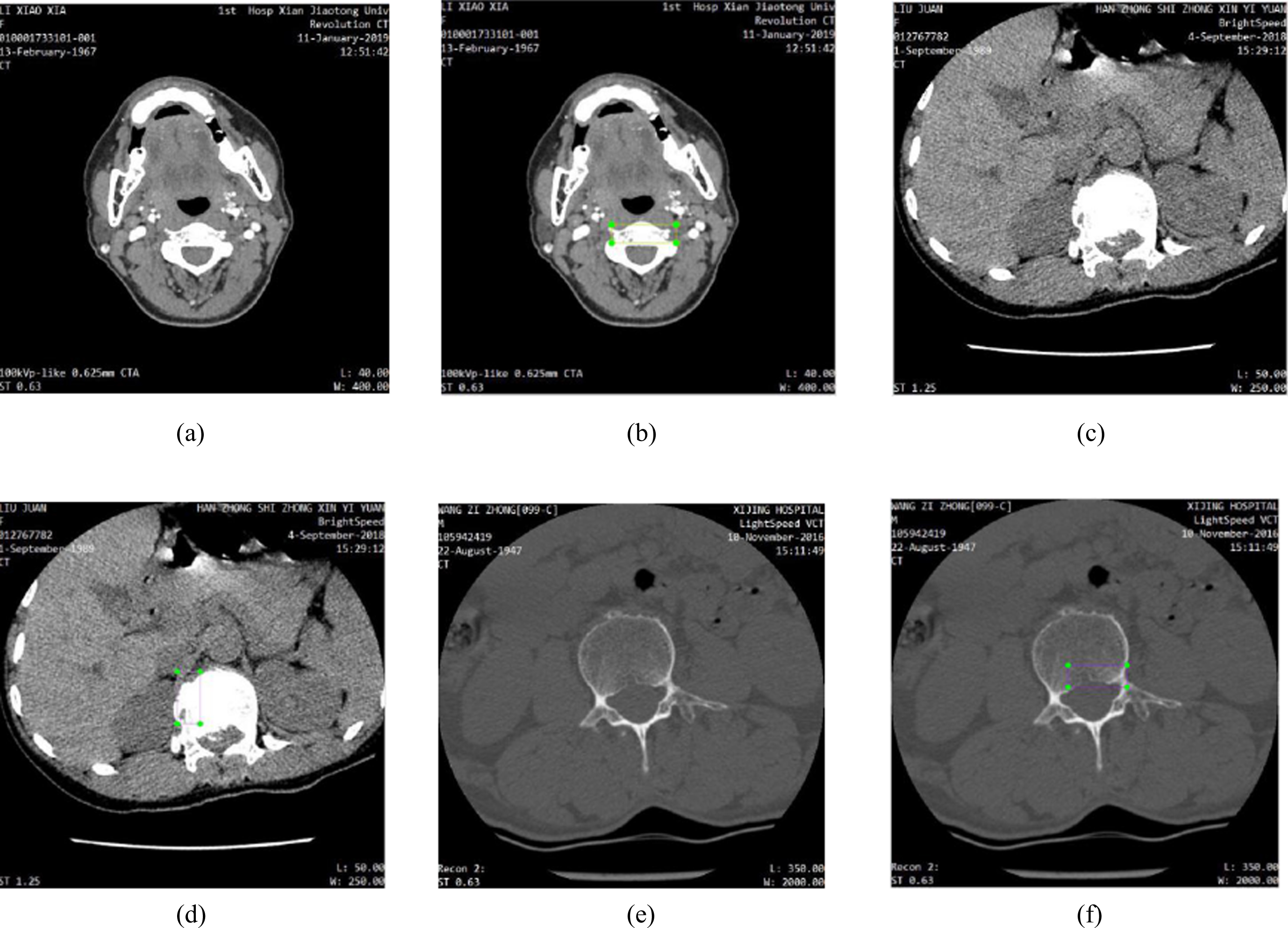
Label fracture lesions: (a) original cervical CT image, (b) cfracture labelled by labelImg, (c) original thoracic CT image, (d) tfracture labelled by labelImg, (e) original lumbar CT image, (f) lfracture labelled by labelImg.
Due to we can not cover all kinds of spinal fracture lesions, we randomly select 40 series of spinal fracture CT images, which consists of 5134 images. There are 1368 CT images of cervical fracture lesions, 2489 CT images of thoracic fracture lesions and 1277 CT images of lumbar fracture lesions.
For deep learning needs a large amount data, we expand our training data set by data enhancement, which rotates the CT image 90 degrees, 180 degrees, 270 degrees, horizontal flip, vertical flip.
We can get more information about spinal lesions after data augmentation through observing lesions from different views. Data augmentation changes the directions and positions of spinal lesions, but the shapes and sizes of lesions are not changed in CT images. The lesions with distinctive directions and positions in CT images are classified as same lesions in training, which is very important to training network.
After data augmentation, the lesions data are expanded to 10268 CT images. We randomly splits data set in accordance with ratio of 4:1 for training, testing and verification, so 80%, 8215 CT images are used for training, 10%, 1027 CT images are used for verification and 10%, 1027 are used for testing.
Methodology
In this section, we describe improvements of proposed scheme in detail, which are highlighted yellow in Fig. 2. First, we replace VGG16 [27] with RseNet50 to increase network depth for improving lesions detection performance, then modify RPN network and choose appropriate anchors, replace NMS with soft-NMS to avoid missed detection of overlapped lesions, and improve the classifier for accurate detection, finally we introduce multi-scale training strategy in training.

Overview of lesions detection scheme based on Faster-RCNN.
We extract feature information of spinal lesions from input CT images. First, the input CT images are normalized as same sizes, then lesions feature information are extracted by backbone network in Faster-RCNN, the lesions feature information are send to RPN and Fast-RCNN to make predictions. In Faster-RCNN, VGG16 is backbone network to extract feature information, VGG16 adopts the 3×3 convolutional kernel in all layers and sets the stride of convolutional layers as 1.
