
Abstract
Navigation of a mobile robot in an unknown environment ensuring the safety of the robot and its surroundings is of utmost importance. Traditional methods, such as pathplanning algorithms, simultaneous localization and mapping, computer vision, and fuzzy techniques, have been employed to address this challenge. However, to achieve better generalization and self-improvement capabilities, reinforcement learning has gained significant attention. The concern of privacy issues in sharing data is also rising in various domains. In this study, a deep reinforcement learning strategy is applied to the mobile robot to move from its initial position to a destination. Specifically, the Deep Q-Learning algorithm has been used for this purpose. This strategy is trained using a federated learning approach to overcome privacy issues and to set a foundation for further analysis of distributed learning. The application scenario considered in this work involves the navigation of a mobile robot to a charging point within a greenhouse environment. The results obtained indicate that both the traditional deep reinforcement learning and federated deep reinforcement learning frameworks are providing 100% success rate. However federated deep reinforcement learning could be a better alternate since it overcomes the privacy issue along with other advantages discussed in this paper.
Introduction
Navigation and obstacle avoidance are the two most crucial problems for mobile robots, this can be aerial robots such as Unmanned Aerial Vehicles (UAV) or based on ground such as Unmanned Ground Vehicles (UGV) [1]. The goal of navigation is to guide a robot to move from a starting position to a destination position in an optimal way and also to overcome obstacles in its path. To achieve this, there has been a considerable amount of work done. Traditional methods such as simultaneous localization and mapping (SLAM) has been widely used [2]. SLAM does have few disadvantages such as data association problems. The computational complexity increases as the map size grows, making real-time implementation challenging. Sensor calibration and synchronization are crucial for accurate SLAM but can be time-consuming. Drift and error accumulation, handling dynamic environments, and robustness to environmental variations also pose significant challenges. Path planning algorithms have also been utilized, but they may encounter drawbacks such as grid-based map incompatibility and computation-intensive real-time re-planning in dynamic scenarios, limiting responsiveness.
The emergence of Deep Learning Techniques and Reinforcement Learning (RL) has significantly expanded research opportunities in mobile robot navigation and the broader field of robotics. These advancements offer the potential for more sophisticated and adaptable navigation strategies. Though this also leads to sharing of data which might cause privacy issues. However, it also has to be analyzed if the performance remains the same.
Deep learning-based path planning has become a prominent focus in the field of robotics because it has the capacity to acquire intricate navigation strategies directly from gathered data, which has garnered considerable interest. One of its key advantages is its capacity to handle high-dimensional input spaces and learn intricate spatial representations, enabling robots to navigate in dynamic and unstructured environments with improved adaptability. Deep learning-based path planning can also handle partial observability and noisy sensor data, enhancing the robot’s robustness [3]. However, it comes with challenges, such as the need for large labelled datasets and substantial computational resources for training complex neural networks. Additionally, the lack of interpretability in deep learning models can make it difficult to understand and debug their decision-making processes, posing potential safety concerns in critical applications [4]. Balancing the advantages and disadvantages of deep learning in path planning is crucial for harnessing its potential while addressing its limitations in real-world robotic systems.
RL has emerged as a powerful paradigm in robotics, enabling robots to learn and adapt their behaviours through interactions with their environment. By combining trial-and-error exploration with the use of rewards or penalties, RL algorithms enable robots to optimize their decision-making processes [5]. RL empowers robots to acquire complex skills, handle dynamic and uncertain environments, and generalize their knowledge to new situations. It offers the ability to learn directly from raw sensor inputs, allowing robots to autonomously acquire behaviours without the need for explicit programming or hand crafted rules.
In the field of mobile robotics RL has been revolutionizing the way mobile robots navigate and interact with their surroundings [6]. By utilizing RL algorithms, mobile robots can learn optimal control policies through trial and error, enabling them to make decisions based on environmental feedback and rewards. This allows mobile robots to autonomously adapt their behaviours and optimize their navigation strategies in response to changing environments and objectives. RL empowers mobile robots to handle complex and dynamic scenarios, overcome obstacles, and reach desired destinations efficiently and safely.
In mobile robots, securing the data they use and collect is important as they often interact with sensitive information and personal spaces. In industrial or public spaces, privacy measures prevent unauthorized access to data collected by robots, preserving the confidentiality of sensitive information and safeguarding against potential breaches. Overall, privacy in mobile robots is an essential element in ensuring responsible and secure human-robot interactions. Therefore, in this work deep reinforcement learning (DRL) is used for the path-planning of a mobile robot which is trained in a federated learning (FL) approach to overcome privacy issues since only the gradients of the model parameters are being sent rather than the raw data. The contributions of this work are: An implementation of a mobile robot capable of autonomously navigating from an initial state to a destination state within a greenhouse environment, with a primary objective of efficient charging, has been achieved through the application of deep reinforcement learning. The mobile robot selects and navigates through the shortest path and overcomes obstacles. The utilization of the Federated Learning approach in the training of these autonomous agents has proven to be instrumental in addressing privacy concerns, thereby ensuring the protection of sensitive data. A Multilayer Perceptron model is proposed as the Deep Q-Network. This design choice simplifies the computational load. A completely self-organized mechanism without the dependence on sensor data and local observations is implemented reducing the complexity of the mobile robot.
The paper’s organization is as presented next. Section II provides an overview of the current literature on the subject, discussing various aspects such as path planning and other trivial algorithms are provided as well as the application of RL and FL techniques in the field of robotics and mobile robots are discussed. Section III describes the methodology of the this work, which also includes the system and model architecture incorporated. Section IV discusses the training algorithm, hyperparameter tuning, results and simulation observations obtained. The paper then is concluded and an outline of future prospects is provided in Section V.
In this section, the key findings from a comprehensive literature survey on mobile robot, RL and FL will be discussed. Initially survey and review papers were studied to gather the overall work executed in this domain. Rubio et al. [1] explored mobile robots with autonomous mobility and intelligent decision-making based on environmental perception. It highlights emerging trends in robotics driven by artificial intelligence, autonomous driving, and human-robot interaction, applied across various sectors, including medicine, industry, and service robotics, with ongoing evolution anticipated. There are various path planing strategies for mobile robots. Kolhatkar et al. [2] reviewed mapping and localization techniques for mobile robots, emphasizing the use of low-cost sensors like RPLIDAR and Microsoft Kinect, as well as hardware boards. It also compares various localization methods within the Robot Operating System (ROS) framework and benchmarks algorithms for future research selection. Zhang et al. [3] introduced a novel method for guiding mobile robots within familiar indoor settings using an innovative path planning approach. It combines deep learning using GoogLeNet for obstacle classification, ray tracing for static obstacle avoidance and the Rapidly-exploring Random Tree (RRT) approach for determining the route from the initial location to the destination point. Garaffa et al. [4] reviewed recent research on using RL for designing exploration strategies in unknown environments for both single and multi-robots. It analyzes the employed RL algorithms, exploration strategies, challenges addressed, experimental approaches, and discusses progress, limitations, and future directions in this field. Aradi et al. [5] covered vehicle models, simulation options, and computational needs for autonomous driving, along with various observation models. It surveys state-of-the-art solutions based on tasks and autonomous driving levels, concluding with open questions and future challenges in the field. Zhu et al. [6] reviewed DRL methods and their applications in navigation, including local obstacle avoidance, indoor navigation, multi-robot navigation, and social navigation. It also outlines the development and challenges of DRL-based navigation.
Path Planning is required for various kinds of robots such as UAVs and UGVs [7, 8]. In mobile robot there has been plenty of work. Patle et al. [9] extensively reviewed mobile robot navigation techniques, comparing classical and reactive approaches in different environments. Reactive methods are favoured, often used to enhance classical ones in hybrid algorithms for mobile robot path planning, as indicated by data and charts. Path planning for mobile robot has been implemented using QR code and for indoor navigation [10, 11]. Karur et al. [12] introduced novice practitioners to path planning algorithms for automated and unmanned systems. It provides a broad overview, definitions, summaries, and comparisons of key algorithms to help beginners understand their potential applications in robotics and embedded systems. Vagale et al. [13] reviewed path planning algorithms for autonomous surface vehicles, focusing on their classification and highlighting aspects such as vessel autonomy, regulatory frameworks, and industry advancements. It also clarifies terminology and discusses the potential need for new regulations in the context of autonomous surface vehicles. There have also been implementations for obstacle avoidance [14]. In this paper, three active sensor-based methods for obstacle avoidance and path planning: Bug algorithms, Potential Field methods, and the Vector Field Histogram method have been implemented. In [15], an overview of path planning algorithms, emphasizing their application with autonomous ground vehicles and other surface-based robots is presented. Santos et al. [16] investigated the utilization of path planning techniques in agricultural settings, particularly concerning the tasks of field coverage and point-to-point navigation for agricultural robots. Their findings suggest that coverage path planning is a more developed and effective approach within this domain.Campbell et al. [17] offered a comprehensive summary of path planning techniques used in guiding mobile robots through both unchanging and constantly changing environments, covering a wide range of methods including global and local approaches, classical strategies, and heuristic-based methodologies.
RL is used in various domains such as communications, networking, robotics etc. Trivial algorithms for path-planning have also been used [18]. In [19] a RL-based path planner for mobile service robots in dynamic environments is introduced. Ruan et al. [20] explored the application of D3QN for navigation in mobile robots in unknown surroundings, using dueling network architectures and RGB-D camera data. The results demonstrate that the mobile robot successfully reaches its target destinations without collisions, showcasing the effectiveness of the D3QN algorithm in autonomous navigation. Beom et al. [21] presented a navigator for mobile robots utilizing independently designed avoidance and goal-seeking behaviors, combined by a behavior selector using fuzzy logic and RL, effectively guiding the robot through complex environments. Q-learning algorithm have also been used [22]. In this paper, an approach combining Q-learning and neural networks for autonomous mobile robot obstacle avoidance was introduced, demonstrating improved learning and task completion in complex environments through simulations. Wang et al. [23] introduced G2RL, a globally directed RL strategy for multi-robot path planning, incorporating an innovative reward framework that can be adjusted to different environments. G2RL outperforms existing techniques and performs comparably to fully centralized benchmarks in various scenarios, demonstrating its effectiveness and versatility. Xin et al. [24] provided an end-to-end mobile robot path planning method using a deep Q-network (DQN) trained on RGB images. The DQN approximates the state-action value function, enabling the selection of optimal robot actions to reach the goal while avoiding obstacles. Experimental results in the DeepMind Lab platform demonstrate the method’s effectiveness in path planning. Jiang et al. [25] discussed the limitations of conventional global information-based navigation techniques and highlights the promise of DRL for dynamic and map-less navigation. It identifies five key limitations in DRL navigation, emphasizing the need for addressing these challenges for the widespread deployment of service robots in human environments. Gao et al. [26] presented an incremental training approach for DRL-based path planning in mobile robots, combining 2D and 3D environments and incorporating TD3 with PRM for improved efficiency and generalization. Dong et al. [27] introduced an improved RL algorithm for laying down path for a mobile robot, incorporating a priori knowledge and an adaptive exploration strategy, demonstrating successful path finding, superior performance, shorter computation time, and faster convergence compared to Q-learning and SARSA.
