
Abstract
Short text classification task is a special kind of text classification task in that the text to be classified is generally short, typically generating a sparse text representation that lacks rich semantic information. Given this shortcoming, scholars worldwide have explored improved short text classification methods based on deep learning. However, existing methods cannot effectively use concept knowledge and long-distance word dependencies. Therefore, based on graph neural networks from the perspective of text composition, we propose concept and dependencies enhanced graph convolutional networks for short text classification. First, the co-occurrence relationship between words is obtained by sliding window, the inclusion relationship between documents and words is obtained by TF-IDF, long-distance word dependencies is obtained by Stanford CoreNLP, and the association relationship between concepts in the concept graph with entities in the text is obtained through Microsoft Concept Graph. Then, a text graph is constructed for an entire text corpus based on the four relationships. Finally, the text graph is input into graph convolutional neural networks, and the category of each document node is predicted after two layers of convolution. Experimental results demonstrate that our proposed method overall best on multiple classical English text classification datasets.
Keywords
Introduction
Text classification is a fundamental problem in the field of natural language processing (NLP), which has numerous applications such as sentiment analysis, spam detection, and extractive question answering [1–3]. With the widespread use of mobile internet, a large amount of short text information has emerged. How to extract and use this information has piqued the interest of academia and industry. Short text classification is a classification method based on the given classification system for forums /BBS, messages and replies, suggestions and feedback, mobile phone short messages/network notes, instant chat records (MSN/QQ/POPO) etc. Compared with long text, the short text has less content. The short text usually consists of several to a dozen words, the longer text is about 100 words, the content is less and the features are not obvious. The sentence expression of short text may have non-standard behavior. The short text’s ability to describe information is weak and the corresponding text representation is more sparse. Traditional short text classification methods are mainly based on machine learning [4–7], resulting in severe feature sparsity and weak feature expression ability when processing short texts. With the development of deep learning, convolutional neural networks (CNN) [8, 9], recurrent neural networks (RNN) [10, 11], and the attention mechanism [12, 13] have also been used to solve problems of short text classification, but CNN generally can only represent the semantic information of context in the local window, and the attention mechanism mainly focuses on the sequence of local continuous word, so these methods still cannot effectively solve the problem of short text feature sparsity. Graph neural networks (GNN) have also been used to complete short text classification, but there are few studies on feature expansion of short text classification based on GNN [14–17].
Feature expansion is an effective method to solve short text feature sparsity. There are two commonly used feature expansion methods. One is based on the content of the text. For instance, in 2019, Gao et al. [18] proposed a new short text conditional random regularization topic modelling model, which aggregated short texts into pseudo-documents to address the problem of short text feature sparsity, and by using random field regularization model to realize semantically related words sharing the same topic assignment, semantic disambiguation was achieved. The dependency between words is the relevant information extracted from the content of the short text. For short text, long-distance dependencies have more significance and can compensate for semantic deficiency to a certain extent. The other is based on the introduction of external knowledge, for example, Sahami et al. [19] used the web search results as the feature expansion items of keywords to enrich the features of short texts. However, because feature expansion based on search engines heavily relies on the open interface of search engines, the results obtained in practical application scenarios are unstable and unfeasible.
Currently, many scholars combine knowledge graphs with graph neural networks to solve NLP tasks [20–22]. For example, Wang et al. [23] proposed a knowledge awareness GNN with smooth regularization of labels for recommendation systems. This model combine graph convolutional network (GCN) with knowledge graph and aggregates neighborhood information with different weights using user-specific relational scoring functions. Ye et al. [24] proposed an improved GNN-based method that can reason over multiple paragraphs with entities and construct entity graphs using relational facts in a knowledge graph to explicitly capture connections between entities. Zhou et al. [25] designed a GCN sentiment classification model based on syntax and knowledge. The model combines a syntactic dependency tree and a commonsense knowledge graph simultaneously for aspect-level sentiment classification, and to enhance the ability of sentences to represent a given aspect, two strategies are developed to model the syntactic dependency tree and the commonsense knowledge graph, respectively. Syntactic relationship is the study of the rules governing the ways different constituents are combined to form sentences in language, or the study of the interrelationships between elements in sentence structures. However, there are few studies on the combination of knowledge graph and GNN to solve the task of short text classification [26]. In order to solve the problem of sparse features, Yan et al. [27] constructs a knowledge graph and injects the triples contained in it into sentences as domain knowledge to realize feature expansion, thus solving the problem of feature sparsity.
