
Abstract
Although re-entrant hybrid flow shop scheduling is widely used in industry, its processing and delivery times are typically determined using precise values that frequently ignore the influence of machine failure, human factors, the surrounding environment, and other uncertain factors, resulting in a significant gap between theoretical research and practical application. For fuzzy re-entrant hybrid flow shop scheduling problem (FRHFSP), an integrated scheduling model is established to minimize the maximum completion time and maximize the average agreement index. According to the characteristics of the problem, a hybrid NSGA-II (HNSGA-II) algorithm is designed. Firstly, a two-layer encoding strategy based on operation and machine is designed; Then, a hybrid population initialization method is designed to improve the quality of the initial population; At the same time, crossover and mutation operators and five neighborhood search operators are designed to enhance the global and local search ability of the algorithm; Finally, a large number of simulation experiments verify the effectiveness and superiority of the algorithm.
Keywords
Introduction
The re-entrant hybrid flow shop scheduling problem (RHFSP) combines the characteristics of re-entrant scheduling and hybrid flow shop scheduling. It has been widely applied in industrial fields, such as thin-film transistor liquid crystal display and semiconductor wafer manufacturing. However, in prior studies, the processing time and delivery time were regarded to be accurate values. In reality, it is difficult to get a precise time because of the effect of different elements such as equipment, personnel, and the environment. As a result, it is more practical to regard processing and delivery times as fuzzy values. This kind of issue is referred to as the fuzzy re-entrant hybrid flow shop scheduling problem (FRHFSP). Due to its large scale and high complexity, RHFSP are difficult to solve effectively in an acceptable time using traditional mathematical modeling methods. In addition, according to the “No Free Lunch” theorem [1], no algorithm can achieve better results for all application problems, so it is important to design and develop new intelligent optimization algorithms to solve it.
With the ongoing growth and refinement of fuzzy theory, many researchers have been interested in the use of fuzzy numbers to define and solve uncertain job shop scheduling optimization problems. Lei [2] developed a genetic algorithm based on co-evolution to handle the fuzzy flexible flow shop scheduling problem (FFJSP). To solve the FFJSP, Gao et al. [3] suggested a discrete harmony search algorithm. Wang et al. [4] suggested an enhanced distributed estimating algorithm in which they incorporated a left shift approach to the decoding to fully use the machine’s idle waiting time. Huang et al. [5] initialized the operations sequence using six heuristic rules and developed an improved discrete particle swarm optimization algorithm to solve FFJSP. Wang et al. [6] introduced a hybrid artificial bee colony algorithm for FFJSP, which uses a range of ways to establish the population and increases the algorithm’s local search capabilities via variable neighborhood search. Gao et al. [7] developed an enhanced artificial bee colony algorithm for solving FFJSP, aiming at minimizing the maximum fuzzy completion time and total machine load. Arik et al. [8] investigated a kind of multi-objective parallel machines scheduling problem with fuzzy learning effect, fuzzy deterioration effect and fuzzy processing time. Cai et al. [9] studied the fuzzy distributed two-stage hybrid flow shop scheduling problem considering sequence-dependent setup times, and took the total agreement index and fuzzy makespan as the optimization objectives. Gao et al. [10] suggested a differential evolution algorithm enhanced by a selection mechanism for the job shop scheduling problem with the fuzzy processing time. Engin et al. [11] prosed an genetic algorithm to solve the hybrid flow shop scheduling problem (HFSP) with fuzzy processing time and a fuzzy due date. Focus on the cellular manufacturing system considering automated guided vehicles under fuzzy processing time, a hybrid genetic algorithm and a whale optimization algorithm are developed [12].
To summarize, research on scheduling problems with fuzzy processing time and delivery time is still in its early stages, while research on FRHFSP is even more limited. Recent study indicates that the hybrid algorithm can complement the qualities of two or more algorithms and is more adaptable and robust than a single algorithm. It is an important direction for researching and solving FRHFSP. The local search algorithm based on NSGA-II is described in this research, and a hybrid NSGA-II is developed to solve the issue with the optimization objectives of minimizing the fuzzy completion time and maximizing the average agreement index.
The rest of the paper is structured as follows: Section 2 describes the FRHFSP in depth and establishes the mathematical model. The suggested HNSGA-II algorithm is discussed in depth in Section 3. Section 4 depicts the experimental simulation and outcome analysis. Section 5 includes a conclusion and a prospect.
