
Abstract
Image segmentation is a very studied area, looking for the best clustering of pixels. However, it is sometimes a complicated task, especially when these pixels are at the edges of regions, where there is a gradient and it is difficult to decide to which region to assign it. Hesitating fuzzy sets (HFS) better describe these situations, allowing to have multiple possible values for each element, giving more flexibility. This type of sets has been mainly applied in decision-making problems, obtaining better results than other types of fuzzy sets. This research proposes a fast and automatic method based on fuzzy hesitant clustering (FAHFC), which does not require parameters since it is capable of determining the number of clusters, using the Calinski-Harabasz index, in which the segmentation is performed, solving the initialization problem in clustering; it also proposes an alternative to construct the HFS through the use of fuzzy relations. The experiments show superiority in terms of clustering quality and convergence over some selected state-of-the-art algorithms.
Introduction
Clustering is an unsupervised learning task, which aims to divide a set of data according to their similarity, so that objects belonging to the same cluster are as similar as possible, while those belonging to different clusters are as different as possible [1]. This kind of learning, unsupervised, has been used in different fields, such as, machine learning, image segmentation, pattern recognition, among others [2–7]. Image segmentation has been studied with the objective of separating the image into more homogeneous regions that have similar characteristics, i.e., that belong to the same object [8]. It is a complicated task, because the images have different characteristics.
One of the most studied algorithms in this task is the Fuzzy C-means algorithm (FCM), which allows a fuzzy clustering analysis, in other words, each data is assigned a degree of membership in the interval [0, 1] with respect to each of the groups or regions, simultaneously, in such a way that each data belongs to a certain degree to each of the groups [1, 9].
There are different algorithms based on the FCM algorithm, making improvements to achieve better segmentation quality performance, such as the FRFCM algorithm that employs morphological reconstruction to smooth images [10]. AFCF [11] is inspired by the image superpixels, the DP algorithm and the prior entropy-based fuzzy clustering. The RSSFCA [12] utilizes regularization under Gaussian metric to obtain proper sparse memberships that can effectively reduce non-homogenous interference and achieve better classification, also employs the CCF-ADB to achieve automatically region merging. FCM_SICM [13] is another improved FCM with spatial and adaptive intensity constraint and membership binding.
The FCM algorithm exhibits a deficiency in its expression of degrees of membership with precise values, a limitation that becomes particularly pronounced when dealing with imprecise values along the boundaries of regions. This issue extends to other theoretical extensions, including intuitionistic fuzzy sets, interval-evaluated fuzzy sets, and type 2 fuzzy sets, all of which share a common challenge: the unclear assignment of the degree of membership to a fixed set due to a set of possible values rather than a probability distribution or a precise value [14]. In response to these limitations, Hesitant Fuzzy Sets (HFS) [15] emerge as a pivotal alternative. Proposed as a generalization of the fuzzy set, HFS excels in describing situations where uncertainties arise during decision-making processes, offering a more flexible approach to expressing preferences over objects. Unlike its counterparts, HFS allows for several possible membership values for a single element within a reference set [14, 16].
While traditional approaches to constructing HFS rely on expert input, determining the appropriate number of experts presents a challenge that significantly influences clustering performance [17]. Previous studies, such as the clustering algorithm PHFCM, have showcased superiority over state-of-the-art alternatives. However, their dependence on expert knowledge remains a limiting factor [18]. In this context, the proposed alternative aims to generate hesitant fuzzy information independently, reducing reliance on other algorithms and enhancing the adaptability of hesitant fuzzy sets. By addressing the deficiencies of FCM and other theoretical extensions, HFS emerges as a robust solution, offering a nuanced and flexible representation of uncertainty in scenarios where precise membership assignments prove challenging.
In this research, the theory of hesitant fuzzy sets is integrated into the field of clustering, presenting a method called Fast and Automatic Hesitant Fuzzy Clustering (FAHFC). The emphasis is on its application to data clustering, specifically in the context of image segmentation.There are four main features of FAHFC: (1) The algorithm dynamically calculates the optimal number of clusters c by utilizing the Calinski-Harabasz (CH) index, this eliminates the need for manual intervention, enhancing its adaptability across diverse datasets. (2) FAHFC generates fuzzy hesitant information through the implementation of fuzzy relations, this departure from conventional methods, which rely on alternative clustering algorithms or expert input, underscores the distinctiveness of our approach. (3) A image reduction technique is incorporated within FAHFC to minimize execution time by reducing iteration steps. This enhancement contributes to the algorithm’s efficiency, particularly when dealing with large datasets. Comparative analyses consistently demonstrate that FAHFC outperforms some of the state-of-the-art methods in terms of segmentation quality. This highlights the efficacy of our proposed algorithm in achieving improved clustering results.
The remainder of this paper is organized as follows. Section 2 describe some concepts used for the formulation of the proposed algorithm. The mathematical justification of the proposed algorithm is detailed in Section 3. Section 4 presents the experimental results and finally the conclusions in Section 5.
Background
This section briefly describes some basic concepts used for the formulation of the proposed algorithm, such as the theory of hesitant fuzzy sets and their distance measures, as well as the index used to select the number of clusters.
Hesitant fuzzy sets
The concept of hesitant fuzzy set was defined by Torra and Narukawa (2009) to deal with problems in which the membership of an element to a set is not clear and can express it more completely than other extensions of the fuzzy set. The HFS allow to have a possible several values instead of a one precise value (fuzzy sets) or a possibility distribution (type 2 fuzzy) even a margin of error (intuitionistic fuzzy set, interval-valued fuzzy set). HFS, mostly used in the decision making process, are a generalization of the fuzzy set, to better describe situations in which there are doubts when giving preferences over elements, allows several possible member- ship values for a single element in a reference set. Formally, can be seen as fuzzy multisets [16].
For a better comprehension, a HFS can be represented by a mathematical symbol [16]:
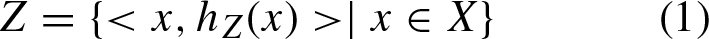
where h Z (x) is a set of some values in [0, 1], which denotes the possible membership degrees of the element x ∈ X to the set Z. h = h z (x) is called Hesitant Fuzzy Element (HFE).
