
Abstract
Blogs, internet forums, social networks, and micro-blogging sites are some of the growing number of places where users can voice their opinions. Opinions on any given product, issue, service, or idea are contained in data, making them a valuable resource in their own right. Popular social networking services like Twitter, Facebook, and Google+ allows expressing views on a variety of topics, participating in discussions, or sending messages to a global user. Twitter sentiment analysis has received a lot of attention recently.Sentiment analysis is finding how a person feels about a topic from their written response about it and it can be separated into positive and negative through its use. Doing so enables to classify the tweets made by a user in to appropriate classification category based on which some decisions can be made. The literature proposed approaches to develop the classifiers on the Twitter datasets. Operations, including tokenization, stop-word removal, and stemming will be performed. NLP converts the text to a machine-readable representation. Artificial Intelligence (AI) combines NLP data to evaluate if a situation is positive or negative. The document’s subjectivity can be identified using ML and NLP techniques to categorize them in to positive, neutral, or negative. Performing sentiment analysis in Twitter data can be tedious due to limited size, unstructured nature, misspellings, slang, and abbreviations. For this task, a Tweet Analyzing Model for Cluster Set Optimization with Unique Identifier Tagging (TAM-CSO-UIT) was built using prospects to determine positive or negative sentiment in tweets obtained from Twitter. This approach assigns a +ve/-ve value to each entry in the Tweet database based on probability assignment using n-gram model. To perform this effectively the tweet dataset is considered as a sliding window of length L. The proposed model accurately analyses and classifies the tweets.
Introduction
Individuals can join social networks and share information, such as expertise, multimedia documents, or even thoughts. Others may find these useful, for example, in better understanding a particular problem [1]. Science, news, photos, trivia, and humor are some of the topics discussed in the messages [2]. These kind of messages and videos let people keep in touch and learn, explore each other in the actual world by connecting them online. YouTube, Facebook [3], Twitter [4], SnapChat [5], and LinkedIn are just a few examples of popular social media sites.
Several social network sites are shown in Fig. 1.

Social Network Websites.
Millions of people throughout the world use social networking sites like Facebook and Twitter on a daily basis as depicted in Fig. 1. Due to the multiplicity of spammers’ tactics, Twitter is unable to identify these attacks [6]. People are discouraged from utilizing it by receiving random false URLs in the mail and through the distribution of advertising [7]. As a result, individuals may be completely unaware of the problem until it is addressed. Regular Twitter users are constantly under threat of being spammed [8] when communicating with other users on the service. Persons on Twitter [9] have the option of manually deleting information and users they don’t recognize, as well as bogus accounts [10]. Thus, specialists and Twitter are working together to come up with novel solutions to the problems legitimate users are running against.
Many categorization algorithms are utilized during the data mining approach to determine spam in the tweets sent by users. This approach categorizes each tweet produced by the user and uses that data to determine several attributes [11]. Among the criteria included in the Twitter dataset are “Id,” “number of supporters,” “content” and the dates the records were created, as well as the number of “status updates” [12] that each record had received. This is known as “high dimensionality” because of the large area of useless or superfluous information that can be removed [13]. When it comes to classification and feature extraction, relevant traits are important because they work well together. The sum extraction technique eliminates unneeded and pointless characteristics, resulting in better classification performance and reduced processing time [14]. The process of identifying specific features that are helpful in classification processing is referred to as feature extraction. However, even after utilizing supervised learning classifications and optimization [15], classifier accuracy lags behind despite the availability of multiple methodologies for feature extraction [16]. Since most datasets are now explicit, straightforward, and continuously formatted [17], real-world facts are collected in a continuum format. The effectiveness of various data mining methods is harmed by features with continuous format [18].
Twitter is a microblogging service that allows people to send and read brief messages known as “tweets” in real time as of now, Twitter has over 284 million monthly users, posting almost 500 million messages every day. Twitter was launched in 2006, and since then, its user base has grown tremendously [19]. These startling figures have prompted a bustle of companies to create official Twitter accounts [20] as a means of connecting with their constituents. It’s critical for companies that want to learn more about their customers to examine the content of tweets, whether they’re old or fresh.
Text classification is a technique for automatically classifying text information. Using text categorization techniques such as tokenization [21], term-frequency analysis [22], stemming, and document-frequency, the text categorization method can be used more effectively to this situation. In order to create a movie recommendation system [23], textual features such as movie genres and actors/actresses, comments, and narratives are used. Similarly, textual information about books was treated as documents while creating a book recommender system. Classifying incoming tweets into predetermined categories automatically [24] is the purpose of this research. When working with a multi-class machine learning problem, input instances/documents can be classified into more than two categories. Categorization is therefore more difficult than classification into a single class [25].
Individuals can communicate with people all around the world through social media platforms such as Twitter, Facebook, and Instagram. They can have a huge effect on politics and business by writing their own customer reviews or by sharing their favorite experiences. Almost every significant corporation has a presence on Twitter to monitor customer feedback on the product or services [26]. Words can be classified as positive or negative using opinion mining, which is also called sentiment analysis. In this research, a Tweet Analyzing Model for Cluster Set Optimization with Unique Identifier Tagging model was built using prospects to determine positive or negative sentiment in tweets obtained from Twitter.
Qamar et al. [1] focused on analyzing tweets written in English that come from various KSA telecommunications firms, and opinion mining is performed on them using supervised machine learning methods for classification. TF-IDF (Term frequency –inverse document frequency) was used to gauge the importance of a given word in a tweet. TF-IDF Embedded sentiment analysis in Arabic tweets and Facebook comments is developed by Duwairi et al. [2]. Several words weighting methods were tested to evaluate how they affected sentiment analysis accuracy using supervised machine learning algorithms like Support Vector Machine (SVM) and Nave Bayes. A sentiment analysis of 4700 tweets in the Saudi dialect was performed using (k = 0.807) by Hossam et al. [3], which used natural language analysis to Arabic text. To better understand Egyptian dialect, Assiri et al. [4] used a collection of data including tweets and product reviews. Natural language processing is used to decipher the Egyptian dialect. They also classified the information based on a vocabulary.
