
Abstract
In reality, the data generated in many fields are often imbalanced, such as fraud detection, network intrusion detection and disease diagnosis. The class with fewer instances in the data is called the minority class, and the minority class in some applications contains the significant information. So far, many classification methods and strategies for binary imbalanced data have been proposed, but there are still many problems and challenges in multi-class imbalanced data that need to be solved urgently. The classification methods for multi-class imbalanced data are analyzed and summarized in terms of data preprocessing methods and algorithm-level classification methods, and the performance of the algorithms using the same dataset is compared separately. In the data preprocessing methods, the methods of oversampling, under-sampling, hybrid sampling and feature selection are mainly introduced. Algorithm-level classification methods are comprehensively introduced in four aspects: ensemble learning, neural network, support vector machine and multi-class decomposition technique. At the same time, all data preprocessing methods and algorithm-level classification methods are analyzed in detail in terms of the techniques used, comparison algorithms, pros and cons, respectively. Moreover, the evaluation metrics commonly used for multi-class imbalanced data classification methods are described comprehensively. Finally, the future directions of multi-class imbalanced data classification are given.
Keywords
Introduction
In the field of machine learning and data mining, classification of imbalanced data is an important research direction. The classes with fewer instances in the data are called minority classes, and minority classes are often the interested aspect for researchers. The distribution of classes in data collected from many applications is often heterogeneous, such as network intrusion detection [1], credit card fraud detection [2] and disease diagnosis [3]. This imbalanced distribution of data can lead to difficulties in classification, as classifiers tend to process the majority classes and misclassify the minority classes. Many algorithms have been proposed for imbalanced data, but most of them address the two-class problem. However, two class cannot cover all real-world scenarios, and imbalanced multi-class data is often more likely to occur in real-world applications. Learning from multi-class imbalanced data is more difficult than the two-class case. Not only is it necessary to classify multiple classes, but the boundaries between classes may overlap. In addition, there may exist multiple minority classes or multiple majority classes in the data [4], as shown in Fig. 1.
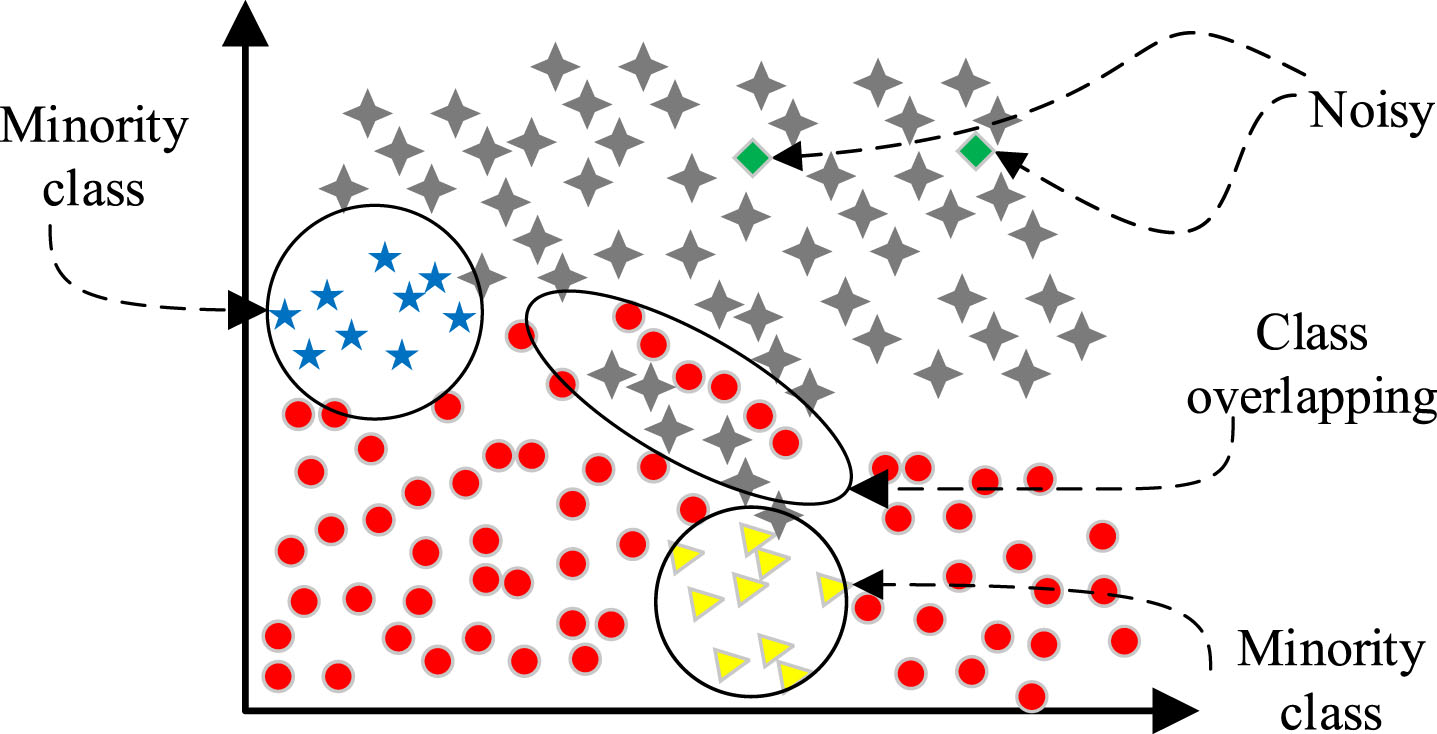
Dataset with multi-class, imbalance, overlapping and noisy.
The earlier methods to deal with multi-class imbalanced data are mainly divided into two types. One of types are applying decomposition strategies on multi-class. Tan et al. [5] proposed an ensemble learning method based on OVO decomposition by decomposing multi-class datasets and training different base classifiers to construct ensemble to accommodate the imbalanced distribution of classes. Another approach is to deal with the multi-class imbalance problem directly, which was first proposed by Sun et al. [6]. By combining cost-sensitive with Boosting ensemble and using genetic algorithms to find the optimal cost of each class to construct the cost matrix to learn on multi-class imbalanced data.
Most of the existing surveys of imbalance data classification methods have been based on two-class imbalance problems. There are only a few surveys summarizing multi-class imbalance classification methods. Sahare et al. [7] mainly introduced data preprocessing techniques combined with neural networks, but only summarized a fewer number of multi-class imbalance methods, and their perspective and review were not comprehensive. Tanha et al. [8] analyzed the application and performance of various Boosting ensemble methods on multi-class imbalance datasets. However, other types of multi-class imbalance classification methods were not described and analyzed. Sridhar et al. [9] introduced sampling methods, decomposition techniques, neural network and ensemble strategies for multi-class imbalance data, but no specific models and algorithms were studied and analyzed. Li et al. [10] summarized the methods in recent years from the perspective of decomposition methods and extemporaneous methods, which collectively referred to cost-sensitive, ensemble learning and deep networks as extemporaneous methods. In the existing surveys, most of the research perspectives are too partial, and no researchers have developed comprehensive description and analysis of multi-class imbalanced data classification methods and evaluation metrics.
This article summarizes and introduces the multi-class imbalanced data classification methods published in recent years. Instead of the perspective of existing surveys, this article provides a comprehensive analysis and summary of both data preprocessing methods and algorithm-level classification methods, as well as a detailed description and explanation of the techniques and performance used by algorithms. The general framework of this article is shown in Fig. 2. The main contributions are as follows:
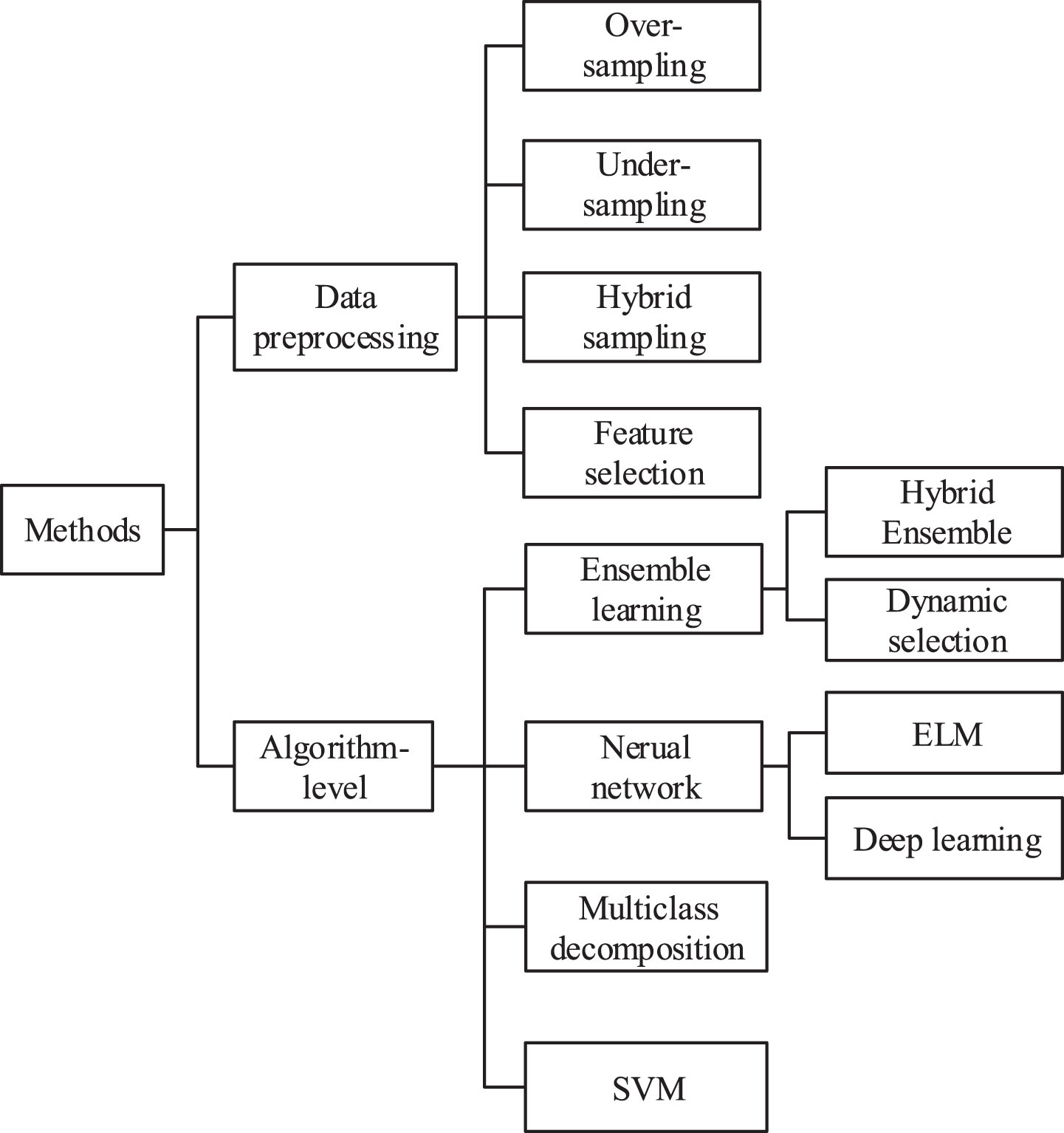
Multi-class imbalanced data classification methods.
