
Abstract
Recent technological advancements have enabled users to conduct more sophisticated business transactions via Wi-Fi enabled networks. Typically, a compromised access point (CAP) can handle all traffic between a user and an Internet server, thus becoming a serious security hazard. In addition, an attacker can easily control the entire network using the CAP remotely and compromise as many victims as possible to form a botnet. This paper presents a hybrid recommendation prediction model for forecasting CAP attacks based on network traffic in a private network. This model combines various prediction techniques likethe time-series model, the kNN model and cross association algorithm for attack prediction. This hybrid blacklisting recommendation system effectively improves the prediction rate significantly as well as the robustness against poisoning attacks.
Introduction
Because a Wi-Fi-based wireless network (WWN) provides users with continuous Internet access, it has grown rapidly and become a popular network in recent years. Many companies and enterprises implement WWN to offer vital services to users while in transit or in public places without the hassle of a physical connection. The open nature of the communication medium in WWN allows anyone, including cyber criminals can access all packets; thus, the root attacker can perform a variety of attacks like packet sniffing, man-in-middle, wardriving, warshipping, MAC spoofing, authentication compromise, certificate theft, etc. The CAP based attack becomes very effective and is more common. An access point, which is compromised and controlled remotely by an adversary is referred to as a CAP. A remote attacker can install a CAP that contains a valid service set identifier as a legitimate AP, collect the user’s private information, and can perform a man-in-middle attack. Table 1 lists a classification of various classifications of access points and their corresponding exploit methods.
Classifications of access points and exploit methods
Classifications of access points and exploit methods
Usually, an interaction between WWN and the user starts by validating the authentication process which is coupled with cryptographic operations to ensure services like confidentiality. The authentication process can be performed in different ways, like 802.1x-based authentication, open-based authentication, and public cryptographic based authentication. The first method was specifically designed for 802.11i with a key management scheme and mutual authentication technique to make the security mechanism more robust. The last two authentication methods were designed for IEEE 802.11 wireless networks and proved insecure. Different protocols have been designed for WWN. First, a wire-equivalent privacy protocol for protecting wireless traffics was released. It relies on the RC4 security scheme. Later, security strength was improved by introducing protocols like WPA2 and WAP3 that rely on AES algorithm. Each protocol was designed with a different authentication technique to protect wireless data; however, there is no method that allows a client to validate the authentication of an AP in WWN.
For example, an Evil-Twin (ET) Access Point (ET-AP) is a trap set by an eavesdropper to target smartphone users [1–4]. After getting connected with an ET-AP, it guides them to link to deceptive website with the intent of stealing the user’s sensitive data. The eavesdropper discovers and obtains the Service Set IDentifer (SSID) and its corresponding unique MAC address associated with the network of the legitimate AP to setting up ET-AP. When a user’s device scans the connected Wi-Fi APs in the current network, it discovers only a unique SSID associated with an AP. ET-AP spoofs both the SSID and its corresponding MAC address of the legitimate AP. When multiple APs with the same SSID are found, nearly all modern operating systems are programmed to find the nearest AP with the strongest signal strength. It is true that if an ET-AP is present in a network and its signal strength exceeds that of a legitimate AP on the same network, the user’s device is associated with the ET-AP. It is also true that an AP with higher signal strength typically offers minimal frame loss and higher throughput. Therefore, a device always chooses to discover and associate with an AP that offers higher signal strength. An eavesdropper typically tries to launch an attack while standing near places like cafeterias, hotels, airports, public hotspots, which act as Wi-Fi deliverable locations.
In addition, the eavesdropper can make the attack more effective based on the selection of the protocol and authentication scheme to be used. Recently, there have been a few reports of hackers using a CAP in an open WWN to steal sensitive private information such as bank account numbers, passwords, and mobile phone numbers. In addition, CAP based attacks in an enterprise have become a serious issue [5] that question the security of the entire private network. As a result, almost all smart devices used by users fail to authenticate an AP before connecting to it, which makes identifying an illegal AP more complex. Therefore, it is essential to study and formulate a CAP detection technique that protects the entire WWN.
The rest of the paper is organized as follows: Section 2 discusses background information and motivation. Section 3 discusses recent works related to the proposed method. Section 4 formulates the problem. Section 5 presents the proposed recommendation to perform prediction of malicious access points. Section 6 gives experimental results and discussion, and finally, Section 7 concludes the suggested work.
As, the protocol used in 802.11 does not offer a service for identifying a strong signal to any device to be connected, it makes use of two IDs to utilize Wi-Fi instantly: the Basic SSID and the SSID [6]. Furthermore, because 802.11 networks failed to design a control range of signal, the eavesdropper could easily obtain both the basic SSID and the SSID. The AP of a wireless network is typically protected using both password credentials and a sophisticated encryption scheme, but for a sophisticated attacker, it is easy to crack them. However, the security algorithm, namely wired equivalent privacy for the IEEE 802.11 network, resolves the previously mentioned issues with the intention of improving the confidentiality of user data. Despite providing an improved version with strong authentication mechanisms, data integrity, and confidentiality, the wired equivalent privacy algorithm has been shown to be insecure, and an eavesdropper can easily break it after obtaining the initialization vector value and its associated frames [7].
