
Abstract
Reusing design knowledge of products is a useful way to solve the efficiency issue of complex product design. The design knowledge is tacit, empirical, and unstructured and there exists insufficient case matching and inefficient design reuse in complex products design process. Aiming at these problems, this paper presents an improved case-based reasoning methodology combining ontology with two-stage retrieval. Firstly, a knowledge domain ontology model of complex product design is constructed, and the technology of ontology-based data access is introduced to automatically generate a case knowledge base with semantic information. Then, a new two-stage case retrieval method integrated semantic query with similarity calculation is proposed. The case subset is selected by query statements. It has the characteristic of isomorphism with design problem. The retrieval mechanism is applied to compress the traversal space, reduce the redundancy of semantic similarity calculation, improve the retrieval efficiency, and fulfill the target of case reuse. Finally, a variant design of the chiller unit as an example is executed to illustrate the use of the proposed method, and experiments are organized to evaluate its performance. The result shows that the proposed approach has an average precision of 92% and high stability, outperforming existing methods.
Introduction
Complex products can be defined as large-scale products, systems, or infrastructure with high cost, technology intensive, customized by users, single piece, or small batch production [1]. Under the background of “Industry 4.0”, with the gradual maturity of the interactive innovation mode, customer needs are gradually diversified, product functions are increasingly abundant, and product manufacturing technology is constantly improved. Therefore, how to respond to the drastic changes in the external market through rapid updating and iteration of complex products is an important challenge for complex product enterprises.
A complex product generates a large amount of data, knowledge, and information in the whole lifecycle, and its design process has strong experience dependence. Rational reuse of mature product design knowledge can accomplish complex product design quickly. Case knowledge belongs to an important form of tacit knowledge and has large granularity and high integration [2]. Its application performs better than general knowledge. Therefore, the acquisition and utilization of case knowledge is of great practical value for enterprises.
Case-based reasoning (CBR), based on the principle that problem solving can benefit from cases and solutions to past problems, is an important branch of artificial intelligence [3]. As an effective method of case knowledge reuse, CBR has been widely used in the remanufacturing process [4, 5], fault diagnosis [6, 7], and automated disassembly decision-making [8]. There are also some successful applications in the fields of design. Hu et al. [9] presented a CBR method according to the characteristics of parametric machinery design. Kim et al. [10] applied CBR to the process of weapon system design to provide models that satisfy the requirements. For design applications, CBR takes design knowledge and cases as basis. And it has the advantages of wide adaptability and no dependence on statistical assumptions. Meanwhile, CBR can retrieve reusable cases through some important attributes and parameters, which simplifies the design model and improves the design efficiency. Moreover, it updates and expands the new effective cases after retrieval with self-learning ability, which makes future reasoning ability stronger. However, CBR largely depends on previous experience and knowledge characteristics, and the content of case base affects reasoning quality. With the advent of the era of knowledge economy, facing large-scale case knowledge the existing CBR methods have problems of low transfer efficiency, complex retrieval, and low matching accuracy, which affects the reuse rate of case knowledge and cannot meet the requirements of complex product design with economic efficiency. From this point, the adaptation of case and retrieval is urgent for CBR application.
CBR can typically be described as a cyclical process comprising the four steps of retrieval, reuse, revising, and retaining [11]. Case representation is the basis of CBR, and case retrieval is the core of CBR. The existing studies mainly discuss these two aspects in CBR. In terms of case representation, Guo et al. [12] integrated ontology into CBR as the basis for constructing the knowledge base in view of the lack of semantic understanding of the CBR system, and developed an injection mold design support system. Chen et al. [13] realized the disassembly decision-making products process fully automated and cost-saving by ontology and CBR. Amna et al. [14] proposed an ontology-based CBR approach for personalized itinerary search systems for sustainable urban freight transport. Hamrouni et al. [15] developed a production-oriented software system, and the system was a multi-case base domain-independent reasoning architecture for extracting, analyzing, sharing, and providing experiences. Mabkhot et al. [16] combined ontologies with CBR to achieve a decision support system for manufacturing process selection.
Therefore, the emergence of ontology technology provides new ideas for solving case representation problems. The combination of ontology and CBR can effectively improve the sharing of case knowledge and the performance of the CBR system.
On the one hand, case representation results provide the semantic basis for CBR, which is the key to case retrieval [17]. On the other hand, the initial number of case base also affects the efficiency of case retrieval [18]. Aiming at this issue, Xu et al. [19] manually selected the classes and attributes of the fault diagnosis ontology by experts, archived the corresponding data of historical cases, and added cases to the ontology model to form a case library. Wu et al. [20] used natural language processing to extract text information from the collected text accident reports and semi-automatically converted the annotation of the accident case to the instance layer in the ontology model. Zhang et al. [21] manually added design instances into the established domain ontology and converted them into RDF language to realize the graph retrieval algorithm of the case base.
It can be found that in the construction process of CBR case base, the existing literature mainly relies on manual recognition or the use of text processing technology to semi-automatically add cases into the ontology model of case knowledge representation. Although automatic ontology construction technology has been mature in the ontology research field, it focuses on the automatic construction of the concept layer, which includes how to realize the automatic extraction of concepts and relations from data sources [22]. Therefore, automatic ontology construction techniques, such as machine learning and natural language processing, have not been well applied in CBR case base research. To reduce the workload of ontology instance construction, a method of automatically generating an ontology case base is urgently needed to expand the case base scale and improve the efficiency of case-based reasoning.
In fact, design data are mostly stored in databases. So, we can take the case representation ontology model combined with database into consideration. Calvanese et al. [23] proposed that ontology-based data access (OBDA) technology can combine these two forms and has been applied in the literature. Ding et al. [24] analyzed the significant parts of geographic information of multi-source heterogeneous data by ontology exploration based on the concept layer access data principle. Bereta et al. [25] proposed an OBDA approach for accessing geospatial data stored in relational databases. Kalayci et al. [26] used OBDA to reveal the hidden knowledge in a large-scale sensor database and improved the prediction system for analyzing dynamic data. Therefore, OBDA technology can provide a shared conceptual view of data sources based on ontology, enabling access to knowledge representation-oriented case data sources stored as databases.
Case retrieval is based on some search matching strategies to find the case or case set that best meets the design requirements from the case base, which is the key to CBR [27]. Lasolle et al. [28] considered the annotation context related to the resource being edited and ranked similar resources already annotated in the database. Zhang et al. [29] proposed a mixed similarity measurement method considering different case attribute types to obtain the most similar cases. Mitra et al. [30] adopted the structural similarity method for feature selection and verified the effectiveness of this method in classification and clustering tasks. Jiang et al. [31] used rough set to select case features and weights and calculated local similarity of features to determine the global similarity. Ruiz et al. [32] obtained a comprehensive similarity calculation method based on semantic distance measurement and other influencing factors built on an ontology structure tree. Akmal et al. [33] presented an ontology-based approach that can determine the similarity between two classes, and the approach was measured by feature-based similarity replacing features with attributes.
Thus, the existing case retrieval methods mainly achieve matching by evaluating the attribute or semantic similarity between design problems and the case base. Unfortunately, when case knowledge is complex and the data volume is large, the case retrieval method that achieves case matching by evaluating the attribute or semantic similarity between the design problem and the case base must traverse the whole case base, resulting in many computing tasks, slow retrieval speed and low efficiency.
