
Abstract
The automatic semantic similarity assessment field has attracted much attention due to its impact on multiple areas of study. In addition, it is also relevant that recent advances in neural computation have taken the solutions to a higher stage. However, some inherent problems persist. For example, large amounts of data are still needed to train solutions, the interpretability of the trained models is not the most suitable one, and the energy consumption required to create the models seems out of control. Therefore, we propose a novel method to achieve significant results for a sustainable semantic similarity assessment, where accuracy, interpretability, and energy efficiency are equally important. We rely on a method based on multi-objective symbolic regression to generate a Pareto front of compromise solutions. After analyzing the output generated and comparing other relevant works published, our approach’s results seem to be promising.
Introduction
Determining semantic similarity between pieces of text is a significant challenge for the scientific community since the results achieved in this domain can impact a wide range of disciplines, including retrieving information of a textual nature. As a result, numerous solutions have been proposed to address the problem. Among them, recent advances in the abstract representation of words and sentences achieved by BERT [9] and ELMo [43] stand out. These approaches and their different variants have achieved remarkable results in several competitions. However, some inherent drawbacks are often overlooked.
For example, these approaches need vast data to be adequately trained. Furthermore, while it is usually not difficult for general-purpose solutions to find large amounts of data, it is often a problem in much more restricted domains. In addition, these solutions are hardly interpretable. This means that a human operator can provide input and obtain an output. Nevertheless, it is impossible to explain how the model has produced this output. Although it may not seem so, this leads to problems of a legal and ethical nature and various practical issues. Since people are not likely to trust systems that they cannot fully understand. Therefore, this is a very limiting factor of this kind of solution.
Last but not least, the latest advances in neural computation require significant investments in hardware with very high associated energy consumption to deploy the models. Despite the efforts to date, no sufficiently good alternatives to the problem have been found. Therefore, motivated by the reasons mentioned above, our research focuses on developing a more sustainable solution.
This manuscript is structured as follows: Section 2 describes the state-of-the-art concerning methods and tools for automatic semantic similarity assessment using computers. Section 3 presents the foundations that explain our sustainable semantic similarity measurement approach. Section 4 reports the findings extracted from several experiments, including using the most popular benchmark datasets in this context, and we compare these results with those obtained by other approaches. Finally, we remark on the strengths and flaws of our proposal and discuss the future work in Section 5.
State-of-the-art
It is widely assumed that automatically evaluating the semantic similarity between pieces of textual information is a complex research problem that requires a multidisciplinary approach to address it. Nevertheless, because of its importance to industry and academia, this challenge has attracted much attention recently [2, 46]. The rationale for this is that models that can accurately identify the semantic similarity between two pieces of text could open up new ways to impact such diverse sectors as basic research or the business world.
The scientific community has long aspired to automatically determine the semantic similarity of textual fragments reflecting the same real-world thing or idea, even if their lexicography differs. For many years, semantic similarity methods have been used in many computer-related fields [6]. Even today, a substantial and expanding corpus of academic study based on a variety of techniques exists [14, 50]. In recent years, new neural embedding approaches have gained much traction [39]. To such an extent that today, these seminal works have inspired state-of-the-art solutions such as BERT [9] or ELMo [43]. However, three main issues persist: The first issue is that these techniques rely on large amounts of data to train models. Whether developed or detected using pre-trained deep models, the input features may be impacted by noise inherent in raw data, making them imprecise. In addition, the mappings between data features and objective variables must be robust to data noise and other factors such as outliers and the adoption of a non-optimal model structure. We have discussed the use of semantic similarity controllers in the past as a way to solve these challenges [36]. These controllers are artifacts that may be developed automatically to avoid the issues we discussed before. However, understanding fuzzy code still needs a certain degree of mastery. The second issue is the lack of interpretability, i.e., the inability of a human operator to understand the model. This is a characteristic since understanding a model with many interconnected nodes is widely considered rather difficult. The reason is that a human operator can specify which outputs correlate to which inputs and the deep neural network will automatically design a mapping function. However, the human operator will not know what happens inside the model. As a result, these models are often described as black-boxes because they do not show their operation insights to the users. Although in recent times much research is indeed being carried out to mitigate this problem [45], the solutions are not yet entirely satisfactory. The third issue is that energy saving is one of the major concerns in today’s societies. It is relevant to note here that data centers worldwide consume more than 320 terawatt-hours of electricity currently, which is more than 3% of the world’s total electricity consumption
1
. Data centers assume that facility expenses have become significant cost factors. Moreover, highest energy impact of deep learning models is not just because of their training but rather because of their deployment in the cloud, being continuously online, making computations in real-time for thousands or millions of parameters. These reasons explain that the engineers in charge of maintaining these centers strongly warn that if energy consumption continues to grow, the expenses of the model’s life cycle may exceed the cost related to the hardware by a wide margin, not to mention its environmental impact (e.g., carbon footprint). Some works have tried to improve our understanding of the consumption patterns of a program for writing sustainable, energy-efficient, and green code [1, 32]. Now, we go a step further since one of the advantages of symbolic regression is that it can reduce software energy consumption by optimizing the source code.
Therefore, to date, very little attention has been paid to the sustainability of the models [13]. The novelty of this work lies in that we present a strategy for building more sustainable semantic similarity assessment systems for the first time. We emphasize the importance of facing a threefold goal: to make the models accurate, interpretable, and energy-efficient at the same time. Furthermore, we will rely on symbolic regression and MOO techniques to build our system. This approach is innovative in that it:
The challenge of finding a symbolic expression to identify the relationship between defined inputs and output variables has already been studied by the community. The key idea is that the expressions generated should be flexible enough without being restricted to a particular structure [47]. This technique is constrained by the choice of operations that are permitted in the sought equations [20]. Nevertheless, the resulting model is an equation that can be executed and interpreted in the context of the situation [37].
Concerning multi-objective symbolic regression, several works have appeared in recent times that address the problem [24, 30]. Such techniques, as [16], aim to model problems involving conflicting objectives in the classical ways. Although there are some improvements, e.g., using semantic genetic programming [5], its applications have been little explored to date. In this work’s context, we focus on combining symbolic regression with MOO, allowing us to shape our model in the way we need, for the first time.
In summary, neither the interpretability of semantic similarity measurement nor generating energy-efficient models have yet been explored in depth. Therefore, in the remainder of this work, we will focus on developing sustainable methods for automatically assessing semantic similarity between pieces of textual information. To do that, we aim to reach sustainability using a MOO similarity learning problem whereby three orthogonal objectives (accuracy, interpretability, and energy efficiency) are to be pursued simultaneously.
Sustainable semantic similarity assessment
To face the challenge of designing more sustainable methods for semantic similarity assessment, we aim to combine symbolic regression, performed via genetic programming (GP), with MOO techniques. Symbolic regression explores the space search of all computer programs to find the one that best solves a given problem. No particular assumption is made as a starting point. This characteristic gives us enormous advantages in designing highly efficient approaches from the beginning. This approach takes nothing for granted, so the method is free to evolve to forms with high accuracy, interpretability, and low energy consumption. This is whereby MOO comes in since this approach involves more than one goal to be simultaneously met. MOO is helpful in scenarios where decisions need to be taken regarding two or more orthogonal objectives.
We can define our problem formally as follows: K
O
: R
p
→ R that best fits a given training dataset T = {(x1, y1) , …, (x
n
, y
n
)} of n input and output pairs with x
i
∈ R
p
, y
i
∈ R defined as
Furthermore, research problems with two or more orthogonal objectives have received much attention in recent decades. In this way, meta-heuristics have successfully addressed MOO problems, resulting in numerous techniques that offer an accurate approximation to the Pareto front of the solved issue. The decision-maker must next determine which alternatives are the most appropriate based on a set of criteria or preferences. We will also study which kind of meta-heuristic strategy best fits the problem.
Symbolic regression is a computational approach that explores extensively across the space in which all equations are specified to discover the formula that best matches a specific dataset. Symbolic regression has already been applied previously in [15]. The authors proposed a method to solve specific problems associated with the identification and learning functions in that work. This application is possible thanks to Abstract Syntax Trees (ASTs), which allow identifying any function from past solves cases. This makes it easier for a human operator to grasp it and apply it to other issues of a similar kind [37].
Our aim is for the?AST to grow to the point where it can find an expression that matches the input and output pairs supplied as training data and then validates that expression in a different situation. In each iteration, all candidates in the population are evaluated for how well they satisfy the objective. Those with higher scores are more likely to pass on to the next iteration. By introducing sources of random variation in each candidate solution, new candidates are generated, each with a possibility of being closer to the actual target solution.
To do that, we seek to aggregate modern similarity techniques strategically. The possible mistakes that a method could make lose importance on an ensemble of techniques that generally blur any of these mistakes [35]. In this way, only if all methods produce the same error does the aggregation lose its usefulness. Popular operations in this field are the arithmetical mean or the median. However, their strategy is widely considered to be short-sighted and does not usually lead to optimal results in this context [33].
Therefore, we combine methods with mathematical operators and numerical constants to get the goal function. As mentioned in [25], this model may evolve owing to an evolutionary algorithm. The result is obtained by assessing the nodes and then applying the parent operation to the children [37]. Our research leads to three interesting facts: first, the symbolic regression can find an expression that can adequately consider each of the measures of semantic similarity; second, in contrast to other neural network-based models, the generated expression can be recognized and understood by a human being without requiring any special training; and third, the energy consumption of the expression, although we can assume it is not very important for a single run, could be optimized to see a positive effect after millions of repeated executions.
In our strategy, the automatic generation of the AST must be guided by the three aforementioned main objectives. The problem is that, in the realm of MOO, there is not a single solution that can meet all of the goals at the same time. As a result, solutions that cannot improve the objectives without harming the remainder must be prioritized. In this way, the collection of Pareto optimum points from the search space leads to a Pareto front, representing the best feasible compromise between the examined orthogonal objectives [38]. In our specific case, the three orthogonal objectives that define our learning phase are the following: Concerning accuracy, we try to maximize the Pearson or the Spearman Rank correlation coefficients since the research community usually measures semantic similarity as the difference in the correlation of human judgment (or ground truth) and artificially generated solutions. Therefore, the unit of measurement will be the degree of correlation with human judgment. Concerning interpretability, we try to minimize the size and the complexity of the final mathematical equation generated by the evolutionary strategy. To do so, we will work with individuals of a specific maximum size to reduce them as much as possible. Therefore, the unit of measurement will be the length of the generated mathematical equation, taking into account that the size is measured in the number of nodes. Concerning energy efficiency, we try to minimize the energy consumption. To do that, we use the pyRAPL
2
model to calculate the energy required by the execution of the symbolic program at run-time. This model is valid only on Intel CPUs (it remains future work to study other processors). The unit of measurement will be the Joule since it represents the energy dissipated as heat in the CPU.
Figure 1 shows a clear example of the solutions we are looking for. We want a three-dimensional solution Pareto front, where a human operator can choose the solution that best fits his specific needs. Since the three parameters are challenging to optimize simultaneously, choosing a solution that optimizes two will almost always be possible—for example, accuracy and interpretability, accuracy and energy efficiency, or interpretability and energy efficiency.
