
Abstract
The general population increasingly uses digital services, meaning services which are delivered over the internet or an electronic network, and events such as pandemics have accelerated the need of using new digital services. Governments have also increased their number of digital services, however, these digital services still lack of sufficient information security, particularly integrity. Blockchain uses cryptographic techniques that allow decentralization and increase the integrity of the information it handles, but it still has disadvantages in terms of efficiency, making it incapable of implementing some digital services where a high rate of transactions are required. In order to increase its efficient, a multi-layer proposal based on blockchain is presented. It has four layers, where each layer specializes in a different type of information and uses properties of public blockchain and private blockchain. An statistical analysis is performed and the proposal is modeled showing that it maintains and even increases the integrity of the information while preserving the efficiency of transactions. Besides, the proposal can be flexible and adapt to different types of digital services. It also considers that voluntary nodes participate in the decentralization of information making it more secure, verifiable, transparent and reliable.
Introduction
The connectivity of new electronic devices has increased in recent decades [1], the term internet of things (IoT) [2] has become increasingly popular. The general population in developed and medium-developed countries has stealthily adopted electronic devices with network connectivity, such as TVs, clocks, washing machines, refrigerators, etc. The same is expected to happen in cities as consequence of the increase of public smart devices such as traffic lights, lights, cameras, sensors, solar panels, etc. that even now the term “smart cities” [3] is also heard. This new concept for cities will promote the creation and use of devices connected to the network.
On one hand, all these devices have created a need for infrastructure and specific software that manages, validates, protects, and automates the information that is generated by them. On the other hand, blockchain has created new functionalities and ways of decentralizing information.
However, it still needs improvements so that implementation with multiple information flows is feasible. Nowadays, because blockchain has scalability problems with the speed of transactions, that is not possible. Once a transaction limit is reached, new transactions are delayed and become more expensive [4].
The governments of multiple countries have acted as a consequence of the increase in digital services, regulating some and implementing the digital services that they offer to their taxpayers to streamline procedures and reduce costs [5]. At the same time, citizens demand from their governments more and more transparency in the use of their resources [6]. For all these reasons, the information handled by the various digital services required to be secure to become reliable. Therefore, these services also require to increase their trust before the population can actively use them.
The governments of different countries have already recognized the advantages of blockchains. Some of them have already launched projects to incorporate blockchains into digital services. However, they have encountered difficulties functioning in the best way possible way [7]. That is why proposals that improve these disadvantages are required so that blockchain can be implemented and be feasible.
Therefore, a proposal of a multilayer blockchain is presented. The model has four independent layers of blockchain. Each layer focuses on a specific type of information, having the quality of flexibility to set up different governmental digital services that could use only some layers depending on the functionality they want to obtain.
This article presents the modeling of the proposal for a multilayer blockchain. The paper consists of 5 sections. This is an introduction; section 2 contains the necessary concepts for understanding modeling, section 3 includes the multilayer proposal, section 4 contains the results, and section 5 the conclusions.
Blockchain types and consensus algorithms
Blockchain is a decentralized database made up of multiple blocks interconnected by cryptographic hash from previous blocks. Its origin dates back to October 31, 2008, when Satoshi Nakamoto published the article “Bitcoin: A Peer-to-Peer Electronic Cash System" in a cryptography forum. In this paper, he proposed a distributed and politically decentralized system to send money through digital tokens. By using asymmetric cryptography, hash functions and a consensus protocol transactions can be validated by users through the same network nodes that are voluntarily connected, eliminating control of the network to a single person or organization [8].
Each node that joins the blockchain obtains a copy of the chain of blocks, being distributed in different computers, and creating a physical decentralization. Through consensus, algorithms are synchronized and updated.
The general operation of the blockchain is as follows: In a block the information to be recorded is added. In this block, the previous block’s hash is added (which must meet the characteristics of being valid). This hash creates a link with the previous block, so the resulting blocks cannot be modified. A nonce number is added, which is modified when the block’s hash is calculated (this is done when the block is extracted). Since the hash is necessary to comply with a specific structure, it is required to vary the content of the block and the nonce number until the expected result is obtained. While the block is being validated, to add more information to it is impossible (i.e. it is not changeable). Validation is done following the proof-of-work mechanism used throughout the network. This process is also known as block mining. In this validation, the nonce number is modified until the block hash meets certain specifications. This verification takes some time, depending on the difficulty of the proof-of-work mechanism used. When the block validation process is complete, the hash of that block is added to the next block, which will contain new data by then.
Any change made to a validated block will be easily detected, as the block’s hash will change completely, and thus it will become an invalid block. This will happen when the next block, which contains the current block’s hash, is validated, making any inconsistencies in the information to be detected. Similarly, the modified block will also have to be validated again, and all the blocks that appear after it.
This validation process makes the information stored in a chain of blocks reliable, given the difficulty and time required to validate the blocks in front of the modified block again.
Although blockchain emerged as a politically decentralized system, later blockchain implementations emerged that were not politically decentralized, obtaining some variants, thus generating more types of blockchain.
Types of blockchain
In general, three types of blockchain are identified. In a public blockchain, any node can join the blockchain network, download the complete chain of blocks, and even, in some cases, add its information to the blocks. Only specific computers authorized by the owner of the network can participate in a private blockchain. A consortium blockchain is when the network is managed privately but by organizations that share the responsibilities of monitoring and maintaining this network.
