
Abstract
Multi-Pursuers Multi-Evader Game (MPMEG) is considered as a multi-agent complex problem in which the pursuers must perform the capture of the detected evaders according to the temporal constraints. In this paper, we propose a metaheuristic approach based on a Discrete Particle Swarm Optimization in order to allow a dynamic coalition formation of the pursuers during the pursuit game. A pursuit coalition can be considered as the role definition of each pursuer during the game. In this work, each possible coalition is represented by a feasible particle’s position, which changes the concerned coalition according to its velocity during the pursuit game. With the aim of showcasing the performance of the new approach, we propose a comparison study in relation to recent approaches processing the MPMEG in term of capturing time and payoff acquisition. Moreover, we have studied the pursuit capturing time according to the number of used particles as well as the dynamism of the pursuit coalitions formed during the game. The obtained results note that the proposed approach outperforms the compared approaches in relation to the capturing time by only using eight particles. Moreover, this approach improves the pursuers’ payoff acquisition, which represents the pursuers’ learning rate during the task execution.
Keywords
Nomenclature
Description
The inertia weight
The particle’s velocity
The particle’s position
generated numbers in the range of [0, 1]
The Acceleration parameter
The coalition fitness
the agent’s ability coefficients.
The reward’s ability
The coalition representation
the Euclidean distance
the agent’s internal velocity
The changes’ percentage of each particle
the maximum of the possible changes
A pursuit group
the number of possible agent’s next states.
The discount factor in the range of [0, 1]
The step-size sequence
The number of possible pursuers
Average reward obtained per pursuit
Introduction
Multi- agent Pursuit-Evasion Game (PEG) [1] is considered as one the most attractive research field in distributed artificial intelligence. This kind of game consists on a set of pursuers’ agents requiring a task coordination mechanism [2] to form pursuit coalitions with the aim of allocating the different tasks. These tasks concern the question “how the pursuers should be grouped to stop the motion of each detected pursuer”. Furthermore, the pursuers require a path planning mechanism [3] allowing them to take a decision regarding their displacements during the pursuit steps. Knowing that, the motion decision could be made in a centralized [4] or decentralized way [5]. On the one hand, the centralized way regards the case where the pursuers have to cooperate via the generation of an intelligent and collective path planning strategy. In other words, the path of each agent depends on the other agents’ trajectories. On the other hand, the decentralized approach concerns the case where the pursuers are independently moving until they reach their common objective.
In relation to the number of pursuers and evaders used in PEG, we can distinguish three variants of the PEG. In the case of a single pursuer purchasing a single evader SPSEG [6], only a path planning strategy must be provided to the pursuer in order to be able to perform the pursuit. However, if a set of pursuers are available to chase a single evader MPSEG [7], a task coordination mechanism could be also incorporated to select the most convenient pursuers that can form the single pursuit group. In the case of MPMEG [8], the task allocation concerns how the available pursuers will be grouped in different and optimal pursuit groups in order to parallelly perform the multi-pursuit game.
In general, Metaheuristic approaches [9] can be defined as iterative stochastic algorithms aiming to provide solutions for hard optimization problems. Multiagent (MAS) approaches and metaheuristics are closely linked to each other knowing that both are based on the social metaphor exploitation as well as the self-organization paradigm. Consequently, multiagent principles are hugely used in metaheuristics, especially for hybrid, distributed, and population-based metaheuristics. The positive points concerning the utilization of multiagent approaches in combination with metaheuristics can be vindicated by the distribution and robustness characterizing the multiagent systems, in addition to the flexibility and the modularity requirements. In relation to MAS, a metaheuristic can be defined as an organization aiming to efficiently explore the search space in order to discover highly advantageous solutions in accordance to the temporal constraints.
Among the existing Metaheuristic approaches, Particle Swarm Optimization (PSO) [10] is considered as one of the most popular. PSO is defined as a population-based optimization approach taken inspiration from the swarm movement of bird flocks as well as schooling fish. PSO has several similarities in comparison with evolutionary computation methods [11]. At the initialization step, the system generates a population reflecting random solutions, and the location of the optimal solution is carried out through the update of the generations. Contrary to Genetic Algorithms [12], PSO is not based on evolution operators, such as crossover and mutation. In PSO, the probable solutions, known as particles, change their positions in the problem space by following the actual optimum particles. From a computational point of view, PSO provides more performance in terms of both velocity and memory requirements [13]. In relation to the discrete problems, PSO algorithm is usually extended to discrete versions in order to be applicable. In [14], the authors introduced a novel discrete PSO model through a hybrid approach. Precisely, the hybrid approach takes into consideration the local search of the particle to move in accordance to its own experience, as well as the Path relinking to move in accordance to other particles’ experience. Knowing that the bionic PSO approach was designed for the continuous problems, many PSO-based optimization methods suffered due to the random displacements of the particles, which is caused by their inappropriate discretization strategies. To counter these issues, a PSO-based static load balancing algorithm aiming to appropriately affect every federate to an available host was recently introduced [15]. In other words, they improved the Personal best update of a given particle in the population through the use of better solutions stored in the external archive dominating it. In addition, a probability-based discretization approach was proposed to adapt the PSO algorithm to the discrete problem via the modification of the particles’ velocities and positions updates. In another context [16], a multi objective optimization method regarding the palm vein feature selection based on the discrete Particle Swarm Optimization (PSO) was recently introduced. The proposed multi-objective function takes into account the accuracy of the biometrics system as well as the size of the selected feature vector with the aim of increasing the accuracy of the system and decreasing the size of the feature vector.
In recent years, PSO is hugely combined with MAS in order to process several problems such as collaborative work planning strategy [17], expert systems optimization [18], medical image segmentation control [19], and Travelling Salesman Problem (TSP) [20]. Specifically, in this last, the original PSO algorithm was improved with the aim of incorporating the desired learning capacities into the agents. In relation to these lasts, they were designed to perform parallel calculations of fitness values based on the personal best of many neighborhoods and save the result in the belief database in order to be reused. The proposed work has improved the conventional PSO by increasing both the intelligence and autonomy rates of the swarm.
In this paper, we process the MPMEG via the proposition of a MAS coalition formation based on Discrete PSO approach in order to allow an optimal pursuits tasks’ allocation. The principal motivation of using this metaheuristic approach is that it allows an interesting exploration of the search space through the number of used particles as well as their dynamism provided by their velocities. Knowing that, the particles’ velocities are iteratively updated in relation to their personal best solution and also to the global best solution achieved in the search space. Moreover, the particles’ velocities calculation is based on different coefficients allowing the control of the solution convergence. The proposed approach is applied to MPMEG in comparison with dynamic task coordination methods. The necessity of dynamic approaches in MPMEG is due to the fact that the pursuit coalition dynamically changes according to the new environment positions of the mobile pursuers at each pursuit iteration. In comparison with the recent heuristics applied to the MPMEG for providing coalition formation, such as MAS organizational models and game theoretic methods, the proposed approach is categorized in the range of meta-heuristics. Knowing that meta-heuristics are problem-independent, the proposed approach can be applied to other np-hard problems. However, organizational models can only be used in order to coordinate the agents’ behavior. The game theoretic approaches based on the iterated elimination of dominated strategies need the generation of all the possible combinations in order to be efficient, which can lead in some cases to combinatorial explosions. Moreover, the strategies used in the dominance principle are considered as statics by the fact that they are not iteratively modified unlike the particles that continuously change according to their dynamic velocities. Furthermore, the proposed approach can also be efficient through the utilization of a small number of particles as demonstrated in section 5. This fact means that there are no risks to stuck in a combinatorial explosion via the use of the proposed approach. The main contributions of this work can be resumed as follows:
The proposition of a discrete version of Particle the Swarm Optimization (DPSO) for the Multi-Pursuer Multi-Evader Game (MPMEG). The study of the impact of the particles’ number on the pursuit processing as well as their velocities changes during this process. The comparison study of the proposed DPSO with recent optimization methods processing the MPMEG. This comparison study aims to prove the feasibility of the proposed DPSO in relation to the pursuit capturing time and the pursuers’ acquisition payoffs during the pursuit.
The paper is organized as follows: in section 2, we discuss some related works regarding the pursuit coalition formation as well as the application of PSO in MAS. In section 3, we define the PSO algorithm and PEG problem and how they are linked in this work. In section 4, we introduce the proposed pursuit coalition formation algorithm based on PSO via the explanation of the different algorithm’s steps. The simulation results in comparison with recent related cases are showcased in section 5 of the paper in order to showcase the improvement brought by the new proposal. Finally in section 6, we conclude our work by a brief summary of the work effectuated in this paper and some perspectives of our future works.