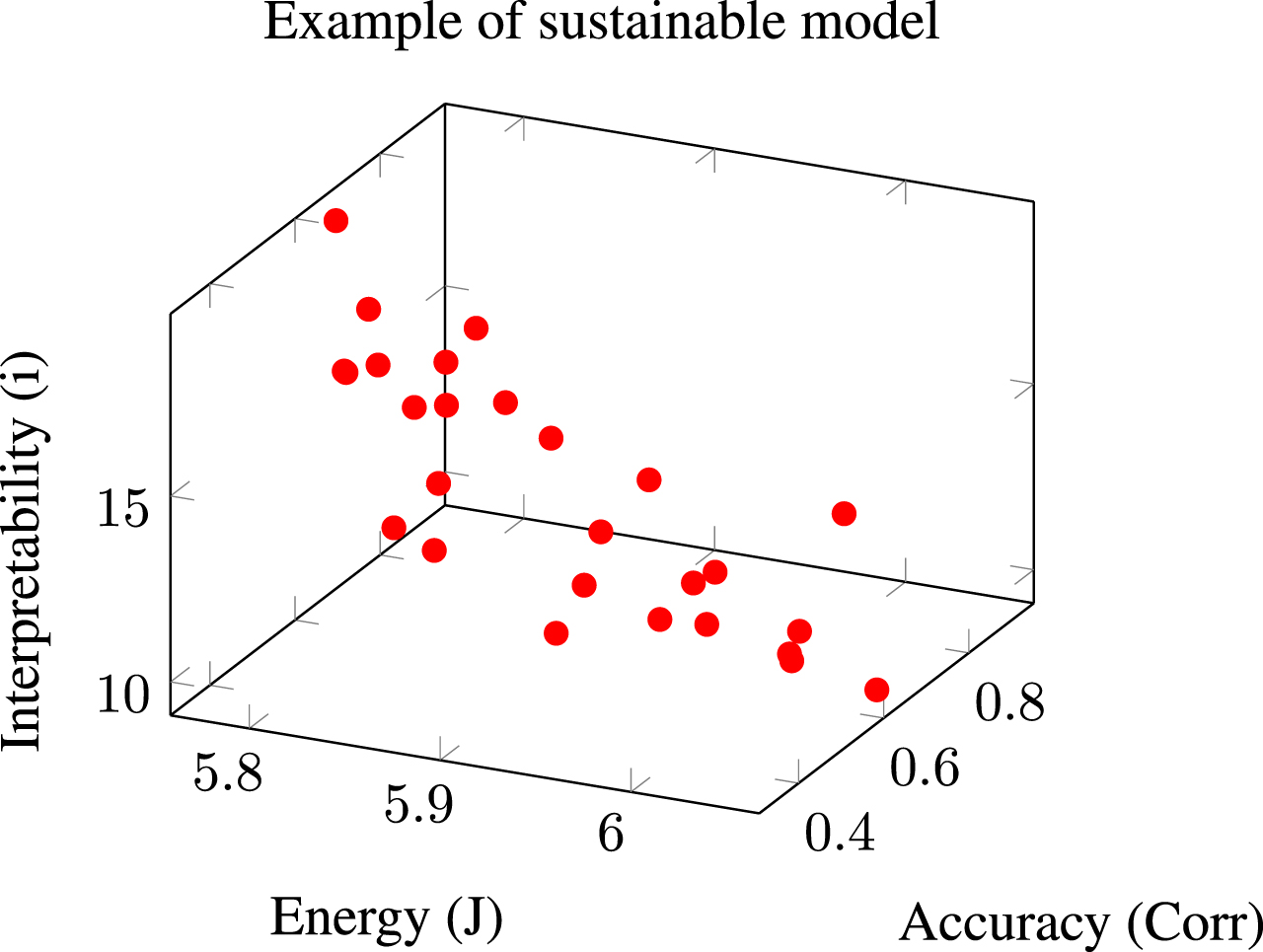
Three-dimensional visualization of the front-end Pareto generated when learning an equation that optimizes accuracy, interpretability and energy efficiency at the same time. The X-axis represents the energy consumption in Joules. The Y-axis represents the interpretability in AST items, or if preferred, the size of the resulting model or mathematical equation. The Z-axis expresses the degree of correlation with respect to human judgment.
From now on, we will explain the details of the empirical study for the sustainable calculation of semantic similarity. In addition, we will provide an analysis of the applicability of this novel strategy to production environments.
The outcomes we got in our experiments are presented here. To accomplish so, we outline our experimental strategy setup, including the benchmark datasets we have used, the different objectives to be reached, and the base configuration of the approaches under consideration. We thoroughly examine the various MOO techniques explored and the empirical results. Furthermore, we provide a comparison with previous studies, including those that emphasize accuracy. We also offer a temporal analysis of the different training phases for the approaches under consideration and discuss the outcomes obtained.
Experimental setup
First, we will go through the benchmark datasets that we have utilized, the objective functions our strategy should aim towards, and finally, the base setup we used in the test we performed, ensuring that the experiments are repeatable.
Datasets
Our research uses a dataset that has become standard for working with general-purpose solutions. The dataset is known as the Miller & Charles [40] dataset. This benchmark compares textual information from various general-purpose contexts, i.e., terms we can find in many traditional settings. We use the version with 30-word pairs (MC30), while many researchers utilize shorter versions (e.g., 28-word pairs) due to problems concerning dictionary coverage.
Goals
The fitness function guides the learning process through the Spearman Rank correlation and Pearson Correlation Coefficient. This last one is calculated between two vectors and aims to assess the linear relationship between both vectors. On the other hand, if the Spearman Rank correlation is used, a coefficient to measure how equals the vectors generated by the human and the machine. The correlation defined by Spearman is a reasonable goal when results need to be compared on an ordinal base. The distinction between these two correlations is that Pearson’s correlation is better for situations with an absolute scale, while Spearman’s correlation works better with relative scales.
Parameter setup
A standard grid search strategy has made us choose the following parameter settings: Set of functions {+ , - , · , exp, /, max, min} (where division is protected) Individual sizes [0 –50]: Highest number of constants permitted [0 - 5]: Maximum allowed depth [2 –5]: Population length [10 –100]: Mutation percentage [0.00 –0.5]: Crossover percentage [0.3 –0.95]:
The optimization of values guides the learning process in the training phase. Because the approaches we use are of stochastic nature, this procedure has been repeated 30 times so that it can be possible to achieve more robust results.
Analysis of strategies
MOO aims to learn a function that meets several orthogonal objectives simultaneously. There is no single optimal solution for problems of this kind. Therefore, according to the state-of-the-art in the area, our proposed approach is compared concerning five of the most representative strategies within the MOO domain. Furthermore, we have made such a selection based on the explanations of [11]. In our scenario, we want to reduce the energy used and the size of the generated equation while also increasing the correlation to human judgment (accuracy). In addition, it is helpful to emphasize one crucial point: our technique serves as a guide for achieving the best feasible outcome on a training dataset. However, the findings that we describe were obtained using a blind data set. This is appropriate to ensure that the final model has learned a correct setup for generalizing the results.
Concerning the different MOO strategies, we rely on the framework MOEA 3 . The different strategies, in alphabetical order, are: CellDE [10], CMAES [19], DBEA [22], GDE3 [26], MOEA/D[48], MSOPS [18], NSGA-II [7], NSGA-III [8], PAES [23], and SMPSO [41]. After a preliminary study, we show the five most promising (in terms of quantity and quality of the solutions) ones below: CellDE [10], CMAES [19], GDE3 [26], MOEA/D [48], and NSGA-II[7].
CellDE
CellDE [10] is a popular approach in the field of MOO. It obtains outstanding results for several reasons: it relies on efficient differential evolution and takes the idea of storing non-dominated solutions from other MOO approaches. These two design features give the strategy outstanding results in scenarios involving more than two orthogonal objectives.
We can see that it is feasible to gain more accuracy by using more sophisticated models, as demonstrated in Fig. 2. It can also be shown that more energy is necessary to make the generated equation more interpretable (i.e., less complex).