Research on network analysis has grown out of OSNs’ rapid expansion and large data flow through social media analyzed by Alamsyah et al [6]. Customers’ interactions with one another and how they acquire things have changed as a result of OSNs. Digital marketing and focused customer analysis have benefited from this shift in dynamics and sophisticated data mining tools. It has been shown that studies on sentiment analysis and community detection for consumer targeting, segmentation and topic modeling studied by Diamantini et al. [7] as well as sentiment analysis for opinion mining are particularly useful. Sentiment analysis helps us figure out how individuals feel about a subject after reading some text. When studying the offered material, we’re looking for connotations such as “positive,” “negative,” and “neutral”.
Twitter is a widely studied Online Social Networking (OSN) site among many others. Levy et al. [8] performed a study that uses sentiment analysis to look at tweets from Twitter. The creation and discussion of various sentiment analysis methods is also the subject of numerous studies. Models like these can be used to decipher the tone of a piece of writing. We need labelled data to build a classification model. The use of emojis and hashtags to gather and categories data has been studied for this purpose. As a result, community detection necessitates some degree of arbitrary decision-making, as well as common sense.
Fortunato et al. [9] undertook a comprehensive analysis of community detection algorithm design. According to the author, community detection may be used in many different fields like criminal justice and public health as well as politics. It can also be used in consumer segmentation and targeted marketing as well as network summary. Deitrick et al. [11] focused on applying sentiment analysis to boost community discovery in rare cases when the two have been combined. In order to improve the detected community, they leverage various Twitter-specific features. Using LDA for topic modelling, sentiment analysis, and text mining techniques, Saura et al. [13] developed a three-stage text mining system.
Using user modelling for personalized news recommendation, Alsini et al. [14] enhanced the semantics of Twitter activity by adding tweets to news items. User modelling was examined using a variety of strategies, including conversation, entity-based, and hashtag-based approaches. Users’ profiles can be searched by searching for certain events across time, which they can then analyse for patterns. DBpedia’s categories, classes, and related entities were used by Ansari et al. [16] to extend user interest profiles, and they discovered that their method outperformed previous approaches when it came to link recommendations.
Bhatnagar et al. [17] suggested a dynamic user simulation models recommendation system that incorporates information gleaned from tweets and YouTube’s video ranking algorithm based on the profile of the same user. This model helped make the video recommendations a lot more useful. The semantic connection between Twitter entities was discovered by Boon et al. [18] and used to provide mediation between them, allowing users to access the valuable content of their choice. Using a combination of content - based and collaborative recommendation algorithms, Chunaev et al. [21] came up with a system for constructing user profiles. Users’ preferences are taken into account while developing content-based recommendation systems. The collaborative suggestion, on the other hand, discovers users with similar tastes and makes recommendations based on this similarity. Shahriare et al. [22] proposed a novel ML classification approach named TcustVID on Covid-19 Datasets and proposed similar clustering approach using k-means and k-medoids method.
Proposed model
Unstructured text data has a broad dimension, thus cleaning and processing it is necessary before analysis. Pre-processing the data can include a wide range of tasks, depending on the study’s objectives. The text from the tweets was parsed to create a data frame. After that, URLs, stop words like “the,” “a,” and “to,” and other punctuation were removed from the text, as well as usernames and accounts, numbers, and unnecessary spaces. The initial stage in data analysis and mining is to purge the text of any extraneous symbols. The table below outlines the steps involved in de-noising a tweet before sending it out. Table 1 depicts the procedure.
Tweet Before and after Cleaning
Tweet Before and after Cleaning
To differentiate them, each tweet was assigned a number around 1 and 0, with the labels 1, -1, and 0. Using two text files, one with positive words and the other with negative ones, plus other terminology related to the issue, this is accomplished. We search for similar phrases in positive and negative articles to see whether any tweets have more positive or negative words. The process of tweet analysis is shown in Fig. 2.
Tweet Analysis Process.
A Tweet Analyzing Model for Cluster Set Optimization with Unique Identifier Tagging (TAM-CSO-UIT) model was built using prospects to determine positive or negative sentiment in tweets obtained from Twitter. The model under consideration has a quick learning curve and better execution when it comes to speculating. It’s not possible to change the hidden layer’s underlying parameters for each nonlinear task represented as covered neurons. Thus, in the resulting work with M covered neurons, R distinct specific cases like { (xi, yi, zi) |xi∈ DS (n) , yi ∈ DS (m) , i = 1, …, R } are presented as in Equation (1)
δ depicts the resultant of information as an information space between the data tweets, that presents the coefficient of determination of information as the M neurons and the consequent neuron of the concealed layer are shown by R(i). The proposed model framework is shown in Fig. 3.