To overcome the limitations of existing knowledge reuse methods, this paper proposes a new CBR methodology framework based on ontology to quickly reuse complex product design schemes. This paper studies the design of case knowledge classification, properties, structure and relationship, determines the framework of case knowledge representation, analyzes the form of case data, constructs a CBR case knowledge base, considers the representation of design problem, and designs a retrieval algorithm to match cases to support case-based reasoning of complex products. The innovation of this paper lies in improving the efficiency of the case base generation and the case retrieval algorithm. Compared with the existing studies, our work makes three distinctive contributions. Considering the scale of the case base, a case knowledge representation model is constructed. The domain ontology model is linked with a case database by a mapping mode, generating the case base with semantic information automatically, replacing the traditional method of manually adding case entities, and improving the efficiency of case base construction. The design problem expressed by multiple groups of RDF statements provides the ability of multi-granularity case retrieval to focus on the terminal leaf or any branch of the tree, making the retrieval requirements more flexible and extensible. A two-stage case retrieval method integrating query statements and semantic similarity is proposed to form a relatively perfect retrieval process by compressing the case retrieval scope and calculating the comprehensive semantic similarity. This process can reduce the semantic similarity computation redundancy and improve the retrieval efficiency and accuracy.
The rest of this paper is structured as follows. Section 2 provides the basic framework of the CBR system which integrates domain ontology and mapping technology. Section 3 introduces the knowledge domain ontology model in detail, including constructing the concept layer and filling the instance layer. Section 4 proposes a two-stage retrieval algorithm based on semantic queries and similarity calculations. Section 5 provides a case study to evaluate the efficiency of the improved method. Section 6 contains a discussion. Finally, Section 7 concludes this paper and points out further research.
Overview of the framework
This paper puts forward a modified method of case-based reasoning taking the complex product as the research object. In general, knowledge reuse based on CBR mainly includes the representation of design cases and the construction of knowledge base, the retrieval of similar cases from the case base, the modification and optimization of the searched cases and the storage and management of cases. The framework of the existing CBR methods is shown in Fig. 1. In case representation, feature vector and ontological theory are mainly adopted to improve the efficiency. During the construction of the case knowledge base, the existing studies add instance data to the case representation model manually and semi-automatically, and complete the case retrieval process based on a variety of matching rules. From the Introduction, we review the relevant literature and summarize some shortcomings about the existing CBR methods. Specifically, due to the complexity of complex product design knowledge, the workload of manual adding case data to generate case knowledge base is too heavy, and it is easy to make mistakes when identifying instance classes and attributes. Meanwhile, the case data are heterogeneous, and it is complicated to traverse the whole case base to achieve retrieval during semantic similarity calculations. Hence, the current CBR methods have certain constraints when adding a large number of cases, and the retrieval methods cannot meet the accuracy and efficiency of semantic similarity calculations with the large-scale heterogeneous cases.

The framework of existing CBR methods.
Based on the existing CBR methods, this paper introduces ontology-based Data Access (OBDA) technology into the case base construction process and proposes a two-stage retrieval method that integrates query statements and semantic similarity calculations to improve the efficiency of CBR. The overall framework is shown in Fig. 2. The improved CBR method consists of four parts case representation, ontology mapping, semantic query, and comprehensive similarity calculation. In case representation, semantic relations between concepts are formed, and classes and attributes can be controlled. The domain ontology of complex product design knowledge is constructed to provide the semantic basis for the generation of the case base. To avoid adding case data into the domain ontology manually, OBDA technology is used to edit the mapping files to ensure that the classes and attribute relations of the case data are consistent with the ontology. Therefore, the automatic filling of the instance layer in the domain ontology is realized. And the CBR case base with semantic information is obtained. The retrieval process is divided into two stages, namely, semantic query and similarity calculation. A subset of cases that are isomorphic to the design requirements is inferred through query statements from the case base. Comprehensive semantic similarity is further calculated to obtain the most similar case. According to the calculation results, the case knowledge reuse can be completed. The key technical of this improved CBR method is to realize the automatic filling of the domain ontology instance layer through OBDA mapping, avoiding manually adding case data and writing mapping statements. Meanwhile, changing the representation form of CBR case base and using query statements can reduce the subsequent calculations of semantic similarity, compress the traversal space, and improve retrieval efficiency.

An improved CBR combined with OBDA.
Domain ontology modeling
Case representation provides a semantic basis for CBR. The structure and content of cases affect the case-based reasoning process. A case of CBR is composed of a single knowledge entity or multiple knowledge entities linked through relations. The key point of case representation is the way to structure, share, and externalize tacit knowledge. The ontology model represents conceptual entities and relations between them in abstract form [34]. The construction of a domain ontology can provide a unified semantic structure for the standardized representation of complex product design case knowledge and improve the efficiency of knowledge representation.
To construct a domain ontology, the source and scope of knowledge are first determined. The hierarchical structure of the acquired domain knowledge is constructed. Then, they are transformed into ontology form. To ensure the universality and shareability of case knowledge, the semantic vocabulary and concepts structure level in the ontology can be derived from existing documents, such as terms, general design rules, and technical conditions. Considering case knowledge characteristics, the key concepts, relationships, attributes, and examples of design are regarded as the basis of knowledge reuse. Describe the case knowledge domain ontology model in the form of a quaternion, which can be expressed as:
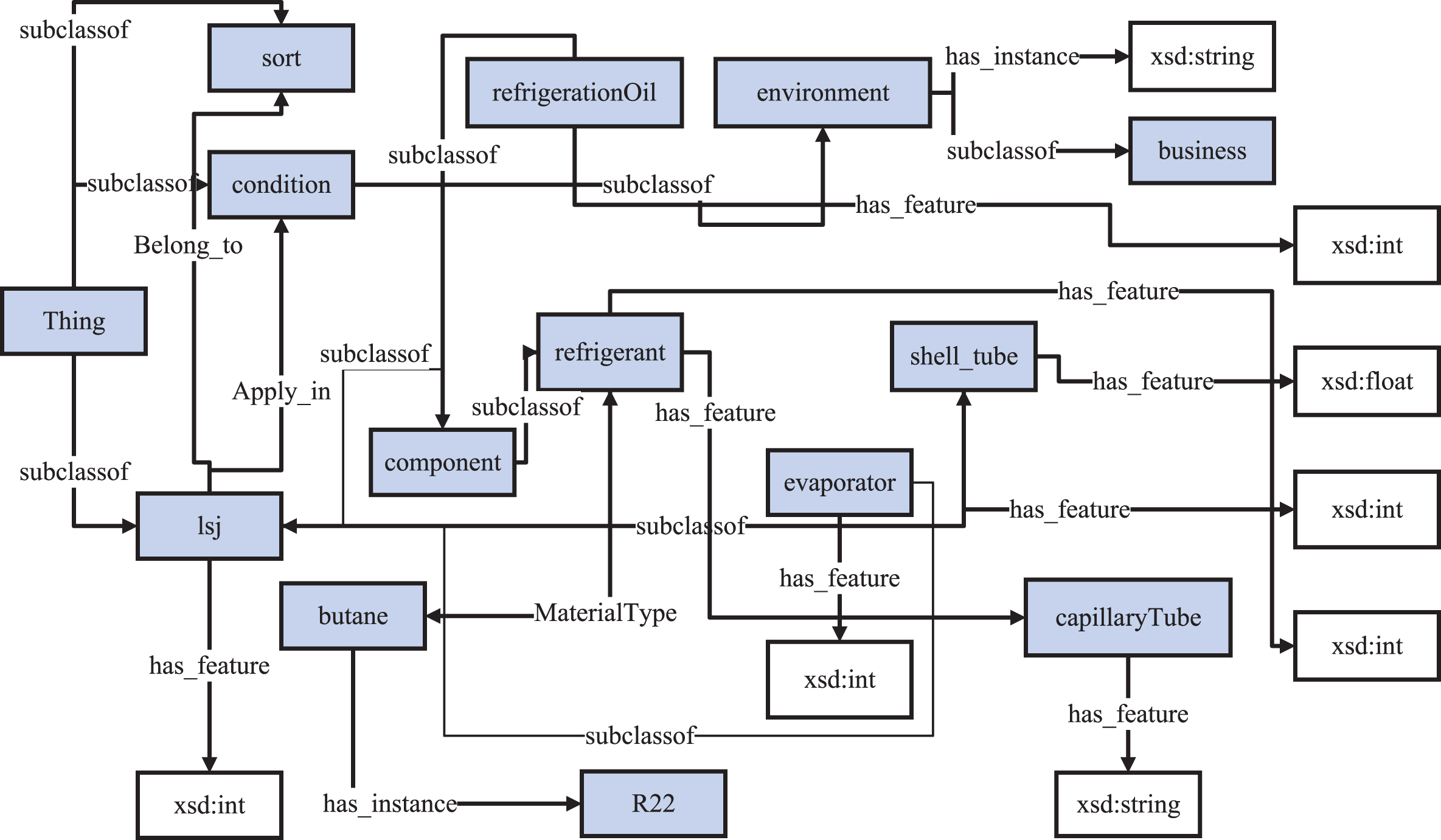
Domain ontology model(portion).
