
Abstract
With the evaluation of the software industry, a huge number of software applications are designing, developing, and uploading to multiple online repositories. To find out the same type of category and resource utilization of applications, researchers must adopt manual working. To reduce their efforts, a solution has been proposed that works in two phases. In first phase, a semantic analysis-based keywords and variables identification process has been proposed. Based on the semantics, designed a dataset having two classes: one represents application type and the other corresponds to application keywords. Afterward, in second phase, input preprocessed dataset to manifold machine learning techniques (Decision Table, Random Forest, OneR, Randomizable Filtered Classifier, Logistic model tree) and compute their performance based on TP Rate, FP Rate, Precision, Recall, F1-Score, MCC, ROC Area, PRC Area, and Accuracy (%). For evaluation purposes, We have used an R language library called latent semantic analysis for creating semantics, and the Weka tool is used for measuring the performance of algorithms. Results show that the random forest depicts the highest accuracy which is 99.3% due to its parametric function evaluation and less misclassification error.
Introduction
Automatic software classification in different databases is gaining attraction because it minimizes manual work intensely. Several software depositories have sprung up in the previous era, many of which contain huge volumes of source code and other software artifacts [38]. To the discovering these sources easier, software schemes are classified into different types. Since there are so many people involved in software maintenance, well-organized software repositories benefit them in two ways. Users can choose which features to put in their apps in the same category by grouping apps with similar qualities.Second, users may be able to figure out the problems or issues that are communal to various apps in a similar class and predict the problems or issues of future apps in the same category may encounter. This kind of prediction could be utilized as an excellent control technique to discover common scents or programming problems [1]. To categories software programs, text classification algorithms are typically used; keywords are mined from the source code and used as characteristics. Although automatic categorization techniques may not achieve perfect accuracy, participants can still benefit from classified applications while dealing with software issues and maintenance obligations [30].
Categorization is the ability and activity of recognizing common characteristics or similarities among elements of one’s world experience (such as objects, events, or ideas), and then organizing and classifying that expertise by assigning it to a more abstract collective (that is, a category, class, or type) based on traits, attributes, similarities, or other evaluation [31]. Software categorization and detection of similar software can be beneficial for a variety of reasons, including knowledge exchange, application understanding, and rapid prototyping. To take advantage of open-source projects’ extensive availability and showcase their functionality-based product updates to search engines, automatic classification and categorization of similar software detection approaches are necessary. Automatic software categorization and search for identical applications are critical in two scenarios: Software migration from one platform to another. When their system necessities and implementation circumstances are modified, developers might transfer their applications to different software or hardware platforms [32]. Consequently, application mechanisms and libraries that worked in one environment might not be feasible to the other platform [2, 3]. Alternative software solutions are available for architects and developers to find or build to replace the software that isn’t working.
Automatic categorization is a new technology aimed at limiting the flood of unorganized, unindexed, and unstructured digital content that threatens to suffocate knowledge workers in corporations and government [29]. Auto-categorization software solutions give the capacity to categories digital material according to defined taxonomies, extract ideas and entities for the construction of taxonomies and tag information with subject-related metadata tags. Open-source software repositories like SourceForge.net store massive volumes of source code and software artifacts to make things easier to access and search (text editors, for example, are grouped into categories like anti-virus software, databases, and so on). Systems must be manually classified into these groups by users or administrators based on their functionality [33]. Time-consuming and labor-intensive classification demands an understanding of the software projects’ underlying functionality in the repository. Identifying parallel software projects through several programming languages is difficult for a variety of ins and outs. Consequently, present methods are incapable of cross-language identification or have limited cross-language identification capabilities of linked systems. By the development of the open-source platform the variety of software programs that have been created, an instrument that can discover and categorize similar apps using numerous programming languages would be useful [4].
Three problems are addressed: (1) matching items described on the web with structured annotations, (2) supplementing an existing product database with web-based product data, and (3) sorting items into categories [34]. Extract product attributes from textual descriptions using Conditional Random Fields and Convolutional Neural Networks for these tasks. Generating decision trees classes is a common method in supervised machine learning. A machine learning system is used to input their properties. As a result, the rule generator generates rules for a hypothetical category collection. Latent Semantic Analysis is a statistical way for extracting and visualizing the meaning of words in context from a large corpus of text [36]. LSA can be used for a variety of things, including investigating the human mind. It’s also used for clustering when it comes to data mining. A software system’s components, as well as their recovery linkages from a document to a source. Code clones are replicated code sections that appear throughout the source code in different places [5].
