
Abstract
Degradation prognostic plays a crucial role in increasing the efficiency of health management for rolling element bearings (REBs). In this paper, a novel four-step data-driven degradation prognostics approach is proposed for REBs. In the first step, a series of degradation features are extracted by analyzing the vibration signals of REBs in time domain, frequency domain and time-frequency domain. In the second step, three indicators are utilized to select the sensitive features. In the third step, different health state labels are automatically assigned for health state estimation, where the influence of uncertain initial condition is eliminated. In the last step, a multivariate health state estimation model and a multivariate multistep degradation trend prediction model are combined to estimate the residence time in different health status and remaining useful life (RUL) of REBs. Verification results using the XJTU-SY datasets validate the effectiveness of the proposed method and show a more accurate prognostics results compared with the existing major approaches.
Keywords
Introduction
As an incredible critical component of rotating machinery, rolling element bearings (REBs) are widely used in aerospace equipment, transportation tools and wind power generation equipment [1]. The wear of the bearings can cause damage to the mechanical equipment, which may lead to serious accidents. Degradation prognostic is the key part of health management in condition monitoring (CM), remaining useful life (RUL) prediction, and operation optimization [2]. The goal of degradation prognostic is to avoid catastrophic failure, improve the stability, and extend the life-span of equipment. Therefore, developing the degradation prognostics techniques of REBs have become an urgent need.
Generally, the degradation prognostics mainly include two categories: 1) model-based method and 2) data-driven method [3]. The model-based method builds a corresponding model according to the physical structure, operating principle and degradation mechanism of the system [4–6]. This method can clearly describe the degradation process of the system, which leads to a good prediction performance for the system with simple physical structure and clear degradation mechanism. However, in practical engineering, the operating conditions of the equipment are extremely complex and dynamic. Therefore, the general physical model cannot match the actual situation perfectly, which may affect the prognostics results [7]. The data-driven method establishes a degradation prognostic model based on the historical CM data collected by the sensors [8–12]. The health status and RUL of the equipment can be predicted by analyzing the degradation trend of the features. This method does not require the knowledge about the physical structure of the system, and thus, it is very suitable for the complex system like rotating machinery.
Data-driven prognostics methods can be further classified into three major branches [13]: 1) direct prognostics modeling; 2) univariate prognostics modeling and 3) multivariate prognostics modeling. Direct prognostics modeling learns the relation between the current observed degradation trend and the RUL by using the historical CM data, and then the degradation prognostic model can be established according to the relationship [14]. Finally, it can match the online observed data with the prognostic model to calculate the corresponding RUL of the equipment, as shown in Fig. 1(a). This model does not need to set the failure threshold (FT). However, it needs to train abundant CM data in order to obtain an accurate prediction model, and thus, it is difficult to realize in engineering because of its high complexity and large calculation.

Classification of data-driven degradation prediction methods.(a) Direct prognostics modeling. (b) Univariate prognostics modeling. (c) Multivariate prognostics modeling.
Univariate prognostics modeling obtains the RUL by constructing an one-dimensional health index (HI) [15, 16]. The prognostics is completed when the HI reaches the predefined FT, as shown in Fig. 1(b). The advantage of this method is that it doesn’t need to know the whole life data of the equipment. However, it is very difficult to get a precise and reasonable HI [17].
In multivariate prognostics modeling, clustering analysis and classification methods are usually adopted for dividing the historical degradation data into several subsets, which represent the different health status [18]. Regression analysis or time-series analysis can be used to build multivariate degradation model for calculating the time interval between the current state and the failure state, as shown in Fig. 1(c). This model has two major advantages: 1) Comparing with the direct prognostics modeling, it does not need much training and can improve the computational efficiency. 2) Comparing with the univariate prognostics modeling, multivariate CM data can provide more comprehensive degradation information, making the prediction results more accurate.
Multivariate prognostics modeling is initially proposed in [19], and the implementation details of this method are given in [20]. In recent years, it has gradually become an emerging technique in prognostics field [21–25]. However, the existing approaches rarely take into account the residence time of different health states and uncertainty of the initial condition, and they often need to preset a FT. In reference [21], degradation process of the REBs is divided into health status and failure status according to a preset FT. Then, Kalman filter (KF) is used to estimate the RUL of REBs. However, this method only divides the degradation process into two discrete states, which is hard to formulate a flexible maintenance strategy. At the same time, the preset FT also reduces the accuracy of the prognostics results. As the further improvement in [22], the Markov classifier is implemented to divide the continuous degradation process of the engine into four different health states. However, this method ignores uncertainty of initial conditions and cannot calculate the residence time of different health states. In reference [23, 24] and [25], deep neural network (DNN), support vector machine (SVM) and hidden Markov model (HMM) are, respectively, implemented to construct health states classifiers. However, the implementation of these methods both need a preset FT and the influence of uncertain initial condition is also ignored. Therefore, a new degradation prognostic approach is proposed, which takes into account initial condition uncertainty and does not need to preset a FT. Meanwhile, the residence time in different health states of the REBs can be calculated, which facilitates to formulate the maintenance strategy more flexibly.