Let X be a image of size M × N, in image segmentation, it is commonly that the image is transformed to a vector of the form: X = {x
ij
|i = 1, 2, …, N ; j = 1, 2, …, D}, where n = M * N and D are the image channels. Next, it is required to be expressed in terms of hesitant fuzzy information, so each pixel is transformed to the fuzzy domain with:
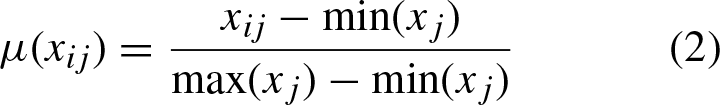
Then, the Hesitant Fuzzy Set is a function that when applied to a reference set returns a subset of [0, 1] [15]; mathematically is expressed by A = {x i , h A (x i )} , i = 1, 2, …, n, where h A (x i ) is a set of some values in [0, 1], denoting the possible membership degrees of each element x i ∈ X. The function h = h A (x i ) is a hesitant fuzzy element, according to the literature, it is defined by experts who provide preference information about a set of alternatives.
Image segmentation using a clustering algorithm requires a minimizing objective function (i.e., minimizing the distances between cluster centers and data, since the closer a data is to a center the higher its degree of membership). Then Hesitant fuzzy clustering objective function is:

where X HFS = {h1, h2, …, h n } represents n hesitant fuzzy elements corresponding to each pixel x i = h (x i ):
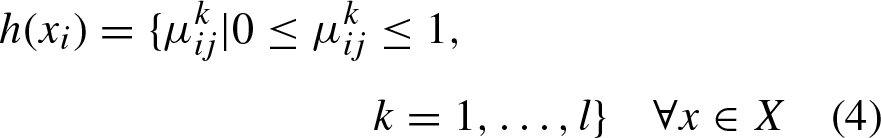
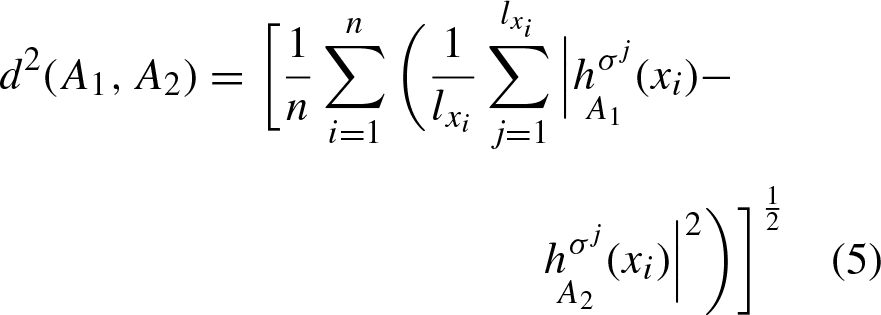
For the objective function J
HFS
to be minimized the membership degrees are optimized to fixed parameters of the clusters, then, V
HFS
is optimized for a fixed membership degrees matrix, repeating this process until a certain stopping criterion is met. The optimal values at each of these steps can be calculated using the parameter update equations. These formulas are obtained by setting the partial derivative of the objective function J
HFS
(Equation 3) with respect to the parameter to be optimized equal to zero using the Lagrange multipliers [22]:
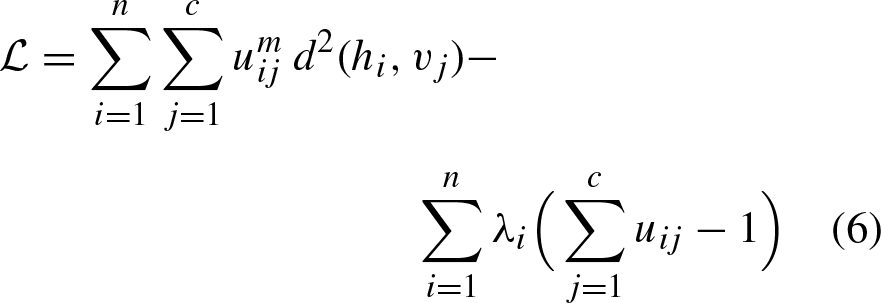
The membership degree update equation is defined by:

The centers of the groups are calculated from the following expressions:
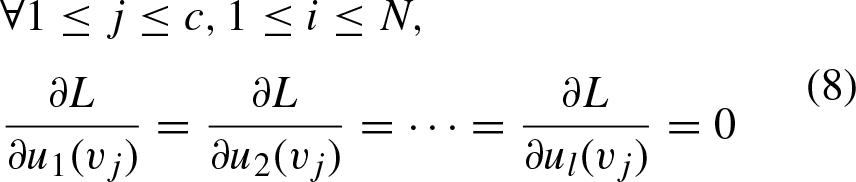

The Calinski-Harabasz Index, introduced by Calinski and Harabasz in 1974 [23], is a measure of how similar an object is to its own group (cohesion) compared to other groups (separation). Cohesion is a function of the distances of the data in the group to the group centroid and separation is based on the distance of the group centroids to the global centroid [24, 25]. The formula for the Calinski-Harabasz index, for K groups in a data set X = [x1, x2, … d
n
], is defined as:
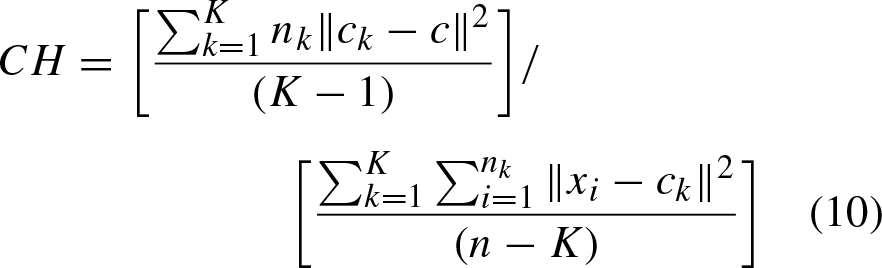
In this paper, a color image segmentation method is proposed, which is shown in Fig. 1. This method has three main stages: 1) filter the image X, and make a reduction, f, to find the number of clusters C using the Calinski-Harabasz (CH) index, at this stage we also obtain the hesitant fuzzy matrix of the image f, H f ; 2) the matrix H f is used to calculate the centroids which will pass to stage 3) as the initial centroids that will segment the image X, for this third stage it is necessary to calculate the hesitant fuzzy matrix H x .
