
Abstract
In present scenario, Heart Disease has become the vital cause of mortality and diagnosis of heart diseases is a great confrontation in the field of medical data analysis. Data Mining is an efficient technique for processing and analyzing larger databases for deriving hidden knowledge appropriately. Hence, it is incorporated in medical data analysis for assisting in effective decision making and disease predictions. With that concern, this paper concentrates on framing an Integrated Model for Heart Disease Diagnosis (IM-HDD) using the advanced data mining conceits. The model considers the significant features of patient data that are available in benchmark datasets. Here, the main objective of the proposed model is to enhance the classification accuracy of patient data on classes under NORMAL and ABNORMAL. For enhancing the classification accuracy, the proposed integrated model utilizes the algorithms such as Decision Tree Algorithm, Naive Baye’s Classification and Ensemble Classifiers called Random Forest and Bagging. Further, performance evaluation is performed for analyzing the proposed work. For that, images from UCI repository are utilized and the comparative analysis shows that the proposed work produces better results than the existing models compared.
Keywords
Introduction
Medical Data Mining in Health Care Management and Disease Diagnosis is considered as more significant that has to be processed in efficient and accurate manner [1]. According to the report of World Health Organization (WHO), heart related diseases that may affect both men and women equally in all ages and also be the first leading death causing disease [2]. Based on the survey, it is determined that 76%of world deaths will occur by the 2030 due to the non-communicable diseases [3]. It is always complicated to detect the heart related diseases due to the causative risk aspects such as high Blood Pressure (BP), diabetes and so on. There are several methodologies on data mining and machine learning has been developed for determining the brutality of heart diseases. Classification Algorithms are also used for disease diagnosis in accurate manner [4, 5]. The combined methods of medical science and data mining are used for diagnosing many formats of cardiovascular diseases. As in common data mining operations, the medical data mining process includes clustering, rule mining, classification and so on.
There are many techniques used for knowledge representation using the methodologies of data mining for heart disease diagnosis. In this process, several experimentations are carried out for constructing an accurate diagnosis model by integrating efficient models. Moreover, Neural Network based detection techniques are used for predicting medical records such as Left or Right Bundle Branch Block, Atrial Fibrillation, Second Degree Block and so on for detecting the appropriate patient status in accordance with heart functions [6, 7]. It is stated that the Artificial Neural Networks are considered as the model that produces better results in predicting heart related diseases and brain abnormalities [8, 9].
There are great developments in Machine Learning methods incorporated with Internet of Things (IoT) for medical data mining [10]. Specifically, in medical data mining, appropriate decision making on disease diagnosis can be attained by combining the classification models and give automated training on the dataset through which the hidden patterns of medical data are evaluated and utilized for future disease predictions on patients. Hence, through medical data mining, the model is effective to provide the patient’s medical history and can also provide medical support in the complete treatment and analysis process. For further disease and clinical analysis, the knowledge patters are very much important. Here, the medical data mining uses the classification techniques that are very much significant for determining the heart diseases before the emergency occurs. Moreover, the used classification model can be trained and tested in such a manner to detect the patient’s health state and nature of being suffered by cardio vascular or heart related diseases.
In this proposed work, a new Integrated Model for Heart Disease Diagnosis is introduced. The major motive of this model development is to find the heart diseases of test samples with higher accuracy rate and precision. In many available models, there are several limitations on feature selection for execution conveniences. In a different way, the proposed model considers all the available features and Integrated Model is developed with base classification algorithms such as Decision Tree Algorithm and Naive Baye’s Classification, and Random Forest and Bagging classification techniques, for enhancing the result accuracy in predicting heart diseases when compared with available medical data mining models. The contributions of the proposed IM-HDD are listed below.
The medical data of patients that are acquired from the benchmark dataset are pre-processed. Significant feature selection and feature reduction is performed for avoiding missing attributes and achieving better accuracy with minimal time. Integrated Model is framed with the traditional and ensemble based classification models such as Decision Tree Algorithm and Naive Baye’s Classification, and Random Forest and Bagging. Performance Evaluation is carried out for evaluating the proposed model efficiency in determining heart diseases.
