
Abstract
Anomaly detection for sensor systems is one of the most researched topics for the Internet of Thing systems. Researchers have been attracted to machine learning classification problems that are considered the most effective techniques. The novel model is proposed by combining anomaly pattern Symbolic Aggregate Approximation (SAX), processing imbalance data and machine learning techniques for sensor anomaly detection. The advantage of anomaly patterns and machine learning leads to the the proposed model to have better performance. The proposed model consists of three phases: finding anomaly pattern features, processing imbalanced data, exploring data by machine learning model. In this paper, the main contributions with respect to previous works can be listed as follows: (i) Successful modeling the new method of SAX for time series data for finding complex and dynamic anomaly patterns. (ii) Archiving applied anomaly pattern feature into machine learning model Random Forest and hyperparameters optimisation of these model. (iii) Fitfully proposed a model combining SAX, imbalance technique, and random forest to anomaly detection. (iv) Achieving applied proposal model in automatic meter intelligence system in Vietnam. The experiential results of the proposed model have described the robustness and better performance for detecting anomalies of power meter sensors.
Introduction
The Internet of Things, (IoT), including electronic sensors and mobile phones, are generators of big data that satisfies variety, velocity, veracity, and variability. The role of IoT are essential of many systems such as a health system, cyber security system, predictive maintenance, industrial automation and fault prevention system. However, researching anomaly detection faces three challenges that are data arriving rapidly and time series data, imbalanced label data, and complex and dynamic anomaly patterns [4, 14]. Thus methods of anomaly detection in sensor systems are attractive not only to academy researchers but also to industrial researchers recently [4, 16].
Three types of anomalies are considered [6]: Point anomaly: one point that is the range value of normal point of the time series. Contextual anomaly: one point is a normal point of the time series but when given some value before and after or the range of value, the anomaly in context occurs. Collective anomaly: a sub-sequence series extract from the series that does not expect value or match with the normal pattern.
Various techniques of anomaly detection have been developed for application domains [1]. The authors in [19] compare detection techniques (statistical learning, rule-based and machine learning algorithm). Its result for wireless sensor network (WSN) data sets improves performance of machine learning algorithm but with complexity computational. I. Gethzi Ahila Poornima et al. [15] use Online Locally Weighted Projection Regression (OLWPR) and get a good result with low complexity. Another approach is using autoregressive data-driven model and classify anomaly points that deviates significantly from prediction interval [9]. LSTM [13] reconstructs the time series of normal behavior and detect anomalies from reconstruction error. The survey of anomaly detection in sensor researches is described in Table 1.
Anomaly detection in sensor researches
Anomaly detection in sensor researches
From previous studies, it can be shown that there are two main methods for the machine learning approach in time series anomaly detection problems. That is, classification techniques and regression techniques depend on the data set’s property. The classification techniques are mainly used with good anomaly labeled data sets while regression techniques are used when the set of labeled anomalies are not sufficient and diverse that is described in Table 2. In our study, since our data set are well labeled, we use classification techniques as the main method to tackle the time series anomaly detection problem.
Machine Learning in Time series anomaly detection researches
Symbolic aggregate approximation (SAX) is a method that transforms a time series into discrete symbolic sequences [3, 20]. It is widely used in many subjects such as pattern recognition, anomaly detection. The authors in [5] use HOT-SAX algorithm to detect anomalies in water management. TSAX [21], SAX_CP [20], TrSAX [17] are newly SAX techniques and improve performance [18] in classification. Table 3 shows the survey SAX in time series.
SAX in time series researches
One of the challenging tasks of anomaly detection is imbalanced data. It makes classification less effective in a minor class, which is the anomaly class [12]. There are various techniques to solve the problem: oversampling the major class, under-sampling the minor class, or combine over and under-sampling methods.
In this paper, a combination of time series pattern analysis and machine learning techniques is investigated into the problem of sensor anomaly detection. Selection techniques of anomaly pattern Symbolic Aggregate Approximation (SAX), data balance data and machine learning modeling are integrated to detect anomaly sensors.