By dynamically collecting legitimate frames exchanged between communicating parties or intermediate devices, the recent wired equivalent privacy-based attack can be capable of defying the aforesaid protocol with negligible time [8]. Hence, the wired equivalent privacy protocol was replaced by the protocol namely, Wi-Fi Protected Access. However, it has failed to solve a few security issues. As, the management and control-frames of the Wi-Fi protected access protocol can be easily forged, the entire underlying wireless local area network is susceptible to various attacks like identity attacks and denial of service attacks [9]. After a user is attached to a CAP, the eavesdropper can easily control the entire network to which the user is attached. Furthermore, privacy violations, data tampering, and denial of service can also be posed against either the user or device.
According to IEEE 802.11, if a user’s device receives signals from several APs nearby, the AP associated with the strongest signal is to be chosen [10]. As a result, the best location for the bogus AP is very close to the attack object. This form of attack is referred to as a "fishing attack" that can be classified into two types namely active fishing attack and passive fishing attack. Among them, passive fishing attacks are very dangerous. This is because it does not attack legitimate AP but instead typically tries to increase the attack rate. An active fishing attack aims to connect to a CAP, remove the pre-established connection between the user’s device, and act as a legitimate AP.
In order to compromise a legitimate AP in a WWN, an eavesdropper performs the following operations: First, the eavesdropper performs traffic analysis between the client device and the victim AP to infer important information depending on the protocol used. After successfully obtaining information, the eavesdropper setup AP settings similar to legitimate AP, as shown in Fig. 1.
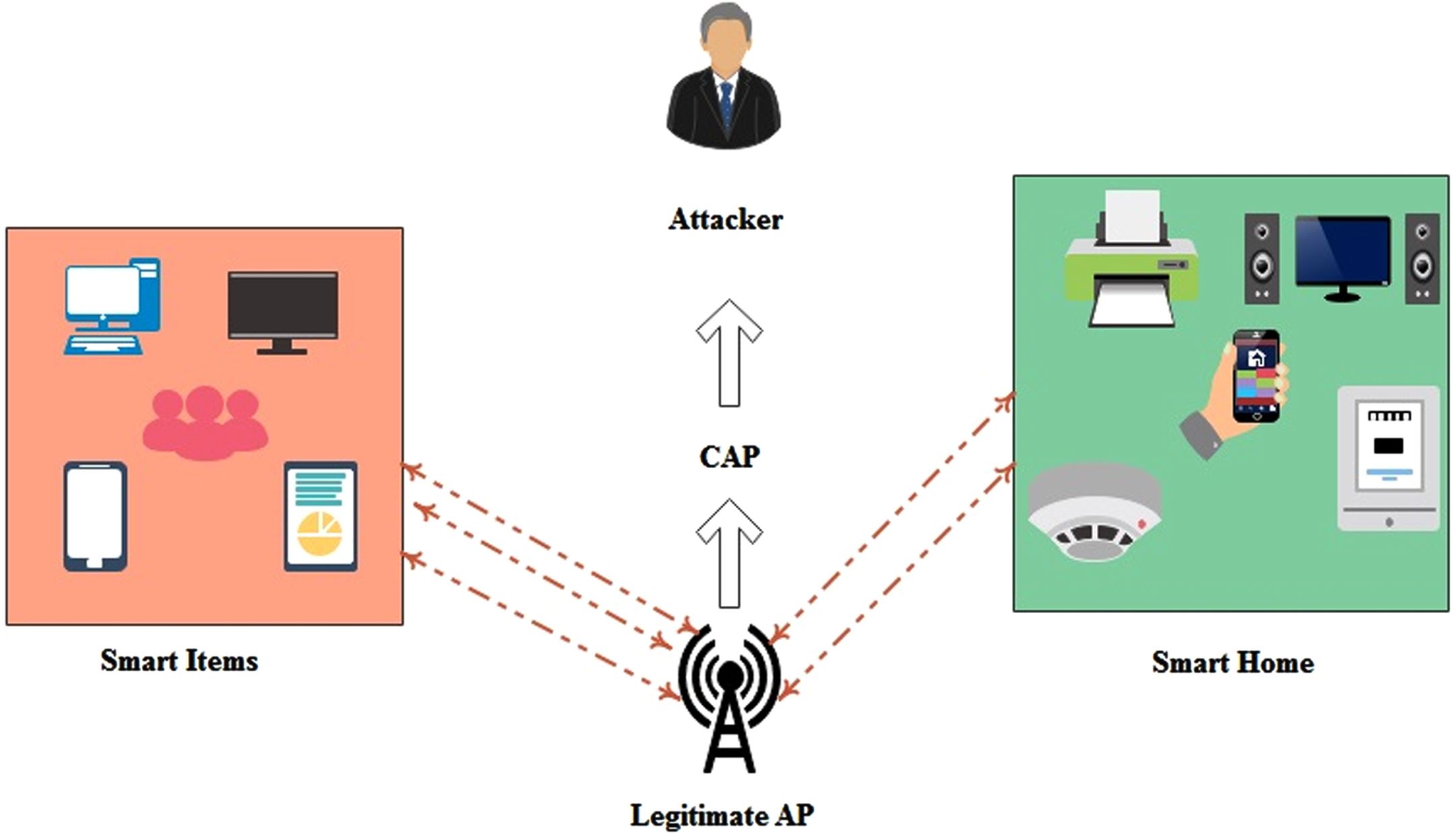
A scenario of compromised AP.