Relationship description between ontology concepts
The case knowledge representation framework based on domain ontology effectively organizes the case knowledge of complex product design and provides a high consistent ontology concept layer for the case base below.
After completing the construction of the conceptual layer TBox, the instance data layer ABox needs to be filled in [35]. Considering the heavy and error-prone workload of manually adding multiple concepts, relationships, and attributes under instances of the ontology model, OBDA technology based on the concept layer is introduced into the instance layer filling process. This technology can integrate relational databases with ontology and transform the data access mode between them through mapping assertions [36]. The OBDA framework is shown in Fig. 4, where the conceptual layer is expressed in the form of Ontology Web Language (OWL) and the data layer is stored in a relational database. The mapping file combines the domain ontology with the case database, which is a key part of OBDA. The independent domain ontology and relational database can form a new ontology through semantic mapping. The new ontology can be defined as:
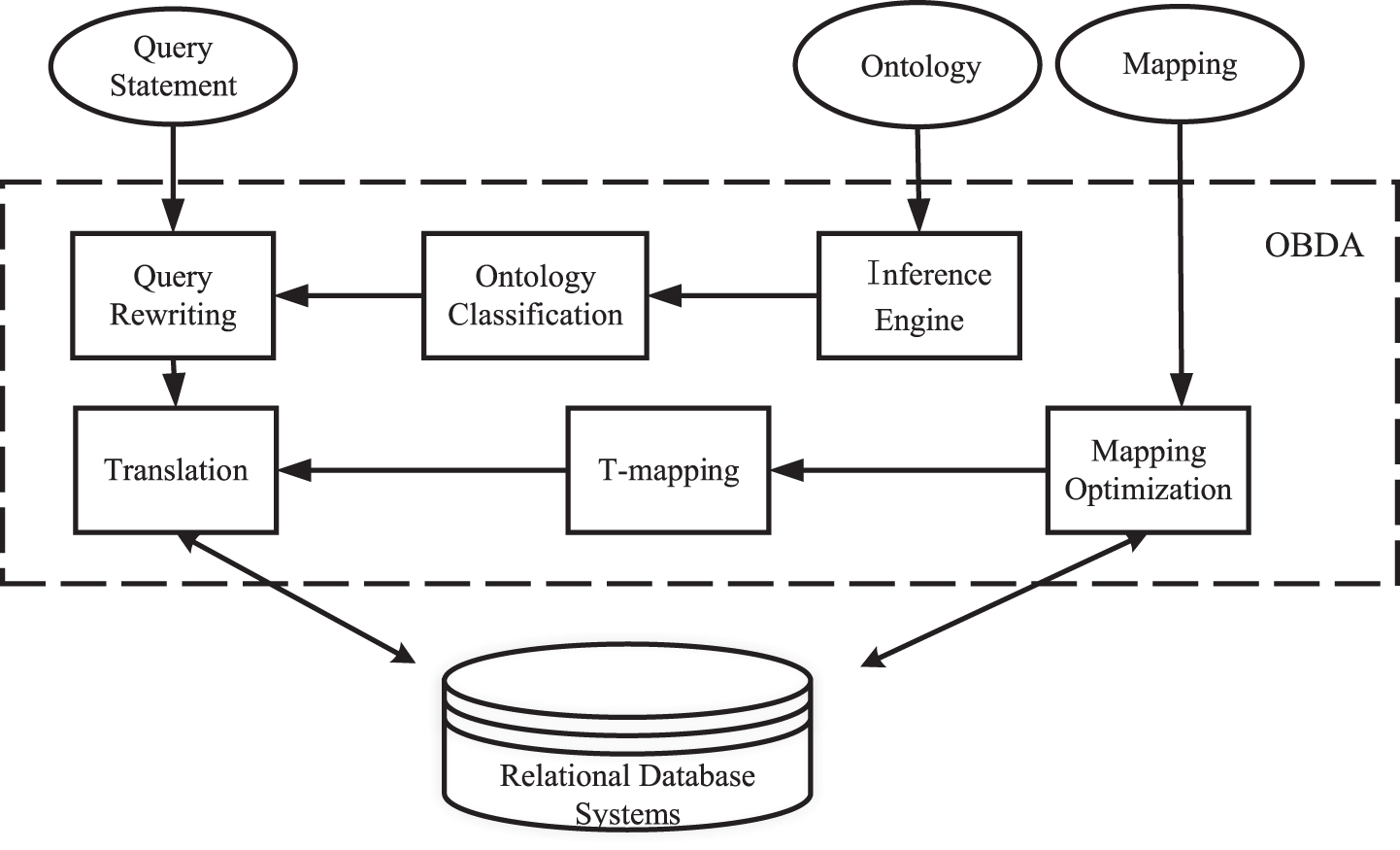
Structure of OBDA.
In equation 2, O is the original domain ontology, DB is the relational database of the case, and M is the mapping assertion from the data source to the ontology.
The mapping set M is composed of several mapping assertions. Each mapping assertion includes a data source query and a target query, which is shaped like a first-order logic expression from function O to function DB, such as φ X → φ X . Source query φ X is used to retrieve values and separate SQL queries are written for each table and column for a relational database. φ X is a target query connected ontology. The value of the source query is constructed as a triplet describing the ontology object relations. The triplets are aligned with the domain ontology vocabulary. Mapping assertions include type assertions and data-to-object assertions. They describe the relationships between instances of data sources and ontology concepts to directly recognize the classes and attributes of entities. According to the relational database schema and domain ontology, the mapping assertions are constructed to realize the filling of the ontology instance layer automatically. Thus, the CBR ontology case base with semantic relationships is generated, shown as:
The OBDA scheme provides a query reasoning engine and supports Simple Protocol and RDF Query Language (SPARQL) for Resource Description Framework (RDF). To query cases in the ontology efficiently, the representation form of the case base is transformed into RDF language. The domain ontology is represented by OWL form, which is essentially a collection of predefined terms to define classes and attributes. While RDF is a data model that provides a unified standard for describing entities or resources. Hence, OWL provides a semantic basis for RDF. We determine to parse the ontology stored in OWL into RDF statements.