The ways to improve performance of training network either are data augmentation or increase depth of training network. So the depth of training network is very important to optimize training network performance [28]. Also, there are some problems such as disappearance or explosion of gradient emerged when increase depth of training network blindly, which may reduce detection performance. We solve this problem by combining residual unit proposed by K.He et al. [29].
The convolutional blocks with kernel sizes of ResNet50 are, in conv2_x layer(1×1×64, 3×3×64,1×1×256), in conv3_x layer(1×1×128, 3×3×128, 1×1×512), in comnv4_x(1×1×256, 3×3×256, 1×1×1024), in conv5_x(1×1×512, 3×3×512, 1×1×2048) respectively. Every convolution block in ResNet50 contains a number of residual units, each residual unit performs three convolution operations. Residual units and identity [30] shortcut connections can solve disappearance or explosion of gradient and detection accuracy decreases, meanwhile the training network is deepened.
VGG16 mainly performs convolution operations sequentially then sends output to next convolutional layer directly, and has fixed convolutional kernel size. ResNet50 gets next step input after every two or three convolutional layers, which is different from VGG16. The design of Resnet50 follows two rules: one is that each layer has the same number of filters, the other is that the filter number will be doubled if the size of characteristic graph is halved, in order to maintain time complexity in each layer. So ResNet50 can accelerate the training network and improve lesions detection accuracy.
Improve region proposal network
In Faster-RCNN, first,the backbone network locates the a concrete kind of spinal fracture lesion. Second, it extracts lesions feature information from spinal CT images. Then input the feature map to RPN and determines the feature map whether foreground or background by softmax classifier, meanwhile it uses genuine range of spinal lesions to make corrections on proposal region, and generates candidate proposal range of spinal lesions. Finally, the classification network generates spinal lesions detection by feature map and proposal lesions region.
In RPN training, it generates labels for lesions proposal boxes, the positive label is whether lesion proposal box, which is the biggest one for IOU(Intersection Over Union) with genuine area, or the lesion proposal box with IOU is bigger than 0.7 for a genuine area. The other labels which with IOU are less than 0.3, are negative labels and are dismissed.
RPN generates a series of anchor boxes, and every anchor is associated with one scale and aspect ratio, then RPN makes the anchor boxes and outputs into two different output: one is objective score, which means the probability of anchor is one certain spinal fracture lesion, and the other is proposal bounding box score. The anchor scales are 128, 256, 512, anchor box ratios are 1:1, 1:2 and 2:1, so generate 9 anchors in sliding window in traditional RPN. For a feature map with size of 7×7, there are 441 anchors in total, which is shown in Fig. 3.
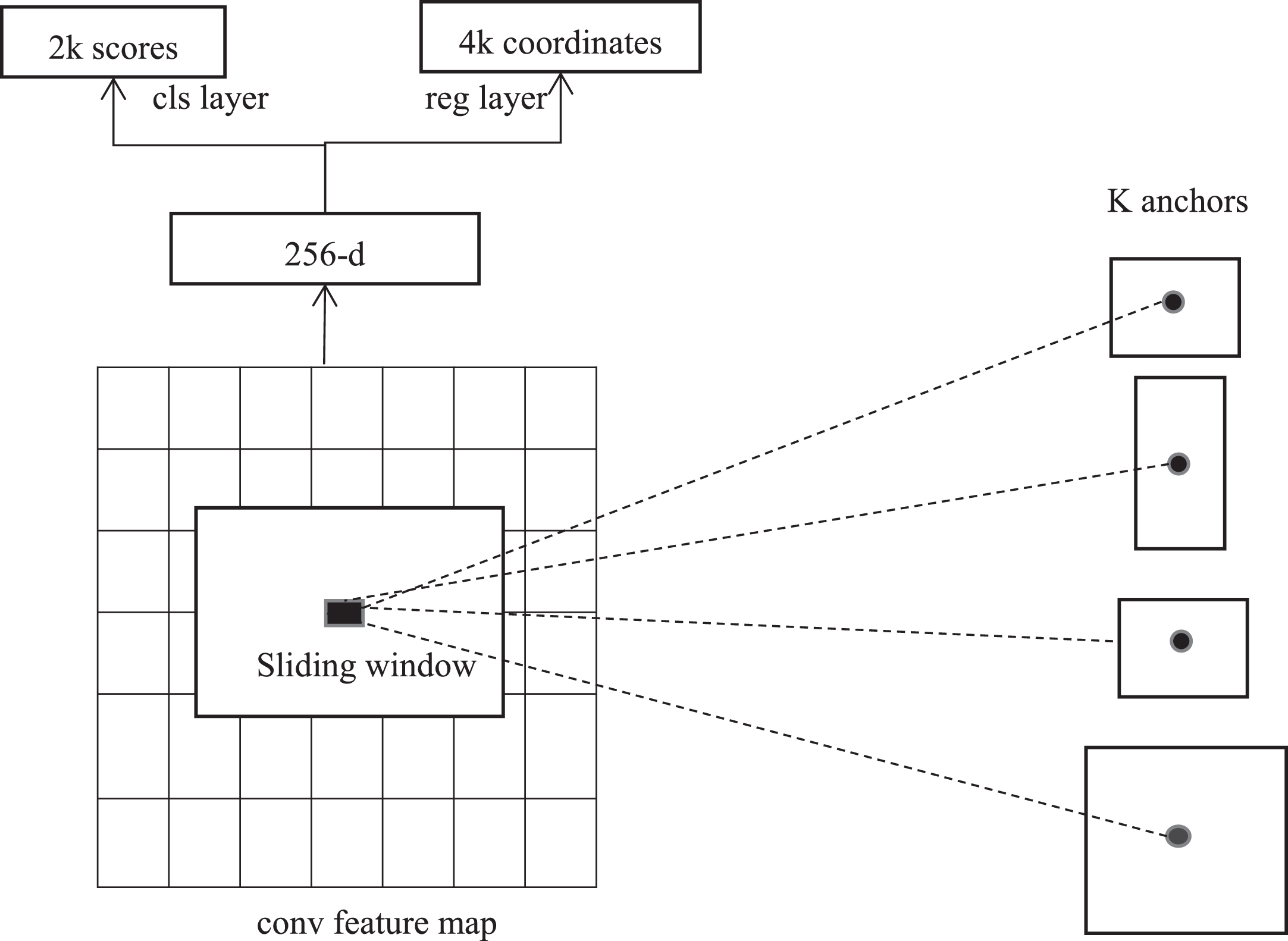
RPN sliding window and anchors [33].
