
Abstract
The use of generative models in image synthesis has become increasingly prevalent. Synthetic medical imaging data is of paramount importance, primarily because medical imaging data is scarce, costly, and encumbered by legal considerations pertaining to patient confidentiality. Synthetic medical images offer a potential answer to these issues. The predominant approaches primarily assess the quality of images and the degree of resemblance between these images and the original ones employed for their generation.The central idea of the work can be summarized in the question: Do the performance metrics of Frechet Inception Distance(FID) and Inception Score(IS) in the Cycle-consistent Generative Adversarial Networks (CycleGAN) model are adequate to determine how real a generated chest x-ray pneumonia image is? In this study, a CycleGAN model was employed to produce artificial images depicting 3 classes of chest x-ray pneumonia images: general(any type), bacterial, and viral pneumonia. The quality of the images were evaluated assessing and contrasting 3 criteria: performance metric of CycleGAN model, clinical assessment of respiratory experts and the results of classification of a visual transformer(ViT). The overall results showed that the evaluation metrics of the CycleGAN are insufficient to establish realism in generated medical images.
Keywords
Introduction
In recent years, studies have increasingly focused on generative models for image synthesis [5]. These advances have increasingly influenced areas of medical research where artificial intelligence (AI) has become increasingly common in the handling and processing images, text, and sound. However, the need for these volumes of data presents a critical problem associated with the costs of time and resources to collect this information. Moreover, this issue also entails the challenge of acquiring substantial quantities of annotated data in order to effectively train CNNs that yield superior performance. CycleGANs [1] have been widely used in various domains, medical imaging being one of the most relevant [4, 7–9]. Some important works in the use of CycleGANs for medical image generation and quality assessment such as the one of Wolterink et al. [21] the authors present the application of GANs, including concepts similar to CycleGANs, to generate Computed Tomography (CT) images from Magnetic resonance imaging (MRI) images. This showcases the capability of such networks in the domain of medical imaging. While some recent works such as the one of Wang et al. [22] and the one of Malygina et al. [23] where the authors have explored the use of CycleGANs as a way of data augmentation for improving a CNN classification pneumonia, there are few works such as the one of Joyce et al. [24] that focus on establishing the relationship between the performance metric of a GAN model and the quality but not in the realism of the generated image, does synthetic image quality translates into how real it is?
In this work, a 256×256 CycleGAN model [1] was used to generate chest X-ray images associated with general pneumonia [25], bacterial pneumonia, and viral pneumonia. To evaluate if the quality of the generated images in regards with the FID and IS [2] translated to how real the pneumonia images are. The FID and IS metrics were contrasted with the evaluation by 3 respiratory care specialists through the application of a series of questionnaires. Likewise, the generated images were evaluated using a Visual Transformer (ViT) model [18–20] trained for the classification of chest-x-ray images into 2 classes: pneumonia and normal.
The contributions of this work are: 1) FID and IS metrics are shown to be lacking [2] as an objective way of assessing the realism of pneumonia chest X-ray generated images by a CycleGAN model. 2)Medical expert assessments are suitable and necessary in a clinical setting for decision making and diagnostics but the use of predictive models such as ViT are tools that can serve to ensure that synthetic images are realistic enough to use in learning models or other practical applications.
This paper is structured as follows: Section 2 presents the materials and methods employed in this work. Section 3 describes the experimental results. Section 4 discusses the results obtained and Section 5 give the conclusions and future works.
Materials and methods
This section introduces the GANs, CycleGANs and ViT. The CycleGAN model was used for the generation of synthetic images of pneumonia while the ViT model was used for the classification of the images. This section also describes the 256×256 architecture of the CycleGAN used in this work, description of the used ViT model is also given, the datasets used in the experiments and the questionnaires applied to the specialists are described.
Dataset
The dataset used for this work is Labeled Optical Coherence Tomography (OCT) and Chest X-Ray Images for Classification [16]. The dataset is organized into 3 folders (train, test, val) and contains subfolders for each image category (Pneumonia/Normal). There are 5,863 X-Ray images (JPEG) and 2 categories (Pneumonia/Normal). Each Pneumonia image is also label as of viral or bacterial origin.
GANs
A generative adversarial network (GAN) [3, 4] is a type of deep learning model consisting of two neural networks: a generator network and a discriminator network. The GAN framework was introduced by Goodfellow in 2014.
The main objective of a GAN is to produce synthetic data that exhibits a high degree of realism, particularly in the context of generating images, which closely resemble samples from a specified target dataset. The generator network accepts either random noise or a latent input as its input and endeavors to produce samples that closely resemble the distribution of the target data. Conversely, the discriminator network undergoes training to differentiate between authentic samples provided from the target dataset and synthetic samples produced by the generator.
The training process of a GAN entails a competitive interplay between the generator and discriminator neural networks. The primary objective of the generator is to generate samples that exhibit a higher degree of realism in order to deceive the discriminator. Conversely, the discriminator’s primary goal is to accurately distinguish between real and counterfeit samples. The learning process is driven by the antagonistic connection between the two networks.
CycleGANs
CycleGANs, are generative models designed for unsupervised image-to-image translation tasks. They can learn mappings between two domains without needing paired training data. CycleGANs were introduced to enable image translation between two domains [1]. The fundamental concept underlying CycleGANs involves the incorporation of cycle consistency loss. This characteristic highlights the importance of preserving the original content when a picture is translated from one domain to another and subsequently translated back to its original domain. By integrating the concept of cycle consistency, the model is able to acquire significant mappings between the domains, even in the absence of paired training examples. It was introduced as a new way to learn mappings between two different image domains without needing paired training data. The CycleGANs architecture is different from other GANs in a way that it contains 2 mapping functions (G and F) that act as generators and their corresponding Discriminators (D x and D y ): The generator mapping functions are as follows:
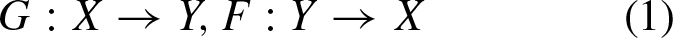
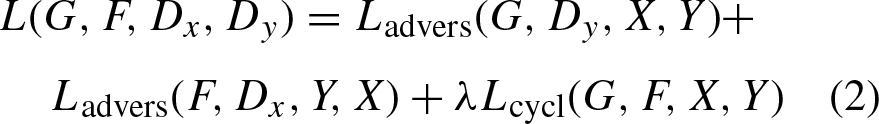
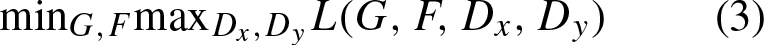
The training process of a CycleGAN involves two main components:
A fundamental weakness of the CycleGAN model is that it learns deterministic mappings. In CycleGAN and other similar models [4, 6], the conditionals between domains correspond to delta functions:
The CycleGAN generator is composed of three distinct components, namely the Encoder, Transformer, and Decoder. The UNET architecture will be employed for the generator. In order to construct the generator, we establish our downsample and upsample techniques. The process of downsampling involves reducing the two-dimensional dimensions, specifically the width and height of an image, by a factor known as the stride. The stride refers to the measurement of the distance covered by each step taken by the filter. Given a stride value of 2, the filter is applied to alternate pixels, resulting in a reduction of both the width and height dimensions by a factor of 2. In this work, instance normalization was employed as an alternative to batch normalizing.