Problem statement and mathematical model
Problem statement
In FRHFSP, some jobs need to go to some stages several times, and the processing time of each operation and the delivery time of each job are fuzzy numbers. The diagram of RHFSP is shown in Fig. 1. The main objective of this paper is to assign jobs to machines, determine the set of operations on each machine, calculate the fuzzy start and end time of each operation, and optimized the solution with the objective of minimizing the maximum completion time
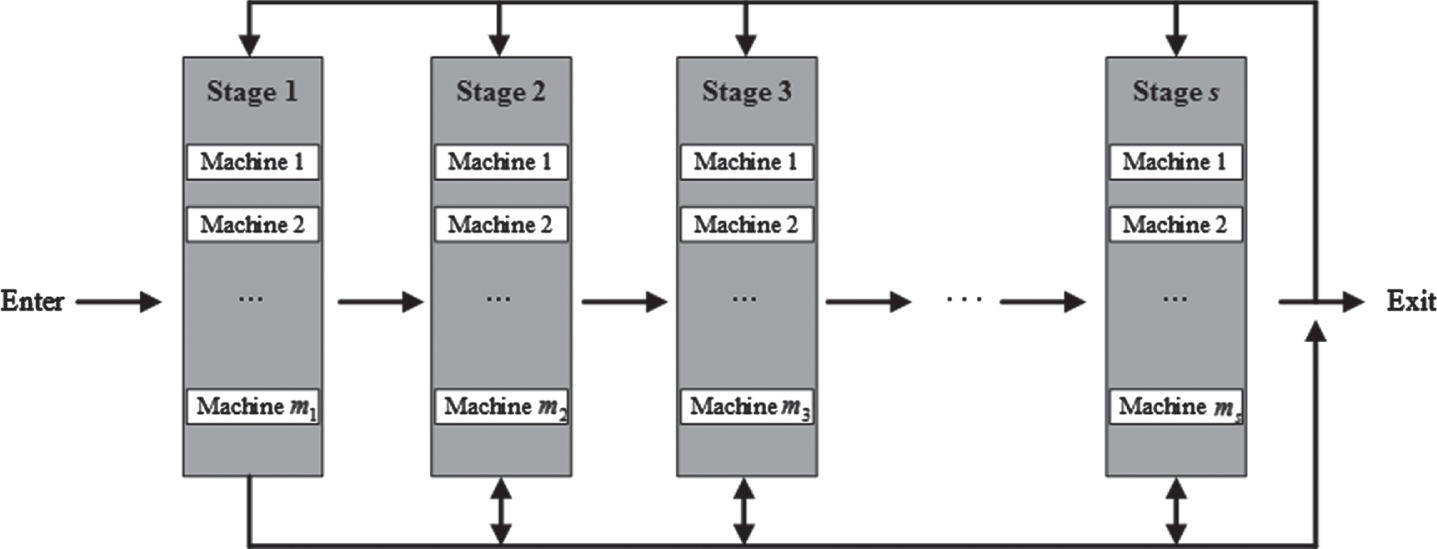
Re-entrant hybrid flow shop scheduling.
In the study, the fuzzy processing time of operation O
jk
is represented by the triangular fuzzy number
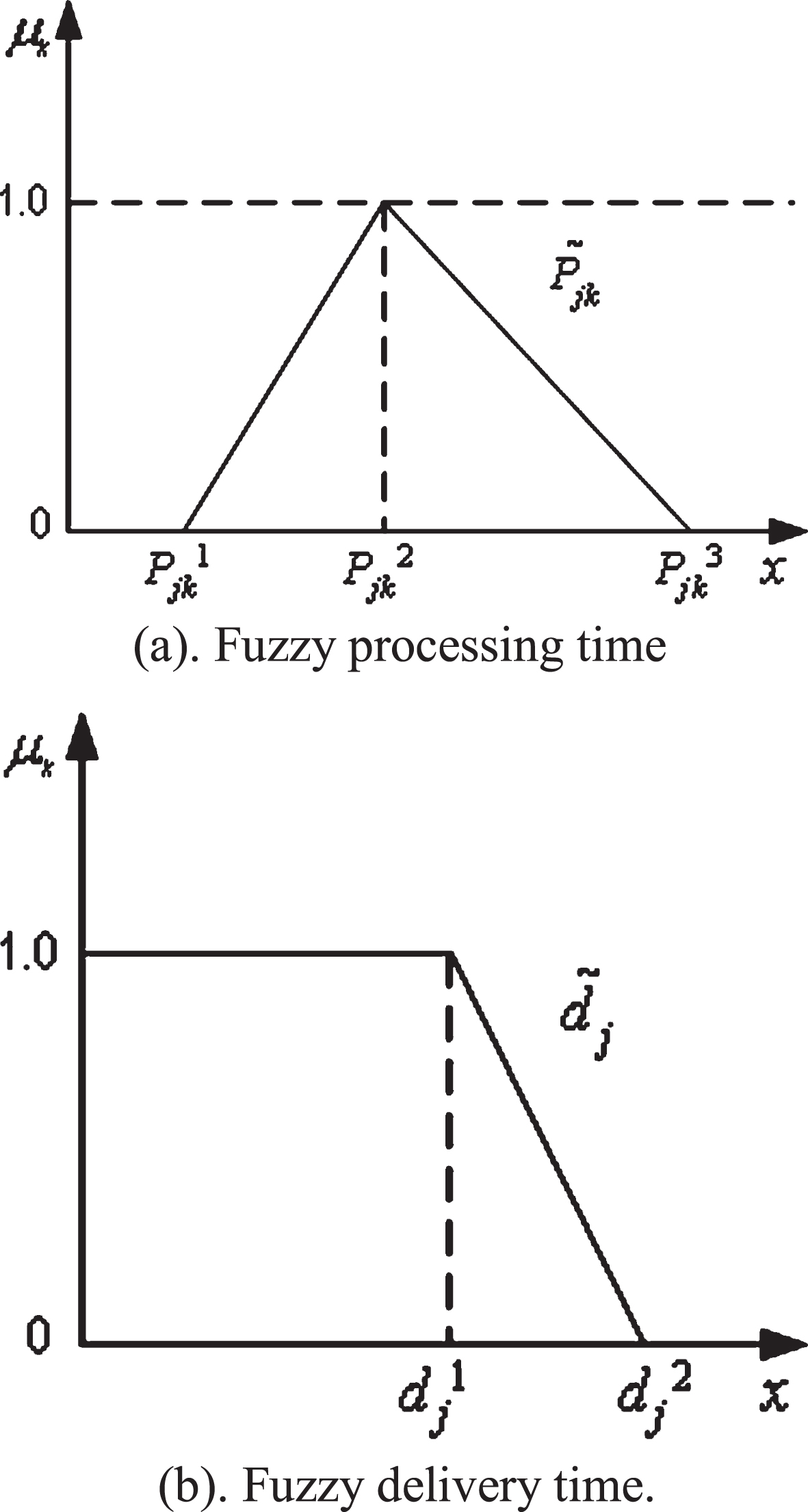
Fuzzy processing time and delivery time.
The larger-taking operation is used to calculate the fuzzy start time of each operation in fuzzy scheduling, the addition operation is used to calculate the fuzzy completion time of jobs, and the comparison operation is primarily used to measure the relationship among the solutions. Assuming two fuzzy numbers
Addition operation:
Comparison operation:
(1) if
(2) if
(3) if
Larger-taking operation:
if
The mathematical symbols in the model and their meanings are as follows:
n: total number of jobs;
j, j′: serial number of jobs, j, j′ = 1, 2, . . . , n;
s: total number of stages;
i: serial number of stages, i = 1, 2, . . . , s;
m i : number of parallel machines at stage i;
l : serial number of machines at stage i, l = 1, 2, . . . , m i ;
q: number of machines based on all machines;
N j : total number of processes of job j;
k: serial number of operations of job j, k = 1, 2, . . . , N j ;
O jk : the k - th operation of job j;
M: a positive number large enough;
U i : the set of operations at stage i;
M il : the l - th machine at stage i;
AI j : the agreement index of job j;
r ijkl : 1, if the operation O jk is processed by the l-th machine at the stage i, and 0 otherwise
Zjkj′k′: 1, if the operation O jk is processed before Oj′k′, and 0 otherwise
