
Abstract
This study takes a new perspective on the procedural content generation (PCG) evaluation problem, extracts current PCG evaluation methods from previous works, and presents a novel classification of these methods while showing each method’s capabilities. Also, the present study introduces a novel concept called Panda Evaluation. Additionally, the soft and hard launches were presented as two evaluation methods and possible building blocks of PE. A group of papers was analyzed to understand previous works and find new opportunities. In doing so, some missing PCG evaluation areas were found, and some new methods were proposed for future PCG evaluations. To the best of our knowledge, this is the first time these concepts have been presented in PCG evaluation.
Keywords
Introduction
Digital games are becoming more and more popular worldwide [12]. One of the proposed solutions for more competitive game content creation is “procedural content generation” which can have several benefits in the game development industry, such as decreasing content creation cost, the ability to create infinite content, etc. [1].
Content in PCG research is most of what is contained in a game: levels, textures, quests, stories, game rules, items, vehicles, maps, weapons, characters, etc. [82].
PCG is not online or offline player-generated content. It is the algorithmic creation of game content with limited or indirect user input [102]. It is a young research topic and not only it has been used in much game-related research, but also several practical papers other than games like architectural models [24, 78]. Figure 1 shows a brief overview of the most popular keywords in PCG related studies. The map in Fig. 1 was created based on the data retrieved from
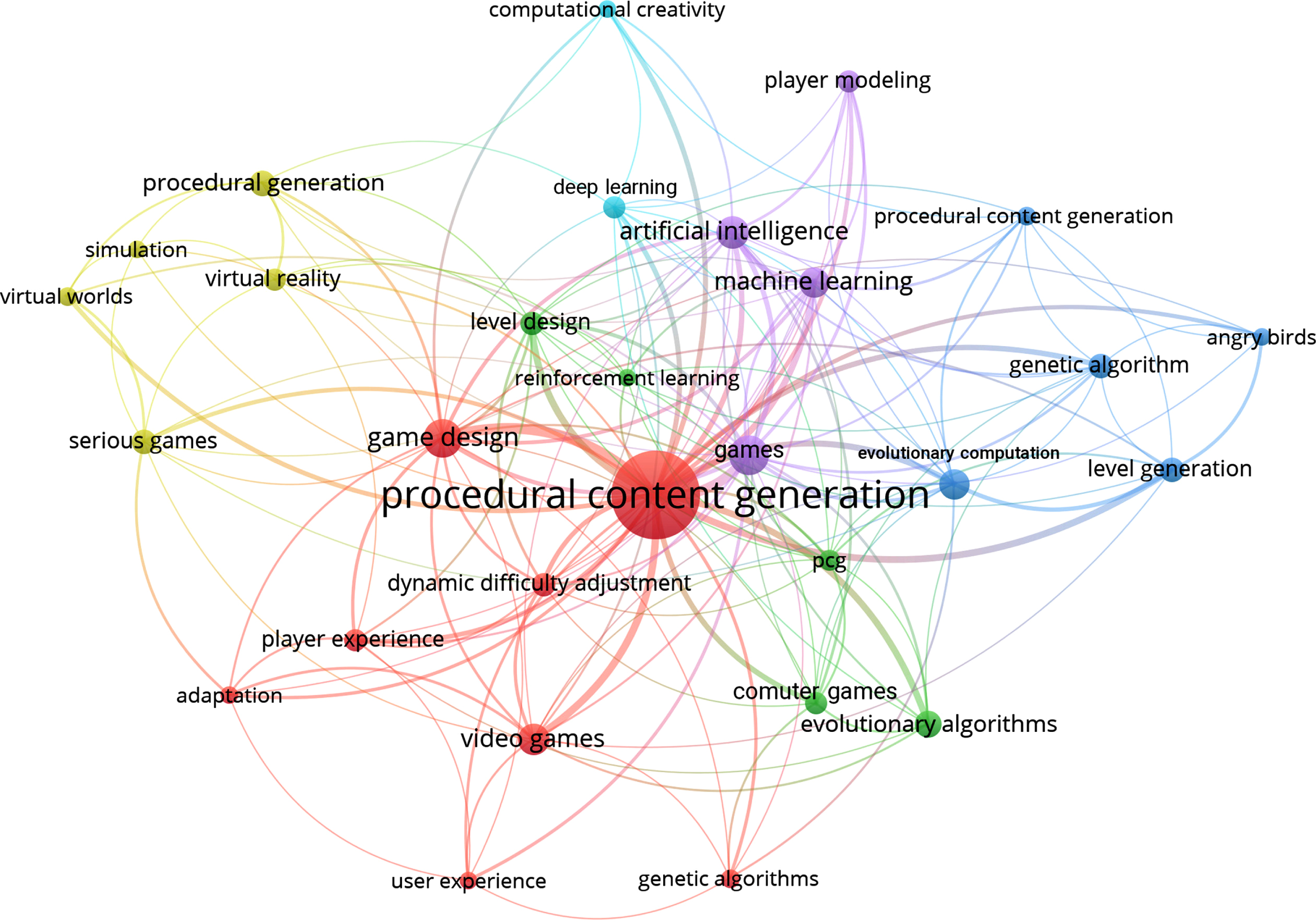
Popular keywords in PCG research field.