This article presents a comprehensive overview of data preprocessing methods in dealing with multi-class imbalance problems, including oversampling, under-sampling, hybrid sampling and feature selection. In addition, this article provides a detailed description and analysis of algorithm-level classification methods for multi-class imbalance data from the perspective of ensemble learning, neural network, support vector machine and multi-class decomposition technique for the first time.
In this article, the experimental results of data preprocessing methods and algorithm-level classification methods using the same dataset are compared and analyzed respectively. Meanwhile, the techniques used, comparison algorithms, pros and cons of the various algorithms are described in detail.
This article comprehensively introduces the evaluation metrics commonly used in multi-class imbalanced data classification methods and provides statistics on the evaluation metrics of all the algorithms.
Finally, this article summarizes the current problems in the field of multi-class imbalanced data classification and proposes corresponding solution ideas, such as handling multi-class imbalanced data streams by dynamic selection methods, tackling the concept drift problem in multi-class imbalanced data streams and coping with complex multi-class imbalanced datasets.
The existing multi-class imbalance data preprocessing methods include resampling and feature selection. The resampling method under-samples the majority class samples or oversamples the minority class samples in the imbalanced data before training the classifier, thus balancing the class distribution. Feature selection is mainly used to filter out redundant data features and retain relevant data features to improve the performance of the classifier. In this chapter, the multi-class imbalance data preprocessing methods are analyzed from four perspectives: oversampling, under-sampling, mixed sampling and feature selection.
Data preprocessing method based on oversampling
Oversampling is the most commonly used method for preprocessing multi-class imbalance data. It solves the multi-class imbalance problem by introducing new instances of minority classes to rebalance the original biased data distribution [11].
The Synthetic Minority Oversampling Technique (SMOTE) is the most representative method among the oversampling methods, which artificially synthesizes new samples based on the minority class samples to add to the dataset. However, the learnability of minority class samples would be compromised by generating wrong samples, which leads to overgeneralization of minority classes to majority class regions.
To address the weaknesses of existing SMOTE methods, a number of researchers have improved it. Considering the overgeneralization problem that may arise when training on multi-class imbalanced data, Zhu et al. [12] proposed Synthetic Minority Oversampling technique for Multi-class imbalance (SMOM) based on k-nearest neighbors (k-NN), which assigned selection weights to the k-NN direction of each instance when processing the data and granted lower selection weights to the neighboring directions that may produce severe overgeneralization. In addition, Neighborhood-Based clustering for Discovering the clusters of Outstanding instances (NBDOS) is applied to avoid the calculation of selection weights for minority class instances, and the computation of distance between a large number of instances is reduced using two round-robin filters to improve the time performance of the algorithm. Sampling Safety Coefficient for Multi-class Imbalance Oversampling (SSCMIO) [13] also proposed a mechanism to avoid overgeneralization by oversampling the safety coefficients based on the instance neighborhoods and assigning smaller weights to regions that may cause overgeneralization. Different from the SMOM algorithm, SSCMIO employed the reverse nearest neighbor sampling safety factor to prevent the newly generated instances from intruding into the regions of other classes, which could effectively reduce the occurrence of class overlap. Based on Hellinger Distance and SMOTE algorithm (HDSMOTE) [14] guides the direction of the synthesized samples by comparing the Hellinger distance [15] within the neighborhood of minority class instances, and proposes sampling quality assessment based on the Hellinger distance strategy to evaluate synthetic instances so as to solve the overgeneralization and class overlap effectively.
Several researchers argued that the majority class also contained vital information. Synthetic Over-sampling with Minority and Majority classes (SOMM) [16] is a method to synthesize instances by considering information from both minority class and majority class neighbors. Experiments showed that SOMM could improve the performance of the classifier and outperformed the SMOM algorithm. Sridhar et al. proposed a method that combined SMOTE and Z-Score (SMOTE&Z-Score) [17]. By using Z-Score to separate majority class samples from minority class samples to find the correlation patterns. After random oversampling, the SMOTE is used to constrain the results. The experiment proved that the method ensured that the correlation patterns of the balanced data could maintain a high degree of consistency with the original data.
Combining SMOTE oversampling with spectral clustering can effectively deal with outliers in the dataset. One-versus-one and Spectral Clustering (OSC) [18] is an oversampling method based on spectral clustering, which uses the spectral clustering method to divide minority classes in the dataset into subspaces and conducts SMOTE according to the distribution characteristics of the data, thus avoiding oversampling outliers.
The Adaptive Synthetic oversampling algorithm (ADASYN) [19] is also used to deal with data with multiple class imbalances. The method adaptively generates minority class instances by providing different weights for different minority class instances based on the density distribution of the classes, thus balancing the skewed class distribution. Kurniawati et al. [20] proposed the ADASYN-N and ADASYN-KNN methods by improving the algorithm to handle nominal datasets. ADASYN-N method calculates the k-NN of the class by the value difference metric, and then ADASYN-KNN generates synthetic data based on the evaluated nearest neighbor instances. Rahayu et al. [21] further analyzed the ADASYN-N method by conducting experiments on the values of the parameter k in the process of nearest neighbor search, and the results showed that the method has the best performance when the value of k was 5, 7 and 9.
Over-sampling after sorting the class instances according to certain ways can produce better results. Sampling Technique based on Composite weights and Sorting (STCPS) [22] first ranks the internal samples of each class based on the distance of the sample data to the hyperplane. Then the data density around the sampling point is calculated and used as a weight to sample the original samples. The new data is assigned according to the information of the neighborhood of the sampling point, which maintains the characteristics of the original data and can effectively solve the small sample problem existing in multi-class imbalance. Dentamaro et al. [23] proposed Less Important Components for Imbalanced multi-class Classification (LICIC) method by considering that all classes in the data have the same importance. The method works in the transformation space and applies permutations to the proportion of components and similar instances belonging to the same class, thus creating synthetic instances for each minority class. LICIC does not add new information and randomness during data preprocessing, so the classification model has a good generalization capability. Meanwhile, Complexity-based Over-Sampling Technique (COSTE) [24] was also used to deal with the multi-class imbalance problem. Differently from the proximity-based SMOTE method, this method first normalizes the data min-max and calculates the complexity of each instance and ranks them, then selects instances that are similar in complexity to synthesize sample instances to balance the dataset. Lestari et al. [25] applied the COSTE method to multi-class imbalance problems and showed that it works better on G-mean compared to SMOTE.
In oversampling methods, the use of distributed features of classes to synthetic instances can effectively improve the classifier’s ability to recognize minority classes. In this issue, Multi-Class Radial-Based Oversampling (MC-RBO) [26] has shown good performance. The main advantage of this algorithm is that it uses the local data features of each class with intelligent oversampling and does not change the features of the original class. In addition, information from all classes is utilized in the artificial instance generation process. Experiments show that MC-RBO is more robust when minority classes form multiple disjoint clusters.
Data preprocessing method based on under-sampling
Under-sampling balances the class distribution by removing the number of majority class instances [27]. Since under-sampling methods tend to lose important sample information and their classification results are unstable, oversampling methods have been mostly used to deal with the multi-class imbalance problem. However, some researchers have been able to obtain better classification results by improving and adapting the under-sampling method.
In multi-class imbalanced data, the existence of class overlap problem can lead to ineffective identification of class boundaries, which reduces the performance of the classifier. Wu et al. [28] proposed Based on LOF and Overlap (BLO), which used LOF local outlier point factor and box plot to clean the noisy samples in the training dataset, and under-sampled the important samples after extracting them according to the class overlap. As a result, the original data distribution is maximally maintained and the accuracy of the classifier is improved.
The clustering method combined with under-sampling can effectively deal with majority classes in imbalanced datasets. The Clustering-based Under-Sampling (CUS) [29] clusters the majority class instances and then under-samples the instances with the largest information to form multiple balanced datasets. Experiments show that the method achieves high accuracy in classifying both majority class and minority class instances.
The general sampling method for multi-class imbalanced data first balances the dataset and then trains the classifier. Unlike existing methods, One-Class SVM-Under-Sampling (OCSV-US) [30] is a two-stage algorithm combining under-sampling and genetic algorithm, which processes multi-class imbalanced data using a training-then-balancing approach. In the first stage, M single-class classifiers are trained based on the number of multi-class, and each classifier will return a set of class instances with the highest information values for the next sampling stage. In the second stage, multiple randomly under-sampled subsets of data are created based on the class instances from the previous step, and the best dataset for classification is obtained by applying Genetic Algorithm to evolve the subsets until the fitness function of the subsets can no longer be improved. The results show that the two-stage strategy realized by this method can improve the computational time efficiency and classification accuracy.