Based on the existing literature [13, 14], a mathematical model for bi-objective FRHFSP is presented. To solve the FRHFSP, each operation must be performed on an appropriate machine under fuzzy circumstances, and in a sensible order. An essential index in the scheduling problem is the maximum completion time. Improving this index may assist enhance production efficiency. The fuzzy completion time of each job is equal to the last operation’s fuzzy completion time, and the maximum value is
The second optimization objective is to maximize the average agreement index AI
i
. For convenience, we simplify it by converting it to a minimal issue, as illustrated in Formula (2)
The agreement index AI
i
is the ratio of the graph area

Agreement index of job j.
The constraints of the objective functions are:
In which, Formulas (1) and (2) denote the two objective functions; Constraint (4) assures that the start of operation Ojk+1 does not occur before the completion of operation O jk ; Constraint (5) ensures that each operation can only be processed by one machine on the corresponding statge; Constraints (6), (7), and (8) guarantee that each machine performs no more than one operation concurrently; Constraint (9) establishes the start and end times of operation O jk ; the maximum completion time is described by Constraints (10) and (11); Constraint (12) restricts the value range of each job’s agreement index.
In bi-objective optimization, solution X1 dominates X2(denotes as X1 ≺ X2), if and only if ∀i ∈ {1, 2} , f i (X1) ⩽ f i (X2) ∧ ∃ i ∈ {1, 2} , f i (X1) < f i (X2). A solution X is the non-dominant solution when there is no solution that can dominate it.
The NSGA-II [15] is a well-known multi-objective evolutionary algorithm that has been extensively used in engineering domains, such as route planning [16, 17], site selection [18, 19], scheduling [20, 21], and parameter optimization [22].
The study proposes a hybrid algorithm (HNSGA-II) based on NSGA-II. To enhance the algorithm’s performance, a double-layer coding method based on operation and machine, a hybrid population initialization method based on greedy machine selection and complete random methods, crossover and mutation operators, and five neighborhood search operators are designed. Finally, the simulation experiment verifies the superiority of HNSGA-II in solving FRHFSP. The flowchart of HNSGA-II algorithm is shown in Fig. 4.

