
Abstract
Feature selection is one basic technology for data mining. This paper investigates feature selection for interval-valued data via fuzzy rough iterative computation model (FRIC-model). To depict the similarity between samples in an interval-valued decision information system (IVDIS), the fuzzy symmetry relation in an IVDIS is first introduced from the perspective of “The similarity between information values is fed back to the feature set”. After that, several attribute evaluation functions, such as fuzzy positive regions, dependency functions and attribute importance functions are defined. Subsequently, FRIC-model for interval-valued data is established by using the iterations of these functions. Next, An feature selection algorithm in an IVDIS based on this model is presented. Lastly, numerical experiments and statistics tests are carried out to estimate the performance of the presented algorithm. The experimental results illustrate that the presented algorithm maintains high classification accuracy, and does not occupy too much memory. These findings will provide new perspective for feature selection in an IVDIS.
Introduction
Rough set theory (RST) is a significant method to handle uncertainty. Its idea is to use the known knowledge to describe the uncertain knowledge. An information system (IS) was presented by Pawlak [30, 31]. RST can effectively deal with the uncertainty of an IS. The application of RST is mostly related to an IS [25, 43].
In real life, some data are expressed in the form of interval-valued numbers, such as estimating the price of an item, the age of a person, the length of a sample, etc. Thus, interval-valued data is an important type of data. An interval-valued information system (IVIS) means an IS where its attribute values are interval-valued numbers. When the conditional attribute values of a decision information system (DIS) are interval-valued numbers, it is called an interval-valued decision system (IVDIS). IVISs and IVDISs are regarded as the generalization of IS and DIS, respectively, which can describe imprecise samples more accurately. Some scholars have studied IVISs and IVDISs. For example, Dai et al. [9] studied uncertainty measurement for an IVDIS via extended conditional entropy; Zhang et al. [43] presented incremental updating of rough approximations in an IVIS under attribute generalization; Xie et al. [37] considered new measurements of uncertainty for an IVIS; Liu et al. [23] proposed attribute reduction algorithm via the fuzzy α-similarity relation in an incomplete IVIS.
Feature selection as an important technology of data processing in machine learning can effectively reduce redundant selections and improve the accuracy of classification. According to feature selection process whether relys on the learner, feature selection methods are usually divided into three categories: filtered [21], wrapped [20] and embedded [18]. Feature selection of RST can delete redundant attributes of conditional feature set while maintaining the dependency between conditional attributes and decision attributes in a decision table. It is a filtered feature selection method. Many researchers studied feature selection. Dai et al. [8] presented attribute attribute via conditional entropies for an incomplete DIS. Zhao et al. [44] put forward mixed feature selection in an incomplete DIS. Chen et al. [1] introduced a fuzzy kernel-feature selection method for heterogeneous data. Jia et al. [19] proposed similarity-based feature selection in RST from clustering perspective. Hu et al. [16] presented a robust and fast feature selection method on the basis of separability for a fuzzy DIS. Wang et al. [34] explored feature selection by means of local conditional entropy.
Fuzzy rough set (FRS) was proposed by Dubois et al. [6]. Moresi et al. [26] presented the axiomatic definition for FRS. Cornelis et al. [2] considered feature selection with FRS. Chen et al. [4] gave an feature selection algorithm based on FRS. Hu et al. [17] developed kernelized FRS. Wang et al. [35] investigated feature selection with FRS. Yuan et al. [40] studied unsupervised feature selection for mixed data based on FRS. Thippa et al. [33] discussed two of the prominent dimensionality reduction techniques. Gadekallu et al. [13] used the improved hybrid bat and firefly algorithms to calculate feature selection. Wang et al. [36] studied feature selection for categorical data based on FRS. The biggest advantage of intelligent algorithm is that it is fast and can deal with all kinds of datasets, but it is difficult to reduce the number of attributes while ensuring the classification accuracy.
Classical rough set model can deal with categorical data. The deficiency of this model is that it is sensitive to noise in classification learning due to the stringent condition of an equivalence relation. Thus, a fuzzy relation is introduced to describe the similarity between samples with categorical data. By the way, FRS model is established to manage feature selection for categorical data.
In order to handle interval-valued data, we usually use “The similarity between information values is fed back to the sample set”. But we can deal with interval-valued data from the perspective of “The similarity between information values is fed back to the feature set". Based on this perspective, a fuzzy relation can be defined to describe the similarity between samples, a variable parameter can be introduced to control the similarity between samples and FRIC-model can be established. This paper studies feature selection for interval-valued data via FRIC-model.
This paper is organized as follows. Section 2 recalls interval-valued numbers and IVDISs, and then introduces the fuzzy symmetry relation induced by each subsystem. Section 3 presents several attribute evaluation functions. Section 4 proposes FRIC-model in an IVDIS. Section 5 gives a feature selection algorithm in an IVDIS via FRIC-model. Section 6 implements comparative analysis. Section 7 executes statistical analysis. Section 8 concludes the paper.
Preliminaries
Throughout this paper, O signifies a finite set, 2 O denotes the family of all subsets on O, |X| expresses the cardinality of X ∈ 2 O ,
Put
Put
(1) s = t ⇒ s1 = t1, s2 = t2.
(2) s ≤ t ⇒ s1 ≤ t1, s2 ≤ t2;
s < t ⇒ s ≤ t, s ≠ t.
(1) ∀ s, t ∈ Ω, 0 ≤ PD(s, t) ≤1;
(2) ∀ s ∈ Ω, PD(s, s) =0.5;
(3) ∀ s, t ∈ Ω, PD(s, t) + PD(t, s) =1.
(1) ∀ s, t ∈ Ω, SD(s, t) = SD(t, s);
(2) ∀ s, t ∈ Ω, 0 ≤ SD(s, t) ≤1;
(3) ∀ s, t ∈ Ω, SD(s, t) =1 ⇒ s = t.
noindent
(O, A, d) is known as a decision information system (DIS), if (O, A ∪ {d}) is an IS, where A is the conditional feature set and d is the decision feature.
If B ⊆ A, then (O, B, d) is known as a subsystem of (O, A, d).
An IVDIS
An IVDIS
Let (O, A, d) be an IVDIS with B ⊆ A and θ ∈ [0, 1]. Define
Apparently,
In this paper, denote
In
Clearly,
(1) If B1 ⊆ B2 ⊆ A, then ∀ θ ∈ [0, 1],
(2) If 0 ≤ θ1 < θ2 ≤ 1, then ∀ B ⊆ A,
Since B1 ⊆ B2, we have ∀ o, o′ ∈ O,
So ∀ o, o′ ∈ O,
Thus,
(2) By Definition 2.9,
Since 0 ≤ θ1 < θ2 ≤ 1, we have ∀ o, o′ ∈ O,
So ∀ o, o′ ∈ O,
Thus,
(3) If 0 ≤ θ1 < θ2 ≤ 1, then ∀ B ⊆ A, ∀ X ∈ 2
O
,
(1) (i) Given B ⊆ A, θ ∈ [0, 1], X ∈ 2
O
. Then by Definition 2.9, we can obtain that
This implies that
So ∀ o ∈ O,
Thus ∀ o ∈ X,
Note that ∀ o ∉ X,
It follows that ∀ o ∈ O,
Thus
(ii) Clearly,
Then ∀ o ∉ X,
Note that ∀ o ∈ X,
This implies that ∀ o ∈ O,
Thus
From the above,
(2) (i) Note that B1 ⊆ B2 ⊆ A. Then by Proposition 2.10,
So ∀ o ∈ O, o′ ∉ X,
This implies that ∀ o ∈ O,
Thus ∀ o ∈ O,
Therefore,
(ii) Note that B1 ⊆ B2 ⊆ A. Then by Proposition 2.10,
This implies that ∀ o ∈ O, o′ ∈ X,
So
Thus
Hence
(3) (i) Note that 0 ≤ θ1 < θ2 ≤ 1. Then by Proposition 2.10,
So ∀ o ∈ O, o′ ∉ X,
This implies that ∀ o ∈ O,
Thus ∀ o ∈ O,
Therefore,
(ii) Note that B1 ⊆ B2 ⊆ A. Then by Proposition 2.10,
It follows that ∀ o ∈ O, o′ ∈ X,
So
Thus
Hence
(1) If B1 ⊆ B2 ⊆ A, then ∀ θ ∈ [0, 1],
(2) If 0 ≤ θ1 < θ2 ≤ 1, then ∀ B ⊆ A,
(1) If B1 ⊆ B2 ⊆ A, then ∀ θ ∈ [0, 1],
(2) If 0 ≤ θ1 < θ2 ≤ 1, then ∀ B ⊆ A,
In this section, we establish FRIC-model in an IVDIS with the help of the iterations of fuzzy positive regions and dependency functions.
Let (O, A, d) be an IVDIS. Given B ⊆ A and θ ∈ [0, 1]. For i = |B|, |B|+1, ⋯ , |A|, denote
Similarly,
Then
Thus
Thus
Then
Thus
Thus
This part presents an feature selection algorithm in an IVDIS via FRIC-model.
REQUIRE An IVDIS (O, A, d), D ∈ O/d, θ, δ.
ENSURE A feature selection subset B.
1: Let n = |O|, B =∅, i = 1;
2: Computer matrix R =(roo′) n×n, where o ∈ D and o′ ∈ O - D, then roo′ = 0, otherwise roo′ = NaN;
3:
4:
5: Computer
6:
7: get each matrix
8:
9: i = 0;
10:
11:
12:
13:
14: Compute
15:
16:
17:
18: Find a* with maximum value
19: Compute
20: if sig(a*, B, d) i+1 > δ
21: B = B ∪ {a*};
22:
23: i = |B|;∥
24:
25: break;
26:
27: end while
28: return B.
Algorithm 1 has a parameter δ, which is a threshold used primarily to control algorithm termination conditions. When the significance of attribute B exceeds δ, the algorithm continues to be executed, and when it is less than δ, the algorithm terminates. Here we analyze the time and space complexity of algorithm 1. The second step is to calculate a matrix, and the time complexity is O(|O|2). The third to eighth steps need to calculate |A| matrices, so the time complexity is O(|A||O|2). The time complexity of steps 10 through 27 is
In order to verify the effectiveness of the algorithm, 10 datasets were used for testing. The Fish, car and water are real-life interval-valued datasets [5, 14]. The other seven datasets are real-valued from UCI database [12]. See Table 2 for details of each data set. Since some data are not interval values, they need to be transformed into interval values. We adopted the method in the reference [7]. Let (O, A, d) be an IVDIS. ∀ a ∈ A, o
i
∈ O, we compute
Data sets
Data sets
Ten graphs are drawn to show the effectiveness of the proposed algorithm and the size change of the reduction set caused by the change of parameters θ and δ. Figures 1-10 shows the curve change of 10 reduced sets obtained by running the FRM-IV algorithm proposed in this paper. The horizontal axis represents the value of δ, from 0 to 0.18. The vertical axis represents the size of the reduction set. Each picture has four curves, and the parameter θ of each curve is 0.6, 0.7, 0.8 and 0.9 respectively. The blue curve represents parameter θ = 0.6, the orange curve represents θ = 0.7, the Yellow curve represents θ = 0.8, and the purple curve represents θ = 0.9. It can be seen from the image that the size of the reduction set decreases with the gradual increase of variable δ for each curve. When θ takes four different values, the downward trend of each curve is close. This shows that the effectiveness of the algorithm is closely related to δ, but it has little to do with θ. In order to find the optimal values of δ and θ, we establish a mathematical model: z = max(δ, θ). z represents classification accuracy. This mathematical model has no explicit expression and is difficult to be solved by the usual method. Therefore, it is solved by the traversal method. First fix the value of δ, and then take the variable θ from 0.5 to 0.99 in steps of 0.01. Adjust the value of δ and traverse θ again. This is repeated until the parameters δ and θ with the maximum classification accuracy are found.

Reduct (Fish).
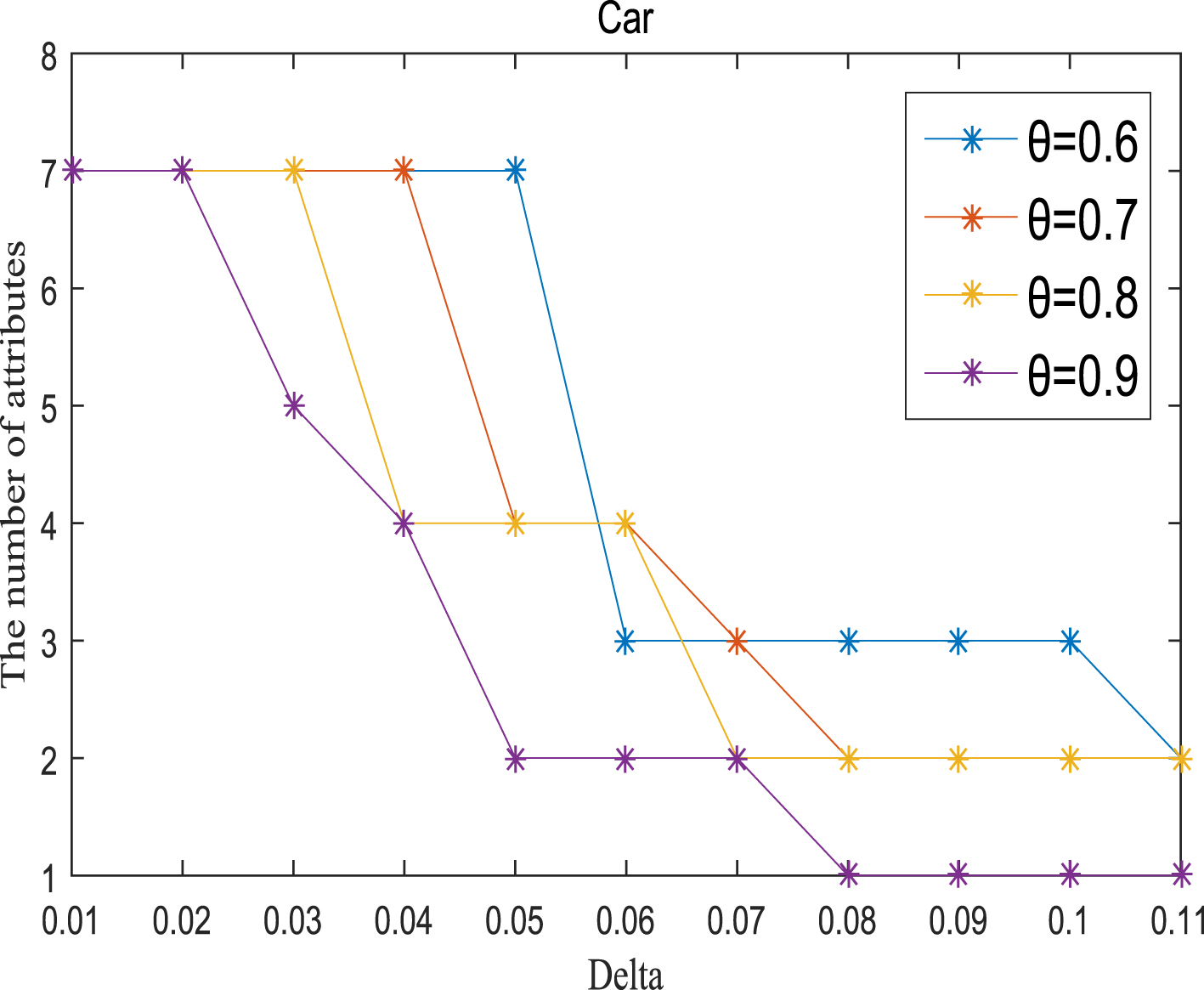
Reduct (Car).

Reduct (Water).

Reduct (Ion).

Reduct (SH).

Reduct (IS).

Reduct (Wdbc).

Reduct (Dia).

Reduct (Hill).
