
Abstract
Multi-source information fusion is a sophisticated estimating technique that enables users to analyze more precisely complex situations by successfully merging key evidence in the vast, varied, and occasionally contradictory data obtained from various sources. Restricted by the data collection technology and incomplete data of information sources, it may lead to large uncertainty in the fusion process and affect the quality of fusion. Reducing uncertainty in the fusion process is one of the most important challenges for information fusion. In view of this, a multi-source information fusion method based on information sets (MSIF) is proposed in this paper. The information set is a new method for the representation of granularized information source values using the entropy framework in the possibilistic domain. First, four types of common membership functions are used to construct the possibilistic domain as the information gain function (or agent). Then, Shannon agent entropy and Shannon inverse agent entropy are defined, and their summation is used to evaluate the total uncertainty of the attribute values and agents. Finally, an MSIF algorithm is designed by infimum-measure approach. The experimental results show that the performance of Gaussian kernel function is good, which provides an effective method for fusing multi-source numerical data.
Keywords
Introduction
With the continuous enhancement and development of sensor and Internet technologies, the acquisition of data is no longer limited to a single form of data source, but is stored and described in the form of multiple sources [1, 2]. The samples of data from multiple information sources have varied knowledge structures that express information from different points of view [3]. Data from different sources or description information from different angles of the same data will enrich the knowledge structure contained in the data. The information of knowledge structure reflects different perspectives of the learning task in different applications, which facilitates a comprehensive understanding of the multiple information embedded in the data [4–9]. In view of this, it is necessary to design reasonable and effective multi-source information fusion (MsIF) models and algorithms.
Up to now, lots of MsIF methods have been proposed for complex multi-source data. For example, Yager provided a general framework for MsIF based on a voting like process that tries to adjudicate conflict among the data [10]. Xu and Yu investigated two types of confidence degrees to estimate the reliability of each information source in multi-source information systems [11]. Li and Zhang introduced an MsIF method in a multi-source incomplete information system based on information entropy [12]. To make full use of the information from multiple sources, Sang et al. proposed three kinds of multi-source decision models in multi-source information system [13]. Based on rough learning techniques, Wei and Liang et al. came up with a survey of existing information fusion models and methods from five perspectives, i.e., multi-source, multi-modality, multi-scale, and multi-view information systems [14]. Che et al. employed three methods to solve the information fusion and numerical characterization of uncertain information in multi-source information systems [15]. Huang et al. put forward a new fusion technology based on fuzzy information granulation, which can translate multi-source interval-valued data into trapezoidal fuzzy information granules [16]. From the perspective of granular counting, Zhang et al. studied multi-granularity fusion multi-source information fusion model and multi-source homogeneous information fusion [3, 18].
Information is the source of knowledge for human beings to understand and transform the world. Because the real world is diverse, complex, and dynamic, people’s expressions of things and information are often imprecise, uncertain, and vague. The variety of information people are exposed to is sometimes deterministic, but more often, it is uncertain. Whether the information is certain or uncertain, it does not matter whether it is good or bad. The problem lies in correctly understanding certainty and uncertainty and grasping the essential law of knowledge uncertainty. In recent years, research on information uncertainty has drawn more and more attention. For example, uncertainty and information system were handled using rough set theory [19–22], measuring fuzzy and relation uncertainty [23–25], and a variety of entropy measures uncertainty [26–28], etc. However, even though there are various fusion methods and models, dealing with the uncertainty in multi-source information fusion is still a challenging problem. In general, the uncertainty resulting from the attribute values (data itself) and the distinctions across information sources is included into the process of fusing numerous information sources. It is worthwhile to research how to decrease uncertainty in the information fusion process.
Information sets [29], proposed by Aggarwal, which is a useful tool for the representation of uncertainty in the granulized attribute values by making use of the entropy framework. In addition, the method is complementary to fuzzy sets to a certain extent, and has more advantages in dealing with uncertainty problems. The main notion of the information sets gives a universal formalism for representing uncertainty to link the value of an information source with the agent’s appraisal of it, which produces an entropy value that we refer to as the “information value”. An information set is a collection of various information values, the sum of which quantifies the uncertainty of the information source. The fundamental idea enshrined in the information set is to unravel uncertainty by the parametric gain function by the values of the information source. It can also give the uncertainty in the possibility distribution (provided by membership function) by capturing this distribution through the information gain. At present, research on information set has been applied in many fields, i.e., decision making [30–32], face recognition [33, 34] and others [35]. To the best of our knowledge, the fusion of multiple information sources using the information set method has not been reported in any existing literature.