In order to solve the above problems, we propose a short text classification method of graph convolution networks with enhanced concept and dependencies(KDGCN). We use two feature expansion methods to solve the feature sparse problem of short texts. First, based on the semantic information of the short text itself as an expansion item, Stanford CoreNLP1 is used to analyze the dependency of the text, and select the words belonging to the long-distance dependency to expand the text graph. At the same time, external knowledge is introduced for feature expansion. We extract concepts corresponding to short text features from the Microsoft Concept Graph to enrich the context features of short texts. The following related papers are referred to when calculating the experimental results [28, 29]. In summary, our main contributions of this study can be summarized as follows:
(1) On the basis of existing text classification models based on GNN, the relationship between concepts and words, the co-occurrence relation between words, the relation between documents and words, and long-distance word dependencies are introduced into the text graph construction process.
(2) A text graph containing multiple relationships is introduced into GCN and a novel short text classification model based on GCN with enhanced concept and dependencies is proposed.
(3) Experiments are conducted on several benchmark datasets and experimental results show that our method overall better than existing baseline models.
Related work
At present, typical text classification algorithms include those based on machine learning, deep learning, and GNN.
Common short text classification methods
Text classification algorithms mainly include support vector machine [30], naive Bayes [31], and other machine learning algorithms that ignore the natural order structure or context information in text data, making learning semantic information about vocabulary extremely difficult. Many scholars have conducted studies to improve the above problems. For example, Bouaziz et al. [32] combined data enrichment with semantics using a random forest classifier for short text classification to overcome the sparseness and deficiency of contextual information.
With the advancement of deep learning, relevant research on text classification algorithms based on deep learning has expanded. Chen et al. [33] applied CNN to text classification tasks for the first time. To solve the problem of sparse features of short texts, Wang et al. [34] proposed a framework that combines knowledge using CNN. This model first uses a taxonomy knowledge base to map entities in short texts to corresponding concepts through isA and isPropertyOf relations. Then, words and related concepts are combined in a pre-trained word vector to obtain short text embedding. Hao et al. [35] proposed a Chinese short text classification method based on mutual attention CNN, which can integrate word-level and character-level features so that the model will not lose too much feature information. Chen et al. [36] proposed a deep short text classification method based on knowledge-driven attention. This model retrieves knowledge from external knowledge sources, treats conceptual information as a kind of knowledge, and integrates it into a deep neural network to enhance the semantic representation of short texts. To distinguish the importance of different knowledge, an attention mechanism is also introduced. Xu et al. [37] proposed a Dual Embeddings Convolutional Neural Network (DE-CNN). Firstly it uses the dual-embeddings to extract concepts and contexts, then uses attention layer to extract context-relevant concepts from the extracted concepts, finally the context-relevant concepts are merged into the text representation, and convolutional neural network is used to conduct short text classification.
Short text classification based graph convolutional networks
GNN has gained popularity due to their powerful expressive ability, and they are also used to solve the problem of text classification [38–41]. GCN is one of the typical variants of GNN proposed by Kipf et al. [42]. Defferrard et al. [43] first applied GCN to text classification tasks. In 2019, Yao et al. [44] improved the model proposed by Defferrard et al and transformed the text classification problem into a node classification problem. First, a text graph with global relations between documents and words is constructed based on the entire text corpus, and then, document nodes are classified by GCN. For short text classification tasks, Hu et al. [45] proposed a semi-supervised short text classification method based on heterogeneous graph attention networks. This model uses the heterogeneous information network framework to model short texts, which can contain any additional information and capture rich relationships between texts and additional information. Tayal et al. [46] proposed a regularized GCN for short text classification that uses extra knowledge between text and labels to enhance short text information. Wang et al. [47] modelled the short text dataset as a hierarchical heterogeneous graph consisting of three type graphs which introduce more semantic and syntactic information, and then dynamically learned to facilitate effective label propagation.