In spinal fracture lesions detection, in order to get more accurate lesions detection and because there are some tiny lesions, we change the anchor scales to 64, 128, 256, 512 to avoid tiny lesions missed detection, due to the anchor box ratios are not changed, so 12 anchors are generated in sliding window, for a feature map with size of 7×7, there are 588 anchors in total, which is shown in Fig. 4.
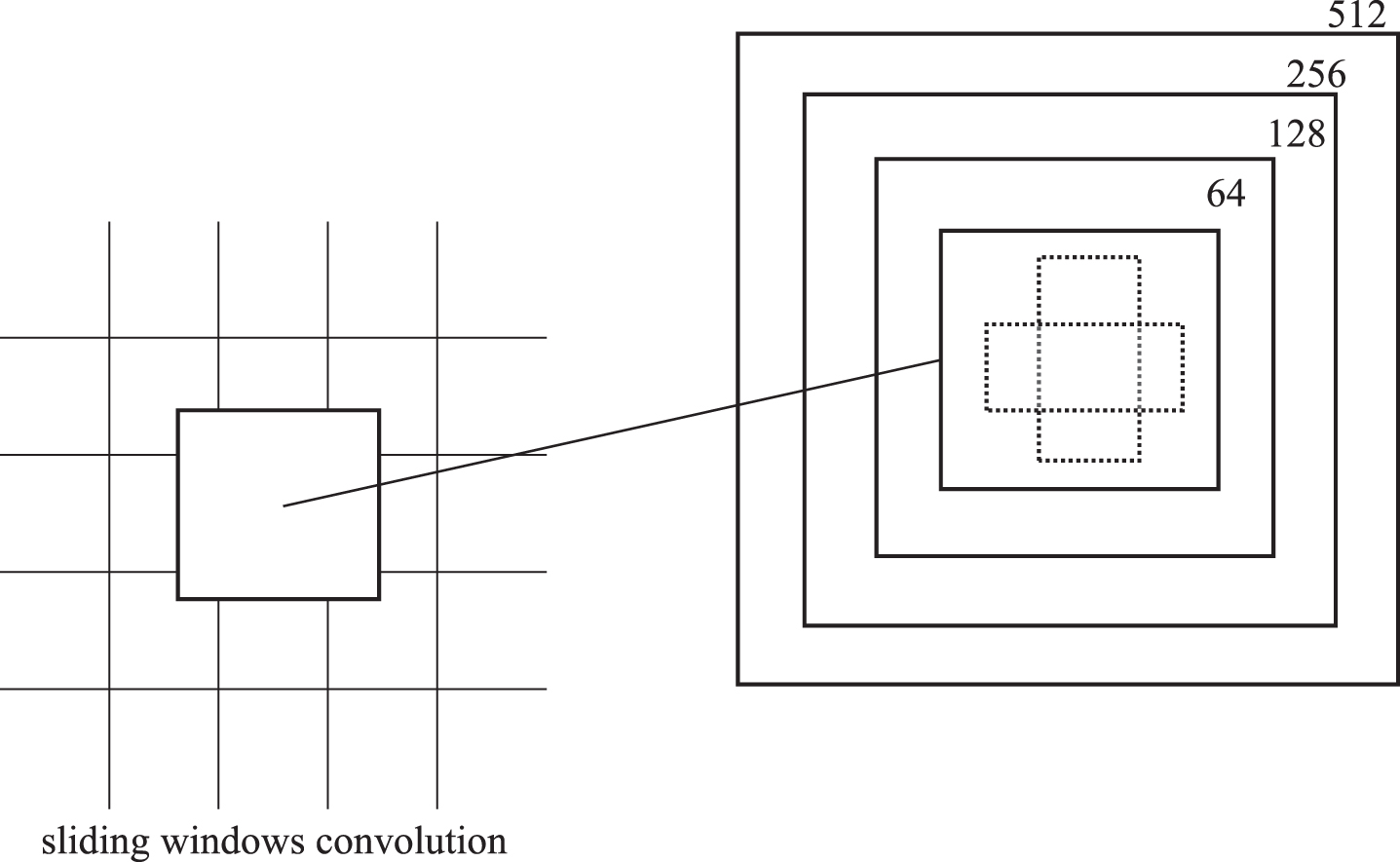
Modified RPN anchors.
The RPN generates many proposal regions, each proposal region means probability of spinal fracture lesion and location information of spinal lesions. The traditional RPN uses 3×3 and 5×5 convolution neural kernels, outputs 256 target feature maps, which is shown in Fig. 5(a). To reduce calculations and accelerate training speed, we simplify the network structure, only use 3×3 convolution neural kernels to generate 256 feature maps, which is shown in Fig. 5(b), these 256 feature maps are used to get 256-dimensional eigenvectors.