Based on this, this paper proposes the multi-source information fusion model based on information sets. Our main contributions are as follows. Introducing the idea of information set into MsIF, which is beneficial to multi-source numerical data fusion. Four different membership degree functions are used as the components of information sets when calculating the entropy functions. Shannon agent entropy and Shannon inverse agent entropy are defined, their summation can be used to quantify the uncertainty of information sources. An MSIF algorithm is designed on the basis of infimum-measure strategy. The experimental results show that the proposed algorithm is reasonable and effective.
The rest of this paper is organized as follows. Section 2 briefly introduces some basic concepts about information systems, multi-source information systems and information sets. In Section 3, membership degree functions and uncertainty measurements for agents and attribute values are defined. Multi-source information fusion algorithm based on infimum-measure is designed in Section 4. Section 5 shows experimental results and analyses. Conclusion and future work are given in Section 6.
Preliminary
This section shades light on the preliminary definition of information systems, multi-source information systems and information sets. In addition, the symbols and abbreviations involved in the article are shown in Table 1.
Abbreviations
Abbreviations
According to [39], anything that can be considered to be sensing its environment qualifies as an agent. Just like animals use their eyes, nose, ears, or other organs to perceive information from the outside world. In the age of artificial intelligence, many machine tools, such as aircraft, robots, and controller stations, mostly use sensors to sense and transmit information. In fuzzy set (FS) theory, a FS can be characterized by a membership function that maps attribute value a (x
j
) to the degrees of membership μ (x
j
). Therefore, the membership degree can be viewed as the role of an agent. In [29], the term information gain g
a
(x
j
) and agent are both used interchangeably. For example, Agarwal and Hanmandlu used Hanman-Anirban entropy function to represent the uncertainty of attribute values, and is denoted as
Let MsIS = {IS
i
|IS
i
= (U, A, V
i
)} be an MsIS where U = {x1, x2, ⋯ , x
n
} and A = {a1, a2, ⋯, a
l
}. For any a ∈ A, the mean attribute values can be denoted as amean =
Four types of representative membership degree functions
In what follows, three uncertainty measures are defined to evaluate agents and attribute values.
By Definition 8, the larger the value of
There are discrepancies in order of magnitude and dimensionality in real-world datasets. As a result, the numerical attributes of the original information sources are normalized before data processing. In this paper, min-max normalization is used as follows. For any x j ∈ U, then
The next step is to perform fuzzy modeling on the normalized data by different membership degree functions, which allow mapping from fuzzy sets to information set. According to the aforementioned definition, a multi-source information fusion algorithm is designed as follows.
Multi-source information fusion based on information sets (MSIF)
1: Normalizing the original information sources by Equation (11);
2: Calculating the membership degrees by Table 2;
3: Calculating information sets by Equation (4);
4: Calculating SGE by Equation (7);
5: Calculating SIGE by Equation (8);
6: Calculating TUT by Equation (9);
7: Calculating the TUT of the k-th attribute of all information sources by Equation (10), A′ ← ∅ , N ← N ∪ { a k };
8:
By Algorithm 1, Steps 1-4 are to compute the membership degrees of each information source, whose time complexity is O (n × l). Then, for all information sources, the time complexity is O (n × l × m). Steps 5-9 focus on computing different uncertainty measures, whose time complexity is O (n × l). The time complexity of Steps 10-15 is O (l × m). Based on this, the total time complexity of Algorithm 1 is O (n × l × m + n × l + l × m).
An MsIS
According to Algorithm 1, the raw information sources in Table 3 are normalized by Equation (11), which is shown in Table 4.
The normalized MsIS
In this example, Gaussian membership degree is used as the agent. Then, by Equation (6), Table 5 lists the Gaussian membership degrees for all attribute values.
Gaussian membership degrees of all attribute values in the MsIS
Subsequently, by Definition 5, all information values of each information source can be calculated as in Table 6.
All information values of each information source
It is important to note that the 0 values have a very small ɛ= 0.0001 to prevent issues with the logarithmic function. In this paper, the base of the logarithmic function is 2. According to Definitions 6-8, the SGE, SIGE and TUT are calculated as in Table 7.