To train the model, huge amount of data is required and there is a possibility of privacy issues. To overcome this there have been various methods but in this work FL is incorporated. It has been used in various domains and uses the concept of edge intelligence [28]. In [29], both centralized and federated strategies in the training of machine learning models through V2X communication for the purpose of predicting steering angles based on visual data inputs was implemented. Study finds that FL outperforms the centralized approach, especially in scenarios with higher bit error rates, offering improved performance and bandwidth efficiency. Xianjia et al. [30] provided a comprehensive review on how FL is applied to autonomous robots, assesses the significance of Distributed Ledger Technology (DLT) and FL in this context, and provides an introduction to essential background concepts and research considerations. In [31], InVision, a deep FL method for robot target recognition was proposed. It enhances perception with deep geometric learning, ensuring user data privacy through federated metric learning. Zhou et al. [32] presented a Privacy-Perceiving Asynchronous Federated Learning (PPAFL) framework based on Peer-to-Peer (P2P) technology. The objective is to facilitate distributed model training to enhance the security and robustness of mobile robotic systems operating in 5G and upcoming network environments. In [33], A proposition was made for vision-based obstacle avoidance in mobile robots, along with an investigation into the use of FL in distributed systems to enhance accuracy through ongoing learning in both simulated and real-world situations. Additionally, the study examined the integration of FL and RL.
Zhuo et al. [34] introduced FedRL, a novel DRL framework for federated model building while preserving data privacy. FedRL employs Gaussian differentials to protect shared information during local model updates and is evaluated in Grid-world and Text2Action domains against multiple baselines for performance assessment. This combination were experimented in various domains. Wang et al. [35] proposed the FADE framework which uses Federated Deep Reinforcement Learning (FDRL) to enable base stations to cooperatively learn and optimize edge caching strategies, reducing performance loss and average delay while improving hit rates and offloading backhaul traffic. In [36], the article introduced an I-UDEC framework for 5G UDN environments, optimizing task execution and resource allocation through a two-timescale Ts-DRL approach, with FL for model training, demonstrating its effectiveness in the I-UDEC framework. Li et al. [37] utilized the DDPG algorithm for enhanced prediction accuracy and integrates it into a FL framework called FedDRL, which achieves accurate predictions without sharing private data, ensuring data privacy and reducing communication load while outperforming traditional methods in forecasting accuracy, as confirmed through simulations. In the domain of robotics there have been few works. Liang et al. [38] introduced an online federated reinforcement learning approach for real-time knowledge sharing among autonomous driving agents, eliminating the need for sequential pre-training and fine-tuning. The approach is validated with a collision avoidance system, demonstrating a significant improvement in obstacle avoidance and collision reduction between simulator and real-world car agents. Liu et al. [39] introduced Lifelong Federated Reinforcement Learning (LFRL) as a solution to enable robots to fuse and transfer their experience, enhancing their adaptability in new environments. Recent advancements in DRL have enabled automatic controller design for swarm robotic systems, but central server reliance poses issues in unstable communication environments. In [40], a FL-based DRL training approach, FLDDPG was introduced which exhibits superior robustness and generalization in limited communication scenarios compared to baseline methods. FLDDPG shows promise for swarm robotics in challenging environments like high-radiation, underwater, or subterranean conditions. Therefore, in this work federated deep reinforcement learning in the domain of robotics.
Methodology
In this section the RL formulation would be discussed. The overall system and model architecture proposed will be explained along with the evaluation criteria.
Reinforcement learning formulation
The RL formulation was initially performed to understand and model the mathematical framework. All the components were defined to describe and analyze the nuances of the overall problem statement. This would provide clarity on the problem statement and objectives, reducing ambiguity in guiding algorithm selection.
Environment
A grid world environment of a greenhouse scenario, created in Webots Simulator, consisting of obstacles, initial state and destination state is defined as the environment. This is shown in Fig. 1. The initial state could be any random location. The destination state is the charging point. The obstacles are the various plants present in a greenhouse.

The robotic environment.

Epuck Mobile Robot(Agent).
This robot, designed by EPFL and GCtronic, is a compact, open-source mobile robot primarily created for educational and instructional use. It features four wheels and is equipped with various components, including infrared sensors, a camera, a gyroscope, a Bluetooth communication module, and eight LEDs situated on its body. Notably, none of the robot’s sensors were utilized in the context of this study.
State space
The state space is the location (x, y) of the mobile robot, where x and y are the point values in the coordinate space. It is a discrete state space where x, y ∈ W, in which W is a set of Whole Numbers.
Policy
The agent must navigate efficiently, avoiding collisions with obstacles, and reach its destination, which is the charging point.
Action space
The action space consists of 4 actions, namely Left, Right, Up and Down.
Rewards
The rewards were provided depending on the action performed by the mobile robot and the result of the action. The reward formulation is shown in Equation (1).
Deep Q-Learning is a robust reinforcement learning (RL) algorithm that merges classical Q-learning with deep neural networks. Within the context of Deep Q-Learning, an agent acquires the ability to make a series of decisions in an environment with the goal of maximizing its overall reward. The core idea of Deep Q-Learning revolves around the estimation of the Q-function, which assesses the expected cumulative reward when taking a specific action within a particular state while following a specific policy. Rather than managing a Q-table, which can be unwieldy for extensive state spaces, Deep Q-Learning employs deep neural networks to estimate the Q-function. These neural networks accept the present state as input and produce Q-values for all feasible actions, enabling the agent to select the action expected to yield the highest cumulative reward.
In the realm of robotics, Deep Q-Learning has emerged as a promising approach for training robots to perform complex tasks. Robots often need to make decisions in dynamic and unstructured environments, and Deep Q-Learning’s ability to handle high-dimensional sensory input makes it well-suited for such scenarios. By integrating sensors like cameras and lidars, robots can perceive their surroundings and represent this information as input to a deep neural network. This network can then approximate the Q-function, enabling the robot to choose actions that maximize its expected cumulative reward while navigating, manipulating objects, or interacting with humans.
System architecture
The overall system architecture is provided in Fig. 3. After the environment was designed, the states are extracted and passed through a neural network model to predict the state-action value. Based on this set of values, the next action for the agent can be determined. The reward given to the agent depends on the chosen action. This process continues for a finite number of episodes till the agent is able to navigate and reach the destination efficiently. At this point the neural network has completely been trained.

High level system architecture.
The Q-Network utilized in this study is represented in Fig. 4 and is based on the Multilayer Perceptron (MLP). An MLP is a form of artificial neural network composed of multiple layers of interconnected nodes or neurons. Neurons within each layer are linked to neurons in adjacent layers through weighted connections, and these weights are adjusted during the training process to acquire a deep understanding of intricate data patterns and relationships. In this specific configuration, the MLP comprises 2 neurons in the input layer, 64 neurons in both hidden layers, and the output layer consists of 4 neurons, which were determined through hyperparameter tuning. The Rectified Linear Unit (ReLU) activation function was employed.

Multilayer Perceptron Model (Q-Network).
The Traditional Deep Reinforcement Learning Framework is the widely accepted approach that is frequently employed. It is a trivial approach and the system’s structure for this approach is shown in Fig. 5. In this setup, a single mobile robot gathers its experience by interacting with the environment and trains the neural network model present in a server. However, there are privacy concerns in this framework. The learned model or policy may contain sensitive information about the agent’s strategies or behaviours. In some cases, this information may need to be protected. Adversaries may attempt to infer sensitive information about an agent’s environment or experiences by observing its actions and responses. This can be a privacy risk if the adversary can learn information about the agent’s surroundings or tasks. While DRL agents don’t typically transmit raw sensor data, they still collect data from their environment, which might include indirect information about the environment or users. Therefore it is important to add a protective layer in a framework and this can be performed using federated learning.

Traditional deep reinforcement learning framework.
The Federated Deep Reinforcement Learning Framework is incorporated for training the neural network. The motivation for this approach was to provide a foundation to enable overcoming privacy issues. The framework is shown in Fig. 6. Here 2 clients or agents are used, initially, both clients are provided with a replay buffer. Each agent trains a local Q-Network for a certain number of episodes. Then the gradients are shared with the central server where the aggregation is performed. This could be performed for a certain number of communication rounds. Then the global model obtained is expected to converge and perform equally well as the traditional approach. Federated Averaging is used for aggregation.

Federated deep reinforcement learning framework.
The overall process performed in the clients and the servers are provided in Equations (2) and (3).
At Client:
In this scenario, w is used to indicate the parameter vector, η is employed to denote the learning rate, b refers to the mini-batch size, and ℓ represents the loss function, which quantifies the Mean Squared Error (MSE) between the model’s predictions and the true or intended values.
At Server:
In this scenario,
The generalized FDRL using deep Q-network is shown in Algorithm 1.
The Federated Deep Q-Network (FDQN) algorithm begins by initializing global DQN parameters θ. In each iteration, a subset of clients is chosen to participate, and for each selected client, it downloads the global DQN parameters from the central server and initializes a local DQN agent with these parameters. The client then runs episodes in its local environment, following an ∈-greedy policy to select actions based on the local DQN or choosing random actions with probability ∈. Actions are taken in the environment, and resulting state-action-reward-state tuples are stored in a local replay buffer. In this process, each client selects minibatches of data from this buffer and calculates target Q-values, which take into account both rewards and the highest Q-value estimate from the subsequent state. To minimise the difference between the predicted and desired Q-values, the parameters of the local DQN are changed locally using gradient descent. After completing their local training, clients communicate their new parameters to the central server, which aggregates them by calculating their mean. As a result, the global DQN parameters are changed, and the process is repeated until convergence or a preset maximum number of iterations is reached, resulting in the finalised global DQN parameters known as theta. This algorithm facilitates collaborative reinforcement learning among decentralized agents while safeguarding data privacy and minimizing communication overhead.
