
Abstract
Network resources and traffic priorities can be utilized to distribute requested tasks across edge nodes at the edge layer. However, due to the variety of tasks, the edge nodes have an impact on data accessibility. Resource management approaches based on Virtual Machine (VM) migration, job prioritization, and other methods were used to overcome this problem. A Minimized Upgrading Batch VM Scheduling (MSBP) has recently been developed, which reduces the number of batches required to complete a system-scale upgrade and assigns bandwidth to VM migration matrices. However, due to poor resource sharing caused by suboptimal VM utilization, the MSBP was unable to effectively ensure the global best solutions. In order to distribute resources and schedule tasks optimally during VM migration, this paper proposes the MSBP with Multi-objective Optimization of Resource Allocation (MORA) method. The major goal of this proposed methodology is to take into account different objectives and solve the Pareto-front problem to enhance lifetime of the fog-edge network. First, it formulates an NP-hard challenge for MSBP by taking into account a variety of factors such as network sustainability, path contention, network delay, and cost-efficiency. The Multi-objective Krill Herd optimization (MoKH) algorithm is then used to address the NP-hard issue using the Pareto optimality rule and produce the best solution. First, it introduces an NP-hard challenge for MSBP by accounting in network sustainability, path contention, network latency, and cost-efficiency. The Pareto optimality rule is then implemented to overcome the NP-hard problem and provide the optimum solution employing the Multi-objective Krill Herd optimization (MoKH) algorithm. This increases network lifetime and improves resource allocation cost efficiency. Finally, the simulation results show that the MSBP-MORA distributes resources more efficiently and hence increases network lifetime when compared to other traditional algorithms.
Keywords
Introduction
The Internet-of-Things (IoT) is driven by the need to connect real-world data to an online platform. Sensor and edge node layers are common in such platforms. In future generations, the number of sensors in a sensor layer is predicted to reach 50 billion. Modern approaches and notions for cloud infrastructure must easily be incorporated [1, 2].
Unlike highly regarded and accessible protocols, the proliferation of IoT networks and applications will not be possible to attain a massive scale. Emerging IoT standards give intermediate services for specifying particular constraints [3, 4].
Issues including affordability, stability, resource optimization, and how resources may be allocated with system resilience have been addressed. The connectivity of IoT technologies is still a difficult issue to address unique demands. Expanded smart intelligence and virtualization with intellectual capabilities can help with the above [5–8]. To address these issues, a cost-efficient strategy has been recommended for virtualization. The information observed by the diverse sensors is virtualized and broadcast to the VM. All edge nodes on the edge system layer that manages the closest VMs wherein computing capabilities of sensor data from the sensing field are encapsulated to lessen an extra expense and delay for transferring VMs to the distant cloud. Besides, edge nodes can allocate local VMs adaptively via verifying with another edge system.
Numerous resource management approaches have been recommended in the past to solve VM schedule for increasing the edge node’s resilience and reliability [9–11]. A smart technique has been recommended for recycling nodes in distributed systems. NP-hard data, probabilistic level prediction, and minimal constraint analysis were stated as an aspect of the minimum upgrading batch VM selection problem [12]. After that, the MSBP was created. To minimize the number of batches required to perform the network-level upgrade, a greedy method was first used. The VM migration matrix for each batch was then created. In addition, the Shortest Trajectory First (STF) and Least Bandwidth Utilization First (LBUF) have been used to schedule trajectories and throughput for VM migration formulations. In STF, the shortest space migration route was discovered along with the best connectivity with the most feasible residual bandwidth. Moreover, the transmitting power for the edge nodes for relaying the sensed data has been measured. Nevertheless, the suboptimal use of VM may limit the resource distribution. Also, the MSBP was based on heuristics, which were inefficient and costly in terms of ensuring global optima.
Therefore in this article, the MSBP-MORA scheme is proposed which enhances the network life through appropriate resource distribution. The optimised Krill Herd (KH) algorithm is used to allocate prioritized tasks to appropriate resources when tasks are handled in the fog-edge layer. The Pareto-front problem arises as a result of the outcome, which does not provide rapid convergence and search capabilities. To efficiently solve the Pareto optimality law and find the best Pareto optimal solution, the MoKH optimizer is proposed. With promising solution quality, the convergence speed towards the Pareto-front is also accelerated. As long as the Pareto-optimality law is followed, multi-objective solutions guarantee that no greater network performance can be achieved without increasing overall costs. As a result, by allocating resources to required tasks using the multi-objective parameter, the proposed system MSBP-MORA accomplishes its main purpose of increasing network sustainability
The following are the remaining sections of this paper: In Section II, we describe recent work on task and resource scheduling techniques in cloud-fog-edge computing. The MSBP-MORA system is described in Section III, and its efficacy is demonstrated in Section IV. Section V summarises the paper.
Literature survey
A comprehensive study comparing base learning algorithms with well-known ensemble methods [13] was presented to categorize the text. It needs to consider the robust and scalable algorithms for further improvement. A feature selection model [14] was developed based on the genetic rank aggregation for classifying text sentiments. But, its efficiency was impacted by the fixed parameters. A hybrid ensemble pruning method [15] has been developed depending on clustering and randomized search to categorize the test sentiments. But, the efficiency was impacted by the characteristics involved in defining text documents. An ensemble scheme [16] has been developed depending on language function analysis and feature engineering to classify text genres. But, the accuracy was not effective. An efficient multiple classifier methods [17] were presented to classify the text based on swarm-optimized topic modeling. But, it needs a huge amount of data to enhance efficiency.
