
Abstract
Tangut characters were created by the Tangut of the Western Xia (Xi Xia) Dynasty in ancient China and are over 1000 years old. In deep-learning-based recognition studies on Tangut characters, the lack of category-complete datasets has been problematic. Data augmentation cannot augment the character categories of unknown styles, whereas the use of image generation can effectively solve the problem. In this study, we consider the generation of antique book calligraphy styles of Tangut characters as a problem of learning to map from existing printed styles to personalized antique book calligraphy styles. We present M-ResNet, a multi-scale feature extraction residual unit, and Tangut-CycleGAN, a model for generation Tangut characters that combine M-ResNet and a cycle-consistent adversarial network (CycleGAN). This method uses unpaired data to generate Tangut character images in the calligraphy style of ancient books. To enhance the response of the model to significant channels, a squeezing-and-excitation (SE) module is introduced based on Tangut-CycleGAN to design the Tangut-CycleGAN+SE method for generating images of Tangut characters. This method is not only suitable for Tangut character image generation, but also can effectively generate calligraphy with aesthetic value. In addition, we propose an overall quality discrepancy evaluation metric, FA (Fréchet inception distance + Accuracy), to evaluate the quality of character image generation, which combines style discrepancy and content accuracy metrics.
Introduction
The recognition of Tangut characters through deep learning-based recognition methods can help researchers quickly and effectively study the historical, cultural, social, and other fields of the Western Xia Dynasty.
Most of the Tangut characters in ancient books are presented using movable type or are handwritten, which are calligraphic characters with certain artistry. Moreover, there is a distinct style discrepancy between the same category of characters, further increasing the difficulty of recognizing Tangut characters. Recognition methods based on deep learning require enough data and datasets of Tangut characters are scarce. By generating Tangut characters with similar calligraphy styles to ancient books, a category-complete dataset is formed to solve the problem of the lack of datasets faced by deep-learning-based Tangut character recognition. In this study, as the target style, the Tangut characters are generated in the calligraphy style of the ancient books of Tangut, as shown in Fig. 1.

Tangut characters are generated in the target calligraphy style of ancient books. (a) The Four-Corner System (of coding Tangut characters) of Tangut characters. (b) Modern printed Tangut characters. (c) Tangut characters in the calligraphy style of ancient books. (d) Generation of Tangut characters in the calligraphy style of ancient books.
In work-related character generation, alphabet-based languages have an extremely limited number of letters; for example, English has only 26 letters, and its style transform is equivalent to transferring different combinations of these 26 letters, while Tangut has 6077 different characters. Therefore, it is more difficult to generate such characters based on different styles. Because fewer Tangut characters in the style of ancient books are available for known categories, there is a need to automatically generate Tangut characters with such styles on a smaller number of character datasets.
Tangut characters are like Chinese characters, all of which are square shaped. Although no studies on the generation of Tangut characters have yet appeared, there are several existing approaches to the generation of Chinese characters that can be drawn upon. Most earlier studies [1–3] have relied on a hierarchical representation of simple strokes, which first decomposes Chinese characters into strokes and then combines the strokes to imitate a personalized writing style. Because this approach only focuses on the local representation of the Chinese character, rather than the overall style, the shape, size, and stroke position of each new character needs to be adjusted. By contrast, zi2zi [4] uses paired character images as the training data and learns to transform the font style using pix2pix [5]. However, in the task of generating Tangut characters in the style of ancient books calligraphy, the number of already marked Tangut characters is small, and thus training data for paired Tangut characters are difficult to obtain. In addition, because there are different styles of ancient-style Tangut characters, it is more important to learn the overall style of the character rather than imitating the style of another character. Therefore, the use of unpaired Tangut characters is more appropriate for generating such characters in an ancient book calligraphy style. Fig. 2 shows an example of paired and unpaired training data. The paired training data are a character set having both styles of the same character, while the unpaired character dataset does not necessarily have such a correspondence.

Paired and unpaired data. (a) The paired data consists of instances
The lack of corresponding data is an important reason for the low accuracy of Tangut character recognition and study difficult, and the data is one of the important conditions of research methods based on deep learning. The manual collection of Tangut character images is a difficult task, which is not only laborious but also limited in categories and quantity. This has seriously affected the progress of Tangut character recognition. Generating ideal Tangut character images by deep learning techniques will greatly promote the development of Tangut character research. Therefore, the design of the image generation network of Tangut characters is one of the most important topics. However, there is no generation model for the Tangut characters. The main motivation of this paper is to design a Tangut character generation model and expand the Tangut character database through this model.
Contributions
In this study, for unpaired Tangut characters, the printed Tangut characters are generated into Tangut characters with an ancient book calligraphy style using the Tangut-CycleGAN+SE model. The main contributions of this study are as follows: We present M-ResNet, a multi-scale feature extraction residual unit, and Tangut-CycleGAN, a model for generation Tangut characters that combine M-ResNet and a CycleGAN. To enhance the response of the model to significant channels, a SE module is introduced based on Tangut-CycleGAN to design the Tangut-CycleGAN+SE method for generating images of Tangut characters. The overall FA evaluation metrics for generating character images is proposed based on the style discrepancy (FID) and content accuracy (Accuracy). For Tangut characters, using the model proposed in this study, we can generate high-quality character images, which extends the scale and quality of the Tangut character dataset and solves the problem of missing ancient styles in some categories of the dataset.
Organization
The rest of the paper is organized as follows. Section 2 describes the work related to image and character generation. Section 3 presents the methodological design of this paper. Section 4 details the related experiments and the analysis based on the experiments. Section 5 gives the conclusion and future directions of the paper.
Related work
Generative adversarial networks
where x ∼ p data (x) is a sample of the input data, z ∼ p z (z) is a random noise sample, G (z) is the image generated by the neural network generator G, and D (·) is the probability that the input data are real.
In addition, zi2zi [4] embeds multiple font style categories on top of pix2pix, enabling an end-to-end character style transfer. Compared to earlier methods of generating and transferring the style of the character as a combination of font strokes and radicals [18, 19], zi2zi discards complex auxiliary information such as stroke marks, allowing for a more flexible generation of multiple styles of fonts and reduced usage costs.
Image-to-image transformation methods can divide into two types according to the type of training data: paired and unpaired training data methods.
Using the nonparametric structure model [21] on a single input to output a training image and use the input-output example dataset to learn the parameter transformation function [22] of a convolutional neural network (CNNs), these methods apply paired training data as data support. The pix2pix framework proposed by Isola et al. has achieved excellent results in several areas, including a semantic layout [23] and sketch-based image synthesis [24]. This framework uses the widely applied cGANs to learn the mapping of the input and output the images.
CycleGANs conduct a style transformation of the images on unpaired training datasets and can effectively address the challenge of image generation when data are unpaired or difficult to pair.
