
Abstract
The rise of social media and micro-blogging platforms has led to concerns about hate speech, its potential to incite violence, psychological trauma, extremist beliefs, and self-harm. We have proposed a novel model, Odio-BERT for detecting hate speech using a pretrained BERT language model. This specialized model is specifically designed for detecting hate speech in the Spanish language, and when compared to existing models, it consistently outperforms them. The study provides valuable insights into addressing hate speech in the Spanish language and explores the impact of domain tasks.
Introduction
Due to the heightened interconnectedness among individuals, the rise in popularity of social media and micro-blogging platforms continues to have uncharted consequences for our daily lives. Even though this connectivity has potential benefits [1, 2], the prevalence of hate speech and associated problems frequently overshadows them. If this is not addressed effectively and continues to attack people and organizations, it could fuel violence on a global scale.
Eventually, this can target communities based on their characteristics or affiliations not only to provoke violence but also to exacerbate the already-existing marginalization and discrimination experienced by minority communities [3, 4].
The troubling aspect of this phenomenon is that vulnerable members of society are more likely to constantly be exposed to such harmful marginalization through online platforms and social media. For instance, one of the most concerning consequences of prolonged exposure to hate speech is the significant psychological trauma it can cause. Individuals who are subjected to this phenomenon may suffer from anxiety, depression, and a sense of hopelessness, which can have a profound impact on their mental well-being [5].
To tackle all the above problems, various researchers have proposed automatic methods to detect hate speech incidents. Some of them use feature-based linear classifiers, which belong to a category of machine learning algorithms. The objective of linear classifiers is to make predictions based on a set of features or attributes associated with input data [6–9]. Beside linear classifiers, deep learning methods, particularly deep neural networks like CNN, LSTM, Bi-LSTM, and RNNs have been employed [10–14]. Also, language models that had already been trained, such as BERT [15], RoBERTa [16], T5 [17], XLNet [18], ELEC-TRA [19], and GPT [20, 21], were used to test how well they could find hate speech.
The outcomes in the realm of natural language processing (NLP) and different approaches to this task vary greatly as they are extremely dependent on a wide diversity of circumstances, prominently encompassing the dataset and the architectural choices made.
This inherent variability in results has led to some intriguing observations. Linear classifiers have consistently demonstrated their competitive performance, often rivaling, and in some cases surpassing, the effectiveness of neural networks across machine learning tasks [22–24].
However, the advent of pretrained language models known as GPT-3, BERT, RoBERTa, and their variants, have achieved unprecedented state-of-the-art results across a wide spectrum of NLP tasks. They achieved this by harnessing the power of massive pretraining on vast and diverse text corpora, enabling them to capture rich semantic and contextual information. Their versatility and capability show that they can generalize to a wide range of language-understanding tasks.
In spite of language models’ proficiency in handling general-purpose language understanding tasks, they may falter when confronted with more specialized or domain-specific language varieties. The reason for this limitation lies in their training data, which comprises a diverse array of languages and topics, making them exceptionally well-rounded but potentially less attuned to specific jargon, terminology, or nuances that are prevalent in niche domains. To mitigate this challenge effectively, it becomes necessary to fine-tune these pretrained models on domain-specific data using transfer learning. Toward this concept, many studies have attempted to train and build domain-specific GPT as pretrained language models. These are BioGPT for biomedical tasks [25], DialoGPT for conversation activities [26], EmoDialoGPT: generating response for emotion [27], BERT pretrained language models such as FinBERT for financial domain [28–30], LEGAL-BERT for legal domain [31], BioBERT for the biomedical task [32, 33], HateBERT for English hate speech domain [34].
These domain-specific models fine-tuned on domain-specific data allow for higher accuracy and better performance when compared to models built for general tasks [32]. They offer several advantages over generic NLP models. Such advantages are often crucial for addressing hate speech detection.