The remainder of this paper is framed as follows: Section 2 deliberates the related models and survey works that are derived for disease diagnosis in Medical Data Mining. Section 3 discusses about the complete work process and operations involved in the proposed model with data flow. Section 4 contains the model results in data classification and also the comparative analysis with existing works. Lastly, the conclusion and future enhancement ideas are presented in the Section 5.
State of art
A comparative study [11] analyzed about the works processed with bagging with C4.5 and Naive Baye’s Algorithm in heart disease detection. In this, the only ensemble technique used was bagging, by using additional classifiers might increase the result accuracy. Further, the results obtained for Naive Bayes, K-Nearest Neighbour and Decision Tree algorithm has been done [12] and [13] used Naive Baye’s Classification for heart disease detection. The works have not considered about the computational speed on disease diagnosis, which was the major factor in disease prediction. The authors [14] have developed an Intelligent Heart Disease Prediction System (IHDPS) using Artificial Neural Networks, Naive Bayes model and decision trees. The model utilized only the traditional classification techniques. In the work [15], the authors stated that the Random Tree Algorithm model produced higher rate of accuracy in heart disease prediction and classification. Moreover, the model utilized multilayer filtering process that may increase the processing time.
Random Forest Classifier [16] has been used for classifying Coronary Heart Disease through the events related to Coronary Heart Diseases. K-Nearest Neighbour (KNN) [17] based classification has been used for training, in which the model has not considered any assumption based data distributions. Moreover, using KNN with voting based technique has been used. The mostly determined common class among the KNN has been assigned for new data class. Further, Sequential Minimal Optimization (SMO) [18] based classification model has been used. In the work [19], for detecting the heart diseases, 493 patient samples were acquired from cerebrovascular disease prevention program. The model used Bayesian classification, ANN and DT for disease detection. Coronary Artery Disease based evaluations are carried out with 303 data samples [20]. Further, feature enhancement has been employed and Information gain has been determined for the effective feature selection from the input images. Achieving cost effectiveness with increasing accurate prediction rate has been the future work of this model.
Based on heart rate signals, automatic disease detection method has been proposed and narrated [21]. For dimension reduction process, component analysis technique was used and the selected features were given into four kinds of classifiers such as ANN, KNN and SVM. In a different way, a genetic algorithm based classification model [22] for classifying the data with disease factors. The model has no declaration about the cost effectiveness and processing speed in diagnosis. A Weighted Fuzzy rule based heart disease diagnosis [23] model has been developed based on the two following phases:
Automated Weighted fuzzy rule generation process Proposing Fuzzy rule based decision support model
Further, a comparative analysis experiment has been performed with various mining methods for predicting heart diseases using 15 attributes with neural networks [24]. The authors derived K-Means and Apriori algorithm based detection model in [25]. A real-time based prototype has been developed with modified Apriori algorithm [26] for defining the new method for disease diagnosis. Pruning Classification Association Rule (PCAR) [27] was derived from Apriori algorithm that involved in deleting the minimal occurred data and duplicated content. But, the model considered basic features for classification, and that may decrease the accuracy rate of disease prediction.
Least Square- Support Vector Machine (LS-SVM) based model that used binary decision tree for data classification in detecting diseases on cardiotocogram inputs [28]. A comparative evaluation has been carried out between the statistical and data mining analysis. Multilayer Perceptron (MLP) [29] based model has been utilized for classifying the input data under five major cardiac diseases. Moreover, the model used back propagation model for sample training. And, the model is not cost effective.
The work in [31] proposes a suitable Machine Learning (ML) technique that is commonly adopted and optimized depending on the requirements to predict the cardiac diagnosis based on imaging factors. Non-imaging predictors are frequently incorporated into the ML model and generally increase model performance. The study in [32] uses Weighted Associative Rule Mining to predict cardiac disease based on the scores of key aspects. A set of important part scores and criteria for identifying heart illness were discovered, and cardiologists were engaged to ensure the validity of these guidelines. Experiments on the UCI open dataset, which is widely utilized in heart disease research, provided the highest probability value of 98 percent in heart disease prediction.