Two separate software systems are defined as the proportion of total lines of code clones to total lines of code the similarity of the full lines of software. In real-world applications, text categorization usually needs a system that can handle tens of thousands of categories spread across a broad taxonomy. Automated text categorization has grown popular due to the time and cost of manually generating these text classifiers. It has gained in popularity over time [35]. The text classification problem is well-served by machine learning-based classification techniques. Text classification or categorization is the process of assigning documents to a predetermined category [6]. A depository is a simple entity on GitHub that commonly comprises the source code and resource records for a software project. The history of the project’s development is archived. GitHub hosts a wide range of projects, including database software, operating systems, gaming, web applications, smartphone apps and much more. GitHub is used by large corporations such as Google, Microsoft, and Facebook to host their open-source projects. GitHub hosts millions of repositories, and many of them provide related functionality [37]. Nonetheless, they are created by a variety of people and organizations. Inappropriately, to the greatest of our familiarity, there is currently no technology on GitHub that can determine the resemblance of depositories. GitHub is a platform that allows you to share and has a search engine to help designers to find out important information amongst the millions of depositories that it hosts [7].
This research seeks to classify and identify manually uploaded source code to determine what category it belongs to. A research gap is how a user understands which category a new source code belongs to once it is published into a repository. To do this a semantic analysis has been performed on the source code by using latent semantic analysis (LSA) in which several keywords and variables are found, these keywords and variables differ in each application. Therefore, We split all keywords and variables into an array of 10 words and stored them by assigning their category. Two classes are created for the machine learning model; one belongs to the application category and the other belongs to application keywords. Many machine learning classifiers were used to categorize software and it proved to be a cost-effective option for software classification.
The rest of the paper is structured as follows. Section 2 presents the related work. Section 3 outlines about the research methodology while Section 4 presents the implementation and results. Section 5 focuses on the discussion. Finally, Section 6 offers conclusions and future directions.
Materials and methods
A new accessible and efficient method to Language Agnostic Program Categorization and related application identification was presented by D Altarawy et al. [2]. The almost 103 applications data set was reused, and a new 5,220 applications data set was created with no labels. The source code of programs is subjected to Latent Dirichlet Allocation (LDA) and hierarchical clustering as part of this approach’s methodology. Individually, the Top-1 retrieved applications had 70 and 71 percentiles, respectively. In this study, Guendouz and colleagues proposed a new method for identifying software called LACT, which uses open-source repositories and systems [8]. First, LACT was put to the MUDA Blue test, which classified 41 software systems in C into issue area divisions. In the second investigation, LACT was expanded to 43 information systems fixed in a diversity of programming languages. The results show that LACT can automatically generate meaningful group names and produce classification results that are equivalent to MUDA Blue. The second study’s outcome indicates that it can be used to categorize information applications without regard to the underlying paradigm programming. Ugurel et al. show how to use automatic machine learning to categorize source code in eleven different implementations and ten different programming languages [9]. Their findings show that enormous repositories of heterogeneous data records, text, and source code can be categorized and categorized automatically.
Linares-V
Prana et al. conducted a thorough investigation that included a manual explanation of 4,226 parts of README files from 393 randomly selected GitHub sections [15]. These parts include a classifier and a set of attributes that may automatically categories repositories and architecture. On the manually annotated dataset, we evaluated the classifier’s effectiveness in identifying the most valuable characteristics for distinguishing the various sorts of sections. Using randomly generated data to use the classes to designate parts with badges in hidden GitHub README scripts and viewing GitHub README files the findings give repository owners a benchmark in contradiction of which they can model and review their files, resulting in more consistent software description.
Velazquez-Rodriguez et al. propose an alternative to automated library categorization trained on class and process names by machine learning classifiers [16]. The approach, which was trained on a huge dataset, can designate a current library type. The method is based on text categorization machine learning algorithms that are trained and validated using a text corpus collected from libraries. The results show that the approach is exact, implying that large-scale apps are possible. Qadir et al. proposed a basic static analysis methodology to first remove the functionality of the android device software groups based on purpose and intent [17]. Whether or not an Android application is found in a database, a list of pre-defined malware is kept. Proposing and implementing a static detection approach for malicious software. As a result, individuals can figure out which applications use functionality that they aren’t supposed to utilize or wouldn’t need. Auch M et al. described a complete literature evaluation for software applications that uses current similarity, categorization, and significance research approaches [18].