Related work
Multi-agent organizational models are often used to provide pursuit coalition formation algorithms. In [21], the authors proposed a fuzzy logic extension of Agent Group Role (AGR) organizational model to allow dynamic grouping of the pursuers. In other words, they equipped each pursuit group with a membership function determining the membership degree of each agent in relation to each group. The role of this membership function is to attribute the roles proposed by the group to the agents according to their membership degrees. Also, they studied the PEG by using AGRMF with static and dynamic coalition formation to showcase pursuit the impact of the groups’ dynamism. In another work [22], they have based on the Yet Another Multi-Agent Model (YAMAM) to process the PEG. thus, they used the concepts Agent, Role, Skills, and Task forming YAMAM organizational model to create a pursuit access mechanism to each pursuit group. They also introduced an interesting path planning method based on Reinforcement learning to allow a decentralized multi-agent motion strategy.
Game theory approaches are also usually used in relation to PEG. In [23], the authors were inspired by the Iterative Elimination of Dominated Strategies model (IEDS) to process the PE problem. In other words, they proposed a pursuit coalition formation algorithm based on IEDS. They considered a possible pursuit coalition as a strategy returning a specific reward according to the agents’ roles. After that, the pursuers in turn and iteratively eliminate the dominated coalitions according to their rewards’ impacts. The remaining strategy is considered as the selected pursuit coalition through this process. The process is repeated before each pursuit iteration allowing the dynamism of the pursuit coalition.
In relation to PEG, PSO algorithm was often used in different ways. In [24], PSO was used in order to control the mobile agents’ path planning. In other words, both pursuers and evaders are considered as particles. The motion strategy of evading particles is devised into local moving functions. Through the application of PSO algorithm, the pursuit particles resolve these local functions. On the one hand, the closest function value in relation to the evading particles is considered as the local best value. On the other hand, the global best value can be acquired in the case where the evading particle is captured. In [25], they proposed a binary PSO alliance generation for multi emotional robots chasing single evader. Specifically, each particle is considered as a possible pursuit alliance. The position variable of the alliance (i) is characterized by (m) dimensions (m represents the number of the existing pursuers’ robots). The size of the particle’s position variable can only take the value 0 or 1 in each dimension, meaning that the concerned pursuer belongs to the alliance or not. The size of particle’s velocity variable reflects the pursuit alliance adhesion probability of the concerned pursuer, whereas the global best variable is a record of the optimal solution of this alliance obtained during the best coalition finding process.
Metaheuristic approaches are hugely utilized in order to provide coalition formation algorithms. In [26], an improved particle swarm optimization (IPSO) was introduced for resolving the problem linked to the generation of the task-oriented optimal agent coalition formation. With the aim of overcoming the premature and local optimization problem in the original version of the PSO algorithm, they proposed a variation of inertia weight PSO algorithm through the analyze of the feasibility regarding the particle optimization process in PSO. In [27], PSO-based optimal multiple agents task allocation algorithm was proposed to process the cooperative timing mission problem. The traditional PSO-based algorithm for the cooperative timing mission was improved via the use of the graph theoretic constraints to guarantee the simultaneous arrivals. Recently in the context of task allocation [28], the authors proposed an efficient stability quantum particle swarm optimization (SQPSO) algorithm, which provides high payoffs acquisition, benefit division, coalition stability guarantee, as well as a historical task mechanism concerning the search acceleration. In addition, they designed an effective establishment quantum particle swarm optimization (EQPSO) algorithm for coalition scheduling, which is improved by a coalition similarity judgment aiming to decrease the coalition formation time cost. In another type of MAS games known as Coalitional Resources Games (CRG), which could be defined as a natural and formal framework based on agents desiring to form coalitions to pool their infrequent resources with the aim of reaching a set of objectives satisfying all members of a coalition, the research activities provided a large variance of task coordination mechanisms allowing the agents’ coalitions. In relation to PSO, the authors in [29] studied the possibility of involving binary particle swarm optimization (BPSO) in the role of stochastic search process in order to identify the Maximal Successful Coalition (MAXSC) in CRGs. To achieve their goals, they proposed a one-dimensional binary encoding scheme, and developed methods for encoding repair to guarantee the approximate validity and the logical consistency of each encoding in every iteration process. Finally, they discussed some essential properties regarding repair methods.
Moreover, other types of metaheuristic algorithms are also used to generate coalition formation approaches. In relation to Genetic Algorithms [30], they considered three variants of the coalition formation problem, which are, the single-task single-coalition formation, the multi-task single-coalition formation, and the multi-task multi-coalition formation. With the aim of decreasing the total cost, and at the same time satisfying the ability requirement constraint, the mathematical models of the three coalition variants were formulated. An effective genetic algorithm with heuristic initialization and repair strategy (GAHIR) was introduced to resolve the coalition formation problem. Multiple initialization and repair approaches using the prior knowledge of the specific problems were showcased to ameliorate the solution quality. In [31], the authors were inspired by Quantum Evolutionary Algorithms to expose a leader-follower coalition formation algorithm in a large-scale UAV network in order to constitute the best possible coalitions of the agents to perform the detected tasks in an unknown environment. Three principal goals have been taken into consideration in this coalition formation, the first objective was the decrease of resource consumption during the execution of the assigned tasks on time. The second objective regarded the upgrade of the coalitions’ reliability. Finally, they differentiated the most trustworthy UAVs from the self-interested UAVs in constituting the coalitions. In [32], taking into account the UAV coalition loss cost and time cost during a multi-task allocation problem, an ameliorated quantum genetic algorithm was suggested with the aim of resolving the task allocation problem of multi-UAV coalition. Based on the principles of quantum genetic algorithm, the historical optimal solution memorization method as well as the distribution estimation algorithm were proposed for respectively accelerating the convergence speed and decreasing the probability falling into the local optimum of the algorithm. Furthermore, in order to enhance the performance of the algorithm in relation to the problem background, a gene repair was incorporated.
Recently in [33], MPSEG was processed in the case where the evader’s velocity is higher than velocity of the pursuers. Knowing that in the discussed approach, the evader is randomly moving in the environment. To perform the capture, the authors proposed a new collaborative path planning aiming to provide an equilibrium that allows the pursuers to form an encirclement and to decrease the distance separating them from the evader at the same time. In the same pursuit context (MPSEG), in [34], deep reinforcement learning was used to process the problem related to the environment sensing as well as the decision-making. Specifically, a control mechanism inspired by the multiagent deep deterministic policy gradient (MADDPG) algorithm was constructed with the aim of implementing a multi-agent cooperative path planning decision-making to cross the limitation of the tedious state variables needed for the complex modeling treatment.
In relation to SPSEG, a general stochastic multi-agent Pursuit Evasion differential game based on additive Gaussian noise in the dynamics has been proposed in [35]. For avoiding the complexity linked to the multiplicity of the agents in conventional Dynamic Programming methods, a class of suboptimal approaches was introduced to reach a suboptimal solution with an enhancing property based on the optimization with restricted look-ahead.
In the case of MPMEG path planning [36], the authors proposed a pursuers’ path planning algorithm based on Theta* search to decrease the expected distance to the probability distribution of the concerned evader, which is measured via Markov localization principle. Also, they introduced a new repetitive pursuer assignment algorithm based on an excessive number of pursuers in order to minimize the expected time required to capture the evaders.
Background
In this section, we introduce the principles of PSO algorithm in subsection 3.1. Moreover, a large definition of PEG and the necessity of forming pursuit coalitions are detailed in subsection 3.2. Finally, we explain how the PSO principles will be used in order to provide a pursuit coalition formation algorithm.
Particle swarm optimization algorithm
In mathematics and computer science, an optimization problem refers to the problem of finding the best solution among all feasible ones. In the simplest terms, an optimization problem has for objective to maximize or minimize a real function known as the objective function through the systematic selection of input values according to a specific set and calculating the value of the function.
In general, an optimization problem can be described as follows:
An optimization algorithm can be defined as a set of instructions which are iteratively executed via the comparison of different solutions until finding an optimum or a satisfactory solution. The PSO algorithm introduced firstly by Kennedy and Eberhart [37], is a population-based optimization algorithm using a swarm of particles. It was inspired by the social behavior of individuals (particles) within a swarm to solve the optimization problems. In the PSO, a number of particles are stochastically generated and moving in the search space with a velocity determined according to its own search experience and the experience of its neighbors in the swarm. In [38], an important PSO version was introduced. Specifically, the authors introduced a new parameter known as the inertia weight aiming to balance the global search as well as the local search. Generally, Each particle is represented by a current position X i =(x1, x2 … x N ), which is considered as a solution of the optimization problem, a velocity Vi =(v1, v2 … V N ) used for updating the particle’s position, and their best position visited Pbest =(p1, p2 … p N ). where N is the number of decision variables of the optimization problem. In the PSO algorithm, all particle’s positions are randomly initialized in the search space. Also, each particle updates its position at each iteration by adding a velocity (displacement step) to its current position as shown in the Equation (2) [38].