Table 2’s first-row search query (All PCG resarch in the computer science filed). This query was run on the Scopus database [79] on 2020/12/25, most popular keywords were selected. In this map, keywords that share the same papers are connected.
Search queries used to mine PCG research data from the Scopus database
Procedural content generation is a growing research field that studies the automatic creation of game content using algorithms. Research on content generation techniques should complement research in semi-automatic evaluation of the generated content [39].
Procedural content generation via machine learning (PCGML)
Machine learning addresses the question of how to build computers that are automatically improved through experience [44]. It is an evolving branch of computational algorithms designed to copy intelligence or humans through environmental learning [66]. In the field of artificial intelligence, machine learning has emerged as the method of choice for developing practical software for content generation applications [5, 15] or several general applications, including natural language processing, speech recognition, controlling robots, computer vision [44], gesture recognition [3], algorithm optimization [71], etc.
In recent years, there has been more use of machine learning in a PCG called procedural content generation via machine learning. PCGML is suited for repair, critique, and content analysis because it focuses on modeling existing content [96].
Brief comparison of PCG and PCGML
Although several approaches have been proposed in PCG research, much work remains to be done to characterize the quality, learnability, interestingness, utility, even playability, and other elements that may be important for users’ experience.
On the other hand, challenges in machine learning approaches are sometimes different from other PCG methods. For example, playability cannot be guaranteed easily in machine learning approaches for procedural generation of 2d platformer games [53], and some studies could not guarantee playability [31–35, 76].
However, some other studies guarantee playability, such as [103], in which an agent was used to check the playability of the generated content of introduced PCGML, or [90], in which playability constraints were used to its core sampling algorithm. Furthermore, in some PCGML research, playability is a value to be optimized or a constraint to be satisfied [92].
That it is sporadic in current PCG with machine learning approaches to test the system results with an actual player to see if their methods’ outputs are usable in game development or not (more details in Section 3, Fig. 5).

Case study methods and their evaluation methods. Notably, five methods did not use any kind of evaluation method.
On the other hand, unlike search or grammar-based PCG, PCGML does not require hand authoring of original content or rules [32]. Instead, PCGML is typically framed as the task of fitting a generative model to full-scale examples [46] and relies on existing content and black-box models, which can be challenging to tune or tweak without expert knowledge. This is especially problematic when a human designer needs to understand how to manipulate their data or models to achieve the desired results [33].
Table 1 presents a brief comparison between PCGML and other PCG methods. It should be noted that PCGML algorithms also need labeled data in the case of supervised learning methods [96].
A brief comparison between PCG and PCGML
Platformer games are a video game genre and subgenre of action games. In a platformer, the player-controlled character must jump and climb between suspended platforms while avoiding obstacles. Environments often feature uneven terrain of varying heights that must be traversed. The player often controls jumps’ height and distance to prevent their character from falling to death or missing significant jumps [86]. Famous examples of platformer games are Super Mario Bros [26], Mega Man [68], Donkey Kong Country [56], Kirby’s Adventure [37], kid Icarus [67], Sonic [80].
Selecting platformer genre as the case study enables us to consider different evaluation methods in these papers. because the platformer genre is one of the deeply studied evaluations compared to other genres.
What has been done in this paper?
In this paper, a brief history of PCG evaluations is presented, and then popular evaluation methods are staged and analyzed, focusing on each method’s pros and cons. What each evaluation method can and cannot do is also reviewed briefly. Our main purpose here is to find the missing part of executing PCG evaluation in current studies, introduce a novel discipline of evaluation called “Panda Evaluation,” and redefine soft launch and hard launch as a critical tool in the PCG evaluation area.
Throughout this research, several research papers and their evaluation methods are analyzed and compared. In the end, two algorithms are presented using flowcharts, PE, and soft launch.
Also, it is suggested to use analytics tools or questionnaires in the hard launch, which are costly but very powerful in demonstrating the actual performance of almost any PCG. It is concluded that each of the presented evaluation methods can complete a piece of the evaluation puzzle. The Recommended Panda Evaluation (RPE) is presented to minimize evaluation costs while maximizing evaluation quality and performance.
Case study papers
To study current PCG methods and choose case study papers, the following steps were taken. First, a brief analysis of previous PCG methods and their evaluation was provided, focusing on platformer games. Second, the platformer genre was chosen as a case study, enabling us to consider different evaluation methods in these papers.
Criteria for choosing case study papers
Chosen case study papers are those that introduce a complete PCG method in the platformer game genre or used their proposed method within a produced platformer game. The reason is to make it possible to analyze their evaluation method and compare these evaluations with others.
So the papers that did not use their new PCG method to produce different levels of a platformer game were not chosen as case study papers. Choosing PCG for the platformer genre as a case study
In the present study, PCG for the platformer genre was chosen as the case study for studying PCG evaluation methods. Platformers are one of the oldest yet most popular digital game genres [18, 65]. Although platformers are very important in PCG research, the gameplay level is the most popular form of the genre content to be generated procedurally [7]. Furthermore, in the present study, data research has been done on the Scopus database. checking platformer game genre popularity in recent PCG studies. The search queries were presented in
Table 2 and the analysis of the results is represented in Fig. 2. As shown in Fig. 2, more than one-third of all the PCG research (including non-game research) are in PCG for the platformer games field.

This pie chart shows research in PCG for platformer games, versus all the research in the PCG area.