In this paper, a novel four-step data-driven degradation prognostic approach is proposed, consisting of degradation feature extraction (step 1), degradation feature selection (step 2), offline health state assessment and degradation trend prediction modeling (step 3), and online RUL prognostics (step 4). Firstly, a series of degradation features are extracted by analyzing the vibration signals of REBs in time domain, frequency domain and time-frequency domain. Then, three indicators regarding the monotonicity, correlation and robustness are utilized to select the sensitive features. On this basis, the offline health state estimation model and degradation trend prediction model are established respectively. Finally, the above two models are combined to estimate the residence time in different health states and the RUL of REBs. The main contributions of this paper are summarized as follows:
1) A variety of degradation features are extracted by comprehensive analyses of time domain, frequency domain and time-frequency domain.
2) Different health state labels can be assigned automatically. It also eliminates the influence of uncertain initial condition on the prediction results.
3) The degradation prognostic is finished when the two termination conditions are both met instead of predefining an unreasonable FT. Therefore, the proposed approach can obtain a higher prediction accuracy.
4) With a health state estimation model and a degradation trend prediction model, the residence time in different health states of REBs can be estimated, which facilitates to formulate the maintenance strategy more flexibly.
The remainder of this paper is organized as follows. Section II shows the framework of the proposed data-driven degradation prognostics approach. Section III provides details of the four-step degradation prognostics approach. Section IV presents the verification results by using the data set from the accelerated degradation testing of REBs. Finally, the conclusion is drawn in Section V.
Fig. 2 shows the framework of the proposed data-driven degradation prediction strategy for REBs, and the two initial hypotheses of the proposed method are as follows.

Framework of the data-driven degradation prognostics strategy.
On these bases, this paper proposes a novel degradation prognostic strategy, which includes the following four main steps.
1) Degradation feature extraction. In the first step, multiple degradation features are extracted from the raw vibration signals, consisting of statistical features and nonlinear features. The statistical features are calculated by time domain and frequency domain analyses. Complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN) and Hilbert-Huang transform (HHT) time-frequency analysis are used to calculate the nonlinear features.
2) Degradation feature selection. In the second step, the optimal features are picked out by analyzing the three indicators on correlation, monotonicity and robustness of the original degradation features.
3) Offline health state assessment and degradation trend prediction modeling. In the third step, firstly, the health state labels are assigned to the unfolded 2-D optimal feature matrix automatically by the density peak clustering (DPC) algorithm, and then the features with completed labels are input into the multivariate deep forest (DF) classifier to train for getting the offline health state assessment model. Secondly, all univariate GRU networks of the selected features are combined to obtain the multivariate multistep GRU network for degradation trend prediction.
4) Online RUL prognostics. In the final step, the GRU based degradation trend prediction model is utilized to predict the feature value at the next moment, and then the health state assessment model is used to estimate the health state of the predicted value. The above two models are combined to perform multistep prediction until the termination conditions of REBs are met. Therefore, the residence time in different health status and the RUL can be obtained.
Step 1: Degradation feature extraction
First of all, moving average method and data standardization technology are performed on the raw vibration signals to eliminate the influence of noise and dimension. Then, the following two types of features are extracted from the preprocessed vibration signals respectively.
Statistical features extracted by time domain and frequency domain analyses
Statistical features in time domain and frequency domain have been widely used in the field of degradation trend prognostics for convenient calculation and high efficiency [26]. In this paper, nine time-domain features are calculated, including mean value (MV), maximum absolute value (MAV), root mean square (RMS), kurtosis coefficient (KC), skewness coefficient (SC), waveform factor (WF), crest factor (CF), impulse factor (IF), and margin factor (MF). MV, MAV, and RMS contain the amplitude change information of the signals, and KC, SC, WF, CF, IF, MF reflect the distribution of the signals. In frequency domain, the preprocessed vibration signals are converted into spectrum by Fourier transform (FT), and then root mean square frequency (RMSF) and root variance frequency (RVF) are extracted from the spectrum. RMSF can characterize position information in the main frequency band of the power spectrum, and RVF indicates the degree of energy dispersion. The specific calculation formulas of the 11 statistical features are shown in Table 1. Where i = 1, 2, …, N represents the sample points number of a preprocessed vibration signal.
