
Abstract
Most existing classifiers are better at identifying majority classes instead of ignoring minority classes, which leads to classifier degradation. Therefore, it is a challenge for binary classification to imbalanced data, to address this, this paper proposes a novel twin-support vector machine method. The thought is that majority classes and minority classes are found by two support vector machines, respectively. The new kernel is derived to promote the learning ability of the two support vector machines. Results show that the proposed method wins over competing methods in classification performance and the ability to find minority classes. Those classifiers based-twin architectures have more advantages than those classifiers based-single architecture in classification ability. We demonstrate that the complexity of imbalanced data distribution has negative effects on classification results, whereas, the advanced classification results and the desired boundaries can be gained by optimizing the kernel.
Introduction
Data classification is an important links in the field of data mining. Currently, data classification has been successfully used in image recognition, medical diagnosis, digital recognition etc. Usually, classification includes binary classification and multi-classification. Although there are many mature methods and models in the field of classification research, those classification methods and those classifiers are better at classifying on balanced distributions or assume that the data is balanced distribution. Those classification methods and those classifiers may drop in classification performance once they suffer from an imbalanced data distribution.
Usually, the data is imbalanced distribution in applications, for example, the proportion of normal electricity consumption data is much larger than that of abnormal electricity consumption data in the electricity consumption data. Therefore, this type of datasets is often referred to as imbalanced datasets. Imbalanced datasets are composed of majority classes and minority classes. Since the number of minority classes is much smaller than that of majority classes [1], minority classes can hide in any subspace so that they are difficulty discovered [2, 3]. Most existing those classifiers are better at finding the majority class instead of ignoring the minority class, which results in classifier degradation. Furthermore, Class imbalance may cause that the minority class is masked by the majority class [4, 5], thereby difficulty finding suitable classification regions to distinguish minority classes from majority classes. Consequently, binary classification on imbalanced data is a tough task.
Some efforts have been presented to address the classification of imbalanced data, such as (i) resampling-based methods, which apply under-sampling techniques and oversampling techniques to balance classes. And (ii) cost-sensitive learning-based methods, which focus on the costs associated with misclassifying samples. And (iii) ensemble learning-based methods, which improve classification accuracies through combining several classifiers. Additional, deep network architectures-based methods are also used to handle the issue of imbalanced classification, due to the high learning capacity. However, these classification methods tend to favor majority classes in order to gain high classification score, clearly, the classification result obtained in this way is unfair.
The main contributions of this paper are summarized, as follows. A novel twin-support vector machines method is proposed for binary classification on imbalanced data, and the new kernel is derived. For imbalanced data, the complexity of data distribution has negative effects on classification results, however, through using optimizing kernels, those advanced classification results can be gained and those desired boundaries are learned.
The rest of this paper is organized as following. Section 2 summarizes the related work. Section 3 presents the proposed model, including the model implementation, the derivation of the kernel and the model training. Experiments are given in Section 4. Section 5 presents and discusses the results. Section 6 draws a conclusion and directs the future work.
Related work
For a binary classification task, classifiers pay more attention to the accuracy of the majority class and tend to classify unknown instances into the majority class [6]. Such classification operation can improve the accuracy of sample classification, but little attention is paid to minority class instances, or may ignore minority class instances. In fact, these operations are unreasonable to imbalanced data, since the finding of minority classes has greater valuable, for example, the identifying of cancer cells and normal cells in medical filed, generally, the number of cancer cells (the minority class) is is more concerned than that of normal cells (the majority class). Usually, classification methods of imbalanced data can be classified into sampling technique-based methods and machine learning-based methods [7]. