
Abstract
A robust collaborative system of active products (a product is called active when its ownership does not get transferred from provider to requestor at the time of its usage) should have an in-built mechanism which can make entities (service provider(s) and requestor(s)) to decide with whom to collaborate. In the absence of such a mechanism, the system is bound to have high job failure rate, resulting in wastage of resources. This paper proposes a Trust based Multi-Agent Framework (TbMAF) for collaborative systems of active products which enable only trustworthy entities to collaborate, safeguarding both users’ sensitive applications and providers’ resources. The trustworthiness of service provider(s) and requestor(s) is computed using Fuzzy Inference System (FIS) and Radial Basis Function Neural Network (RBFNN) methodologies, respectively. A prototype based on the proposed system has been tested using real time data of a collaborative system namely, EGEE (Enabling Grids for E-science). This paper finds evidence that the job failure rate is lower when collaborations take place only between trustworthy entities. Further, the proposed framework is found to be robust against malicious entities and can capture the evolving behavior of entities as well.
Introduction
Globalization of services, infrastructure and advent of new technologies (Cloud Computing, Internet of Things, Decision Support Systems etc.) have made collaborative systems a norm rather than practice. In simple words, ‘collaboration’ is said to take place when entities work together towards a common goal. Various studies [1] based on relationship of entities ascertain that no entity can exist in isolation, and it needs to collaborate for existence. One such advantage of collaboration is the ability to harness the large number of resources/services. Despite this advantage, entities (service provider(s) and requestor(s)) hesitate to work together (collaborate) [2, 3]. Major reason for non-collaboration between entities is their inability to manage risks when interacting and collaborating with previously potentially unknown entity. This risk increases multifold if the service/resource, involved in collaboration, is active. An active product is defined as the product whose ownership does not get transferred from provider to requestor at the time of usage, contrary to passive products where requestor becomes the owner of the service/resource by purchasing it. Hence, active product necessitates its provider to verify the authenticity of the requestor before collaboration because any damage done by the requestor to the product ultimately results in a loss for him.
In the absence of an assurance and a central authority to dictate collaboration rules, entities are concerned about integrity and security of their sensitive resources. The requestor’s concern is due to the fact that their application may get hosted on a malicious provider’s resource and the provider’s main concern is regarding protection of resources from malicious users.
Trust is perceived as a fundamental factor in human relationships enabling collaboration to happen between strangers to reduce risk. Thus, trust can be used to effectively guide collaborations where entities are previously unknown, and their resources and/or applications are at stake. Employing the concept of trust implies that collaborators can ascertain trustworthiness of each other quantitatively.