Knowledge graph
Knowledge graph is a concept proposed by Google based on the semantic web, which has been widely used in NLP tasks. Knowledge graph improves the storage and acquisition methods of knowledge and can extract high-quality knowledge, effectively solving the problem of sparse short text features. In 2016, Microsoft research institute released Microsoft Concept Graph, which is expressed in the form of a triad of instances, concepts, and relationships, among which the IsA relationship is between concepts and instances, such as triad (Microsoft, company, IsA) indicates that Microsoft is a company. A short text may directly contain concept words in a knowledge graph, but it is more common that the text include instance information related to these concepts, such as “It’s a very valuable film” and “More than anything else, kissing Jessica Stein injects freshness and spirit into the romantic comedy genre.” Both sentences correspond to the concept of “film”, but the first sentence contains the concept word “film” directly, and the second sentence represents the concept of “film” with the instant message “kissing Jessica Stein”, the concept is obtained by mapping text information into Microsoft Concept Graph. Obviously, by conceptualizing the text information, we can obtain the extended words with the highest semantic relevance, which can expand the representation of short text features and improve the accuracy of short text classification.
Graph convolutional networks
GCN is a multi-layer neural network work, which operates directly on the graph and induces the embedding vector of nodes according to their neighborhood attributes. The input of GCN contains N × D dimensional eigenmatrix H formed by N nodes and their features, and N × N dimensional adjacency matrix A formed by the relationship between each node. GCN also needs to introduce a degree matrix, which is used to represent a node is associated with how many nodes. In GCN, the features of the neighbors are summed directly. The aggregation equation of neighbor nodes is as follows:
In general, each layer of GCN is multiplied by the adjacency matrix A n and the eigenmatrix H l to get the summary of the neighbor features of each vertex, then multiplied by a parameter matrix W l . Add the activation function σ and do a nonlinear transformation to obtain the matrix H l + 1 of the features of the aggregate adjacency vertices, so that the output vector of the last layer of GCN contains not only the initial features of nodes but also the topological features of the network.
Existing methods based on machine learning and deep learning have significantly improved short text classification, but the combination of concept knowledge, word dependencies and GNN has not been considered to tackle short text classification tasks. Therefore, it is of great significance to explore GCN for short text classification based on concept and dependencies enhancement.
The model structure of the proposed method is shown in Fig. 1. Firstly, the data cleaning of the text is carried out. Secondly, we obtain entity information, dependency relationship and word co-occurrence information in the text through TAGME, Stanford CoreNLP and sliding window technology respectively, and then map entity to Microsoft Concept Graph to obtain corresponding concept. Thirdly, the obtained information is constructed through the following four relationships: word co-occurrence relationship, distance dependency, association relationship between concepts and words, and inclusion relationship between texts and words. Finally, the text map is input into the two-layer GCN network, and the text label is obtained through training.
