
Abstract
Traffic congestion is a challenging issue faced by people and government traffic agencies. Traffic congestion not only increases travel time but also increases noise pollution, air pollution, and financial losses. There are many factors which affect the speed of a vehicle. Some of the factors are weather, wind speed, road conditions, and construction work. On highways, the low speed of vehicles can cause traffic congestion or delays. Machine learning can play a vital role in the detection of traffic congestion and hence in avoiding delays. When accurate parameters and correct structure are fed to the machine learning model, traffic congestion can be predicted accurately. This paper designs a technique to predict traffic congestion states with the help of the Extra Tree Classifier machine learning model. The proposed Extremely Randomized Machine Learning (ERML) system model predicts 94% accuracy for congestion state classification. It gives better results as compared to other machine learning models.
Keywords
Introduction
One of the major problems in large cities is traffic congestion. It not only impacts the daily lives of people but also impacts the social development and economy of the country. Government bodies constantly monitor and try to resolve traffic congestion in the cities. Owing to its non-predictable nature traffic congestion prediction is very difficult.
Traffic congestion is a pervasive and growing problem that affects societies worldwide, with profound impacts on various aspects of daily life. It refers to the situation in which the demand for road space exceeds its capacity, resulting in slower speeds, longer travel times, and often complete standstills. The consequences of traffic congestion extend far beyond mere inconvenience, touching on critical facets of society, including travel time, noise pollution, air pollution, and financial losses. Accurate prediction of traffic congestion is pivotal for mitigating these issues and improving traffic management.
There are many factors responsible for traffic congestion. There may be dynamic or non-dynamic factors like traffic speed, accidents on roads, construction of new roads, weather conditions, sudden malfunctioning of traffic beyond mere inconvenience, touching on critical facets of society, including travel time, noise pollution, air pollution, and financial losses. Accurate prediction of traffic congestion is pivotal for mitigating these issues and improving traffic management.
There are many factors responsible for traffic congestion. There may be dynamic or non-dynamic factors like traffic speed, accidents on roads, construction of new roads, weather conditions, sudden malfunctioning of traffic lights, etc. A non-dynamic factor like weather conditions directly affects traffic conditions. Due to heavy rain, the visibility of the road for drivers becomes very challenging and results in a decrease in the speed of vehicles. Owing to these factors analyzing traffic congestion is challenging. Many researchers have tried to address this issue. Solutions for congestion prediction-based problems can be categorized as hardware-based equipment and vehicular ad-hoc network technology. Advancements in Vehicular Ad-hoc Networks (VANETs) can increase the capability of finding traffic congestion. Integration of VANET with the Internet of Things i.e. IoT forms a network called the Internet of Vehicles (IoV) [5]. With the help of IoV, it becomes very easy to predict environmental factors like temperature, weather conditions, etc. Intelligent devices can also predict road conditions, accidental areas, and jam conditions. It can help us to get data and send the information directly onto the cloud server resulting in prior information on avoidance of congested roads and following an alternate fast route. Figure 1 shows the model of IoV for vehicular communication.
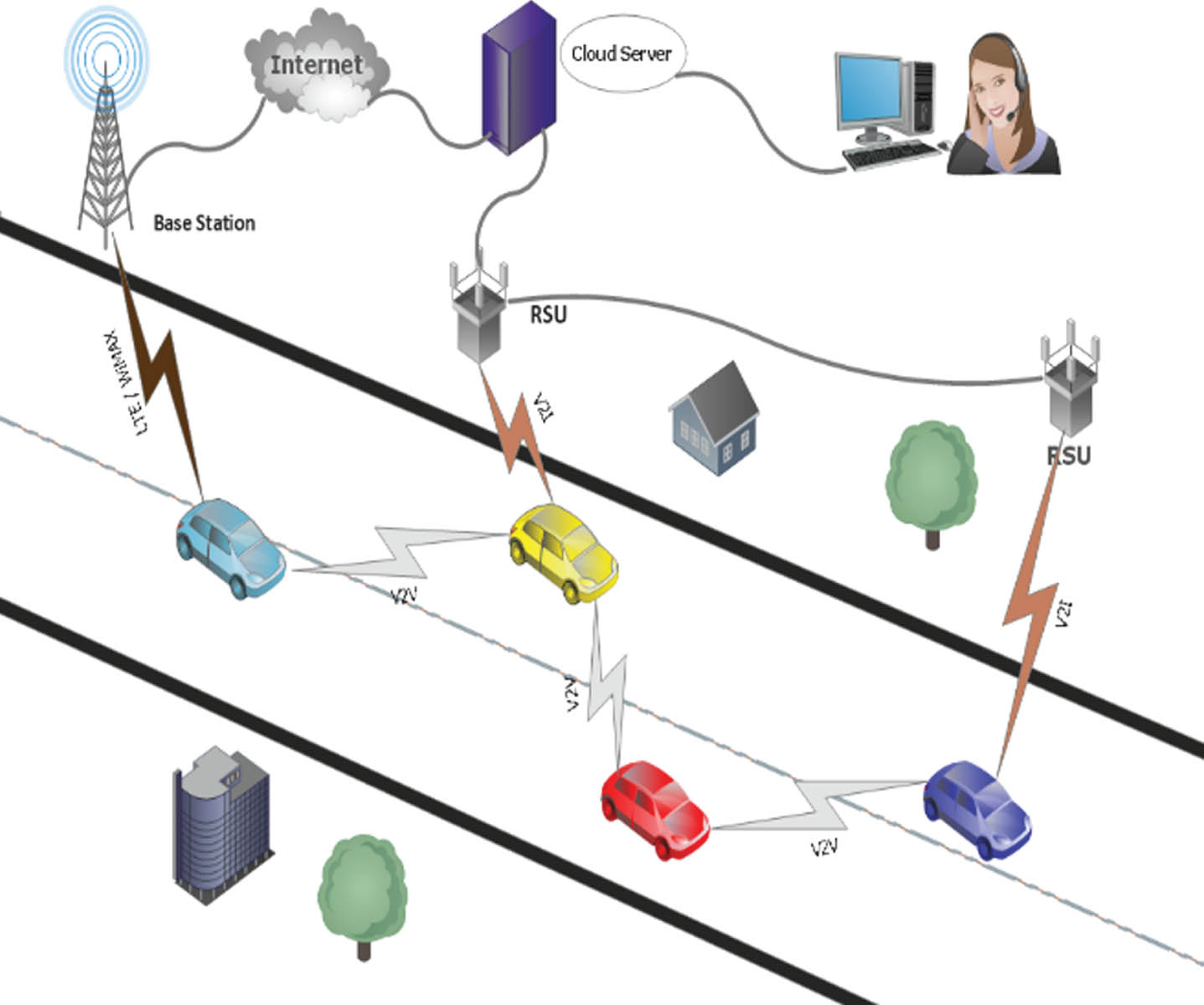
IoV model for vehicular communication.