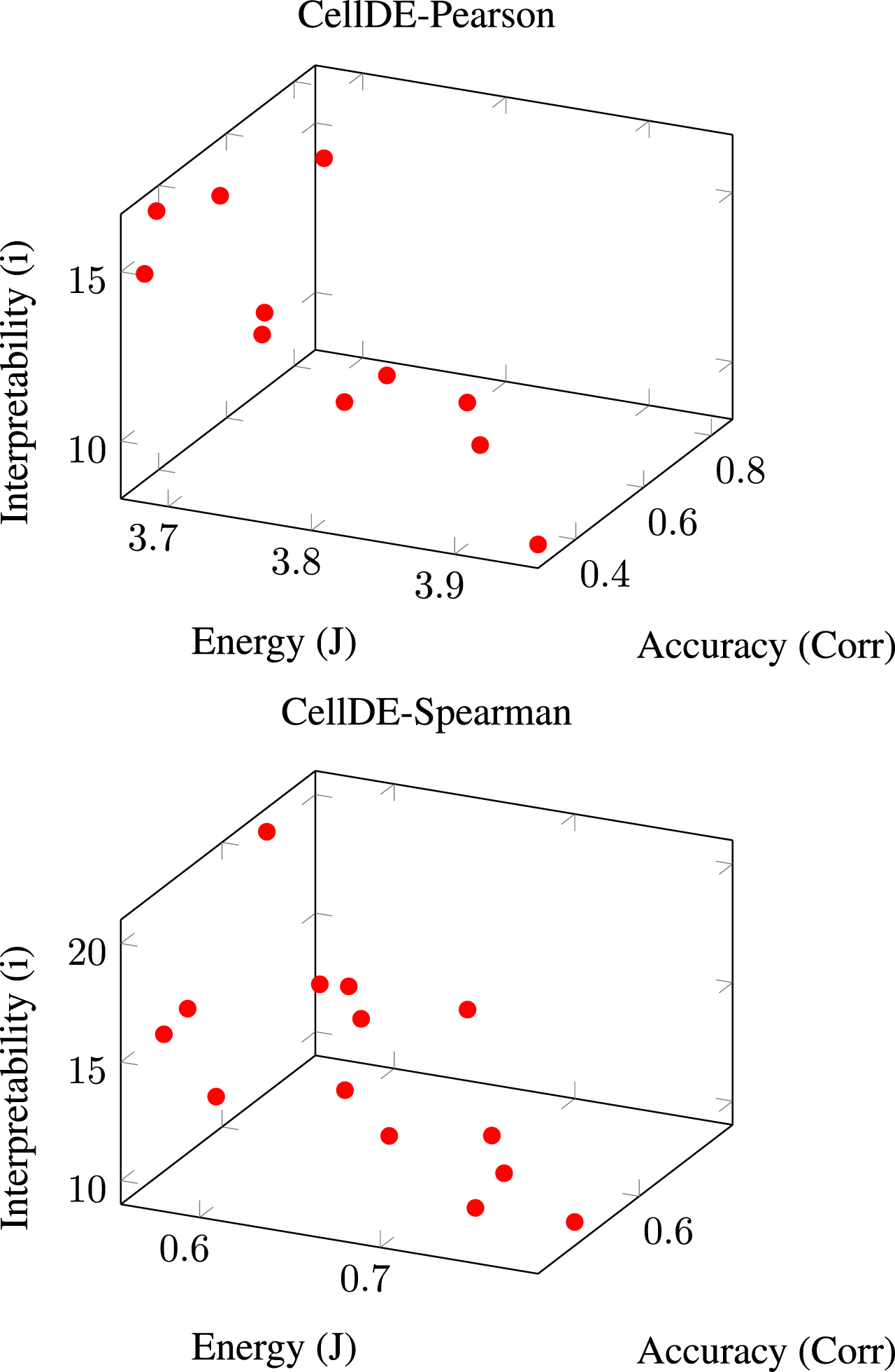
CellDE was used to create a Pareto front of non-dominated points. The Pearson Correlation Coefficient is depicted in the first plot, while the Spearman Rank Correlation is depicted in the second.
CMA-ES [19] is a stochastic approach that is usually involved in the optimization of non-convex continuous problems. Its design is supported by two ideas: the core notion of maximum likelihood and the analysis of evolution records, which are used to monitor the correlation between consecutive iterations.
A solution front is shown in Fig. 3, where a more straightforward way to comprehend the model is acquired at the expense of accuracy and vice versa. Furthermore, there is a substantial divergence between the Pearson correlation coefficient and the Spearman rank correlation.