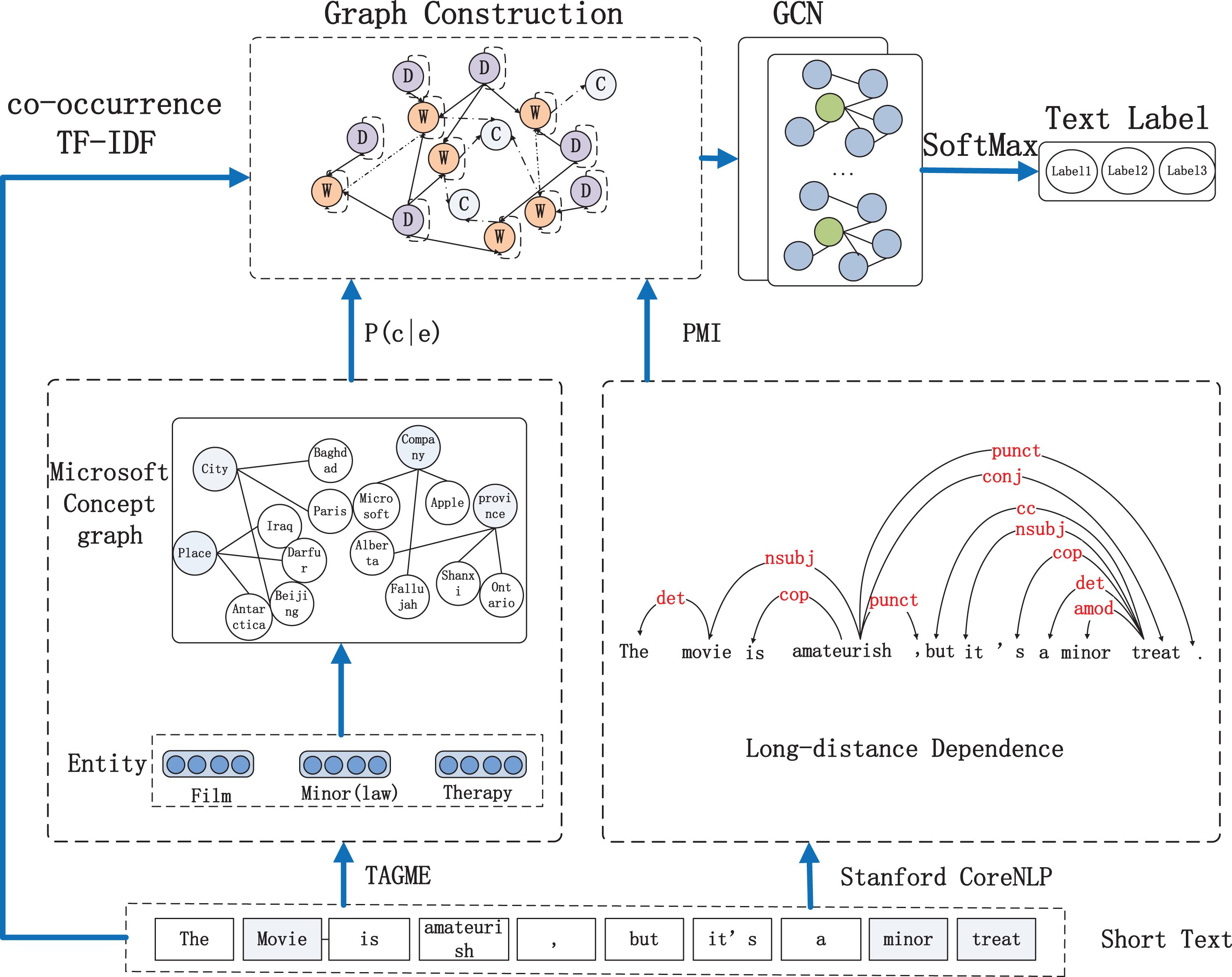
KDGCN overall architecture diagram. “D” are document nodes, “W” are word nodes, “C” are concept nodes, and lines indicate edges between nodes.
We take concepts, documents, and words as nodes and establish edges between nodes based on four relationships: the relationship between concepts and words, word co-occurrence, the relation between documents and words, and long-distance word dependencies. Establish a text graph G = (V, E) for corpus, where V (|V| = n) and E represent sets of nodes and edges, respectively. X ∈ Rn*m is an eigenmatrix, where n refers to the number of nodes, m represents the dimension of the eigenvector, X v ∈ R m refers to the eigenvector of node v, and the eigenmatrix is defined as the identity matrix.
Associated edges of document and word nodes
Edges between word nodes are constructed on the basis of word co-occurrence, where word co-occurrence information is obtained by a sliding window with a fixed size, and the weight between two words is calculated using point wise mutual information (PMI). When the PMI value is negative, the semantic correlation between words in the corpus is low or non-existent, so only edges with a positive PMI value are retained. The weight of an edge between node i and node j is defined as
If a word appears in a document, a linking edge is constructed between the document and word, and the weight of the edge between the document and word is calculated by term frequency-inverse document frequency. We use Stanford CoreNLP, an NLP toolkit of Stanford University, to analyze the dependence relationship between texts, and words with long-distance dependencies are selected from the obtained dependencies to expand the text graph. The relationship between two words in a sentence that are dependent on each other and there are many lexical intervals between them is called long-distance word dependencies. The weight of edges constructed on the basis of long-distance word dependencies are calculated by PMI, where edges with positive PMI are only retained. The PMI calculation method used here is as follows:
The most important parts of a sentence are the subject and predicate. The subject is the center of the sentence, and the predicate is the action or state of the subject. From the example in Fig. 2, “the subject predicate relationship” points to the key point of the sentence, the subject-predicate relationship refers to the relationship between the executor of the action and the action. In general sentences, if there is a predicate, there will be an object, which is the object and receiver of the action. For example, the “punch” in the example sentence in Fig. 2 is crucial for the semantic expression of the sentence. The verb-object relationship refers to the relationship between the receiver of the action and the action, and the juxtaposition relationship refers to the correlation between sentences or words, they are carried out at the same time or in the same place. The juxtaposition relationship can be different things related to each other, or different aspects of the same thing, or different actions of the same subject. Eventually, through numerous experiments, we select above three kinds of dependencies as the long-distance dependencies of the model, as shown in Table 1:

Dependency graph structure.
Long-distance dependency
First, identify entities in the document and map them to Wikipedia using an entity linking tool TAGME2. For the word “cast” in the text, the linked entity and related information obtained through TAGME are shown in Table 2.