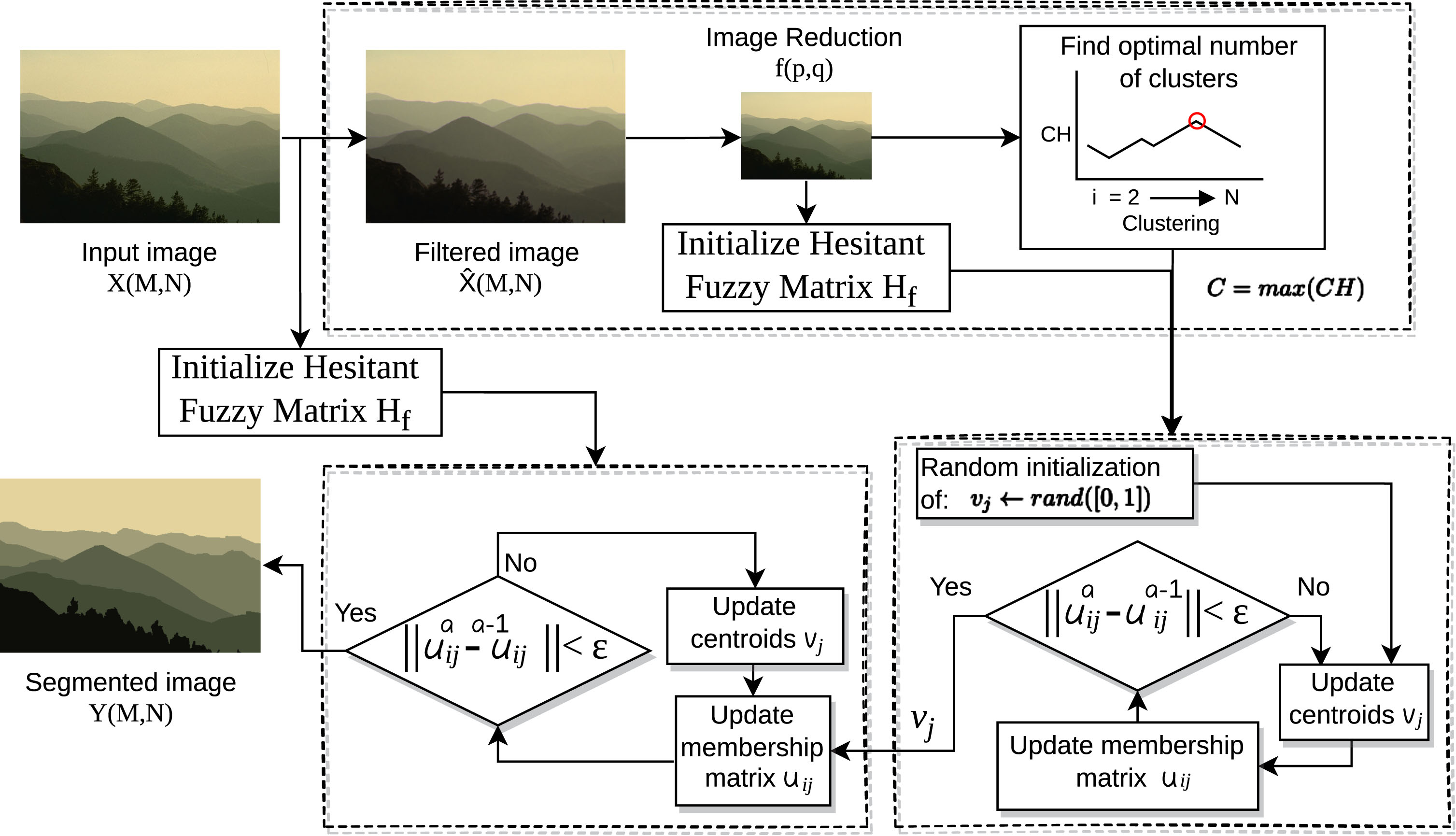
Process of the Fast and Automatic Hesitant Fuzzy Clustering algorithm for image segmentation.
The literature describes that there is no database that contains hesitant fuzzy information, since this is given by experts, in this article it is proposed an alternative to generate this type of information, and it is by means of membership functions based on fuzzy relations, described below: Homogeneity, computed within a neighborhood of 3 × 3, is considered a fuzzy set and its membership function is defined as: Color space, a transformation to the IJK color space is performed, which is a rotation to the RGB color space. First it is necessary to transform each pixel of the image to the fuzzy domain, using:
Textures, statistical approaches are used to describe the texture of the images, with the objective of having an algorithm that is simple to implement. The techniques to describe the textures used by the algorithm are: Fuzzy entropy, which quantifies the uncertainty of the image content, defined by:
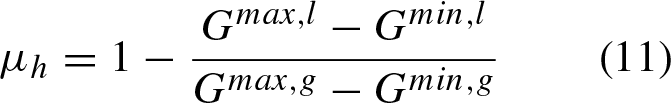
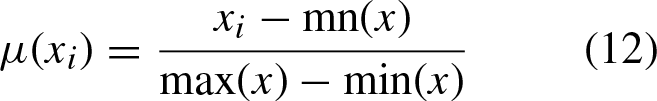

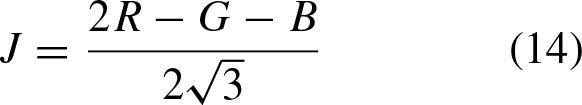
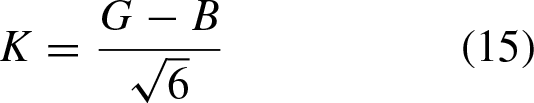
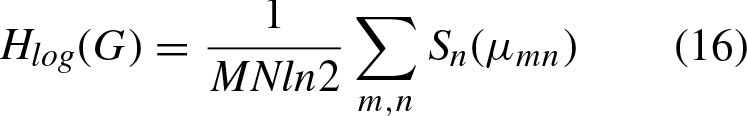
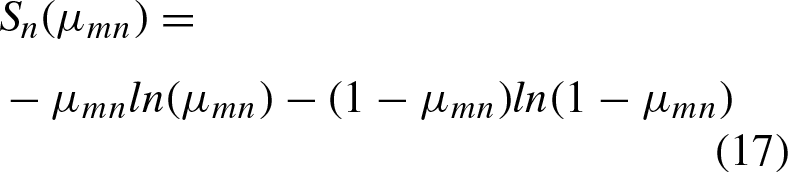

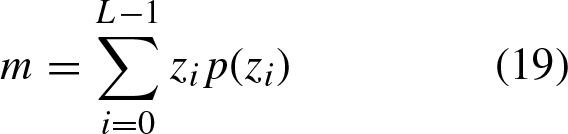
As previously mentioned, the hesitant fuzzy matrix contains a set of values in [0, 1] that denote the possible degrees of membership of an element in the set. Therefore, the proposal is to make use of the three described relations to initialize this matrix, as indicated in Equation 4 where k represents each of the l established relations (homogeneity, color and textures).
