
Abstract
Semantic relations have been adopted in many research fields, including the semantic web, information retrieval, and Q&A systems. The aim of the semantic relations is to remove conceptual and terminological confusion. This is achieved by specifying a set of general concepts that characterize domains and their definitions and interrelationships. This research describes how to detect semantic relations, including synonyms, hyponyms, and hypernym s based on WordNet and entities of a knowledge graph (KG). This KG was built from two resources: ACM Digital Library and Wikipedia. We used natural language processing and the deep learning approach for processing data before generating the KG with an effective algorithm. We chose five of 245 categories in the ACM Digital Library to evaluate the proposed method. The generated results show that our system has excellent performance.
Introduction
Human knowledge is rich, varied, and complex. There are many methods to rep-resent human knowledge. A knowledge graph (KG) is a natural candidate for this. A KG includes vertexes that represent entities, classes, subclasses, and edges that represent relationships among the vertexes. NELL [1, 2], Freebase [3], and YAGO [4] are examples of large KGs that include millions of entities and semantic relations. Se-mantic relations are expressed as triples of two entities and a binary relation. There are several kinds of semantic relations, such as IS-A, Include, Synonym, Hyponym. A KG with semantic relations can be applied in many computing fields, such as search engines, information retrieval, and Q&A systems. However, there are challenges to building a KG related to data, methods, and tools. Therefore, a KG is either created over a long period or is focused on one domain.
The contributions of this research are shown as follows: (i) We crawled and categorized a large-scale dataset from Wikipedia and ACM Digital Library focusing on the computing domain to build a KG. The KG approach tends to focus on the relationships/links of words rather than independently evaluating individual words. (ii) We propose an algorithm for the detection of several semantic relations, including synonyms, hyponyms, and hypernyms based on the KG and WordNet.
This paper is organized as follows: Section 2 describes related works; section 3 discusses the detection of semantic relations based on the KG; section 4 includes the experimental results and discussion; section 5 provides conclusions and future works.
Related work
Kotnis and V. Nastase [5] proposed KGs with only positive relation instances, lead-ing to the emergence of various methods for selecting negative examples. Empirical research was also conducted on the impact of negative sampling on the learned em-beddings, assessed through link prediction. State-of-the-art KG embedding methods were applied, including Rescal, TransE, DistMult, and ComplEX, but the results were based on the subsets of Freebase and WordNet. Dasgupta et al. [6] in 2018 presented HyTE (Hyperplane-based Temporally), a knowledge graph embedding technique, which explicitly incorporates time in the entity-relation space with a hyperplane corresponding to a timestamp. The method can present KG inferences using temporal guidance and predict temporal scopes for relational facts with missing time annotations. However, this method can only exploit temporally scoped facts of KG to pre-sent link prediction and time scopes for unannotated temporal facts. B. Ding et al. [7] investigated the potential of using simple constraints to improve KG-embedding, but this research only focused on two constraints, namely, the non-negativity constraints on learning compact, interpretable entity representations and the approximate entailment constraints. K. Wang et al. [8] proposed a new kind of information, called entity neighbors, which contain both semantic and topological features of a given entity. The research is limited regardless of the semantics of entity neighbors. A. Kutuzov et al. [9] created path2vec, a novel approach for identifying graph embeddings that relies on structural measures of pairwise node similarities. Further research is planned on training embeddings to approximate multiple similarity metrics at once. Generally, there are various techniques used to apply KGs to different fields. Re-search has shown approaches related to natural language processing (NLP), ma-chine/deep learning, or hybrid approaches. In this research, we use NLP and the deep learning approach for data training to build a KG focusing on the computing domain. Semantic relations are then detected based on this graph.
Heterogenous document-based knowledge graph embedding
Building a KG from text documents of the ACM Digital Library
The process for training text documents of the ACM Digital Library involves two steps: Data pre-processing. Applying the Keras framework, including a word embedding model of text data.