Machine learning can play a vital role in the detection of traffic congestion and hence in avoiding delays. When accurate parameters and correct structure are fed to the machine learning model, traffic congestion can be predicted accurately. This paper designs a technique to predict traffic congestion states with the help of the Extra Tree Classifier machine learning model.
In this paper, a comparative analysis of various traffic congestion detection techniques has been discussed in Table 1, and then an ERML system model has been proposed for intelligent traffic congestion prediction. The arrangement of this paper is as follows: Section 1 describes the introduction. Section 2 describes the related work. The different machine learning model is presented in Sub-section 2.1. The proposed ERML system model is described in Section 3. Section 4 presents the results and discussion. Section 5 presents the practical challenges in implementing a proposed system for traffic congestion prediction in the Internet of Vehicles (IoV) and Section 6 presents conclusion & future work of thispaper.
Comparative analysis of various traffic congestion detection techniques
The success of an efficient transportation system requires several challenges and limitations which must be addressed. Currently, most of the smart vehicles are equipped with internet connectivity and vehicles can communicate with each other through smartphones. Thus, analysis of data generated from the vehicle’s sensors can be easily done. Analyzing data on cloud servers can help in the identification of patterns and detection of traffic congestion.
Dureja and Suman [6] in his paper discussed various challenges and future aspects related to IoV and presented state-of-the-art advancements and future trends in efficient transportation using IoV.
Qi Liu et al. [19] in their paper “A random projection-based ensemble model for short-term traffic flow prediction” proposed a random projection-based ensemble model for short-term traffic flow prediction. The proposed model uses a combination of random projection and gradient boosting to build an ensemble of decision trees and was shown to achieve state-of-the-art performance on several traffic prediction datasets.
Hao Wu et al. (2021) in their paper “Random Feature Embedding for Traffic Flow Prediction” proposed a random feature embedding method for traffic flow prediction that uses random Fourier features to map the input data to a high-dimensional feature space. The proposed method was shown to outperform several state-of-the-art methods on several traffic prediction datasets.
In year 2021 Yidan Zeng et al. proposed a multi-scale spatio-temporal model for traffic forecasting that integrates convolutional and recurrent neural networks with a meta-learning framework. The model was evaluated on large-scale traffic datasets and shown to outperform state-of-the-art methods.
In 2019, a deep learning approach was used to predict traffic flows from camera images captured in the wild. The approach uses a Fully Convolutional Network (FCN) with residual connections to predict traffic flow at each pixel in the image and was shown to achieve state-of-the-art performance on several benchmark datasets. [Baojie Yang et al. (2019)]
Another technique graph convolutional neural network (GNN) was used for traffic prediction that takes into account the complex relationships between different locations in the traffic network. The model was evaluated on real-world traffic datasets and shown to outperform several state-of-the-art baselines. [Bing Yu et al. (2020)]
In [8], researchers proposed a trajectory-based machine learning technique for traffic congestion monitoring. For the prediction of traffic congestion, a machine learning approach was used with multiple parameters like hard delay and vehicle speed. For the prediction of the vehicle’s speed, the Gaussian approach was used. In [1], the Artificial Back Propagation Neural Networks approach was used for traffic congestion monitoring and smart road traffic congestion control model. The parameters like time, traffic speed, traffic flow, wind speed, air temperature, and humidity were considered for input to the neural network, and the output parameter delay time was considered for the prediction of traffic congestion. The hidden Markov Model (HMM) technique was used to find accurate and efficient traffic prediction [7]. Input parameters such as time ingestion, No. of vehicles and traffic rate was considered for training the model and feature selection was done by using the Hybrid Ant Colony Glowworm swarm technique in [21]. Visual features can also be used for traffic flow estimation. In [11], researchers divided the main process of traffic flow prediction into three stages. The first stage is vehicle detection using high-quality cameras. The second stage is visual feature extraction which is used as input parameters for the vehicle classifiers. The final stage is traffic state classification in terms of light, medium, and heavy vehicles on the road. Machine learning and Deep learning models were used for the prediction of traffic state classification. Sabah Tamimi in [18] used a fuzzy logic approach for the estimation of traffic delay. In this, researchers have considered road conditions, visibility, traffic volume, and weather conditions as input parameters and estimated delay as output parameters for the proposed fuzzy inference system. Nguyen, [13]. proposed a traffic congestion monitoring scheme based on fuzzy rules. Fuzzy rules were used to determine the Traffic Congestion Coefficient (TCC) for each road segment. This TCC is based on the velocity performance index and density performance index.