The velocity of each particle is updated by using the personal best position and the global best position (the best position of all particles of the swarm) as presented in Equation (3) [38].
At each iteration, the performance of each particle x is calculated using its current position and the fitness function f(x). After that, the Pbest and Gbest are updated. The PSO algorithm automatically stops after a predefined number of iterations.
Multi-Pursuer-Multi-Evader game is considered as np-hard multi-agent problem in which the existing pursuers P = {p1, p2 … p j } cooperate with each other in order to generate a collective intelligent behavior allowing the capture of the detected evaders E = {e1, e2 … e k }. The main objective of a coalition formation algorithm is to provide a task coordination mechanism to the pursuers with the aim of minimizing the pursuit iterations used in the chase process. A coalition formation can be defined as follows:
The pursuit environment allows the localization of the agents according to their cartesian coordinates. In this work, the pursuit-evasion world is represented by a limited grid of cells environment. Each cell represents a position that can be occupied by only one agent at each pursuit iteration. Knowing that each agent can only percept the information contained in the adjacent cells. Consequently, the pursuit environment can be considered as partially observable. Moreover, each pursuer can move from a cell to another one according to its internal velocity. An evader is considered as captured if only all its adjacent cells are occupied by pursuers. The capture of an evader is checked according to the following expression:
In relation to PSO algorithm, we have seen the usefulness to consider each possible coalition formation as a particle. Knowing that the particle changes each position according to its velocity at each iteration, this fact provokes the dynamism of the coalition formation according to the new pursuers’ positions. Also, the number of used particles increases the coalition formation possibilities. The Global best position represents the selected pursuit coalition formation. Knowing that the global best position can change from an iteration to another allowing the dynamism of the selected coalition.
PSO is a metaheuristic algorithm that has demonstrated its performance on several continuous optimization problems. However, in some special problems such as MPMEG, the solutions are restricted to discrete values knowing that continuous version of the metaheuristics cannot be directly applied to this kind of optimization problems. Several discretization techniques are described in the literature [40]. The modification of the position’s equation is a very popular method regarding the transformation of continuous space into a discrete space by using discrete operators. In this paper, a new Discrete PSO (DPSO) is proposed and used for the PEG optimization problem with the aim of improving the performance of pursuit coalition selection. In this section, we introduce the proposed PEG algorithm based on DPSO. Through the pseudo-code showcased in algorithm 1, we detail how the PEG is inspired by the particles swarm behavior. Moreover, we explain how the personal-best of each particle as well as the global-best are updated during the different steps of the pursuit.
The different algorithm’s steps can be explained in the subsections 4.1, and 4.2. In the first subsection, the particles’ encodings and initializations are detailed in addition to the particles’ fitness calculation and the pursuers’ displacement in the pursuit environment. In subsection 4.2, the particles’ velocities and the positions updates used to maintain the particles’ feasibility are explained. Finally, in subsection 4.3, a demonstration example regarding the calculation of the particles’ velocities as well as the update of their positions is provided.
Particles’ encodings and initializations
At the beginning of the PEG, the number of used particles is initialized. Knowing that each particle represents a possible coalition formation dedicated to all the detected evaders, the particles’ values are randomly generated. At the particles’ generation step, the particles are conditioned by a certain feasibility in order to be usable. With the aim of understanding the particle feasibility, we take an example where 2 evaders need successively 2 and 3 pursuers to be captured knowing that there exist 6 agents that can play the role pursuer. In this case, the coalition is structured as follows:
Gr1, Gr2: the pursuit groups regarding the capture of evader 1 and 2.
in this example, the coalition must contain the value 1 twice, the value 2 three times, and the value 0 once in order to be feasible, for example:
After the particles’ generation, the fitness of each particle is generated according to the ability factors of each agent in relation to the role played through the concerned coalition. The fitness of each coalition (particle’s position) is calculated as follows:
n: the number of agents that can play the role pursuer.
α, β: the agent’s ability coefficients.
R: the reward ability, which is proportionally inverse to the distance between the pursuer and the concerned evader. It is calculated in the following way:
γ (P, E): represents the distance between the pursuer P and the evader E.
S: the agent’s internal velocity, or how many pursuit cells the agent can cross during a pursuit iteration.
The initial coalition value of each particle known as the particle’s initial position is considered as the initial Pbest value of each particle. From the fitness of the Pbest values, the Gbest value is calculated in order to select which coalition the pursuers have to follow. The Gbest is represented by the particle with the highest fitness value.
After the coalition selection (Gbest selection), the pursuers execute a pursuit iteration according to their internal velocity. However, the agents that do not belong to any pursuit group move randomly in the environment with a specific internal movement’s velocity in order to increase the exploration of the search space. To allow the pursuers’ displacement in the environment, we have based on Reinforcement learning method known as Q-learning [39]. Via this learning method, the pursuers can maximize the expected reward at each pursuit iteration:
z: the number of possible agent’s next states.
ƛ: The discount factor (ƛ ∈ [0, 1]).
η i : The step-size sequence.
After the first pursuit iteration, the velocity of each particle is updated according to algorithm 2. As shown in this algorithm, the position values of each particle are compared with the personal best and the global best positions in order to estimate the difference degrees, which represent the second and the third parts of the velocity update equation (equation 03). Knowing that, the initial value of each particle’s velocity is 0 as reflected in algorithm 1.
In order to update its position according to the principles of equation 02, each particle changes the roles of its agents according to its new velocity. However, the feasibility of each particle must be preserved. The changes’ percentage of each particle in relation to the updated velocity is calculated as follows:
After that, the changes are performed according to the percentage of each particle and the maximum number of the possible changes (℧) that we can effectuate on the particle. In order to preserve the feasibility of the particle, the changes are effectuated through the permutation of the agents’ roles in the case where these roles are different. Consequently, the change number of a particle must be an even number. From the above example, we consider that the maximum of the possible changes (℧) is 6, then:
From the equation (14), we can generalize the Vi+1 calculation as follows:
After that, the personal-best value of each particle is updated as well as the global-best value. Noting that the agents change their environmental position after each pursuit iteration, these updates are performed after the update of each particle’s fitness calculated according to equation (10). Each particle compares its Pbest fitness value with the fitness value of its new position. The fitness value of the new position is considered as the particle’s Pbest position if it is superior to the particle’s Pbest fitness value. in the same way, the Gbest is updated by the Pbest with the highest fitness value if it is superior to the Gbest actual fitness value according to equation (16). The update process is repeated after each pursuit iteration (Pursuers’ displacement) until the capture of the purchased evaders. An evader is considered as captured in the case where all its adjacent cells are occupied by pursuers.
To clarify the velocities as well as the positions updates process proposed in this section, we showcase the following example: in relation to the particle position reflected in equation (9), we assume that the Pbest position = [2, 2, 2, 1, 1, 0], Gbest position = [2, 1, 2, 2, 0, 1], and
Simulation results
To showcase the performance of the new proposal, we have carried out the simulation experiments by using Netlogo platform 5.0.4 [41] running on Windows 8.1 64 bits, and a processor intel i5 4300M (2.6 GHz) accompanied with 12 GO of memory. The choice concerning the choose of this multi-agent platform is related to the fact that it provides a MAS environment known as patch, which allows the control of the agents’ motion. The studied case in this section is based on 2 evaders requiring each one a pursuit group formed of 4 pursuers to be captured. Knowing that, there exist 10 agents that can play the role pursuer. With the aim of specifying the simulation inputs, we have seen the usefulness of indicating the initial Cartesian coordinates of the agents in the pursuit environment as shown in Table 1. These agents are situated in 100*100 grid of cells environment and they can move in specified directions at each pursuit iteration according to a specific velocity. In these simulations, the agents’ velocities change according to role of the agent. Specifically, the agents playing the role Pursuer have a specific velocity. However, the velocity increases in the case where the agent does not play any role in order increase the dynamism chances of the selected coalition. During these simulations, the inertia (w) as well as the acceleration parameters (c1, c2) are used according to the original PSO principles (w = 1, c1 ∈ [0, 1] , c2 ∈ [0, 1]) as detailed in section 3.1 of this paper. Knowing that Metaheuristic approaches play the role of organizational models in MAS, the proposed approach is compared with two recent approaches based on organization and another game theoretic optimization method. furthermore, we note that the principles of the 3 compared cases are well discussed in section 2 of this paper:
Agents’ initial positions
Agents’ initial positions
Case 1: in this case, the coalition of the agents is based on AGRMF organizational model [21].