Many software projects patterns have been created and cataloged as alternative solutions to a design challenge. In the designing phase of a project, the available automatic algorithms for design pattern selection assist inexperienced software developers in selecting the most relevant design pattern(s) from a list of suitable patterns to address a design challenge creation of software. However, present automated solutions are confined to semi-formal specifications, multi-class problems, sufficient sample sizes for precise learning, and individual classifier training to establish a candidate design pattern class and recommend more relevant patterns [21]. From the literature review, there are numerous approaches mentioned to solve the problem of the categorization of the source code is explained in Table 1.
Recent approaches of software categorization
Recent approaches of software categorization
The research methodology section explains the proposed machine learning approach for classification. It also explains the proposed research methodology in detail, the dataset used, data preprocessing, and approach architecture.
System model
The proposed model consists of two steps, one represents a semantic analysis of GitHub repositories, and the second applies to machine learning techniques that are used for software classification. In the first step, dataset preprocessing, semantic analysis and dataset preparation for machine learning models have been explained. In the second step, selected machine learning models working behavior are described in detail.
Dataset preprocessing
Over 29 million repositories have been created on GitHub by more than 11 million developers from all over the world. In GitHub, a repository is a fundamental unit that generally comprises a software project’s source code and resource files. It keeps track of the project’s progress and high-level features, as well as the people that develop, contribute, and maintain it. Start with a fork and keep an eye on it. We have downloaded almost 150 codes of java language from GitHub which are different codes according to their work, but the language of all projects is the same. We have put all these codes into one folder as depicted in Fig. 2 and we have created an MS Access sheet in which we saved these codes in arrangement as code ID, Project name, Programming language, Author, URL, Main category, and Subcategory as shown in Fig. 1.
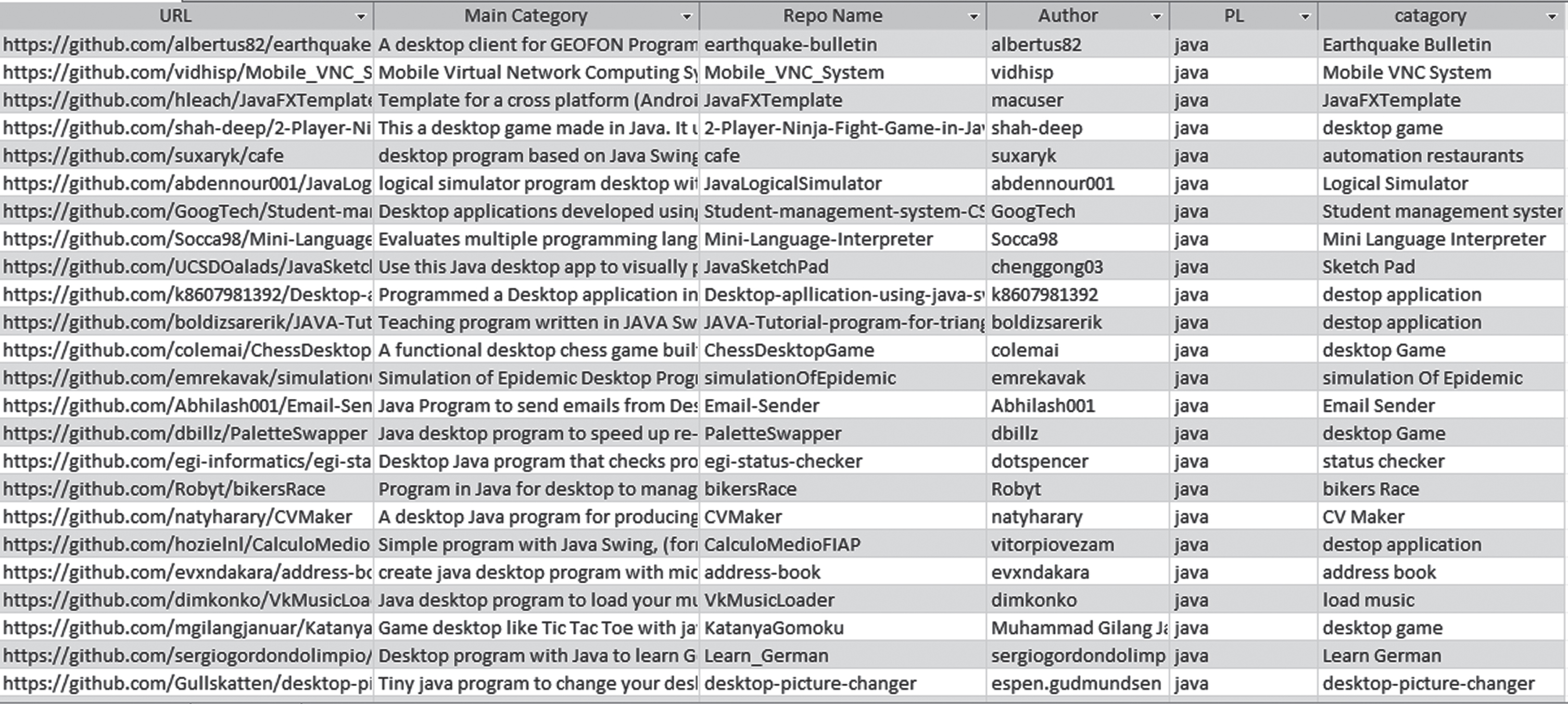
Dataset Gathered from GitHub.
