
Abstract
Artificial music tutors are needed for assisting a performer during his/her practice time whenever a human tutor is not available. But for these artificial tutors to be intelligent and fulfill the role of a music tutor, they have to be able to identify errors made by the performer while playing a musical sequence. This task is not a trivial one, since all musical activities are considered as open-ended domains. Therefore, not only there is no unique correct way of performing a musical sequence, but also the analysis made by the tutor has to consider the development level of the performer, the difficulty level of the performed musical sequence, and many other variables. This paper describes an ongoing research that uses cascading connected layers of symbolic processing as the core of a human-performed error identification and characterization module able to overcome the complexity of the studied open-ended domain.
Introduction
Musical sequences are the standard means for communication with the musical language, just as phrases or sentences play the same role in a natural language. A musical sequence or sequence of musical phenomena has time, tonality and tempo information embedded, as well as a set of dynamics and timbral specifications [13], but above all it carries semantics. The semantics of a musical sequence always maps to emotions, and regardless of the type, complexity, and intensity of the communicated emotions, a sequence of musical phenomena is always needed because individual sounds, chords or even arpeggios alone are incapable of conveying such a complex message. Music is indeed one of the most intriguing activities of human intelligence.
Our current scientific understanding of the human brain is still insufficient to fully explain its behavior when engaging in musical activities (i.e. hearing, learning, composing, performing, etc.). Even short and long term memory responses seem to operate different in musicians and non-musicians [7]. But recent research with Event Related Potential graphs (ERP) has clearly shown some behavioral patterns in response to stimuli sequences [5]. Those patterns very much resemble the brain response when stimuli are phrases in natural language. The cognition process of determining the semantics of a stimuli sequence exhibits steady electrical brain activity when faced with a semantically correct natural language phrase. Nevertheless, it also exhibits a significant negative electrical response to a semantically incorrect phrase [6, 8]. Apparently, the brain’s response to musical sequences follows a very similar behavior [5, 9] even though the semantics of a musical sequence is much harder to specify.
Even in the presence of all the above limitations it seems clear that understanding the structure, attributes and relevance of musical sequences, as well as acknowledging the complexity and expressiveness of music notation enables us to understand the role of a human music teacher during the teaching-learning process, and in doing so, it allows the identification of the essential characteristics that an artificial music tutor must exhibit.
However, musical activities are open-ended domains [3] where, despite the presence of a universally accepted symbolic language, the semantics of such language is subject to interpretations, experience-related bias and emotional states. Moreover, in an open-ended domain there are never correct or incorrect solutions for a task. Consequently, in such a domain there is no easy way to formally define problems, and no exact way to test an agent or assess an answer. This scenario has posed serious obstacles for the development of artificial intelligence tools for the music domain [1], and has led some researchers to think that the pattern extracting and learning capabilities of connectionist models could help to overcome some or all of these obstacles. In this research we adopt a strictly symbolic approach and argue in favor of symbolic processing as an adequate means for dealing with the imprecision and open-endedness of the musical tasks domain. An important characteristic of the symbolic processing proposed herein is that it is structured as a sequence of symbolic processing layers, each of which has its own objective and solves a different part of the whole task. Also, each layer takes the output of the previous layer as input, in some sort of deep symbolic processing architecture.
This paper describes the ongoing construction and testing of a human-performed error detection and characterization module that is proposed as part of the core for future intelligent music tutors capable of assisting a student when learning to play a (monophonic) musical instrument.
Related previous works
Much in the state of the art research related to musical sequences (sometimes referred to as melodic sequences) points in two main directions: 1) sequence similarity measurement, and 2) pattern discovery and extraction. On one hand, the problem of defining and measuring the similarity between two musical sequences is commonly studied as part of a much bigger context related to plagiarism and copyrights [10–12], but it can also be a core part in automatically learning the particular composing or performing style of a human musician [16–18]. On the other hand, pattern discovery and extraction within musical sequences is a very general problem with applications in music-generating systems [15–21], content-based retrieval [19, 22], and automatic music transcription [20, 23]. However, research aimed at designing and/or constructing artificial tutors in the music domain is more scarce. Much effort is placed on the teaching of singing and folk music because of the social and intercultural consequences of that knowledge [26, 27]. But when available, this type of research focuses on constructing software tools that operate within a well defined and heavily restricted domain. Depending on the application area, these tools present the student with some previously organized exercises and carefully constrained task environments. Also, they restrict their analysis of the student’s solution to finding some discrepancies with a pre-programmed model of the solution [24]. In other words, these applications do not deal with the open-endednes of the activity they intend to tutor [4].