Parameters returned by TAGME
Parameters returned by TAGME
Concepts embody our knowledge of the kinds of things there are in the world. Tying our past experiences to our present interactions with the environment, they enable us to recognize and understand new objects and events. Concepts mainly refer to collections, categories, object types and types of things, such as people, geography, etc. We map the reserved entities to different semantic concepts in Microsoft Concept Graph. We can obtain the concept corresponding to the entity and its mapping probability by requesting the official website for the corresponding API function. Among the obtained concepts, a concept with a mapping probability greater than 0.5 is selected as one of the nodes of the text graph, and an edge is established between the corresponding word and concept, and the weight between the edges is represented by the mapping probability. Microsoft Concept Graph provides six algorithms for calculating the correlation degree between entities and concepts, namely, P (c ∣ e), P (e ∣ c), mutual information, point mutual information, standardized point mutual information, and conceptual reasoning algorithms. For the word “Microsoft”, some concepts are obtained according to different algorithms, such as "company”, “vendor”, “client”, and the mapping probability between "Microsoft” and these concepts such as 0.611, 0.089, 0.048. We select three groups of data with the highest probability to show in Table 3.
The corresponding concept of “Microsoft” and its mapping probability
Following the example in Table 3, we compare the six calculation methods and find that the concepts and mapping probability calculated by P (c ∣ e) are more reasonable and accurate. Thus, we use P (c ∣ e) to calculate the degree of association between entities and concepts.P (c ∣ e) is the probability that concept c is the corresponding concept of an entity e.
After constructing the text graph, we input the text graph into a simple two-layer GCN. The activation function is used in the first layer. The main function of this layer is to make each node receive information from neighboring nodes for fusion and update its representation and perform a nonlinear transformation of all feature information about nodes by the operation. The second layer of node embedding has the same size as the label set and inputs information from layer 1 into SoftMax. A represents the adjacency matrix, and D represents the degree matrix and assumes that each node is connected to itself, X is a matrix containing all n nodes with their features.
Datasets
The experiment uses four public text classification datasets for model verification, including Movie Review (MR), Ohsumed, R8, and R52. The statistics of the datasets are summarized in Table 4.
Summary statistics of datasets
Summary statistics of datasets
•MR is a binary sentiment classification film review dataset, including 5331 positive reviews and 5331 negative reviews. The training set includes 7108 documents, and the test set includes 3554 documents.
•Ohsumed comes from the medical database MEDLINE10, and its content is the title or abstract of medical journals. After removing documents with multiple labels, only 7400 documents belonging to one category are retained, including 3357 documents for the training set and 4043 documents for the test set.
•R8 is a subset of the Reuters 21578 dataset and includes 8 categories, including 5485 documents for the training set and 2189 documents for the test set.
•R52 is a subset of The Reuters 21578 dataset and includes 6 categories, including 6532 documents in the training set and 2568 documents in the test set.
To evaluate the performance of the KDGCN model, we use six baseline models as follows:
•CNN: CNN proposed by Kim et al. [33], uses convolution kernels of different sizes to conduct convolution and maximum pooling operations for word embedding to obtain text representation, which can better capture local correlation.
•Long short-term memory (LSTM) proposed by Liu et al. [48]: LSTM uses the last hidden state as the representation of text, which can solve the problem of gradient vanishing to a certain extent. Bi-directional LSTM is another LSTM which operates bi-directionally which can better capture contextual information in sentences than unidirectional LSTM.
•fastText proposed by Joulin et al. [49]: it is an open-source word vector and text classification tool of Facebook, providing a simple and efficient method for text classification and representation learning.
•Graph-CNN-C: a graph CNN model proposed by Defferrard et al. [43], which performs a convolution operation on word embedding similarity graphs, where the Chebyshev filter is used for the convolution operation.
•Text-GCN: the text classification model based on GCN proposed by Yao et al. [44], which first constructs a single large-scale text graph for the entire corpus and input the text graph into GCN.
•SGC: A simplified graph convolution model proposed by Wu et al. [50], which is obtained by repeatedly removing the nonlinearity between GCN layers.
•BERT+LR: This model [51] uses BERT as the encoder to obtain a document representation and then uses the Logistic Regression as the classifier.
•BERT: Bidirectional encoder representation from transformers [52], which is a pre-trained language representation model.