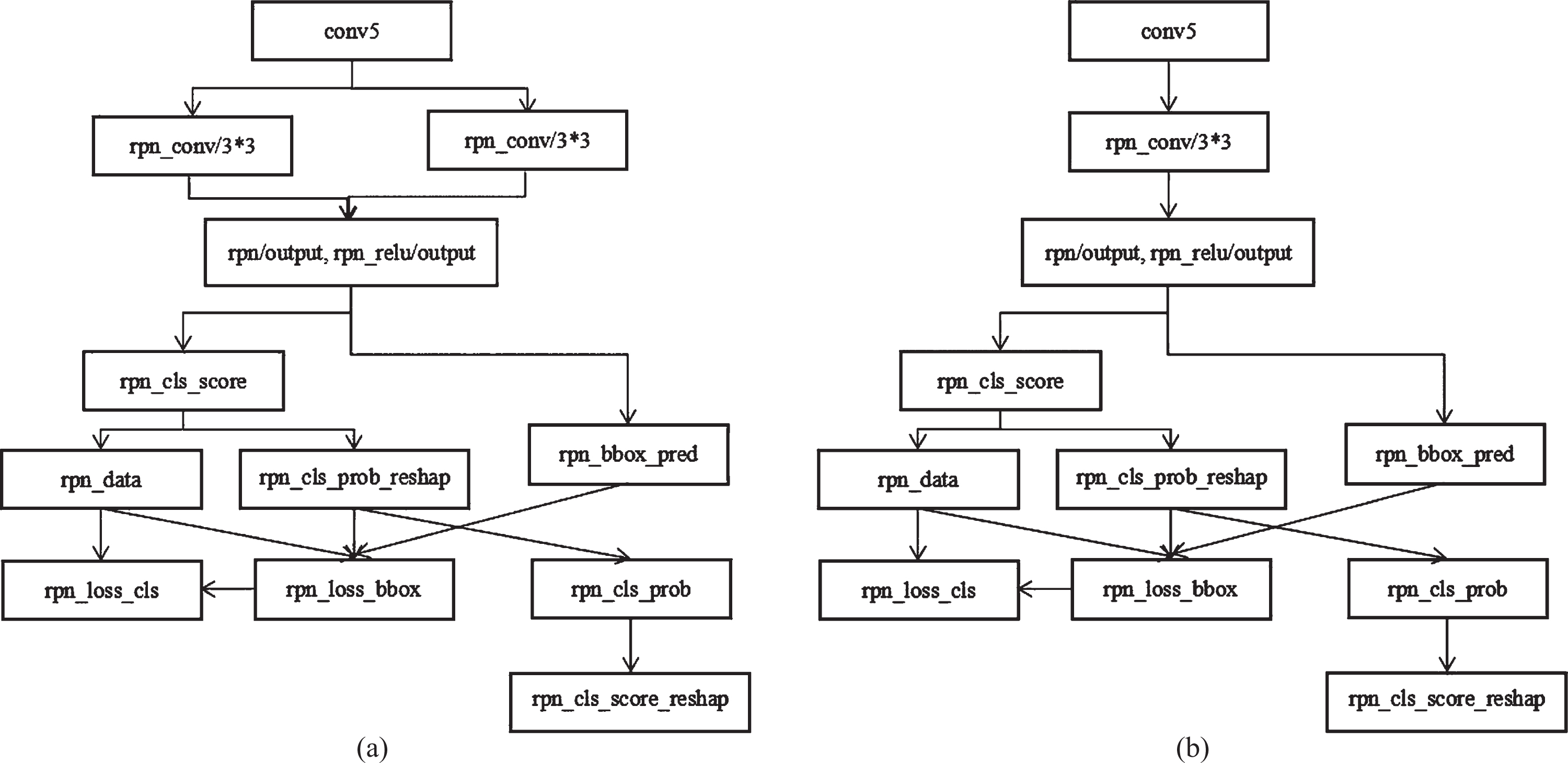
Modify RPN, (a) original RPN, (b) Modified RPN.
NMS(Non-maximum suppression) is very important in target detection algorithms, it sorts the detecting scores of spinal lesion proposal boxes and gets the largest score (e.g. M), then calculates the overlap IOU(Intersection over Union) between the other lesion proposal boxes(e.g. N) and N, if the overlap is higher than the presupposed value(usually 0.7), the lesions proposal box B is removed. NMS repeat this calculating process recursively until finding a appropriate lesion proposal box. The IOU is the overlap between two lesion proposal box A and B, which is Eq.1,
Here S I the intersection area of lesion proposal box A and B, S A is the area of proposal A, S B is the area of proposal box B. The traditional NMS is described as Eq.2,
Here the S i is the score of lesion proposal box, M is the proposal box with biggest score, the b the lesion proposal set, and b i is the ith lesion proposal box in set b,IOU(M, b i ) is the overlap between b i and M, N t is the presupposed threshold value. While the overlap value between proposal box (e.g. L) between M is very high, NMS also removes the lesion proposal box L, which generates a missed lesion detection.
To solve this problem, Navaneeth Bodla [32] proposed the soft-NMS algorithm, which only need to make a simple modification of the traditional NMS, not includes additional parameters and has the same algorithm complexity as the traditional one, the soft-NMS is shown in Eq.3,
The soft-NMS avoids spinal lesion missing detection by attenuating the detection score of adjacent proposal box which overlaps with detection proposal box M.
In this paper, we use soft-NMS in spinal fracture lesion detection to reduce missed detection of overlapped lesions and improve lesions detection performance.
The main goal of ROI(Region of Interest) pooling layer is to pool feature maps with different sizes into feature maps with same size, then output to next convolutional layer. We can transform the bounding boxes into appropriate regions in ROI by the corresponding relationship between feature map information and input CT images, so the feature map of spinal lesions with fixed size are achieved by ROI pooling layer in Faster-RCNN. ROI pooling layer can accelerate spinal lesions detection performance and implement end-to-end training [34].
As we can see in Fig. 2, the modified classifier is in last stage of proposed network and consists of two FC(Fully Connected) layers, one softmax classification layer and one bounding box regression layer. Inspired by the depthwise separable convolution [35], the structure of modified classifier is shown in Table 1, which can reduce computation complexity of backbone network, avoid over fitting and accelerate lesions detection speed than original classifier in Faster-RCNN.
The structure of modified classifier
The structure of modified classifier
The softmax classification layer calculates the probability of spinal lesions or background by feature information transmitted from the first FC layer, and the bounding box regression layer revises proposal bounding boxes of detected spinal lesions by feature information transmitted from the second FC layer.
