
Abstract
Semantic alignment is a key component in Cross-Language Text Matching (CLTM) to facilitate matching (e.g., query-document matching) between two languages. The current solutions for semantic alignment mainly perform word-level translation directly, without considering the contextual information for the whole query and documents. To this end, we propose a Dual-Level Collaborative Rough-to-Fine Filter Alignment Network (DLCCFA) to achieve better cross-language semantic alignment and document matching. DLCCFA is devised with both a coarse-grained filter in word-level and a fine-grained filter in sentence-level. Concretely, for the query in word-level, we firstly extract top-k translation candidates for each token in the query through a probabilistic bilingual lexicon. Then, a Translation Probability Attention (TPA) mechanism is proposed to obtain coarse-grained word alignment, which generates the corresponding query auxiliary sentence. Afterwards, we further propose a Bilingual Cross Attention and utilize Self-Attention to achieve fine-grained sentence-level filtering, resulting in the cross-language representation of the query. The idea is that each token in the query works as an anchor to filter the semantic noise in the query auxiliary sentence and accurately align semantics of different languages. Extensive experiments on four real-world datasets of six languages demostrate that our method can outperform the mainstream alternatives of CLTM.
Keywords
Introduction
Cross-lingual text matching (CLTM) is a valuable but challenging task in information retrieval and natural language processing areas, which can be considered as a primary form of information searching across language boundaries [1–3]. Given a query-document pair, CLTM aims to predict their semantic relations. Recently, due to requriment of information processing and management, as well as the explosive growth of the online resources, CLTM is becoming increasingly more important. Apart from this, CLTM can be very useful in some scenarios. For example, imagine a journalist who wishes to monitor the latest news of Corona Virus Disease 2019 (i.e., COVID-19) around the world in real time. He/She might issue a query in Chinese, and desire to search all relevant news in any language to obtain different perspectives for his/her press release. The cross-lingual alignment is of primary importance to cross the language barrier in CLTM models.
There are several ways to bridge sematic gap in CLTM models. Traditionally, the most effective way to cross the language barrier is to utilize query translation approach [4–6], document translation approach [7, 8] or by using both query and document translation approach [9]. All these approaches involve a pipeline of two components: query translation and monolingual matching model. Firstly, the query in the source language is translated into the target language by using a machine translation (MT) or a bilingual lexicon. Then, the translated query is used to match relevant documents in the target language. Rahimi et al. [10] built an effective translation model from comparable corpora for CLTM. Qin Ying et al. [11] proposed to utilize bilingual dictionaries to tackle the ambiguity and multiple matching problems. Wang et al. [12] leveraged statistical estimation of translation probabilities for CLTM. However, the performance of this pipeline workflow is fundamentally limited by the quality of machine translation, especially for low-resource languages. That is, due to the accumulation of translation errors, it will have a great impact on subsequent matching task and even directly lead to the correlation prediction failure.
Inspired by great success achieved by pre-trained word embedding techniques(e.g., Word2vec or GloVe [13, 14]), many solutions utilizing word embeddings have been proposed to enhance CLTM. These works often project different languages into the same hidden space. On the basis of Word2Vec, Ivan Vulić et al. [15] utilized a comprehensive typology to generate cross-language word embeddings (CLE) over a randomly shuffle parallel corpus. Litschko et al. [16] introduced a completely unsupervised cross-language information retrieval framework that leverages off-the-shelf pre-trained CLEs to combine query translation with semantic space ranking. Some efforts have also extended the pre-trained language models for jointly cross-language embedding learning, i.e., encoding over 100 languages into a shared CLE space (e.g., mBERT [17]). However, these word embeddings usually need to be pre-trained with high-quality bilingual dictionaries, which is infeasible for many low-resource languages.
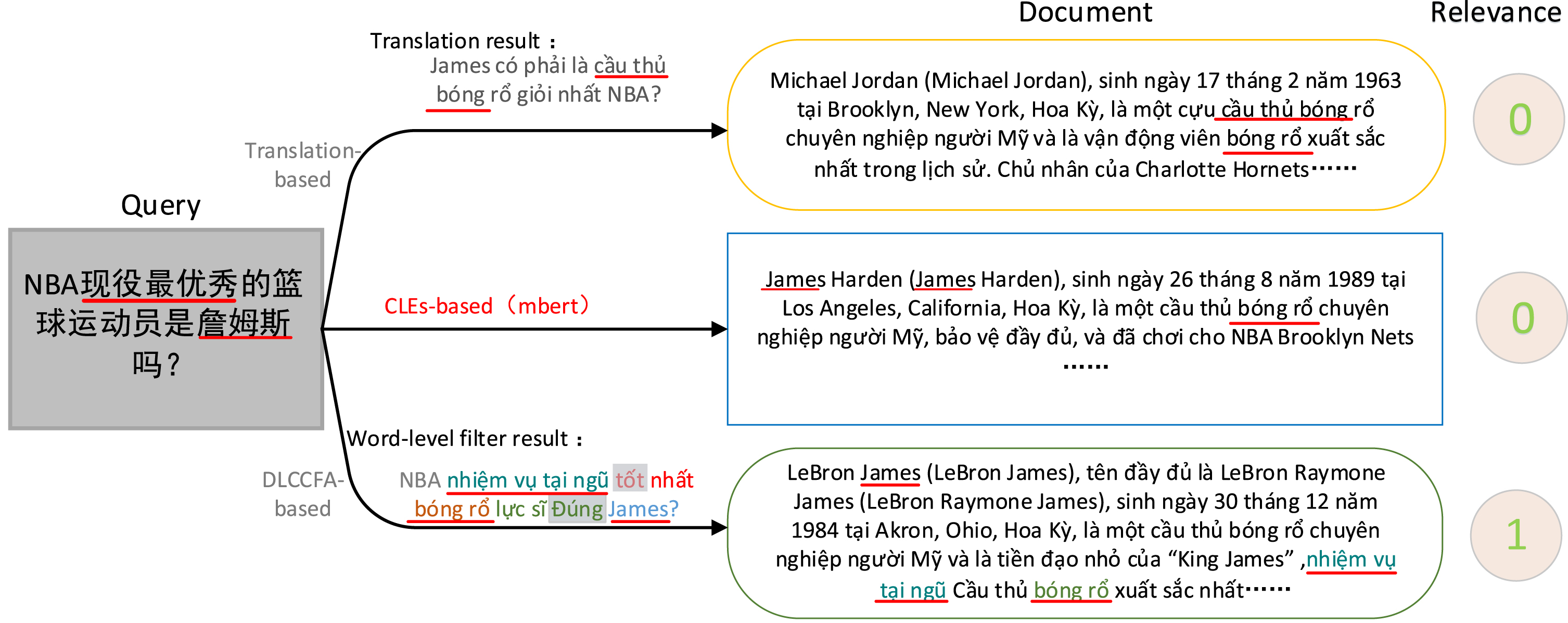
The top-1 retrieval results of different methods under the same query in Zh-Vi dataset. The words underlined in red color represent relevant information in the corresponding the query and the documents. The part highlighted in grey color represents the semantic noise after word-level coarse-grained filtering. The number in the most right side indicates the relevance ranking of different methods for the query.