Finally, the eavesdropper can perform any illicit operation in the underlying WWN using the new rogue AP as shown in Fig. 2.
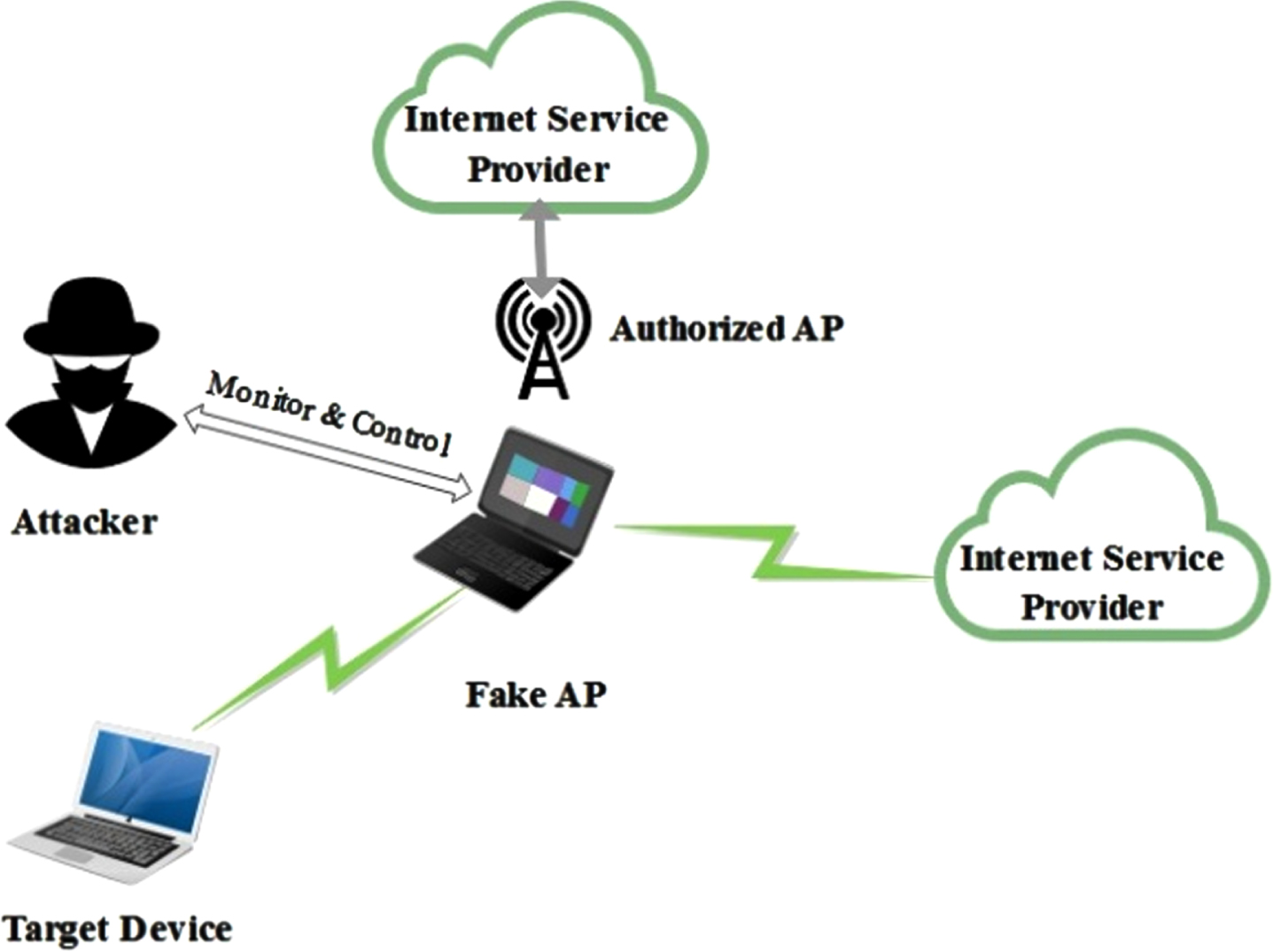
Example scenario where a CAP act as legitimate AP.
The word ‘prediction’ represents the use of either fields or variables inferred from the dataset to forecast anonymous or impending outcomes of other parameters of our interest. Major methods in the context of prediction are usually regressions that can be classified into linear and non-linear regressions. When using multiple predictors, the regression cannot be visualised in two-dimensional space using the aforementioned methods.Thus, other effective prediction algorithms are used, such as time series analysis and the nearest neighbor prediction algorithm, for forecasting unknowns.
Time series analysis comprises methods for analyzing time series data in order to extract meaningful statistics and other characteristics of the data. This method of forecasting unknowns is a form of forecasting impending events based on experience inferred from the past. Time series analysis is commonly plotted using line charts. A multi-stage prediction prototype is typically used to predict unknown attacks in a wireless network and consists of the following critical stages: First, devise the problem to be solved using a practical structure inspired by a recommendation system. In particular, outline the issue of "predictive blacklisting" that aims to predict the type of network being embattled by whom based on past historical data. Also, modelling an implicit recommendation system in which different data items will be preferred by the user based on past experience. Secondly, comparing and combining more than one effective technique, like the time-series forecasting analysis technique for capturing temporal and historical data from log files, the neighborhood modelling technique to capture traces about the attacker or victim, and the singular value decomposition technique to generate a global spatial unique pattern, is also important. The overall outcome is about integrating multiple prediction models to discover the attacker’s source on the victim’s system or network. Thirdly, systematically analyzing network traffic and disclosing prevailing spatio-temporal samples of malevolent traffic.