We can distinguish proposal regions into spinal lesions and background, and regulate bounding boxes for detected lesions. The convolutional layers in classifier are followed with one BC(batch normalization) layer and one ReLu(Rectified Linear Unit) layer.
The loss function of proposed method is defined as follow,
Here, i is the ith candidate proposal box and p
i
the probability that the ith candidate proposal box is spinal fracture lesion. If i is spinal fracture lesion,
Here (x,y) is the center point coordinate for the bounding box, (x a , y a ) is the coordinate of the proposal box, (x*, y*) is the coordinate of the genuine spinal lesion, w and h are the width and height of the bounding box which contains genuine spinal lesion. This algorithm is to find a map between the original proposal box P and a regression proposal box, which is closer to the genuine spinal lesion box G(Ground truth). The loss function of classification is as follow,
The regression loss function is as follow,
Here R is the smooth function defined as follow,
In this paper, we describe the performances of our proposed method by using AP(average precision), mAP(mean average precision), IOU(Intersection of Union), and time T. T is the cost time in detecting one CT image, average precision evaluates the accuracy of detection from the perspective of recall rate and precision rate, which can evaluate the detection performance of one certain spinal fracture lesion.
Here, sensitivity means the percent of accurately spinal lesions prediction, itemized as spinal fracture lesions. specificity means the proportion of correctly non-spinal lesions prediction results. accuracy means the correction rate of detected spinal lesions to the global CT image. TP is true positive which means the correctly detection lesions number. TN is true negative which means detection number of not spinal fracture lesions. FP is false positive which means the not spinal lesions number. FN is false negative which means the number of lesions detected not correctly.
The (Dice similarity coefficient) f1 value is average of precision and recall which can represent accuracy of spinal lesions detection, and it is defined as follows
In this section, we describe the experimental environment, evaluation metrics, experimental results and comparative experiments and discussions.
Experimental environment
The experiments in this paper are performed on Intel Core i7-6700 @3.40GHz×8, memory 32G, GPU GTX1070, Ubuntu 16.04, Caffe, Cuda8.0 and Cudnn6.0. We detect spinal fracture lesions with convolutional neural networks by transfer learning, which means we can use pre-trained weight to our proposed training network model, and gain a better detection performance rapidly.
Experimental results
We randomly select three group spinal CT images, which includes three cervical fracture lesions, three thoracic fracture lesions and three lumbar fracture lesions respectively, the experimental results detected by backbone network with VGG16 and proposed method are shown in Fig. 6 Fig. 8.

The predicted cfracture of backbone network with VGG16 and proposed method, (a), (b), (c) are cfractures detected by backbone network with VGG16, (d), (e), (f) are cfractures detected by proposed method.

The predicted tfracture of backbone network with VGG16 and proposed method, (a), (b), (c) are tfractures detected by backbone network with VGG16, (d), (e), (f) are tfractures detected by proposed method.
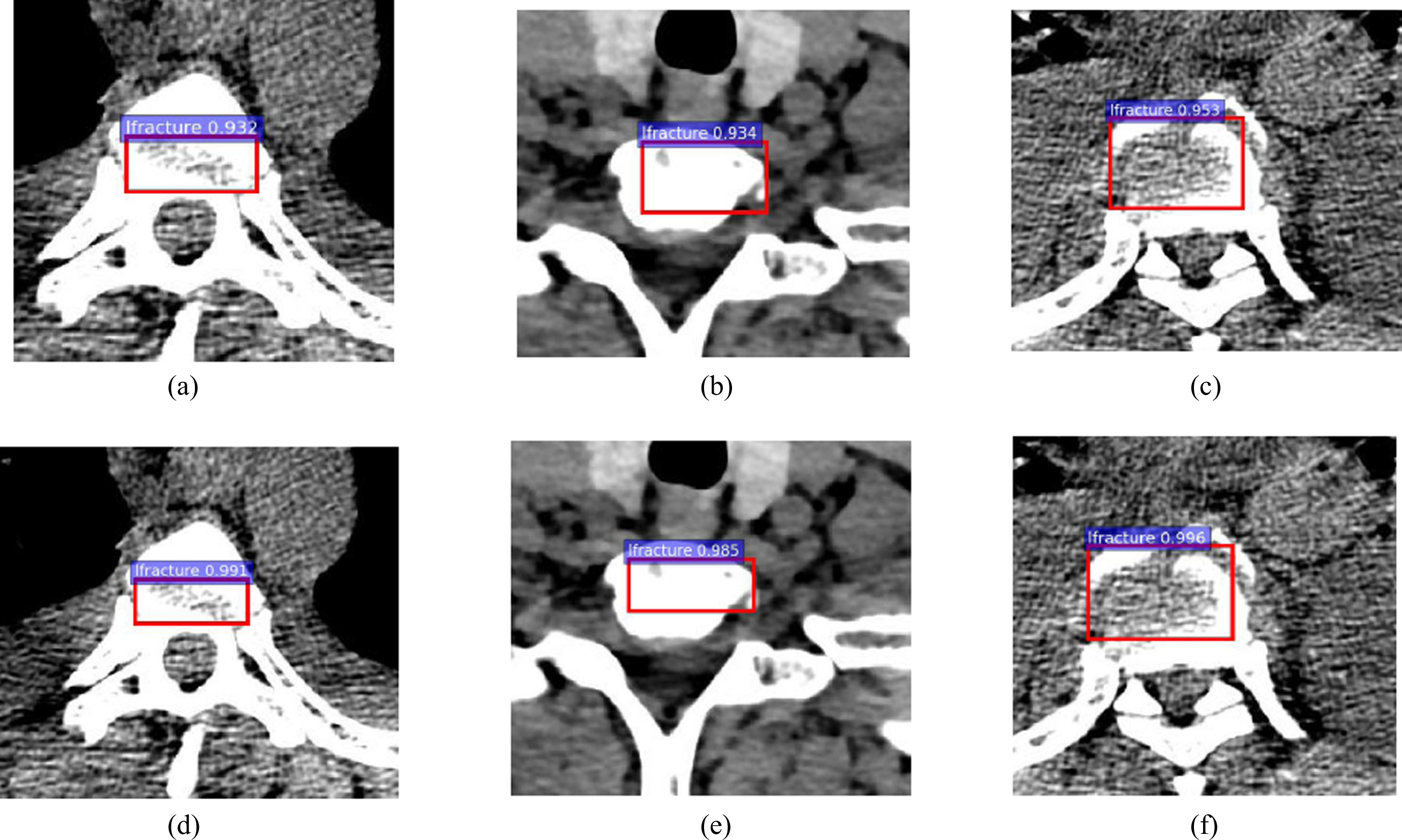
The predicted lfracture of backbone network with VGG16 and proposed method, (a), (b), (c) are lfractures detected by backbone network with VGG16, (d), (e), (f) are lfractures detected by proposed method.