A group of RDF triples can be regarded as a sentence or a piece of knowledge. A case is composed of multiple sentences or knowledge, expressed as {S, P, O}. The subject S and object O usually point to the Uniform Resource Identifier (URI) about corresponding resources. The object can also be a character attribute value. And the predicate P represents the URI that belongs to an attribute. The CBR case base is stored in RDF triple form. This form can fully preserve large-scale cases in the relational database and increase semantic information. Meanwhile, it also facilitates semantic reasoning based on the domain ontology and lays the foundation for case retrieval.
Knowledge retrieval from case base
Design problems include structural requirements, functional requirements, and so on. The traditional CBR methods express them as a fixed template, lacking semantic information and flexibility. However, a complex design problem usually contains multiple design objectives and constraints. It involves a series of design variables and parameters. Therefore, we decide to decompose the design problem into multiple simple design requirements. The design requirements information can be represented as ontology model. The new design problem uses RDF triples to represent unstructured design problems uniformly, expressed as:
In triple 4, C′ represents the ontology concept set of design requirements, R′ indicates the subordinate relationship between concepts, and P′ means the attribute set of concepts. The design problem diagram can be expressed as Fig. 5.
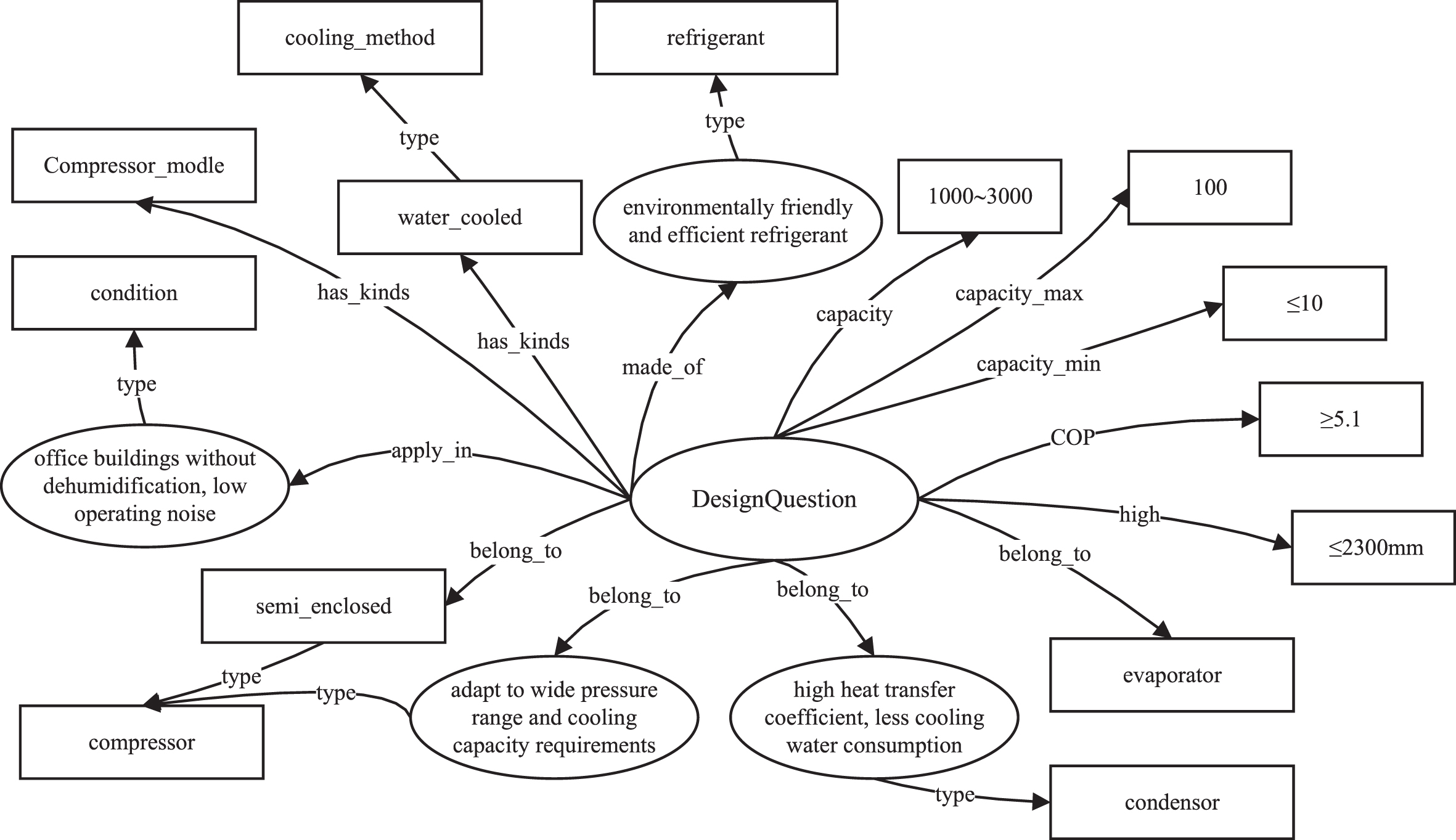
The graph of design question.
When a new design task occurs, the most suitable cases will be matched by different retrieval strategies from CBR case base. In fact, for a new design problem, it is difficult to match cases that fully meet the design requirements from the case base. Only similar cases can be obtained. Traditional retrieval algorithms mainly calculate attribute and semantic similarity. The calculation methods of attribute similarity include attribute category statistics, exact value, determined interval value, and fuzzy interval value similarity calculation. Semantic similarity is mainly calculated based on distance or information theory. The specific calculation formulas are shown in Fig. 6.