The paper is organized into four sections: Section 2 shows the methodology of anomaly detection, SAX, imbalance and the proposed model are presented. The experiments and results of the smart meter sensor are shown in Section 3. Lastly, the conclusion and discussions are provided in Section 4. In addition, some notations are summarised in Table 4.
Table of nomenclature
Anomaly detection formula problem
In this paper, an energy meter is a sensor that measures the automatic electricity load of a consumer by time. This sensor is binary classified into anomaly and normal. If the sensor has an anomaly status, it will inspect and check.
Sensor data set has an input with N features:
Consider the data of a sensor
Overview anomaly detection system
The research procedure of time series anomaly detection system contains four phases that are described in Fig. 1.
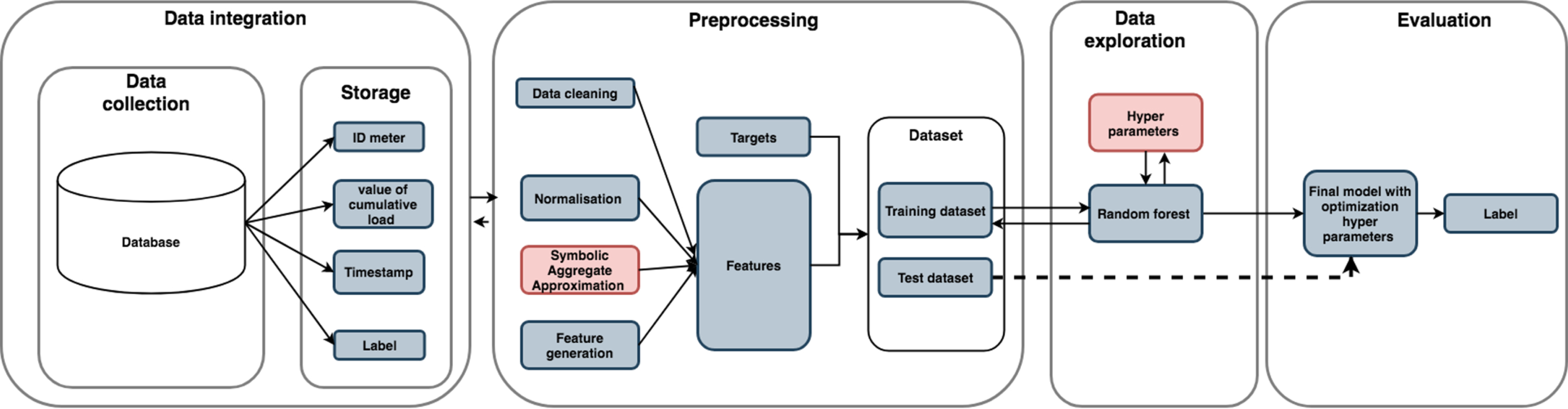
Four phases for anomaly detection sensor system.
Phase 1: Integrating Data: Gathering data from various sources and combining it into one data set.
Phase 2: Pre-processing Data: Raw data collected from the previous step can be in various formats and may be inconsistent. This step involves data cleaning, data normalization and features generation is conducted to overcome this problem.
Phase 3: Modeling: Processed data set will be split into two sets: the training set and the test set. The training set will be used to train a classifier.
Phase 4: Evaluation: This step helps to select the best model corresponding to criteria and evaluate the performance of the selected model in the future. If the model’s performance is poor, go back to the data pre-processing step to clean data and generate more predictive features or the modeling step to tuning the model’s hyper-parameters.
SAX algorithm proposed by Lin el al.[3] is a classical symbolic approach in data mining applications of time series data. In this paper, the novel SAX is proposed for pattern recognition of the time series data of a sensor.
Time series of the energy meter is generated by consumer activity. The behavior of humans has seasonal daily, weekly, monthly, and yearly patterns. The behavior patterns are created from historical data that difficult to process for the usual time series statistical analysis such as AR, ARIMA, SARIMA, SARIMAX, and spectral models.
A new method to find a normal pattern of seasonal with w time step are described below:
Step 1: Consider a time series of length n: X = {x t 1 , x t 2 , …, x t n }, in the observed time period T = [t0, t n ].