Handwritten Chinese character generation
Studies [18, 25] have treated Chinese characters as a combination of radicals and strokes, and Chinese characters have been generated using a method applying the shape of the characters, which transforms the shapes of strokes into a parametric representation, which is a concise method of stroke generation. However, this is costly and inflexible. Here, zi2zi [4], an end-to-end method for generating Chinese characters, is a new attempt at Chinese character style translation applying adversarial generation networks. Although the method can directly change the style of Chinese characters, its generated fonts suffer from fuzziness and a lack of stroke fluency, which is even worse on unpaired training data. In the literature [19], an end-to-end style generation model based on generative adversarial networks was able to generate better Chinese characters, with some degree of improvement compared to zi2zi. However, its training data are still paired data and require more data for training, which increases the training cost.
Tangut character generation
The structure of a Tangut character is more complex than that of a Chinese character, and the Tangut character style transformation method is limited by the difficulty of obtaining paired training data. In this study, we propose Tangut-CycleGAN, a Tangut character generation model based on the CycleGAN multi-scale feature extraction residual unit for unpaired training data, which can effectively generate Tangut character images in the specified style.
Method
Network architecture
This study aims to transfer a print-style Tangut character into a Tangut character having an ancient book calligraphy style. For this task, the model is trained using unpaired training data to generate a character of the target domain style from a character of the source domain style, maximising the ability of the generated character style to be close to the target domain character style, with the same content as the source domain. In this study, such a task is defined as learning a mapping GX→Y : X → Y from the source domain font style X to the target domain font style Y, where the training data samples are
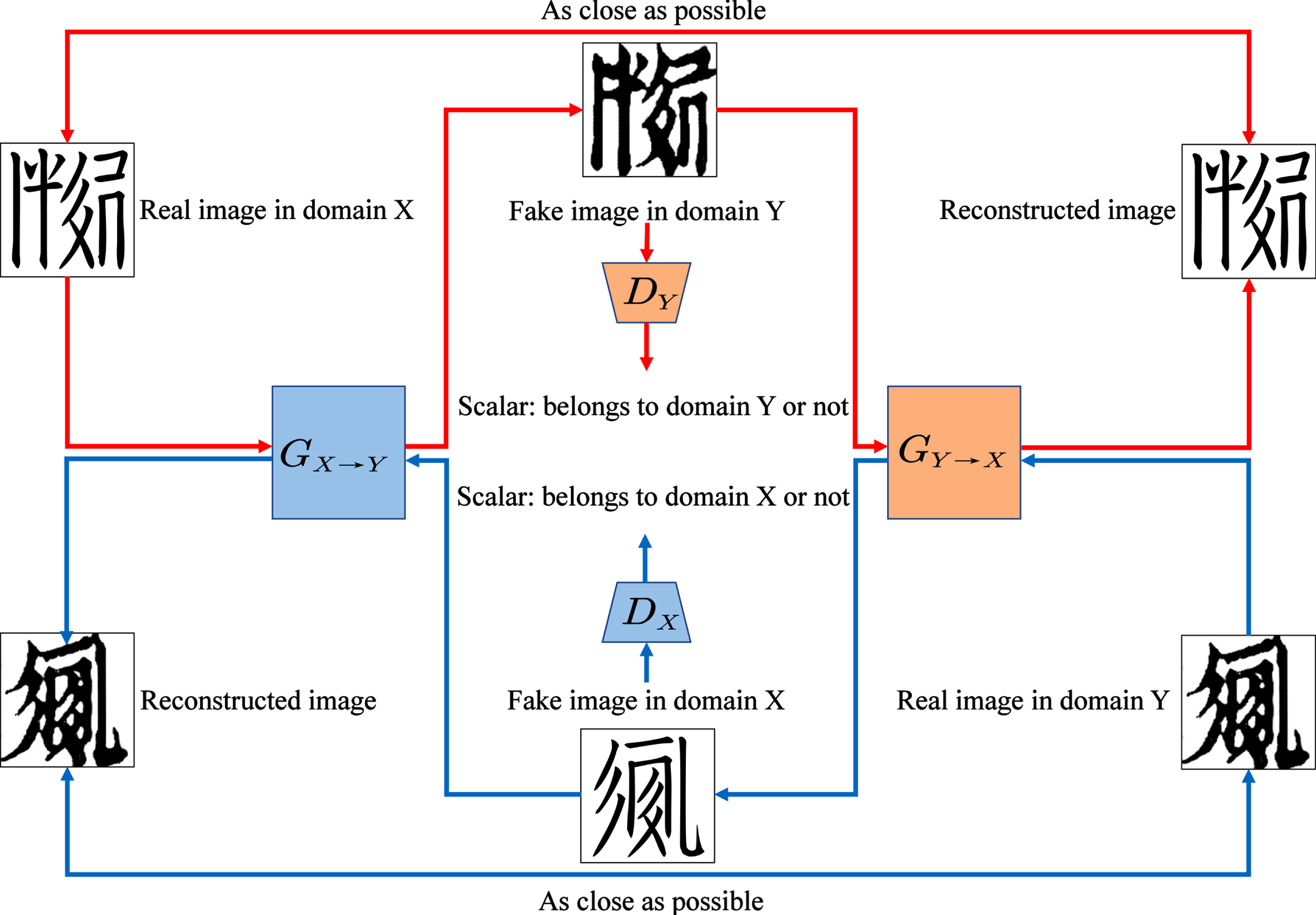
Structure and processing flow of CycleGAN. The cycle marked by the red arrow is the process by which the source domain X generates the target domain Y. The cycle marked by the blue arrow is the process by which the target domain Y generates the source domain X. Here GX→Y denotes the generator that generates the target domain Y from the source domain X, and D Y is the discriminator that determines whether the generated image has the same distribution as the target domain. Similarly, GY→X denotes the generator that generates the source domain X from the target domain Y, and D X is the discriminator that determines whether the generated image has the same distribution as the source domain. The generators GX→Y and GY→X, and the discriminators D X and D Y , respectively use the same structure.
In this study, we propose Tangut-CycleGAN, in which G : X → Y is equivalent to the generator of the GANs, which consists of an encoder, a transfer module, and a decoder, the structure of which is shown in Table 1. Conv-Norm-ReLU indicates a Convolution-InstanceNorm-ReLU layer and Deconv-Norm-ReLU is a Fractional-strided-convolution-InstanceNorm-ReLU layer. The architecture of the transfer module is more flexible. In CycleGAN, the transfer module contains six ResNet units:
The structure of Tangut-CycleGAN
where xl-1 and x l are the input and output of the first ResNet unit, respectively, and H l denotes the composite functions of the convolution operation, batch normalization (BN) [26], and rectified linear unit (ReLU) [27]. The purpose of ResNet using an identity skip connection to bypass nonlinear transformations is to facilitate a gradient back-propagation.