In Fig. 6 we can see that the cfracture lesions detection accuracy are increased by 0.053, 0.066 and 0.068 respectively, in Fig. 7 we can see that the tfracture lesions detection accuracy are increased by 0.072, 0.064 and 0.086 respectively, in Fig. 8 we can see that the lfracture lesions detection accuracy are increased by 0.059, 0.051 and 0.043 respectively.
So the spinal lesions detection accuracy of proposed method are better than backbone network with VGG16 in Faster-RCNN, while the increments of tfacture accuracy are the biggest while the increments of lfracture accuracy are the smallest.
The comparative experiment with different data set
For the robustness and efficiency of detecting lesions by proposed model, we make comparative experiments by proposed method, with different split ratio of data set.
The comparative experiment with different data set
The comparative experiment with different data set
The data set A is that, in the section of 3.3. Data augmentation, we randomly split data set in accordance with ratio of 8:1:1 for training, testing and verification, so 80%, 8215 CT images are used for training, 10%, 1027 CT images are used for verification and 10%, 1027 are used for testing.
The data set B is that, we randomly split data set in accordance with ratio of 7:1.5:1.5 for training, testing and verification, so 70%, 7187 CT images are used for training, 15%, 1540 CT images are used for verification and 15%, 1540 are used for testing.
The data set C is that, we randomly split data set in accordance with ratio of 6:2:2 for training, testing and verification, so 60%, 6160 CT images are used for training, 20%, 2053 CT images are used for verification and 20%, 2053 are used for testing.
As we can that the values of sensitivity, specificity, f1 and accuracy which are trained with data set A are better than data set B and data C.
The reason is that, in data set A, we put 80% CT images in training set, so we can extract more effective and useful lesions information by proposed method for detection. So we utilize data set A in our later experiments.
In Fig. 9, we depict the three spinal fracture PR curves of Faster-RCNN and proposed method, (a) is the PR curve of cfracture by Faster-RCNN, (b) is the PR curve of cfracture by proposed method, (c) is the PR curve of tfracture by Faster-RCNN, (d) is the PR curve of tfracture by proposed method, (e) is the PR curve of lfracture by Faster-RCNN, (f) is the PR curve of lfracture by proposed method.
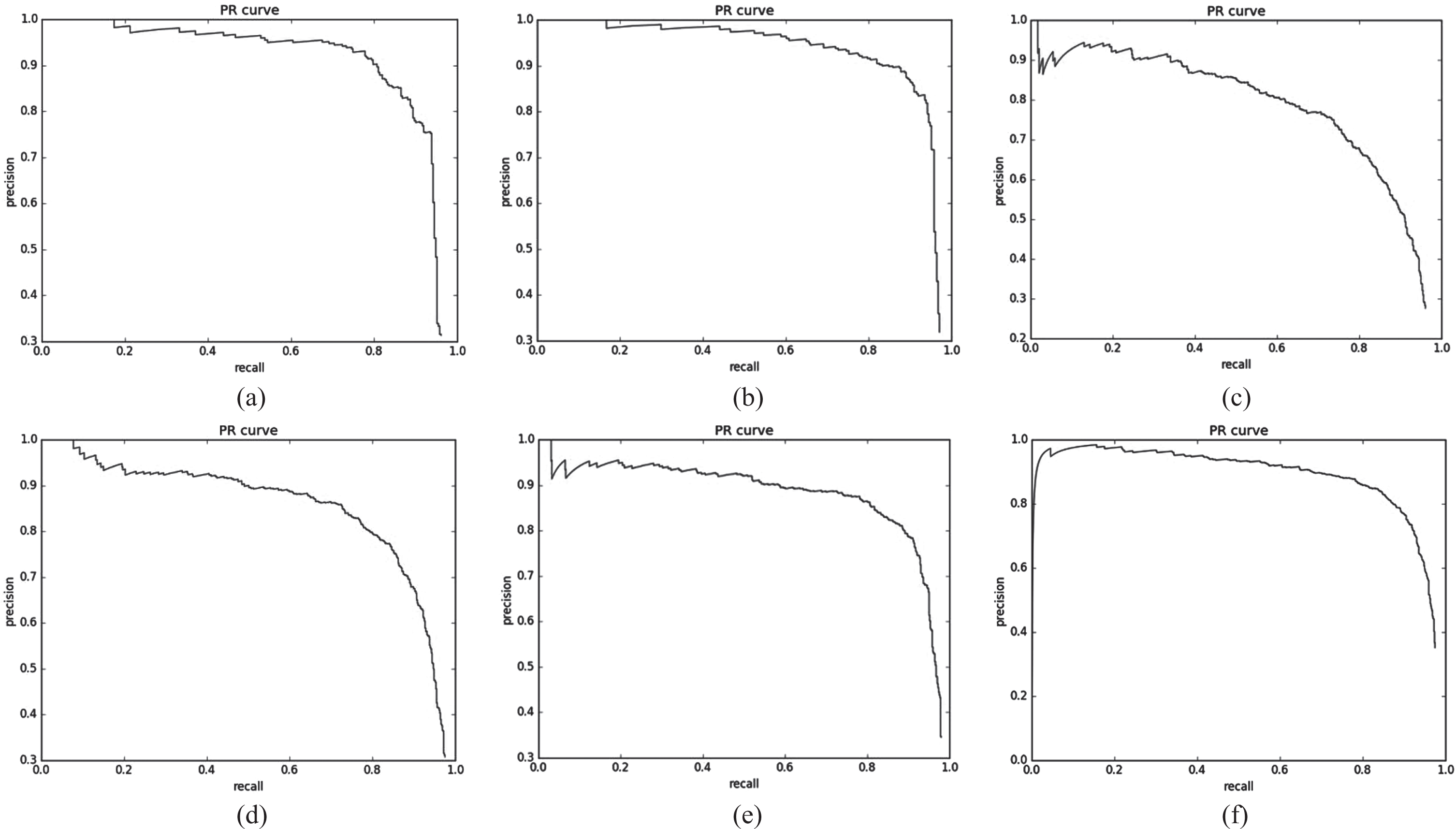
The PR curve, (a) is the PR curve of cfracture by Faster-RCNN, (b) is the PR curve of cfracture by proposed method, (c) is the PR curve of tfracture by Faster-RCNN, (d) is the PR curve of tfracture by proposed method, (e) is the PR curve of lfracture by Faster-RCNN, (f) is the PR curve of lfracture by proposed method.