1: Initialize the global DQN parameters θ
2:
3: Select a subset of clients to participate in the current round.
4: for each selected client Ci
5: Client Ci downloads the global DQN parameters θ from the central server.
6: Initialize a local DQN agent with parameters θ i←θ
7: Initialize the local environment for Ci .
8:
9: Reset the local environment for Ci .
10: Initialize the initial state s.
11:
12: Select an action a using ∈-greedypolicy based on the local DQN:
13:
14: a← random action()
15:
16: a← argmax(Q(s, θ i))
17:
18: Take action a in the local environment, observe reward r and next state s'.
19: Store the (s, a, r,s') tuple in Ci ’s local replay buffer.
20: Sample a minibatch of experiences from the local replay buffer.
21: Compute the target Q-values for the minibatch:
22:
23: Update the local DQN parameters θi using gradient descent:
24:
25:
26:
27: Client Ci uploads the updated local DQN parameters θ i to the central server.
28:
29: The central server combines the local DQN updates received from the clients:
30: Compute the aggregated DQN parameters θagg as the average of all θ i .
31: Update the global DQN parameters:
32: Set θ ←θ agg.
33:
34: Return the trained global DQN parameters θ.
The evaluation criteria helps in evaluating the agent and displays the extent to which the agent is performing. Here the success rate is used as the evaluation criteria to validate the proposed approach. This tells if the agent is learning in every episode. It can be defined as the proportion of successful episodes out of the total number of episodes attempted by the agent. Higher the value, the better the agent has learnt and hence better would be the overall performance.
Experiments and performance evaluation
In this section the training algorithm is provided. The hyperparamter tuning, results and simulation are also discussed. The implementation was done using the Pytorch Framework and the simulation was performed in the Webots 3D Simulator.
Training algorithm
The flow diagram represents the method taken to implement the deep Q-learning algorithm after the RL formulation was completed for mobile robot navigation. The flow diagram is shown in Fig. 7.

Flow diagram of the training algorithm.
Deep Q-Network is used to predict the Q values. Two neural networks namely Q-Network and Target Network are used, which have the same architectures. The target network helps in predicting the next state-action Q value. Every 100 episodes the parameters of the Q-Network are copied to the Target Network. From the environment, the states are derived and passed as input to the Q-Network, this network is used to predict the current state-action Q value. The model is trained using Back propagation for minimizing the loss. Here the loss function considered is Mean Squared Error (MSE). The equations of this process is shown in Equation (4) and Equation (5).
The list of notable Hyperparameters are Network Architecture, Replay Buffer Size, Batch Size, Learning Rate, Epsilon-greedy Exploration, Discount Factor. The tuning was performed step-by-step in a systematic way. It was performed in the same order as provided. First, the number of neurons and number of hidden layers were varied and tested. Two hidden layers were providing better results. The performance of different number of neurons in the hidden layers is provided in Fig. 8. 64 neurons is giving the best success rate compared to 5, 16 and 32 neurons.

Training success rate for different neurons.
Second, the learning rate was varied. The ADAM optimizer was used and the learning rate was tested for three trivial values, 0.001, 0.002 and 0.003. The performance is shown in Fig. 9. Learning rate with the value of 0.003 is providing the best results.

Training success rate for learning rates.
Thirdly, the discount factor was varied between the values 0.5, 0.7 and 0.9. The performance is shown in Fig. 10. Discount factor of vale 0.9 is performing the best.
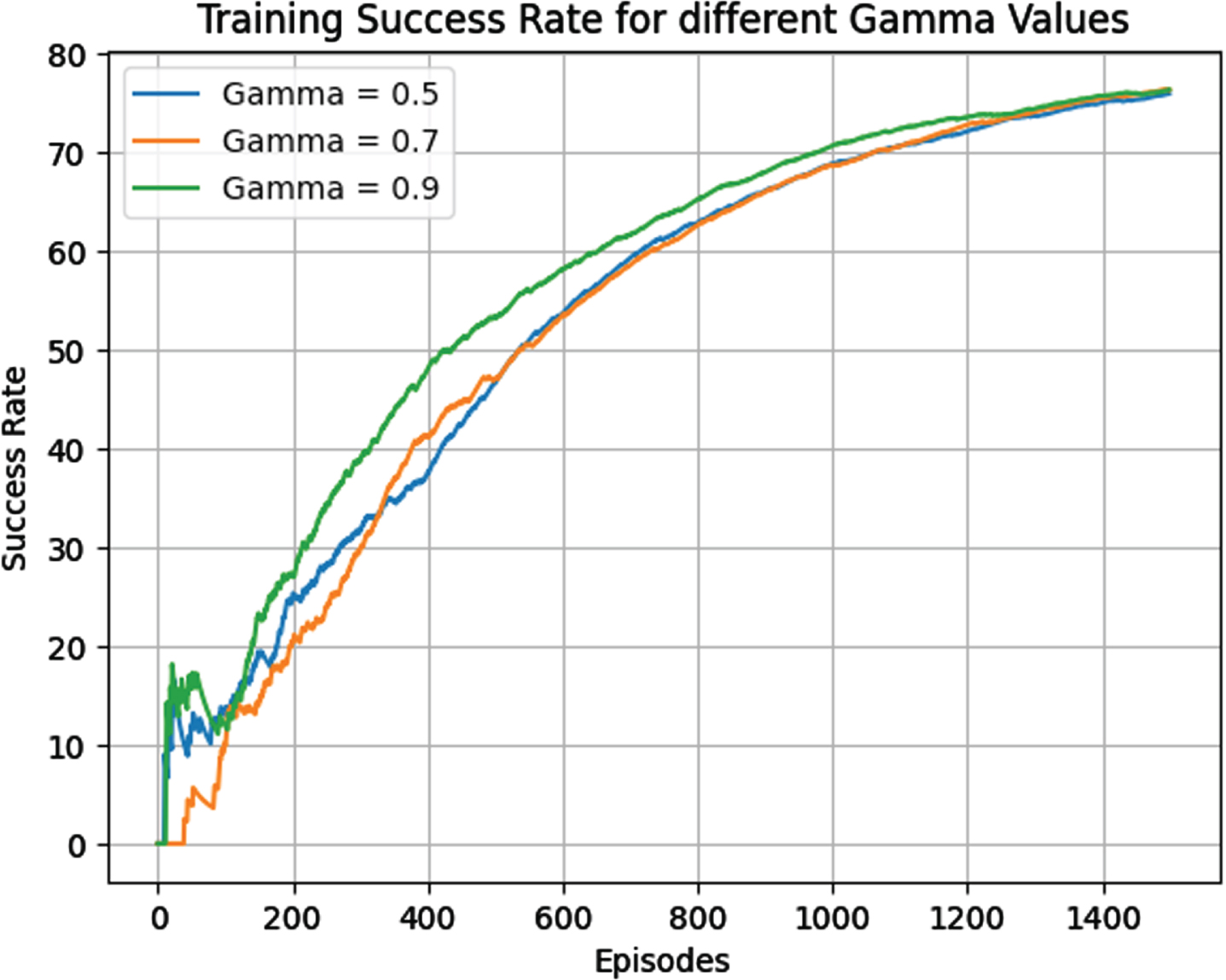
Training success rate for discount factor.
All the other hyperparameters were having default values and the performance was highly satisfactory. The hyperparameter and their final values are shown in Table 1.
Hyperparameter values
Here the training is performed using an epsilon decay approach. This helps the model to explore the environment for a certain number of episodes depending on the threshold provided, as the epsilon value gets decayed, a stage arises where the model starts to perform exploitation. The range of the epsilon value is between 1 to 0.1.
After performing hyperparameter tuning the agent was trained using the traditional deep reinforcement learning framework. It was trained for 1500 episodes and the success rate obtained was 74.6% . The plot is shown in Fig. 10. The convergence can also be confirmed by plotting the loss graph, which is the Mean Square Error (MSE) vs episodes. This is shown in Fig. 12.
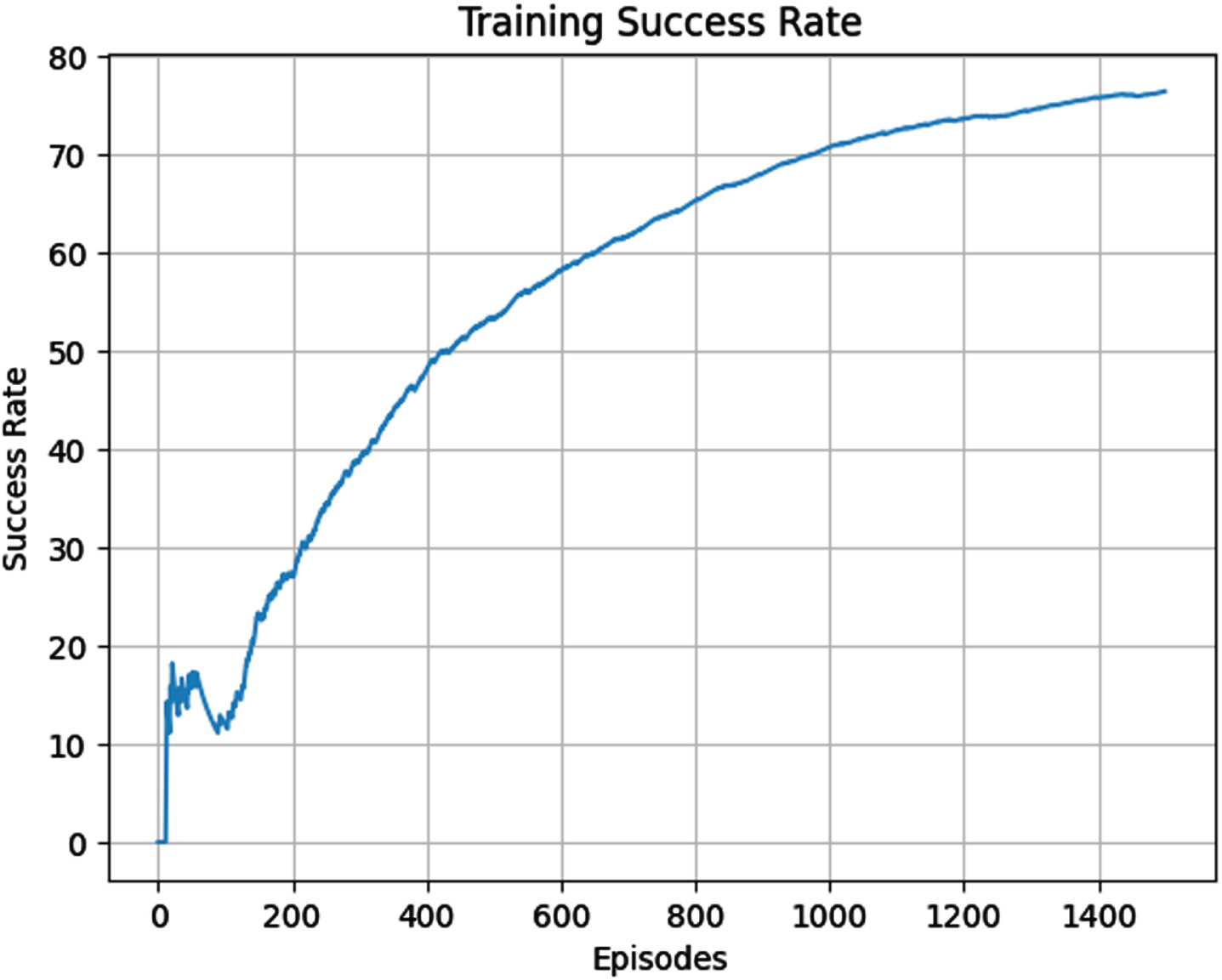
Training success rate.