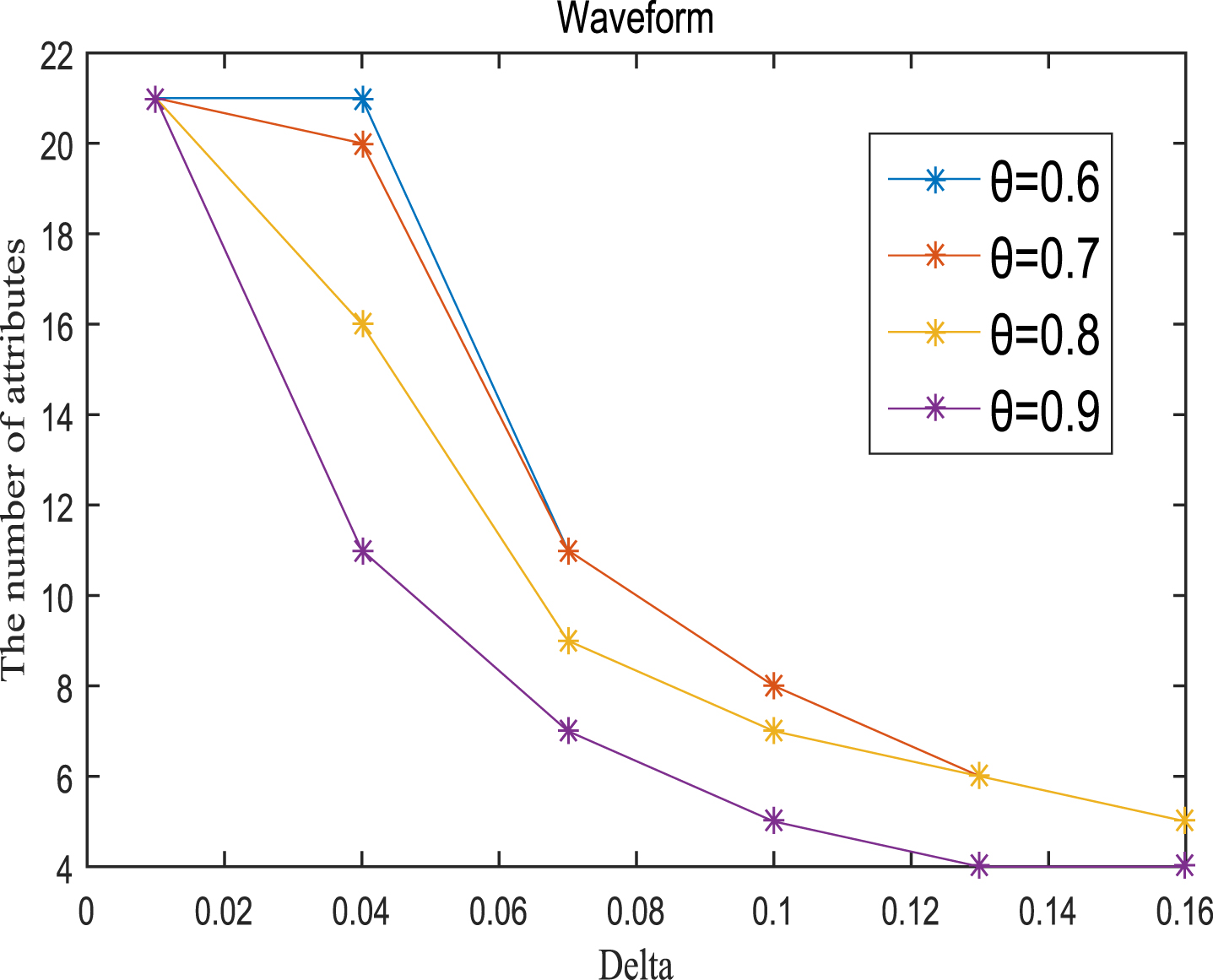
Reduct (Wave).
Next, the accuracy of the algorithm is tested. We randomly select 80% of each data set as the training set and the remaining 20% as the test set. Each data set is trained 10 times, and the accuracy is taken as the average value. Because the current classifiers cannot process real valued datasets, we use the same K-Nearest Neighbor (KNN, K=3) and Probabilistic Neural Network (PNN) classifiers in the reference [7]. The specific formula for measuring the distance between two samples is also shown in the reference [7]. Figures 11-20 show the change of KNN classification accuracy when θ and δ take different values. Figures 21-30 show the accuracy change of classifier PNN when θ and δ take different values. From Figures 11-30, it can be seen that the accuracy curves presented on most images change regularly, and the overall trend increases or decreases gradually. However, it can be clearly seen from Figures 11, 12, 21 and 23, that The four curves on the precision image of datasets fish, car and water vibrate obviously and have no obvious law, indicating that when the δ increases and the reduction set becomes smaller, taking different θ will affect the accuracy of the data set.
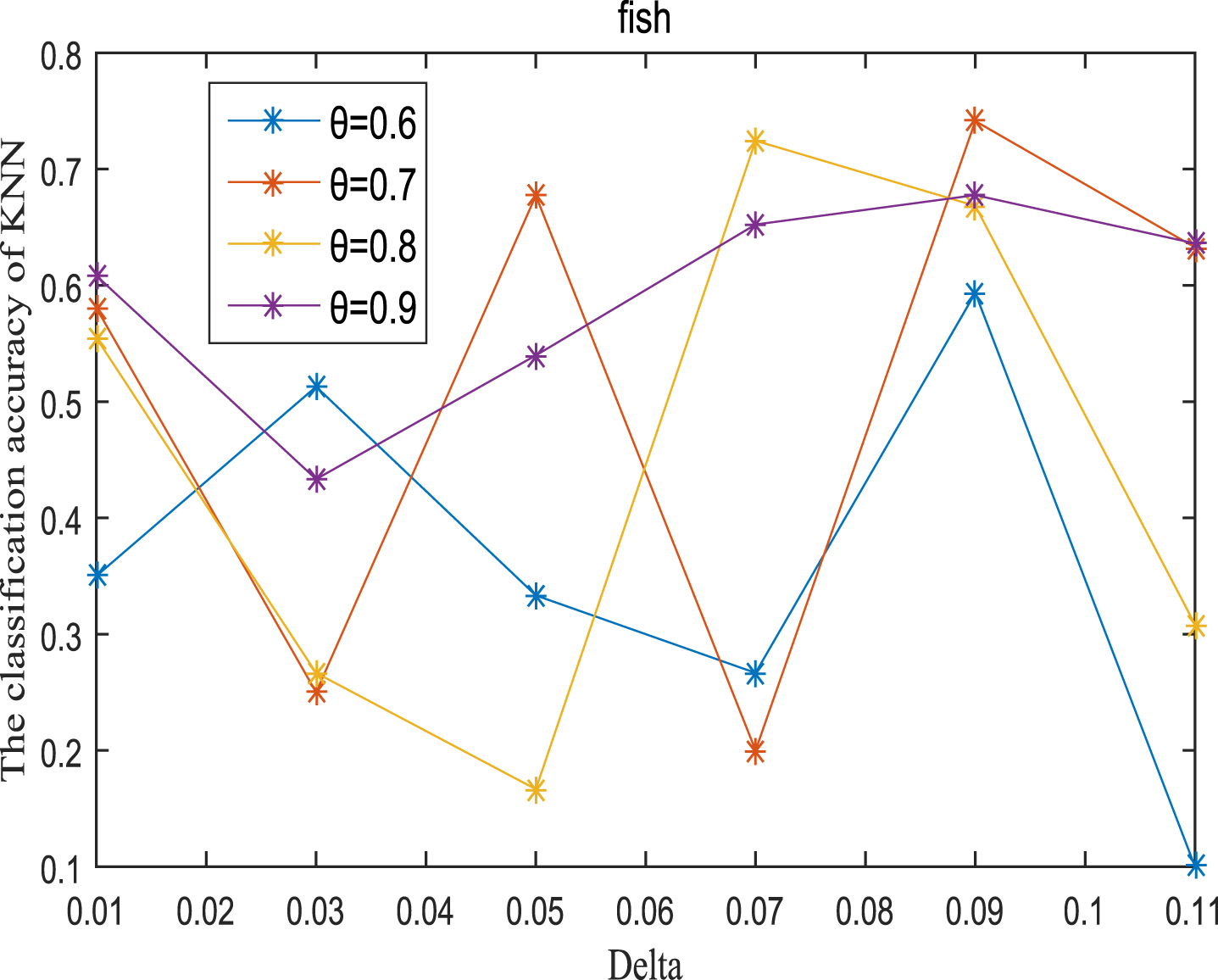
KNN classification accuracy (Fish).
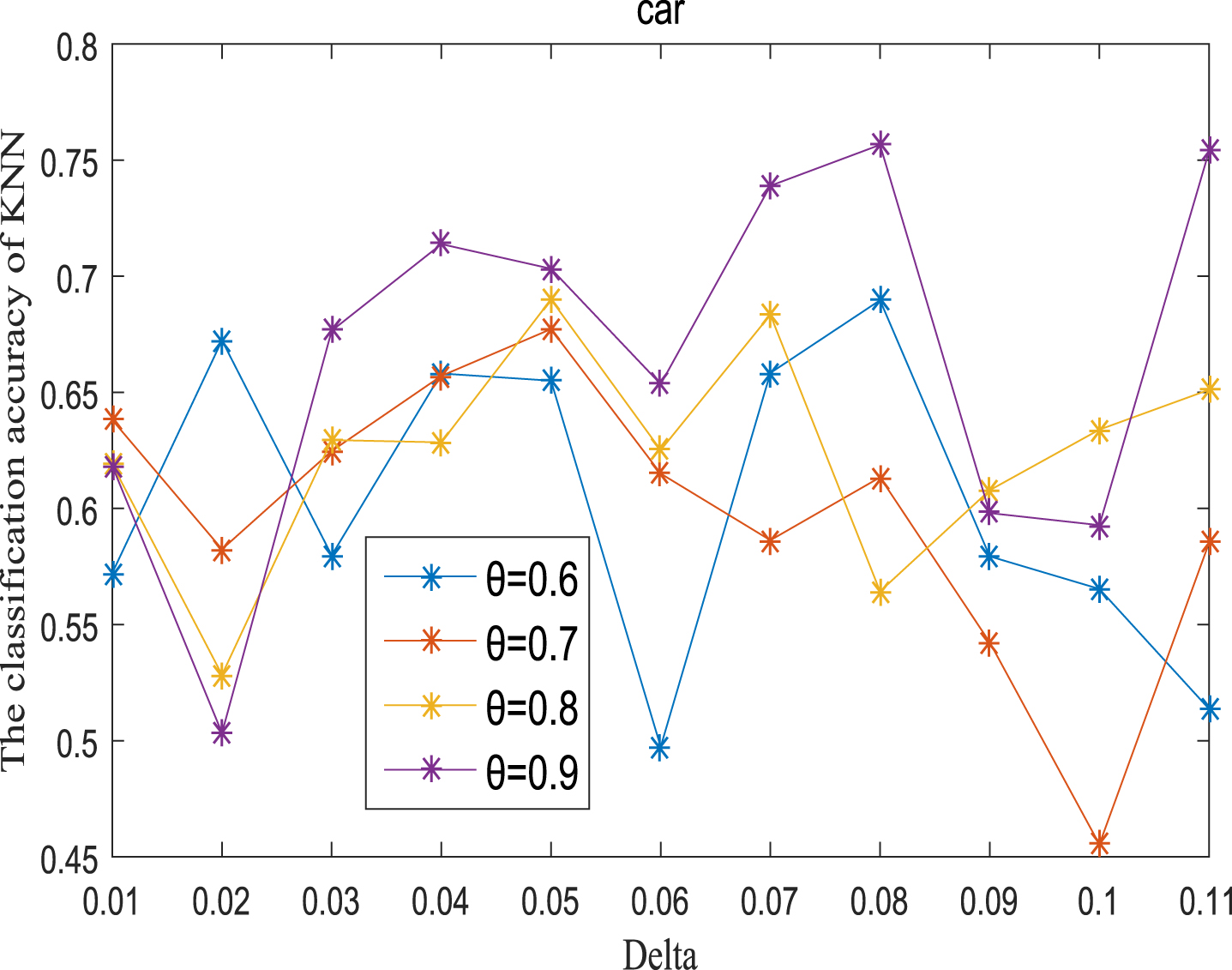
KNN classification accuracy (Car).
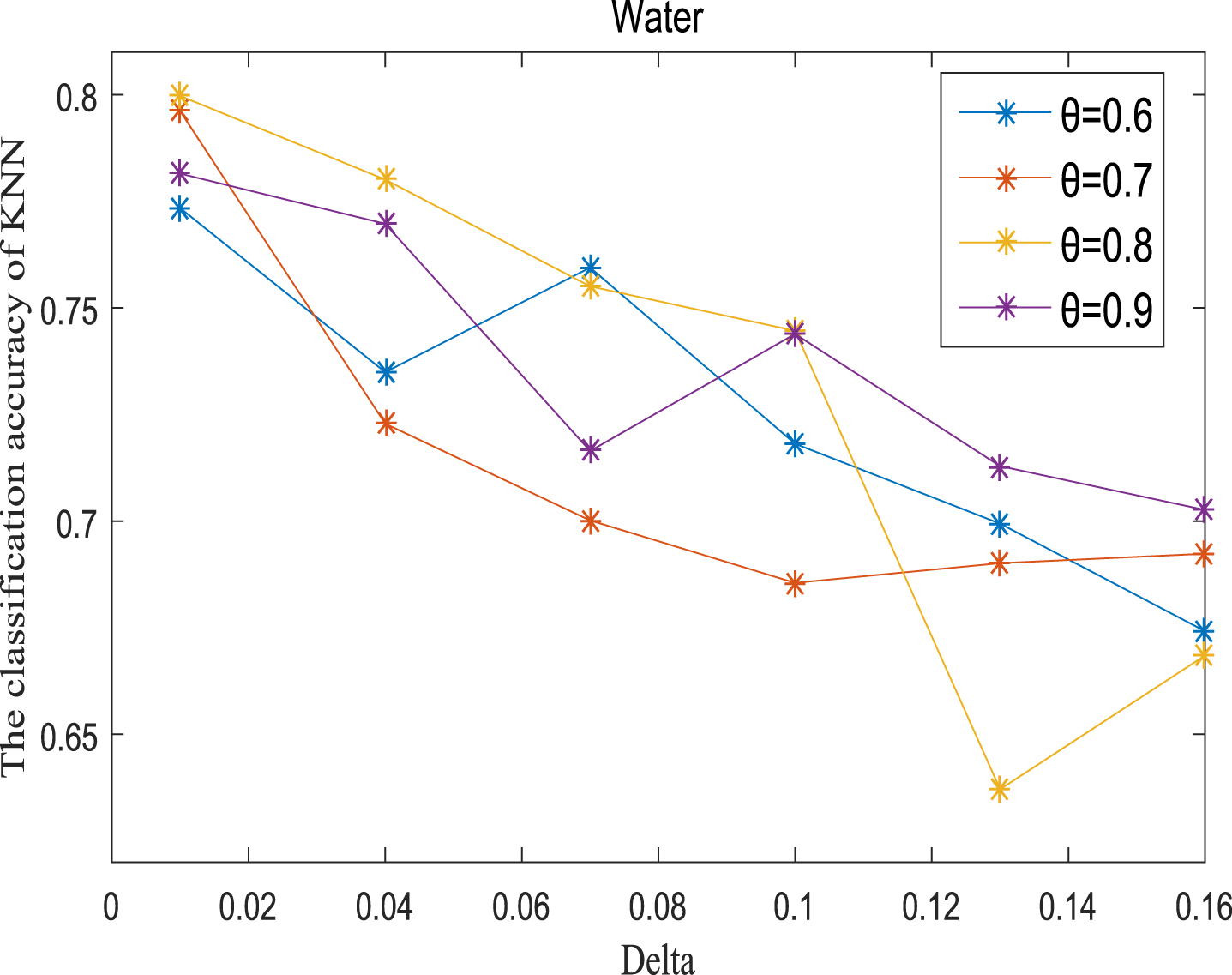
KNN classification accuracy (Water).