The main advantage of private blockchains is the high speed of transactions that you can obtain, so they are also more efficient when controlling the equipment that makes up the network. Consequently, they also use less electrical energy compared to a public type blockchain [9]. Although private blockchains can make the content of their blocks public, then content could be vulnerable by the blockchain owner since the teams that control the blockchain are in their possession. They could make changes in past blocks because the older the block, the more difficult it will be to modify it. In public blockchains, it is almost impossible to modify a past block. Therefore, the information is highly reliable, and, certainly, it will not change for the interests of some. However, to keep the network protected, it is necessary to implement a robust consensus algorithm that protects the information against possible nodes that maliciously modify the data. In the case of the consortium blockchain, it can share the responsibilities of maintaining the blockchain among the participating organizations. These shortlisted organizations determine who can submit transactions or access the data.
Depending on the blockchain type used, one can obtain different behavior in the network, making necessary to define the type of service you want to implement to choose the best one.
Once the best type of blockchain has been selected, we can ensure security on the information. The speed of transactions per second that the network can perform is another point to improve. Various proposals have emerged of different degrees of modification to the original blockchain to enhance the scalability of the speed of transactions in blockchain. The former sought to solve the problem without modifying the operation of the blockchain, one of which was to increase the size of the block by a particular percentage [10]. However, these solved the problem partially. Later, it was proposed to remove the block size limit [11], but that would generate large blocks, and only companies with large amounts of storage could be miners. This would make the blockchain network centralized. There are other modifications similar to those mentioned, and in general, between one and the other, two of the following three attributes can be obtained [12]: security, decentralization, speed of transactions. The critical part for a blockchain to define its attributes is the consensus algorithm it uses.
Blockchain consensus algorithms
The consensus algorithms were created to support group decisions, where each individual within the group participates and supports a decision that will work best among the group members. It is a form of democratic resolution in which the members support the decision of the majority. Consensus is easy when everything is going well. However, when failures arise due to various circumstances such as imperfect channels, participant drops, violation of synchronizations, or even when some may conspire so that this consensus does not occur (malicious behavior), other more complex requirements for consensus arise. This is the case on distributed systems and decentralized systems where the failures mentioned above usually occur [13].
Then, a consensus algorithm is a protocol used to agree on a single data value between distributed systems or processes. These algorithms are mainly used to achieve reliability in a network involving multiple distributed nodes containing the same information [14]. In the case of the blockchain, the consensus algorithm is the element that defines how the blocks are created, distributed, and validated [15]. Different proposals for consensus algorithms have emerged to optimize blockchain implementations depending on the properties that blockchains must maintain. More information on the characteristics of these consensus algorithms can be found in [16].
Related work
In this section some work related to the separation of functions and/or information in layers on Blockchain are presented.
Cheng and Zhang (2017) in [17] present a proposal for a blockchain-based network model to improve the implementation of IoT devices, maintaining network security by combining cloud storage protocols and proposing two types of layers: external layers and high-level layers. The external layers operate centrally as cloud servers commonly do, while the high-level layers connect to external layers and behave like connected IoT devices. Unlike the outer layer, at the high-level layer, the network is decentralized.
Badr et al. (2018) in [18] describe a multilayer model for clinical patient data, resuming the model proposed by Cheng and Zhang but reconfiguring the layers into 3 main levels. The first level for the patient’s devices and sensors, the second level corresponding to hospitals, laboratories, medical bodies, etc. The third level for centralized cloud storage.
Chang et al. (2018) in [19] propose a two-layer blockchain-based model to preserve clinical patient data and ensuring their privacy. Deep learning algorithms are added and used to ensure data distribution without sacrificing data privacy.
Zhou et al. (2018) in [20] propose a multilayer architecture from which a cryptocurrency called MOAC is implemented. The proposal maintains security, decentralization and speed of transactions using smart contract functionality through two-layer splitting. The base layer is used for storing the files and the top layer to execute smart contracts.
These proposals present models of two or more layers in which different type of layers are considered. Some divide the general model into different layers and others focus only on the blockchain layers they initially defined. All seek to improve efficiency and data privacy, some by using smart contracts others do not. All proposals are tied to a specific use case, i.e. they would not work for any other type of problem. None of the proposals add document storage functionality.
A four-layer model based on blockchain
The blocks that make up a blockchain usually contain different types of information. Examples of this information are hash values, index tables, encrypted data, transaction information, smart contracts, among others. As far as we know, the files are not stored on the blockchain. This is because the size of the blocks will increase affecting the speed of transactions [21].
The model consists of four independent and interconnected layers. Each layer stores a different type of information that is distributed on the nodes participating in such layers. In this way, each layer is ordered and specialized on the requirements given by the type of information is being stored. These layers are the following four: Layer one: Index-Keys, Layer two: Transactions, Layer three: SmartContracts, Layer four: Files.
Layer one is dedicated to store index tables, cryptographic keys and the identifiers of transactions, smart contracts, and documents. The consensus algorithm implemented in this layer is PoW (Proof of Work) [8]. The purpose of this layer is to have the most significant distribution, ensuring its availability and security. Layer two is dedicated to transaction storage. It stores the necessary information corresponding to all transactions that take place. To improve the speed of transactions, this layer is less decentralized than layer one. The consensus algorithm implemented in this layer is the PBFT (Practical Byzantine Fault Tolerance) [22]. Layer three stores all the information related to smart contracts, the consensus algorithm implemented in this layer is also PBFT. Layer four stores the files in the formats required by the application. This layer uses the IPFS (InterPlanetary File System) [23], a protocol and a network between nodes that is used to store and share data in a distributed fashion.