Collection of Applications Folder.
Data preprocessing is implemented for the whole dataset to get the required shape of a dataset. The normalization process is used to equalize the dataset types and the number of required values for further processing. After taking the necessary adjustment, semantic analysis has been performed on the given dataset. The default structure of one application folder is shown in Fig. 3. This structure has a complex nature having multiple folders, their subfolders, and so on. For extracting the values of keywords and variables, the Latent Semantic Analysis (LSA) library has been used. LSA is a singular value decomposition that contains a bag of words by considering the text as a vector space and it corresponds to the semantic structure of a document as shown in Fig. 4. After applying LSA, a CSV file is generated that contains multiple rows and columns, in the first column all keywords and variables are displayed while in other columns their occurrence frequencies are kept in a cell. These columns contain some unnecessary values like empty cells, special characters, and numbers. These values have been removed manually by using predefined excel sheet functions. The dataset cleaning and feature selection based on semantics have been done in this phase.

Structure of Application Folder.
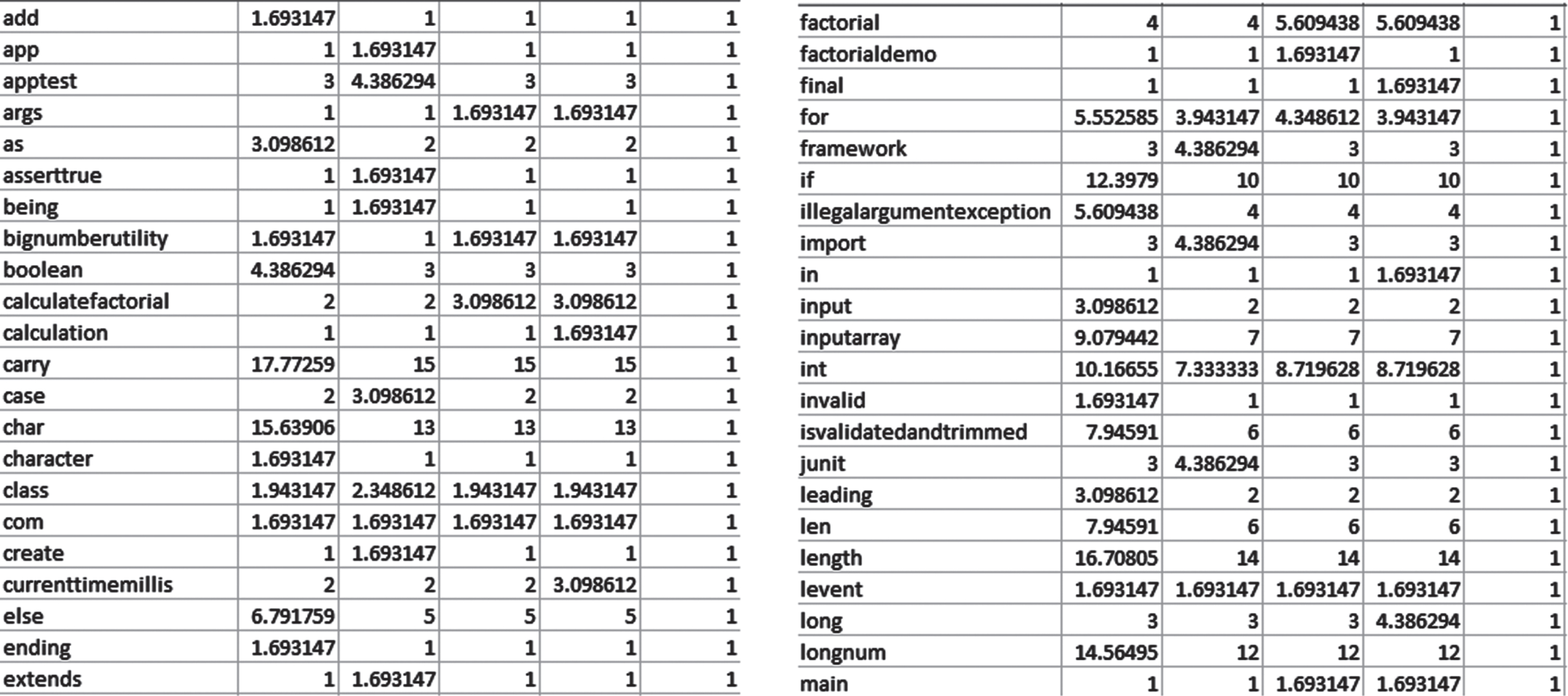
Latent semantic analysis of keywords and variables.