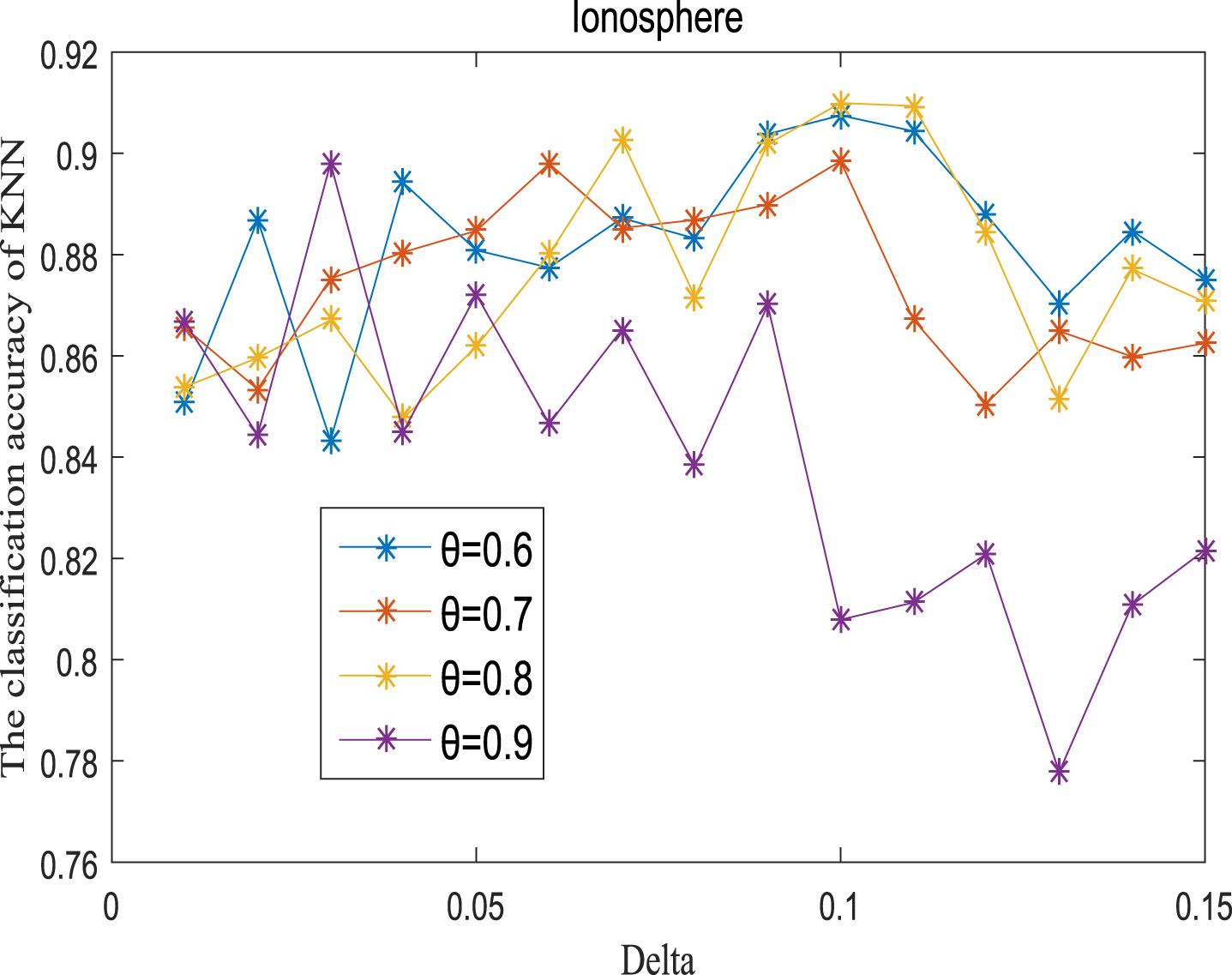
KNN classification accuracy (Ion).
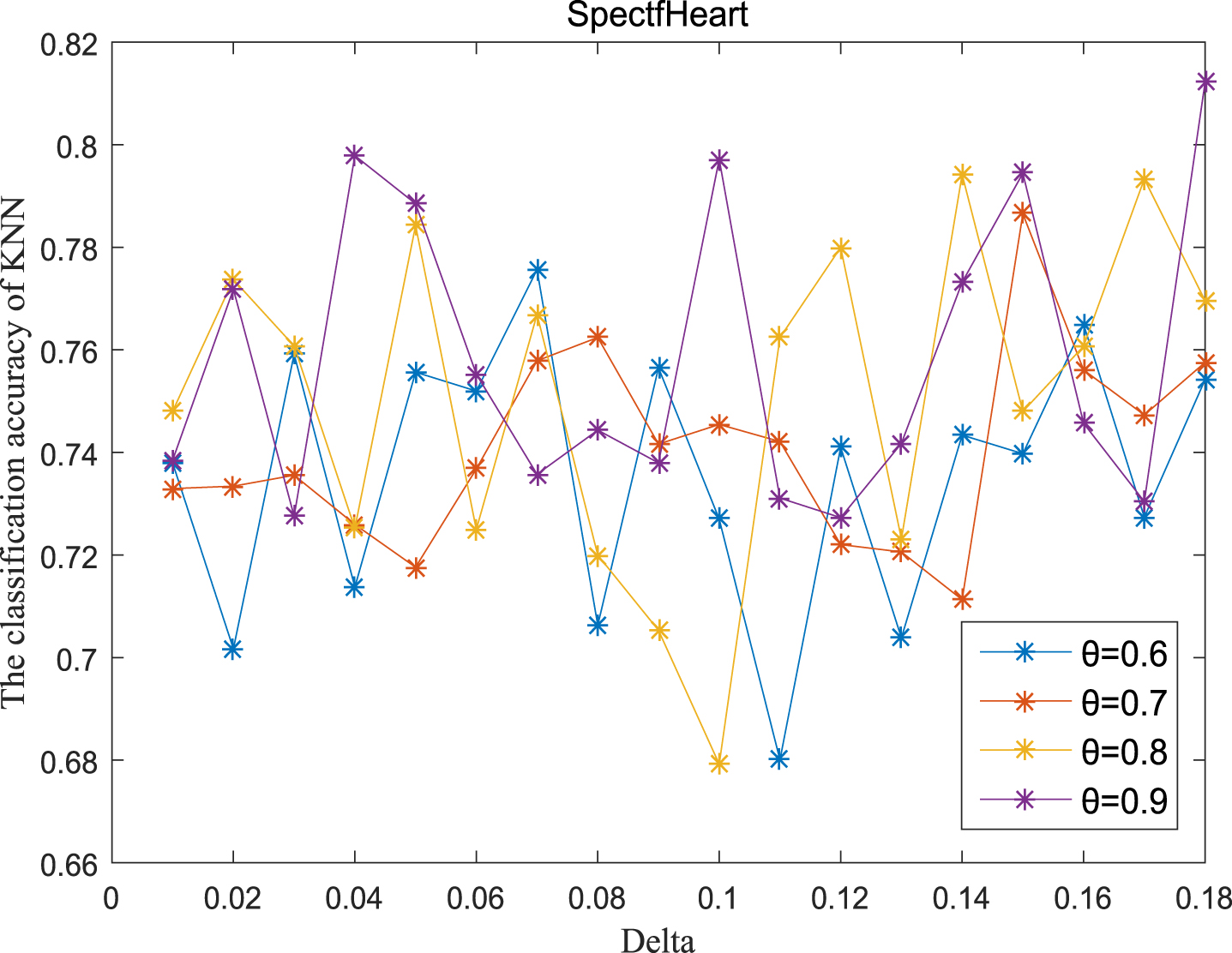
KNN classification accuracy (SH).
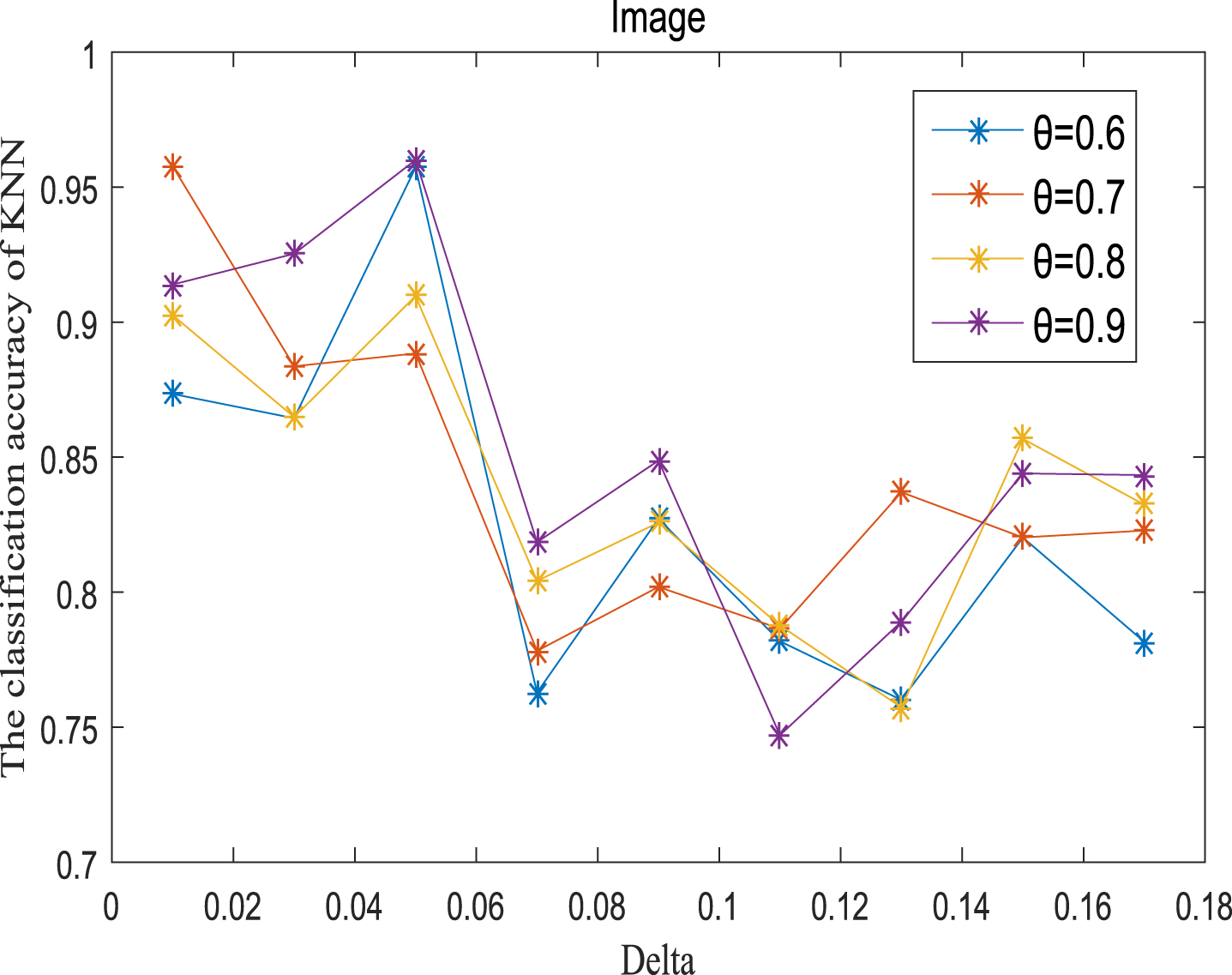
KNN classification accuracy (IS).
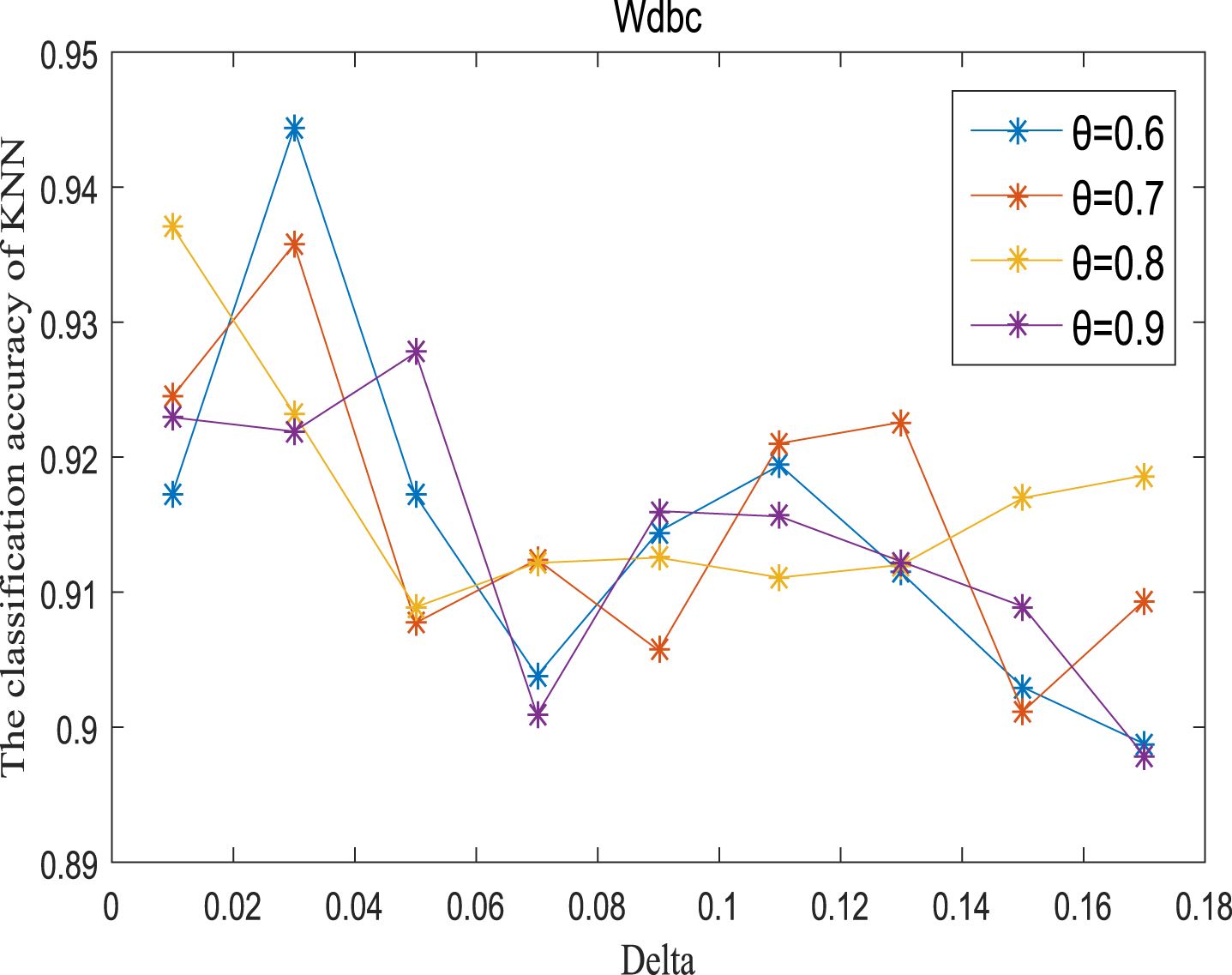
KNN classification accuracy (Wdbc).
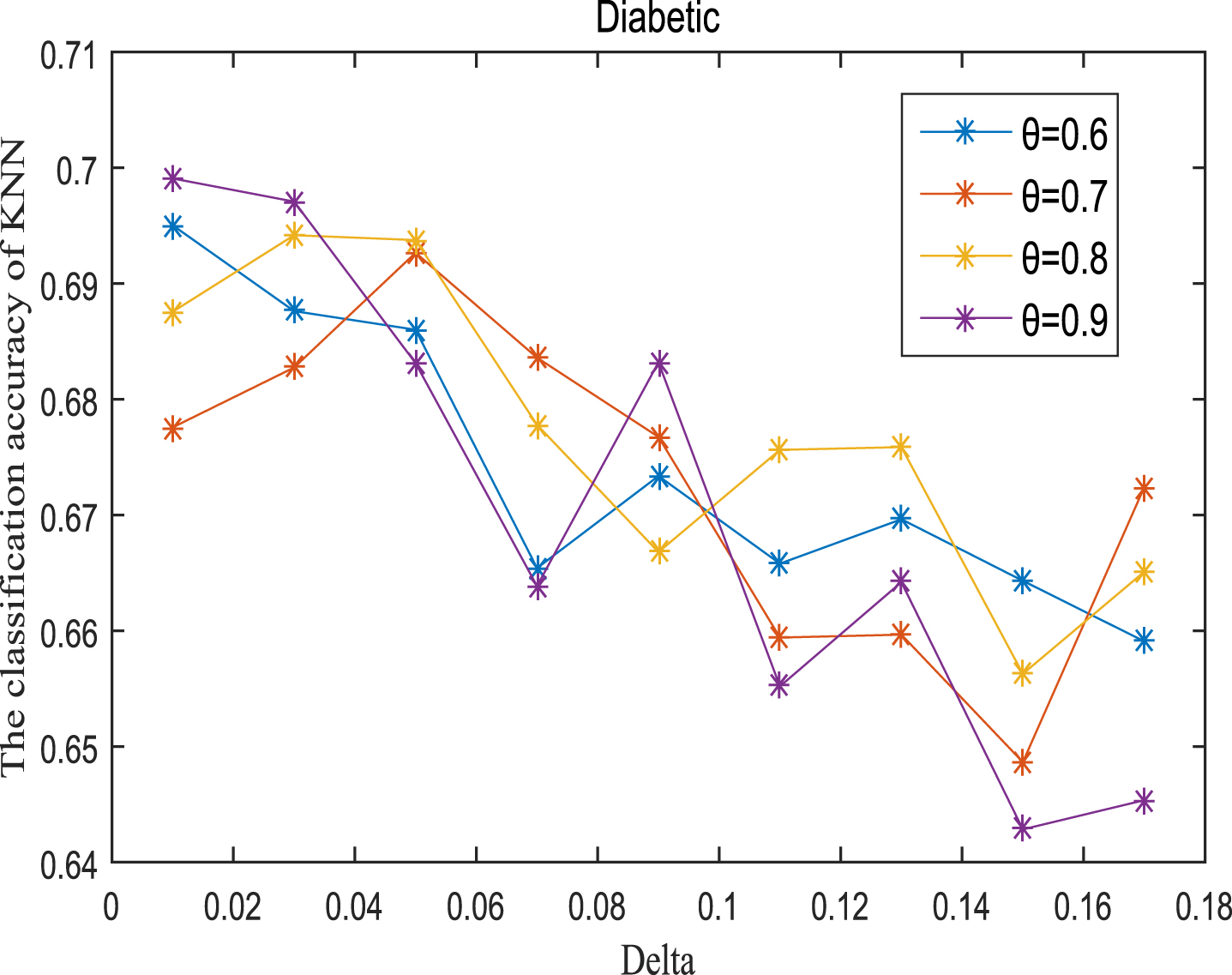
KNN classification accuracy (Dia).