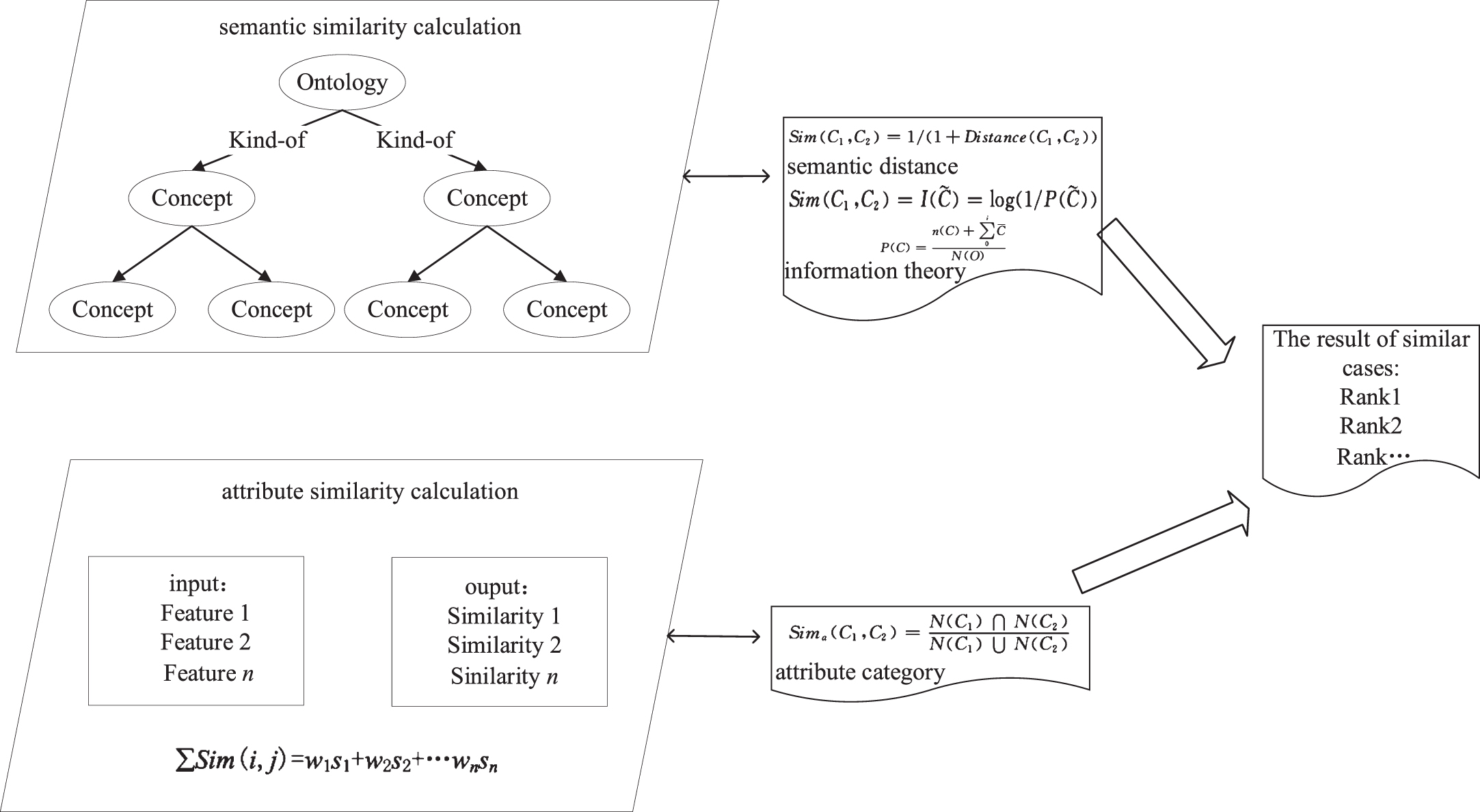
Basic retrieval algorithm.
The design problem representation and case base storage mode are adapted to improve the flexibility of case knowledge retrieval. Hence, the traditional retrieval algorithms are no longer applicable to the improved CBR methodology. Integrated query sentences and semantic similarity calculations, a corresponding case retrieval algorithm is proposed. The matching mechanism is shown in Fig. 7. According to the RDF triplet graph of the design problem, the corresponding semantic query statements are written. To ensure that the case subset obtained in the first retrieval stage is isomorphic to the design requirements, the query statements should be aligned with the concept set, attribute set, and relation set in the ontology model. To obtain the most similar design case, the comprehensive semantic similarities are evaluated by calculating concepts and attributes similarity of the candidate subset in the second stage. Three influencing factors are comprehensively considered in terms of semantics and attributes.
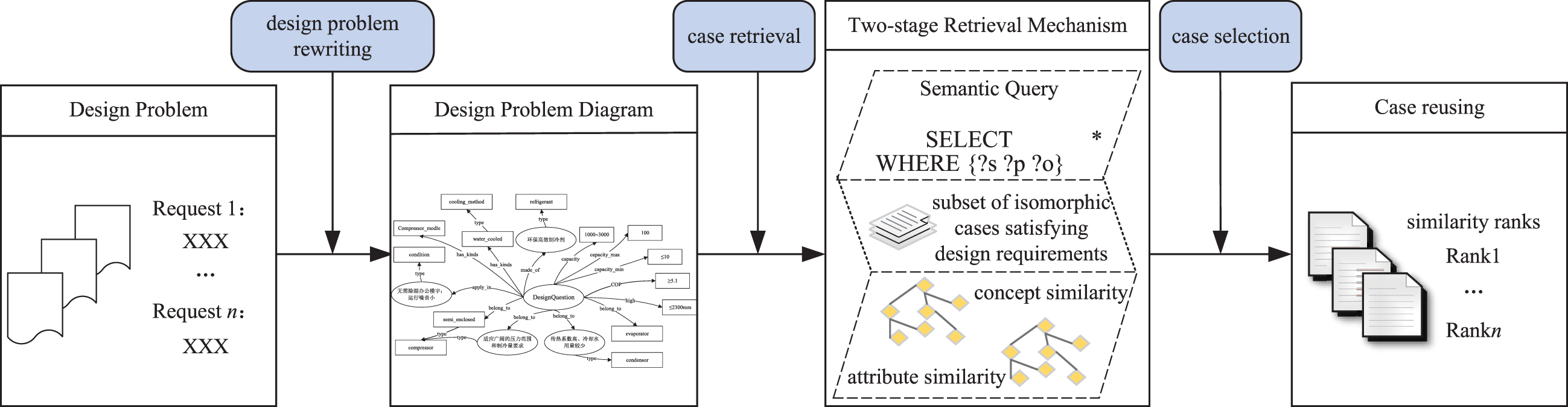
Algorithm of case retrieval.
The goal of the first semantic query retrieval stage is to find cases with the same structure and similar content as the design problem from the case base. Considering that the design problem and case base representation both are RDF, queries can use SPARQL, a semantic Web community language that can access and manipulate RDF data. SPARQL contains four key parts SELECT, WHERE, FROM, and PREFIX. The query mode is expressed as subject-predicate-object, such as SELECT * WHERE {? s ? p ? o}. The statement is essentially an RDF graph with variables. Considering that some design parameter values are in the interval range, FILTER is added to the variable value for testing. Since the query occurs in the same ontology case base, FROM can be omitted here. PREFIX constrains the namespace of the subject and predicate by adding URI.
Executing the query, a case subset that is isomorphic to the design requirements is obtained. The subset provides isomorphic candidate cases for semantic similarity calculation, which is beneficial to compress the retrieval traversal space and reduce the complex calculation because of heterogeneous characteristics.
Semantic similarity for cases
The subset of candidate cases needs further semantic similarity calculations. In the ontology model, concepts and attributes are important factors affecting semantic similarities. Therefore, in the second stage, the calculation of comprehensive semantic similarity is based on them. According to the similarity ranking, the most similar case with design problems is obtained.
(1) Concept similarity
The traditional semantic similarity computing method uses the path length between nodes to measure concept similarity, only considering the semantic distance but ignoring the influence of other factors. To improve the accuracy of the retrieval results, we calculate the concept similarity based on the path length, node depth, and density between ontology concept nodes.
a. Distance of ontology concept node
Semantic distance similarity refers to the position between concept nodes in the ontology structure tree and the difference is indicated by the shortest path. In the domain ontology structure tree, the closer the distance between nodes is, the more similar the two concepts are. The computational formula can be expressed as:
In formula 5, path (c, c′) indicates the length of the shortest path that connects conceptual nodes c and c′.
b. Depth of ontology concept node
Node depth refers to the distance between the conceptual node and the root, which can be expressed as the shortest path connecting two nodes. Generally, if the conceptual node level located a higher position in the structure tree, the node covers wider area and the meaning is more abstract, resulting in lower similarity.
In formula 6, dep (c) represents the depth of the node c located on the branch, and dep max (c) represents the maximum depth of the node c′ on the branch.
c. Density of ontology concept node
Node density refers to the number of first-generation child nodes contained by the parent node. In the structure tree, the lower position signifies the more specific conceptual node. With more direct child nodes, the density and similarity are higher.