The architecture of the discriminator employs the PatchGAN discriminator. The distinction between a PatchGAN and a conventional GAN discriminator lies in their respective mapping functions. In the case of a standard GAN, the mapping is performed from a 256×256 picture to a singular scalar output, which serves as an indicator of authenticity (real or fake). On the other hand, the PatchGAN operates by mapping from a 256×256 image to a different output as shown in Fig. 1, which encompasses many patches inside the image to an N × N (here 64×64) array of outputs X, where each X
ij
represents whether the patch ij in the image is real or fake–first, a 4×4 convolution-InstanceNorm-LeakyReLU layer with 128,256 and 512 filters and stride of size 2.
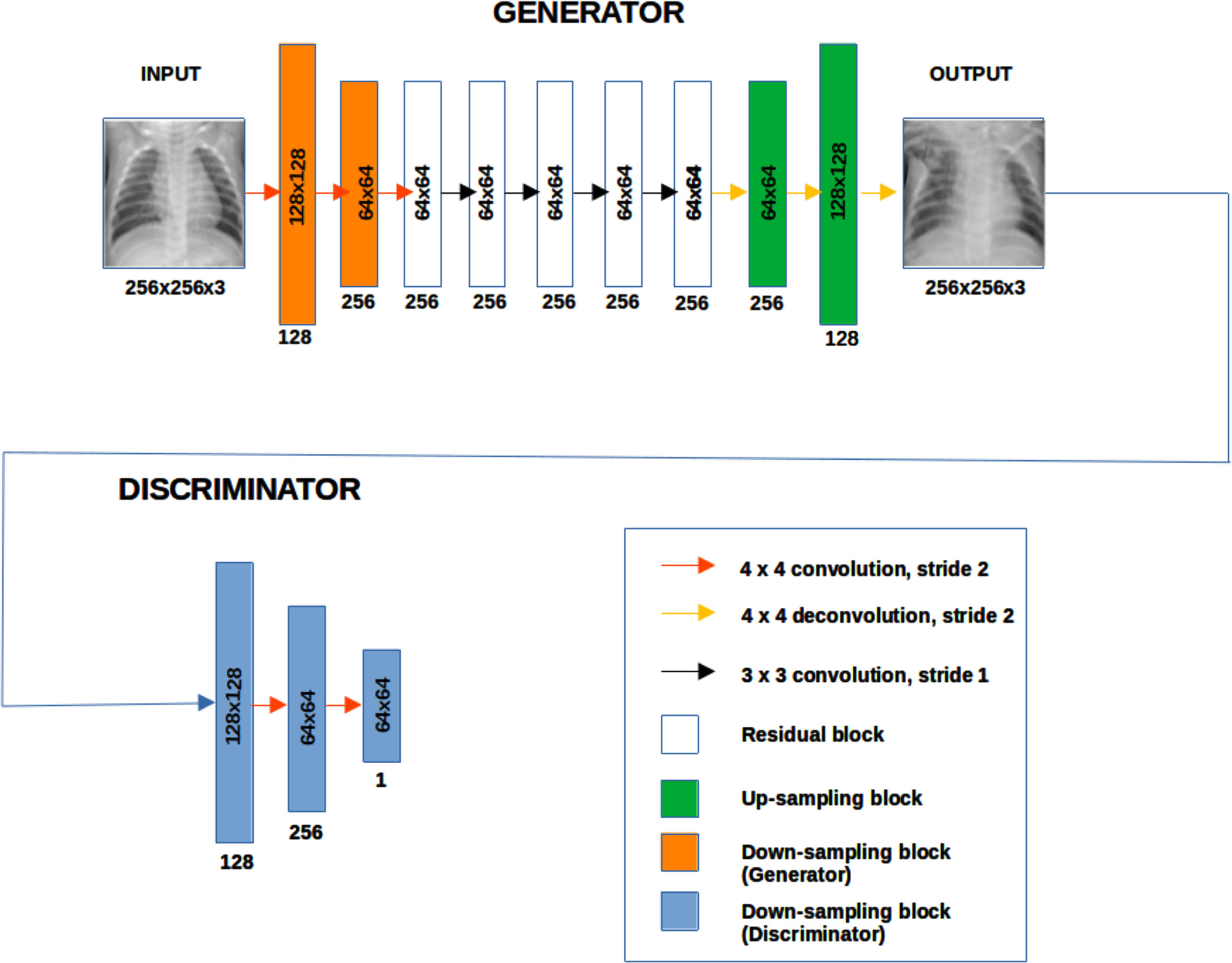
Architecture of 256×256 CycleGAN model.
The performance metrics for evaluating the CycleGAN generated images [2]:
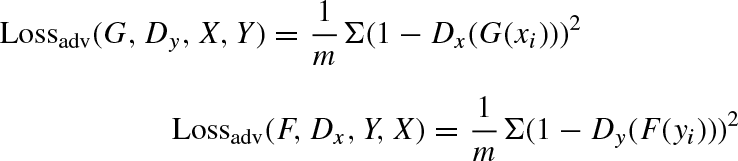
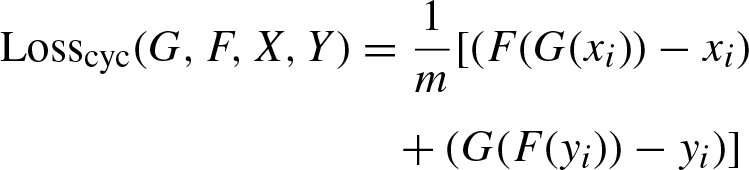
ViTs have become a central topic in the deep learning community due to their effectiveness in image classification tasks [15–17], previously dominated by CNNs. The basic idea is that instead of using the traditional convolutional layers as in CNNs, ViTs leverage the transformer architecture, which was originally designed for natural language processing tasks, to handle images.
For the preparation of the input the images are divided into fixed-size non-overlapping patches. Each patch is linearly embedded into a flat vector. Then positional embeddings are added to these vectors to maintain the spatial information of patches since transformers do not inherently understand the spatial layout.The sequence of embedded patches is then fed into the transformer.
The core of the transformer architecture is the self-attention mechanism, which weighs input elements differently based on their content and relative positions.Multi-head attention and feed-forward neural networks, alongside normalization and residual connections, constitute a transformer block. Several such blocks are stacked to form the complete transformer model. It is also important to consider some important challenges [15] since ViTs, especially larger models, require substantial amounts of data and computing resources for training from scratch. They can be slower and more memory-intensive than CNNs, especially for smaller-sized input images. Vision Transformers approach image understanding in a way fundamentally different from CNNs. Instead of focusing on local patterns and hierarchical structures, ViTs break down images into patches and use transformer mechanisms to capture both local and global contexts.
