
Abstract
This work creates, evaluates, and optimizes a domain-based dictionary using labeled domain documents as the input. The dictionary is created using selected unigrams and bigrams from the labeled text documents. Dictionary is evaluated using the Naïve Bayes classification model. Classification Accuracy obtained is used as a metric to evaluate the effectiveness of the dictionary. The paper also studies the impact of applying the Stochastic Gradient Descent (SGD) technique, with Lasso and Ridge Regularization, on the effectiveness of a domain-based dictionary. Both, Lasso and Ridge regularization, with Ridge faring better than Lasso, help to optimize the dictionary size, without any significant reduction in the accuracy. The created dictionaries are evaluated on the dataset used for their creation and subsequently on an unseen dataset as well. The applicability of a created dictionary to classify the documents belonging to a different dataset gives an idea about the generality of that dictionary. The paper establishes that the dictionaries created using the above methodology are generic enough to classify documents of other unseen datasets.
Introduction
Retrieving the right information related to a given context can be facilitated by the knowledge of the terms and vocabulary relevant to that context. The domain-based dictionary consists of the terms that appear recurrently in a specific domain and hence are relevant to the domain context. Such dictionaries can be used in a variety of applications like recommendation systems, sentiment analysis, topic identification, automatic machine translation, etc. This paper presents a technique to build a domain-based dictionary from text documents and evaluates the effectiveness of the created dictionary. Apart from the above applications, a domain-based dictionary can be used to enhance text classification performance. Such a dictionary can retain substantial text features that are good representatives of predefined categories. A limited selection of text features can help reduce the computational cost of classification due to the reduction in feature space dimensionality. This is one of the main motivations behind this work.
The proposed technique extracts frequent unigrams and collocations as terms from the text, referred to as, the original dictionary. Different values of the frequency thresholds have been experimented with within this work. It then uses a Stochastic Gradient Descent classifier with Lasso (L1) and Ridge (L2) regularization to further select features from those terms. These features are then used as vocabulary to represent the text documents as vectors and train the Naïve Bayes classifier to predict the category of unseen text. Classification accuracy is used as a metric to evaluate the effectiveness of the created dictionary
This work contributes to the literature by establishing the following results: Sparse L1 and L2 dictionaries obtained by using the SGD model with L1 and L2 regularization select relevant, recurring representative words of a category. Sparse L1 and L2 dictionaries achieve comparable accuracy with smaller dictionary sizes in comparison to the dictionary. If the original dictionary was approximately the same in size as the L1 or L2 dictionary, the accuracy of the L1 and L2 dictionary was better than the accuracy of the original dictionary. L1 and L2 sparse dictionaries when evaluated on an unseen dataset, gave better classification accuracy than the original dictionary Amongst L1 and L2 regularization techniques, the L2 dictionary yields better accuracy and retains better representative terms of the domain than the L1 dictionary.
This paper is organized as follows: Section 2 discusses the background and related work in the area; Section 3 describes the methodology in detail; Section 4 presents experiments performed; Section 5 elaborates on the analysis of the obtained results; Section 6 lists the future scope and concludes our work.
Background, literature, and related work
Domain Modelling deals with the extraction and representation of knowledge and concepts underlying a selected set of information source [3]. Domain models have been referred to by various names in literature like Ontology [11], Lexicon, Conceptual Graph [2], Semantic Network [21], etc. to name a few. An appropriate representation of concepts, in form of terms and relationships between those terms in a corpus, can be helpful in a variety of research disciplines like Artificial Intelligence, Natural Language Processing, and Information Retrieval [5, 20].
Two paradigms exist for building domain models, Statistical (Data-driven) modeling and Symbolic (Knowledge-driven) modeling [3]. While Data-driven models majorly rely on statistics associated with the extracted terms like their co-occurrence frequency, knowledge-driven models tend to use lexical databases to establish the term relationships like synonyms, hyponyms, etc. Knowledge-driven models generally utilize fully or semi-structured knowledge sources like Wordnet, and Wikipedia [17] respectively to establish relations between different terms but such models may not cover all the domain-specific concepts making them inappropriate for very specific domain-based applications. This paper focuses on building domain models using Data-driven modeling.
Data-driven modeling is further divided into three types of strategies namely, Unsupervised, Weakly Supervised, and Supervised learning [3, 10]. Supervised learning requires annotated data which is difficult to create and obtain but if available, can be helpful to generate precise models. Weakly Supervised learning requires some human labor to identify leads that can be used to identify other new patterns. For example, ‘X then Y’ establishes a relation between X and Y, but X should be identified as a seed pattern beforehand. Unsupervised learning faces difficulty to generate exact and specific models but then generated models could be quite a good approximation, without much of the manual effort to create annotated training data. This paper works on the supervised learning strategy of Data-driven modeling for creating a domain-based dictionary.
Evaluation of the created domain models throws another challenge to the users. [3, 15] lists three types of evaluation strategies, Qualitative criteria-based, Task-based and Quantitative evaluation. Qualitative criteria-based evaluation is majorly done by the users of the model to check if the model identifies the semantically equivalent concepts as synonyms, whether two different concepts are isolated or not etc. Since this technique is dependent on user judgment, it is labor-intensive and may vary as per user perception. Task-based evaluation judges the appropriateness of the domain model for a specific task, for example, classification of articles into predefined categories. Quantitative strategy evaluates a model keeping in view an existing benchmark model. This strategy is useful for static domains. This paper uses a Task-based strategy for evaluating the created domain model.