Data preprocessing method based on hybrid sampling
Of the multi-class imbalanced data preprocessing methods, the hybrid sampling method is the combination of oversampling and under-sampling or other approaches, which can effectively alleviate the overfitting problem caused by oversampling and the information loss caused by under-sampling.
Combining SMOTE with other under-sampling techniques is a common approach in hybrid sampling schemes. SMOTE and Clustered Under-sampling Technique (SCUT) [31] generates synthetic examples using SMOTE for minority classes and under-sampling for majority classes using Expectation Maximization clustering, which is suitable for scenarios with high imbalance ratio. In dealing with the class overlap problem, Fuzzy C-Mean and SMOTE (FCMSMT) [32] combines SMOTE and fuzzy c-mean clustering so that all classes have a similar number of class instances and randomly select instances from each cluster, which can effectively solve the problem of class imbalance and overlap. Class Imbalance Aware Review (CIAR) [33] uses a combination of SMOTE and Random Under-sampling [34] to oversample and under-sample the majority and minority classes, respectively, in the data preprocessing stage. The method further divides the balanced sample instances into N subsets to provide to the base classifier for training as a way to improve the time efficiency of the classifier, and experiments show that the CIAR model has the best prediction performance.
A number of researchers have argued that the overfitting of SMOTE is unavoidable and can be especially severe in the case of extremely imbalanced datasets. Therefore, they proposed a new oversampling scheme in hybrid sampling. Minimizing Overlapping Selection under Hybrid Sampling (MOSHS) [35] balances multi-class based on the overlap of classes and uses minority-based oversampling with Edited Nearest Neighbors (ENN) [36] to sample minority and majority classes, respectively. Experiments demonstrate that the method has better results in terms of recall and other metrics. In Similarity Oversampling and Under-sampling Preprocessing (SOUP) [37], the most influential majority class samples are first under-sampled, and then the most important minority class samples are oversampled by analyzing the security levels generated by their neighborhoods. The results show that SOUP performs better than the Static-SMOTE and Global-CS methods.
The Random Balance [38] strategy is a two-class imbalanced data preprocessing strategy that uses random class proportions to randomly under-sample and oversample the data. Based on this, Rodríguez et al. [39] proposed the Multi-class Random Balance (MultiRandBal) to extend random balance to multi-class imbalanced datasets. Contrary to the previous approach, the method uses randomly generated priors for sampling instead of class proportions. Hartono et al. [40] combined dynamic ensemble selection with MultiRandBal in their Hybrid Approach Redefinition-Multiclass Imbalance (HAR-MI) method, maintaining the diversity of data and classifiers and achieving higher performance using few classifiers.
Data preprocessing method based on feature selection
Datasets with high dimensionality add difficulty to classification, and classifiers may not be able to respond to and process the features efficiently. Feature selection [41] is an effective method in the field of data mining which aims to select more relevant data features to provide a concise and clear description of the data to improve the time and memory efficiency of learning models. In recent years, the use of feature selection for processing multi-class imbalanced data has gradually received attention from researchers.
Fernández et al. [42] proposed Ensemble classifier from a Feature and Instance Selection by means of Multi-Objective Evolutionary Algorithm (EFIS-MOEA), which was mainly used to solve the problem of class overlap. The method uses a multi-objective evolutionary approach to simplify class boundaries by limiting features that may pose difficulties for class boundary identification, making it easier to distinguish different classes. Then it finds the appropriate class distribution based on instance selection to solve the imbalance problem, while eliminating noisy instances. EFIS-MOEA can be embedded in any classifier and is highly universal.
To be able to handle both labeled and unlabeled instances, weighted Pattern Matching approach for Classification (PMC+) [43] is proposed by Sreeja et al. PMC+ classifies unlabeled instances by computing the absolute difference between the feature values of instances and unlabeled instances. To further improve the performance of PMC+, a pyrotechnic algorithm based on feature weight selection was also proposed for feature selection, and a storage pool and a selection pool were set up. The storage pool initially stores all the features of the dataset, and the selection pool stores the selected features, weight and Kappa. The algorithm dynamically updates the pools in each iteration until the optimal features and weights for classification are retained in the selection pool. Experiments prove that the algorithm performs well on AUC.
Rough set theory [44] is an effective method to deal with the ambiguity and uncertainty of datasets and can be applied to feature selection. Roughly Balanced Bagging (RBBag) [45] draws on the ideas of random subspaces and random forests to randomly select a subset of attributes from the set containing all attributes and use them as samples to train the base classifier. The algorithm adds decision bounds for rare and unusual instances to ensure that instances of minority classes are correctly classified and can effectively address the case of class overlap. Experiments were conducted on UCI dataset and real dataset to demonstrate the effectiveness of the method. Rough-Set-based Feature Selection Algorithm for Imbalanced Data Multi-class (RSFSAID-M) [46] considers the imbalance distribution of classes by feature significance, which calculates the feature significance of each attribute based on the granular structure of each instance in the boundary region, and then selects the feature dataset to provide to the classifier based on the feature significance. The calculation of feature significance is shown in Equation (1).
Where the
Sun et al. [47] proposed Feature Reduction algorithm for imbalanced data using Similarity-based feature clustering and AWKNN (FRSA). Initially, the method first uses the differences of samples in each dimension to build a similarity measure matrix to measure the similarity between clusters, and constructs a new hierarchical clustering model to generate new samples. Secondly, the normalized information gain is introduced to design the symmetric uncertainty between each feature and other features. Then the initial feature clustering centers are determined automatically by symmetric uncertainty-based adaptive weighted k-NN. Finally, the optimal feature subset is selected from feature clustering using symmetric uncertainty-based feature parsimony method to improve the accuracy of the classifier.
This chapter summarizes the multi-class imbalance data preprocessing methods in terms of oversampling, under-sampling, hybrid sampling and feature selection. In order to further explore the performance of data preprocessing methods on handling multi-class imbalanced datasets, algorithms using the same datasets are analyzed and compared in this chapter. Table 1 lists the datasets commonly used by the data preprocessing methods and describes the parameters of the datasets. Table 2 lists 10 algorithms using these four datasets.
Dataset parameters
Dataset parameters
Algorithms using the same datasets
On the Ecoli, Yeast and Wine-Quality datasets with multiple minority classes, SCUT outperforms all other algorithms. The classifier used by SCUT is the decision tree J48, which achieves the highest values of 90.7 and 93.8 for G-mean and AUC on Ecoli, respectively. This is due to the fact that SCUT does not overuse sampling, to some extent maintains the original class distribution and balances all class instances. The best performance on the Vehicle dataset with relatively balanced class instances is SOUP, which also uses the decision tree J48 classifier, with a G-mean value of 91.5. However, the performance on the other three datasets is worse, so SOUP is not suitable for datasets with a large number of classes and multiple minority classes. The SMOM based on improved SMOTE was experimented on Ecoli, Yeast and Vehicle datasets, using MAUC as the evaluation metric, and its average MAUC value reached 87.8. In the feature selection methods, experiments were conducted mainly on Ecoli and Yeast datasets. EFIS-MOEA uses multi-objective evolution and instance selection with an AUC of 84.41, which is easier to distinguish different classes and achieves good results in general. EFIS-MOEA is better than PMC+, but PMC+ can handle unlabeled instances in the dataset. RBBag only uses G-mean as evaluation metric, and the algorithm only performs better on the Yeast dataset with G-mean value of 81.5.
It can be seen from the analysis that oversampling and hybrid sampling methods that take class distribution information into account can achieve better results on datasets with multiple minority classes. Due to the poor performance of under-sampling on multi-class imbalance, there has been more research on oversampling methods. Most of the oversampling method is based on the improved SMOTE, which boosts the percentage of minority class instances in the original data. Another oversampling method is to balance the skewed class distribution based on the density or weights of classes without changing the original class characteristics. The results are shown that it can improve the generalization ability of classification models. Hybrid sampling combines the advantages of oversampling and under-sampling, which can solves the overfitting and information loss problems effectively. Experiments show that the hybrid sampling-based approach works better than using oversampling or under-sampling alone. Compared with the sampling-based method, the classifier constructed using the training set after feature selection can better ensure the class distribution and improve the performance of the classifier. The multi-class imbalance data preprocessing methods are summarized and compared in Table 3 in terms of technique, dataset, comparison algorithm, pros and cons.
Multi-class imbalance data preprocessing methods
Algorithm-level classification methods improve the accuracy of class prediction by optimizing the base classifier or classification model. Currently, algorithm-level classification methods for multi-class imbalance classification can be classified into four categories: ensemble learning, neural network, support vector machine and multi-class decomposition techniques.
Algorithm-level classification method based on ensemble learning
Ensemble learning is a method for solving imbalanced multi-classification problems, which is usually superior to methods using single classifiers. Ensemble learning combines multiple single classifiers after training and generally uses majority voting mechanism for classification.
Ensemble learning based on hybrid strategy
Hybrid ensemble creates balanced training sets for the base learner by combining ensemble learning methods with data-level methods. The combination of ensemble and data-level methods will result in the creating balanced set before training the base model, which can improve the performance of the ensemble classifier. The hybrid ensemble learning model is shown in Fig. 3.