ViT architecture
The ViT model used in this work was pre-trained on ImageNet-21k (14 million images, 21,843 classes) at resolution 224×224. It was introduced in the work of Dosovitskiy et al. [18] and first released at https://github.com/google-research/vision_transformer. The ViT is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k. Images are presented to the model as a sequence of fixed-size patches (resolution 16×16), which are linearly embedded (see Fig. 2. The model was trained on TPUv3 hardware (8 cores). All model variants were trained with a batch size of 4096 and learning rate warm-up of 10k steps. For ImageNet, the authors found it beneficial to additionally apply gradient clipping at global norm 1. Pre-training resolution is 224. Note that for fine-tuning, the best results were obtained with a higher resolution (384x384).
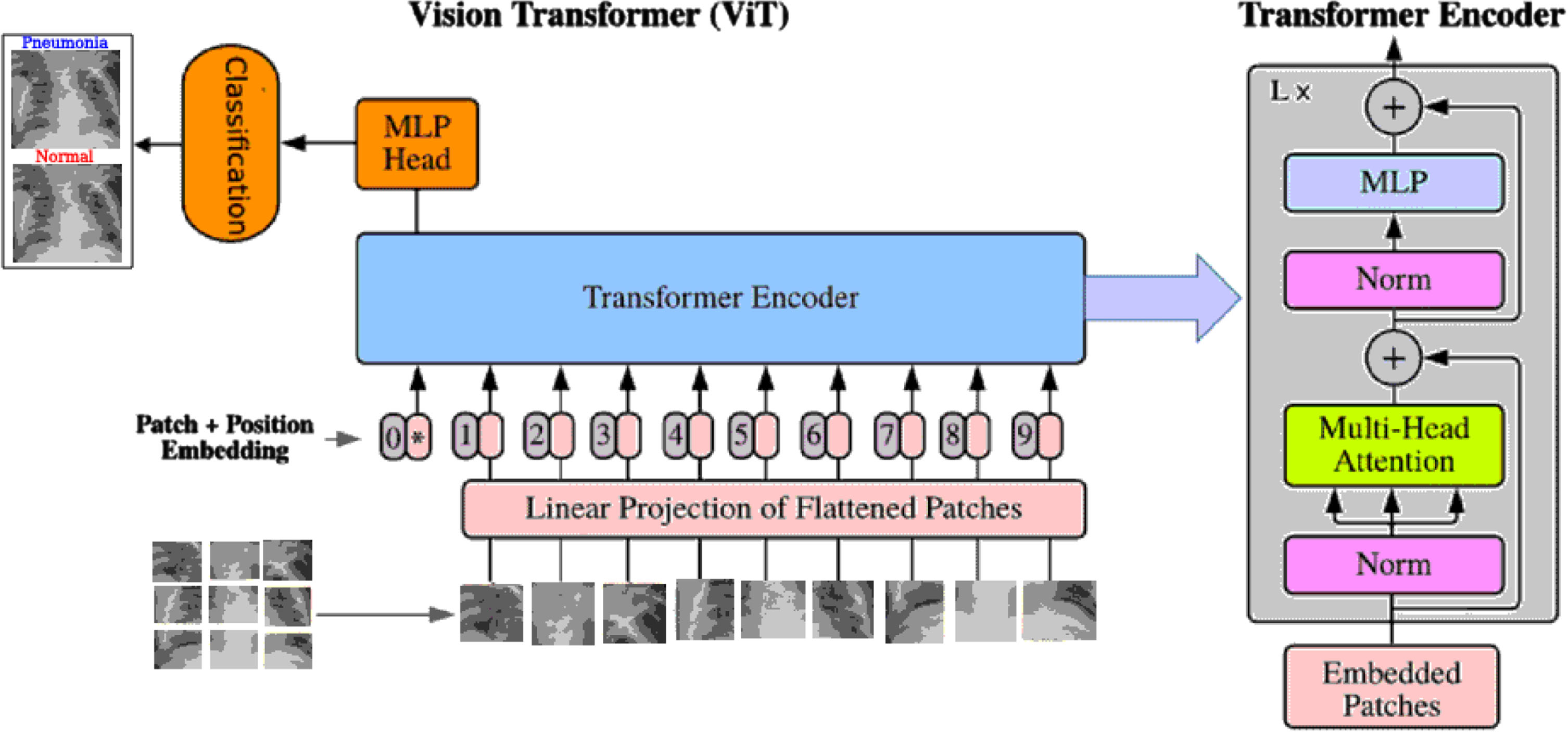
Architecture of ViT.
Three electronic questionnaires were made with Google Services application Google Forms. Each questionnaire consist consist of 100 generated and real images. The images were divided into four sections for evaluation. Out of the 100 images, 80 were generated, and 20 were real. In the questionnaires, they were given the option to choose if the image they saw was real or fake and if the image corresponded to general pneumonia (any possible cause of pneumonia such as fungal) [25], bacterial pneumonia, viral pneumonia, or did not correspond to pneumonia.
Experiments
This section presents the experiments and the results obtained through the evaluation of the generated images. The performance metrics FID and IS of the generated images were contrasted with the results obtained by the ViT classification of the generated images and the results of the applied questionnaire to the medical experts.
Data pre-processing
The images of the dataset 2.1 were divided into 3 files: 1341 normal X-ray images, 2531 bacterial pneumonia images and 1345 viral pneumonia images. The images were resized to 256×256 pixels. Then the images were processed into
Results and analysis
The CycleGAN model was trained for 100 epochs with a total of 1,341 synthetic images generated of general pneumonia (GP), bacterial pneumonia (BP), and viral pneumonia (VP). The quality of the generated images was assessed at the epochs: 25, 50, 75 and 100. For each set of generated images, its corresponding FID and IS values were calculated (as seen in Table 1) with its corresponding loss functions (as seen in Fig. 3). One loss function for the generator of the Pneumonia-like images, another for the generator of the Normal Chest X-ray images and two more for their corresponding discriminators.
