
Abstract
The visual data attained from surveillance single-camera or multi-view camera networks is exponentially increasing every day. Identifying the important shots in the presented video which faithfully signify the original video is the major task in video summarization. For executing efficient video summarization of the surveillance systems, optimization algorithm like LFOB-COA is proposed in this paper. Data collection, pre-processing, deep feature extraction (FE), shot segmentation JSFCM, classification using Rectified Linear Unit activated BLSTM, and LFOB-COA are the proposed method’s five steps. Finally a post-processing step is utilized. For recognizing the proposed method’s effectiveness, the results are then contrasted with the existent methods.
Keywords
Introduction
The video data’s quantity is explosively augmenting, which introduced new challenges to numerous video processing tasks [1]. Greater attention has been given to video summarization [2]. Video Summarization (VS) aims to generate a shortened video skim expressing the gist of its original version [3]. It mostly contains 2 categories storyboard and video skim [4]. A few image sequences are selected from original videos and anticipated to be an approximate illustration of the entire video’s visual contents [5]. Since it highlights the exact key points within the video, the generating process is easy [6]. Therefore, the time axis is eliminated by the keyframe aimed at VS [7]. A group of video shots offer interesting video contents is compiled by video skims [8]. The summary contains both audio and motion elements that enrich emotions, quantity of information transmitted by the summary [9]. However, the difficulty lies in the categorization of important video segments [10]. The video browsing’s efficiency can be enhanced by a video summary [11]. Furthermore, summarizing a long video to a shorter form is focused by Single Video Summarization (SVS) [12]. Summarizing multi-view videos into informative video summaries is called Multi-view Video Summarization (MVS) [13]. As a consequence SVS is less difficult contrasted to MVS [14]. Hence, the time along with cost needed for analyzing video information is reduced by VS [15]. But, a difficult issue is creating a summarization from a sequence of topic-associated videos [16]. With several existing techniques’ computational complexity is extremely high because of redundant frames [17]. Moreover, the high-level semantics are often neglected by most approaches [18]. Thus, utilizing LFOB-COA and RBLSTM algorithms, efficient deep learning (DL)-centered video summarization is proposed here.
This paper is systematized as: Section (2) proffers the literature works. Section (3) exhibits the proposed technique. Section (4) offers the result along with a discussion. Lastly, section (5) concluded the paper.
Literature review
Proposed methodology
An optimization algorithm for effective VS using LFOB-COA with deep features is propounded by this paper. It comprises of preprocessing, FE, Segmentation, Classification and key frame selection. Figure 1 presents the proposed method’s illustration,

Illustration of the proposed methodology.
The input video v
s
is initially collected and converted into m-number frames.
Image rotation
Image rotation is utilized for enhancing the image’s orientation by mapping input image position (split frames f
i
) (a1, b1) with center coordinates (a0,b0) onto a position (a2, b2) through an angle φ,
For improving the image’s visualization, translation through (ψ
a
, ψ
b
) is utilized.
For altering the quantity of information saved in a scene, image scaling is employed. Therefore, the preprocessed images ρ
s
can well be indicated as,
Utilizing a DL model called GoogLeNet, the redundant VF are extracted after pre-processing. Now, using the convolutional layer (CL) along with polishing layers of GoogLeNet, the input’s visual descriptors are extracted. Figure 2 exhibits the GoogLeNet architecture.