Therefore, the platformer genre is one of the deeply studied contexts compared to other game genres. Some tools are currently only available in PCG for platformers, for example, the level metric for measuring the production capabilities of PCG, which is often only used for platformer games.
Table 3 shows a list of research papers collected here as a case study of PCG evaluation methods. Each row of the table is includes a unique research paper, year of paper publication, authors, paper citations based on Google Scholar [30] and also, the bold used methods in each paper.
List of case study research papers for PCG evaluation methods, containing publication date, the number of citations based on Google Scholar reports, and the author’s name
List of case study research papers for PCG evaluation methods, containing publication date, the number of citations based on Google Scholar reports, and the author’s name
Platformer games are one of the oldest game genres, and different platformer games are released in the game industry. However, Super Mario Bros [26] received special attention for some reason, and most of PCG in platformer studies focused on content generation for Super Mario. The reason for this attention can be the Mario AI championship [83] or super Mario fun nature. Figure 3 represents the percent popularity of Super Mario versus other platformer games. It should be mentioned that most of these studies used Super Mario as an example or a base to model their methods. Furthermore, it does not necessarily mean that their algorithm will not work for other platformers. Besides Mario, the other platformer games used in the case study papers are Kid Icarus [67], Mega-Man [68], Kirby’s Adventure [37], Spelunky [25, 101] (initially released in 2008, and later in 2020, the version Spelunky2 was released [38]).

The percent popularity of Super Mario Bros versus other platformer games in the present case study papers.
Evaluation is necessary to measure PCG system functionality due to several main reasons [82]: To understand each PCG method’s capabilities better. It is difficult to understand the capabilities of a content generator by seeing every single instance of its output. To confirm that the generated content can be guaranteed. If the desired content that we want to be able to produce has characteristics, it is crucial to be able to evaluate whether the generated content has the desired quality. To iterate on the generator more easily by checking whether its output matches the programmers’ intent. As with any creative endeavor, the process of creating a procedural content generator involves reflection, iteration, and evaluation. Being able to compare PCG methods with each other, despite different approaches. As the community of researchers working on creating the procedural content generators continues to grow, it is essential to understand how we are making progress concerning the current state-of-the-art.
Current evaluation methods
PCG research community has introduced different evaluation methods. Below is a list of the most well-known evaluation methods in the PCG research area, extracted from case study papers and previous works in the PCG area. Note that two new methods are also presented in the present study, which will be discussed in Section 5.
The Case study papers that used a player questionnaire for their evaluation are [19, 105].
The case study papers that used an expert questionnaire for their PCG evaluation method are [73]
The Case study papers that used an expressive range for their evaluation: [9, 89].
The case study papers that used a learning ability for their PCG evaluation method are [36].
The case study papers that used algorithm validation for their evaluation [32, 103].
The case study papers that used algorithm comparison for their evaluation are: [23, 105].
The case study papers that used an agent for their evaluation are: [32, 93].
For example, facial analysis can be used to detect players’ emotion [17], and some methods only use facial analysis and computer vision techniques to detect emotions [98, 100] It is also used in games, including correlating dimensions of experience [99] and enhancing online games [106–108]. On the other hand, signals, such as HR (Heart rate) and HRV (Heart Rate Variability), are used to detect stress remotely [13, 61–63]. In most cases, however, subjects are instructed to stay still [74], leading to improved accuracy in the estimations. Such behavioral constraints affect the interaction between players and games, making the experience unnatural.
A sensor is a device that converts one type of energy to another [4], it is a device which is able to convert any objective quantity to be measured into a signal which is interpreted [10], in computer software, sensors can also be a non-physical device. There have been studies on non-physical sensors and using them to detect players’ (human) emotions, such as stress or boredom [11].
The case study papers that used a player sensor for their PCG evaluation method are [40].
The case study papers that used in-game ratings for their evaluation are [73, 105].
Level metrics and expressive range
It is essential to find a way to characterize the content generator’s performance in the context of game design concerns to make informed decisions about which content generation method would be best suited for a particular type of content generation problem. A promising approach takes the form of metrics applied to the generator’s output and is used to characterize the generator’s expressive range.
Current level metrics
One weakness of the current PCG evaluation system is the lack of enough attention to the capabilities of the developed PCG method. Expressive range [89] is an excellent example of showing the production capabilities of the PCG method in the case of some game design level metrics, such as linearity and leniency. Unfortunately, no standard definition is currently available for these concepts. On the other side, there are many properties at a level. Some works consider more factors besides leniency and linearity in showing the production capabilities of the PCG method. The current popular metrics used to evaluate levels are only for 2D platforming levels, specifically those created in the Mario AI framework [45]. These metrics are grounded in design theory rather than being extracted from interviews with level designers or a critical design process [14]. In this section, an overview of accessible level metrics is provided in the platformer games genre. Figure 4 shows an overview of introduced level metrics and their progression through time and different studies.