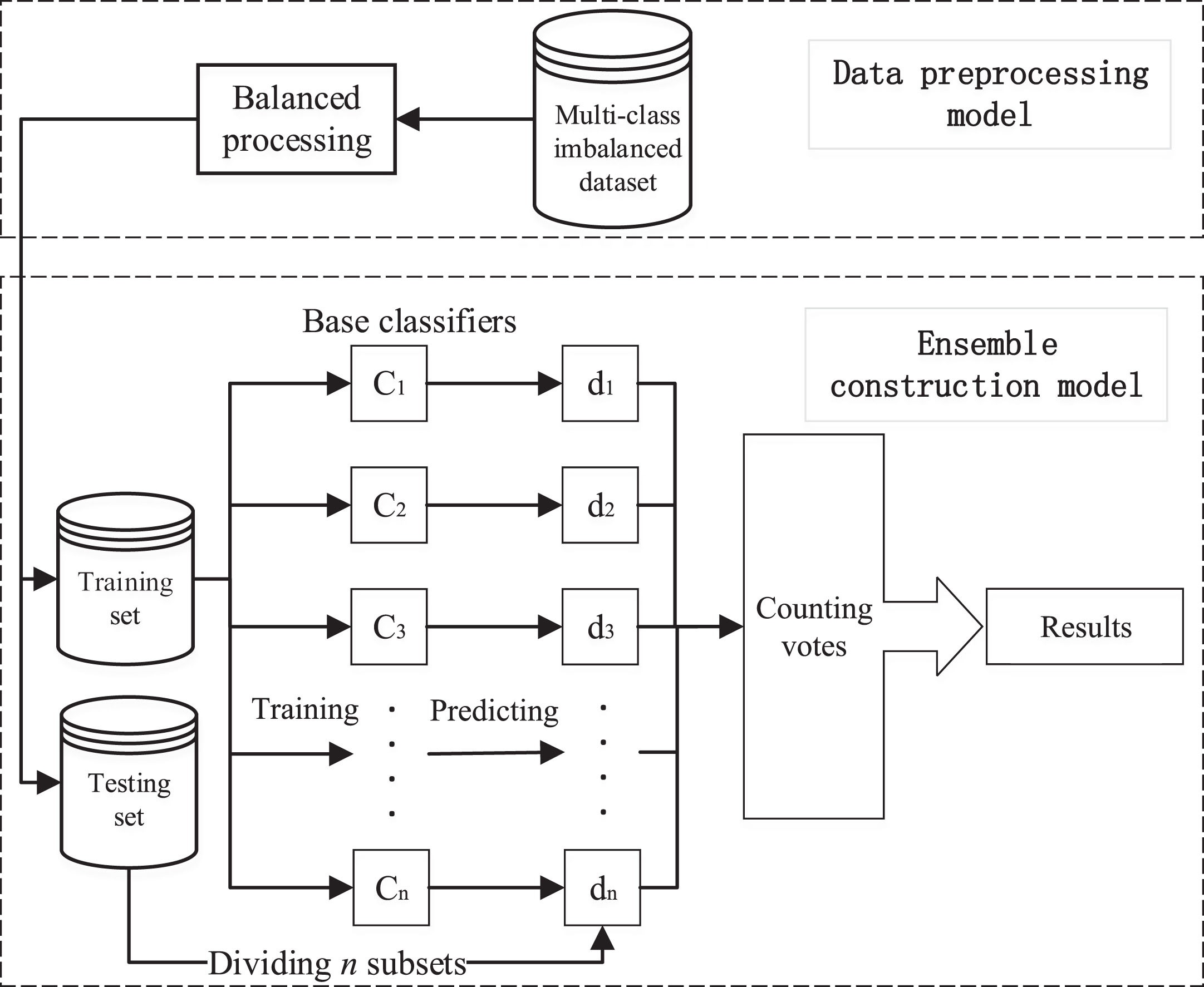
Hybrid ensemble learning model.
Some algorithms combine resampling techniques with ensemble learning methods. Bhowmick et al. [48] proposed Hybrid Ensemble technique for Classification of Multi-class Imbalanced data (HECMI) to deal with datasets with multiple majority and minority classes. The instances of classes with recall below the threshold are oversampled and added to the next data part in the training when constructing the model. The final prediction is done by obtaining the majority votes of the classifiers in the ensemble. The results show that the method can effectively handle and classify multi-class imbalanced data. However, it performs poorly in the case of containing noise and outliers. Purwar et al. [49] proposed Sampling And Genetic Algorithm Based Ensemble Classifier (SA-GABEC), which attempted to find the best subset for given samples that is the most accurate in prediction. SA-GABEC first applies the genetic algorithm to the dataset and then under-samples the majority class. In addition, different subsets of data are used in the learning process of generating classifiers. Finally, the different classifiers are combined together to form ensemble that ensures the diversity of classifiers.
To explore the effect of combining different sampling techniques and ensemble classifiers on the predictive performance of classification models, Sainin et al. [50] conducted experiments on existing ensemble methods and used two combined sampling classifiers and ensemble classifiers, namely the resampling ensemble and the SMOTE ensemble. Meanwhile, different base classifiers were selected and several combinations were constructed, trained and tested on large multi-class imbalanced benchmark dataset. Experiments demonstrate that the ensemble using random forest outperforms any single classifier.
Rather than previous ensemble learning methods, Mahadevan et al. [33] proposed Class Imbalance Aware Review (CIAR) method where Boosting and Bagging were nested in order to create a robust ensemble structure. To begin with, the training set is balanced by SMOTE and RUS techniques, which is used to create the base learner in Bagging ensemble. The CIAR model is constructed by nesting, where the model uses Bagging as the main ensemble. The base learner in the Bagging ensemble is AdaBoost, while the base learner in the AdaBoost is a decision tree. As a result, the base learners constructed by the CIAR model are all enhanced and strengthened. By experimental comparison, the model have the best prediction performance while achieving the highest values on G-mean, F1-score and ROC.
Compared with the hybrid ensemble method based on resampling, applying the threshold shift technique to the ensemble can obtain better classification results. Collell et al. [51] proposed Probability Threshold bagging (PT-bagging) based on the threshold moving technique. Threshold moving technique is an alternative approach to deal with imbalanced data that relies on the weights or posterior probabilities of the classes. PT-Bagging preserves the natural distribution of classes by bootstrapping the sampling to balance the classes. Then, a Bagging ensemble is created that moves the threshold to assign class labels. The algorithm is compared with the resampling-based approach, the results demonstrate that PT-bagging outperforms the resampling-based approach in terms of macro accuracy and macro F1-score. Alam et al. [52] proposed Partition using Balanced Distribution (PBD), which used recursive-based data partitioning techniques to transform multi-class imbalance problems into multiple balance problems. The method first specifies a threshold value to recursively partition the data until the imbalanced data are partitioned into balanced data. Then, a classifier is constructed for each data partition, and then all the classifiers are combined together to construct the ensemble classifier. The ensemble classifier uses a voting mechanism to classify the data. After experiments on several datasets, PBD has high average accuracy and F-Measure.
Several researchers have combined evolutionary algorithms with ensemble. Ensemble of classifiers based on Multi-Objective genetic Sampling for Imbalanced Classification (E-MOSAIC) [53] can eliminate the risk that minority classes in the dataset receiving less attention. The method uses a multi-objective evolutionary algorithm to derive a set of classifiers from an imbalanced dataset and evolves balanced samples in the original data guided by the classification accuracy, thus introducing classifiers with high prediction accuracy and diversity for each class.
The heterogeneous ensemble is a powerful and complex ensemble model, which can effectively handle multi-class imbalanced data. Ensemble Filter Selection Method (EFSM) [54] is mainly used for outlier detection and handling imbalances. The global outliers are filtered and the dataset is resampled using SMOTE in the preprocessing stage, and then the multi-class dataset is binarized by decomposition technique. In the model construction stage, a heterogeneous ensemble model is constructed using Adaboost, random subspace algorithm and random forest as the base classifier. Finally, the constructed classifiers are combined according to the probabilistic average voting rule and evaluated using 10-fold cross-validation. Experiments prove that the model ensures the completeness of majority classes and shows better performance in terms of outlier detection and classification accuracy. Arumugam et al. [55] proposed Neighborhood based Adaptive Heterogeneous Oversampling Ensemble Classifier (NAHOEC). The 5 neighboring instances of the minority class instances are found using k-NN during data preprocessing and these instances are oversampled based on random number and the total number of instances in the current minority class, thus generating a balanced dataset for training. Then, N training datasets are constructed in the ensemble construction process and a list of base classifiers is constructed on each dataset. Finally, the base classifiers are evaluated using test dataset, so that K adaptive classifiers are selected to build the ensemble.
To address the problems of imbalance and concept drift in the data stream, Vafaie et al. [56] proposed Improved SOMTE Online Ensemble (ISOE) and Improved Online Ensemble (IOE) that can dynamically balance the training set. ISOE uses a sliding window of fixed size to process the data instances and sets Poisson distribution rate parameter based on the recall as the threshold. If the class recall is higher than the threshold, the window will be oversampled by SMOTE. Finally, the sampled data is used to train the online ensemble. The rate parameter is retained in IOE while eliminating SMOTE, and minority classes are oversampled by recall-based class weights. Experimental results demonstrate that the IOE performs better than ISOE on G-mean and it produces accurate results on both static and evolutionary data streams. The Poisson distribution rate parameter of ISOE and IOE are shown in Equations (2, 3), respectively. Where r
c
is recall of class c and r
a
vg - excluding - c is the average recall of the classes excluding class c. In Equation (3), where W
c
is the weight of class c and max (W) is the maximum W for all classes.
At present, most of the existing research focuses on static ensemble. In recent years, the application of dynamic selection techniques to multi-class imbalance classification problems has received attention. The technique includes a dynamic selection module for selecting a set of base classifiers from a pool with the given test instances, thus constructing the best ensemble. The dynamic selection ensemble can achieve higher performance than static ensemble on the imbalanced classification problem. The ensemble method for dynamic selection is shown in Fig. 4.