Out of 150 repositories, we are considering 5 major types of a category having more than 30 repositories. These five categories are attendance system, basic calculator, ludo game, ordering system, and desktop applications. As shown in Fig. 5, several keywords and variables are found during the semantic analysis process, these keywords and variables differ in each application. Therefore, we split all keywords and variables into an array of 10 words and stored them by assigning their category. These categories and their keywords are listed in Table 2. In this way, We have prepared our dataset for machine learning models. The dataset is divided into 20% and 80% percentage for testing and training processes.
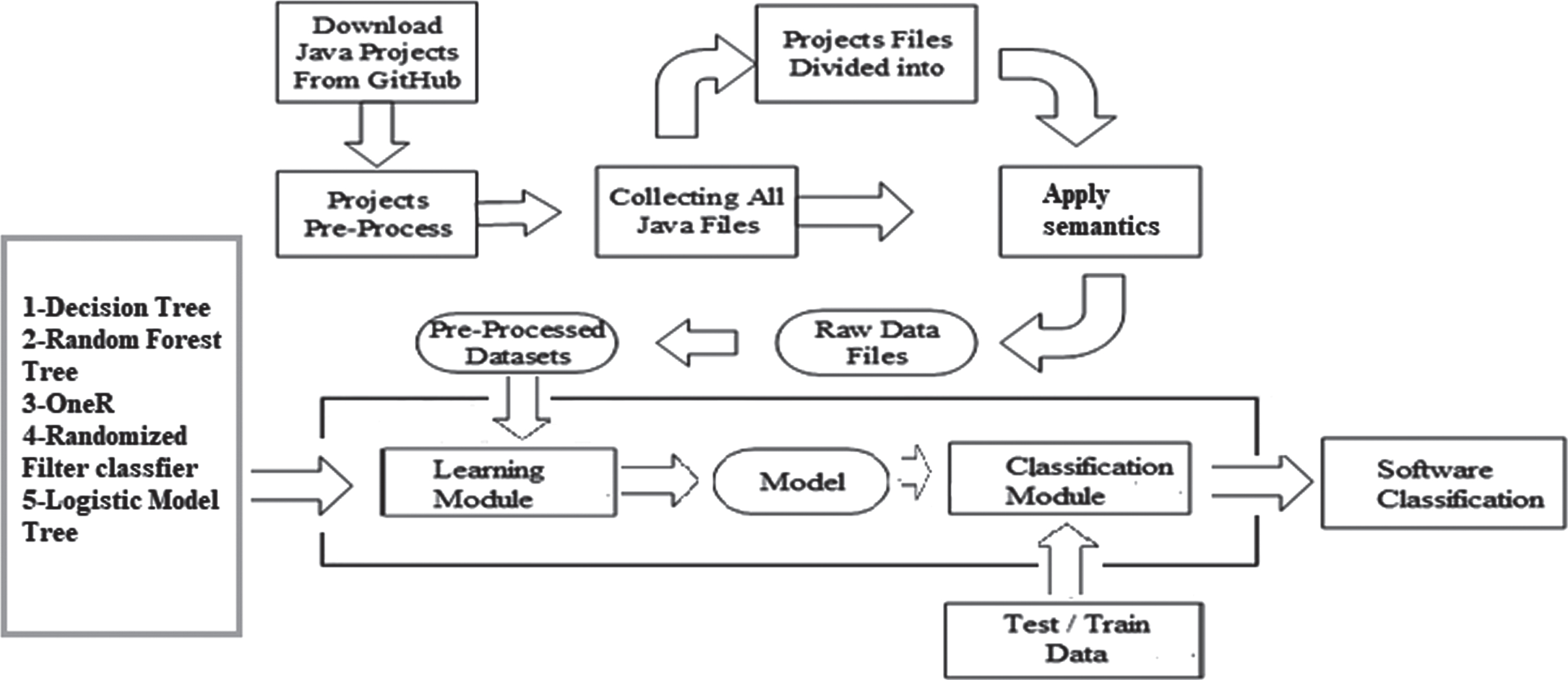
Workflow of the proposed model.