In formula 7, dep(c) represents the number of direct child nodes of the concept nearest parent node, and den(o) indicates the maximum number of direct child nodes for each node in the structure tree. Considering the above three influencing factors, the weighted conceptual similarity is calculated by their proportion. The formula is as follows:
(2) Property similarity
Case data have multiple attribute types, including exact value, fuzzy interval value, and character type.
a. Exact numerical similarity
The exact numerical similarity calculation is determined by the proportion of the numerical difference to the target attribute value. The attribute p of the concept c is the exact value p v .
b. Fuzzy interval numerical similarity
The attribute p of the concept c can meet the design requirements in a certain range. And the similarity is determined by the position of the parameter value p i in the range. The range is divided into an optimal value range and another region. If it falls within the optimal value range, the attribute similarity can be regarded as 1:
In formula 10, (p imin , p imax ) is the value range for the attribute and (p1, p2) is the optimal value interval.
c. Character attribute similarity
Some non-numeric attributes of concept nodes are described by characters p s . There are only two situations of character attributes, where attribute values match or do not match with the design requirements:
Considering the different influences of the three types of attributes on the similarity calculation, the weights are assigned, respectively. The calculation formula of attribute similarity can be defined as follows:
As a typical complex product, full dc inverter chiller design belongs to the linear variant design of innovation for mature products in most situations due to the high cost of complete innovation. Past design knowledge needs to be reused constantly, which results in a strong dependence on past cases. The above characteristics meet the conditions that CBR methodology generates a solution. Hence, chiller products can be selected as the design example to verify the feasibility and comparative advantage of the improved CBR. The system uses Navicat 15 for MySQL as the associated database to store case data. The chiller domain ontology is constructed through Protege5.5. The mapping file is written by using OnTop to realize automatic filling of the ontology case base. And the queries are implemented by an inference machine supported by Java language. Finally, the semantic similarities are calculated to complete the retrieval.
Figure 8 contains the domain ontology model, case base construction, and algorithm realization process. Firstly, OWL language is used to construct the domain ontology concept layer to describe the semantic structure relationship between concepts. It provides the concept layer for the case knowledge base and the semantic basis for case retrieval. Then, according to the mapping link in the OBDA system, the instance layer is filled and the case base expressed as RDF statements is generated. According to the retrieval algorithm proposed in Chapter 4, the isomorphic case subset that meets the design requirements is obtained through query statements. The case space is reduced for further accurate retrieval. Finally, the case subset is matched and retrieved through similarity calculations to realize case reuse.
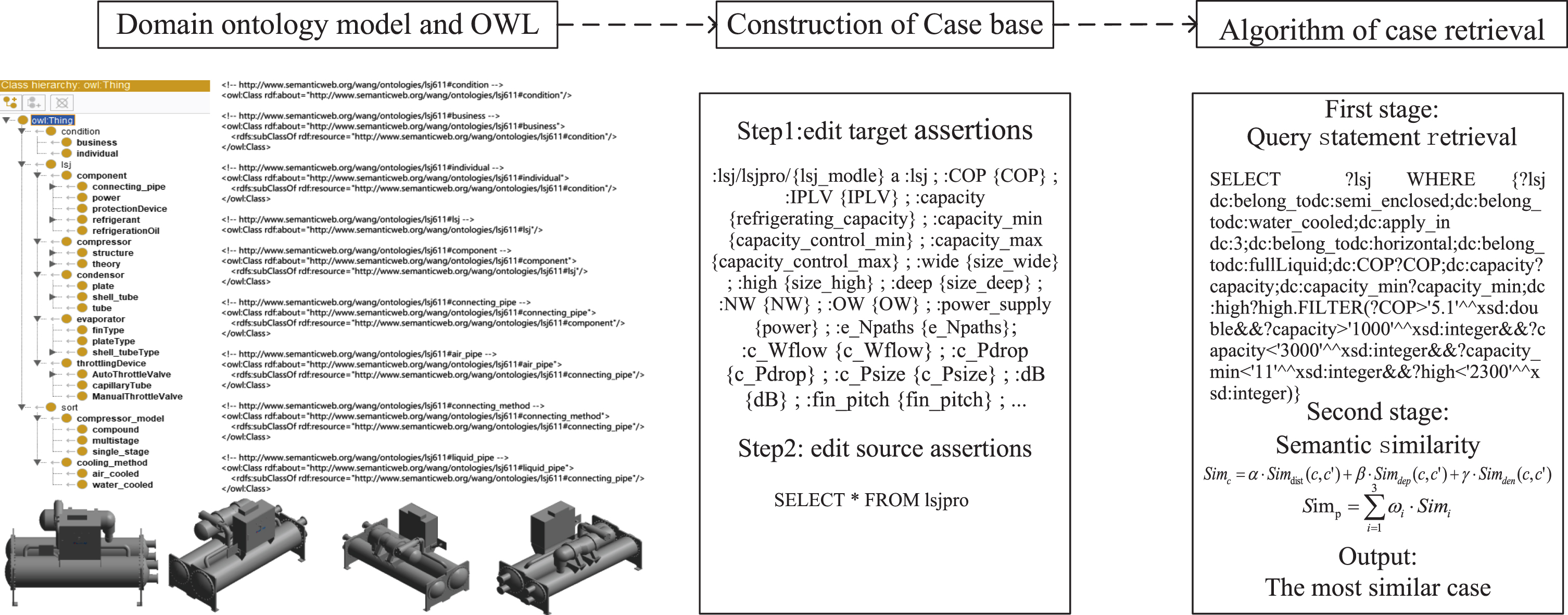
Domain ontology model of chiller design(portion).
Figure 9 shows the features and attributes of the LSBLX1200G product from the case base.

Example of a type of chiller.
The first retrieval result obtains the case subset that has similar content and is isomorphism with design requirements. The subset contains 15 candidate cases, which can be represented as the ternary diagram of ontology annotation. Figure 10 shows the CT series chiller. Based on the annotation graph, the comprehensive semantic similarities of nodes are calculated by formula 8 and formula 12. Figure 11 shows the simplified semantic similarity graph of 15 candidate cases. From the calculation results of the candidate subset, we can obtain the most similar case, namely, the LSBLX1800T high-efficiency centrifugal chiller of the CT series. Therefore, the case knowledge reuse is completed.

Ontology annotation of CT series.
