
Abstract
Traditionally, a few activation functions have been considered in neural networks, including bounded functions such as threshold, sigmoidal and hyperbolic-tangent, as well as unbounded ReLU, GELU, and Soft-plus, among other functions for deep learning, but the search for new activation functions still being an open research area. In this paper, wavelets are reconsidered as activation functions in neural networks and the performance of Gaussian family wavelets (first, second and third derivatives) are studied together with other functions available in Keras-Tensorflow. Experimental results show how the combination of these activation functions can improve the performance and supports the idea of extending the list of activation functions to wavelets which can be available in high performance platforms.
Introduction
Seminal works on artificial neural networks were inspired by human brain models composed by inputs, synaptic connections (weights), activation functions and outputs. In a supervised approach, a first main goal is to calculate the weights such that the training error, obtained by comparing the desired output with the corresponding approximated outputs, decreases when the neural system is excited with the corresponding inputs. Moreover, a second and important goal is to get a minimal testing error. Early stopping prevents overfitting by detecting the minimal point in the test error curve. From this point of view, it imposes a subtle different approach with respect to the mathematical approximation problem, as such, where we can get the lowest training error but a weak generalization. In machine learning, is not only required to approximate but also to generalize in the best way [21].
Neural networks, as connectionist approach, use weights to store and distribute information, which provides fault tolerance that can be assumed as small variations in the weight values or noise in the inputs and, despite this, to obtain correct outputs within an acceptable range of values. Under this connectionist approach, weights seem more relevant to store and process information than the activation function which is, apparently, sufficient to define an activation threshold. In other words, there is no complex information stored or processed within the activation function since it assumes a decision task primarily. In this sense, some bounded and non-decreasing activation functions such as threshold or sigmoidal produce, essentially, the same results. When introducing a gradient based algorithm to train neural networks it is decisive to have analytical expressions and differentiable activation functions. In this sense, functions with singularities, such as threshold, do not fulfill this condition and this is a reason to consider other functions including sigmoidal (logistic), arctangent and hyperbolic tangent.
McCulloch and Pitt’s model for a neuron considers a threshold function [23], and the Perceptron’s Convergence Theorem guarantees convergence for any separable set of samples [2]. For example, for two binary inputs, there are 16 different boolean functions, and a single perceptron is unable to classify the XOR 0-1-1-0 and XNOR 1-0-0-1 output patterns since they represent non-linearly separable problems. However, a model that uses two perceptrons followed by a single output neuron has success for these cases [24]. An interpretation for the pattern “0-1-1-0” could be that a neuron is able to classify the pattern as “0-1-1-1” but as the third output is 1, the second neuron is activated to disable the former and get the right output “0-1-1-0” through the third neuron. Thus, the connections and collaboration between neurons provide data processing.
Cybenko’s Universal Approximation Theorem [8] states a mathematical support for claiming that a neural network with a single hidden layer can approximate functions with finite energy using monotone non-decreasing and bounded activation functions. This theorem presents a sufficient, but not necessary, condition to obtain an approximated solution. Furthermore, it does not directly show how many neurons are required neither how to obtain the weight values, and therefore, more than one hidden layer can be used. Typically, one or two fully connected hidden layers are available in software implementations, and the problem relies on discovering, experimentally or with heuristics, how many neurons should be used for each hidden layer. Optimization techniques based on gradient are often applied to calculate the optimal weight values [10, 12].
