
Abstract
In India, most of the Science and Technology resources available are in English. Developing an Automatic Language Translation Engine from English (source language) to Tamil (target language) is very essential for the people who need to get technical resources in their native language. The challenges in designing such engines using Natural Language Processing (NLP) tools include Lexical, Structural, and Syntax level ambiguity. To solve these challenges, the development of a Part-Of-Speech (POS) tagger is essential. The Verb-Framed languages like Tamil, Japanese, and many languages in Romance, Semitic, and Mayan languages families have high morphological richness but lack either a large volume of annotated corpora or manually constructed linguistic resources for building POS tagger. Moreover, the Tamil Language has a low resource, high word sense ambiguity, and word-free order form giving rise to challenges in designing Tamil POS taggers. In this paper, we postulate a Hybrid POS tagger algorithm for Tamil Language using Cross-Lingual Transformation Learning Techniques. It is a novel Mining-based algorithm (MT), which finds equivalent words of Tamil in English on less volume of English-Tamil bilingual unannotated parallel corpus. To enhance the performance of MT, we developed Tamil language-specific auxiliary algorithms such as Keyword-based tagging algorithm (KT) and Verb pattern-based tagging algorithm (VT). We also developed a Unique pair occurrence-tagging algorithm (UT) to find the one-time occurrence of Tamil-English pair words. Our experiments show that by improving Context-based Bilingual Corpus to Bilingual parallel corpus and after leaving one-time occurrence words, the proposed Hybrid POS tagger can predict 81.15% words, with 73.51% accuracy and 90.50% precision. Evaluations prove our algorithms can generate language resources, which can improve the performance of NLP tasks in Tamil.
Keywords
Introduction
In NLP, the POS tagger plays an important role. Many of the NLP applications such as speech recognition, machine learning information processing, information retrieval, question answering, machine translation, and word sense disambiguation are using POS tags as a part of the application processing. It is observed from the literature survey that the work that has been carried out for POS taggers could be put under two major categories:
A. Rule-based tagger
A Constrained Grammar consists of a sequence of sub grammar each one consisting of a set of constraints that set context conditions. This type of tagger generally gives an accuracy of more than 90%. However, the difficulty in developing this type of tagger is the requirement of sound grammatical knowledge in the language of the POS tagger to be developed and the knowledge of computational linguistics. The rule-based tagger [4] is an error-driven transformation-based tagger. Initially, the algorithm assigned a tag based on the dictionary, some morphological rules and their probability for each word, capitalization, various prefix or suffix strings, etc. After all word tokens have been provisionally tagged, contextual rules are applied iteratively until a threshold is reached to correct the tags by examining small amounts of context.
B. Tagger using Learning-based algorithm
The machine acquires the knowledge by training itself on the tagged corpus. Then this knowledge is used to classify the word as a particular POS. The Learning-based algorithm can be classified as:
a. Stochastic-based Tagger
The supervised stochastic techniques automatically assign a POS to a word based on the probability that a word belongs to a particular tag or based on the probability of a word being a tag based on a sequence of preceding or succeeding words. The unsupervised stochastic techniques do not require a pre-tagged corpus, but instead, use advanced computational methods to induce tag sets and transformation rules.
The POS taggers developed using the statistical method are based on probabilistic measures. The probabilities are calculated using unigram, bigram, trigram, and n-gram methods [11]. For many morphologically rich languages like Japanese and Arabic, the Viterbi algorithm is used for tagging and disambiguation [18, 31]. The model [28] described using Hidden Markov Model (HMM) and Maximum Entropy (ME) based stochastic taggers for Bengali is very simple and efficient for automatic tagging even when the amount of available annotated text is small, had a much higher accuracy than the naïve baseline model.
The supervised system developed by [7] is based on a Conditional Random Field classifier for the task of POS tagging on Code-Mixed Indian social media Text. This system could successfully assign coarse as well as fine-grained POS tag labels for three different language pairs, such as English-Hindi, English-Bengali, and English-Telugu on three different social media platforms -Twitter, Facebook & WhatsApp.
The cross-lingual approach [9] used graph-based label propagation for knowledge transfer. The structure of the word [34] becomes more apparent by combining cues from multiple languages. The fundamental idea of this work is based on the patterns of ambiguity inherent in POS tag assignments that differ across languages. At the lexical level, a word with POS tag ambiguity in one language may correspond to an unambiguous word in other languages. The paper [36] utilized word embedding with anchor-based label propagation to improve the accuracy of cross-lingual part-of-speech tagging under the graph-based framework
b. Neural Networks
The machine learning or deep learning method requires a huge volume of the annotated corpus in a particular language to train the model at word level and character level. After training, the model predicts the tag of the words in the same language in which it has been trained. The tagging has been done in various languages such as Nepali [35], Malayalam [1], and Kannada [30] using Support Vector Machines. In [22], the model is created using two Recurrent Neural Networks. The first network makes the POS tagging of each sentence, while the second one indicates for each word whether it is a component of the subject or the predicate. The model using Bidirectional Long Short-Term Memory [16] showed noticeably better performance when the source language and the target languages belong to the same language family, and competitively performed with the highest average accuracies for target languages in different families.
Related work
In this section we present the literature overview of the automated hybrid part of speech tagging methods. Initially Syntactic structure development in the field of linguistics was extensively studied by Chomsky [5]. Harris [13] explored POS tagging in his initial work and the tagging was done manually by defined set of manually prepared rules. Several rule-based systems have been developed that aimed to improve accuracy and efficiency. However, developing rule-based systems needed a lot of manual effort in framing the grammatical rules and it was time-consuming. Then the statistical and machine learning-based approaches were introduced in the POS tagging task, and these approaches have been widely used for their simplicity and language independence. For example, Cutting et al. [10] proposed an HMM model that used a corpus containing about 500,000 words tagged text of the Brown Corpus and a raw corpus along with the training data. Maximum Entropy model for part of speech tagging was introduced by Ratnaparkhi [26]. Lafferty et al. [20] used Conditional Random Fields (CRF) for POS tagging. Neural Networks for part of speech tagging was used in [6, 15].
The remaining part of this section summarizes the work that has been carried out in the Tamil Language. A linear programming approach for POS tagging in the Tamil Language [8] has been demonstrated using Support Vector Machine (SVM) methodology. As the grammatically tagged corpus is required to develop the SVM model, they have designed their tagset consisting of 32 tags for preparing the annotated corpus for Tamil. They prepared a corpus by collecting corpora from Dinamani newspaper, Yahoo Tamil news, online Tamil short stories, etc. The annotated corpora are not publicly available. AUKBC-Tamil POS Corpus2016 v1 (AUKBC website [3]) is developed by the Computational Linguistic Research Group (CLRG), AU-KBC Research Centre, MIT Campus of Anna University. The Corpus was tagged by using Conditional Random Field and Bureau of Indian Standards Tagset.
The paper [23] proposed a tagger using a morpheme-based language model. In [29], the authors built a rule-based morphological analyzer and POS tagger via Projection and Induction techniques, which improve on rule-based POS tagging. A semi-supervised rule mining approach using morphological features [24] has been employed for Hindi, Tamil, and Telugu languages. The work has used a combination of small annotated and untagged training data to build a classifier model using a concept of context-based association rule mining that worked as context-based tagging rules. The paper [12] has presented a pattern-based bootstrapping approach using only a small set of POS labeled suffix context patterns. The patterns consist of a stem and a sequence of suffixes, obtained by segmentation using a manually created suffix list.
Human annotators [21] can correct the automatically annotated corpus with less effort, and the corrected annotated data set can be used iteratively to re-train the tagger. Thus, graph-based semi-supervised approaches are particularly useful for the POS tagging of low-resource languages such as Tamil. The POS Tagging [25] for the women’s health-related documents is implemented and tested for 53 documents by using Naïve Bayes’ classification method.
The approaches that have been carried out in POS tagging either require deep linguistic knowledge of the language to frame the grammatical rules or require a large volume of the pre-tagged corpus to train the model. The grammatical rules thus framed are not a common rule that could be applied to any language, because the structural ambiguity, lexical ambiguity, word order form, etc., differs from one language to another language. The other requirement that is not much addressed in the existing work is the domain knowledge of the words to be tagged.
The key idea in our proposed work is how to develop the POS tagging system for the Tamil language by eliminating the requirements such as the need for grammatical rules and the need for a large volume of the pre-tagged corpus, which is an overhead to the existing system. Our major contributions to the proposed work focus on building the POS tagging system 1. By applying the Cross-Lingual Transformation Learning technique for transferring the annotations of English words to their equivalent Tamil words and 2. By applying the association rule mining approach in a suitable way such that its support and confidence are used to find the equivalent of Tamil words in English. The above two approaches are language-independent. As our work specifically focuses on Tamil words, we developed a pattern-matching algorithm such as a Keyword-based algorithm and Verb-based algorithm to enhance the system with the use of created word feature set. We also developed an algorithm to find and tag the one-time occurrence of Tamil-English pair words.
The proposed approach
As Tamil is a morphologically rich language, framing the lexical rules of the language in constructing the rule-based tagger is a tedious process. The Tamil language low-resource language due to the less availability of pre-annotated corpus. As the learning-based algorithm requires a pre-annotated corpus, it requires a lot of effort to create the corpus manually. In such an environment, the proposed work seeks to develop a POS tagging system for the Tamil Language and to examine how the developed system with its new practices will contribute to the overall effectiveness by determining the percentage of tagged words, accuracy and precision of the system.
The proposed work starts from preparing the parallel corpus. Three parallel corpora are used in our work to make a comparative analysis of the characteristics of the dataset. The first corpus is taken from Tatoeba Project, the second one is prepared manually from a school textbook and the third one is prepared with the help of Google Translation Engine. All these corpora are less in volume, having less than 200 lines each. The proposed approach predicts the POS tag of words in the Tamil language without the requirement of either intense grammar rules or pre-annotated corpus. The proposed hybrid tagger has Keyword-based Tagger (KT), Verb pattern-based Tagger (VT), Unique pair occurrence Tagger (UT), and Mining-based Tagger (MT). The primary tagger, MT works on the association rule mining technique and uses the maximum likelihood estimation method to predict the POS tag of a word. The significance of MT is it is not language-specific. The performance of MT is improved using the auxiliary taggers viz, KT, VT, and UT. The auxiliary taggers are not only increasing the number of tagged words, accuracy, and precision but also reducing the time complexity of MT. The auxiliary taggers KT and VT are language-specific taggers. The effectiveness of the proposed algorithm on the Tamil tagged corpus is measured in terms of the percentage of the tagged words, accuracy and precision. The performance of the proposed algorithm is compared among the datasets.