Despite the encouraging improvements have achieved by the aforementioned methods, the alignment made with the help of CLE is far beyond the expectation since the contextual information of the query could be easily overlooked. To alleviate the problems caused by the above methods, we observe some examples extracted from the Zh-Vi CLTM dataset. As shown in Fig. 1, the query and the document belong to different languages. As observed from Fig. 1, for low-resource language pairs, the results of MT completely distort the meaning of the query. Therefore, the core difficulty of CLTM is to achieve context-aware semantic alignment between the query and the translated counterpart in different languages. Unfortunately, the alignment based on MT and CLEs may distort the semantics of the query in the source side, leading to the loss of valuable information. This is more useful for low-resource languages since the scarcity of the parallel multi-lingual corpus could easily hurt the semantic alignment.
In order to using the contextual information for the whole query and documents to achieve better semantic alignment and cross-language text matching. In this paper, we explore an efficient method with fine-grained context-aware semantic alignment for better CLTM. Specifically, we propose a cross-language deep matching model based on Dual-Level Collaborative Rough-to-Fine Filter Alignment Network (namely DLCCFA) to achieve better CLTM. This network, is divided into word-level coarse-grained filter and sentence-level fine-grained filter. Firstly, the shared Transformer-encoder is adopted to extract contextual representations for the query and documents. Then, in word-level coarse-grained filter, top-k translation candidates of each token in the query are firstly retrieved based on a probabilistic bilingual lexicon. Then, we propose a translation probability attention (TPA) mechanism by utilizing the Gumbel-Softmax to identify the most appropriate translation candidates, which results in a translated query in target language (namely query auxiliary sentence).
Although the query auxiliary sentence generated by word-level coarse-grained filter could lose the semantic to some extent, it can retain the keyword information of the query. Note that the keyword information has well been validated as the most important signals for query-document matching. In addition, in order to achieve fine filtering and cross-language representation of the query, we introduce a Bilingual Cross Attention and Self-Attention mechanism to form our sentence-level fine-grained filter, where each token in the query works as an anchor to identify the important information from the query auxiliary sentence. Finally, a Bilingual Reranker is further introduced for better cross-language text matching.
The main contributions of this paper are as follows: In this paper, we propose a dual-level collaborative coarse-to-fine filter alignment network to enhance cross-lingual text matching. To the best of our knowledge, our model is the first to utilize both word-level and sentence-level semantic alignments for the precise cross-language query representation learning, leading to better query-document matching. We introduce a translation probability attention (TPA) mechanism and a bilingual cross attention mechanism to generate cross-language query representation in a context-aware manner. Extensive experiments are conducted on four real-world CLTM datasets covering three high-resource languages (i.e., English, Chinese and French) and three low-resource languages (i.e., Swahili, Tagalog, Vietnamese). The experimental results suggest that the proposed DLCCFA achieves promising performance gain against mainstream CLTM methods. Further analysis is also conducted to illustrate the effectiveness of each design choice.
The remainder of this paper is organized as follows. Section 4 is devoted to related work. Section 3 introduces the details of our proposed method. In Section 5, we elaborate the experimental setup, dataset setup, quantitative analysis, and qualitative analysis. In Section 6, we draw our conclusion finally.
Related work
Cross-language text matching has become an increasingly important task in cross-language information retrieval (CLIR) and cross-lingual answer selection. Recently, many deep neural models have been widely used in TM and shown promising results on monolingual datasets. However, since CLTM does not have a large amount of annotated data like monolingual matching model, previous methods that directly model end-to-end CLTM are expensive [18]. Scholars conducted a series of studies and discussions on how to build a communication bridge between a language pair for implementing cross-language sequence matching.
To date, the task of CLTM has achieved remarkable progress. Previous works in this task could be classified into three dimensions, that is, (1) Translation-based CLTM models, (2) Cross-Lingual Embeddings (CLEs)-based CLTM models and (3) Other Existing CLTM Models.
Translation-based CLTM models
A traditional cross-lingual text matching algorithm involves a pipeline of two components: machine translation(MT) and monolingual matching model [9, 20]. These approaches may be further divided into the query translation [4–6, 21], document translation [7, 8], or both query and document translation approach [9]. In order to get the selection of proper translation words, different translation techniques can be used. Among them, word-alignment based probabilistic translation algorithm, is still the most reliably used translation techniques. Zbib et al. [22] presented an effective Neural Network Lexical Translation model for low-resources CLTM that uses source context and character-level encodings of the input. A relevance-based NMT model was designed by [23] using a multi-task learning frame for the CLTM task, and the structure with NMT has found to deliver reasonable performance.
Translation-based CLTM model is a pipeline structure, which is susceptible to the accumulation of translation errors, especially for resource-lean CLTM settings. The accumulation of MT errors will have a greater impact on subsequent matching, and even lead to relevance prediction failures. Therefore, for CLTM in low-resource languages, the above-mentioned MT-based methods are far beyond the perfect [24].
Cross-Lingual embeddings (CLEs)-based CLTM models
Following a broad use of monolingual dense representation pre-training methods for text matching (e.g., the tasks rely on word2vec and GloVe [13, 14] to pre-train word embedding, and directly improve the performance of the relevance matching models [14, 25]), extensive efforts have been made toward developing dense representations to support cross- and multi-languages. Ivan Vulić et al. [15] presented a comprehensive typology of generating cross-language word embedding (CLE) based on randomly shuffle parallel corpus and word2vec. Through the above-mentioned process, various languages representations were designed to learn CLEs in a shared space such that cross-language semantic alignment can be solved regardless of the language. Bonab et al. [26] proposed a cross-lingual embedding (CLE) method, called Smart Shuffling, which draws from statistical word alignment approaches to leverage dictionaries, deriving a novel and effective cross-language word embedding for CLTM.
In addition, there are also many applications of pre-trained cross-language embeddings with the above methods. Vulić et al. [15] proposed an unsupervised semantic ranking method based on cosine similarity. This method was the earliest application of cross-language embeddings in CLTM task. Litschko et al. [16] extended the framework and presented a completely unsupervised cross-language information retrieval framework that does not need to use any bilingual data. It leveraged off-the-shelf pre-trained CLEs to combine query translation and semantic space rankings. Zhao et al. [27] designed a weakly supervised neural model which does not require relevance annotations, instead it is trained on parallel machine translation data as weak supervision.