The proposed method takes less time compared to other methods. The proposed ERML method uses the Extra Tree classification technique which is much faster than other ensemble techniques. The proposed method is less overfitting than other methods because it selects random splits, which reduces the model’s variance. ERML-based methods are robust to noisy features because they use random splits at each decision node, which reduces the impact of noisy features on the model’s performance. The proposed technique monitors traffic congestion efficiently and helps to avoid congested road segments resulting in reduction delay with high prediction accuracy.
Machine learning models
Machine learning also plays an important role in the detection of traffic congestion and hence in avoiding delays. When accurate parameters and correct structure are fed to the machine learning model, the traffic congestion state can be predicted accurately.
Some of the models are discussed here which gives the most promising results.
Decision tree machine learning model
It is a supervised machine learning algorithm that is used to classify problems in an efficient manner [14]. It works very well for dependent variables. In this algorithm, trees can be described by two units namely nodes and leaves. The leaves are responsible for the outcomes. The nodes are sometimes called decision nodes where data is split. Decision trees can be categorized into Classification trees and Regression trees. Classification trees are used to classify the data as fit or unfit, but regression tree classifies data as continuous variables.
The mathematical formulation of a Decision Tree machine learning model involves a probabilistic model that seeks to maximize the information gain for each split. The basic mathematical formulation of a Decision Tree machine learning model is given below.
Let D be the dataset,
Let X be the set of predictor variables and Y be the target variable.
The entropy value can be calculated as:
The entropy H(S) of a set S is defined as:
The information gain IG (S, X) of a set S concerning a predictor variable X is defined
as:
The algorithm starts with a single node that represents the entire
dataset D.
For each node, the algorithm finds the predictor variable X that
maximizes the information gain IG(D, X).
The dataset D is split into subsets Sj for each value j of
X.
For each subset Sj, the algorithm repeats the above steps until a
stopping criterion is met, such as a maximum depth or a minimum number of
examples in a node.
The final decision tree is a tree structure where each internal node
represents a predictor variable, and each leaf node represents a class
label.
To predict the class label of a new example x, the algorithm traverses
the decision tree from the root to a leaf node, following the path that
corresponds to the values of the predictor variables in x.
In conclusion, the Decision Tree machine learning model is formulated as a probabilistic model that seeks to maximize the information gain for each split. The algorithm recursively splits the dataset into subsets based on the predictor variables that maximize the information gain, resulting in a tree structure that can be used to predict the class label of newexamples.
Gradient Boost classifier is an ensemble method that combines the predictive power of base estimators to improve the generalization [Aziz, et al. (2020)]. There are two ensemble methods which are the averaging method and the boosting method. Gradient boost classifier is a boosting method that is used when there is a massive load of data to be classified. This method gives prediction with higheraccuracy.
It combines weak predictors to build a strong predictor. This machine learning method can be used for both classification and regression-type problems, and it can handle mixed types of data.
Random forest classifier learning model
Random decision forest is an ensemble method for the classification and regression of objects [3]. The classification of an object is based on its attributes. In this method, each tree is classified, and the collective decision is taken for the classification. The forest chooses the classification having the most votes. The algorithm used for classification using random forest is given below:
**Initialize an empty list forest to store the decision trees in the forest. For each tree in the forest (repeat n_estimators times): Randomly select max_features distinct attributes from the total C
attributes. This forms a feature subset. Compute the best attribute a and the best-split point for node splitting
based on the selected feature subset. The criterion for finding the best
split can be “gini impurity” or “entropy” for classification tasks. Split the node a into two children nodes using the best-split point. These
children nodes inherit the subset of data points from the parent node. Repeat steps 1 to 3 recursively for each child node until a stopping
criterion is met (e.g., max_depth, min_samples_split, or
min_samples_leaf). Add the constructed decision tree to the forest list. Repeat steps 2 to 3 until n_estimators decision trees are constructed. Output the forest containing the ensemble of decision trees.
x: The training dataset, consisting of N samples and C attributes/features. y: The corresponding labels for each sample in X. n_estimators: The number of decision trees to create in the forest. max_features: The number of features to consider when looking for the best split.
It can be specified as a fixed number or a fraction of total features. max_depth: The maximum depth of each decision tree, which controls tree
complexity and helps prevent overfitting. min_samples_split: The minimum number of samples required to split a node. min_samples_leaf: The minimum number of samples required in a leaf node. random_state: A seed for the random number generator to ensure
reproducibility.
forest: A collection of decision trees that constitute the Random Forest ensemble.
Extra Trees classifier learning model
Extra Trees Classifier is an ensemble technique to combine the results of multiple
estimators. These estimators are sometimes called de-correlated decision trees [10]. These decision trees are integrated to
enhance the robustness of a single classifier. This learning model is similar to the
Random Forest learning model but differs in terms of the construction of decision trees
in the forest. An original training sample is used for the construction of each decision
tree in the forest. Each tree from the forest at each test node finds the best feature
from the random feature set for splitting the data. For the splitting of data, a special
index is computed called the Gini index. Generally, information gain is used as decision
criteria and the formulas for calculating the Information Gain are given in Equation 4.
and Entropy (A) of data is calculated as
Table 1 tabularizes various existing techniques for traffic congestion detection.
IoT devices make it easier to sense environmental data and vehicular data. These devices monitor the environment periodically and send the data to the server; on the server, this collected data can be used for analyzing traffic congestion state efficiently. Figure 2 shows a system model for intelligent traffic congestion state prediction using machine learning techniques. In this model, the sensor layer generates the input parameters like time, speed, starting location, destination, location, and distance traveled by vehicles. These parameters are fed to the machine learning model for the prediction of congestion state levels. Level 0 represents no congestion, level 1 represents a moderately congested route, level 2 represents a congested route, level 3 represents extremely congested, and level 4 represents blockage in the route due to traffic jams, accidents, or any other conditions.