In deep learning, more than two layers are included, although for different purposes such as: data preprocessing, dimension reduction, feature extraction, and classification. Data preprocessing layers aim to replace the “classical” preprocessing step before the classification task, for example the Fourier transform to calculate the frequency components, and instead to use raw data and let the filtering-layer produce distinctive features. A filtering task means to convolve the input data with filters (kernels) so, this kind of layers is named convolutional [26]. Some activation functions used with convolutional layers are ReLU [30] and Leaky-ReLU [3]. Although these piecewise-linear functions are not bounded and have a singular point at zero, a justification to use them is that it is possible to derive them as piecewise which is fast and simple, since they are piecewise-linear, but a stronger reason is that they do not vanish the gradient in backpropagation algorithms. Note that these functions do not fit the unbounded condition of the Universal Approximation Theorem, and however they have shown good results in deep learning [30]. Some other functions have been proposed for deep learning such as ELU [6], GELU [7], Mish [17], and Swish, among others that involves exponential components. Particularly, Swish was proposed experimentally after testing a lot of combinations of linear and exponential components, and its performance can be higher than the original functions [22].
In this paper, motivated and supported by the wavelet theory and some previous works [4, 18], some wavelets have been included in Keras-Tensorflow [22, 27] and now they are available as activation functions. Wavelets are bases of vector spaces with short oscillations and fast decay. The multiresolution analysis states how to decompose functions via linear superpositions of translated and dilated versions of a mother wavelet [11]. Wavelets allow to analyze functions with transient elements with less coefficients (weights) than using other functions such as sine and cosine, as Fourier analysis proposes. A related approach is the Short-Time Fourier transform that aims to analyze local sections by defining an observation window, where a Gaussian window is typically preferred since it has a good time and frequency localization, according to the Heisenberg principle [25].
Certainly, the use of wavelets as activation functions is not a novel concept since there are previous works on the matter. For example, in [29] a wavelet network was presented as an alternative to feedforward neural networks, where the basic idea is to replace neurons by “wavelons". In this approach, wavelet networks are presented as a generalization of radial basis functions with one hidden layer that use wavelets as activation functions. Additionally, genetic algorithms have been applied in [20] and particle swarm optimization with gradient descent algorithms in [31] for wavelet network training. Concerning wavelet convolutional neural networks, in [13] the improvement was to replace sigmoid activations with
The rest of the article is organized as follows: Section 2 presents a study with two-input boolean functions with single neurons that considers wavelets as activation functions and also some properties are discussed. In Section 3, some experimental results are described with Keras and Tensorflow for some cases of study on images. Finally, in Section 4 conclusions and future works are presented according to the experimental results.
Wavelets as activation functions
In this section a single neuron model is studied together with the wavelet reconstruction formula as inspiration to propose the wavelet neuron model. It aims to show how wavelet activation functions may provide additional processing to synaptic connections (weights) given their fast decay, bounded and oscillatory behavior that allows to deal with transient signals, in contrast to non-decreasing and unbounded functions such as ReLU and Heaviside [5].
Although this kind of oscillatory and fast decay behavior may not be fully supported by a bio-inspiration, from an approximation point of view, the reconstruction formula for the continuous wavelet transform provides a formal and powerful mathematical tool. In this sense, given a function f(x) with finite energy, it can be written as [11]:
Specifically, for a single neuron the input X can be multiplied with W, to get an activation potential v, that is translated and dilated to evaluate the wavelet and, in this way, to get the neuron output. Also, equations (1) and (2) can be used to propose neural networks where wavelets
At this point, it is explored how wavelets can approximate boolean functions. For this purpose, consider two binary inputs (0,1). There are 16 output patterns 0000, 0001, ..., 1111 and some of them have well-known names, for example 0111 corresponds to the OR operation, 0001 is known as the AND operation, 0110 as XOR, and 1001 as XNOR.