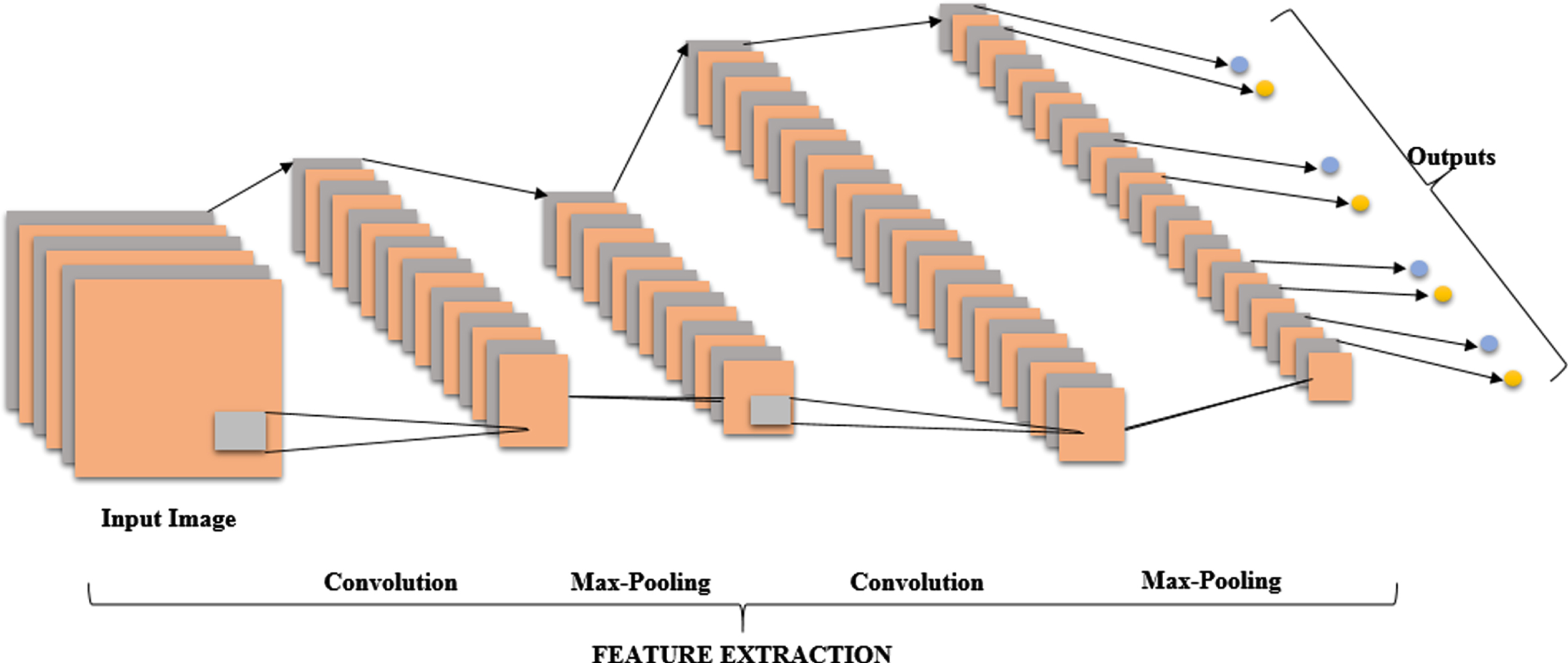
Architecture of GoogLeNet.
The CL’s equation x i at the i th CL’s output is specified as,
Where, n, w i and b i implies the number of filters, filter weight and bias value. Hence, the extracted j = 1, 2, ⋯⋯ , N number of deep feature vector is the GoogLeNet (y j )’s output is,
For shot segmentation, the extracted features (y j ) are classified into a disparate similar group by the JSFCM algorithm. The cluster centers are created centered on the Euclidean distance (ED) in conventional FCM, while in ED, the cluster centers are complicated to implement. Therefore, JS is employed that measures the number of similar and distinct items in two sets. This JS-centered clustering of similar frames in FCM is named JSFCM.
Where, c p indicates the k th cluster center, η Pj symbolizes the membership function (MF) along with z implies the membership function’s fuzziness.
Wherein, l = 1, 2, ⋯ , M represents number of frames from y j and J j (l) signifies the JS, y j (l) , y j (l - 1) defines the l th and (l - 1 th ) frame.
Hence, a collection of possible clusters is attained by contrasting the JS between the color histogram of successive frames. The n number of clustered frames (C
f
) can be indicated as,
Utilizing RBLSTM, the clustered frames are categorized as informative or non-informative sequences. A sigmoid AF is employed by the conventional BLSTM, which vanish the gradient issue. Therefore, rather than the sigmoid AF, ReLU is utilized which overcomes the vanishing gradient issue. This ReLU activated BLSTM is called RBLSTM.
Wherein, t represents every time step, ht-1 signifies the hidden state, W
I
, b
I
, u
I
implies the RBLSTM’s input gate parameters, W
F
, u
F
, b
F
, W
O
, u
O
, b
O
, W
M
, u
M
, b
M
specifies input vector weight, weights at the previous time step, along with bias via the FG’s, output gate’s, memory cell’s network of RBLSTM, the value of I (t) and F (t) ranged betwixt 0 along with 1, M (t - 1) symbolizes that the information is preserved in the preceding memories and χ indicates the ReLU AF.