Feature selection is the process of selecting and shortlisting some relevant input features to build a model for predicting the output variable. Input features could be huge in number, for example in text-based models, all the words appearing in the text could together form the set of the input features. However, not all these features are relevant to the output variable. Hence, feature selection is a crucial step, especially for constructing a statistical model. This not only reduces the memory and time requirements for the model construction but also may improve the model accuracy. Regularization is one of the feature selection methods that also prevents the overfitting of the data. It adds a penalty term dependent on the coefficients (weights) of the input features in the model. L1 regularization or Lasso (Least Absolute Shrinkage and Selection Operator) penalizes the L1 norm i.e., the sum of the absolute values of the feature weights. L2 regularization or more commonly, Ridge penalizes the L2 norm i.e., the square root of the sum of the squares of the feature weights [1]. [14] identifies relevant text features from nursing notes to predict the mortality risk of ICU patients using a stochastic gradient descent classifier with L1, L2, and elastic net regularization. [16] identifies positive and negative words for sentiment analysis in the financial news domain using Bayesian variable selection methods. To tone down the impact of negative news on the audience, the general tendency is to write negative news using positive words, but then this makes identifying the sentiment associated with financial disclosures quite challenging, and hence most of the existing dictionaries in the finance domain become less suitable for the task.
Domain modeling and representation have multiple applications. [13] constructs an ontology for the Chinese social security domain in a semi-automatic way using manual effort, followed by an automatic expansion to include relations in the ontology. [8] creates a Hindi Multi-Domain Sentiment Aware Dictionary (HMDSAD) automatically, using a combination of labeled, unlabeled reviews from a source domain and unlabeled reviews from a target domain to classify unseen unlabeled reviews of the target domain as positive and negative. [4] proposes a framework for advertisement recommendation to the social media users based on their activities on the social networking websites. The framework uses domain ontologies as a knowledge representation technique to transform the user profiles and ad contents into vectors. [6] proposes an ontology-based framework for automatic topic detection from text documents. Ontology is used for dimensionality reduction to represent text as a term weight matrix. The framework is assessed on English and Spanish datasets and has improved automatic topic detection on text documents. [25] presents an approach to adapt an existing sentiment lexicon to build a sentiment classifier and how the approach can be used to improve sentiment classification for multiple domains by varying the word polarity depending on the domain where the word is being used. [22] builds lexicon using the probability distribution of words occurring in product reviews across different ratings received for a product. This helps to identify the sentiment orientation score of each word, which is then used to determine the polarity of reviews. [12] proposes a deep learning-based framework to create a sentiment lexicon for the Chinese financial domain for financial distress prediction. [7] constructs a domain dictionary semi-automatically for the Japanese language and uses it for blog categorization. [24] works on the software localization i.e., translating and adapting software like a mobile application as per the requirements of the target market using a customized RNN encoder-decoder model trained on a large-scale domain-specific translation corpus collected from the applications on Google Play store. [19] proposes an ontology and context-based recommendation system that uses neuro-fuzzy classification to classify the reviews. The system develops fuzzy rules that help to extract context from the reviews. It uses an ontology to maintain a repository of product reviews and store the context of the reviews which then helps to generate recommendations. [9] builds domain vocabulary using news articles and abstracts of research papers as domain documents. Weights are associated with vocabulary terms to establish their relevance for a category, which are then used to predict the domain of unseen documents.
Methodology
This work creates and evaluates a Domain-based dictionary of terms (unigrams and collocations, specifically bigrams) extracted from domain-specific labeled text. The labeled dataset is divided into training (80%) and test set (20%) to create the dictionary and test its effectiveness respectively. This section contains four subsections, namely, dictionary creation, dictionary evaluation, applying Stochastic Gradient Descent (SGD) technique with regularization, and establishing its generality over an unseen dataset. Figure 1 presents the sample output obtained on dictionary creation and application of the SGD technique with L2 regularization on one of the experimental datasets.
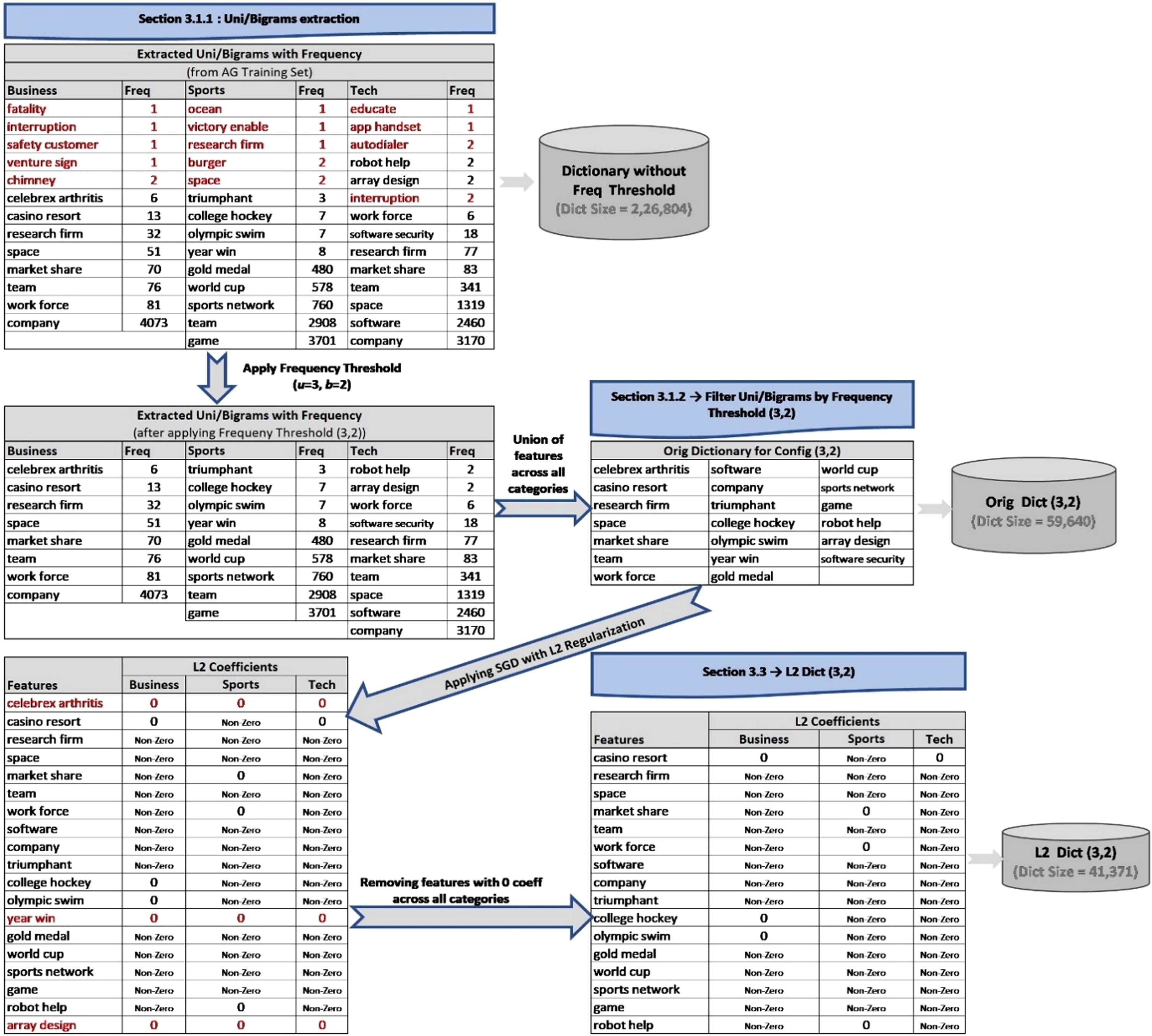
Steps for Dictionary Creation, SGD application with L2 Regularization, and sample output for AG dataset.