For comparison purposes, the individual behavior of a single neuron is explored with the ReLU and threshold activation functions and then with triangular and Haar wavelets [15]. Since there are two inputs x1, x2, plus the unitary bias input x0, the input vector is X = (x0, x1, x2) and the synaptic weight vector is W = (w0, w1, w2) where w0 is the bias weight. The activation potential is:
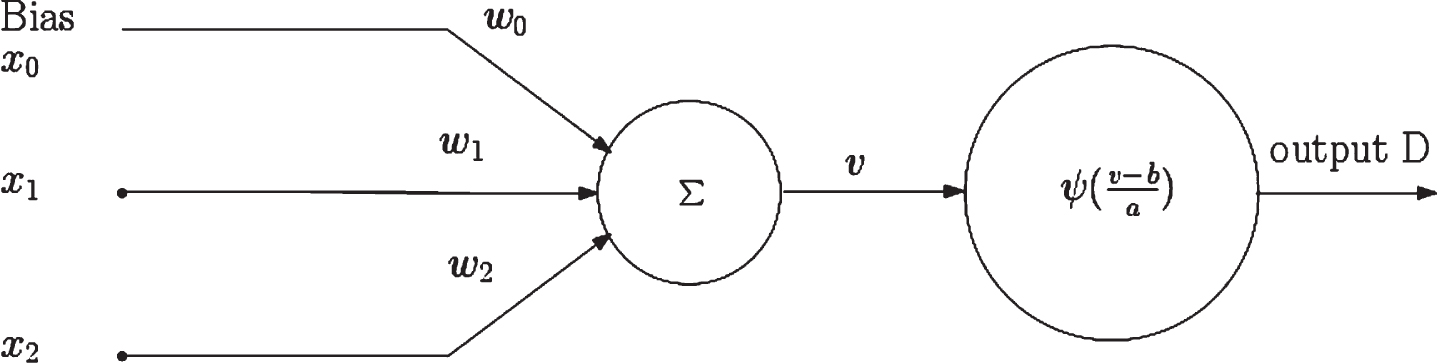
Neuron with weights, translation, and dilation parameters.
In this case, the neuron output is obtained by evaluating
The rectified linear unit ReLU function is defined as:
Parameters for 16 boolean functions optimized by a genetic algorithm using a neuron with ReLU as activation function
In the case of the threshold function H(x) as activation function, Table 1 at column 3 shows its results. It is possible to appreciate two cases (in bold) that are not fulfilled: 0110 and 1001. It is not surprising that this result is consistent with perceptron’s behavior using the threshold function when dealing with the XOR and XNOR cases, because they are non-linearly separable.
Given a function with support [0, 2] defined as:
The Haar wavelet, defined as:
By now, it has been illustrated how triangular and Haar wavelets can define different classification regions to deal successfully with boolean functions. Also, it was presented a relationship of these wavelets with threshold and ReLU functions.
In the previous section, wavelets with piecewise sections were used, and a genetic algorithm was used to optimize the parameters of a single neuron with interesting results. This section involves Keras [14] and Tensorflow [27] using ReLU, GELU, Swish and Mish functions, as well as some wavelets for data classification. In fact, three wavelets were implemented in Keras-Tensorflow as activation functions. Specifically, “Gaussian-family wavelets” have been included which can be expressed as the n-th derivative of the Gaussian function
This paper only considers the cases n = 1, 2, 3, that corresponds to the first, second and third derivative of the Gaussian function. But the same approach can be used to include more wavelets for n > 3. Their mathematical expressions are shown in Eq. (10), Eq. (11) and Eq. (13) respectively, so:
Three experiments are described and some results are discussed.
A first experiment aims to compare how the performance of a basic deep learning architecture is modified when Gaussian family wavelets of equations (12), (13) and (14) are included as activation functions. A second experiment appeals to crossfolding validation to get more evidence of the performance with a different dataset and considering more layers than those of Experiment 1. In fact, Experiment 2 deals with 5 layers architectures where the wavelets are placed in different layers. The performance of these architectures are compared with other that uses Swish, Gelu, Mish and ReLu functions exclusively or in combination. The last experiment compares arquitectures with 10 layers, both in “pure” versions or “mixed” versions of activation functions including wavelets. It led to use a nomenclature to name these combinations in a compact way with no subscripts or superscripts.