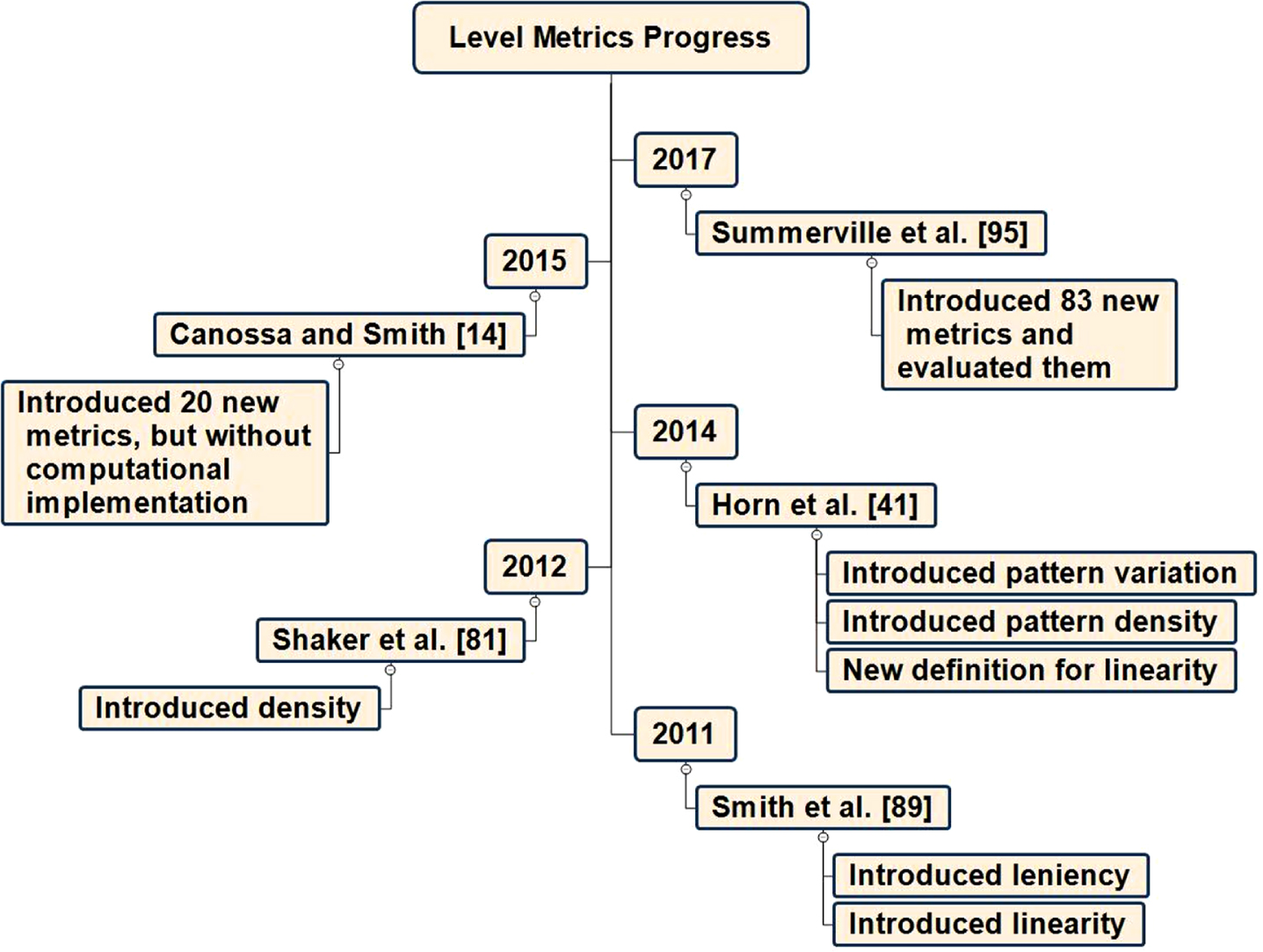
Level metrics progression from 2011.
Also, there are several different metrics, but only a few are popular in the research community. Here, five different metrics are chosen as the most popular ones. This choice is based on previous research and the use of metrics in them. A detailed description of some of these metrics for platformer games was presented in
Table 3, where each column corresponds to different research and its perspective. Note that [95] is not included in this table due to its lack of popularity compared to the other four papers.
Popular level metrics for platformer games
Using level metrics can have many small tricks and may make the evaluation difficult. For example, in studying the effect of enemy spread on the level difficulty, using Super Mario enemies as a sample can lead to false results. It is necessary to consider that one of the enemies in the Super Mario game is “Koopa Troopa,” [52] which may flee from or retreat inside its shells, which can usually be used as weapons [69]. So, Koopa is an enemy that can also be used to defeat other enemies and seen as a recurring weapon horizontally. In the research [95], as an influential study on level metrics in super Mario and platformer games, the effect of such level metrics have been studied on level difficulty.
Discussion on the evaluation methods of the case study papers
Figures 5 6 present the case study papers and their evaluation methods. Figure 5 shows the exact method and name of each evaluation method, while Fig. 6 shows the usage number of each evaluation method in the case study papers.