This paper proposes a comprehensive Trust based Multi-Agent Framework (TbMAF) for collaborative systems of active products which will enable only trustworthy entities to collaborate, safeguarding both, requestors’ sensitive applications and providers’ resources. In this work, we used Fuzzy Inference System (FIS) and Radial Basis Function Neural Network (RBFNN) to compute trustworthiness. FIS based on fuzzy set theory is used to compute the trustworthiness of providers and to handle the uncertainty present in the data. On the other hand, RBFNN, a special neural network, is used for computation of trustworthiness of the requestor(s). It is employed due to its advantages such as fast learning ability, high classification accuracy and quick responsiveness etc. This research thus adopted a multi-method design for trust computation of entities and deemed to be able for providing a richer understanding of the successful collaboration in the system. Our work targets collaborators of active products where each of the entities (Requestor, Service provider) has the capability to harm the other. The proposed framework was tested on real time data of a collaborative system, EGEE (Enabling Grids for E-science). Experimental results show that the framework is robust against maliciousness of the recommenders and is also able to capture the real evolving behavior of service providers.
Key contributions
The main contribution of this paper is as follows: It allows the collaborating entities to evaluate the trustworthiness of each other and helps in deciding with whom to interact (requestors can select trustworthy providers and providers can select trustworthy requestors). It makes the collaborative system robust that is less prone to job failures and hence saves the resource wastage.
Rest of the paper is organized as follows. Section 2 details related studies. The proposed framework is discussed in section 3. Section 4 details experimental study and results followed by conclusions and future work in section 5.
Related study
The models, present in the literature, to compute trust can broadly be classified as Enforcement models and Prediction models [4]. On one hand, enforcement models enforce the trustworthy behavior into entities by giving them reward/punishment whereas prediction models only select the trustworthy entities for collaboration by predicting their behavior. Focusing and referring only on the latter type of models, it was found that for prediction of trustworthy behavior of the entity different sources of information are being used. [5] proposed a model based only on entity’s past behavior interaction records collected as direct experience (firsthand information) arguing that referral information may pollute the prediction due to the malicious nature of recommenders. The model which gave importance to referral information while predicting the trustworthiness also became popular such as, CRM [6]. To combat the uncertainty factor from the referral recommendations, different techniques are used in the literature. Fuzzy systems also get used in creating a reputation-based model for distributed systems (called PATROL-F) [7] for recommender systems [8]. Some studies also took different parameters into account for predication of trustworthiness such as relationship and similarity among entities [9], perception of the trustor’s about trustee [10], nationality [11] [12], gender [13] etc. An adaptive trust model for service-oriented systems is presented in [14] in which honesty, cooperativeness factors were taken for computation of trustworthiness of nodes, however the dynamicity of the behavior of the nodes is not considered. [15] considered maliciousness of the nodes while proposing the system but does not consider social relationships which is an essential component for systems basedon trust.
