
Abstract
Blood vessel segmentation of the retina has become a necessary step in automatic disease identification and planning treatment in the field of Ophthalmology. To identify the disease properly, both thick and thin blood vessels should be distinguished clearly. Diagnosis of disease would be simple and easier only when the blood vessels are segmented accurately. Existing blood vessel segmentation methods are not supporting well to overcome the poor accuracy and low generalization problems because of the complex blood vessel structure of the retina. In this study, a hybrid algorithm is proposed using binarization, exclusively for segmenting the vessels from a retina image to enhance the exactness and specificity of segmentation of an image. The proposed algorithm extracts the advantages of pattern recognition techniques, such as Matched Filter (MF), Matched Filter with First-order Derivation of Gaussian (MF-FDOG), Multi-Scale Line Detector (MSLD) algorithms and developed as a hybrid algorithm. This algorithm is authenticated with the openly accessible dataset DRIVE. Using Python with OpenCV, the algorithm simulation results had attained an accurateness of 0.9602, a sensitivity of 0.6246, and a specificity of 0.9815 for the dataset. Simulation outcomes proved that the proposed hybrid algorithm accurately segments the blood vessels of the retina compared to the existing methodologies.
Keywords
Introduction
Ocular diseases, such as glaucoma, retinal thrombosis, and diabetic retinopathy can be detected using segmented blood vessels of the fundus image. Blood vessels are crucial for carrying oxygen and nutrients to living organs. Any issues with the blood vessels can result in organ malnutrition, lowering the patient’s quality of life. Oscular blood vessels contain various features, among these retinal vessels play a major part, such as thin vessels assisting in the recognition of microaneurysm and thick vessels are used for measurement of diameter [1]. The major goal of detecting and localizing retinal vessels is to isolate the various retinal vascular structural tissues from the backdrop of the fundus image [2], as well as other retinal structures such as abnormal lesions, macula, and optic nerve. It is also possible to segment vessels manually, but it is tedious and requires professional expertise [3]. Furthermore, the results of the analysis may lack objectivity because different experts may produce different results [4]. The demand for fast intelligent analysis of retinal vessel images arises to assist ophthalmologists with this complex work [5]. However, to diagnose retinal diseases, it is imperative that the vessel extraction accuracy be very high, as even the smallest vessel can contribute to an incorrect diagnosis. A robust technique is intended to maintain good vessel segmentation accuracy in all conditions. The fundus image and retinal vessel segmentation are depicted in Fig. 1.

Representation of the fundus image and retinal vessel segmentation (a) color fundus image (b) retinal vessel.
Automatic and optimal accuracy in segmentation is achieved in a lot of studies by using supervised and unsupervised machine learning algorithms. CNN [6, 7] is a new evolutionary strategy that makes decisions based on learned features; numerous studies have lately begun segmenting the retinal vessel using this supervised approach. To resolve the confusing contrast aspects in the retinal fundus image, an EEA-UNET [8] was designed. CNN (Convolutional Neural Network) with the SVM model differentiates the retinal vessels with 97.775 % [9]. The VSSC-Net [10] and DUNet [11] are advanced Fully Connected Network (FCN) models that effectively mask the retinal blood veins. The cascaded model’s low-complex architecture [12] uses a one-pass feed-forward approach to reduce computing costs. Despite the fact that these deep learning algorithms do not require any selection parameters, they are computationally demanding, memory-intensive, and require annotated datasets for gradient descent training. Because supervised methods are dependent on training datasets, they cannot be used if the training datasets are unavailable. Furthermore, when supervised algorithms are trained on a small amount of data, their generalization suffers.
In contrast to supervised techniques, unsupervised techniques do not require training datasets, so they are faster and more computationally efficient. To accurately represent the main structure of objects, they get a priori knowledge without supervision [13]. To identify the retinal vasculature in a fundus image, edge detection-based segmentation [14] and hybrid segmentation [15] use some standard filter techniques. A hybrid strategy is provided in [16] to improve the thin and thick vessel morphology, which achieved 93% segmentation accuracy.