The System architecture is shown in Fig. 1. The English-Tamil corpus is given as input to the system. After it is pre-processed, the proposed hybrid POS tagger tags the Tamil words with the help of a Word Feature set and annotated English corpus. The POS tagged Tamil corpus is obtained as the output of the system along with a bilingual dictionary.
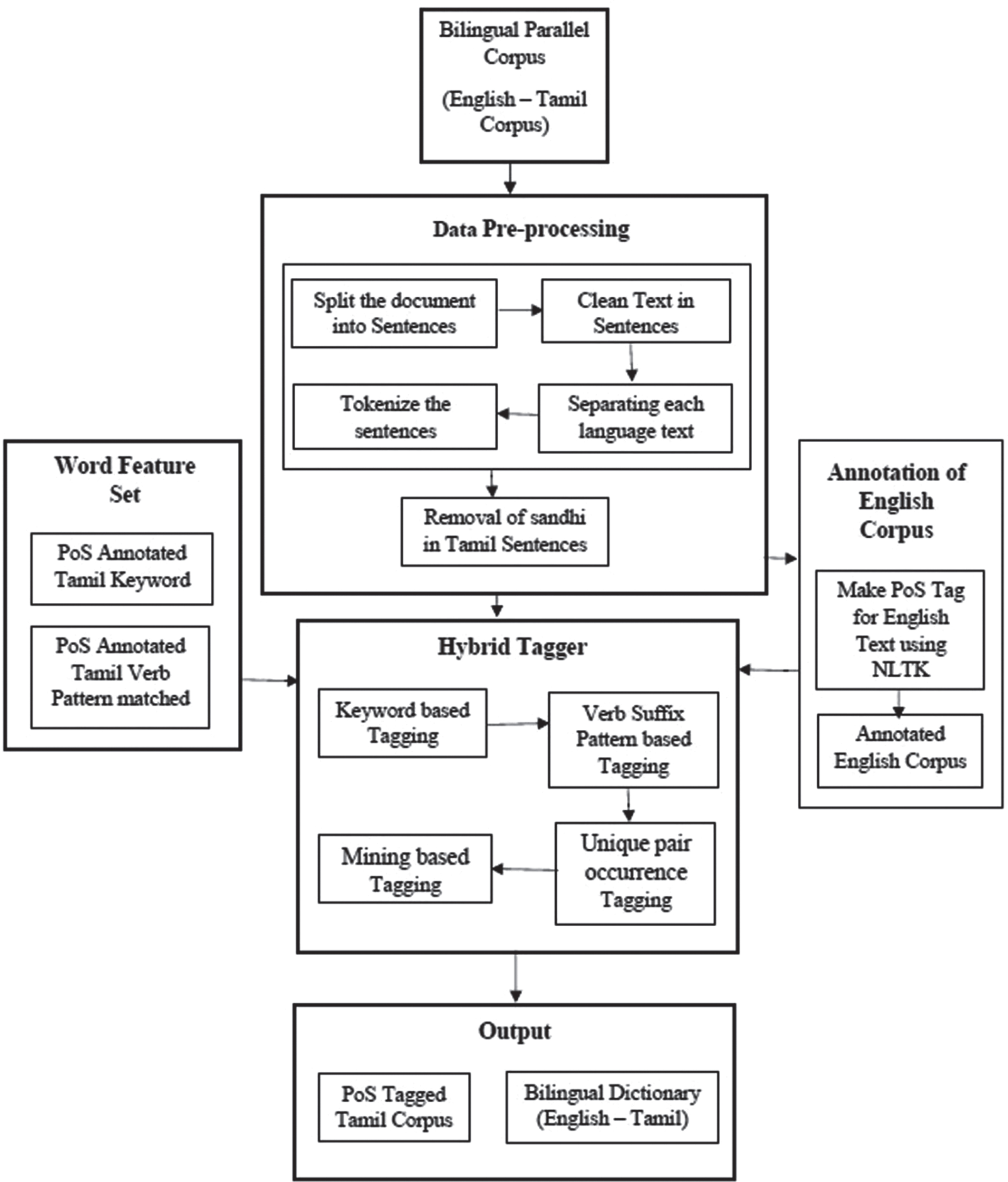
Proposed system architecture.
A corpus is a representative subset of a language having an optimum and adequate size so that it is useful for any linguistic analysis. The bilingual parallel corpus, out of which one language must be in English and the other language is the language in which the words to be tagged, is used as an input to the system. As the proposed work deals with the Tamil words to be tagged, the English-Tamil parallel corpus where each sentence in the English language is paired with its translation into the Tamil language is required. A parallel corpus of literature, religion books, mining of parallel content from the bilingual websites, etc., can be used as an input to the system.
Data pre-processing –sandhi removal
After splitting the bilingual parallel corpus into sentences, which has both Tamil and English sentences is cleaned by removing the punctuations and then the English and Tamil texts are separated. Each word of both languages is tokenized. Sandhi is a joining term for a wide variety of sound changes that occur at morpheme or word boundaries. Sandhi can be either internal which occurs at morpheme boundaries within words or external which occurs at word boundaries. Between two words, there are four possibilities of writing those words based on their pronunciation, namely a letter may be inserted/deleted/altered/come naturally without any change. The proposed work considers the sandhi that has been inserted at the word boundary. Removing this sandhi, makes the proposed hybrid tagger to predict more number of words correctly. The Fig. 2 shows an example.
The word ‘him’ appeared in all four sentences. Its translated text in Tamil is ‘’ which is highlighted. Either one of Sandhi characters  occurred at a word boundary, joins ‘
occurred at a word boundary, joins ‘ ’ with the next word in the Tamil Sentences. Fig. 2(b). Sandhi letters are removed from the Tamil word. Wherever ‘’ appears in Tamil Sentence, its translated sentence has ‘him’. This makes the proposed tagger predict more likely word of ‘’ is ‘him’
’ with the next word in the Tamil Sentences. Fig. 2(b). Sandhi letters are removed from the Tamil word. Wherever ‘’ appears in Tamil Sentence, its translated sentence has ‘him’. This makes the proposed tagger predict more likely word of ‘’ is ‘him’
Preparation of POS annotated Tamil Keyword
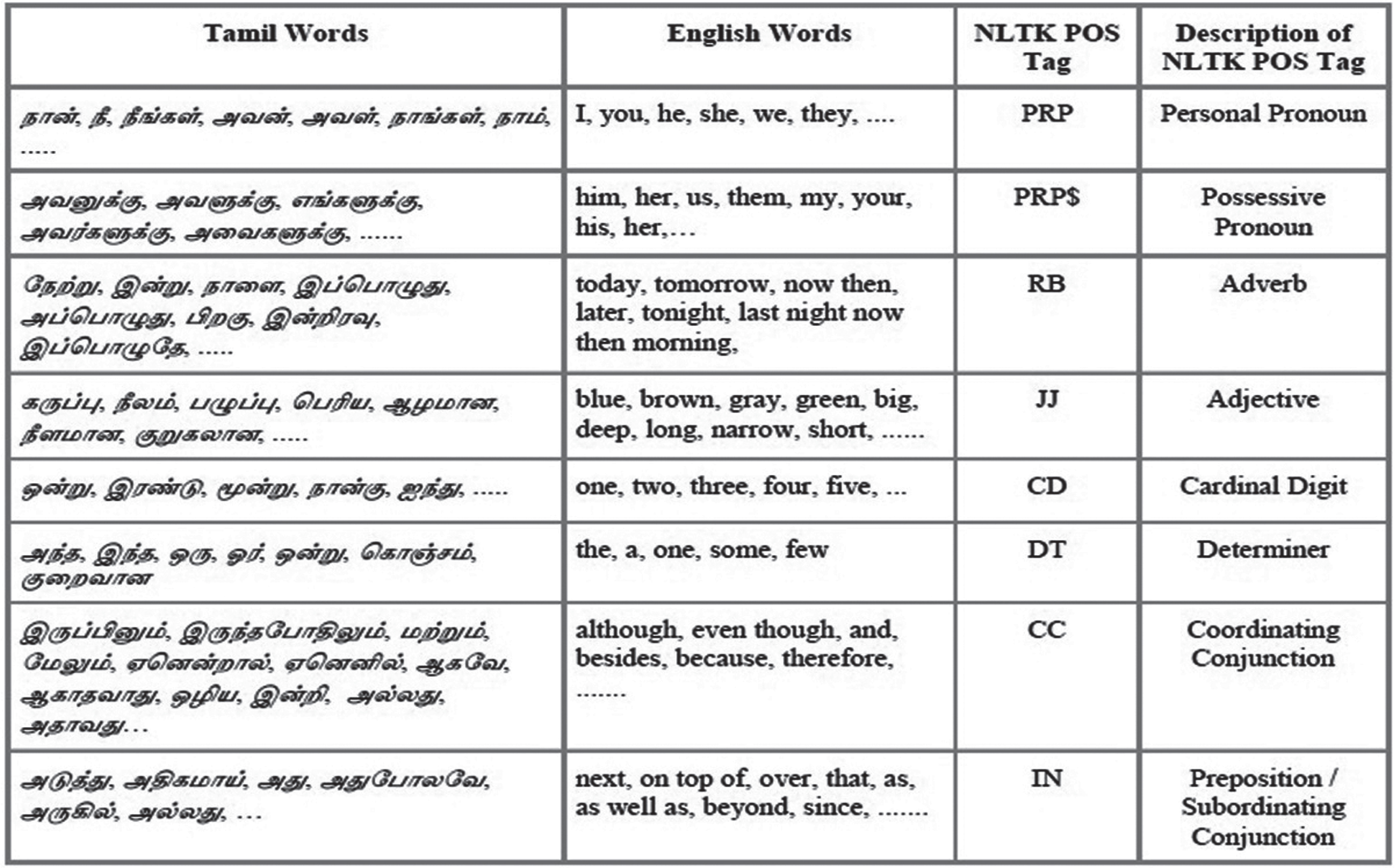
The list of frequently occurred Tamil words from Normal/Conventional Context with its translation in English is prepared and assigned suitable POS tag from NLTK POS Tag List as shown in Table 1. The KT uses this feature set to tag the words by direct mapping without any computation complexity.