Eleven statistical features of rebs
Eleven statistical features of rebs
Due to the influence of loads and external shocks, the collected vibration signals of REBs are usually nonlinear and nonstationary. In this case, statistical features are not comprehensive enough [27]. Therefore, it is necessary to extract the nonlinear features by time-frequency analysis. In this paper, time-frequency analysis of the REBs is divided into two parts: a) intrinsic energy features (IEFs) extraction by CEEMDAN and b) fault frequency features (FFFs) extraction by HHT.
a) IEFs Extraction: CEEMDAN is utilized to extract the IEFs of REBs in this paper, which can help avoid the modal mixture by adding the adaptive noise to empirical mode decomposition (EMD). It can decompose the preprocessed vibration signals into several intrinsic mode functions (IMFs) and a residue. IMFs represent the intrinsic oscillation modes in the signals. When the degradation occurs, the corresponding resonance frequency component will be generated in the vibration signals, leading to the change of intrinsic energy in the IMFs. The specific steps of the algorithm are as follows:
1) Generate a new signal with white noise
2) Perform EMD on X
i
(t) to obtain the first order IMF E1 (X
i
(t)) of each sample, the mean of which can be written as
3) The first order residue and the second order IMF are calculated as
4) The k th order residue and the k + 1 th order IMF are calculated as
5) Repeat step (4) until the residue can no longer be decomposed. The residual can be expressed as
6) Define the calculation formula of the intrinsic energy features as
b) FFFs Extraction: When the critical parts of the REBs begin to damage (e.g., outer ring, inner ring, element, cage), the shock vibration signals, which are of great value for degradation trend prognostics, will come into being in REBs [25]. HHT has high time-frequency resolution which can analyze the shock components in the vibration signals accurately. Therefore, HHT is applied to extract FFFs of REBs, and the specific steps are as follows.
1) Perform Hilbert transform on
2) The frequency f
i
(t) can be formulated as
3) The Hilbert spectral density is calculated as
4) The Hilbert marginal spectrum can be calculated as
5) Calculate the corresponding frequencies of the four components
6) According to Hilbert marginal spectrum, four FFFs can be obtained as
Statistical features, IEFs and FFFs constitute the original features of the REBs when Step 1 is finished, and a 3-D matrix X (M × J × T) can be used to represent the original feature set of all samples. M, J, T represent the number of REBs samples (m = 1, 2, …, M), the number of features (j = 1, 2, …, J), and the lifetime (t = 1, 2, …, T) of the REBs, respectively.
The irrelevant and redundant features can not reflect the degradation information contained in the vibration signals. Therefore, it is necessary to pick out the optimal features which are sensitive to the degradation process, so as to reduce the calculation cost and increase the accuracy of prediction results. According to [28, 29], the optimal degradation features should be well-correlated with item degradation processing, monotonically increasing or decreasing, and robust to outliers. Therefore, three indicators on correlation, monotonicity and robustness are adopted to obtain the optimal features in this paper.
1) Correlation Indicator: The correlation indicator can reflect the linear correlation between the features and operating time of REBs. Pearson correlation coefficient [30] is implemented to calculate the indicator and it can be expressed as
2) Monotonicity Indicator: The monotonicity indicator can reflect consistent tendency of the features [26], which can be expressed as
3) Robustness Indicator: The robustness indicator can reflect the robustness of the degradation features to outliers [31]. Smoothing algorithm is utilized to decompose a feature into a trend part and a residual part, which can be written as
These three indicators affect the rationality of the candidates together in the prognostics. Therefore, this paper defines the following weighted linear combination of these indicators as the selection criteria.
Assume that features can be retained through the degradation feature selection, the 3-D matrix X (M × J × T) of original features will be transformed into a new 3-D matrix
1) Health Status Label Assignment: The DPC algorithm [32] is a new type clustering algorithm. The core idea of the algorithm is based on two important assumptions about the cluster center points (density peak points).
In order to quantify the above assumptions, two important values ρ i and δ i are introduced.
The local density ρ
i
is defined as
The distance δ
i
is defined as
The data points with larger ρ
i
and δ
i
will be selected as the cluster centers, and a synthetical evaluation index γ
i
is defined as
Define C as the number of health state categories. Arrange the feature data points in descending order by the value of γ i and select the first C data points as the cluster centers. Then, the remaining points will be automatically assigned into the cluster of the closest data point with lager ρ i . The specific implementation of health status labels assignment is summarized in Algorithm 1.
1: Set the types of health status labels C = 4;
2:
3: Use Eq. (23) and Eq. (24) to calculate ρ i and δ i respectively;
4:
5: Use Eq. (25) to calculate γ i ;
6; Select the four density centers according to γ i ;
7; Automatically classify the remaining points.
2) Offline Health State Assessment Modeling based on DF Classifier: Based on the 2-D data
In the training phase of the cascade forest, the probability of the sample point
The health state with the maximum mean probability of leaf nodes is taken as the final output result. Algorithm 3, 12 Offline Health State Assessment Modeling Based on DF Classifier illustrates the process of offline health state assessment modeling.
1: Define the following parameters:
m _ level is the sequence of the level in the cascade forest;
n _ forests is the number of forests in each level;
n _ estimators is the number of decision trees in each forest;
v _ accuracy is the verification accuracy;
2: Initialize m _ level, n _ forests, n _ estimators;
3: Set the training accuracy t _ accuracy;
4: Input the training data into the 1 _ level to obtain the feature vector;
5: Expand the level of cascade forest, and input the feature vector obtained from the previous level to the 2 _ level;
6: Calculate the t _ accuracy of current level;
7:
8: Repeat step 5;
9:
10: Obtain the health state assessment model;
11: Calculate the v _ accuracy of the model;
12:
13: Save the DF based health state assessment model;
14:
15: Return to Step 3;
16:
3) Offline Degradation Trend Prediction Modeling based on GRU: In this part, the selected features will be input the corresponding predictors for training to realize the multistep prediction gradually. GRU is a variant of long short-term memory (LSTM) and its internal idea is similar to LSTM, so it can also overcome the problem of gradient vanishing or exploding. Compared with LSTM, GRU has one less gated unit, which can save more computational cost [34]. The GRU network structure is shown in Fig. 5.