Here are some key advantages of using a domain-specific model: Improving the model’s understanding of domain-specific language makes it more contextually relevant. For instance, medical domain-specific models can outperform generic models in medical text-understanding tasks [32]. From a data perspective, it requires less training data compared to training a generic model from scratch. This is because the pretrained base model already has a strong understanding of language, and fine-tuning focuses on adapting this knowledge to a specific domain. This can be a special advantage when labeled data is scarce or expensive to obtain [35, 36]. Since many domains have unique terminology and vocabulary, generic models may struggle with domain-specific jargon; however, domain-specific models can be tailored to recognize and interpret this specialized language more effectively [37]. For instance, domains like law, medicine, finance, and engineering rely heavily on specialized terminology and jargon.
Therefore, the present study proposes ““
The following is a summary of this paper’s significant contributions: Introduction of Odio-BERT, a specialized pretrained BERT model designed for detecting hate speech in Spanish, along with our source code. Compilation of all available Spanish hate speech detection datasets. Evaluation and comparison of our models with existing pretrained language models. Study of the impact of domain tasks and an insightful advice on how to deal with hate speech in Spanish.
For any researchers interested in furthering this research, they can access our source code and a comprehensive hate speech dataset through the following link: 1 . This repository provides access to the tools and resources necessary to build upon our work and delve deeper into the subject. You can also download our models from the following link: 2 . This resource allows easy access to the pretrained models we’ve developed, facilitating further research and experimentation in the field of hate speech detection.
The remainder of the paper is structured as follows: in Section 2, we explore the body of prior research and offer an insightful summary of it. We provide a thorough description of our data collection procedure in Section 3. In Section 4, we provided a detailed discussion of the proposed model. The experiments and their parameters are described in Section 5, the results are discussed in Section 6, in Section 7, we addressed the limitations and ethical considerations of the study, and the paper concludes with suggestions for further research.
Recently, researchers have achieved promising results by using domain-specific NLP models for tasks like hate speech detection. The utilization of domain-specific models can significantly enhance the performance of NLP applications in specific tasks, as highlighted in various studies we review in what follows.
Research focus on specific language
The above results indicate that when a pretrained model is further trained for a particular language, it demonstrates superior performance compared to more generalized models that are not fine-tuned for that specific language. This suggests the importance of language-specific fine-tuning for achieving better results in natural language processing tasks.
Research focus on specific tasks
Hate speech detection
In [46], the researchers conducted an investigation into the most effective attributes for detecting hate speech in the Spanish language. They also explored how these attributes could be integrated to create more precise systems. Furthermore, the researchers analyzed the linguistic characteristics found in different forms of hate speech using explainable linguistic features. They then compared their findings with existing state-of-the-art methods. The results of this research demonstrate that combining linguistic features and transformer models through the integration of knowledge yields better performance than existing solutions when it comes to identifying hate speech in Spanish. Additionally, numerous studies have been conducted to address the problem of detecting hate speech in Spanish. The use of machine learning, [47, 48], deep learning [49–53], and the use of various pretrained language models [54–57] are just a few of the techniques that have been used in these initiatives. Despite these substantial research efforts, there is still a clear void in this area.
Based on the insights gleaned from the above-mentioned study, there are fewer works in Spanish than there are in English. It is crucial to increase the accuracy of hate-speech identification in Spanish. It becomes evident that using domain-specific tasks can significantly enhance performance across various dimensions.
Datasets
In this section, we provide an overview of the Spanish hate speech datasets utilized in our study. To conduct our experiments, we employed hate speech datasets sourced from prior research papers that are publicly accessible. These datasets were compiled by researchers from various social media platforms, including YouTube, Facebook, and Twitter 3 , and were obtained in text format. Our dataset is obtained from the following datasets: (1) Spanish Miso Corpus 2020, (2) Multi-lingual HateSpeech Dataset, (3) HomoMex, (4) HaSCoSVa-2022, (5) HaterNet, and (6) HatEval 2019 dataset.
Furthermore, the dataset provides LASER 1024-Dimensional embeddings for both training and test data, resulting in a total of 12,424 sample texts available for analysis.
The tweets were then subjected to annotation to identify instances of LGBT+ phobia. The dataset was divided into two sets: a training set consisting of 7,000 samples and a test set consisting of 4,000 samples. The primary objective of this task was to detect hate speech, utilizing a multi-class approach that involved categorizing the content into three classes: LGBT+phobic (P), not LGBT+phobic (NP), or not related to LGBT+ (NA).
