
Abstract
This paper describes Onto4AIR2, an ontology to manage theses from open repositories, this fosters unique and formal definitions of concepts from the Mexican repositories domain in English and Spanish languages, its goal is to support the construction of machine-readable datasets that are semantically labeled for further consultations in educational organizations. The ontology instances are sample data of theses from the National Repository of Mexico, an initiative promoted by the National Council of Science and Technology. The paper describes advantages derived from the formalisms of the ontology, and describes an assessment technique where participants are developers and potential users. Developers followed a competency questions-based approach and determined that the ontology represents questions and answers using its terminology; whereas potential users participated in a satisfaction survey; the results showed a positive perception. At present, the level of the ontology is proof of concept.
Introduction
For the National Council of Science and Technology (CONACYT), the main Mexican agency that funds research, a repository, is a centralized technological framework that complies with international standards to store, manage, preserve, and disseminate scientific, technological, and innovative information derived from educational activities, and research processes [1]. According to [2], repositories collect, index, and share the intellectual capital of faculty staff.
In a developing country like Mexico, endeavors to build repositories have been undergoing for several years like the Mexican Network of Institutional Repositories (REMERI, after the initials in the Spanish statement Red Mexicana de Repositorios Institucionales) [3], and the National Repository (NR) [4]. At the time of this writing, the NR interoperates with 107 repositories, integrates 137,927 educational resources, and has answered 19,308,572 queries; its functionality and technical requirements are specified in [1] and [5]. Technically, the NR implements the 2.0 version of the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH protocol) [6], an international interoperability standard that uses unqualified Dublin Core (DC) as the default metadata format [7]. The retrieval mechanisms of the NR match keywords from authors, titles, subjects, and dates.
By exploring metadata from repositories, specially those from theses, there are differences in the use of DC elements. As a way of illustration of the exposed problematic, the
This paper presents Onto4AIR2, an ontology to manage theses from open repositories, the goal is supporting the construction of machine-readable datasets that are semantically labeled for further consultations in educational organizations that use repositories. Onto4AIR2 is an acronym of Ontologies for All/Any Institutional Repositories, this is the newer version of the ontology described in [9], where the number 2 denotes a second version as well as two languages, English and Spanish. At present, the level of the ontology is proof of concept.
The paper is organized as follows. Section 2 contains related work. Section 3 presents the proposed ontology. Section 4 explains advantages derived from Onto4AIR. Section 5 describes the results of an assessment technique. Finally, we conclude in Section 6 with a summary of the present work along with further research perspectives.
Related work
The impact of repositories is reported in databases such as OpenDOAR [17]. Technological platforms such as Eprints [11], Digital commons [12], existDB [13], Greenstone [14], Fedora Commons [15] or DSpace [16] support a lot of open repositories. Usually, these platforms use tables to store resource metadata. This section presents related works that use semantic technologies for knowledge acquisition, data integration, and metadata management.
On one hand, for organizations that use the DSpace platform, authors of [31] propose exporting data and semantically enriched by using the OAI-PMH protocol, the OAICat library, and the Current Research Information System (CRIS). The exported data form datasets that link departments, faculties, and researchers, these links are useful to discover research leaders and common research areas. [32] describes a system that converts the DSpace database into an ontology using a normalized schema, the aim is to share information with other systems to discover common interests; the ontology obtained is integrated to other ontologies through semantic correspondence between entities. On the other hand, [33] propose an ontology-facilitated sharing to integrate repositories data, their method consists of transforming data into ontologies accessible from a unique web page.
SpecINT is a hybrid framework for scenarios where integration is not possible because there are no mapping schemes between bioinformatics repositories, this uses graph eigenvectors, vertices ranking, and existing pattern SPARQL queries to identify data sources [18].
ORDI [20] is an open-source ontology middleware that implements the Resource Description Framework (RDF) data model [19] to integrate structured data sources; this ontology processes and storages metadata and context information regardless of another specific ontologies. Authors of [21] use ontologies to integrate data resources and workflows that support online science activities (semantic e-science); ontologies represent theories, models, online tools, and means of innovation.