Work flow of proposed model in accurate heart disease diagnosis
In the proposed Integrated Model-Heart Disease Diagnosis (IM-HDD), the amalgamation of four significant classification techniques are utilized that belongs to Apriori approach and predictive model that evaluates the attributes of heart related disease from the UCI repository dataset. Moreover, in diagnosing heart related diseases, accurate and timely diagnosis is very much important. But, when the traditional techniques are used in classification, it is found that results are insufficient in adequate disease diagnosis and prediction. Therefore, the proposed model utilizes the back propagation neural networks for processing with the 13 basic coronary disease based attributes as input. The obtained classification results are further compared with existing traditional methods for disease prediction and classification. The functions and possibilities of medical data mining are presented in Fig. 1.

General flow for medical data mining.
The classification process becomes complex, when there is an increase in the number of factors that are considered for disease diagnosis. After diagnosing disease and decision making, proficient and effective treatment process is required. Hence, for providing higher accuracy in disease diagnosis, data mining methods are combined with medical data processing. Specifically, the proposed model is effectively used for predicting abnormalities of patient data that are obtained from heart function monitoring modules, ECG data and so on. The complete work process of the proposed model is diagrammatically represented in Fig. 2. Furthermore, the phases involved in the proposed work are given as follows,
Data Pre-Processing Feature Extraction Implementation of Integrated Model Result Classification Performance Evaluation
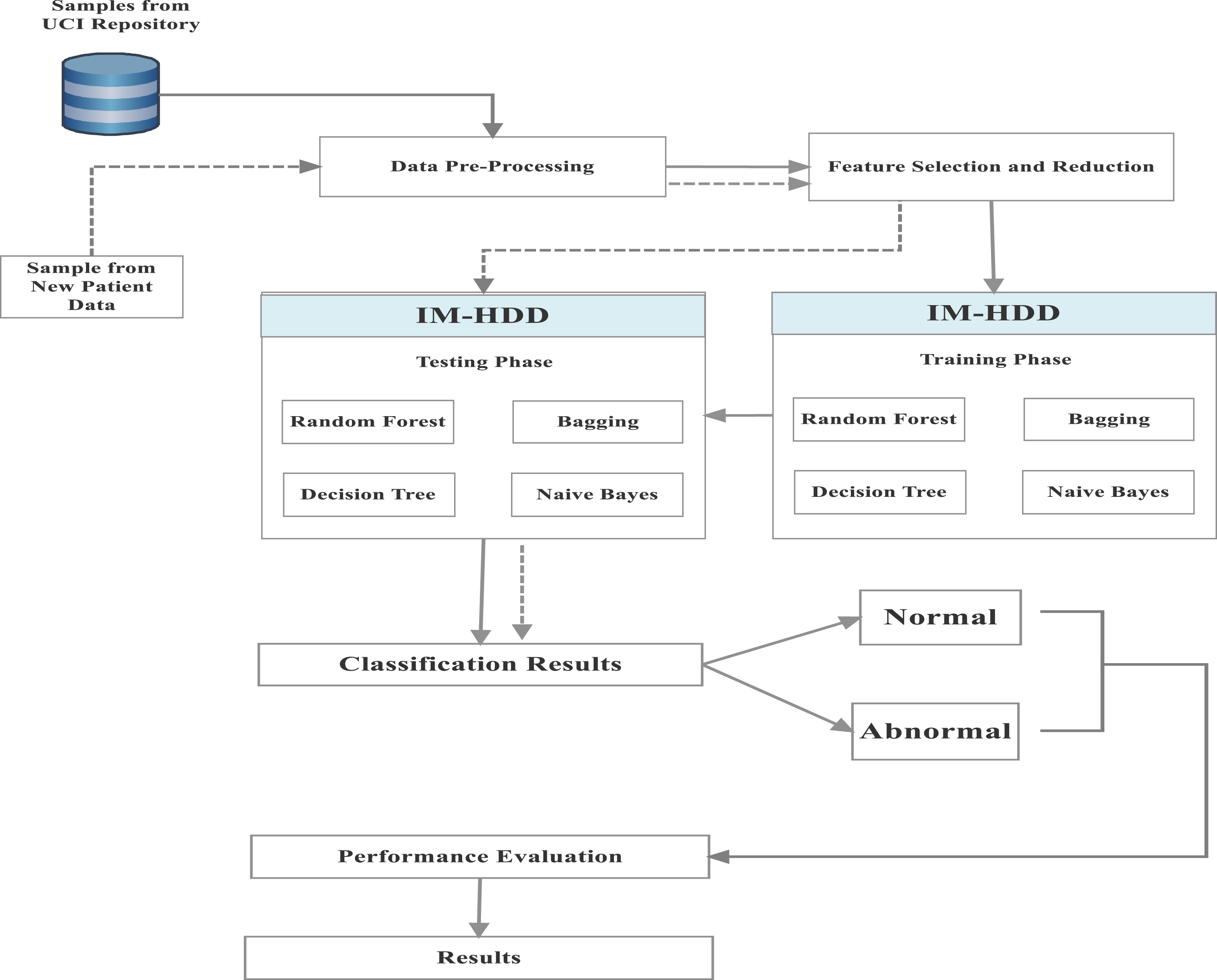
Work flow of proposed integrated model in heart disease diagnosis.