Experiment 1
The case of study is the MNIST dataset, with a training set of 60,000 examples, and a test set of 10,000 examples [1]. The optimizer method was ADAM, with 25 iterations, and Conv2D, MaxPooling2D, and Flatten layers. After the Conv2D, a Mish, Swish, Gelu, Relu,
Training: Loss values for several activation functions
Training: Loss values for several activation functions
Training accuracy for several activation functions
Testing loss values for several activation functions
Testing accuracy values for several activation functions
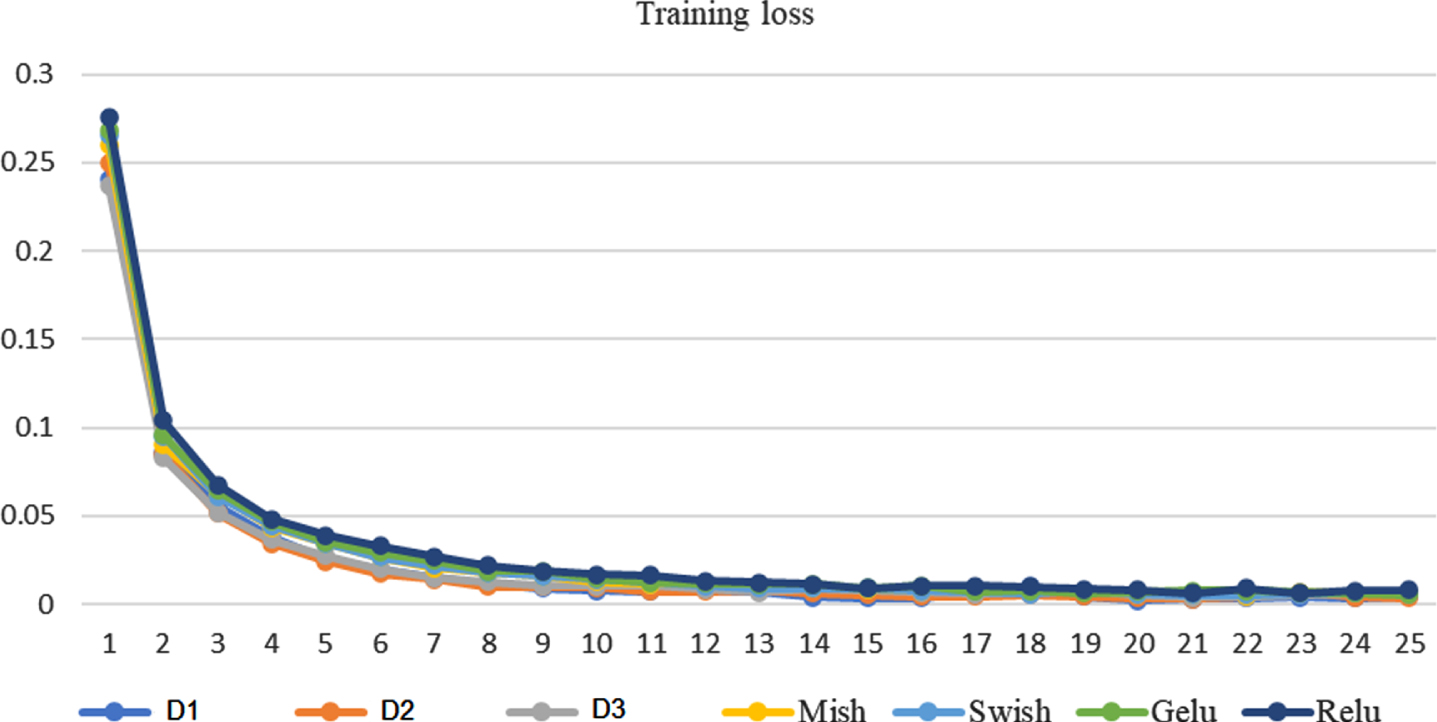
Plot training loss values for several activation functions including wavelets.

Plot training accuracy values for several activation functions including wavelets.