Dataset categories description
Five machine learning classifiers (decision table, random forest, OneR, Randomizable Filtered Classifier, and logistic model tree) are used for software classification. These models used different parameters and protocols to get results on a required dataset for the software classification process. The details of the classifier are given below. Figure 5 shows the workflow of the proposed model.
By generating a set of tasks that describe business-level rules, a decision table is utilized to represent conditional logic. When a collection of requirements must be examined and a specified set of actions must be allocated when the conditions are eventually met, decision tables might be useful. It represents the input values in the tabular form. It is most effective for software testing and initial software requirement management. In our work, it takes software category and classified it into software classification. It gives output in the form of true or false. It works logically against every class of software category and is identified as true against the correctly classified value and false as misclassified value [19].
Multiple decision tree classifiers make up the Random Forests (RF) [20]. In comparison to the DT design, the design can effectively handle the overfitting problem. Rather than making, decision tree it makes forset just taking an average of the prediction values. It works in two parts, one for random sampling of training of dataset, second for random feature selection during the feature classification. It gives output in the form of Yes and No.
OneR stands for “One Rule,” and it is a basic but accurate classification method that generates one rule for each predictor in the data and then chooses the rule with the smallest overall error as its “one rule.” To make a rule for a predictor, We build a frequency table that compares each prediction to the objective. OneR develops rules that are just slightly less accurate than state-of-the-art categorization algorithms while also being easy to understand by people [21]. The abominable filtered classifier is used to randomize the features extracted during the preprocessing phase. This classifier has many filters to classify the features. Based on random features, it takes a classification process [22]. This classifier is the combination of a logistic regression tree and a decision tree. It is also known as MLT having completive resultant values as compared to the other existing techniques. It extracts features during the combination of regression values and decision tree induction [23].
Results
This section briefly explains the results of the implemented methodology. This section covers the discussion about the results and implementation of the proposed method, testing, and training process. The machine learning approach is used for the software classification process. The machine learning approach almost used the five classifiers to classify the software classifications. The Weka tool used to implement the proposed model is with its libraries. The system with 4 CPU, 2.5 GHz, 8GB RAM, and windows operating was used for training and testing purposes
Evaluation criterion
The proposed model used different classifiers for software classification. The evaluation is done with the help of the following equations from 1–7 as mentioned below. The cross-validation process is shown in Fig. 8. True-positive denotes the figure of accurately positive classified images, true-negative characterizes the number of accurately negative classified images, false-positive denotes the number of inaccurately positive classified images, and false-negative characterizes the number of incorrectly negative classified images. The recall, accuracy, and precision were used to measure the model’s output. The MCC shows the Mathews Correlational coefficient
The cross-validation shows the dataset shuffling into different groups to make it feasible for the training and testing process. It provides preprocess data to the trained model for evaluation as display in Fig. 6.

Workflow of the cross-validation process.
The evaluation of proposed method metrics is given in Table 3 and the graphical representation of correctly and incorrectly classification of applications are shown in Fig. 8 in the form of confusion matrix. The decision tree classifier shows the lowest result because this algorithm does not consider a complete process for all the test cases, and it must be feed with more details for all the cases. The random forest reduces overfitting and improved results as compared to decision tree. OneR accuracy is slightly different from random forest because it generates only a one-level decision tree. The randomized filter classifier has an average result due to the random values assigned during the classification process the logistic model tree is simple and having less parametric functionality and performs well as compared to random forest.
Evaluation Metrics of Proposed Models
Evaluation Metrics of Proposed Models
The results in Table 4 show the comparison of classifier results on the software classification dataset. The decision table classifier shows the lowest accuracy of 85.3% because this algorithm does not consider the complete process for all the test cases and it has to be feed with more details for all the cases. The second-lowest is the randomized filter classifier with an accuracy of 90% due to the random values assigned during theclassification process. OneR accuracy is slightly different from 98.9% because it generates only a one-level decision tree. The random forest: 99.3% and a logistic model tree: 99% have almost the same accuracy with minor differences because random forest reduces overfitting and improved accuracy as well while on the other hand logistic model tree is simple and having less parametric functionality. The graph in Fig. 7 shows the accuracy comparison graph. The graph represents the lowest and highest values of accuracies.