Conceptual and theoretical framework
A musical sequence is an ordered list of symbols representing musical phenomena. A musical phenomenon is either a sound corresponding to any of the twelve semitones in the chromatic scale, or a silence. Both, sounds and silences can last for any valid duration, and sounds can be placed in any pitch octave within the sound range of a specific instrument (i.e. its tessitura or tessiture).
Musical notation is a symbolic language used to represent musical phenomena played with instruments or sung by the human voice. Computationally, this notation can be considered as a semi-formal language because, although its syntax is unambiguously defined, its semantics is highly ambiguous [14]. Part of the reason for the ambiguity of this language lies in the fact that, with the exception of tones, all other musical attributes (duration, intensity, pace, etc) are specified with categorical labels instead of mathematical quantities. Therefore, in a strict sense, it is not adequate to consider musical symbols as well grounded symbols. Although during the last century, the habit of describing the tempo of a sequence in beats per minute (bpm) was widely popularized, many other aspects of musical performance remain subject to the performer’s personal interpretation. Among the main conceptual proposals in this paper, such bpm specification can be used as the sole grounding anchor for analyzing and assessing human performed (monophonic) musical sequences without violating any due flexibility in the semantics of the language. In order to adequately solve this task, we carefully slice the analysis process into delimited layers, each one with a clear analysis goal of a concrete aspect of the performed musical sequence. Once the various aspects of the performance are analyzed, the final assessment process (not addressed in this report) can adopt the structure of an expert system, deciding the performance errors to be reported to the performer, as well as the corrective actions to be suggested, based not only on a performance analysis, but also on the experience level of the performer, the difficulty level of the sequence, and any other available and relevant piece of knowledge.
In this research we assume that the module proposed herein will fit into the architecture of a (future) intelligent tutor composed by the following modules [2]: An interactive user interface. A domain model knowledge base. An error detection and characterization module. A recommendation system. A student model knowledge base. A user profiling and management module.
Since the level of rigor or severity for the analysis and assessment process must be configurable, it is of the utmost importance that all layers are human-interpretable so that programmers and users can understand their behavior and output. Therefore, all processing layers operate in a strictly symbolic fashion, where each symbol and operation has unambiguous semantics and thus can be explained and traced back. Even the first layer, whose goal is to translate the acoustic information of the performed sequence into a symbolic intermediate language, operates in the same way by computing a chromagram of the acoustic signal. Since the initial problem statement guarantees that the sequence intended for recognition is strictly monophonic, there is no need at all to include connectionist elements in the first layer, the computation of a chromagram is enough for the intended purpose [25].
Taxonomy of errors
As the proposed module has the goal of identifying errors made during a musical sequence performance, it seems prudent to first make the type and nature of the errors sought clear. One of the guiding principles during this research has been the emphasis on analyzing musical sequences, as opposed to just musical sounds. In musical terms this means we are aiming at detecting solfège errors (i.e. the performer’s ability to correctly read music and perform what is written). But also, since the global task pursued is to tutor the performer in his/her learning process of playing a musical instrument, there is an obvious need to consider mechanization errors which are highly dependent on the specific instrument played.
In order to assess the correctness, usefulness, and generality of the reported module, we have implemented a study case for transverse flute. This wind instrument complies with the monophonic restriction, and at the same time it presents a set of interesting challenges, such as characterizing the effects on sound that can be induced by a poor insufflation technique by the performer. Fig. 1 shows the taxonomy of currently considered errors.