Layer one is the lightest and most decentralized layer, while layer four would barely be decentralized and the one with the largest block size. Layer two must be decentralized to a lesser extent than Layer one but to a greater extent than Layer three and four. In comparison, Layer three must be decentralized to a greater extent than Layer four but to a lesser extent than Layer one and two. This will be of great importance to maintain high transaction speed and enough security. The level of decentralization of the model is variable since it will depend on the layer or layers that are required to be used for certain digital services.
Depending on the service you want to mount in the multilayer blockchain architecture, four different types of information flows are possible.
The first case is the simplest. It occurs when the service does not require storing files, nor is it going to use smart contracts (see Fig. 1). In this case, the first two layers are used. The first to store the operational data of the service and the second to process and store the transactions that occur in the service. Layer one, which has the operational data, generates the required cryptographic hashes and triggers transactions in layer two, which, once processed, inform Layer one to save their respective indexes.
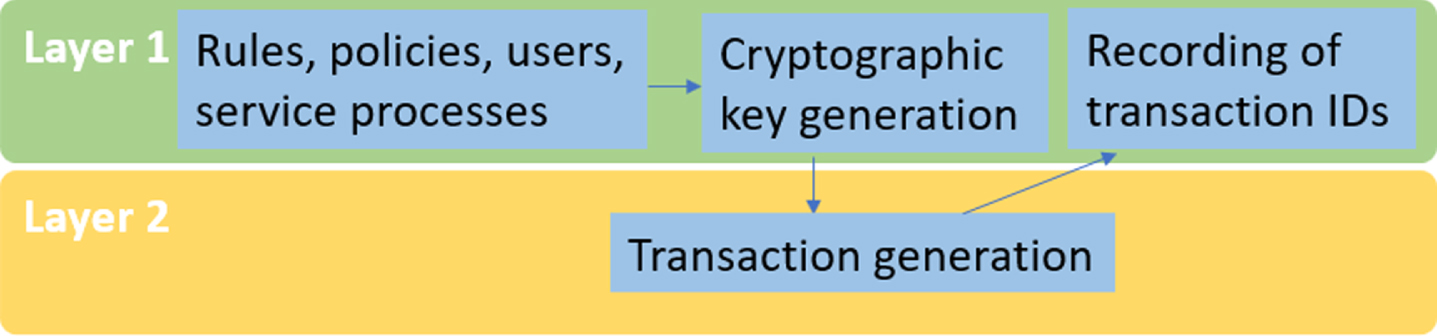
Flow 1: the first two layers are used.
The second case occurs when file storage is not necessary but smart contracts are. Therefore, layer four is not used. As in case one, layer one generates the cryptographic hashes that requires and the necessary transactions, which in turn can create smart contracts in layer three. These smart contracts then will contain one or more transactions triggered by layer two and will send to layer one its indexes to be stored (see Fig. 2).
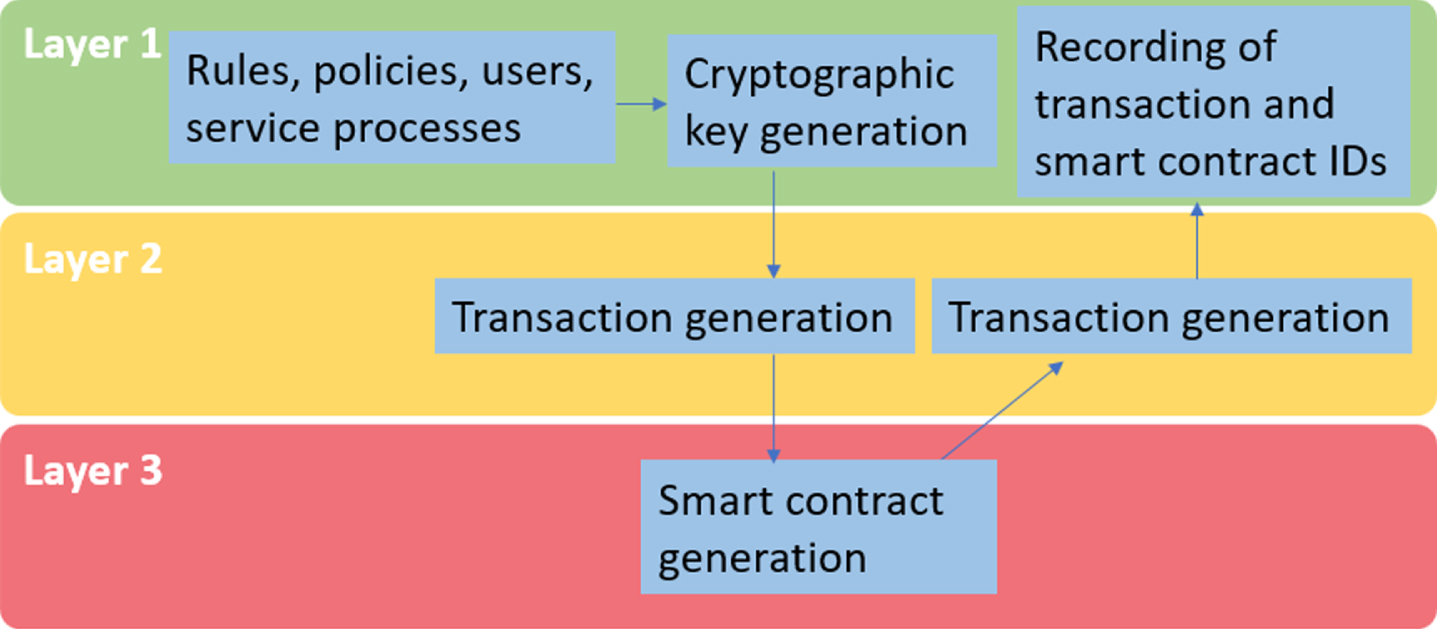
Flow 2: Layers one, two, and three are used.