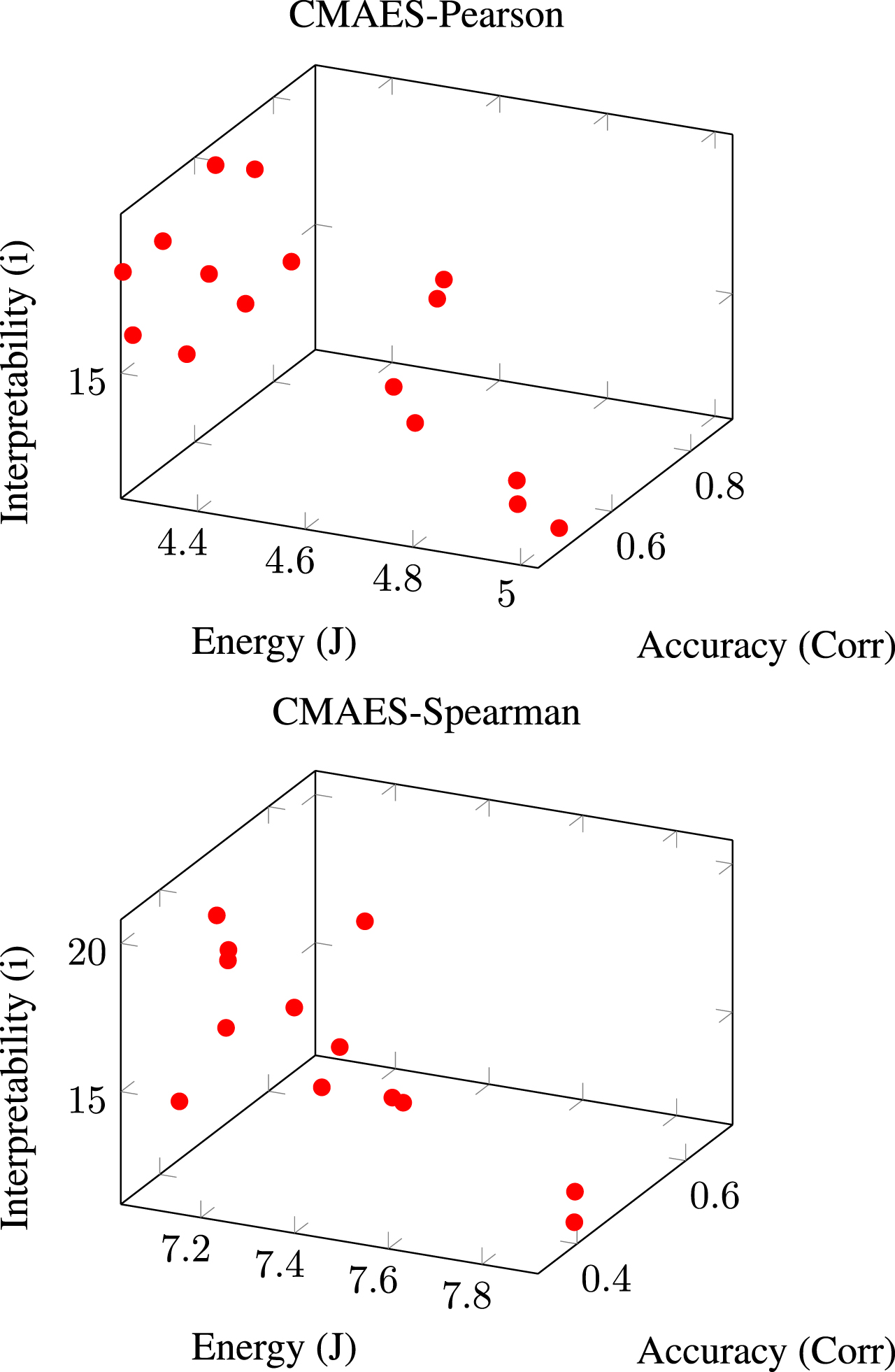
CMAES was used to create a Pareto front of non-dominated points. The Pearson Correlation Coefficient is depicted in the first plot, while the Spearman Rank Correlation is depicted in the second.
GDE3 [26] employs differential evolution to optimize a problem by keeping a population of candidates and merging current individuals using a simple formula to create new candidate solutions. Differential evolution methods are simple, efficient, and frequently produce good results in different MOO settings.
When we look at the experiments, we can see that GDE3 is one of the more successful ways to proceed. The results that GDE can produce for the two correlation coefficients of interest are shown in Fig. 4.
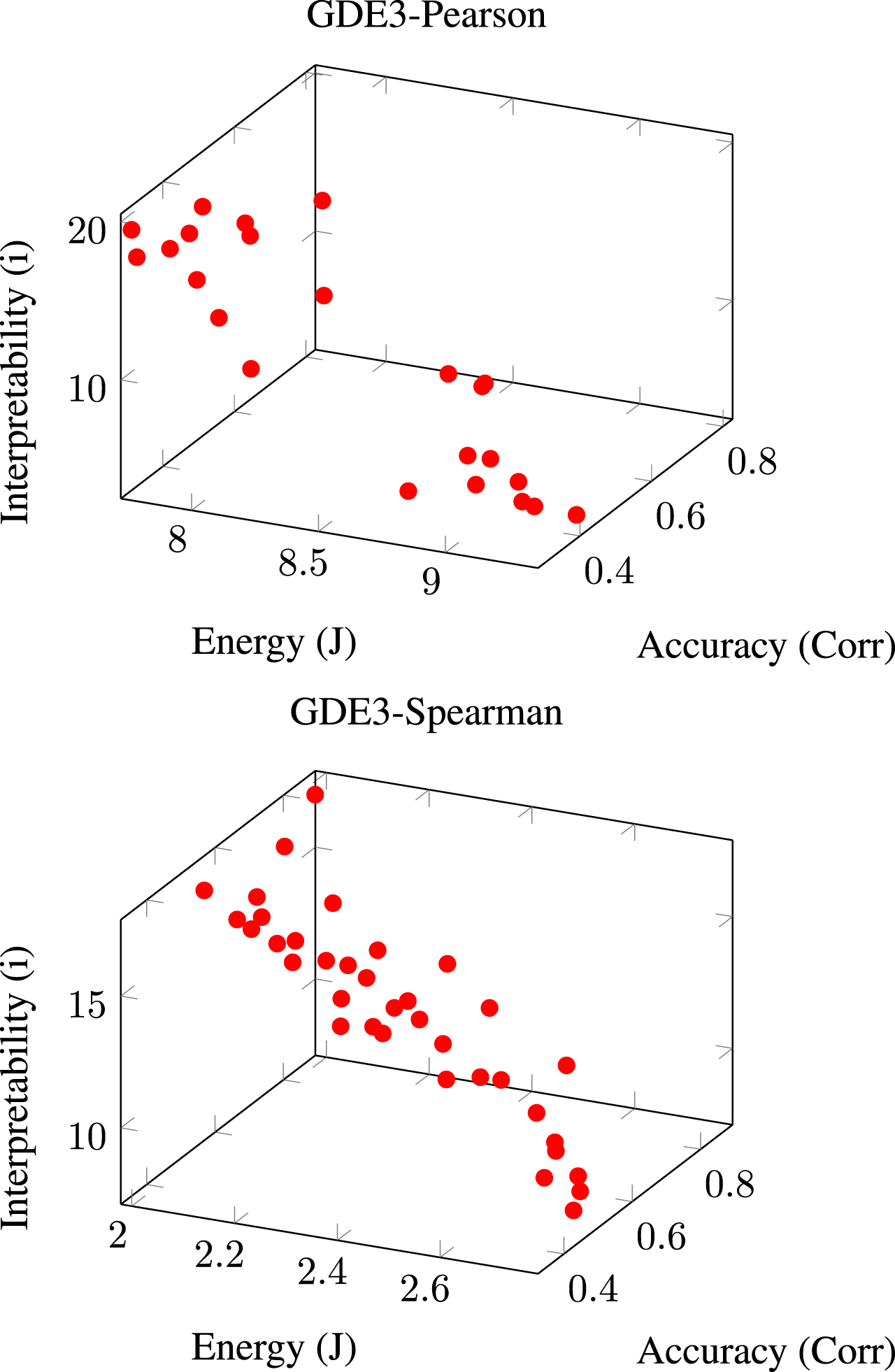
GDE3 was used to create a Pareto front of non-dominated points. The Pearson Correlation Coefficient is depicted in the first plot, while the Spearman Rank Correlation is depicted in the second.