In the first phase, all text files of the ACM Digital Library were merged according to their categories. After merging, each category had only one text file. These text files were sent as input to a tokenizer to split the English sentences into words based on the whitespace character. The tokenized words were then converted to lowercase form, removed of punctuation, and filtered to remove tokens that are symbols or stop-words. These converted text files were directed back to the extractor again for the stemming process. Stemming refers to the transformation of each word to its base. In this research, we used the Natural Language Tool Kit (NLTK) [10] for data pre-processing. In the second phase, we adopted the multilayer perceptron (MLP) with a word2vec [11] presentation for training the data in the Keras framework. The training data process is shown in Fig. 1. The word layer includes the words that were processed in the first phase, and there are four hidden layers.
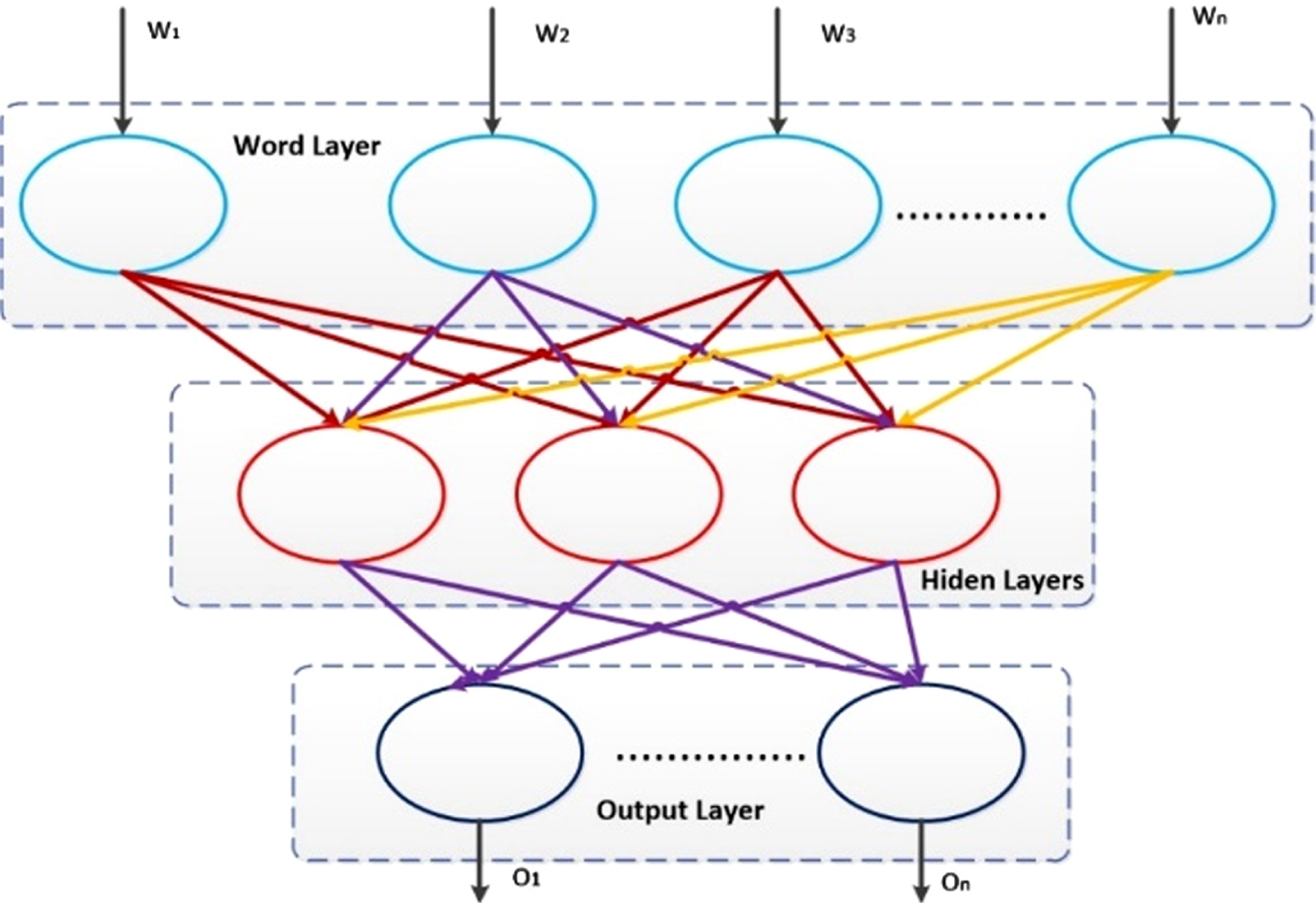
Model using the Keras framework, including word embedding (word2vec).