Proposed Model Accuracy Comparison
Proposed Model Accuracy Comparison
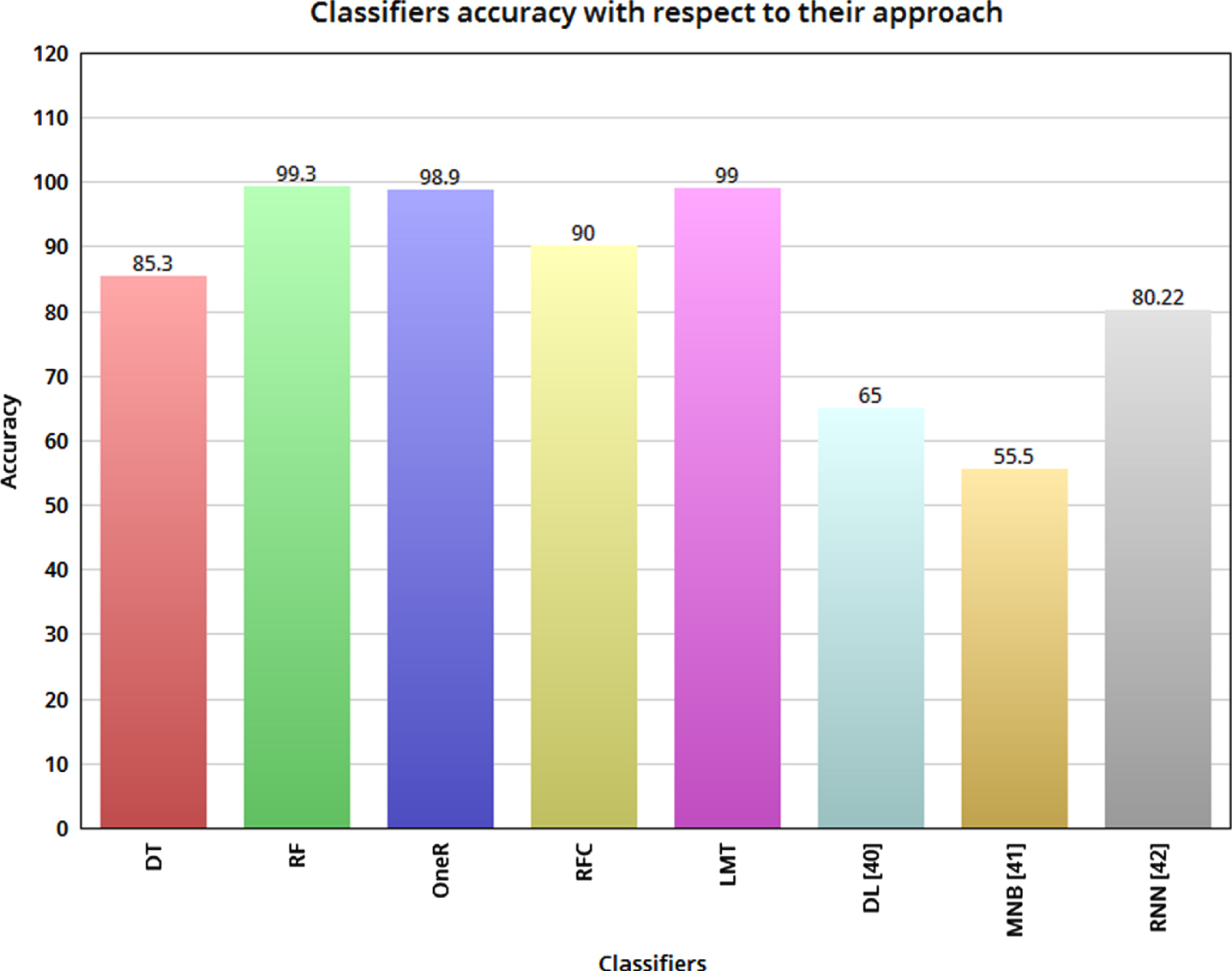
Graphical representation of classifier accuracy comparison.