In this paper, the data from Cleveland UCI repository is utilized for training, since that provides simple visual representation of samples. And, the machine learning process initiated at pre-processing phase and further, entropy based feature selection is processed, performance analysis on classified results with enhanced precision. The process of feature extraction includes feature selection and reduction that has been performed with several iterations for several combinations of data features.
Here, the clear and defined information about the heart related attributes that are considered in the work in Table 1. Further, the performance of classification model is framed based on the significant features and the machine learning techniques that are utilized for each process.
UCI repository dataset attributes for IM-HDD
The data obtained from the dataset repository is pre-processed. The data pre-processing involves in removing the missing values of patient records. In this model, the obtained patient dataset contains 303 patient records, in that, 5 records are having some missing attributes. And, those records are removed from the training dataset, further; the remaining records are used for further processing. The attributes that are listed in Table 1 is processed with binary classification technique for analyzing the occurrence of heart disease. In the obtained data samples, when there is a presence of heart disease, the range is set as 1; otherwise, the range is set as 0, which resembles the absence of heart disease in the dataset. Moreover, in this section, the medical data that are collected with respect to the 3 aforementioned attributes are converted into diagnosis ranges for effective machine learning.
Feature extraction
This section of feature extraction comprises Feature Selection and Reduction. Here, there are 13 major attributes are considered from the dataset and among that, two feature are about the personal data of students such as age and gender representation. Those attributes are not significant for disease diagnosis; hence, the remaining 11 features are considered as significant and taken for feature extraction. Here, feature extraction is performed with Information Gain evaluation for analyzing attributes. In this, each attribute (A) of defined dataset are taken for gain calculation (IG) that corresponds to patient class (PC). And, the computation is given as follows,
For the patient class ‘n’, P (b
n
) denotes the probability value of b
n
, which is the overall features. When ‘
Based on that, the significant features are selected and given for the training process in the Integrated Model that combines efficient classification techniques for Heart Disease Detection.
The Integrated Model for Heart Disease Diagnosis (IM-HDD) combines the classification process of Decision Tree, Random Forest, Bagging Mechanism and Bayesian Model. From the previous works and discussions, the aforementioned models provided better results in classification. Here, clustering of dataset features is performed based on the attribute variables and the measures of features attained with decision tree. Further, the classification techniques are employed in each clustered results for performance determination. The process is explained below.
Decision Tree (DT) algorithm
For training the input samples ‘S’, the trees are generated according to the high entropy inputs. Here, the trees are generated based on the top down process. And, tree pruning is determined for eliminating the irrelevant data samples on ‘S’. The pseudo code is given in Table 2.
Decision Tree Algorithm in IM-HDD
Random Forest is the ensemble classifier that develops several decision trees for providing better results. For tree learning, bagging is the technique used here. For the given data sample, A = {a1, a2, a3, … a
n
} with responses B = {a1, a2, a3, … a
n
} that iterates the process of bagging from x=1 to X. The unknown samples a’ is processed by identifying the mean as,
The uncertainty of detection on DT is obtained with the standard deviation, which is provided in (6).