The next step is to build the KG. The structure of the KG was divided into two layers, with the computing domain as the root of the KG. The first layer is known as the subject layer [12], which includes over 30 categories that were extracted from ACM classification categories [13]. The next layer of KG is known as the object layer, which contains various word vectors that were output from the word2vec word embedding model, e.g., Hardware, SQL Server, Java, CPU, Oracle, Data Structure. The KG representing the computing domain is shown as Fig. 2.
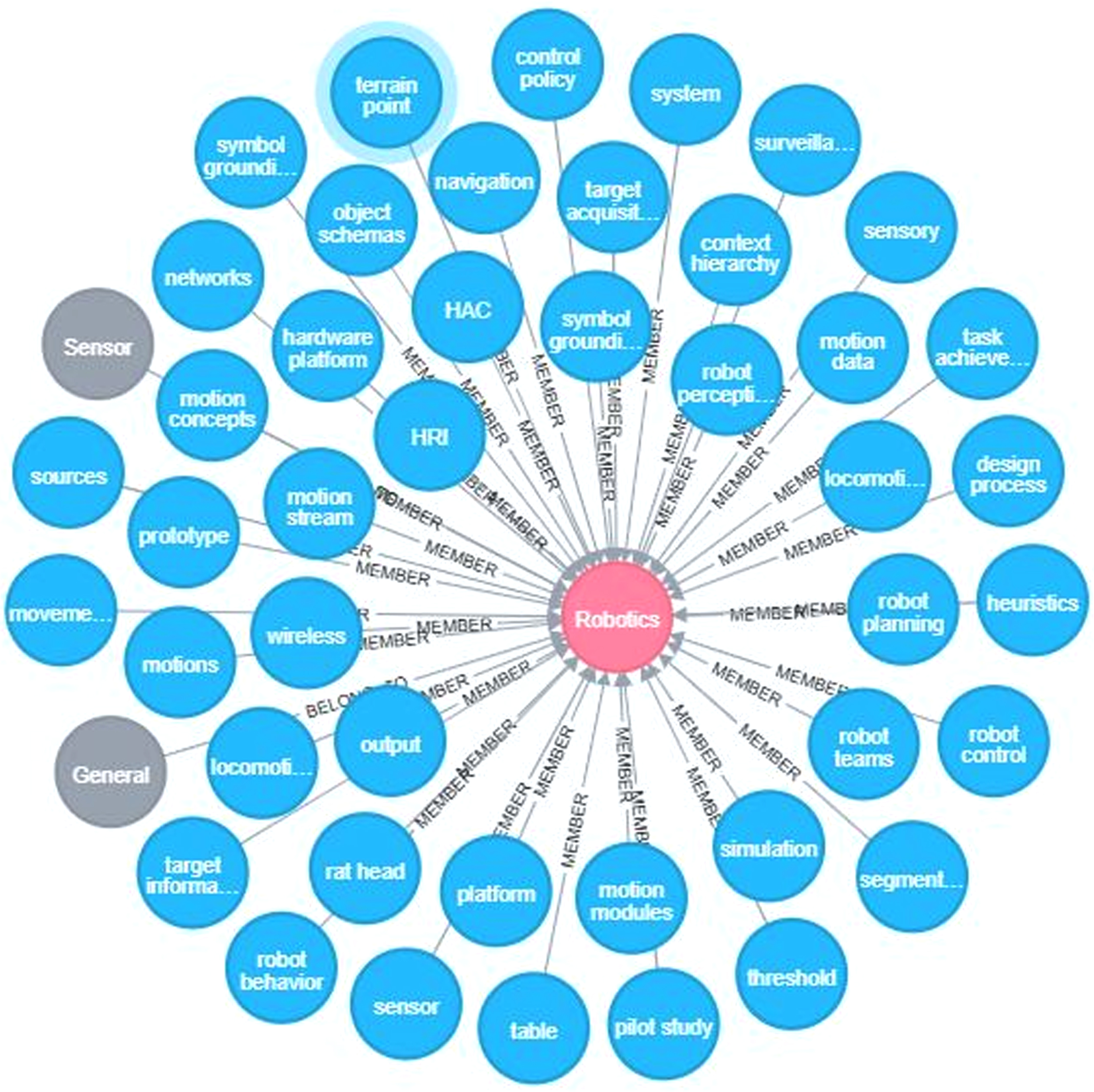
Hierarchy of a knowledge graph.