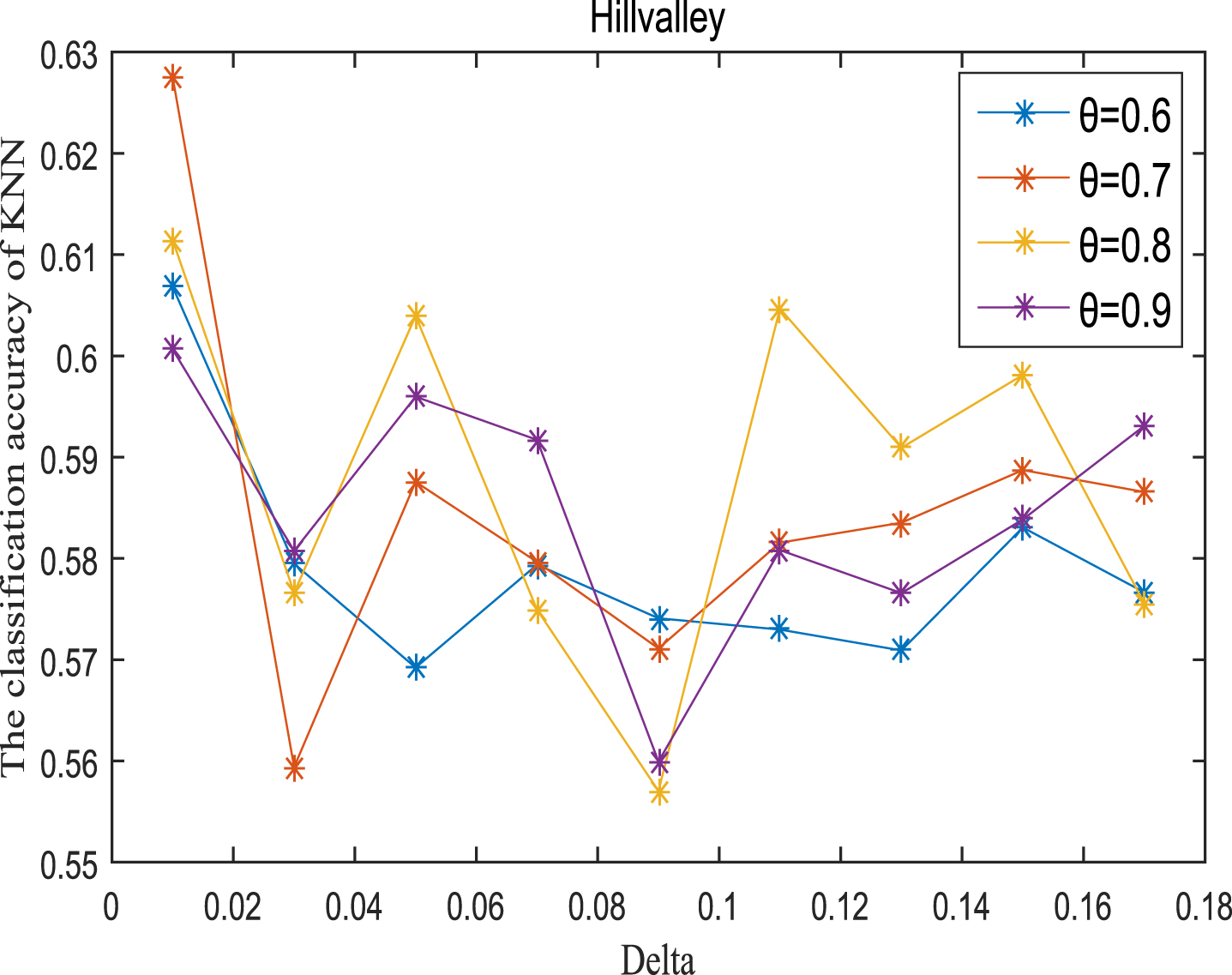
KNN classification accuracy (Hill).
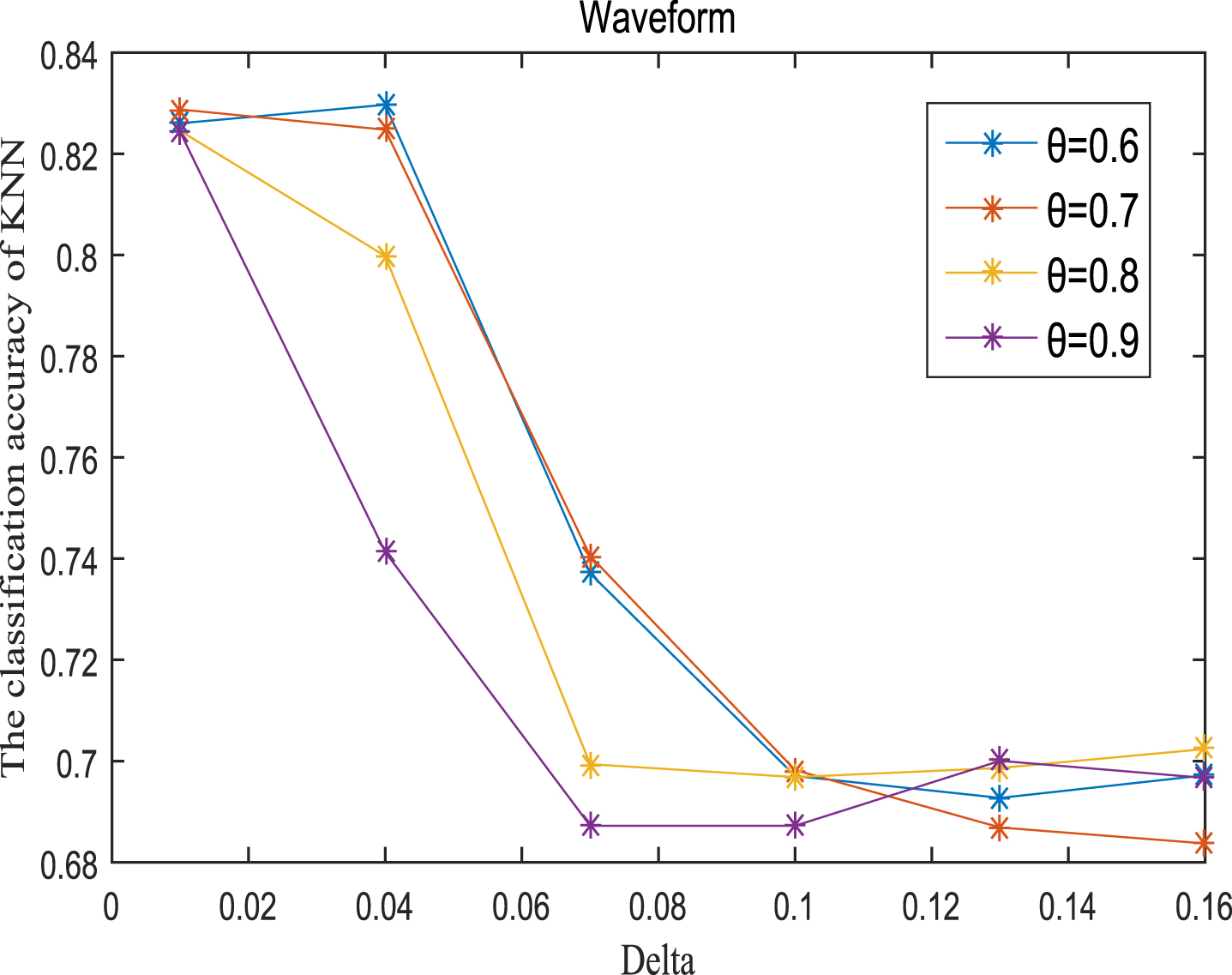
KNN classification accuracy (Wave).
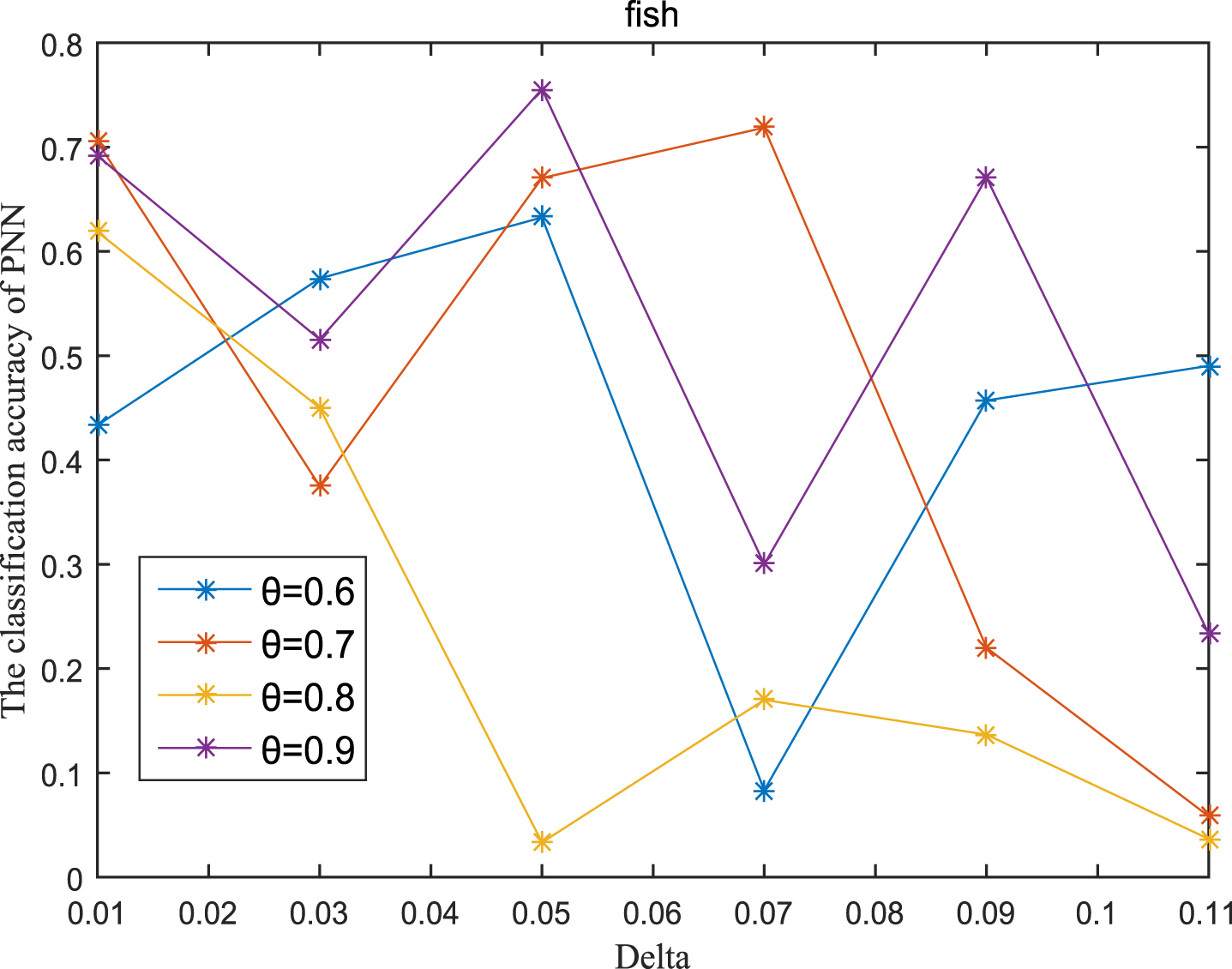
PNN classification accuracy (Fish).
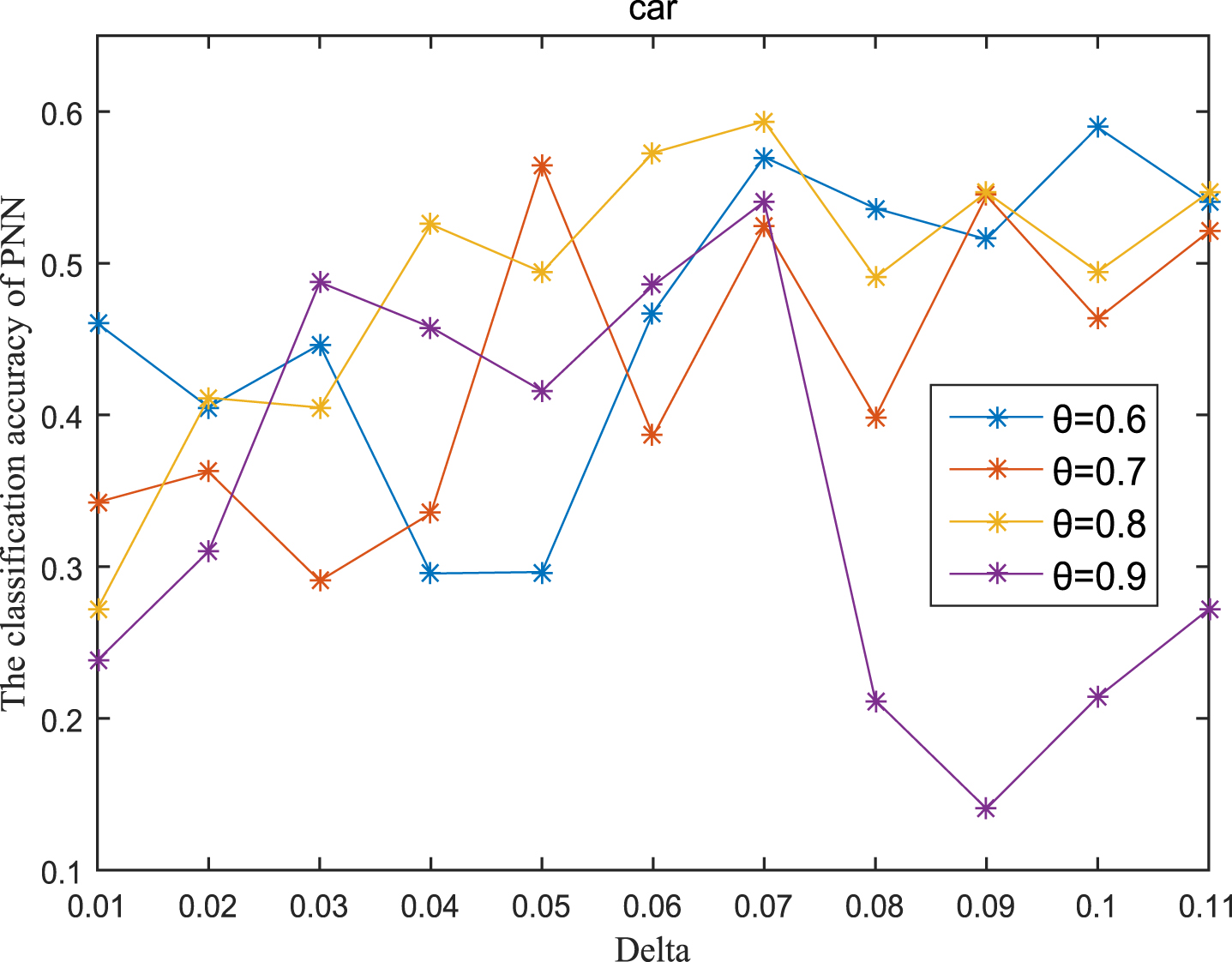
PNN classification accuracy (Car).
