
Abstract
Deep unsupervised learning extracts meaningful features from unlabeled images and simultaneously serves downstream tasks in computer vision. The basic process of deep clustering methods can include features learning and clustering assignment. To enhance the discriminative ability of the features and further improve the clustering performances, a new deep clustering method namely ACMEC (asymmetric convolutional denoising autoencoder with manifold spatial embedding clustering) is proposed. In this method, an asymmetric convolution denoising autoencoder is employed to extract visual features from images, and a manifold learning algorithm is used to obtain more distinctive features, followed by a Gaussian Mixture Model (GMM) is for clustering learning. The stability of feature space is guaranteed using separately training mechanism. In addition, reconstruction from noisy images enhances the robustness of feature networks. Experimental results on nine benchmark datasets demonstrate that the proposed ACMEC method can provide the better performances such as 0.979 clustering accuracy on the MNIST dataset and 0.668 on the fashion-MNIST dataset. ACMEC is a comparable competitor to the N2D (not too deep clustering) algorithm that is with 0.979 and 0.672 clustering accuracies respectively. Moreover, it is 16.1% higher than DEC algorithm on the fashion-MNIST dataset.
Keywords
Introduction
Deep unsupervised learning extracts meaningful feature representation from unlabeled images and simultaneously serves downstream tasks [1]. Clustering is one of the unsupervised learning methods, which automatically divides samples into several clusters so that the similarity of intra-cluster members is as larger as possible. To overcome the limitations of traditional clustering methods influenced by the curse of dimensionality, deep neural networks have become popular to automatically learn high-level visual features for high dimensional images [2]. Autoencoders (AE) is a kind of extraordinary networks with its symmetrical structure composed of encoder and decoder. AE has an excellent effect on reduction dimensionality and feature learning. Usually, the network parameters and features representation are optimized by minimizing the reconstruction loss [3, 4]. The ability of learning features of a deep network is evaluated by the performances of the downstream tasks.
The basic process of deep clustering methods can include features learning and clustering assignment. First a fully connected autoencoder was trained, next the encoder network extracted visual features of the input images, and then the visual features were used as the inputs for the clustering model. A joint embedded clustering algorithm is proposed in [5, 6], which used a fully connected autoencoder and k-means clustering algorithm. Later, several modified versions including convolutional autoencoder and denoising autoencoder were proposed to further improve the clustering performance [7–10]. Compared with traditional clustering algorithms, the performances of these methods are greatly improved on benchmark tasks.
To enhance the discriminative ability of the features, manifold mapping is employed to preserve the geometric structure and neighbor properties of the samples. Nonlinear manifold learning method Isomap [11] focused on global structure, but t-SNE [12] is a kind of local method, while UMAP(uniform manifold approximation and projection) [13] is a local and can preserve global structure.
It is empirically found that image clustering models can deal with three problems: i) the curse of dimensionality caused by high-dimensional images; ii) feature extraction and cluster learning are affected by each other, and iii) limited representation ability of the fully connected autoencoders. We combine these findings and propose a new clustering method namely ACMEC that combines an asymmetric convolutional denoising autoencoder with manifold spatial embedding for learning features, and then a Gaussian Mixture Model (GMM) is used for cluster learning. Features extracted by the encoder are embedded into a manifold space keeping a special locality that is more conducive to cluster learning. By doing so, ACMEC replaces the complexity of the clustering network with a manifold learning method [13–15] and straightforward clustering algorithm, reducing the deepness of the deep clustering, while achieving superior performance via the extra manifold learning step. The main merits of the ACMEC method are as follows: An asymmetric convolutional denoising autoencoder, a not too deep network structure, is presented for obtaining meaningfully visual features; A manifold embedding is employed to disentangle features for more separable clusters; Make good use of local topological information of point to calculate the similarity between two points in feature embedding space; Extensive experiments demonstrate that the proposed ACMEC method outperforms state-of-the-art clustering methods on benchmark datasets.
The purpose of this article is to provide a simple ACMEC method that replaces deep clustering networks with a manifold learning method followed by shallow clusters. According to the experiments, this approach can compete with state-of-the-art deep clustering approaches on several datasets. The rest of the paper is organized as follows. Section 2 mainly reviews the related works. The proposed ACMEC method and network architecture are carefully described in Section 3. Extensive experiments including comparisons and ablation studies of ACMEC are discussed in Section 4. At last, Section 5 states conclusion and future works.