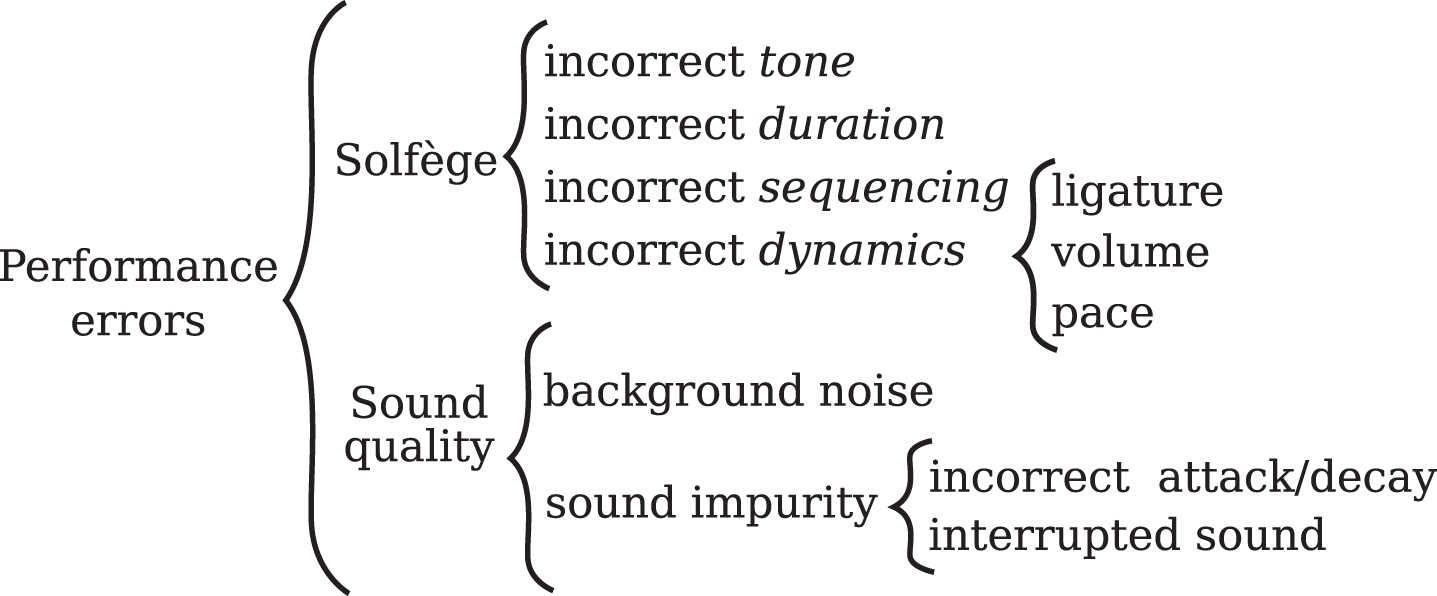
Taxonomy of considered performance errors.
Solfège errors are those related to the reading and execution of a musical sequence independently from the musical instrument played. Along the performance, some notes may be misread or misinterpreted (tone error), and both notes and silences may last longer or shorter than intended (duration error). Some musical phenomena may be out of sequence (sequencing error) if the performer does not adequately read or follow repeat signs (such as da capo or dal segno) or breathing signs (for wind instruments). Lastly, the performer may ignore or misspell some dynamic marks as crescendo or piano-forte (dynamic errors).
Sound quality errors, on the other hand, are related to the mastering level of the musical instrument. In some musical instrument families if a sound is incorrectly emitted it may appear as a non-musical sound (background noise error) or as a series of very short sounds indistinguishably separated (excess vibrato error). Also, it is a common situation that the lack of experience of the performer leads him/her to an abrupt attack or decay of a note (incorrect attack/decay error).
The core of the proposed module is structured as a sequence of five symbolic processing layers, each of which has a distinct goal and solves a different part of the whole processing task. Most important, each layer has its own flexibility criteria, and the accumulated effect of those criteria is what brings the intelligent aspect of the proposed module by closely reproducing particular aspects of the human behavior. An overview of the proposed symbolic processing architecture is shown in Fig. 2, and following is a detailed description of each layer.