Semantic repositories are DataBase Management Systems (DBMSs) or other software components that store RDF data, they have inference mechanisms and provide users of real-time query-answering mechanisms. For example, OWLIM [22] is a set of semantic repositories used in the life sciences, telecoms, and publishing sectors developed as part of the Semantic Knowledge Technologies (SEKT) and Triple Space Communication (TRIPCOM) European Research Projects. OWLIM is packaged as a storage and inference layer for the Sesame open RDF framework, this has two variants: 1) SwiftOWLIM, the free version that uses an in-memory RDF database, an inference-engine, and a query-answering engine and 2) BigOWLIM, the commercial version that handles huge volumes of RDF data.
In [24], an ontology serves as a reference model for a historical organizational memory (HOM) in the business domain, this indexes the resources and use equivalent relationships to support multiple names for terms in different languages. The ontology represents document types, collections, subjects, the audience, and the dissemination channel, their main terms were gathered by interviewing experts.
In academic contexts like the Monterrey Technological Institute (ITESM), an information system, a multi-agent system, a knowledge management system, and a knowledge information interpreter that coordinates repositories, domain ontologies, and databases, compose an intelligent platform for knowledge acquisition; the repositories store theses, journal articles, research-based books, patents, technology licensing, trademarks, and documents of technology-based start-up companies [25]. Authors of [26] present an analysis of ontology-based methodologies for integrating and reconciling information and propose an agile method that minimizes the need for ontological expertise for semi-structured data; ontology instances correspond to university ranking data. In [27], ontologies represent students, teachers, monographs, theses, and the graduation process; the main terms are obtained by interviewing staff of different universities.
The Leigh University Benchmark uses ontologies to describe departments, individuals, and their relationships, LUMB(8000) stores data from 8000 universities and 1.1 billion explicit statements, while LUMB(90000) has over 12 billion explicit statements [28], both ontologies are available in the OWL language [29]. Something similar is true for the Bowlogna ontology, this contributes to the gradual adoption of the overall description of the Bologna reform across European universities, this models academic settings and administrative procedures, a graphical user interface (GUI) enables faceted search and browsing for course information [30].
Finally, the ontological design patterns that are used during the creation, verification, and validation in industrial scenarios is reported in [23].
Description of the Onto4AIR2 ontology
The construction of the Onto4AIR2 ontology implements the steps originally proposed in [35] in the Protégé editor [36], they are summarized as follows:
Determine domain and scope. The Onto4AIR2 ontology is designed to establish a common vocabulary that reduces ambiguity and enables knowledge acquisition, its potential users in educational organizations are document managers, members of evaluation committees of theses, students, teachers, directors, institutional authorities and web users. Table 1 shows the Competency Questions (CQs) that determine its scope; more information about CQs can be found in [37] and [38]. Reuse of existent vocabularies. Table 2 shows some of the vocabularies integrated into the Onto4AIR2 ontology, they are addressed to improve reusability and minimize ambiguity. Enumerate main concepts. The terms are related to the following main concepts: repositories, educational resources such as theses, persons, educational organizations, and knowledge areas. Define classes and construct their hierarchy. Once the main concepts are enumerated, they are defined as classes, then remaining concepts are obtained by generalization, and specialization. Assign properties for classes. Classes have properties, for example, see Table 4; according to the NR specifications [5], properties for a repository are mandatory (M) or recommended (R). Define properties between instances. Table 3 shows the domain and range of properties that link ontology instances; an asterisk means that a property accomplishes a facet. The notation is as follows: functional (F), inverse functional (IF), asymmetric (A), and irreflexive (I). Some of these properties are also used in [39] to describe a collection of posters. Note that: 1) the facets from the Create instances. The instances allow users to have datasets. As a way of illustration, Fig. 2 shows two theses modeled as instances of Onto4AIR2 ontology.