Dictionary is created using feature extraction on the training set through the below-mentioned steps.
Uni/Bigrams extraction
Unigrams and Bigrams are extracted from the training set using the following steps: Preprocessing – sequence of steps applied to clean and refine raw data to transform it into a form suitable for knowledge extraction. The following preprocessing steps are used: Lowercase the contents. Remove accented diacritic characters, non-ASCII characters, and punctuations like ‘ï’, ‘∈’ and ‘!’ respectively. Lemmatize terms to reduce words to their root forms like ‘extracted’ changes to ‘extract’. Apply named entity recognition to remove names of persons to avoid relating people with a domain. Extract terms – unigrams and collocations (specifical bigrams) Extraction of Unigrams – extract noun tagged unigrams using Part of Speech (PoS) tagging. Extraction of Collocations (bigrams) - extract <noun, noun>tagged bigrams using PoS tagging and window size = 2). Noun-tagged terms are retained as they are better representatives of domain compared to adjectives, adverbs, etc. Trigrams and other higher-order n-grams are not extracted as per the conclusion from our previous work [23]. This work built multiple dictionaries using combinations of Uni/Bi/Trigrams and established that adding Trigrams to the dictionary did not lead to a significant gain in accuracy, though the dictionary size became quite high.
Filter Uni/Bigrams by frequency threshold
For a given frequency threshold configuration (u, b), extracted Unigrams and Bigrams that occur at least u and b number of times respectively across all the documents of a labeled category are retained as dictionary terms of that category.
The union of the Dictionary terms of each category constitutes the dictionary for the entire training dataset. The dictionary built using this method is referred to as the original dictionary of configuration (u, b).
Dictionary evaluation using Naïve Bayes classification
A given dictionary is evaluated using the following steps on any given dataset (partitioned into training and test set): Given dictionary’s terms are used as input features to represent the given pre-processed training and test set as feature vectors. Term frequency – Inverse document frequency (Tf-idf) is used for the same. Naïve Bayes (NB) classification model is trained on the given training set feature vectors. This model is then used to classify the given test set into predefined categories. Classification Accuracy obtained on the test set is used as a metric to analyze the dictionary’s effectiveness on the given dataset. Higher accuracy implies that the dictionary contains recurrent and relevant keywords related to a category or domain.
Applying Stochastic Gradient Descent with regularization on created dictionary
Stochastic Gradient Descent (SGD) with L1/L2 regularization is used for feature selection from the created dictionary terms through the following steps: Training set is converted to feature vectors using terms in the created dictionary as input features. Tf-idf is used here, as it computes the importance of these features in a document of the dataset. SGD model is trained on the feature vectors of the training set with L1 and L2 regularization to yield a sparser dictionary under the hinge loss function. Model parameters are tuned by minimizing the regularized training error, i.e., summation of the averaged loss function on the training set and the regularization penalty term. Least Absolute Shrinkage and Selection Operator (Lasso or L1) regularization adds an absolute norm of the model parameters w ∈R
m
shown in Equation (1) as penalty term. Ridge regularization (L2) adds the squared Euclidean norm of the model parameters, Equation (2), as the penalty term. Regularization shrinks model parameters towards the zero-vector using either L1 or L2 penalty term. Features from each category, which have been assigned a non-zero parameter (coefficient) by the SGD model constitute the sparse dictionary of that category.
Size of the dictionary is calculated by taking the size of the union of the sparse dictionaries of all categories.
Three types of dictionaries are referred to from this point on: the original dictionary created in section 3.1, the sparse L1 dictionary (created with SGD using L1 regularization), and the sparse L2 dictionary (created with SGD using L2 regularization).
The generality of a given dictionary is evaluated by using this dictionary to classify the documents of an unseen dataset i.e., to classify a dataset that has not been used for the dictionary creation either as a training set or as a test set. For example, using the training set of Dataset I to create a dictionary and then evaluate this dictionary on Dataset II. This would include the following steps: Create a dictionary on the training set of Dataset I. Use this dictionary’s terms as input features to represent the training and the test set of Dataset II as feature vectors (using Tf-idf). Train the Naïve Bayes model on the training set of Dataset II and use that model to classify the test set of Dataset II. Classification Accuracy obtained on the test set of Dataset II is used as a metric to analyze the generality of the dictionary created on Dataset I. Higher accuracy implies that the dictionary contains relevant and representative terms of a category or domain.
Experiments
Experiments were done using the training and test sets of the same dataset as well as using the training set of one dataset and the testing set of the other dataset.