By incorporating bagging with this, the accuracy rate can be effectively improved of the unstable learning process. In bagging, the dataset is divided into several replicates. Each replicate is independently strained from the S with replacement and the process is performed repeatedly. The bagging based classifier trained from weak learner at each step is integrated into better classifier for attaining higher accuracy, which can be noted as,
In this section, the training model applies Bayesian classification protocols though the independent attributes. Each data instance of dataset S is assigned to the class that is having highest consequent occurrences. Gaussian function is used for training, which is given as,
Finally, the testing data or the new patient samples can be classified using the association probability, which is given as follows,
Moreover, it is to be stated that the training process of data samples using Bayesian classification model is considerably faster than other works.
The proposed model uses UCI dataset is pre-processed and the defined 13 attributes that are related to heart diseases are selected for training. And, classification is carried out with IM that combines DT, RF, Bagging and NB. Moreover, the performance evaluation is carried out with confusion matrix that produces four results namely, True Positive, True Negative, False Positive and False Negative. Based on those values, the following factors are used for deriving the accuracy rate, sensitivity and specificity.
Sensitivity Rate is calculated as the expectation of the derived results to be positive; when accurate classification results are happened. The equation is presented below,
Specificity can be termed as True Positive Rate (TPR) and the computation is presented below.
Precision Rate of the classification result is computed as in (12) and can be defined as ratio of finding positive results from the retrieved instances.
Accuracy Rate is computed as the ratio of total number of correctly identified disease samples among total number of data_samples tested and the equation is presented as,
F-Score is computed as,
For evaluating the efficiency of the proposed model, the implementation and model analysis is performed with WEKA environment. The obtained results are compared with the traditional classification methods such as Support Vector Machine (SVM), Neural Networks (NN) and Naive Baye’s Model (NB) for proving the proposed model efficiency. The dataset description is provided in the following section.
Dataset description
For evaluation, the dataset for HDD is obtained from UCI Machine Learning Repository [30]. Moreover, there are four databases, among that, Cleveland database is selected for processing that can be effectively utilized for Machine Learning based researches and comprises heart related attributes. The dataset characteristics are mentioned as Multivariate with 75 numbers of attributes for 303 data records. In that, 13 heart disease based attributes are presented and that information is presented in Table 1. The Cleveland UCI dataset comprises an attribute denoted as ‘num’ to depict the HDD in heart disease patients on different patterns as NORMAL and ABNORMAL. The data with absence of heart disease is classified under NORMAL and with some references of diseases are classified under ABNORMAL class.
Comparative analysis
Initially, the data attributes from UCI repository dataset is loaded for pre-processing. The subset data samples such as Age, gender, CP, Trestbps, SerumCho, FBS, RestECG, Thalach, Exang, Oldpeak, PeakSlope, NumVessels, Disease and Thal are given for pre-processing. The performance of the proposed work is evaluated based on the metrics defined in Section 3.4. The values obtained for True Positive, False Positive, Sensitivity, specificity, F-Measure and ROC is presented in the Table 3.
Evaluation results obtained for HDD using various classification techniques
Evaluation results obtained for HDD using various classification techniques
Based on the above results, the performance analysis of the proposed model is carried out and compared with existing techniques. In the graph presented in Fig. 3, the classification accuracy between the models is portrayed. It is explicitly shown in the Figure that the proposed IM-BDD produces higher rate of accuracy, 95.8%in average in processing 70 patient data samples. The effective amalgamation of base and ensemble classifier techniques provides better results than other works. Moreover, feature extraction process supports in a great manner for accurate result classification. Analyzing precision is very much significant in performance evaluation. And, the results are displayed in the Fig. 4. Based on the results, the proposed model enhances the precision rate for about 26%than compared works. The precision rate is reducing when the number of processing patient data samples are increasing.