FID and IS evaluation of CycleGAN generated images
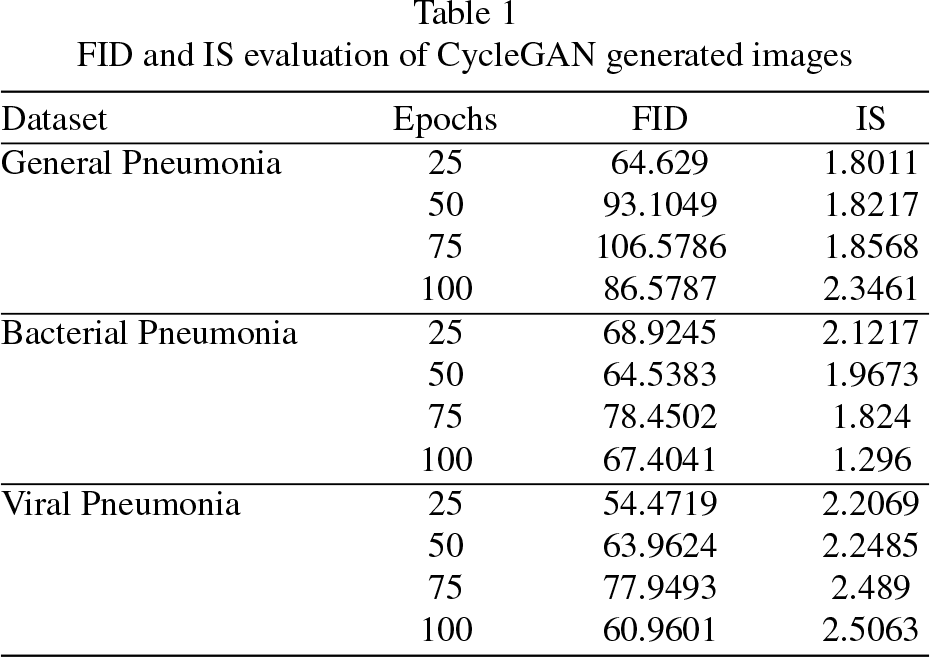
FID and IS evaluation of CycleGAN generated images
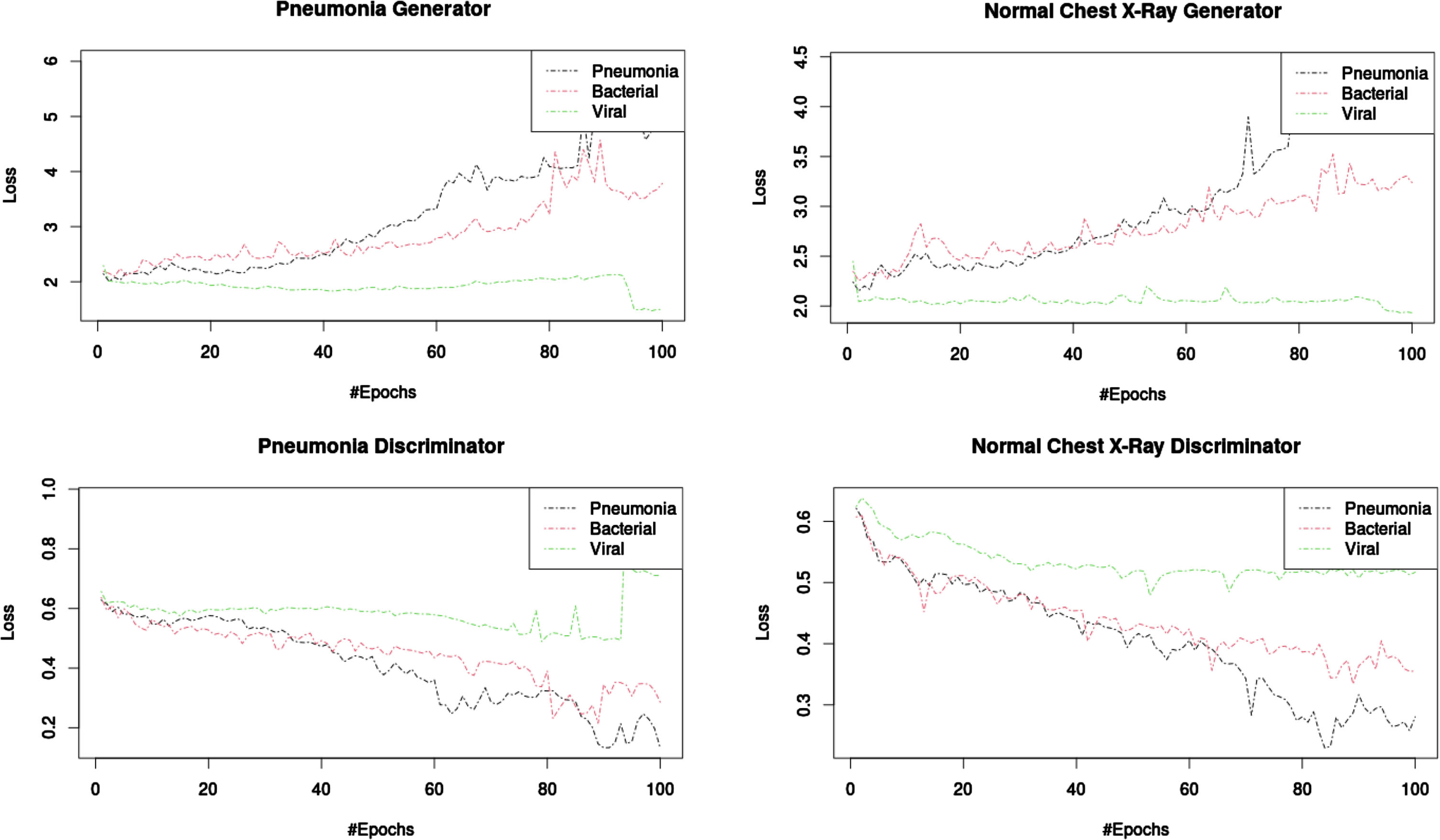
Loss function of 256×256 CycleGAN model during 100 epochs of training.
Visually the output quality of the generated images (see Fig. 4) it’s difficult to asses for someone who does not have medical knowledge but according to the FID and IS values of the generated images the best quality correspond to the viral pneumonia images trained 25 epochs with a FID value of 54.4719. Considering the IS metric, it also corresponds to those of viral pneumonia generated images but at 100 training epochs with an IS of 2.5063.Using this metrics do not tell us much on their own regarding the medical usefulness of the generated images. Thus contrasting to the results obtained from the questionnaires applied (see Table 2) is possible to observe that good performance in the FID and IS values does not translate into the evaluation obtained by the assesment of the medical experts.
