
Abstract
The computing with words is an approach that has unique characteristics and advantages to model cognitive processes, this article explains the relationship and difference between type-1 and type-2 fuzzy sets in the definition of linguistic values. Here, we perform a compressive review and justify because type-2 sets are more appropriate in modeling linguistic values, and a heuristic procedure by examples is carried out to define linguistic values on a continuous variable. A visual comparison of a rule-based system, when linguistic values use crips, type-1, and type-2 fuzzy sets in modeling a cognitive system.
Keywords
Introduction
Cognitive computing covers a large number of areas and disciplines of artificial intelligence, and it is inspired by cognitive sciences and psychology that study the mental and neurobiological processes of the brain involved in the representation and processing of knowledge. The cognitive computing aim is to implement computational systems that can interpret and interact with humans more appropriately.
The Computing with words approach represents a prominent alternative in problem-solving with unique characteristics and advantages that conventional methods cannot incorporate [1]. The use of linguistic values in variables allows a better understanding in the characterization of complex or ill-defined phenomena, and knowledge representation in modeling systems [2]. Through a rule-based system, which can be extracted from knowledge obtained from natural language, human approximate reasoning can be processed [3].
The implementation of cognitive fuzzy systems using computing with words has been developed in different areas of research, such as decision-making applications, control systems [4, 5], robotics [6, 7], and medical diagnosis [8, 9], among others.
Type-2 fuzzy sets, introduced in the mid-70 s as an extension of type-1 fuzzy sets, were developed as a more suitable model for the representation of linguistic values [10]. The foundations’ mathematics and the processing methods of type-2 fuzzy sets have been generated by several authors [11, 12] and it was not until the 2000s that the first implementations of type-2 fuzzy systems were seen in literature.
Likewise, the boom of type-2 fuzzy systems has been also slow, since in principle, the theory was not homogeneous and undoubtedly it was more difficult to understand. Furthermore, the computational complexity of type-2 is greater of type-1 fuzzy systems, and in the early 2000s, the feasibility of these systems was not evident [13].
Several efforts to reduce computational complexity have been focused on the development of efficient methods and techniques for the implementation of type-2 fuzzy systems. And this has done that the application of type-2 fuzzy models currently is booming [14]. Over this direction, type-2 fuzzy sets were classified into two categories known as Interval type-2 or general type-2 fuzzy sets and systems [11].
Interval type-2 fuzzy sets, IT2FS, are more efficient computationally, and are more suitable for modeling the ambiguity and vagueness of fuzzy values, as will be explained in Section 2 in more detail [15]. Whereas, general type two fuzzy sets, GT2FS, allow a weighting of the membership, which makes them more complex and flexible in modeling. However, the complexity that entails general type-2, GT2, systems is higher. Currently, it is common to find works where GT2 fuzzy systems are implemented [16].
Note, in the literature can also find related studies about fuzzy sets such as interval-valued fuzzy sets and type-3 fuzzy sets [17–19], which are not in the scope of this study. This work covers cases with classical sets, also referred to as crisp, or ordinary sets, and in the context of fuzzy systems, these sets also will be referred to as type-0 fuzzy sets.
In principle, the linguistic variables were defined in the context of fuzzy logic, however, as we will show in this work, cognitive systems that use linguistic terms can even make use of classical sets. We are going to develop a dissertation that justifies why type-2 fuzzy sets are more suitable for modeling linguistic values in a cognitive system based on rule-based systems.
The motivation of this work is to present a practical dissertation about the behavior of a rule-based system, where the fuzzy values of the variables are modeled with type-0, type-1, and type-2 fuzzy sets. By examples, we analyze the similarities and differences of these fuzzy systems.
The structure of this work is as follows: Section 1 has presented a brief introduction to linguistic variables in cognitive computing; Section 2 covers the definition of linguistic variables and fuzzy sets and presents the considerations for defining the linguistic values of a variable. Section 3 presents the Mamdani type-1 and type-2 fuzzy inference processing, Section 4 presents an example of a cognitive fuzzy control system using type-0, type-1, and type-2, and analyzes the behavior model surfaces.
Fuzzy sets and linguistic variables
Before defining the linguistic variables, it is necessary to review the concepts of classical sets, type-1, and type-2 fuzzy sets.
Fuzzy sets
In classical set theory, a set is defined as a collection of elements that fulfill a common characteristic or simply elements that satisfy a condition [20]. The concise representation of sets (classical) is used in the cases of numerical variables, and when there exists a very large cardinality of elements, and there is no ambiguity. A set can be defined in a concise representation as Equation (1).

Where x, a belong to the discourse domain X. In the fuzzy approach, crips set A can also be described by a membership function as Equation (2)
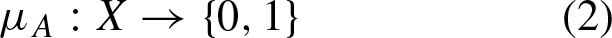
Therefore, each element x, of the universe of discourse X, is associated with A by its membership. If an element belongs to A, then its membership equals 1, or if it does not belong to the set, then its membership equals 0. This representation allows hand crisp sets as fuzzy sets, referred to as type-0 fuzzy sets.
A type-1 fuzzy set is a collection of elements in X, with an associated membership as Equation (3) into the unit interval

Now, Equation (3) extends the two possible membership values of Equation (2) to infinite number of values. If an element has a membership equal to 1, it indicates that there is complete certainty that the element belongs to A. Whereas, if its membership is equal 0, it indicates that there exists a complete certainty that the element does not belong to the set. Then a type-1 fuzzy set A with μ
A
can be represented as a set of pairs

Defining the membership with a numeric value assumes a complete certainty about the belongingness of elements to a fuzzy set, which seems contradictory for many researchers since the fuzzy approach incites to work with vagueness linguistics terms. (discussed in the next subsection).