More recently, the use of pre-trained language models (LMs) based on transformer neural networks (e.g., BERT) significantly improves the accuracy of matching [28–30]. Building on that idea, Ruder et al. [31] surveyed several other recent studies on pre-trained cross-lingual representation learning, some of these even extended the LMs for encoding many (over 100) languages into a shared multilingual semantics space via jointly learning (e.g., mBERT [17], XLM [32], and XLM-R [33]). XLM-R [33] improved upon XLM by incorporating more training data and languages, including more low-resource languages. In CLTM experiments [26], the XLM-R does not perform better than XLM. These neural text representation approaches was treated as translation resources for performing CLTM query translation. Surprisingly, these approaches fail to match the performance of a statistical machine translation (SMT) system for query translation [26].
However, these cross-lingual word embeddings generally need to be pre-trained on large scale corpora using co-occurrence statistics. In addition, in the case of low resources, the lack of high-quality bilingual dictionaries often results in poor word embedding [34].
Other existing CLTM models
Vilares et al. [35] analyzed the impact of misspelled queries on CLTM model and presented a Tolerant CLTM method that is able to operate with such queries. Li and Cheng [36] presented to learn task-specific text representation based on adversarial learning, which seeks a language-invariant and task-specific representation in the embedding space. To support cross-lingual query-document matching research, Sasaki et al. [18] constructed a large-scale dataset derived from Wikipedia comparable corpora, and presented a simple neural learning-to-rank model. However, we found that these neural CLTM models did not consider how to bridge the semantic gap across languages, apparently not the ideal solution.
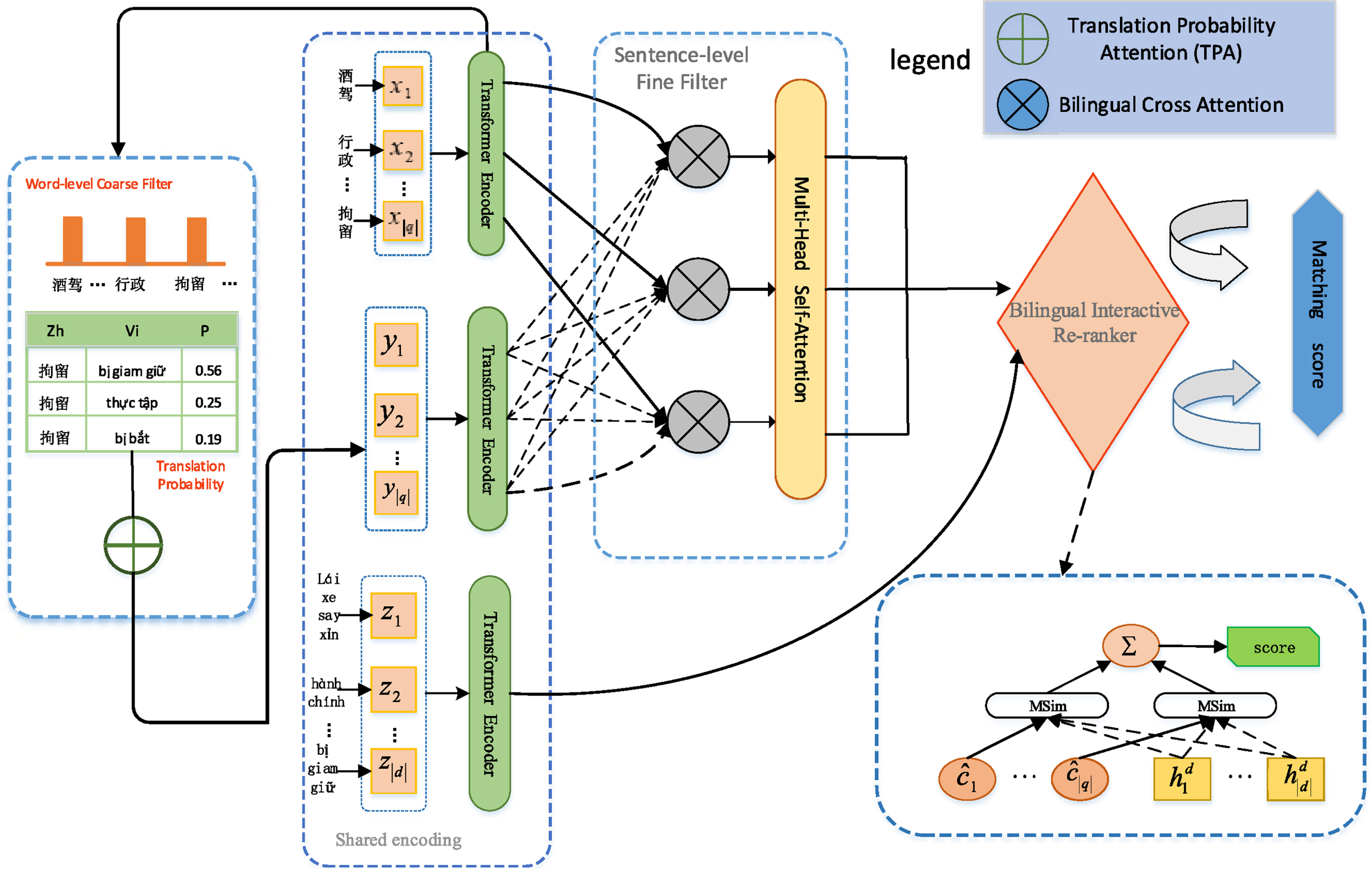
The framework of our proposed cross-language deep matching model based on Dual-Level Collaborative Coarse-to-Fine Filter Alignment Network (
In this section, details of the proposed DLCCFA are presented. Figure 2 illustrates the architecture of
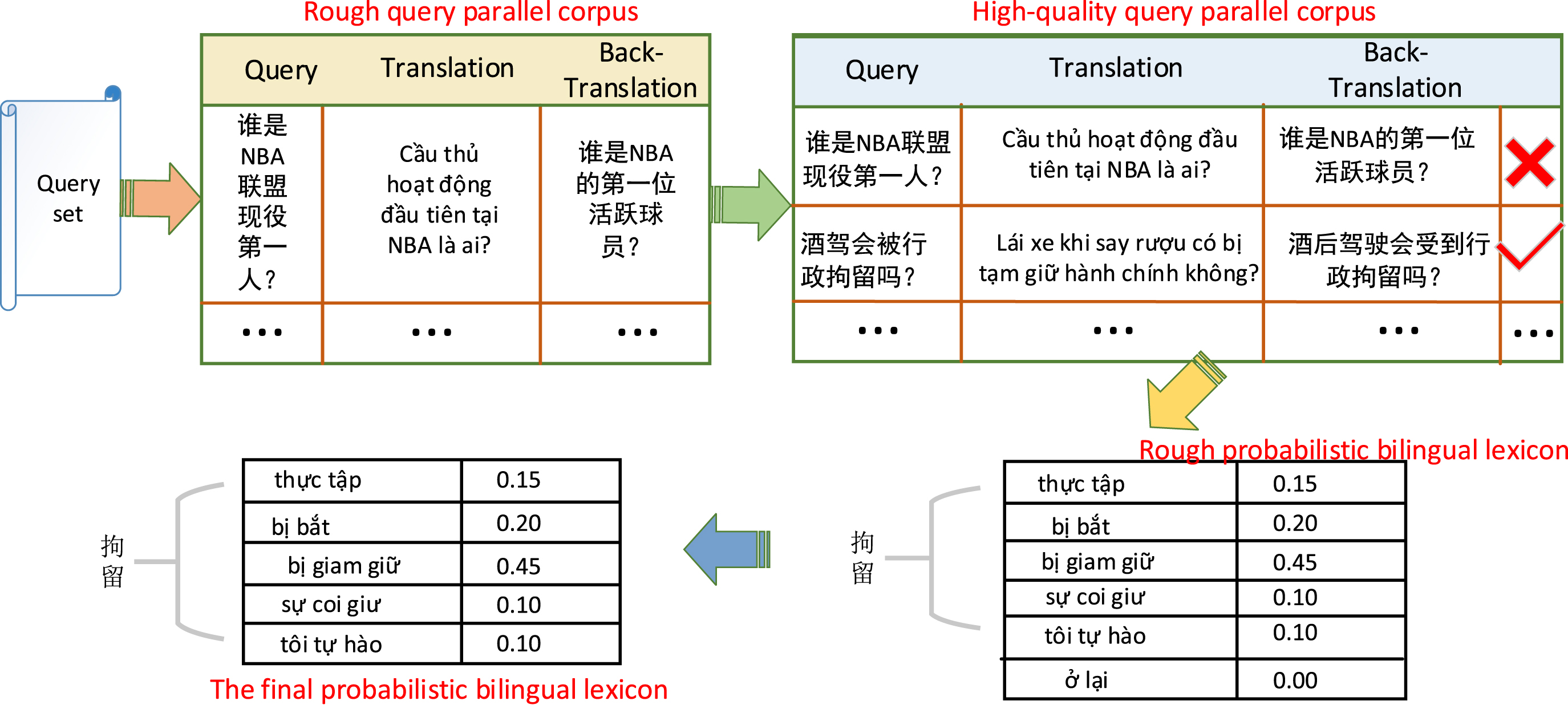