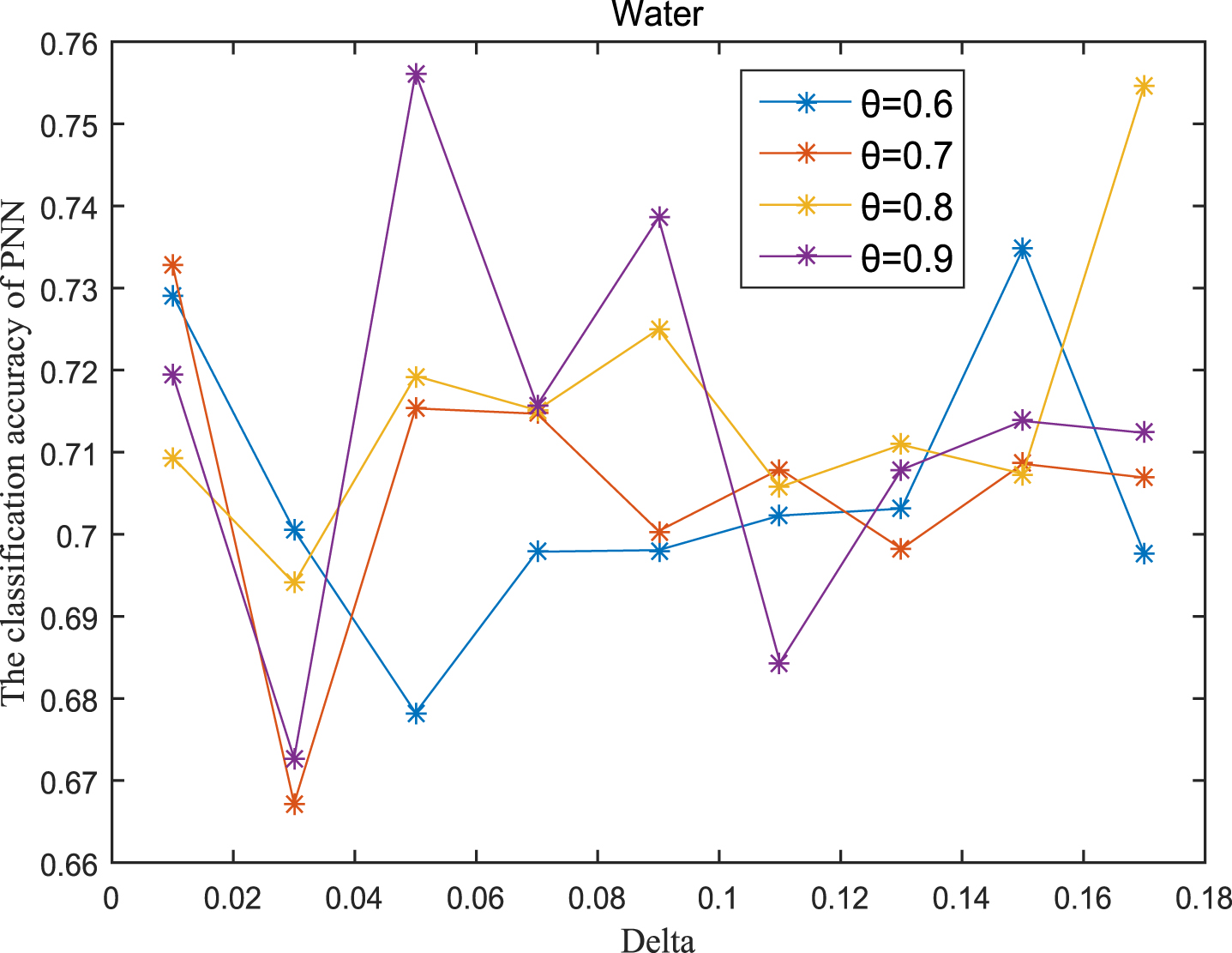
PNN classification accuracy (Water).
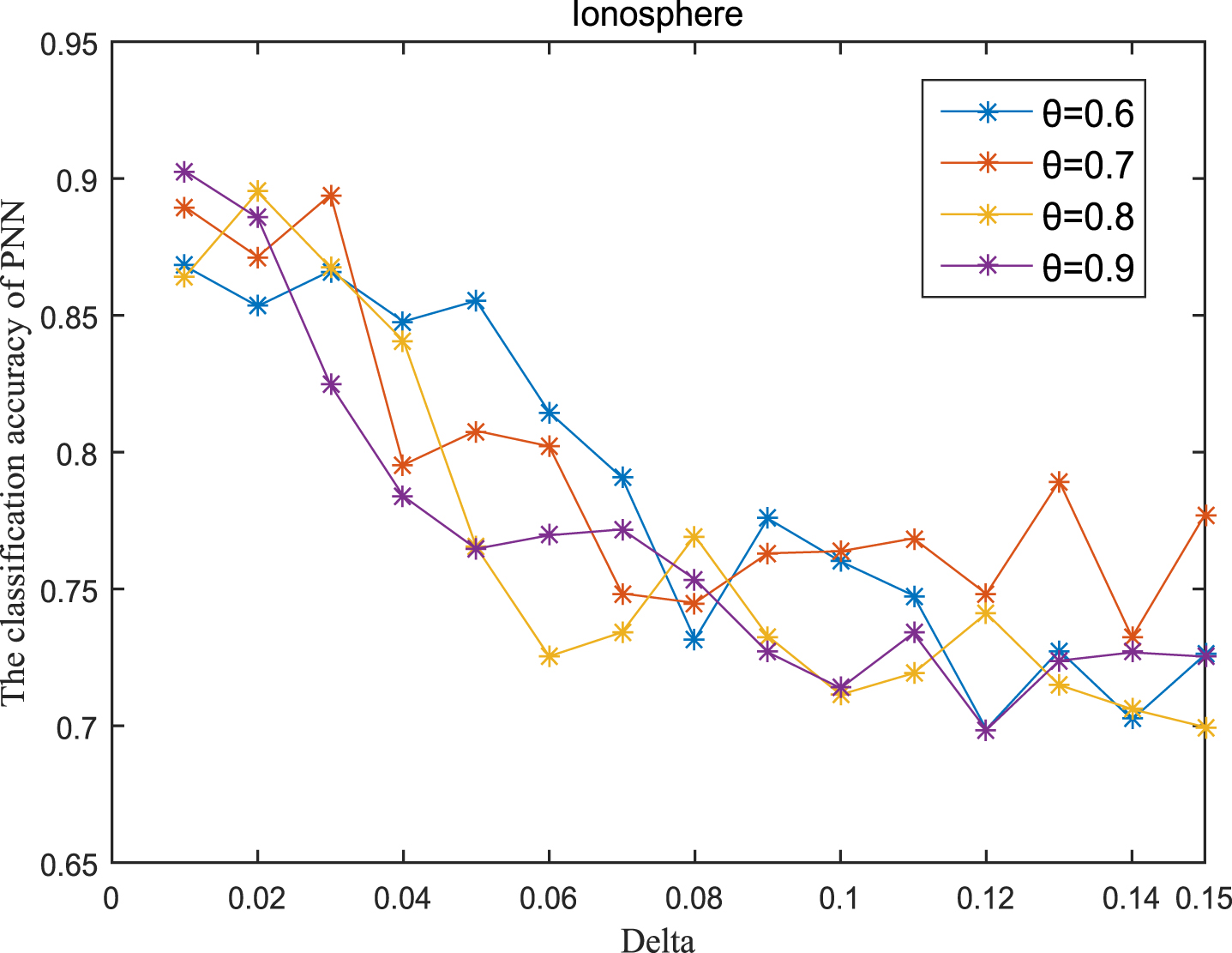
PNN classification accuracy (Ion).
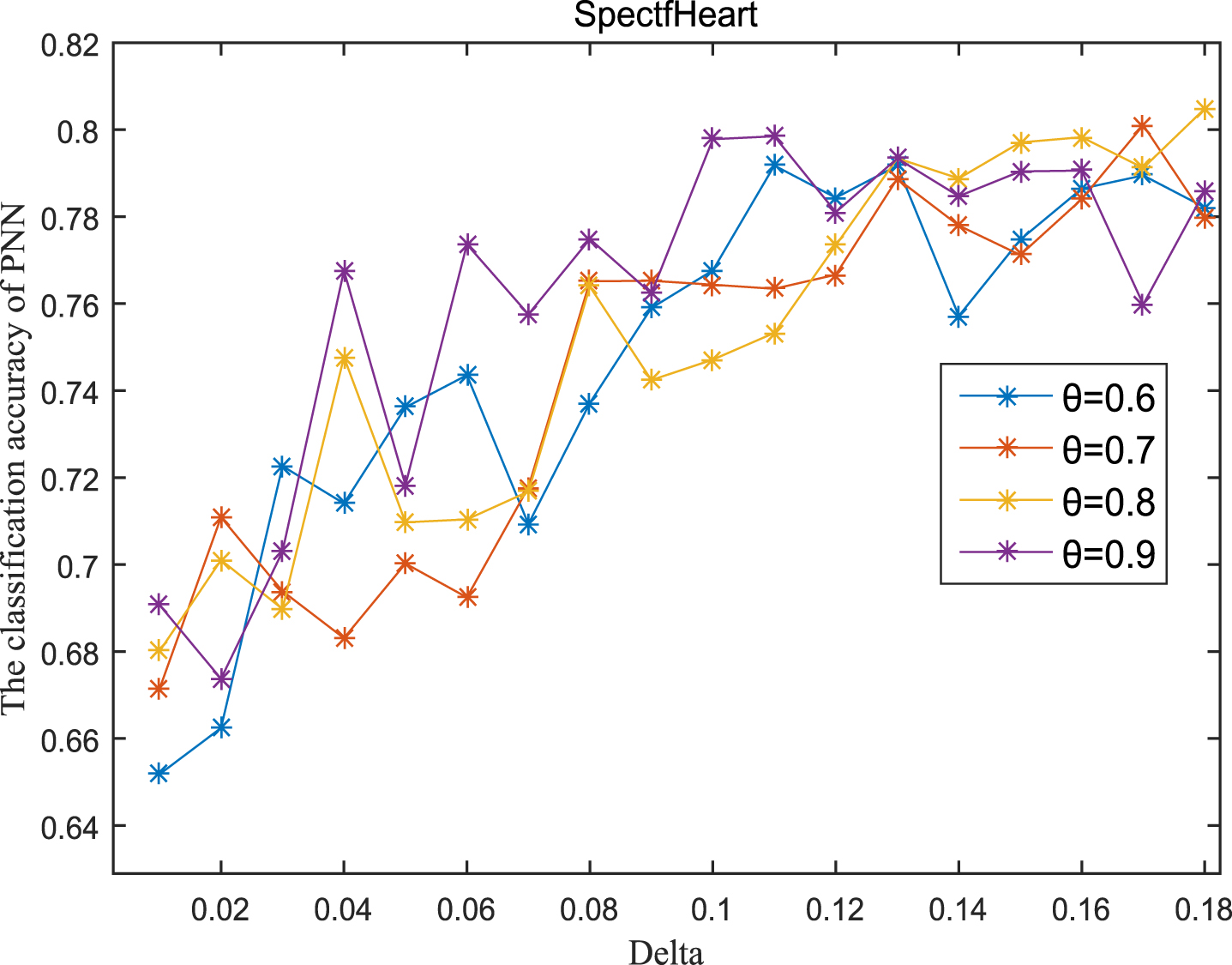
PNN classification accuracy (SH).
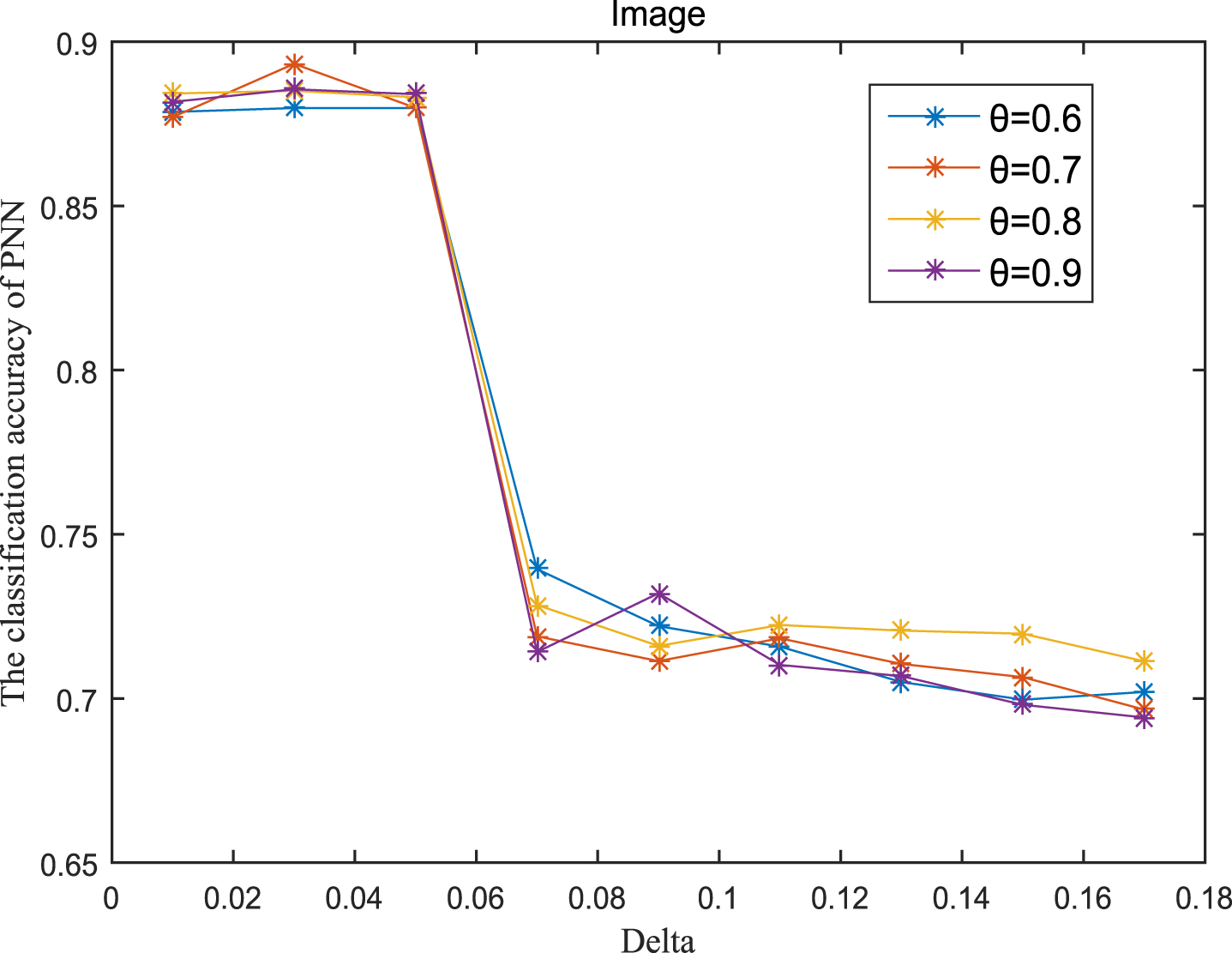
PNN classification accuracy (IS).
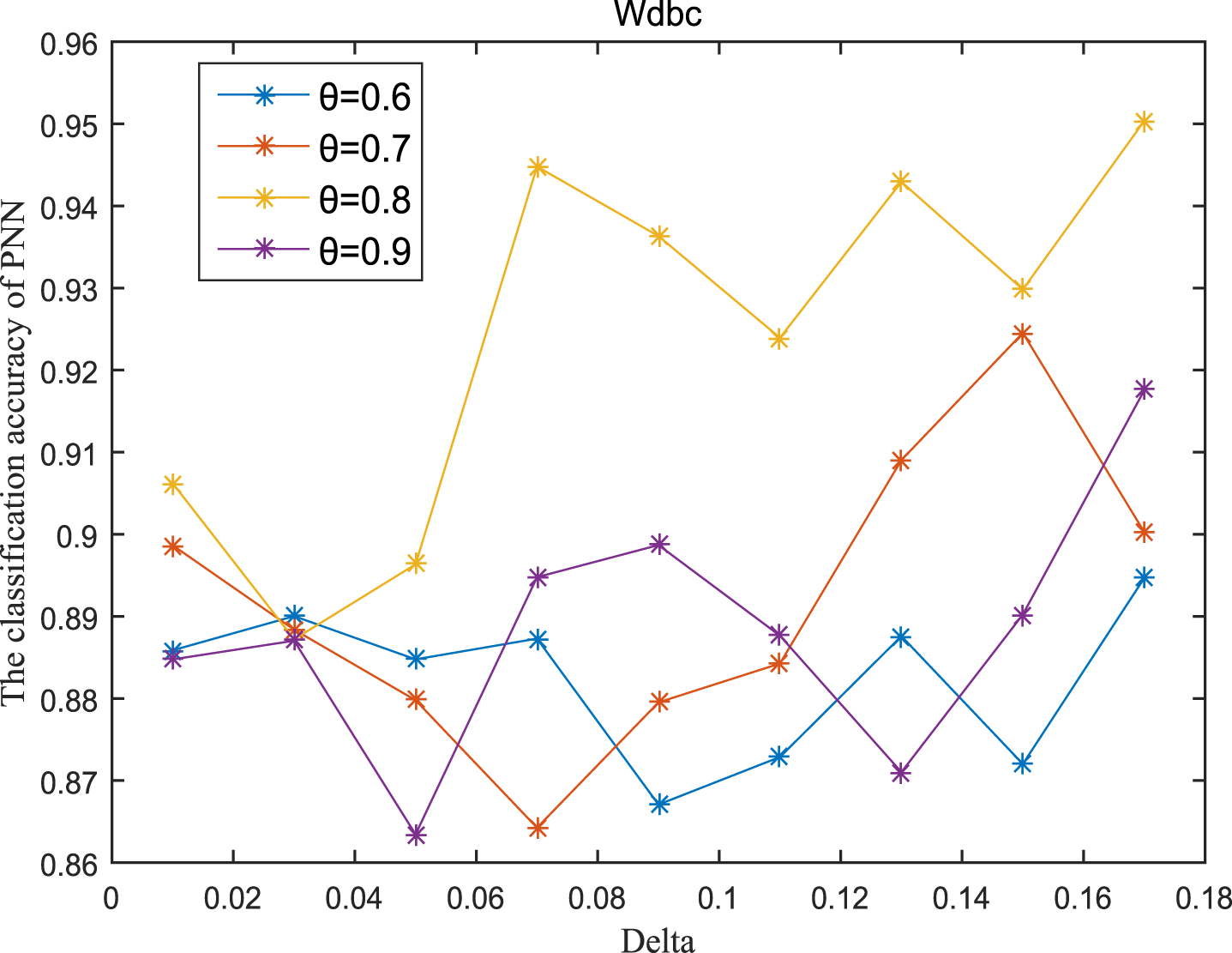
PNN classification accuracy (Wdbc).