Case 2: in this case, the recent coalition formation algorithm based on YAMAM organizational model [22] is applied to allow the grouping of the agents.
Case 3: this case concerns in the game theoretic coalition formation algorithm based on the IEDS principle [23]. In order to determine the internal movement velocity of each pursuer used during these simulations, we proposer the following equation:
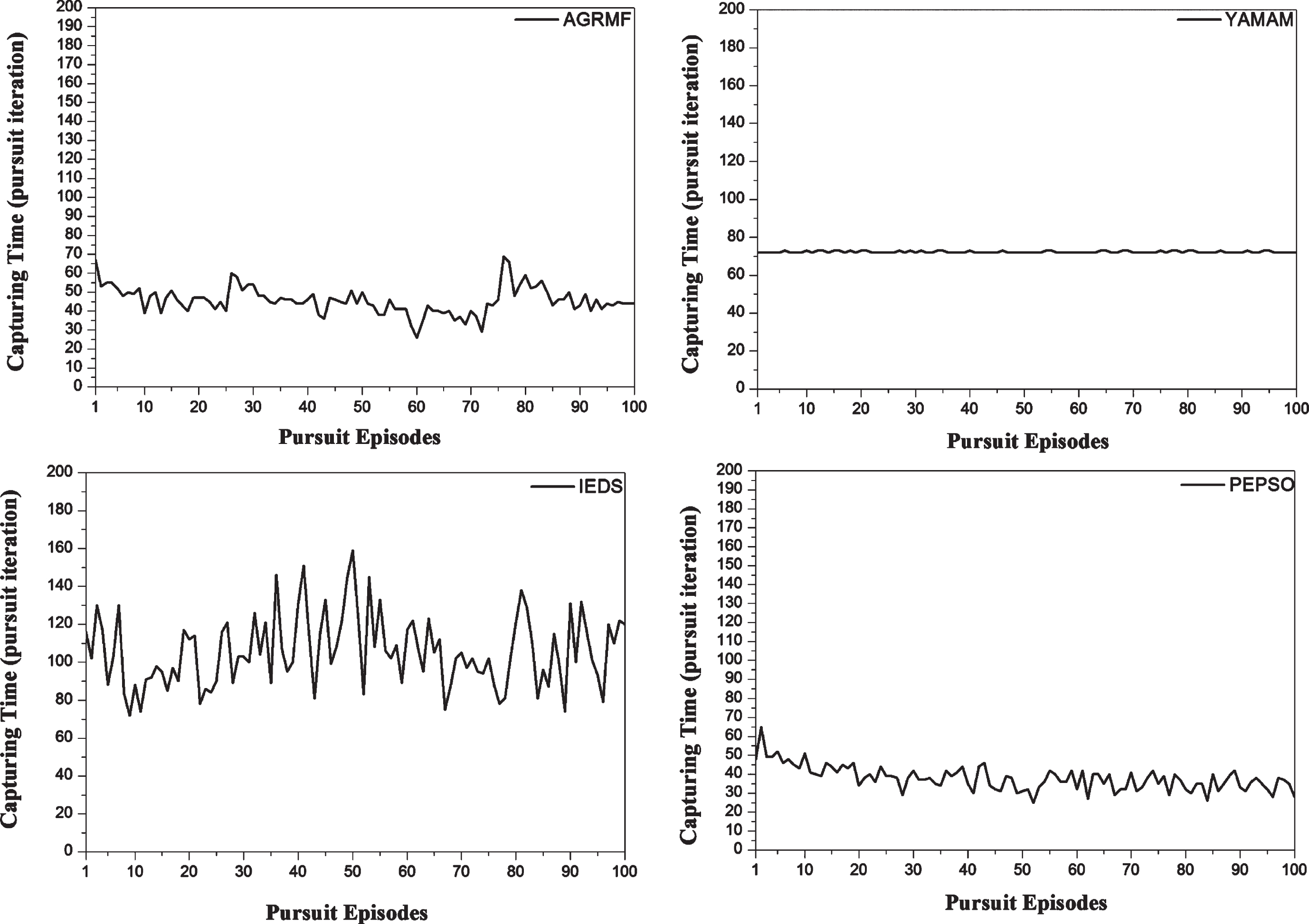
Figure 1 represents the average capturing time obtained after 100 pursuit episodes in the four compared cases. The capturing time is reflected by the number of pursuit iterations effectuated by the pursuers in order to block the evaders’ movements. A pursuer iteration can be defined as the pursuers’ displacements from their current to other positions according to their velocities. From this figure, we can note that the capturing time decreases by 17.07%, 47,62%, and 64.17% by using the proposed approach in relation to AGRMF, YAMAM, and IEDS cases. Knowing that in the proposed algorithm, we have used 100 particles to find the appropriate coalition formation reflecting this result. The stability of the capturing time regarding YAMAM case can be explained by the fact that the pursuit groups are fixed from the first pursuit iteration to the end of the pursuit.
Average pursuit capturing time obtained (Pursuit iteration).
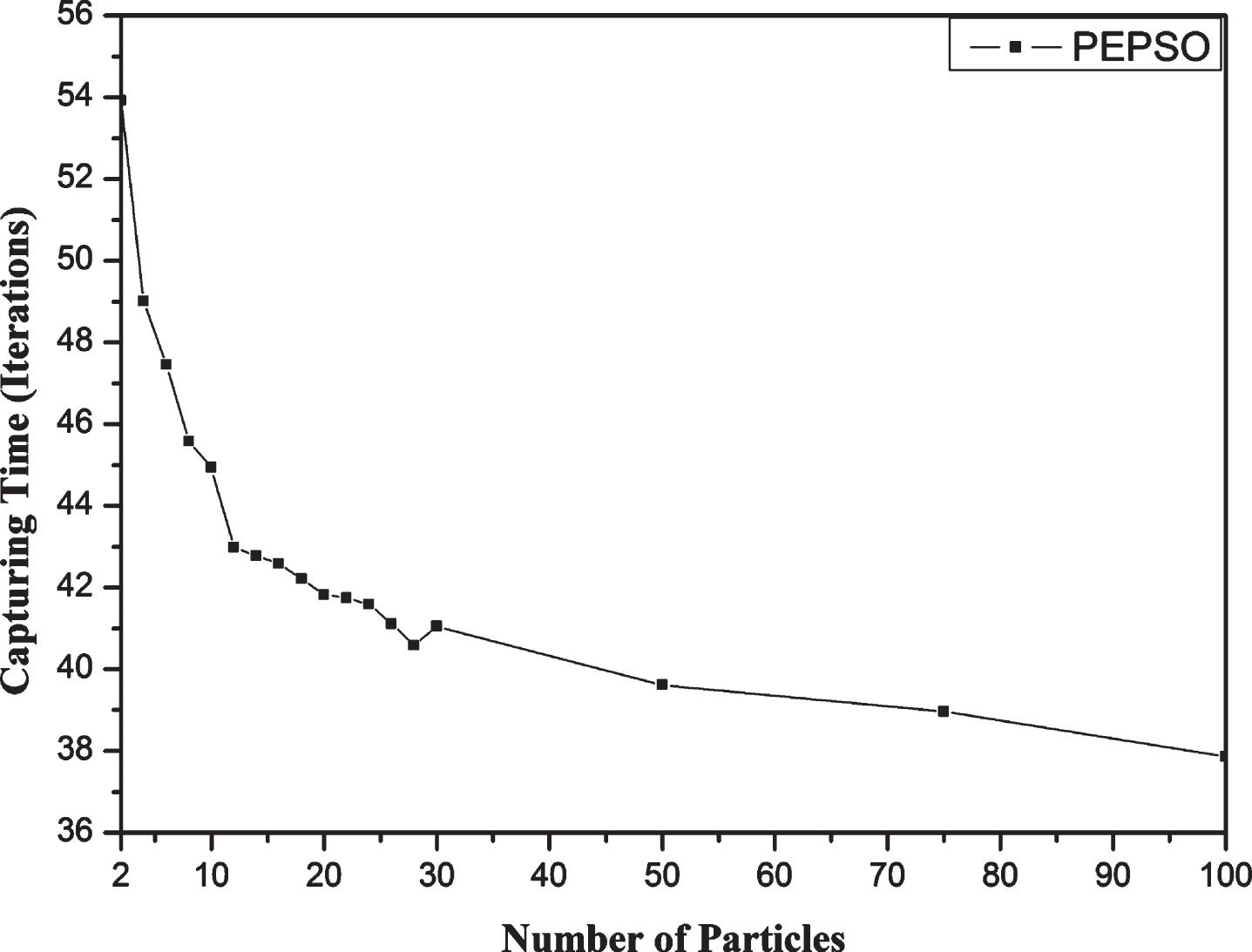
Furthermore, we have studied the capturing time in relation to the number of used particles, as shown in Fig. 2. From the showcased curve, we can easily constate that the capturing time is proportionally inverse to the number of used particles. Also, the average capturing starts to be better than that obtained in AGRMF case after the use of only 8 particles. Specifically, the average capturing time obtained by using 8 particles decreases by 0.197% in relation to AGRMF case. From the results shown in the Figs. 1 and 2, we can prove that the number of particles as well as their velocities allow to consequently decrease the average capturing time in relation to the recent works used in the comparison study.