In our work, we removed 1,777 samples labeled as NA from the training set, resulting in a total of 5,223 data samples used for our experiments.
To create HaSCoSVa-2022, the researchers conducted a comprehensive review of publicly accessible data to identify instances of hate speech against immigrants in the Spanish language. It’s noteworthy that, to the best of their knowledge, there were no existing Twitter corpora that accounted for variations in language.
The motivation behind creating HaSCoSVa-2022 was to facilitate experiments in the domain of immigration. Specifically, the researchers focused on two distinct immigration scenarios: one involving immigration from Latin America and certain African countries to Spain, and the other involving immigration from Venezuela to neighboring countries where Spanish is the official language. Both of these cases were associated with prevalent online discourse marked by discrimination, often stemming from religious, stereotypical, and other factors, which affect a portion of the local population.
One notable characteristic of the HaterNet dataset is its significant class imbalance, where 1,567 documents were annotated as hateful, while 4,433 were labeled as non-hateful. In their evaluation, the authors of HaterNet focused on assessing the F1 score specifically for the hateful class.
Throughout their research, the creators of the HaterNet dataset introduced a novel approach that combined recurrent neural networks and multilayer perceptrons to integrate embeddings, emojis, and other statistical features. This approach yielded promising results, achieving an area under the curve (AUC) of 0.828.
In the context of HatEval 2019, the Spanish subset of the dataset comprised a total of 6,599 tweets, which were further divided into training, validation, and testing sets. In the Spanish binary subtask, the best performance achieved resulted in a macro averaged F1 score of 73% .
Among the datasets mentioned above, we leveraged all datasets for training our new model, with one notable exception being the HatEval 2019 dataset. The HatEval dataset was exclusively reserved for the purpose of evaluating and comparing our novel model against existing models.
Table 1 presents a summary of the benchmark dataset statistics, which encompass the following data sets:
Summary of the benchmark dataset for Spanish hate speech
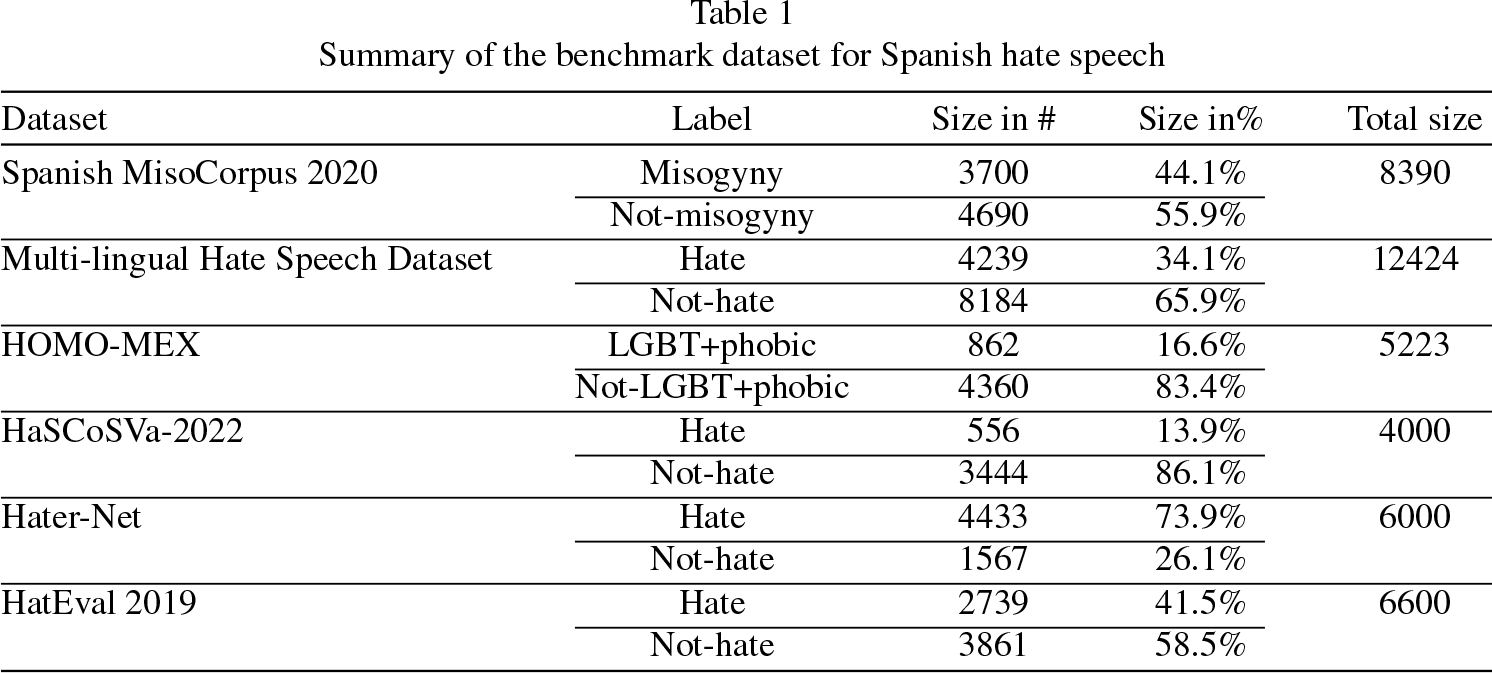
Summary of the benchmark dataset for Spanish hate speech
In total, we gathered 36,037 samples from the sources described in this section except HatEval 2019. After preprocessing the data, we ended up with 34,622 samples, indicating the presence of duplicate entries in the dataset.
Numerous language models have been developed that are exclusively trained on the Spanish language, such as RoBERTuito [38], BETO [62], and BERTIN [63]. However, it’s important to note that pretraining of these models is not tailored specifically for detecting hate speech in Spanish. This means that these contextual models are primarily trained on extensive multilingual datasets but are not fine-tuned for the hate speech domain. As a result, a domain gap exists, and the performance of these models in hate speech detection may suffer.