The contribution of the proposed work among other studies is proposing the framework for a collaborative system of active products where each of the collaborative entities is vulnerable in collaboration. Cost- service duration, trust relationship and time are the factors considered to compute trustworthiness which makes the system more robust.
Hence, understanding the distinguishing feature of collaborative system and its need of robust framework where collaborators of active products should feel safe, gives us a motivation for proposing a comprehensive Trust based Multi-Agent Framework (TbMAF) after completing a contemplative study.
Methodology
The proposed framework Trust based Multiagent Framework (TbMAF) is built following the notion of human society where trust is used by the people to safeguard themselves from the damage of collaboration with unknown people. Similarly, in our system trust is computed based on which collaboration decision is taken.
In TbMAF, every user is represented by an agent. The agents present in the system, take the role of requestor, provider or recommender depending upon the requirement at that instant of time, and exist in a virtual community called ‘web of trust’ which is continuously evolving. In TbMAF, the web of trust among agents is used to get recommendations about trustworthy service providers whereas service provider agent’s own experiences with requestor/customers is used to get trustworthiness of the requestor.
The TbMAF is designed to function in two phases namely SelTrSP (Selection of Trustworthy Service Providers of active products) and DetTrR (Determination of Trustworthiness of Requestor). The functionality of the proposed framework with given two phases is depicted in Fig. 1.
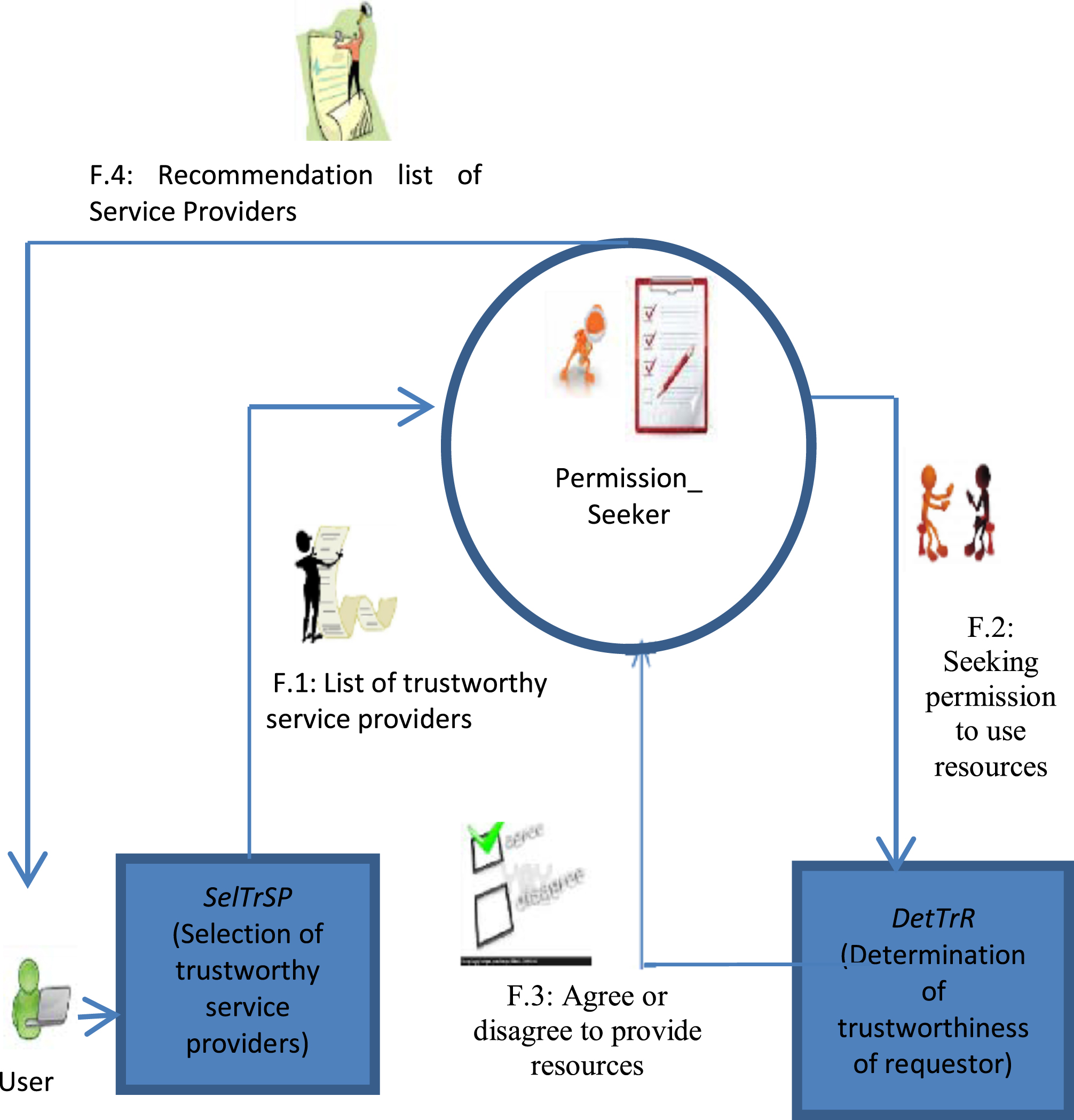
Functioning of the system (TbMAF).
Figure 1 shows that after eliciting the preferences of the requestor of active products, SelTrSP (first phase) of the framework provides a ranked list of trustworthy service providers, marked as F.1 step. This list of trustworthy service providers is given to the permission_seeker module to know whether the providers, present in the list, are interested in providing the services to the requestor or not. So, for each of the providers present in the list, the module, permission_seeker sends the request seeking its permission to acquire the services, marked as F.2 step. After receiving the request, the providers’ agent computes the trustworthiness of the requestor by using the components designed for that purpose in the second phase. Based on the computed trustworthiness of the requestor, providers’ agents send “access is denied” or “access is permitted” to the permission_seeker module, marked as F.3. On getting the reply from the requested providers’ agent, permission_seeker modifies the recommendation list, marked asstep F.4.
In this way collaboration only among trustworthy entities will take place. The phase wise description of the TbMAF is detailed in coming sections.
Various modules such as Recommendation Manager; Fuzzy Trust Evaluator; Boot Strapper; and Trust Updator, are designed for the first phase which work in a cohesive manner to help the requestor in selection of the trustworthy providers of active products. The workflow diagram among all these modules is depicted in Fig. 2.