The study of the capturing time in relation to the number of used particles.
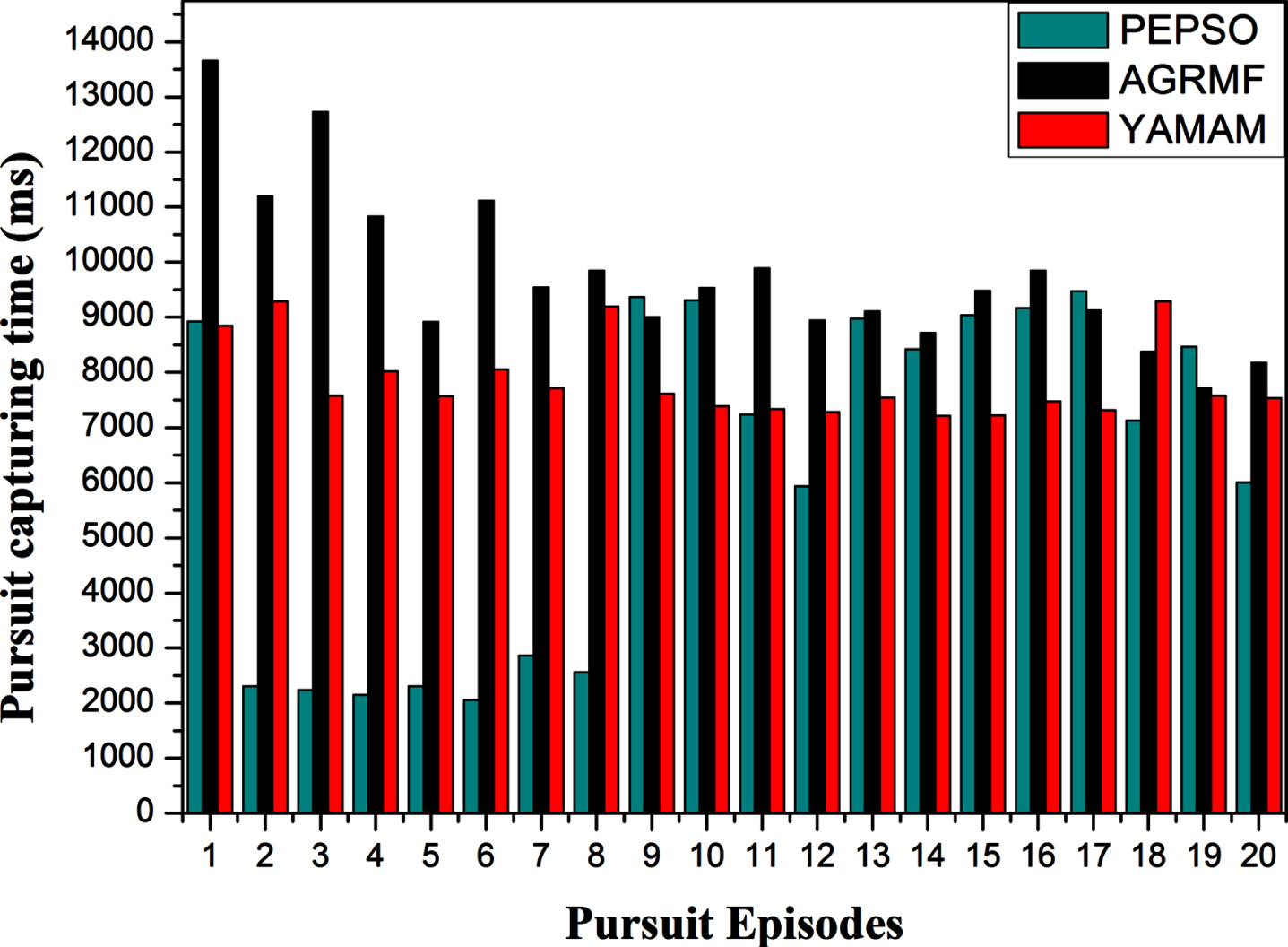
Moreover, the pursuit capturing time in millisecond (ms) was also studied in comparison with AGRMF and YAMAM cases during 20 pursuit episodes as shown in Fig. 3. The showcased result confirms the result obtained in Fig. 1, in which the capturing time was studied in relation to the number of the pursuit iterations. Specifically, the average capturing time obtained through the application of the proposed algorithm (6197.1 ms) decreases by 36.68% in relation to AGRMF (9787 MS), and by 21.06% in relation to YAMAM case (7851.15 ms). Knowing that, we have used 100 initial particles in PEPSO case.
Average pursuit capturing time obtained in millisecond.
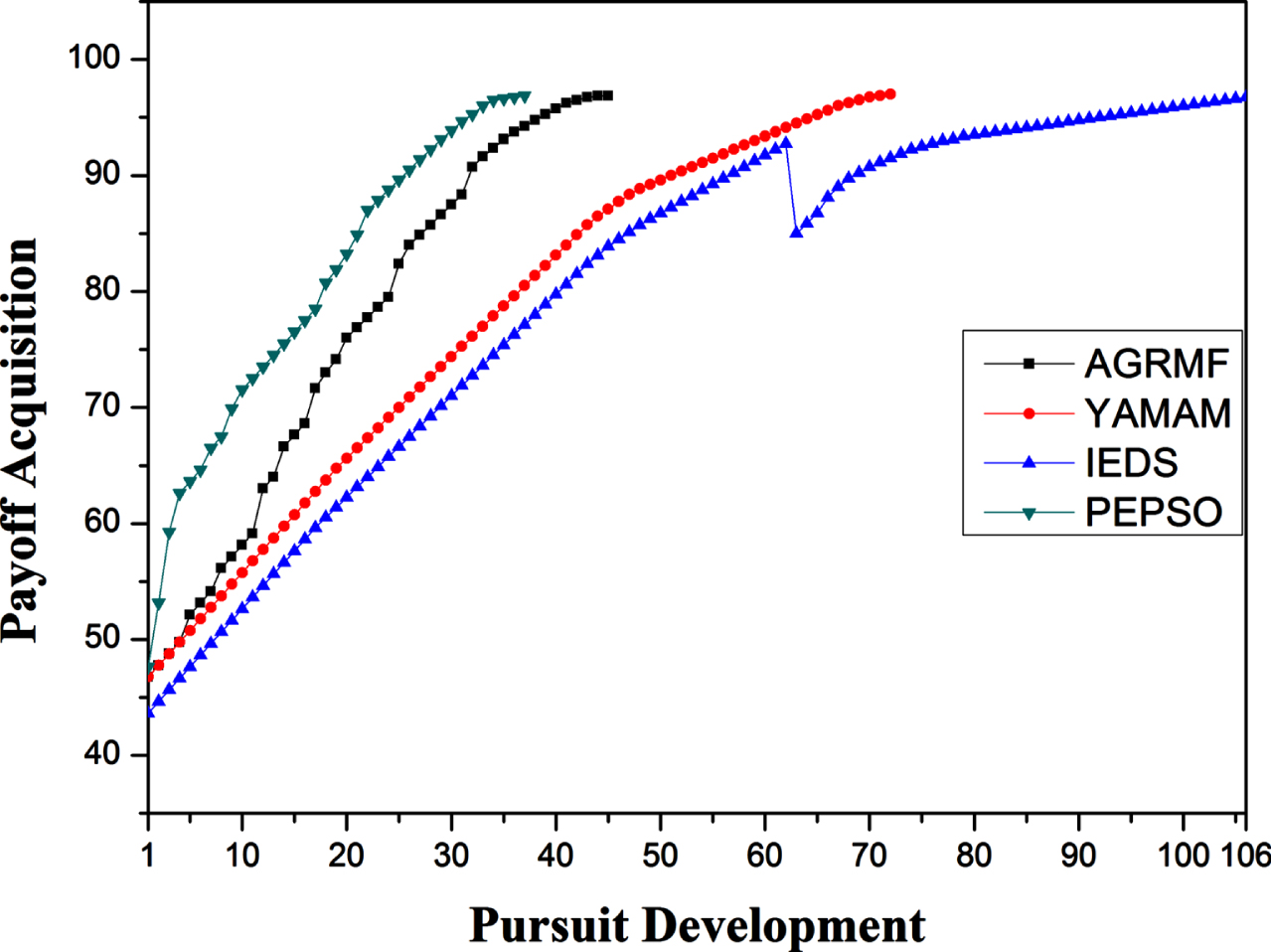
Figure 4 shows the development of the average reward acquisition from the beginning to the end of a pursuit episode. A pursuit episode can be defined as a complete chase from the detection to the capture of the evaders. In relation to PSO principles, this figure represents the fitness development of global-best position. At the first pursuit iteration, we note that the pursuers achieve a higher average reward 47.625 through the proposed approach (PEPSO) in comparison with AGRMF (46.75), YAMAM (46.75), and IEDS (43.625). Moreover, at each iteration, PEPSO achieves a better average. This fact leads to the reach of the maximum average reward after 37 iterations, which means that the pursuers have accomplished the capture of the evaders. According to the reflected results in this figure, we can deduce that the proposed approach clearly increases the learning rate of the pursuers during the pursuit processing leading them to reach the maximum reward in minimal time in relation to the compared approaches.