Related works
As various attacks on the wireless real-time environment become more prevalent [26], the need for developing new novel detection mechanisms to protect both wireless users and devices grows. We classify this section into two subsections, namely, user-side attack prediction and administrator-side attack prediction.
Few traditional approaches [11] namely, LWOL and GWOL aim to produce blacklist of wireless accessing. Security enabled devices installed closer to a particular domain can log activities about malicious software, and thus a precise profile about the most fertile attacking sources can be compiled. However, this approach failed to discover attack traces for the same domain that had never been done in the past. It helps develop a local blacklist capable of protecting the local area network reactively. GWOL represents preparing a blacklist that comprises the most popular attack traces for generating the top most total count of global attacks as same as reported by a trustworthy repository. A notable issue with the GWOL approach is that the few attack traces discovered by the proposed security solution might be irrelevant to victim network. Beyond aforesaid traditional methods, Highly Predictive Blacklisting is presented in [2] with the objective of predicting future attacks based on utilizing both own log files and few new alike victim traces. Prakash et al. [12] presented a Phish Net framework, i.e. an algorithm that is capable of predicting expected malicious URL based attacks. This approach relied on the study that showed attackers frequently construct only trivial variation in previous phishing URLs to produce new rules, the authors specified the mixture and dissimilarity of well identified phishing domains to generate a fresh copy of the same.
End user-side attack prediction
Users can normally send packets to determine different time metrics and use various classes of testing while linking to a specific AP to determine whether packets that travel through either one or more APs will discover a rogue AP. The works presented in [13, 14] applied this type of revealing method. Nicholson et al. [15] presented a solution, namely Virgil, that automatically determines and associates with an AP based on the quality of the received radio signal. It also utilizes bandwidth availability that is associated with a group of allusion servers, making computing the round-trip-time (RTT) of packets possible. Han et al. [14] too employ the RTT value between a client and a DNS server to validate whether the associated AP is a CAP without getting assistance from the wireless network administrator. At the time of revealing a CAP, the associated AP will obtain a DNS query packet from the matching client.
Yang et al. [13] proposed ETSniffer, a statistically based CAP detection method that uses inter packet arrival time and two different algorithms to distinguish one hop channel from other channels in different wireless environments. One noted feature of ETSniffer is that it does not require support from the network administrator, Internet service provider, or some authoritative APs; thus, ETSniffer is well suited for typical end-users. However, end-user side attack (EUS) detection faces some security issues that must be addressed. Firstly, EUS detection normally transmits special packets. If an eavesdropper knows the workings of the EUS detection method, it is possible to evade the entire detection scheme. Secondly, EUS generally exploits different time-based metrics associated with special packets like the TTL packet to differentiate the CAP from genuine AP. As, there is always a change in traffic volume, network structure, or network ability, time-based metrics also could not work aptly while dealing with similar kinds of special packets. In addition, for an end-user whose travel varied dynamically at diverse time intervals, the EUS detection failed to function properly. A solution that overcomes these issues is in the form of indoor localization [16, 17] which is capable of identifying the CAP among various access points.
Administrator-side attack prediction
Beyah et al. [18] make use of the temporal characteristics of inter-packets like arrival time to determine CAP in a wireless environment. The authors claimed that it is scalable and does not depend on any wireless technology. Shetty et al. [19] presented a programmatic classification method that discovered CAP by using the median value of the RTT value. Watkins et al. [20] observed that the use of the RTT value during packet transmission has taken less time than wireless counterpart. Thus, the authors utilize RTT as an important metric to spot both authorized and malicious AP. Wei et al. [21] proposed a scheme for distinguishing packet flows travelling in both wireless LAN and Ethernet. The authors’ main intention is to identify wireless hosts. This would help to identify the malicious AP. Venkataraman et al. [22] focused on collecting features of medium access control packets as the main footprint in 802.11 to sort out the difference between wired traffic and wireless traffic.
Ma et al. [23] designed a multi level CAP detection framework that integrated traffic from both the gateway-side and wireless monitoring devices. The authors used the time space between interpackets as one of the vital CAP detection metrics. Contrasting to their method, Kao et al. [24] utlized IP address of packets that travels through an AP to identify suspicious victim AP. Most of the solutions (i.e., administrator-side attack detection) discussed in this section required deep analysis of packets that travelled through the main gateway device. Besides, this kind of detection method should use legitimate IP addresses or APs, which can be collected only by the administrator of the specific network, and the ability to decide whether the traffic being handled belongs to wired or wireless traffic. As, a CAP typically conceals its traces behind an authorized AP, detecting the CAP is not an easy method. The proposed work utilizes the traces of in network traffic to capture vital information about IP traffic from multiple victim APs and is focused on predicting potential malevolent IP traffic.
Problem formulation
Recommendation system vs attack prediction
A recommendation system aims at inferring and computing anonymous user rankings concerning items from well-known (i.e., past) rankings or ratings. The most well-known recommender system is Amazon’s product recommender system, which is designed to make predictions based on a composite and user-defined rating method rather than random selection. A rating matrix is produced as a result of some superimposed tasks, some of which are instinctive, while others require revealing and deciding through a precise analysis of the test dataset.