A multi-objective task scheduling method [18] has been developed to solve the task allocation issue in the cloud system as an NP-hard optimization dilemma. For this reason, the Fractional Grey wolf Multi-objective optimization-based Task Scheduling (FGMTS) algorithm was applied which determines the fitness value based on time, cost and resource usage for optimum allocation. But, its convergence rate and accuracy were not effective. Abd Elaziz [19] developed the Hybrid Moth Search Algorithm and Differential Evolution (HMSADE) to schedule the tasks in cloud networks. The DE was applied as a local search strategy which improves the exploitation ability of the MSA. But, the time complexity of this algorithm was high and it was suitable for single-objective optimization issues.
Xu et al. [20] designed a Laxity-based Priority (LBP) to create a task allocation string with an appropriate priority which improves the sensitivity of task latency. After that, Ant Colony Optimization (ACO) was applied to get the approximate optimum allocation method globally to reduce the overall power usage. But, it does not consider the multi-objective optimization problem for task allocation in cloud systems. Rafique et al. [21] designed a New Bio-Inspired Hybrid Algorithm (NBIHA) by hybridizing the Modified Particle Swarm Optimization (MPSO) and Modified Cat Swarm Optimization (MCSO) to handle resources at the fog layer. The resources were allocated and handled based on the requirements of arriving requests. But, the energy usage and processing cost were still high.
Akintoye & Bagula [22] investigated the task assignment and VM allocation challenges in a single cloud/fog computing system. Also, the Hungarian Algorithm-based Binding Policy (HABP) for task assignment and the Genetic Algorithm (GA) for VM allocation were presented. But, its time complexity was high and it does not consider the multi-objective optimization problem. Li et al. [23] developed an Energy-efficient Computation Offloading and Resource Allocation (ECORA) method for reducing the network cost. First, the potential game was used to analyze the optimal offloading decision. Then, the resource allocation based on iterative policy was used to obtain the optimum energy and resources for the fog-cloud systems. But, its computational complexity was high.
Zhang et al. [24] developed a Particle Swarm Optimized NSGA (PSONSGA) to optimize the tradeoff between the total expense and system latency. However, it needs to consider other parameters like system sustainability, link capacity, etc., to enhance the network efficiency. A topic-enriched word embedding method [25] was presented to identify sarcasm. But, its accuracy was not effective because of a limited dataset. To handle the imbalanced training, a consensus clustering-based undersampling method has been designed [26]. But, it needs to integrate optimization algorithms to increase efficiency. A 2-level topic mining model for bibliometric data analysis [27] was presented depending on word embeddings and clustering. However, it needs to extend this model by optimizing the weight values to word embeddings. A Recurrent Neural Network (RNN)-based model [28] has been developed for opinion mining on instructor analysis reviews. But, student data systems may not be used to handle key activities of the training task.
Reddy et al. [29] addressed the stability of energy reduction at the fog layer via intelligent sleep and wake-up cycles of the fog nodes which were context-aware. Then, a VM control method was presented to efficiently assign task requests with a smaller number of active fog nodes using the GA. Also, reinforcement learning was applied to optimize the fog node’s duty cycle time. But, it has a high computation burden and it does not consider the multiple objectives for optimal resource sharing.
Chen et al. [30] developed an Improved Whale Optimization Algorithm (IWOA) to allocate the cloud tasks with the multi-objective optimization framework, intending at enhancing the efficiency of the cloud network with the specific computing resources. But, the allocation overhead in the existence of huge workloads was high. Also, the convergence speed of IWOA was less. Ni et al. [31] presented a 3-layer allocation framework depending on the whale-Gaussian cloud. The WOA Strategy based on the Gaussian Cloud paradigm called GCWOAS2 was applied in the second layer for multi-objective task allocation in cloud networks. In this strategy, opposition-based training was utilized to initialize the allocation process for creating the optimum allocation method. After that, an adaptive mobility factor was used to adaptively extend the hunting range. Moreover, the GCWOAS2 was performed to obtain the global optimum allocation method. But, the efficiency was not satisfactory since the operating cost was high.
Alsadie [32] developed a Meta heuristic model called MDVMA to allocate VM adaptively using the optimized task allocation in cloud computing. It focused on designing a multi-objective allocation scheme based on a Non-dominated Sorting Genetic Algorithm (NSGA)-II to optimize task allocation and obtain trade-offs for the data centers according to their demands. But, the convergence of NSGA-II was limited by the use of crowding distance. Ababneh et al. [33] presented a hybrid multi-objective method called Hybrid Grey Wolf and the WOA (HGWWO) to allocate the tasks in cloud computing. The major aim of this method was to reduce the makespan, cost and energy usage during task allocation. But, its optimum solution was influenced by the selection of fitness criteria and their ranges. Wu et al. [34] developed a multi-objective Estimation of Distribution Algorithm (EDA) to train and optimize the fuzzy offloading method in fog computing. It was applied to split the applications into separate groups and all groups were assigned to the respective tier for further analysis. So, the network resources were conserved by creating allocation decisions in a less search space. But, it has a high time complexity and the fuzzy membership values must be chosen properly.