Related work
The performance of the clustering approach is heavily dependent on the quality of feature learning. Therefore, it is necessary to design a network structure with high representation ability whatever meets kinds of images. Existing geometry transformations include linear transformation like Principal Component Analysis (PCA) [16, 17] and nonlinear transformation such as kernel methods and spectral methods [18–20]. However, how to describe features in latent space is still a challenge. In this case, deep neural networks (DNN) including convolutional neural networks and generative adversarial networks can be utilized to learn high-level representation [21, 22]. Existing deep clustering methods mainly combine feature learning with conventional clustering methods together, by minimizing clustering loss to update network parameters and clustering performances [23, 24].
In 2014, a deep embedded network (DEN) was proposed to extract effective representations for clustering [25]. DEN firstly utilizes an autoencoder to learn representation from raw data. Secondly, a locality preserving constraint is implemented to preserve the local structure of the original data. An unsupervised deep embedding method (DEC) [5] was proposed in 2016 to implement feature extraction and clustering tasks simultaneously. It discards the decoder after training an autoencoder by minimizing reconstruction loss. Clustering allocation is iteratively optimized by minimizing KL(Kullback-Leibler) divergence. On the basis of the DEC method, the improved deep embedded clustering (IDEC) [26] and discriminatively boosted clustering (DBC) [27] were presented successively in 2017 and 2018. IDEC uses both clustering loss and reconstruction loss to disentangle feature space, and incomplete autoencoder term maintains local structure. In DBC, a convolutional autoencoder replaces the fully-connected autoencoder to mine the representation ability of network mapping.
Joint unsupervised learning of deep representations (JULE) [28] was proposed to jointly learn meaningful features and clusters, where a convolutional neural network is employed for representation learning and hierarchical clustering is used for clustering. JULE optimizes its objective function in a recurrent process. In 2017, a deep embedded regularized clustering (DEPICT) [7] was proposed that is a sophisticated method consisting