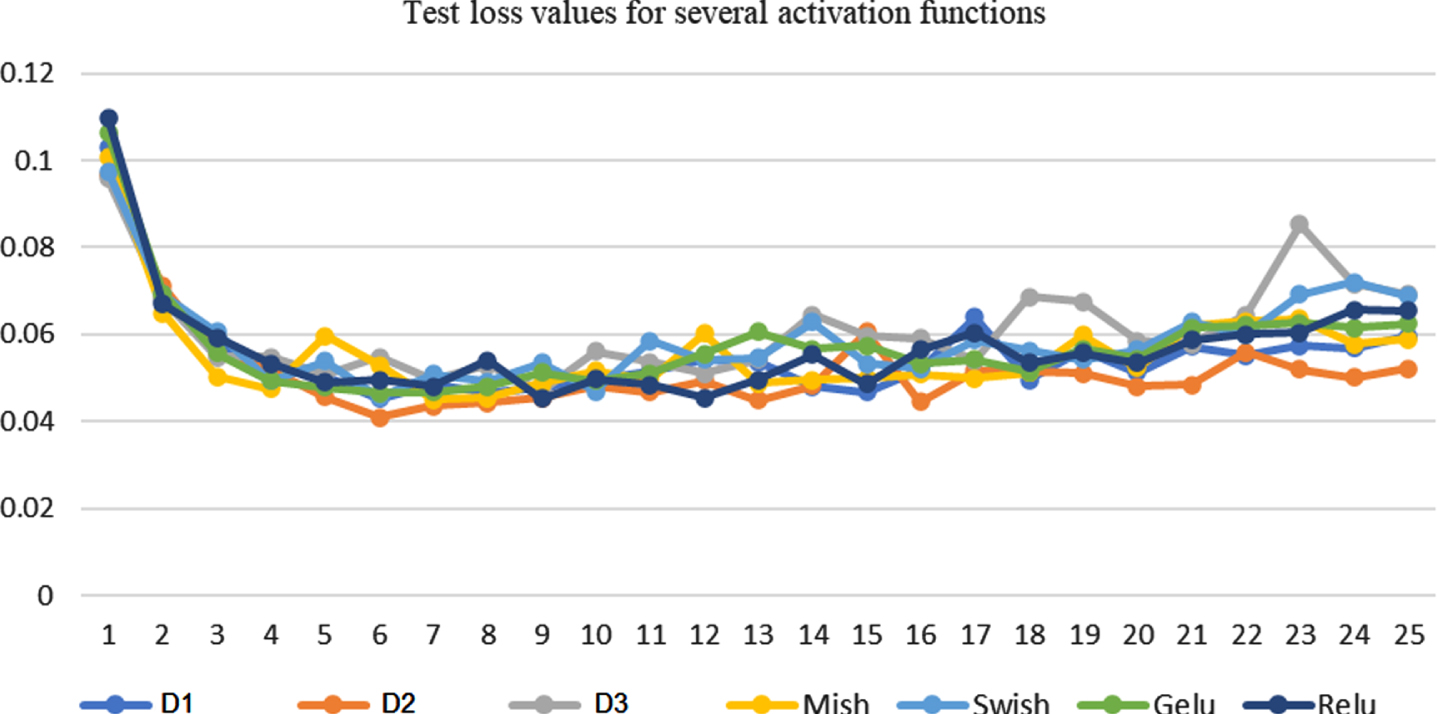
Plot testing loss values for several activation functions including wavelets.