Type-2 fuzzy sets emerge as a need to deal with the implicit uncertainty in linguistic terms. type-2 fuzzy sets generalize the concept of fuzzy sets. In a type-2 fuzzy set, the membership is weighted by a bivariate function as Equation (5)

Then a type-2 fuzzy set

A special case of T2FS is when all secondary memberships only have values of 0 or 1 values. Then the map performed in Equation (5) is replaced to a map of only two values as in Equation (7)
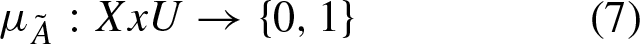
This kind of fuzzy set is called interval T2FS. And these sets are the most popular T2FSs used in the literature [21, 22]. To mark a difference between T2FSs that are not IT2FS, are called general T2FSs, or GT2FSs for short.
Another representation of a T2FS is as a fuzzy set with a linguistic membership value, that is, the membership value is a type-1 fuzzy set. The function that defines a T2FS using linguistic values is defined as
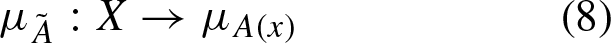
Professor Zadeh presented linguistic variables in the context of fuzzy sets in [10]. These variables contain linguistic values instead of traditional numerical values. According to Zadeh, a linguistic variable is defined by five components.
A linguistic variable is characterized by a quintuple {x, X, T (x) , M, G}, where x is the study variable with linguistic values, and it can be identified by its name, X is the domain or universe of discourse of the variable. T (x) is the set of linguistic values assigned to x, M is the semantic rule that associates a meaning to each linguistic value or fuzzy set (by a membership function) and G is the syntactic rule to generate linguistic terms.
Although linguistic variables can be used in both quantitative and qualitative cognitive systems [5, 23, 24]. Here we will only focus on quantitative problems, initially x is in real space and this is translating to the linguistic approach. We will explain by examples the computing with words method in problems with quantitative variables, such as position, speed, and height. And we will see why type-2 fuzzy sets are more suitable for modeling linguistic variables.
Syntactic rule and set of linguistic terms
By definition, a variable must have at least two values. From a linguistic perspective, these can be two qualifying adjectives for the variable, which are antonyms. If for some specific application, instead of having two values, it is desired to have three, four, or more values, then we only extend this criterion by generating linguistic qualifiers with gradual values. Table 1 shows some possible examples of variables with two, three, and four linguistic values. The extension to more values is direct, and in principle, a variable could have an infinite number of linguistic values.
Linguistic variables and possible labels for linguistic values

Linguistic variables and possible labels for linguistic values
The number of linguistic values depends on the application, for example from the perspective of psychology and cognitive sciences, a variable should have seven linguistic values (plus-minus 2) for effective human processing information [25]. In practice, most applications such as control [26], robotics [27], or other areas [28, 29], regularly input variables of fuzzy cognitive systems have between 3 to 5 fuzzy sets.
In principle, the number of linguistic values can be defined through a syntactic rule with context-free grammar [10], however, in general, the number of linguistic values is determined by trial and error and may depend on different factors such as the number of inputs, the input space partitioning, which influence the well-known dimensionality course problem.
The semantic rule is the procedure for giving meaning to linguistic qualifiers by using mathematical formality [1]. The use of parametric membership functions that characterize fuzzy sets in continuous variables allows the linguistic qualifiers to have memberships with a gradual transition.
On the other hand, regardless of the type of the fuzzy set (including type-0), the linguistic qualifiers, that is, the linguistic labels assigned to the values of the variable, e.g., as those shown in Table 1, clearly carry uncertainty, a problem known as linguistic imprecision. Therefore, determining the parameters of the membership functions depends on the problem and these are very subjective and depend on the application.
Determining the parameters of the membership function is very subjective and contextual to the problem. Many researchers support that “words mean different things to different people”, however, the authors of this work maintain that linguistic imprecision goes beyond a simple subjective interpretation of the qualifiers, rather it depends on the application, variable, the universe of discourse of the variable, among other factors. For example, a membership function to the qualifier “hot”, may have a very different numerical relationship in different contexts, that is, the “hot” qualifier may be associated with a different number when it is describing the temperature of their cup of coffee, or when it is referred to water of their shower. Inclusive, frequently it may be different when someone asks, how do you like your coffee, cold or hot? that if the question is, how do you like your coffee, hot or very hot?
Therefore, we extend the phrase “words mean different things to different people” to “words mean different things to different people, and at different contexts”. This idea is developed in more detail by examples in the next subsection
Designing linguistic values in the context of cognitive systems
The considerations about how to determine the semantics of linguistic values for the context of computing with words for cognitive systems are developed by examples. We assume that the study variable, its domain and the syntactic rule, that is, x, X, and T (x) are known, and the analysis considers the use of crisp sets, type-1, and type-2 fuzzy.
a) We will start the problem using the crisp sets. As was mentioned, defining which elements belong to a linguistic value is subjective and according to the context of the problem. In this general example, the criterion to apply is simple and only divides the universe of discourse into two parts. Temperatures less than 20 will be cold, and those greater than 20 will be hot. Figure 1 shows the cold and hot sets.