The process of constructing a Chinese-Vietnamese probability bilingual dictionary (take the Zh-Vi dataset as an example). Where, the orange arrow indicates the process of translation and back translation. The green arrow indicates the operation of manual screening and correction. The yellow arrow indicates the operation of extracting word alignment using the fast-align tool. The blue arrows indicate the process of filtering word pairs and use the maximum likelihood to find the probability. The red check mark indicates the parallel sentence pair we think is correct, otherwise it will be discarded.
Given a source language query q and a target language document d, where |q| and |d| are the number of words in q and d respectively. Each word in q or d is represented as a n-dimensional vector. This representation way (i.e., word embedding [13, 14]) can be formulated as: {
To bridge the semantic gap between two different languages, we choose to share a single text encoder for both source language query and target language documents. Specifically, a Transformer Encoder [37] with a stack of N identical layers is used to generate the word contextual representations. Each identical layer is divided into two sub-layers. The first sub-layer is a multi-head self-attention mechanism, and the other is a fully connected feedforward network. A residual connection is added outside the each of sub-layers, followed by layer normalization. According to the formula:
We firstly perform word alignment for each token in the query via a word-level coarse-grained filter. Specifically, we utilize a Probabilistic Bilingual Lexicon and a Translation Probability Attention (TPA) mechanism here.
On the contrary, due to lack of sufficient number of parallel documents, the above method is difficult for low-resource languages. In this scenario, we resort to using Google translator 1 to help us construct some reliable parallel corpora. Specifically, we first use the Google translator to translate each query in the CLTM dataset into the target language. Then, this target language translation is back translated again into the source language. Lastly, high-quality sentence pairs are selected from the resultant parallel query sentence pairs. Finally, we apply the fast-align tool to construct high-quality probabilistic bilingual lexicon. Furthermore, we remove the word alignment pairs (t1, t2) such that P (t1 ⇒ t2) ≤ 0.05, and obtain the final probabilistic bilingual lexicon [41]. This process is illustrated in Fig. 3.
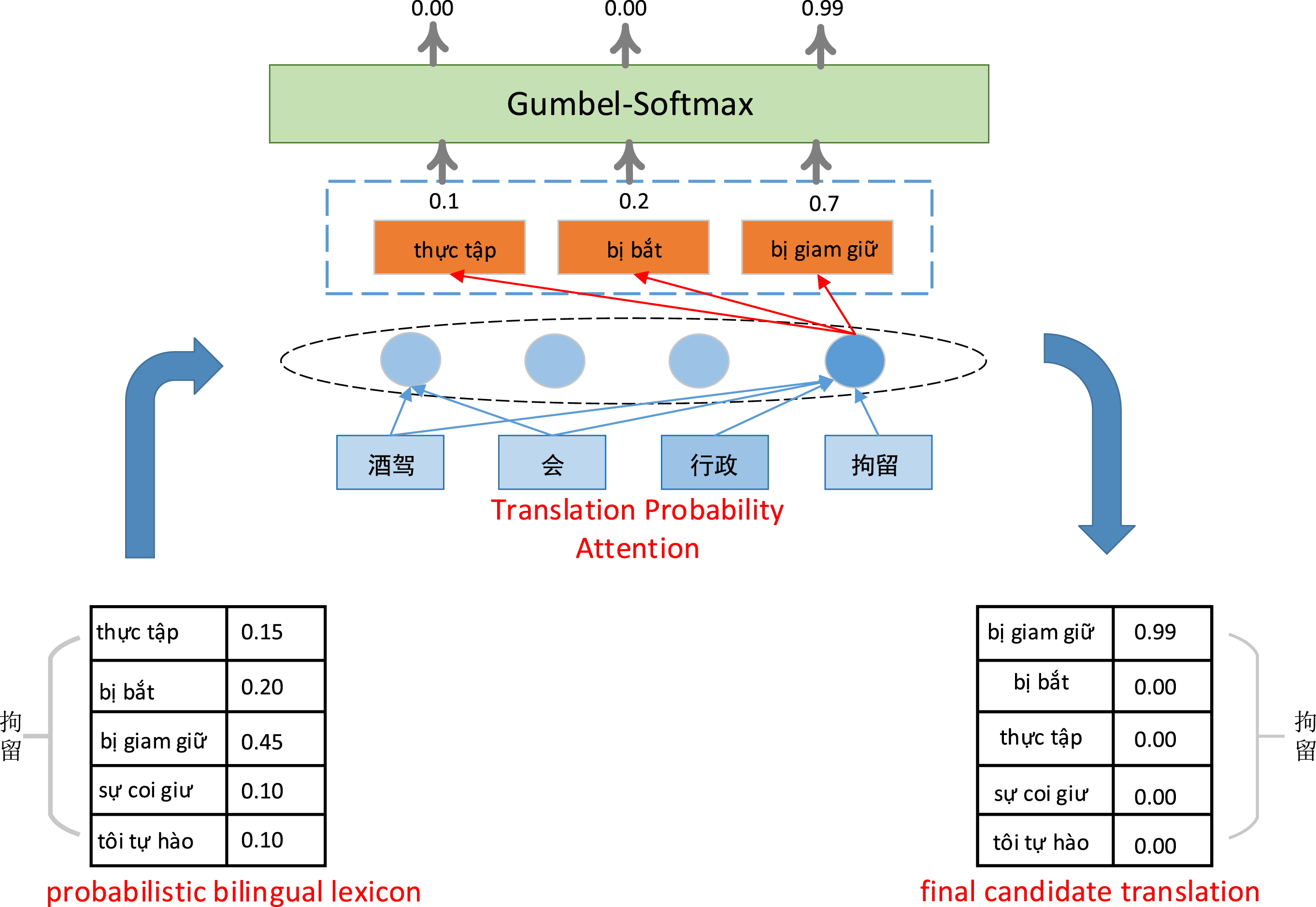
The framework of our proposed Translation Probability Attention (TPA).