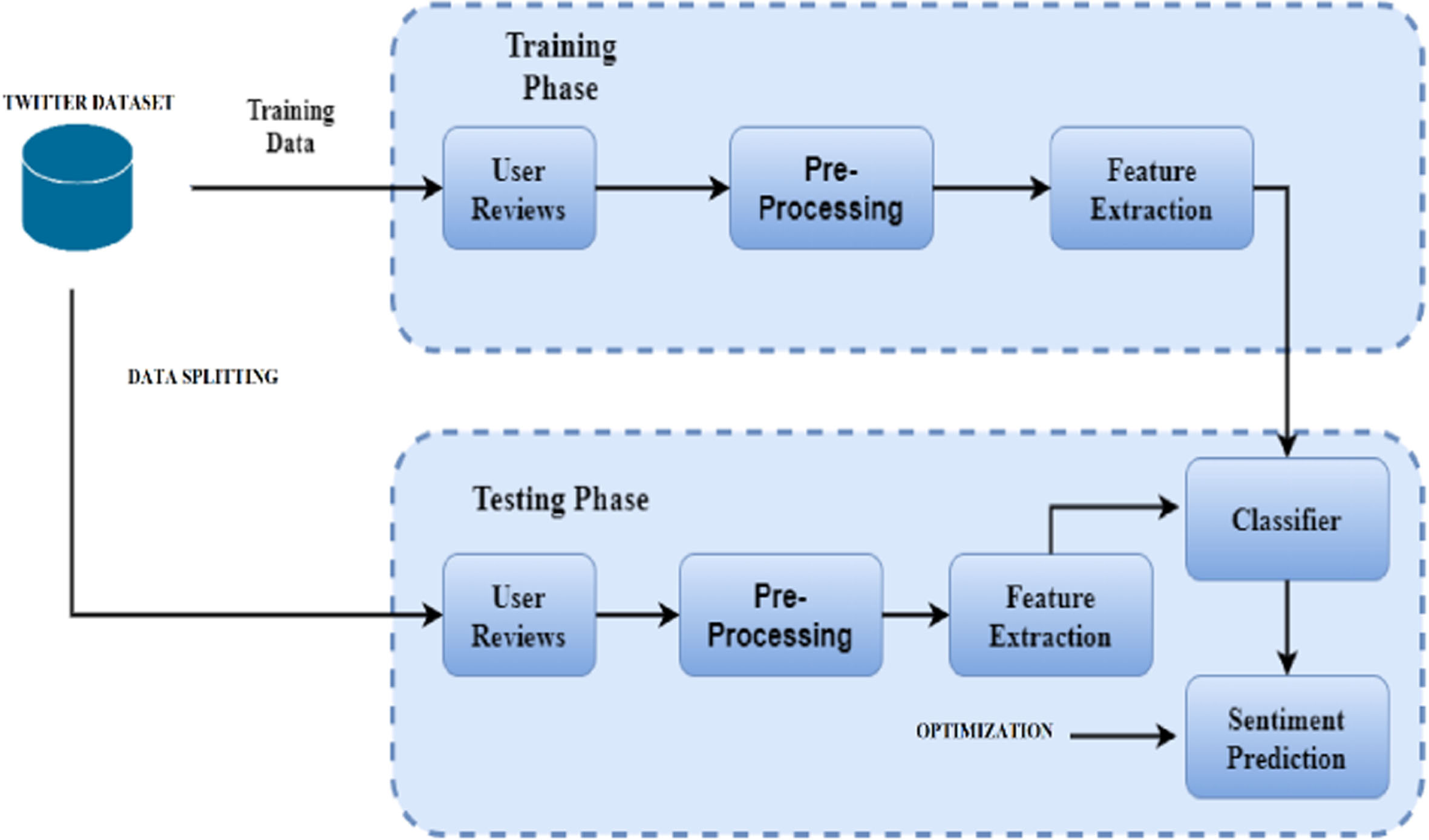
Proposed Model Framework.
It is possible to restrict preparation inaccuracy and loads at the same time in order to improve the representation of speculation in the neural system, and this is offered by Equation (2)
The features from the twitter dataset are extracted and a feature set is maintained. The feature extraction from the dataset is performed as Equation (3)
The p channels are currently applied to a sliding window of length L over each sentence S, but this will be changed soon. Suppose that we want to connect word vectors WVi and Si+L, and we use S [L: WVi+Si+L].
The sentence analysis with the window length is performed as Equation (4)
The basic n-gram language model is used to assign a probability Pr(H) to every possible word sequence WS in a tweet. The sentiment derived are represented as Equation (5)
The tweets after analysis will be allotted with a value among 1 or 0 for positive and negative tweets. The values are assigned by unique identifier tagging process as Equation (6)
The cluster set will be generated for the tweets separately as positive and negative and the cluster set is separately generated for each that is generated as Equation (7) and (8)
The cluster set Optimization is performed to reduce the cost function. The optimization is performed as Equation (9)
The accuracy levels of the proposed model are calculated by calculating the parameters like precision, recall and F-measure.
Lexical and pragmatic analysis of tweets is undertaken to minimize systematic error during the classification process. Following precise categorization and sentiment analysis, the system creates a user interest-based profile by studying user tweets to learn about user interests. The proposed model is implemented in Python and executed in GOOGLE COLAB. The twitter dataset is available inthelink. https://www.kaggle.com/kazanova/sentiment140?select = training.1600000.processed.noemoticon.csv. The proposed Tweet Analyzing Model for Cluster Set Optimization with Unique Identifier Tagging (TAM-CSO-UIT) model is compared with the Traditional Topic Based Method for Sentiment Analysis (TBM-SA) Model [10]. The parameters like Data Pre-processing Time Levels, Pre-Processing Accuracy Levels, Clustering Accuracy Level, Unique Identifier Tagging Time Level, Unique Identifier Tagging Accuracy Levels, Feature Extraction Accuracy Levels, Sentiment Analysis Accuracy and Error Rate are considered and analyzed among the proposed and traditional models.
A data mining approach that converts raw data into a comprehensible format is known as data pre-processing. Raw data is always incomplete, and thus cannot be processed by a model. Certain errors would result as a result of this. That is why data must be pre-processed before being sent via a model. The data pre-processing time levels of the proposed and traditional models are represented in Fig. 4.