For the defined list of Tamil Words, a suitable POS tag from the NLTK POS tag list is assigned. The translation of Tamil words in English and the description of the NLTK POS tag is also shown.
For the defined list of Tamil Words, a suitable POS tag from the NLTK POS tag list is assigned. The translation of Tamil words in English and the description of the NLTK POS tag is also shown.
Tamil is an agglutinative language in which suffixes are added to a nominal or a verbal lexical root to convey grammatical information, like a person, number, and cases. Most of these affixes can be derivational or inflectional. The list of suffixes, which ends with verbal words are prepared as shown in Table 2 and then assigned a suitable NLTK POS tag. VT uses this feature set to tag the words by suffix pattern matching.
Verb suffix patterns of Tamil words are identified and assigned suitable NLTK POS tags for those patterns.
Verb suffix patterns of Tamil words are identified and assigned suitable NLTK POS tags for those patterns.
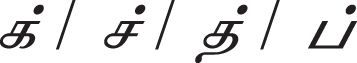
There are many POS taggers in NLTK Library namely Unigram Tagger, Bigram Tagger, Trigram Tagger, Perceptron Tagger, Brill Tagger, Conditional Random Fields Tagger, and Classifier Based POS Tagger. Among these taggers, the results from [27] show the highest accuracy up to 88.7% with the perceptron tagger having 80% of the train data and dropping to 1.6% when using half of the data as the training set. Hence, the perceptron tagger is used to tag the English words of our corpus.
Hybrid POS Tagger
The procedure of the proposed hybrid tagger has KT, VT, UT, and MT. These taggers are invoked in the order given in Algorithm 2 so that the untagged Tamil words are passed to successive taggers.
Keyword-based Tagger
The KT treats each Tamil word as a keyword and searches the lookup table of POS Annotated Tamil Keyword feature set for direct mapping of the keyword. If the keyword is there in the feature set table, then the KT assigns its corresponding feature i.e. tag to the keyword. This direct mapping is done for the closed set of POS tags - Personal Pronoun, Possessive Pronoun, Adverb, Cardinal Digit, Determiner, Coordinating Conjunction an,d Preposition / Subordinating Conjunction, with the finite number of words in each tag. As these words frequently occur in the sentence with less or no ambiguity of assigning POS tags, it does not require much computation in finding the tags of a word. Thus, direct mapping reduces the computation complexity of MT.
Verb Suffix pattern-based Tagger
The VT uses the POS Annotated Tamil Verb Pattern matched word feature set to tag the words that match with the verbal suffix pattern. The feature set has some finite verb suffix patterns with its corresponding tags. In Tamil, the verb with suffixes could convey many features like tense, person, number, gender, etc., But as the proposed work restricted to tag with NLTK tag list for generic purpose, it considers only the tense of the verb.
Unique pair occurrence Tagger
The UT is useful to tag when both Tamil word with their translated text in English, occurs only one time in the same sentence of the whole corpus. In any application of an NLP system, the word that occurs one time in the corpus has not been considered. The results from the General text corpus show that around 5% of such words are tagged with 4% accuracy.
Mining based Tagger(MT)
The mining approach
The primary tagger MT employs the association rule mining technique and maximum likelihood estimation method. The association rule mining technique uses support and confidence to find how far a Tamil word in a sentence is associated with all the words in English in its translated sentence. The maximum likelihood estimation method uses this association or correlation values to find more likely associative English word of given Tamil and then assigns POS tag of the more likely associative English word to Tamil word. This technique is not a language-specific one.
The significance of bringing the association rule mining for tagging the words in the NLP system is the words of any language could be tagged with neither the requirement of framing the lexical rules nor the pre-annotated corpus. The only requirement is the input to the system has to be in the form of the bilingual parallel corpus, the language in which the words to be tagged act as source language and its translated text in the English language will be the target language.
Consider a sentence from parallel corpus, shown in Fig. 3. English is a fixed word-order language whereas Tamil language word-order is flexible. Flexibility in word order represents that the order may change freely without affecting the grammatical meaning of the sentence. Figure 3 shows the two versions of the word-order difference of Tamil sentences for the English sentence “Where are we”. The word “ ” appears as the first word in the first diagram and the second word in the second diagram and the meaning of the word “
” appears as the first word in the first diagram and the second word in the second diagram and the meaning of the word “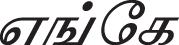 ” in English is “where”. The association of the word “” with the remaining three words “where”, “are” and “we” are found by using the mining method. The more likely associated word of “” is done by the maximum likelihood estimation method. After predicting the more associated word “where”, the POS tag of “where” is assigned to “”
” in English is “where”. The association of the word “” with the remaining three words “where”, “are” and “we” are found by using the mining method. The more likely associated word of “” is done by the maximum likelihood estimation method. After predicting the more associated word “where”, the POS tag of “where” is assigned to “”

(a) and 3(b) are the free word-order form of Tamil words in the sentence.
Consider the language of the word to be tagged by a source language and its translated text in English be a target language.
Association rule mining. Association rule mining is one of the data mining techniques that finds interesting association or correlation relationships among a large set of data items. This discovery of interesting association or correlation relationships among huge amounts of transaction records helps in finding the association relationship of words in the source language with the target language. Let us consider the following assumptions for representing the Association rule in terms of mathematical representation,
C be the Bilingual Sentence Pair Parallel Corpus
S and T be the set of Parallel Corpus in the source language and target language
L, M, and N be the number of sentences in parallel Corpus, number of unique words in S, and number of unique words in T respectively
S_W={sw1, sw2, . . . , swM} be a set of words in S
T_W={tw1, tw2, . . . ,twN} be a set of words in T
SWi={sw1, sw2, . . . , swm} be a set of words in an ith sentence of source language S
TWi={tw1, tw2, . . . ,twn} be a set of words in ith sentence of target language T
SSi and TSi be the ith sentences of S and T and are the set of words such that SSi⊆SWi and TSi⊆TWi
SPi ={SSi, TSi} be the ith line of parallel sentence pair of SSi with its translation in TSi
Support(X->Y) refers to the number of sentences SPi that contain a word X in SSi and Y in TSi to the total number of sentences.
Where the symbol |.| denotes the number of sentences in the corpus, is an indication of how frequently the words X and Y together appear in SPi in the Corpus.
Let X, Y be the words in SSi and TSi where i∈L and an association rule of words in S and T is an implication expression of the form X⇒Y where X and Y are disjoint word sets i.e., X∩Y=Ø.
Support determines how often a rule applies to a given word set, while confidence determines how frequently a word Yappearsr in its translated sentence that contains the word X. Confidence suggests a co-occurrence relationship between words in the antecedent and consequent of the rule. For a given rule X ⟶ Y, the higher the confidence, the more likely it is for Y to be present in the parallel sentence pair that contain X. It also estimates the conditional probability of Y given X.
Maximum likelihood estimation. The likelihood of a word SWij, jth word of an ith sentence from S being translated as TWij is found by finding the conditional probability of every other word in an ith sentence of the target language. The TWij that has the highest probability with the SWij is likely to be the translated word of SWij,
Algorithm to find an association between the source and target word. Algorithm 6 uses the confidence to check the association between a source word(S) in Tamil and a target word (T) in English. Confidence is the ratio of Support(S ->T) to Support(S). Support(S->T) is the number of sentences in the corpus that has the word S in a Tamil sentence and word T in its translated sentence. Support(S) is the number of sentences in the corpus that has the word S in the Tamil sentence. The time complexity is given by O(LW), where L is the total number of lines in either Tamil or English corpus and W is WT+WE, the total number of words in both Tamil and English corpus.
Algorithm to find more likely associated word. Algorithm 7 finds the more likely translated word of a Tamil source word. Among the target words in a sentence, the word that has more confidence with the source word is more likely to have an association with the source word. Then the POS tag of the target word is assigned to the source word. The above process is repeated for all source words of all sentences in the Tamil Corpus. The time complexity is O(L* WT *WE).
The complexity of the overall mining tagger that uses algorithm 6 and algorithm 7 is O(L* WT *WE *L *(WT+WE)), approximated to O(L2W2). To reduce this complexity, the algorithm skips the source word that is already POS tagged by the first three algorithms KT, VT, and UT. After finding the association between a Tamil word of a sentence with all of the English words in its translated sentence using the above algorithm, the more likely associated words or translated word of a Tamil word is found by this algorithm.