Flowchart of the improved HNSGA-II.
Since FRHFSP mainly consists of two subproblems, machine assignment and process ordering, this paper adopts a two-layer encoding method based on machines and operations to maximize the search of the algorithm in the entire solution space. The individual’s length is equal to the total of all jobs’ operations. The OS part indicates the sequence of all operations, in which the number represents the job index, and the number of occurrences represents the corresponding operation. The machines used in each operation are listed in the MS part, and the number in the MS component corresponds to the machine number. FRHFSP with three tasks and two stages (two parallel machines at each stage) is an example. Table 1 shows the fuzzy processing and delivery times for all operations.
Example involving two stages and three jobs (hour)
Example involving two stages and three jobs (hour)
The processing time
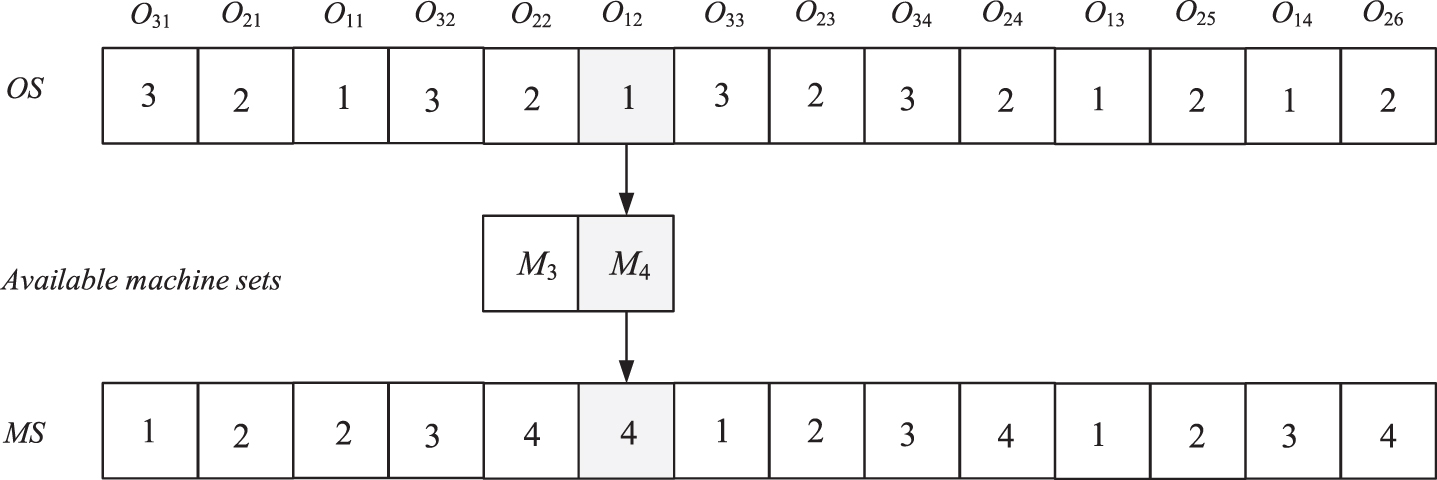
Two-layer encoding chromosome.
The primary goal of decoding is to establish the start and finish time of each operation. Detailed instructions for decoding are as follows.
Step 1: Select job j from OS and assume that the corresponding operation is O jk .
Step 2: Find the machine q corresponding to operation O jk from MS.
Step 3: Calculate the start time and completion time of operation O jk according to Formulas (13) and (14).
Step 4: Step 1- Step 3 should be repeated until all jobs in the OS have been traversed.
Step 5: Calculate the two objectives.
Taking the individual in Fig. 5 as an example, under various constraints, the Gantt chart of the scheduling scheme obtained after decoding is shown in Fig. 6, and the two objective functions are f1=(7 12 18) hours and f2=0.53, respectively. As an illustration, consider the individual shown in Fig. 5. As illustrated in Fig. 6, under different constraints, the Gantt chart of the scheduling scheme after decoding is shown. The two objective functions are f1=(7 12 18) hours and f2=0.53, respectively. As shown in Fig. 6, the operation with the processing time (0,0,0) is not displayed in the Gantt chart, and O31 denotes the first operation of the job 3 with non (0,0,0) processing time, and so on.

Scheduling scheme of all jobs.
According to the two-layer coding strategy, the solution space is large enough, and using the completely random method to initialize the population will seriously affect the solution effect of HNSGA-II. Population initialization is a key part of the HNSGA-II algorithm. This work employs greedy machine selection and entirely random approaches to produce the initial population to increase the quality and variety of the initial population solution. In Algorithm 1, the pseudocode is presented.
The detailed process of the greedy machine selection strategy is as follows.
Step 1: Randomly generate the OS part. Select the z-th gene j from the OS and select a suitable machine from the available machines set randomly according to its corresponding operation, z = 1.
Step 2: Select the (z + 1)-th gene j′ from the OS and suppose the corresponding operation is Oj′k. Select the machine for the operation from the available machines set MS that can finish it earliest. The specific process is as follows.