of multiple striking tricks. It has a softmax layer stacking on the top of a multi-layer convolutional autoencoder. It minimizes a relative entropy loss and a regularization term for clustering [29]. In 2019, the ClusterGAN method [30] proposed a novel balanced self-paced learning to gradually bring samples into training. In 2020, deeply embedded dimensionality reduction clustering (DERC) [9] formed a deep clustering algorithm through optimizing image embedding, dimensionality reduction, and cluster learning. In 2021, Not too Deep (N2D) [10] learned an autoencoder embedding and further searched the manifold to replace the deeper network for clustering. Comparing the manifold learning methods found that combining UMAP (uniform manifold approximation and projection) with autoencoder is the best popularity. To conquer the offline limitation, contrastive clustering (CC) provided an online deep clustering method. Actually, CC is intended to train the classification model in the unsupervised setting using invariant information loss [31]. Figure 1 shows several “milestone” methods and clustering accuracies on the MNIST dataset.
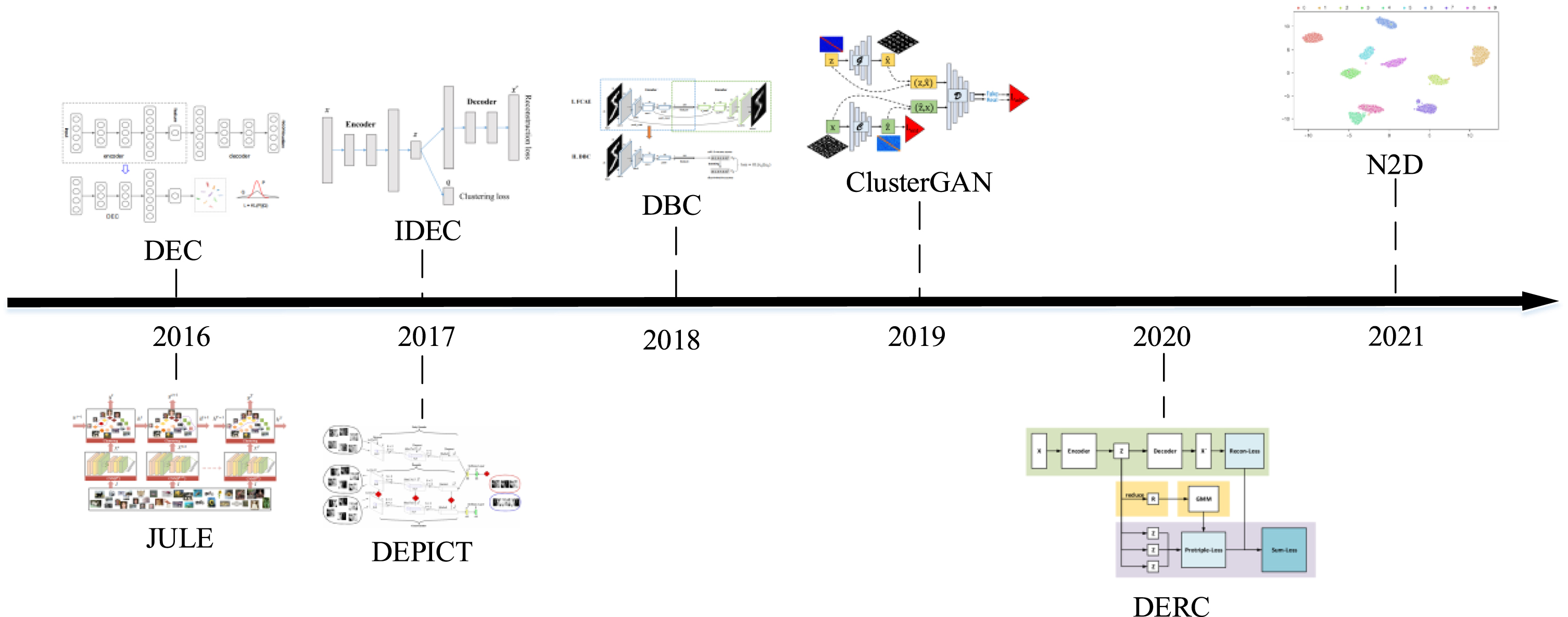
Milestones of popular clustering methods.
Several cluster learning problems from different aspects made some promising performances. However, there are still have some issues, for example, clustering results are still not satisfied. To further improve the feature extraction ability of network and clustering performance, a new clustering model is studied in this paper, which maps visual features into appropriate embedding space that brings better clustering results.
Let’s consider a clustering task to group N images
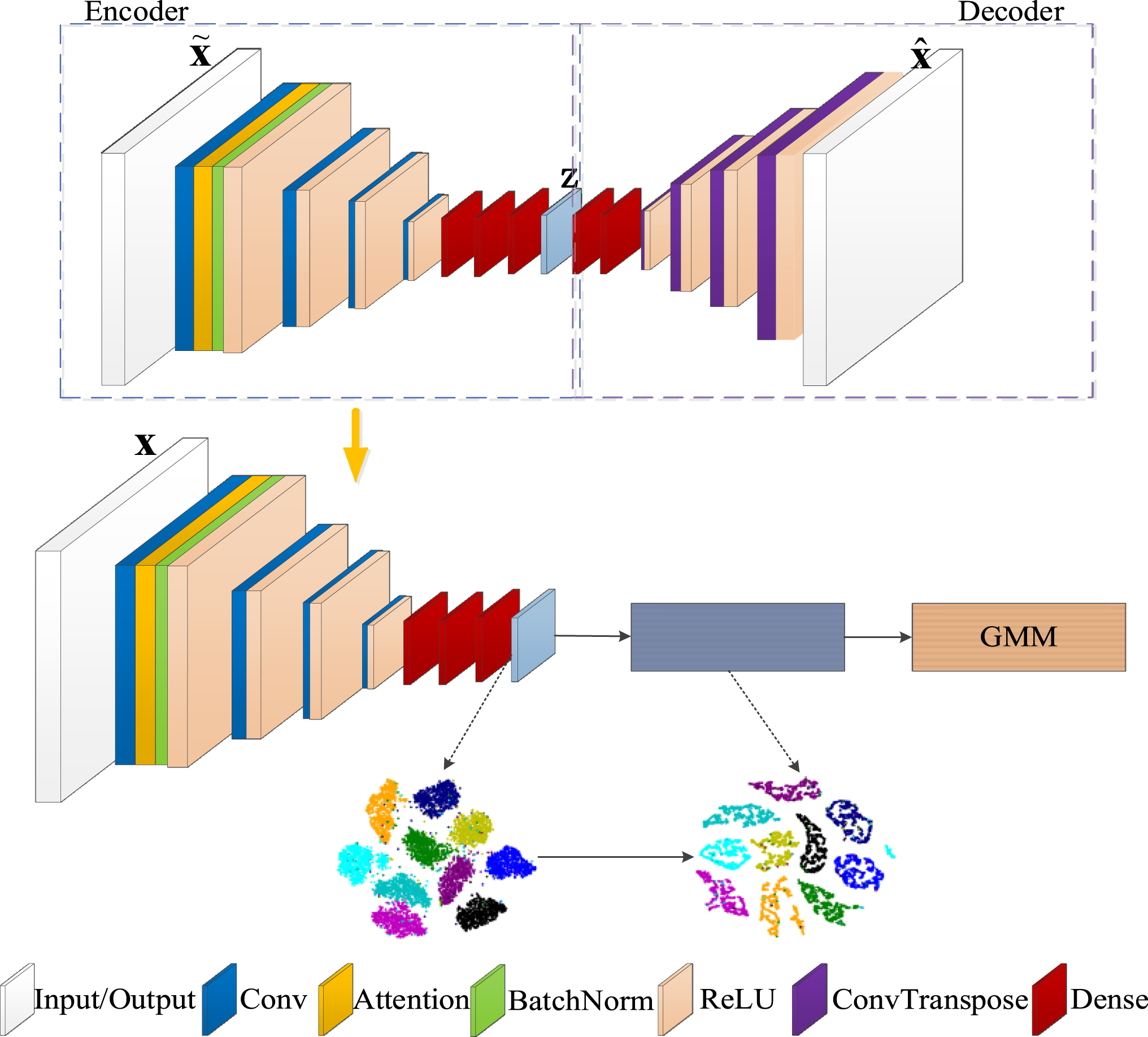
The framework of ACMEC method.
The upper part of Fig. 2 is an asymmetric convolutional denoising autoencoder network (ACDAE). To avoid trivial solutions when training our autoencoder, the inputs of ACDAE are those images distorted by Gaussian noises denoting as Training ACDAE by minimizing the reconstruction loss to update network parameters; Collecting the visual features and mapping them into a manifold embedding space, and then clustering assignment by a GMM.