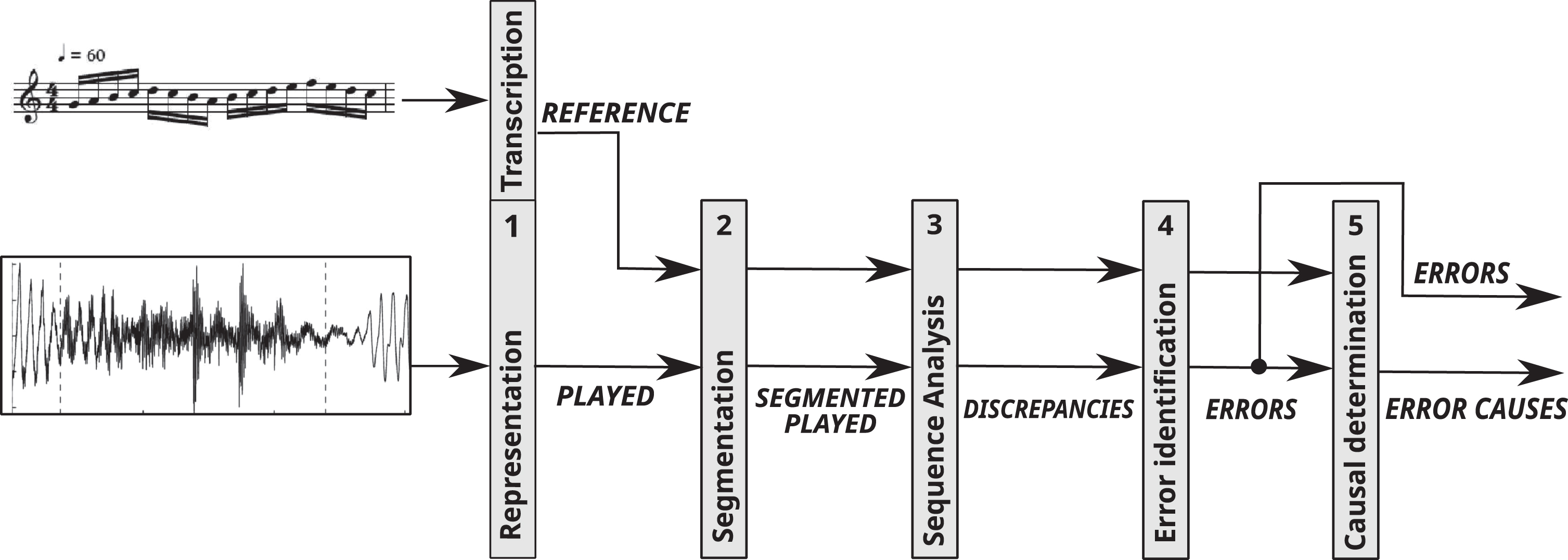
The proposed cascading layered architecture.
The main working hypothesis is that the accumulated effect of all previous layers adequately approaches the behavior of a human tutor when identifying error in performed musical sequences.
In order to assess the precision and usefulness of the process described above, we designed a simple multi-sequence, multi-user test. The goal of this test was to compare the number of errors detected, during the performance of selected musical sequences with diverse challenging conditions.
Although the restrictions associated with the current COVID-19 pandemic are making it extremely difficult to experiment, we managed to bring together a set of four transversal flute performers of intermediate and advanced expertise levels. For the test, we carefully selected/designed four short musical sequences for test purposes. These musical sequences were specified as to test a wide variety of experience levels and performance abilities in the test subjects. A brief explanation of each sequence follows:

Test sequence #1. G-Major scales.

Test sequence #2. Intervals.

Test sequence #3. Unpatterned sequence.

Test sequence #4. Patterned and syncopated sequence.
The four test subjects were initially labeled for their experience level as intermediate or advanced. Tables 1, 3 and 4 show the analysis of errors of each test subject while performing each test sequence. These tables show the number of errors detected in each performance and the ratio of those errors to the total number of musical phenomena in each sequence. Also, errors are grouped by type (solfège and sound quality errors) and a total and an average are indicated for each performer on each group. The total is just the sum of all errors made by the performer, while the average is the arithmetic average of the percentage of error versus the total number of phenomena in each performed sequence.