This paper proposed a hybrid algorithm, for accurate segmentation of blood vessels. This proposed technique combines three different pattern recognition techniques using binarization: Matched Filter (MF), Matched Filter with First-order Derivation of Gaussian (MF-FDOG), and Multi-Scale Line Detector (MSLD). The final optimal segmented result is obtained with weighted average binarization. For the performance evaluation of the proposed technique, several trials have been made on the DRIVE dataset image.
This study aims to develop a low-complexity, data-independent model that precisely segments retinal blood vessels to assist ophthalmologists in diagnosing ocular conditions.
Our proposed model’s key contribution is outlined below. A novel hybrid algorithm is proposed to segment the retinal vessel of the fundus image. The hybrid algorithm utilizes the advantages of the various pattern recognition algorithm (MF, MF-FDOG, and MSLD) and binarization to obtain the optimal segmented vessel. The individual segmented results were merged using weighted average binarization, ensuring that the segmented image did not omit any pixel data from the thin and thick vessels. The proposed unsupervised hybrid algorithm performance evaluation is carried out with a publicly available DRIVE dataset.
This paper is comprised of the various sections as follows; Section 2 includes a brief description of existing strategies as well as a summary of their drawbacks. Section 3 presents the particulars of materials and methodologies used in this proposed framework. section 4 contains the result of the proposed work and an association of enactment of the proposed technique with the existing techniques and section 5 concludes the study.
Diagnosing vision impairment pathologies begins with analyzing retinal blood vessel attributes. However, segmenting it manually can be immensely time-consuming and difficult. Recently, several supervised and unsupervised intelligent techniques have been devised to separate retinal vessels from fundus images. This session provides an overview of some of the merits and shortcomings of these techniques.
In 2020 Shukla, A.K.et al., [17] devised a fast method to separate the retinal blood vessels in a fundus image. Herein local covariance and fractional filter were utilized as a segmentation approach. The experimental evaluation was carried out with the STARE and DRIVE datasets. Manual parameter updates were a drawback of this strategy.
In 2020, Li, X., et al., [18] developed a lightweight attention CNN for retinal vascular image segmentation that made efficient use of global information. The feature was efficiently fused using the attention-based U-Net model for enhanced segmentation. Although this model had a performance rate of 0.97, it had a weak generalization ability.
In 2020, C. Zhou et al., [19] used an unsupervised technique to segment the retinal vasculature. The segmentation was done using a weighted line and Hidden Markov algorithms, which solve the problems of false detection and vessel missing. For the DRIVE dataset, this technique scored 94.75 %. However, wide vessel pixels were missing in the resulting image, and this method failed to dynamically adjust to varied resolutions.
Ramos-Soto, O., et al., [20] proposed an autonomous retinal blood vessel segmentation algorithm in 2021. For segmentation, a harmonic filter and an enhanced top-hat algorithm were used, and morphological operations were performed using post-processing techniques. Obtaining appropriate parameters was a tedious task in this case.
B. Toptaş and D. Hanbay [21] developed a pixel-based feature extraction approach for autonomous retinal vascular segmentation in 2021. The recovered 18-D feature vector was used to train an ANN model. Finally, using the learned features, the trained ANN segmented the retinal vasculature. Although this model has a low time efficiency, it requires a large amount of annotated data for efficient segmentation.
In 2021, Tang, S., and Yu, F. [22] developed a segmentation method based on the properties of the retinal vasculature. The feature vector of the model was extracted using typical filtering methods. The back propagation NN model was used to produce the final segmentation. This technique, however, did not prevent substantial lesion interaction.
Sayed, M.A., et al. [23] used both supervised and unsupervised techniques to construct a retinal blood vessel segmentation methodology in 2021. A multi-scale line detector was used for initial segmentation, then a supervised classifier was used to remove the vessels that were incorrectly categorized. This model outperformed the previous models by 2%. For gradient descent training, however, the supervised model needs annotated data.
In 2021, Boudegga, H., et al. [24] developed a deep learning-based retinal vascular segmentation framework. Lightweight convolution layers were added to this network to reduce the traditional layer complexity. To boost segmentation accuracy, data augmentation and preprocessing methods were added, resulting in a 98 percent success rate. The performance of this approach varied depending on the resolution.