For more details, Algorithm 1 summarizes the implementation of this method, which has as input a color image, which will be subsequently filtered, in the experiments the median filter is used, since it presents real pixels within the image, and it is less sensitive to extreme values. Then a reduction of the image (Algorithm 2) is done to find the number of groups in which the image will be segmented, as well as to find the initial centroids, all this in the reduced image f. In steps 4 and 5, the transformation of the image X to the hesitant fuzzy domain is performed, and the initialization of the hesitant fuzzy matrix using the alternative described above, using the fuzzy homogeneity, color and texture relations. Finally, an iterative process is performed to update the centroids of the groups and the fuzzy membership matrix and obtain the segmented image.
1: Set m and ɛ (m = 2 and ɛ = 0.00001 as default)
2: Reduction (Algorithm 2)
3: X HFS ← X
4: H X ← h (x) ∈ [0, 1]
5:
6:
7:
8:
9:
10:
1:
2:
3: F HFS ← F
4: Find number of clusters (Algorithm 3)
5: H F ← h (f) ∈ [0, 1]
6: v j ← rand ([0, 1])
7:
8:
9:
10:
11:
As mentioned before, the number of clusters is determined by the Calinski-Harabasz index described in Equation 10, this is calculated with the clustering result of the FCM algorithm for 2 to n clusters, and the index with the highest value is selected; the process is detailed in Algorithm 3.
1: Set n (n = 15 as default)
2:
3: clusters (i) ← FCM (X, i)
4: CH (i)← Equation 10
5:
6:
7:
8:
9:
10:
The algorithm proposed in this paper is applied to image segmentation, for this aspect the metrics considered to measure image segmentation performance are: Probabilistic Index Rand (PRI), [33] which measures the similarity between the segmented images and the ground truth. Variation of information (VOI) [34] is defined by: Global consistency error (GCE), [32], evaluates the extent to which the segmentation can be considered to refine the others. Boundary displacement error (BDE), [35], which evaluates the average pixel displacement error at the edges between two segmented images by calculating the distance between the pixel and the nearest pixel in the other segmentation.
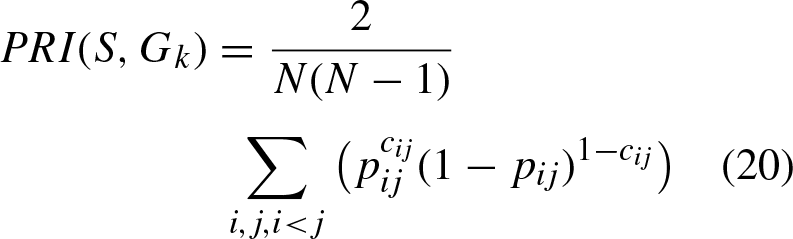


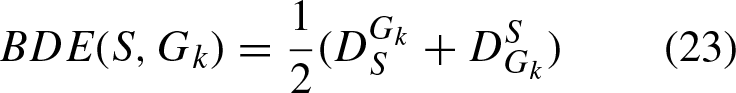
On the other hand, different metrics are considered to evaluate the quality of the clustering, which are described below: Adjusted Rand Index (ARI), computes a similarity measure between two clusterings by considering all pairs of samples and counting the pairs that are assigned in the same or different clusters between the clustering result and its ground truth. [36, 37]. Accuracy (Acc), discovers the one-to-one relationship between clusters and classes. Let li and Normalized mutual information (NMI) measures the clustering quality [38]. Purity, measures the degree to which the groups contain a single class [38].
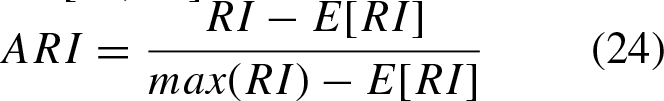
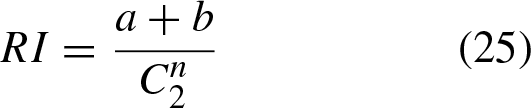

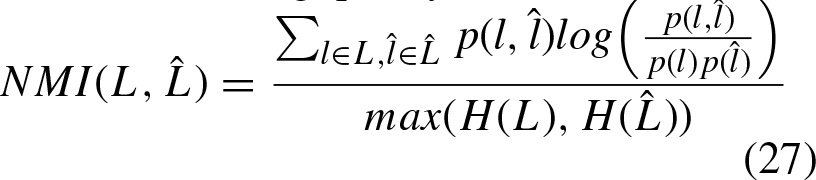

In this section, the performance of the proposed method is demonstrated through three experiments: 1) First, it is necessary to measure the execution time of each algorithm to expose the advantage of the proposed method. 2) Then, it is required to quantify the segmentation quality in metric terms and make an objective comparison with other state-of-the-art algorithms such as Fast and Robust Fuzzy C-Means Clustering (FRFCM) [10], Automatic Fuzzy Clustering Framework for Image Segmentation (AFCF) [11], Robust Self-Sparse Fuzzy Clustering (RSSFCA) [12], FCM with adaptive spatial & intensity constraint and membership linking (FCM_SICM)[13] and Parallel Hesitant Fuzzy C-Means (PHFCM) [18]. 3) Finally, the quality of clustering in UCI repository [26] is evaluated, comparing the results with some algorithms from the literature such as FCM [27], Kmediod [28], HPSOFCM [29], FRFCM [10], KMM [30] and FCM-ELPSO [31]; in addition, it is verified if the algorithm is capable of correctly find the number of clusters in each dataset.
The proposed method and comparative algorithms were implemented in MATLAB R2021a, on a PC equipped with a quad-core Intel Core i7-4510U @ 2.00 GHz and 8 GB of RAM. The operating system was Ubuntu 18.04.6.
Databases
The evaluation of this algorithm was performed with images from the Berkeley Segmentation Data Set 500 (BSDS500) database [32], image size is 481×321 pixels. Figure 2 presents some of the images with which the evaluation was performed, most of the images in this database are complex because they have different textures and lighting changes.

Sample images from the database.