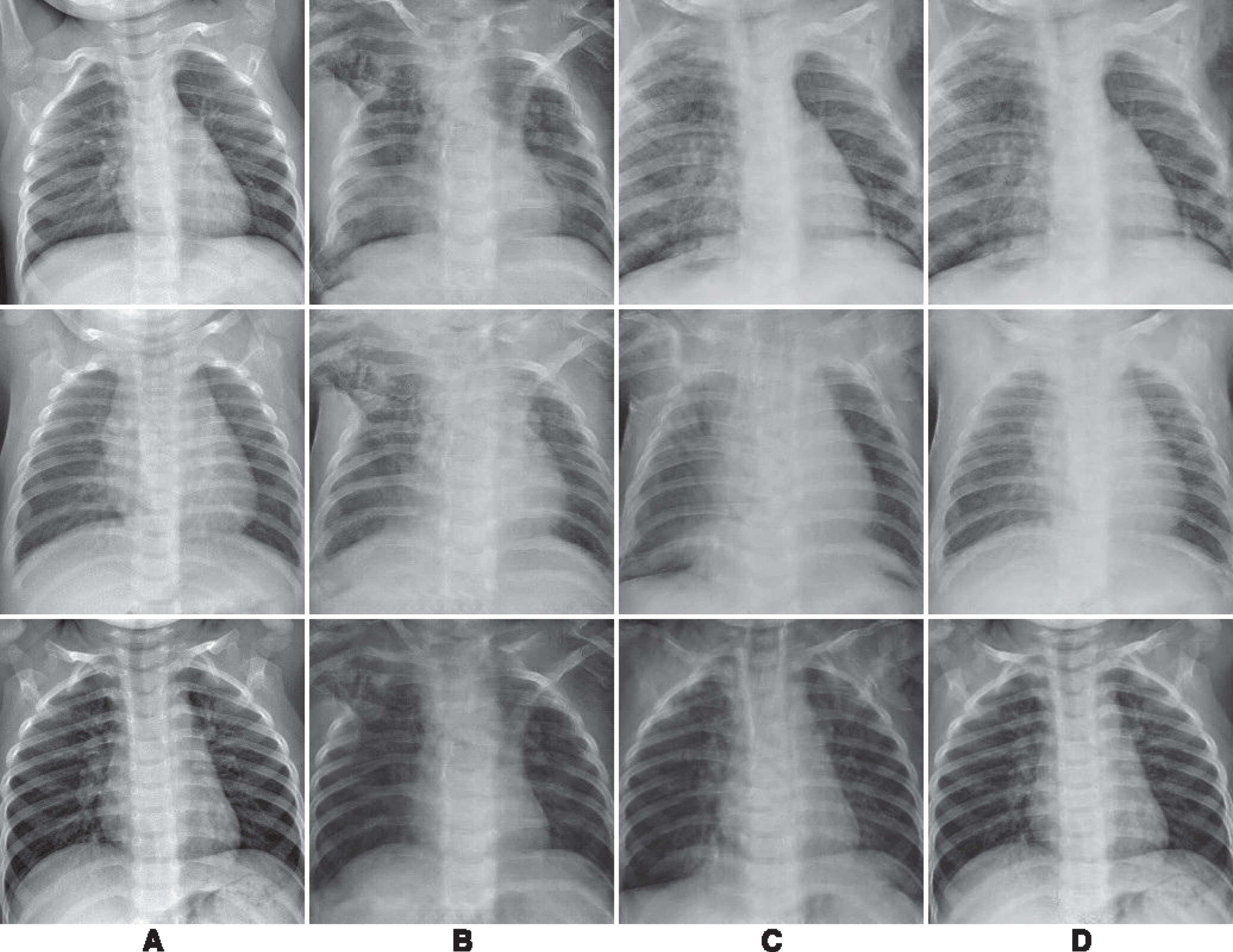
Results obtained from CycleGAN: A) Original Image, B) General pneumonia, C) Bacterial pneumonia, D) Viral pneumonia.
For the GP generated images the best expert assessment average was of 0.58 with 25 epochs of training and matches with the best FID but not IS score of its group. The best BP generated images were with 75 epochs of training and got an average expert assessment of 0.9 that does not match the best FID or IS score of its group. Overall this group got the best score images assessment-wise. And for the VP generated images the best expert assessment average of 0.53 was obtained with 100 epochs of training which does not match the best FID or IS of its group. The results obtained give us evidence that the images generated score either FID or IS do not translate into their ability to pass as images of real pneumonia [2]. This evaluation by the experts is important but also presents problems since the number of images that can be shown to the experts to asses has to be a reasonable amount but also a representative one of the almost limitless images that the CycleGAN model can generate.
Experts evaluation of generated images
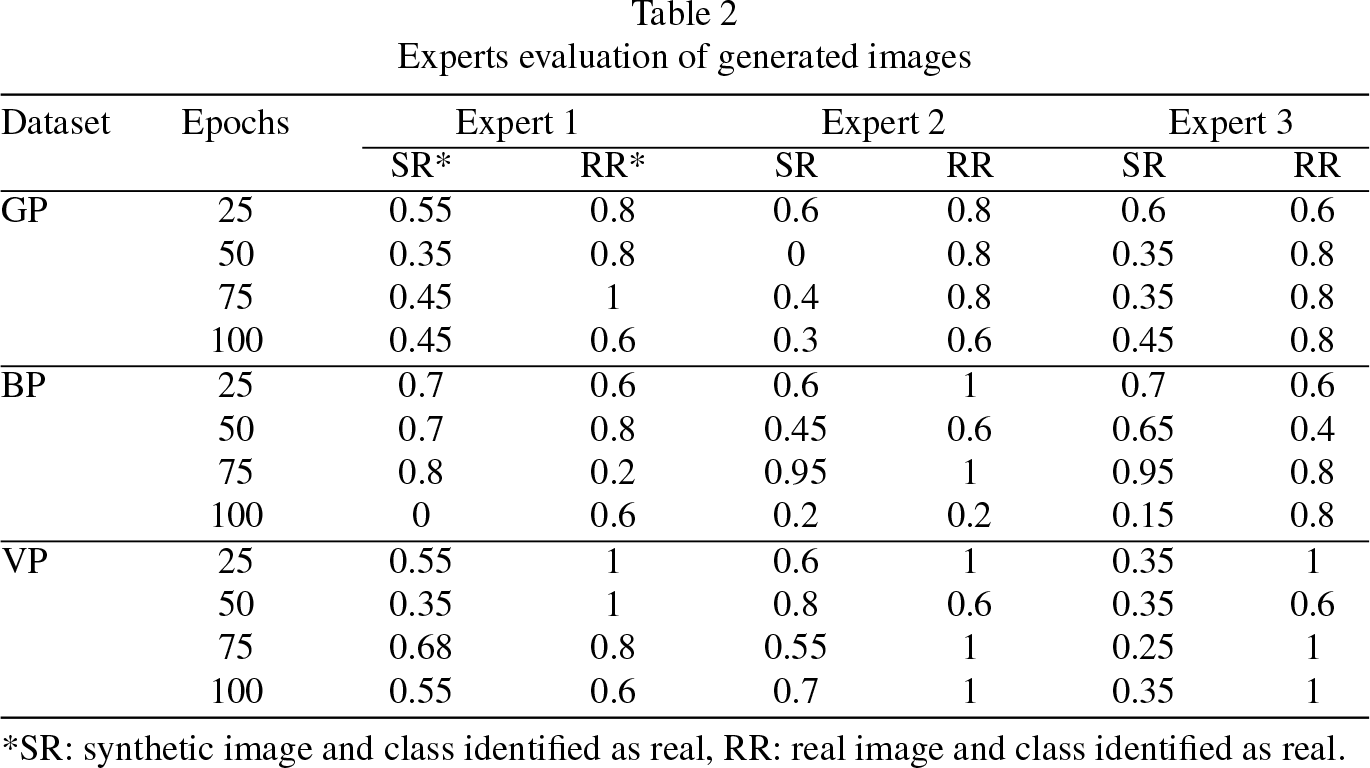
*SR: synthetic image and class identified as real, RR: real image and class identified as real.