Experimented datasets
Experiments were conducted on two benchmark datasets namely, BBC News dataset - news articles from the BBC news website corresponding to the five topical areas (Business, Entertainment, Politics, Sport, and Technology), published from 2004 to 2005 (downloaded from http://mlg.ucd.ie/datasets/bbc.html). Small database of ∼ 2K articles Average article size ∼ 400 words AG’s corpus - news articles corresponding to four categories (World, Sports, Business, Technology) gathered from more than 2000 news sources in more than 1 year of activity (downloaded from http://groups.di.unipi.it/∼gulli/AG_corpus_of_news_articles.html [news_articles.html]). Large database of ∼ 1.2L articles Average article size ∼ 30 words
Experimented datasets were created by picking up the articles corresponding to the common categories present in both datasets. These datasets named Dataset I & Dataset II were used for further experimentation. Figure 2 lists the properties of the actual and experimented datasets.
Experimental setups

Dataset Properties.
The following experimental setups were used to create and evaluate the dictionary: Setup I – Create an original dictionary using a specified unigram and bigram frequency threshold on the training set followed by an evaluation of its effectiveness. Setup II – Use the original dictionary (from Setup I) to create a sparse L1 dictionary by applying SGD with L1 Regularization with subsequent evaluation of this sparse dictionary’s effectiveness. Setup III – Use the original dictionary (from Setup I) to create a sparse L2 dictionary by applying SGD with L2 Regularization to be again followed by an evaluation of this sparse dictionary’s effectiveness.
The above three setups were used to create multiple dictionaries depending on the unigram and bigram occurrence frequency thresholds and the type of regularization.
Below mentioned configurations of Unigram and Bigram Frequency Thresholds were used for experimentation. The frequency threshold in the range of 3 to 5 gave good accuracy in reasonable dictionary size as per the results established in our previous work [23]. However, we have explored a wider range of these thresholds to create 42 different dictionaries using Setup I: Unigram frequency - ranging from 3 to 9 (7 values) Bigram frequency - ranging from 2 to 7 (6 values)
The above 42 dictionaries were used as an input to Setup II & Setup III to create 42 additional sparse L1 and sparse L2 dictionaries respectively.
These dictionaries differ in their sparsity and effectiveness and were evaluated using Naïve Bayes Classification (as per Section 3.2). Default parameter values were used for the SGD and the Naïve Bayes classification models except for alpha: the variable that controls the regularization strength. Its optimal value is computed as described in section 5.
Evaluating original dictionary and its generality (Setup I)
This section presents the results of Setup I run on BBC, AG dataset for 42 different unigram/bigram frequency thresholds. Figure 3 presents the accuracy and the size of the original dictionaries created and evaluated on the BBC dataset and similarly those created and evaluated on the AG dataset. It also gives an insight into the generality of the 42 original BBC dataset dictionaries when evaluated on the AG dataset.
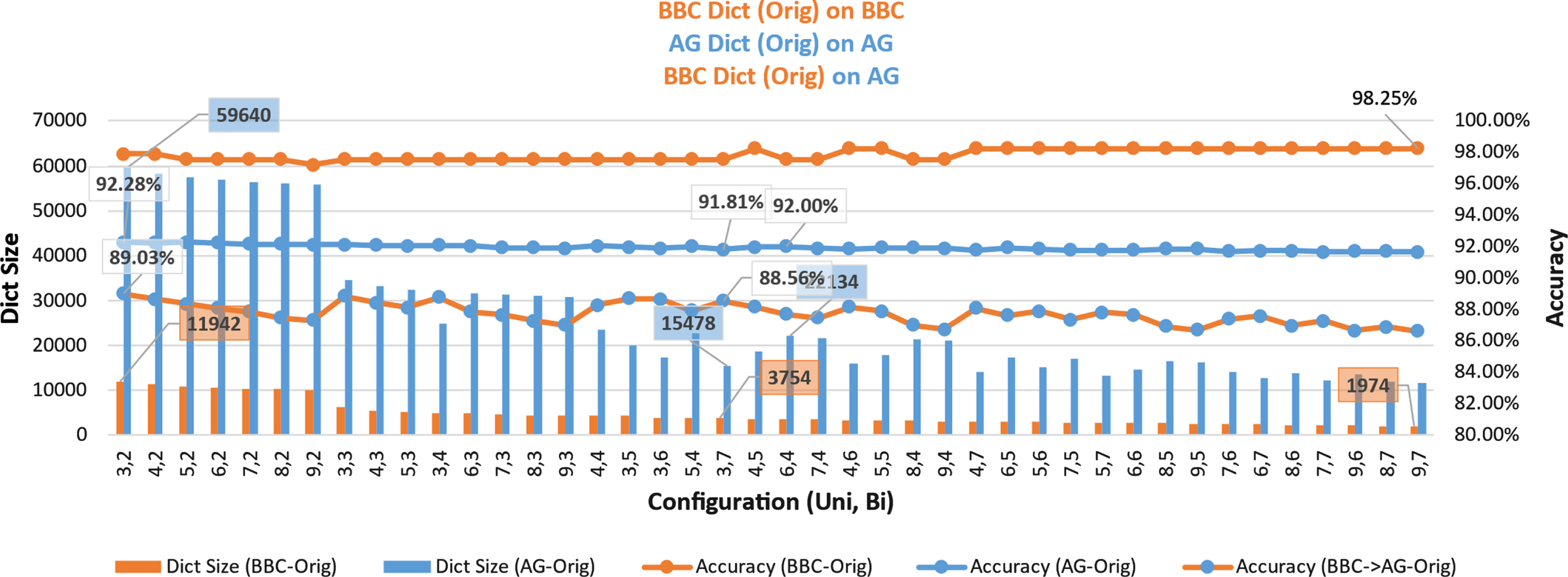
Size, Accuracy for original dictionaries – BBC, AG, and Generality of BBC original dictionaries over AG.