The criteria for evaluating the performance of PR curve is that, if the area included in PR curve A is greater than PR curve B, so A has a better performance than B. Also we can compare the performance between PR curve A and PR curve B according to BEP(Break Even Point) value while P is equal with R.
As we can see that the PR curves of proposed method are closer to the coordinate of (1,1) than backbone network with VGG16, which means the PR curves of proposed method have greater areas than the PR curves of backbone network with VGG16, so proposed method has a better lesions detection performance.
We present the average loss curves of three spinal fracture lesions detected by Faster-RCNN and proposed method in Fig.10. In Fig.10, (a) is the average loss curve of cfracture by Faster-RCNN, (b) is average loss curve of cfracture by proposed method, (c) is average loss curve of tfracture by Faster-RCNN, (d) is average loss curve of tfracture by proposed method, (e) is average loss curve of lfracture by Faster-RCNN, (f) is average loss curve of lfracture by proposed method.
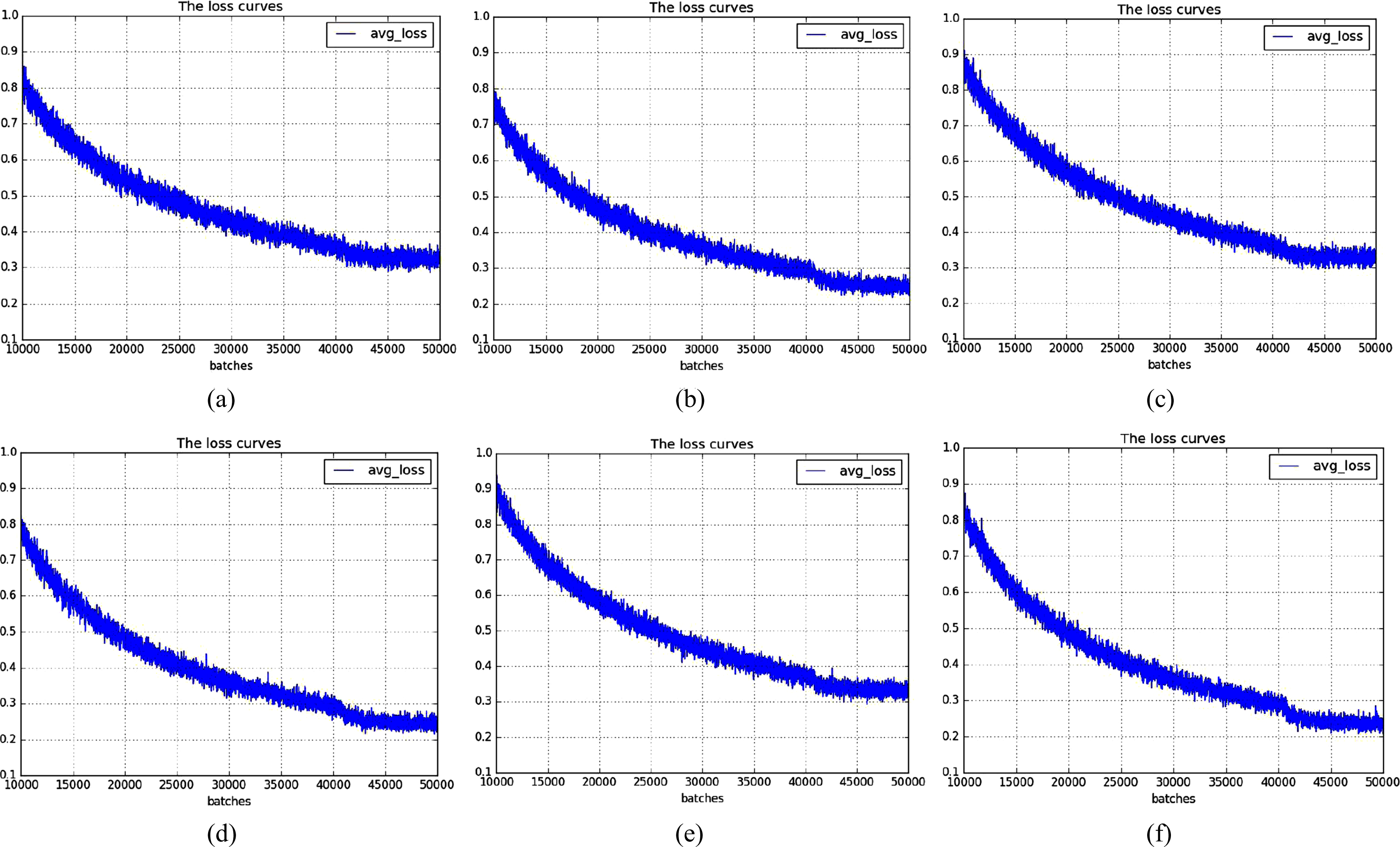
The average loss curve: (a) is the average loss curve of cfracture by Faster-RCNN, (b) is average loss curve of cfracture by proposed method, (c) is average loss curve of tfracture by Faster-RCNN, (d) is average loss curve of tfracture by proposed method, (e) is average loss curve of lfracture by Faster-RCNN, (f) is average loss curve of lfracture by proposed method.