Given an attacker and victim sets, ’r’ is linked with each (time, attack _ source, victim _ destination) triplet inferred after analyzing log files. For example, ’r’ can signify, total number of times an eavesdropper has been reported to attack the target victim over a specific time interval. As illustrated in Fig. 3, there are significant differences between the conventional recommendation system and the attack prediction model. The passion of an attack may differ over time while in conventional recommendation system deals with statistical matrices. The attack rating is assumed implicit in attack prediction model and it should be explicitly provided in case of traditional recommenda-tion system.
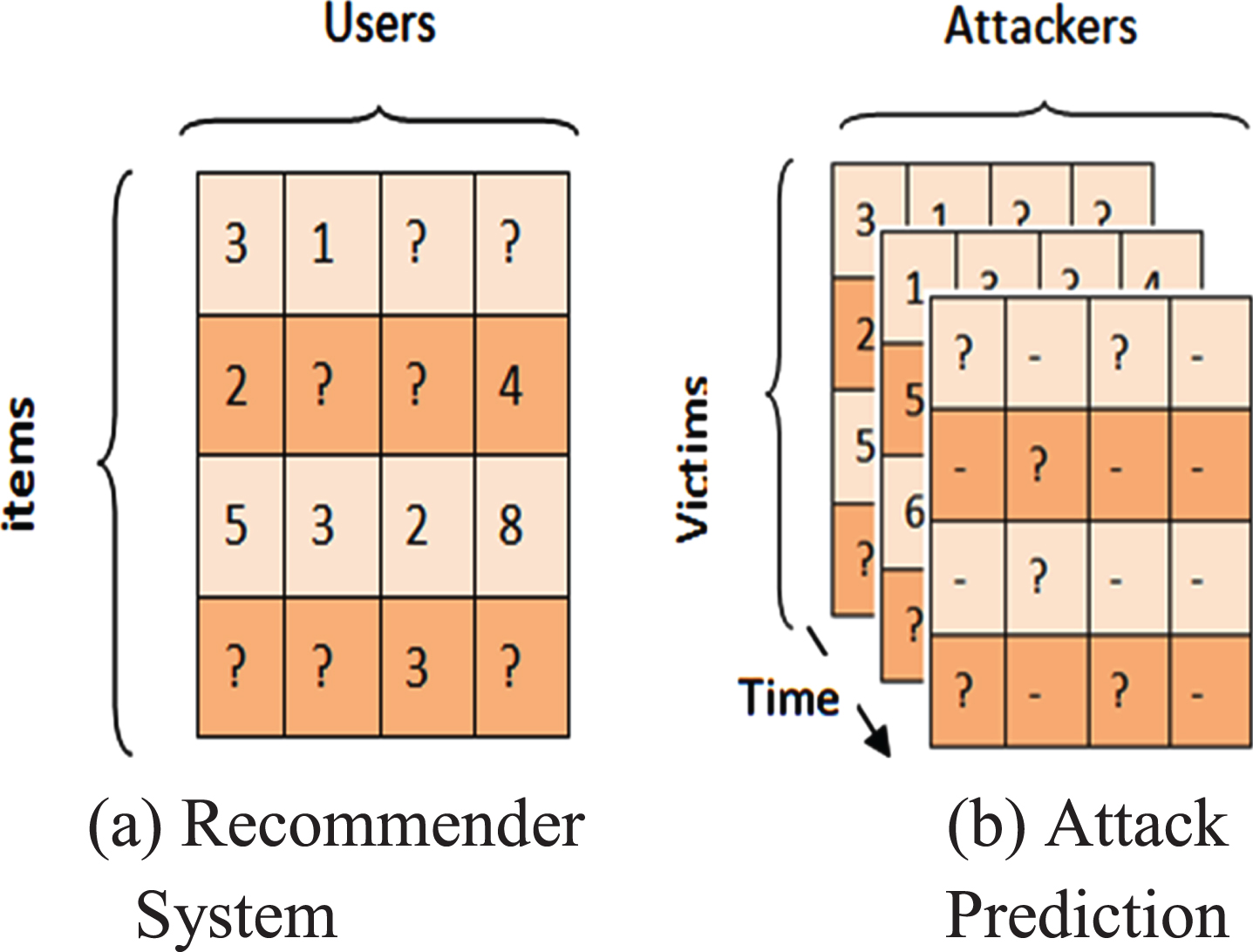
Recommendation system vs attack prediction.
A recommendation system is characterized as k
u
= arg max k| ∈
Let ’A’ denotes the set of remote attackers i.e., the IP address of the source where an attack being launched and ’V’ represents the set of victim network. Let ’t’ indicates the time of an attack was launched according to system log file ’ra’ and v(t) represents the total number of attacks counted on a particular day ’t’ from a ∈ A to v ∈V. Also, we used ’B’ as a binary matrix to denote whether an attack has occurred or not i.e. ba, v(t) = 1 iff ra, v(t) >0 and ba, v(t) = 0 otherwise. The main problem of predicting an attack is formalized as given in Equation 2 and 3.
In addition, we examine that the false positives is defined by finding every blacklist, BL against its testing period, TP as given in Equation 4.