Step 2: Select a fixed size of window w and divide time series into
Thus the original data now is represented by M window
Step 4:
Each symbolic vector has w positions that run from 1 to w. The set of all symbolic at position j of M symbolic vector has form
The meaning
Step 5: After
Where mode(.) the statistical operator returns the symbol has the highest frequency of a given set; symdict (.) is Jaccard distance is defined for two symbolic vectors A and B:
Figure 2 shows an example of using SAX to encode time series. The sub sequences of raw time series data in window w are encoded into a symbolic vector using SAX. Figure 3 shows the symbolic anomaly vector using SAX. The anomaly vector is very different from the normal behavior of sensors.
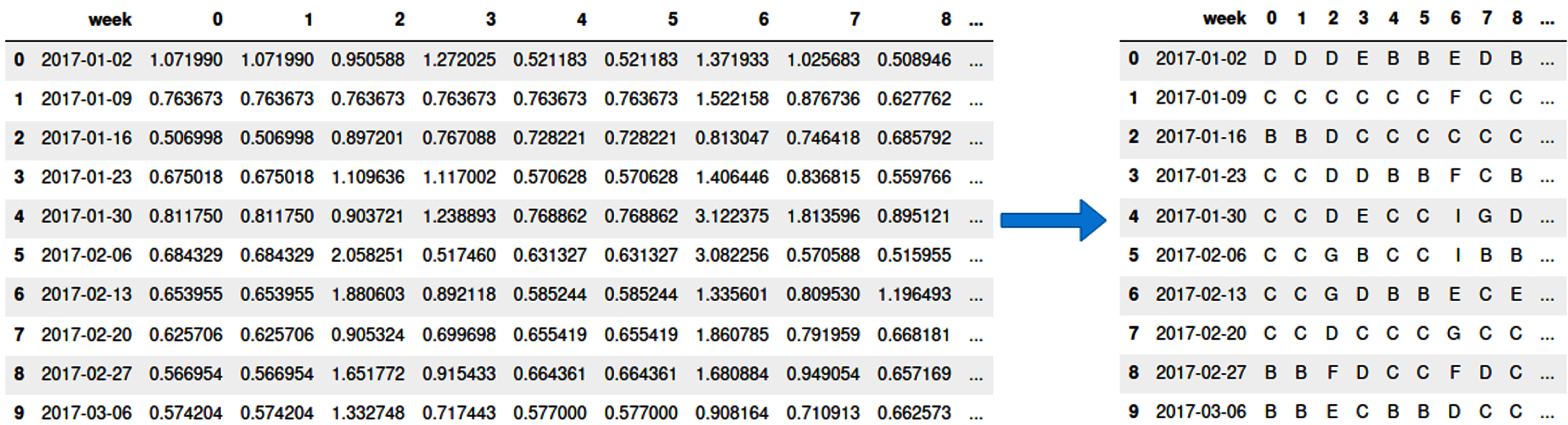
SAX encodes sub sequence time series in window w into symbolic vector.

Extract symbolic anomaly vector using SAX
It is using this distance for analyzing the new features of two normal and anomaly classes. The advantage of SAX is tolerated the noise of time series data a and its variance is small, but it can not detect abnormal sub-sequence of w time step.
The random forest model is an effective ensemble learning method, mostly used for classification problems due to their high performance. The random forest model operates by constructing many decision trees (weak-learners) and train them on sub-samples of the data set individually. Finally, the random forest model make predictions by averaging all weak-learners predictions to overcome the over-fitting problems of the weak-learners and ensure consistency [2].
The random forest model applies the bagging technique to train individual tree learners. Given a training set Sensor has an input with N features:
For tree = 1, . . . , N:
Sampling M < d instances examples and k < N features from training data set Train a classification tree f
tree
(.) on
After training, the random forest model makes a prediction for an unknown label instance
This bagging process of the random forest model pay a role in de-correlating the single tree learners that help to the decrements in the variance of individual model prediction without increasing the bias.