In 2021, K. Mardani and K. Maghooli [25] devised an unsupervised learning technique to improve the segmented outcome of the retinal vasculature. In this case, the input images were separated into blocks and processed in the DBSCAN model, after which the noise was removed using morphological restoration and classical filters. In this segmentation model, several veins were represented. However, distributing parameters to distinct regions, in this case, was a time-consuming task.
In 2022, Saranya, P., et al. [26] used both supervised and unsupervised models to create a retinal vascular segmentation model. The conventional filtering method was used to find the initial neovascularization; following that, the deep learning model classifies the result and offers the best results. This model takes an inordinate amount of time to process, and its performance was entirely dependent on the dataset images.
Based on the analysis of the literature review, some existing strategies use a supervised deep learning model, but their performance is limited by their sophisticated computation and gradient descent training. Furthermore, their performance was entirely dependent on the number of images in the dataset. The performance of the unsupervised learning-oriented experiments was poor, and the segmentation result missed certain thin and thick vessel pixels. As a result, a high-performance segmentation model must be implemented to aid ophthalmologists. In this study, an optimal retinal vessel segmentation framework is proposed based on the hybrid model which comprises various pattern recognition techniques. In the segmentation phase, the Inverted green channel image is given to various vessel segmentation algorithms. The output of each segmentation method is obtained and combined using the image fusion method with the empty 2D array. The combined output is transformed into an image.
Proposed hybrid retinal blood vessel segmentation
So far, blood vessels are segmented with multiple algorithms. Each algorithm focuses on certain areas of the blood vessel segmentations like thin vessels, thick vessels, etc. The foremost aim of the proposed algorithm is to utilize the benefits of multiple techniques and enhance the blood vessel segmentation. The framework for segmenting the blood vessel from the retinal image is illustrated in Fig. 2. The main parts of this proposed method are discussed as follows.
Block diagram of the proposed hybrid algorithm.
For retinal image processing, inverted green channel information provides superior contrast of the vessels than the background objects. So, pre-processing phase encompasses the abstraction of the green channel from the retinal image. Along with the green channel information, an empty image is constructed to accumulate the results of multiple algorithms. In the segmentation phase, the processed green channel information is fed into multiple algorithms (MF, MF-FDOG, and MSLD) to obtain the segmented image of each algorithm.
Each of these algorithms implements its binarization techniques to enhance the result of the segmentation. Finally, all the outputs were collected into an array in the form of binarized segmented images. The hybrid algorithm uses a weighted average to blend the binarized images from each algorithm into a single binarized segmented image. Finally, the resultant image is further binarized with the adaptive binarization method to remove the unwanted noise. The output of these images was matched against the actual output and accuracy is calculated. This proposed overall method contains the following phases: Dataset selection Pre-processing Segmentation Post-processing
Various datasets are publicly available for analyzing the retinal image like STARE, DRIVE, ARIA, CHASE, HRF, IMAGERET, REVIEW, ROC, and VAMPIRE. To analyze the enactment of the suggested hybrid technique, the DRIVE dataset is used here. This dataset contains images with high resolution and no proper tagging for healthy images or disease-affected images. This dataset contains 40 retinal images and those were obtained through the Netherland screening program. Images have been captured using Canon CR5 non-mydriatic 3-CCD at the field of view of 450. Every image size is 584
Pre-processing
Raw retinal images from the DRIVE dataset are pre-processed to extract the green channel of the image. The Green channel of the image provides the highest contrast in intensity which enables the blood vessels easily distinguishable from the background. Further, the green channel is inverted to focus on the interest region.
Segmentation process
The pre-processed image further undergoes the process of segmentation of blood vessels, which applies multiple segmentation techniques to the pre-processed retinal image. Each segmentation technique has its own merits and demerits. This proposed hybrid algorithm is developed based on the merits of each segmentation algorithm. Various techniques used for this proposed hybrid algorithm were briefly discussed in the following subsection.
Matched filter (MF)
Segmentation of the blood vessel based on the Matched filter was developed first by Chaudhuri et al. (1989) [27]. Vessels are detected by this algorithm by assuming that they are Gaussian in nature. Matched filters are accomplished by correlating the known and unknown signals using the Gaussian shape filter. So that the current shape of the unknown signal can be identified.