Data output
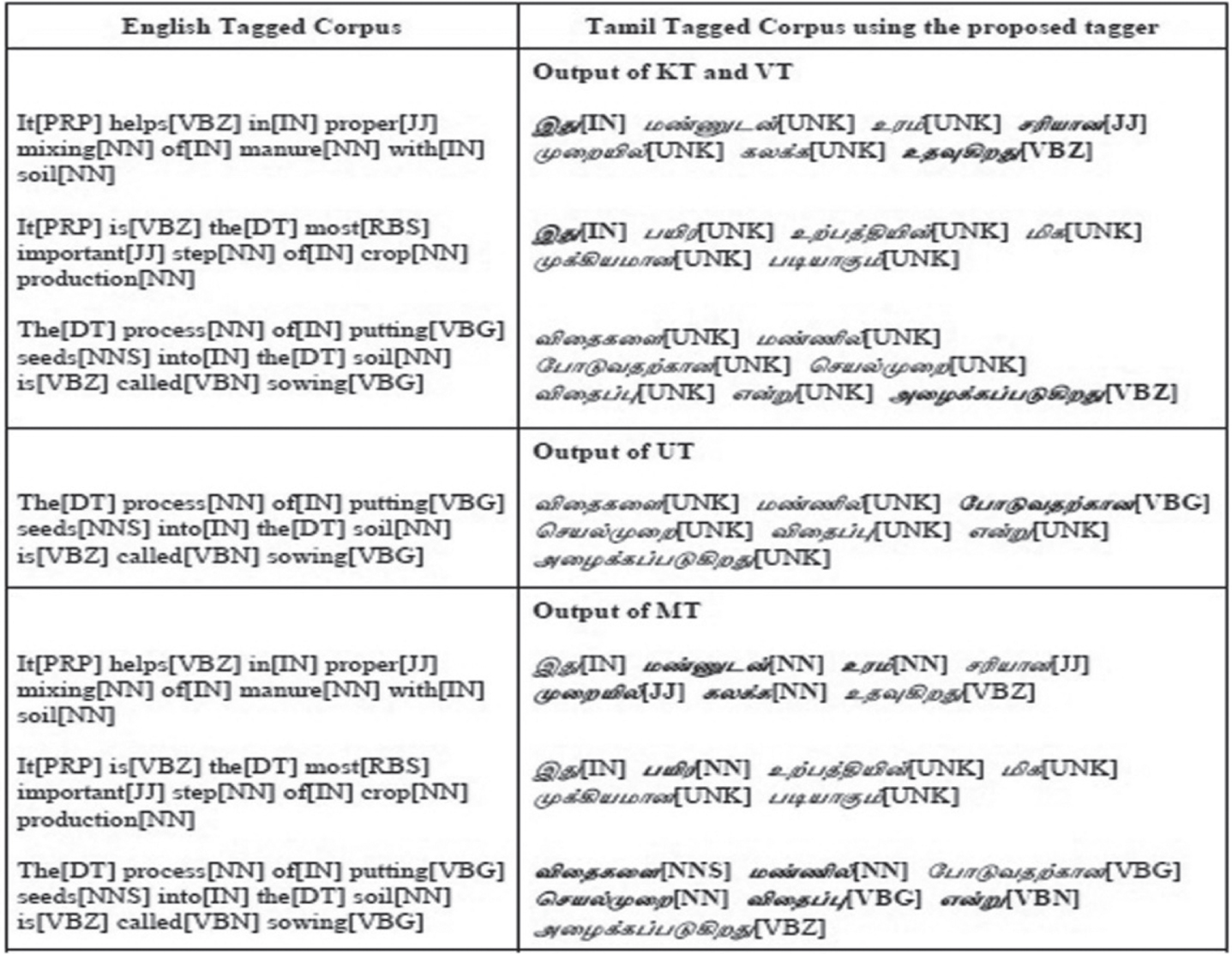
The proposed Hybrid POS tagger outputs the POS annotated Tamil Corpus shown in Table 3. As basically the MT works on mapping the Tamil words with its translated text in English, the proposed system creates a bilingual dictionary with its annotations, shown in Table 4.
Three sentences of Tamil Tagged words of Corpus III are shown along with its parallel tagged text in English. The UNK in the Tamil Tagged Corpus represents the tag of those words that are unknown. For the same three sentences, the table shows the tagged words in ‘bold’ text that is tagged by the various proposed hybrid tagger.
Three sentences of Tamil Tagged words of Corpus III are shown along with its parallel tagged text in English. The UNK in the Tamil Tagged Corpus represents the tag of those words that are unknown. For the same three sentences, the table shows the tagged words in ‘bold’ text that is tagged by the various proposed hybrid tagger.
Tamil-English dictionary created by proposed mining tagger for the words appeared in three sentences of Table 3. Here Tamil word is a searching word, its associated word in English, and its POS tag. The remarks show the correctness of the associated word of Tamil in English, which is entered manually.
Dataset
The dataset is a collection of Tab-delimited Bilingual Sentence Pairs Parallel Corpus. The parallel corpus contains a collection of original texts in the source language is English and their translations into a target language in Tamil. The dataset is neither aligned nor annotated corpus. There are three datasets used here namely,
A. General Text Corpus (Corpus I)
The English-Tamil Language sentence pair dataset from the collection of Tatoeba Project datasets is downloaded from the website: https://www.manythings.org/anki/. This corpus has 199 lines, 987 English words, 777 Tamil words and contains a collection of colloquial sentences pair. Out of 777 words in Tamil sentences, 407 words have occurred only once in the corpus. The remaining 370 words appeared more than once in the corpus.
B. Crop Production Corpus (Corpus II)
The corpus from the English Version and its translated Tamil Version of the Science Textbook of Tamil Nadu State Board Syllabus of Standard 8 is prepared manually. Though the sentence pairs of Corpus II are not an exact translation of Tamil Sentences with English Sentences, it provides a similar contextual meaning of the sentence. There are 1582 words in English and 1206 words in Tamil Texts available in 124 parallel sentences, out of which 663 Tamil words have appeared only once.
C. Crop Production Corpus –Google Translated Text (Corpus III)
As the Crop Production Corpus has not had exact translated text in each sentence, Corpus III is developed by taking the English sentences from Crop Production Corpus, and its translated sentences are taken from Google Translate (GT) by giving line by line to GT Engine. It has 124 English Sentences is as same as in Corpus II with its GT translated Tamil Sentence. There are 1144 Tamil words, in which 555 words have occurred only once.
Performance evaluation metrics
Accuracy is defined as the number of Tamil words that are correctly tagged concerning a total number of Tamil words in the dataset/corpus.
Precision is defined as the number of Tamil words that are correctly tagged concerning a total number of tagged words.
Experimental analysis
The English words were tagged by using the NLTK POS Tagger Library. The proposed Hybrid POS Tagger algorithm was run on POS annotated English Sentences to tag Tamil Words. The performance of each tagger in the proposed hybrid tagger is studied to know the contribution of each tagger. The performance of overall hybrid system is also analysed on each corpora. The analysis was made on all three corpora by both considering one-time occurrence words and not considering one-time occurrence words. It is observed from all three datasets, nearly 50% of Tamil words appear only once in each of the corpora. The precision of KT is 100% in all three corpora as it is purely based on matching words.
A. General Text Corpus (Corpus I)
The evaluation metrics like percentage of tagged words, accuracy, and precision of each of the taggers in the proposed hybrid tagger system are shown in Fig. 4(a) and the same metrics after leaving one-time occurrence are shown in Fig. 4(b). Corpus I has more casual and conservative words, the more words are pronouns and verbs in nature. The KT and VT of the proposed Hybrid Tagger play a major role in identifying and tagging the Tamil words shown in Fig. 4(a) and 4(b). There is a drop in the percentage of tagged words by VT in Fig. 4(b) which indicates that not only the UT tags one-time occurrence words, the VT also tags the one-time verb that matches the suffix pattern.
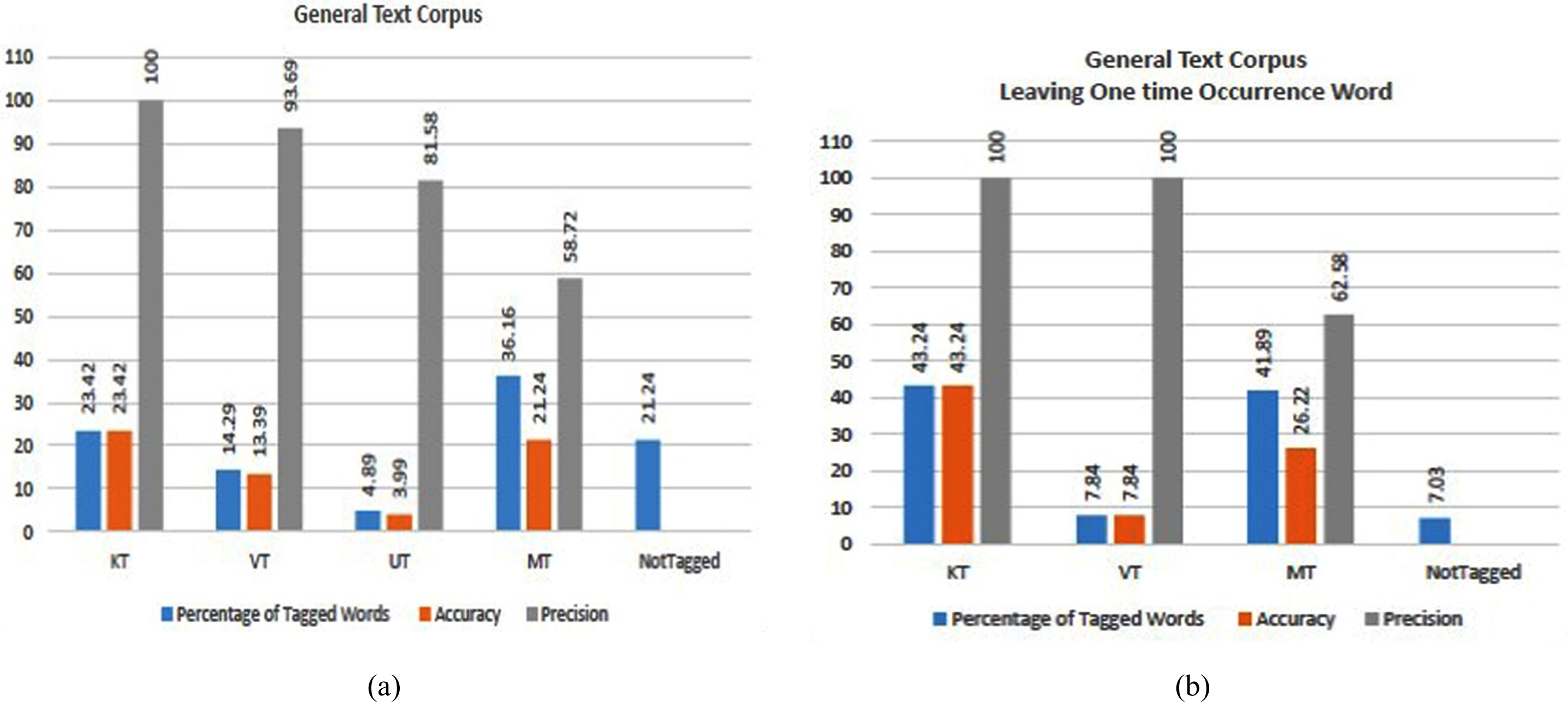
The output of proposed taggers KT, VT, UT, and MT. The precision of KT, VT, and UT is better. The 4% of one-time tagged words are correctly tagged by UT. 21% of words are not tagged. Figure 4(b) Output of proposed taggers KT, VT, and MT after leaving one-time occurrence words. Compared with 4(a) there is a drop in the output of VT, a reduction in the percentage of not tagged words. The output of VT and MT is improved.