Competency questions for the Onto4AIR2 ontology
Competency questions for the Onto4AIR2 ontology
Vocabularies integrated into Onto4AIR2 ontology
Object properties of the Onto4AIR2 ontology
Data properties for the
Some advantages derived from the formalisms of Onto4AIR2 ontology useful for the staff of educational organizations, for example, see Fig. 3, are the following: Capacity to insert incomplete information. Examples of use: Insertion of theses or students without any scholar identifier Insertion of theses without subject Modeling persons as instances. An instance can belong to one or more subclasses of the Person class, some subclasses are disjoint while others have common elements. Examples of use: Insertion of information about university applicants An undergraduate teacher can also be a graduate student A person directs a thesis and reviews another Working with disjoint classes. The type of educational resource is unique because its subclasses are disjoint. Examples of use: An educational resource is a thesis or an article but this can not be of both types simultaneously A thesis associated with two or more types of educational resources will produce an inconsistence, that enables managers to identify automatically incorrect information
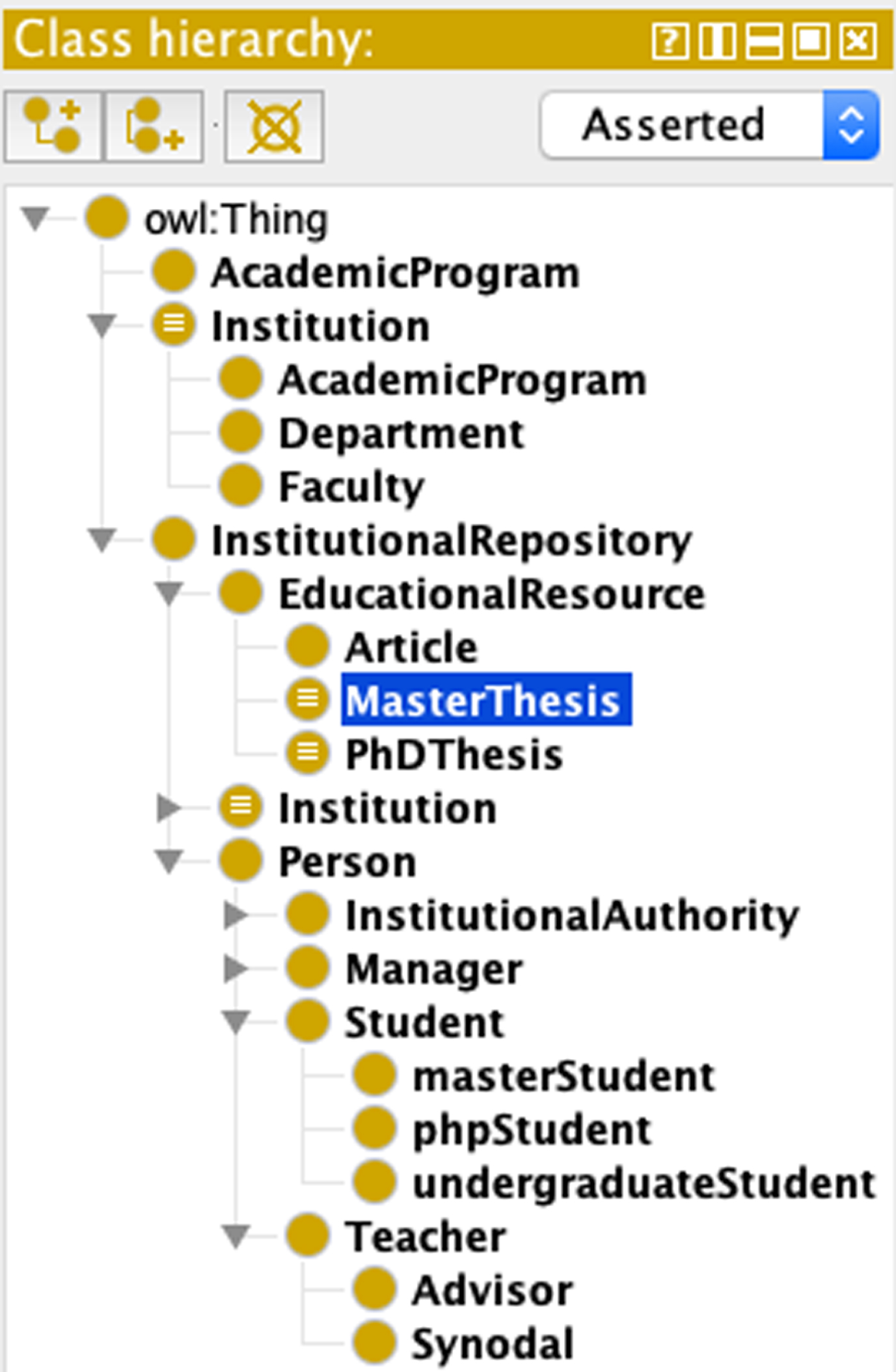
An excerpt of the class hierarchy of the Onto4AIR2 ontology.