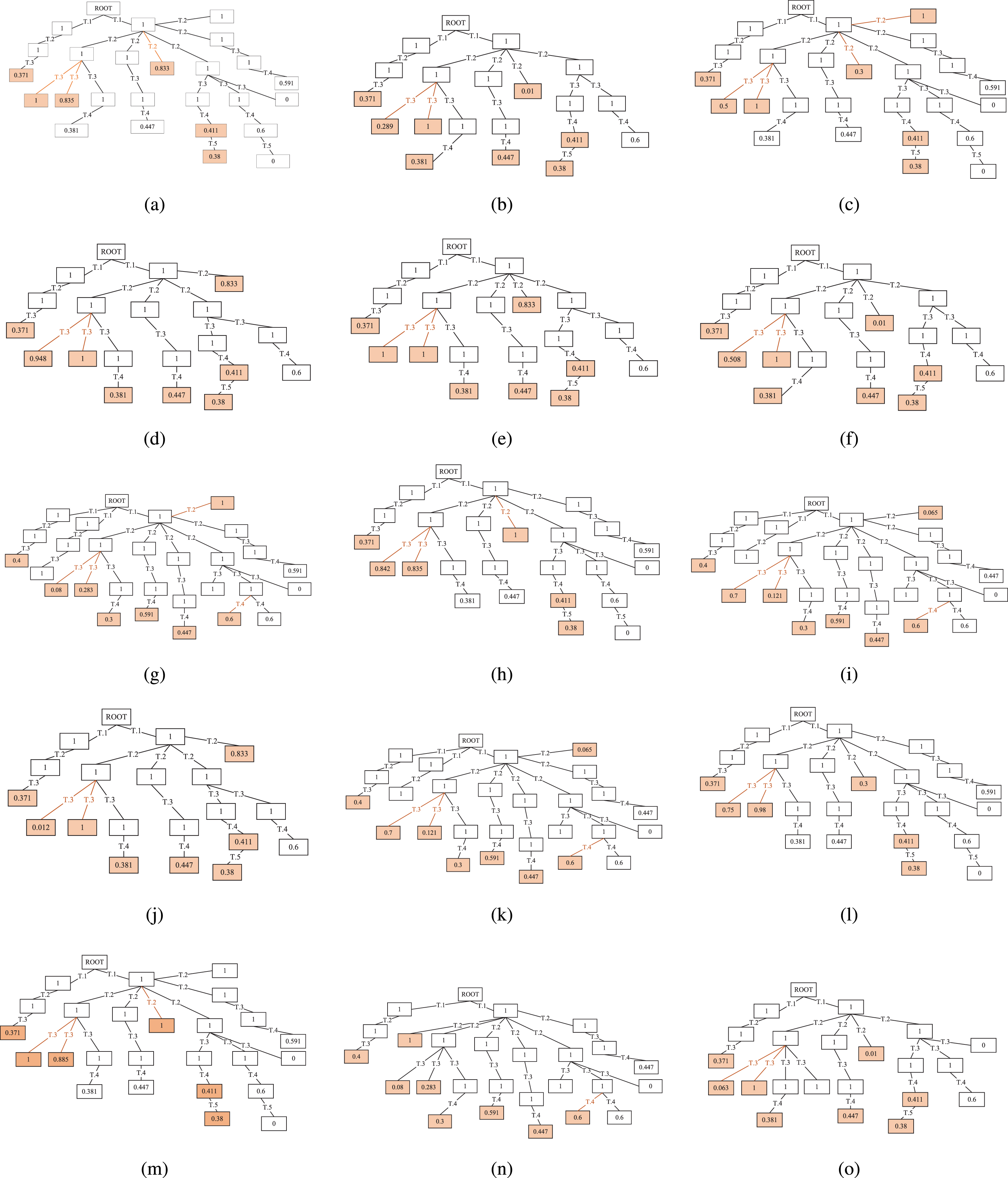
Graphs of node semantic similarity.
To prove the effectiveness of the proposed method, we conduct two groups of experiments. First, the specific steps of case base construction are counted. Second, the case retrieval results are calculated. Compared with the different CBR methods, the influences of different methods on the overall retrieval performance are determined.
Experiment 1 is planned to select the traditional case database construction method for comparison with the method in this paper. The traditional method refers to the method used in literature [19] and [21] to complete case base construction by manually adding instance data. Taking the characteristics of this paper’s case data as an example, the construction of the traditional case base includes dividing the concept classes and attribute classes of each case data. And these properties need to be added to 39 concept entities. After analyzing the data types, data attributes under each class are added to the corresponding entities. Completing the above work, the semantic information of each case data is obtained to generate the CBR case base. While, in the proposed CBR, only 21 mapping assertions are constructed to add instances to generate a case base automatically. The workload comparison is shown in Table 2. It can be seen that the workload is different between the two construction methods when the same number of case data is added. The efficiency of the improved CBR methodology is significantly higher than that of the traditional method.
Comparison of case base construction workload
Comparison of case base construction workload
The retrieval results
Experiment 2 is designed to test the retrieval effect of the proposed two-stage retrieval method, which represents the ability of the proposed method to accurately retrieve appropriate cases from the case base. To evaluate the relative advantages of the proposed algorithm more completely and accurately, three case retrieval algorithms are selected for comparative analysis. The first is the basic retrieval algorithm used in the literature [29]. This basic algorithm considers the attribute similarity of cases and the main steps include determining the attribute calculation principle and weight. According to the characteristics of the cases, 13 related case features are mainly involved in the basic algorithm calculation. The second algorithm is an improved retrieval algorithm used in the literature [20], which is partially improved on the basis of the basic algorithm. This algorithm is also the mainstream idea of improving technology at present, which is representative. This algorithm mainly considers the structural similarity and semantic similarity based on the ontology model and adds the fitness of case reuse difficulty so as to obtain the retrieval results. The third algorithm is the proposed algorithm in this paper, a two-stage improved algorithm based on semantic queries and comprehensive similarities.
To comprehensively evaluate the performance of each algorithm, three evaluation indexes including feasibility, accuracy, and stability, are selected as references. Firstly, according to the previous description of each algorithm, it can be found that the similarity traversal of the whole case base is carried out by both the basic algorithm and the algorithm in the literature [20]. And the computations are more complex than that of the proposed algorithm in this paper. The feasibility indicator can be obtained by judging whether the results of the most similar case retrieved meet the design requirements and effectiveness. The precision indicator means accurate retrieval of viable cases. The literature [20, 37] often use it to measure and evaluate performance. The precision index can be calculated by the equation 13:
To increase the reliability of the dataset in this paper, ten groups of comparative experiments are carried out on the data set. Ten design problems are defined and three algorithms are used to retrieve the data set, respectively. In this paper, retrieval cases with similarity greater than 0.75 are selected as the retrieval results. Then, experts verify the feasibility of the most similar cases and conduct to determine whether the results belong to TP or FP.
The correlation calculation results are listed in Table 4. It can be found that the cases with the most similar retrieval results of the three algorithms are all feasible, which verifies the feasibility of the retrieval algorithm in the experiment. Table 4 separately shows the three algorithms’ value of TP, FP, and precision under each test pair. There are obvious differences in the precision of the three algorithms. The precision index curve of the proposed algorithm is almost above the other two curves in Fig. 13. The average precisions of the three algorithms remain at 0.64, 0.73 and 0.92, respectively. Therefore, the precision of the basic algorithm is low, followed by the algorithm used in the literature [20]. The precision of the proposed algorithm in this paper remains at a high level. As illustrated in Fig. 12, the MCC indicator values of the proposed algorithm in this paper are all close to one. In fact, a value of 1 indicates a perfect prediction of the candidate case. And a value of 0 indicates that the prediction is worse than the random prediction. Thus, the results of the precision indicator are reliable.

MCC of the proposed algorithm.
Figure 13 shows the results of variance in the three approaches under ten tests. We can see that the variance of the proposed algorithm in this paper is obviously lower than the other two algorithms. A Lower value of variance means that the deviation of the similarity calculation is small, which indicates a higher stability of the retrieval algorithm.