Modules used in selection of trustworthy service providers (First Phase – SelTrSP).
In Fig. 2, when the user/requestor specifies query to its agent (mentioned as UA1) with the goal of finding the trustworthy service providers for accomplishment of his/her task, then the agent first, calls the Recommendation manager module (shown as U.1 step) to form a query from those specifications and calls Recommendation requestor to pass it to its trustworthy acquaintances to get recommendations. The information about trustworthy acquaintances is obtained using the database (Information Repository) maintained by the user agent, shown as U.2 step. The trustworthy acquaintances may further take recommendations from their acquaintances and so on, depending on hopcount value, shown as U.3.
The generated query is also passed to Recommendation collector, shown as U.4. It collects the recommendations from requested trustworthy acquaintances, marked as U.5. All the collected recommendations are sent to the Recommendation aggregator module for aggregation of direct experiences and referral recommendations of agents, as shown by U.6. The Recommendation aggregator module further sends the aggregated recommendations to Fuzzy trust evaluator module, marked as U.7, to handle uncertainties and compute the reputation of the recommended service providers, which are finally, placed in a list, and marked as U.8. The specifications for each of the modules is given below.
The Recommendation requestor module first, generates the request vector by taking service demand requirements from the user. The request vector in our work consists of n requirements that are specified by the requestor, R = <r1, r2, r3, ... ,rn>, for which a 5-tuple query is generated as Q = <qid, Acquaintance_agent_id, Requesting_agent_id, R, hopcount>to be sent to trustworthy acquaintances for recommendations where qid is the unique identification number of each query and hopcount, is specified by the user agent initially, decremented at each acquaintance before further sending query to their acquaintances for recommendations.
Recommendation collector module collects recommendations based on Q from the requested trustworthy acquaintances and sends it to recommendation aggregator module for further processing. The collected recommendations, representing experiences of acquaintances on various service attributes acquired either after direct experience with service providers or through referral recommenders, is calculated using Equation 1.
here w1 and w2 are the weights assigned to direct and referral components present in the recommended aggregated service attributes such that w1 + w2 = 1 and w1, w2 ∈ [0, 1],
DEC (s
ix
(t)) represents the direct component corresponding to ith service attribute of service provider calculated using Equation 2, and REC(s
ix
(t)) represents the referral component corresponding to ith service attribute of service provider which is computed using Equation 5.
Here, s
i
represents the ith service attribute as experienced by agent x after direct interaction with service provider. x is the recommender agent. t represents the time of recommendation. w represents combined weight obtained due to the two factors (Cost-service duration factor (f
sd
), temporal-effect factor (ft),) and used as average i.e.
Cost-service duration factor (f
sd
) in the study is taken because active products are involved in collaboration among entities, the usage duration and cost spent for active products affects the direct experience component. That is the products which are used for longer duration and are expensive normally, increase the interactions of recommender(s) with service provider(s) and hence its experience about service attribute(s) of provider(s). Hence, to capture this cost and duration aspect of active products, Cost-service duration factor (f
sd
) is computed mathematically using Equation 3 in TbMAF.
Here, slope of exponential curve is controlled by the constant β which is application cost dependent and the total time for which the services are used is represented by T t .
Moreover, Temporal-effect factor f
t
is taken as an exponential function based on the fact that trust decays with time therefore, old interaction records contribute less than the recent records, computed using Equation 4.
α is a variable which is application dependent and can be adjusted according to application requirement, i.e., if past interaction is still a valuable source of information, then assign smaller value to α, otherwise more emphasis on the recent information can be given using large value of α. t is the time of the recommendation, t i is the time of interaction.
The computation of the referral component present in Equation 1 is done using Equation 5.
Where no_acq stores the number of trustworthy acquaintances of agent x. s i denotes the ith service attribute as recommended by trustworthy acquaintances and trust level of agent x on its k trustworthy acquaintance is represented by t _ l k .
The aggregated service parameters, computed using Equation 1, provided by the recommendation aggregator module to the requestor agent, represent experiences of various trustworthy acquaintances agents and contain a lot of fuzziness and vagueness. So Fuzzy inference system (FIS) is employed to quantify subjectivity, vagueness and uncertainty from those aggregated attributes recommended by recommenders [16]. Using those aggregated attributes, FIS helps in computing a metric called reputation, based on personalized and adaptive fuzzy rules given by the user agent itself, and ranks different service providers in an exhaustive list. The fuzzy rules supplied to FIS may vary according to the user’s need, for example, an optimist agent’s demand will have stricter demand for trustworthy behavior of the service provider than a pessimist agent.
Trust updator module helps in updating the trust value on recommenders of the transaction and is invoked, after completion of each transaction between requestor and provider and helps in keeping only valuable recommenders. For updation, the difference (d) in reputation of a service provider, as obtained from the recommended service attributes by a recommender and as computed from the actual experienced service attributes of the service provider by the agent itself, is taken. The requestor agent updates the trust value on all its recommender using Equation 6.
Where Trustnew(R) shows the updated value of trust on the recommender(R), Trust old (R) is the previous value of trust on the recommender (R), d is the computed difference in reputation value, φ is the threshold whose value will be decided by recommendation collector.
It is observed that as the first phase of the model works on the societal belief of trust so initially, when a new agent enters to collect the recommendation of its user then the bootstrapper module helps to weave a web of trust for it using Equation 7.
where Trustleveli represents the trust computed on ith recommended acquaintance. Popularityi is a factor based on the count of the agents recommending ith acquaintance. Variancei is a factor based on the variance in the trust levels of ith trustworthy acquaintance as recommended by various agents. This module is not only invoked by the new agent to create web of trust but is also used, periodically, by those agents who may want to increase their number of recommenders to have good recommendations or when the number of acquaintances of any agent goes below a minimum number of recommenders due to periodic update of trust on recommenders.
The phase (SelTrSP) of framework, helps in prioritizing the providers of active products based on their trustworthiness (reputation), can also be used in the systems where providers are not providing the active products.
Various modules namely; Policy Manager, History Maintainer, Attribute Collector, and Trust Calculator, are defined in second phase DetTrR of TbMAF helps the requested provider agent to know the trustworthiness of the requestor agent. The interaction among those modules is shown diagrammatically in Fig. 3.