A deep learning-based method [35] has been developed, which combines TF-IDF weighted Glove word embedding with CNN-LSTM structure to sentiment analysis on product reviews obtained from Twitter. But, the accuracy was not effective since it needs a huge amount of data. Onan et al. [36] developed a Bidirectional Convolutional Recurrent Neural Network (BCRNN) structure with a group-wise enhancement strategy to categorize the text sentiments. But, it has to be employed in the different applications to analyze its efficiency.
Proposed system
The MSBP-MORA scheme is briefly explained in this section. It is considered a fog computing structure with a fog layer in a cloud (as shown in Fig. 1). The assumptions and notations that were employed in this investigation are first stated. Then, using MSBP, an NP-hard issue for resource allocation is created. Furthermore, the MoKH is used to solve the NP-hard problem and efficiently obtain the best resources for distribution.
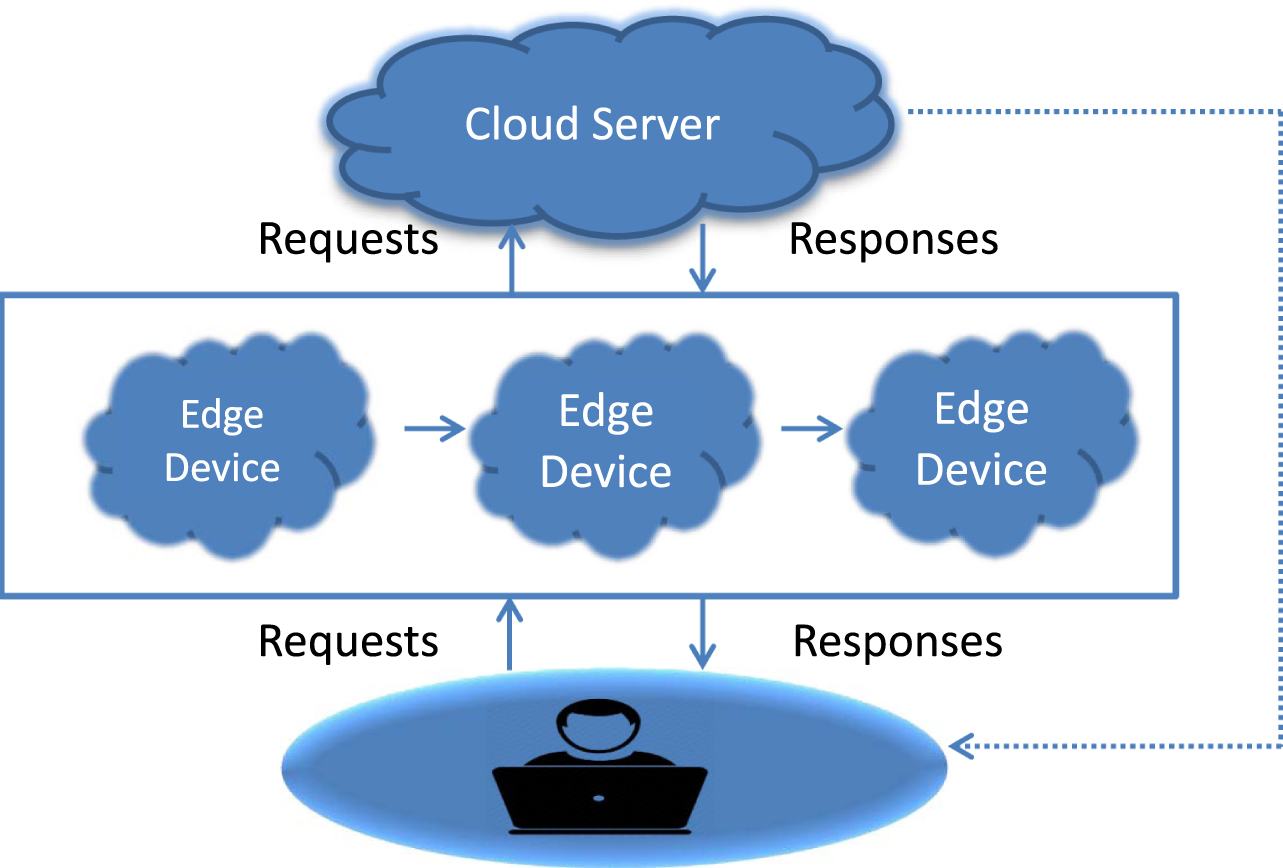
Structure of resource distribution in cloud and fog layers.
This MORA computes the optimal amount of batches, resources, and tasks between the fog nodes and cloud for a set of edge client requests. In terms of the Pareto-optimality rule, multi-objective solutions ensure that improving network efficiency does not come at the expense of increasing total cost. The following assumptions are taken into account when creating the system model: The upper edge is occupied by the cloud layer, which is made up of cloud servers, while the middle is populated by the fog layer. Each fog node is made up of many micro-server nodes and virtual machines (VMs). Fog node resources, such as storage and virtual machines, can be used in the network. The cost and bandwidth availability of all links between fog nodes and the cloud are evaluated. Each client sends a request to the nearest fog node at the bottom, which manages the fog node’s resources, such as CPUs and virtual machines. After the fog node accepts the client’s request, the following steps are taken: The request is ignored if it cannot be fulfilled within the specified time frame. Alternatively, based on the priority level, period, and available resources, the fog server controller calculates the priority queue for the query. The fog server manager prioritizes queries according to their significance. If the query’s specific resources are available on the fog node, the request is granted, and the result is sent immediately to the client. The task is sent to one or more fog nodes in the fog layer if the fog layer has the resources required. The request is routed to the cloud layer for processing when the fog layer lacks the requisite resources. The fog nodes transmit a rate (η) of their total request to the cloud servers.