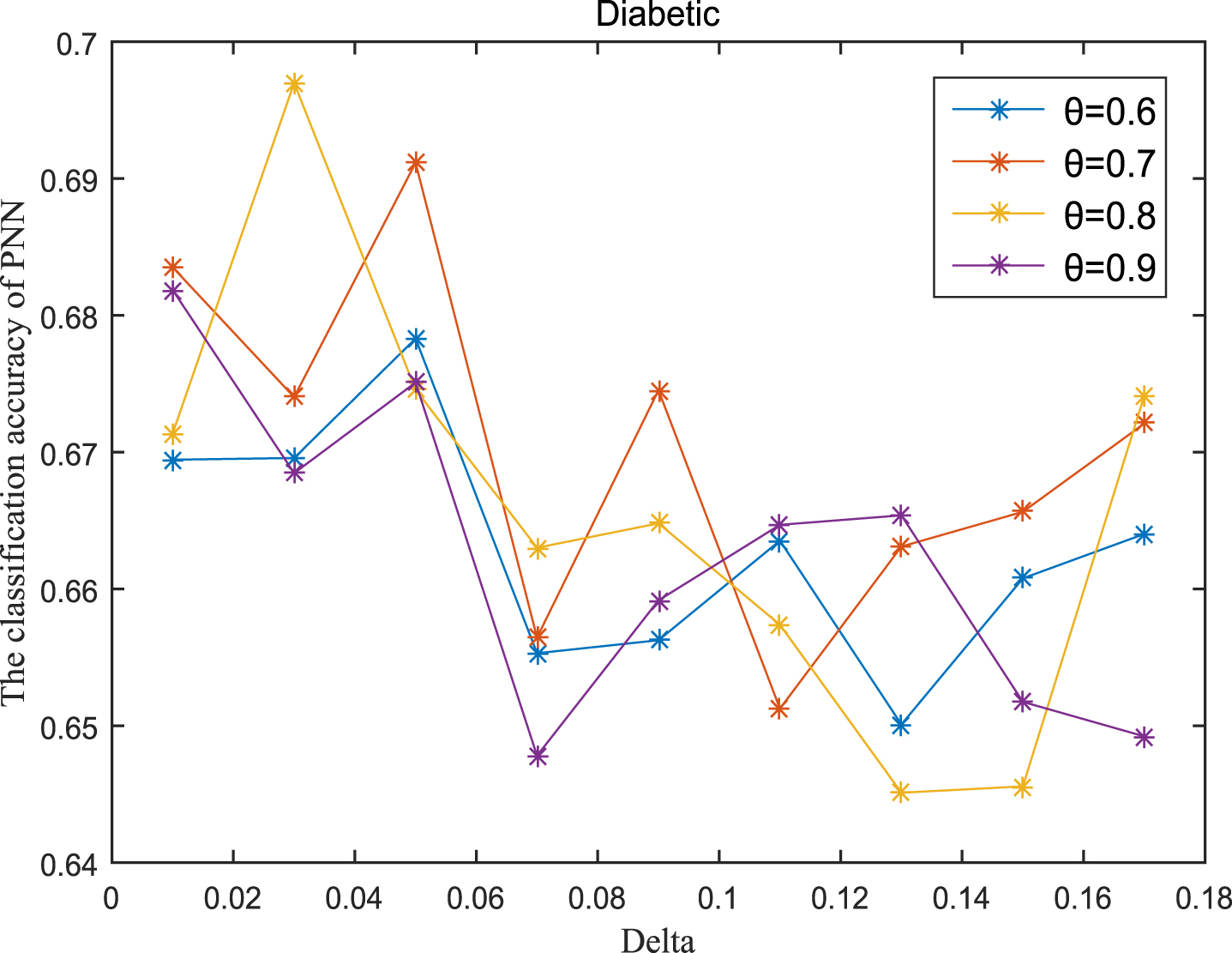
PNN classification accuracy (Dia).
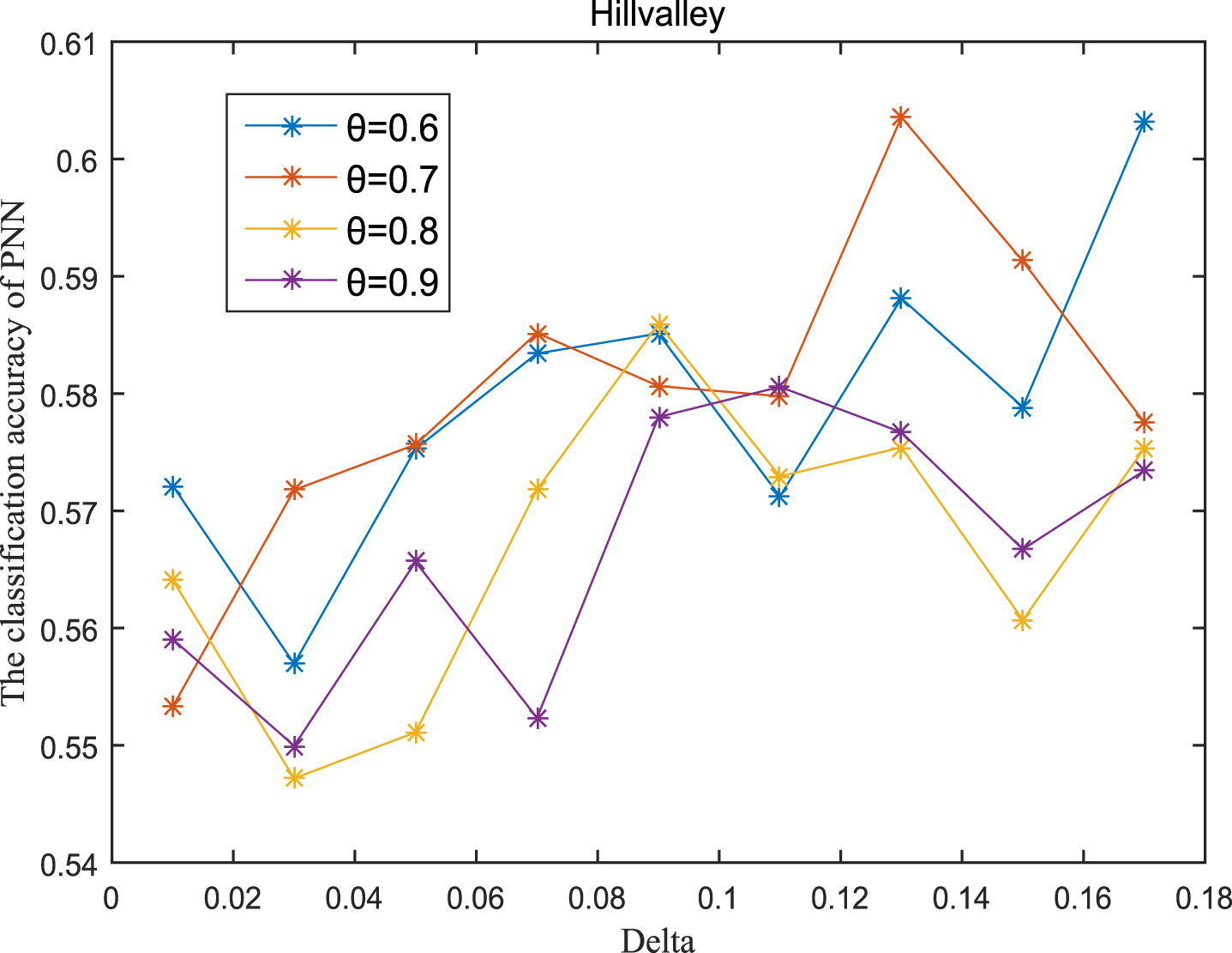
PNN classification accuracy (Hill).
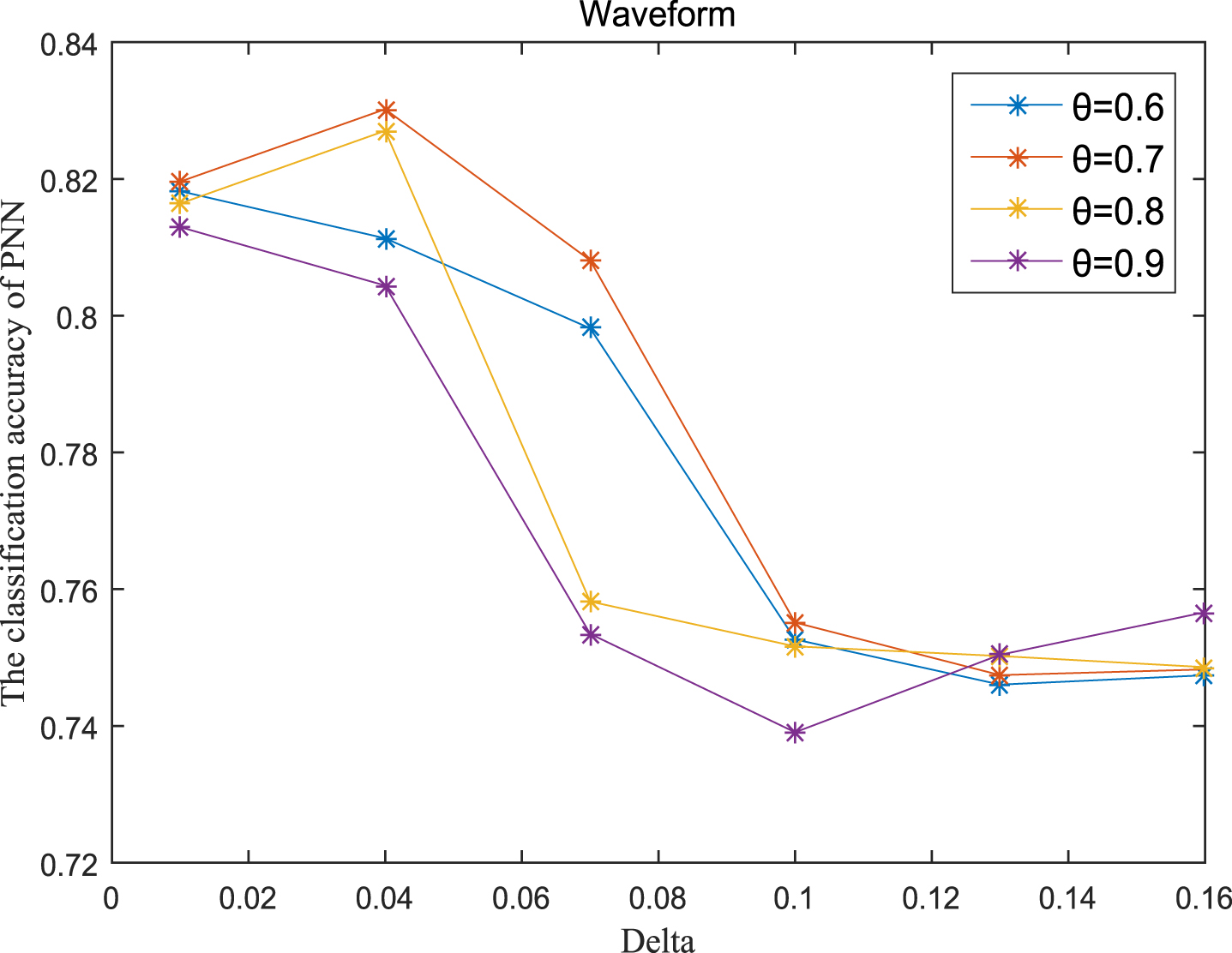
PNN classification accuracy (Wave).
In this section, we implement comparative analysis.
In order to show the advantages and disadvantages of the proposed algorithm, we choose the other five algorithms to compare with the proposed algorithm in this paper. One is PCA mentioned in the reference [33], whose contribution rate of characteristic root is assumed to be 0.95; one is FSRAR in the reference [23]; one is “DAI" in the reference [7]. The other two algorithms are COEN and DEP from the reference [3]. The computer used for the experiment is Lenovo PC, which is configured with Intel Core i7-4790cpu @ 3.60GHZ and 16G memory. The algorithm was programmed by Matlab 2015b. The four algorithms are tested with 10 datasets given in Table 2. Because the parameters selected by each algorithm are inconsistent, there will be multiple reduction sets calculated by one algorithm. We choose the set with the highest average classification accuracy as the reduction set. The classification accuracy is that each algorithm randomly selects 80% of the data as the sample, the remaining 20% of the data as the training set, runs 10 times and takes the average value.
Table 3 shows the best reduction set under the maximum accuracy of the four algorithms. The ‘raw data’ list shows that the datasets has not been reduced. It can be seen from Table 3 that Hillville dataset has not been reduced under COEN. The reason is that the data set must be α-consistent, but α cannot satisfy the conditions from 0.1 to 0.99, so the algorithms have no effect on the dataset. The reduction effect of DEP and FRM-IV algorithm is the best, and the average set size is 7.1. Figure 31 graphically shows the reduction effects of various algorithms under 10 datasets.
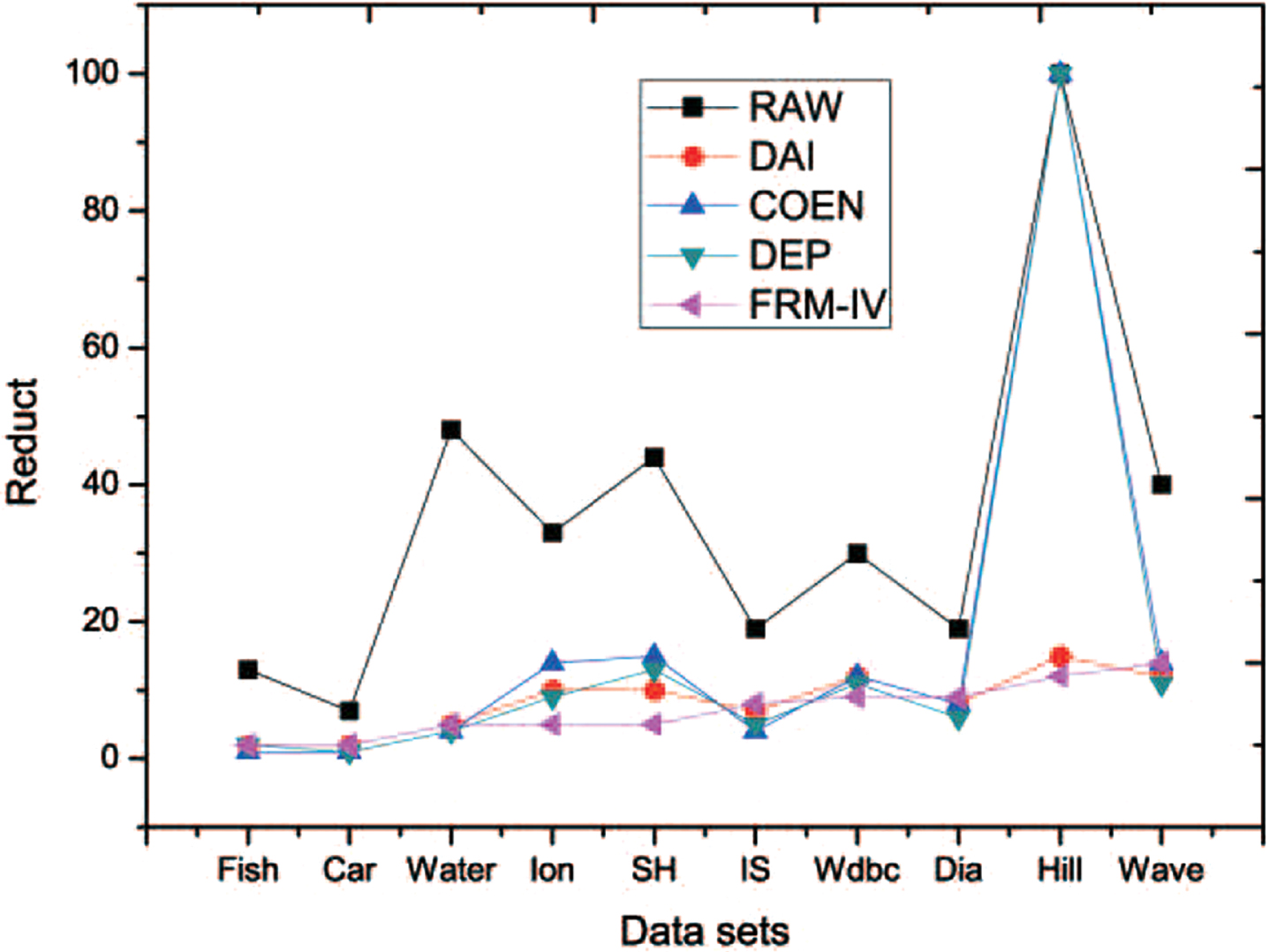
Reduced set comparison.