Parameter settings
The performance of two-layer GCN is better than that of single-layer GCN, when the networks are stacked with multiple layers, the features between nodes are too smooth, resulting in over-fitting. Therefore, the number of GCN layers is set as 2 in this paper. If the sliding window size is too small, it cannot generate enough global collaborative information, while if it is too large, an edge may be added between nodes that are not closely connected. Therefore, the sliding window size is set to 20 in this paper.If DropOut is too small, it will easily cause over-fitting, while if it is too large, it will drop important features, resulting in underfitting. Therefore, in this paper sets the DropOut at 0.5. We randomly select 10% of the training set as the verification set. Train KDGCN for up to 200 epochs and stop when the loss of 10 consecutive epochs is not reduced.
Experimental results
We use the accuracy rate to evaluate the performance of the model. We run the proposed model 10 times and report mean ± standard deviation, we refer to the following methods [53, 54]. The results of the other nine baseline models come from different papers [44, 55]. The specific experimental results are shown in Table 5.
Test Accuracy on document classification task
Test Accuracy on document classification task
Table 5 shows the test accuracy of each model. Experimental results show that the proposed method outperforms overall best, which demonstrates the effectiveness of the proposed method in short text classification. The experimental results of CNN are obtained through training with randomly initialized word embedding. CNN can build continuous and short-distance semantic models well; however, because the pooling layer of a CNN will lose a lot of valuable information when processing context information and ignore the association between local and global words, its performance on the four datasets is relatively poor. LSTM and Bi-LSTM were training with pre-trained word embeddings. LSTM and Bi-LSTM models are improved RNN, which can solve the problem that RNN cannot address with long-distance dependencies and can alleviate the sparsity of short texts to a certain extent. However, there are still some deficiencies. The fastText model only reduces the training time significantly, but its accuracy is comparable to the deep learning model. The fastText trained with bigrams.
Graph-CNN-C operates convolutions over word embedding similarity graphs, and performs well on the MR dataset, which indicating that the model can maintain grammatical and semantic relationships between words by constructing word similarity graphs and provide additional information for text. The text graph constructed by Text-GCN can capture not only the relationship between documents and words but also the relationship between global and local words. The label information can be propagated to the entire graph through nodes, so its result is better than that of a deep learning model. However, it can neither delve deeply into the potential information of short text nor introduce external knowledge to solve the problem of sparse features of short text. SGC has better performance than Text-GCN on some datasets, we conjecture this performance boost is caused by SGC has fewer parameters than Text-GCN, therefore SGC suffers less from overfitting.
It can be seen that KDGCN and BERT are comparable in multiple datasets, but BERT performs very well in MR, because MR is a binary sentiment classification dataset. Context information is very important in the task of sentiment classification, and BERT takes good account of the context information of words when encoding text.
The proposed method extends the composition method of the existing text classification algorithm based on graph neural network, and introduces the semantic information hidden by the text itself and the concept information from the external Microsoft Concept Graph to expand the feature representation of the short text. As a result, the method proposed in this paper performs best on the whole, however, despite we introduce concept knowledge into the text graph construction process, but because of the current knowledge graph is still incomplete, some entities in the short text do not have corresponding concepts, resulting in a low coverage of concept knowledge. Therefore, KDGCN did not achieve the best results on all datasets, but compared with Text-GCN, the model proposed in this paper performs better.
It can be seen from the experimental results that the proposed KDGCN model uses the association relationship between concepts and words, the dependency relationship between distant words in sentences, the co-occurrence relationship between words, and the inclusion relationship between documents and words for composition, which can solve the problem of sparse features in short texts to a certain extent.
To verify the influence of features such as association relationship between words and concepts, long-distance word dependencies, word co-occurrence, and inclusion relationship between documents and words on the proposed model, we conducted ablation experiments regarding the four relationships using the four datasets, and the experimental results are shown in Table 6.