In order to enhance the ability of feature representation, an asymmetric convolutional denoising autoencoder (ACDAE, referring to Fig. 3) is employed for features extraction. Encoder network is composed of four convolutional layers and three fully connected layers, while decoder part includes two fully connected layers and four deconvolutional layers. The detailed structure of ACDAE is described in Section 4.2.

The detailed architecture of encoder network of ACDAE.
Encoder network is a kind of nonlinear mapping, i.e.
The purpose of autoencoder transformation is to extract high-level visual features of images. Although here we use quite simple network for feature extraction, which are quite beneficial to consequent clustering task.
Recent works have shown that the local structure information guides networks to pursue the fine-grained features for samples discrimination and clustering. For example, the recent proposed manifold learning method namely UMAP (Uniform Manifold Approximation and Projection) [13] can better preserve global structure and inherit local benefits. First a spectral layout is used to initialize the manifold embedding. The manifold embedding space is optimized by minimizing cross entropy.
In our work, in order to achieve more local topological structure to further disentangle the visual features, a manifold mapping is employed to project features
Gaussian Mixture Model (GMM) [32] is a most representative model-based clustering method, where the observations are depicted by K Gaussian distributions. So, the likelihood of a manifold feature
After that, GMM is used to predict probability of
Here posteriori probability ψ
M
(
Many deep clustering models iteratively and alternatively update network weights and clustering assignment by joint training mechanism. However, the clustering performances of joint training degenerated in the experiments especially on MNIST dataset. The reason is maybe that the spatial structure of latent feature space is partly destroyed and lead to clustering degeneration. So, our proposed ACMEC method separately train ACDAE, manifold mapping and clustering. The pseudo-code of ACMEC description is shown in Algorithm 1.
This section mainly verifies the clustering performances of the ACMEC algorithm and compares it with other clustering algorithms on public image datasets. Section 4.1 introduces the datasets and evaluation metrics. In Section 4.2, ACDAE network configurations and parameters are carefully discussed. The exhaustive clustering analyses and visualizations are displayed in Section 4.3.