BBC original dictionary evaluated on BBC dataset Best Accuracy of 98.25%, achieved on (UniFreq=9, BiFreq=7), for a dictionary size of 1974 terms (Precision: 0.9825, Recall: 0.9825, F1-Score: 0.9824) AG original dictionary evaluated on AG dataset Best Accuracy of 92.28%, achieved on (UniFreq=3, BiFreq=2), for a dictionary size of 59640 terms (Precision: 0.9229, Recall: 0.9228, F1-Score: 0.9227) Reasonably good Accuracy of 92.00%, achieved on (UniFreq=6, BiFreq=4), for a significantly smaller dictionary size of 22134 terms (Precision: 0.9203, Recall: 0.92, F1-Score: 0.9199)
Figure 4 depicts how accuracy decreases as the unigram and bigram frequency threshold increases for the AG dataset. Accuracy Drop - AG dataset on increasing Uni/Bigram frequency threshold.

Effectiveness of original BBC dictionary (as compared to original AG dictionary) over AG dataset: The maximum accuracy that one of the original BBC dictionaries (UniFreq=3, BiFreq=2) could achieve on the AG dataset was 89.03%, with a size one-fifth (11942) of that of the corresponding AG dictionary (59640) on this configuration. The accuracy drop was just 3.25%. (Precision: 0.8905, Recall: 0.8903, F1-Score: 0.8903) Reasonably good accuracy of 88.56% achieved by original BBC dictionary (UniFreq=3, BiFreq=7, dictionary size - 3754) on AG dataset, with just one third size dictionary in comparison to original AG dictionary size 15478, accuracy – 91.81% on this configuration. The accuracy drop was just 3.25%. (Precision: 0.8824, Recall: 0.8823, F1-Score: 0.8823)
These observations indicate that the original dictionary created from the BBC dataset (having just ∼1.4 K articles) has a good generality and applicability to another unseen AG dataset (having ∼1 Lakh articles). Table 1 summarizes the above observations.
Best and Reasonable accuracy - original BBC dictionary applied over AG
Best and Reasonable accuracy - original BBC dictionary applied over AG
Tuning L1 regularization strength
Experimental Setup II applies the SGD technique with L1 regularization to create a sparse dictionary. This subsection explores different values of Alpha – a constant that controls the strength of regularization (higher the value, stronger the regularization) to find an optimal value for Alpha.
Figure 5 presents the experimented values of Alpha (ranging from 0.000001 to 0.8) and dictionary size, accuracy obtained on these Alpha values for Setup II - L1 dictionary on AG dataset for UniFreq=3, BiFreq=3, as this configuration gave good accuracy and reasonable size amongst all the 42 configurations. Similar experimentation was done to shortlist the alpha value for the BBC dataset. The following results were obtained:
BBC Dataset: Alpha 0.0001 gave reasonable accuracy of 97.54% on a dictionary size of 4504 terms
AG Dataset: Alpha 0.0001 gave reasonable accuracy of 92.08% on a dictionary size of 28825 terms
Accordingly, in subsequent experiments, Alpha = 0.0001 (common value for both datasets) was chosen for applying SGD with L1 regularization (Setup II).
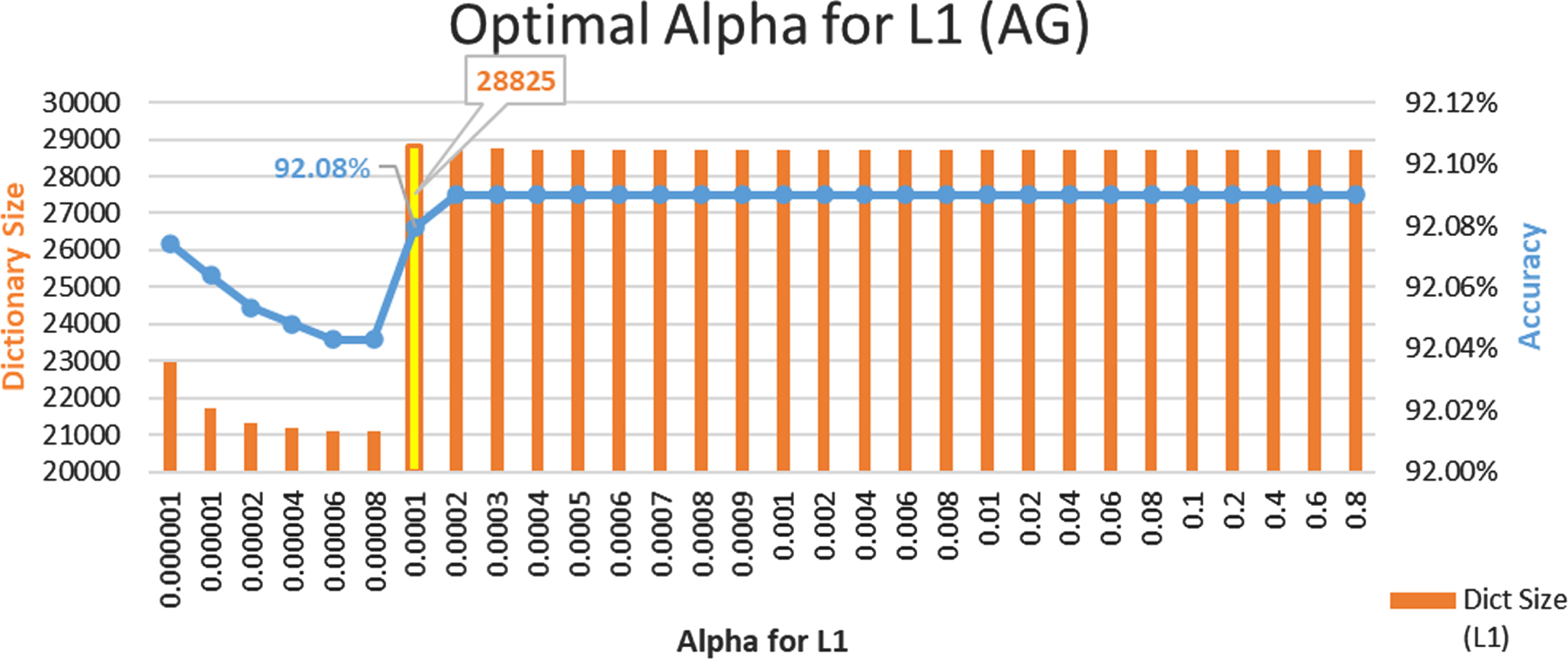
Impact of Alpha on Sparse L1 Dictionary Size and Accuracy - AG dataset.