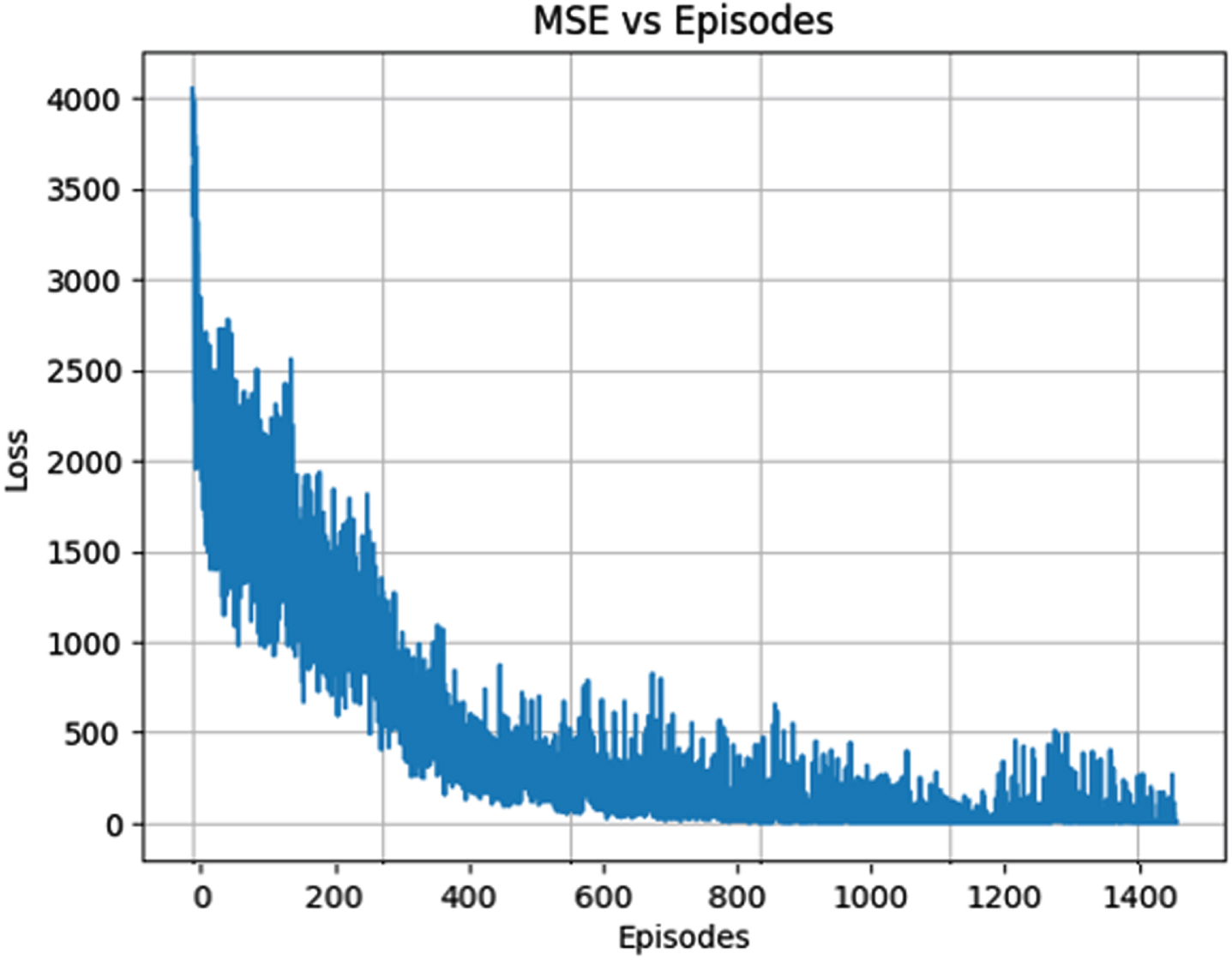
Training loss graph.
The accumulated rewards for traditional DRL after 1500 episodes are shown in Fig. 13. For better interpretation, only from episodes 1000 to 1500 are plotted. Though there are few negative rewards, there is an overall improvement and the model has learnt to navigate. The test success rate was equal to 100% .
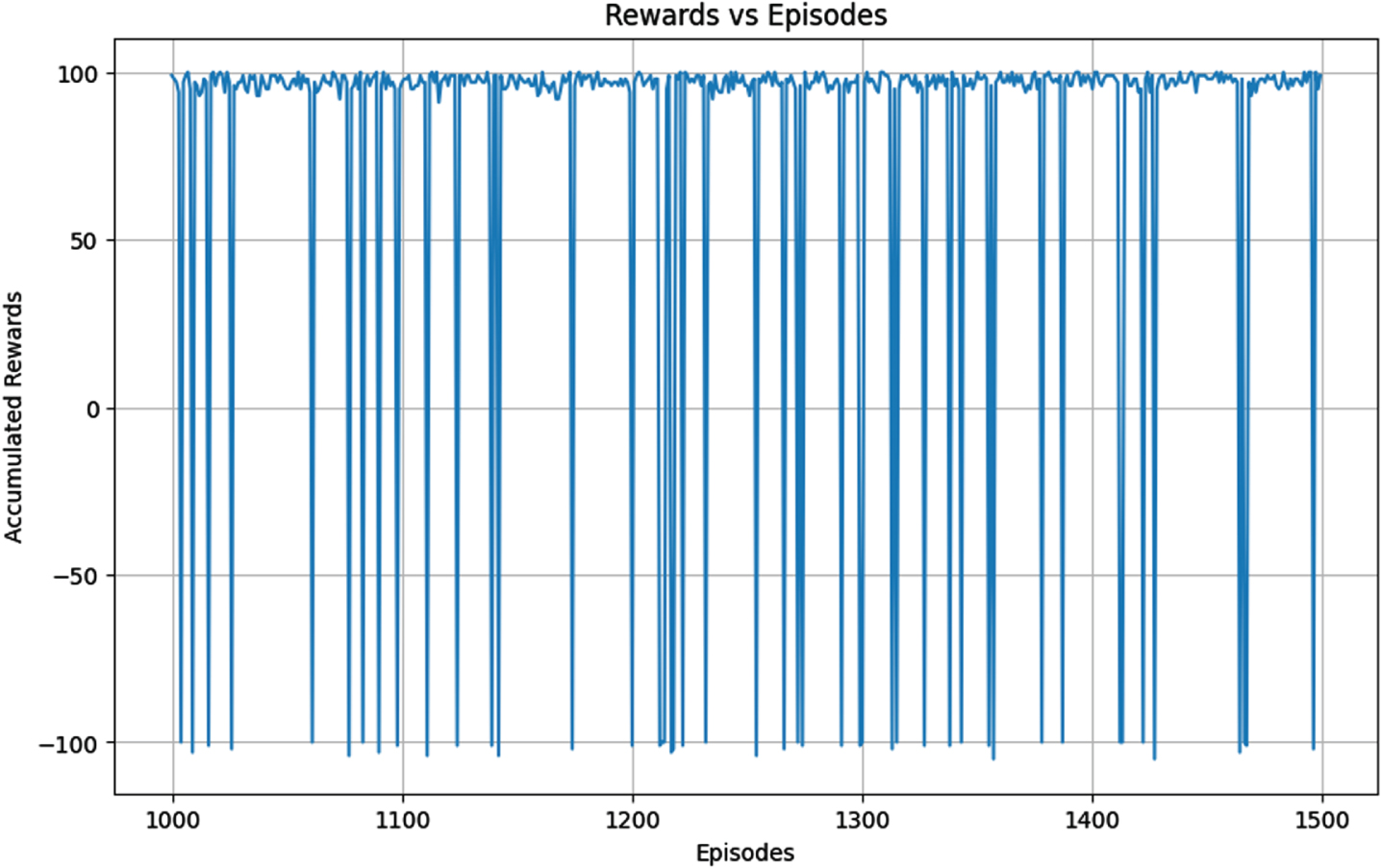
Accumulated rewards for DRL.
The FDRL framework was then experimented. Here however there are 2 clients, each client is trained for 1500 epochs. The rewards accumulated by client 1 and client 2 are shown in Figs. 14 and 15. Though there are negative rewards, the number of positive rewards is comparatively more. The server needs to confirm the performance of the global model. Therefore the test success rate of the global model was plotted and is displayed in Fig. 16. The success rate was equal to 100% which was the same for the traditional deep learning framework.