In particular, for each word q
i
in the query, we can extract top-k candidate translations based on the probabilistic bilingual lexicon. Let
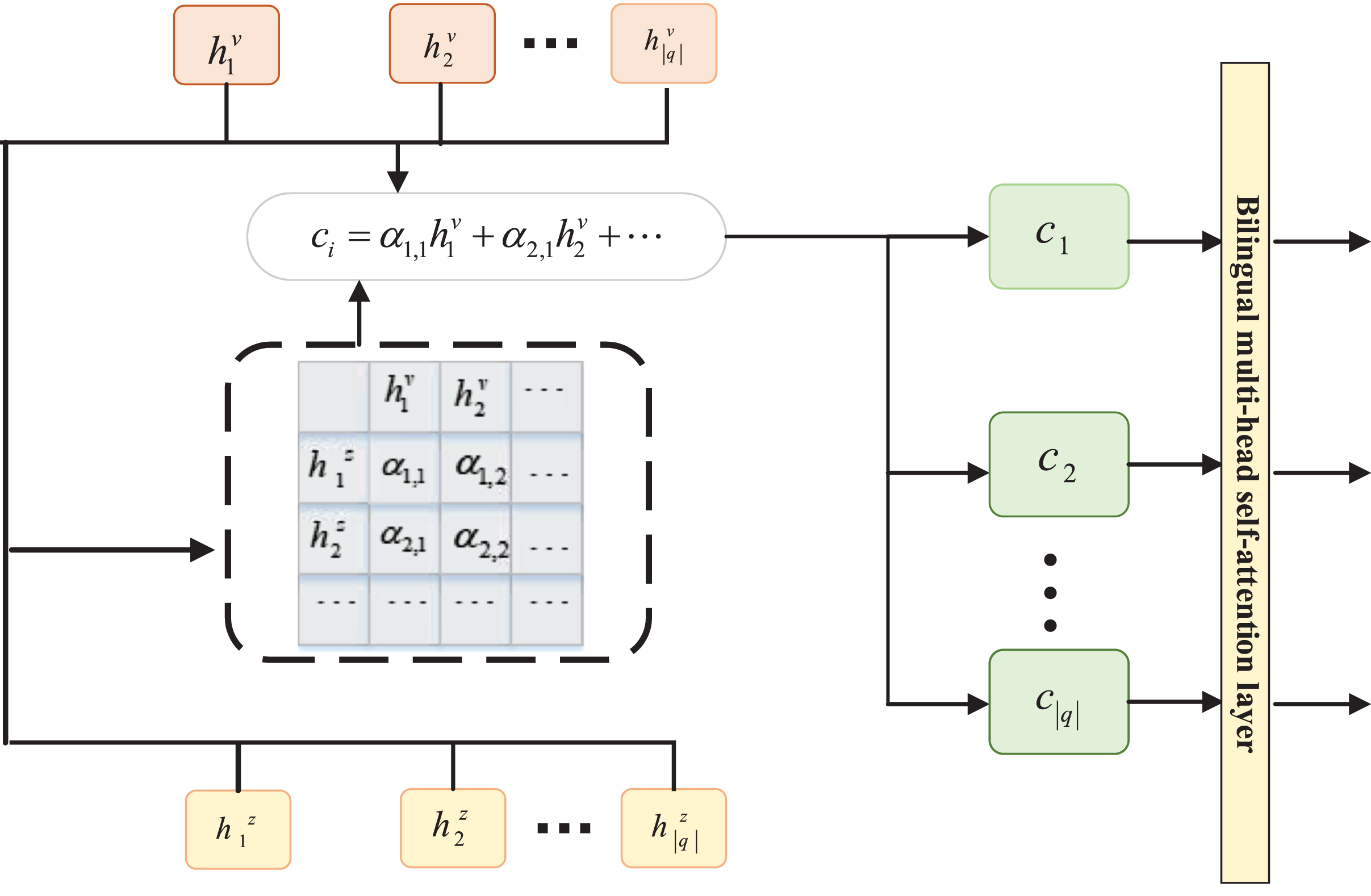
The overall framework of our proposed Sentence-level Fine Filter.
Afterwards, it is straightforward to take the translation word with the largest probability for each query word as the alignment. However, this process is discrete in nature, which is infeasible to enable model training via back-propagation. To tackle this issue, we integrate a Gumbel-Softmax [42] layer into TPA to ensure model training. Specifically, given i-th word of query q, the translation probability is calculated as follows:
There would be potentially many semantic noises in the representation matrix
With both
The model parameters θ of DLCCFA include the feature embeddings and {Transformer-Encoder (·),
Zh-Vi CLTM dataset construction
We construct a Zh-Vi (i.e., Chinese-Vietnamese) CLTM dataset from Wikipedia. The core idea is to extract an English sentence as query, and label foreign-document pages via Wikidata links as relevant. We apply the same techniques [18] to create Zh-Vi CLTM dataset. Figure 1 illustrates the whole construction process.