According to these assumptions, the below notations are described: L ={ 1, …, l, …, m } is the collection of available resources to deploy fog nodes, where m is the remote cloud server.
J is the collection of edge nodes that should be handled by the fog nodes or the cloud. All edge nodes have combined storage, VM and data requests. τ
j
is the overall amount of VM needed by an edge node j ∈ J. ζ
j
is the overall amount of storage needed by an edge node j ∈ J. I
j
is the total data created by an edge node j ∈ J. κ
j
is the link speed of an edge node j ∈ J. SL
j
is the sustainability of j
th
edge node and calculated as: F is the collection of fog nodes that can be deployed using different resources. α
k
is the overall amount of VM available for a fog node k ∈ K. λ
k
is the overall amount of storage available for a fog node k ∈ K.
P is the collection of links that can be executed using various resources to handle paths to the cloud servers. β
p
is the transit bandwidth maximum range for link p ∈ P.
pcl is the path contention level, i.e. the variance between the highest link bandwidth usage (b
max
) and the mean link bandwidth usage (b
mean
). It is determined as: d
uv
= dist (u, v) is the Euclidean distance between coordinates of nodes u and v. γ is the processing latency. Because the request is accepted, analyzed and transmitted, all routers or switches in the routing path contribute certain latency. The amount of hops between the client and the fog/cloud determines the processing time as:
ψ is the transmission latency. The amount of time required for transferring data via the communication channel. It is determined based on the link speed and packet size. μ is the propagation latency. It is the time required for information to propagate from its origin to the target. It is dependent on the channel considered and determined as:
D (d
uv
) is the system utilization between all clients and the fog services, which defines the network delay experienced by clients or the data transmitted to the cloud. A small increase in the delay can cause considerable service level degradation. So, in this study, D (d
uv
) is considered the end-to-end latency. x
lj
is a decision variable ranging from 0 to 1 such that x
lj
= 1, when the edge node j ∈ J is linked to the fog node deployed using resource l ∈ L. y
lk
is a decision variable range between 0 and 1 such that y
lk
= 1, when a fog node k ∈ K is deployed using resource l ∈ L. z
lp
is a decision variable range between 0 and 1 such that z
lp
= 1, when a path p ∈ P is deployed using resource l ∈ L to link to the cloud.
This MSBP-MORA using MoKH effectively minimizes overall network latency, overall cost to install the fog-cloud network, and path contention level to achieve the maximum system performance and cost-efficiency. It also improves the whole system’s long-term viability. The resource allocation challenge is also NP-hard since it has four objective functions: total cost, network latency, path contention level, and system sustainability. The resource allocations for deploying the cloud-fog network are stored in the decision variables. This is a multi-objective combinatorial conundrum when it comes to resource allocation. The MoKH optimization algorithm solves this problem. The parameters used to calculate the proposed system efficiency are determined. Evaluation metrics are formulated as: Cost minimization:
Latency minimization:
System sustainability maximization:
Path contention level minimization:
Subject to
Similarly, the capacity criteria for VM and storage at the node level (given in Equations (15) & (16)) guarantee that the overall resource requirement does not exceed every fog node’s hardware ability.
To solve the NP-hard problem of prioritized tasks allocation in cloud-edge network, a basic KH algorithm is adopted which deals with the multiple objectives. A basic KH algorithm is used to address the NP-hard problem of resource allocation in the cloud-fog network, which leverages a d-dimensional Lagrangian idea for searching in the solution space.
In Equation (17), MI
i
is the krill’s motion stimulation, FA
i
is the foraging motion and RF
i
is the random diffusion. Highest iteration
This method is repeated until the maximum number of iterations has been reached and the greatest resources linked with the best krill have been chosen. As a result, the number of resources available to fog servers (edge devices) is tuned for effectively tackling NP-hard server consolidation or VM migration challenges. However, if several objectives are stated, it does not ensure speedy convergence and search ability, resulting in the Pareto-front problem. As a result, the MoKH is introduced, which addresses various objectives. The goal is to perform a multi-objective optimization that achieves fast convergence and approximation in order to estimate the true Pareto front. Furthermore, its answers are diverse enough that at the end of iterations, the applicable solution for the problem under consideration is obtained. The minimal distances of each individual krill from food and the maximal density of the herd constitute the objective function for krill movement in KH. It proposes a solution to a single-objective optimization conundrum.
However, it does not deliver significant and optimal solutions. Alternatively, the best answers to a multi-objective optimization issue could be an endless number of tradeoff solutions, also known as Pareto optimum or non-dominated solutions, which can be sorted exclusively by perception. To enhance the convergence rate and population diversity in MoKH, the beta distribution is applied in the inertia weight modification.
At the end of iterations, a truncation technique is used to blend the parent and child krill populations. The non-inferiority and crowding distance criteria are used to grade the combined krill populations in order to keep the solutions. To determine the worldwide best krill, a similar ranking is performed, and 10% of the top-ranked krill is chosen at random. When a result, krill that explore a less populous and less dominated area have a greater chance of influencing each other as the algorithm iterates. The MoKH algorithm’s pseudo code is shown below.