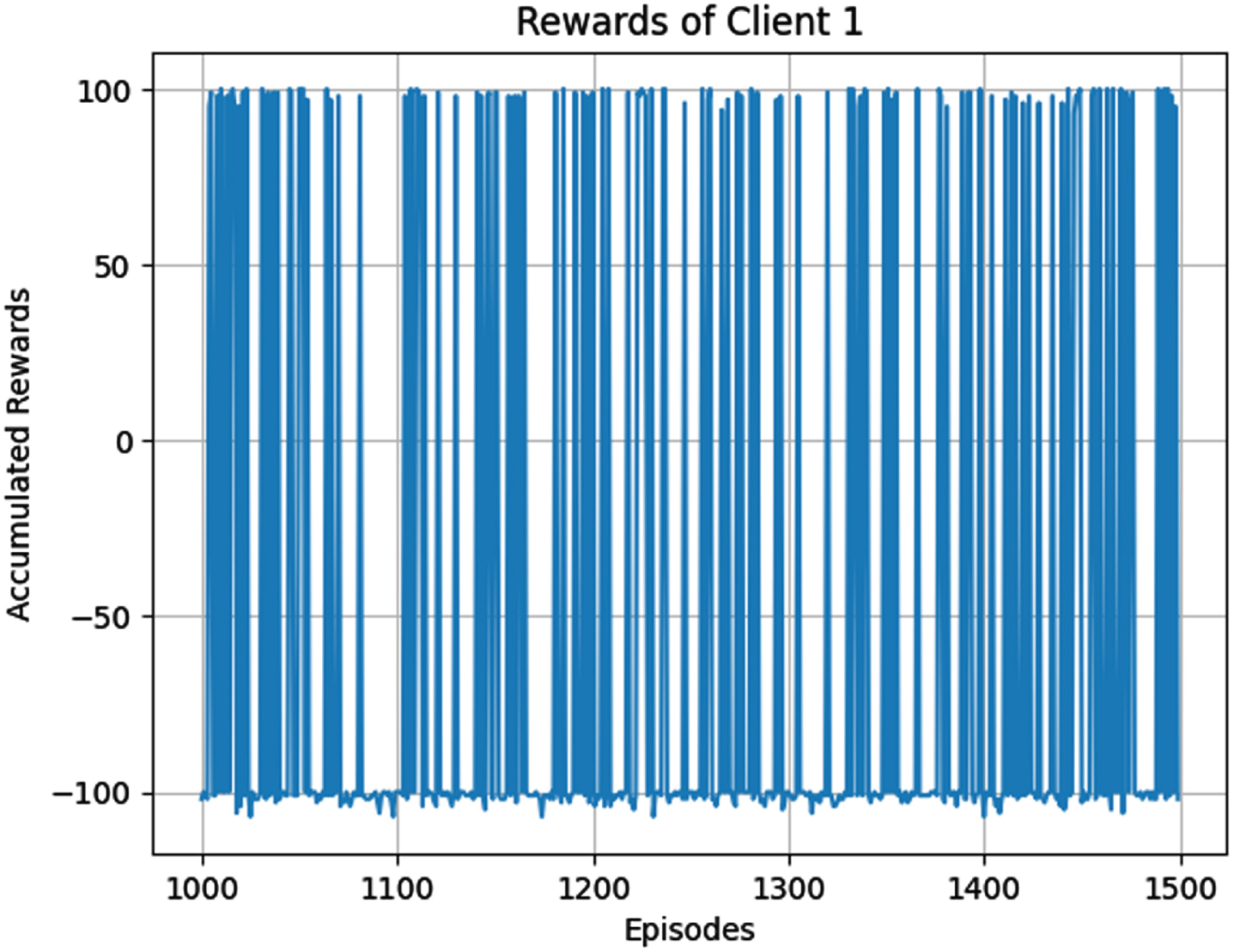
Accumulated rewards for client 1 (FDRL).

Accumulated rewards for client 2 (FDRL).
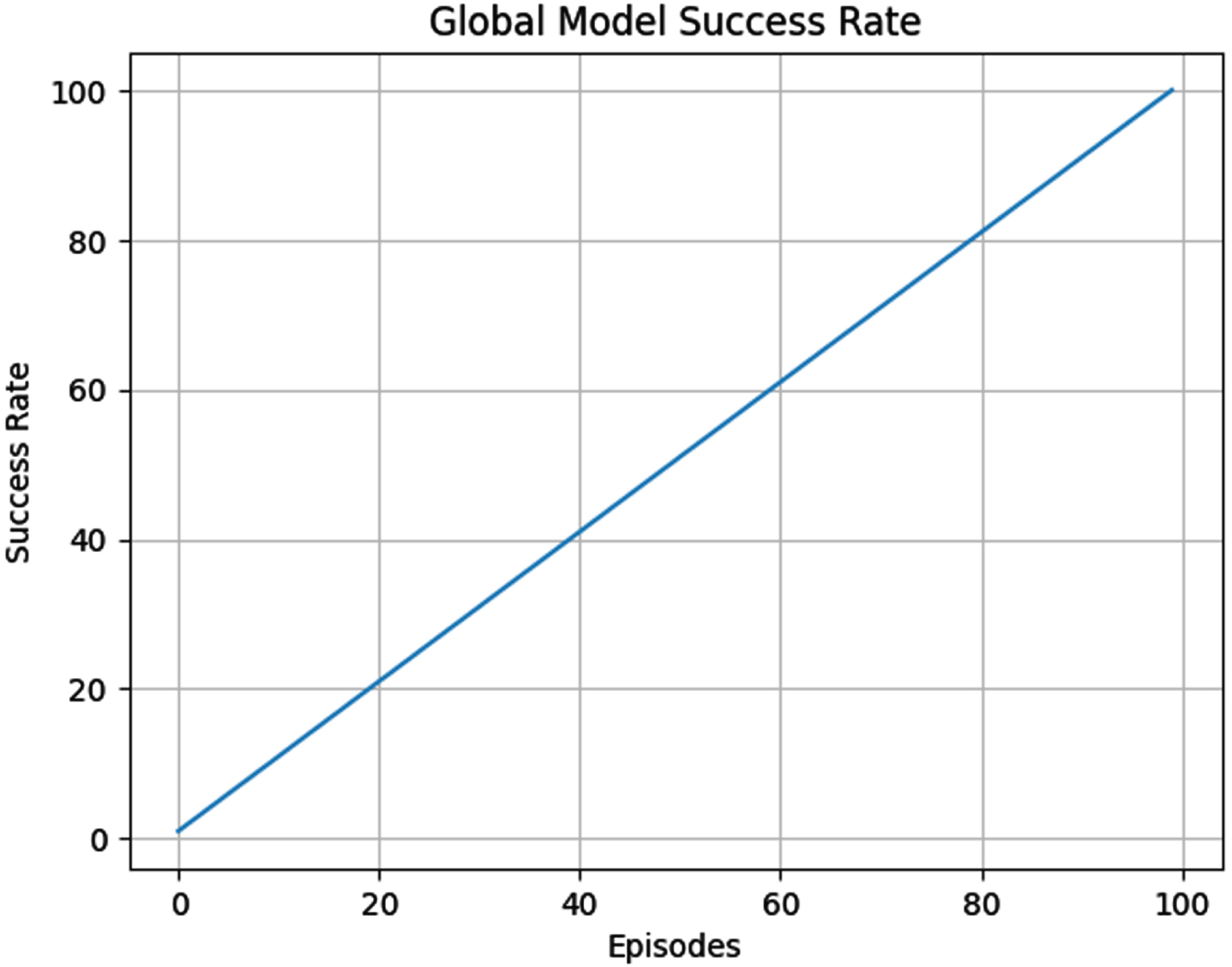
Test success rate for the global model.
After training, the model was imported to the Webots 3D simulator. The location of the robot was selected at random and the charging station location was provided. The agent was able to perfectly navigate from initial to the destination location using both traditional deep reinforcement and federated deep reinforcement learning frameworks. The simulation window is shown in Fig. 17.

Path of the mobile robot using both DRL and FDRL.
Both the traditional deep reinforcement and federated deep reinforcement learning results were evaluated against several other trivial algorithms such as depth-first search (DFS), breadth-first search (BFS), Dijkstra’s algorithm, A-Star algorithm, greedy best-first search, rapidly exploring random trees (RRT), RRT-Connect and R-Star. To conduct this comparison, a Java-based path planning simulator is utilized [41]. In this simulator, the greenhouse environment is replicated with an identical number of cells and then assess the generated path against the one produced by the proposed algorithm. In the Java-based path planning simulator, the grey cells are obstacles. The robot is marked in red color and the destination charger is marked in green color. The path traversed by all the algorithms including the proposed algorithms is provided in Figs. 17–25.