The above Equation (1) defines MF, where s represents the filter scale, and L signifies the span of the neighbour vessels, and it is used for noise smoothening. Constant t is generally set to the value 3. Based on the parameter s the values of L are chosen. L value is set to small when s value is small and vice-versa. For detecting the different orientations of blood vessels with the maximum response, implementation of f (x, y) will be rotated.
Mostly the green channel of the retinal image was used for the implementation of the MF algorithm. The reason behind the selection of channel was the level of intensity contrast it provides between the vessels in the retinal image and its background. Edge filters are the most common kernels used for the identification of blood vessels. In this algorithm, the Gaussian kernel is used for identifying the edges of a blood vessel in the pre-processed retinal image.
After applying the gaussian kernel filter, the binarization technique is used to differentiate the blood vessels visually and more clearly. Here, the adaptive gaussian threshold technique is used to binarize the processed image. The chief advantage of this technique is to identify the drastic variation of intensity at the edges of the blood vessels.
MF-FDOG has been suggested by Zhang et al. (2010) [28] and it was known as a Matched filter with modifications. In order to differentiate Gaussian vessel structures from non-vessel edges, the MF-FDOG uses two filters instead of only one filter, since the vessel cross-section is a uniform Gaussian function while the step edge is irregular. This proposed method comprises of zero-mean Gaussian function with original MF as defined in equation (1) and the First order Derivative of Gaussian (FDOG). It is expressed as,
This method supports a two-level approach, in the beginning, MF-FDOG is used to detect the centrelines, then to produce a better result, an orientation map is combined with the shape of the vessel. Background grey level variation in the image is normalized for obtaining an enhanced vessel image by computing maximum principal curvature.
Then FDOG is applied to this for enhancing the vessel image. Then the candidate pixels of vessel centrelines are identified using image statistical measure. Finally detected centrelines of the vessel are combined with an orientation map and shape for obtaining the segmented vessel tree.
After applying the FDOG, the adaptive gaussian threshold technique is used to binarize the processed image. This algorithm helps to retain the centre lines of the thick blood vessels which might be lost in the previous algorithm.
Nguyen et al. (2013) [29] suggested a method of generalized line detector for improving the blood vessel detection and making that work for multiple scales.
Multi-scale techniques perform well at fluctuating retinal image resolutions; where low resolutions are used for extracting the large vessels and high resolutions are used for fine vessels. The advantage of this approach is its increased processing speed and high level of robustness.
Whenever the blood vessels of the retina appear brighter, at first the green channel is inverted and then the basic line detector is applied. The window of W × W pixel is considered for every pixel of the image and computed the average grey level
This MSLD is attained by simply changing the primary line detector length. The response of this MSLD is combined to bifurcate the vessels of the retina. The MSLD equation (3) is redefined as,
Where 1≤L≤W,
Weighted average Binarization
The Binarization technique is already applied while segmenting blood vessels with each algorithm to ensure a better result for the corresponding algorithms.
On top of the binarized image from each algorithm, the hybrid algorithm applies a weighted average to combine them into a single binarized image. When three images with different features are available, it is feasible to construct a single image that has the characteristics of all images. This guarantees that the details of both images are maintained and displayed in the resulting fusion image. Since each algorithm provides better results for different attributes of the segmented image, the weighted average helps to ensure the pixels of the corresponding segmented image are enhanced or suppressed. Identification of different types of disease requires a different set of weighted averages to segment the blood vessel of the retina better and to accurately identify the disease. Finally, the resultant image is further binarized with the adaptive binarization method to remove the unwanted noise
Computation of weighted average
For any disease, a few sample images of the disease were picked and processed with each of the above-mentioned algorithms. Segmented images of these algorithms were matched against the actual output and accuracy is calculated. The average accuracy of these sample images is considered the average accuracy of the algorithm for the disease. Using the average accuracies of all algorithms, the percentile is calculated for the accuracies. The calculated percentile is used as the weighted average of the algorithm for the disease. For each disease, the above process is used to compute the weighted average for the binarization of the hybrid algorithm. Lastly, the enactment of this proposed technique is likened to the prevailing methods.