The overall performance of the proposed hybrid system for Corpus I is shown in Fig. 5(a). The proposed hybrid algorithm with leaving one-time occurrence words outperforms when one-time occurrence words are considered. The subset of words in the entire corpus is considered when the one-time occurrence words are not taken into account. It is found that the percentage of tagged words is 92.97%, accuracy is 77.3% and the precision is 83.14%.
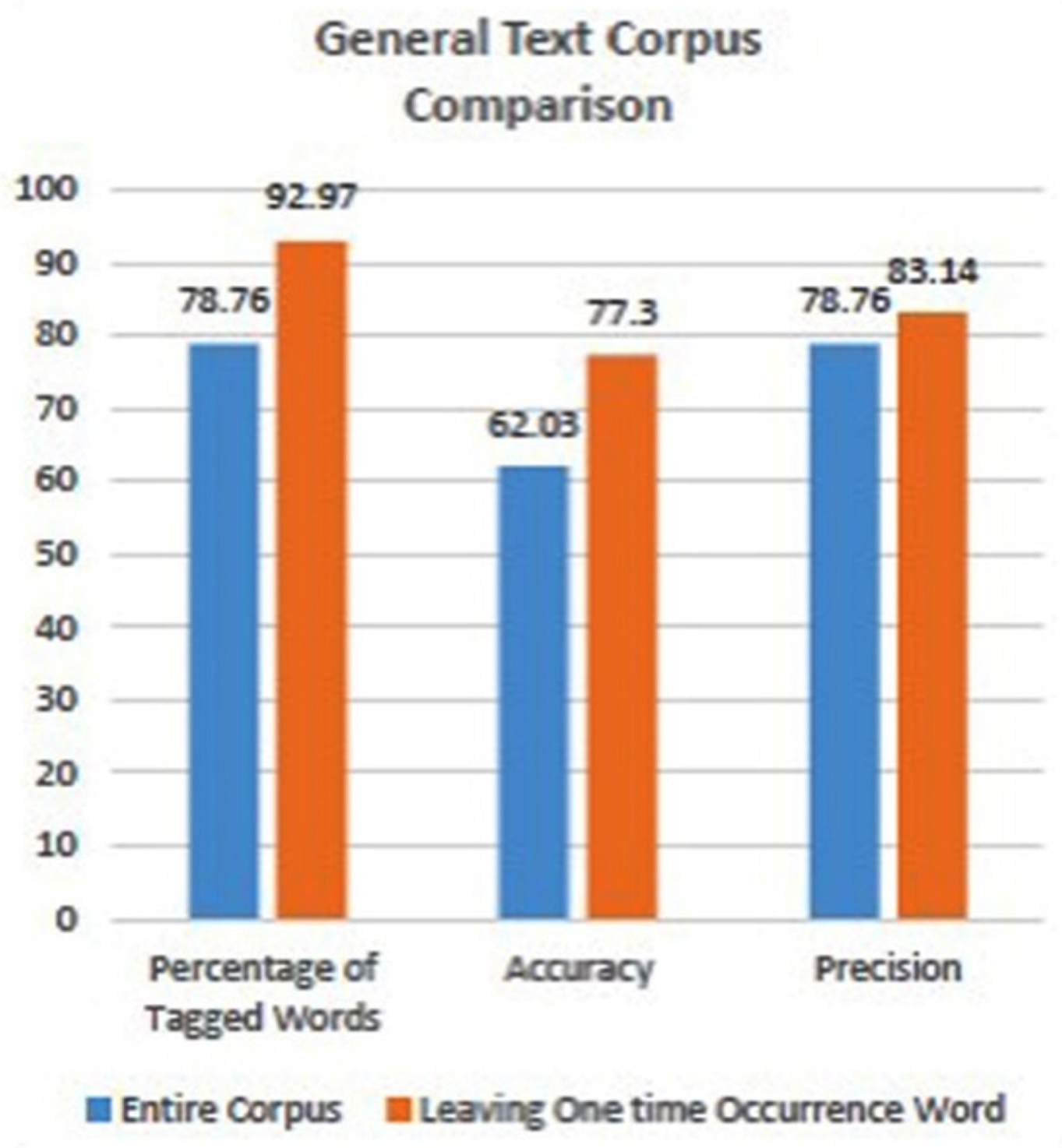
Comparison between the overall performance of the proposed hybrid system including and excluding one-time occurrence word of General Text Corpus.
The precision of tagged Tamil words of the entire corpus I and after leaving one-time occurrence words is shown in Fig. 6(a). The words are classified as 16–18 categories of POS tags such as PRP (Personal Pronoun), NN (Noun), RB (Adverb), JJ (Adjective), etc., The X-axis shows that words that are classified as particular POS tags mentioned in NLTK library. The following is the list of POS tags of what each POS stands for: CC - coordinating conjunction, CD - cardinal digit, DT- determiner, EX - existential there, FW - foreign word, IN - preposition/subordinating conjunction, JJ - adjective ‘big’, MD - modal could, will, NN –singular noun, NNS - plural noun, NNP –singular proper noun, NNPS - plural proper noun, PDT –predeterminer, POS - possessive ending, PRP - personal pronoun, PRP$ - possessive pronoun, RB - adverb, VB - verb base form, VBD - verb, past tense, VBG - verb, gerund / present participle, VBN - verb, past participle, VBP - verb singular present, VBZ -verb, third person singular, WDT - wh-determiner which, WP - wh-pronoun who, what, WP$ possessive wh-pronoun whose, WRB - wh-abverb where, when, etc., The proportions of precision of categorization of POS tags are shown in Fig. 6(b) and 6(c).
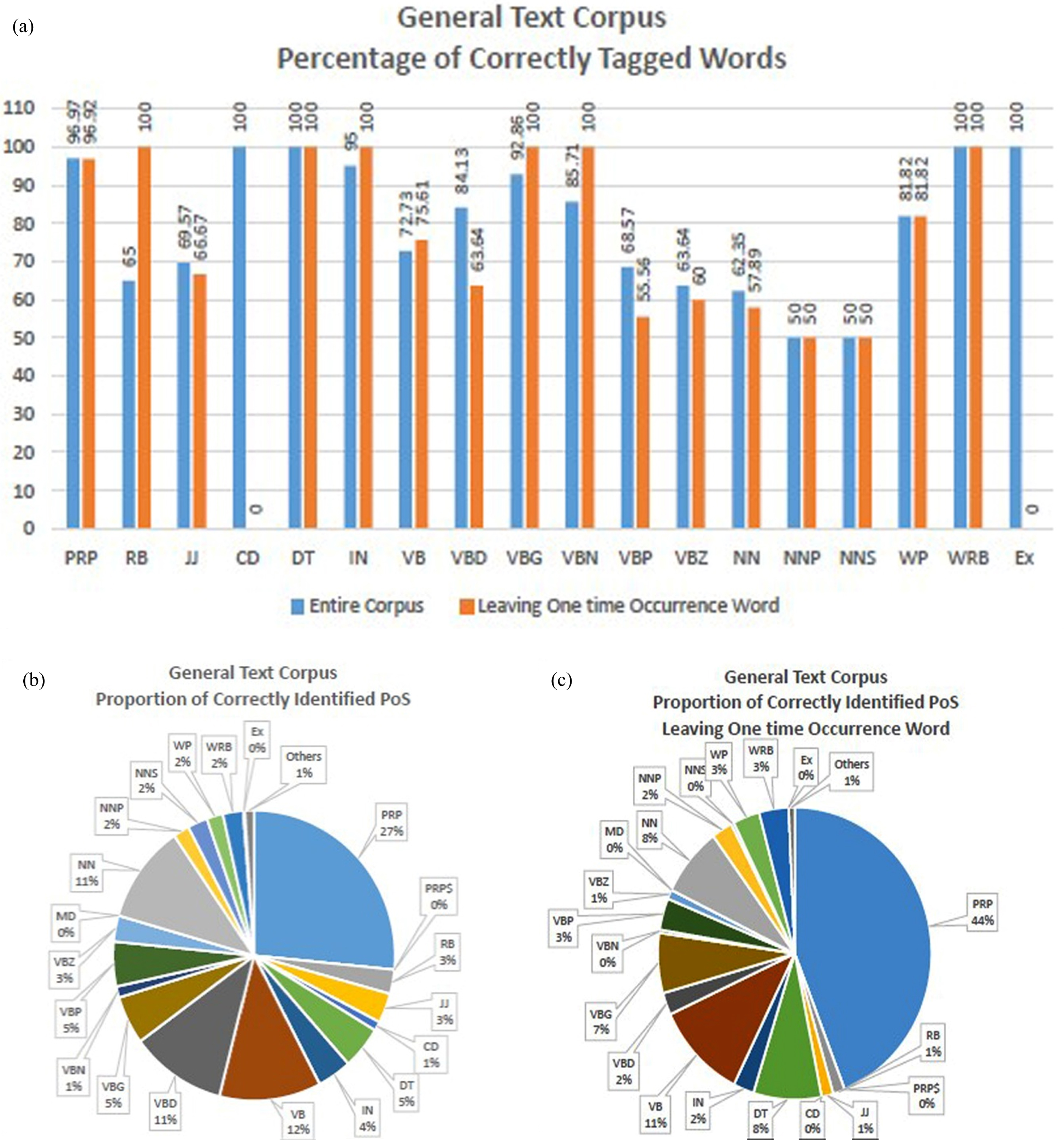
The precision of Tagged Tamil words under the various category of POS tags. Fig. 6(b) and (c). The proportion of precision of various POS tags for the entire corpus and after leaving one-time occurrence words.