Proposed model
The data set of sensors include cumulative time series, which represent power consumption per unit time. In this section, the workflow of the proposed model is described below. It consists of three main stages: Pre-processing: Transform original time series data to consumption time series. Then, normalize them based on the time period per day. Feature engineering: Create feature from processed data. After that, add statistic features an Modeling and evaluate: Apply imbalance processing techniques for the train set. Then it’s trained using the random forest model with selected hyperparameters. We evaluate and choose a trained model with optimized hyperparameters.
We visualize output and testing the final model by using evaluation metrics. The overview model of this approach is shown in algorithm Figure 4, respectively.
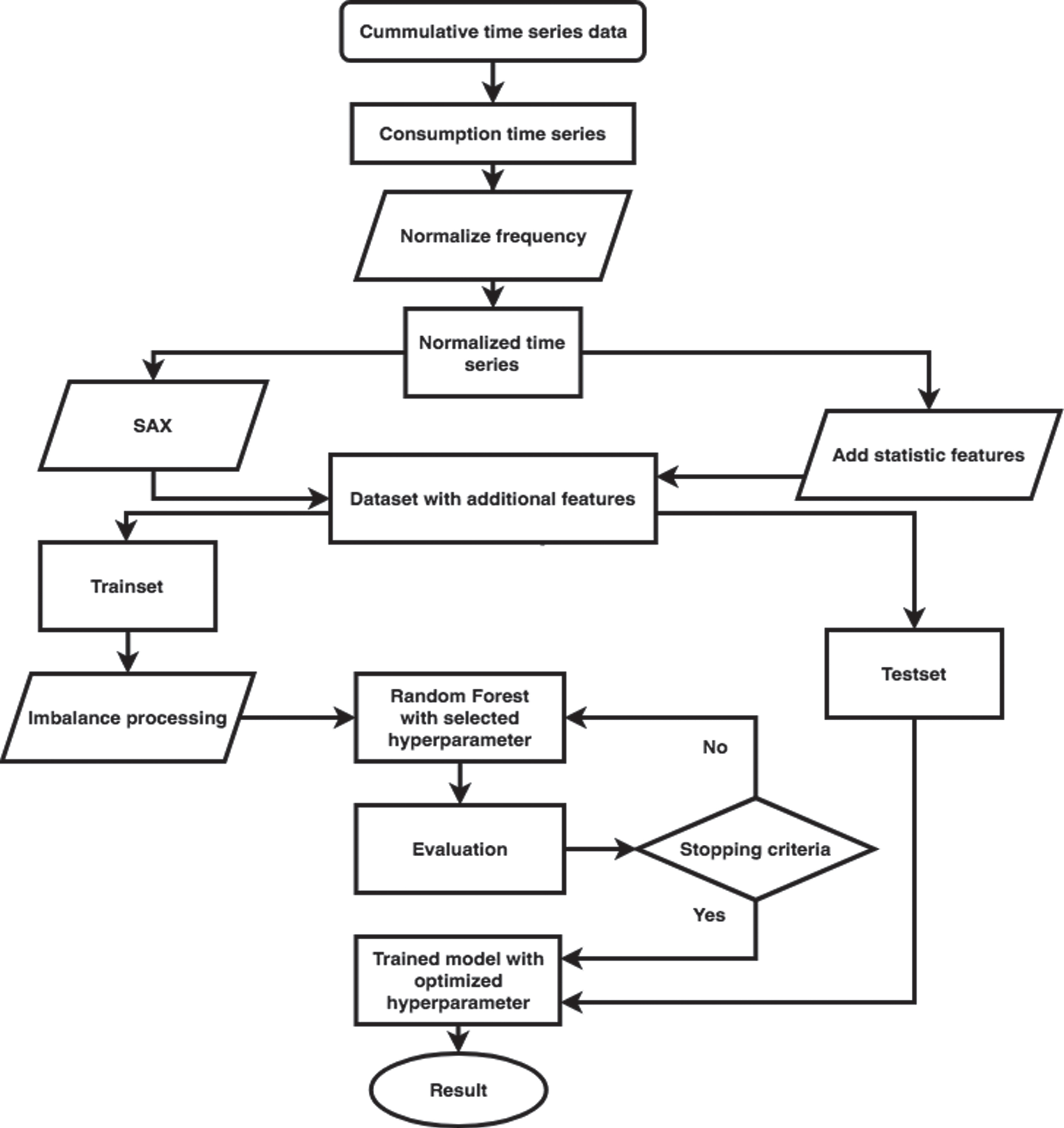
Proposed model anomaly detection using machine learning and pattern recognition.