Where,
Employing LFOB-COA, the keyframes from the informative frames are chosen after the frame’s classification. The COA is centered upon the coyote’s social behavior and its adaptation to the environment. The COA is liable to decay in local optimum and needs examination with the proper blending of exploitation. Therefore, Levy flight (LF) and Opposition-centered learning are incorporated in the COA (original) for overcoming such limitations. This LF and Opposition-based COA is entitled LFOB-COA.
Wherein, ζ indicates the initial social condition, U
i
, L
i
symbolizes the upper and lower bound of i
th
decision variable and R
i
implies the real random number within the range [0, 1] using LF distribution.
Where, μ, ν symbolizes the normal distribution function. φ implies a fixed parameter with standard gamma function γ,
Where, Rp,t indicates the coyote’s ranked social conditions.
Where, p1, p2 implies random coyotes within p, i1, i2 signifies two random decision variables, p (s) and p (a) indicates the scatter and association probabilities, T
i
denotes a random number within the D dimensional decision variable limit and n
i
represents the random number within the range [0, 1] created utilizing Equation (23). Therefore, p (s) and p (a) is signified as,
Thus, the candidate fitness
The global solution to the optimization issue is the coyote’s social condition that best adjusted itself to the environment. Lastly, for obtaining the input video’s video summary, the selected keyframes (K S ) are merged together. Finally, the post-processing is performed which utilizes color histogram difference for discarding frames of the same shots in the summarized video. The pseudocode of LFOB-COA is exposed in Fig. 3,

Pseudocode of LFOB-COA.
The proposed technique’s performance is examined with the conventional systems. Grounded upon the performance metrics namely precision, recall, accuracy, f-measure, frame count, along withexecution time, the performance examination of the proposed JSFCM, RBLSTM, and LFOB-COA are analogized with existing techniques. Five surveillance videos are selected from the CAVIAR, CViSOR datasets to perform the analysis [26]. Figure 4 exhibits the input VF and also the chosen keyframes from the sample video of the CAVIAR, CViSOR dataset,

(a) Input frames, (b) Selected key frames.
Herein, centered on recall, precision, f-measure, and also accuracy, the proposed JSFCM’s performance for shot segmentation is weighted against the prevailing methods like FCM, K-means, along with K-medoids.
It is exemplified from Table 1 that high precision and also recall values when analogized with the prevailing methods are possessed by the proposed JSFCM’s performance. 96.4325% precision along with 95.8796% accuracy is expressed by the proposed work for video-1. Likewise, higher precision along with recall when contrasted with the conventional techniques is exhibited by the proposed work for the remaining videos. Thus, superior performance when analogized to the existent methodologies is demonstrated by the proposed one.
Performance comparison (a) precision and (b) Recall
Performance comparison (a) precision and (b) Recall
Performance measurement by means of F-measure
From Fig. 5, the F-measure of 95.2809% is displayed by the proposed work for video-2 while the prevailing systems namely FCM, K-means, and also K-medoids attain 93.4782%, 91.2976%, 89.2647% F-measure, correspondingly. Meanwhile, the proposed method’s accuracy is 95.8827% for video-3, however, the existing technique’s accuracy like FCM (94.9865%), K-means (91.3746%), and K-medoids (90.2536%). In addition, higher performance is attained by the proposed one for the remaining videos. This affirms that enhanced performance results are attained by the proposed one when analogized with the conventional methods.