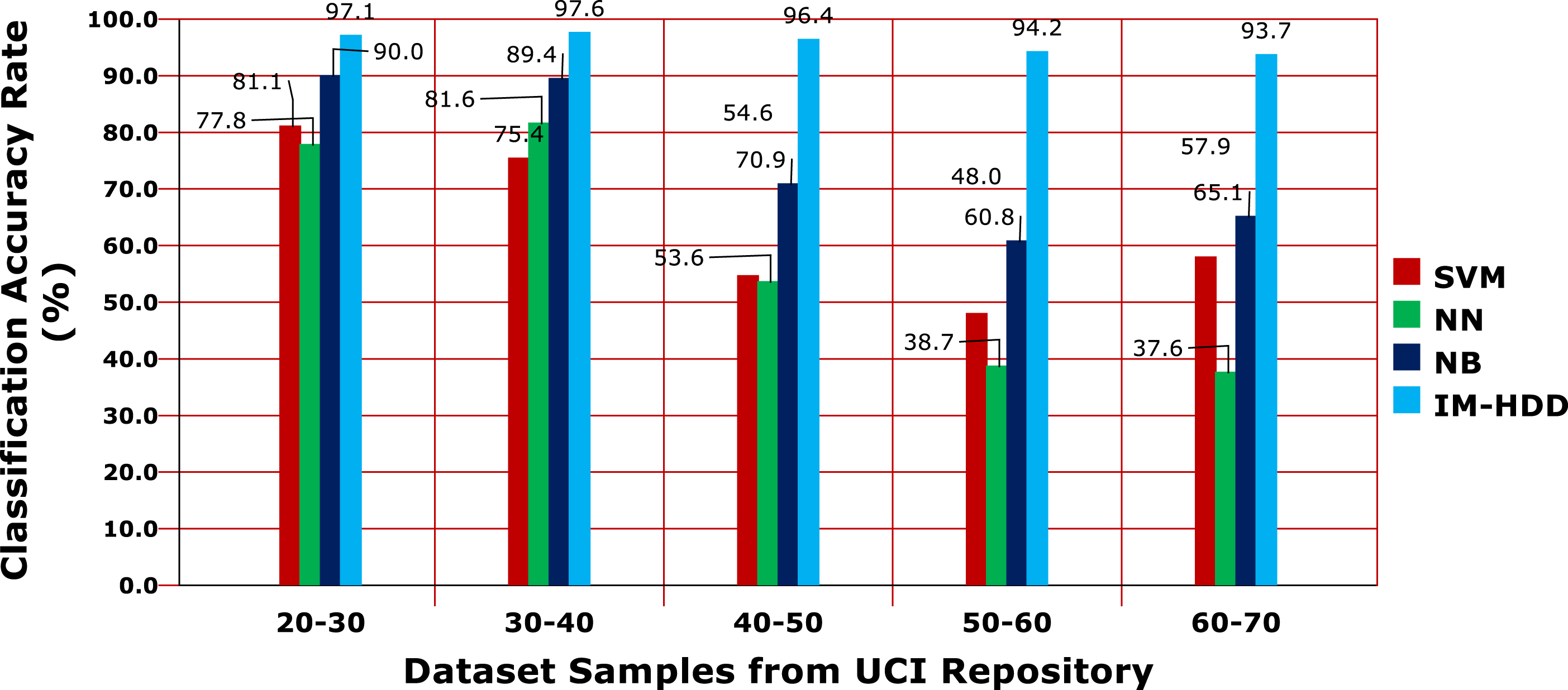
Accuracy rate comparisons.

Evaluation based on precision rate.
The above mentioned Fig. 5 represents the Error Rate Analysis. Since, the proposed model produces higher True Positive Values and accurate results of classifying patient data; the error rate is minimal in the work. In average, the proposed integrated model produces 0.78%error rate, which is the lowest among compared works. Further, the results obtained for processing time for classification is presented in Fig. 6. The processing time for each model is evaluated with respect to the patient data from 10 to 70 samples and average time value is considered for comparison between models. And, it is obvious from the figure that the proposed work acquires lesser time for classification that other existing classification techniques. The computational complexity analysis and results are given in Fig. 7, evidences that the proposed model is effective than other compared works.

Error rate analysis.

Processing time for data classification.

Computational complexity vs samples.
Accurately detecting the heart diseases by processing the raw health care information is very much helpful in treating the diseases earlier and in effective manner and saves people life. For that, efficient data mining and machine learning techniques are incorporated and developed a new model called Integrated Model for Heart Disease Diagnosis (IM-HDD). The model integrates the classifiers namely, Random Forest, Decision Tree, Bagging and Bayesian Classification techniques for patient data classification. The model evaluation is carried out by processing with UCI repository dataset and the results show that the proposed model achieves better rate of classification accuracy with reduced error and processing time. Further, novel and effective feature selection techniques can be developed for defining significant data features for enhancing precision. The study can be further extended in desirable manner to point the research with real world data samples, instead performing simulations.