Number of selected features
Table 4 shows the classification accuracy obtained by calculating 10 datasets with KNN classifier, where k = 3. Underlined values indicate the highest accuracy. It can be seen that FRM-IV algorithm does not perform well on fish and car datasets, but shows high accuracy on other eight datasets. Figure 32 shows the KNN classification accuracy curve on 10 datasets. The horizontal axis represents 10 datasets, and the vertical axis represents the classification accuracy. Through figure 32, we can more intuitively see that the data set reduced by algorithm FRM-IV is significantly better than the other three algorithms in classification accuracy.
Comparison of classification accuracies of reduced data with KNN

Comparison of classification accuracy (KNN).
Table 5 shows the accuracy of the reduced datasets classified by PNN classifier. It can also be seen that FRM-IV algorithm is not good enough in fish and car datasets, and the classification accuracy is not as good as the other three algorithms. However, the algorithm achieves high classification accuracy on the other eight datasets. Figure 33 is a visual display of data in Table 5. In general, the proposed algorithm can reduce the number of attributes and obtain better classification accuracy than the other three algorithms.
Comparison of classification accuracies of reduced data with PNN

Comparison of classification accuracy (PNN).
In addition to the comparison of algorithm accuracy, the reduction speed of several algorithms is also compared. Because PCA algorithm is the dimensionality reduction of data and does not involve feature selection, it does not compare the time consumption. In this work, the time consumption of five algorithms is compared. Adjust the termination conditions so that the algorithms will not stop until all attributes in the set are reduced. All algorithms start from the time of reduction. Figures 34-41 shows the time consumption comparison of five algorithms under different datasets. It is easy to see from the figure that the algorithm FRM-IV proposed in this paper is faster than the other four algorithms. It takes less time to reduce all attributes. The second fastest is FSRAR, the third fastest is COEN and the slowest is DEP. When a dataset with a large number of attributes is encountered, such as Water, Hill and Wave, DEP algorithm does not perform well, and the time consumption curve shows a straight line trend. In general, algorithm FRM-IV in this paper is better than other algorithms in terms of reduction set size, classification accuracy and operation speed.
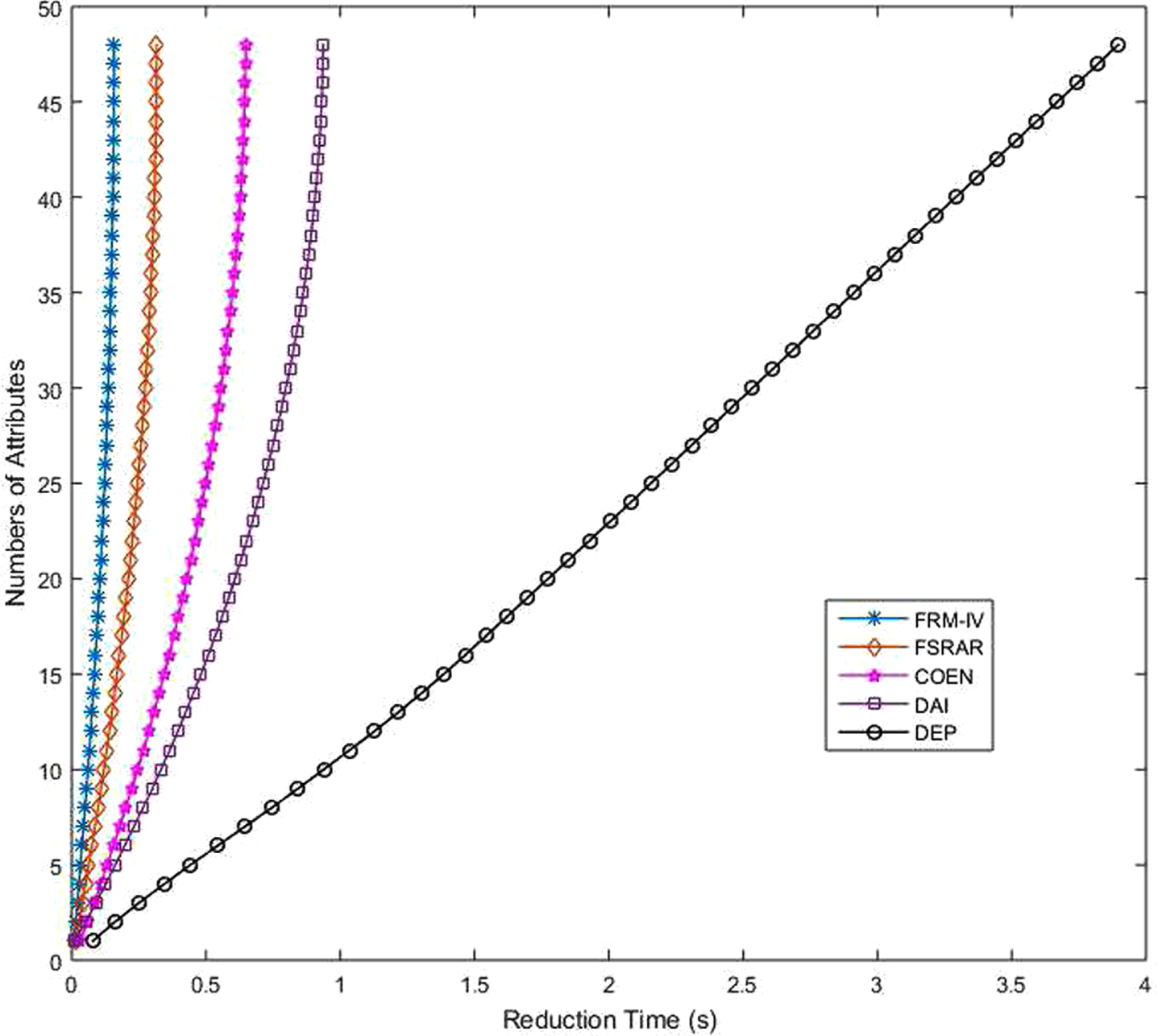
Time consuming comparison (Water).
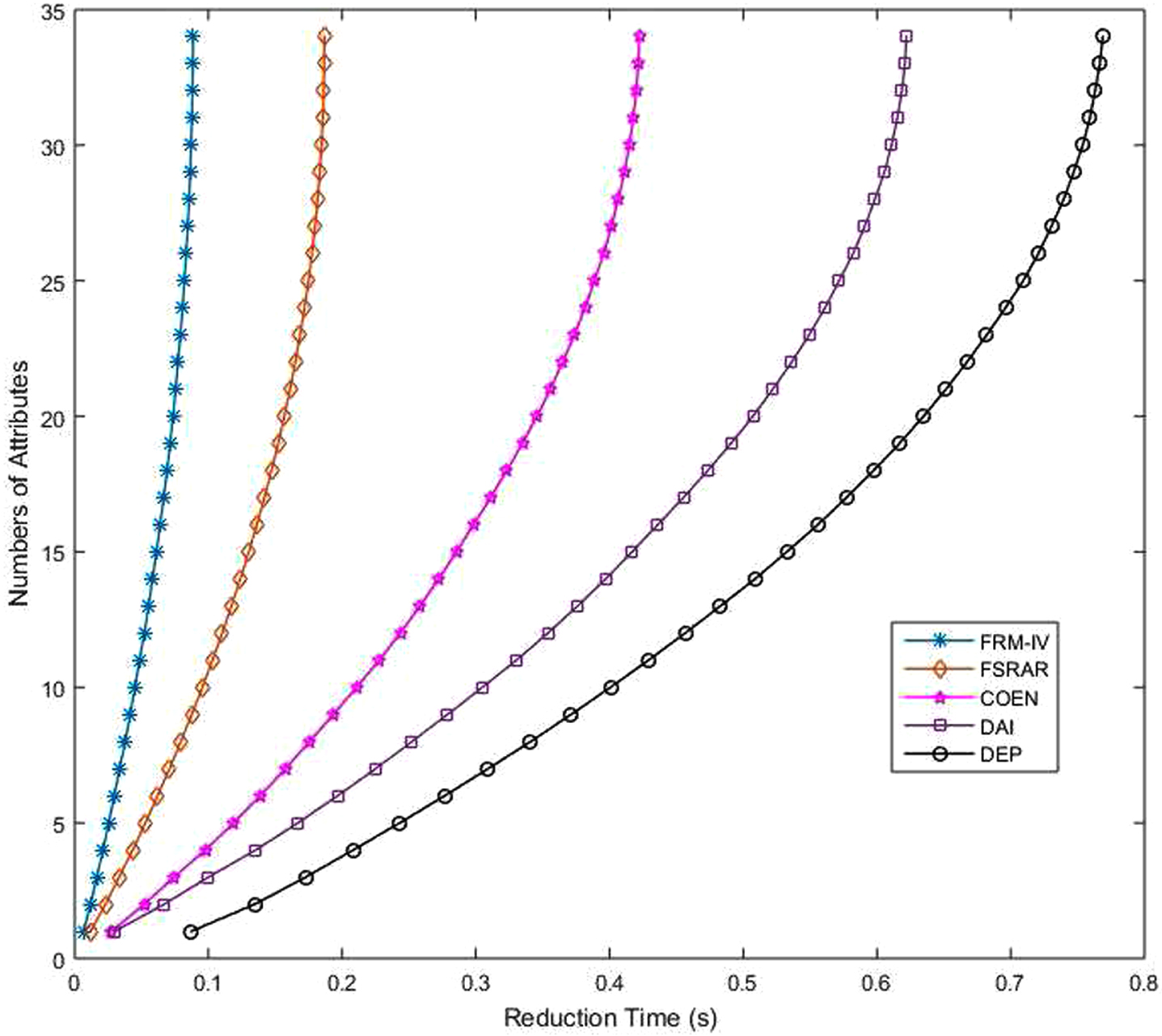
Time consuming comparison (IS).

Time consuming comparison (SH).
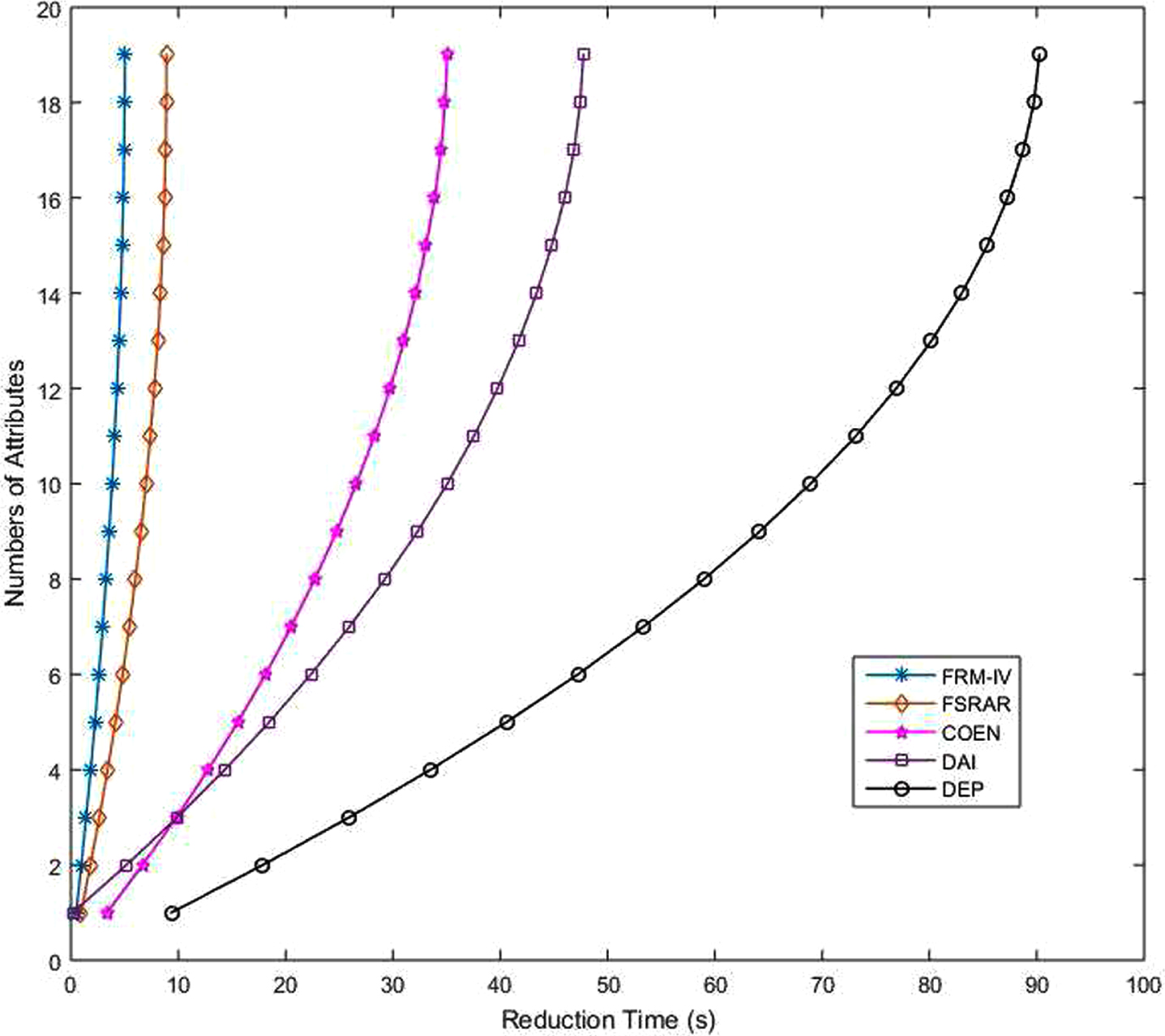
Time consuming comparison (IS).
