
Abstract
With technological advancement, visual search has become an effective tool for searching important information by providing images. We propose a practical medical equipment recognition that can be used in visual search through deep transfer learning. We evaluated three deep learning models, i.e., VGG-16, ResNet-50, and Inception-v3, to recognise ten different classes of medical equipment. A data set consisting of 2,666 images had been collected and augmented to measure the models’ effectiveness. The models pre-trained with the ImageNet data set were transferred to the final models, and the last layers were replaced and trained with the collected data set. A grid search method was then used to find the best combination of hyperparameters, such as optimiser, batch size, epoch number, dropout rate, and learning rate. We tested the models using photos captured using smartphones. The results showed that Inception-v3 outperformed the other two models with the highest accuracy of 0.9454. This is the first study that uses deep transfer learning for recognising medical equipment to our best knowledge. Such recognition technology can potentially be implemented in visual search for helping consumers to check the validity of medical equipment.
Introduction
Visual search is on the edge of a breakthrough in the era of artificial intelligence. Consumers use visual search to look for information they are interested in by providing images. According to ViSenze [1], an artificial intelligence company, 62% out of 1,000 generation Z and Millennial consumers want visual search features than any other search features. Visual search technology is dominating among the retailers, i.e., eBay [4], Alibaba [5], Microsoft Bing [6], etc. One of Pinterest’s quickest growing and most important features is visual search. It has over 600 million searches each month, and the number is still rising [2]. Gartner, a global research and advisory firm, forecasts brands that revamp their website to integrate visual and voice search observes a 30% boost in their e-commerce income [3]. In short, visual search using image recognition is demanding and expected to lead in the future.
The problem of unqualified medical equipment has been going on for a long time. Consumers who are worried about the safety of the medical equipment may face trouble in confirming the equipment’s validity. Therefore, visual search on medical equipment especially registered medical equipment, has come to our attention. US Food and Drug Administration (FDA) enforce regulations and ensure medical equipment are validated and approved before being released in the market [7]. The Malaysian’s Medical Device Authority (MDA) also plays the same role. To know if a piece of medical equipment is approved, MDA allows consumers to search the information in its website [8]. Consumers can search equipment by name, registration number or brand name. With the emergence of technology, a precise recognition system for medical equipment can be developed for searching registered medical equipmentvisually.
Visual search using image recognition empowered by deep learning technologies is the focus of this study. Deep learning technologies have shown remarkable accomplishments in many fields such as image recognition [9], speech recognition [10], translations [11], sign language recognition [12], etc. The technologies overcome the limitations of traditional machine learning approaches, particularly low accuracies in recognition. Transfer learning is a technique that transfers the knowledge learned from a deep learning model to another for similar tasks [13]. Instead of starting everything by scratch, transfer learning provides an alternative that learns previous patterns using a pre-trained deep learningmodel.
This study aims to realise the medical equipment recognition to aid visual search through three deep learning models, i.e., VGG-16, ResNet-50, and Inception-v3, with transfer learning. To train the models, we build a data set with ten equipment classes. They include commodes, wheelchairs, walking frames, blood pressure monitors, breast pumps, thermometers, rippled mattresses, oximeters, crutches, and therapeutic ultrasound machines. The contributions of this study are summarised as follows. 1) To our best knowledge, this is the first study using transfer learning on deep learning models to recognise medical equipment. 2) The medical equipment can be searched using photos instead of the conventional text method. 3) The deep transfer learning models used in this study do not need feature engineering as required in traditional machine learning. 4) We obtained an outstanding performance in recognising medical equipment. 5) The outcome of this study can be transferred for the visual search of registered equipment as described earlier.
The remaining of the paper is organised as follows. Section 2 provides a review of traditional machine learning and deep learning. We also provide an overview of the deep learning models: VGG-16, ResNet-50 and Inception-v3 models as well as related works of equipment recognition in this section. It is then followed by an overview of the data set we collected and the detailed algorithm for training and testing the deep learning models in Section 3. Subsequently, we present and discuss the experimental results for the deep learning models in Section 4. Finally, we conclude the study in Section 5.