In order to decrease the influence of random initialization on the performances, experiments are repeated 30 or 50 times and show the highest clustering accuracy. The experimental environment includes IntelCorei5-6300HQ processor, NVIDIA 2.0GB video memory, and 8.0GB RAM graphics card. The running code of ACMEC is built on the open-source Keras library.
Datasets and metrics
Here we briefly review two handwritten digits datasets, three daily clothes and necessities datasets, and four smaller face datasets. The detailed descriptions are displayed in Table 1.To unify our network structure, all images are resized to 28×28 dimension. In addition, the colorful images are transformed into gray-scale.
The detailed information of datasets used in experiments
The detailed information of datasets used in experiments
Three evaluation indicators, widely used for evaluation clustering tasks, i.e. clustering accuracy (ACC) [33], normalized mutual information (NMI) [34] and adjusted rand index (ARI) [35], are described here. The closer the value is to 1, the more accurate the clustering result is.
Clustering accuracy (ACC) is calculated as follows:
Mutual information MI (Ω, C) = H (Ω) - H (Ω|C) describes information gain of clustering partition Ω for the given clustering allocation C. MI grows higher with the increasing of similarity between Ω and C. NMI normalizes mutual information into [0,1], which is:
ARI is bounded into the range [–1,1]. The negative ARI value indicates not ideal clustering result, while the larger positive value, the higher similarity the two clustering distributions.
The asymmetric convolutional denoising autoencoder, i.e. ACDAE network is trained by minimizing the reconstruction error between Gaussian noisy images and reconstructed images, and then the encoder network is used to collect features Z for the original images. Batch normalization is followed by each convolution layer with a ReLU activation function. Batch normalization is used to reduce the risk of falling into a local solution. The ACDAE configurations are summarized in Table 2, while the structure is plotted in Fig. 3 in Section 3.1.
The network configuration of the encoder in ACDAE
The network configuration of the encoder in ACDAE
Note that the convolution kernel size in the first convolution lay is equal to the stride, which can extract local feature information of image patches and reduce computation complexity simultaneously. The size of bottleneck is set as 2K, where K is a parameter of clustering task. The higher dimensionality of the bottleneck (also called as feature vector) is greatly beneficial for the downstream clustering tasks. Section 4.4.2 will display the experimental results and detailed analyses for the reason 2K here. Adam is used as the optimizer, and the learning rate is 1e - 4. In manifold embedding, the number of nearest neighbors of a feature is configured as the number of final clusters K.
In this section, the proposed ACMEC method is compared with the state-of-the-art approaches on the public image datasets. The comparison results on three datasets are listed in Table 3. The performances of the competitors are from the literature [9, 10], and the mark (-) means no available results. The distinguishing difference between ACDAE and ACMEC is that ACDAE is without manifold learning for clustering while ACMEC with.
The comparisons of ACMEC with the competitive clustering methods on three datasets
The comparisons of ACMEC with the competitive clustering methods on three datasets
According to Table 3, ACMEC can achieve higher ACC and NMI, which demonstrate ACMEC is better than the state-of-the-art approaches on the given datasets. ACMEC is a comparable competitor to N2D (not too deep clustering) method which are with 0.979 vs. 0.979 and 0.679 vs. 0.672 on clustering accuracies respectively. In addition, ACMEC approach is easy to be understood, which is composed of quite simple operation and not too deep network structure.
In order to further evaluate clustering performances of different learning algorithms, Friedman test is employed. First, sort ACC performances of six algorithms and the results are listed in Table 4. The last row in Table 4 are average rank values of each algorithm.
Sorting ACC performances of six algorithms on three datasets
Statistic τ
F
is computed using Equation (11):
Assuming null hypothesis H0 being the performances of the six algorithms are equal to each other. According to Table 4 and Equation (11), we can compute τ F = 5.39 that is greater than the critical value 3.33(significance level α =0.05). Thus, null assumption is rejected, i.e., there exits statistically significant difference between six algorithms.
Next, the post-hoc test Nemenyi is adopted to further distinguish the algorithms. The critical range of average rank value is:
In this paper, q α = 2.85, the critical range is CD = 4.35. According to the average order value in Table 4, the deviation between ACMEC and K-means 4.67 exceeds the critical range 4.35, so the performance of the two algorithms is significantly different.