This section employs the CloudSim API 3.0.3 to test the MSBP-MORA scheme’s efficacy with the MoKH algorithm and compare the results with the results of other optimization algorithms such as MSBP [12], NBIHA [21], PSONSGA [24] and NSGA-II [32]. The authentic 16-node and 27-node RedRIS are used as the sample IoT frameworks in this scenario, with each OXC node being implemented with an edge node, i.e. 16 fog distributers. Two opposing VM migration channels are thanks to the optical link. Assume that each optical link has a primary weight of one i.e. c l = 1, l = 1, …, 27. The quantity of resource units determines the edge node’s overall processing capability. Initially, there are n virtual machines (VMs) linked to the network. The comparison takes into account the number of batches, system durability, the proportion of migrated VMs, overall reaction time, and total cost.
Number of batches
When various objectives are considered concurrently to allocate resources, the MSBP-MORA-MoKH system achieves minimal batches relative to all other schemes. If the edge node’s computation capability is 170, MSBP-MORA-MoKH has 87.5 percent lesser batches than MSBP, 80 percent lesser batches than the MSBP-MORA-NBIHA, 66.67 percent lesser batches than MSBP-MORA-NSGA-II, and 50 percent lesser batches than MSBP-MORA-PSONSGA schemes. Table 1 presents the number of batches obtained by the existing and proposed algorithms.
Comparison of number of batches
Comparison of number of batches
Comparison of network sustainability
Figure 2 illustrates the number of batches obtained by the MSBP, MSBP-MORA-NBIHA, MSBP-MORA-NSGA-II, MSBP-MORA-PSONSGA and MSBP-MORA-MoKH schemes under distinct computation abilities of edge nodes.
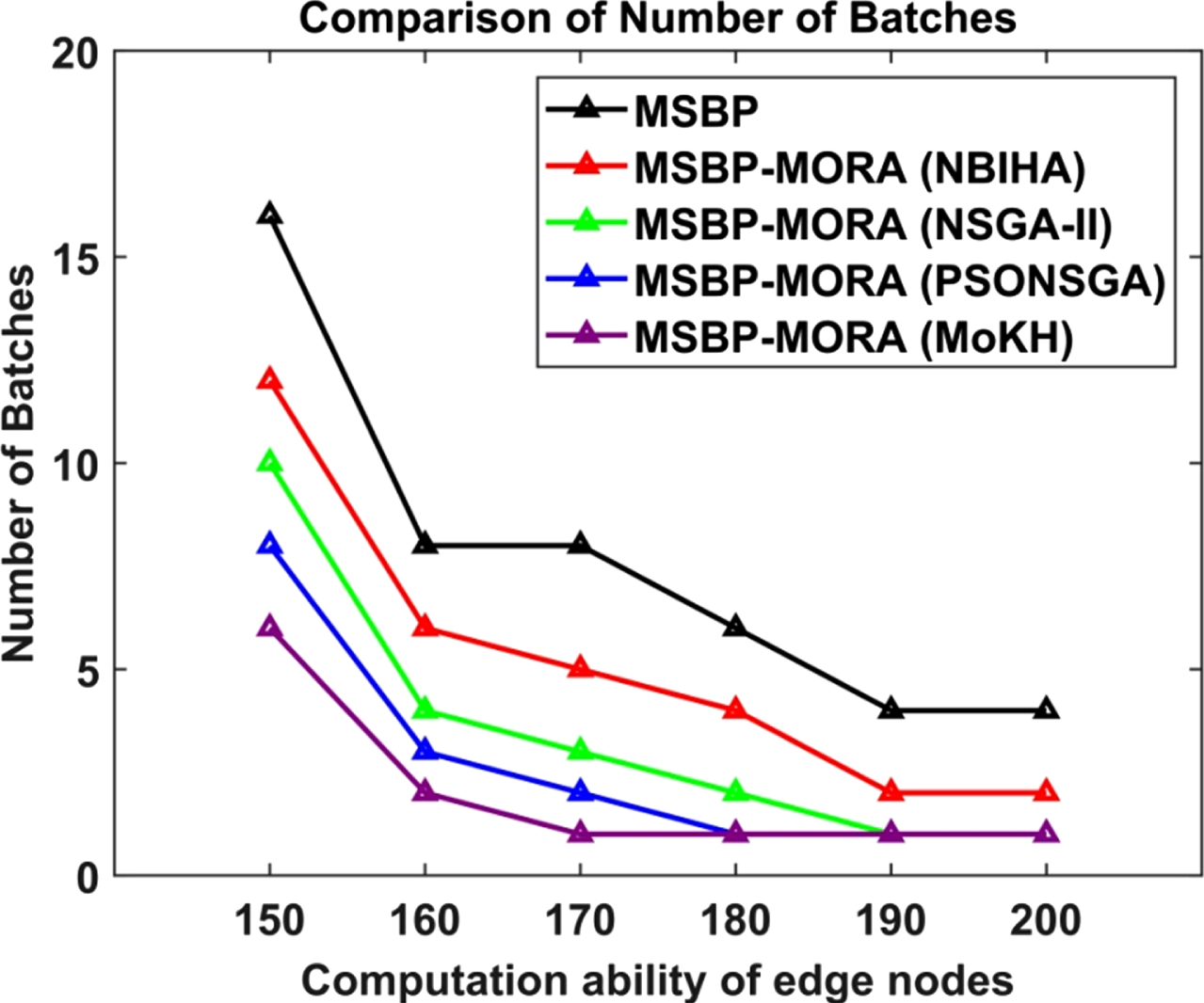
No. of batches vs. computation ability of edge nodes.