MOEA/D [48] is an evolutionary approach that relies on the concept of dividing the scene into several single-objective problems. MOEA/D usually performs better with MOO problems involving more than three conflicting objectives.
We have got a solution front for the two scenarios under study, as shown in Fig. 5. The orthogonality explains the relationship between accuracy, the complexity of the equation required for the technique, and energy usage. The Spearman values are somewhat higher than the Pearson values in terms of accuracy.
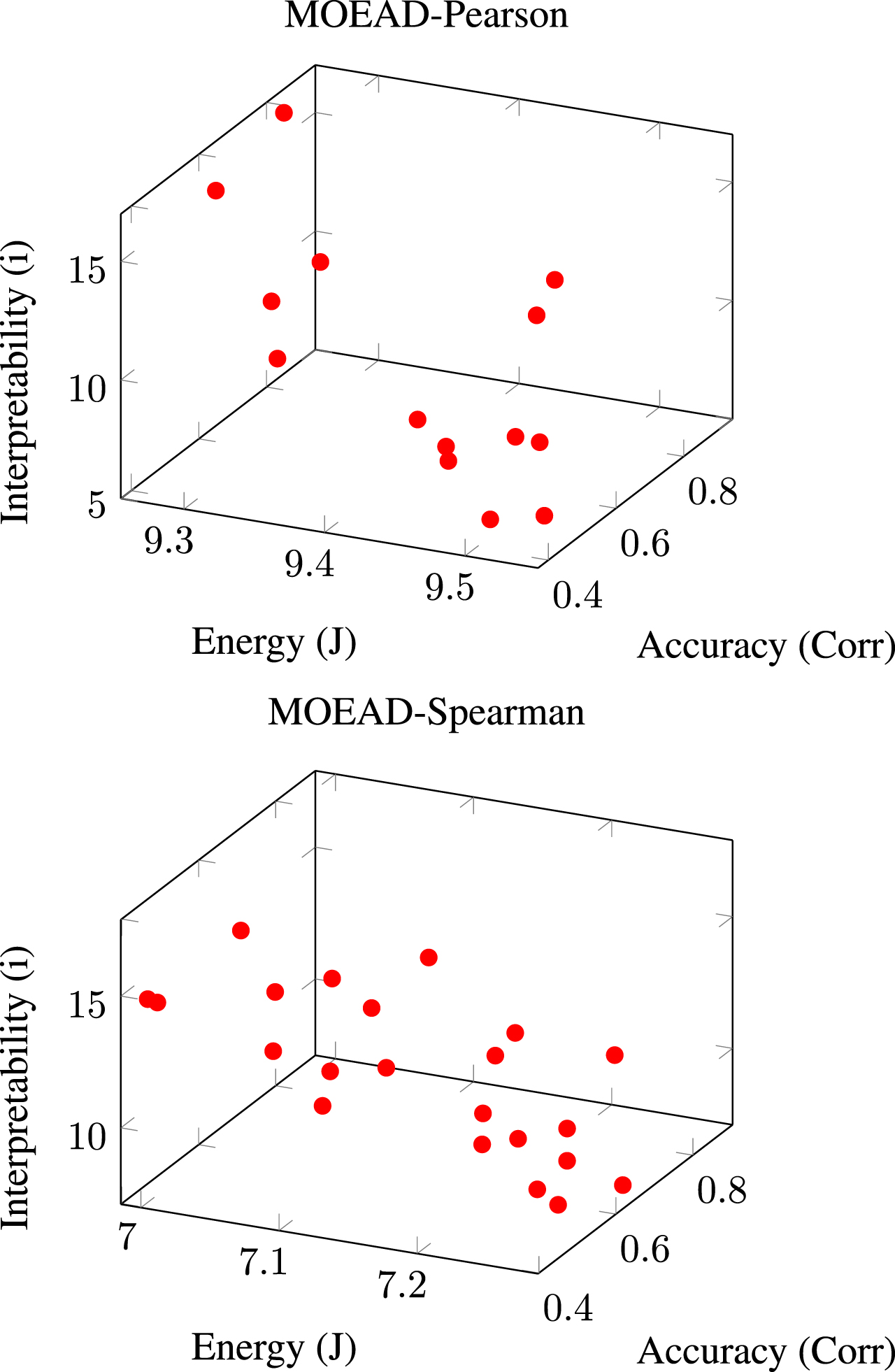
MOEA/D was used to create a Pareto front of non-dominated points. The Pearson Correlation Coefficient is depicted in the first plot, while the Spearman Rank Correlation is depicted in the second.
When the goals number is modest, NSGA-II [7] is a popular way to implement a MOO strategy. The algorithm employs the critical notion of dominance to provide better results than others since it enhances a single target without degrading others.
In general, NSGA-II-based methods provide good results. In both circumstances, this method comes out on top. This is because this method has been demonstrated to function well when several objectives are being pursued simultaneously. The outcomes of employing the NSGA-II approach are shown in Fig. 6.