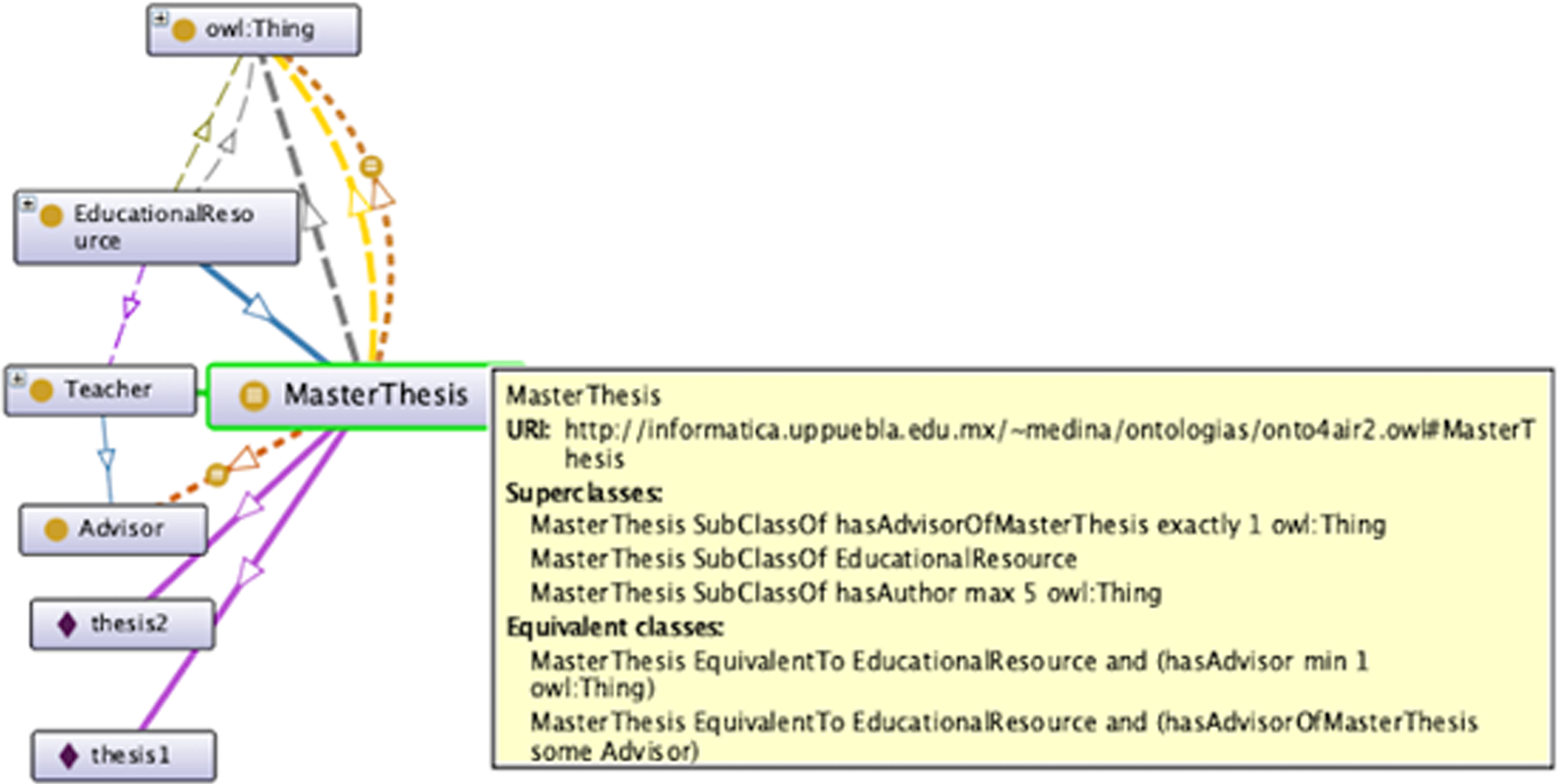
Two theses modeled as ontology instances.

Description of the MasterThesis class.