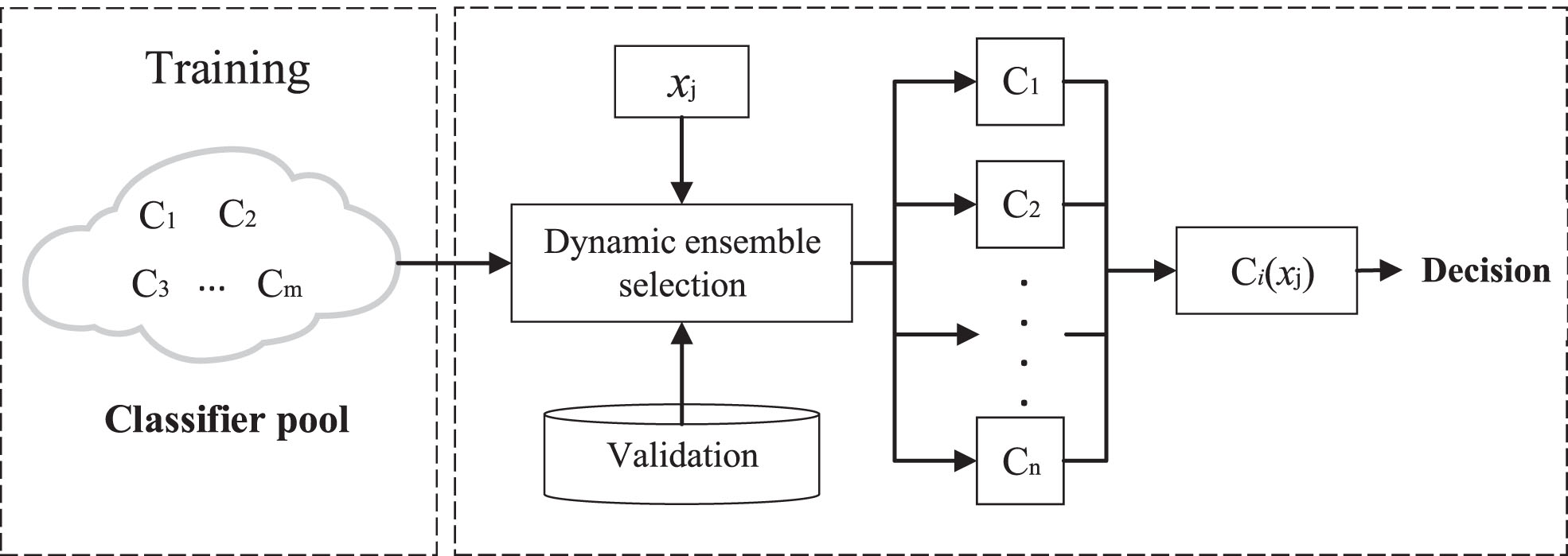
Dynamic selection of ensemble method.
Roy et al. [57] and Cruz et al. [58] proposed to apply a combination of dynamic selection techniques and data preprocessing techniques to handle multiple types of imbalanced data. They proposed a combination of multiple preprocessing methods and dynamic selection. An experimental analysis is performed on Bagging, while a comparison is made with static ensemble in datasets with different degrees of imbalance. The results show that the application of dynamic selection and data preprocessing techniques can improve the performance of the ensemble classifier in classifying minority classes and outperform the static ensemble approaches.
The combination of dynamic selection with static ensemble can lead to a better combination of classifiers. Zhao et al. [59] proposed to combine dynamic selection strategy with the currently popular multi-class imbalanced static ensemble methods and experimented with 14 static ensembles. The dynamic selection strategy is applied in the training process, and the weights of each neighbor sample are calculated based on the k-NN of the test sample x
i
. Then the classification ability of each base classifier h for neighboring samples of x
i
is calculated and ranked based on the ability values of the classifiers, so that the top N classifiers for predicting x
i
are selected and added to the ensemble. Finally, the classifier in the ensemble classify x
i
by voting. Experiments prove that the MAvA and F-measure of the improved static ensemble after dynamic selection are significantly enhanced and can achieve the desired classification performance. The classification ability calculation formula and voting method are shown in Equations (4, 5), respectively. Where x
it
is the t-th neighbor instance of x
i
, w
it
is the weight of x
it
and y
t
is the true label of x
it
.
The Dynamic Ensemble Selection for Multi-class Imbalanced datasets (DESMI) [60] method handles multi-class imbalanced data through two phases. In the first stage, a preprocessor is developed that mixes random under-sampling, random oversampling and SMOTE to balance the training set. In the second stage, the ensemble is constructed with a weighted voting approach, which evaluates the ability of candidate classifiers based on the weighted instances in the neighborhood. Then, a set of classifiers with strong classification ability for minority class instances is selected to construct the ensemble, and the ensemble outputs the final classification results by voting. The results show that DESMI can effectively process and classify multi-class imbalanced data, but the method has a high time complexity.
In the field of machine learning, there are various algorithms that have been proposed for classification problems. Nevertheless, for imbalanced multi-class classification tasks, existing classifiers may not be able to adapt to such complex data environments. Due to the strong robustness and fault tolerance of neural network, some researchers have applied them to multi-class imbalanced classification scenarios. Recently, extreme learning machine and deep learning methods have obtained more researchers’ attention.
Extreme learning machine classification method
Extreme Learning Machine (ELM) is an efficient algorithm proposed by Huang et al. [61]. Unlike traditional machine learning algorithms such as BP-based neural network or Support Vector Machine (SVM), the learning parameters of the hidden layer of ELM are randomly generated and the output weights can be calculated by least squares method. In addition, ELM is easy to implement, which has better generalization performance and faster learning speed. Figure 5 shows the structure of ELM.
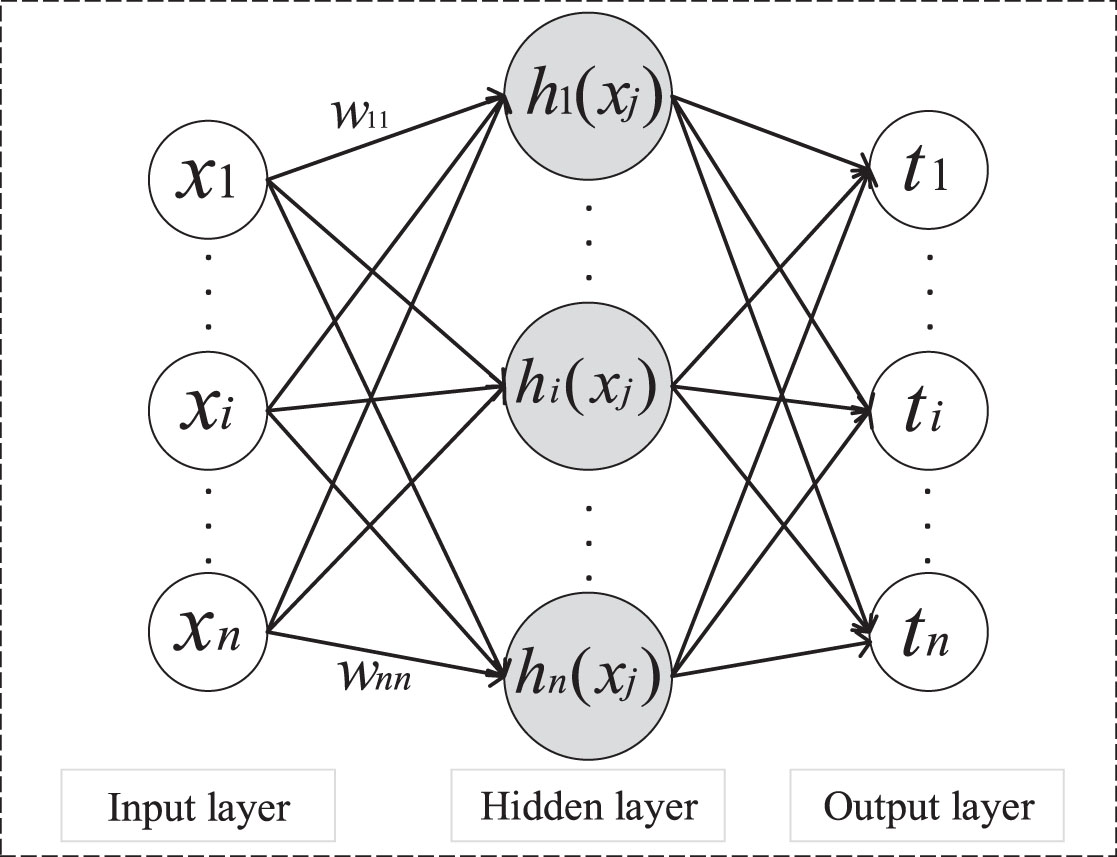
Structure of extreme learning machine.
To improve the learning performance of the classical ELM algorithm for multi-class imbalanced data, several researchers have improved ELM and combined it with other advanced techniques. The G-mean and Probability ELM (GPELM) [62] algorithm uses the probability of training samples in each class to calculate the G-mean. In addition, the probability that the training samples belong to each class is introduced in the design of the cost function in order to maintain the initial data distribution. Then, an ELM parameter optimization problem is constructed to minimize the 2-norm of the weight matrix and the G-mean-based cost function calculated by the probability function. The algorithm has the best performance on G-mean.