This sub-section presents the results of Setup II run on BBC, AG dataset for 42 different unigram/bigram frequency thresholds. Figure 6 presents the accuracy and the size of the sparse L1 dictionaries created and evaluated on the BBC dataset and similarly those created and evaluated on the AG dataset. It also gives an insight into the generality of the 42 sparse L1 BBC dataset dictionaries when evaluated on the AG dataset.
BBC sparse L1 dictionary evaluated on BBC dataset Best Accuracy of 98.25%, achieved (UniFreq=9, BiFreq=7) for a dictionary size of 1780 terms (Precision: 0.9825, Recall: 0.9825, F1-Score: 0.9824)
AG sparse L1 dictionary evaluated on AG dataset Best Accuracy of 92.27% achieved (UniFreq=3, BiFreq=2) for a dictionary size of 45078 terms (Precision: 0.9229, Recall: 0.9227, F1-Score: 0.9226) Reasonably good Accuracy of 92.06% achieved (UniFreq=4, BiFreq=4) for a significantly smaller dictionary size of 20731 terms (Precision: 0.9208, Recall: 0.9206, F1-Score: 0.9205)
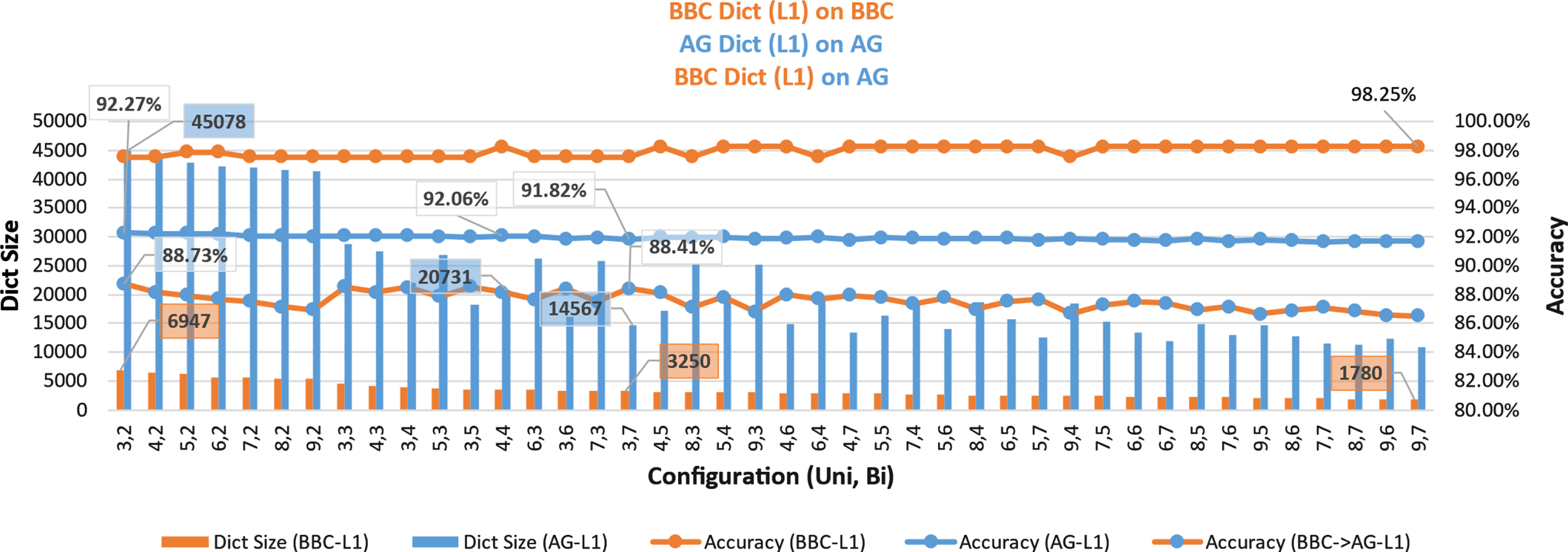
Size, Accuracy for sparse L1 dictionaries – BBC, AG, and Generality of BBC sparse L1 dictionaries over AG.
Effectiveness of sparse L1 BBC dictionary (as compared to sparse L1 AG dictionary) over AG dataset: The maximum accuracy that one of the sparse L1 BBC dictionaries (UniFreq=3, BiFreq=2) could achieve on the AG dataset was 88.73%, with a size one-sixth (6947) of that of the corresponding AG dictionary (45078) on this configuration. The accuracy drop was around 3.54%. (Precision: 0.8874, Recall: 0.8873, F1-Score: 0.8873) Reasonably good accuracy of 88.41% achieved by sparse L1 BBC dictionary (UniFreq=3, BiFreq=7, dictionary size - 3250) on AG dataset, with just one fourth size dictionary in comparison to sparse L1 AG dictionary size - 14567, accuracy - 91.82% on this configuration. The accuracy drop was around 3.42%. (Precision: 0.8843, Recall: 0.8841, F1-Score: 0.8841)
These observations indicate that the sparse L1 dictionary created from the BBC dataset (having just ∼1.4 K articles) has a good generality and applicability to another unseen AG dataset (having ∼1 Lakh articles). It can achieve similar accuracy and generality in a smaller number of words than the original dictionary. Table 2 summarizes the above observations.
Best and Reasonable accuracy - sparse L1 BBC dictionary applied over AG
Best and Reasonable accuracy - sparse L1 BBC dictionary applied over AG
Tuning L2 regularization strength
Experimental Setup III applies the SGD technique with L2 regularization to create a sparse dictionary. This subsection explores different values of Alpha to find an optimal value for the same.
Alpha values ranging from 0.000001 to 0.8 and dictionary size, accuracy obtained on these Alpha values for Setup III – L2 dictionary on BBC and AG datasets for UniFreq=3, BiFreq=3 was explored. The following results were obtained: BBC Dataset: Alpha 0.00001 gave reasonable accuracy of 97.89% on a dictionary size of 3838 terms AG Dataset: Alpha 0.00001 gave reasonable accuracy of 92.11% on a dictionary size of 26993 terms
Accordingly, in subsequent experiments, Alpha = 0.00001 (common value for both datasets) was chosen for applying SGD with L2 regularization (Setup III).