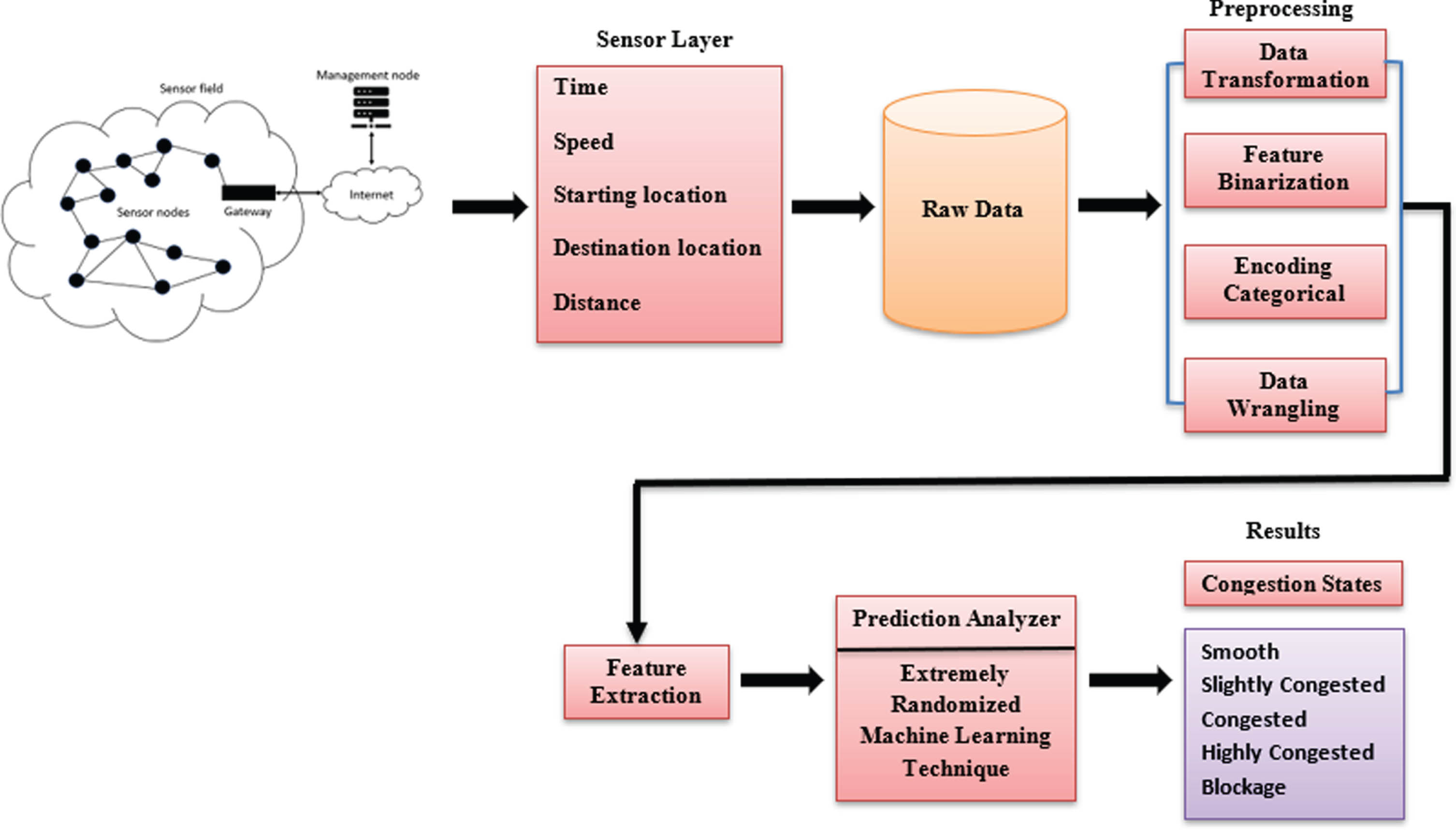
Proposed ERML system model for intelligent traffic congestion prediction.
The sensor layer is responsible for the collection of data regarding environmental conditions, such as weather, temperature, speed of the vehicle, starting location, destination, and total distance covered by the vehicle, etc. Sensors in the sensor layer act like an interface between the real world and the digital world. These are responsible for converting analog to digital signals. There are different types of sensory devices like meters, probes, sensors, and actuators that can get data like temperature, distance, location, humidity, etc. Sensors in the sensor layer cooperatively pass these data through the network to the server.
This layer is also called the perception layer, that layer belongs to two major tasks perception and Montage. A different type of inbuilt vehicle sensor gathers information from a central location and transfers it to cloud servers which focus on big data storage and processing. Handling large-scale Internet of Vehicles (IoV) data while maintaining prediction accuracy as the system scales up requires careful consideration of both data processing techniques and system architecture. Using distributed computing frameworks like Apache Spark or Hadoop facilitates the parallelization of data processing tasks. This allows for the efficient processing of large volumes of IoV data by distributing the workload across multiplenodes.
Preprocessing phase
Before extracting the features from the input data set, preprocessing of data is required. The preprocessing phase is divided into several sub-phases. The first sub-phase is data transformation in which data is converted into a particular format. In our model, the location data has come into numerical values.
In the second sub-phase, feature binarization has been used for getting Boolean values. In our case, we have represented congestion states into numerical values. Level 0 represents No Congestion; Level 1 represents Moderately Congested and so on. In the third sub-phase encoding categorial, special features like “Yes” or “No” for holiday parameters, are coded into binary values 1 or 0. The last sub-phase of preprocessing is Data Wrangling. It is the process of cleaning and unifying dirty and complex data sets in order to make them more accessible and analyzable.