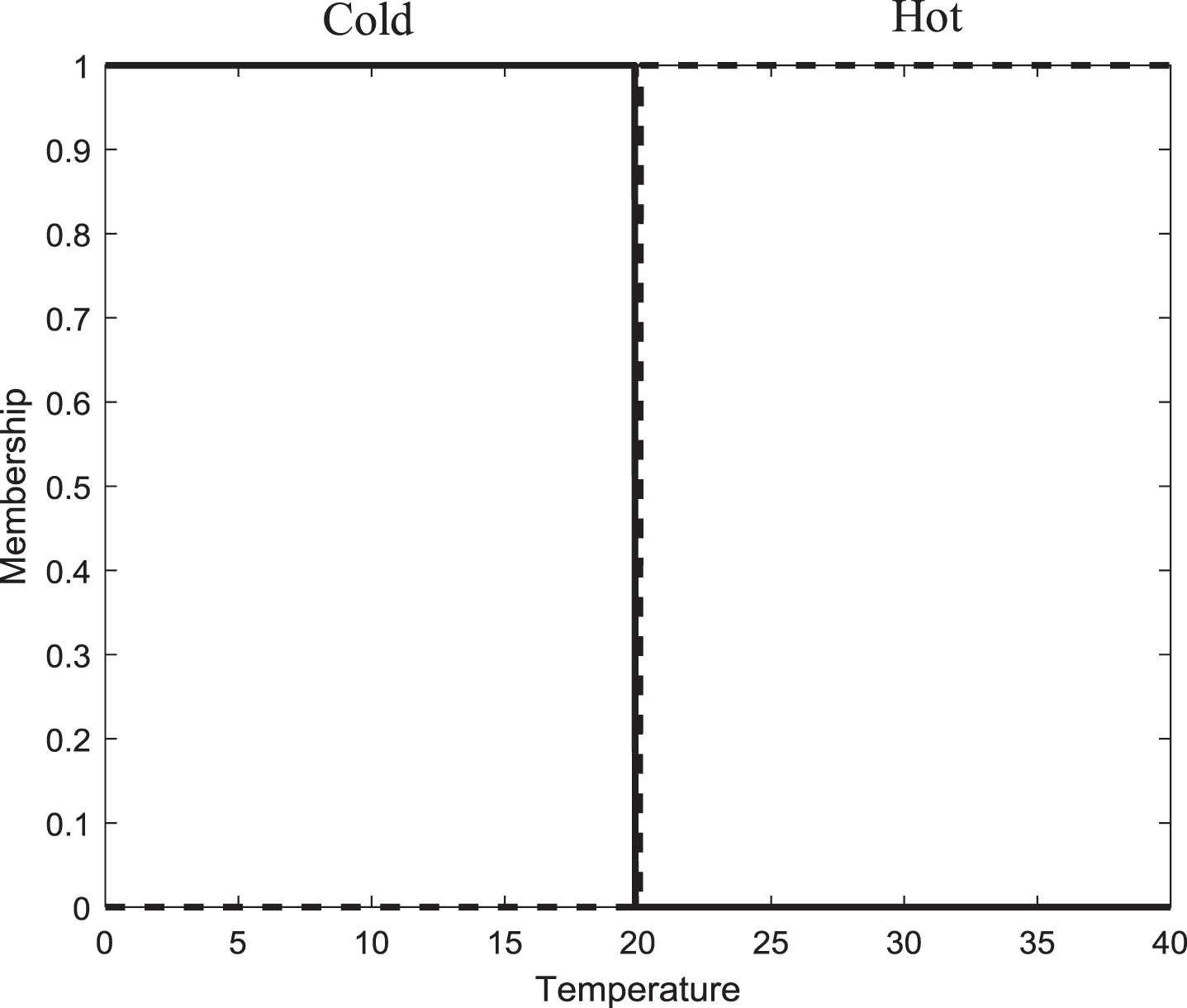
Two linguistic values with type-0 fuzzy sets.
We see that type-0 fuzzy sets, applying the established criterion, semantically makes sense, and in general, anybody will agree that the linguistic labels are well represented by the sets. However, as it has been widely documented, the problem with type-0 sets is the sharp boundary, or transition value, that determines among other cases that a temperature of 19.99 is cold whereas a temperature of 20 is hot.
b) Type-1 fuzzy sets solve the sharp boundary problem, these let have a membership function that can handle a gradual membership. Figure 2 shows a case of defining Cold, and Hot values with type-1 fuzzy sets for temperature variable.
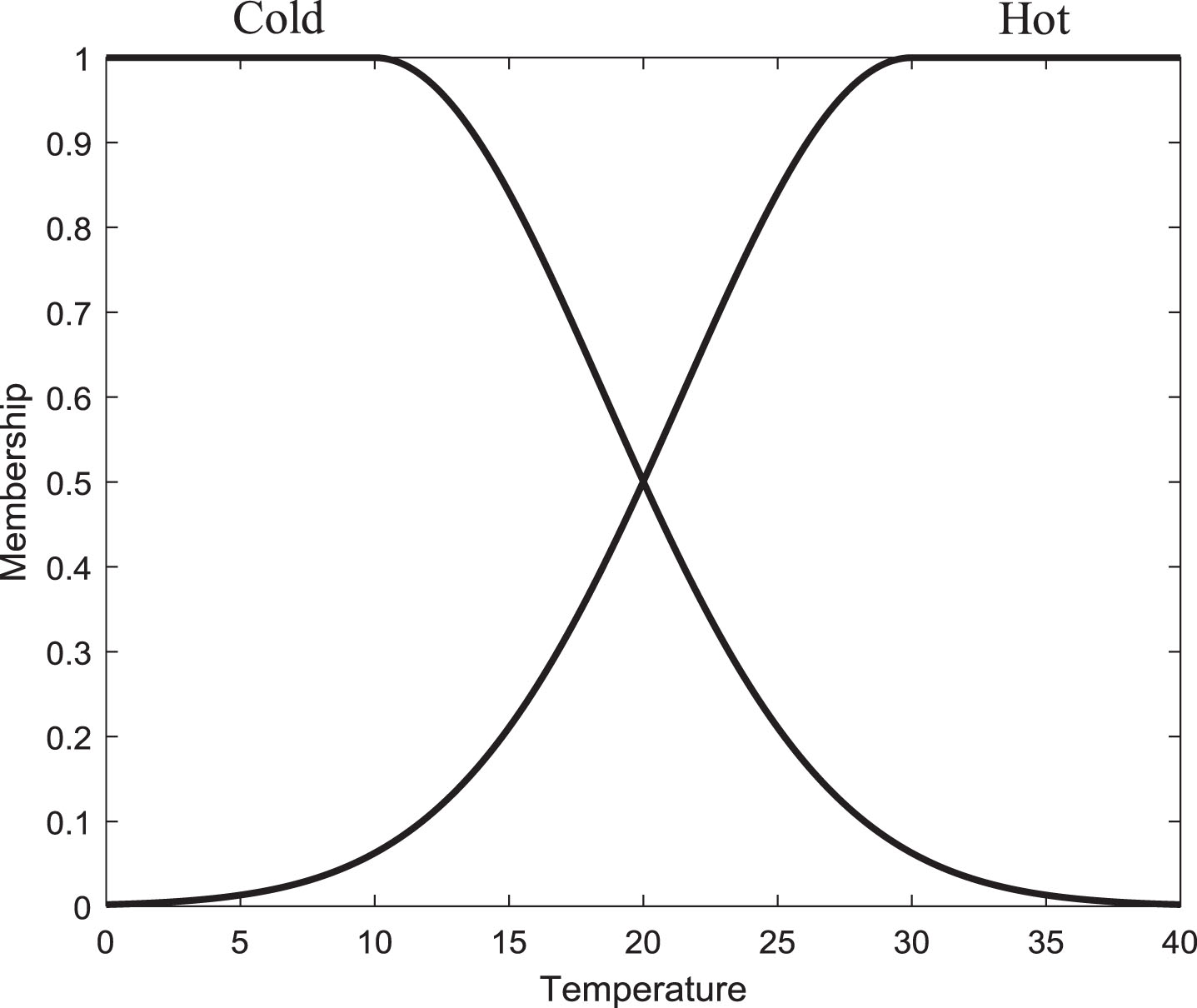
Two linguistic values with type-1 fuzzy sets.