Corpus II is not an exact parallel corpus, but it has context-based translated text. The number of words in the parallel sentences and the structural pattern of the parallel sentences is not mapped. Each sentence in Tamil / English might have one or more sentences in its translated sentence. This type of corpus is a challenging dataset for any type of tagger. However, this type of corpus is readily available in large volumes on the Web and Social Media in almost all areas like politics, health care, movies, religious books, law, etc.,
As this Corpus does not have many words that are in the proposed word feature set, the percentage of tagged words by KT and VT are less, which is shown in Fig. 7(a) and 7(b). The Corpus does not have the words suitable for UT, only 0.17% of words are tagged by UT. Here the MT plays a major role in assigning the POS tags to Tamil words. Figure 7(a) and 7(b) shows that approximately two-thirds of correctly identified tags have come from MT.

The output of proposed taggers KT, VT, UT, and MT. The precision of KT and VT is 100%. The accuracy of MT is 17.58% and its precision is 61.63%. 59.2% of words are not tagged. Figure 7(b) Output of proposed taggers KT, VT, and MT after leaving one-time occurrence words. Compared with 7(a), the accuracy and precision of MT is increased to 34.99% and 67.62%.
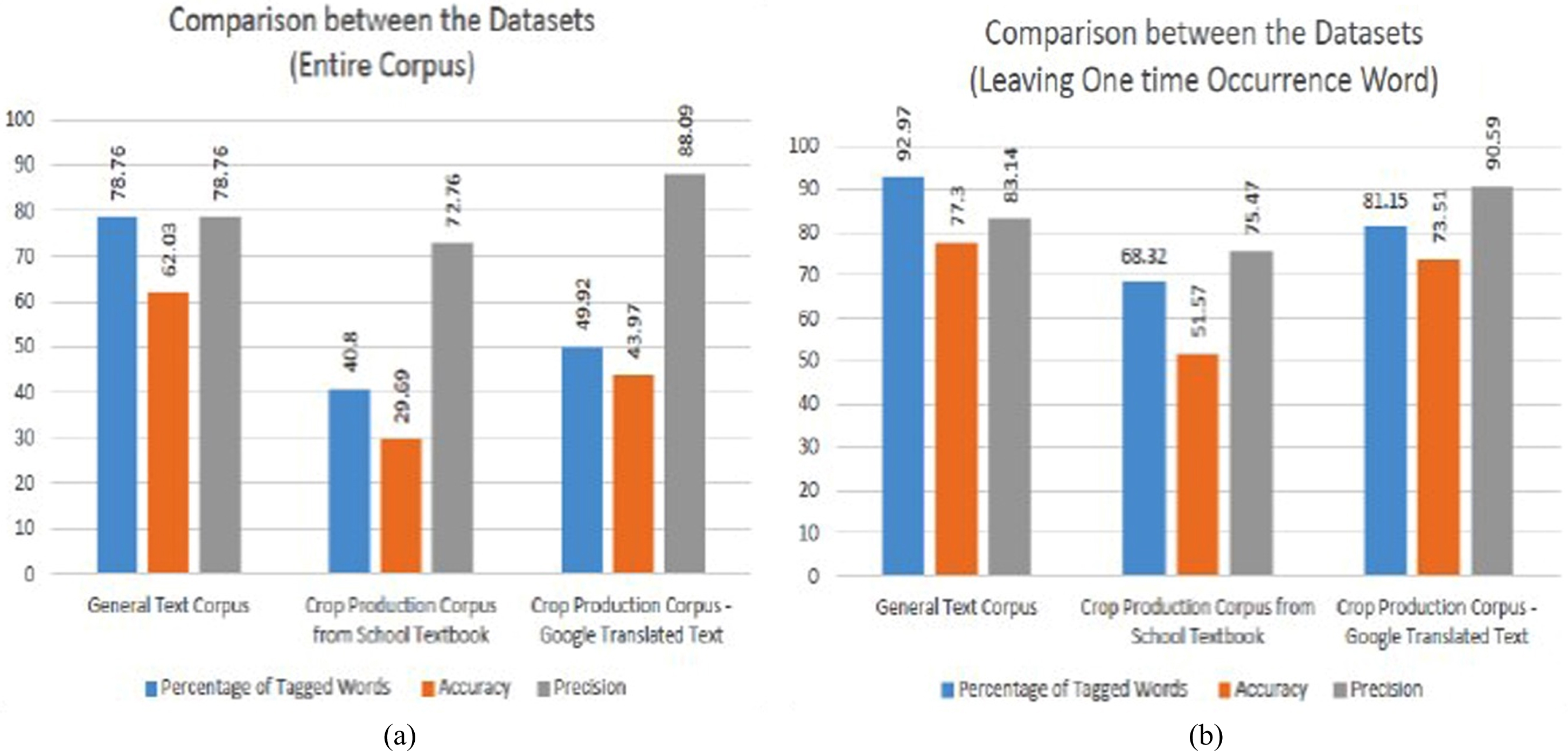
Despite its challenging characteristics of the morphological richness of the Tamil Language, quality of corpus parallel text suitable for computation, the volume of the corpus, and nearly 55% of onetime occurrence Tamil words in this corpus, the proposed Hybrid algorithm has produced good results that are shown in Fig. 8. After leaving one time occurrence words, the proposed algorithm increases the percentage of tagged words from 40.8% to 68.32%, increases the accuracy from 29.69% to 51.57% and increases the precision from 72.76% to 75.47%.
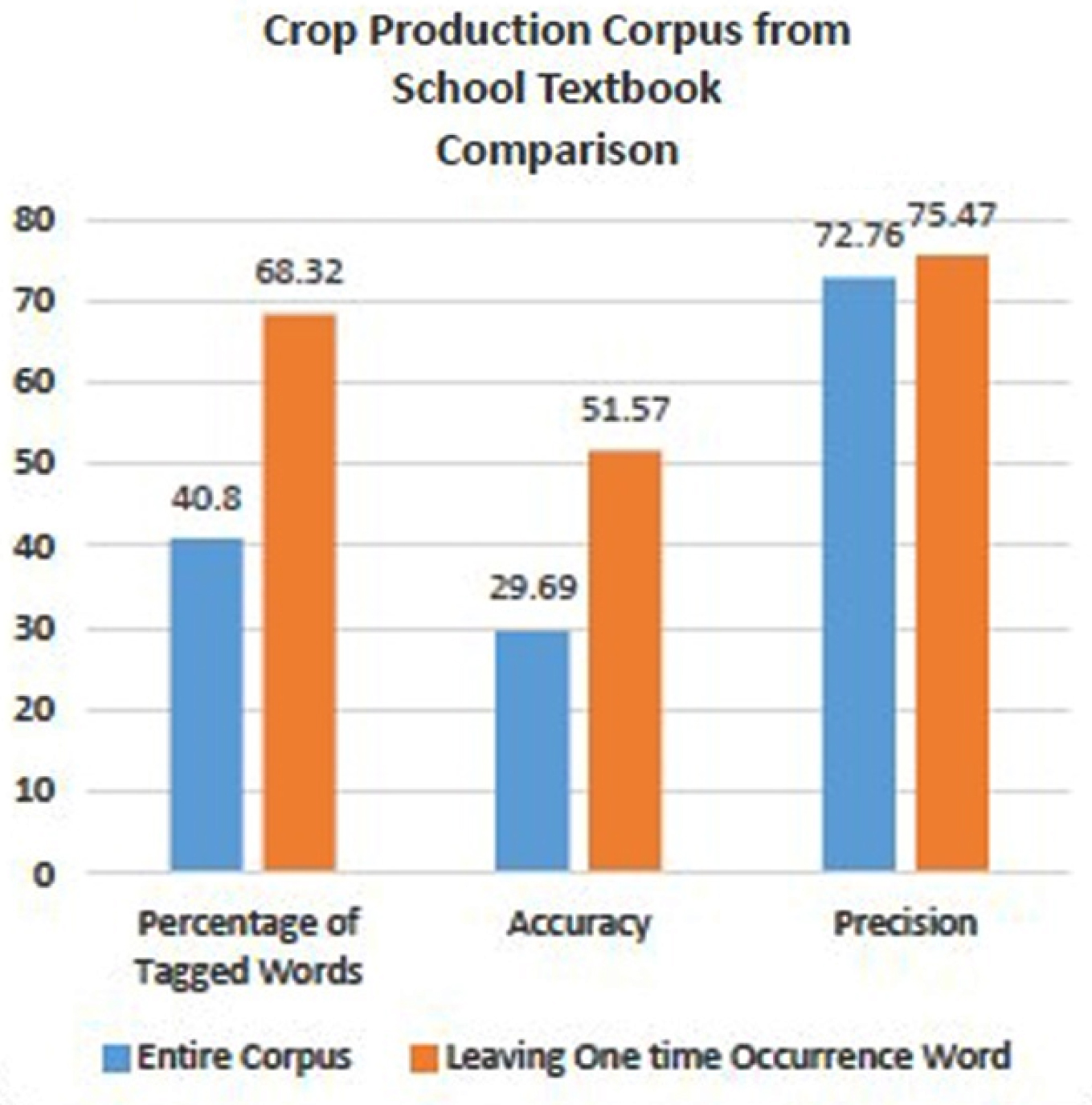
Comparison between the overall performance of the proposed hybrid system including and excluding one-time occurrence word of Crop Production Corpus (Corpus II).