In this study, a multi-scale feature extraction residual unit (M-ResNet) is proposed to process the input at multiple filter sizes, the network structure of which is shown in Fig. 4. Filters with different convolutional kernel sizes can capture different levels of detail, with smaller kernels in the receptive field capturing a small range of detailed information, whereas larger kernels capture a larger range of information and improve the overall credibility. To reduce the number of parameters and the computational cost of the convolution of the model, the M-ResNet unit uses the grouped convolution shown in Fig. 5, where the convolution is the standard convolution when the number of groups is 1, and the total number of parameters is reduced to the original
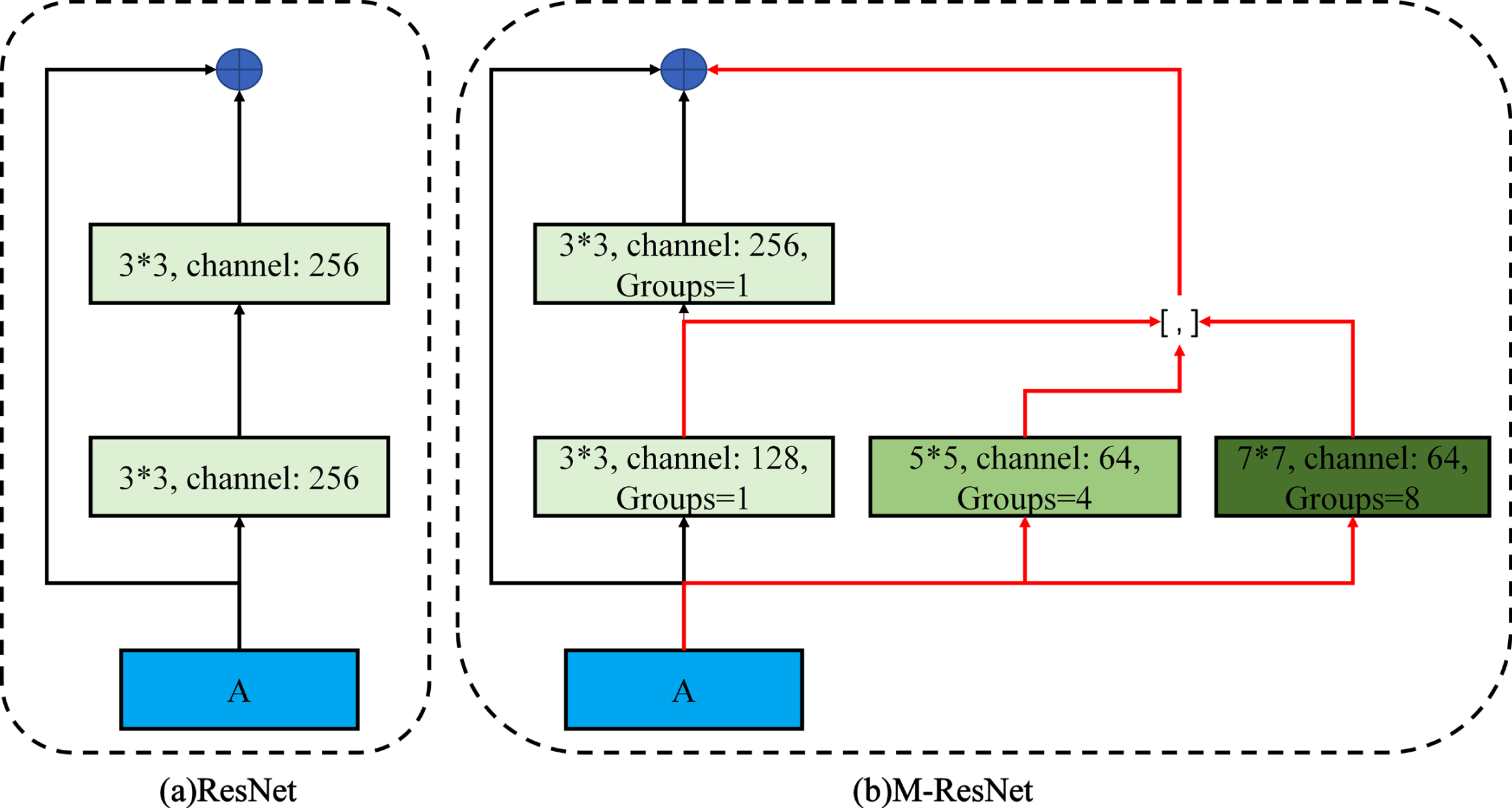
Structure of ResNet unit and M-ResNet unit.
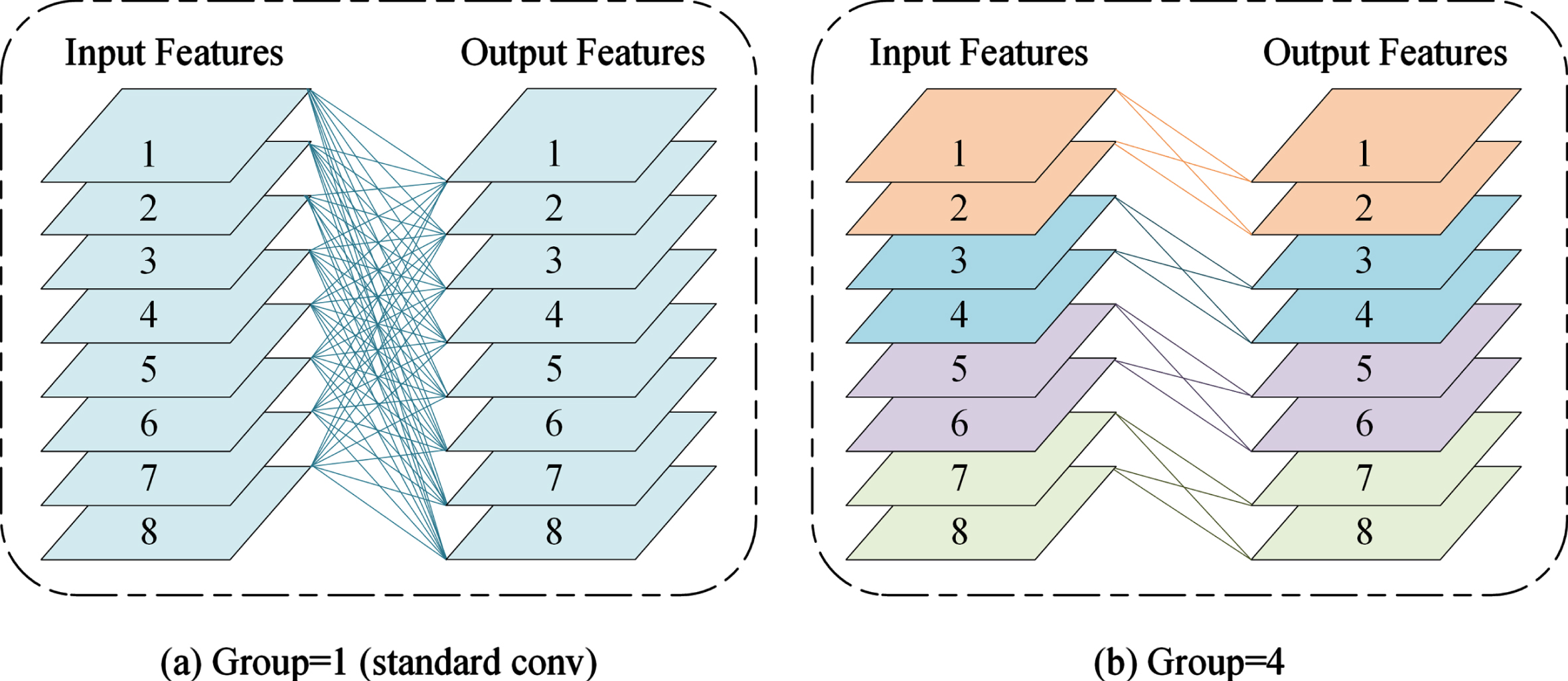
Grouped convolution.