Step 3: Select machine q from MS, get its fuzzy idle time periods
Step 4: Determine an appropriate insertion position for Oi′j in accordance with Formula (16). If no idle time period meets the requirement, set the start time of operation Oi′j as
Step 5: Traverse all of the machines in MS, then repeat Steps 3 - Step 4 to find the smallest
Step 6: Calculate the completion time of operation Oi′j, as shown in Formula (17).
Step 7: Step 2-Step 6 should be repeated until all of the jobs in the individual have been processed.
Step 8: Individual based on the two-layer encoding strategy is generated according to the above scheduling scheme.
According to the characteristics and various constraints of FRHFSP, not every operation can be processed by all machines. In addition, a significant number of infeasible solutions will be constructed if the jobs and the machines are crossed directly. To assure the feasibility of the solution, the JBX (job based crossover) crossover technique is used in both the OS and the MS parts of the solution. Firstly, the jobs are divided into two subsets set1 and set2 randomly, and the number of jobs in set2 is greater than 1. Then, the genes belonging to the jobs in set1 in parent PO1 and PO2 are copied into offspring O1 and O2 at the same position respectively. Finally, the genes belonging to the jobs in set2 in parent PO2 and PO1 were added to offspring O1 and O2 in the original order. The cross process of OS part is shown in Fig. 7, where set1 = [1] and set2 = [2, 3].
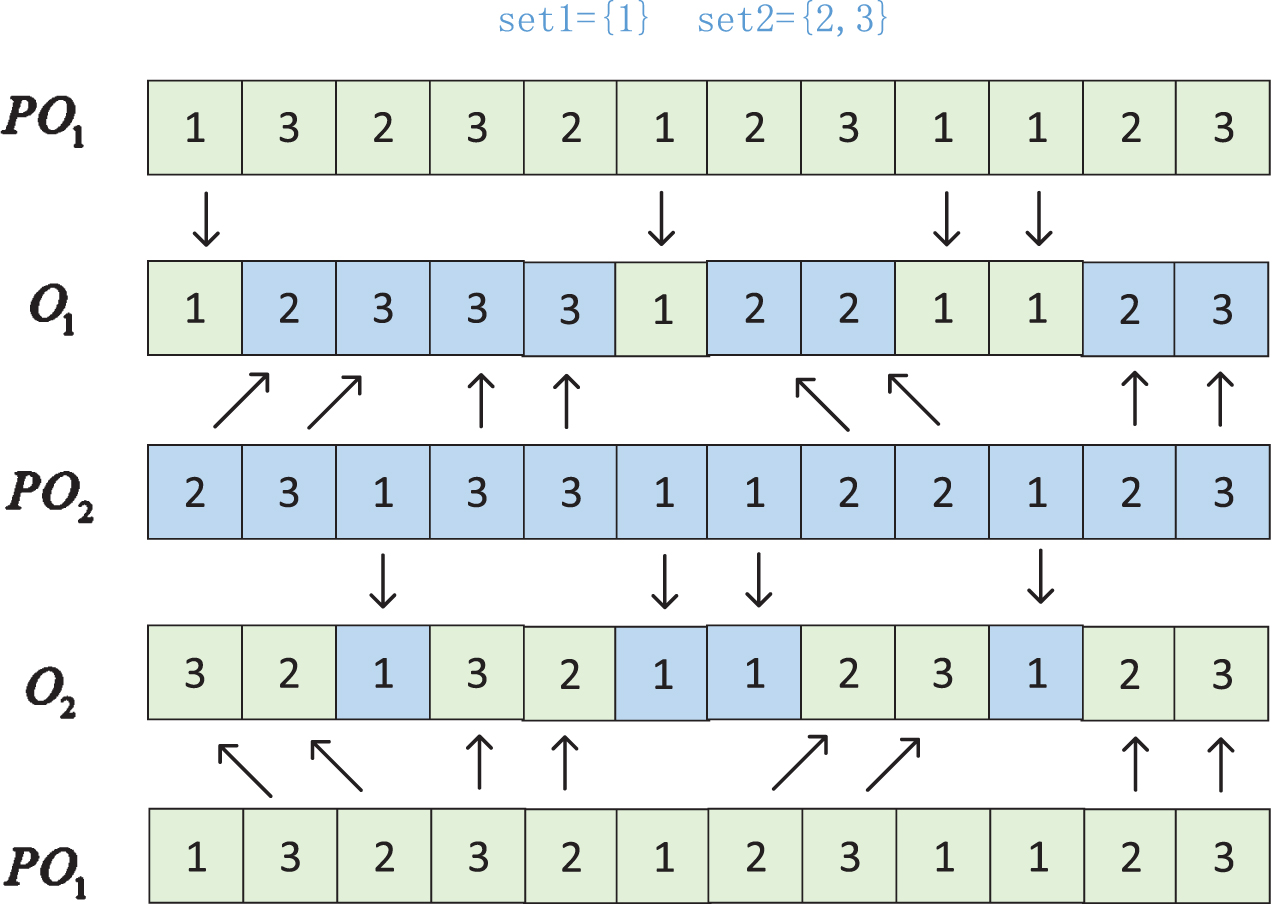
Crossover operator.