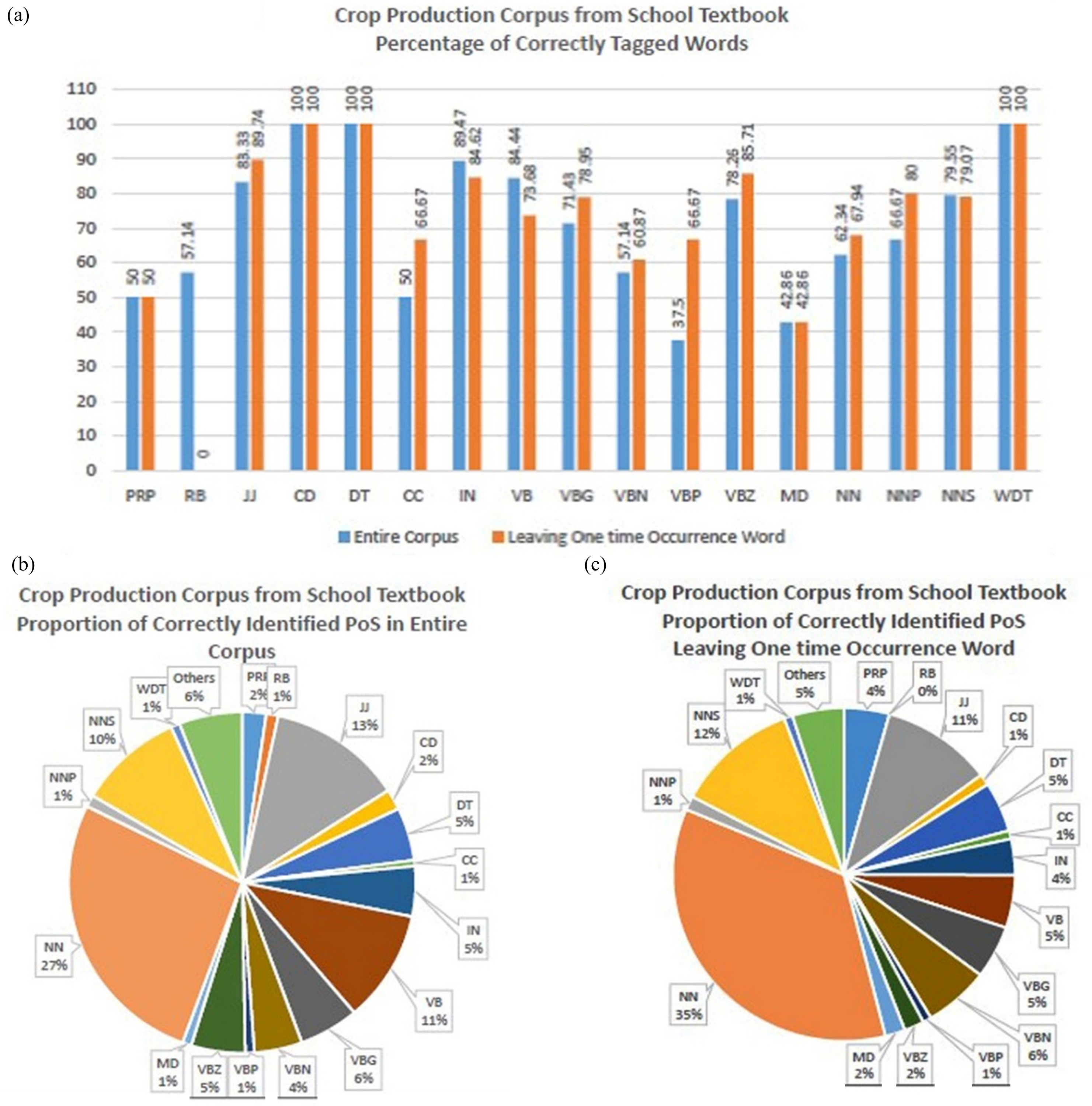
Shows the precision of tagged words under the various category of POS tags and Fig. 9(b) and 9(c) shows the proportions of precision of various POS tags.
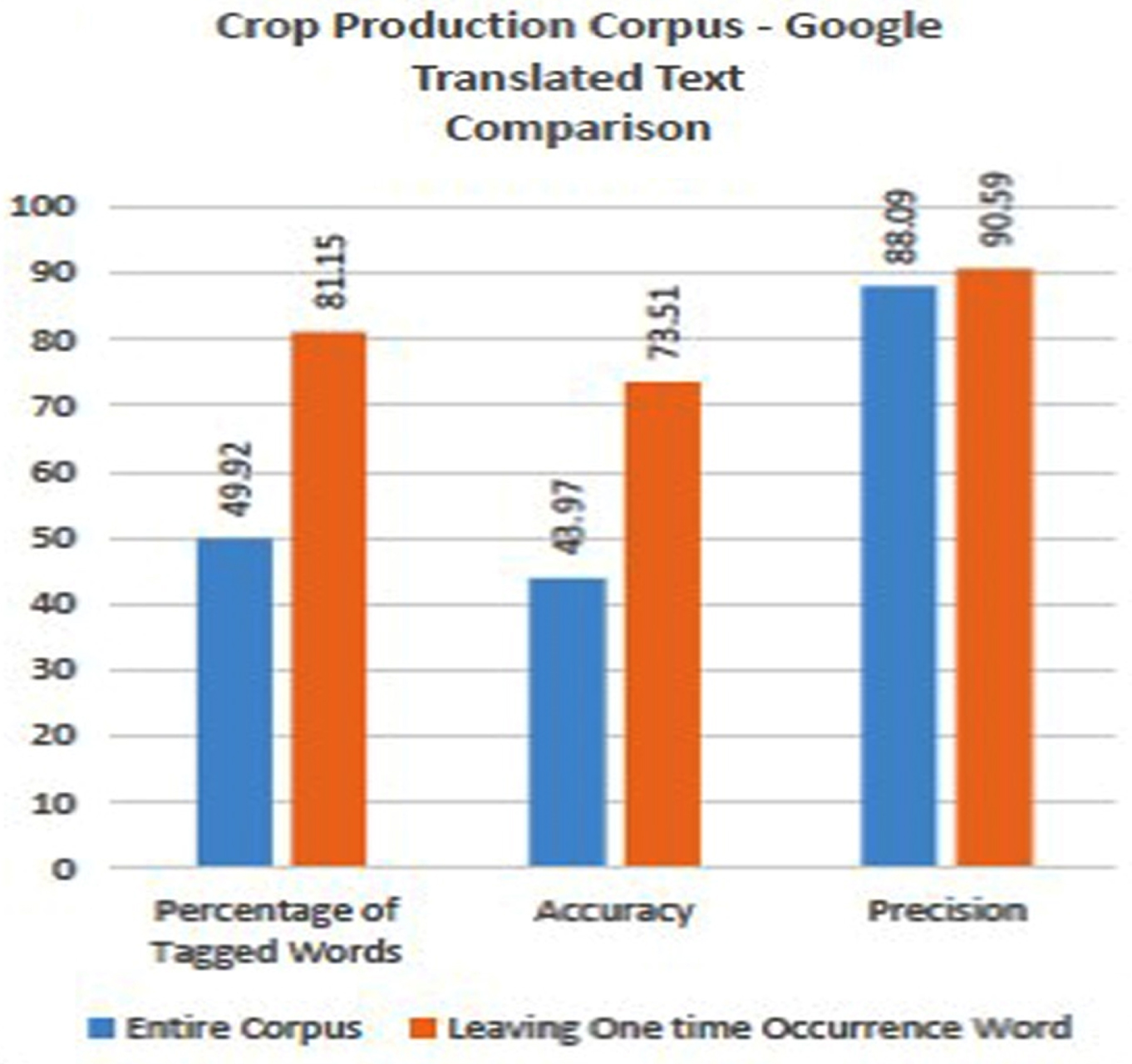
In the case of Corpus III, since the sentence-by-sentence translation is made by using the GT engine, the quality of the corpus that suits the computation is improved when compared with Corpus II. Though the corpus has 48.5% of one-time occurrence words, the proposed Hybrid tagger can predict 81.15% of words, out of which 73.51% of words are accurately correct tagged words and the precision is 90.50% which is shown in Fig. 11. The Fig. 10(a) and (b) shows that 50.1% and 18.9% of words are not still tagged respectively. This is due to the insufficient volume of the dataset. All taggers in the proposed hybrid tagger are improved compared with Corpus II in Fig. 8. The proportions of categorization of POS tags are shown in Fig. 12.
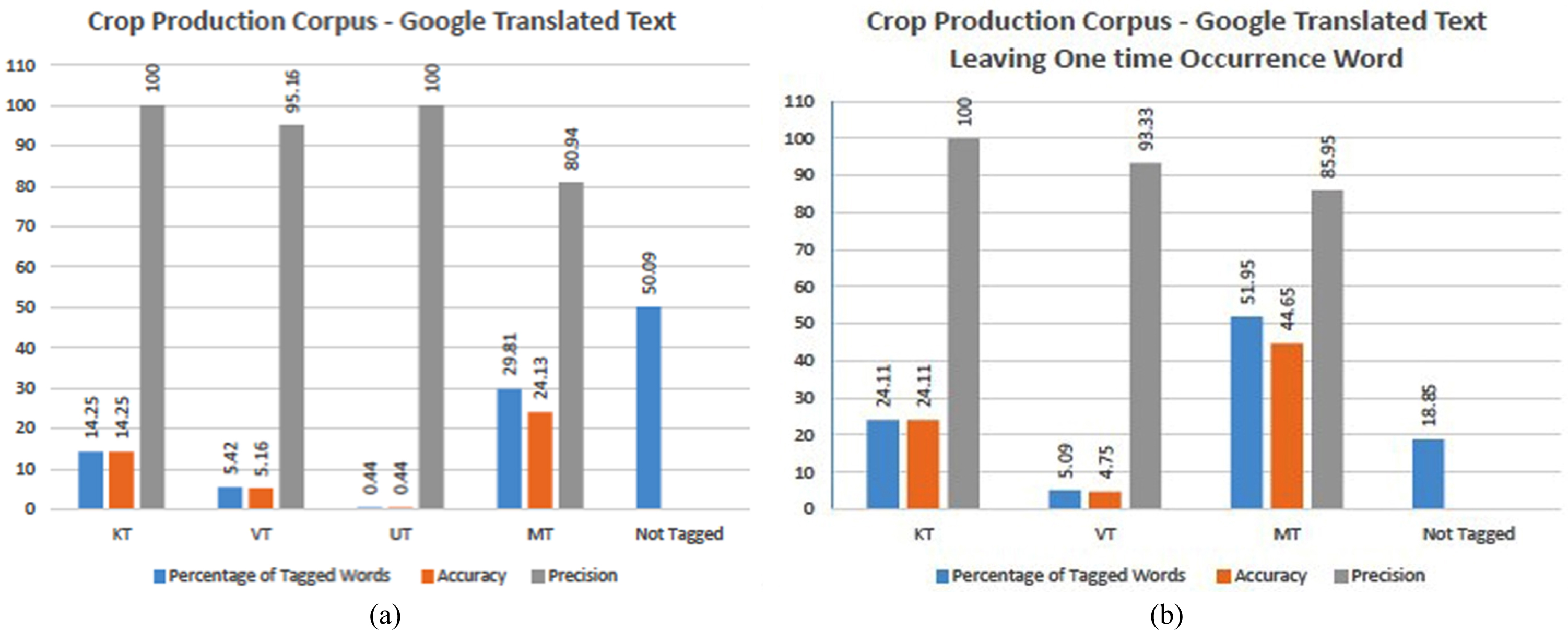
Around 50% of words are tagged. Fig. 10(b). Around 82% of words are tagged.