Practical test on sequence 1
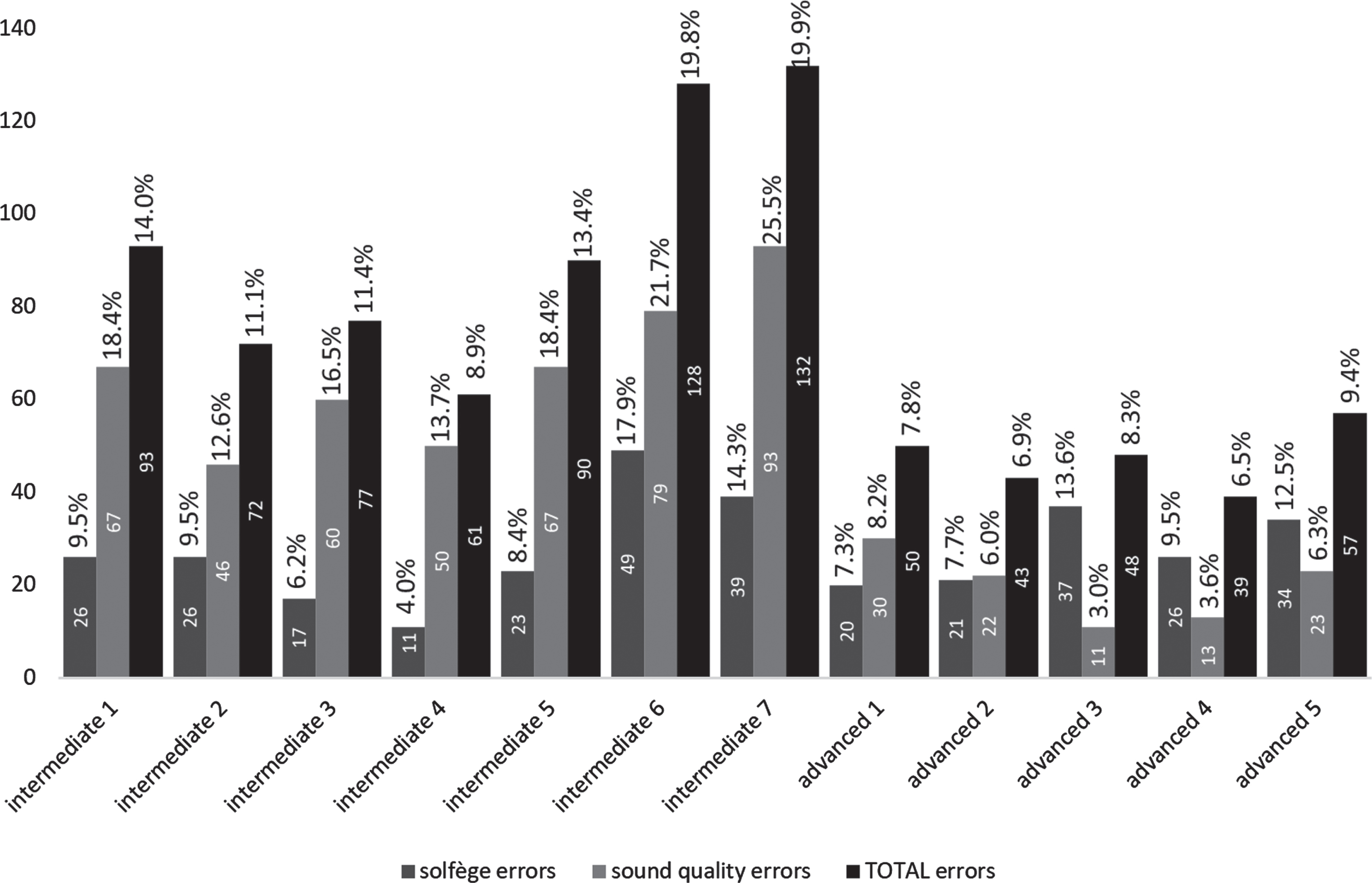
Practical test on sequence 2
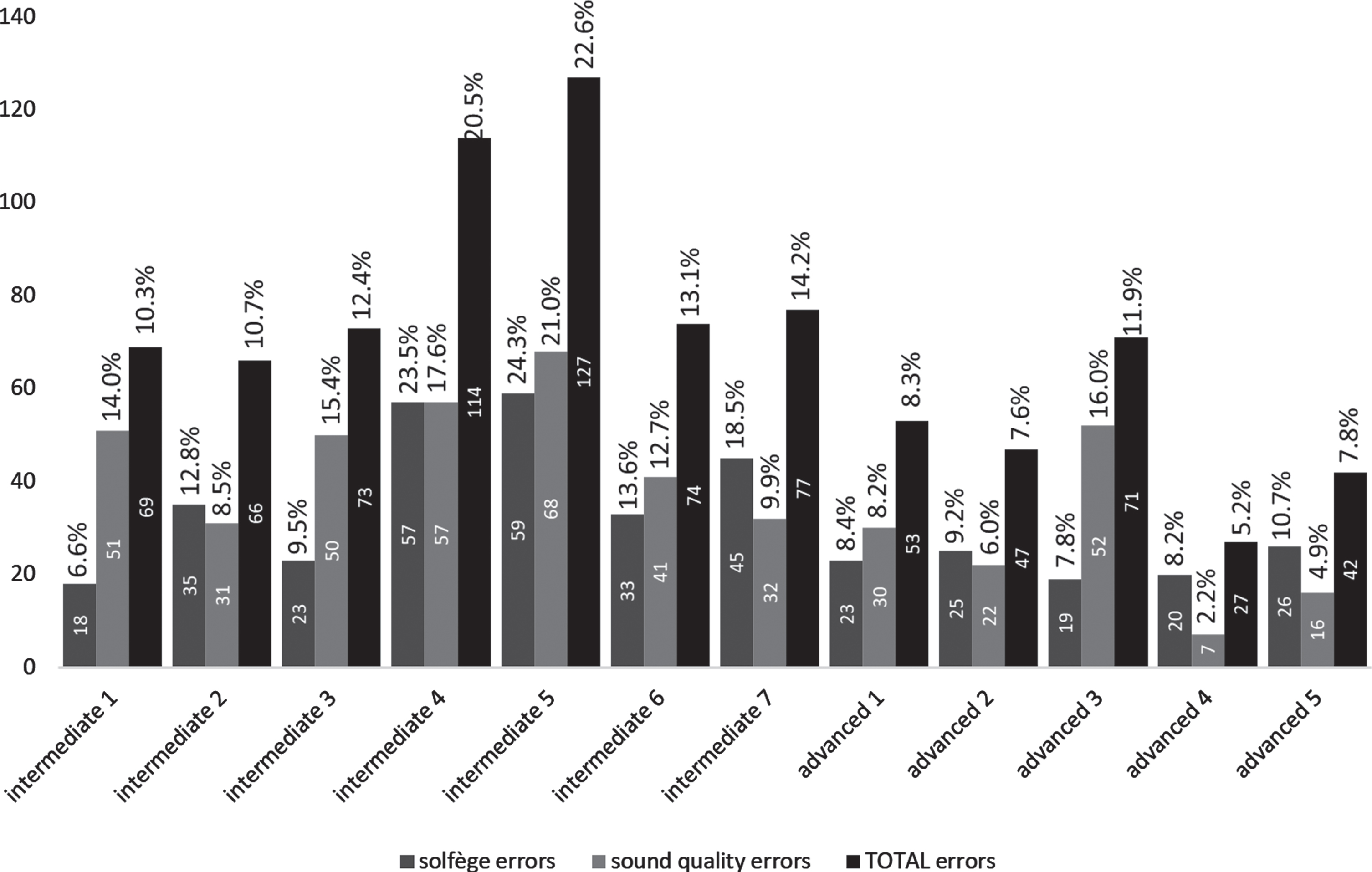
Practical test on sequence 3
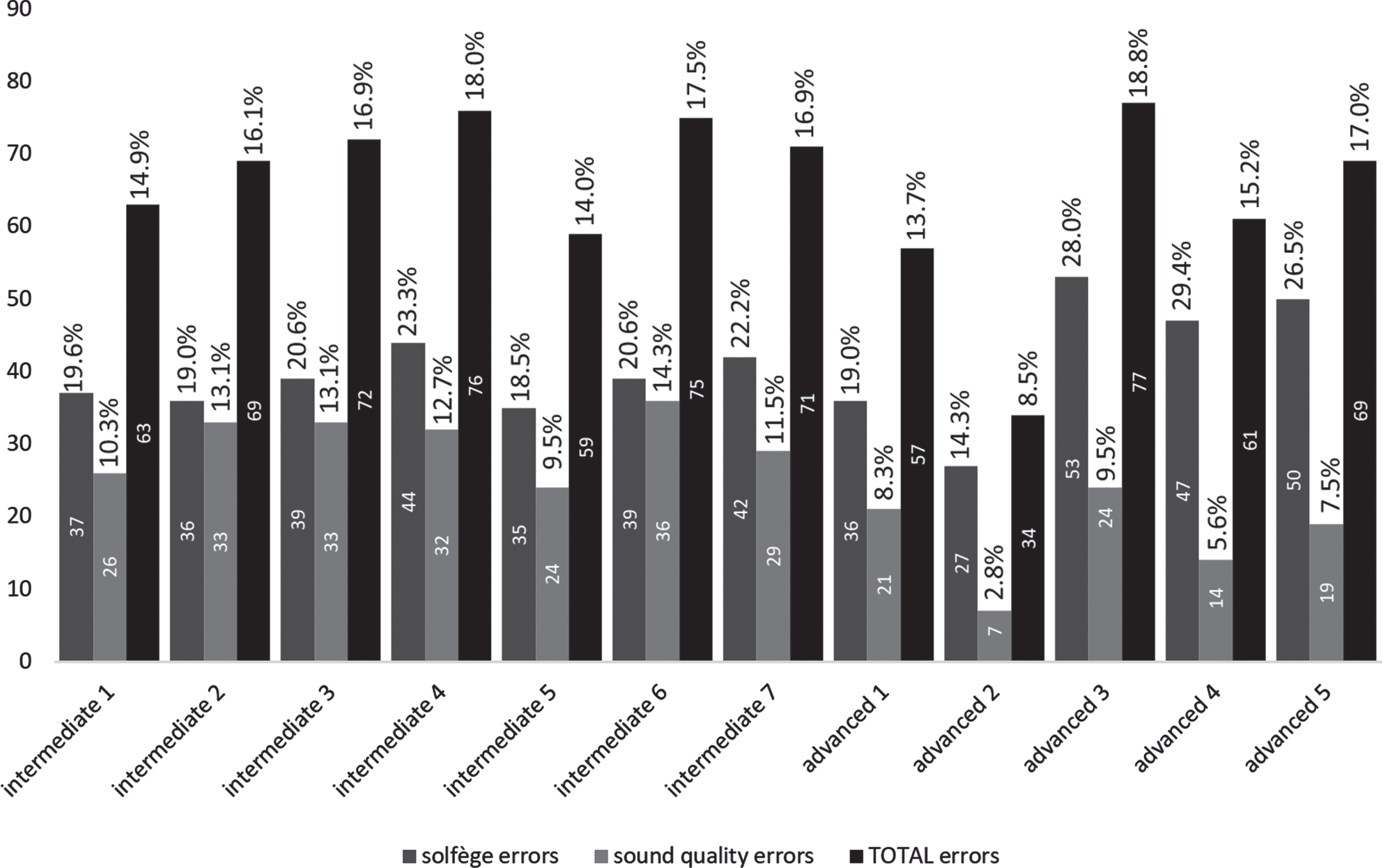
Practical test on sequence 4
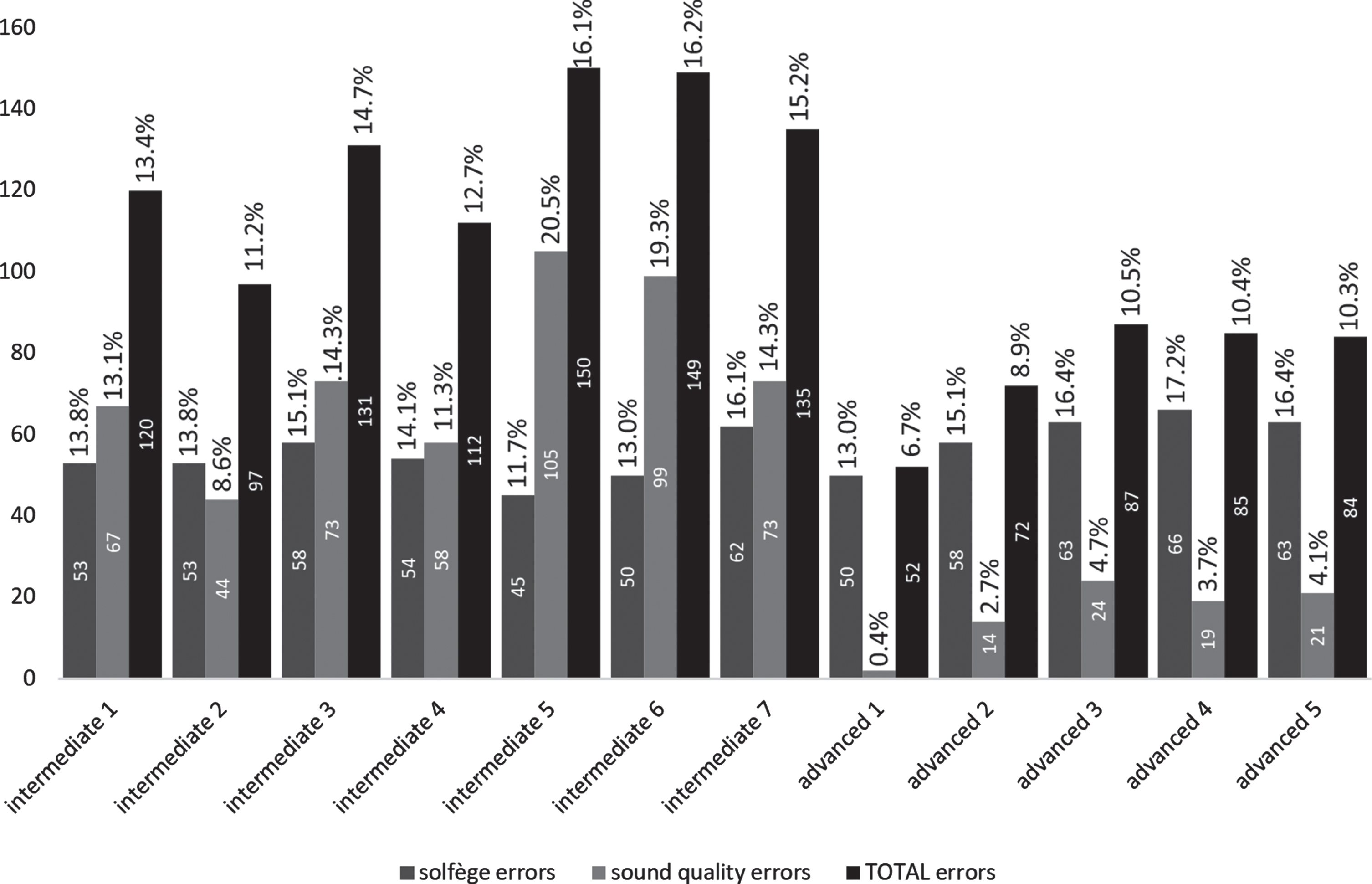
Since errors detected during the test are part of two different groups, solfège errors and sound quality errors, it would be an oversimplification to try to characterize test subjects just with their total number of detected errors. Solfège errors are caused by either incorrectly reading or executing what has just been read. Sound quality error, on the other hand, evidence the performer’s mastery of a specific instrument. The skills needed to avoid both types of errors are achieved only with years of practice, consistency and dedication.