As can be seen, a type-1 fuzzy set overcomes the sharp boundary problem. From an element-by-element perspective, these sets are a suitable model to face the uncertainty of what elements belong to a set, replacing how much is the belongness to it. However, from the conceptual point of view of a linguistic variable, type-1 sets define the qualifiers Cold and Hot with precision, it could be contradictory due to the implicit uncertainty, and vagueness of linguistics terms.
c) Figure 3 shows a way to define type-2 fuzzy sets to represent the linguistic qualifiers Cold, andHot . The membership can be defined by the boundaries of two membership functions, known as lower and upper membership functions, LMF and UMF (thick lines). This representation allows us to get a better model of the implicit uncertainty in linguistic qualifiers through the generation of a region of uncertainty. The region formed between UMF and LMF is known as the footprint of uncertainty, FOU (gray region generated into UMF and LMF). In Fig. 3, it is assumed that all secondary memberships equal 1. sets of this kind can be interpreted as follows: due to uncertainty in the linguistic qualifier, it can start from most left membership and finish at most right membership functions. Numerous sources define the foundations of fuzzy sets [11, 12].
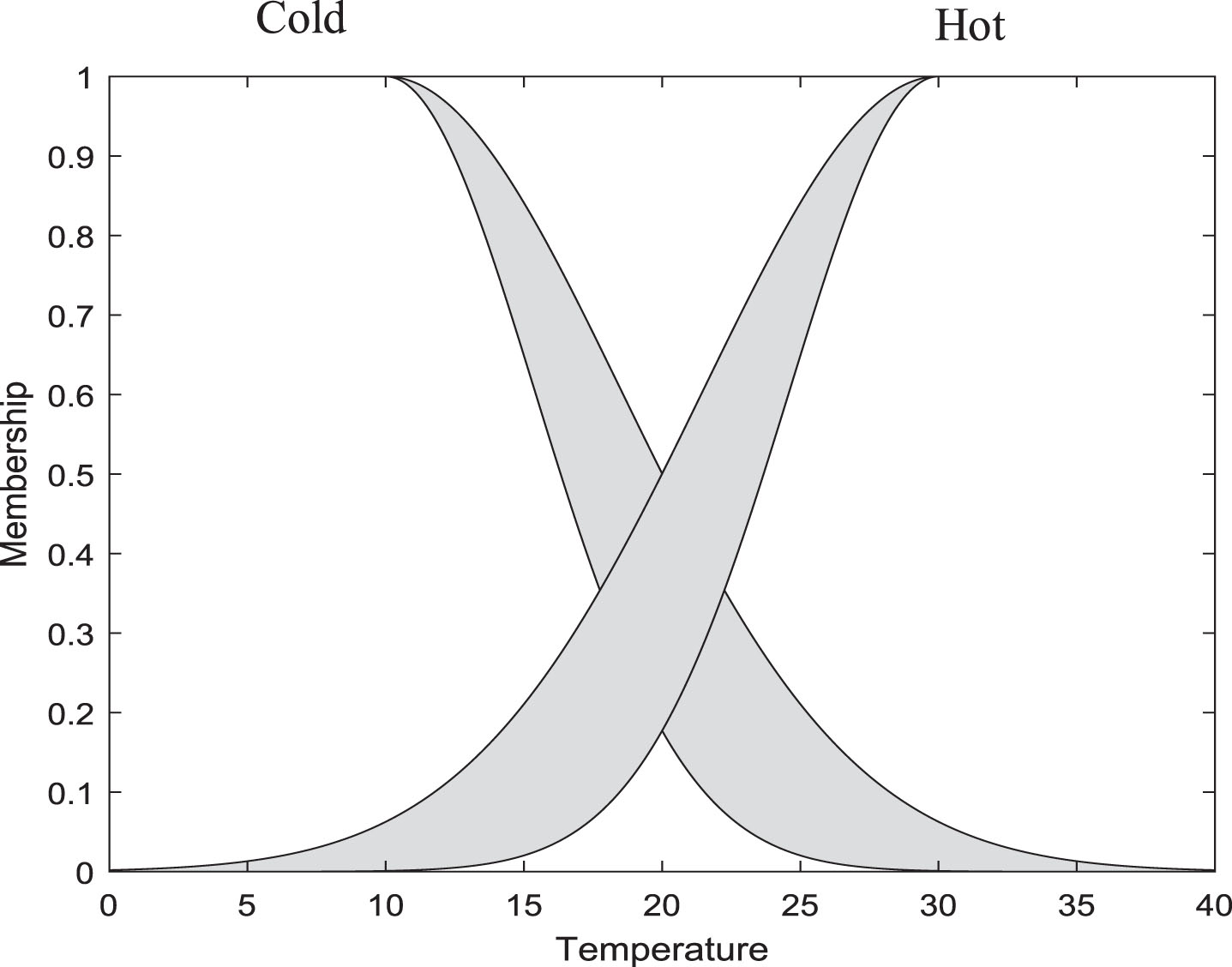
Two linguistic values with type-2 fuzzy sets.