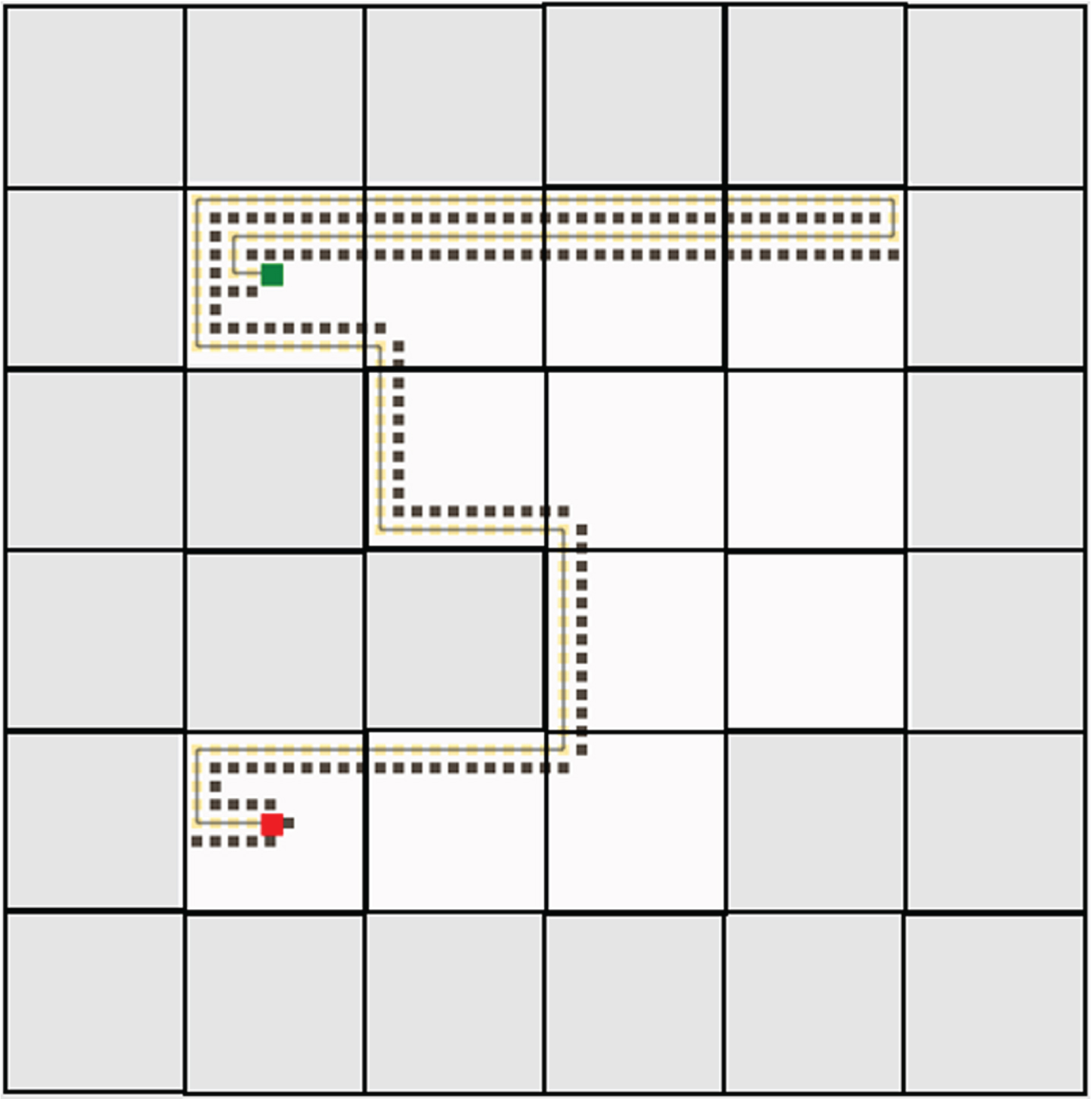
Depth first search algorithm.
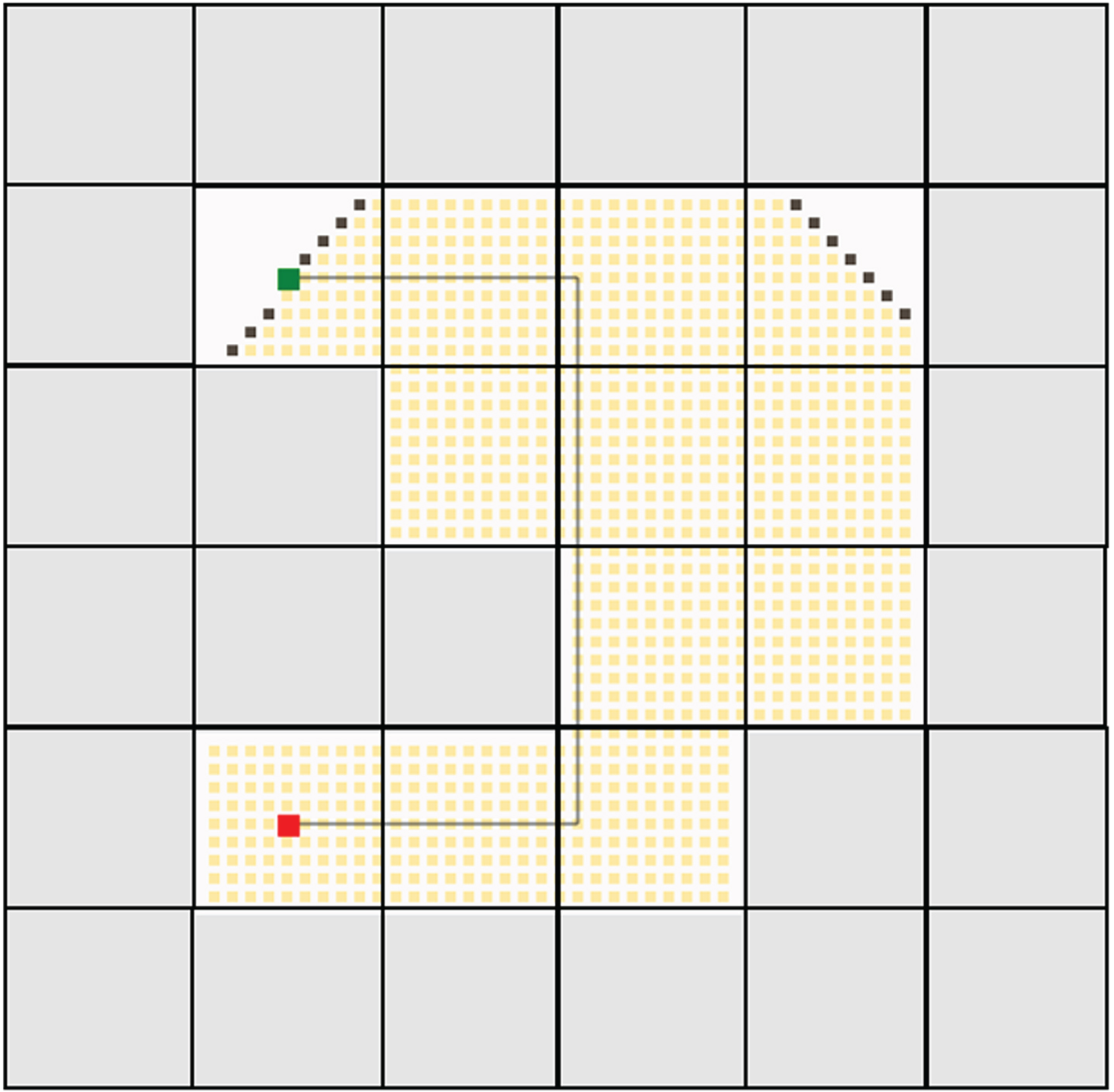
Breadth first search algorithm.
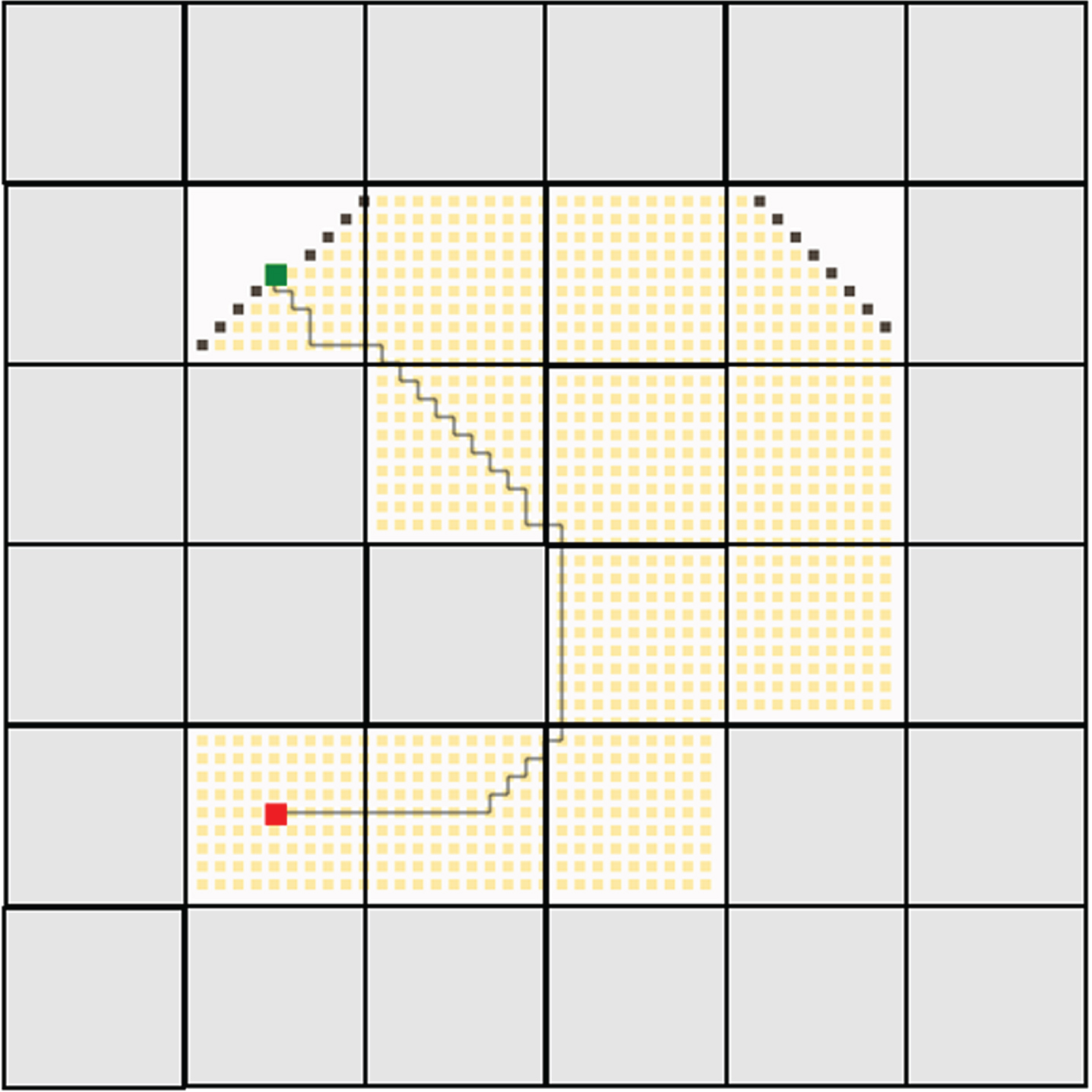
Dijkstra’s algorithm.