Review
Traditional machine learning
Traditional machine learning requires feature descriptors, such as Scale-Invariant Feature Transform (SIFT) [14], Binary Robust Independent Elementary Features (BRIEF) [15] and Speeded-Up Robust Features (SURF) [16] to recognise an object in an image. Thus, a feature engineer must perform manual extraction and select useful features in images. Edge detection, corner detection or threshold segmentation are the techniques used in feature extraction [17]. Traditional machine learning works fine with small data sets and a small number of output classes. As more data and objects are involved, the effort needed for feature extraction increases. In general, feature extraction takes long and relies heavily on expert domain knowledge [17].
The big data era has led to the evolution of the artificial intelligence industry. The advancement of deep learning has provided new opportunities in artificial intelligence. Deep learning has the advantage of processing massive amounts of data [18]. As the data size increases, the performance of deep learning models improves. Unlike deep learning, traditional machine learning usually reduces a real-world problem into multiple simple problems. The experts shall analyse each problem to get the final solutions. Machine learning requires domain experts to figure out the features and then recognise the patterns in images before feeding them into training algorithms [19].
Deep learning comes with an end-to-end model to train using the data and enables the automation of feature extraction by itself [20]. It consists of a deep number of layers to incrementally process a large number of data. Moreover, deep learning requires longer training time as the model architecture is huge and complex. High computational power processors, such as GPUs, are preferred to run the deep learning models [21]. Despite its disadvantage in training time, deep learning models provide high accuracy compared to the traditional machine learning models [22]. In short, deep learning surpasses traditional machine learning in object recognition with its capabilities in processing big data and providing outstanding accuracy.
Deep learning models
In the following section, we shall explain three deep learning models of Convolutional Neural Network (CNN) types: VGG-16, ResNet-50, and Inception-v3.
VGG-16
Simonyan and Zisserman [23] presented VGG-16 in 2014 and attained an astonishing achievement in the 2014 ImageNet Large Scale Visual Recognition Challenge (ILSVRC 2014) [23, 24]. The model comprises 16 layers containing 138 million trainable weights.
The main characteristic of VGG-16 is the fixed kernel size. The fixed convolutional kernels are 3x3 with one stride, while max pool kernels are 2x2 with two strides. The first layer of VGG-16 is a convolution layer that receives an input size of 224 x 224 RBG images. The subsequent layers comprise two or three convolution layers followed by a max-pooling layer. It is then continued with three fully connected layers and ended with a prediction layer, a softmax activation layer, for 1000 object classes [25]. VGG-16 follows the arrangement as described and sums up a total of 16 layers. Rectified Linear Unit (ReLU) [26] is used as the activation function for the convolutional layers and the fully connected layers to achieve efficient computations. We chose VGG-16 in this study for its performance due to its simple architectures in the layer arrangement and fixed kernel sizes.
ResNet-50
He et al. [27] introduced ResNet-50 in 2015 and won the first prize in ILSVRC 2015. It has 50 layers with 25.56 million parameters. ResNet-50 solves the vanishing gradient problem. When a convolutional neural network goes deeper and deeper to extract features and fits in more data, a vanishing gradient problem may happen [28]. The vanishing gradient problem causes the gradient of the loss function to approach zero. Thus, model training is difficult to continue. ResNet-50 can skip one or more layers in the connections of the model to solve this problem.
With its skipping connections characteristics, ResNet allows intense deep neural networks. ResNet has different versions and layers, i.e., 18, 34, 50, 101 and 152. In this project, ResNet-50, the smaller version of ResNet-152, was implemented and evaluated in this study.
Inception-v3
Szegedy et al. [29] introduced Inception-v3 and won the first runner up in ILSVRC 2015. Inception-v3 consists of 48 layers and 23.83 million parameters. The main feature of Inception-v3 is the implementation of multiple kernel sizes to capture more complete features from images. Each Inception-v3 module consists of four operation layers in parallel, which are 1x1 convolution layer, 3x3 convolution layer, 5x5 convolution layer and max-pooling layer. Common features can be captured by a 5x5 convolution layer, while a 3x3 convolution layer can capture area-specific features. The researchers presented a few optimisation ideas to efficiently scale up the convolutional network. The optimisation ideas include factorisation convolutions with a large filter size, auxiliary classifiers, efficient grid size reduction, and model regularisation via label smoothing. Thus, Inception-v3 can speed up the computation process to increase training efficiency using the optimisation ideas. Inception-v3 has been intensively used in image classification and video processing.