Modules used in predicting the trustworthiness of requestor (Second Phase – DetTrR).
In Fig. 3, it is shown that on getting the request of services, marked as S.1, from requestor agenti, attribute collector module of the service provider agent calls the policy manager to search for an appropriate policy for specified request, shown as S.2. The apt policy is sent to the attribute collector based on which attributes are collected from the requestor agent, marked as S.3.
All collected information (apt policy for the specified request and attributes of the requestor) is given to the trust calculator module for prediction of trustworthiness, marked as S.4. Trust calculator also needs provider’s experience data acquired because of servicing different types of users from the history maintainer module, marked as S.5. S.6 step is performed only when the requested provider agent gave resources to the requestor (marked as red arrow) and stores the result of recent interaction with requestor agent’s attributes in history maintainer. Detailed functioning of all the modules involved in this phase is given below.
Policy Manager Module, stores the access control policies made by provider agent defining actions on the resources, allowed only to authorized users. Formally, it is written as follows Pol = < <Res, Act>, Trustworthiness>, where <Res, Act>defines the actions (Act) permissible on the resource (Res) only when Trustworthiness is satisfied by the requestor. Trustworthiness is based on trust threshold and interpreted as when the computed trust on requestor is greater than or equal to threshold defined by service provider agent than the requestor is trustworthy otherwise not. Mathematically, it is defined in Equation 8.
Where c is an adjustable positive constant or threshold and can be tuned by each of the providers depending upon the type of resources. For illustration, expensive resources may only be provided to highly trustworthy people in comparison to less trustworthy users.
Besides maintaining the policies, this module also helps in finding the appropriate policy for the specified request. The following assertions are used to find appropriate policy, as written in Equations 9 and 10.
Assertion: Apt_Policy
Assertion: NotApt_Policy
where Pol.Res and Pol.Act represent resource and action allowed on that resource written in the policy, whereas Req.Res and Req.Act show specified resource and action on it as needed by the requestor and specified in its requirements. Equations 9 and 10 detail that when condition ((Pol.Res = Req.Res) and (Pol.Act = Req.Act)) is met, only then the requestor’s attributes are collected from the requestor by the attribute collector. Finding appropriate policy is necessary because providers may require different access permissions, for various resources based on their cost and mode of access etc., to protect them. For illustration, user may specify hard disk(Res), write(Act) in the requirement set and provider may want to give only read access to hard disk then in that specified case using Equations 9 and 10, as ((Pol.hard disk = Req.hard disk) but (Pol.read ¬ = Req.write).
History maintainer module maintains all the previous interactions of the provider with different users to whom the provider had already provided the services. Formally, history interaction of ith user is represented as Ii, defined as tuple <ai, ei>where ai is the set of attributes based on which access was provided to the user. ei is the interaction’s evaluation, which equals to 1 if the interaction had been satisfactory to the provider (i.e., the provider’s interest was safeguarded by the requestor) and 0 otherwise.
Attribute collector module is placed in the system with the understanding that attributes-based access control is mandated for systems comprising dynamic entities and where it is difficult to recognize the entities based on their identity certificates. So whenever there is a request to access the resources providing a particular service, the service provider agent calls this module. This module then, first requests to get the appropriate policy for specified request, by sending the same request to the policy manager. In case of finding the apt policy for the specified request by the policy manger, the requestor agent is requested to ask for its attributes. The attribute collector collects all this information (appropriate policy and attributes of the requestor) and gives that to the trust calculator, for further processing.
The module, trust calculator, predicts the trustworthiness of the requestor for requested service (active product). For predicting the trustworthiness of the requestor following techniques namely, Binary Logistic Regression (BLR), Multilayer Perceptron (MLP) and Radial Basis Function Neural Network (RBFNN), have been used and compared.
a. Trust computation using Binary Logistic Regression (BLR):
In our framework, trustworthiness is taken as the dependent variable and computed using the attributes of the requestor taken as independent variables passed by the attribute collector module to the trust calculator module. Trustworthiness of the requestor is computed using Binary Logistic Regression employing Equation 11.