In application problems such as cognitive systems, there is no unique predetermined way to know the number of linguistic values of each variable. Therefore, in the optimization of fuzzy systems, one way is assigning a small number of values and increasing it until get desired results in the system.
Now the linguistic terms can be T (x) = {Cold, Moderate, Hot}. We know, that the semantics to determine are subjective, in Fig. 4 is shown how these linguistic values could be defined in a specific application. For the case of type-0 fuzzy sets, the Cold value remains without change, and now the term that was considered Hot is divided, generating Moderate and Hot values. When type-1 and type-2 model these linguistic values, the sets replace those defined for type-0 in Fig. 4a).
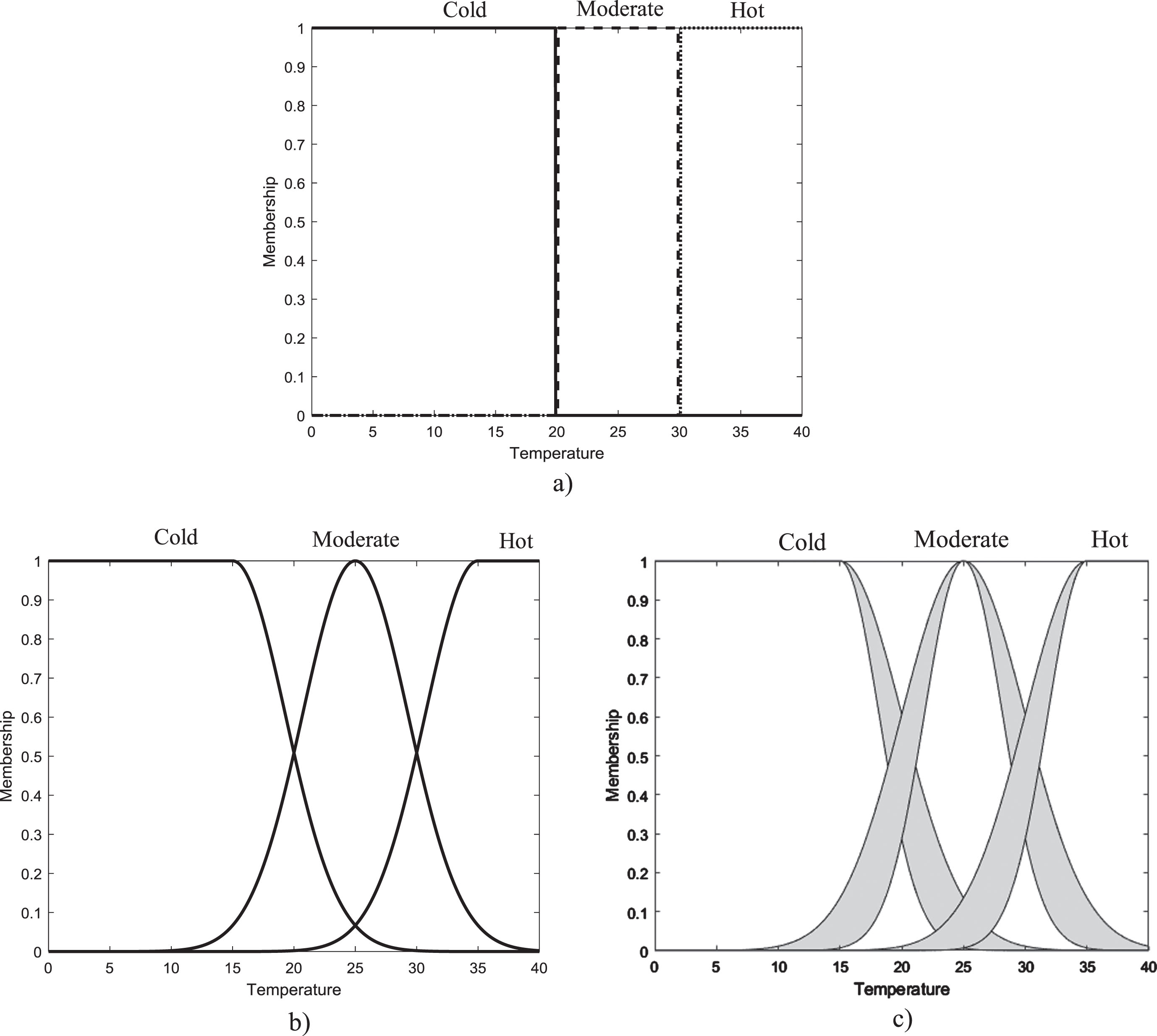
Temperature variable with three linguistic values: a) type-0; b) type-1; and c) type-2.
Increasing to more fuzzy values is direct, and the only thing is to remember that the semantics that characterize the linguistic values are subjective and in the context of the application. In examples 1 and 2, the semantics that define the linguistic values were established by applying only intuition about the concept. However, in real-life applications, frequently the membership functions that characterize the fuzzy value are optimized by using learning methods and strategies.
Figure 5 shows a hypothetical example of a linguistic variable with three optimized fuzzy values. For simplicity type-0 is not considered, where it can be seen that there is no linguistic rule that determines the final values of the membership functions, also for type-2 fuzzy sets, the uncertainty is independent in each linguistic value. However, the semantics can be easily inferred, the fuzzy sets seen from left to right represent ascending linguistic values, e.g., low, high, and very high.