The third case occurs when file storage is required, but smart contracts are not. Then, layer one again generates the cryptographic hashes to later store transactions in layer two. Once storage is completed, saves the necessary files in layer four and reports the respective indexes to layer one to also be stored (see Fig. 3).

Flow 3: layers 1, 2 and 4 are used.
Finally, the fourth case occurs when all layers are used. This happens when a service uses smart contracts and also requires file storage. In this case, layer one that contains the operational data of the service generates their respective cryptographic hashes to generate transactions in layer two. Later the necessary smart contracts are generated in layer three, where files are created to be saved in layer four. This generates one or more transactions in layer two, which respective indexes are stored in layer one (see Fig. 4).
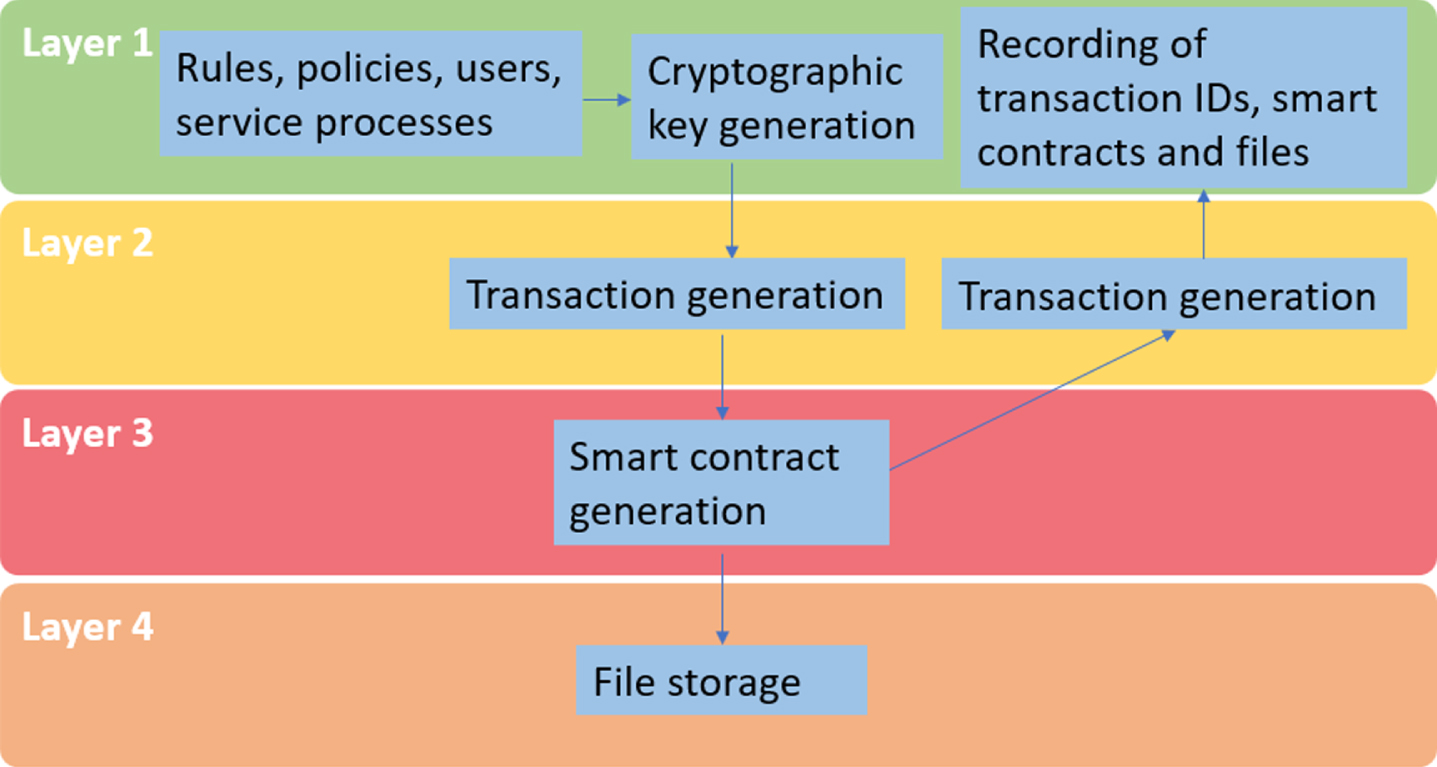
Flow 4: all 4 layers are used.
By implementing this structure between blocks and layers, the speed of transactions depends on the number of layers that the application uses. The higher the number of layers used, the lower the validation rate of the information in the blocks is. Otherwise, the lower the number of layers used, the speed of validation of the blocks will be higher.
In this section, a probabilistic analysis was performed to check the completeness and modeling of the overall behavior of the proposal is presented.