Pre-processing
1: Transform TS to consumption time series TS′
2: Normalize TS′ to normalize time series TS0
3: F0 ⟵ gen (TS0)
4: F SAX ⟵ SAX (F0)
5: F stat ⟵ stat (F0)
6: F ⟵ F0 ∪ F SAX ∪ F stat
7: return F
The proposed model
1: F ⟵ Pre - processing (TS)
2: Split F to train set F train and test set F test
3: F train ⟵ SMOTE (F train )
4:
5: RF ⟵ fit RF model(F train , n - estimators, max - depth)
6:
7: E ⟵ Evaluation (RF (F test ))
8: return E
Data set description
The data set contains the time series data of the cumulative energy of 1067 sensors from 1/1/2017 to 31/3/2018 in a province of Vietnam. The data include about 2.5 million rows, and 3 attributes are described in Table 5.
The description of the data set
The description of the data set
- -Four measures used in our experiments to evaluate five methods: classification accuracy, Precision, Recall and F1 score. These criteria are calculated by the following formula:
TP and TN are the proportion of correct classification that positive and negative class data points; FP and FN are the proportion of incorrect classification that positive and negative class data, respectively.
We use three scenarios for the experiment, there are: Scenario 1: Decision Tree with different parameters are applied for data set with 28 based-features. Scenario 2: The random forest model with different parameters are applied for data set with 28 based-features. Scenario 3: Use proposed model with different parameters for data set with additional features (28 based-features + feature from SAX algorithm and statistic features).
We use SAX algorithm to calculate the normal behavior of electricity consumption by the week for each meter. Figure 5 shows electricity consumption by week of normal and fraud meters. The big and red lines in each figure represent normal behavior. The figures show clearly that the normal behavior of normal meters is periodic and stable. By contrast, the normal behavior of fraud meters is unstable.

(a) (b) Graphs of electricity consumption by the week of normal meters. (c) (d) Graphs of electricity consumption by the week of fraud meters
The hyperparameters we fine-tune in the experiment for the proposed model and the random forest model include the number of trees in the forest and the maximum depth of the tree. For the decision tree model, we tune the maximum depth of the tree. The number of trees in the forest we choose are 200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000, and the maximum tree’s depth are 10, 20, 30, 40, 50, 60, 70, 80, 90, 100. The result of three models with the different sets of hyper-parameters which choosing at random is shown in Table 6.
Results of scenario 1, scenario 2, scenario 3
Figure 6 shows the results of the models corresponding to 3 methods. It can make clear be seen from Fig. 6 that, for the decision tree model, the average value of F1-score is approximately 10.85% and the average value of precision is about 6.35%. Similarly, for the random forest model, the average value of F1-score and precision are 28,49% and 24.57%, respectively. For the proposed model, the average F1-score and average precision are 39.32% and 43.38%, respectively. Compared to the decision tree and the random forest model, the proposed model gives us many superior results.