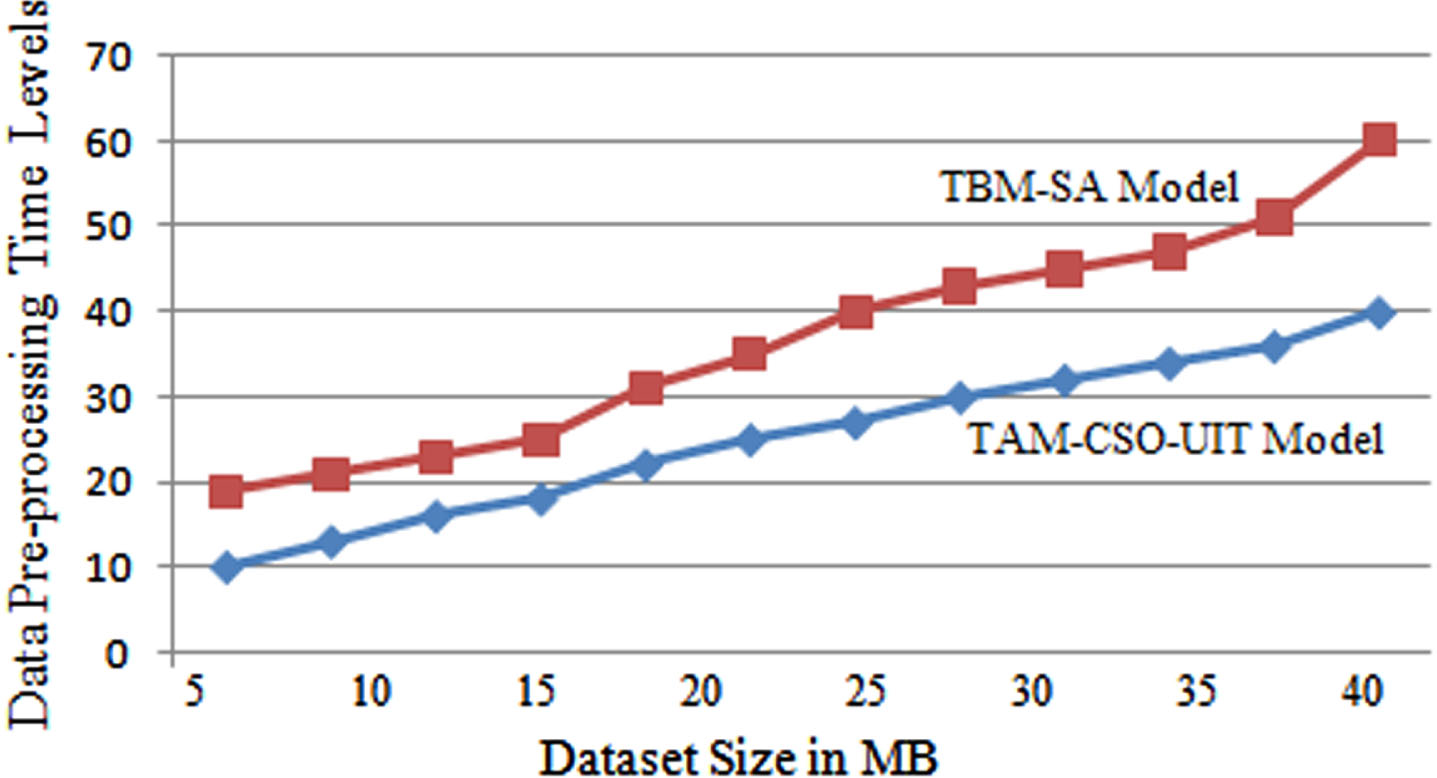
Data Pre-processing Time Levels.
The goal of data preparation is to make the training/testing process easier by suitably converting and normalizing the entire dataset. Before developing the machine learning models, pre-processing is required. Outliers are removed during pre-processing, and the features are scaled to an appropriate range. The proposed model performs data pre-processing to get a clean data for analysis. The Pre-processing accuracy levels of the traditional and proposed models are shown in Fig. 5.
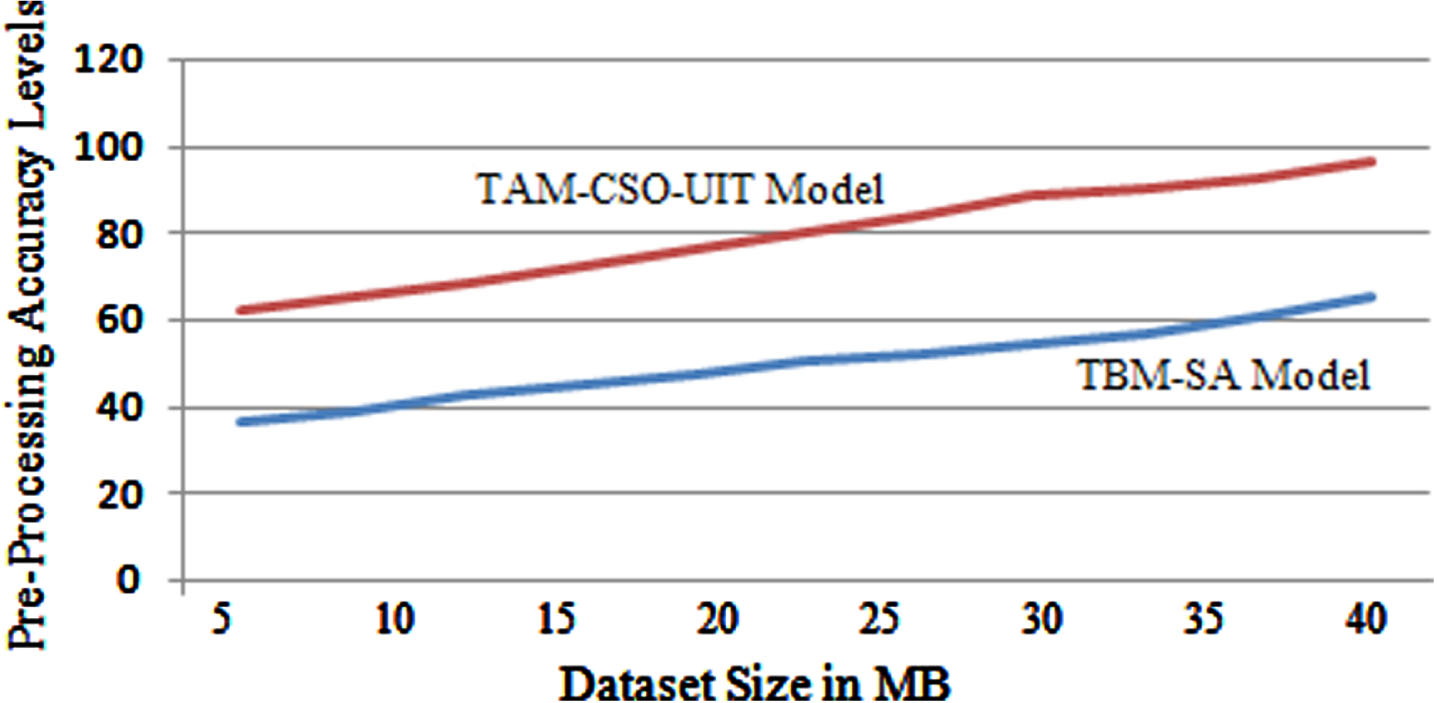
Pre-Processing Accuracy Levels.