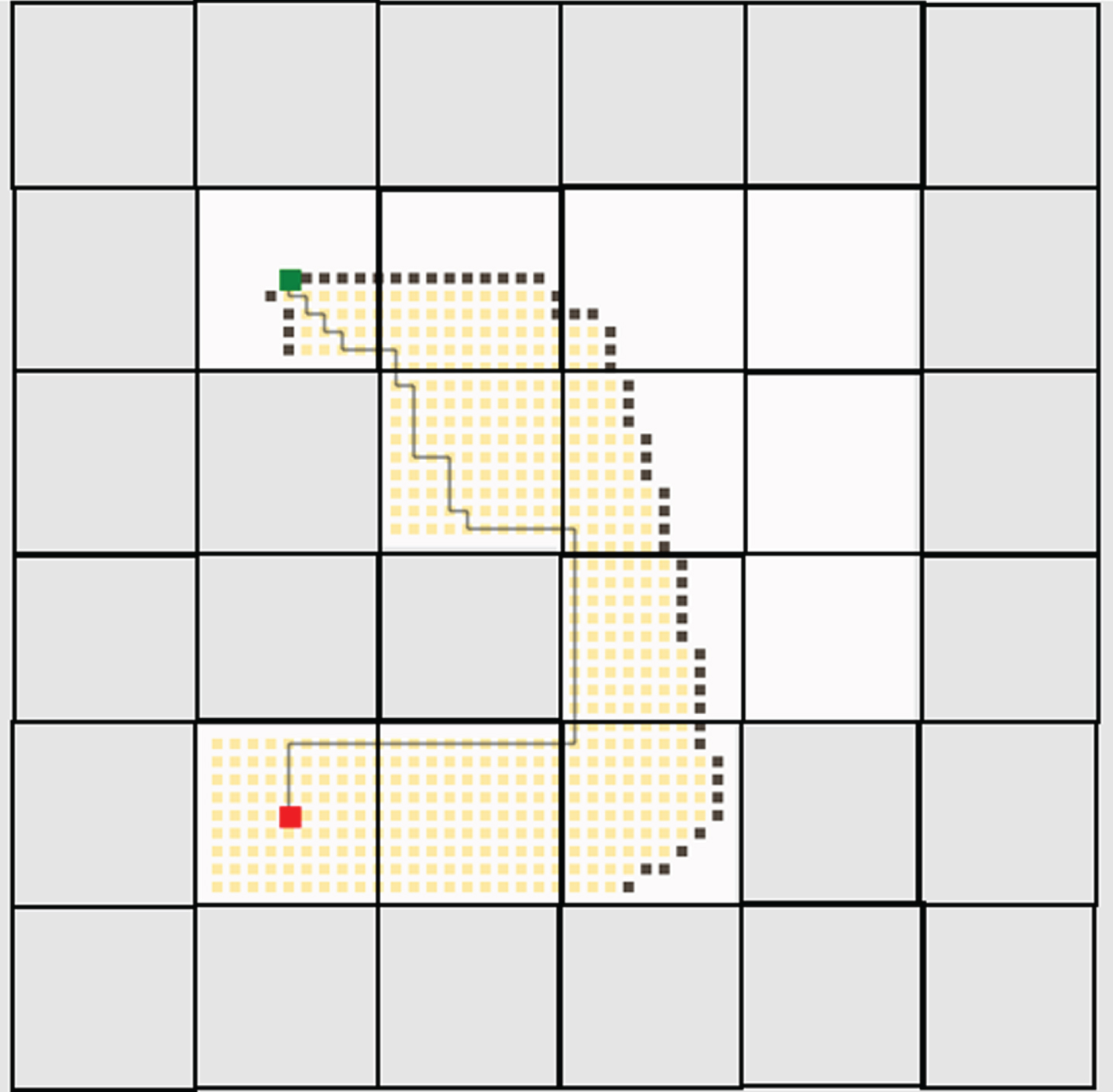
A-star algorithm.
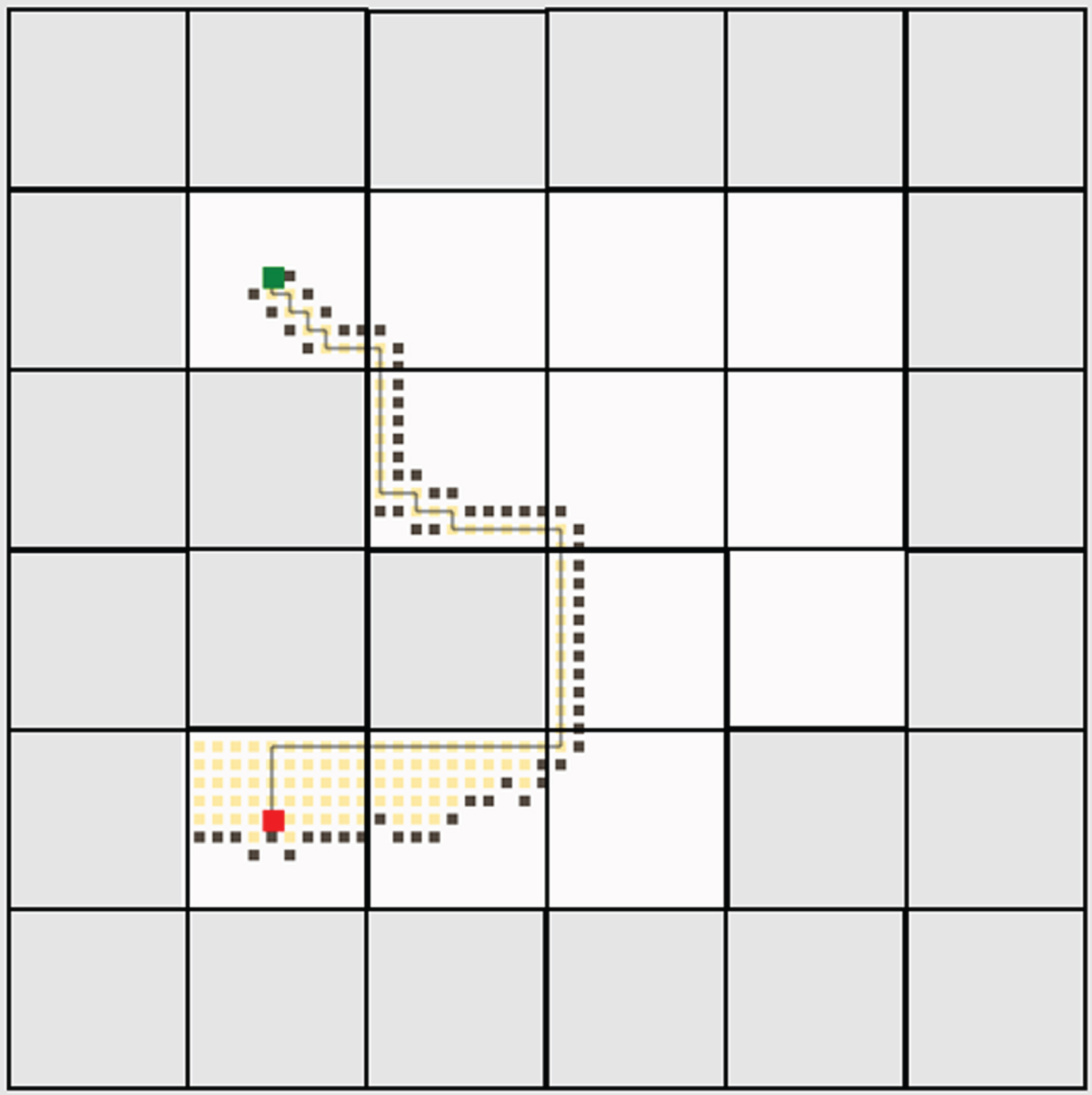
Greedy best first search algorithm.
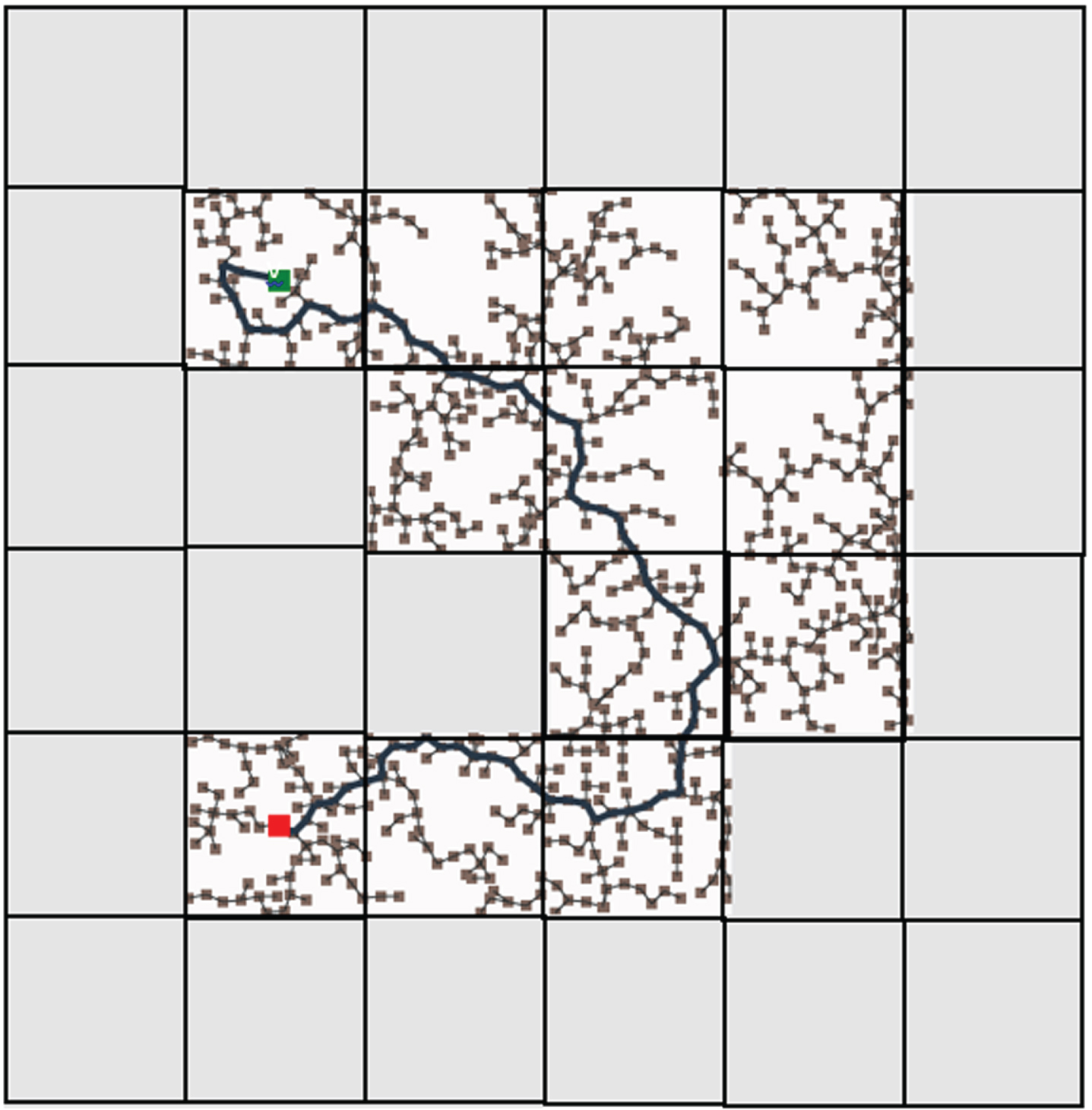
RRT algorithm.