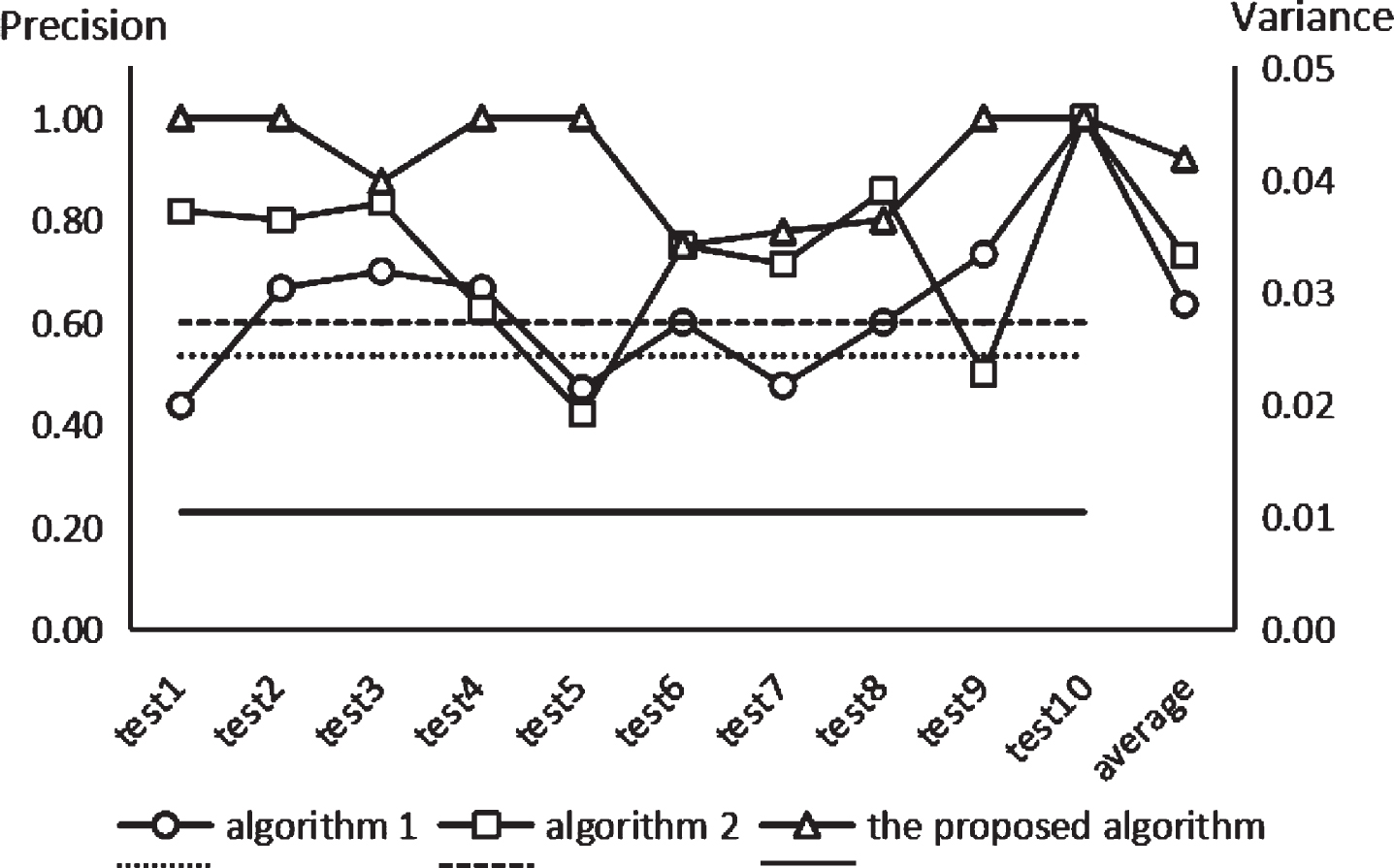
Comparison of algorithm performance.
In addition, we also found that although the reuse trends of the case retrieval results of the three algorithms are the same, the similarity values of the first two algorithms are lower than that of the third algorithm. When the fitness threshold is set at a higher level, the retrieval can be easily affected to reduce the matching accuracy.
According to the results of the experiments, we can conclude that the proposed method can effectively cope with large-scale case knowledge and retrieval. Compared with the basic method and the improved algorithm in recent research, the proposed method of this paper has better performance and contains less computation, higher accuracy, and stronger stability. For the reality situation where the case structure is more complex and the case base is larger, the advantages of the proposed CBR are more obvious.
In previous studies, most CBR studies have been carried out based on case representation and case retrieval [12, 19]. Compared with these two aspects, the case base construction has been neglected by many studies. The construction process of the case base is executing after case representation but before case retrieval. And it is a necessary step to accomplish reasoning. However, when the structure of knowledge representation is complex and the amount of case data is large, the existing manual or semi-automatic construction method may lead to a large amount of work and even errors. A better approach is to associate the case data with the case representation model to realize the automatic construction of the case base. This paper addressed this problem by using the mapping method. The advantage of the method is that it considers both the characteristics of the knowledge representation model and the storage mode of the case. They are constructed to form corresponding relationships, which saves the complicated workload of manual adding entities.
The design of the retrieval algorithm is a crucial step in case base inference. Different retrieval strategies can lead to different case similarities. Thus, different case results may be matched. In previous studies, various algorithms have been proposed to retrieve case base to improve the reasoning capability of CBR, such as attribute similarity, semantic similarity, the analytical hierarchy process, and genetic algorithm [38]. Case representation combined with ontology technology is the application trend of CBR. Considering the ontology model characteristics, the retrieval method based on semantic similarity calculation is adopted. However, solely using this algorithm to deal with complex case data can cause calculation traversal of the whole case base, which results in in low retrieval efficiency. Motivated by these previous studies, this paper proposes a two-stage algorithm based on query statements and semantic similarity to form a complete retrieval process. Meanwhile, the representation of case base is improved to be adaptable for query statement. This paper has made some explorations into the automatic construction of the CBR case base and retrieval algorithm, but further improvements will be needed in the future.
Conclusion and future works
It is difficult to formally represent implicit, empirical, and unstructured design case knowledge. In traditional CBR methods, the case base construction is complicated and the case data scale is small, which result in low efficiency of case retrieval. Aiming at these issues, this paper presents a new case reuse model integrating OBDA and CBR, and verifies it through design examples. The innovations of this research can be summarized as follows.
In the case representation phase, an improved design knowledge representation framework considering the domain ontology and OBDA system is proposed to construct a case base. Case data in the relational database are automatically filled into the case representation ontology model instance data layer through the OBDA system. This process greatly reduces the workload of manual adding case entities, provides a solution for building a large-scale case base, and lays the foundation for subsequent case retrieval.
In the case retrieval phase, a retrieval algorithm that integrates queries and similarity calculations is presented to complete knowledge reuse. The case retrieval narrows the computing space through SPARQL query statements and avoids passing through the whole case base when calculating the comprehensive semantic similarity. The proposed algorithm is beneficial for reducing the computational complexity and improving the efficiency of the traditional case retrieval methods. The proposed method performance is evaluated by experiments and the results validate its superiority to the existing methods.
However, this paper still has some limitations that may be alleviated in future studies. First, design knowledge ontology model of this paper is constructed manually. To some extent, this process depends on the product designers? professional knowledge and experience, which are summarized from the relevant data and information generated of the previous product design. Future studies can adopt machine learning methods, such as knowledge extraction. By these methods relevant knowledge in the complex product design field can be identified. Entities, relationships, and events can be extracted to automatically generate a design knowledge representation model. Second, regarding the retrieval algorithm, setting retrieval limits is only based on design requirements, ignoring knowledge inference rules. To explore the implicit connection between design requirements and cases, future research can focus on fuzzy similarity rules of case knowledge and the application of fuzzy number, contributing to further improving the efficiency of case reuse.
Footnotes
Acknowledgment
This work was supported by the National Natural Science Foundation of China (Grant No. 72072072), the Natural Science Foundation of Guangdong Province (Grant No. 2019A1515010045), Innovation Leading Team Project of Guangzhou (Grant No. 201909010006) and the Outstanding Innovative Talents Cultivation Funded Programs for Doctoral Students of Jinan University (Grant No. 2021CXB027).