To find clusters of related tweets, researchers employ clustering algorithms. When doing cluster analysis, data is divided into groups such that instances assigned to the same group are more comparable. The proposed model performs clustering more accurately as each tweet is analyzed briefly. The clustering accuracy levels of the proposed and traditional models are represented in Fig. 6.

Clustering Accuracy Level.
The proposed model performs tagging to the tweets based on the attribute value. The unique identifier tagging of tweets helps in accurate analysis. The time levels of the proposed and existing models are shown in Fig. 7.
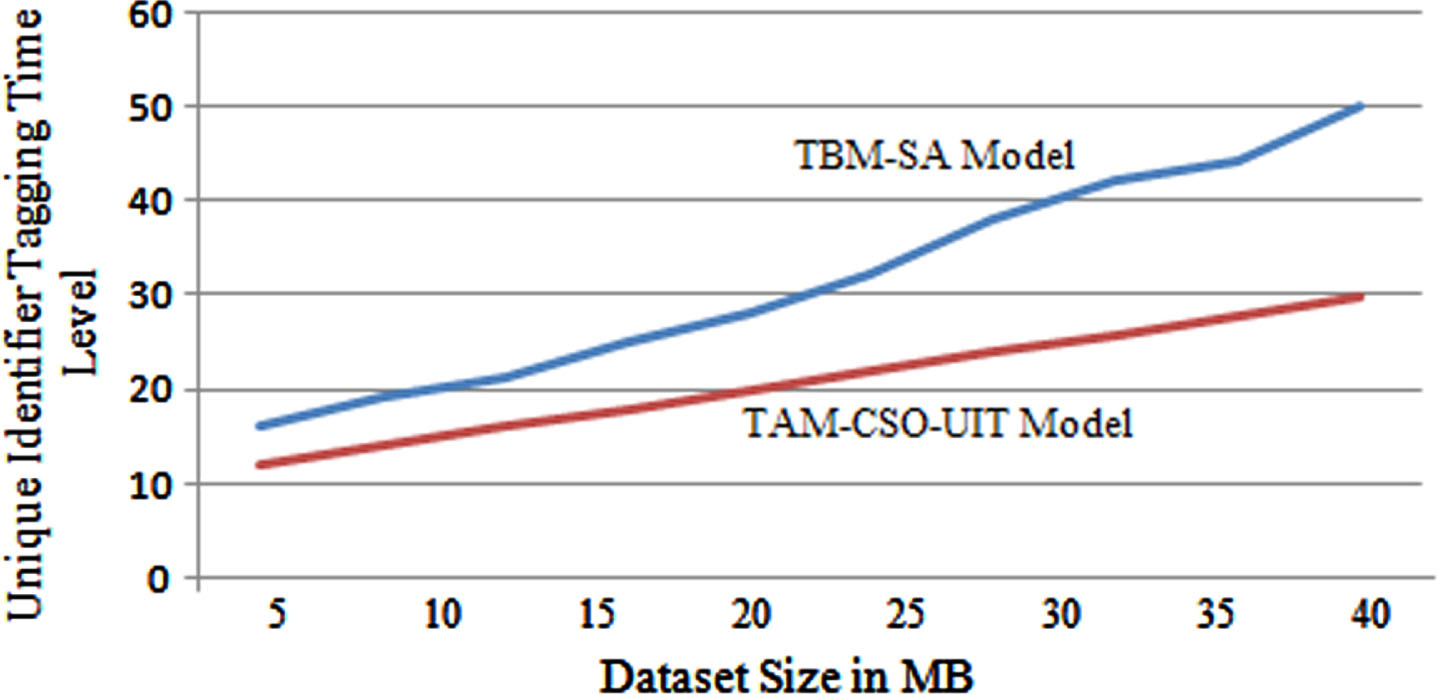
Unique Identifier Tagging Time Level.
The Unique identifier tagging accuracy levels of the proposed and existing model are shown in Fig. 8. The accuracy levels of the proposed model are high when compared to the traditional method.