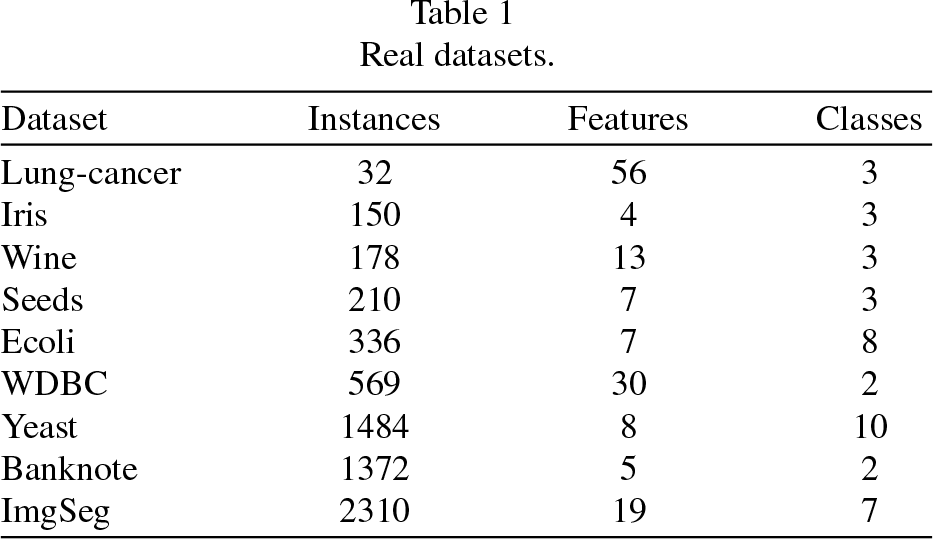
On the other hand, the databases obtained from the UCI repository are summarized in Table 1, selecting different numbers of instances, characteristics and the classes in which each dataset should be clustered to have a reference in the evaluation.
Real datasets.
The results of this experiment are presented in Table 2, it is observed that the AFCF and RSSFCA algorithms, obtain the highest number of iterations, this is because they are set by default at the beginning of the algorithm, therefore, the execution time is also high. Another important fact is that although the FCM algorithm is faster, the number of iterations is higher.
Average execution performance
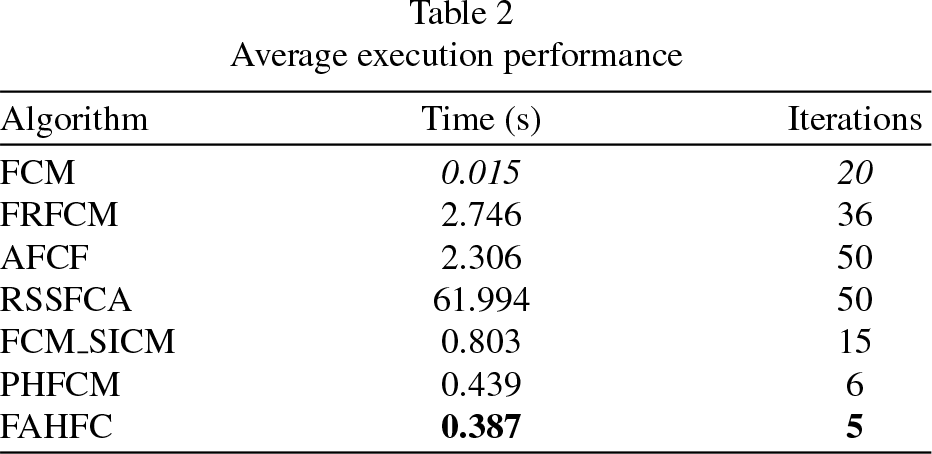
Average execution performance
On the other hand, the proposed method converges in less number of iterations and in a considerable time, less than the majority of the algorithms with which it is compared, t even has a better performance than the PHFCM algorithm, this is due to the second stage, where the initial centroids are calculated through a reduction of the original image; since the image is smaller, the iterative process to update centroids and membership matrix is done in less time, the centroids obtained are used in third stage, given the approach they have to the optimal values, they make the algorithm converge in fewer iterations, in an average of 5. The approach towards the final centroids that is carried out in the second stage allows the proposed algorithm to improve the quality of the segmentation with respect to the FCM algorithm, sacrificing processing time.
One of the main contributions of this article is that the algorithm automatically determines the number of clusters into which the data will be grouped, solving the initialization problem. Figure 3 details the results obtained by the CH index for each of the databases, it is important to show that this index correctly finds the number of clusters for each of the databases, the graph shows the maximum value obtained by the index which identifies the number of clusters in which each database has to be clustered.
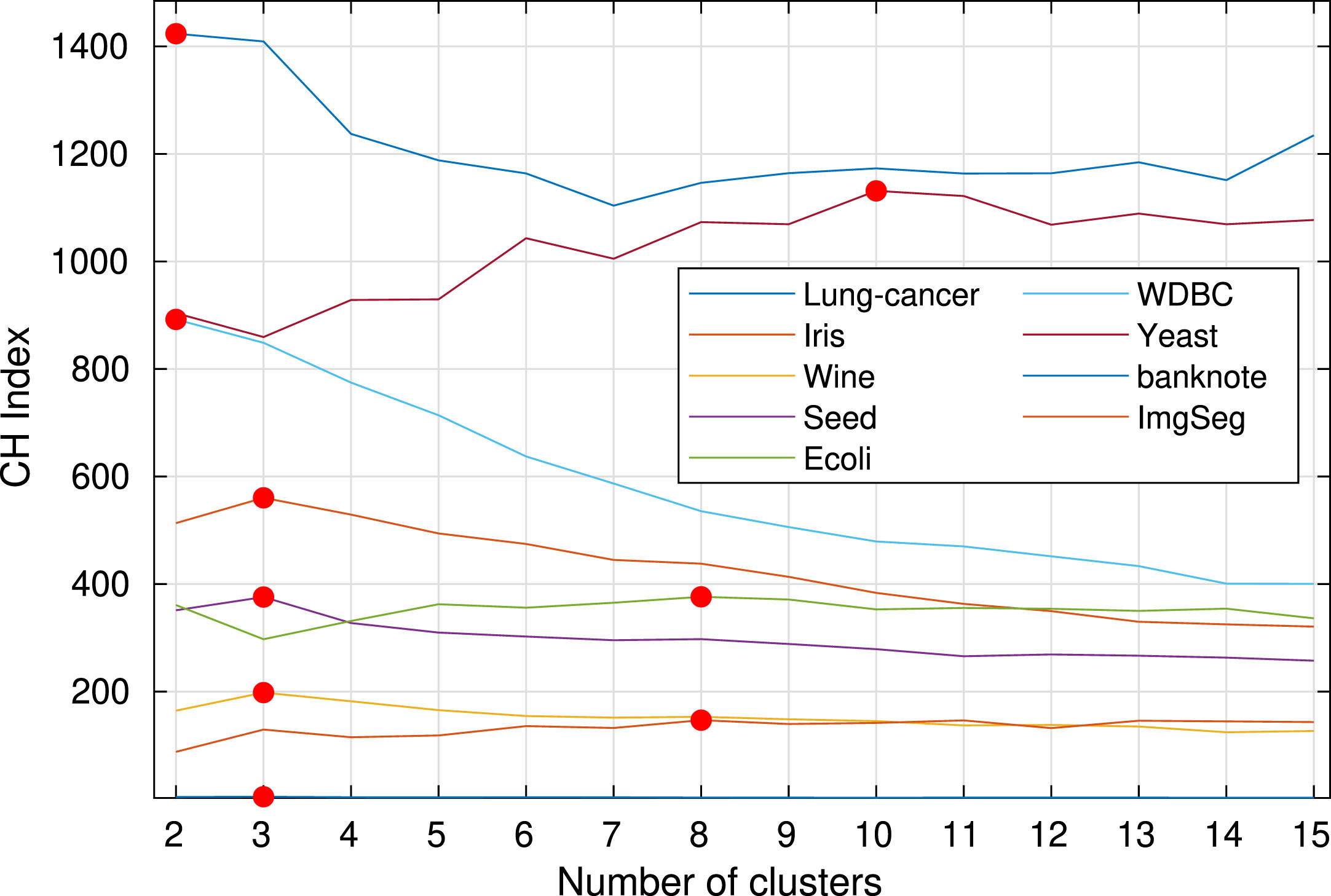
CH index result for each database.