Results and discussion
In this session, the effectiveness of the proposed hybrid technique is discussed. The enactment of the proposed algorithm on the retinal image can be evaluated by likening the segmentation outcomes to the Gold Standard values. This proposed method is coded using Python with OpenCV and performed several trials on the openly accessible datasets DRIVE as mentioned in the earlier section.
Performance measures
Different performance indicators were used to evaluate the suggested approach. Accuracy (ACC), Sensitivity (SN), and specificity (SP) performance measures were used to evaluate the segmentation image and the ground truth image. It is required to understand the four basic parameters TP, TN, FP, and FN in order to employ these performance metrics.
In the segmented image of each algorithm, the pixels are differentiated as vessels and non-vessels. These have been indicated through coloured lines. The true-positive (TP) values represent the pixels that have been classified as vessels in both segmented and ground truth images. These pixels are indicated by green lines. The false-positive (FP) values represent the pixels that have been classified as a vessel in the segmented image but non-vessel in the ground truth image. These pixels have been indicated using red lines. The true-negative (TN) represents the pixels that have been highlighted as a non-vessel in the segmented and ground truth image. These pixels are indicated using black lines. The false-negative (FN) represents the pixels that have been highlighted as non-vessel in the segmented image however as a vessel pixel in the ground truth image. These pixels are indicated using the blue line.
The result of segmentation can be classified as accurate segmentation, under segmentation, and over-segmentation. Accurate segmentation: If both SN and SP are high, then vessels are properly segmented. Under segmentation: If SN is low and SP is high, the vessels are not appropriately recognized. Over segmentation: If the SN value is high and SP is low, the vessels are over-segmented.
Result images and performance evaluation