The process to update the KG by entities extracted from Wikipedia includes three steps: Prepare the XML files, including entities belonging to categories of ACM Digital Libraries Pre-process the data in the XML files from the previous step Reuse the Keras framework to train the data after pre-processing.
Additionally, to access and extract data belonging to a category from Wikipedia, the API functions provided by Wikipedia were used.
Algorithms for the detection of the semantic relations based on the KG
This paper focuses on semantic relations, including synonyms, hyponyms, and hypernyms, which play a vital role in information retrieval. The KG and WordNet can be used to determine these semantic relations. Our proposed algorithm is as follows.
Algorithm 3.1. Algorithm for searching the semantic relations based on graph database
After the above algorithm was applied, we extracted the semantic relations from WordNet corresponding to the entities of the KG. Some results are shown in Table 1.
Set of Synonyms, Hyponyms, and Hypernyms corresponding with entities of the KG
From Table 1, some semantic relations are evident between an instance of the KG with its synonyms, hyponyms, and hypernyms, such as the following: DB is Database Network Services such as Network Monitoring Machine learning includes Neural network ROM is Read-Only Memory
We implemented numerous experiments to study the efficiency of the proposed approach. We selected 100 papers, based on their abstracts, for each of the five categories from the ACM Digital Library: Artificial Intelligent Operating System Logic Design Software Process Management
We use three measures: Precision (P), Recall (R), and F-measure (F1) for experimental evaluation.
where C i denotes a category in the KG; Correct(C i ) denotes the semantic relations number found in the KG, belonging to the category C i ; Wrong(C i ) denotes the semantic relations number found in KG, not belonging to category C i ; Missing(C i ) denotes the number of the semantic relations not found in the KG. The results obtained are shown in Tables 2–5.
Evaluation results on instances of KG
Evaluation results on a set of synonym relations
Evaluation results on the set of hyponym relations
Evaluation results on the set of hypernyms
The results in Table 2 revealed that the number of instances extracted after pre-processing is related to the precision, recall, and F-measure. The Application category had higher number of instances and, therefore, resulted in higher precision and percent recall among the categories. The Process Management category had fewer instances, and, therefore, its precision and recall remained the lower. The results of this experiment show that the accuracy of a semantic relation found based on the KG of a category is directly proportional to the number of instances of that category.
Table 3 shows that the Application category had the better synonym relations and higher precision and recall among the categories. The Process Management category had fewer synonym relations, but its precision and recall were higher than those of the Application category. The results of this experiment show that the accuracy of synonym relations found based on the KG of a category is not directly proportional to the number of synonym relations in that category.
Similarly, Table 4 shows that the Process Management had the better hyponym relations and higher recall among the categories. The Application category had fewer hyponym relations, but its precision was higher than that of the Process Management category. The results of this experiment show that the precision and recall of hyponym relations found based on KG of a category are not directly proportional to the number of hyponym relations in that category.
Table 5 also slows that the Application category has the better hyponym relations but lower precision and recall among the categories. The Process Management category has fewer hyponym relations, but its precision and recall were higher than those of the Application category. The results of this experiment show that the precision and recall of hypernym relations found based on KG of a category are not directly proportional to the number of hyponym relations in that category.
The quantity of semantic relations obtained from the KG is shown in Fig. 3. Out of all the categories, Application has the highest number of instances and, therefore, the highest number of synonym, hyponym, and hypernym relations.