With the amount of data and data sources continually rising and developing, it’s becoming increasingly difficult to keep up. So, this method usually requires manually transforming and representing data from one raw plan to another to simplify data consumption and organization. Another serious concern is that the precision and dependability of predicting traffic congestion are significantly influenced by the quality of the input data. The model’s performance may be adversely affected if the data gathered from IoT sensors or other sources is characterized by noise, incompleteness, or outdated information. To address this concern, we have implemented a rigorous data preprocessing and cleaning pipeline. This process involves identifying and handling outliers, inputting missing values, and ensuring that the dataset is up to date through regular updates. Additionally, we have employed advanced filtering techniques to reduce the impact of sensor inaccuracies and outliers in the collected data.
Furthermore, our methodology incorporates a validation framework that allows us to assess the quality of the input data and its influence on the model’s performance. By conducting sensitivity analyses and cross-validations, we can gain insights into the robustness of our predictions and identify any potential weaknesses arising from data quality issues.
Feature extraction phase
The feature extraction phase is the most important phase of the proposed system model.
One important feature is the congestion level which can be measured in terms of delay. The
congestion level can be defined in terms of an index whose value can be more than or
equivalent to zero. This index is called the Congestion index and can be calculated as:
tl = least time for the road section.
Table 2 shows the various congestion index ranges with traffic state levels.
Traffic state levels
These congestion labels can be calculated on the basis of road segments. For each road segment, we can calculate the congestion index using Equation 6.
After extracting features, different randomized machine-learning techniques can be applied as prediction analyzers for the prediction of the congestion states. We have applied various techniques like decision tree classifier, random forest, KNN, gradient boost, Adaboost, logistic regression, and extra trees classifier.
Security concern
The gathering and real-time transmission of data from vehicles gives rise to apprehensions regarding the privacy and security of the information. It is imperative to safeguard sensitive data, such as the locations of vehicles, to prevent unauthorized access. To ensure the protection of individual vehicle identities in real-time data collection, various encryption and anonymization techniques can be applied. We have implemented robust encryption measures and access controls to safeguard the confidentiality and integrity of the collected data. Certificate-based Encryption is used to protect sensitive information. We have considered public-key infrastructure (PKI) and digital certificates to encrypt communication between vehicles and infrastructure. This ensures secure and authenticated data transmission without revealing sensitive details.
Results & discussion
Different types of machine learning algorithms have been applied to the dataset [26] for predictions. In an ERML-based model, the input variables for these machine learning algorithms [16] are parameters like weather conditions, holidays, source location, destination, and special conditions. The parameters of learning models have been adjusted to get the best results. Extra Classifier machine learning algorithm has been found to give better results than other algorithms.
A dataset consisting of nine input variables namely weekday, current time, weather conditions, peak hours’ time, rare conditions like a traffic jam, road accident, source, destination, fastest route name, and fastest traveling time have been used for simulation. This dataset also contains one output variable in terms of congestion state. The congestion state can be non-congested, moderately congested, and extremely congested. This dataset is taken from an Internet source [26]. The input variables and an output variable are shown in Table 3.
Input and Output variables
Input and Output variables
The dataset size is 945673 records and consists of nine columns. System time is the current machine time. Traffic data has been obtained from Google Map API. Table 4 shows the prediction accuracy of different machine-learning methods.
Accuracy score of different learning models
K-Fold cross-validation is used as an evaluation metric. Cross-validation is a procedure used for the evaluation of different machine learning methods. This metric divides the data samples into no. of groups called fold. This fold value is chosen in such a way that we can get higher accuracy. In the proposed model, 10 folds have been used for the evaluation of different machine learning models. Figure 3 shows that the Extra Trees Classifier gives the highest accuracy validation score as compared to other machine learning models and other traditional supervised algorithms.
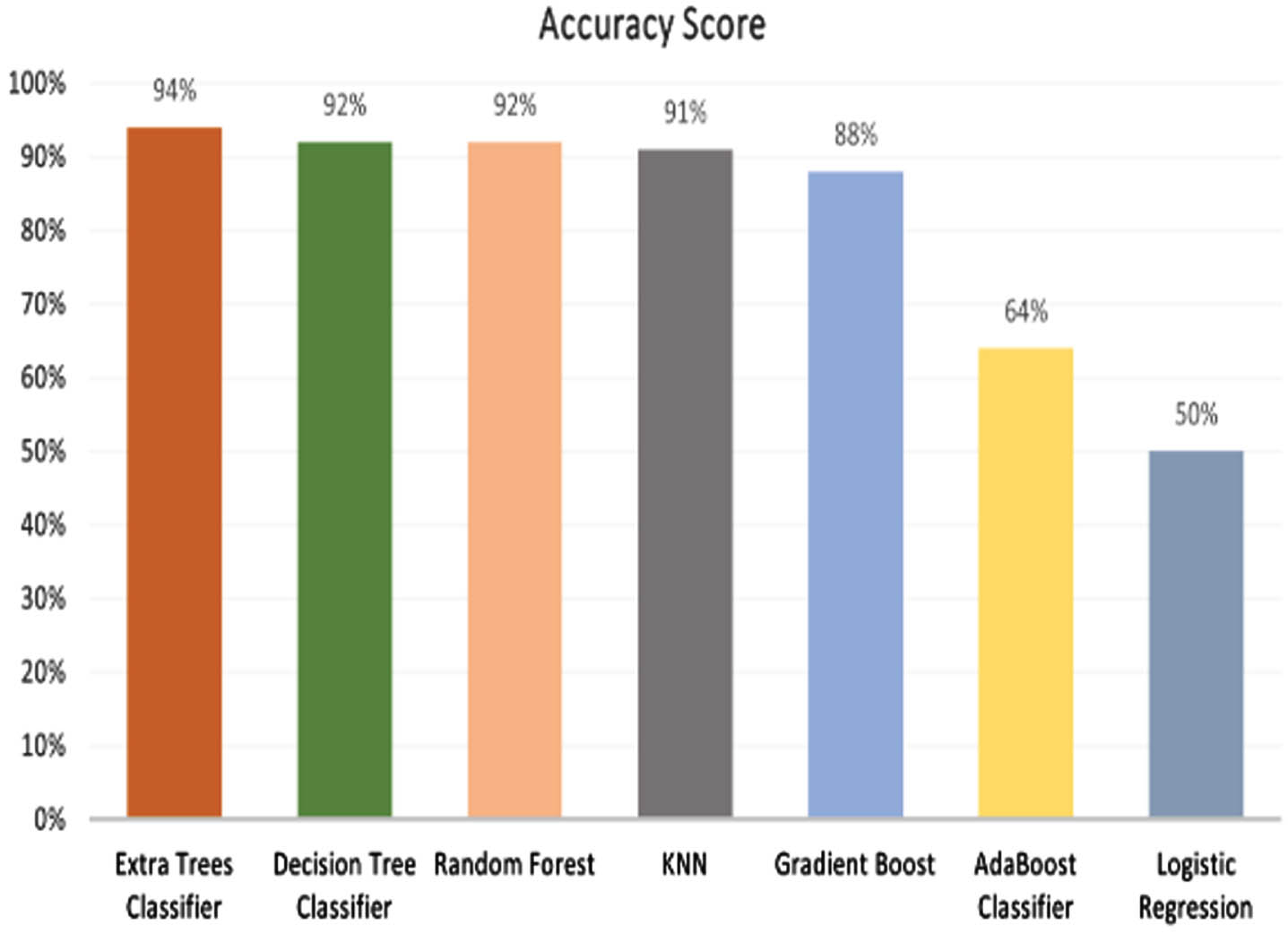
Accuracy score of machine learning algorithms.