The kernelized ELM has better learning results compared to the traditional ELM using random input parameters. Li et al. [63] proposed the Parallel one-class ELM (P-ELM). In P-ELM, the training dataset is first divided into k subsets according to the number of classes. Then, the divided training dataset is fed into the corresponding k kernel-based one-class ELM classifiers, and each one-class classifier executes the operation parallel. The output function of the P-ELM classifier constructs an estimate of the probability density. Therefore, the class properties of the samples can be directly determined by comparing the output function values of each kernel-based single-class ELM classifier. After analysis and validation, P-ELM has good classification accuracy and time efficiency. Generalized Class-Specific Kernelized ELM (GCSKELM) [64] maps the data to the kernel space by applying Gaussian kernel functions, which avoids the non-optimal hidden node problem and reduces the computational effort of the classifier caused by existing ELM methods. Meanwhile, the algorithm uses class-specific regularization parameters determined by class proportions to improve the generalization performance. Class-specific Cost Regulation ELM (CCR-ELM) [65] introduces the class-specific regulatory cost when classes are misclassified as a trade-off between structural and empirical risk. In addition, the optimal combination of all output function parameters is obtained by grid search, which reduces the effect of the number of class samples and the degree of data dispersion. In addition, the algorithm introduces a kernel function matrix for dealing with the case of class overlap. Experiments demonstrate that CCR-ELM can significantly improve the classification performance and is applicable to both multi-class and two-class imbalance classification scenarios. The classification formula of CCR-ELM is shown in Equation (6). Where
Learning on multi-class imbalanced data streams is also worthy of attention, and several researchers have applied online learning to ELM. Mirza et al. [66] first proposed a sequential classifier to solve multi-class imbalanced data streams, which was called Voting based Weighted Online Sequential ELM (VWOS-ELM). This method extends the weight matrix of WOS-ELM [67] to multi-class and constructs several independent WOS-ELM-based networks to accommodate the constant arrival of new data. VWOS-ELM can tackle the class imbalance problem in one-by-one and block-by-block patterns without storing the previously learned samples. Weighted Online Sequential ELM with Kernels (WOS-ELMK) [68] also improves the WOS-ELM by using implicit kernel mapping instead of random feature mapping. With the use of kernel mapping, it is possible to adapt to some random initialization of new data and maintain the stability of the classifier even if only a single classifier is used. In addition, WOS-ELMK implements a fixed memory scheme to save the computational load on large imbalanced data streams. Yu et al. [69] proposed Generative WOS-ELM (GWOS-ELM) using a two-stage gaming strategy. There are data generation stage and model update stage in this method. In the data generation stage, minority class samples are generated using two dynamic least squares with a game strategy to balance the class distribution. In the model update stage, the classification model is updated according to the current prediction performance and cost sensitivity. The method establishes the relationship between the new weights and individual classifiers based on the changing imbalance ratios. These strategies help to reduce fitting errors. Experiments show that GWOS-ELM can effectively predict changing data streams and improve the generalization performance of classifiers for online prediction. Post-Boosting using extended G-mean (PBG) [70] is a novel learning method that effectively addresses the challenge of sequentially arrived multi-class imbalanced data by post-adjusting the classification boundaries under extended G-mean. Moreover, with maximizing the extended G-mean, PBG can dynamically focus more attention on those classes that are prone to misclassification.
Multi-class classification on highly imbalanced datasets is more difficult and requires consideration of classifier accuracy and training efficiency. Vong et al. [71] designed the Sequential Ensemble Learning (SEL) framework on ELM to address these problems simultaneously. This framework improves the accuracy of classifiers on highly imbalanced datasets by dividing the samples of majority class into multiple small and disconnected subsets for training weak classifiers. The experimental results conclude that the SEL is suitable for scenarios with short training time and high classification accuracy.
Recently, researchers have proposed many deep learning-based methods for classifying multi-class imbalanced data due to deep learning has the powerful performance and ability to handle complex data.
AdaBoost-CNN (AdaBoost-Convolutional Neural Network) [72] combines CNN with AdaBoost ensemble to be able to maintain high classification accuracy in large datasets. In AdaBoost-CNN, weights are assigned to each training sample based on the learning ability of the weak learner on the sample. Then, AdaBoost-CNN uses a migration learning strategy during training to transfer the knowledge gained to the next CNN estimator when training a single CNN estimator and update the weights of the training samples to reduce the computational effort of the CNN. Experiments on multiple types of datasets show that AdaBoost-CNN reduces the deep learning algorithm time complexity and can effectively classify large datasets and highly imbalanced datasets.
In the problem of medical image analysis, Yuan et al. [73] proposed a Regularized Ensemble Framework of Deep Learning (REFDL) for cancer detection. The algorithm builds ensemble by Adaboost.M1 and uses Deep Neural Network (DNN) as the base classifier. A regularization parameter is introduced during training to correct the classifier error. In addition, the algorithm uses a weighted hierarchical sampling technique to sample each class according to the data distribution thus balancing the dataset. The experiments demonstrate that REFDL is able to handle the multi-class imbalance problem on high-dimensional image datasets and train a classifier with stable performance.
The multi-class imbalance problem also often arises in the field of Hyperspectral Image (HSI) classification. Lv et al. [74] combined ensemble classification with deep learning and proposed Enhanced random feature subspace based Ensemble CNN (EECNN). Firstly, the number of instances of each class is sorted in descending order and the dataset is randomly oversampled by the oversampling rate thus obtaining the balanced dataset. The oversampling rate is shown in Equation (7), where N
l
is the number of instances of the lth class and N1 is the number of instances of the largest class. Then, a subset of features is extracted by random feature selection to train T CNN classifiers to build the ensemble model. Finally, the final classification results are obtained by majority voting. The experiments show that the model has better performance and robustness compared with other traditional algorithms.
On the text imbalance multi-classification problem, Tong et al. [75] proposed a multi-model based deep learning framework, DistilBERT BI-LSTM Predictor (DBLP), which is mainly used to classify short text datasets. Firstly, DistilBERT is applied at the encoder layer to obtain sensitive dynamic word embedding as the input of BI-LSTM. Then, the hidden key features are extracted from the text by the BI-LSTM network and stored in the feature matrix to improve the classification performance. In addition, a max-pooling layer is built to reduce the dimensionality of the feature matrix. Finally, the obtained feature matrix is used as the input of the softmax layer and normalized to obtain the final classification results. Experiments prove that the model maintains state-of-the-art performance on the short text multi-class imbalance classification problem and has lower time complexity.
SVM [76] is a machine learning method based on statistical theory. The main problem of SVM is how to select kernels, improve accuracy, increase speed and correctly set the values of key parameters during training and testing to obtain the best generalization performance [77].
There are often noisy samples in the dataset that affect the classification accuracy. To address this problem, Wu et al. [78] proposed Fuzzy SVM (FSVM). The algorithm uses the distance from the training samples to the class centers and the weighted class overlap method to design the sample fuzzy affiliation function, and assigns the corresponding affiliation value according to the importance of the samples, which means increasing the weights of the support vectors and decreasing the weights of the noise. Meanwhile, the improved class overlap degree method is used to distinguish the support vectors that play a decisive role in hyperplane classification and assign them a higher affiliation value. Experimental results show that the algorithm can solve the imbalance and noise problems in multi-class data more effectively.
Abdalazie et al. [79] proposed a hierarchical classification model based on Multi-class SVM (Multi-class SVM) in order to obtain more accurately minority or rare instances and assign them to a minority class. The model uses a grouping algorithm to generate new balanced synthetic samples from the original imbalanced classes, which are classified by a hierarchical step. In addition, the model conducts experiments on the issue of whether to assign weights or not, and the class weights are calculated as shown in Equation (8). The results show that the model performs best in terms of G-mean when weights are given to the class instances. The Multi-class SVM hierarchical model structure as shown in Fig. 6.
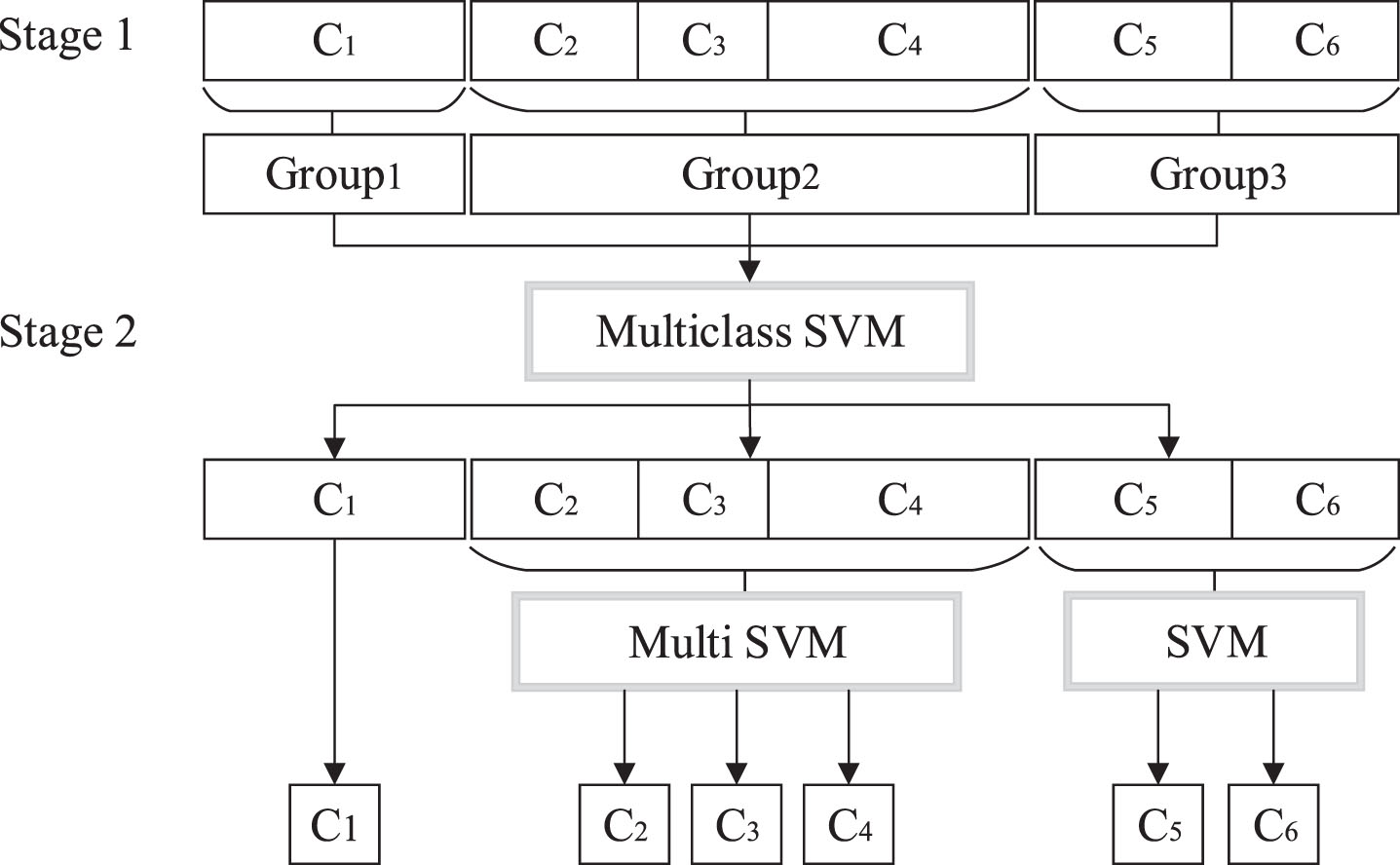
Multi-class SVM hierarchical model structure.