Management of cardinality restrictions. Unlike relational database schema, cardinality restrictions can have a minimum, maximum, or exact value. Examples of use: A thesis has only a first author that belongs to the An evaluation committee has exactly a fixed number of members An advisor directs a thesis An advisor collaborates or works in one or more educational organizations A thesis has exactly one title, although there can be alternative titles Data properties management. Properties between instances and data types have domain and range restrictions. Examples of use: The theses have a title and a publication date The first author of a thesis is an instance of the The members of evaluation committees are instances of the A thesis is associated with states such as registered, in process, or finished Inference mechanisms. The reasoners use universal and existential restrictions to infer new knowledge. Examples of use: A person is an advisor if there is a thesis that has been directed by him or her The members of an evaluation committee are related to at least one thesis, this activity is considered academic partnership Any thesis has an evaluation committee Functional facets. Examples of use: A student belongs to an educational organization A thesis is associated with a unique academic program
Equivalence relationships between classes support English and Spanish languages, different names for the same instance can also be used.
This section describes an assessment technique to explore the quality and relevance of the Onto4AIR2 ontology. Participants were organized in two groups: 1) managers - developers and 2) potential users.
Assessment by managers and developers
Three managers and developers experts in semantic web applications and repositories used the CQ-based approach described in [38] to verify the satisfiability of CQs, (see Table 1). As a way of illustration, Fig. 4 answers CQ1 while Fig. 5 answers CQ4, this shows the labels of a SKOS for the knowledge areas in Spanish and English languages of CONACYT, the SKOS is available at http://www.mauxmedina.com/re3/re3.html.

Definition of a repository.
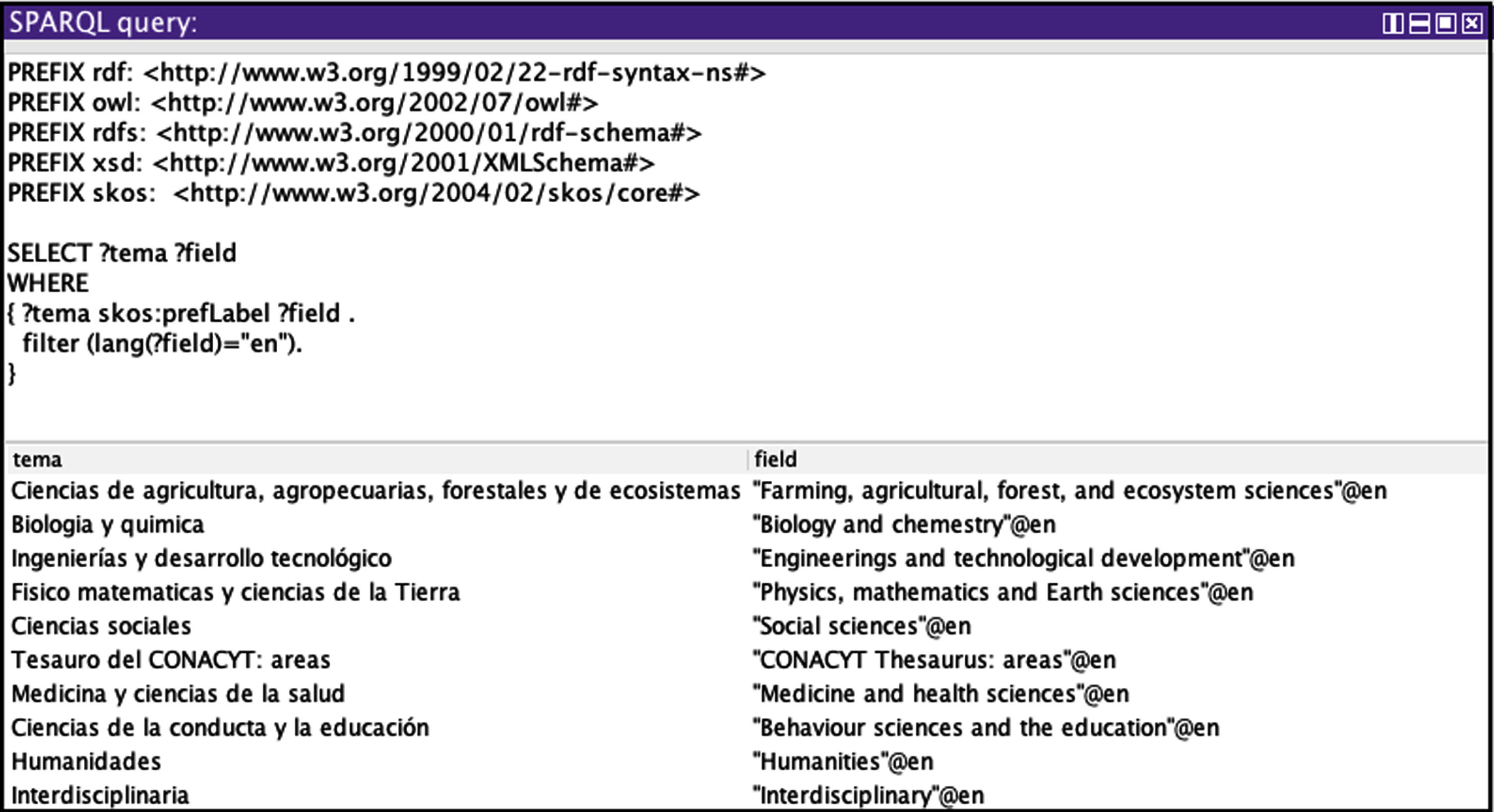
Knowledge areas proposed by CONACYT.
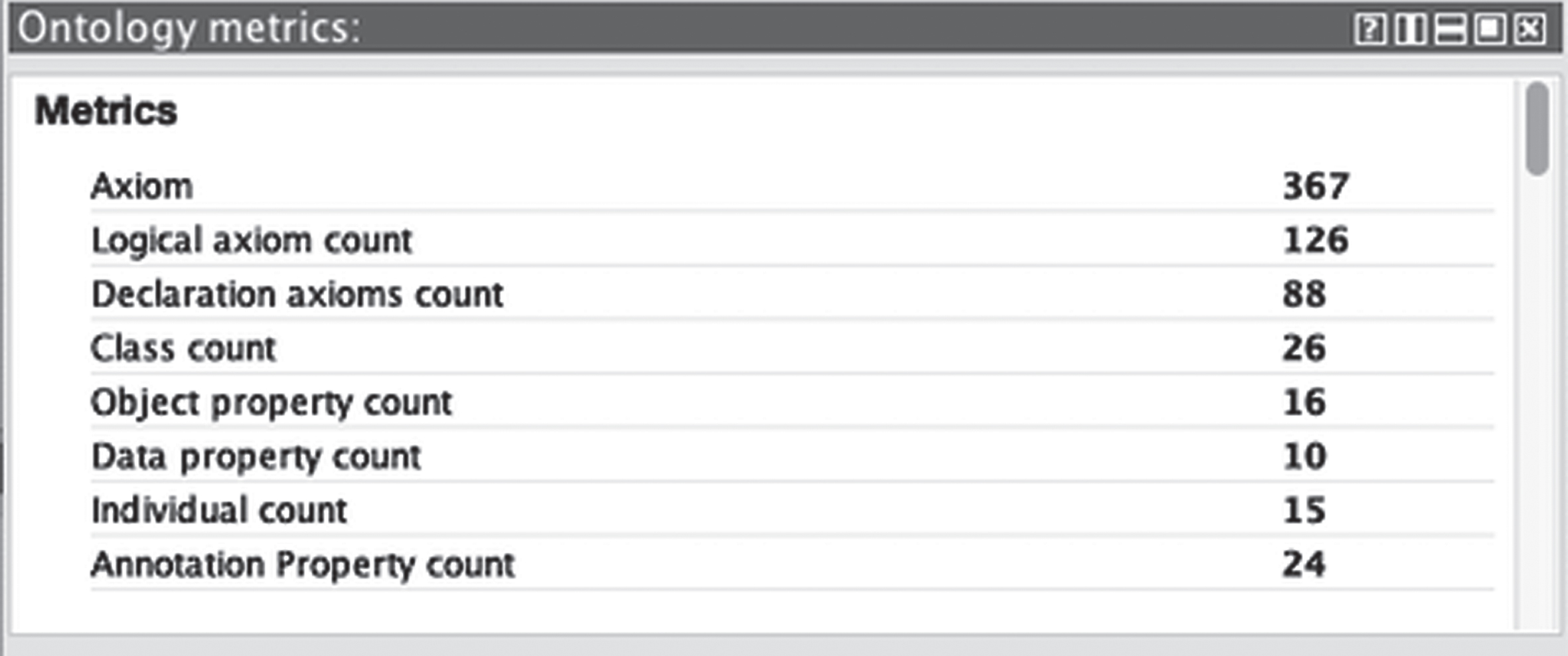
Metrics for the Onto4AIR2 ontology.