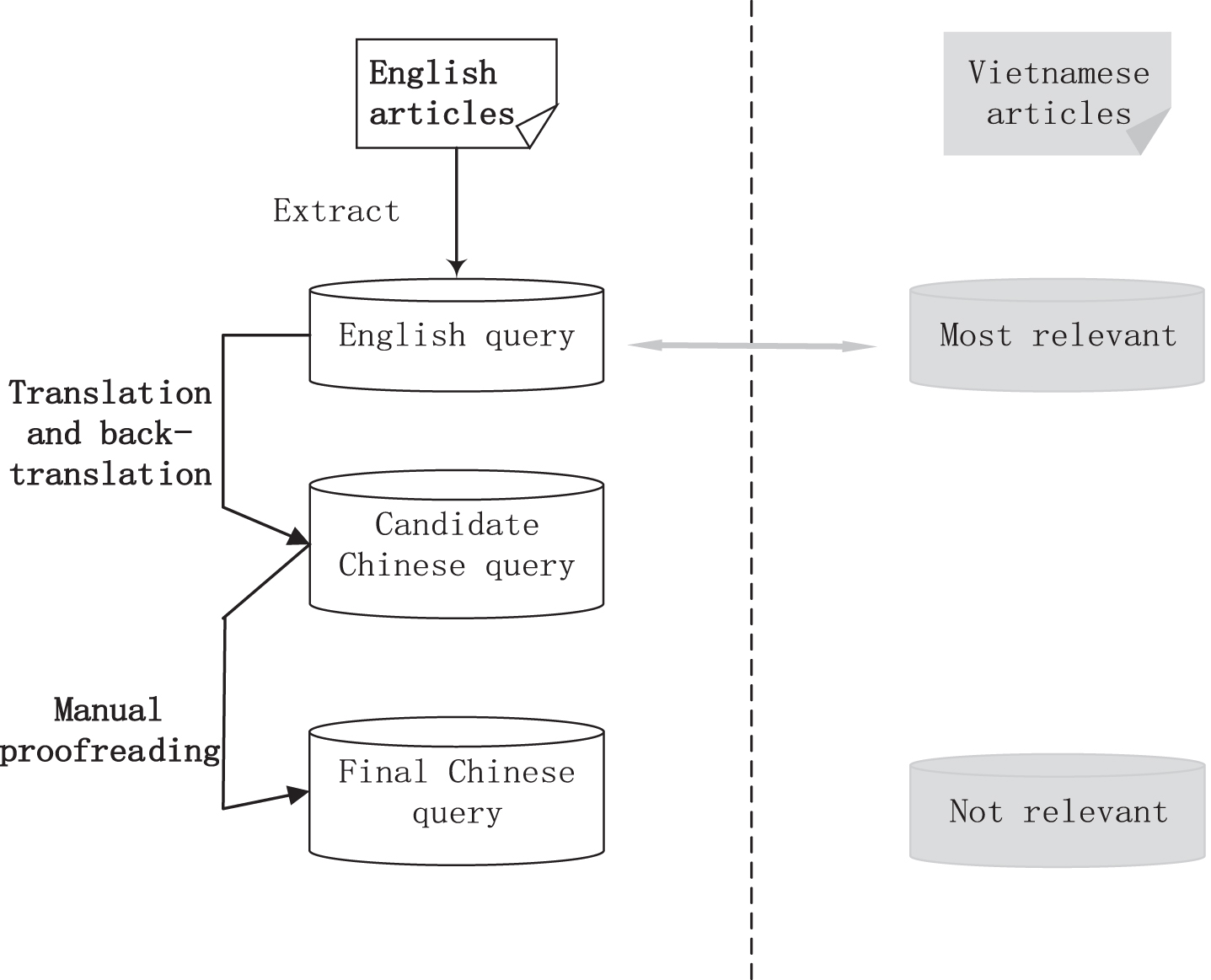
Zh-Vi CLTM dataset construction process: we first extract the English query from an English article. Then by using the inter-language link, we obtain the most relevant Vietnamese document. All other articles are not relevant. Finally, based on the translation results in both directions, we manually selected high-quality Chinese queries.
Specifically, we first download the English Wikipedia dump and then extract the first sentence of each article as English queries. Then the cross-lingual linked Vietnamese documents from the same article are taken as the relevant documents. From a practical point of view, the first sentence of an English article is usually a summary of the article. To prevent the simplification of the task, the core subject terms from the queries are removed. Afterwards, we use the Google translator to translate the query sentences into Chinese, and further generate new English query sentences with the back-translation. Finally, based on the translation results in both directions, we manually select high-quality Chinese queries.
We then truncate each document to retain only the first 200 tokens of each article. The triples of the Zh-Vi CLTM dataset will be obtained via a series of pre-processing. Here each triplet is in the form of (q, d, r), where q is Chinese query and d is denoted as Vietnamese document. r is denoted as relevance judgment, in which r ∈ {0, 1} represents relevance groundtruth.
To validate the proposed DLCCFA, we conduct experiments on four CLTM datasets: En-Fr (i.e., English-French) dataset, En-Tl (i.e., English-Tagalog) dataset, En-Sw (i.e., English-Swahili) dataset, and Zh-Vi(i.e., Chinese-Vietnamese) dataset built by ourselves. En-Fr, En-Tl and En-Sw datasets is derived from a large-scale CLTM data from Wikipedia [18]. The first language is the query-side language and the second is the language of the document collection. The length of all queries and documents is limited to 30 and 200, respectively. For each query in the training set, we pick candidate documents in which only one document is positive. As for testing set, the number of candidate documents for each query is in range of 15 - 40 for a query, except for Zh-Vi CLTM dataset where the number of test documents corresponding to a query is in the range of 200 - 350. As mentioned above, each instance (eg Figure 1) in a CLTM dataset is formed as (q, d, r), where q is the query and d is denoted as targe-language document. r is the relevance judgment, in which r ∈ {0, 1} represents relevance groundtruth. The statistics of the four datasets after pre-processing and manual proofreading are shown in Table 1.
The statistics of the four CLTM datasets
The statistics of the four CLTM datasets
To perform a fair evaluation, five widely used metrics ([43, 44]), i.e., MRR(Mean Reciprocal Rank), P @ k (Precision at k), R @ k (Recall at k), MAP (Mean Average Precision) and NDCG @ k (Normalized Discounted Cumulative Gain), are applied to measure the performance for cross-lingual matching. In the following, we describe these metrics in detail.