We get that the average losses of three spinal fracture lesions detected by Faster-RCNN are 0.3, and the average losses detected by proposed method are less than 0.3, almost equal to 0.2. The average losses are improved by almost 0.1, due to we replace VGG16 with ResNet50 in backbone network, so we can detect spinal lesions accurately by proposed method.
The reason is that, the lesions detection performances are improved after we deepen training network, to detect lesions effectively and correctly, meanwhile cut down detection errors.
In Table 3, we can see that after replacing the original VGG16 in Faster-RCNN with Resnet50, lesions detection accuracy is increased by 0.018%, from 0.915 to 0.931, and after using the soft-NMS in backbone network, detection accuracy is increased by 0.014%, from 0.915 to 0.929.
The performance of spinal lesions detection model
The performance of spinal lesions detection model
The reason is that after we replace VGG16 with ResNet50 in backbone network, the depth of feature extraction network is increased, so we can get more feature information of spinal lesions. Meanwhile, the residual units and identity shortcut connections in ResNet50 can solve disappearance or explosion of gradient and detection accuracy decreases while the training network is deepened. So we can obtain the best spinal lesions detection accuracy by introducing ResNet50 into backbone network in Faster-RCNN and soft-NMS can avoid missed detection of tiny spinal fracture lesions.
In Table 4, we give a comparison of our proposed method with the state of the art object detection algorithms, such as Faster-RCNN, SSD300, SSD512, Yolov2, Yolov3, Yolov2-tiny, Yolov3-tiny, we can see that the series of Yolo algorithms have a fast lesions detection speed but the detection accuracy is not good, and SSD300 and SSD500 are not accurate by comparing proposed method. So the proposed method have a relative accurate detection accuracy of spinal fracture lesions, which can give assistance for the treatment of spinal diseases. Meanwhile, the detection time in proposed method is the biggest in Table 4, compared to Faster-RCNN, the detection time is increased 0.008 second, from 0.045 second to 0.053 second. Also, we compare proposed model with the algorithms of Ma,S, et al. [3] and Zhou,Y, et al. [12], we can see that, both the methods of Ma,S, et al. [3] and Zhou,Y, et al. [12] are faster than proposed method in detecting lesions, but the value mAP are less than proposed method.
Comparison of different network
Comparison of different network
The reason is that the computation time in RPN layer is increased after we increase anchors number for detecting tiny spinal lesions in sliding window, so the whole time for lesions detection is increased. For the whole lesions detection in proposed method based on Faster-RCNN, this increment of detection time is not great, but we can obtain accurate spinal lesions detection.
In order to verify the performance of proposed method, we use different training strategies to train and test, the results are shown in Table 5. There are 9 anchors in sliding window in traditional RPN, aspect ratio is (1:1, 1:2, 2:1) and the scales is (128, 256, 512), but the dataset in Faster-RCNN is VOC2007 and coco dataset, which has 20 kinds data, so it does not fit the spinal CT images. In this paper, we do not change the aspect ratio with (1:1, 1:2, 2:1), but adding a scale for small spinal fracture lesions and our anchor scale is (64, 128, 256,512), so we get 12 anchors in sliding window in proposed method. As we can see in Table 5, compare the strategy 1 and strategy 5, we can see the mAP is increased by 4.1%, and IOU is increased by 2.9% after we choose the appropriate anchors number. Compare the strategy 5 and strategy 6, we can see the mAP is increased by 1.4%, the IOU is increase by 0.9% after we modify RPN layer. Finally, we get the mAP is 90.6%, IOU is 88.5% at cost of increasing spinal lesions detection time.
The comparison of different training strategies
The comparison of different training strategies
The reason is that we introduce multi-scale training strategy(we set three input scales [400, 600, 800]) to reduce missed detection rate of tiny spinal lesions in spinal lesions detection. In training network, each spinal CT image is randomly assigned a scale to train, while the backbone network has a widely feature characteristic learning ability. The experiments show that multi-scale strategy can reduce the missed detection of tiny fracture lesions and improve the lesions detection performance of training network.
In this paper, we present a framework based on Faster-RCNN to detect spinal fracture lesions from CT images. By replacing VGG16 in backbone network in Faster-RCNN with ResNet50, modifying RPN layer, using soft-NMS and choosing appropriate anchors number and aspect ratio, meanwhile adopting multi-scale training strategy, the proposed method has a good performance in detecting spinal fracture lesions.
The experimental results show that we increase mAP by 5.3%, from 85.3% to 90.6%, IOU is increased by 4.7%, from 83.8% to 88.5%, at cost of the elapsed time of detecting each spinal CT image increases, from 0.045 second per each CT image to 0.053 second.
The spinal CT images used in this paper are all transverse section, so it is inevitable that there will be deviation in description of spinal fracture lesions. In future, we will try to label training data automatically not manually in currently, and study spinal fracture lesions detection in three-dimensional convolutional neural network.
Declarations
Ethical approval
Not applicable
Consent to participate
Not applicable
Consent to publish
Not applicable
Authors contributions
Junsheng Wu contributed to the conception of the study; Gang Sha performed the experiments, contributed significantly to analysis and manuscript preparation and the data analysis and wrote the manuscript; Bin Yu helped to perform the analysis with constructive discussions
Conflicts of interest/Competing interests
The authors declare that they have no conflicts of interest.
Acknowledgments
The project in this paper is supported by Biomechanical Modeling of Lumbosacral Spine and Surgical Evaluation System”, Fund Number Nos. 61172147.