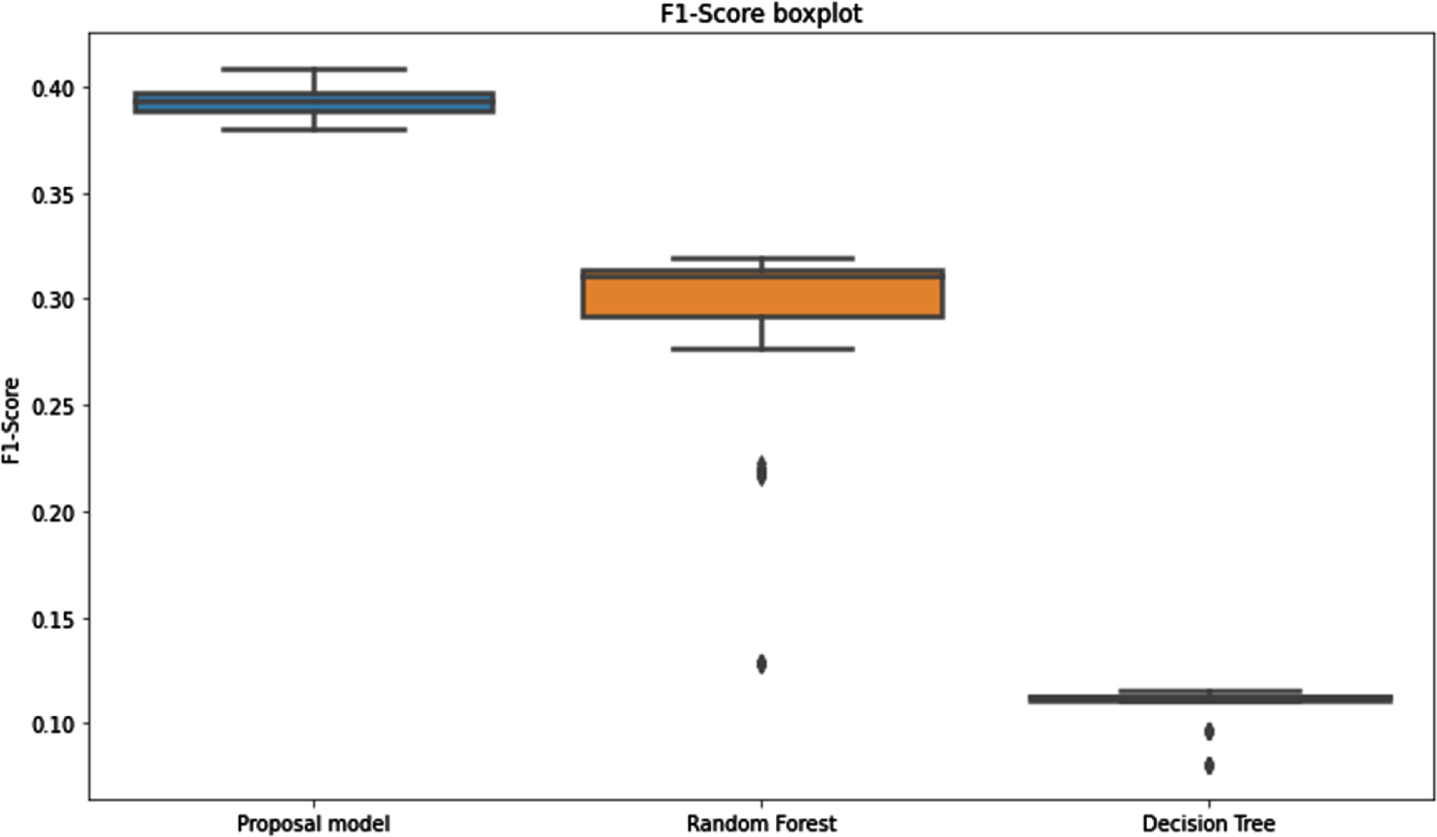
Evaluation metric F1-score of the three methods.
Three precision of three methods is described in Fig. 8. Once more time, the proposed model, the average precision from 39.9% much better than two other method decision tree with average precision 11% and 30.5%. Thus, comparing the average precision of three methods decision tree and random forest model, the proposed model gives high performance.