Structure of the DF classifier.
The update of the parameters in the network can be shown as
1: Initialize the network parameters of sequence-to-sequence regression GRU;
2:
3:
4: Set time series from
5:
6: Train the GRU network based on the input and output of Step 4;
7: Calculate the value of the loss function, and adjust the model weight through the Adam optimization algorithm;
8: Save the well-trained GRU network when the network reaches convergence;
9:
10: Output the F degradation trend prediction models.
In the final step, the GRU based degradation trend prognostics model is utilized to predict the feature value at the next moment, and then use the health state assessment model to estimate the health state of the predicted value. Finally, through judging the switching of the health status, the durations of different status can be obtained. Instead of defining a FT, the RUL prognostics method in this paper is terminated when the output of GRU network is evaluated as the last state and degradation trend of one feature is constant. Detailed process of the online RUL prognostics is shown in Fig. 6.
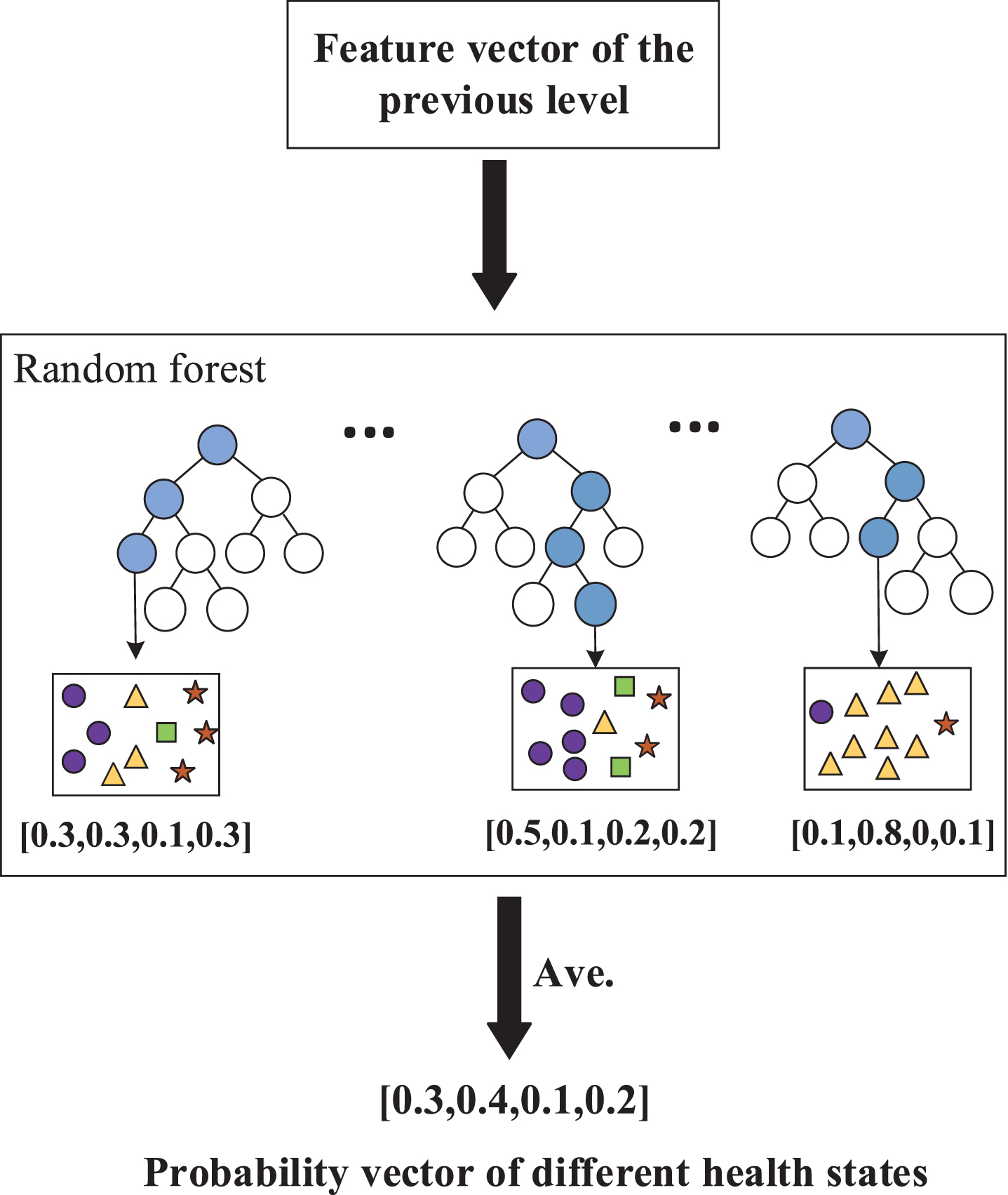
The generation process of different health states probability vector.