Pursuers average reward development.
To clarify the reward acquisition study, we have focused on the average reward obtained per pursuit iteration, calculated according to equation (18), and shown in Fig. 5. According to the results shown in this figure, we can note that there are no negative values in PEPSO case unlike in IEDS case. This fact means that the proposed approach is goal-oriented. In addition, the average reward per iteration in PEPSO case increases by 16.9%, 48.52%, and 63.23% in relation to AGRMF, YAMAM, and IEDS cases. According to the results depicted in Figs. 4 and 5, we can conclude that the number of particles and their dynamism also improve the agents’ internal development during the tasks execution.

Average reward obtained per pursuit iteration.
t: the pursuit iteration index.
In order to study the particles’ velocity development during the pursuit, we have compared the velocity of each particle at the First Pursuit Iteration (FPI) with its velocity at the Last Pursuit Iteration (LPI), as shown in Fig. 6. At FPI, the particles achieved an average of 21% in relation to the maximum velocity value. However, at LPI, they reached an average of 60.16% in relation to the maximum value. Furthermore, we can notice that the particle number 12 achieved a velocity of 83.33% . In relation to PEG, the particle’s velocity corresponds to the degree of roles’ changes in the coalition formation. Consequently, if the particle velocity is high, then the coalition’s dynamism is strongly impacted. Moreover, the obtained results prove the performance provided by the PSO principles regarding the exploration of the search space. In some cases, we can note the decrease of the particles’ velocity. This fact is due to the use of the acceleration parameters c1 and c2, which can impact the particles’ velocities. knowing that, these parameters take random values between 0 and 1 at each pursuit iteration as shown in equation (03).
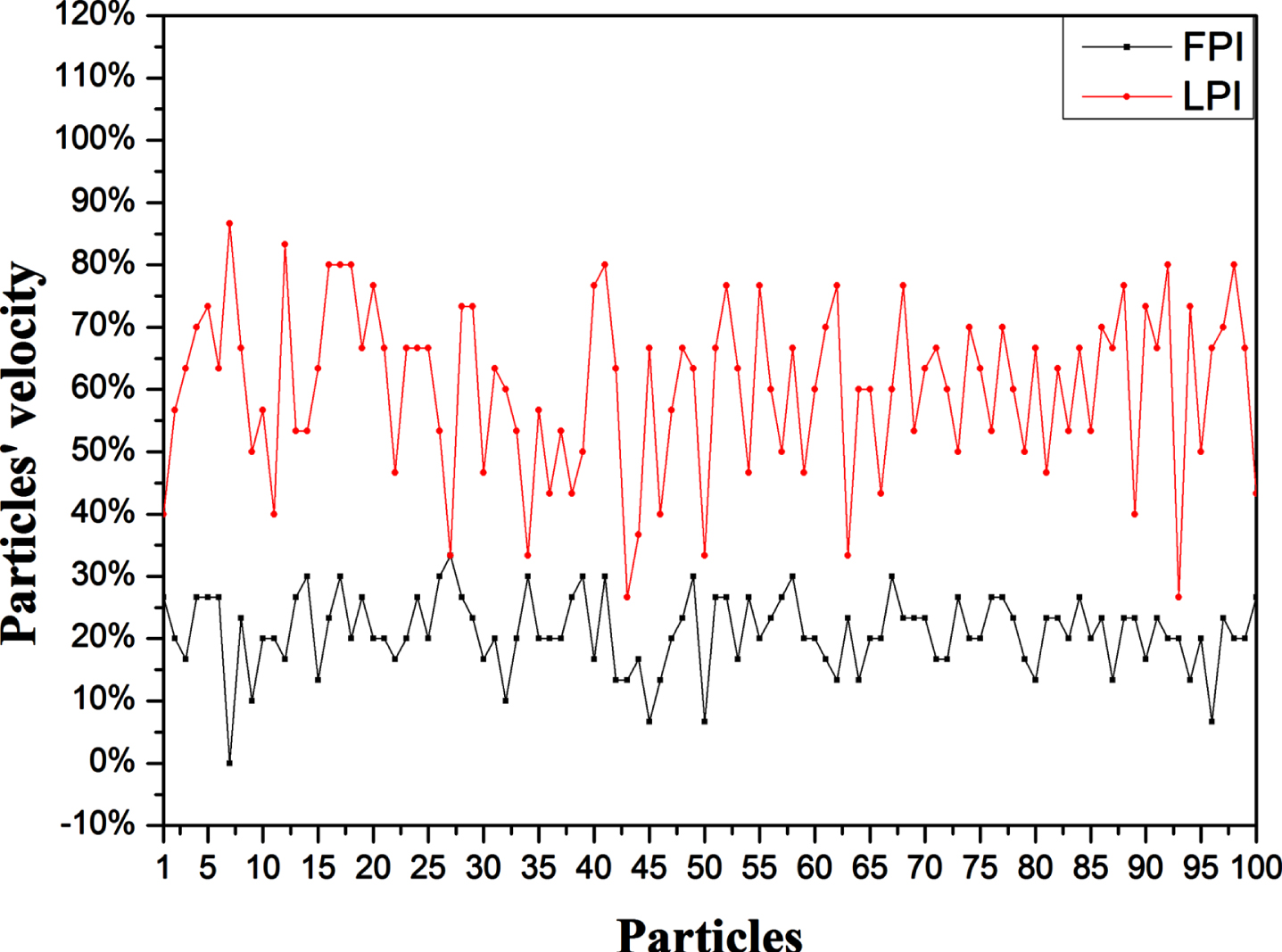
Comparison between the particles’ velocities.
Also, we have studied the dynamism of the global-best during a complete pursuit episode, as showcased in Fig. 7. In relation to PEG, the global-best corresponds to the selected coalition formation. From this result, we can note that the selected coalition changed 10 times during the studied pursuit. These changes are based on different velocity degrees contained between 20% and 80%. At the first pursuit iteration, we note that the percentage of changes achieves 80%, which means that the 8 required pursuers are selected. However, the values 40% and 20% means that a coalition with higher fitness degree (⋌) was achieved by the proposed pursuit algorithm. The percentage determines the degree of changes (permutations) between the values of the new and the precedent global best particle.