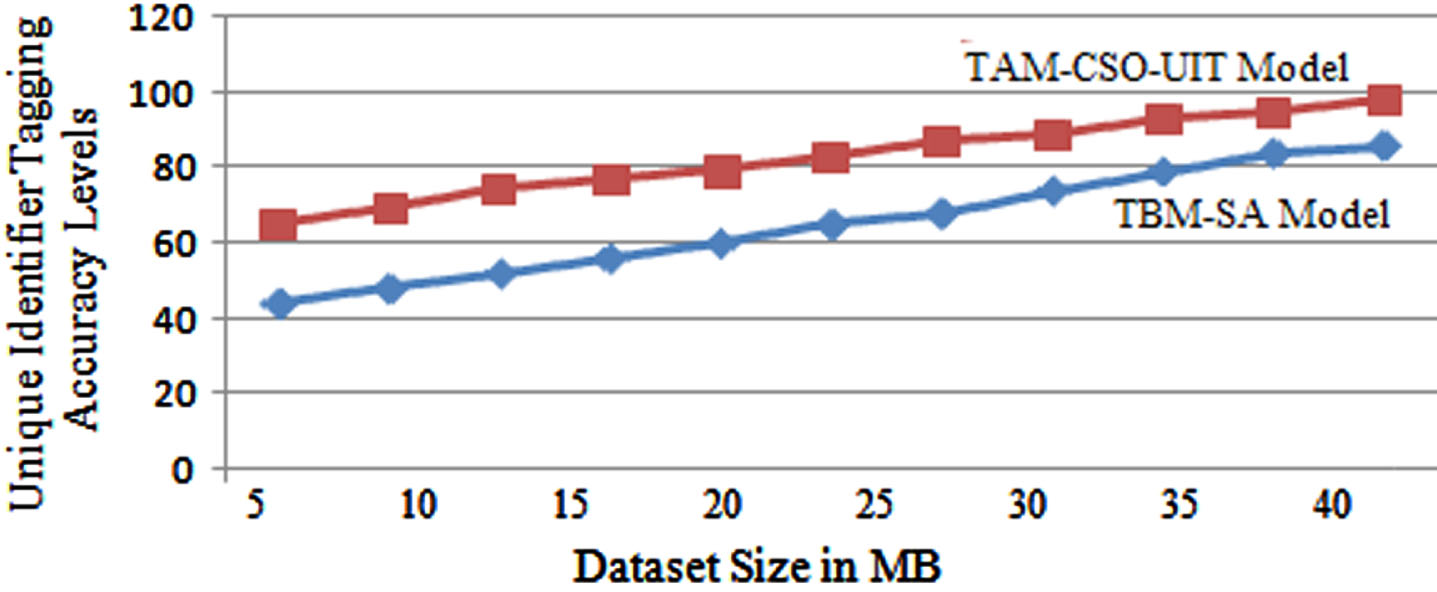
Unique Identifier Tagging Accuracy Levels.
Feature extraction identifies tweet features that customer are commenting on, sentiment prediction identifies text containing sentiment or opinion by determining sentiment polarity as positive, negative, or neutral, and finally the concise summary module. The feature extraction accuracy levels of the proposed and traditional models are indicated in Fig. 9.
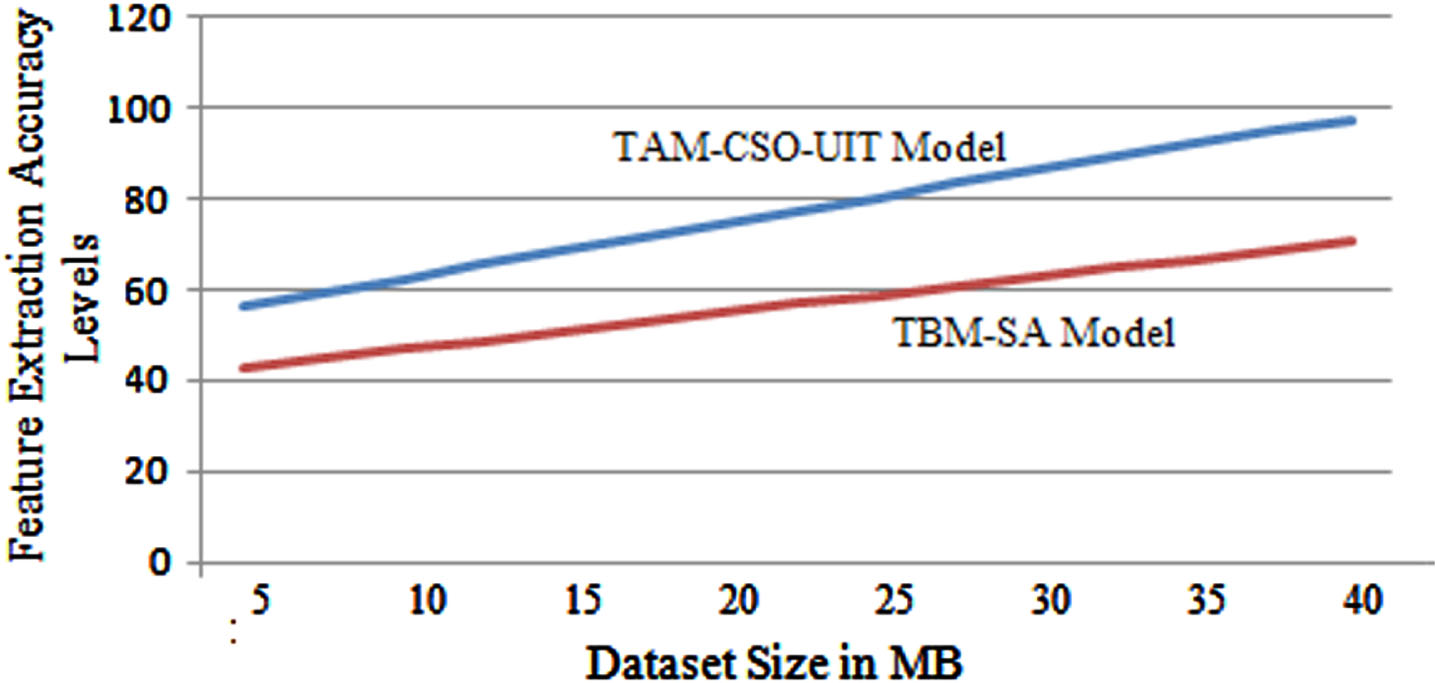
Feature Extraction Accuracy Levels.