Due to the optimization of several objectives for resource and task assignments, the MSBP-MORA-MoKH scheme outperforms all other schemes in terms of network sustainability. If the compute ability of the edge node is 170, the network sustainability of MSBP-MORA-MoKH is 0.31, which is greater than the other methods, which are 0.05, 0.15, 0.24, and 0.27, respectively, for MSBP, MSBP-MORA-NBIHA, MSBP-MORA-NSGA-II, and MSBP-MORA-PSONSGA. Table 2 presents the ranges of network sustainability for the existing and proposed algorithms. Figure 3 shows the network sustainability achieved by the MSBP, MSBP-MORA-NBIHA, MSBP-MORA-NSGA-II, MSBP-MORA-PSONSGA, and MSBP-MORA-MoKH schemes when edge nodes have varying compute capabilities.
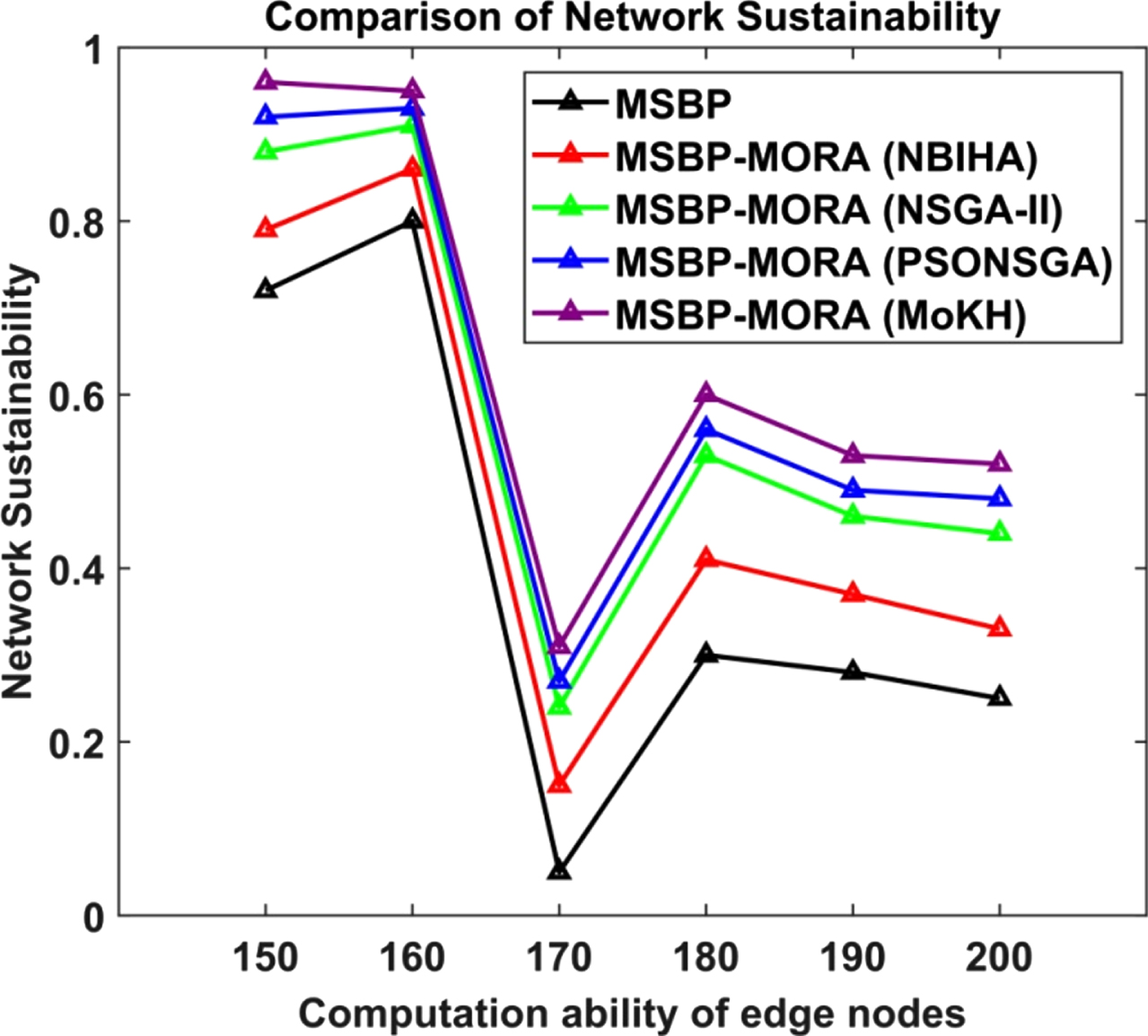
Network sustainability level vs. computation ability of edge nodes.
This experiment showsthat the MSBP-MORA-MoKH scheme, when compared to all other schemes, minimizes the percent of moved VMs by optimizing resource allocation based on numerous factors. If the edge node’s computation capability is 170, the fraction of migrated VM for MSBP-MORA-MoKH is 68.18 percent lower than MSBP, 58.82 percent less than the MSBP-MORA-NBIHA, 50 percent lower than MSBP-MORA-NSGA-II, and 36.36 percent lower than MSBP-MORA-PSONSGA.