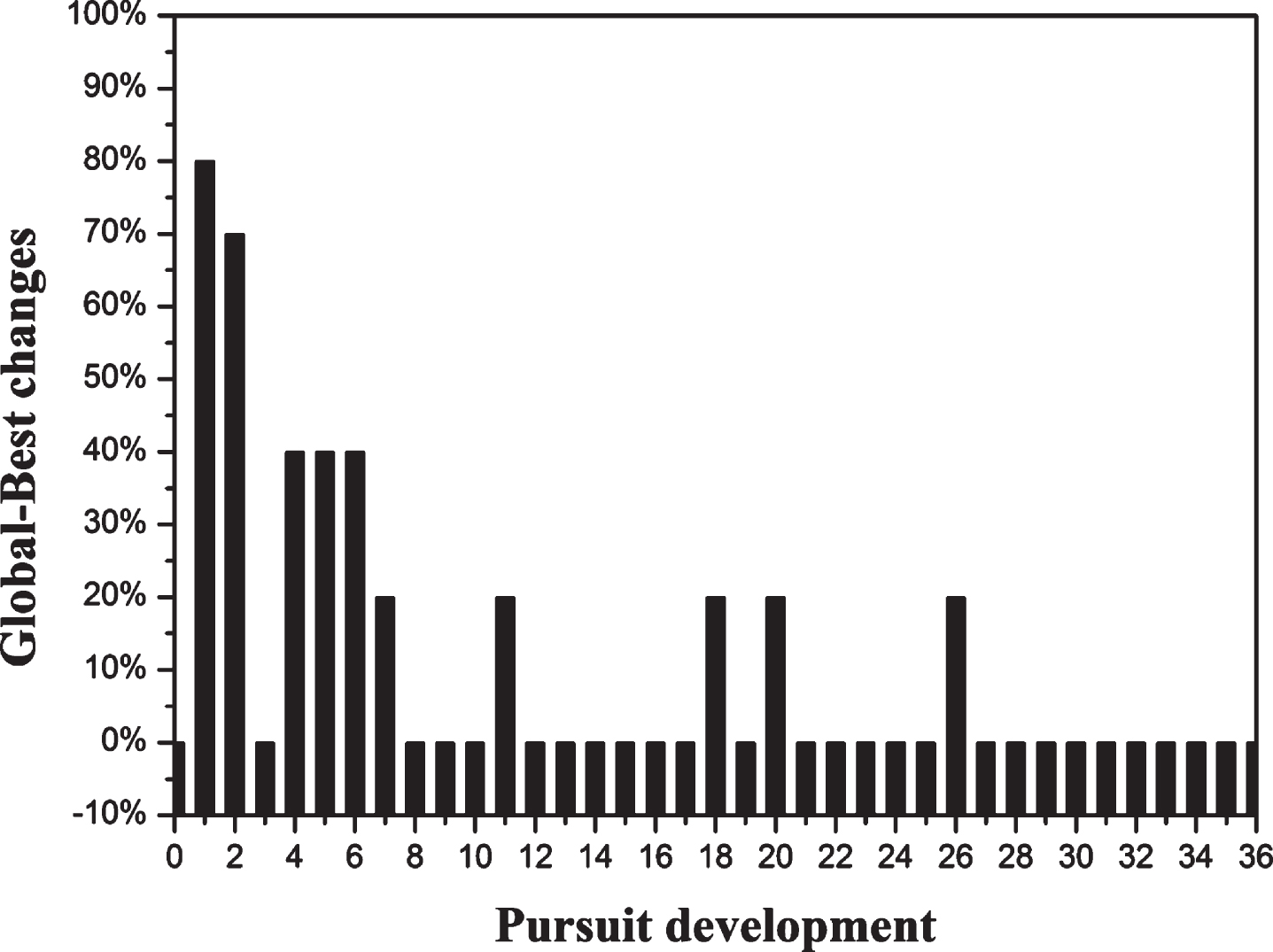
The selected coalition dynamism degree changes.
In addition, we have seen the usefulness to compare the proposed approach with a recent path pursuers’ planning method known as Theta Based Pursuer Control (TBPC) [36], which is based on finding the shortest path separating the pursuer from the concerned evader in the case where the position of this last is known. As shown in Fig. 8 where 100 pursuit episodes were effectuated comparing the proposed PEPSO to TBPC, we can easily constate that the proposed approach achieves better results than those achieved by TBPS regarding the pursuit capturing time, as shown in Table 2. This fact is due to the reason that TBPC is not equipped with a task sharing mechanism allowing the grouping of the pursuers in different pursuit groups in order to parallelly execute the multi-task problem. However, the proposed approach is equipped with a task sharing mechanism based on DPSO. Thus, we can constate that the use of coalition formation algorithms in PEG has a consequent impact on the pursuit processing even using an adequate collaborative path planning. Knowing that, a coalition formation algorithm aims to provide an
Average pursuit capturing time (PEPSO vs TBPC). Simulation results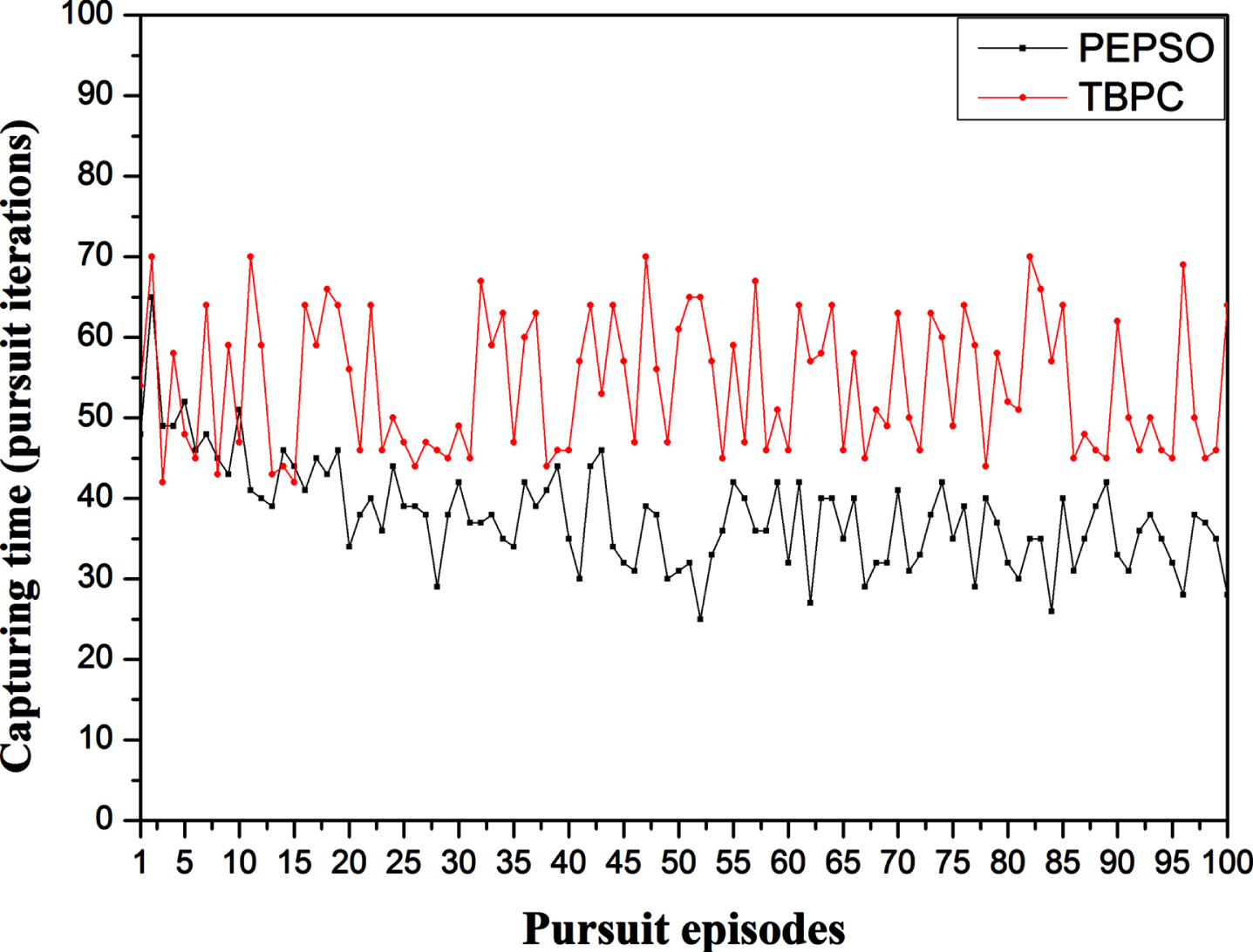
Finally, we have also studied the reward’s acquisition development of the proposed approach in comparison with TBPC method during a complete pursuit episode, as shown in Fig. 9. At the first pursuit iteration, we note that TBPC (51.375) reaches a better average reward in comparison with PEPSO (47.625), which is due to the reason that TBPC allows the pursuers to independently undertake the path returning the maximum reward in order to follow the shortest trajectory. After the two first iterations, PEPSO overtakes PBPC due to the goal-orientation of the approach provided via the application of the coalition formation algorithm based on DPSO. Consequently. The maximum average reward is achieved after 37 pursuit iteration in PEPSO, and after 54 iterations in TBPC case. As shown in Table 2, we can note that the average reward obtained per iteration (Ω) increases by 24.77% in PEPSO in relation to TBPC.