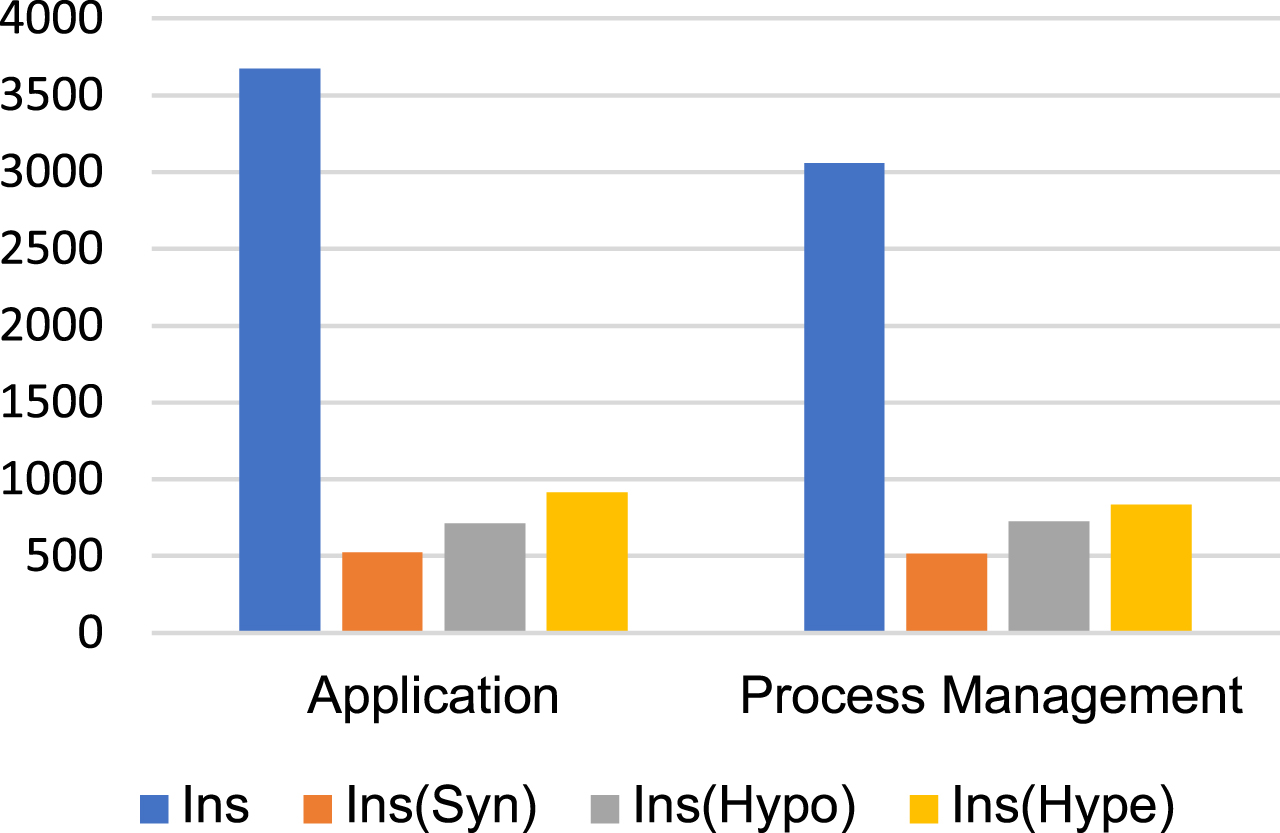
Number of instances of synonym, hyponym, and hypernym relations obtained per category.
The comparison between the precision of the different categories is shown in Fig. 4. The comparison between percent recall of the different categories is shown in Fig. 5.