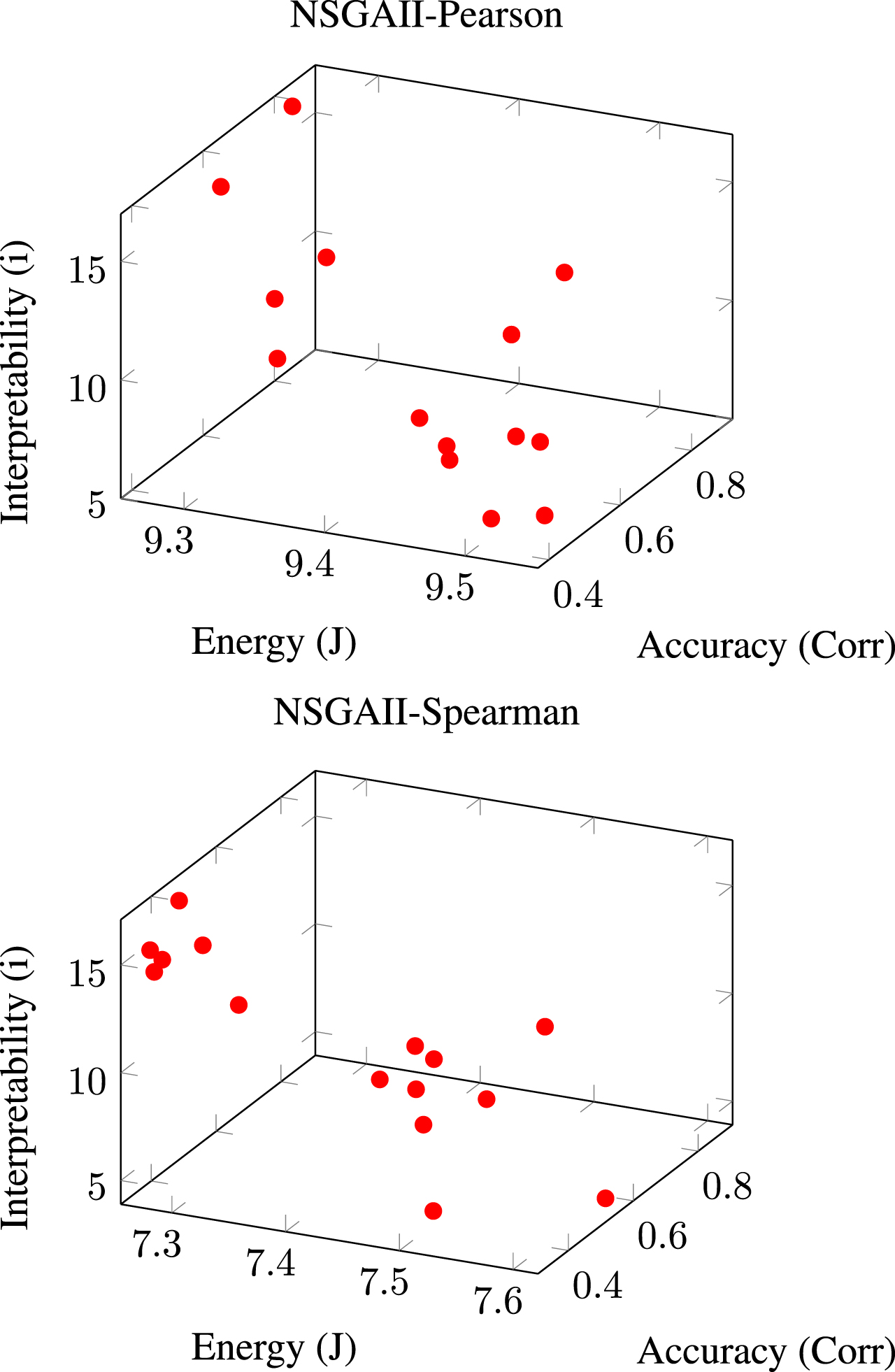
NSGA-II was used to create a Pareto front of non-dominated points. The Pearson Correlation Coefficient is depicted in the first plot, while the Spearman Rank Correlation is depicted in the second.
The best solutions found utilizing the various MOO techniques are compared here. It is not possible to directly compare our technique to any other existing proposal since it is the first to investigate the trade-off between accuracy, interpretability, and energy efficiency when measuring semantic similarity. Consequently, we will evaluate the findings for each factor studied about the wide range of available methods for automatically calculating semantic similarity.
In Table 1 the values for the Pearson Correlation are compared when solving the MC30 instance. Please note that in that table are shown the best findings from our empirical analysis. Even though the outcomes are contingent on how the model is trained, we can see that some configurations can produce superior results than those achieved using traditional approaches. Once again, we choose the average value because we deal with non-deterministic methods.
Correlation according to the Pearson for the existing approaches when the MC30 dataset is tested
Correlation according to the Pearson for the existing approaches when the MC30 dataset is tested
The best results achieved while solving the MC30 dataset with the Spearman Correlation coefficient are listed in Table 2. We provide the state-of-the-art and the top outcomes obtained using our method. As can be shown, some combinations can produce superior results than those produced using traditional approaches. There is, however, greater variety than in the prior situation. Furthermore, the complexity of the equation and the amount of energy consumed are also considered.
Correlation according to the Spearman Rank for the existing approaches when the MC30 dataset is tested
We can observe that our approach can place different configurations among the best ones for the MC30 benchmark dataset, which represents a good result if we also consider that the model’s interpretability and its energy consumption, have been considered to achieve this score. This confirms our hypothesis that such a strategy can make sense when solving challenges such as the one studied here.
We also analyze the performance for the training phase. In Fig. 7, we show the average time for each of the MOO strategies considered. These times represent the average time (in milliseconds) resulting from 30 independent runs.
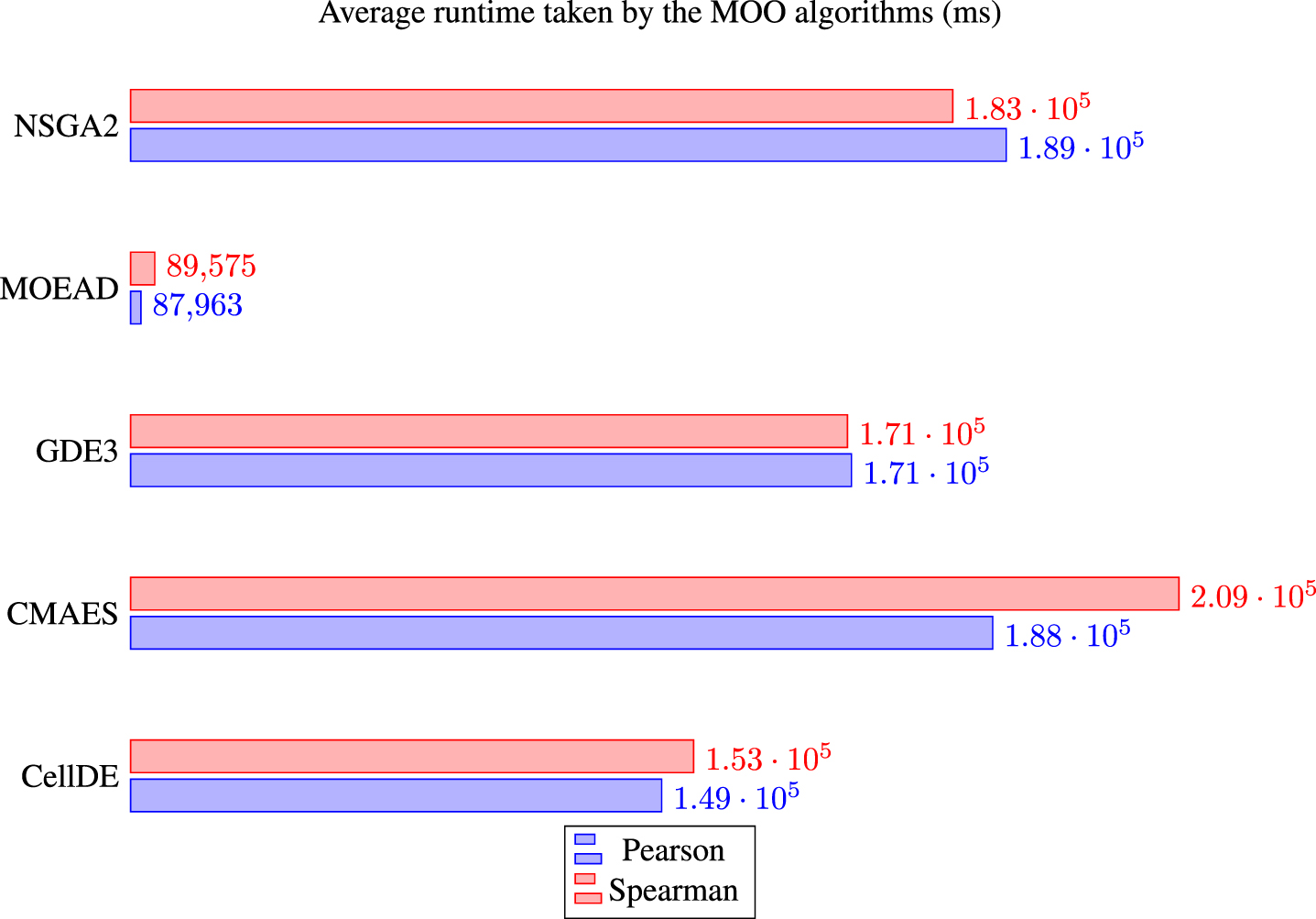
Average execution time of the MOO strategies considered. The figures are given in milliseconds.
On the one hand, the MOEA/D method is the fastest approach. However, the this approach does not rank among the top. On the other hand, techniques that produce superior results, such as NSGA-II, need higher operation times to achieve the Pareto fronts.
Experiments prove that it is feasible to find a solution whose accuracy, interpretability, and energy-efficient values cannot be improved except at the expense of the others. However, by studying the results separately, one can observe that it is possible to optimize two values at the cost of the other. There may be accurate and interpretable solutions, but they will require more CPU time to execute (think, for example, the max operator that requires much computation underneath even though it only occupies one item of the AST). There may be accurate and energy-efficient solutions but not interpretable (since they need large equations). Finally, there may be interpretable and energy-efficient solutions but will not be accurate (they will be executed quickly and cheaply but will not achieve the best results). These results are novel in that, to date, the community has not been very concerned about the development of solutions that give rise to sustainable models.
Regarding accuracy, it is necessary to remark, that additional experiments show us that performance decreases as the size of the input data increases. But this is true for all existing models that work with semantic similarity [28]. The reason is that it is necessary to learn more general models that deal with much more volume and diversity in the data to be processed.