Block integrity validation
The proposal of a multilayer model represents a possible solution to the problem of trust in digital services. It allows a higher decentralization of information, and by the creation of layers, better management is carried out. In this way system efficiency due to the speed of transactions is not reduced when transactions are created by a service.
In the multi-layer architecture proposed, the integrity of the information is key and currently crucial in all systems. If data integrity is not guaranteed, to have an effective and efficient system is useless. The integrity of the information is inherited from the same original characteristics of the blockchain.
On one hand, layers two, three, and four the integrity of the information rests mainly on the trusted nodes in charge of validating transactions, since they uses consensus algorithms implementing private blockchains. The set of cryptographic techniques used in these consensus algorithms makes easy to identify when a node wants to act dishonestly, because the node must authenticate itself and through the use of hashes it is possible to detect who issued the transactions.
On the other hand, layer one uses a consensus algorithm that implements a public blockchain. In this type of blockchain, the origin of the nodes that join the network to verify transactions is unknown. The objective is that anyone who wants to participate can do it, therefore, the information is susceptible to malicious modifications. One consensus algorithm used in these type of blockchain is PoW that has proven to be strong in the face of these events. In this case, analysing how the integrity property is guarantee on PoW is important.
This analysis is taken from the work [8], where the first and most popular cryptocurrency, Bitcoin, is presented. This work concludes that it is computationally hard to maliciously modify the information contained in the blocks and later argue that that modified data is valid.
Below is the probability that an attacker will achieve honest block generation. The attack consist on a node generating an alternative chain (one that gives it some benefit) and later trying to make that alternative chain a valid one.
x is the probability that an honest node is the one who validates and adds the following block to the chain.
y is the probability that a attacker node will validate and add the following block to the chain.
y n is the probability that the attacker node reaches the chain integrates from n blocks behind.
Assuming that the computational power (and not the number of nodes) of honest participants is greater than the computational power of participants who want to modify the information to their advantage (dishonest nodes), it is verifiable that the probability drops exponentially as the number of blocks the attacker has to reach increases. With the probabilities being against the attacker, if he does not have a lucky break that gets him ahead from the start, his chances will fade as he falls further and further behind.
The time a given receiver would need to wait to be sure that a transaction is valid and will not change is obtained as follows: the sender is assumed to be a malicious node that wants the receiver to believe (at least for a while) that malicious information it has managed to add to a block (e.g. trying to spend the same token twice) will change that information at its convenience. The receiver will eventually receive a warning when this happens, but the sender hopes that it is already too late. Once the transaction has taken place, the malicious sender must hurry and secretly validate new blocks on a parallel chain containing an alternative version of its transaction. The receiver waits until the transaction has been added to the block and n blocks have been added after it. It does not know the amount of progress the attacker has made, but assuming that honest blocks have taken the expected average time per block, the attacker’s potential progress will be a Poisson distribution with an expected value:
To get the probability that a rogue node can add the last few blocks, we multiply the Poisson density for each increase in progress it could have made by the possibility it could have reached from that point:
Rearranging it:
The probability results are calculated in the first 10 blocks, in increments of 0.05 from y = 0.05 to y = 0.25 (in percentage 5% -25%), which represents the maximum probability of 25% of rogue nodes adding the following block (see Table 1).
The probability in percentage of an attacker’s success decreasing as more blocks are generated in the chain
It can be seen that in case of y = 0.05 in block number 3 the attacker has less than 1% success and the same happens in block 4 when y = 0.10, for y = 0.15 the block is number 5, while for y = 0.20 it is in block 7 and for y = 0.25 it is in block 10.
The analysis shows that although the attackers have an excellent initial probability of violating information, as more blocks are added to the chain, the likelihood of being successful decreases exponentially (see Fig. 5). For the analysis to be valid, it is assumed that the attacker must maintain his initial computing power of the attack and continue without being detected.