One part of the M-ResNet unit uses a similar structure as the residual network, and the other part uses convolutional kernels of different sizes to capture different levels of detail. The features extracted from the two parts are then concatenated in a multi-scale feature extraction residual unit in the following manner:
where H
l
(xl-1) + xl-1 denotes ResNet unit, H
j
represents the composite function when using different sized convolution kernel convolution operations, BN, and ReLUs, where the difference i indicates the difference in the size of the convolution kernels, the size of the convolution kernel for i = 0 is
The input to the generator GX→Y in the Tangut-CycleGAN comes from the source domain X. First, the source domain image is passed through a decoder to obtain features in the lower dimensions of the source domain. The output of the encoder is then passed through the transfer module to obtain the features in the target domain. Finally, the output of the feature from the transfer module is decoded by the decoder.
The adversarial discriminator D uses a PatchGAN with a size of 70×70 to evaluate whether the generated image meets the expectations of the target domain. The mapping GY→X : Y → X and corresponding discriminator D X are similarly defined.
The loss function of the Tangut-CycleGAN consists of two main components: an adversarial loss function and a cycle consistency loss function. The purpose of the adversarial loss function is to match the generated image to the target domain image in terms of the data distribution. For the mapping function GX→Y : X → Y and its discriminator D
Y
, the objectives are
Cycle consistency loss can be seen as a regularisation process, the strength of which can be adjusted by λ. The overall objective of the Tangut-CycleGAN is
In previous vision tasks, the SE module [28] achieved excellent results in ImageNet 2017. The SE module is divided into two steps: squeezing and excitation. A squeeze obtains global compressed features of the feature map through global mean pooling, which obtains the weights of each channel in the feature map through a two-layer fully connected bottleneck structure and uses the weighted feature map as the input to the next layer of the network. SE is used in MobileNetV3 [29], MSENet [30], FuSENet [31], and other computer vision tasks, and has achieved fruitful results.
Based on the M-ResNet unit, this study adds the SE attention module to the transfer module to improve the overall quality and details of the generated images. In this study, the SE attention module is added to the first and third layers of the M-ResNet unit, and the final Tangut character generation model Tangut-CycleGAN+SE is constructed. The generator structure of Tangut-CycleGAN+SE is shown in Fig. 6.

Tangut-CycleGAN+SE generator structure. The source domain image is fed into the transfer module through the encoder E with low-dimensional spatial features, and the output of the transfer module, i.e., the extraction of the target domain style features, is finally decoded by the decoder D.
Tangut-CycleGAN+SE draws on CycleGAN-based ideas to transform Tangut character images of different domains using unpaired data. The M-ResNet unit with efficient, flexible, and scalable design. The capability to extract features at different levels is increased through different receptive fields, which expands the vision of the network to generate target images more accurately. At the same time, the grouped convolution is used to reduce model parameters, lower training difficulty, and improve model efficiency. Since the generative network should be both content-accurate and stylistically similar to the target domain, attention mechanisms are fused at different locations of the network to improve the content and style quality of the generated images.
Datasets
TCD-G is a dataset used to generate images of Tangut characters. It is composed of 6077 classes of modern printed Tangut characters and some randomly selected ancient book calligraphy style Tangut characters from the TCD, and the images are resized to a pixel resolution of 128×128 and then binarized. The TCD-G is divided into a training set and a test set. The training set contains two folders, A and B. Folder A contains 818 different images of modern printed Tangut characters, whereas folder B contains 818 images of ancient book calligraphy style Tangut characters. The test and training sets remain the same, with the only difference being that folder A in the test set holds 6077 different Tangut characters, intending to verify the generation result of all such characters.
Similar to TCD-G, the Lanting calligraphy dataset is divided into a training set for a test set, where the training set contains two folders, A and B. Folder A contains 300 different images of SIMKAI fonts, whereas folder B contains 300 images of semi-cursive characters. The test and training sets are the same, and both folders A and B contain 24 images.
Evaluation metrics
There are already many evaluation metrics for generative models, most of which are evaluated independently in terms of both style and content, lacking an overall quality evaluation of character generation models. To evaluate the performance of the Tangut character generation model, in this study, an overall evaluation metric, FA, that combines content and style is proposed.
The recognition accuracy of HCCR-CNN9Layer on the TCD dataset
To verify the validity of the overall evaluation metrics, this study trained a Tangut character generation model using CycleGAN, then generated nine groups of Tangut characters, and evaluated these nine groups of character images using each of the three evaluation metrics. The results are shown in Figs. 8. In Fig. 7, the accuracy is converted from a percentage into a value from zero to 100 for observation purposes. As shown in Fig. 7, FA provides a more objective evaluation of the overall quality of the generated images relative to the FID and ACC. In this study, two cases that contradict the FID and ACC evaluation metrics were analysed separately.
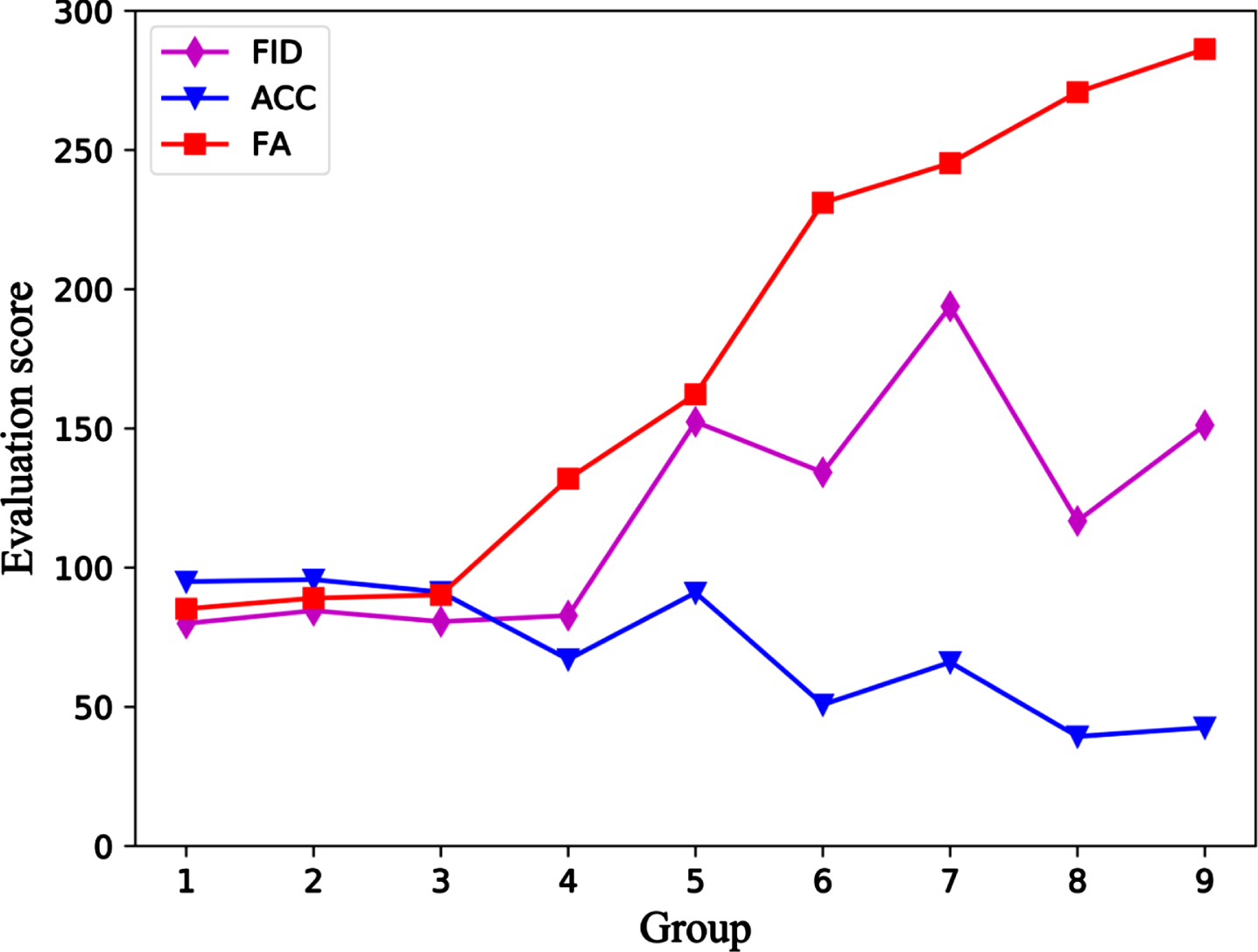
Performance of the 3 different evaluation metrics on the 9 sets of generated images.