Mutation operation improves the diversity of the population by randomly changing some genes of the chromosome. To assure the solution’s feasibility after mutation, this research employs two-point exchange mutation. After the jobs in the OS part are exchanged, the MS part needs to be repaired. The schematic diagram of mutation operator is shown in Fig. 8, where r1 = 2 and r2 = 5.
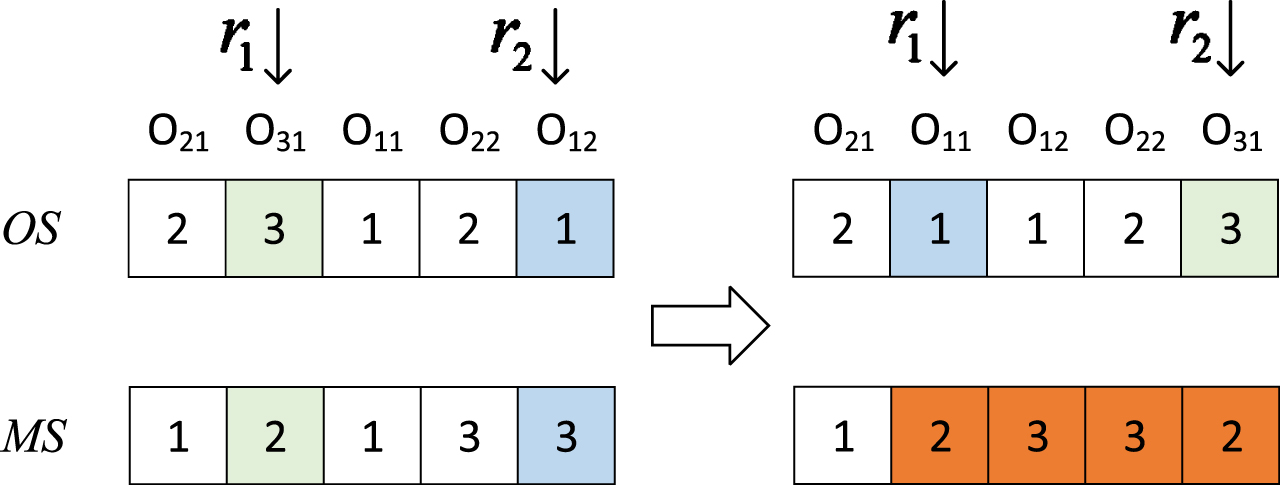
Mutation operator.
Step 1: Select an individual from the population and mark two positions r1 and r2.
Step 2: Exchange the jobs at r1 and r2 positions in OS, and adjust the MS part.
Step 3: Repair the operations between r1 and r2, and randomly select an available machine for each operation.
Step 4: Get new individual X′.
As a result of randomness, it is difficult to assure that the quality of the population evolves in a positive direction when using crossover and mutation operators. In this paper, five kinds of neighborhood search operators are designed. Randomly select a neighborhood search operator and if the updated individual dominates the original individual, the original individual is replaced. The pseudo code is shown in Algorithm 2.
Step 1: Randomly select an individual X, and find the machine Mmaxload with the largest load according to the scheduling scheme generated by the decoding strategy.
Step 2: Randomly select a job j on the machine Mmaxload.
Step 3: Insert job j tentatively into all possible insertion points on machine m gk at the same stage to obtain a new individual X′, and calculate its objective function value.
Step 4: Find the best new individual X′ according to the dominance relationship.
Step 1: Randomly select an individual X, and find the machine Mmaxload with the largest load according to the scheduling scheme generated by the decoding strategy.
Step 2: Randomly select a job j on the machine Mmaxload.
Step 3: Try to insert the job j into all possible insertion points on the machine Mmaxloadto get a new individual X′, and calculate its objective function value.
Step 4: Find the best new individual X′ according to the dominance relationship.
Step 1: Randomly select an individual X, and find the machine Mmaxload with the largest load according to the scheduling scheme generated by the decoding strategy.
Step 2: Randomly select a job j on the machine Mmaxload.
Step 3: Try to switch the job j with the other jobs processed on the machine Mmaxload in order to get a new individual X′.
Step 4: Find the best new individual X′ according to the dominance relationship.
Step 1: Choose an individual X at random, and find the machine Mmaxload with the largest load according to the scheduling scheme generated by the decoding strategy.
Step 2: Randomly select a job j on the machineMmaxload.
Step 3: Swap job j tentatively with all jobs on machine m gk at the same stage to obtain a new individual X′, and calculate its objective function value.
Step 4: Find the best new individual X′ according to the dominance relationship.
Step 1: Randomly select an individual X, and find the machine Mmaxload with the largest load according to the scheduling scheme generated by the decoding strategy.