Sentiment analysis is the process of recognizing and categorizing the sentiments represented in a text source. When analyzed, tweets are typically beneficial in providing a large volume of sentiment data. The sentiment analysis accuracy levels of the proposed and traditional models are depicted in Fig. 10.

Proposed Approach Accuracy.
The proposed model efficiently analysis the tweets with cluster set optimization. The classifier performance levels are indicated in Table 2.
Classification Results of ML Algorithms
In sentiment analysis, a ratio is a score that considers the representation of negative and positive remarks. This is usually expressed on a scale of –1 to 1, with the lower end of the scale denoting negative reactions and the high end denoting positive responses. The error rate of the proposed and traditional models is shown in Fig. 11.
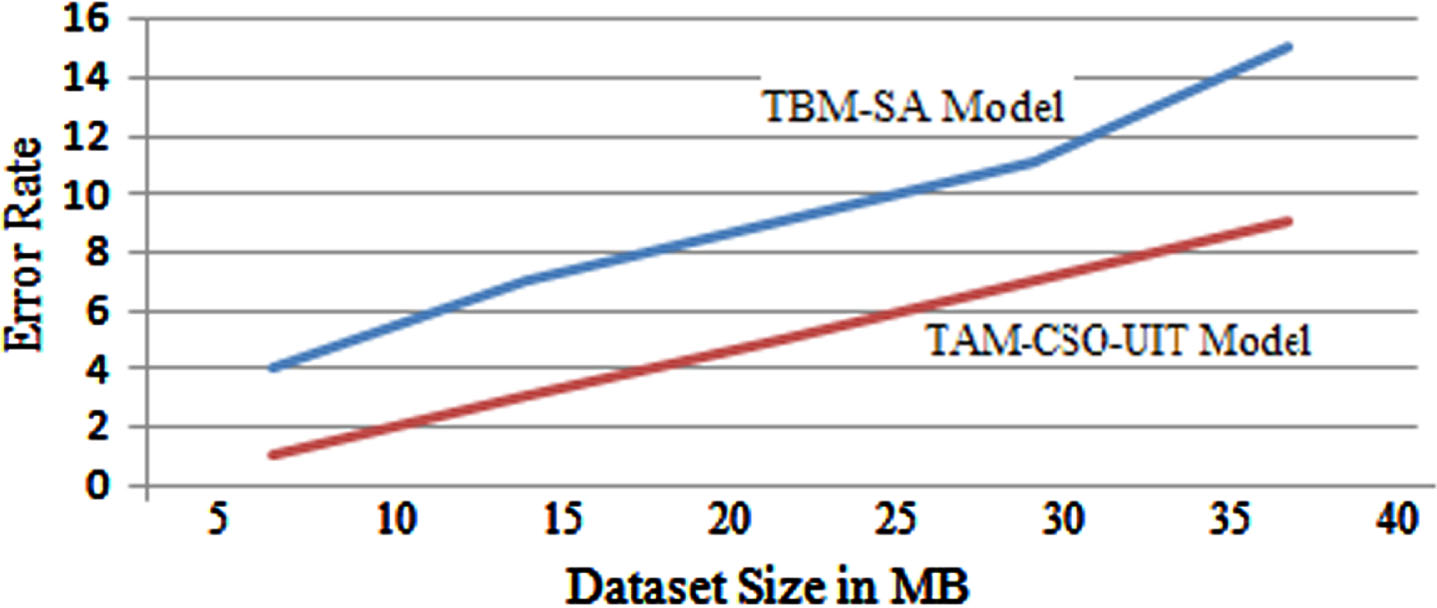
Error Rate.
The most frequently occurring words are represented in Fig. 12 that clearly indicates the words that are classified by analyzing the tweets.