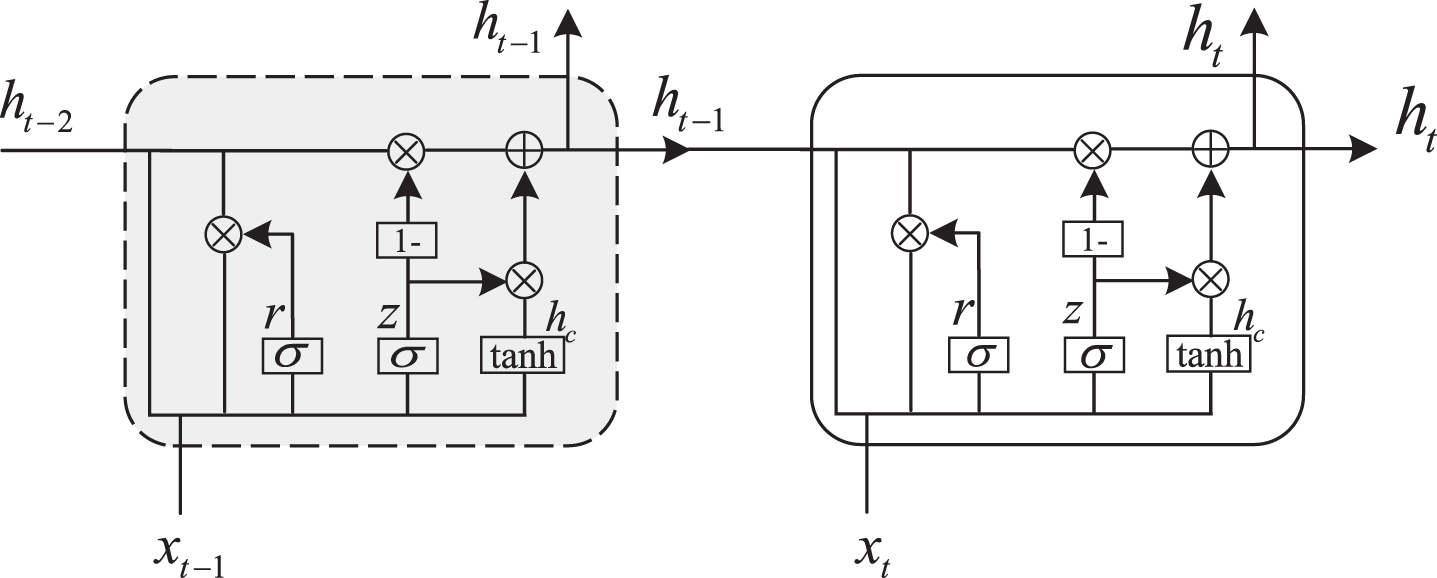
The GRU network structure.
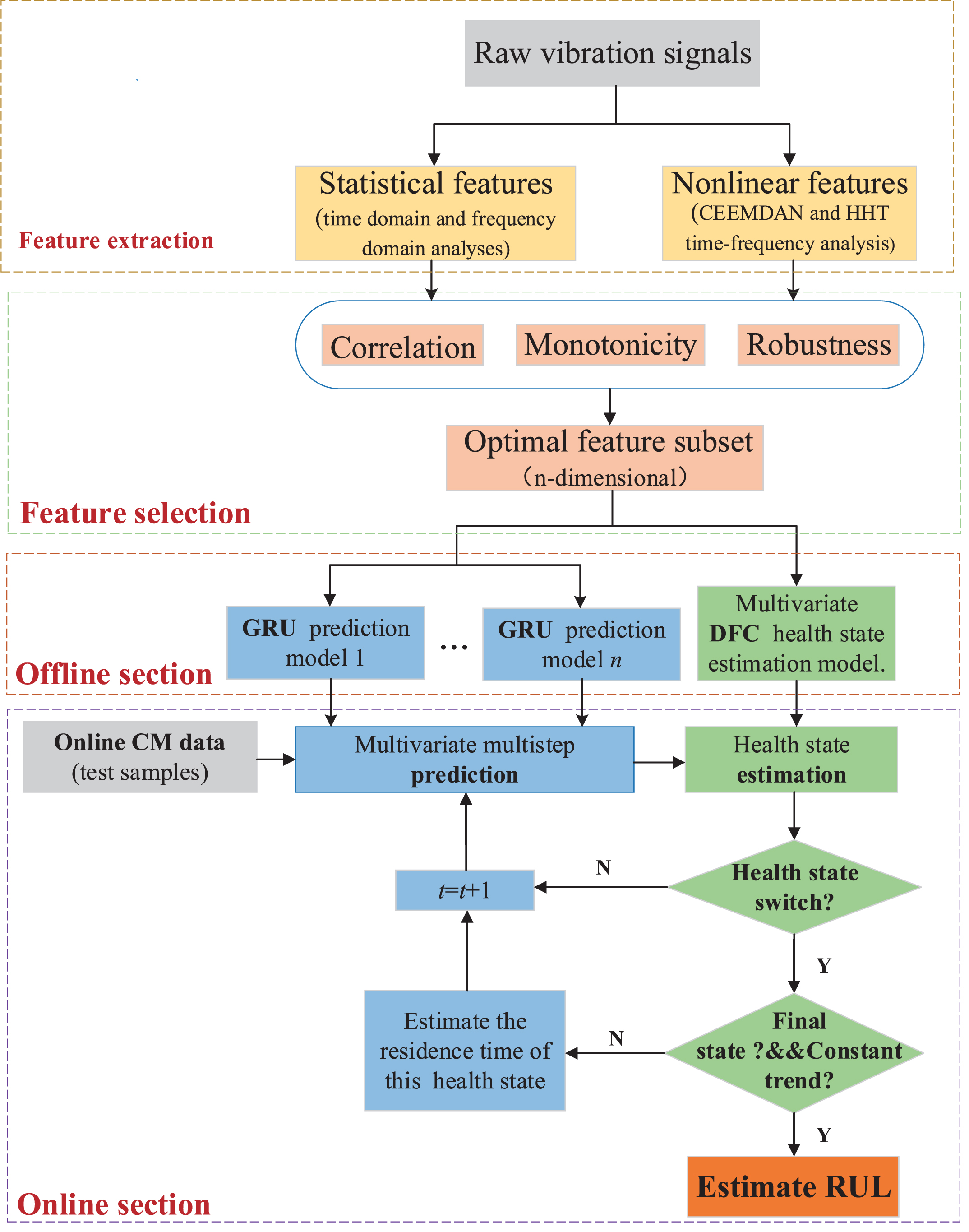
Detailed process of the online RUL prognostics.
In this paper, the error of online RUL prognostics is calculated as
Description of run-to-failure data
The aim of this section is to illustrate the effectiveness of the proposed approach with the run-to-failure datasets (XJTU-SY) [36] of REBs. The datasets were obtained from a laboratory experimental platform of Xi‘an Jiaotong University and the REBs testbed is shown in Fig. 6.
Table 2 lists the 15 REBs which are tested under 3 different operating conditions. Each condition contains 5 complete run-to-failure subsets, where, the first three subsets are used as the training dataset, and the remaining subsets are used as the testing dataset. The sampling frequency is 25.6 kHz, and 32768 samples (i.e., 1.28 s) can be recorded in 1 min. The experiment will be terminated once the vibration signal amplitude is higher than 20 g (g ≈ 9.8m/s2). The basic parameters of the tested REBs are tabulated in Table 3.
Information of the experiment
Information of the experiment
Basic parameters of the testing rebs