To address this issue, we took the initiative to pretrain a BERT model on domain-specific data, specifically, the hate speech dataset, which we extracted from various sources as discussed in Section 3. The choice of BERT for pretraining was deliberate, as it has demonstrated impressive performance and is gaining increasing popularity as a competitive, efficient, and swift solution for adapting pretrained language models to new languages and domains, as exemplified by [34]. We give the name Odio-BERT to our novel, fine-tuned BERT.
BERT models have already acquired substantial knowledge about language and context from extensive general text data. When fine-tuned on domain-specific data, this knowledge becomes tailored to the nuances of a particular domain, often resulting in a significant boost in task performance. Pretraining on the hate speech corpus equips Odio-BERT with an understanding of the intricacies of social media, including common issues like spelling mistakes, grammatical errors, and emoticons. Consequently, it enhances Odio-BERT’s capabilities in comparison to other models like BERT and BETO [62].
Our experiments provide clear evidence of Odio-BERT’s effectiveness, underscoring the importance of bridging the domain gap across the various datasets we compiled. This work highlights the value of adapting language models for specific domains, ultimately leading to superior performance in the task of hate speech detection.
Experiments
For our experiment, we merged all the datasets described in Section 3 and carried out a stratified split into training, development, and test sets in the respective proportions of 32,122, 500, and 2,000 samples. These splits remained consistent across all Odio-BERT experiments, ensuring that the results can be compared between different models and configurations.
To assess the impact of varying the amount of labeled data, we chose a subset from the dataset and repeated this selection process 12 times with different random sets. We then averaged the performance across these repetitions. The subsets we used were stratified samples, with sizes of 10, 20, 30, 100, 200, 300, 1,000, 2,000, 3,000, 10,000, 20,000, and 30,000. This approach enables us to evaluate the impact of utilizing more or less labeled data, both within specific orders of magnitude and across them. The results reveal that there can be substantial variations in performance when fine-tuning on limited data.
To mitigate performance discrepancies among different sets, we employed 5 distinct random seeds for each sample size in our experiments.
Figure 1 shows that our experiments exclusively revolved around Transformer based models. The reason behind this choice is the remarkable performance that Transformer models have exhibited in recent times across various hate speech detection tasks, as evidenced by several prominent studies [64–66]. These models, characterized by their advanced self-attention mechanisms, have consistently demonstrated their proficiency in capturing nuanced contextual information, making them the prime candidates for our investigation.