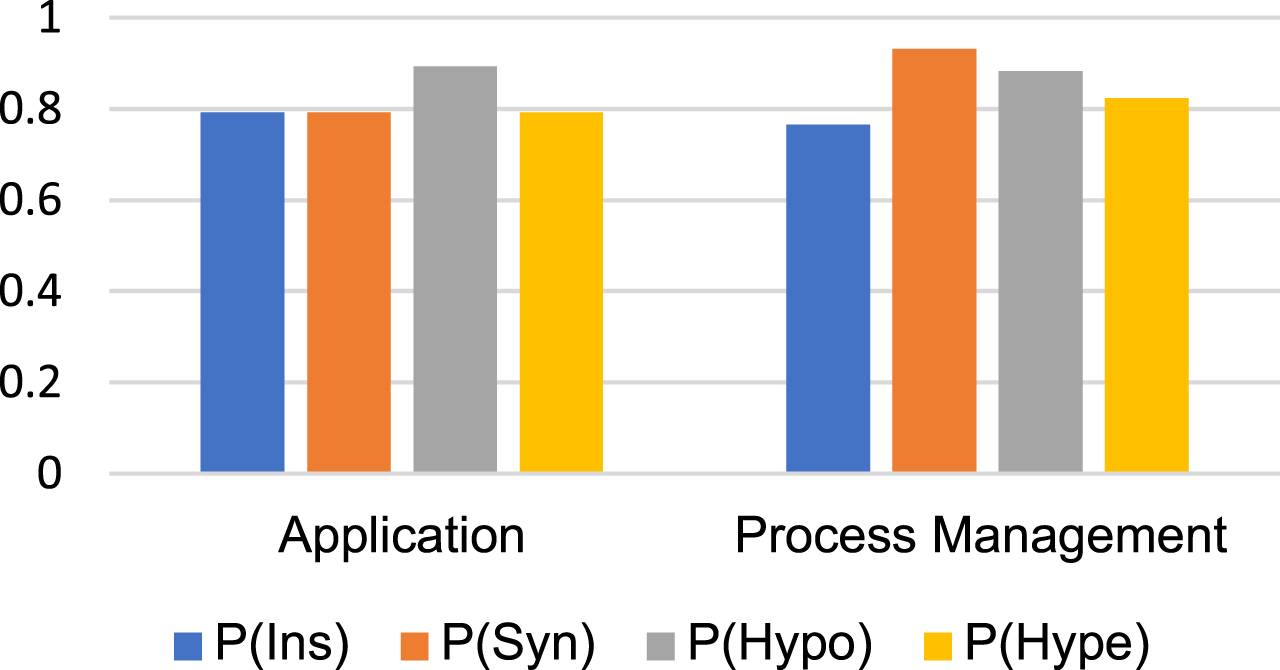
Precision of synonym, hyponym, and hypernyms relations.

Percent recall of synonym, hyponym, and hypernyms relations.
To compare the precision and recall of the instances obtained from our model, the Stanford CoreNLP 1 for the comparative evaluation method was applied. Stanford CoreNLP is a tool for the extraction of instances and relations from text documents. Stanford CoreNLP supports the API functions to develop the applications related to NLP. We chose two categories for comparability; the result is shown in Table 6. The scores reported in Table 6 reveal that the number of instances obtained from the Stanford CoreNLP tool is greater than that obtained from the deep learning model, but the precision and recall of our proposed approach are higher than the CoreNLP tool. The deep learning model focuses on context when processing the words in text documents, which is more reliable. Generally, the proposed method outperformed the Stanford CoreNLP tool.
Comparative evaluation method
The experiment in this study detected semantic relations, including synonyms, hyponyms, and hypernyms based on the KG and WordNet. These semantic relations play an important role for applications related to Question answering and information extraction systems. The KG approach, in particular, considers the relationships/links of words rather than independently evaluating individual words, and the KG is only focused on the computing domain. The currently available KG is cumbersome with 170 categories and one million entities. To solve the problem, we proposed an approach that has two steps—data training for building the KG and determining the semantic relations based on the KG and WordNet. We used the Keras model with word embedding and hidden layers for data training after pre-processing the data, which were extracted from the ACM Digital Library and Wikipedia. The Neo4J Graph Database was used to build the KG after the data training. To detect semantic relations, we applied a search algorithm based on KG and WordNet. Three measures were obtained, including precision, recall, and F-Measure, to evaluate the proposed approach. The connection of WordNet ontology to the proposed method takes more time to define the sematic relations. This is improved by attaching the WordNet into the KG to develop a Question answering system before identifying the semantics relations.