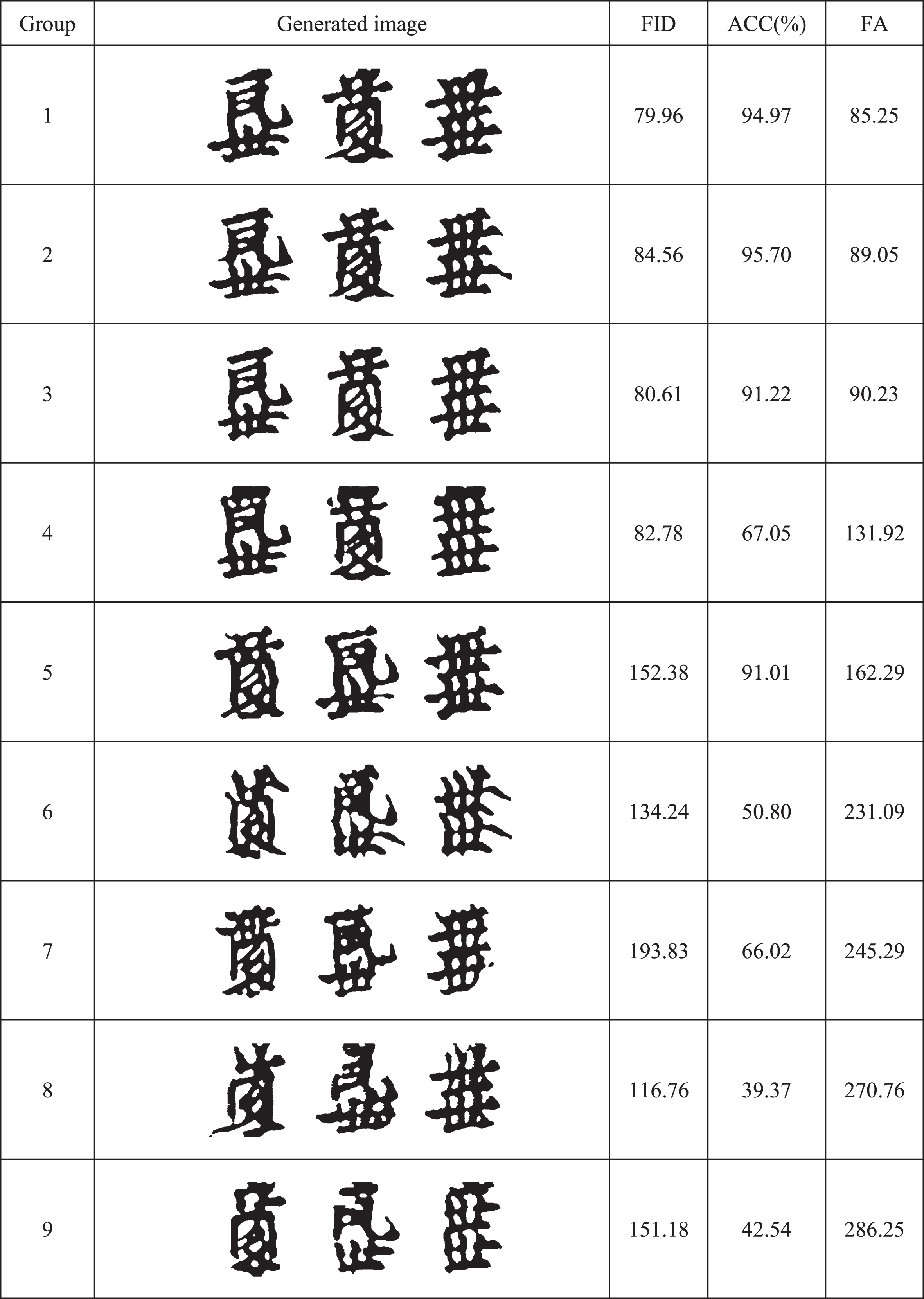
Three sets of evaluation metrics for the nine sets of Tangut character images.
Case 1: When the value of the FID is low, the overall quality of the generated image is not necessarily high.
As shown in Fig. 7, in the evaluation of the group 4 images, the FID scores were similar to those of groups 3 and 2. If the evaluation scores of the FID are followed, the quality of the images generated in group 4 should be similar to that of the two groups before. However, it can be seen that the ACC scores of the group 4 images are lower than those of the two groups before, indicating that the accuracy of their image content is lower than these other groups, at which point the FID scores will not accurately reflect the quality of the generated images. By contrast, the FA score, which is the evaluation metric proposed in this study, is higher than that of the two groups of images before, indicating that its overall quality is lower. Among them, groups 2, 3, and 4 of Tangut character images and their three sets of evaluation metrics are shown in Fig. 8.
Case 2: When the value of ACC is high, the overall quality of the generated image is not necessarily high.
As shown in Fig. 7, the ACC score of group 2 was slightly higher than that of group 1. Based on the ACC score, the overall quality of the images of group 2 should be higher than that of group 1. However, group 1 had better results than group 2 in terms of style similarity, as shown in Fig. 8, and it can be seen from the observation that group 1 generates better results than group 2. The scores of the evaluation metrics FA proposed in this study are slightly lower for group 1 than those for group 2, indicating that the overall quality of the generated images is higher for group 1 than for group 2. The three sets of evaluation metrics for groups 1 and 2 of the Tangut character images are shown in Fig. 8.
It is also apparent from the scores of several other groups that the evaluation metric FA more accurately represents the overall quality of the images generated by the model. In the experiments conducted in this study, the performance of the model was evaluated in both quantitative and qualitative terms.