Precision is around 90% which means 90% of tagged words are correct.
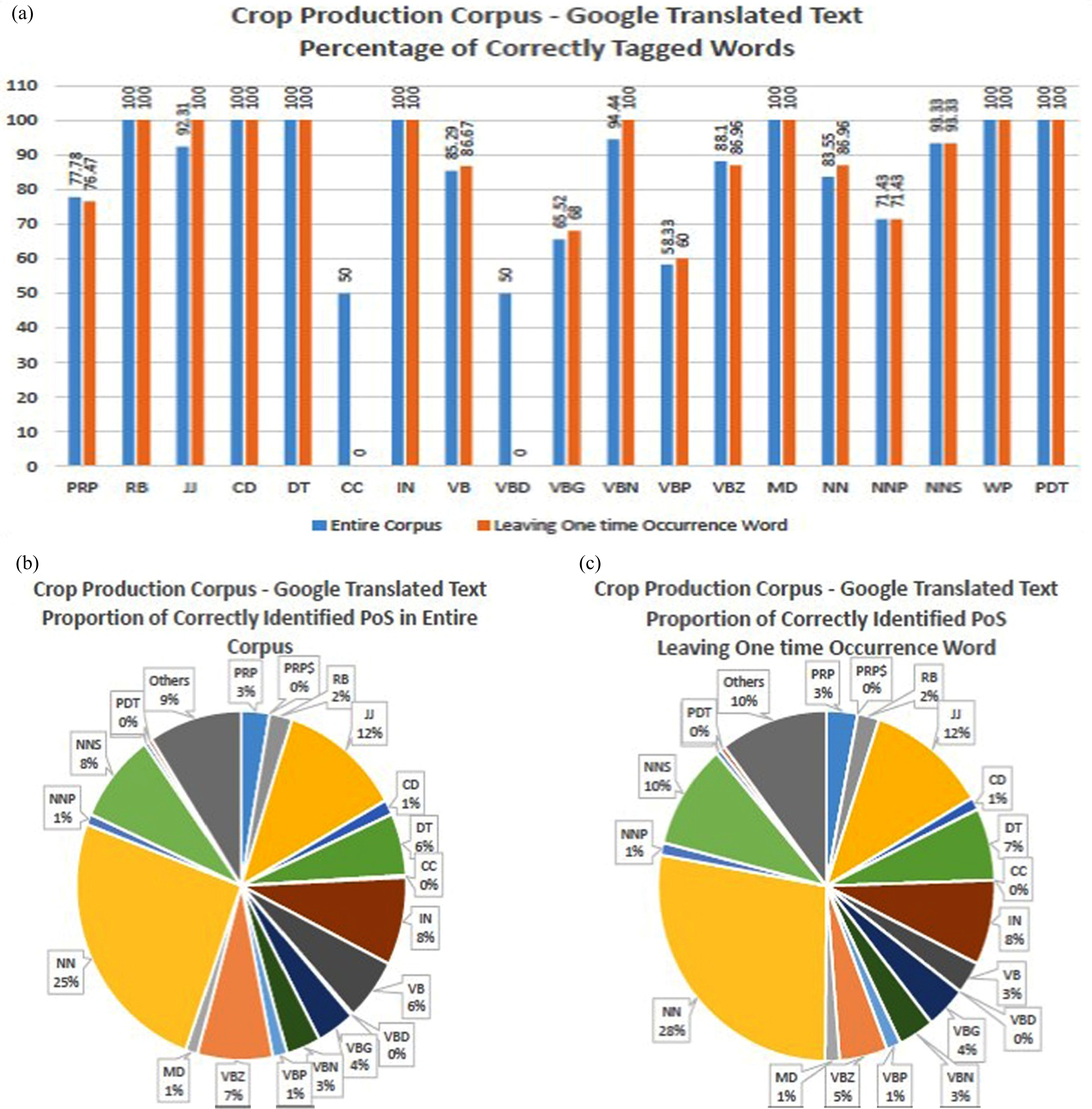
Shows the precision of tagged words under the various category of POS tags and Fig. 12(b) and 12(c) shows the proportions of precision of various POS tags.
Comparison among Corpus I, II, and III
It is observed from Fig. 13(a) and (b) that by not considering the one-time occurrence words in Corpus I, II, and III, the percentage of tagged words, accuracy and its precision has improved by a reasonable amount and around 19 types of POS tags are found in the corpus. The MT plays a significant role in correctly identifying the POS tags in Corpus II and III. The MT does more than 50% of identified tags. In Corpus I, the KT, VT, and MT contribute more or less equally for identifying the tags. The one-time tagger contributes very little in all three corpora as these do not have much data to fit for this tagger.
Bilingual Dictionary created from Corpus I
The analysis is made on the 18.85% of untagged words in Corpus III shown in Table 6. 111 words contribute to this 18.85% and fortunately, 51 words of these untagged words are found in the created dictionary. Out of 51 words, 36 words are found to have either suitable context or translated text in English connected with correct POS tags. So these 36 untagged words could be tagged using this developed dictionary. Hence the accuracy is increased from 73.51% to 79.63%.
Analysis of untagged words in Corpus III
Analysis of untagged words in Corpus III
The performance of the proposed tagger is compared with other POS taggers for languages such as English, Hindi, Malayalam, Kannada, Tamil and Sanskrit. The accuracy of the proposed tagger for all three Corpora considered is shown in Table 7. The accuracy of the system depends on both volume of dataset and the characteristics of the dataset. The accuracy of the proposed algorithm on Corpus II is 51.57%. It is because the Corpus II dataset is Context-based Bilingual Corpus. The same dataset is converted as a Bilingual parallel corpus in Corpus III. Now the accuracy is improved to 73.51%. The accuracy of the proposed algorithm is lesser than other taggers. However, the proposed tagger uses a very small dataset which is lesser than 10% of other models and works without the requirement of a tagged corpus. Hence the accuracy of the proposed tagger is an acceptable value.
Comparison of Proposed Hybrid POS Tagger with other Models
Comparison of Proposed Hybrid POS Tagger with other Models
The proposed algorithm of UT and MT in the proposed hybrid tagger is language-independent. The UT does not play a major role for Corpus I, II, and III, as these corpus does not have the data suitable for this tagger. The proposed MT algorithm was run on the English-Hindi Corpus to identify the POS tag of Hindi words. This corpus is downloaded from the website: https://www.manythings.org/anki/. The corpus contains 2867 lines of various lengths. The majority of the words were tagged correctly shown in Table 8.
Tagged Corpus using the proposed algorithm. The nine lines from the corpus are shown. The English words are tagged by NLTK POS Tag Library. The Hindi words are tagged using MT of the proposed hybrid Tagger.
Tagged Corpus using the proposed algorithm. The nine lines from the corpus are shown. The English words are tagged by NLTK POS Tag Library. The Hindi words are tagged using MT of the proposed hybrid Tagger.

The proposed Hybrid POS Tagger has four taggers namely KT, VT, UT, and MT. As the KT and VT are developed based on the word feature set of a language, these two algorithms are language-specific. The UT is useful when the sentences in both languages have a unique word. The MT is developed using the cross-lingual information retrieval technique and the association rule mining technique with the maximum likelihood estimation method to tag the words. This MT algorithm is language-independent. As the proposed work is focused mainly on tagging the Tamil Words, a bilingual corpus of English-Tamil is required. The three corpora are used in studying the performance of the proposed hybrid tagger. Corpus I is downloaded from the website. Corpus II and III are prepared from Standard 8 Tamil Nādu Textbook and Google Translation Engine.
The proposed hybrid algorithm was run on these three corpora with and without considering one-time occurrence words and, its accuracy and precision are measured. The performance of the proposed algorithm outperforms on all three corpora when one-time occurrence words are not considered. The data in Corpus I is in such a way that the proposed KT and VT with the defined list of word feature set plays a major role in correctly tagging the 65% of tagged Tamil words. But in Corpus II and III, the data is in such a way that the proposed MT plays a major role in identifying the tags of Tamil words. The 69% and 62% of correctly tagged words in Corpus II and Corpus III respectively by the proposed MT alone. The performance of the proposed system in Corpus II is improved in Corpus III by improving the Context-based Bilingual Corpus of Corpus II to the Bilingual parallel corpus in Corpus III. It is found that after leaving one-time occurrence words, the proposed Hybrid POS tagger can predict 81.15% words, with 73.51% accuracy and 90.50% precision. The Tamil words were tagged/classified as nearly 20 different types of POS tags.
The proposed hybrid algorithm also produces a Bilingual Dictionary as a by-product. This dictionary could be used to tag the untagged words of the same corpus as a part of the looping system. The proposed MT algorithm was executed on tagging the Hindi words. It is found that the majority of the tagged words were correct.
The proposed hybrid algorithm is a novel approach that used a mining technique on the bilingual corpus to tag the words. This algorithm could be used for the languages lacking a large volume of annotated corpora in the field of study of words and for the languages lacking manually crafted linguistic resources sufficient for building the NLP applications. The proposed algorithm produces good accuracy with high precision even for the less volume of corpus. So, the proposed hybrid POS tagger can be a preferable choice tagger.
Footnotes
Acknowledgment
This work is funded by the All India Council for Technical Education under Research Promotion Scheme (AICTE-RPS).