Although the criteria of experts cannot be substituted, it is important to have a way to evaluate the huge amounts of images that can be generated considering a more objective criterion that is whether the generated image is capable of passing for a chest image x-ray with pneumonia or not.Since it is a classification problem, the validated and trained ViT model vit-xray-pneumonia-classification was used, which is a fine-tuned version of the model architecture ViT (as seen in Fig. 2.5.1) trained on the NIH Chest X-rays dataset. The trained ViT model performance (as seen in Fig. 5): Loss: 0.0868, Accuracy: 0.9742.
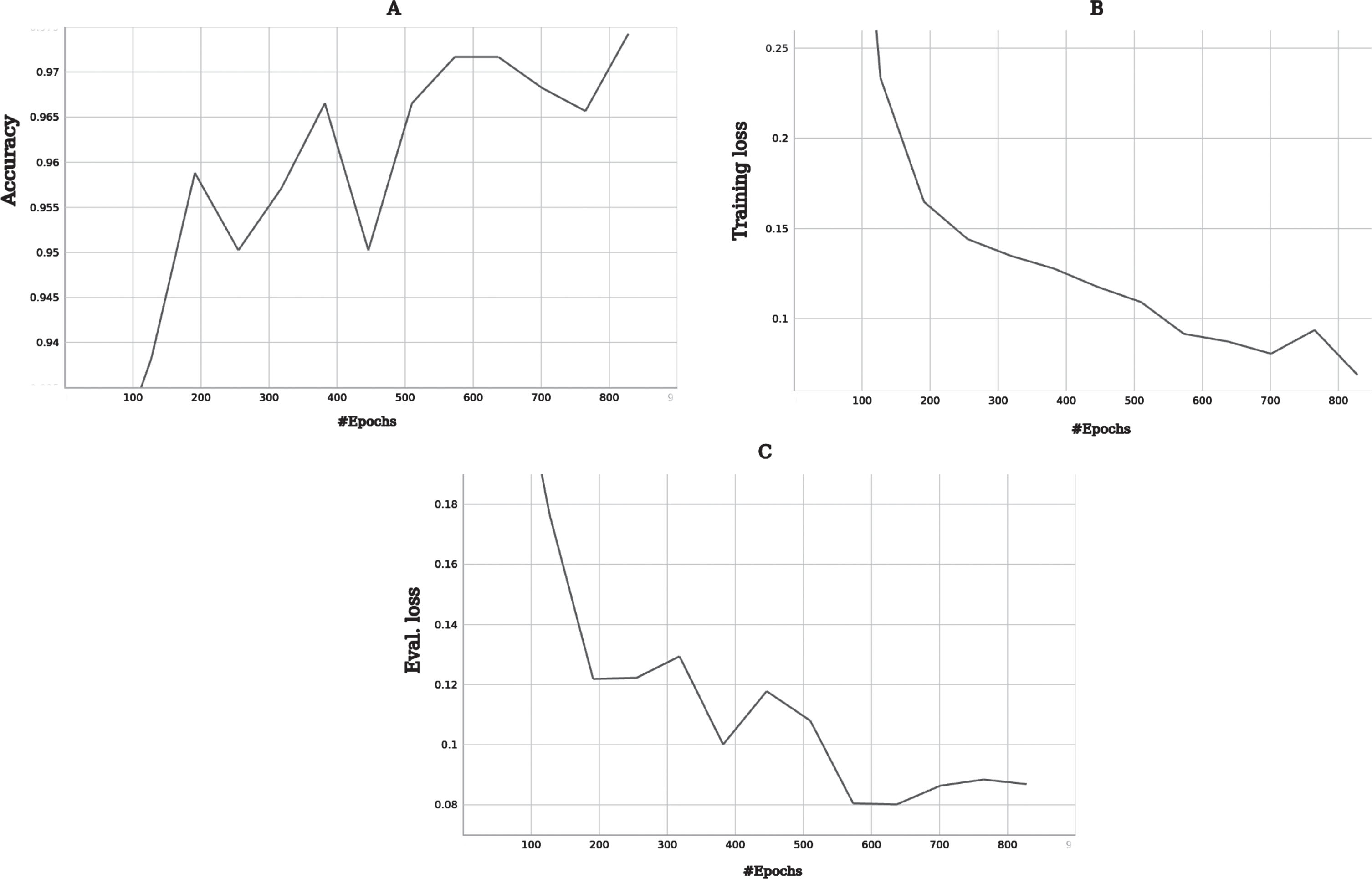
Performance of ViT pneumonia classification model: A) Accuracy, B) Training loss, C) Evaluation loss.
For a basal evaluation of the ViT model, 4 batches of 1000 real images each were given to the ViT model to classify (as seen in Table 3): general pneumonia, bacterial pneumonia, viral pneumonia and normal chest x-ray images. Since the ViT model used in this work only classifies into 2 classes (pneumonia and normal) with a probability associated with each class, a probability of classifying into a class above 0.98 was established as a selection threshold.
Evaluation of ViT on real images
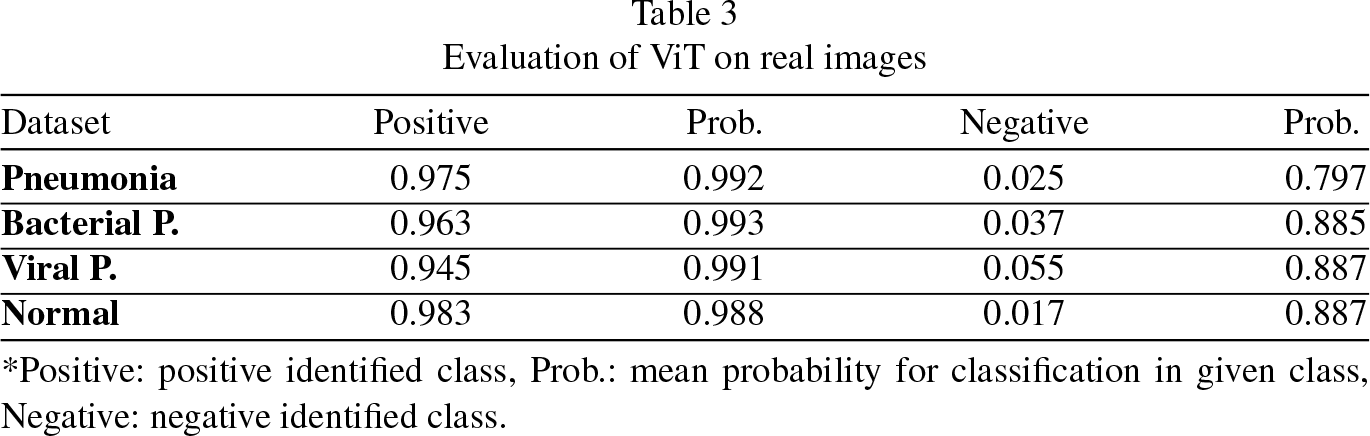
*Positive: positive identified class, Prob.: mean probability for classification in given class, Negative: negative identified class.