The calculation results of SGE, SIGE and TUT
Finally, driven by Definition 9, we have
The new information system (U, N, V)
Therefore, a multi-source information system is fused into a new information system, which contains the information of agent and information source itself with minimum uncertainty.
In this section, to demonstrate more clearly the correctness and validity of the conclusions drawn from the cases in the previous section. We conducted some experiments to show the performance of the proposed fusion method in terms of classification accuracy. Six datasets are selected from UCI database 2 , which are shown in Table 9.
The description of datasets
The description of datasets
Given that current public databases rarely involve multi-source data, we employ the technique of introducing white noise and random noise into the initial datasets to get the necessary multi-source data for the experiment. First, q numbers (N1, N2, ⋯ , N q ) are generated that satisfy the (N (O, σ)) distribution where σ is the standard deviation. The white noise is added by following formula.
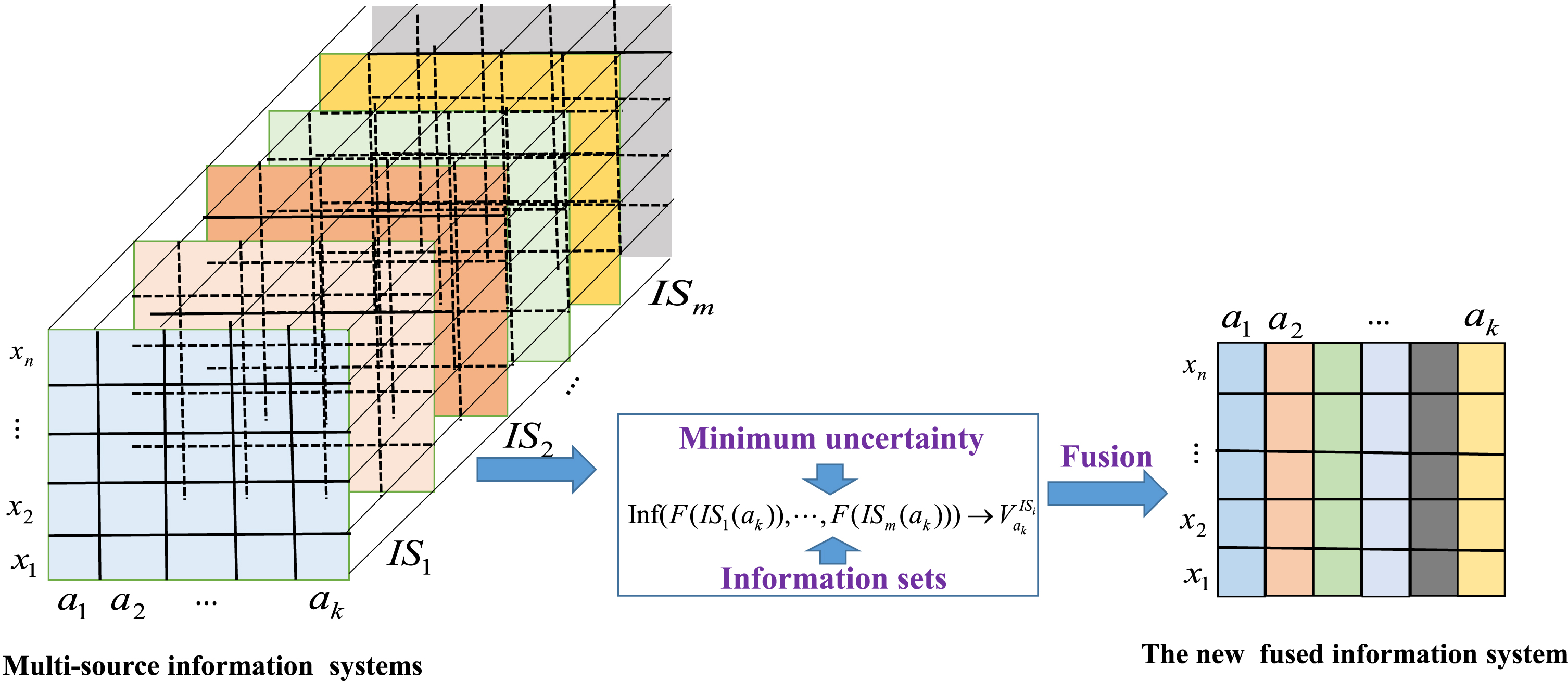
The fusion process of the proposed method.