Subsequently, by verifying that the algorithm is capable of determining the number of groups, the quality of the grouping was evaluated, the average value of each metric is summarized in Table 3, here it is observed that the performance of the AHFCM algorithm is superior compared to the others, having advantage of the four metrics selected to evaluate the quality of clustering. To visualize the evaluation of the clustering quality of the previous table, Fig. 4 is presented with the results of the metrics in each of the databases, in this figure it is observed that the AHFCM algorithm obtains the highest values in most of the databases, thus corroborating the quantitative results.
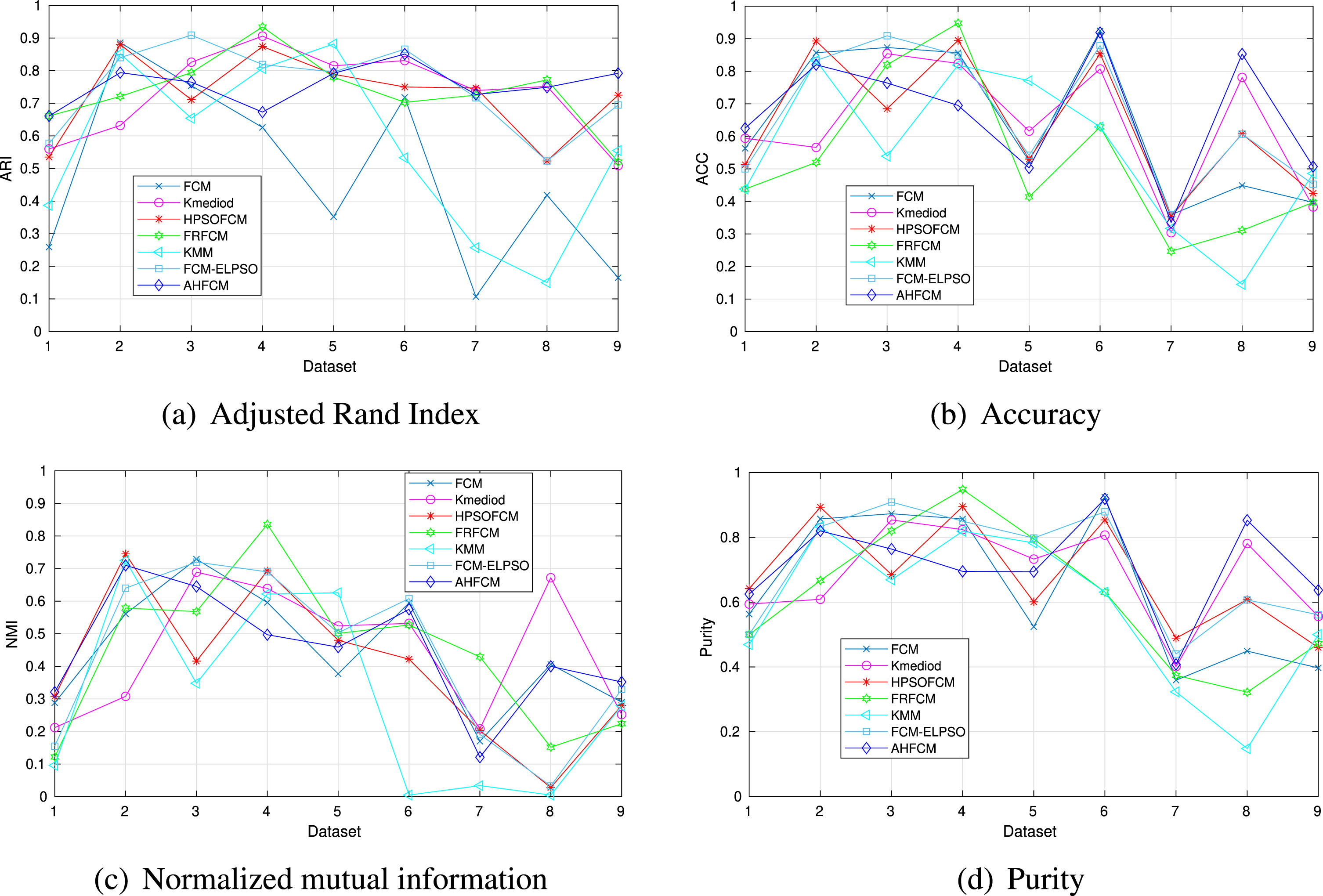
Quantitative results graphs.
Average result of each algorithm
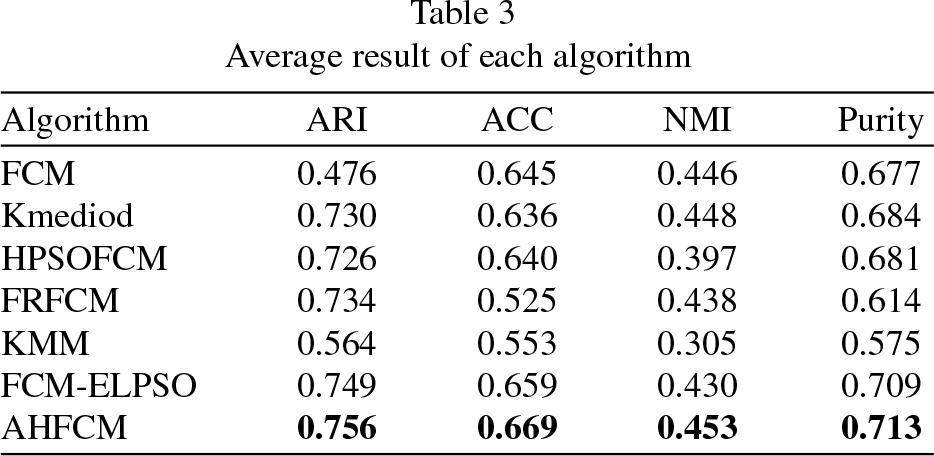
The average result of each metric is summarized in Table 4, where the advantage of the proposed FAHFC algorithm over the other algorithms is observed in most of the metrics, for example it is superior to the PHFCM algorithm in the PRI and GCE metrics with differences of 0.02 and 0.06, respectively; while in the VOI metric it has a difference of 0.12 over RSSFCA, just to visualize the analysis of these results, the performance of each algorithm is shown as a graph in Fig. 5.
Average result of image segmentation

Average result of image segmentation
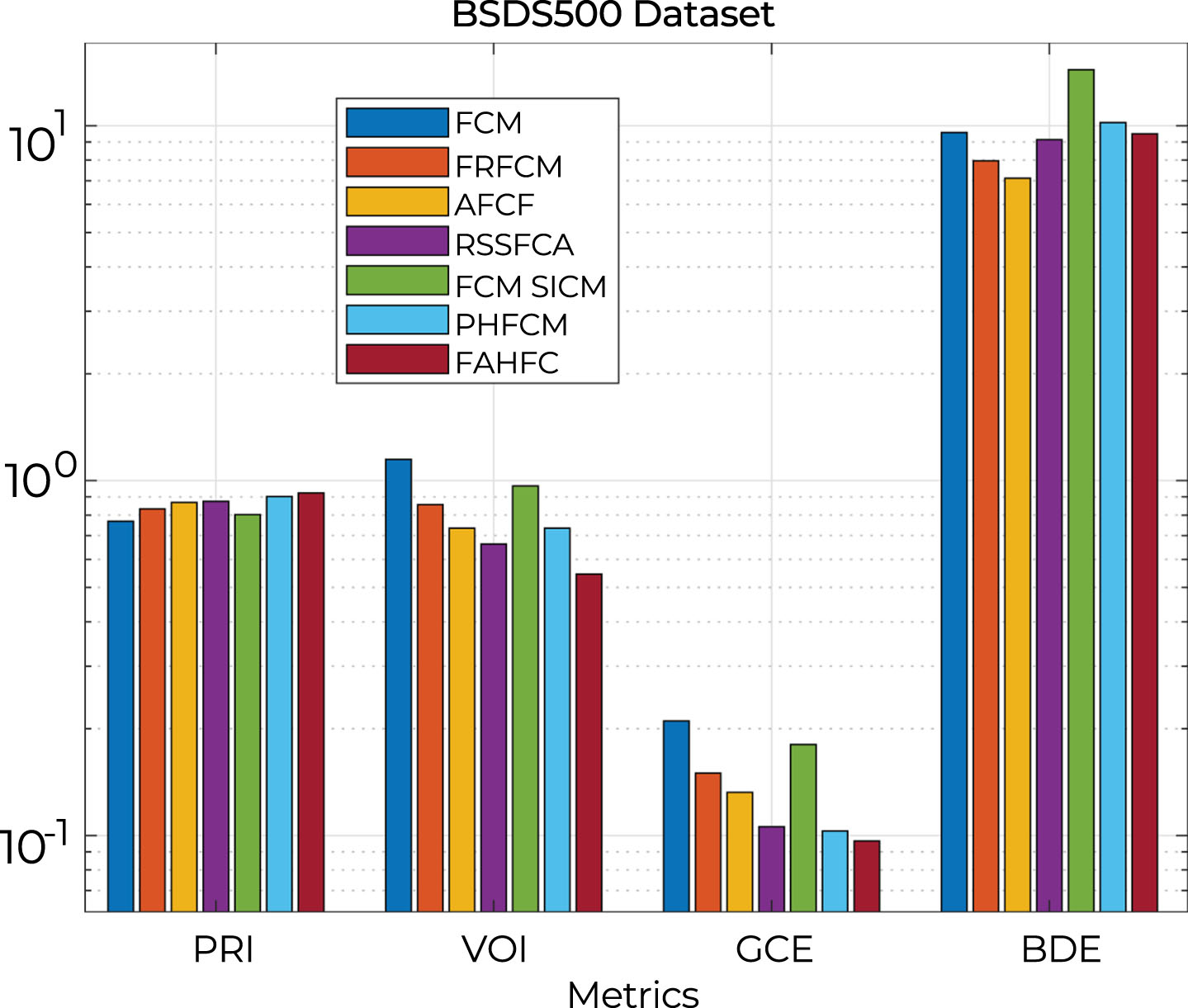
Quantitative results.
Finally, a subjective evaluation is presented in Fig. 6 showing the result of the segmentation of some sample images, with the different algorithms to compare the performance of each one. In this figure the parameter c is added, which suggests the number of regions in which each of the images is segmented, in addition its ground truth is also added.
Most of the images shown are complicated to segment, due to their textures and illumination changes, however the proposed algorithm, FAHFC outperforms the results of the other algorithms with which the comparison is made, being visually more similar to the ground truth, generates more homogeneous regions and delimits them better. The image also reveals the difference between the PHFCM and the proposed FAHFC algorithms, although both are based on the theory of hesitant fuzzy sets, they do not generate the same results, the advantage is FAHFC, which uses three different fuzzy relations to initialize the hesitant fuzzy matrix and achieve better performance, while PHFCM still uses FCM.