The generative model architecture in this study was implemented using the Pytorch platform, and the recognition model architecture was implemented using the TensorFlow platform, with all parameters set by default.
Prior to training, the dataset used was pre-processed with the relevant pre-processing, and in generating the experiments, only the training images were resized to a pixel resolution of 128×128, and no other pre-processing methods (e.g. cropping and flipping) were used. During all training, the regularisation strength was set to λ = 10, and a total of 200 batches were trained using the ADAM [37] optimizer with a batch size of 6. The learning rate was 0.0002 for the first 100 batches, after which the learning rate began to decay linearly to zero. The number of iterations in each batch of training depends on the side having a higher number of images between the two styles.
For quick completion, all image generating experiments in this study were conducted on a PC with a 3.40-GHz Intel(R) Core(TM) i7-6700 CPU, 16 GB of RAM, an NVIDIA TITAN V 20 GB GPU, and Windows 10. All scoring tests and recognition experiments were conducted on another PC with a 3.50-GHz Intel(R) Xeon(R) E5-1620 v3 CPU, 64 GB of RAM, a 39.9-GB NVIDIA GeForce RTX 2080 GPU, and Windows 10.
Generated results of Tangut characters
In this study, we use printed Tangut characters as the source font and processed ancient book calligraphy style Tangut characters as the target font. Because the number of characters in some styles is limited in practical applications, the goal of this study is to use as few training sets as possible to train the model and to test the style transformation effect on the test set.
Ablation experiments using M-ResNet units
The purpose of this experiment was to examine the optimal number of M-ResNet units, where the number of M-ResNet units of the transfer module was set from 1 to 6. The results are shown in Table 3, which indicates that when the units of M-ResNet are set to 1 to 5, respectively, the values of FID and FA are smaller than those of CycleGAN (ResNet-6) [14], which shows that the M-ResNet units have an obvious advantage in terms of style and overall image quality. There is a clear advantage in generating high-quality Tangut character images in terms of style details and overall quality, and the overall quality of the generated character is the highest when the number of units of M-ResNet is 1, 2, or 3, at which point the FA scores are reduced by 14.21, 13.10, and 11.67, respectively, as compared to ResNet-6.
Experiment results for the three metrics of M-ResNet unit versus ResNet unit
Experiment results for the three metrics of M-ResNet unit versus ResNet unit
(1) Ablation experiments with the addition of single-SE modules
This experiment is based on the experiment described in 4.4.1, which aims to examine the effect of an image generation after the model is added to the SE module. We added the SE module to M-ResNet-1, M-ResNet-2, and M-ResNet-3, the experiment results of which are shown in Table 4. Here, +SE0, +SE1, and +SE2 denote the addition of the SE module after the first, second, and third modules of the M-ResNet unit, respectively, and all occurrences of +SEn after that are the same. Among all model combinations, the FA scores of M-ResNet-2+SE0 and M-ResNet-3+SE2 were 67.91 and 71.79, respectively, which were significantly lower than those of the other models. This is a decrease of 4.24 and 1.79, respectively, compared to before the introduction of the SE module. In the three combinations of M-ResNet-3, the primary stage of the network is biased to focus more on image content through the channel attention, whereas at the end of the network, it is biased to focus more on image style through the channel attention.
Experiment results of adding SE modules to M-ResNet-1, M-ResNet-2, and M-ResNet-3
Experiment results of adding SE modules to M-ResNet-1, M-ResNet-2, and M-ResNet-3
(2) Ablation experiments with the addition of multiple SE modules
In the ablation experiments with the addition of a single SE module, it was found that the addition of channel attention to the first and third M-ResNet units can improve the overall quality of the generated images in terms of both content and style. Therefore, further experiments were conducted in this study with different combinations of the location and number of SE additions, the results of which are shown in Table 5. The FA scores of the M-ResNet-3+SE0+SE2 model with SE modules added after the first and third M-ResNet units, respectively, were reduced by 27.24 compared to that of ResNet-6 and 15.57 compared to that of M-ResNet-3. At the same time, the FA scores were reduced by more than 10 compared to the other methods of adding SE modules. The experiment results show that the M-ResNet-3+SE0+SE2 model is the most effective for a style transformation among the several models compared.
Experiment results of adding multiple SE modules to M-ResNet-2 and M-ResNet-3
This experiment compares the strengths and weaknesses of the proposed model with those of other models in both quantitative and qualitative terms. Among them, a natural style transfer [38] used VGG-19 as a pre-training model, with relu4_2 of VGG-19 applied for content loss, and relu1_1, relu2_1, relu3_1, relu4_1, and relu5_1 used for style loss; in addition, paired data were applied for training, the best results were selected, and the other methods used unpaired data. Coordinate attention (CA) [39] is an attention mechanism that embeds location information into channel attention. This attention accomplishes the encoding of precise location information into channel relationships and long-term dependencies through two steps: coordinate information embedding and coordinate attention generation. It considers not only the relationship between channels but also the location information in the feature space. CA has been widely used in classical mobile networks such as MobileNet V2 [40], MobileNeXt [41], and EfficientNet [42]. CA0 and CA2 denote the addition of CA modules in the first and third bottleneck layers, respectively. M-ResNet-3+CA0 and M-ResNet-3+CA0+CA2 are the two optimal models among all combinations selected in this study.
In Table 6, the ACC values of the proposed method differ less than those of the other methods, but significantly outperform the other methods for two metrics, the FID and FA, where the reduction in both metrics is more than 10 in comparison to DensNet CycleGAN (DensNet-5) [33] and ResNet-6. In Fig. 9, it can be seen that the method described in this study has more advantages in the detailed processing of character images, particularly the model M-ResNet-3+SE0+SE2, which can generate more realistic images, including the stroke of the character, which can be better captured.
Experiment results of different methods on the Tangut character dataset
Experiment results of different methods on the Tangut character dataset
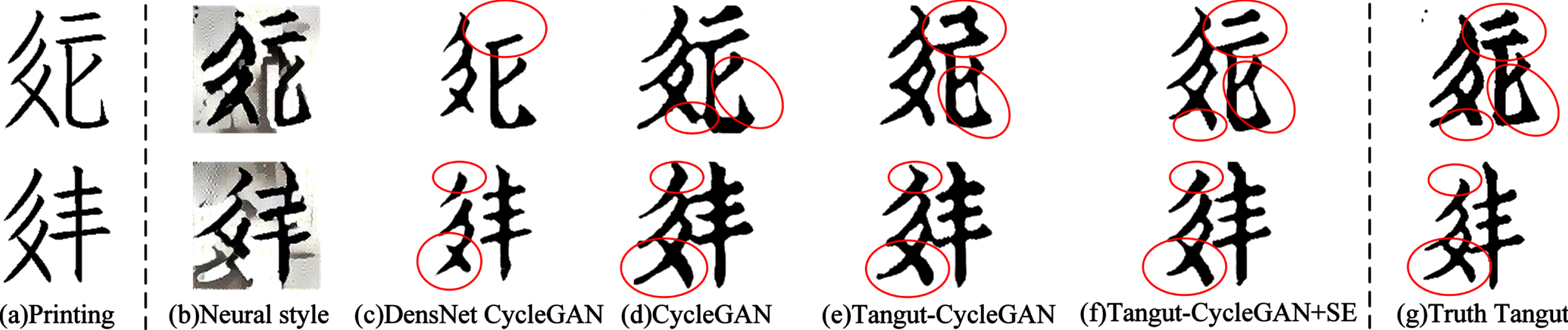
Different methods used to generate ancient book calligraphy style Tangut characters. (a) Printed characters, (b)–(f) characters generated using natural style transfer, DensNet-5, ResNet-6, M-ResNet-3, and M-ResNet-3+SE0+SE2, respectively, and (g) actual ancient book calligraphy style of Tangut characters. The images generated through the natural style transfer have major flaws and even errors in the content. The parts of the character generated in the first row (c)–(e) circled in red show various degrees of defects in content or style, whereas the character generated in (f) is closer to the actual ancient book calligraphy style of Tangut characters in terms of content and style.