During the test of all four sequences, the most common error, both in intermediate and advanced performers, was always the duration error. That fact is consistent with the initial explanation that music is an open-ended domain, and that the quantification of the pace in beats per minute was used as the only grounding element for the symbols. From the moment a chromagram is computed (in the first layer of the proposed architecture), all the following time-related analyses on the played sequence are made in terms of time-frames, and so even a one frame error can be detected, which is not audible by the human ear. Depending on their magnitude not all duration errors shown in test tables should be reported to the user, but that is a decision other future modules should make.
The observed behavior of all other errors falls within the normal and expected parameters. There is no test subject, either intermediate or advanced, with the best performance in all four sequences. But the diversity and precision of the errors reported by our architecture supports the initial hypothesis that the cascading connected layers architecture is an adequate means for emulating a human tutor’s ability to detect performed errors without transgressing the open-ended conditions of the problem and without the need of any connectionist element.
The immediate next steps in this research will follow two main directions. First, the development of layer #5, the causal characterization layer that will require the construction of an instrument-specific knowledge base. Then, the many extension possibilities must be examined, including upgrading to the full musical notation language, and eliminating the monophonic restriction on instruments. Also, in the quest for the best possible conditions of practical application, several tests should be made, particularly with beginners. Those tests should yield information on particular needs to be fulfilled by the error identification and characterization module, as well as by the future intelligent artificial tutors.
Footnotes
Acknowledgments
This work was supported in part by the Mexican Government through Instituto Politécnico Nacional (IPN) under SIP Multidisciplinary Project 2083, Projects SIP 20210189, 20211424, EDI, COFAA-SIBE, BEIFI-IPN; and CONACyT.