This section contains sample result images and performance values obtained using Python with Open CV for various segmentation approaches and the proposed hybrid algorithm method. For this randomly selected 20 images of the DRIVE dataset are tested.
Result obtained using MF (Matched Filter) has been given in Table 1 and the sample result image obtained using python is given in Fig. 3. MF is not a complicated approach. It is an efficient method for segmenting blood vessels by thresholding and filtering the original image. However, from the resulting image, we can observe that MF responds to non-vessel edges too, like vessels. Because of that, false vessels can also be detected.
Performance result of MF (implemented using Python with OpenCV)
Performance result of MF (implemented using Python with OpenCV)
Sample result of Matched Filter using Python on DRIVE database; TP (green), FP (red), FN (blue), TN (black).
Table 2 contains the result obtained using MF-FDOG (first-order derivative) method and sample result images are given in Fig. 4. MF-FDOG is a straightforward method. It significantly minimizes the detection of the false vessel than the original MF.
Performance result of MF-FDOG (implemented using Python with OpenCV)

Sample result of MF-FDOG using Python on DRIVE database.
Many fine vessels which are not identified by the MF are also identified by this method. In addition, this method performs well for the segmentation of vessels from pathological images.
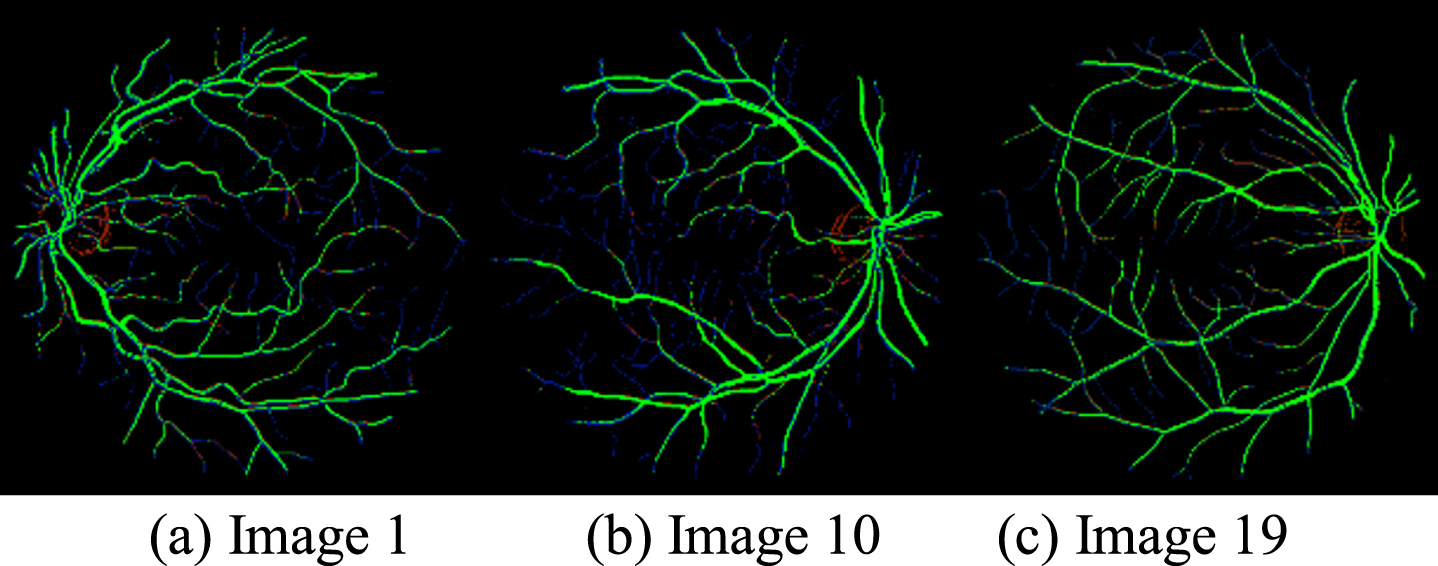
Result obtained using the method MSLD has been given in Table 3 and the sample result images are given in Fig. 5.
Performance result of MSLD (implemented using Python with OpenCV)

Sample result of MSLD using Python on DRIVE database Image 19. TP (green), FP (red), FN (blue), TN (black).
Figure 6 shows some examples results of the segmentation, which provides visual evidence of performance enhancement for the proposed hybrid algorithm. For instance, this proposed technique segments additional retinal vessels appropriately, particularly at the border. The integral geometrical structure is preserved well by this method.
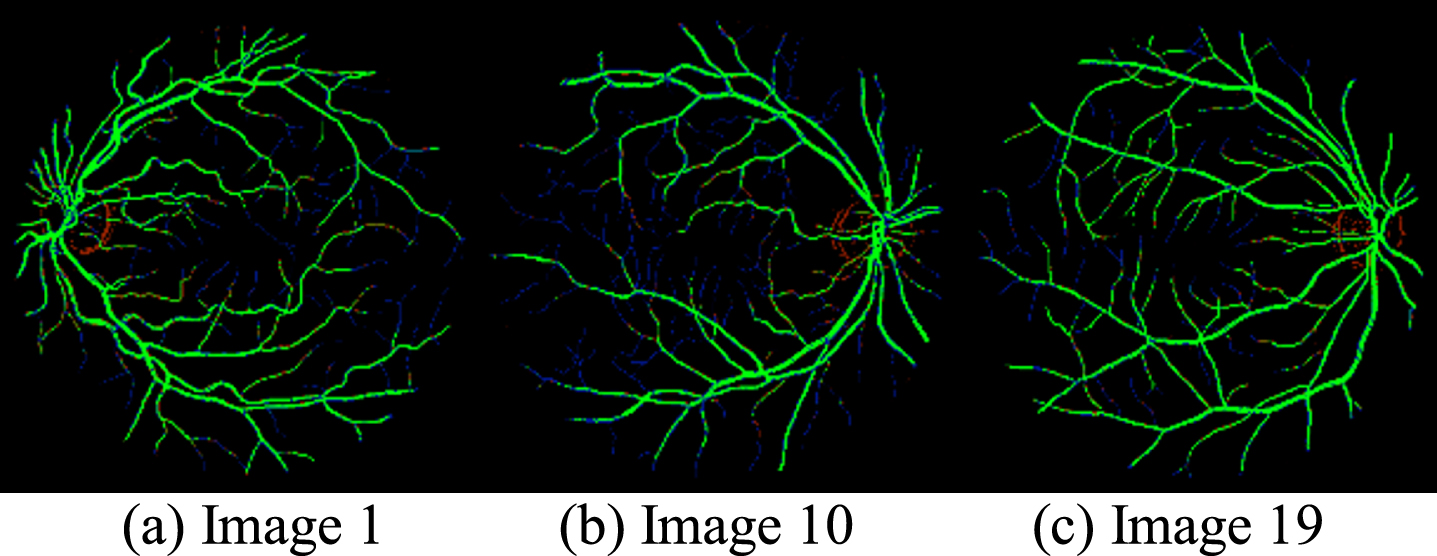
Sample result of proposed Hybrid algorithm using python on DRIVE database Image 19. TP (green), FP (red), FN (blue), TN (black).