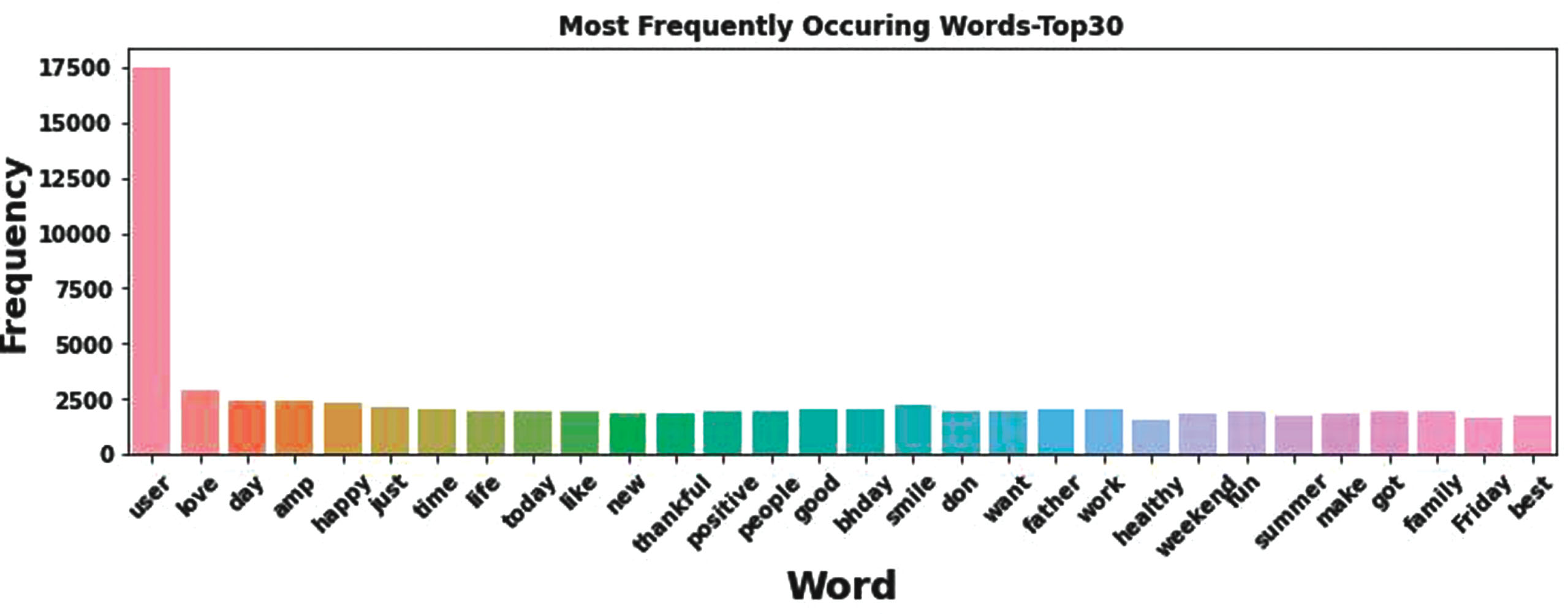
Most Frequently Occurring Words.
The hashtag and the count of the words identified and the tweet analysis result is shown in Fig. 13. The tweets are represented clearly.
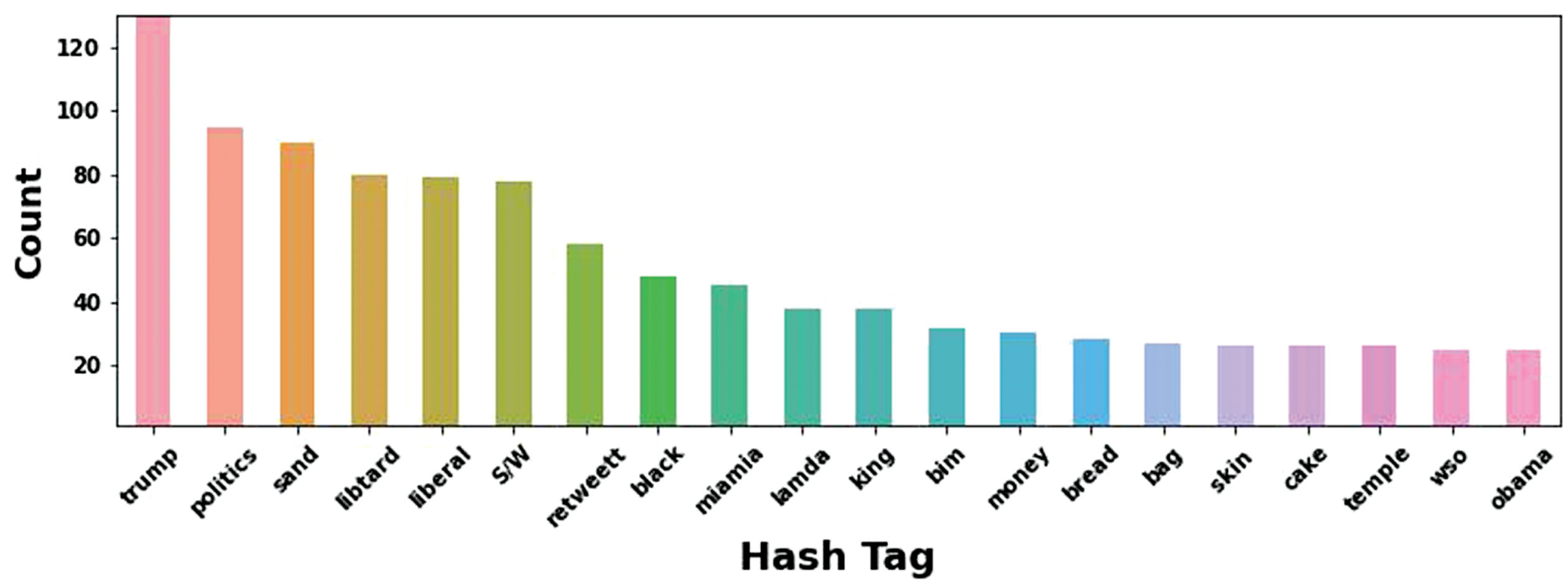
Hashtag and Count of Word Levels.
Using techniques such as sentiment analysis, researchers are able to identify people’s true feelings from the words they use. To improve the accuracy of identifying tweets as favorable, negative, or neutral, this tweet analysis optimization model is proposed. Various metrics were utilized for testing, and cross validation showed that maximal entropy with the highest degree of accuracy. The proposed research tries to arrange the data in to subsets of sliding window of Length L and each of these window forms a channel of information and in total P channels gets formed. For each such channel an n-gram model is applied to assign the probability to sets of words to categorize them in to either positive or negative or neutral. Twitter dataset is analyzed using proposed classifier model to find out how accurate it is in classifying. This work is confined as sets of tasks and grouped as a model named as Tweet Analyzing Model for Cluster Set Optimization with Unique Identifier Tagging model using prospects to determine positive or negative
Compared to Literature the proposed approach achieves superior accuracy.
The Future research can enhance this approach by including weight assignment prediction strategies for better approaches from Machine Learning and Deep Learning. In future multi-level optimization can be applied and user reviews can be considered for updations.