The results of ablation experiments
The results of ablation experiments
•WC: Simultaneously use the inclusion relationship between documents and words and word co-occurrence;
•WC + L: Simultaneously use long-distance word dependencies, word co-occurrence, and the inclusion relationship between documents and words;
•WC + C: Simultaneously use the association relationship between concepts and words, word co-occurrence, and the inclusion relationship between documents and words;
•WC + LC: Simultaneously use the association relationship between concepts and words, long-distance word dependencies, word co-occurrence, and the inclusion relationship between documents and words;
Table 6 illustrates that when only concept information is added, the datasets are improved to varying degrees relative to the baseline models, which indicates that the addition of external knowledge can alleviate the shortcomings of short text classification features sparsity to a certain extent. When long-distance word dependencies are only added, the performance of the MR dataset decreases because the text length in the dataset is generally short, with an average length is only 20.39. At this time, the effect of adding long-distance word dependencies is not obvious. For the R8 and R52 datasets with relatively long text lengths, a certain degree of improvement can be seen. On most of the datasets, the results are improved when concept information and long-distance word dependencies are added simultaneously compared to the models which only add one type of knowledge. As a result, the experimental results show that the proposed KDGCN model can capture richer semantic information by simultaneously using the relationship between concepts and words, the co-occurrence relationship between words, the containment relationship between documents and words, and the dependence relationship between distant words in sentences for composition.
In order to understand the importance of introducing concepts and long-distance dependency for text classification, we annotate the entity information in sentences, as shown in Fig. 3, and annotate words with long-distance dependency, as shown in Fig. 4. The highlighted words are closely related to label, which explains the effectiveness of the model proposed in this article for text classification tasks.
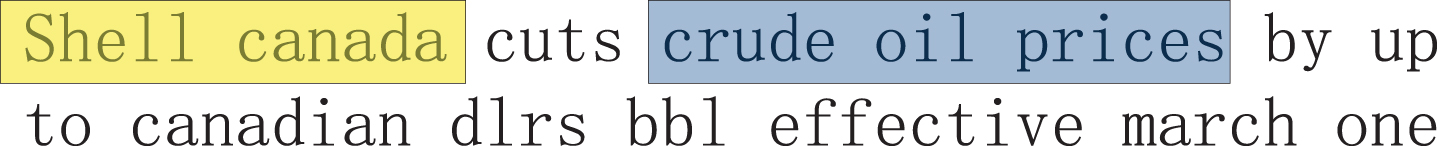
Concept visualisation in ohsumed.
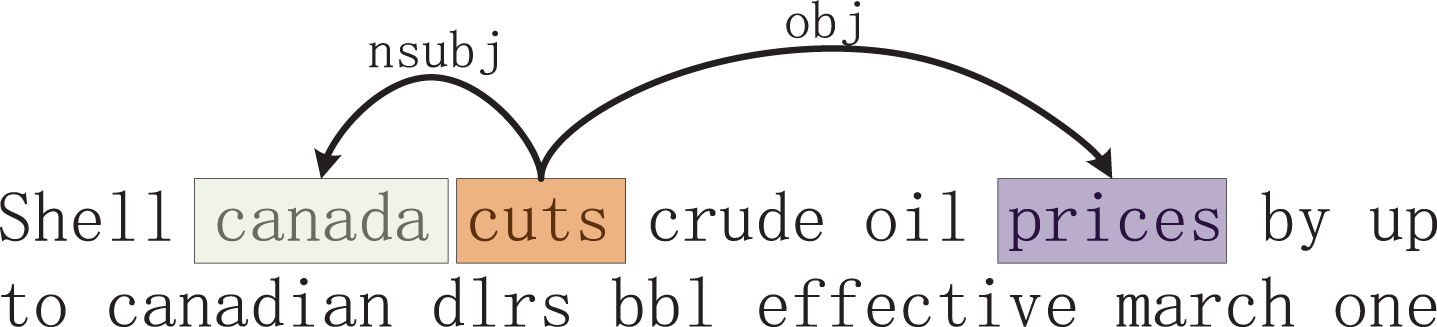
Long-distance dependency visualisation in hsumed.
To verify the influence of the number of GCN layers on experimental results, this study analyzes the influence of the number of GCN layers on the classification results of the four datasets on the premise that other parameters remain unchanged, and the trend changes are shown in Fig. 5. Figure 5 shows that F1 values show an increasing trend and then a decreasing trend on all four datasets. Because GCN contain the operation of aggregating the features of neighbor nodes, when the networks are stacked with multiple layers, the features between nodes are too smooth, resulting in over-fitting. Therefore, the best effect can be achieved when the number of stacked layers is 2.

Accuracy with different GCN layers. The horizontal axis indicates the size of the GCN layer and the ordinate indicate the accuracy on the datasets.
Figure 6 shows that the accuracy rate increases first and then decreases with the size of the sliding window. When the sliding window size is increased to 20, the accuracy rate reaches the maximum. This shows that a sliding window that is too small cannot generate sufficient global word co-occurrence information, whereas a sliding window that is too large may cause edges to be formed between nodes not closely related.