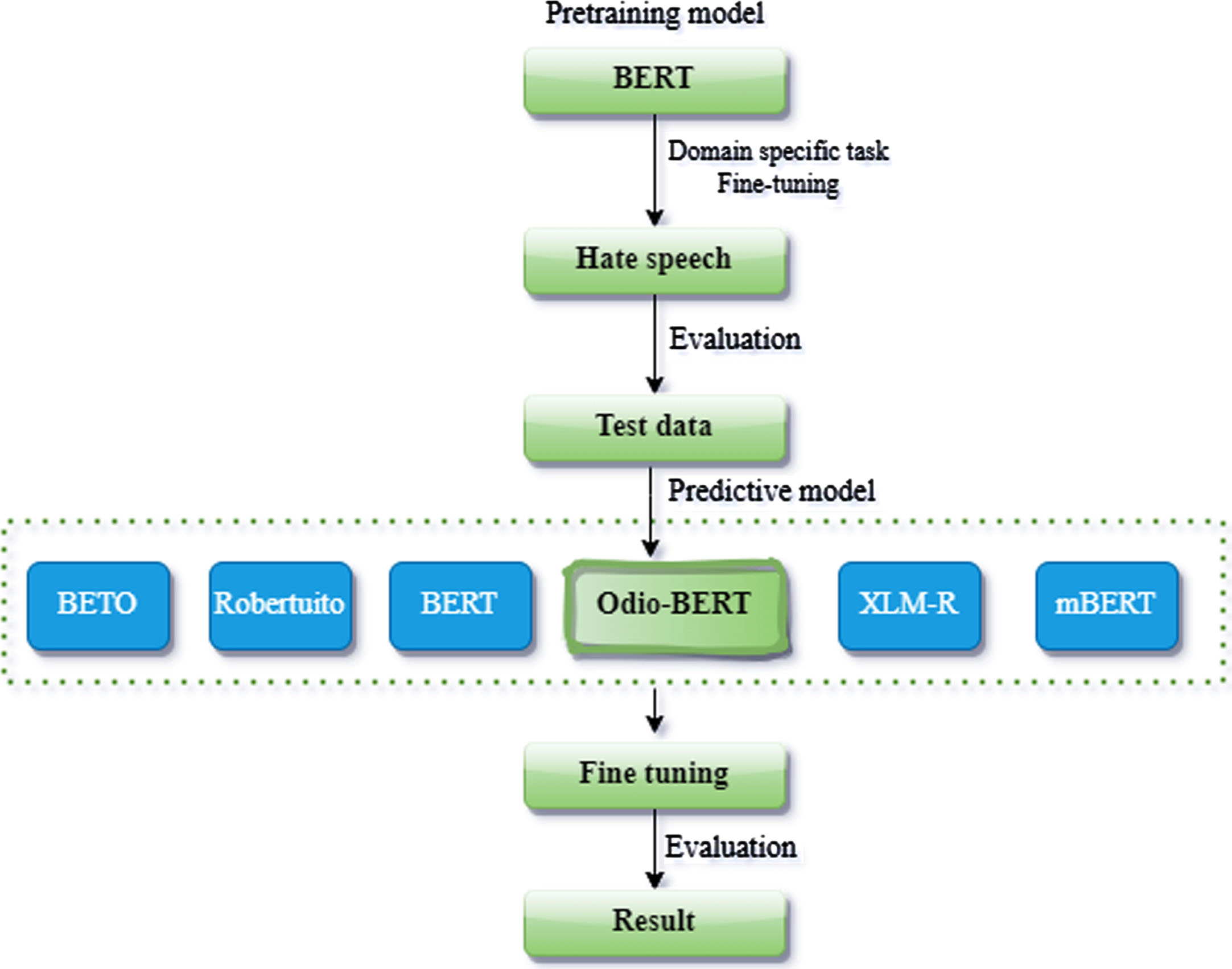
Proposed framework for Spanish hate speech detection.
As indicated by Table 2, the effectiveness of fine-tuning improves as the size of the training data increases. Drawing insights from our experimental results, we chose a model that had been trained with 20,000 samples as the foundation for our novel model.