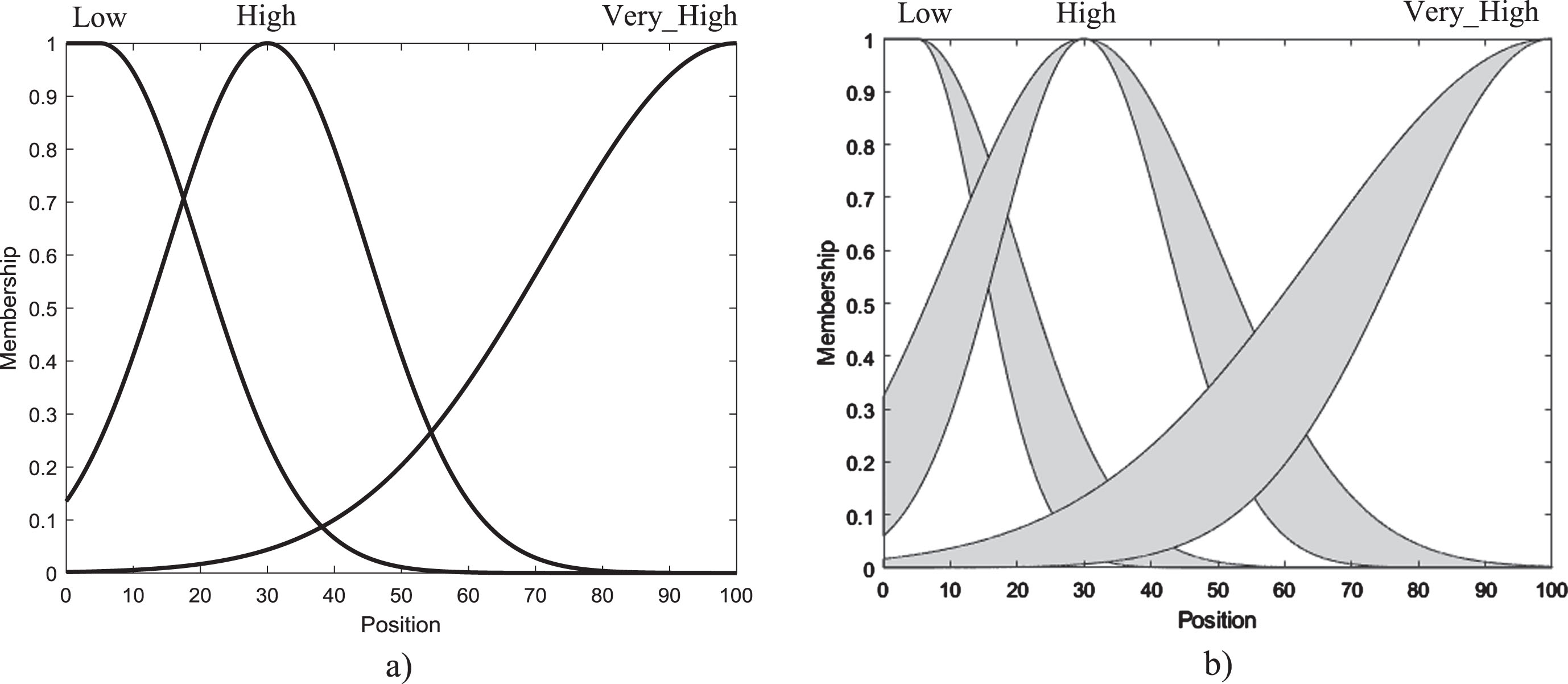
Position variable with optimized linguistic terms: a) T1FS; and b) T2FS.
In general, the optimization process of fuzzy systems helps to improve the performance, efficiency and precision of fuzzy systems, and this depends largely on the learning rule, the metaheuristic or optimization method, and the number of system parameters. Typically, a type-2 fuzzy system has more parameters than an equivalent type-1 system and a type-1 system has more parameters than a type-0. Therefore, it is to be expected that the optimization cost will be higher for a type-2 but its performance, efficiency and precision will be better.
The semantic values that define the extreme values, that is, the smallest and largest values in a linguistic variable, must be characterized with membership functions known as open-left and open-right respectively to give correct semantics [30], these functions also can be called to as left and right shoulder membership functions [11]. Whereas intermediate or non-extreme linguistic values must be characterized by closed (interior) membership functions. This condition should be maintained in the design and optimization of a rule-based system. In examples 1,2,3, the linguistic variables have met the condition of extreme and intermediate values.
A fuzzy system can be implemented using a rule-based system that can store, describe, or manipulate information. In a Mamdani fuzzy system, the rule base of the fuzzy system is independent of the type of fuzzy set. The structure of the l-rule for a system with p-inputs and 1-output is as Equation (9)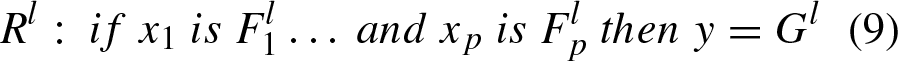
In Fig. 6, the four main components of a general Mamdani fuzzy system are shown. The fuzzification module is the input of any fuzzy systems, and this transforms numerical input values to some type of fuzzy sets mentioned in section 2.1. The rule base, that describes the behavior of the model, can be defined by a set of rules with the structure in Equation (9). The fuzzy inference process module carries out the mathematical operations of fuzzy reasoning, and the defuzzification module converts the set fuzzy output at a crips value. In a type-2 fuzzy system, the defuzzification module is usually divided into two, adding a type reducer module, which converts a type-2 fuzzy set to a type-1 fuzzy set.