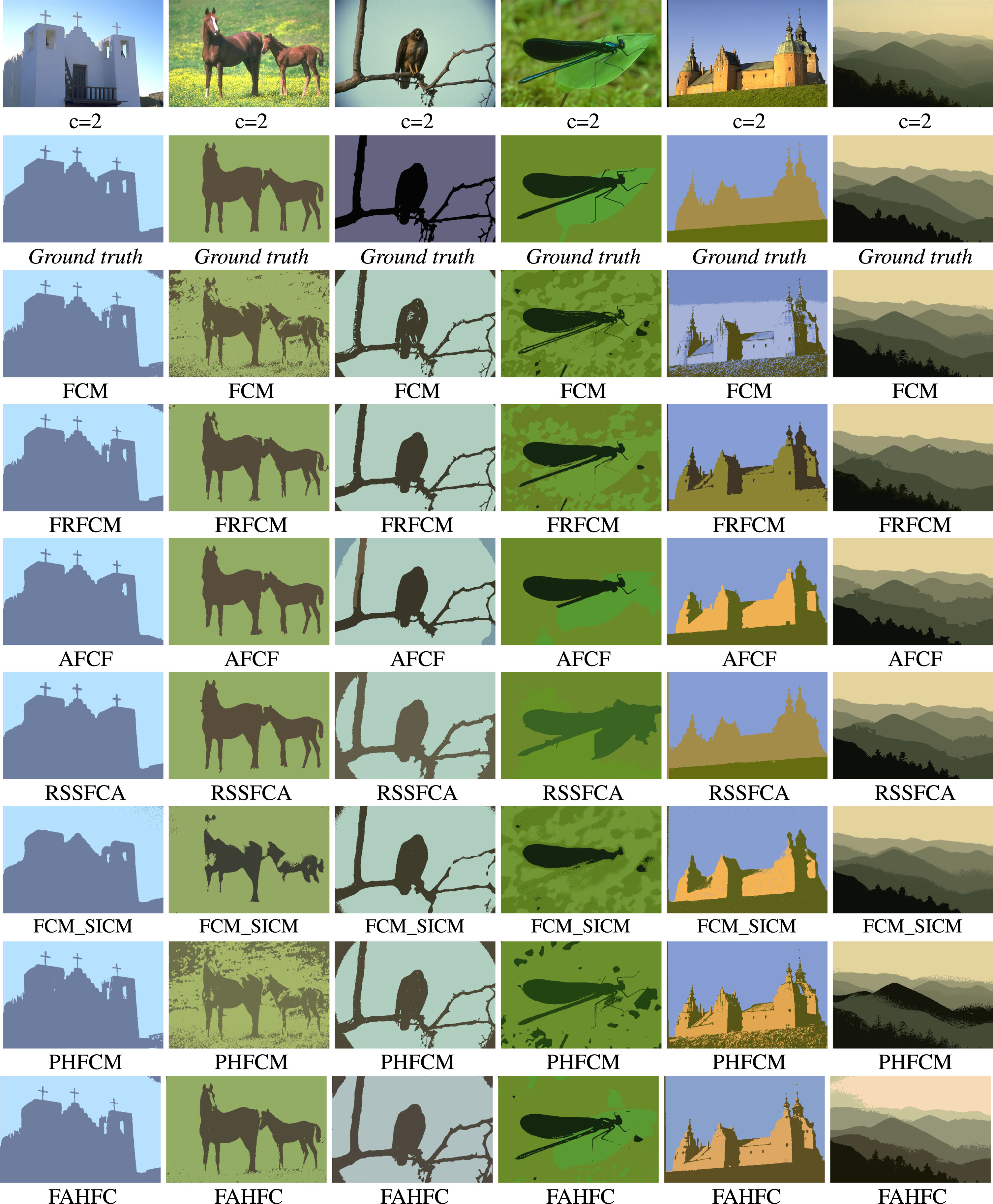
Segmentation result of some sample images.
In summary, our research has introduced an method for color image segmentation based on hesitant fuzzy sets (HFS) and fuzzy relations for initializing the hesitant fuzzy matrix. The FAHFC (Fast and Automatic Hesitant Fuzzy Clustering) algorithm, utilizing the Calinski-Harabasz (CH) index, has demonstrated effectiveness in accelerating processing time through image reduction and centroid utilization, leading to convergence in a limited number of iterations. It is noteworthy to highlight that, in comparison with the baseline FCM algorithm, our approach does involve a slight sacrifice in processing time, but this trade-off is justified by the notable enhancement in segmentation quality. Experimentation has revealed that the proposed FAHFC method not only speeds up the processing time but also significantly improves the segmentation quality compared to the PHFCM version. While both approaches leverage HFS for clustering, the distinguishing factor lies in the initialization process of the hesitant fuzzy matrix, where FAHFC uses fuzzy relations and PHFCM employs the FCM algorithm. Furthermore, the metrics results have consistently indicated the superiority of the proposed algorithm over other state-of-the-art methods, both in the domain of image segmentation and in the clustering of data obtained from the UCI repository.
Considering future research directions, it is important to expand comparative studies to include other types of fuzzy techniques, such as intuitionistic fuzzy sets, possibilistic fuzzy sets, type-2 fuzzy sets, interval-evaluated fuzzy sets, and more. This extension aims to provide a comprehensive understanding of how hesitant fuzzy sets compare and complement different fuzzy methodologies in the context of image segmentation. Additionally, the trade-off between processing time and segmentation quality is recognized, especially in comparison with the widely used FCM algorithm. Despite a slight increase in processing time, the notable improvement in segmentation quality justifies this trade-off. Future investigations will focus on fine-tuning the algorithm to optimize processing time without compromising segmentation precision. Furthermore, it is planned to explore the incorporation of different types of textures during the initialization of the vacillating diffuse matrix, anticipating that this improvement will allow the algorithm to effectively segment degraded images with noise, contributing to its adaptability in real-world scenarios with various visual complexities.
In conclusion, this research not only advances the theoretical understanding of hesitant fuzzy sets in image segmentation, but also emphasizes the practical implications and potential real-world applications of the proposed methodology. The future research directions described aim to further refine and expand the capabilities of the algorithm, contributing to the continued evolution of fuzzy clustering methodologies in the field of image processing and pattern recognition.
Footnotes
Acknowledgments
The authors express their gratitude to CONACYT, as well as to the Tecnológico Nacional de México/CENIDET for their support of this research through the CONACYT National Scholarships.
Conflict of interest
The authors declare that they have no conflict of interest.