For each query q, Let the number of relevant documents be G
q
, and the number of irrelevant documents be Y
q
. Both P @ k and R @ k are calculated as follows:
Let the ranking positions of the real relevant documents be k1, k2, ⋯ , k
r
, where r is the number of all positive documents in the entire list. The MAP score can be calculated as follow:,
When we only consider the top ground-truth positive document k1, MRR can be derived as follows:
We also employ the widely used NDCG (normalized discounted cumulative gain) as evaluation metrics. Given a query q, let δ
i
be the relevance groundtruth indicator of the i-th document ranked by the model. The NDCG @ k is calculated as follows:
We consider Chinese [Zh], French [Fr] as high-resource languages and Tagalog [Tl], Swahili [Sw], Vietnamese [Vi] as low-resource languages. The dimension of word embedding is set to be 300 for each language. We train all DLCCFA model with learning rate 5e - 5 and a batch size 32. We train our model using transformer encoder with 6 layers and 512 as the hidden dimension. The number of candidate translations is set to 5 (i.e., k = 5). We adopt Adam [45] for optimization. The maximum number of training epochs is set to be 5 on En-Fr dataset and 80 epochs on other datsets respectively. The temperature τ in Gumbel_Softmax is initialized as 0.5, and updated according to exponential decay:
In this section, we compare the proposed DLCCFA with uptodate SOTA alternatives:
Results of three CLMT datasets.
Results of three CLMT datasets.
For two low-resource languages, a summary of results of all models are reported in Table 2. Here, we have the following observations:
The NDCG @ K curves on three datasets. The first row shows the comparison result with the traditional method. The second row represents the comparison result with the CNN-based deep learning methods. The third row represents the comparison result with pre-trained-based the language model. The conventional MT-based pipeline techniques like CLTM-TQ and CLTM-TD generally perform worse than deep learning methods on both datasets. It is clear to see that both CLTM-TQ and CLTM-TD are essentially limited by the quality of machine translation as the pipeline architecture is easy to accumulate translation errors. However, the two traditional translation-based methods have better accuracy than some pre-trained language models. This phenomenon is more intense in low-resource languages. It may be that the pre-trained low-resource language data is insufficient. It is clear that deep learning methods perform better than pipeline techniques on both low-resource datasets. This explains the effectiveness of applying deep neural network to capture the latent semantics of different texts. Among these models, we observe the performance of the cosine model and the deep models are very close. The reason might be that deep models with larger parameters may require more sufficient training data. The MAP value of CLTM-S-DEEP500 model is about 2.5 - 15% higher than the conventional MT-based pipeline techniques. Since multilingual pre-training models can project different languages into the same hidden space, it has gradually become the dominating technique for multilingual semantic alignment. It is worthwhile to highlight that the performance order is: mBERT > LASER > XLMR > XLM. This suggests that the alignment effect of mBERT is better than other LMs in the case of low resource settings. In addition, XLMR and LASER have achieved the state-of-the-art results for cross-language sentence retrieval. However, they are not very effective on the two low-resource datasets. This is reasonable since there is a big gap in length between query and document and the alignment performance of the pre-trained language model on low-resource languages is largely affected by this discrepancy. All in all, our proposed DLCCFA achieves the best performance against all the methods on En-Tl dataset. For En-Sw CLTM dataset, DLCCFA outperforms CLTM-TQ and CLTM-TD on all the metrics. Compared to CLTM-S-COS and CLTM-S-DEEP500, DLCCFA outperforms or achieves comparable performance on most metrics. Especially on MAP, DLCCFA has 2.7% and 1.7% improvements, respectively. As for the baselines based on pre-training CLTM, our model achieves comparable or surpass mBERT-based metheds on all the metrics. In sum, the experimental results demonstrate the effectiveness of utilizing both word-level and sentence-level semantic alignments.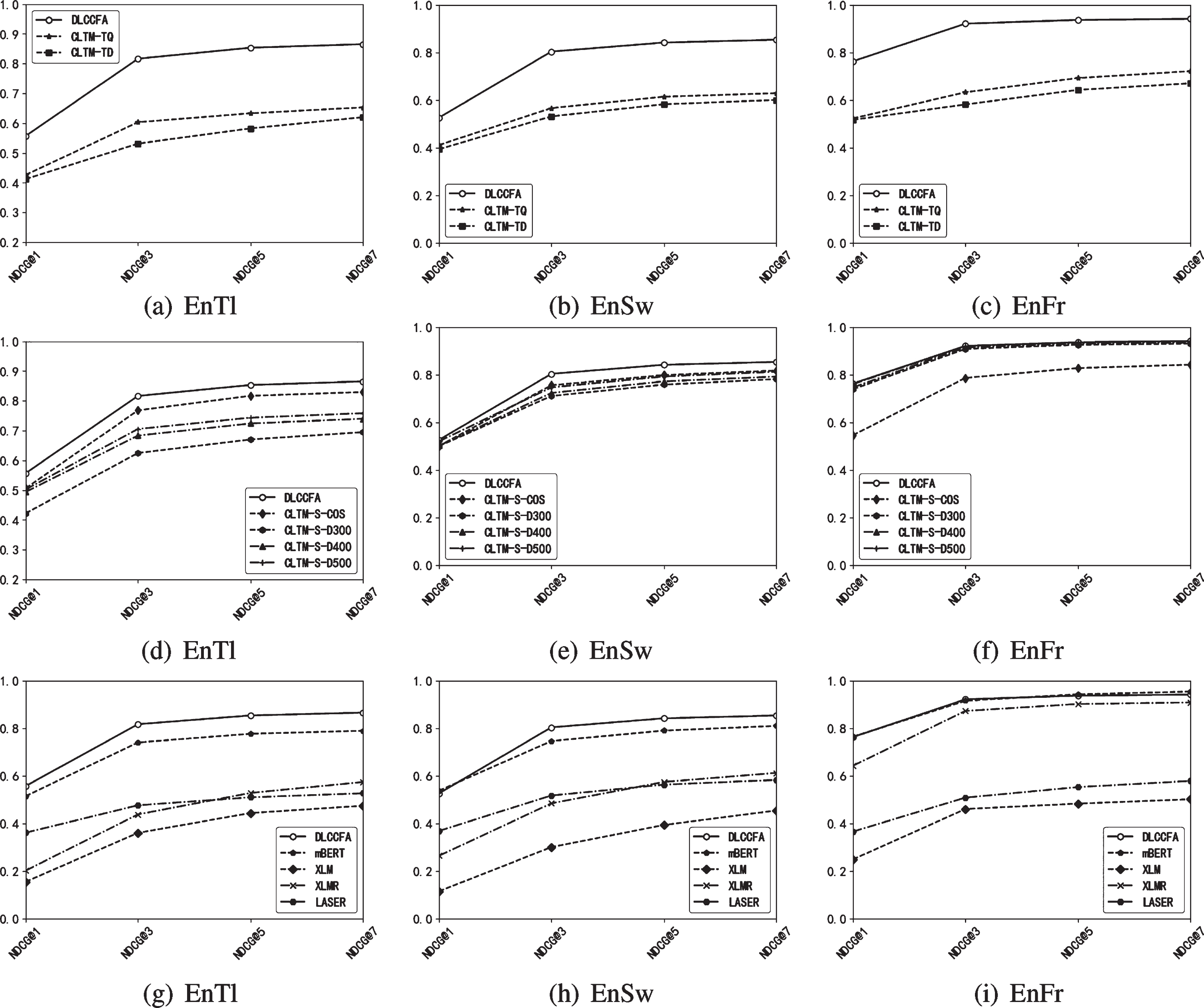
For En-Fr CLTM dataset, a summary of results is reported in Table 2 (En-Fr dataset). Unlike low-resource languages, the deep models outperform the cosine model on all the metrics, suggesting that deep networks can require sufficient data in learning more expressive representations for both query and document. Except for mBERT-based model, DLCCFA outperforms all baseline models on all the metrics. It suggests that the alignment made by our proposed DLCCFA is more accurate in the case of low resources. At the same time, this also proves the generalization of the model for high- and low-resource languages.