Evaluation of sparse L2 dictionary created on BBC & AG datasets
This sub-section presents the results of Setup III run on BBC, AG dataset for 42 different unigram/bigram frequency thresholds. Figure 7 presents the accuracy and the size of the sparse L2 dictionaries created and evaluated on the BBC dataset and similarly those created and evaluated on the AG dataset. It also gives an insight into the generality of the 42 sparse L2 BBC dataset dictionaries when evaluated on the AG dataset.
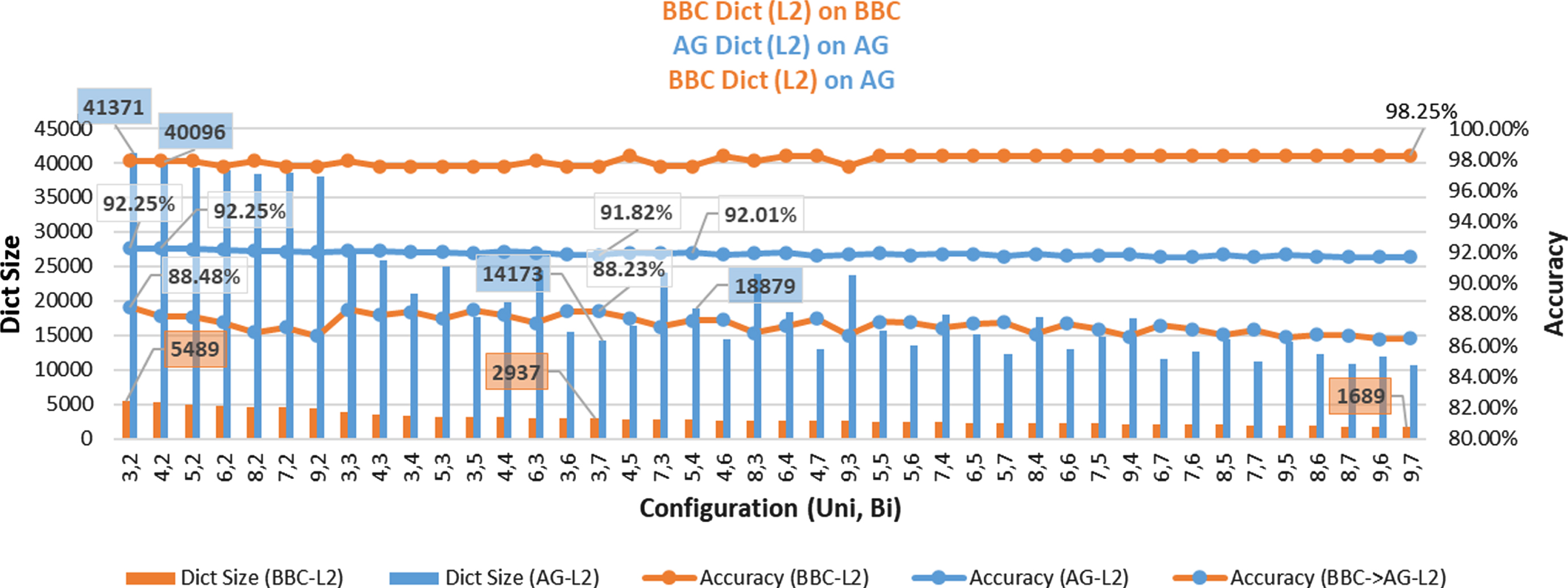
Size, Accuracy for sparse L2 dictionaries – BBC, AG, and Generality of BBC sparse L2 dictionaries over AG.
BBC sparse L2 dictionary evaluated on BBC dataset Best Accuracy of 98.25% achieved (UniFreq=9, BiFreq=7) for a dictionary size of 1689 terms (Precision: 0.9825, Recall: 0.9825, F1-Score: 0.9824)
AG sparse L2 dictionary evaluated on AG dataset Best Accuracy of 92.25% achieved (UniFreq=4, BiFreq=2) for a dictionary size of 40096 terms (Precision: 0.9227, Recall: 0.9225, F1-Score: 0.9224) Reasonably good Accuracy of 92.01% achieved (UniFreq=5, BiFreq=4) for a significantly smaller dictionary size of 18879 terms (Precision: 0.9202, Recall: 0.9201, F1-Score: 0.9199)
Effectiveness of sparse L2 BBC dictionary (as compared to sparse L2 AG dictionary) over AG dataset The maximum accuracy that one of the sparse L2 BBC dictionaries (UniFreq=3, BiFreq=2) could achieve on the AG dataset was 88.48%, with a size one-seventh (5489) of that of the corresponding AG dictionary (41371) on this configuration. The accuracy drop was around 3.77%. (Precision: 0.8849, Recall: 0.8848, F1-Score: 0.8848) Reasonably good accuracy of 88.22% achieved by sparse L2 BBC dictionary (UniFreq=3, BiFreq=7, dictionary size - 2937) on AG dataset, with just one fifth size dictionary in comparison to sparse L2 AG dictionary size -14173, accuracy - 91.82% on this configuration. The accuracy drop was around 3.5%. (Precision: 0.8822, Recall: 0.8822, F1-Score: 0.8822)
These observations indicate that the sparse L2 dictionary created from the BBC dataset (having just ∼1.4 K articles) has a good generality and applicability to another unseen AG dataset (having ∼1 Lakh articles). It can achieve similar accuracy and generality in a smaller number of words than the original dictionary. Table 3 summarizes the above observations.
Best and Reasonable accuracy – sparse L2 BBC dictionary applied over AG
Best and Reasonable accuracy – sparse L2 BBC dictionary applied over AG
Applying SGD with L1/L2 regularization reduces dictionary size significantly with a relatively small impact on accuracy.