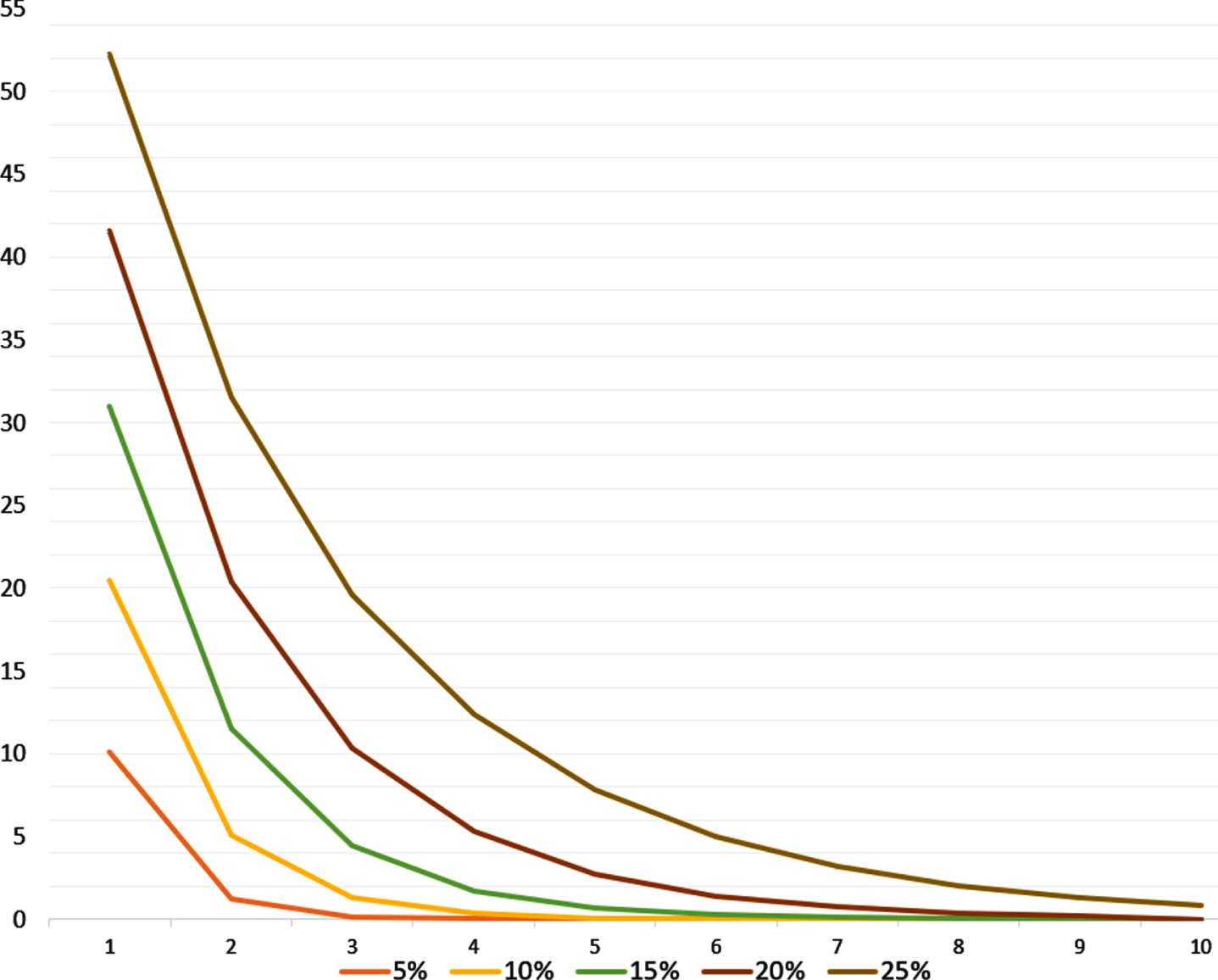
Exponential downward trend as more blocks are generated.
A well-decentralized blockchain network makes it difficult for a single node to have 25% processing power or more. Still, the calculations were made assuming that the attacker starts with 30%, 35%, 40% and 45% and the block in which the attacker would have less than 1% success would be block 16, 27, 58, and 220, respectively. Therefore, also found an exponential upward behavior to approach the 50% probability of an attacker’s success. When y ≥ 0.5 or more the integrity of the blocks is at risk since it means that half or more than half of the nodes have the greatest processing power, which is why decentralization is of great importance, to greater decentralization greater the difficulty for a set of nodes to exceed 50% of processing power.
On the other hand, it is observed that the probability that attackers with sufficient computational power, when trying to modify the information and want to make it pass as good. Should have several strokes of luck in a row and find the valid hashes faster than the other nodes to give the chain dishonest as it is correct. That time plays a role against them because as the chain grows, their probability decreases exponentially. Eventually, they will no longer represent a risk and assume that they are not detected and blocked before.
The following section establishes the definitions and properties that define the unique architecture of the multilayer proposal.
This section includes the modeling of the proposal. To do so, we will first present the notation used for it. This includes each of the elements of the model presented in 4. The main element of our proposal is a layer. Thus, we present the following definition.
In the blocks, the transactions that are generated are saved and these are defined as follows.
To control the speed with which the blocks are generated it is necessary to add the time unit, which will allow configuring the block generation speed according to the needs of the service to be used, therefore the time unit is defined as follows.
Blockchain uses asymmetric cryptography, so the nodes use a key pair. So, the keys of a node p1 are kp1 (public key) and
From these definitions, the following properties are defined. These describe the generation of the blocks and the connection between the lower layers.
The transaction rate is the ability to process different amounts of information in a given period. The greater the amount of data, difficult it becomes to maintain and reduce the time necessary for processing. That is why the transaction rate is affected by the size of the blocks. The level of decentralization and the speed of generation of the blocks, following properties refer to each of these.
In Layer one the set C1 = {x1, x2, . . . x n } such that x i are blocks that are generated sequentially every ut1 units of time.
In Layer two the set C2 = {y1, y2, . . . y n } such that y i are blocks that are generated sequentially every ut2 units of time.
In Layer three the set C3 = {z1, z2, . . . . z n } such that z i are blocks that are generated sequentially every ut3 units of time.
In Layer four the set C4 = {d1, d2, . . . d n } such that d i are blocks that are generated sequentially every ut4 units of time.
Therefore, the blocks are generated with the following temporal relation ut1 > ut2 ≥ ut3 > ut4.
These property is achieved by the consensus protocol used in each layer. Lets analyse each layer.
If C1 uses PoW as consensus protocol and has p
i
nodes, then the validation of a block xn+1 created by p1 requires: [–] In the best case, where majority of nodes agreed, [–] In the worst case, where all nodes have to agree, (p
i
) -1 messages sent by p1 to all the nodes on the layer.