Step 2: Randomly select a job j on the machine m gk .
Step 3: Insert job j tentatively into all possible insertion points on machine mg(k+1) at the same stage to obtain a new individual X′, and calculate its objective function value.
Step 4: Find the best new individual X′ according to the dominance relationship.
External archive
Using the Pareto dominance relation, the non-dominant solutions in the evolutionary process are stored in the external archive. The mechanism of updating is as follows: If any solution in the external archive dominates a newly generated solution X, the solution X is disregarded. If solution X dominates certain solutions in the external archive, it is added to the external archive and the dominated solutions are deleted. If the solution X and any one of the solutions in the external archive do not dominate each other, the solution X is added to the external archive. If the number of solutions in the external archive exceeds the number of populations, the solutions with the shortest crowding distance will be deleted.
Experimental simulation and result analysis
Three multi-objective optimization algorithms, MOGWO, MOPSO, and NSGA-II, were chosen for comparison to test the efficacy of HNSGA-II in solving the proposed model.
Description of the experimental data
The author took the test problems in the literature of Cho et al. [23] as the experimental data, which includes 120 small-scale and 120 large-scale test problems. In this paper, we randomly choose 5 small-scale problems and 5 large-scale problems to test. Due to the fact that the original example is for the RHFSP and both the processing and delivery times are fixed, this work extends the example above to the scheduling problems under fuzzy constraints as defined by Formula (18).
In which,
In this paper, IGD [24], Ω and Δ [25] are used to measure the performance of the HNSGA-II, where IGD is used to determine an algorithm’s convergence and the distribution of non-dominated solutions, Ω is the percentage of non-dominated solutions found by an algorithm that are also optimum Pareto solutions, and Δ measures the diversity of non-dominated solutions in the Pareto front. In addition, due to the existence of triangular fuzzy number in the target value
Parameters setting
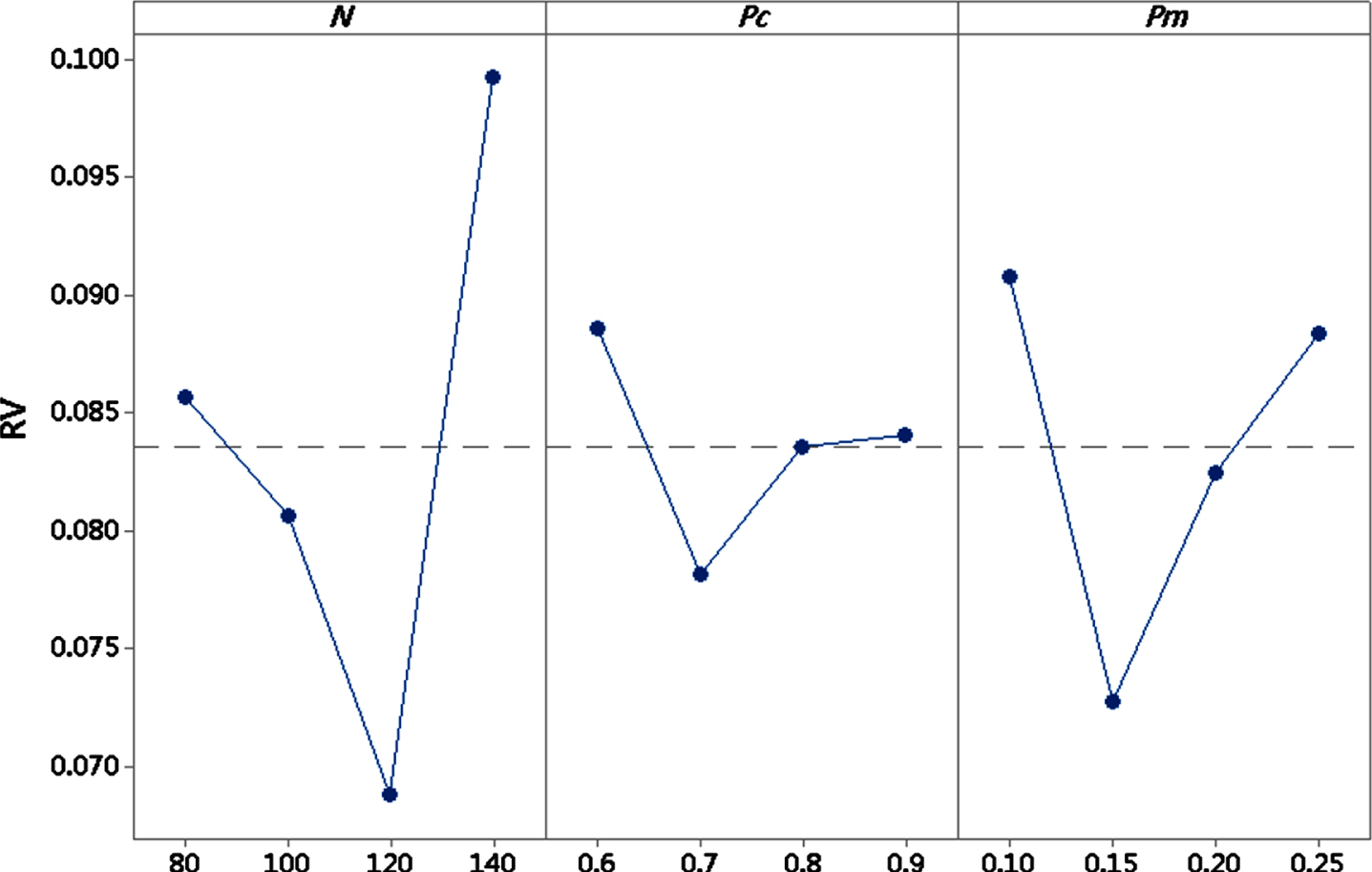
Population size N, Crossover probability Pc, and mutation probability Pm are the three most important parameters of the HNSGA-II algorithm. To determine each parameter value, a four level Taguchi [26] experiment is designed by using the example S-05-01. Table 2 shows the parameter values for each level, whereas Table 3 shows the orthogonal table. The response variable (RV) is defined as the average value of IGD, and the optimum pareto front is defined as the union of non-dominant solutions achieved by twenty runs. The trend of each parameter’s influence is shown in Fig. 9. Based on Table 4 and Fig. 9, it can be concluded that the optimum algorithm performance is achieved when the parameters of HNSGA-II are set at N = 120, Pc = 0.70 and Pm = 0.15.