The SMOTE-Least Square SVM (SMOTE-LSSVM) [80] applies intelligent optimization algorithm to the parameter optimization problem and builds a classifier to deal with the multi-class imbalance problem by using SMOTE and least square SVM. The method first decomposes the multi-classes and then uses SMOTE to balance the data. Finally, the parameters of the LSSVM classifier are optimized according to the particle swarm optimization and gravitational search algorithms, which combine the global search capability of the former with the local search capability of the latter to improve the performance of the classifier. After an in-depth analysis of the effects of class imbalance and class overlap in traditional learning models, Devi et al. [81] proposed the One-class SVM and Under-Sampling technique (OSVM-US). The model first uses a one-class SVM to detect overlapping instances as outliers. Then, under-sampling of majority class instances is performed by Tomek-link pairs, and the boundary, redundancy and overlap cases are eliminated based on sparse neighborhood. Finally, the refined training set is fed to the final stage of learning to train the three classifiers and their performance is evaluated. The experimental results demonstrate that the model improves the classification accuracy of the minority class. Moreover, only the largest number of majority class instances are eliminated, thus ensuring the completeness of the other majority classes. However, the performance of the classifiers in this method decreases as the class overlap rate increases. Mehmood et al. [82] also investigated the class overlap problem by proposing Modified SVM with AdaBoost (MSVM-AdB). In the data processing stage, the overlapping and non-overlapping regions of the multi-class dataset are divided using the Euclidean distance formula. Then, regions with dense overlapping samples are mapped to higher dimensions according to a kernel mapping function based on custom standard support vector machine in order to facilitate the base classifier to find the optimal hyperplane, thus predicting the minority class samples and improving the final classification accuracy.
With the processing of multi-class imbalance problems, a strategy is to classify the data by decomposing the multi-class problem into two-class sub-problems using division rules, and then applying the two-class imbalance learning algorithm to these sub-problems.
The main decomposition methods currently are One Vs One (OVO) decomposition and One Vs All (OVA) decomposition. In the OVO decomposition, an m class problem is divided into m (m - 1)/ - 2 two-class sub-problems, where each problem is handled by independent base classifiers that are responsible for different pairs of classes. OVA creates a classifier for each class, which considers all other classes as a whole when classifying. Figure 7 (a) and (b) shows two ways to decompose the multi-class problem.
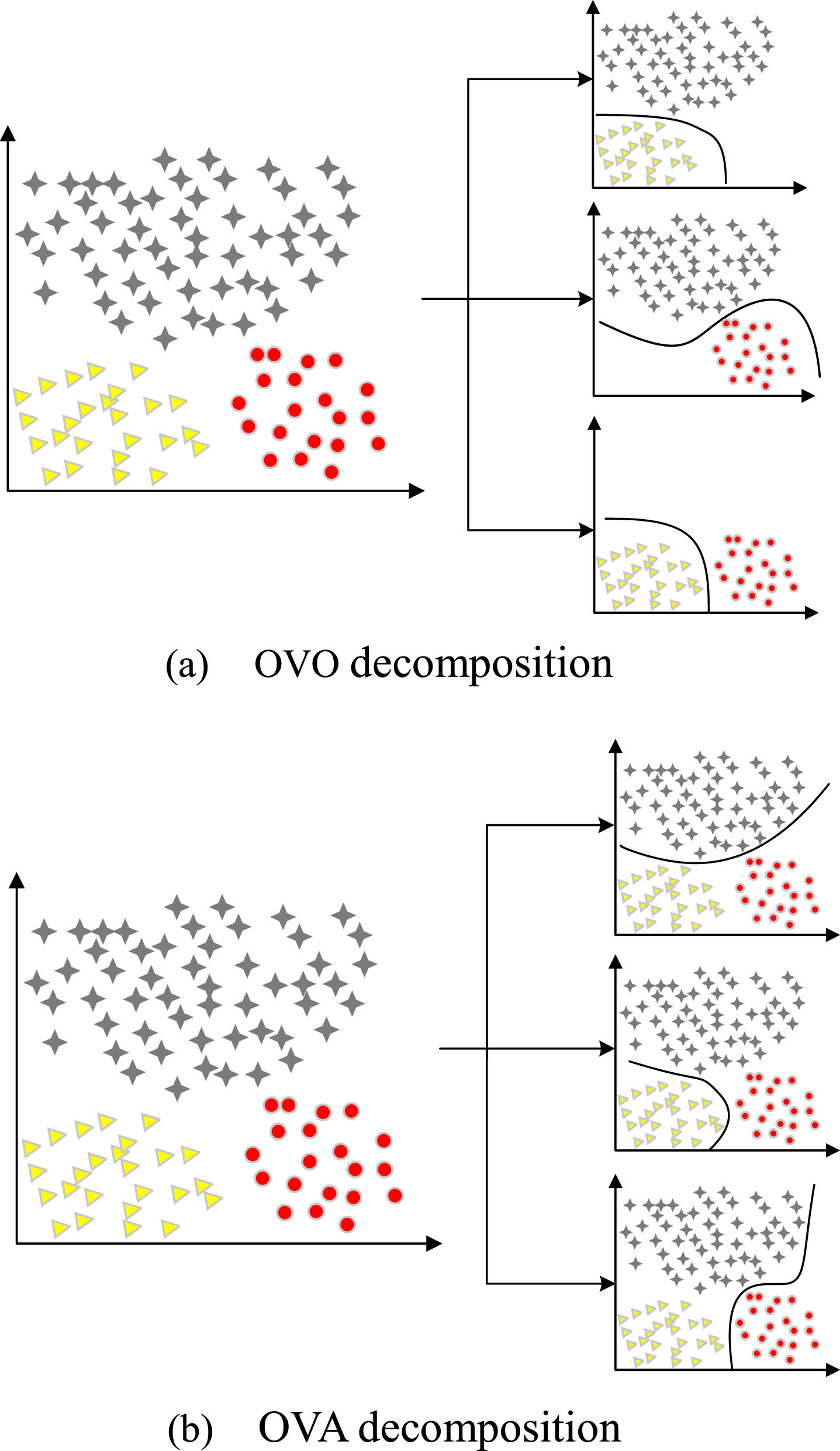
Multi-class decomposition methods.
Zhang et al. [83] explore the application of OVO and OVA decomposition techniques on multi-class imbalance classification problem and combine them with two-class ensemble learning approach. First, the dataset is decomposed using OVO or OVA techniques. Then, a SMOTE-based ensemble learning approach is used to synthesize minority class instances to balance the distribution of the training set and create a two-class classifier for each paired-class. Finally, once the classifier for each class is obtained from the ensemble learning, an aggregation strategy is used to provide the final output from the score matrix. The experimental results show that the proposed OVO decomposition strategy combined with two-class ensemble learning obtains very competitive results. The use of composite learners for each pair of classes captures better local features of the classes, thus improving the classification accuracy. In addition, Rodríguez et al. [39] argued that the Random Balance method could be extended to multi-class problems by using OVO or OVA decomposition techniques, which proposed OVO-Random Balance (OVO-RandBal) and OVA-Random Balance (OVA-RandBal). In OVO-RandBal, all pairs of classes are formed and a classifier is built for each pair of classes. The ensemble consists of c (c - 1)/ - 2 classifiers, each classifier votes for the classes it has trained. The final classification result is obtained by majority voting at the end. OVA-RandBal creates c two-class classifiers, where each classifier is paired with all remaining classes. In the experimental results, the use of OVA in the background of random balance is more advantageous than the use of OVO, especially when the evaluation metric is MAUC.
To solve the synergistic problem between imbalance learning and dynamic classifier weighting in OVO, Zhang et al. [84] proposed Distance-based Relative Competence Weighting with Adaptive Synthetic Example Generation (DRCW-ASEG). The method decomposes the original multi-class imbalanced dataset according to the OVO strategy and then generates synthetic instances based on the neighborhood of a minority class instances in the dynamic weighting process stage to deal with the imbalanced distribution of classes, which improves the classifier’s capability. In addition, the method considers using the Heterogeneous Value Difference Metric (HVDM) to calculate the distance between two instances and uses it as the weight of the classifier. The results reflect a considerable improvement in classification performance using the DRCW-ASEG method and outperform previous methods on most of the datasets. The HVDM is shown in Equation (9). Where x and y are the input instances, f is the number of attributes, d
a
(x, y) is the distance between x and y for attribute a.
The OVA decomposes multiple imbalanced classes by treating one class as positive and the other classes as negative, which can lead to extremely imbalanced situations [85]. As a result, OVA may reduce the identification rate of all minority class instances to some extent. However, some researchers have still been able to obtain good classification results by applying OVA decomposition.