Moving average method and data standardization technique are performed on the raw vibration signals, and the moving window size is set 20 in this paper. Since the load is added in the horizontal direction, the accelerometer can capture more useful horizontal information. Therefore, the horizontal vibration signals are adopted for degradation prediction of REBs in this paper.
Take the training dataset REB1_1 of condition 1 as an example. First of all, 11 statistical features (F STA = [F1, F2, …, F11]) are extracted by analyzing the time domain and frequency domain signals of REB1_1. Then, CEEMDAN method is utilized to extract the IEFs as Eq. (9), that is, the preprocessed vibration signals of REB1_1 are decomposed into 12 IMFs (F IEF = [F1, F2, …, F11]) and a residue with ensemble number I = 100. After that, 4 FFFs (F FFF = [F1, F2, …, F11]) can be extracted by using HHT method. The frequencies of inner ring, outer ring, rolling element and cage are calculated to be f i = 172 HZ, f o = 172 HZ, f b = 172 HZ and f c = 172 HZ according to Eq. (17). Fig. 8 shows the Hilbert marginal spectrum of REB1_1. It can be seen that the amplitude of the FFFs change with time. At this point, there are 27 original features (F = F STA + F IEF + F FFF = [F1, F2, …, F27]) in total, the training dataset X (3 ×27 × T) and the testing dataset X′ (2 ×27 × T′) can be obtained under each condition.

REBs testbed.