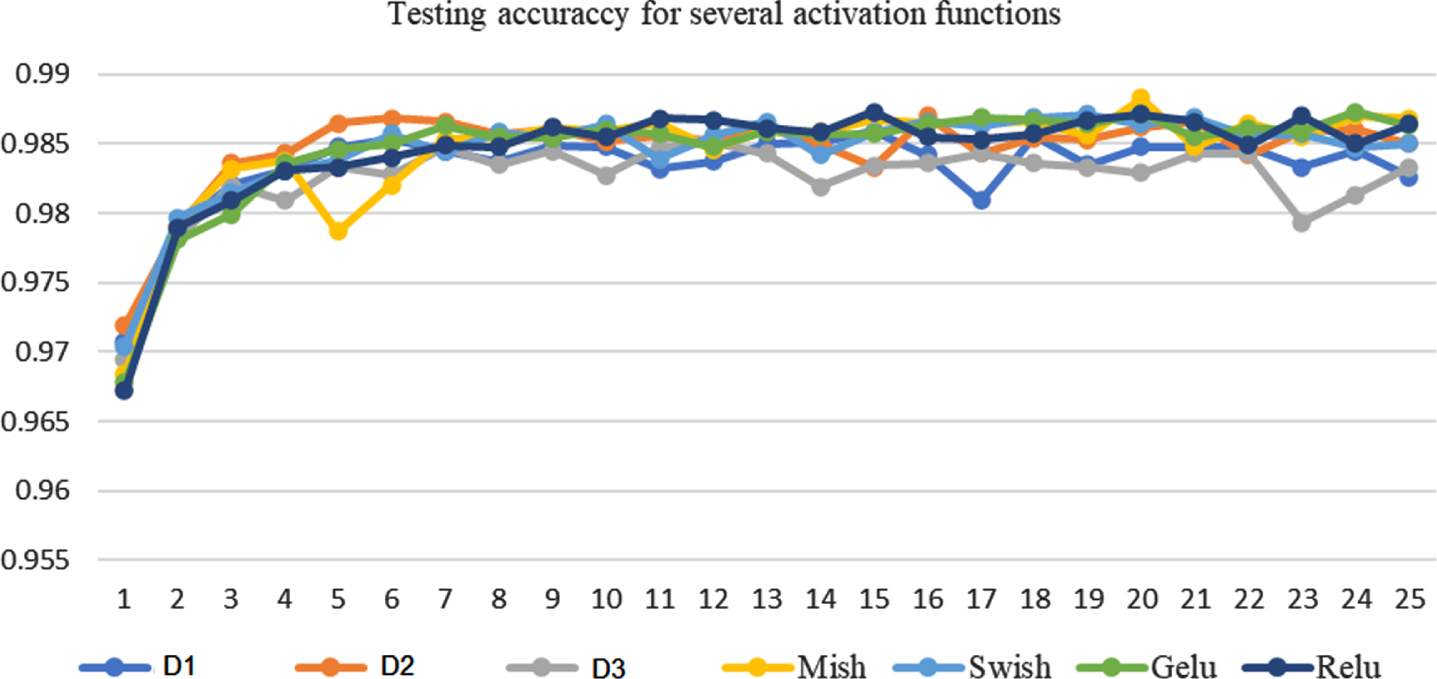
Plot testing accuracy values for several activation functions including wavelets.
Table 2 has the numerical values for training-loss metrics. Note that from the first iteration, wavelet functions have a better performance, and so they have a competitive behavior.
Also, concerning to training step, Table 3 has the numerical values for the accuracy metrics, where three wavelets achieve higher values than the functions of the last four columns. See for example the second and last rows.