There is a slight variation in the accuracy of algorithms due to weather conditions. The more the accuracy of weather data, the more the accuracy of results will increase. Figure 4 shows the impact of weather conditions on the correctness of algorithms.
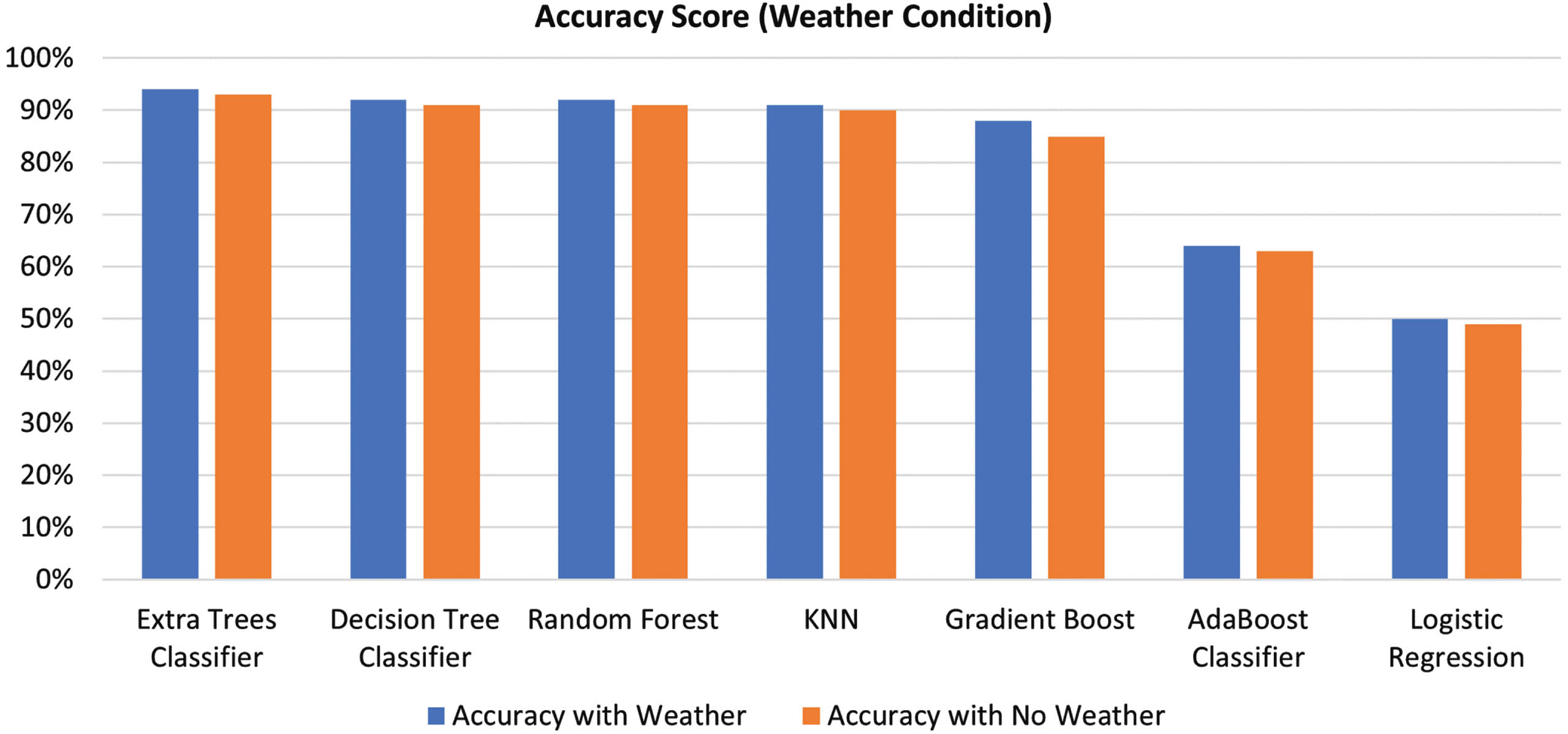
Accuracy score of machine learning algorithms with weather conditions.
Figure 4 shows there is an increase in the accuracy of the Extra Classifier from 94 percent to 94.4 percent and a major change in the case of the Gradient Boost model.