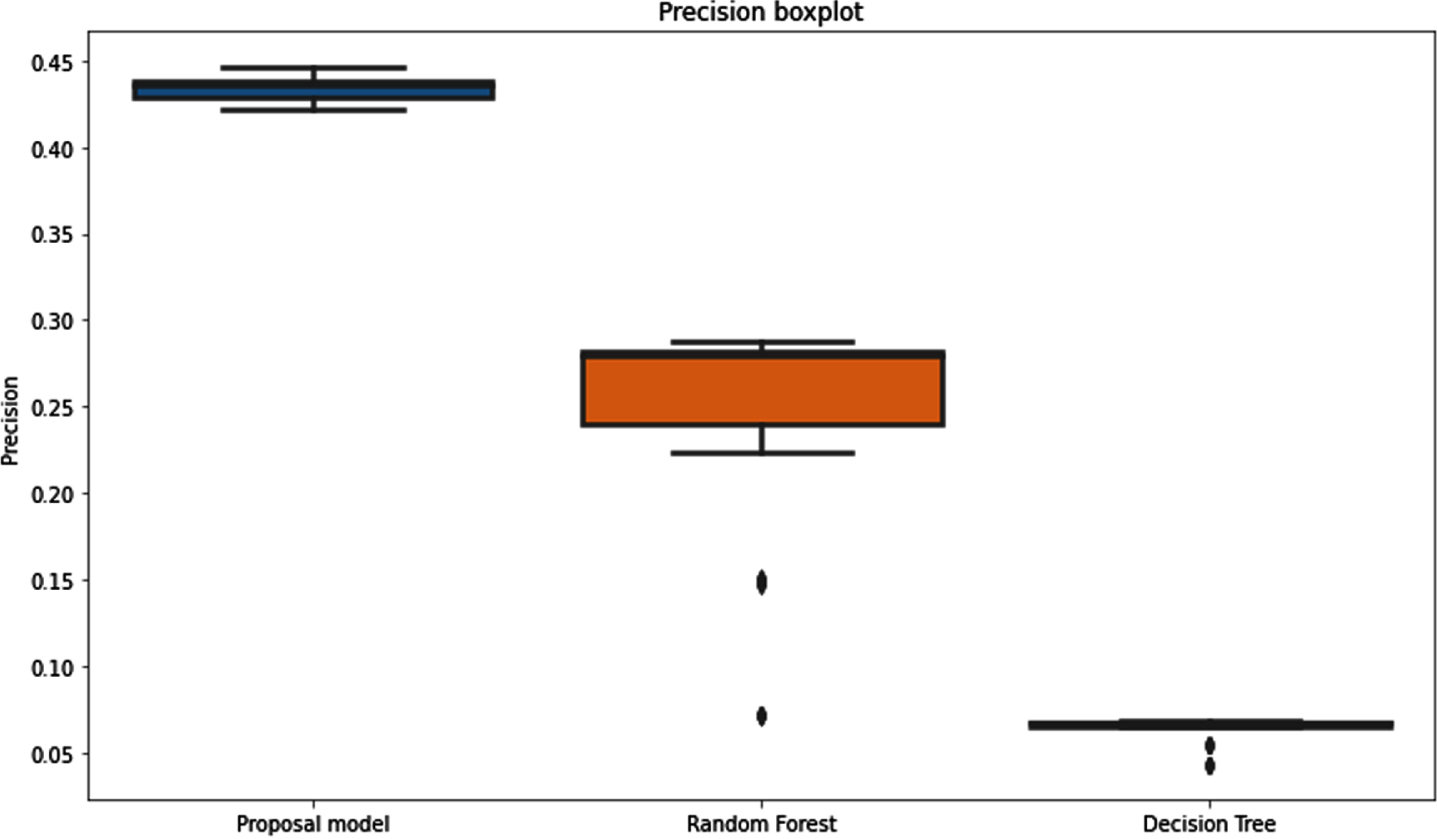
Evaluation metric precision score of the three methods.