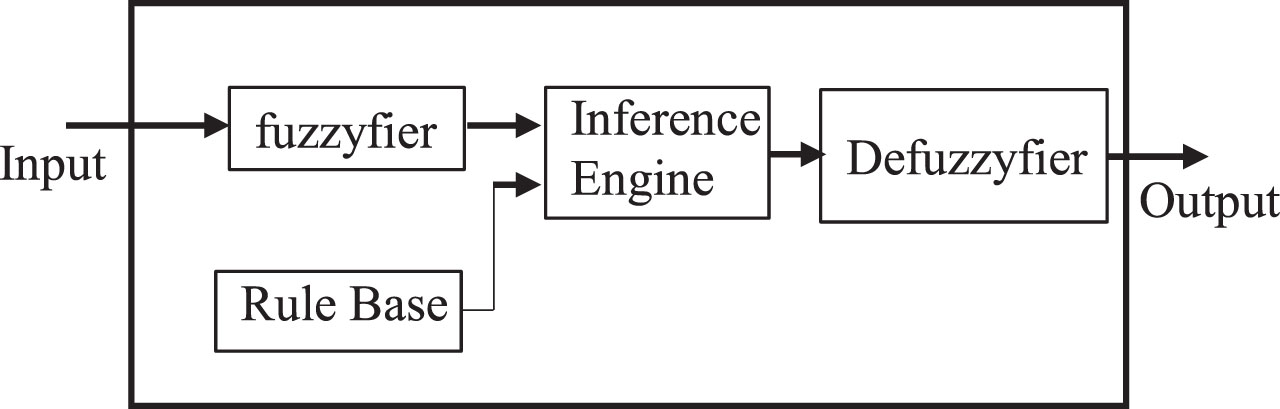
Fuzzy Inference System.
The fuzzy inference processing with a rule-based system and type-1 fuzzy sets can be summarized as follows: crips inputs are transformed to linguistic values by using fuzzy sets; then a degree of compatibility is obtained for each input; by t-norm functions, a firing strength of each rule is computed; and an induced consequent fuzzy set is generated in each rule; then all induced sets are aggregated to obtain the inferred fuzzy set. Finally, a crisp output value can be obtained from the defuzzifier module.
There exist several ways to perform the inference procedure operations [12]. The general calculation of fuzzy inference systems is as follow. If x* is a numeric input, the fuzzy system sees it as a fuzzy singleton, and the degree of compatibility for input x
i
is
From the antecedent part of the l-rule, the firing strength can be computed by using t-norm operators T as in Equation (10)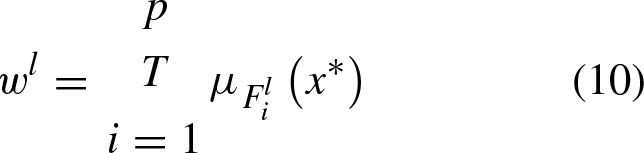
By the generalized implication rule, the induced consequent fuzzy set B
l
is getting as
Performing the aggregation of all M-rules of the rule base, the inferred fuzzy set is computed by the S norm operator as
Finally, a crisp value is obtained from the defuzzification of B, the centroid of the set is computed as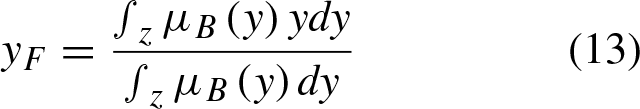
The inference processing of type-2 fuzzy systems, can be performed by considering only the LMF and UMF, when the sets are IT2FS. If the lower and upper membership functions are 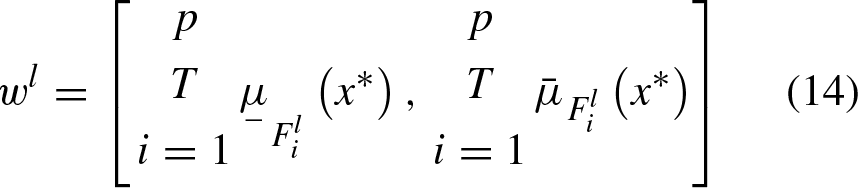
The LMF and UMF, of the induced consequent fuzzy set of l-rule is computed by Equations (15) and (16)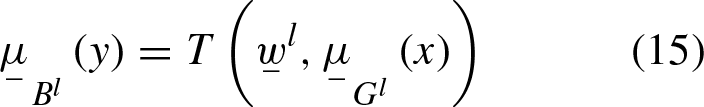
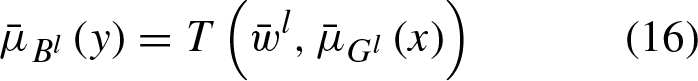
The inferred type-2 fuzzy set is computed as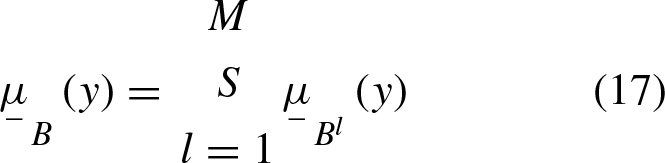
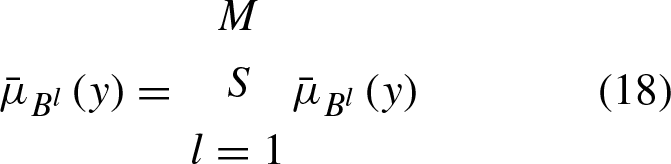
Apply the centroid type-reduction method to reduce the inferred type-2 fuzzy set, and by implementing the Enached Karnik-Mendel Algorithm [31], the most left and the most right centroids are as follows: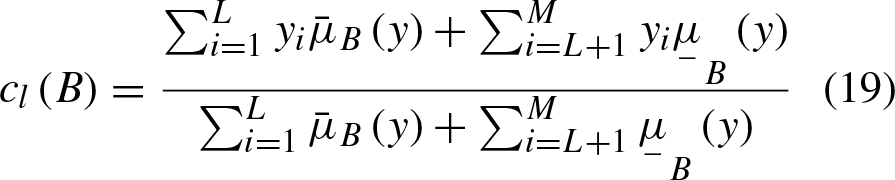
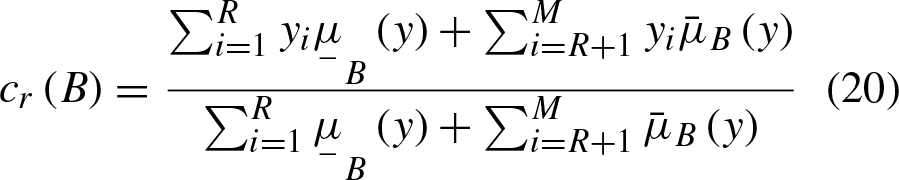
The crips value can be obtained by the mean of the most left and the rightest centroids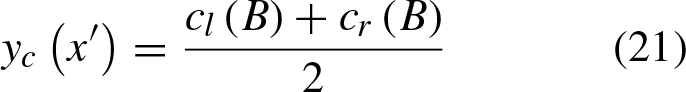
This section presents the behavior of a rule-based system that uses linguistic values implemented with type-0, type-1, and type-2 fuzzy sets.