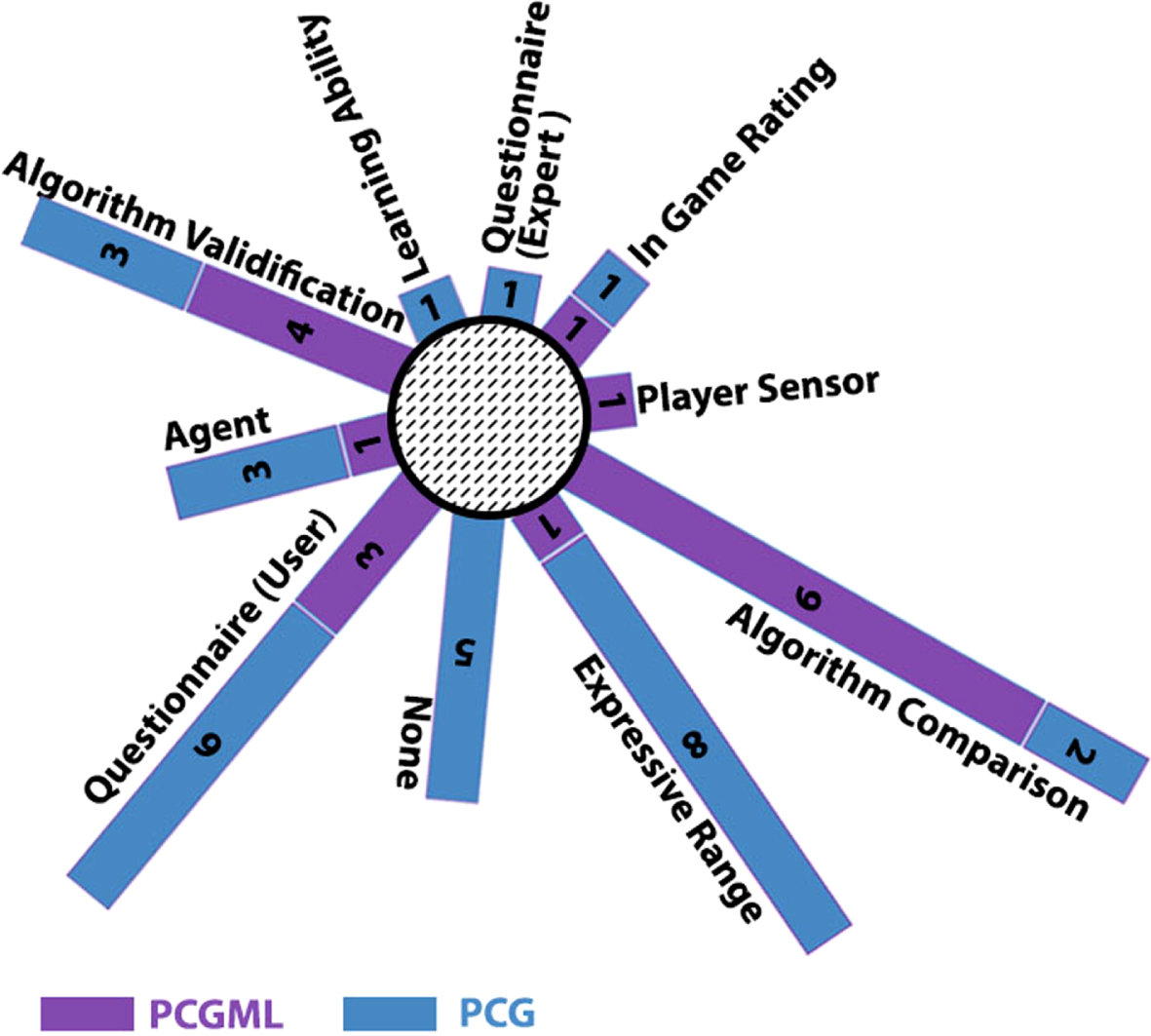
Evaluation methods and their usage in case study papers. The darker color corresponds to PCGML, and the lighter color corresponds to PCG without ML.
According to the figures, some notable points can be explained. These points will be used to find where the PCG research community has worked and which areas still need the community’s attention and progress.
All the case study papers that used PCGML have somehow included an evaluation system, but most of them used only algorithm comparison/validation. This means that many of these methods have never tested the quality of their output from the player’s perspective. Comparing and validating algorithms may help prove the algorithm performance. This tells us the algorithm does what it is meant to do, but it will never show us if the output is suitable for end-users or not. For example, one may implement a random algorithm that randomly places game objects in the space level. This algorithm error is most likely zero because it is entirely random as it is meant to be. However, it does not mean players would like to play this level.
Some methods have not evaluated their implemented method at all
It is worth mentioning that five paper [6, 59], on the PCG methods were never tested their output. It means that readers will have no idea how to measure these papers’ methods.
Some methods lack expressive range evaluation
However, most of these methods used at least one type of evaluation. As shown in Fig. 5, only some methods used expressive range evaluation [9, 89], which currently seems necessary because the expressive range is the only way of showing how the outputs of the implemented algorithm are different. So, we strongly suggest that every PCG research should use the expressive range as a part of its evaluation method. Otherwise, the usability of its method may not be trusted. Unfortunately, expressive range calculation is currently only prevalent in PCG for platformer research.
Some methods used only expressive range as evaluation
Some methods only use expressive range as their evaluation [9, 89]. The expressive range is also significant, but it does not show players’ ideas about created levels. For example, it is possible to develop a random algorithm with an acceptable expressive range, but this does not mean that a randomly generated level is acceptable. Indeed, the expressive range can only measure one aspect of Panda Evaluation, which will be discussed in section 5.
Soft launch and hard launch
Soft launch and hard launch are two methods that are new to the PCG research community. Even though hard launch and soft launch have a long history in digital software production, but to the best of our knowledge, this is the first time they are suggested for PCG method evaluation.