Figure 5 shows the PR curves for all classes represented for congestion prediction. Level 0 represents Uninterrupted, level 1 represents Moderately Congested, level 2 represents Congested, level 3 represents Extremely Congested, and level 4 represents the road is blocked due to special conditions like accidents, etc.
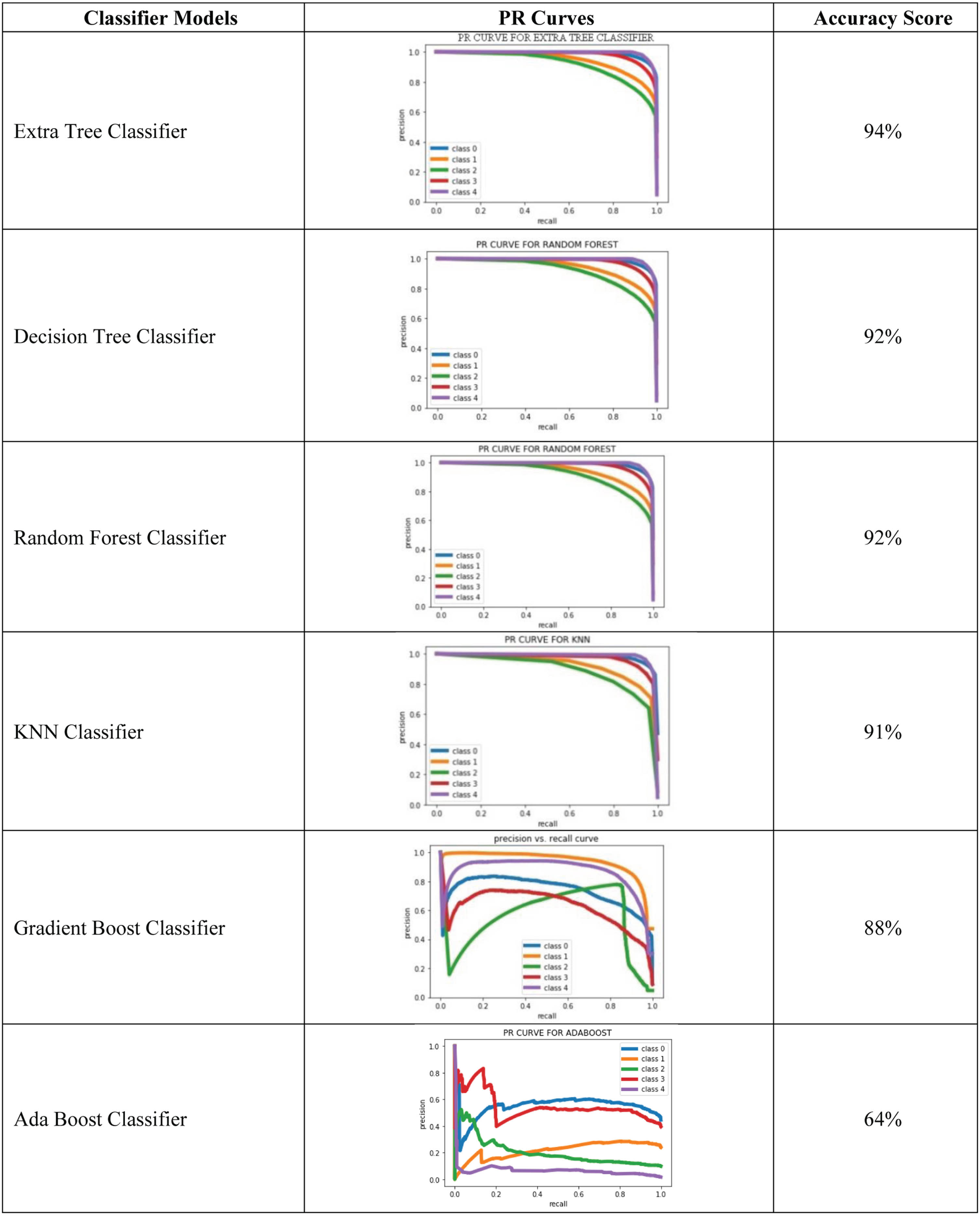
PR Curves for all classifiers with accuracy score.
Extra Tree Classifier gives the best result in terms of accuracy score than other
classifiers. Equations (7)–(10) demonstrate
the parameters to measure the performance of the proposed model.
In the PR curve of the Extra Tree Classifier, the smoothness and blockage are almost touching value 1. This represents a higher accuracy score.
Table 5 shows the recall value, precision value, and F-1 score of the Extra tree classifier model.
Recall, Precision, and F-1 score of Extra Classifier
The confusion matrix is a powerful method for analyzing classification problems [12]. It describes how the data belonging to a single class can be assigned to multiple possible classes. Normalized confusion matrix for representing the traffic congestion classes. The normalized confusion matrix that has been used for simulation is shown in Fig. 6. In this figure, diagonal elements represent true positive elements. For uninterrupted traffic, level 0 has 0.94 true positive elements, level 1 depicts moderate congestion with 0.83 true positive elements, level 2 represents traffic congestion with 0.74 true positive elements, level 3 depicts extremely congested with 0.93 true positive elements, and class 4 stands for the blocked road.