The impact on dictionary size & accuracy varies across different Unigram/Bigram configurations. Since both size and accuracy vary with the dictionary creation technique, it is not straightforward to determine whether applying SGD would yield a better domain dictionary. Hence, to compare the effectiveness of dictionaries created using different techniques say T1, T2 where T1, T2 belong to Original, L1, L2, the mechanism given in sub-section 5.4.1 and 5.4.2 was adopted.
Comparing dictionary creation techniques in terms of accuracy (similar size)
For each of the 42 configurations of T1 dictionaries, pick the best match in terms of size from the 42 configurations of T2 dictionaries. If the two dictionaries differ in size by at most 100 terms, add it to the set “MatchingSize”.
Count the number of T1 dictionaries having better accuracy than T2 dictionaries in the set MatchingSize. This gives an idea about how many times the T1 dictionary did better than the T2 dictionary in terms of accuracy when they both were of a similar size.
Table 4 presents the comparison in terms of Accuracy between original, sparse L1, and sparse L2 dictionaries created and evaluated on the AG dataset. Implications are: L1/L2 dictionary retains better representative terms of the domain as compared to an original dictionary of similar size and hence L1/L2 yields better accuracy. For comparable dictionary size, L2 dictionaries give better accuracy than L1 and L1 dictionaries give better accuracy than the original dictionary.
Evaluating Orig/L1/L2 in terms of Accuracy (similar size) – AG
Evaluating Orig/L1/L2 in terms of Accuracy (similar size) – AG
For each of the 42 configurations of T1 dictionaries, pick the best match in terms of accuracy from the 42 configurations of T2 dictionaries. If the two dictionaries differ in accuracy by at most 0.1%, add it to the set “MatchingAccuracy”.
Count the number of T1 dictionaries having a smaller size than T2 dictionaries in the set MatchingAccuracy. This gives an idea about how many times the T1 dictionary was smaller than the T2 dictionary when they both had similar Accuracy.
Table 5 presents the comparison in terms of Size between original, sparse L1, and sparse L2 dictionaries created and evaluated on the AG dataset. Implications are: L1 and L2 dictionaries achieve comparable accuracy as that of the original dictionary but with a smaller size. For comparable accuracy, L2 dictionaries are the most compact, followed by L1 and then the original dictionary.
Note: Comparison of original, sparse L1, and sparse L2 dictionaries was done for only the AG dataset as the BBC dataset, being quite small, had very less variations in accuracy even with a significant difference in dictionary size.
Evaluating Orig/L1/L2 in terms of Dict. Size (similar Accuracy)-AG
Evaluating Orig/L1/L2 in terms of Dict. Size (similar Accuracy)-AG
This paper created, evaluated, and optimized domain-based dictionaries for two datasets namely BBC and AG. The two datasets differ in their size, article length, and the number of predefined categories. 42 dictionaries were created for each of the datasets varying unigram frequency in the range 3 to 9 and bigram frequency in the range 2 to 7. These dictionaries were optimized through the SGD technique using L1 and L2 regularization. All these original and L1 and L2 optimized dictionaries were evaluated to analyze the impact of SGD optimization. A dictionary was evaluated by using the terms of that dictionary as input features to vectorize the train and test set of a dataset, train the Naïve Bayes classification model on the training set, and then use the NB model to classify the test set. Classification accuracy was used as a metric to evaluate the effectiveness of a dictionary.
Results indicate that dictionaries optimized using L1 and L2 regularization, created on the training set of a dataset, when evaluated on the test set of the same dataset, were able to achieve comparable accuracy with a smaller dictionary size in comparison to the original dictionary. In our experiments, for a similar accuracy, 74% of the time L1 dictionaries have a smaller size than the original dictionaries, and 81% of the time L2 dictionaries have a smaller size than the original dictionaries. Also, if the original dictionary was approximately the same in size as the L1 or L2 dictionary, the accuracy of the optimized dictionary was better than the accuracy of the original dictionary. In our experiments, for a similar size dictionary, 88% of the time L1 dictionaries have higher accuracy than the original dictionary, and 73% of the time L2 dictionaries have higher accuracy than the original dictionaries. Hence, applying the SGD technique with L1/L2 regularization optimizes the original dictionary in terms of size as well as effectiveness. In our experiments, amongst L1 and L2 regularization techniques, 75% of the time L2 dictionaries yield better accuracy and retain better representative terms of the domain as compared to the L1 dictionary of similar size. Also, for a similar accuracy, 69% of the time L2 dictionaries have a smaller size than the L1 dictionaries.
The generality of the original, LI and L2 dictionaries was evaluated by analyzing the effectiveness of the dictionary created from the BBC dataset (having just ∼1.4 K articles) to classify documents of an unseen AG dataset (having ∼1 Lakh articles). The observations indicate that L1 and L2 BBC dictionaries have a better generality and applicability to another unseen AG dataset than the original BBC dictionary.
So, we can conclude that the optimized L1 and L2 dictionaries achieve similar accuracy and generality in a smaller number of terms than the original dictionary. Also, L2 regularization fares better than the L1 regularization technique for domain-based dictionary creation.
This work can be used to enhance the performance of text classification by creating a dictionary of selected, recurring and relevant text features that are good representatives of predefined categories. Apart from improving the classification performance, computational cost will be reduced as well due to a reduction in the feature space dimensionality. In the future, this work can be applied to other areas like sentiment analysis, blog categorization, etc. to analyze its effectiveness for other applications.
This work can be extended further to explore other regularization techniques like elastic net and other different feature selection techniques like balanced accuracy measure, distinguishing feature selector, etc. Comparison with different feature selection techniques and their impact on classification accuracy can further give an insight into the efficiency of the proposed technique. The evaluation of the proposed approach is limited to just the Naïve Bayes classification model. However, other Machine Learning based classification models like Decision Tree, Random Forest, Artificial Neural Network, etc. can also be explored to analyze the proposed approach. Also, the generality of the dictionaries created in this paper can be evaluated over additional unseen datasets. Similarly, the effectiveness of regularization techniques can also be validated over additional datasets.