Pursuers average reward development (PEPSO vs TBPC).
Table 2 summarizes the results obtained during the simulation experiments concerning the pursuit capturing time as well as the pursuers’ internal development analyzed in this section of the paper.
In order to provide a visualization of the pursuit environment, we have seen the usefulness to study the coverage zone degree after the pursuit processing. Figure 10 represents the initial state of the pursuit environment in which the agents are initially positioned according to the data reflected in Table 01. The green agents represent the pursuers, which have to be reached in order to perform the tasks. On the one hand, the red agents represent the pursuers that have the role to capture the evader E1. On the other hand, the blue agents are the pursuers having the role to capture the evader E2. However, the yellow agents are not yet affected and move randomly in the environment at each pursuit iteration. Knowing that, this pursuit coalition is generated according to the application of the proposed DPSO algorithm based on 100 initial particles.

Pursuit environment before the pursuits’ processing.
Figure 11 reflects the pursuit environment after the capture of the detected evaders (E1, E2). The red cells represent the covered zones by the pursuers during the pursuit episode. A covered cell can be defined as a cell that has been already occupied by a pursuer. From this example, we can note that the pursuers have exactly overed 7.37% of the pursuit environment in order to perform the captures. The covered cells far from the objective cells (containing the evaders) are due to the fact that the pursuers not belonging to the pursuit groups are randomly moving in the environment with a high velocity (10 cells / iteration). According to the selected trajectories shown in Fig. 11, we can easily constate that the DPSO algorithm provides a significant goal-orientation during the coalition selection process. This goal-orientation proves that the proposed discrete PSO version avoids the selection of inappropriate particles, which is a crucial problem in continuous PSO versions.
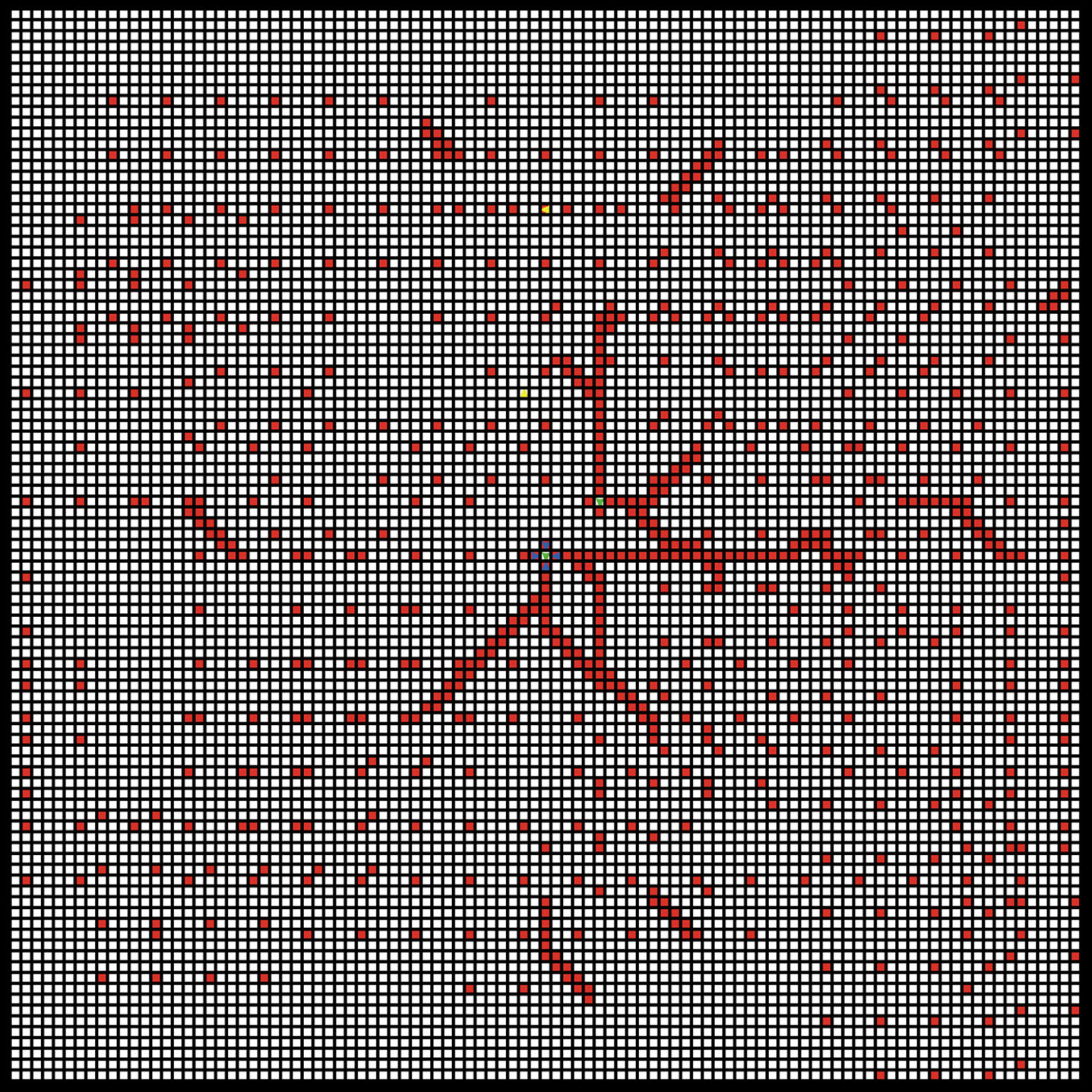
Pursuit environment after the pursuits’ processing.
In this section, we have studied the proposed approach in comparison with (04) recent approaches processing the PEG [21–23, 36]. During these simulations, we have studied the pursuit capturing time reflected through the used pursuit iterations as well as the development of the pursuers’ acquisition rewards. From the obtained results, we can conclude that the proposed approach brings an interesting enhance regarding the processing of PE problem. Moreover, we have studied the pursuit capturing time in relation to the number of used particles (from 2 to 100 particles). According to this study, we have concluded that the capturing time decreases in relation to the number of particles’ increase. The effectiveness of the obtained results is proved by the fact that all the showcased results are obtained after an average of 100 pursuit episodes.
In this paper, we proposed a new pursuit coalition formation algorithm based on metaheuristic approach with the aim of providing an optimal and dynamic grouping of the pursuers’ agents. Specifically, we were inspired by the intelligent swarm behavior provided by PSO approach to model the pursuit problem. In relation to the Pursuit-Evasion game, the particle’s position represents a possible coalition that the agents can form to improve the chase. At each pursuit iteration, each particle is metamorphosed according to its updated velocity. Moreover, the Personal-best of each particle is updated after each pursuit iteration. The selected pursuit coalition represents the Global-best particle, which is also updated after each pursuit iteration. The global-best is updated in relation to its precedent value as well as the maximum p-best of each particle at the current iteration. The new approach is considered as discrete knowing that the particles’ items can have more than two different values. In order to reflect the impact of the proposed approach, we have effectuated comparison studies with recent coalition formation algorithms regarding the pursuit capturing time and the pursuers payoff acquisition during the pursuit processing. According to the results obtained in section 5 of the paper, we can deduce that the proposed Discrete PSO algorithm decreases the pursuit capturing time and increases the pursuers’ internal development. Furthermore, we have studied the pursuit capturing in relation to the number of used particles as well as the particles’ velocities development during the Pursuit. Specifically, the proposed approach consequently decreases the pursuit capturing time by respectively 17.07%, 47,62%, 64.17%, and 30% in relation to the compared cases shown in Table 2, which are classified among the last research activities in this field. Moreover, this approach respectively increases the pursuers’ learning rate by 16.9%, 48.52%, 63.23%, and 37.5% in relation to the latest cited research activities. In relation to the real-world application, the proposed approach can easily be applied in order to control the cooperative behavior of mobile robots or unmanned aerial vehicles during the processing of complex problem such as zone coverage or targets’ detection. Knowing that the showcased results are effectuated in the case of static evaders, the proposed algorithm should be improved in future works with the aim of reflecting the efficiency of the Discrete PSO on the Pursuit-Evasion game based on dynamic evaders. In addition, we will improve the proposed algorithm via the particles’ initialization phase in order to increase the exploration of the search space. Finally, we will focus on the particles’ velocities parameters, which are used in the current work according to the original PSO principles. In other words, we will study the impact of the inertia weight on the pursuit game, knowing that this parameter aims to balance the exploration as well as the exploitation of the search space.