If C2 uses PBFT as consensus protocol and has p
j
nodes, then the validation of a block y
j
created by p1 requires: In the best case, where majority of nodes agreed, In the worst case, two thirds of nodes have to agree,
If C3 uses PBFT as consensus protocol too and has p
s
nodes, then the validation of a block z
s
created by p1 requires: In the best case, where majority of nodes agreed, In the worst case, two thirds of nodes have to agree,
C4 does not use a consensus protocol, because it is used to store files in a decentralized way, but if has p e nodes. So only two node needs to be available among all the available nodes p e - ((p e ) -2).
As we can see in worse case
The level of decentralization refers to two aspects. First, it is the number of nodes that keep a complete copy of the information (architectural decentralization) and, second, how these copies are maintained updated. Therefore, this property depends on the consensus protocol and the type of blockchain used in each layer.
Let C1 be layer one, C2 be layer two, if x i in C1 and y j in C2 then ∀x : f (x i ) = xi+1 where f receives a block x and generates the following block xi+1 both in C1, ∃x : g (x i ) = y j where g joins a block x i in C1 with a block y j in C2. Both functions f and g generate the decentralization level dc1.
Let C2 be layer two, C3 be layer three, if y i in C2 and z j in C3 then ∀y : f (y i ) = yi+1 where f receives a block y and generates the following block yi+1 both in C2, ∃y : g (y i ) = z j where g joins a y i block in C2 with a z j block in C3. Both functions f and g generate the decentralization level dc2.
Let C3 be layer three, C4 be layer four, if z i in C3 and d j in C4 then ∀z : f (z i ) = zi+1 where f receives a block z and generates the following block zi+1 both in C3, ∃z : g (z i ) = d j where g joins a z i block at C3 with a d j block at C4. Both functions g f and g generate the decentralization level dc3.
Let C4 be layer four and d j in C4 then ∀d : f (d i ) = di+1 where f receives a block d and generates the next block di+1 both in C4. The f function generates the decentralization level dc4.
Therefore, the levels of decentralization meet the following relation dc1 > dc2 > dc3 > dc4.
If C1, C2, C3 and C4 has p
i
, p
j
, p
s
and p
e
nodes respectively, then each will have an updated copy of the blokchain. This is achieved by distributing a valid node to all the neighbour nodes. In the worst case, each node sends the validated block (x
i
, y
i
, z
i
and d
i
) to the rest nodes. If all the nodes perform the same action, the total of sent validated blocks is p (p
n
) -1.
But it is assumed that i > j > s > e, why it is best for each layer’s consensus algorithm, then
p i (p n ) -1 > p j (p n ) -1 > p s (p n ) -1 > p e (p n ) -1
therefore property 5.2 is satisfied.
The block size significantly influences the rapid distribution to all nodes, so depending on the digital service, must be configured adequate block size, but must meet the following.
Letx i inC1, y i in C2, z i in C3 and d i in C4 then the maximum size of the information contained within the blocks, has a limit such that |x i | < |y i | < |z i | < |d i |.
The block size is defined by the designer of the application. An application can decide to use PoW to include an image as part of the transaction, with all the implications in time and cost that this decision might have. In our model, each layer will store certain type of information in each block, therefore, limiting its size. C1 will store index-keys on the blocks x
i
that have a size between 0.5 MB and 1 MB. C2 will store transaction (T
i
) on the blocks y
i
that have a size between 1.1 MB and 2 MB. C3 will store Smart Contracts (SC) on the blocks z
i
that have a size between 2.1 MB and 5 MB. C4 will store files on the blocks x
i
that have a size between 5.1 MB and 10 MB.
If we take the worst case in each of out layers then 1MB < 2MB < 5MB < 10MB, therefore property 5.2 is satisfied.
With these properties, the number of blocks per layer is limited and their maximum size. In this way, we ensure the level of decentralization in each layer and the transaction rate of the blocks.
By joining these layers, the following behavior is created. Lets analyse one example in which all layers are used.
Depending on the use case, a different number of layers will need to be used. The following subsection describes the general architecture and the various instances in which not all layers are used. When a transaction request is made, the requester is checked for cryptographic keys in C1, after being validated in C2 the transaction T1 is generated, which is stored in a block y
i
+ 1, a node p
j
validates the block and is distributed to p
j
- 1 remaining nodes. If the transaction carries the instruction to generate a smart contract, the yi+1 block generates a zi+1 block in C3 where a p
s
node validates the block and is distributed to p
s
- 1 remaining nodes. If the transaction carries the instruction to save a file, the block zi+1 generates a block di+1 in C4 where a node p
e
validates the block and the file is distributed in fractions on some nodes. Finally the block indexes and hashes are stored in a new block xi+1 in C1, where the block is validated by the competition of all nodes p
i
where at the end the first one that completes the proof of work distributes it to the other nodes p
i
- 1.
If we add up together all these number, then the measures of this properties for one transaction on our complete model is: Block generation speed is high in C2, C3 and C4, in a few seconds a generated block is validated and distributed to the other nodes. In C1 the blocks would take a few minutes, until the proof of work is finished. Level of decentralization is staggered, the lower the number of nodes the less time it takes to update all nodes with the same information, being C1 the one with the highest number of nodes. Block size is an important factor to speed up the block distribution. Being C1 blocks of smaller size.
With the proposal, a transaction will be confirmed in the order of seconds, including the generation of smart contracts and possibly files saved. In addition, indexes are saved in a public blockchain copy. Contrary, if we do the same in an application based only on PoW, the transaction times would be in the order of minutes being not possible to store files or use smart contracts. In conclusion, the block distribution and confirmation times would increase considerably.