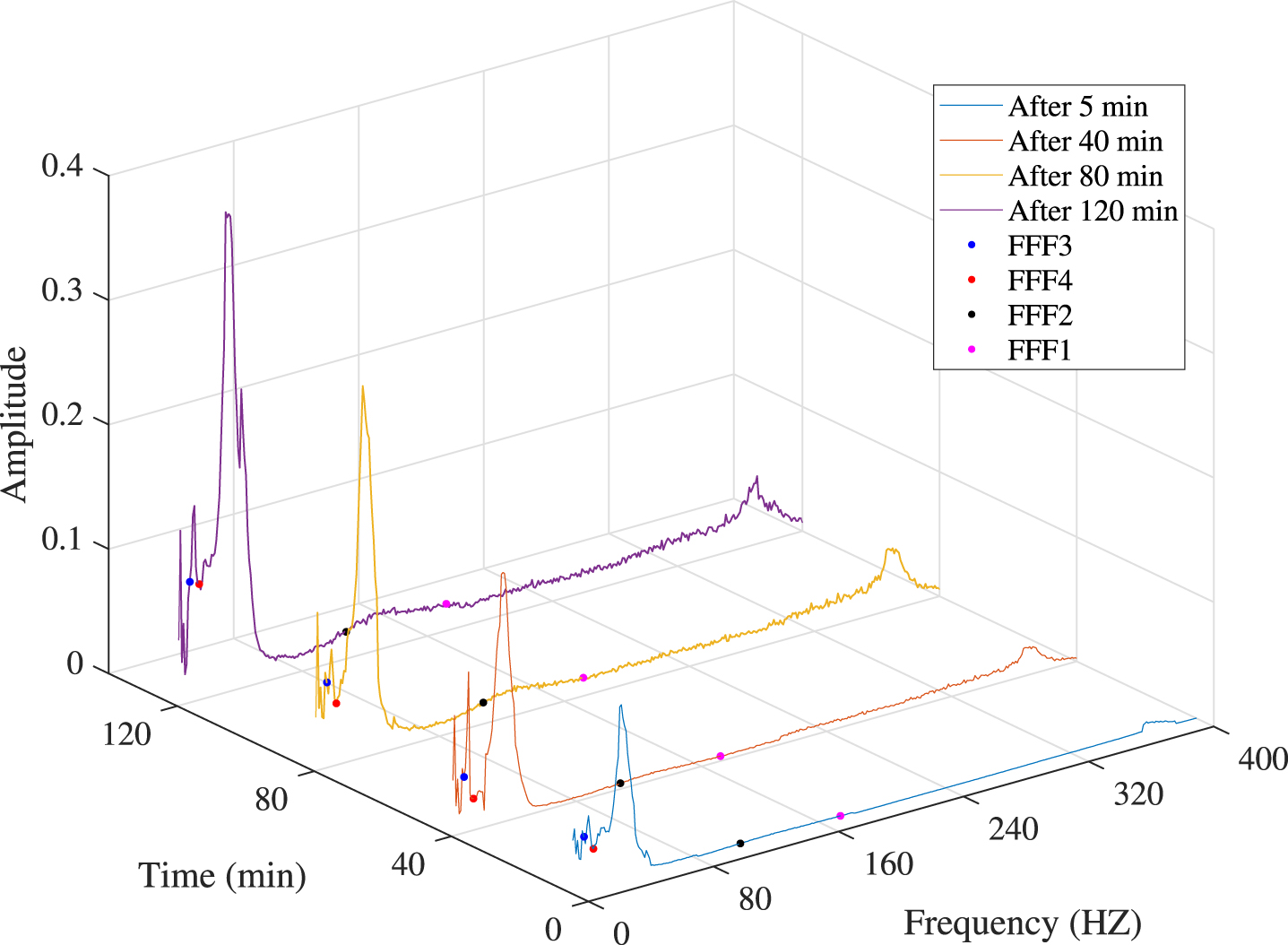
Hilbert marginal spectrum of REB1_1.
The irrelevant and redundant features can not reflect the degradation information. To increase the accuracy of prediction results, degradation feature selection is implemented in this paper as described in Section II-B. Fig. 9 shows the score of the three training bearings (REB1_1, REB1_2, REB1_3) in condition 1, which can be calculated according to Eq. (22). In this article, the features with D ≥ 0.6 are selected (Fig. 10). Thus, statistical features (i.e., KC, RMS, MF, RVF, RMSF), IEFs (i.e., IEF2, IEF3, IEF6) and FFFs (i.e., FFF1, FFF2, FFF3, FFF4) are picked out, and they are arranged in a 3-D training dataset X (3 ×27 × T).