We also included Inception-v3 in this study for medical equipment recognition. We summarise the comparison of the three deep learning models in Table 1.
Comparison summary for the three deep learning models, i.e., VGG-16, ResNet-50 and Inception-v3
Comparison summary for the three deep learning models, i.e., VGG-16, ResNet-50 and Inception-v3
Many works recognise medical images using deep transfer learning, especially CNN, but not for medical equipment. We thus review studies that recognise equipment and machinery using deep transfer learning models.
Han et al. [39] performed infrared image recognition of electrical equipment using a deep CNN in embedded devices, such as substation robots and cameras. A CNN recognition model was built based on MobileNet. To overcome the limited training data problem, they transferred weights trained on ImageNet to Mobilenet and performed data augmentation in training. Data augmentation methods included cropping, rotation, flipping and zoom. Data augmentation expanded each class of the data set to prevent data unbalance. The data set size was increased from 984 to 3547 infrared images. MobileNet was selected for the application as ResNet-50 and Inception-v3 are too complex for industrial embedded devices, even though much research proved that these models performed better than MobileNet. A fast region of interest (ROI) selection approach was applied to improve recognition accuracy. The proposed approach achieved accuracies of 98.53% and 97.72% for the training and the validation, respectively, where the ROI selection approach boosted the confidence in the testing by 8%.
The study by Zhang et al. [38] introduced a CNN named AMTNet to enhance the Inception-v3 model for recognising seven types of agricultural machinery images. A comparison between ResNet-50, Inception-v3 and AMTNet was made. AMTNet showed the best performances with the highest accuracies of 97.83% and 100% on their two validation sets compared to ResNet-50 and Inception-v3. A test set of 200 images for each of the 13 machines was used to analyse the performances of AMTNet further. The average AUC and F1 scores for AMTNet were 92% and 96%, respectively.
Region-based fully convolutional networks (R-FCN) was implemented to recognise construction equipment [40]. In this paper, a data set called the advanced infrastructure management group (AIM), with five classes and 2920 images comprising dump truck, excavator, loader, concrete mixer truck, and road roller, was created to train the recogniser model. R-FCN extracts the important features of an object through the convolutional layers, predicts the occurrence of a target and its location in the region proposal network using position-sensitive score maps and pooling layers. The model used in feature extraction was ResNet-50 with weights trained on the ImageNet data set. Experimental results showed that the proposed R-FCN model performed well with a mean average precision of 96.33%.
Improved Faster Regions with CNN Features was used to detect the presence of workers and excavators in real-time [41]. It was developed to improve safety and productivity in construction sites. 91% and 95% accuracy were achieved for detecting workers and excavators, respectively.∥The work we reviewed shows that the pre-trained models of CNN are widely used to recognise equipment and machinery, and the accuracies achieved are excellent. We also utilised pre-trained models of CNN as the models can be transferred and incorporated for equipment recognition in our study. Thus, they do not require many labelled images to train and can accurately recognise equipment.
Methodology
Data set
We built a data set containing ten equipment classes: commodes, wheelchairs, walking frames, blood pressure monitors, breast pumps, thermometers, rippled mattresses, oximeters, crutches, and therapeutic ultrasound machines. We collected from online resources around 220 images for each medical equipment class. As shown in Fig. 1(a), these images were resized to 200 px width x 200 px height. Besides collecting the images, we also utilised the data augmentation technique to increase the number of images for training the deep learning models.
(a) Training images gathered from online resources (b) testing images captured by smartphones.
A total of 22,600 images were gathered as a result of data augmentation (see Table 2). Augmented images were created for each epoch during training, and ten epochs were involved. On the other hand, the test set contains images captured from smartphones, as shown in Fig. 1(b). Test images were captured using smartphones since it is more practical and common for users to conduct a visual search using these images. Each image class in the test set has around 40 images. The number of test images captured by smartphones was not enough for some classes of medical equipment, we thus collected images from the Internet to achieve the number required. The data set we created can be downloaded from [42].