According to the results in Table 4, Friedman test diagram of six algorithms is plotted in Fig. 4, where vertical axis is the algorithms and horizontal axis shows the average rank values. For each algorithm, a dot displays average rank value, and the line segment with the dot located in the center indicates the size of the critical value range.
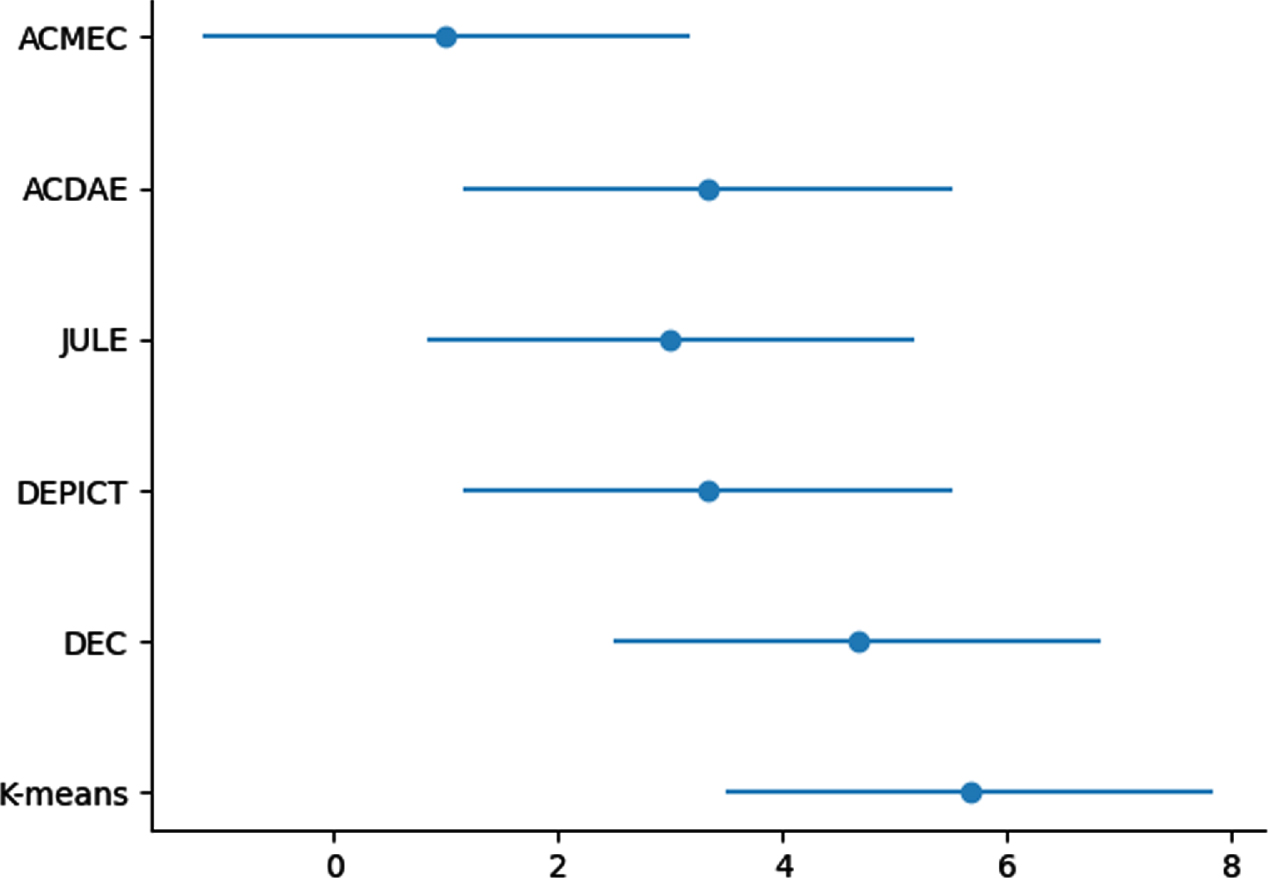
Friedman test diagram of six algorithms.