The macro average F1 scores on the respective test datasets for models fine-tuned using

In addition to introducing our novel model, we aimed to comprehensively assess and combat hate speech in the Spanish. To achieve this, we considered a range of approaches.
The rationale behind our selection of BERT models lies in our desire to examine the distinctions between the standard BERT and our fine-tuned variant, referred to as Odio-BERT. Furthermore, we opted for two models from the pool of multilingual language models, specifically XLM-R and mBERT. These choices were made because both models were trained on extensive datasets encompassing various languages, including Spanish. Our objective is to assess how well these multilingual models perform in downstream tasks when supplied with training data in diverse languages.
In addition to our multilingual focus, we also made deliberate selections of two models that are centered around the Spanish language. These models, BETO and RoBERTuito, were chosen with the aim of conducting a comprehensive analysis and comparison between models designed for language-specific tasks and those tailored for domain-specific tasks, thereby shedding light on their respective performance levels.
mBERT introduced by [67], represents a significant milestone in the field of natural language processing. mBERT is a variant of the BERT model that has been pretrained on a massive corpus of text from 104 languages including Spanish, making it a powerful and versatile tool for multilingual NLP tasks. The primary objective of mBERT is to learn a universal language representation that can capture the nuances of language across various languages and tasks. By pretraining on text from multiple languages, mBERT aims to create a model that can understand and generate text in multiple languages, effectively breaking down language barriers in NLP.
XLM-R [68] is a powerful and versatile natural language processing model that has made significant contributions to multilingual and cross-lingual tasks. One of the notable aspects of XLM-R is its pretraining on a massive corpus of text from a wide range of 100 languages including Spanish. This diverse pretraining enables XLM-R to learn rich representations of text, allowing it to transfer knowledge across languages and perform well on a variety of language-related tasks.
BETO is pretrained on a massive corpus of Spanish text, allowing it to learn rich linguistic features and nuances of the Spanish language. It leverages the same transformer architecture as BERT, which is based on self-attention mechanisms. This architecture enables BETO to capture dependencies and relationships between words in a bidirectional manner, making it highly effective for various NLP tasks and we discussed about RoBERTuito in subsection 2.1.
To sum it up, the state of the art models we chose for the experiments to compare with our proposal are the following: 1) BERT, 2) BETO, 3) RoBERTuito, 4) XLM-R and 5) mBERT. We used such diverse models to comprehensively assess hate speech detection in Spanish, addressing various linguistic challenges and data scenarios. Results will be discussed in Section 6.
To assess the performance of our novel model in comparison to existing models, we employed the HateEval 2019 data set for evaluation. The primary factor motivating our choice of this dataset is its characteristic balance between classes, which minimizes bias and ensures a fair representation of different categories. This balanced distribution allows for a more reliable and equitable evaluation of model performance. By using this dataset, we aimed to conduct a thorough and unbiased assessment of our new model’s capabilities in the context of hate speech detection.
Our experiments were carried out using the NVIDIA System Management Interface (NVIDIA-SMI) with CUDA version 12.1, a powerful framework for GPU acceleration. In our setup, we harnessed the capabilities of an NVIDIA GeForce GTX 1080 graphics processing unit (GPU) equipped with 8 gigabytes (GB) of memory, which is equivalent to 8,192 mebibytes (MiB). This high-performance GPU played a critical role in the execution and optimization of our computational tasks, ensuring efficient and robust results in our experiments.
During the training of a domain-specific task, we utilized a training batch size of 8 while configuring a maximum sequence length of 512. For the evaluation phase, a batch size of 16 was employed, and our training regimen spanned a total of 3 epochs.
When we fine-tuned selected models for analysis with various approaches, we maintained the same settings, except for the epoch count, which was extended to 5. This adjustment allowed us to gather more comprehensive insights during the analysis phase.
As we discussed in Section 5, we conducted a series of experiments to assess the effectiveness of our novel model compared to existing models. Table 3 presents the evaluation results for hate speech detection, where we report accuracy and the macro average F1 score to gauge model performance.