Figure 10 shows the generation results of M-ResNet-3+SE0+SE2 for 10 similar Tangut characters that were not used in the model training, and Fig. 11 shows a comparison of the results of 10 randomly selected images of Tangut characters generated by different models. As shown in Figs. 10, the Tangut character generated by M-ResNet-3+SE0+SE2 is closer to the content and style of the Tangut character found in ancient books calligraphy.

Results generated using M-ResNet-3+SE0+SE2 for 10 similar Tangut characters with Four-Corner System 2486–2495. The first row shows the printed characters; the second row shows the generated ancient book calligraphy style characters. It is noteworthy that none of these Tangut characters were involved in the training, and the generated Tangut characters are still clearly visible, of high overall quality, and with a similar calligraphy style and aesthetics to an ancient book of Tangut.

Results of the proposed method and several other approaches for generating ancient book calligraphy style Tangut characters. (a) Printed characters, (b)–(e) characters generated using DensNet-5, ResNet-6, M-ResNet-3, and M-ResNet-3+SE0+SE2, respectively, and (f) actual ancient book calligraphy style Tangut character characters. Among them, the characters generated in (b)–(e) have a greater enhancement in terms of content, style, and details, particularly the characters generated by (e), which is most similar to an actual ancient book calligraphy style Tangut character overall.
In this study, the generated Tangut characters were added to the original Tangut character dataset (TCD) for training and testing, and the experiment results are shown in Fig. 12. When 5, 10, and 15 images generated by the model of this study were added to each category of Tangut characters on top of the TCD dataset, the accuracy of Tangut character recognition showed an increasing trend in sequence. Compared with TCD, the Top-1 accuracy increased by 3.31%, and the Top-10 accuracy increased by 1.63% for TCD+15. The results show that the Tangut character generated in this study helps to improve the accuracy of Tangut character recognition and can effectively extend the Tangut character dataset.
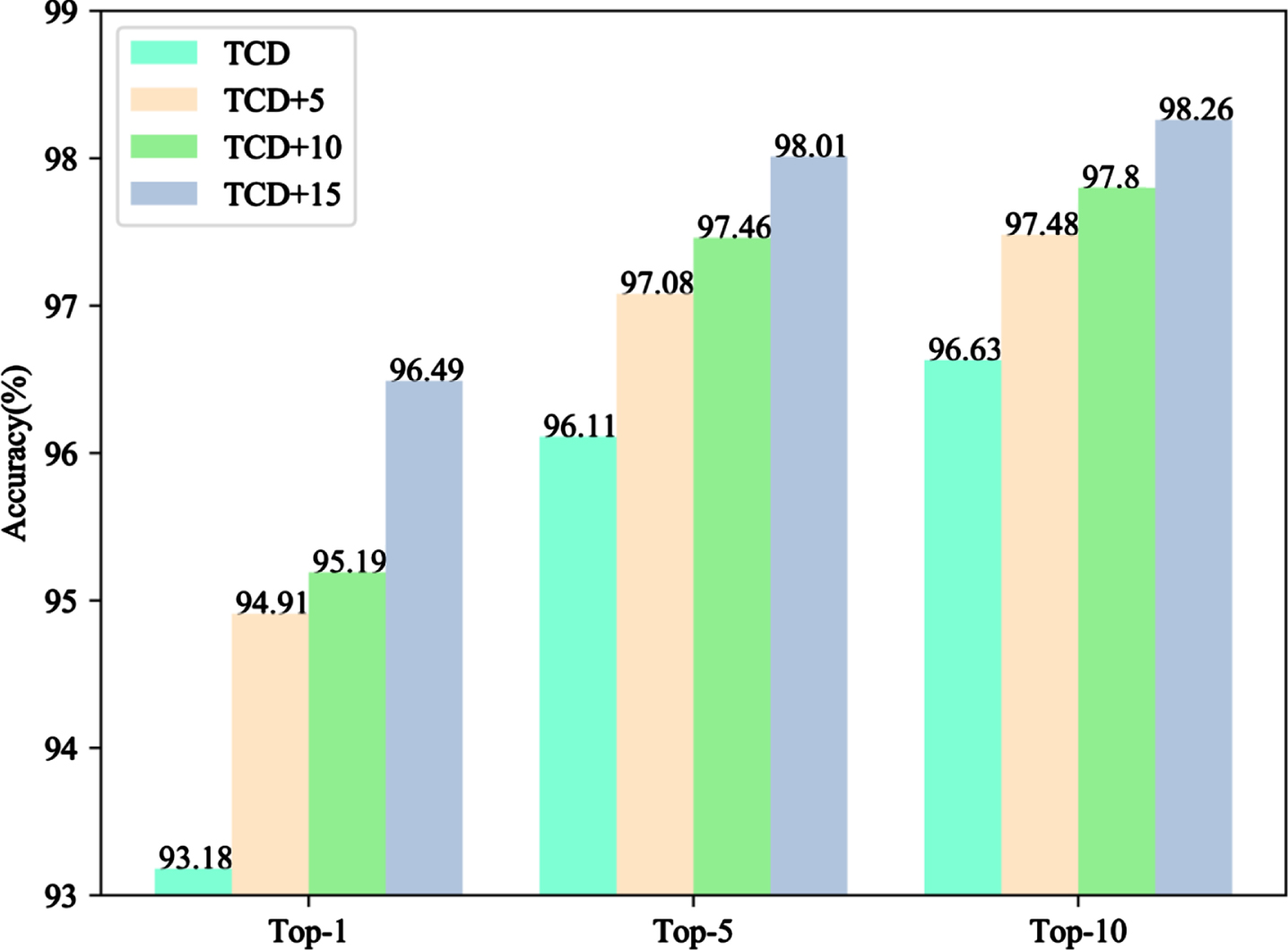
Recognition accuracy after adding the generated Tangut character.
To verify the general validity of the methods described in this study, an experiment was carried out on the calligraphic characters of Lantingji Xu. As shown in Fig. 13, experiments on character image generation were conducted for four methods, and it can be seen from the experiment results that several methods captured the overall character style of Wang Xizhi and generated reasonable character images. Compared with ResNet-6, M-ResNet-3 and M-ResNet-3+SE0+SE2 generate images with fewer missed strokes, and the character thickness, stroke fluency, and overall quality generated by the method proposed in this study are better than the other methods, indicating that the method proposed herein yields better results in terms of the key details and overall style. However, these four methods are limited in their ability to learn certain features of Wang Xizhi’s semi-cursive style. For example, in the last line of the character qing, the strokes circled in red have a joined writing style in Lanting calligraphy, whereas the character ‘qing’ generated by the four methods did not learn this style.