In product development, one can adopt two different approaches when it finally comes to taking a product to market: soft launch or hard launch.
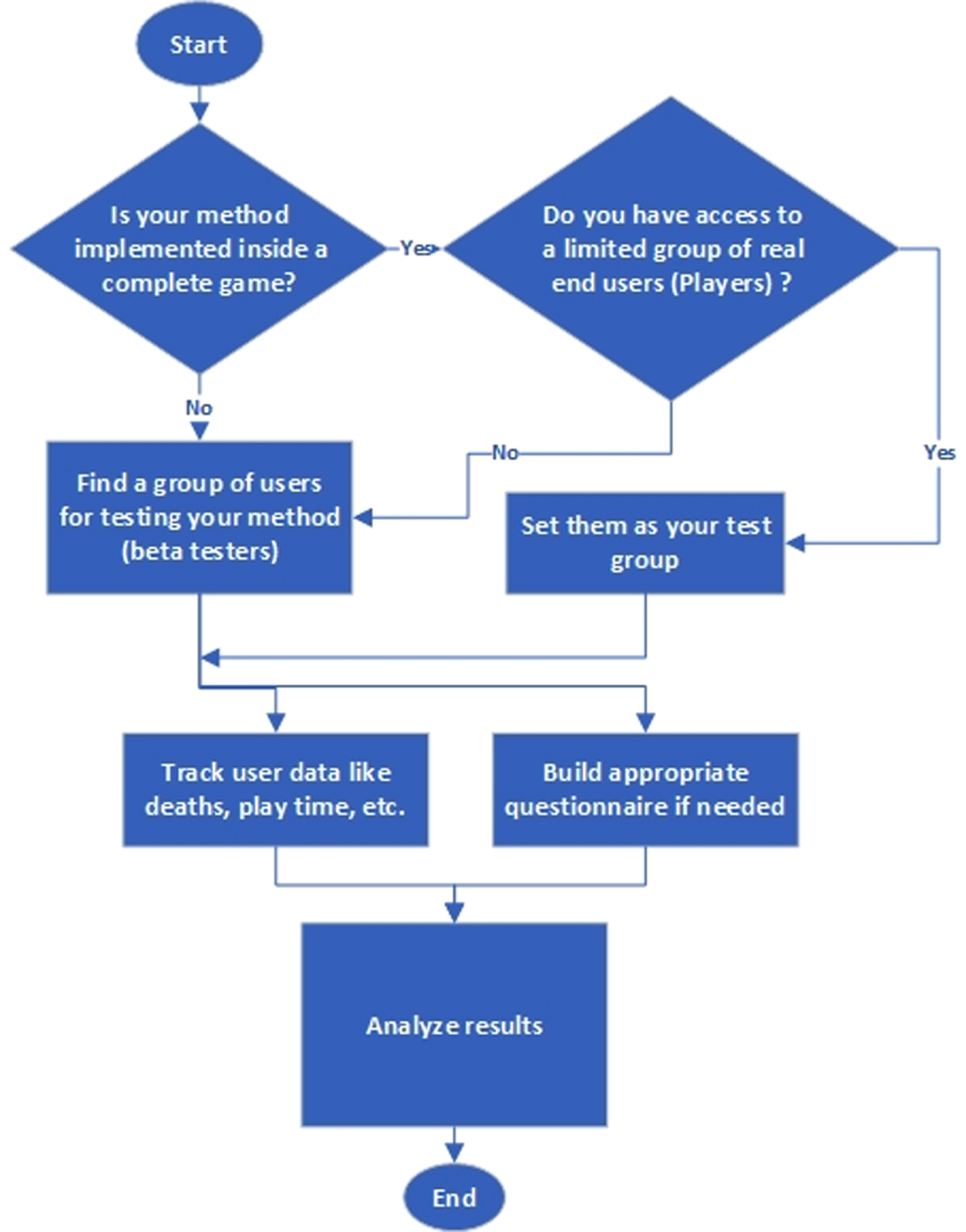
Flowchart of our recommended soft launch algorithm.
The idea of a hard launch as an evaluation method is to remove users’ balances, thresholds, and background about the research and the game and find the real value of the developed PCG method by releasing it in the real world with real users.
The soft and hard launch is not recommended to be used alone. Launching without tracking the user’s actions may not be a wise decision, and it is necessary to take users’ ideas and monitor their activities and analyze these data. Tracking users’ actions can be done using third-party frameworks while programming the target game, such as Google analytics [29] or game analytics [28]. On the other hand, an “in-game questionnaire” can be used to gather user ideas and feelings about evaluating methods.
Throughout this paper, some missing points of current evaluations were presented. Also, a group of papers was analyzed in the case of the evaluation methods.
In this section, first, each of the current evaluation methods is studied concerning their ability to measure a specific dimension of the target PCG method and is referred to as “Method Usage,” as defined in D5, since each evaluation method can measure a specific dimension(s) of a PCG method.
In the current paper, these dimensions are called “Evaluation Metrics,” as defined in D4. Of course, this is different from the definition provided for level metrics in Section 3.2
PE is a concept that tries to standardize the PCG evaluation by defining several steps for each PCG evaluation method. Of course, here, the focus is on PCG for platformers as it is one of the most studied areas in PCG for game research in case of evaluation. However, the same PE concept can be applied to a different PCG area in games and even PCG in general.