Figure 3 plots the training accuracies, and it is possible to appreciate how
Table 4 has the numerical values for testing loss metrics. The lowest value 0.041 (at row 6) is first reached by the
Figure 4 shows the testing loss values, and although there is no full dominance of
Table 5 has the numerical values for testing accuracy metrics. In the first 6 iterations, the maximum 0.9868 is reached by
Figure 5 shows the testing accuracy, and although the highest values 0.9883 is achieved by Mish at iteration 20,
Figure 2 shows the training loss, and we can appreciate that
Figure 3 plots the training accuracies, and it is possible to appreciate how
Table 4 has the numerical values for testing loss metrics. The lowest value (row 6) is first reached by the
Figure 4 shows the testing loss values, and although there is no full dominance of
Table 5 has the numerical values for testing accuracy metrics. In the first 6 iterations, the maximum is reached by
Figure 5 shows the testing accuracy, and although the highest values are achieved by Mish at iteration 20,
It uses the CIFAR dataset with 60000 samples, 10 iterations and 10-crossfolding. Crossfolding was applied to get a broader perspective on the performance of the network architectures that use 5 layers: three Conv2D-MaxPooling2D layers, two Dense Layers with Swish, Gelu, Mish, or ReLU activation functions, followed by a single Dense layer with Softmax function. These architectures can be identified in abbreviated form as “5Swish: 5S", “5Gelu: 5G", "5Mish: 5M", “5Relu: 5R". When including wavelets, modified version were obtained by replacing the first activation function with
Accuracy for 10-crossfolding with CIFAR dataset and 5 layers
Accuracy for 10-crossfolding with CIFAR dataset and 5 layers
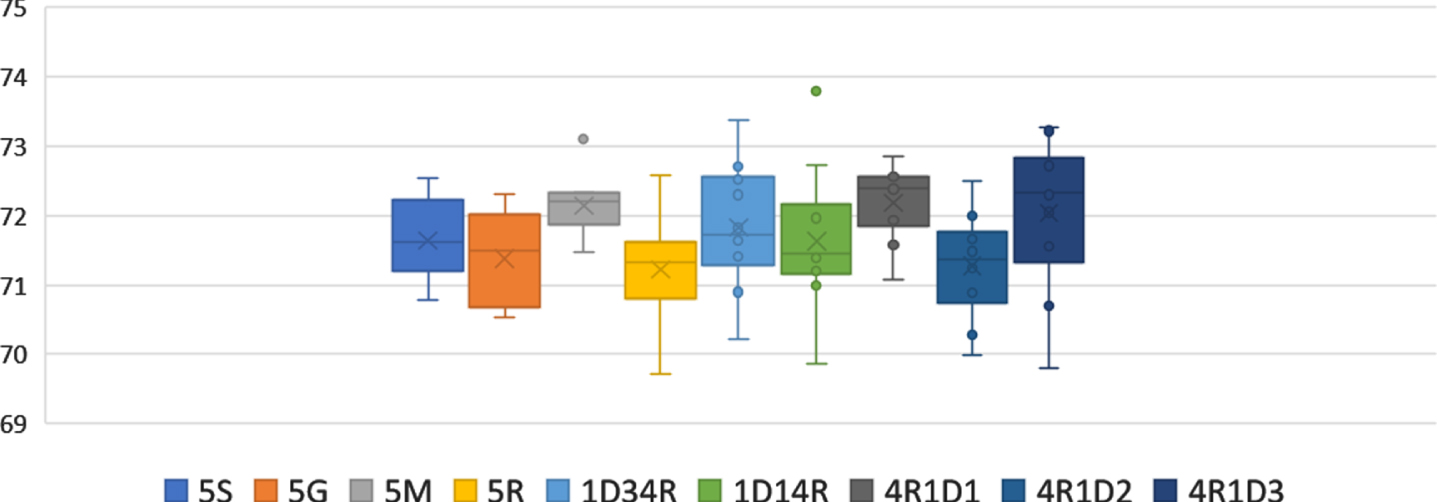
Boxplots for 10-crossfolding for several arquitectures with 5 layers including wavelet activation functions.
The most consistent case for all the 10 folds is achieved with 4 ReLU followed by
Experiment 3 considers 10 layers with 11 combinations of activation functions and an output layer with SoftMax. The naming nomenclature for each combination is an integer followed by the kind of layer: “S” is Swish, “M” is Mish, “G” is Gelu and Dn is the n-th Gaussian derivative, so for example 1D19R means a layer with first Gaussian derivative followed by 9 layers with ReLU as activation function and an output layer with SoftMax (not written). Hence, these architectures are: 1) 10S, 2) 10G, 3) 10M, 4) 10R, 5) 1D19R, 6) 1D39R, 7) 8R1D31R, 8) 9R1D3, 9) 8R1D11R, 10) 9R1D1 and 11) 4R1D35R.