The proposed work mainly integrates three various prediction models for predicting and discovering malicious CAP in a wireless network. They are: Construction of a time series model (CTM) which is mainly used to converting the given dataset associated with the contributing networks into a prediction model. KNN model to predict identical peers or APs in a wireless network in terms of performing similar kind of operations. The cross-association algorithm which is responsible to determine the similarities between attacker AP and victim AP. Finally, the rating prediction stage (RPS) produces a single prediction or rating process based on combined prediction models given as input to the recommendation system. This procedure is also named as blacklisting recommendation system as depicted in Fig. 4.
Blacklist prediction model.
We deduced from Section 3 that multiple attacks from the same source could occur within a short period of time. Thus, future activity powerfully depends on the past. Motivated by this study, we utilize the exponential-weighted moving average model to predict future values based on past values. Superior prediction accuracy can be determined when applying the EMA model to the binary versions of R and B. This can happen, when multiple attacks launched by the attackers in the recent past may not necessarily be performed in the future. The attacker can decide to stop the predefined activities at any time. The set of coordinated attackers is more likely to keep attacking a same source or victim continuously for a longer time or for a large number of days, as can be determined independently from different reports. Hence, we devise an improved forecasting model based on B as given in Equation 5.
Where α(a,v) denotes the smoothing coefficient trained for each specific pair (attacker, victim),
If two victim networks can atleast share a few common attacks from a single attacker then they are said to be ’neighbor’. The average number of neighboring networks is expressed as a function that includes some common attackers. Typically, most victims share just a few attacks since there are a few source IPs frequently attack nearly all victim network. The two classes of neighborhood models are: (i) kNN, which is utilized to capture the similarity between victims, and CA that aims to capture similarity level of (attacker, victim) pair.
Victim neighborhood model (kNN)
One of the most accepted approaches in any recommendation system is the integration of neighborhood model to build a prediction model on the idea of trusting identical peers in terms of performing operations. For every pair of victims, (u, v), we define their similarity (Suv) as shown in Equations 7.
Besides the victim neighborhood model explored by the kNN, there exists a joint neighborhood model for determining (attacker, victim) pair. It is very important that the similarity level between attackers and victims be considered when constructing the blacklists. In order to determine similarities among attackers and victims all together, it is vital to apply the cross association (CA) algorithm. The CA algorithm is a fully automatic clustering algorithm that discovers column and row clusters of sparse binary matrices.
Equation 9 denotes the density level of a cluster that includes the pair (a, v) at time t. We also improve the CA based prediction accuracy by confining the perseverance of the victim-attacker relationship over time. It is particularly useful to apply the EWMA model to a time series of density to forecast the rating value. The perception is that if an eavesdropper is constantly visible in the vicinity of a victim, the eavesdropper is more likely to attack the victim again. Formally, it is expressed as given in Equation 10.
The observations made during the analysis of malicious traffic motivated us to integrate various algorithms, such as a time series approach to represent temporal trends, a kNN model to determine the victim’s similarity, a clustering algorithm to model persistent clusters of (victim, attacker) pairs, and the SVD model to capture latent factors. A typical approach to combining predictors is to consider the average of individual predictors. More particularly, kNN is defined as given in Equation 11.
The perception is to rely more on kNN when ’v’ has a strong neighborhood of similar victims. When ∑u∈N
k
(v, a) . S
uv
value is small, then it is advisable to prefer predictors. The weight for the CA algorithm is defined as given in Equation 12.
Finally, the single prediction or rating is based on combining rules of all methods as given in Equation 13.
For evaluating the effectiveness and performance accuracy of our proposed method, we utilized WPA2 Dataset [25]. This network scenario connects two APs to the local switch of a private network, and they are coupled with an authentication server through the Internet. This testing network holds five different stations, three of them for generating network traffic, one for supervising the underlying system, and one for performing hacking purposes. Even though the setup scenario helps to demonstrate different types of attacks, we focus on monitoring attacks against fake AP. The attack discovery against an AP and its response were conducted through experiments with the use of unique training and testing sets. The first 50 percent of the dataset was employed to build training with the aim of detecting attack classifiers. The remaining 50 percent of the data was utilized to inject attack profiles. Based on the training dataset and method described above, binary classifiers were built to classify profiles as either attacks or authentic. For comparison, different prediction models were implemented, like CTM, kNN, CA and the proposed combined recommendation model.
Performance metrics
We employed 10-fold out-of-sampling to determine and evaluate the performance of our presented methodology. The performance of the presented methodology is assessed using metrics like accuracy (ACY), true positive rate (recall), precision (PSN), and F-Measure (F-M). These metrics are calculated as given below: True Positive (TP) - This denotes the count of positive observations and expected to be discovered correctly as positive. True Negative (TN): - This denotes the count of positive observations and expected to be discovered incorrectly as positive False Positive (FP): This represents the count of negative observations but discovered as positive. False Negative (FN): This represents the count of positive observations but inferred as negative.
ACY =
Recall =
PSN =
F-M =
Where ’TP’ denotes true positives of the system, ’TN’ represents true negatives of the system, ’FP’ implies false positives of our method, and finally ’FN’ denotes false negatives produced by the system. Once preprocessing has been completed successfully, it is important to analyze traffic reliant log files and records, thus, important features are extracted to characterize every instance. Then, the captured dataset is used for training, testing, and validation. More importantly, the training dataset is utilized to build the detection system, while the dataset used for validation aims to assess the model by avoiding overfitting. The accuracy of the classification model can be reduced when the dataset contains either inappropriate or superfluous attributes. Hence, each link towards an AP is expressed with 11 different features as described in Table 2 which would help us to identify the traffic or connection type as either legitimate or an unauthorized attack attempt.