Discussion on panda evaluation
To define PE, first, it is necessary to find out what metrics should be the ideal evaluation measures in every PCG in the game algorithm. Table 5 presents a suggested list of these metrics. The following steps were considered to generate data in Table 5:
List of introduced evaluation metrics. Each evaluation method measures at least one of the mentioned metrics
List of introduced evaluation metrics. Each evaluation method measures at least one of the mentioned metrics
We advise that a full aspect evaluation examine the implemented method in all introduced aspects given in Table 5. In this paper, such an evaluation is named Panda Evaluation. To do so, it is worth mentioning Figs. 8 9 information. Each evaluation method is represented with a diamond node in these two figures, while each evaluation metric is represented with a trapezoid. Each node in the evaluation method is connected to the metrics that it can measure. Note that launch evaluation methods are presented separately in Fig. 9 for simplifying the graph. Figure 9 shows the launch method plus data analysis or user questionnaire usage. Each of these two methods has different and shared applications.
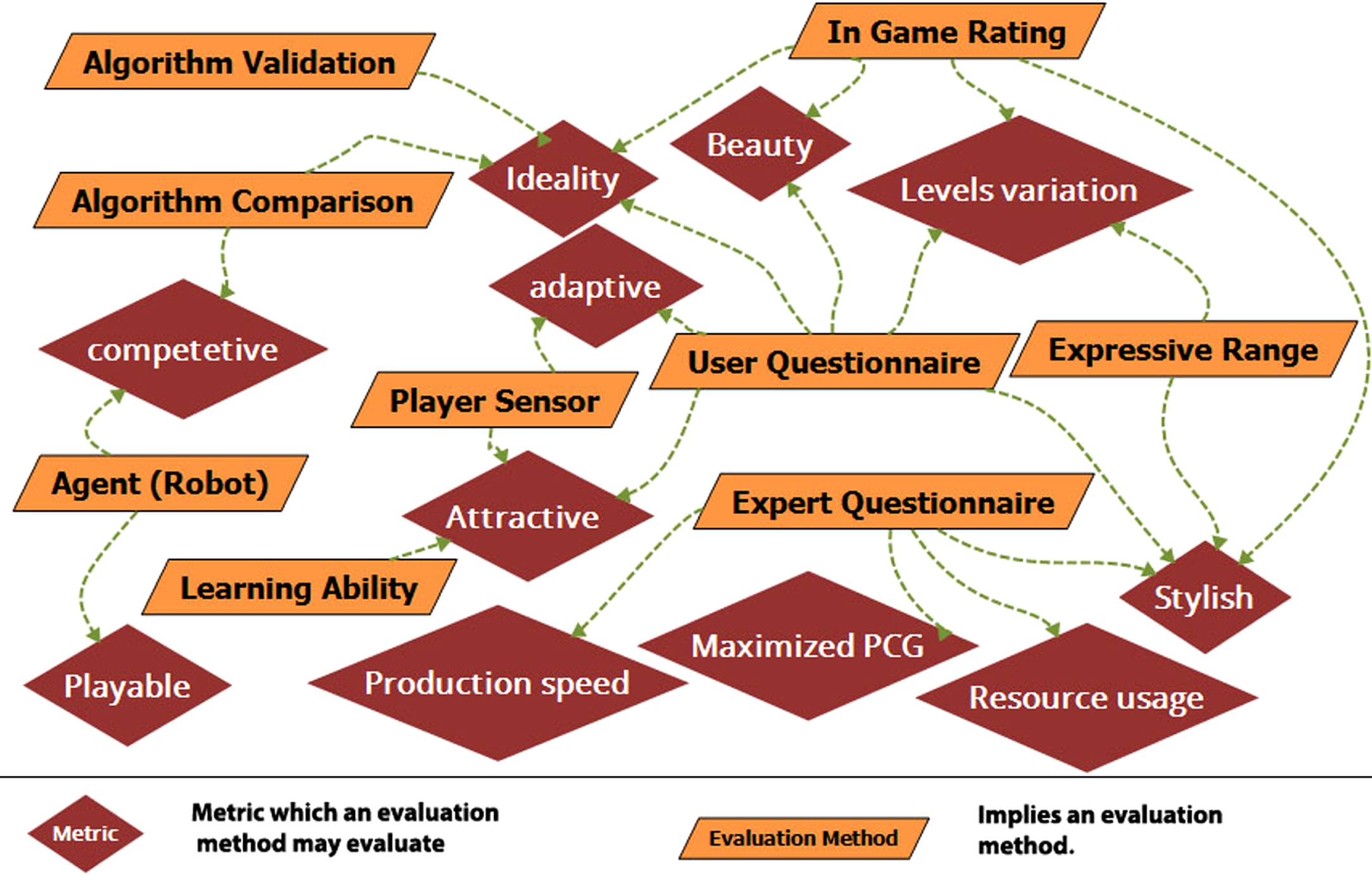
This EV Graph shows the application of each of the previous evaluation methods. Note that these are common applications of each method. One may use an agent or other methods in a novel way to evaluate a PCG method.