Accuracy for 10-crossfolding with CIFAR dataset and 10 layers
Accuracy for 10-crossfolding with CIFAR dataset and 10 layers

Boxplots for 10-crossfolding for several arquitectures with 10 layers including wavelet activation functions.
We remark that results for D2 were not included in Table 7 and Figure 7 since its performance was relatively too low, with an average around 55%.
1D19R has a similar behavior to 10R, but it presents a minimum of 98.25 in Table 7 column 6.
1D39R reaches a higher value of 99.3 greater than 99.17 of 10R, but it has a minimum of 98.57 that is lower than 98.61 of 10R.
8R1D31R also reaches a high value equals to 99.29 and a competitive average performance, even though it has a worst case of 98.46.
A peculiar behaviour is shown by 8R1D11R ("the second best place") that preserves a consistent performance for all the 10 folds, in fact its lowest value is similar to the average performance of 10R, 10G, 10M and 10R at the first 4 columns of Table 7, and it reaches a maximum of 99.21 greater than 99.04 of Swish, 99.18 of Gelu, 99.15 of Mish and 99.17 Relu cases.
Another interesting architecture, considered as “the best” in this experiment is 9R1D1 with a minimum of 98.66, a maximum of 99.4 and a very competitive average performance. Except for 8R1D11R, it outperforms the rest of the networks and it is shown in Figure 7.
Concerning the execution time, Table 7 shows the average time in seconds required for each of the 10 folds and is shown just below each architecture name. Note that the best architecures: 9R1D3, 8R1D11R and 9R1D1 required 971 seconds, 850 seconds and 992 seconds, that are similar to 966 seconds of the case of Relu (10R) and they are lower than the time for 10S, 10G and 10M, i.e., 1117, 1287 and 1192 seconds respectively. In other words, in experiment 3, the inclusion of wavelets increases the performance and keeps a competitive execution time.
The search for new activation functions of neural networks still being an open research area. According to the experimental results, some contributions of this paper can be highlighted related to wavelet as activation functions.
Firstly, in this paper, a model neuron with translation and dilation parameters has been introduced, and several activation functions have been studied. Both types of functions: non-decreasing functions such as ReLU, unit step, and GELU were considered, as well as wavelets Haar, triangular, and Gaussian-derivatives over all the 16 two input boolean functions. An important observation is about how a single wavelet-neuron can deal with all combinations via an evolutionary optimization. It supports the idea that wavelets can model different separation regions than “basic functions". Here the term “basic functions” means that is possible to get some wavelets conceived as “composed functions", such as Haar in terms of Heaviside and triangular wavelet in terms of ReLu functions. It motivates to reflect on the importance of considering wavelets as activation functions even though they do not follow the same behavior as other widely used as activation functions.
Secondly, experimental results support the idea that activation functions may assume some part of the data processing, when using in deep learning layers, which complement the connectionist approach where synaptic weights store distributed information and provide fault tolerance. Whereas other research approaches propose activation functions supported by simplicity, derivability, easy and fast computation and non-vanishing gradients or guided by computer experiments for searching new activation functions, our approach relies on the wavelet theory.
Thirdly, three Gaussian-derivative wavelets were implemented in Keras-Tensorflow platforms and the results on an image database were executed using gradient optimization methods. Certainly, all wavelet functions do not consistently improve the performance, but some of them improves the performance when combining with ReLU and maintains high competitiveness, which promises to take up this research area for future works.
Since wavelet functions were implemented for Keras-Tensorflow, that are widely used frameworks, the applications are multiple and include all areas where deep learning is already applied. In particular, according to wavelet theory, the contributions are expected to be relevant when dealing with data having non-stationary behavior: financial time series, edge detection in image processing, speech recognition with localized and non-periodic noise, as well as anomaly detection, among other applications.
Finally, is made known that the source code to include wavelet activation functions in Keras-Tensorflow is available [19].