Feature selection
Feature selection
During this stage, many trials are conducted to assess the accuracy of the proposed recommendation model. We use a confusion matrix aiming to determine the accuracy rate of individual prediction methods, including the integration of all these models. The accuracy rate is determined by splitting the input data set into a training part (75%) and testing part (25%). The testing process is mainly adopted to determine the accuracy of our system using the confusion matrix. Tables 4 depict the performance of the proposed recommendation model with and without considering the feature set. From the results tabulated in Tables 4, we inferred that the precision, recall, F-M and accuracy of identifying the CAP are above 95 % including and excluding the most relevant attributes extracted from traffic flow in the pre-set simulation environment.
Performance of the proposed recommendation model excluding feature set
Performance of the proposed recommendation model excluding feature set
Performance of the proposed recommendation model including feature set
In addition to the accuracy of discovering the CAP in a wireless network, we also compared classifiers like CTM, kNN, CA and the proposed integration model against each other. The accuracy of each individual prediction model is shown in Figs. 5 and 6. Its false positives is shown in Fig. 7. We inferred from these figures that rather than using each classification method individually to determine a CAP, it is wise to integrate different classification models into a recommendation system. Building each prediction model has taken a reasonable amount of time except for SVM and MLP. Although NB can take slightly less time than the proposed method, its accuracy is much lower. This demonstrates that the proposed methodology can outperform other techniques with improved accuracy and simpler models, even with a few selected attributes.
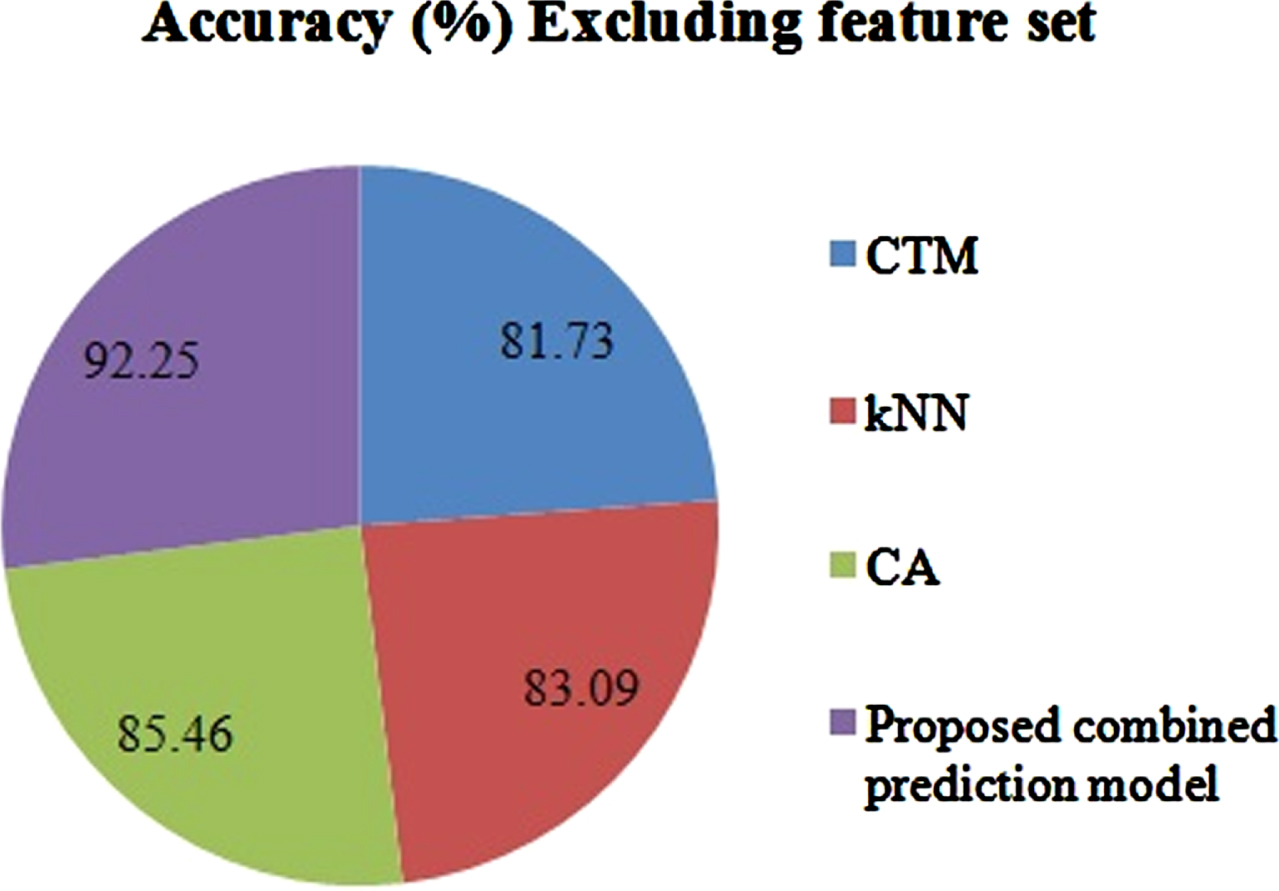
Accuracy of the proposed system –excluding feature set.