Experimental results of the models including our model
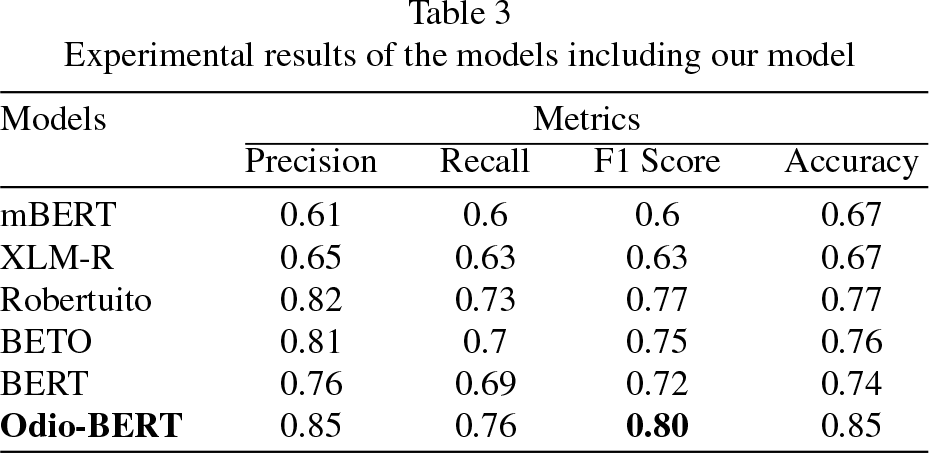
Experimental results of the models including our model
The outcomes of our experiments monolingual experiments indicate that the BERT model surpasses multilingual models. This superiority is attributed to its proficiency in capturing language-specific intricacies, nuances, and contextual cues. In cases where the objective revolves around deciphering language-specific hate speech, the language-specific model outperforms its multilingual counterparts.
Notably, our findings reveal that models tailored for the Spanish language demonstrate superior performance compared to mBERT, XLM-R, and BERT models. This enhanced capability is attributed to their adeptness at grasping the linguistic structures of the Spanish language, stemming from their pretraining and fine-tuning using a substantial Spanish corpus.
Conversely, the multilingual model, which encompasses Spanish, exhibited suboptimal performance in hate speech detection when juxtaposed with existing models. The difference is because multilingual models are made to understand a lot of different languages, but they might miss the finer points that are important for certain tasks that are only important for one language. For endeavors such as hate speech detection, where cultural and linguistic contexts play a pivotal role, language-specific models hold a competitive edge [69, 70].
In summary, our model consistently outperformed the spectrum of pretrained models discussed in the previous Section 5. This underscores the value of domain-specific fine-tuning, which enhances a model’s capacity to capture task-specific intricacies, as elucidated in Section 1.
Conclusion
We embarked on a domain-specific task utilizing a pretrained language model to effectively identify hate speech in the Spanish language. The process involved the amalgamation of diverse data sources provided by multiple researchers, which, in turn, served as the foundation for training the model. We thoughtfully curated and created a benchmark dataset tailored to the intricacies of hate speech. Fine-tuning the BERT model with this data was pivotal in comprehending and capturing the nuances of hate speech.
We carefully looked at different model sizes using different parts of the benchmark data and eventually chose a model trained on 20,000 samples as our domain-specific solution. This model is called Odio-BERT. Our proposed model does better than all the other models that have been used before. Tests using fine-tuned monolingual, multilingual, and Spanish-focused models on the HatEval dataset demonstrated this.
As a recommendation for future researchers in this field, we suggest that further enhanced results can be achieved through the fine-tuning of Spanish-centric models. The prospect of conducting a comprehensive study using a large-scale Spanish monolingual model for hate speech detection holds promise; however, we defer this endeavor to future research initiatives.
Footnotes
Acknowledgments
The work was done with partial support from the Mexican Government through the grant A1S-47854 of CONAHCYT, Mexico, and grants 20241816, 20241819, and 20240951 of the Secretaría de Investigación y Posgrado of the Instituto Politécnico Nacional, Mexico. The authors thank the CONAHCYT for the computing resources brought to them through the Plataforma de Aprendizaje Profundo para Tecnologías del Lenguaje of the Laboratorio de Supercómputo of the INAOE, Mexico, and acknowledge the support of Microsoft through the Microsoft Latin America Ph.D. Award.