Differential Partition Sampling Ensemble (DPSE) [86] splits the multi-class dataset into multiple binary datasets by OVA, and the number of majority and minority samples in each binary sub-set are used as the upper and lower bounds of sampling, respectively. Based on this range, DPSE simulates the construction of arithmetic progression to generate a collection of sets with different numbers of samples and equal intervals. In addition, DPSE handles safe samples according to the ROS, while SMOTE handles edge and rare samples. Then, a binary classification model is trained using the balanced training set. Experimental results show that this method performs better than other typical imbalanced learning methods in the OVA scheme.
Dong et al. [87] proposed the One-Against-All-based Hellinger Distance (OAHD). To begin with, the OVA scheme is introduced in the Hellinger distance calculation process to decompose and balance the dataset. Next, it designs a modified Gini coefficient to handle the distribution and number of different classes simultaneously, thus ensuring the purity of decision tree nodes. The experimental results show that OAHD has significantly improved in accuracy, MAUC and other metrics compared with other decision trees.
The OVA decomposition-based approach can handle multi-class imbalanced data streams as well. To solve the uncertainty problem of learning in imbalanced data streams, Mohammed et al. [88] combines the OVA decomposition strategy with ensemble learning and proposes One-Vs-All Adaptive Window Re-Balancing with retain Knowledge (OVA-AWBReK). The method first quickly processes the received data streams and decomposes them using OVA. Then incremental rebalancing method is used to train the classifier, which adaptively passes the previously learned knowledge to the subsequent windows as increments. In addition, an adaptive window is designed to dynamically adjust the window size by the imbalance ratio, thus reducing the uncertainty in the learning process of imbalanced data streams. Experiments demonstrate that the method performs better on multi-class datasets with high imbalance ratio.
This chapter introduces algorithm-level classification methods for multi-class imbalanced data in terms of four aspects: ensemble learning, neural network, SVM and multi-class decomposition techniques.
To further analyze the performance and efficiency of multi-class imbalance algorithm-level classification methods, algorithms using the same dataset are compared in this chapter. The parameters of the datasets are listed in Table 4. The 13 algorithms using these four datasets are listed in Table 5.
Dataset parameters
Dataset parameters
Algorithms using the same datasets
In the Ecoli dataset, E-MOSAIC has the best performance with the base classifier Multi-layer Perceptron, which achieves 96.1 and 82.22 in MAUC and G-mean, respectively. E-MOSAIC outperforms DRCW-SEG, OSC and ELM methods in general. That is due to E-MOSAIC being able to identify minority class effectively and ensure the diversity of classifiers during training. PT-Bagging was experimented on Ecoli, Yeast and New-thyroid. The algorithm was evaluated using AUC, macro-accuracy and macro-F1-score. PT-Bagging improves the overall performance of the classifier by preserving the natural distribution of classes. In the above four datasets, DESMI, DRCW-SEG and DPSE performed similarly and achieved good overall results on MAvA, as all of their base classifiers used CART decision trees. However, the time complexity of DRCW-SEG and DPSE is higher compared to DESMI because they require decomposing multi-class. Among the ELM-based classification methods, WOS-ELMK has the best performance and outperforms other ELM methods on G-mean. That is due to the fact that WOS-ELMK uses implicit kernel mapping, which improves the adaptability of the classifier to new instances. It is worth mentioning that all current methods are unable to effectively classify Yeast and Wine-Quality Red datasets with large number of instances and multiple minority classes. The G-mean value of these methods are under 65 on Yeast, and both G-mean and AveAcc values are under 43 on Wine-Quality Red.
By comparing and analyzing the above types of multi-class imbalance algorithm-level classification methods, the following conclusions can be drawn. In the hybrid ensemble, the performance of the ensemble classifier in classifying multi-class imbalanced data is improved by combining the data-level method with the ensemble learning. In addition, by applying dynamic selection in the ensemble learning, the best combination of classifiers can be selected during the training process, thereby improving the classification accuracy. Among the neural network-based methods, the ELM is easy to implement and the weights of hidden layer nodes can be randomly or artificially given, which has better generalization performance and faster learning speed. Meanwhile, ELM has the better results in dealing with extreme imbalance datasets and multi-class imbalance data streams. Deep learning classification methods are more suitable for dealing with complex data types such as images and text. SVM shows excellent performance in solving problems such as class overlap and noise in multi-class imbalance. In addition, SVM can effectively solve the overfitting in the training process, which improves the stability and performance of the learning algorithm. The multi-class decomposition technique divides the multi-class problem into a two-class problem, thus allowing the use of the current more advanced classification methods for the two-class imbalance problem. The existence of multi-class decomposition techniques simplifies the complexity of multi-class imbalance, which makes it more widely applicable. However, it leads to worse time performance. Table 6 summarizes and analyzes the multi-class imbalance algorithm-level classification methods introduced in this chapter.
Multi-class imbalance algorithm-level classification methods
On the issue of classification of multi-class imbalanced data, the traditional evaluation metrics based on two-class imbalanced data are still used by many researchers as criteria for algorithm performance evaluation. The AUC value, Accuracy, Recall and F-measure are the commonly used evaluation metrics. F-measure combines the results of Precision and Recall. To further illustrate the metrics, the two-class confusion matrix is mainly used to represent the above metrics. The two-class confusion matrix is shown in Table 7, and the formulae for the above assessment metrics are shown in Equations (10, 11).
Confusion matrix of binary class
Confusion matrix of binary class
F-Measure (also known as F1-score) is the harmonic mean of Precision and Recall. In some cases, Precision and Recall can be contradictory, and the values of both cannot be high. Therefore, it is necessary to apply the F-Measure evaluation metric, which takes into account the values of Precision and Recall.
However, the traditional evaluation metrics for two-class imbalanced data cannot reflect the performance of multi-class classification algorithms well. Therefore, some researchers have improved the evaluation metrics of the two-class problem and extended them to the evaluation metrics of the multi-class problem. Meanwhile, the two-class confusion matrix also needs to be extended into a multi-class confusion matrix, as shown in Table 8.
Confusion matrix of multi-class
G-mean is a combination of TP and FP, which is a common algorithm performance evaluation metric in the field of imbalance. Sun et al. [89] extended G-mean by proposing a multi-class G-mean based on the recall values of each class, so that the performance of multi-class imbalance classification methods can be effectively measured, as shown in Equations (12, 13), where
The F-measure can be modified to Multi-class F-measure (MFM) [90] by calculating the F-measure value for each class, as shown in Equation (14), where m is the number of classes and i is the subscript of the positive class.
Accuracy is a common metric used in algorithm performance evaluation. In a multi-class setting, it needs to be extended. Marco Average Arithmetic (MAvA) [90] (also known as AveAcc) can be derived by computing Accuracy for each class, as shown in Equations (15, 16), where m is the number of instances, n is the number of classes, f (i, j) denotes the actual probability that instance i belongs to class j, and C (i, j) denotes the predicted probability that instance i belongs to class j.
The Macro F1-score is an evaluation metric that regards each class equally. It considers each class individually as a positive class and then averages its corresponding F1-score, as shown in Equations (17–19).
MAUC [91] is an effective measure of the performance of multi-class algorithms, as shown in Equation (20). For any pair of classes i and j, define
Table 9 summarizes the commonly used evaluation metrics for different types of multi-class imbalance data classification methods.
Evaluation metrics for multi-class imbalanced data classification methods
The algorithms and models proposed for the multi-class imbalance classification problem have made considerable progress and development, but there are still many problems that need to be solved and further research and optimization of the existing methods are needed. The following discusses the current problems and future research directions for multi-class imbalance classification.
(1) Handling multi-class imbalanced data streams with dynamic ensemble selection
Multi-class imbalance learning on data streams is a direction that has received few studies, and most of the available data stream classification algorithms have been developed for the two-class imbalance problem. There have been some researchers who have proposed algorithms on multi-class imbalanced data streams and achieved good results. However, the problem of uncertainty in multi-class imbalanced data streams has not yet been addressed. For example, the majority class may become the minority class after a period of time, while the minority class may become the majority class, and new classes may arrive as time changes. To address these issues, the author plan to combine the sliding window and dynamic selection ensemble in future studies, which processes the data in batches while evaluating and removing weak classifiers from the ensemble and retaining the more capable ones.
(2) Tackling concept drift in multi-class imbalanced data streams
The concept drift problem is common in various application scenarios at present, and it also exists in multi-class imbalanced data streams. In the environment of data streams, concept drift detection becomes very demanding. Because it is necessary to deal with multiple classes of concept changes and imbalanced class distributions simultaneously, which cannot be solved by traditional drift detection techniques. In subsequent research, the capability of the classifier can be improved by designing a drift detection mechanism that combines the ratio of multi-class imbalance with ensemble learning.
(3) Coping with complex multi-class imbalanced datasets
The data generated in real-world applications are bulky and complex. Apart from the problems of biased class distribution, class overlap, multiple majority and multiple minority classes, there are also extreme imbalances, noise and conceptual drift in multi-class imbalanced data. However, most of the existing methods are devoted to solving only one or two of these problems. More efficient and comprehensive methods for classification in this complicated environment should be investigated.
Conclusion
This article presents a review of existing data preprocessing methods and algorithm-level classification methods based on multi-class imbalanced data. Firstly, oversampling, under-sampling, hybrid sampling and feature selection are introduced in the data preprocessing methods. Secondly, a detailed introduction and summary of the algorithm-level classification methods are presented in four aspects: ensemble learning, neural network, SVM and multi-class decomposition techniques. Moreover, the performance of part of the algorithms using the same dataset is compared and analyzed, and the pros and cons and performance of all the algorithms are analyzed and summarized. Finally, the next research directions and solutions are proposed for the challenges and problems faced by the current multi-class imbalanced data classification.
Footnotes
Acknowledgments
This work was supported by the National Nature Science Foundation of China (62062004), the Ningxia Natural Science Foundation Project (2022AAC03279) and the Graduate Innovation Project of North Minzu University (YCX22191).