The result of offline health state assessment
As discussed in Section II-C, the 3-D dataset
The parameters of Algorithm 3, 12 Offline Health State Assessment Modeling Based on DF Classifier are set as [33]: n _ forests = 2, n _ estimators = 101, t _ accuracy = 90. Then, an offline health state assessment model can be established. Fig. 11 and Fig. 12 illustrate assessment results of REB1_1 and REB1_2 respectively. Fig. 11(a) and Fig.12(a) are the health state labels of the REBs, and Fig. 11(b) and Fig. 12(b) are the corresponding confidence levels. It can be seen that REB1_1 and REB1_2 are in two different initial states. Instead of assuming that all REBs are in the same initial condition, the proposed method can classify the initial state accurately. Therefore,
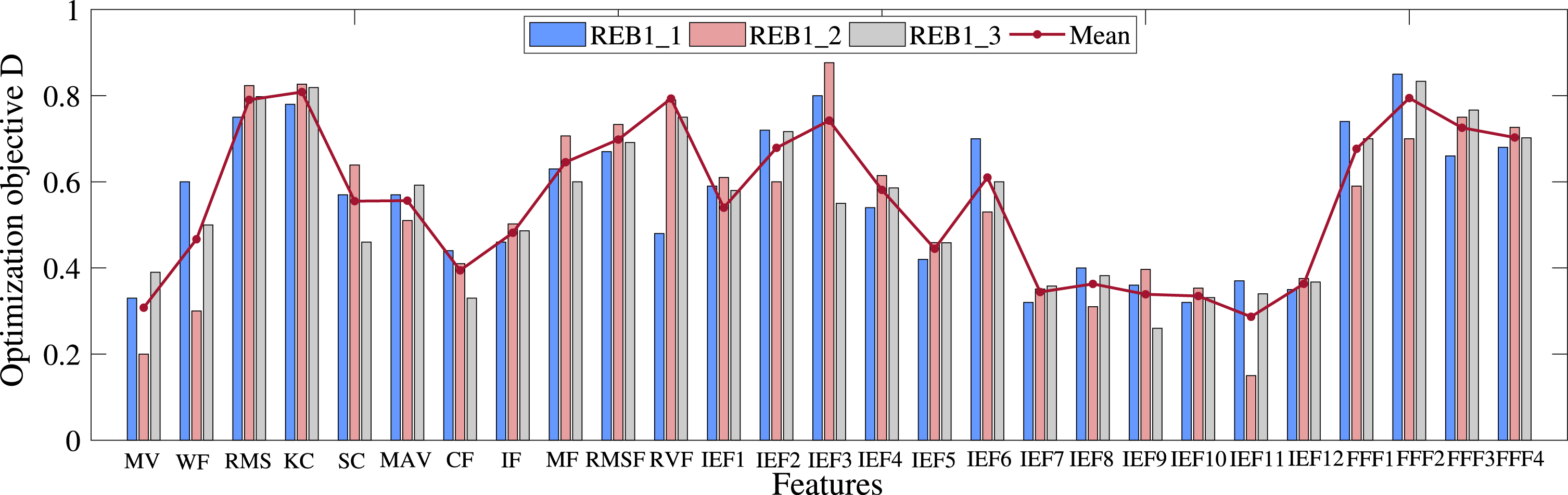
Optimization objective D of the three training REBs.

Optimization objective of original features.

Health state assessment result of REB1_1. (a) Assessment result.(b) Confidence level.

Health state assessment result of REB1_2. (a) Assessment result.(b) Confidence level.
According to Algorithm 3, 12 Offline Degradation Trend Prediction Modeling Based on GRU, 12 offline degradation trend predictors are established respectively. Then, the online RUL prognostics can be finished by combining the offline health state assessment model and offline degradation trend prediction model. Take the testing dataset of REB1_4 as an example. Fig. 13 (a)-(l) show the results of the degradation trend prediction and Fig. 14 illustrates the results of the health state assessment. The prediction starts at the 41st minute, and the actual data in Fig. 14 are not smoothed, so as to distinguish them from the prediction results. When the health state of REB1_4 changes to the last state and the degradation trend of FFF2 is constant, the prognostics is terminated. It can be calculated that the residence time of the health state, mild degradation state, moderate degradation state and near-failure are 28 min, 36 min, 13 min and 7 min respectively. The predicted RUL of REB1_4 is 78 min, while the actual RUL is 82 min. Therefore,

Results of the degradation trend prediction of REB1_4.

Health state assessment result of REB1_2. (a) Assessment result. (b) Confidence level.
Five existing methods are employed to compared with the proposed approach. The prediction errors of these methods can be calculated according to Eq. (29), which are shown in Table 4. The experimental results indicate that there is no lagged prediction in the proposed method. Moreover, the prognostics accuracy of the proposed approach is higher than other listed methods.
Prediction errors of six testing rebs
This paper proposes a novel four-step data-driven degradation prognostics strategy based on the multivariate deep forest (DF) classifier and GRU network for REBs. In the first step, multiple degradation features are extracted from the raw vibration signals, consisting of statistical features, intrinsic energy features (IEFs) and fault frequency features (FFFs). In the second step, the sensitive fault features are selected according to the monotonicity, correlation and robustness metrics. In the third step, a multivariate DF based health state assessment model and GRU based multistep degradation trend prediction model are established. In the final step, the above two models are combined to estimate the RUL of REBs. The verification results show that the proposed approach achieves good performance and has great superiority over the existing major approaches. The proposed approach takes into account initial condition uncertainty and does not need to preset a FT. Meanwhile, the residence time in different health states of the REBs can be calculated. Therefore, the proposed method is beneficial for formulating the flexible maintenance strategy of REBs. In this way, the waste of resources can be reduced in a large extent.
The research in this article assumes that the REBs have a constant working environment. However, in practical applications, the working environment of REBs may change. In the future, the REBs will be considered as a multiparameter hybrid system combining with the physics-based prognostics methods to study the RUL prediction under changing conditions.