Where xi represents potential attributes of the requestor and ai denotes the coefficients assigned to these attributes. To compute trustworthiness of the requesting user, logistic regression is applied, using Statistical Package for the Social Sciences (SPSS) software, on the knowledge base containing data of all those users to whom the provider has already serviced which provided coefficients. Now, once the weight or coefficients present in Equation 11 are known, trustworthiness of new requesting users can be predicted using those known values.
b. Trust computation using Multilayer Perceptron (MLP):
A multilayer perceptron is a feed forward neural network, also used for prediction of the trustworthiness of the requesting user. The training method used was back propagation algorithm. The MLP was made to learn the previous interaction records of already serviced users as training. Training data contains the attributes of the already serviced users with their interaction output as 0 and 1, non-trustworthy and trustworthy respectively. Once training is completed, the network is validated on testing data. If error is less than the threshold for the testing data then the model is ready to be used to predict trustworthiness of the requestor. For prediction of trustworthiness of the requestor, the attributes of the requesting user are given as input and the output is taken as the trustworthiness of the requesting user, which can also be written as Equation 12 (considering that if, output layer consists of only one neuron (ym)).
Here, in Equation 12, φ m (.) represents the nonlinear activation function at the mth layer of the Multilayer Perceptron, comprising only one neuron and takes the input parameter v m . v m is the weighted summation (wim) of output of i neurons which get activated before reaching to mth layer.
c. Trust computation using Radial Basis Function Neural Network (RBFNN):
The trustworthiness of the requestor is also computed using Radial Basis function Neural Network (RBFNN). The non-iterative method involved in construction of RBFNN provides an advantage of fast learning on large data with reasonable generalization ability [17]. The architecture of a RBFNN is n0 nodes, in the input layer, corresponding to each dimension of input data supplied, n1 plus bias term nodes in the hidden layer, where nonlinear functions are applied to each unit. For each possible class, n2 nodes are created in the output layer [18]. Here, in our work, the output layer has only one neuron as, yj which is mapped to trustworthiness of the requestor and is computed using Equation 13.
where, yj is the node present in the output layer for a given input vector. wij is the weight from the ith node in the hidden layer to the jth node in the output layer. ti is the center of the ith hidden node. w0j is the bias to the jth node in the output layer. gi is activation function of the ith neuron present in the hidden layer which is taken as Gaussian function as written in Equation 14;
In Equation 14, σ denotes the width of the hidden node which is controlled by radial basis function (RBF). RBF, like Gaussian density function, defined by its center and width parameter. Width of RBF unit computation takes distances between the incoming variables and the center position; for example, a small width gives a rapidly decreasing function, and a large value gives a slowly decreasing function.
When the requested user is classified as trustworthy by the trust calculator module and got the services of the services provider then at the end of service tenure, trained RBFNN, MLP learns this recent transaction record as a training record due to which service provider always have updated and trained RBFNN, MLP to get used for further verification. Both phases of the framework (SelTrSP and DetTrR) compute trustworthiness i.e. SelTrSP computes trustworthiness of providers of active products whereas DetTrR computes trustworthiness of the requestor but uses different techniques for computation of trustworthiness due to their different behavior in the system. As requestors not being competitors of each other, help each other by giving good/honest recommendations about service providers and hence recommendations of acquaintances are used for computation of trustworthiness of service providers whereas providers cannot rely on the recommendations of their peers as peer providers, being competitors, may not give honest advice about requestor due to their own benefit. Hence, service providers use their own experience to predict the trustworthiness of therequestor.
The proposed framework is implemented adopting multi-agent terminology, where every agent present in the system plays the role of either requestor agent, recommender agent or service provider agent. TbMAF is designed to function in two phases (as discussed in section 3.1 and 3.2) namely, SelTrSP and DetTrR and is evaluated using the data of a distributed system, Enabling Grid for E-SciencE (EGEE) provided by Real Time Monitor (RTM). The RTM presents the activities and job transfers going on the grid onto a 3D globe with the help of imagery services by National Aeronautics and Space Administration (NASA). RTM keeps track of it.
Figures 4 and 5 show the behaviours used by the agent (a4) for asking and aggregating the recommendations, respectively. A set of 60 rules to handle fuzziness in data and provided reputation of the recommended service providers with a coded module of fuzzy trust evaluator is shown in Fig. 6 (the whole procedure of fuzzy trust evaluator is also shown diagrammatically in Fig. 7).