Table 4 provides the outcomes of the proposed technique for the Drive dataset. The tabulated outcomes are the mean value of the 20-independent execution. The average of matrices for the datasets is given at the bottom of the table. According to the result in Table 4, the proposed technique achieved modest values in its corresponding enactment indexes.
Enactment result of the proposed hybrid algorithm on DRIVE dataset
To estimate the enactment of the proposed approach, the accuracy, specificity, and sensitivity of basic methods and a hybrid algorithm for all the 20 images are evaluated. Performance comparison of the DRIVE database amid the proposed technique and the existing techniques are shown in Table 5 and the values given in the table are extracted from the corresponding papers of the author. All the existing methods are mentioned by the corresponding year.
Comparative enactment of the proposed technique with other prevailing techniques on the DRIVE database
Comparative enactment of the proposed technique with other prevailing techniques on the DRIVE database
The comparison shows that this proposed technique improved its performance more than some of the prevailing methods in terms of accurateness and achieves the finest specificity result. The proposed algorithm is simulated using Python3.8 with OpenCV and achieves an average accuracy of 96.02% which is a little closer to the existing supervised methods and better than the unsupervised methods. According to the findings, supervised systems like [4, 24], and [21] outperforms the proposed model respectively 0.018 %, 0.014 %,0.34 %, 0.008 %,0.010 %,0.021 %, and 0.001 %. However, these systems have limitations in terms of time complexity and processing cost, and the model’s reliance on annotated data makes it difficult to extend to real-time data. Our hybridized framework had the advantages of the various segmentation models so that the resultant vessels did not miss any thin or thick vessels, outperforming most unsupervised models. As a result, the suggested hybrid algorithm can be implemented in a community health clinic context and used by ophthalmologists to make decisions about ocular illnesses.
A major objective of the proposed algorithm is to create an optimal retinal blood vessel segmentation algorithm that enables the early diagnosis of ocular conditions. We evaluated the performance of the proposed model with the DRIVE dataset, which segmented the thin and thick retinal vessels with various pattern recognition algorithms and then fused the results with a weighted average. Based on the results, our model obtained 0.9602, 0.6246, and 0.9815 for accuracy, sensitivity, and specificity. The model we developed outperforms the unsupervised model and doesn’t miss any vessel pixels. In addition, it does not have the same computing complexity or data dependence as supervised models. By automating the process of separating retinal blood vessels, the proposed hybrid algorithm can reduce the burden on clinicians. Despite the advantages of our model, manually updating parameters for different diseases is a challenging process. The model that we proposed simply detected positive instances of different diseases.
Conclusion
In this paper, a hybrid algorithm has been devised to accurately segment the blood vessel from a retina image and classify them. This proposed algorithm has achieved high accuracy and high specificity. Instead of using a single algorithm for implementing the segmentation, this algorithm hybridizes three algorithms by combining the advantage of each algorithm. This hybridization algorithm of the proposed approach allowed to improve the performance of the results.
Based on our achieved segmentation outcomes, it is probable to classify and differentiate the bio-marks in the retinal image and utilize them for clinical purposes. Also, this proposed framework can be applied to other types of publicly available datasets for segmenting extended structures. This proposed methodology gives an acceptable improvement in average accuracy and specificity, there are still certain features that can be further discovered. In the future, we will implement some optimization strategies to dynamically determine the weighted average and further we add a few more data sets to evaluate our model performance.
Footnotes
Acknowledgments
The authors with a deep sense of gratitude would thank the supervisor for his guidance and constant support rendered during this research.
Funding statement
The authors received no specific funding for this study.
Conflicts of interest
The authors declare that they have no conflicts of interest to report regarding the present study.