The number of images involved for the train set, after augmentation, and test set
We used Algorithm 1 to train and test deep learning models. The inputs of this algorithm were a medical equipment data set (med_equip_data) and medical equipment test set from smartphones (test_st) that contains ten classes. Initially, we defined the img_shape 200 width x 200 height and the num_classes 10 (Line 1, Algo. 1). We also used a set of hyperparameters, i.e., optimiser, batch_size, num_epochs, dropout_rate and learn_rate, to fine-tune the model (Line 2, Algo. 1). Table 4 lists the value range of each hyperparameter.
We defined a function CreateModel to create a model from a pre-trained model (Line 4-17, Algo. 1), and it required parameters, i.e., img_shape, dropout_rate, num_classes, optimiser, and learn_rate. We used three pre-trained deep learning models: VGG-16, ResNet-50, and Inception-v3. Each pre-trained model was imported from the Keras library to create the base_model (Line 5-6, Algo. 1). We instantiated the base_model with pre-loaded weights trained on ImageNet [24]. The output layer was also excluded from the base_model to extract features. We then built the model by chaining all the layers (Line 7-14, Algo. 1). The layers included input_layer, data_augmentation, preprocess, base_model, dropout_layer, and output_layer. The following paragraph explains the detail of each layer.
We passed the constant value of img_shape to the input_layer (Line 7, Algo. 1). In the data_augmentation layer, images were flipped horizontally and rotated by a factor of 0.2, which was -20% to 20% of 360 degrees (Line 8, Algo. 1). We also processed med_equip_data by converting the pixel values from RGB to BGR. The original data pixel values were in the range of [0, 255]. We rescaled the pixel values to the range of [-1, 1] in the preprocess layer (Line 9, Algo. 1).
The algorithm is then followed by forming the model. We firstly added the base_model (Line 10, Algo. 1); all layers in the base_model were frozen. Then, we added a dropout_layer by specifying the dropout_rate (Line 11, Algo. 1). An output_layer with ten prediction classes was then formed and associated with the softmax activation function (Line 12, Algo. 1). The softmax activation function was applied to convert the outputs into a single prediction. Lastly, all layers defined were chained to form the deep learning model (model) (Line 14, Algo. 1).
We used loss and accuracy to compare the models’ performance. Since there were more than two output classes, sparse_categorial_crossentropy was used to compute the loss, while sparse_categorical_accuracy was used to compute the accuracy. The model was then compiled with loss, accuracy, optimiser and learning rate (Line 15, Algo. 1). The function CreateModel was ended by returning the model.
We used a stratified k-fold cross-validation method to split the med_equip_data into k folds of train set (train_st) and validation set (val_st). Using this method, we can preserve the class percentage and prevent the class unbalance in each fold. The selected k number was 5; med_equip_data was shuffled and split into five folds. For each k iteration, four folds were used as the train set, and the remaining fold was used as the validation set. The iteration ensured that all the folds had become the validation set once (Line 18-25, Algo. 1).
We called CreateModel to create a deep learning model (Line 20, Algo. 1). The best model with the highest validation accuracy was saved to a.h5 file called model_k_file and assigned to a checkpoint (Line 21, Algo. 1). The checkpoints for each epoch will be saved in the callbacks, callbacks_list (Line 22, Algo. 1). The model’s training was executed by fitting the model with train_st, val_st, batch_size, num_epochs, and callbacks_list (Line 23, Algo. 1). During the training, the training accuracies and validation accuracies were printed. In addition, the callbacks saved the best model at the end of every epoch. After the training, the best_model was loaded from the model_k_file (Line 24, Algo. 1).
Subsequently, we tested the models using the photos captured by smartphones. The best model out of the five folds (best_k_model) was loaded from the model_k_file (Line 26, Algo. 1). The best_k_model was then evaluated with the test set, test_st (Line 27, Algo. 1). We then recorded the testing accuracies.