Evaluation of ViT on the generated images
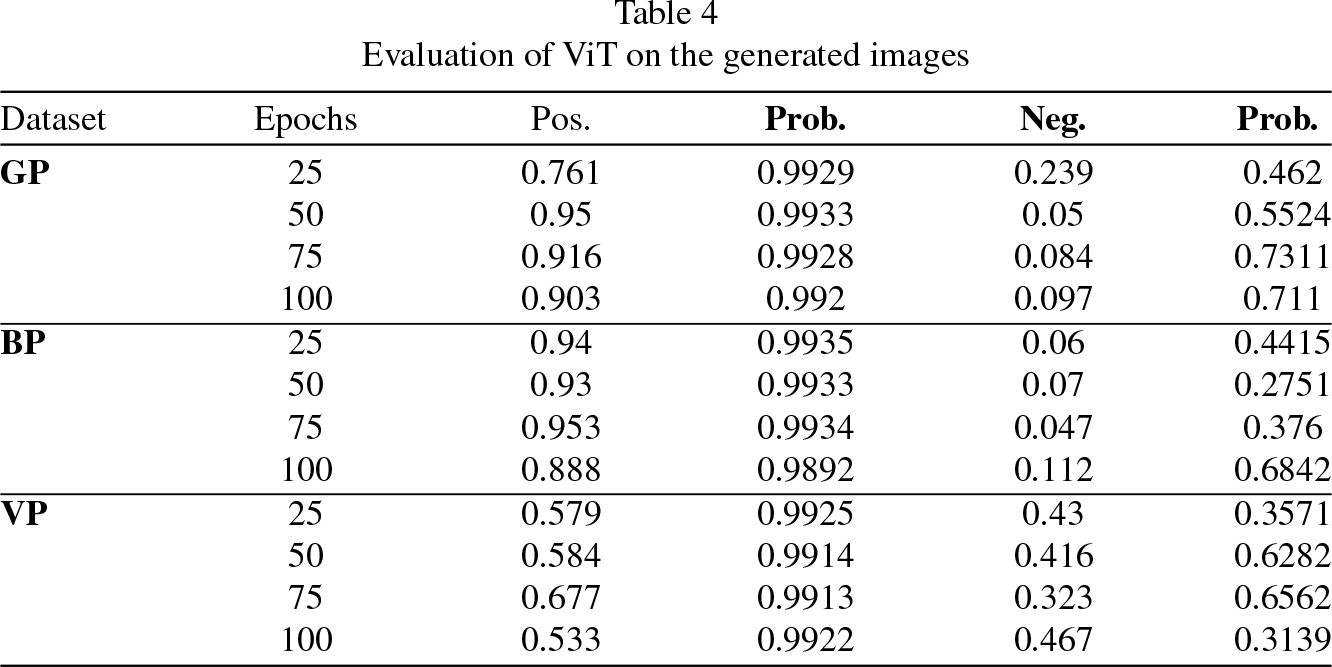
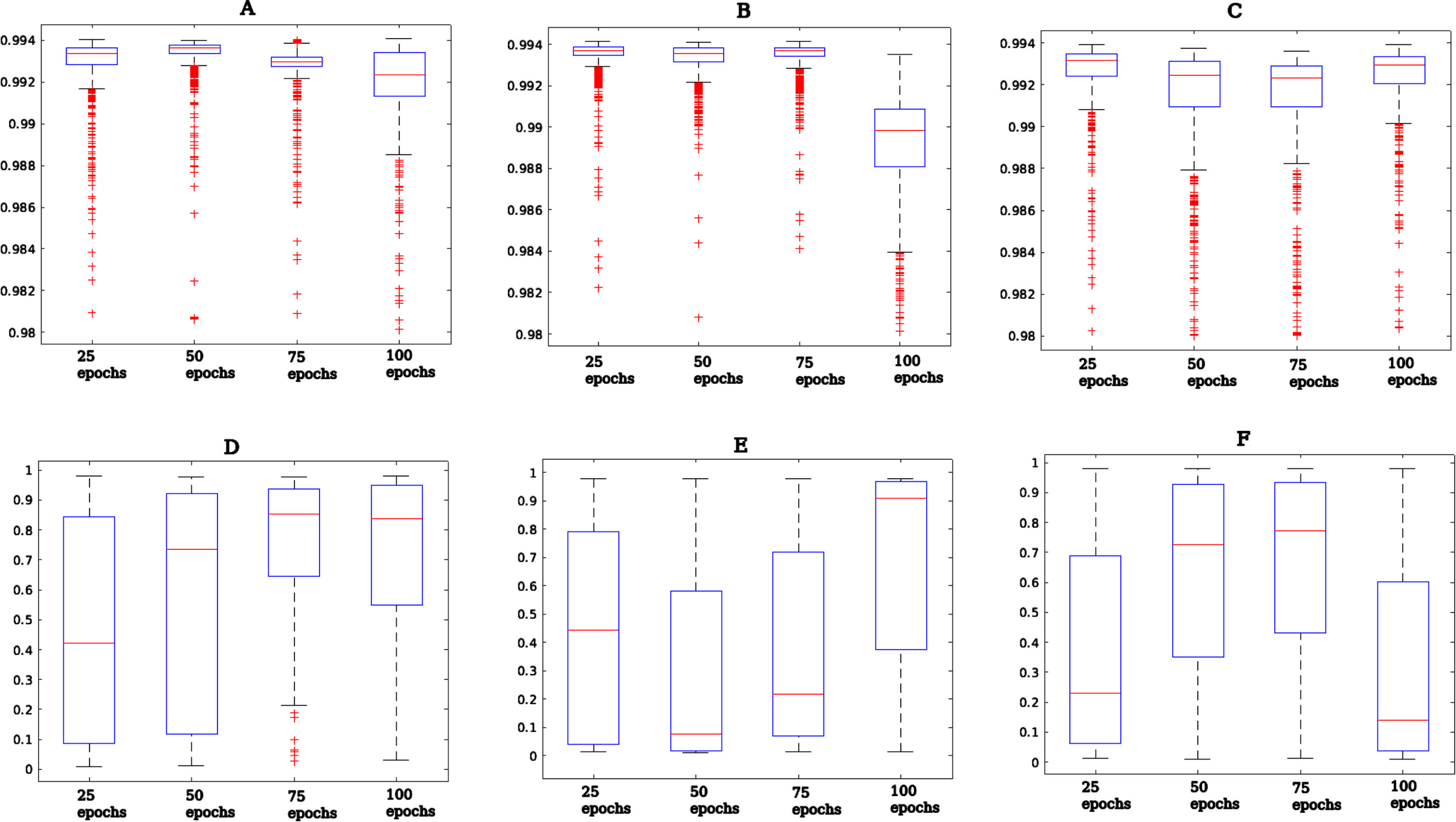
Overall results of probability classification of ViT of generated images: a) General pneumonia positive, b) Bacterial pneumonia positive, c) Viral pneumonia positive, d) General pneumonia negative, e) Bacterial pneumonia negative, f) Viral pneumonia negative.