We further vary k values of NDCG @ k to verify the performance patterns of DLCCFA in different language pairs. The curives are plotted in Figure 7. We can see that comparing with all baselines (i.e., MT-based CLTM, CNN-based CLTM and pre-trained-based models), DLCCFA obtains a better performance. This observations on three high- and low-resource datasets are almost consistent. These experimental results further suggest that our model can not only be generalized to high-resource language pairs, but also in the case of insufficient training data for low-resource languages. It demonstrates the effectiveness of integrating both word-level and sentence-level semantic alignments for cross-language representation learning in CLTM.
In this section, we examine the impact of each design choice made in DLCCFA by a series of ablation studies on the Zh-Vi CLTM dataset. For a fair comparison, all the studies take Transformer Encoder as the encoder, and use MRR(Mean Reciprocal Rank) and R @ k(Recall at k) as evaluation metrics.
The influence of word-level coarse-grained filter
Ablation study results obtained on Zh-Vi CLTM dataset.
Ablation study results obtained on Zh-Vi CLTM dataset.
The experimental results are reported in Table 3. From Table 3, we can see that, TE+WLF+Rank outperforms TE+Rank on all the metrics, with an increase of 10.93% on R @ 3. Experimental results well validate our claim that word-level coarse-grained filter is effective in selecting the translation candidate by taking the contextual semantics of the whole query into account. This also verifies the importance of word-level alignment to help bridge the semantic gap across languages.
Whether to share encoder the comparison test results obtained on Zh-Vi CLTM dataset. Best value in each column is highlighted in bold.
Whether to share encoder the comparison test results obtained on Zh-Vi CLTM dataset. Best value in each column is highlighted in bold.
In order to reduce the amount of parameters in DLCCFA, and bridge semantic gap across the two different languages, we share a single transformer encoder for both the query and the document. We also conduct a comparative study to prove whether the shared encoder is effective to enhance the CLTM performance for DLCCFA. The results on Zh-Vi CLTM dataset are shown in Table 4. From Table 4, we can see that, when we use a shared encoder, MRR, R @ 3, R @ 5, and R @ 10 are increased by 0.59%, 0.32%, 2.22%, 3.60%, respectively. It indicates the necessity of shared encoder to extract compatible features across language.
Sentence-level fine-grained filter is one of the most important components of our model, which is used to identify the important information and obtain the cross-language representation of the query. We propose the following three different strategies:
Results of models on Zh-Vi CLTM dataset with different strategies to obtain the cross-language representation of queries. Best performance in each metric is highlighted in boldface.
The results are shown in Table 5. As we can see, three different strategies will directly lead to different retrieval performance. Where, by comparing CLTM+c_att with CLTM+MTL, it has 9.69% improvement on MRR, 10.70% improvement on R @ 3, 10.92% improvement on R @ 5, and 10.06% improvement on R @ 10. In addition, compared to CLTM+concat, CLTM+c_att outperforms it on MRR, R @ 3, R @ 5, and R @ 10. Our conjecture is that the sentence-level fine-grained filter is effective to remove semantic noise for better CLTM.
We further examine the impact of different scoring functions. Without changing the other parts of our model, we also investigate three ranking strategies here.
Results of models on Zh-Vi CLTM dataset with three ranking strategies. Best performance in each metric is highlighted in boldface.
Table 6 reports the retrieval performance by using the three scoring strategies. Compared to CLTM-sent_cos and CLTM-sent_deep, our CLTM-bi_rank outperforms them on the all metrics. This also verifies the importance of an expressive scoring functions to re-rank documents. Ours conjecture is that, since the length difference between the query and the document is relatively large, directly using the features of the document will greatly lose the key semantic information. Note that the bilingual interactive re-ranker of DLCCFA can start from the word-level granularity and more comprehensively calculate the similarity between short queries and long documents.
In summary, this set of experimental comparisons suggests that each design choice in DLCCFA is rational to enahnce cross language query-document matching.
In this paper, we address a semantic alignment problem in Cross-anguage text matching, The proposed cross-language deep matching model based on Dual-Level Collaborative Coarse-to-Fine Filter Alignment Network (DLCCFA) achieves cross-language semantic alignment for CLTM. Specifically, we first extract top-k translation candidates for each token in the query through a probabilistic bilingual lexicon. Then, we devise a Translation Probability Attention (TPA) mechanism to achieve coarse-grained word alignment for generating the corresponding query auxiliary sentence. After that, a Bilingual Cross Attention and cooperate Self Attention is introduced to filter the semantic noise in the query auxiliary sentence and accurately align semantics of both langualges. Extensive comparison experiments are conducted on CLTM datasets of four different language pairs. Experimental results show that our method achieves the state-of-the-art performances.
In our future work, we consider incorporating hashing into our method to achieve fast matching under low memory. Besides, we will also explore multilingual text matching method with limited languages.
Footnotes
Acknowledgments
The research work described in this paper has been supported by the National Key Research and Development Program (No.2019QY1802), National Natural Science Foundation of China (No.61866020), National Natural Science Foundation of China (No.61761026), National Natural Science Foundation of China (No.619 72186), General Project of Yunnan Science and Technology Department (No.2019FB082), Natural Science of Yunnan Province Fund (No.2018FB104) and Talent Fund for Kunming University of Science and Technology (No.KKSY201703015). We thank the anonymous reviewers for their insightful comments and suggestions.
We used BERT-Base, Multilingual Cased.
We used xlm-mlm-100-1280.
We used xlm-roberta-base.