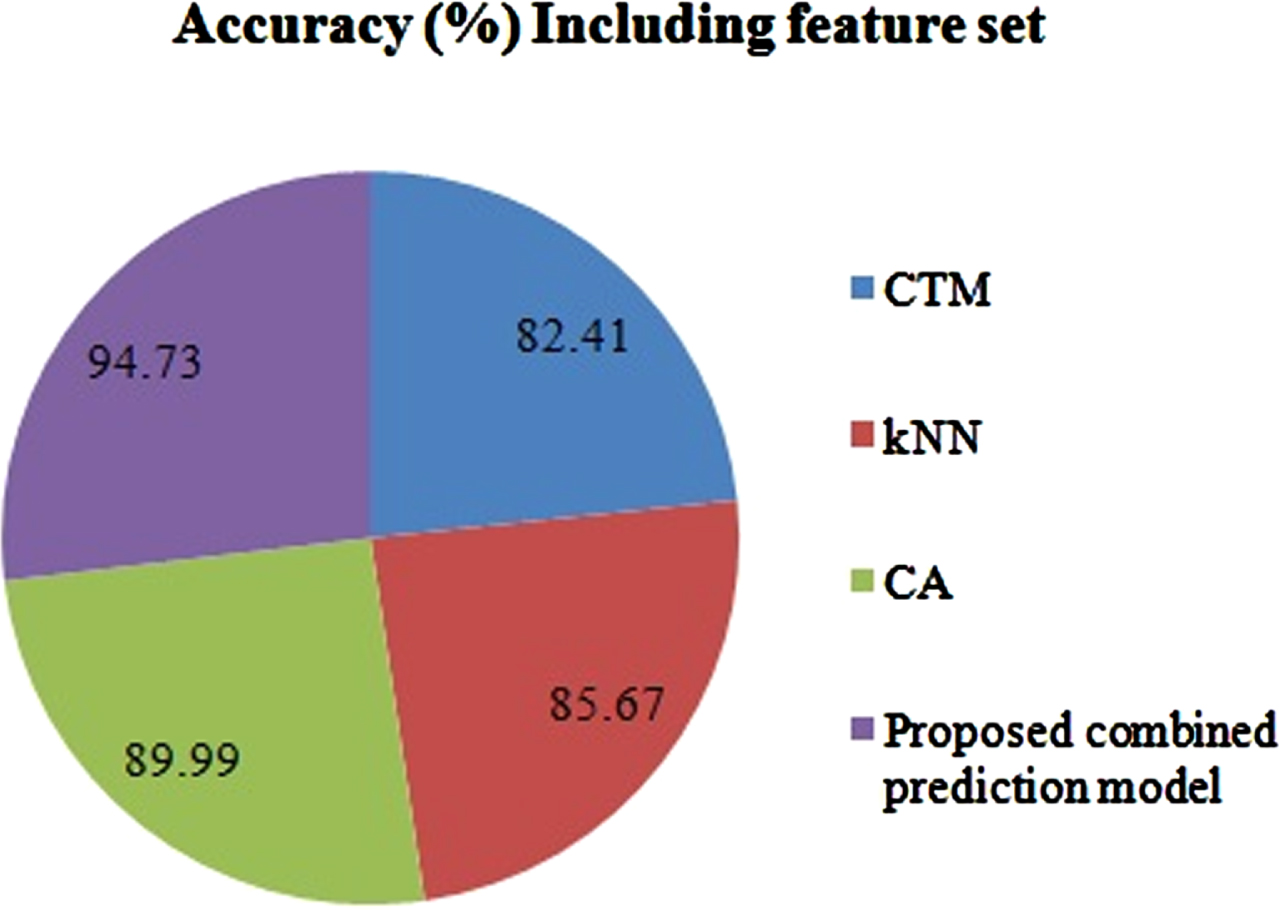
Accuracy of the proposed system –including feature set.

False positive rate.
Table 5 illustrates the accuracy of different prediction models against discovering compromised AP with different testing datasets and training datasets. The ANN model yields three experiments.The results show that even though different percentages of the training and testing datasets were given as input to different prediction models, including their integration, the accuracy did not change much. This proves that our proposed combined prediction model incurs 94 percent accuracy in determining a compromised access point.
Assessing accuracy percent against different testing and training dataset

Mean absolute error of different prediction methods.
In this paper, we present an implicit spatio-temporal based recommendation system for the discovery of malicious wireless APs. Our proposed recommendation model for detecting CAPs integrates various aspects like time series, kNN, and CA. It solves the problem of predicting future malicious activity based on previous observations made available via a shared repository of logs from various victims and contributors.This model is a linear blend of different algorithms, like a time series model to account for the temporal dynamics and two neighborhood-based models. The first neighborhood model aims for the utilization of kNN model for predicting attacks and focuses on similarity between victims being attacked by identical sources, preferably at the same time. Next, the clustering algorithm, which is designed to automatically discover sets of attackers that attack a group of victims at the same time. As the SVD model that mines global patterns does not significantly improve the prediction accuracy, we exclude it from the prediction model. As part of the further work, we plan to research how different classification algorithms may influence the robustness of the detection model.