Behaviour used by agents for taking Recommendations from their trustworthy acquaintances.

Behaviour used by agents for aggregation of recommendations.

Procedure for applying FIS to remove uncertainties present in Recommendations.

Representation of Membership Functions (a) JobTurnaroundTime (b) priorJobSccessRate (c) Reputation and (d) Graphical representation of fuzzy rule base.
The service providers present in the list (given in Table 1), lying above the threshold, were requested for their products.
Recommendation list of Service Providers to be given to Requestor Agent for delegation of its job
A sample list of trustworthy providers of active products is generated and is given to the permission_seeker module. The requested service providers’ agents searched the appropriate policy for the specified request and if found, asked for the attributes of the requestor, using the behavior shown in Fig. 8.

Behavior used by the requested service provider for finding the appropriate policy and to get attributes of the requestor.
The trustworthiness of the requestor was computed using Logistic Regression, Multilayer perceptron (MLP) and Radial basis Function Neural Network (RBFNN) trained on the detailed report containing the attributes of the jobs submitted to CE (service provider), using the behavior shown in Fig. 9.

Behavior used by the requested service provider for computing the trustworthiness of the requestor.
For training, five datasets of randomly selected 1500 jobs from the detailed report of a CE, with status only completed or failed were taken and then segregated into training and testing sets. Each of the data sets was then divided into ten data sets of similar sizes, to handle the influence of the variability of the training set. Finally, nine sets obtained earlier were joined to form a training set and the left behind set was used as a testing set. To use each of the dataset once as a test data set, the stated method was repeated 10 times. Finally, the average of the test results was taken and considered as 10-fold cross validation. The creation of the training and testing set from the collected data was done using a random sampling with replacement using Bagging algorithm. The average sensitivity and specificity obtained for those ten data sets using trained RBFNN (with fewer number of neurons) is presented in Table 2.
Average sensitivity and average specificity results obtained using trained RBFNN
The confusion matrix as obtained using (a) logistic regression and (c) MLP, feed forward neural network (c) RBFNN (with fewer numbers of neurons), on test data-set is shown in Table 3.
Confusion matrix as obtained using ((a) Logistic regression and (b) Feed-forward neural network (c) Radial basis neural network (with fewer number of neurons)
The computed trustworthiness of the requestor helped the Service provider in deciding whether to permit or deny the resources. Based on the reply sent by the requested service providers, the permission_seeker module prepares the final list of the service providers from the list, as shown in Table 1, which is given to the requestor for the delegation of its application.
A series of experiments have been done to analyze the system, corresponding results of which are given and discussed in the next section.
The aim of this experiment was to find the robustness of the system by measuring the number of job failures, when job delegation is given only to reputed providers. To find the number of job failures, a set of user agents (S) was selected randomly, from 30 user agents, for which recommendations were generated using: a. from trustworthy acquaintances b: from random agents. Figure 10 plots such recommendations for an agent of set S. The x axis shows the recommended CEs and y axis shows its priorJobSuccessRate as service attribute.

Recommendations about service providers as given by trustworthy agents and random agents.
It is observed from Fig. 10 that when the user agent took the recommendations from its trustworthy acquaintances then those CEs (service providers) were recommended whose service attributes are good in comparison to CEs who were recommended by random agents.
Now if Ci = (CE1, CE2, ... , CEn) be a ith set of CEs who had assigned to the user jobs and was active at time tx, where Ci was prepared by selecting CEs from recommendations given to different user agents present in the set (S), then job failure rate, at time tx, would be the summation of number of job failures occurred at CEs present in Ci who had been assigned the jobs divided by the number of CEs present in the set Ci. Mathematically, job failure rate is written using Equation 15.
Where n show the number of CEs present in the set Ci at time tx. The job failure rate was obtained for ten such sets, C1, ... ,C10, where each Ci consists of 50 CEs who had assigned the jobs at time ti. The result obtained is shown in Fig. 11. It shows that the number of job failures were less when in system reputed CEs were assigned the jobs in comparison to when the jobs were assigned to CEs as recommended by random agents.

Comparison of Job Failure Rate of the “Trust based System” with “No Trust” System.
The aim of this experiment is to compute the job failures when providers give resources to only trustworthy users. To compute the job failures trained RBFNN on the detailed reports of a CE was used, summary of those reports, at consecutive days is shown in Fig. 12.

Day wise monitoring of the jobs assigned to a computing node of EGEE grid.
The architecture of the trained RBFNN, for the above CE, was taken as 7 nodes in the input layer (number of attributes taken from incoming job), 10 neurons in the hidden layer and 1 node in the output layer (trustworthy, non-trustworthy), where number, center, spread of hidden neurons and weights were predicted. Figure 13 depicts the results of the experiment where performance of the system as job failures measure is shown for a CE. Plot clearly shows the improvement in job failures of CE (provider) when only given access to users who were predicted trustworthy by RBFNN.

Reduction in job failure rate using RBFNN.
The experiment was conducted for verifying the robustness of the proposed framework in presence of malicious entities. In the previous experiment, it was assumed that all recommenders always provide honest recommendations which was not a realistic situation. As in human society, some of the recommenders may behave maliciously and to analyze this effect of maliciousness on the proposed system, a certain percentage of malicious agents was introduced in the system. The number of malicious recommenders varied from 0% to 80% in such a way that they randomly changed the service attributes (increase/decrease) of the providers before providing recommendations.
The difference as error between the reputation of a recommended CE (service provider) with malicious recommenders and without malicious recommenders was plotted in Fig. 14.

Robustness of system in presence of malicious recommenders.
It was observed, although error increases in most of the cases as the number of malicious recommenders increases but even in the worst case when 80% malicious recommenders were there in the system then also, only 30% error was reported which shows that the proposed system is robust against malicious recommendations.
This experiment was performed for evaluating the speed of the model to adapt the oscillating behavior of service providers. In the real world, a service provider may not maintain the same goodness forever but it may rather cheat in order to get a higher self-profit. So the model was tested to know how quickly the actual reputation of the service provider will reach the requestor.
On collecting the real data of the EGEE grid for 2 months, it was observed that service attributes i.e. jobTurnaroundTime and priorJobSuccessRate of computing nodes vary a lot. For the experiment, if there was a change in the service attribute (jobTurnaroundTime or priorJobSuccessRate) of any of the recommended computing nodes then distribution of this change of service attributes was done randomly among recommenders and then kept it same for next 20 transactions.
Then the number of transactions was counted by the user agent to get the actual reputation of the service provider. Outcome of the experiment is shown, in Fig. 15, which states the system was able to capture the real behavior of the providers in less than 10 transactions i.e. in few transactions, recommenders start recommending about the actual behavior of the providers.