Table 3 shows the percentage of VM that has been moved using the existing and proposed techniques. Figure 4 depicts the percent of moved VM for the MSBP, MSBP-MORA-NBIHA, MSBP-MORA-NSGA-II, MSBP-MORA-PSONSGA, and MSBP-MORA-MoKH schemes, as a function of the edge nodes’ computation capacity.
Comparison of percentage of migrated VM
Comparison of percentage of migrated VM
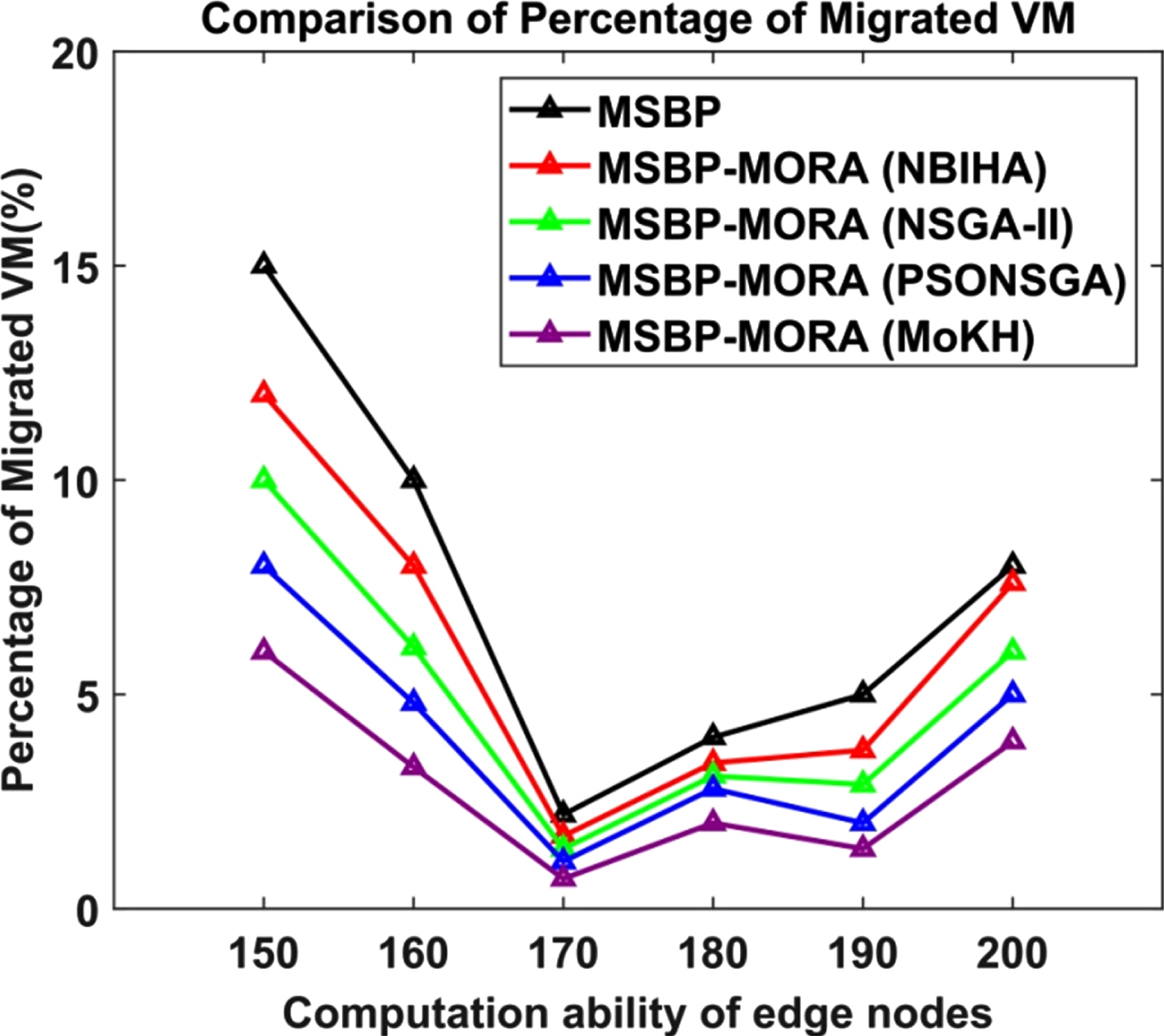
Percentage of migrated VM vs. computation ability of edge nodes.
It recognises that the MSBP-MORA-MoKH scheme, when compared to all other schemes, minimises the mean reaction time by optimizing resource allocation based on various factors. For example, MSBP-MORA-MoKH has a total mean reaction time of 60.27 percent less than MSBP, 49.83 percent less than the MSBP-MORA-NBIHA, 38.6 percent less than MSBP-MORA-NSGA-II, and 27.83 percent less than MSBP-MORA-PSONSGA.
The total reactive period for the known and proposed algorithms are shown in Table 4. The overall mean reaction time (in ms) for the MSBP, MSBP-MORA-NBIHA, MSBP-MORA-NSGA-II, MSBP-MORA-PSONSGA, and MSBP-MORA-MoKH schemes is depicted in Fig. 5.
Comparison of total reactive period
Comparison of total reactive period
It recognizes that the MSBP-MORA-MoKH scheme, when compared to all other schemes based on multiple objectives, minimizes the total cost of network deployment and resource allocation. For example, the MSBP-MORA-MoKH plan costs 75 percent less than the MSBP, 64.71 percent less than the MSBP-MORA-NBIHA, 45.45 percent less than the MSBP-MORA-NSGA-II scheme, and 29.41 percent less than the MSBP-MORA-PSONSGA system.