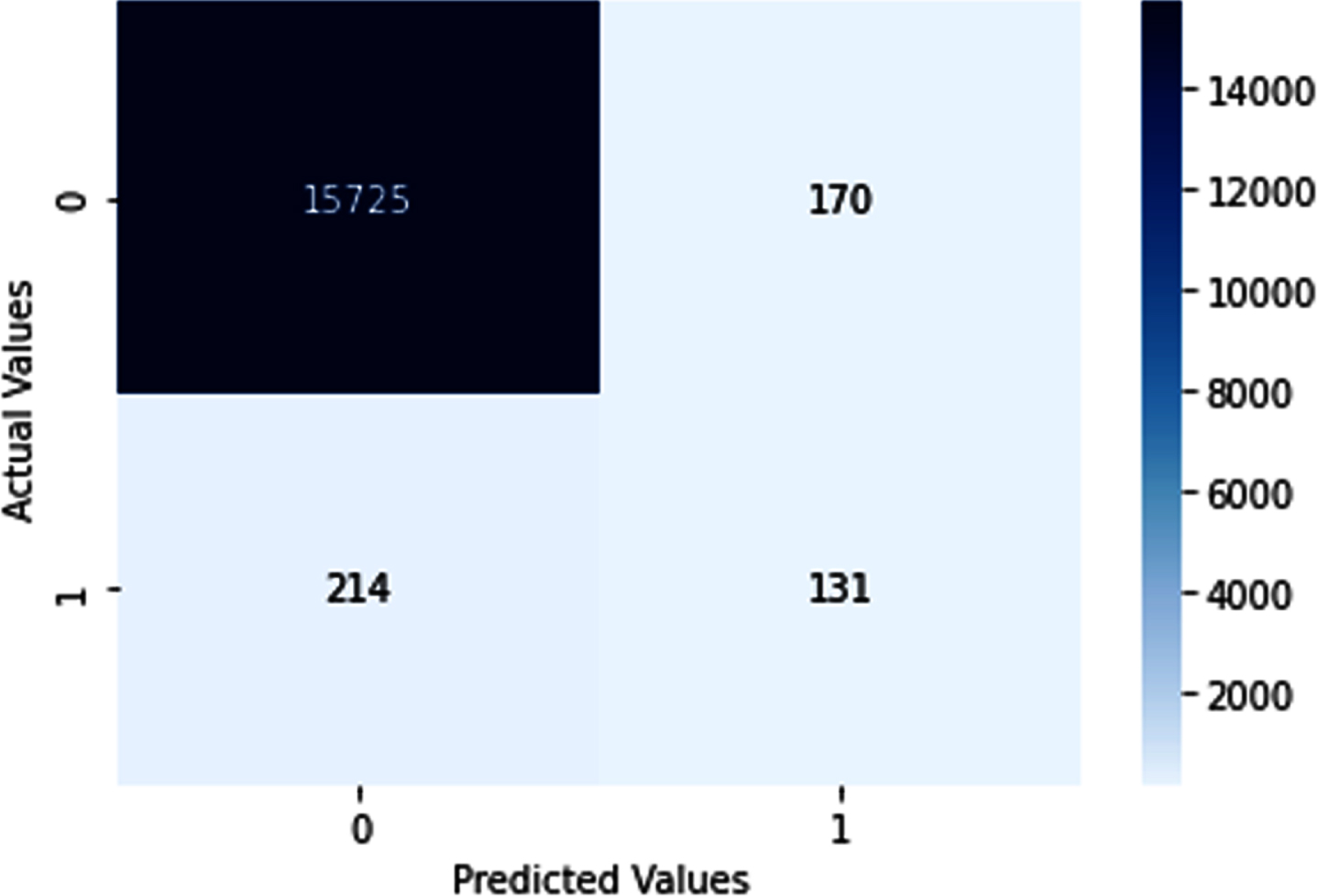
Confusion matrix of proposed model with the best F _ 1 score and precision.
A new proposal model integrates SAX and imbalance for prepare processing, random forest for anomaly detection sensor systems are addressed in our research. Concretely, the contributions of our paper are as follows: Successful finding complicated and dynamic anomaly patterns using SAX for time series data.. Archiving applied anomaly pattern for machine learning model. Fitfully proposed a model combining SAX, imbalance technique and random forest to anomaly detection. Achieving applied proposal model in automatic meter intelligence system in Vietnam.
According to the experimental result, our proposed model has better performance than using well-known machine learning models. The cause of better results are chosen complex and dynamic anomaly patterns in meter intelligence system.
In future work, more sensor anomaly detection applications are researched base on the proposed model. The advanced SAX to find a new pattern will be investigated. The anomaly detection of subsequent of normal symbolic patterns is necessary to study.
Footnotes
Acknowledgment
We want to thank CMC Institute of Science and Technology for supporting this paper.