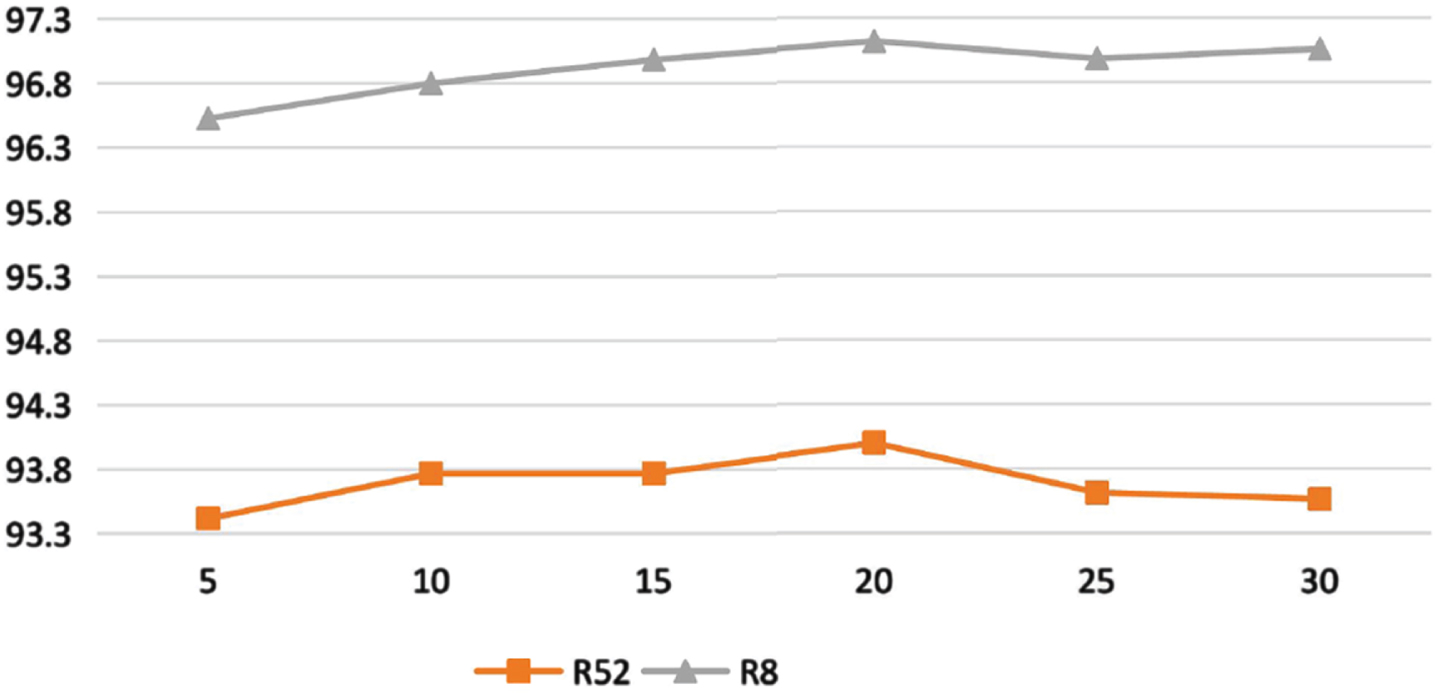
Accuracy with different sliding window sizes. The horizontal axis indicates the size of the sliding window and the ordinate indicate the accuracy on the datasets.
In this study, we propose a short text classification model based on GCN with concept and dependencies enhanced. The model introduces semantic concepts in a knowledge graph and long-distance word dependencies into the text composition process. The model simultaneously uses the relationship between words and concepts, long-distance word dependencies, word co-occurrence, and inclusion relationship between documents and words of an entire text corpus to build a single text graph, which solves the problem of sparse short text classification features to a certain extent. The experimental results show the effectiveness of the proposed method, but there are still some problems. For example, although concept knowledge is introduced into the text graph construction process, but because of the current knowledge graph is still not complete, some entities in the short text do not have corresponding concepts. Therefore, in the future we can consider introducing the attribute information of the entities into the text graph construction process.
Footnotes
Acknowledgments
This work is supported by the National Natural Science Foundation of China (No.62176145).
https://stanfordnlp.github.io/CoreNLP/
http://sobigdata.d4science.org/group/tagme/