Adoption of the System towards Dynamic Behavior of the Service Providers.
The aim of this experiment was to study the conduct of the model for different behavior of providers in the system. To perform the experiment, collected data of each CE was arranged in three groups, based on their service attributes: JobTurnarountTime and priorJobSuccessRate as shown in Table 4.
Data Distribution in Groups
Data Distribution in Groups
The experiment was run for 100 service requests and observed that group 3 service providers which were consistently good in their behavior were recommended most of the time than any other group CE/service providers. Figure 16 shows the results of the experiment. It is inferred from the experiment that when good and consistent behavior service providers are recommended most of the time, it will encourage other service providers to improve their performance and maintain it to get recommended.

Recommendations given by the System for different Behavioral Service Providers.
In open collaborative systems, where collaborating entities have no shared history of each other, the notion of trust minimizes the risks associated with collaboration. The study found that the job failure rate reduced, up to 68% (Experiment 1, Set 7) if active products in the system were only taken from trustworthy providers instead of random agents. Also, 95% of the jobs were able to complete, if providers were giving active products only to trustworthy users (Experiment 2). Hence, the proposed system is validating the need of computation of trustworthiness of both the entities (provider(s) and user(s)) before collaboration. The CTRUST system proposed in the study [19] for Internet of Things (IoT) computed the trustworthiness of the collaborating nodes using various trust parameters, recommendations and belief function. However, the uncertainty factor is not considered in the analysis. In our study, a fuzzy system is employed to handle uncertainty. Moreover study [20] suggested collaboration among entities based on recommendations of random agents or ‘wisdom of crowd’. But such collaborations may not always be beneficial, as in daily life, we prefer to take recommendations from trustworthy acquaintances for costly collaboration and hence in TbMAF recommendations are taken from trustworthy acquaintances only.
The performance of the TbMAF is studied in the presence of malicious recommenders and changing behavior of service providers also. The results of the study show that even in the presence of 80% malicious recommenders, the system was able to recommend trustworthy service providers to the user and reported an error rate of only 30% (Experiment 3). This is due to the fact that malicious recommenders lose trust of the entity (agent) who has taken recommendation from them, gradually and eventually no longer ask recommendations from them (equation 6). Furthermore, experiment 4 found that the shifting behavior of the service providers is captured by the system in fewer transactions (less than 10 transactions). This is because the outcome of each instance of the collaboration between entities (provider(s) and requestor(s)) is used in TbMAF either as recommendation or as direct experience (equation 1) by the agent and hence help the system to weed out the malicious service providers. In addition, it is also observed through experiment 5 that TbMAF helped trustworthy service providers accumulate their reputation, which encourages non-performing service providers to improve. This series of experiments discussed above clearly validates the proposedsystem.
It should be noted that the utility of the trust-based system is recognized in many fields but for open collaborative systems of active products is still evolving and hence the proposed work is an added contribution.
Conclusions & future work
In the open collaborative environment of active products, providers are hesitant to provide products to users due to concern of receiving corrupted or poisoned applications whereas users with critical applications will never use products provided by the provider and will rather prefer to support higher costs to run their applications in closed and secure computing systems.
To address this problem, Trust based Multi-Agent Framework (TbMAF) for collaborative systems of active products is discussed in this article. The framework is designed to work in two phases namely: Selection of Trustworthy Service Providers (SelTrSP) and Determination of Trustworthiness of Requestor ((DetTrR). Each of the phases computes trustworthiness of the provider and requestor respectively, which helps the entities (provider(s), requestor(s)) to collaborate safeguarding themselves and hence do the collaboration without hesitation. The first phase of the system computes the trustworthiness of the providers using Fuzzy Inference system whereas the second phase uses Logistic regression, Multilayer perceptron and Radial Basis Function Neural Network (RBFNN) techniques to compute trustworthiness of the requestor.
The proposed framework is not limited to only collaborative systems of active products only but has a general applicability for all such systems based on collaboration among entities. Moreover, there are certain areas that can be addressed in future research. First, deployment and evolution of the proposed framework in a cross organizational collaboration scenario. Second, extension of the proposed trust computation techniques against strategic altering behavior of entities. Third the system can be analyzed with more service attributes instead of only two (jobTuroundtime, priorJobSuccessRate) using Fuzzy recurrent mapping. It is expected that the proposed Trust based Multi-Agent Framework (TbMAF) will go a long way in making collaborative systems of active products more adoptable.
Footnotes
Acknowledgments
The authors are grateful to the Grid Observatory and the Imperial College London RTM to provide the dataset for this work. The Grid Observatory is part of the EGEE-III EU project.