Regarding a concrete example of interpretability, the AST 4 MAX (MAX (ssm3 · ssm2, 2 · ssm1 + ssm2), ssm4/ssm3) achieves an accuracy of 0.87 when solving the MC30. This AST requires 13 nodes (and 4 free variables). At the same time, the AST MAX (MAX (ssm3 · ssm2, 2 · ssm1 + ssm2), 1) achieves an accuracy of 0.83 with 11 nodes (and 3 free variables). It is therefore up to the human operator to choose the model to be exploited: More accuracy with more complex equations (larger size and more free variables) or less accuracy with simpler equations (smaller size and fewer free variables).
Finally, it also seems clear that the increasingly high speeds that microprocessors can reach pose a compromise to their energy consumption (as well as their reliability and lifetime). Therefore, minimizing their energy consumption is a significant challenge. However, many data centers are usually quite optimized since operators have strong incentives to reduce energy consumption. Thus, the less energy a data center uses, the greater the economic benefit of the organization.
However, using energy-efficient algorithms methods is still largely unexplored to date. It is assumed that as the customer base grows, the energy needed to provide the service grows as well. In this way, both hardware-based solutions and instruction planning are well thought out. However, our strategy can solve this problem by creating assessment strategies offered in a low-energy version of the source code to be executed. When working with large data environments, its impact on energy consumption will be significant. Besides, as the operator is likely to save money, it might encourage its users to use this kind of strategy.
Overall, we find it interesting to remark that we will have little room for improvement if we optimize traditional data science models because they involve many assumptions regarding the parameters they operate with. With symbolic regression and MOO, computer libraries can implement analogous functions (classification, regression, clustering, and optimization) with higher interpretability and lower energy consumption. The reason is that the models generated have to assume those requirements from the beginning. This means, for example, that accuracy has to be as crucial as interpretability and low energy consumption by design. Alternatively, the human operator should be offered a front of orthogonal solutions to decide which configuration best fits the needs of its specific case.
Conclusions and future work
People should be able to trust the data-driven technologies they utilize in their everyday operations as they become more important in many daily situations. Unfortunately, several technological domains have been immersed in a rush to enhance accuracy in recent years. As a result, novel solutions have paid insufficient attention to other critical factors, such as the long-term viability of the models they work with.
To overcome this situation, we have shown how to design a strategy that considers three fundamental objectives to achieve a sustainable assessment: accuracy, interpretability, and energy efficiency. Our study shows that even if it is impossible to get optimal solutions for all the three objectives, it is feasible to obtain a model that allows finding compromise solutions, leaving the decision-maker to choose the most suitable model for the scenario in which it has to operate. This represents a novelty for the community because it focuses, for the first time on sustainable models.
For future work, it would be good to consider that the limited number of libraries for calculating the energy consumption has been a limiting factor of this study. Our experimental setup has been performed only on Intel processors. However, an in-depth analysis of the implications of deploying our approach on processors from other manufacturers (AMD, ARM, etc.) would be desirable. We want to point out that, even if the execution of a single case does not produce significant results, the cloud environment in which these solutions are used, often involving millions of executions, can have considerable savings associated.
Acknowledgments
The authors thank the anonymous reviewers for their comments and suggestions to improve the work. This research has been funded by the project NEFUSI (NGI Zero Discovery) by the NL Foundation and the EU Commission. Project number: 2021-04-069.