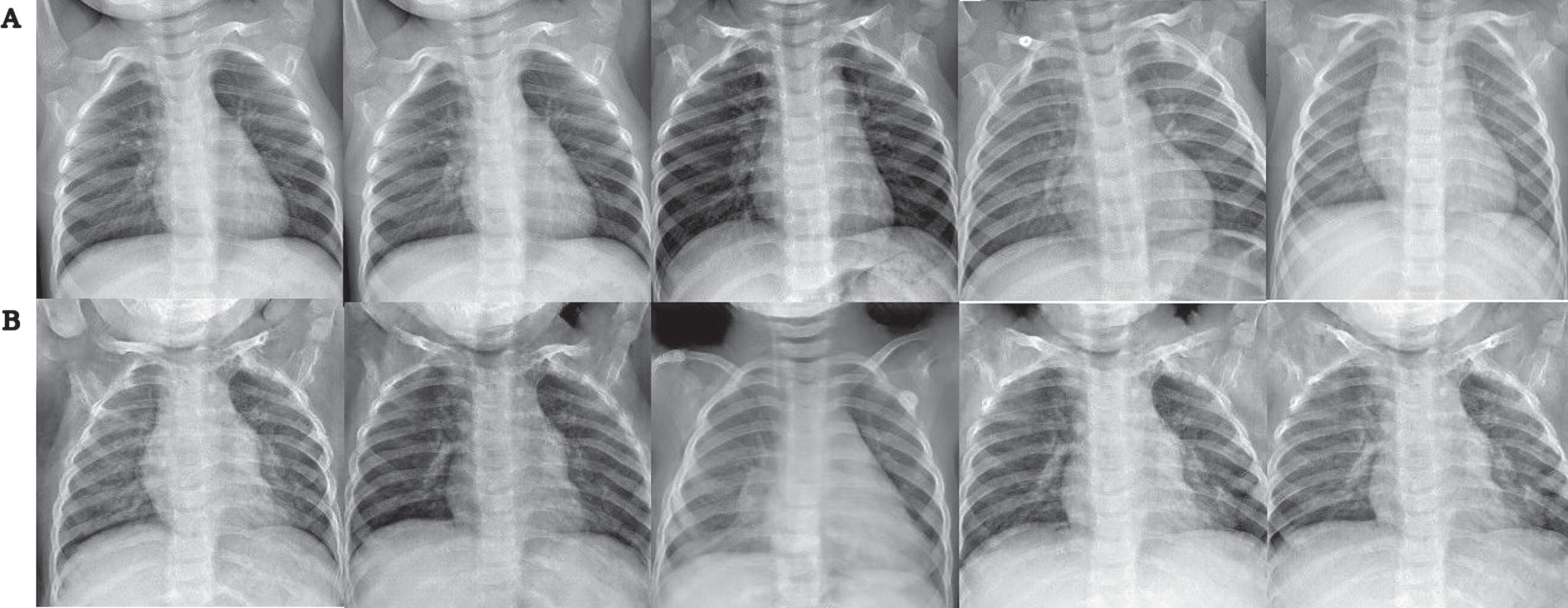
Example of applying Normal Chest X-Ray generator from General Pneumonia trained model: A) Pneumonia Image, B) Normal Chest X-Ray.
For general and bacterial pneumonia images, an average of 80% of generated images identified as pneumonia by the ViT model were obtained. The generated images of viral pneumonia had the worst evaluation by the ViT model classification where almost half of the generated images were not identified as pneumonia. This is quite contrasting since these images had the best FID and IS values and seems to coincide with the experts’ assessment where on average 50% of the images generated were identified as images of viral pneumonia.
The use of CycleGAN in this context offers a two-fold benefit. Firstly, it aids in the augmentation of pneumonia datasets, potentially improving the generability of models trained on them [6, 10, 11, 21–23]. Secondly, the bidirectional nature of CycleGAN provides a way for understanding the differences between healthy and pneumonia chest x-rays [24]. However, challenges persist such as distinguishing between real and subtle synthetic features is critical, and the generated images must be used carefully in clinical applications [7]. Likewise, an advantage of the CycleGAN model lies in the training of two generators to guarantee the cycle consistency of the model. In this work, a comparison between the expert evaluation and the classification of a ViT model was contrasted with respect to the FID and IS values of the generated images. With this comparison it was possible to show that the evaluation of the FID and IS values associated with the quality of the generated images are insufficient to determine how realistic the generated image is, which is quite contrasting since these metrics measure proximity with respect to the distribution of the dataset used for training. This can have several explanations, ranging from the type of GAN model used to the difficulty of the model in understanding the complexity of the distribution that is sought to be learned, this is especially difficult in images.
Conclusion
CycleGANs application in generating synthetic pneumonia chest x-rays showcases the potential of generative models in medical imaging. While promising, care must be taken to validate the clinical relevance of the generated images, ensuring they serve as a boon, not a bane, to medical diagnostics. From this work we show that the FID and IS values associated with the quality of the generated images are insufficient to determine how realistic the generated chest x-ray pneumonia images were. This will suggest the need for a proposal of a better assessment metric that will allow the use of generated images more reliably and helpfully. For future works, a modified ViT model has been proposed for classifying more classes. Also, to help avoid the mode collapse problem, it has been proposed to implement multimodal models such as Augmented CycleGAN [4] and for better quality image it has been proposed the modification of the architecture of this work to 512×512 and 1024×1024 to obtain better image quality.
Dataset & Code
The CycleGAN code used in this paper and the dataset is available at: https://github.com/Lugo1025/PneumoCGAN. The pretrained ViT model for pneumonia classification is available at: https://huggingface.co/lxyuan/vit-xray-pneumonia-classification. The dataset used for the training of the pretrained ViT model for pneumonia classification is available at: https://www.kaggle.com/datasets/nih-chest-xrays/data.
Footnotes
Acknowledgments
We gratefully acknowledge the help with the proffesional assesment of the images to Dr. Yazmin Guillen Dolores from the National Institute of Cardiology, Dr. Gustavo Lugo Goytia and Dr. Sergio Gustavo Monasterios López from the National Institute of Respiratory Diseases. The authors also wish to thank the support of the Instituto Politécnico Nacional (COFAA, SIP-IPN, Grant SIP 20240610) and the Mexican Government (CONAHCyT, SNI).