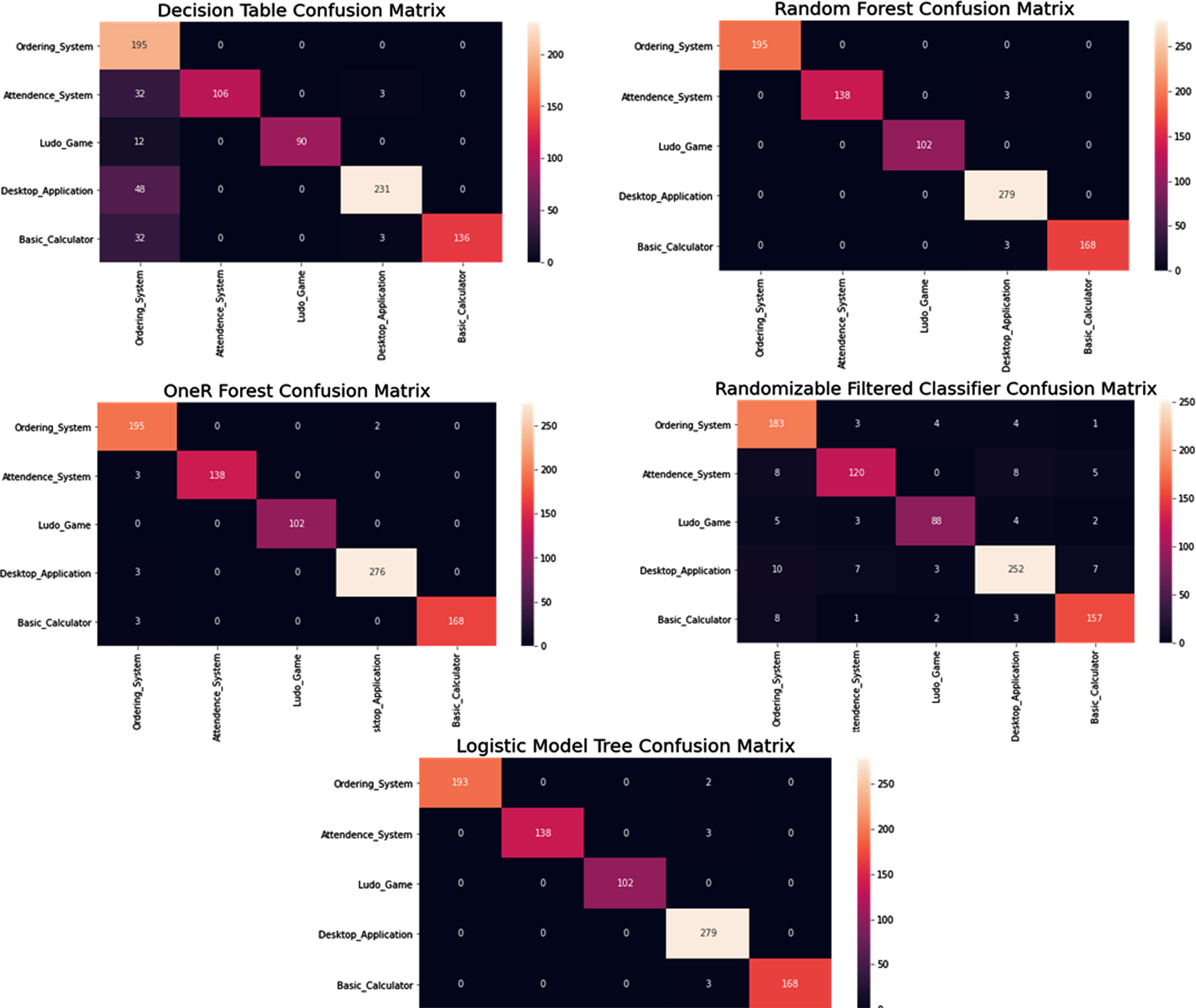
Confusion Matrix of Proposed Models.
This work seeks to a sustainable software process by using multiple machine learning approaches for software classification. For extracting the values of keywords and variables in applications, the LSA library has been used. LSA is a singular value decomposition that contains a bag of words by considering the text as a vector space and it corresponds to the semantic structure of a document. Afterward, the proposed approach used almost five classifiers named as decision table, random forest, OneR, Randomizable Filtered Classifier and logistic model tree to evaluate the model. The model evaluation is done on software classification dataset after preprocessing of dataset. The model evaluates the accuracies as decision table: 85.3%, random forest: 99.3%, OneR: 98.9%, Randomizable Filtered Classifier: 90.0% and logistic model tree: 99.0%. The random forest depicts the highest accuracy which is 99.3%, due to its parametric function evaluation and less misclassification error. The Decision table explain the lowest accuracy which is 85.3% due to misclassification error and less parameter used in the evaluation process. Therefore, based on accuracy values the random forest classifier is the best one for software classification process.
As a future work, we will analyze the resource utilization of same type of applications by adopting mainfold machine learning algorithms.