Processing speed, buffer space, VM capacity, and network throughput all impact the total cost of fog and cloud providers. The total cost of the existing and proposed algorithms is shown in Table 5. The total cost (in dollars) for the MSBP, MSBP-MORA-NBIHA, MSBP-MORA-NSGA-II, MSBP-MORA-PSONSGA, and MSBP-MORA-MoKH schemes is depicted in Fig. 6.
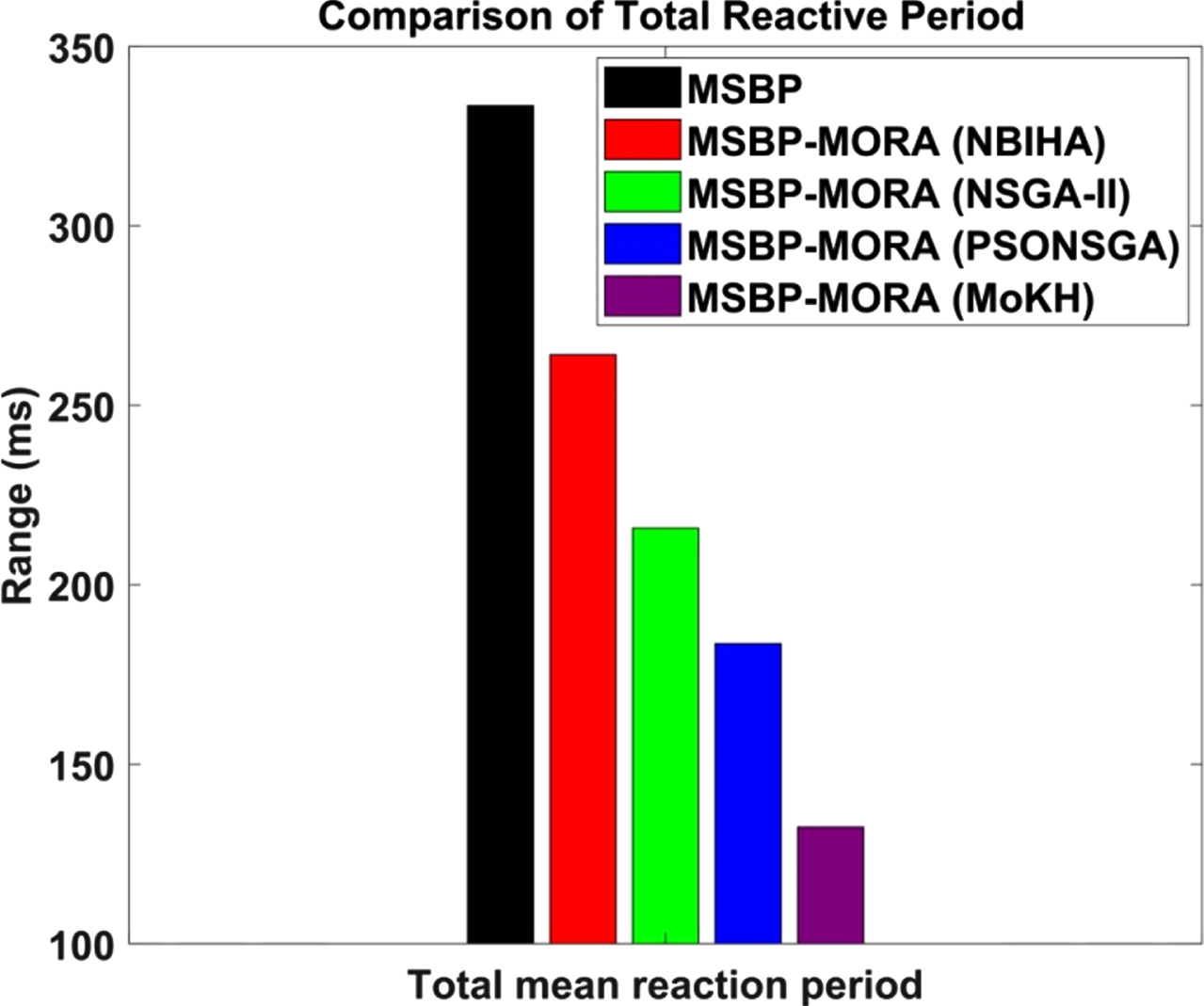
Comparison of total reaction period.
Comparison of total cost

Comparison of total cost.
The MSBP-MORA scheme was provided in this paper as a technique for allocating resources and scheduling tasks in cloud-fog computing systems. Its primary goal is to enhance network lifetime by solving the Pareto-front dilemma in multi-objective optimization-based resource allocation. The NP-hard challenge for MSBP was originally designed with network sustainability, path contention, network slowness, and cost-efficiency. The MoKH optimizer was then used to handle the NP-hard issue and determine the best Pareto optimum solution using the Pareto optimality criteria. The network delay and cost were decreased with a high network sustainability level using this technique. Finally, when the computation ability of edge nodes is 200, the simulation results show that the MSBP-MORA scheme has 1 batch, 0.52 percent of migrated VMs, 3.9 network sustainability, 132.5 ms total average reaction time, and 1.2$ overall expense when compared to other existing resource distribution optimization algorithms.