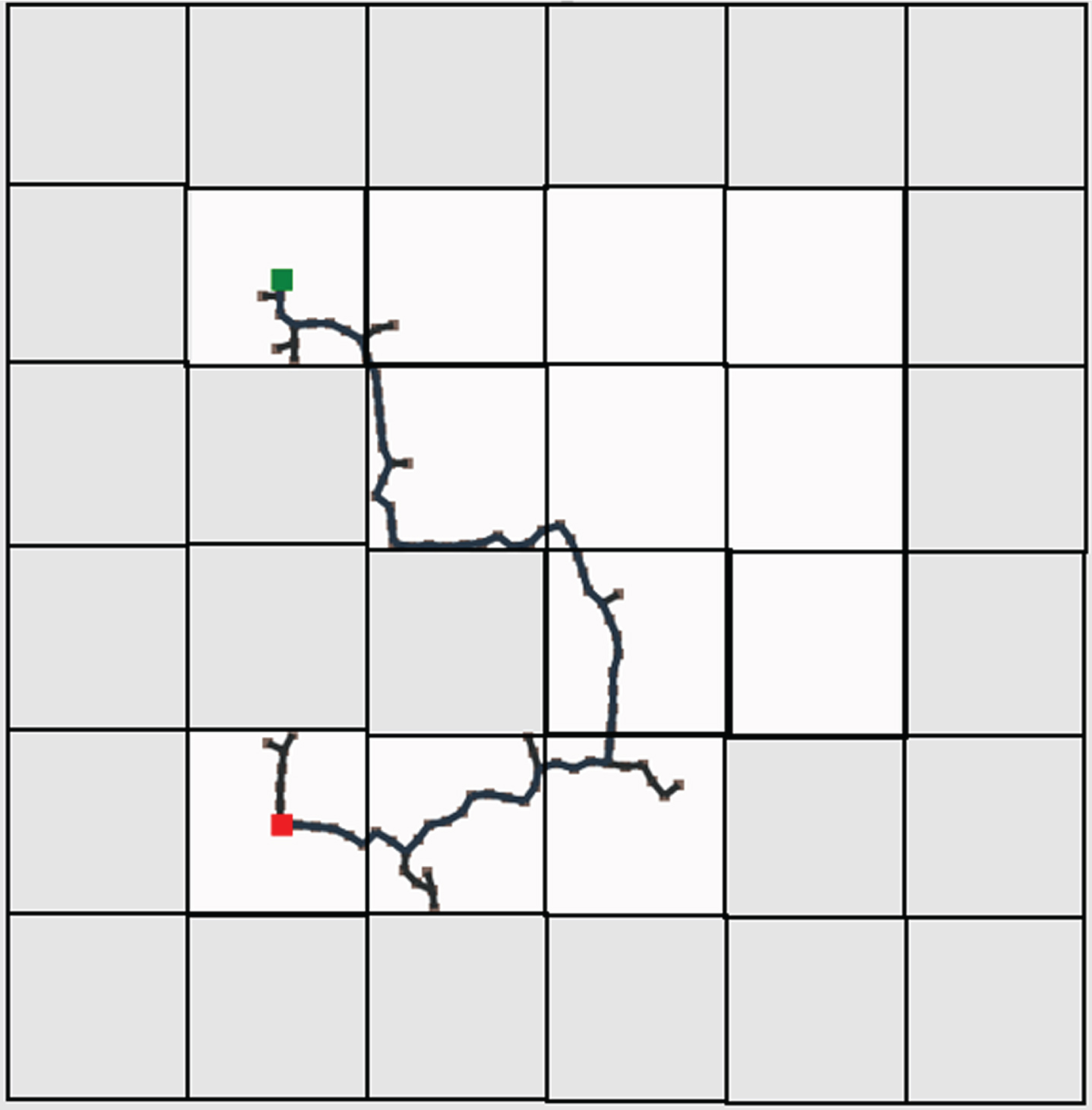
RRT-connect algorithm.
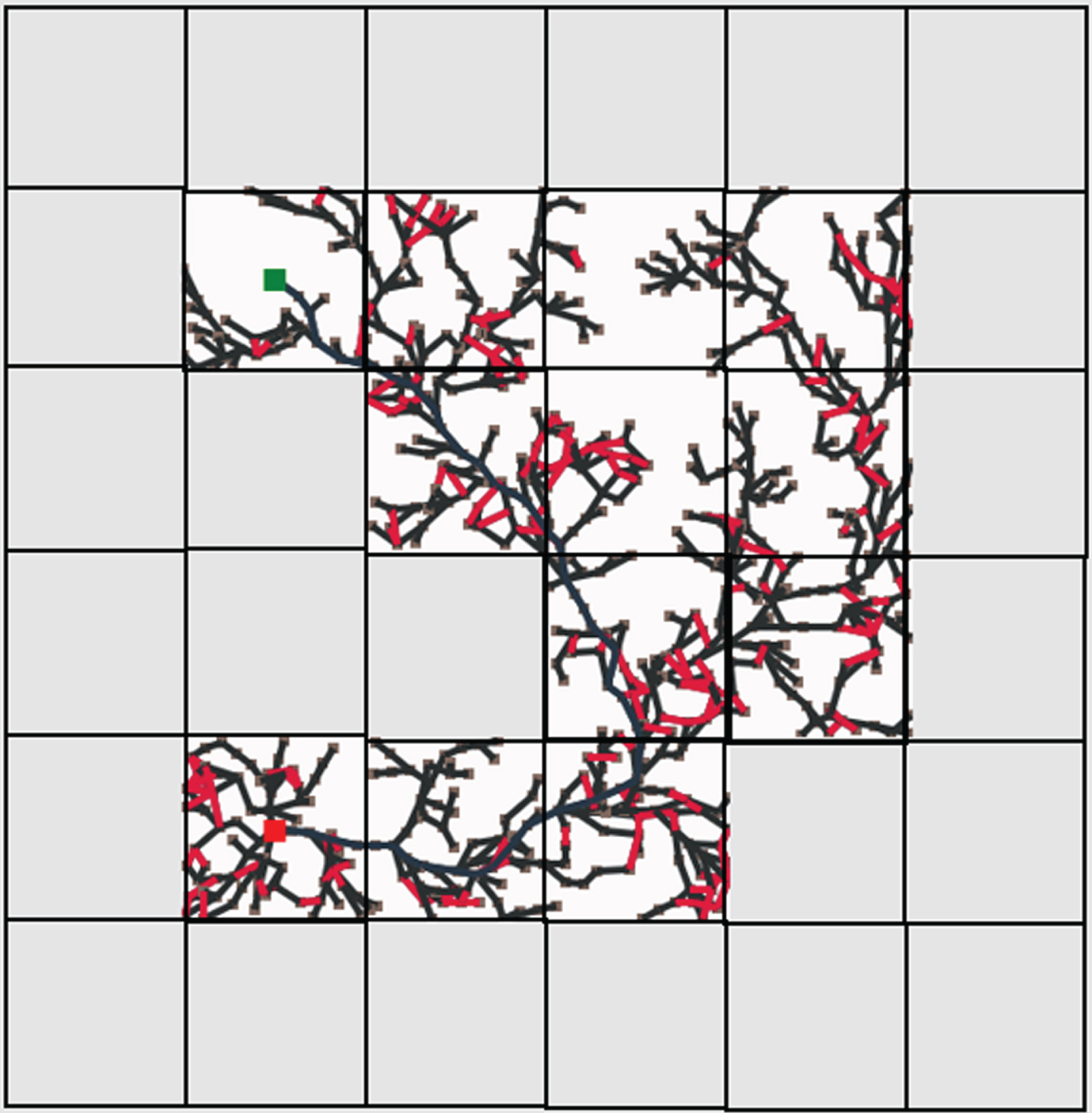
RRT-star algorithm.
Table 2 displays the two parameters used for comparisons and evaluation i.e. path length and search space. Path length is the number of cells through which the robot traversed to reach the destination. Search space is the number of cells searched by the robot to reach the destination. It can be seen that using DRL and FDRL the path length and the search space is the same, in fact the robot trained using these proposed algorithms doesn’t require to search the destination since it has already been trained initially using RL techniques. This is an advantage of the proposed algorithm compared to all the other trivial algorithms.
Analysis of path traversal
The conclusion of the study is that federated deep reinforcement learning (FDRL) framework was used for the navigation of the mobile robot. The agent was able to smoothly travel from its initial location to the charging station in the greenhouse environment without any collision. Both the traditional and federated deep reinforcement learning frameworks provided the same results using a simple multilayer perceptron architecture. This occurs without the agent directly engaging with the environment. The comparative study also suggested that the proposed algorithms worked in par or better compared to other trivial algorithms. However, the FL framework provided other advantages. This framework helped in overcoming the privacy issues allowing robots to learn collaboratively while keeping their data localized, minimizing the risk of data breaches. Robots in a fleet may operate in different environments with varying characteristics. Federated learning allows each robot to specialize in its local environment while sharing knowledge and improvements with others. Theoretically it also helps in minimizing bandwidth consumption as only gradients and model parameters are shared. All these advantages without the compromise in the performance makes FDRL for mobile robot navigation a better alternative.
Mobile robots in greenhouses enhance agricultural efficiency by automating tasks like planting, harvesting, and monitoring, resulting in increased crop yield and reduced labour costs. FDRL for mobile robots in greenhouses offers the advantage of collaborative learning while preserving data privacy. It allows multiple robots to share knowledge and adapt to the evolving greenhouse environment collectively, optimizing tasks like plant care and resource management. However, this work is only limited to the agent moving to a charging station. A mobile robot moving to a random location at a particular instant of time, apart from the charging location could be one of the major future scopes of this work. The use of other RL algorithms could also be tried and tested.