To develop the comparation, this paper uses a simple cognitive map-fuzzy logic controller using type-1 fuzzy sets presented in [5]. This fuzzy system controls the DC-motor speed, and through a learning cognitive system were made up the linguistic values, the optimal rule-based system, and the optimal linguistic values.
The optimal fuzzy controller has two inputs and one output. In Table 2, the variables, their linguistic values, and the domains are presented for the inputs: error and change in error; and the output: voltage, e,
Linguistic variables of the fuzzy controller
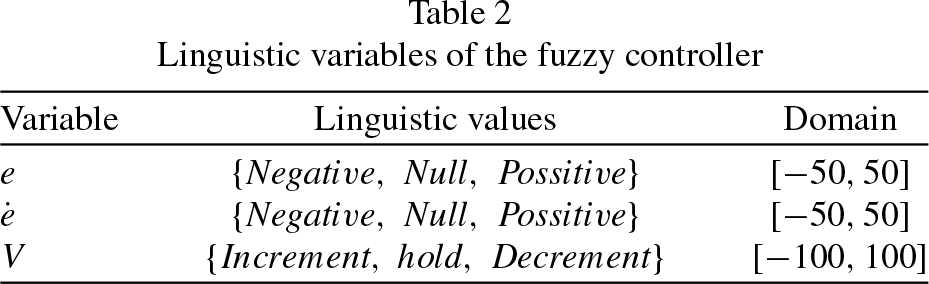
Linguistic variables of the fuzzy controller
Rule-based system of the fuzzy controller

To determine the semantics that define the type-0 and type-2 fuzzy sets, in this example we have only relied on the process described in examples 1, 2 presented in section 3, only instead of starting from a fuzzy set type-0 and approximate type-1 and type-2 according to the semantics of the concept, in this control example we start from the values of the type-1 fuzzy sets, and define the type-0 and type-2 sets that better semantically approach type-1.
Figure 7(a) shows the fuzzy controller mapping using type-0 fuzzy sets. It can be seen that the input space is divided into 9 well-defined regions, and the output variable only has 3 numerical output values, determined by the three linguistic values of the output variable and the rule base.

Fuzzy logic controller with 2-inputs and 1-output: a) type-0, b) type-1; c) type-2 fuzzy sets.
With this example, it is possible to see that computing with words works adequately without using the fuzzy systems approach. However, in applications where the variables are within the universe of real numbers, such as in this example, the solution of cognitive systems is very limited by using the bi-valued logic approach. This limitation is often overcome by using a complex system with many linguistic rules and values, but trying to interpret this rule base is very complicated.
Figure 7(b) shows the output surface of the same system, but the difference is the linguistic values use type-1 fuzzy sets. It can see a more robust input-output mapping, and now the output variable can have values within the range [– 60, 60]. Regarding the input space, although it is possible to see different behaviors by regions, these are no longer well delimited, this is due to the overlap between linguistic values. Then, if the designer wants to have less defined regions, the linguistic values should have more overlap, or if she or he wants to define more exclusive behaviors, then the linguistic values should have less overlap.
Finally, the surface in Fig. 7(c) shows the input-output mapping when the linguistic values in the rule base are type-2 fuzzy sets. At first glance, it can be seen that the surface is very similar to that obtained with type-1 fuzzy sets. However, when looking in more detail, the surface has a rougher appearance, which can be interpreted as small chunks of knowledge. These types of surfaces can be beneficial in systems very sensitive to changes in input, such as control, robotics, or signal processing applications. For example, type-2 fuzzy controllers can generate more robust systems and/or better performance, because the resultant cognitive model has more parameters (degrees of freedom) for its optimization, and it allows better management of linguistic uncertainty and/or other sources of uncertainty.
This article has presented an analysis that shows how type-2 fuzzy sets are more suitable for modeling cognitive systems described through computing with words approach, since they allow model the implicit uncertainty in linguistic qualifiers, in addition, it can see how a type-2 fuzzy system can generate maps with outputs with less sensitive to changes in the inputs (which can be interpreted as noise or sources of uncertainty implicit in measurements in control systems).
Comparative studies that focus on showing the advantages in performance, efficiency and precision of both generalized and interval type-2 fuzzy systems, over type-1 fuzzy systems in control problems have been presented in different works [32–34]. Likewise, as mentioned in example 3 of Section 2, the performance, efficiency, and precision of a system depend on the optimization process that involves various factors, and these are research topics and that are not considered within the scope of this work, and are considered as future works.
In this work, an analysis on the definition of linguistic values using type-2 fuzzy sets was presented. type-0 and type-1 fuzzy sets were used to exemplify the advantages of the computing with words approach using type-2 fuzzy sets. General considerations were presented in the definition of linguistic terms and the cardinality of the set of linguistic terms for continuous variables, and the advantages of type-2 fuzzy systems in modeling a cognitive system were highlighted. As future works, we propose comparative study of type-0, type-1, interval and generalized type-2 of optimized fuzzy systems in control problems and robotics systems.
Footnotes
Acknowledgments
The authors thank to CONAHCYT and Tecnológico Nacional de Mexico/Tijuana Institute of Technology for the support for this research work.