Experimental results
The models’ accuracy, loss, and execution time obtained using the training set and test set are tabulated in Table 3. Fine-tuning the models’ hyperparameters is important for obtaining the best recognition accuracy. We used grid search to search for optimal hyperparameters of each model based on their range of values. Although grid search is inefficient, it allows every combination of hyperparameters to be tested for the best solution. Since the computing cost is feasible for the data set size and bearable for us, we thus opt for the grid search.
The evaluation results of three models using the training set, validation set, and test set
The evaluation results of three models using the training set, validation set, and test set
Acc – Accuracy, Ls – Loss, Tr – Training, Ts – Testing, Val – Validation
Table 4 lists the value range of each hyperparameter and their respective increment value for each iteration of the search. We started by nailing the optimal learning rate, followed by the batch size. Subsequently, we simultaneously searched the optimal values for dropout rate and epochs. The optimal hyperparameters for the models are shown in Table 5. The models were optimised using Stochastic Gradient Descent (SGD) [30] and Adaptive Moment Estimation (Adam) [31]. SGD is the faster version of Gradient Descent (GD), which is noisier but proven to be more efficient than GD [32]. Adam [31] combines the strengths of Adaptive Gradient Algorithm (AdaGrad) [33] and Root Mean Square Propagation (RMSProp) [34] to deal with sparse gradients and online and non-stationary settings. We implemented dropout to address the overfitting issue and enhance the models’ performances. Dropout shall randomly remove some neurons in a layer by a stated probability value [35]. The dropout rate was increased during fine-tuning whenever the results showed overfitting curves. Besides, the epochs were increased to find the best fit for the training and validation loss.
The range of values involved during the hyperparameters tuning using the grid search method
The optimal hyperparameters for VGG-16, ResNet-50, and Inception-v3 models involving different optimisers
We used the learning curves to monitor the model performances to avoid underfitting and overfitting [36]. Besides, they provide the models’ insights at each epoch during training to fine-tune the hyperparameters. A good fit is defined as a training loss and validation loss that gradually reduces to a stable point with a little difference between them [37]. In general, all the models gave good accuracies (above 0.92) using the training and validation sets (see Table 3). Figure 2 also shows good fits of training and validation learning curves. The models were ready to be evaluated using the test set.