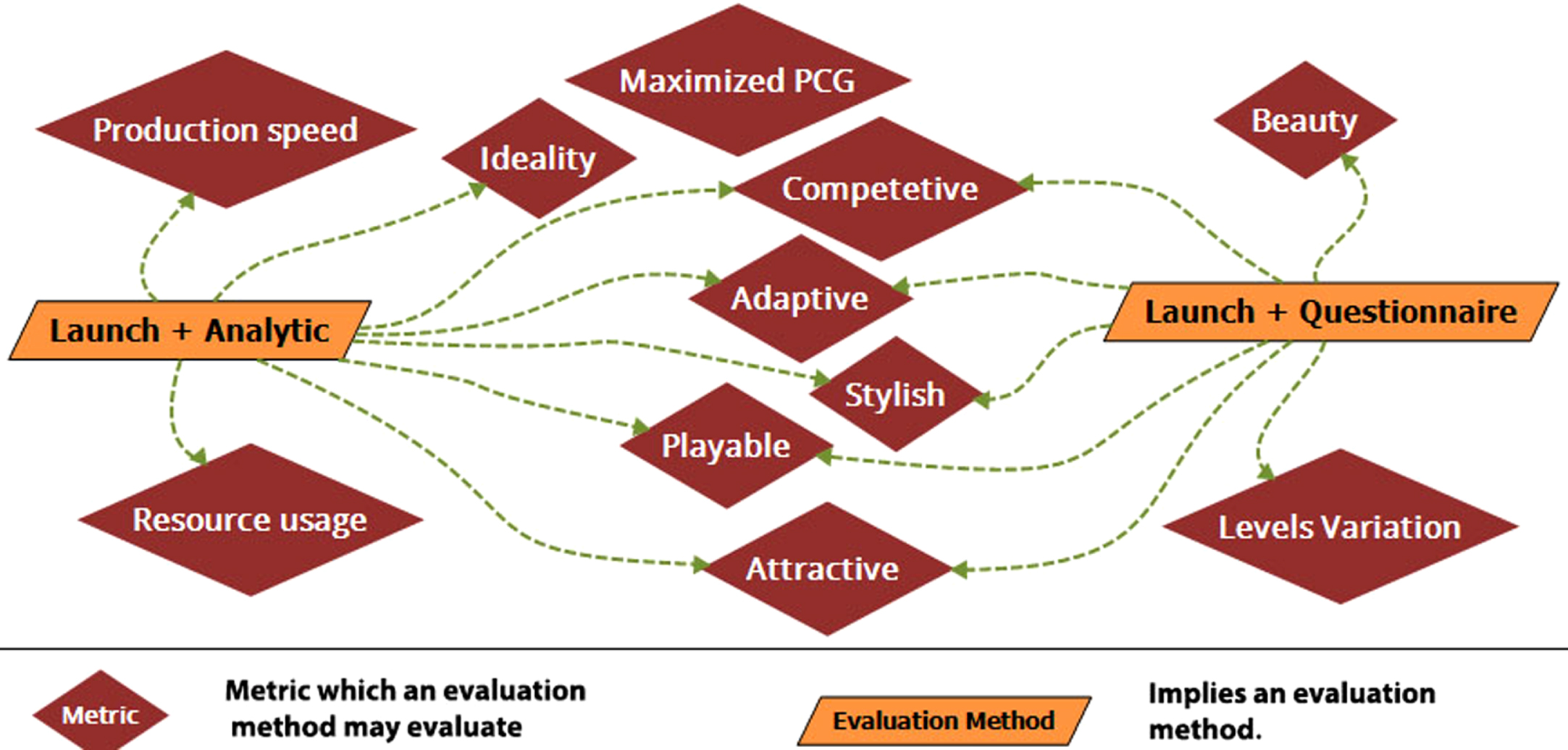
The use of launch methods combined with analyzing player data or questionnaire, as shown in this EV Graph, almost consider all applications presented in this paper, based on case study methods.
Here, any graph, such as those in Fig. 9 and Fig. 10, containing the connected evaluation method and metric nodes, is referred as an evaluation graph (D7), and a full evaluation graph is referred to as FEG (D8). According to the definition of the FEG graph and previous definition of PE, it is now possible to present another definition for PE using FEG (D9).

This flowchart shows the Panda Evaluation steps for each PCG method, focusing on PCG for platformer games.
Based on D9, there are many different PEs, so that each one guarantees to cover all available metrics. PEs can differ in evaluation quality, cost, performance, or other features. In the next section, we have introduced a unique evaluation algorithm to maximize total performance evaluation while minimizing cost.
The previous section showed that PE is not unique. According to D9, there are many ways to have a Panda Evaluation. Each PE has its pros and cons. In Fig. 10, a recommended PE is presented called “Recommended Panda Evaluation”, as it almost considers all presented evaluation methods but agents. Agents are customized for each method and may or may not be necessary for the evaluation. Therefore, they are not included in RPE.
RPE flowchart is represented in Fig. 10. A discussion of its steps is given below:
One may also cover this metric by proving that his/her developed PCG algorithm is procedural enough. Nevertheless, this metric is within the expert’s scope, and therefore he/she has placed him/her in an experts’ position, so it is still “expert opinion.” For this reason, the calculation of the expert’s opinions is critical.
In the soft launch phase, the player’s data will be gathered using an automatic tracker or a questionnaire, or both. The benefits of each of these two are presented in Fig. 9.
At this level, RPE is completed, and its results can be published to show the features of the implemented method.