General architecture of information flows
In this section, we present the general architecture of our model, showing how the number of layers to use depends on the information created by a specific application. It makes our model flexible enough to be used in a variety of settings. To demonstrate this, we present four different information streams that represent the most common scenarios. It is essential to mention that even only these scenarios are presented, these are representative but not restrictive.
Scenario 1
In our first scenario, the application requires storing the indexes of keys and transactions, so it is not needed to store files and smart contracts. In this case, the first two layers are used. The first layer stores the operational data of the service. The second layer processes and stores the transactions that occur in the service. Layer one, which has the operational data, generates the necessary cryptographic keys and triggers the transactions in layer two, which, once processed, informs layer one to store their respective indexes. The administrator registers and configures the set of rules, policies, users, and processes of the service in a block ( The necessary cryptographic keys are generated, such as hashes (), public keys ku1 and private keys Users authorized to carry out transactions do that by signing transactions including the necessary complementary data. Therefore the transaction T
y
is generated with the minimum number of parameters, a transaction identifier ID
y
, the issuer’s signature (SenderSingX
y
), and the transaction data (Data
y
). Once the transaction is carried out, the identifier of the transaction is taken back to layer one to be stored ID
y
.
Scenario 2
In our second scenario, file storage is not necessary, so layer four is not used. Layer one generates the cryptographic keys and the necessary transactions. Layer two, which in turn will create smart contracts in layer three. Subsequently, these contracts will create one or more transactions in layer two and send indexes to be stored in layer one. As we can see, steps 1, 2 and 3 are the same as in scenario 1, therefore, these are not again presented. Some transactions from layer 2, might generate smart contracts SC
z
to automate future transactions in the services. These transactions as minimum will contain the identifier of the smart contract (ID
z
), the information of the transaction that generates it (ID (T
y
)) and the smart contract data Data
z
. Smart contracts generate one or more transactions when executed. Each of these transactions T
y
contains the previously mentioned parameters: transaction identifier (ID
y
), smart contract information (ID (SC
z
)) and data transaction (Data
y
). Once the transactions have been carried out, the identifiers of the transactions ID
y
and smart contracts ID
z
are returned to layer 1 to be saved.
Scenario 3
In our third scenario, file storage is necessary, but smart contracts are not. Then, layer one generates the cryptographic keys to generate later the transactions required in layer two. Once completed, the files are stored in layer four, and report the corresponding indexes are to layer one. Steps 1, 2 and 3 are the same as in the scenario 1, therefore, these are not presented here. In layer four, some transactions might create and store files f
d
, which parameters are the file identifier (ID
d
), information of the transaction that generates it (ID (T
y
)) and the data in the file Data
d
. Once the transactions have been carried out, the identifiers of the transactions ID
y
and the generated files ID
d
are returned to layer one to be saved.
Scenario 4
Finally, in our fourth scenario, indexes of keys, transactions, smart contracts, and files are required, so all layers are used. In this case, layer one generates their respective cryptographic keys to generate transactions in layer two later. These, in turn, create smart contracts in layer three, where files are generated and later stored in layer four. These smart contracts create transactions in layer two, which indexes are stored in layer one. Steps 1, 2 and 3 are the same as in case 1, therefore, these are not presented here. Some transactions might create smart contracts SC
z
to automate future transactions in the services. Their parameters are the smart contract identifier (ID
z
), information of the created transactions (ID (T
y
)) and the smart contract data Data
z
. Smart contracts generate one or more transactions when executed. Each of these transactions T
y
contains the previously mentioned parameters: transaction identifier (ID
y
), smart contract information (ID (SC
z
)) and data transaction (Data
y
). Some transactions might create and store files f
d
, which parameters are the file identifier (ID
d
), information of the transaction that generates it (ID (T
y
)) and the data in the file Data
d
. Once the transactions have been carried out, the identifiers of the transactions (ID
y
), smart contracts (ID
z
) and saved files (ID
d
) are returned to layer one to be saved.
As previously mentioned, the scenario that will be present in each moment of execution will depend on the service offered and the functionalities that such service is implemented.
Conclusions
The presented model can be divided into two essential parts, layer one of public blockchain characteristics and layers two, three, and four of private blockchain characteristics. In the first part, a statistical analysis is presented given the control of unknown nodes that can participate in the network. The decentralization of the information must be guaranteed so it is difficult to maliciously change such information. After reviewing the analysis performed, it should be noted that an attacker has time against him. Since its probability of success drops exponentially as more blocks are generated. The only way to win is to control 50 % or more nodes on the network, which is very difficult to do in practice.
A multilayer blockchain framework is created to deliver an efficient digital service, which decentralizes information at different levels.
After that, three model properties are formalized: (1) block generation speed, (2) decentralization level, and (3) block size. We explain how our system design meet these properties at different levels depending on the information handled by each layer.
The proposed multilayer blockchain model is sufficiently flexible, making it a generic system that can be used in differente scenarios, guaranteeing security, trust, and transparency.
Layer one nodes are decentralized, enabling the participation of nodes that want to join, which allows the validation of the blocks to be more reliable. An opportunity opens up using multilayer blockchain in IoT functionalities. For example, in smart cities where they can be interconnected with the smart contracts that the blockchain makes possible by automatically validating and executing the warrants. We appreciate the support to CONACyT with scholarship number 701979 and UNAM-PAPIIT (TA101021).