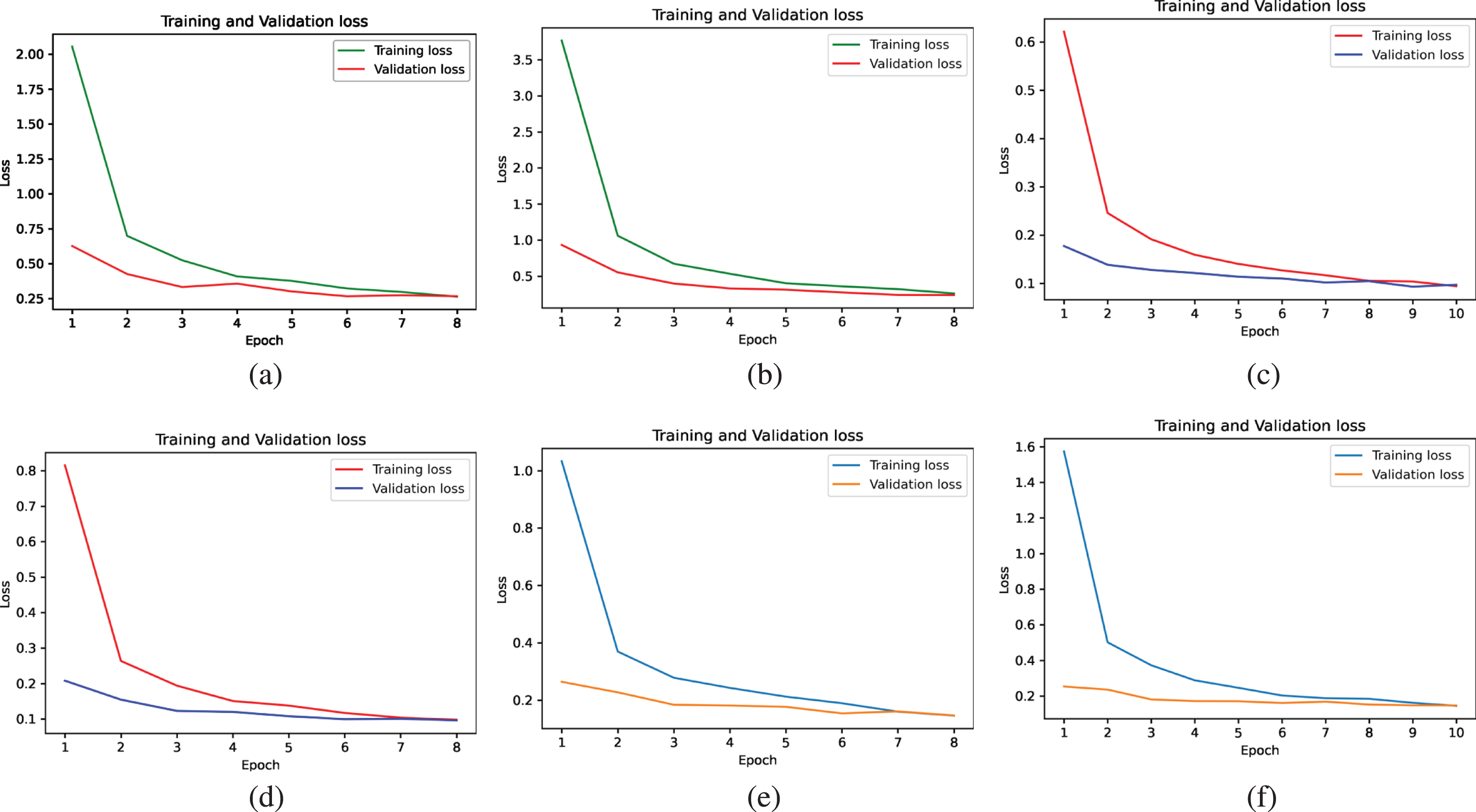
The training loss vs validation loss for VGG-16_SGD (a), VGG-16_Adam (b), ResNet-50_SGD (c), ResNet-50_Adam (d), Inception-v3_SGD (e), and Inception-v3_Adam (f).
As shown in Table 3, Inception-v3_Adam achieves a better result than the other models with the highest testing accuracy of 0.9454 and the least processing time of 39 milliseconds per step, implying a better efficiency than the other models. The model also has the lowest number of parameters (see Table 1). On the other hand, VGG-16 with the least layers and the greatest number of parameters give average accuracies and long execution times. The performance of Resnet-50 is closed to Inception-v3 with slightly longer execution times.
We also developed a mobile application running the models to recognise the ten classes of medical equipment. Photos captured by smartphones were used to evaluate the models. Figure 3 shows the recognition of an oximeter by the mobile application.

An oximeter in different angles was recognised using the developed mobile application running the models.
We evaluated three deep learning models, i.e., Inception-v3, ResNet-50 and VGG-16, to recognise ten different classes of medical equipment. A data set consisting of 2,666 images was collected and augmented ten times to evaluate the models. The models pre-trained with the ImageNet data set were transferred to the final models, and the last layers were replaced and trained with the collected data set. As it becomes more common on using smartphones to capture images, the test data are images captured using smartphones. They are good to evaluate the models’ capability in recognising real-life images, which could sometimes be blurred and noisy.
We fine-tuned the models with different hyperparameter combinations and evaluated them using accuracy, loss, and execution time. Inception-v3_Adam outperforms the other models, with the highest testing accuracy of 0.9454. With such good accuracy, the model can be potentially implemented in visual search for helping consumers in checking the validity of medical equipment. Therefore, this recognition technology can be further applied to specific registered medical equipment in future.
Nevertheless, there is room for improvement in our work. The models were trained using only ten classes of medical equipment images. Thus, future work shall include collecting more classes of medical equipment to improve the usability of the models. It is also important to have more diversified images to increase the models’ accuracy so that real-life photos captured by consumers can be well-recognised. The image diversification can be enhanced with data augmentation methods, i.e., scaling, cropping, padding, translation, brightness, contrast saturation and hue.