Chinese calligraphic characters in the Lanting calligraphy dataset. (a) Lanting calligraphy true characters, (b)–(e) Wang Xizhi style characters generated using DenseNet-5, ResNet-6, M-ResNet-3, and M-ResNet-3+SE0+SE2, respectively.
In this study, we defined an ancient book calligraphy style Tangut character generation through learning to map printed Tangut characters into ancient book calligraphy style Tangut characters. A combination of an M-ResNet unit and an SE attention mechanism was proposed for the design of Tangut-CycleGAN+SE, a generative model for a Tangut character style transfer, which generates Tangut character images with accurate content and a style close to the Tangut characters of the ancient book calligraphy style. On this basis, an overall quality evaluation metric, FA, was proposed by combining the accuracy of the content and a style discrepancy. Many experiments proved the effectiveness of this method, and excellent results were achieved in the generation of Tangut characters.
In this paper, we propose a Tangut character generative model that can generate high-quality images of ancient book calligraphy style Tangut characters, which fills the gap of lack of ancient book calligraphy style fonts in many categories to a certain extent, but there are still many problems and directions that deserve continued research and exploration in the future. They mainly include the following three aspects. Optimize the network, design a more lightweight generation network, improve the quality of generated images, and enrich the image style of the Tangut character database. The method in this paper can only achieve the generation of a single character, and the future study of whole-page text is also one of the important directions, which will rapidly improve the generation efficiency and open up a new direction for information text recognition. The style of Tangut character generation is now only a single mapping, one-to-many style mapping is also an important research direction, and will be extended to other texts to generate a variety of style fonts. For example, art fonts, personalized signatures, and other tasks.
Acknowledgments
This work was supported by the Basic Scientific Research in Central Universities of North Minzu University (FWNX21, 2021KJCX09), the Natural Science Foundation of Ningxia Province (2020AAC3215, 2022AAC03268), the Innovation Team of Computer Vision and Virtual Reality of North Minzu University, and the National Natural Science Foundation of China (61462002).
Appendices
Derivation of Equation (11):
∵ The smaller the FID value is, the closer the style of the generated image to the target style, and the partial derivative of Equation (11) for the FID results in
∴ FA has a positive relationship with FID; in addition, the smaller the FID value is, the smaller the FA value, indicating that the style of the generated image is closer to the target style.
∵ As shown in Fig. 14,
∴ FA has a negative relationship with ACC, and as ACC increases, FA will show a decreasing trend, and the rate of decrease will become slower. The larger the ACC value is, the smaller the FA value, indicating that the style of the generated image is closer to the target style.
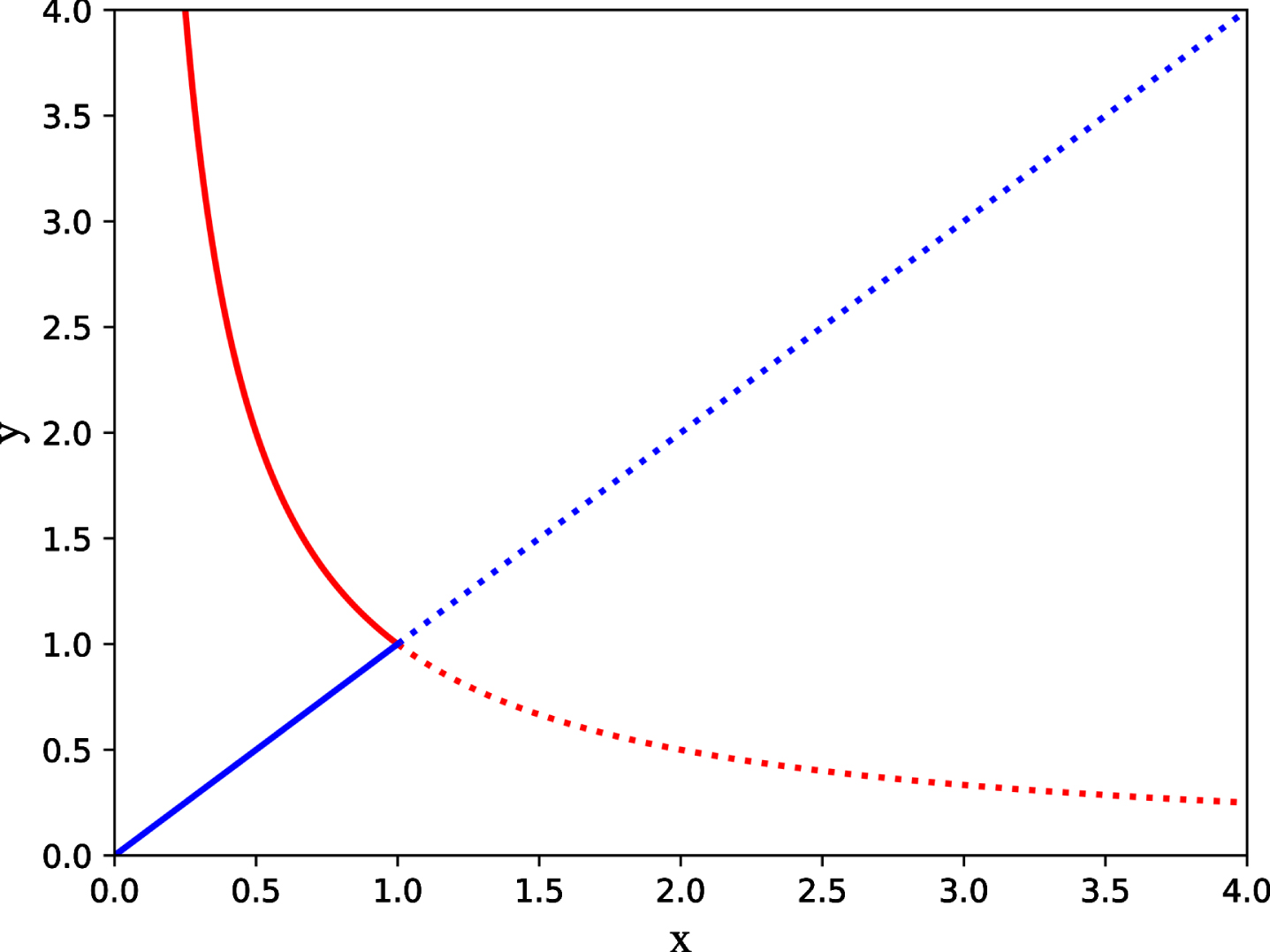
Graph of
∴ In summary, the smaller the FID value and the larger the ACC value, the smaller the FA value is, indicating that the character image generated by the model is more similar to the target domain image. When FID = 0 and ACC = 1, the FA obtains a minimum value of zero.
Declaration of competing interest
The authors declare that there is no conflict of interest related to the submission of the paper.