In Fig. 4, less overlapping between two horizontal lines means higher significant difference between the algorithms. So, there is statistically significant difference between our ACMEC and K-means. However, there is no significant difference between the joint algorithm DEC, in spite of our algorithm being 13.7% higher than DEC in terms of average clustering accuracy on three datasets.
Several ablation experiments are extensively conducted to check the contribution of each component.
Manifold mapping for clustering
A group of experiments are implemented to verify the effects of manifold embedding for clusters learning. The clustering performances displayed in Fig. 5 are generated separately as the following four processes.

The comparison of clustering performances with or without manifold embedding on the four datasets.
Observing four subfigures in Fig. 5, we can find that (i)
To further explain the influence of manifold embedding on the cluster learning, four kinds of features Z, Z’, U, U’ are visualized respectively in Fig. 6, in where the total 1000 features are generated from 100 images per cluster are randomly chosen from MNIST dataset.

T-SNE visualization of features from MNIST dataset.
It is found that Fig. 6(a)–(c) have regular and clear cluster-boundary and incorrect points, while Fig. 6(d) becomes irregular. In addition, there becomes scattered within the clusters in spite of still separation between clusters in Fig. 6(b) and (d).
The comparisons and features visualization illustrate that manifold embedding brings effect on the downstream clustering task. It is also noted that jointly training can improve clustering accuracy, but the corresponding accuracy is hardly improved after adding the UMAP manifold, as in Fig. 6(c) and (d).
The experiments consider the influence of bottleneck dimensionality 2K (i.e. the size of feature Z) on clusters learning. The clustering accuracies provided by ACMEC with the increasing of the size of feature Z on four datasets are plotted in Fig. 7.

The influence of bottleneck dimensionality on clustering accuracy.
Obviously, both two curves have a local optimal at 20 in Fig. 7(a) and (b) while digit 20 is just equal to 2K (K = 10 represents the number of clusters). Another two curves have slight increase with the increasing of the size of feature Z in Fig. 7(c) and (d). According to the observations, the optimal size of feature Z is finally determined as 2K, twice the number of clusters.
Here, a group of experiments are carried out to compare our ACMEC network with a fully connected autoencoder from literature [5] (namely FAE). The result of GMM clustering is the best of 30 runs on every dataset. The ACC, NMI, and ARI are shown in Table 5.
Comparison of FAE and ACMEC networks on eight datasets
Comparison of FAE and ACMEC networks on eight datasets
The clustering performances show that the feature representation ability of ACMEC is better than that of FAE. For example, it can improve 17% of accuracy on the UMISTS dataset. Thus, comparisons prove the effectiveness of asymmetric convolutional denoising autoencoder for feature representation.
The clustering performances provided by ACMEC method on six datasets are displayed in Table 6.
The clustering performances of ACMEC on six datasets
The clustering performances of ACMEC on six datasets
At last, randomly select 10 images per class from MNIST dataset for testing the proposed ACMEC method, and the visualization of clustering results are visualized in Fig. 8.

Clustering results of 100 images using ACMEC method.
It is easy to know that ACC is 0.93 for these 100 images. The incorrect clustering appears to the handwritten digits 9, 1, 5 and 4. Some of them are quite difficult to distinguish such as digit 5 misclassified in the second last row. While some misclustering could be revised when feature disentangled ability is further improved, for example digit 4 in the first row and digit 9 in the last row in Fig. 8(b).
In this paper, we proposed an ACMEC clustering method by extracting discriminative manifold features to enhance the clustering performances. ACMEC is mainly composed of features transformation, manifold embedding, and clustering allocation. Feature transformation mainly deals with feature extraction from input images. The manifold embedding of features is beneficial to visual analysis and improves the clustering performances. Besides the feature extraction, an asymmetric convolutional denoising autoencoder is also used as a features transformation network. UMAP manifold algorithm improves the dispersion of the embedded features, and GMM clustering can achieve the competitive clustering performances. Experimental results on nine challenging datasets demonstrated that ACMEC achieves significant improvement over the state-of-the-art methods.
However, there is larger margins of performances with the increasing of the number of clusters for unsupervised learning. One of the future works is how to improve the clustering performances for larger number of clusters using ACMEC method.
Footnotes
Acknowledgments
This work is supported by the Hebei Province Introduction of Studying Abroad Talent Funded Project (No.C20200302), and partially supported by the National Natural Science Foundation of China (No. 62072024).