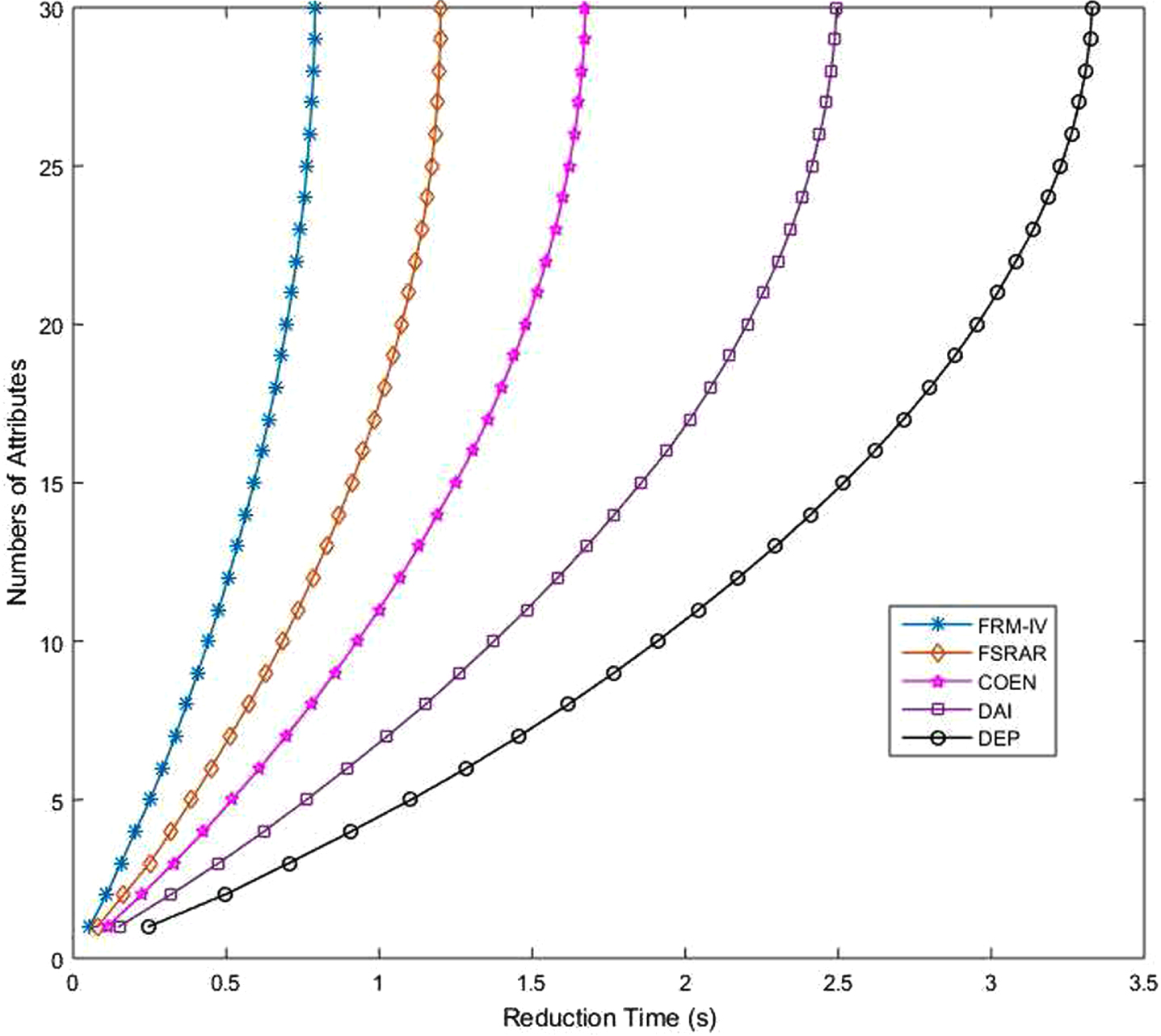
Time consuming comparison (Wdbc).
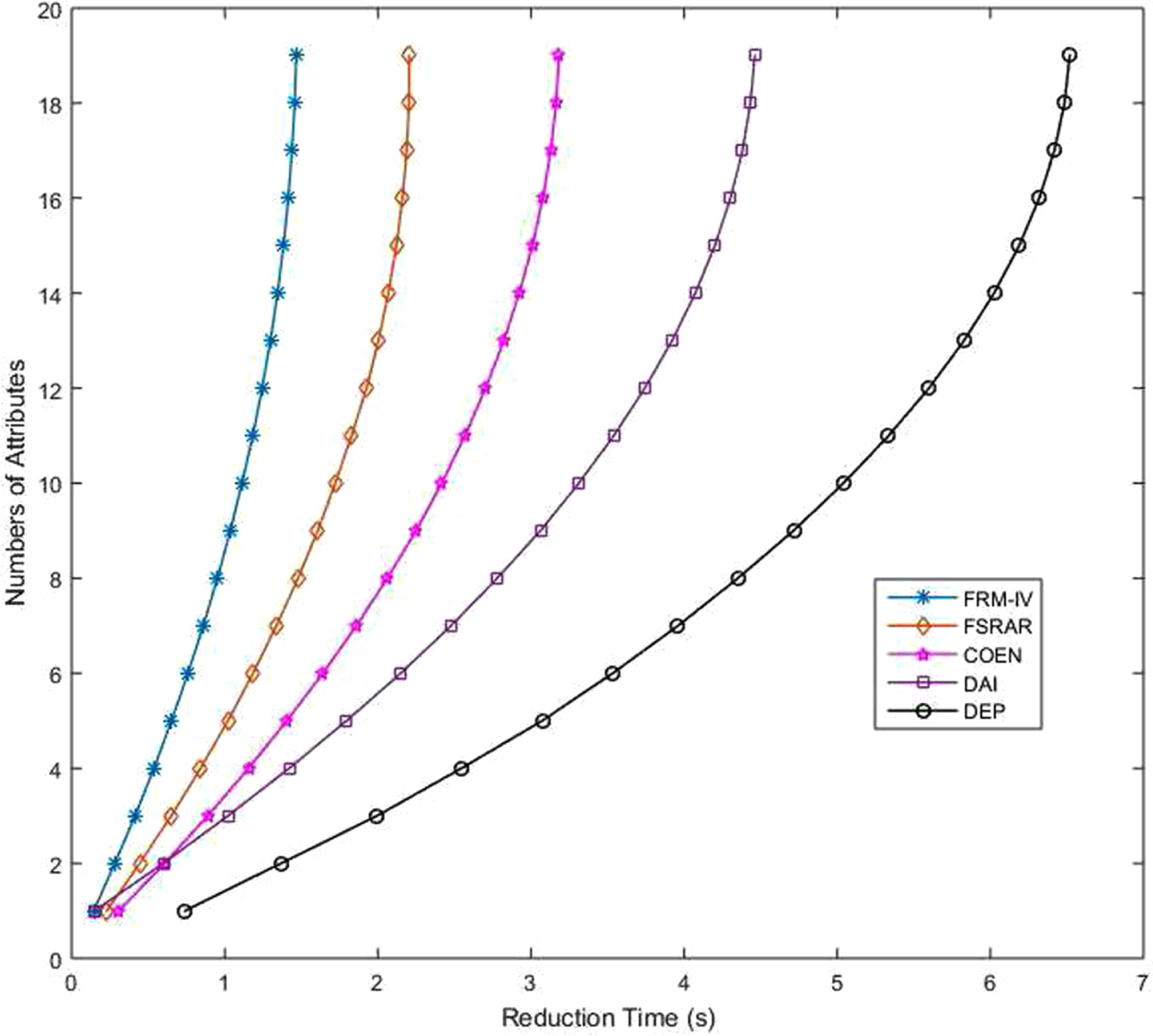
Time consuming comparison (Dia).
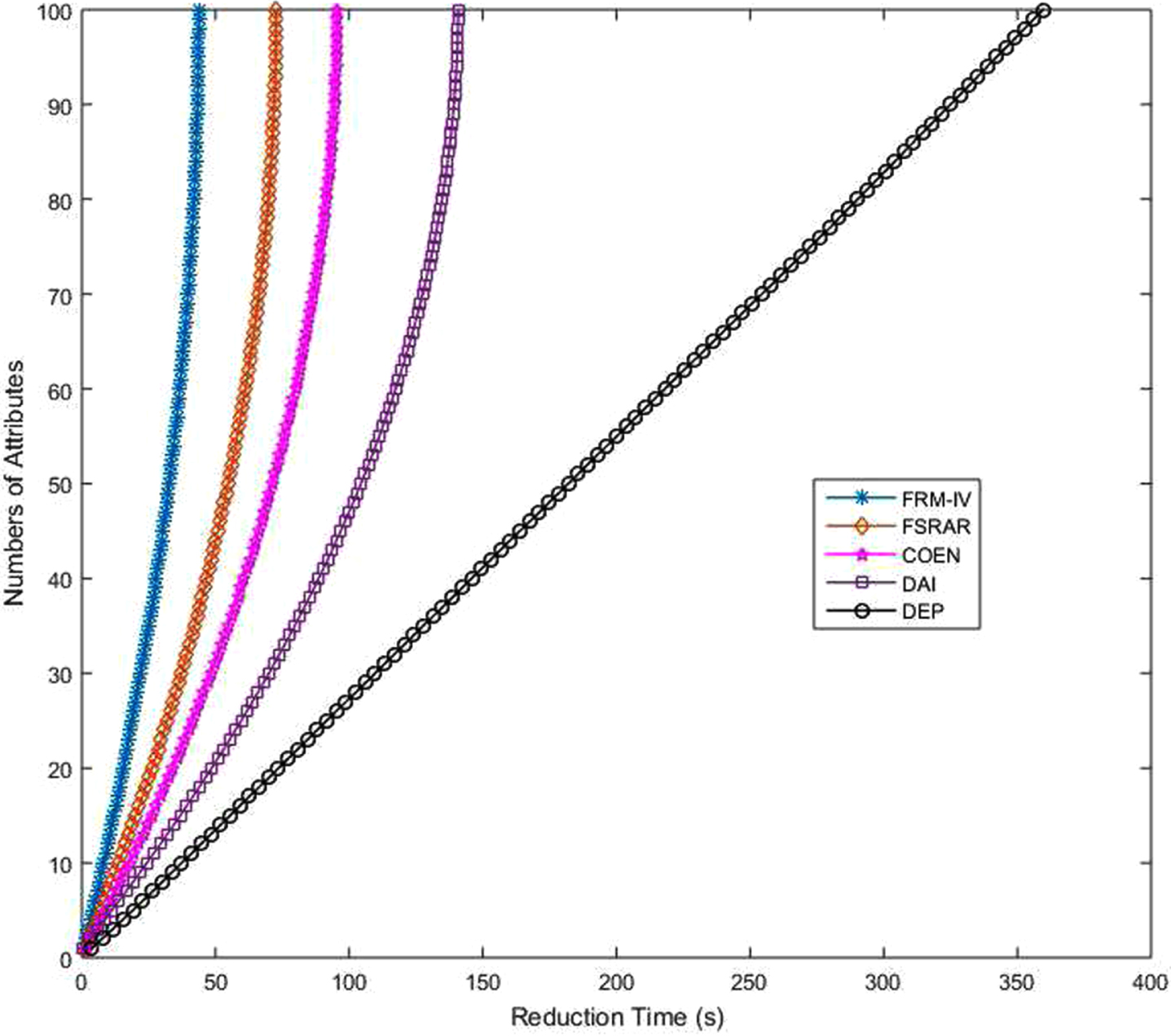
Time consuming comparison (Hill).

Time consuming comparison (Wave).
In this section, Friedman test and its post-hoc test should be performed for illustrating the differences of classification accuracies among the proposed algorithms statistically.
Friedman test [10, 32] is an non-parametric test basing on the following basic ideas: firstly, the algorithms are sorted in ascending order by their comparing index values, and the ranks of each algorithm under different datasets are obtained; secondly, calculating the average ranks of different algorithms respectively and the average rank differences between each pairs of algorithms; at last, comparing the average rank differences with a corresponding critical value of the test.
The specific inspection process is as follows. In a test of m datasets and n algorithms, it ranks the n algorithms by their classification accuracies respectively. For the i-th data set, the algorithm with the highest classification accuracy ranks 1st, the algorithm with the second highest classification accuracy ranks 2nd, and the algorithm with the third highest classification accuracy ranks 3rd,⋯. If the two algorithms have the same classification accuracy, their ranks are averaged. Denoting the rank of the classification accuracy of the j-th algorithm under the i-th data set as a
ij
, then the average rank of the j-th algorithm can be calculated as
(1) Ranking the six algorithms by their classification accuracies on the ten datasets, respectively (see Tables 6 and 7).
Ranks of the six algorithms on different datasets with KNN classifier
Ranks of the six algorithms on different datasets with PNN classifier
(2) Conducting Friedman test. Under the six algorithms and the ten datasets, F follows the distribution F(5.45). Given the significance level α = 0.05, the critical value F α(5.45) =2.422. χ2 = 26.157, F = 9.873, F > F α(5.45), this means the performance of the six algorithms are significantly different under the KNN and PNN classifier.
(3) To check out which algorithms perform better, a post-hoc test, that is Nemenyi test, is introduced. The results of Nemenyi test can be visually represented in Figure 42. The top line in the figure is the interval of CD α, and the second line is the axis on which we plot the average ranks of different algorithms. The groups of algorithms that are not significantly different are connected by a horizontal line. Above all, the following results are obtained:
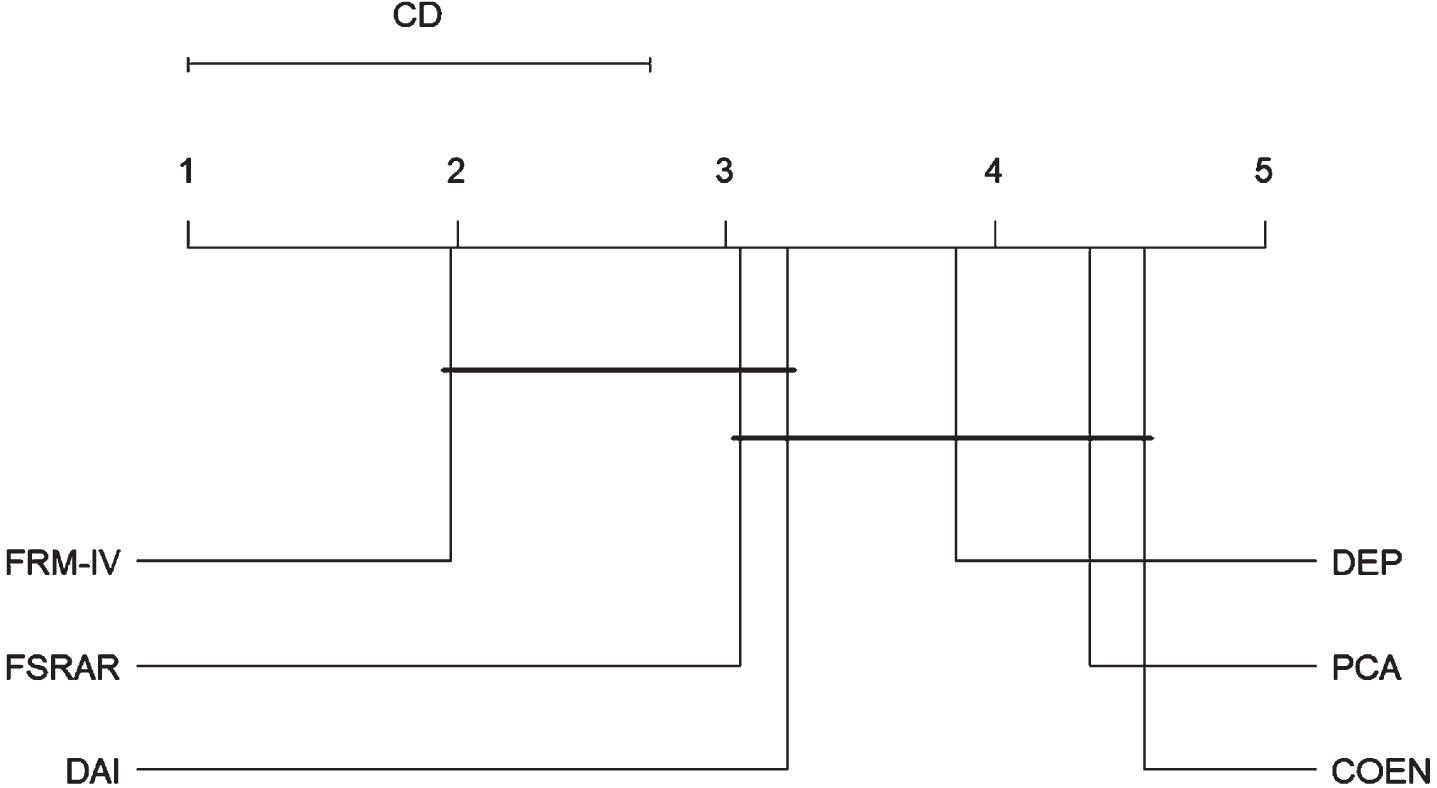
The Nemenyi test result with KNN and PNN.
a) The classification accuracy of FRM-IV is significantly higher than that of PCA, COEN and DEP;
b)The classification accuracy of FSRAR is significantly higher than that of PCA, COEN and DEP;
c)The classification accuracy of DAI is significantly higher than that of PCA, COEN and DEP;
d) There is no significant difference between the classification accuracy of FRM-IV, FSRAR and DAI;
e) There is no significant difference between the classification accuracy of PCA, COEN and DEP.
In this paper, some attribute evaluation functions that express the classification ability of feature selection have been put forward. Based on these functions, FRIC-model in an IVDIS has been established. An feature selection algorithm in an IVDIS has been presented by using this model. Experiments have been carried out and statistical tests have been used to evaluate the performance of the presented algorithm. Experimental results explain that the presented algorithm is more effective than some existing algorithms, and does not occupy too much memory. In the future, we will consider the application of FRIC-model.
Footnotes
Acknowledgments
The authors would like to thank the editors and the anonymous reviewers for their valuable comments and suggestions, which have helped immensely in improving the quality of the paper. This work is supported by National Natural Science Foundation of Guangxi (2022GXNSFAA035552, 2021GXNSFAA220114).