Parameters combination
Parameters combination
Orthogonal array and RV values
RV and rank of each parameter
In this paper, a hybrid initialization strategy is designed for population initialization. It is necessary to compare HNSGA-II (denoted as A) with HNSGA-II1 (completely random initialization scheme, denoted as B) to verify the effectiveness of population initialization strategy. Ten instances are randomly selected, and each instance runs independently for 20 times. The average values of IGD, Ω, and Δ are shown in Table 5. Bold indicates the optimal value of each metric.
Comparison of HNSGA-II and HNSGA-II1
Comparison of HNSGA-II and HNSGA-II1
To verify the effectiveness of the five neighborhood search operators, HNSGA-II is compared with HNSGA-II2 which omits neighborhood search. Ten instances are randomly selected, and each instance runs independently for 20 times. The average values of IGD, Ω, and Δ are shown in Table 6. Bold indicates the optimal value of each metric.
Comparison of HNSGA-II and HNSGA-II2
Comparison of HNSGA-II and HNSGA-II2
The common parameters of the four algorithms are set to the same values in order to fairly compare their performance. Each algorithm is performed 20 times, yielding a collection of [IGD, Ω, Δ] values. The minimum value (Min) and average value (AVG) of each performance metric are shown in Table 7 after twenty runs of the four algorithms. Furthermore, bold writing represents the best result of each metric for each test problem.
Comparison of four algorithms for 10 test problems
Comparison of four algorithms for 10 test problems
Through Wilcoxon signed-rank test of related samples, we can get whether there is significant difference between two algorithms. For the three metrics of all the test problems, HNSGA-II is compared with other algorithms in pairs, and Prob ⩽ 0.05 indicated that the significance level is significant at 0.05. As shown in Fig. 10 and Table 8, for all test problems, compared with other three algorithms, HNSGA-II has significant difference and shows the best effect in terms of IGD and Ω. Therefore, the proposed HNSGA-II has significant advantages over the other algorithms. As for Δ, there is no significant difference between them. The box plots of the three metrics are shown in Fig. 10, which further verify the above conclusion.

Boxplot of three performance metrics.
Wilcoxon signed-rank test of HNSGA-II vs. other algorithms
Taking S-01-01 as an example, the problem has 2 reentries, 5 stages, 17 jobs and the number of machines at each stage is [1, 1]. Since there are triangular fuzzy numbers in the objective functions, in order to represent the solution effect of the algorithm more directly,
Factor level trend.

Pareto fronts for L-01-01 test problem.
A fuzzy Gantt chart.
In this paper, a multi-objective re-entrant hybrid flow shop scheduling problem with fuzzy processing time and delivery time is studied. The optimization objectives are to minimize the maximum fuzzy completion time and maximize the average agreement index. The main contributions of this paper are summarized as follows: The mathematical model of the FRHFSP is established, and the multi-objective HNSGA-II algorithm is designed to solve it. To enhance the algorithm’s performance, a double-layer coding method based on operation and machine, a hybrid population initialization method based on greedy machine selection and complete random methods, crossover and mutation operators, and five neighborhood search operators are designed.
In the future, fuzzy scheduling will be further studied, such as designing better swarm intelligence optimization algorithm, considering the energy consumption of fuzzy scheduling and so on.
Funding
The work is supported by Humanities and Social Sciences Research in Colleges and Universities of Henan Province in 2023 (NO. 2023-ZZJH-074), Doctoral research startup fund project of Nanyang Institute of Technology (NO. NGBJ-2022-50).