In summary, managers and developers determine that Onto4AIR2 ontology represents CQs and their answers using its terminology, they also correct all the inconsistencies detected by the reasoners Fact++ 1.6.5, Hermit 1.4.3.456, and Pellet. Figure 6 shows the main metrics for the Onto4AIR2 ontology.
A group of students and teachers selected for convenience between the potential users of our universities participated in an exploratory and self-management survey designed to gather their perceptions about the Onto4AIR2 ontology, (see Table 5). The values high, medium, and low represent the experience.
Profiles of potential users
Profiles of potential users
A questionnaire gathered information about correctness and language expressiveness, this consists of 1) by five closed questions that are showed in Table 5, with a possible answer between 1 and 5 that describes the level of user agreement, the minimum level is 1, the maximum level is 5, 2) three dichotomy questions with true or false answers depending on whether or not the user completed the task of Table 8, 3) a multiple-choice question with the options that shows Table 9, and 4) a section for suggestions.
Closed-questions of the questionnaire
Perception of users
Results for dichotomy questions
Unlike the last section, the others were mandatory. There were three days to answer the questionnaires sent by mail. Then, a manager integrated the results of closed and dichotomy questions, while the answers to open questions were analyzed by the managers and developers group during online sessions. The suggestions and comments produced newer versions of the ontology; users received the latest version and the questionnaires for a second time.
Table 7 shows the elements referred to in closed questions and the average results, (a Likert scale of five values varying from 1 = total disagree to 5 = total agree was used for this purpose). The overall average suggests the positive perception of users.
Table 8 shows the tasks referred to dichotomy questions, the answers were true or false according to task accomplishment. The incorrect answers in row 2 come from two users who only wrote the title of the thesis; for the third row, four users did not distinguish between author and co-author. The overall percentage of correct answers was 93.33%.
Table 9 shows the possible choices for the Onto4AIR2 ontology and the number of users that identified each one, additional uses were democratization and visualization of information.
Possible choices for the Onto4AIR2 ontology identified by number of potential users
In addition to the results of Table 9, the following suggestions were gathered: Include other types of persons such as designers and librarians Add Change the label of Represent other types of academic partnerships
Finally, the Net Promoter Score (NPS) was also introduced into the questionnaires that were sent for the second time to users, this is a standard question widely used to estimate users’ attitude about a tested object [40]. Users were asked for a numerical answer between 0 and 10, (minimum and maximum value); the answers between [0,6], [7,8] and [9,10] intervals are associated with a detractor, indifferent or promoter attitude, respectively. The average of the answers is considered as the final value for the tested object. The final value of the NPS for Onto4AIR2 ontology was 8.9; this value indicates a positive users’ perception.
This paper described the Onto4AIR2 ontology to represent theses from repositories. The ontology uses established vocabularies such as
Relevant related works have showed the successful use of ontologies for knowledge acquisition, integration and reconciling information in different contexts; however, information about assessment is limited.
In this paper, managers, developers and potential users participated in an ontological assessment method. On one hand, the managers and developers used reasoners for validation of logical consistency and followed a CQ-based approach, the experimental results allowed them to establish that the ontology was able to represent CQs and their answers using its terminology. On the other hand, an exploratory and self-management survey was done to gather the opinion of potential users; the results indicated a positive perception to promote the ontology.
Onto4AIR ontology represents an alternative to increase quality, reliability and reusability of data from repositories. The ontology is of utility as this gives institutional visibility, this can be adopted by other educational organizations with little adjustments such as the incorporation of new terms, object properties, rules or restrictions.
At present, we are working with the implementation of software modules to transform IR data into ontologies instances directly. We expect that our process foster the benefits of open access policies. As future work, we plan to work in the implementation of new extensions that explore potential power of automated reasoning and support data integration for later analysis.