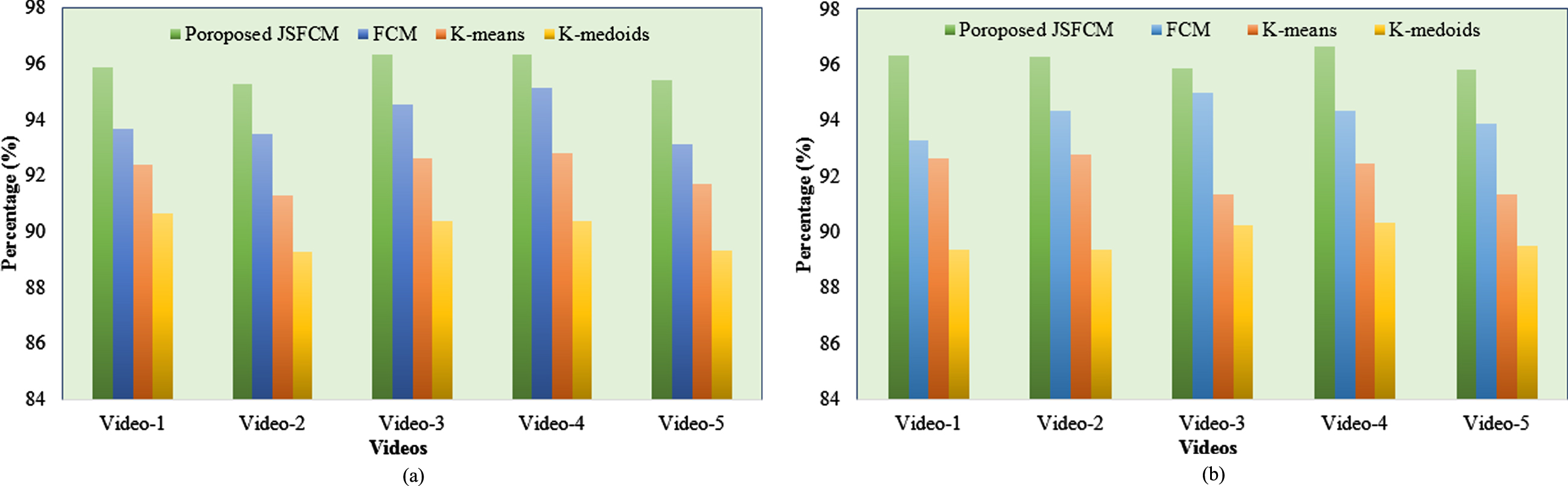
Performance comparison based on (a) F-measure and (b) Accuracy.
Centered on F-measure and also accuracy, the proposed RBLSTM classifier’s performance is analogized with the existent classifiers namely BLSTM, K-nearest neighbor (KNN), and Support Vector Machine (SVM) in this stage.
Grounded on F-measure, the proposed method’s f-measure for video-5 attains a higher performance of 97.2136% as shown by the table, in the same way for videos 1–4, high f-measure is attained by the proposed one when contrasted to the existent methods. Similarly, lower performance is attained by the conventional systems when contrasted to the proposed one for the remaining videos. Therefore, it states that superior performance is displayed by the proposed technique to the existent techniques.
The proposed RBLSTM methodology with the existent method’s performance measure centered on accuracy is exhibited in Fig. 6. For video-4, 97.2334% accuracy is possessed by the proposed work, which illustrates that when analogized with the existent ones, the proposed technique exhibits the maximum accuracy. The existing approaches’ accuracy is low whilst contrasting with the proposed work. Thus, more accuracy is attained by the proposed one when weighted against the existing classifiers.

Performance measure in terms of Accuracy of the proposed RBLSTM.
Centered on frame count and execution time, the proposed LFOB-COA with the existent COA, Normalized K-means (NK-means) and Center Surround Model, and also an Integer Knapsack formulation for K-means (CSMIK-Kmeans) methods’ comparative analysis is described in this phase.
Concerning frame count and execution time, the frame count and execution time offered by the proposed one for video-1 is 172 frames, and 2.6589 sec, correspondingly. But, higher frame count and execution time are expressed by the prevailing techniques. Likewise, the total frames and execution time is more for the existent methods for each video. Hence, it is deduced that the proposed technique is better when weighted against the existing approaches. Figure 7 exhibits the Comparative analysis based on Frame count and Execution time.

Comparative analysis based on (a) Frame count and (b) Execution time.
For the surveillance system’s effective video summarization, RBLSTM and LFOB-COA are proposed in this paper. For examining the proposed method’s effectiveness, the proposed along with the existing method’s performance is contrasted. Higher f-measure (97.2353%), accuracy (97.2334%) for RBLSTM classifier and low frame count (172 frames), and execution time (2.6589 sec) for LFOB-COA centered keyframe selection is denoted by the proposed technique. Thus, better results are exhibited by the proposed technique grounded upon the above performance metrics. Therefore, the surveillance system’s effective video summarization is offered by the proposed RBLSTM and LFOB-COA with greater accuracy and lesser execution time. By deeming the multi-view videos of the surveillance system utilizing the video summarization’s advanced model, the work will be prolonged in the upcoming future.