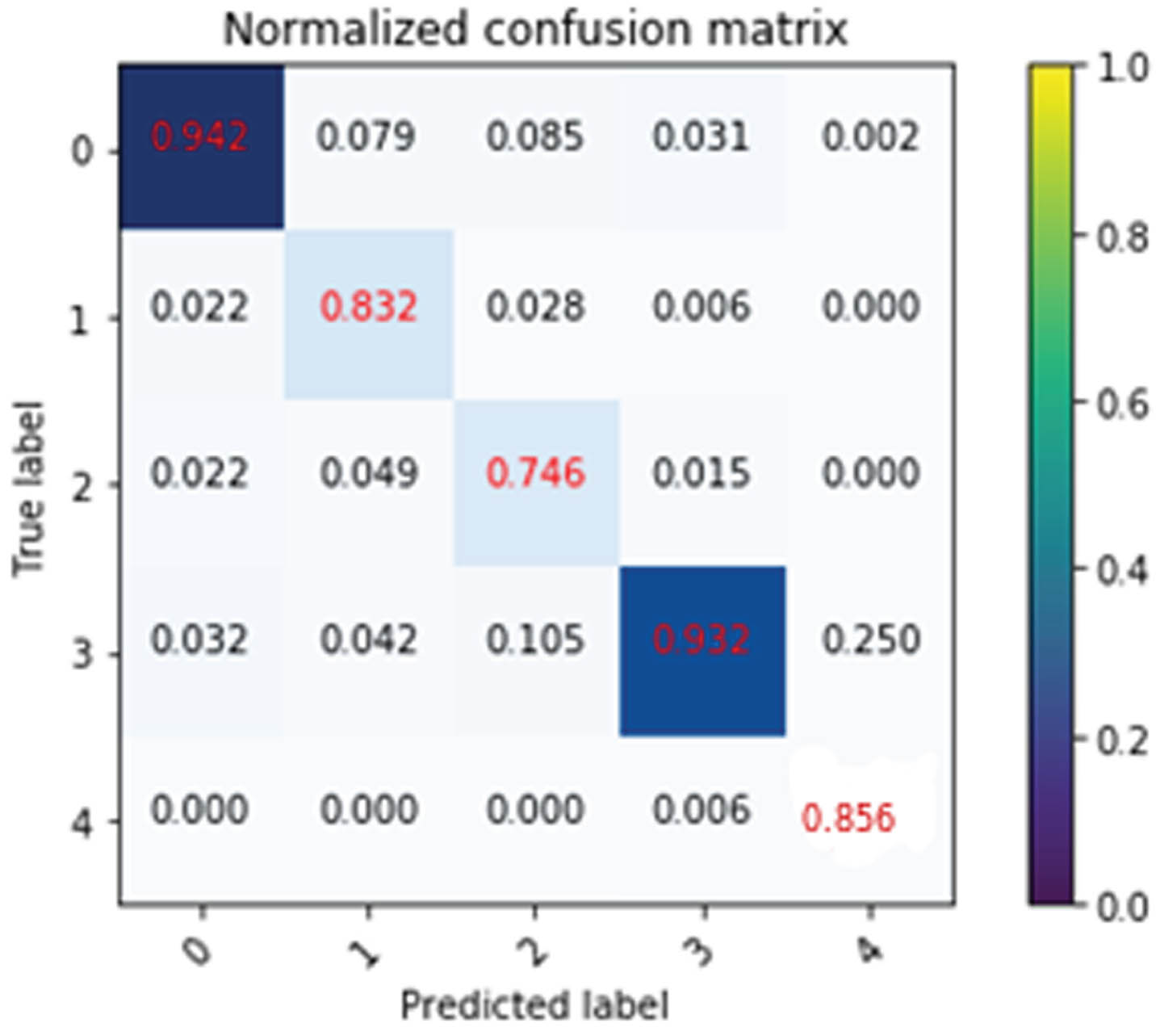
PR Normalized confusion matrix for traffic congestion classes.
Table 6 shows the comparison of the proposed ERML system with other methods in terms of accuracy. In order to assess the practical viability of our proposed model for real-world traffic management applications, we conducted a thorough analysis of its latency characteristics. We measured the time taken for the model to process incoming traffic data and generate predictions under various traffic conditions and deployment scenarios. We found that our model demonstrates promising performance in terms of latency, which is 0.45 seconds with inference times consistently within the acceptable range for real-time decision-making in traffic management. Furthermore, we optimized the model architecture and utilized efficient algorithms to minimize latency without compromising predictionaccuracy.
Comparison between the proposed ERML system and other algorithms
It has been concluded that the proposed ERML system provides better results than the previously proposed methods in terms of accuracy value.
While the proposed system shows promise in enhancing traffic management and reducing congestion, it is essential to acknowledge and address the practical challenges associated with its real-world implementation. This section discusses key challenges, including regulatory compliance, scalability, integration with existing infrastructure, cost and operational considerations.
Regulatory Compliance:
Scalability:
Integration with Existing Infrastructure:
Operational Considerations:
Data Security and Privacy:
Dynamic Traffic Conditions:
Cost:
The expenses associated with establishing the communication infrastructure necessary to enable smooth data transfer among vehicles, roadside units, and central servers. Additional costs involve the ongoing maintenance and upkeep of hardware and infrastructure components, entailing considerations like software updates, hardware replacements, and system optimization to ensure enduring long-term reliability.
Conclusion & future work
IoV includes many vehicle nodes and infrastructure. By communicating among these components, vehicle nodes can obtain information about traffic, helping to reduce traffic congestion. Thus, it is essential to maintain connectivity among these components.
This paper presents an ERML-based methodology to predict the traffic congestion state with higher accuracy. This paper also introduces an IoV & machine learning-based model for intelligent traffic congestion prediction.
Intelligent transportation systems have more impact in the area of traffic management. It provides flexibility to minimize traffic congestion whereas traditional systems do not.
Extremely randomized machine learning techniques have been used for training the dataset. As compared to the past proposed techniques, the current proposed system gives better results i.e., 94% accuracy which is much better than previous techniques.
We think that this work also opens the door to the following research: The work can be extended by applying other machine learning techniques which can
better find out the congestion states. With the fast development of Intelligent Traffic Management Systems, infrastructures
based on sensor devices generate sensing data at the Trillion-byte level to higher.
Such an unprecedented volume of data has posed considerable difficulties for real-time
and fine-grained traffic prediction. Modeling and analysis methods for such situations
are highly desired. Real-time data gathering and analysis can also be the future work.