To reflect the effective of the proposed fusion model, seven fusion methods are compared, including AIS, GMD, TMD, ZMD, SMD, NIA [17] and NIE [17]. The seven comparison methods are summarized as follows. AIS: Average information sources. It can be understood as the average performance of original information sources. GMD: Gaussian membership degree as the agent. Using GMD (f (x ; σ, c)) for fuzzy modeling, the specific formula is shown in Table 2, where σ and c represent the standard deviation and mean value of objects under attribute a, respectively. ZMD: Trapezoidal membership degree as the agent. Using ZMD (f (x ; a, b, c, d)) for fuzzy modeling, the specific formula is shown in Table 2, where a,b,c and d represent the minimum, mean, median and maximum values of the objects under attribute a, respectively. TMD: Triangular membership degree as the agent. Using ZMD (f (x ; a, b, c)) for fuzzy modeling, the specific formula is shown in Table 2, where a,b and c represent the minimum, mean, and maximum values of the objects under attribute a, respectively. SMD: Sigmoid membership degree as the agent. Using ZMD (f (x ; α, c)) for fuzzy modeling, the specific formula is shown in Table 2, where α = 1, and c represents the mean value of the objects under attribute a. NIA: Neighborhood information amount. Using NIA to fuse multiple information sources. NIE: Neighborhood information entropy. Using NIE to fuse multiple information sources.
Since there is no unified method to test the performance of fusion, this paper uses the classification accuracy to evaluate the performance. The classification performance of the fused information source is compared by using three classifiers, i.e., classification and regression trees (CART), k-nearest neighbor (KNN, k=3) and support vector machine (SVM). All classification experiments were derived from ten-fold cross validation. It randomly divides a sample into ten subsets, nine of them are treated as the training set, and the remaining one is regarded as the test set. After 10 rounds, the final performance is obtained by calculating the average and standard deviations of the classification accuracy. All information sources in the experimental datasets were normalized in terms of Equation (11).
The experimental results are displayed in Tables 10-12. “•” indicates that the performance of the fused data is better than that of the average original information source before fusion. From the data in Tables 10-12, we have the following findings: In Table 10, the classification performance of most fusion methods outperforms AIS. TMD and ZMD perform slightly worse on Wine dataset. SMD, NIA and NIE methods are inferior to AIS on the Yeast dataset. Compared with TMD, ZMD, SMD, NIA and NIE, the performance of the GMD method is the best. This demonstrates the benefits of using GMD as an agent to fuse multiple information sources. In Table 11, the classification performance of most fusion methods outperforms AIS. The classification performance of ZMD is poor on Wine and Wpbc datasets. However, NIA and NIE perform poorly on the Iris dataset. Overall, the performance of SMD and GMD is the closest, with the average classification performance of 0.7889 and 0.7861, respectively. In Table 12, GMD, TMD, ZMD and SMD methods perform better in most cases, except for the Glass and Wpbc datasets. The performances of NIA and NIE on Glass and Wpbc datasets are slightly worse than other methods.
In general, the performance of GMD is the best among these three classifiers. This is probably due to the characteristics of the normal distribution of the Gaussian membership function, and it has a good smoothness and symmetry graph. Additionally, the function has no zeros and an obvious physical meaning, which makes it a very good approximation of the membership function. The experimental results show that it is appropriate to use Gaussian membership functions to describe the fuzzy concept of agents. Therefore, it is suggested that the Gaussian membership function can be selected to fuse multiple information sources in real applications.
Classification results of seven methods on CART classifier
Classification results of seven methods on KNN classifier
Classification results of seven methods on SVM classifier
In this paper, a multi-source information fusion method was proposed based on information sets. The information sets can describe both the information source value and the uncertainty information of the agent. We tested the effect of four common agents (GMD, TMD, ZMD and SMD) on the proposed MSIF algorithm. The experimental results showed that GMD has certain advantages in fusing multi-source numerical data. This study can provide a method for possibility modeling and facilitate the further development of multi-source information fusion. This paper only provides a multi-source numerical data fusion model from the perspective of minimum uncertainty. However, related theories and methods still need to be improved. The following three directions need further discussion: 1) How to develop a unified multi-source information fusion model. 2) How to fuse multi-source heterogeneous information. 3) How to develop performance evaluation criteria for multi-source information fusion methods.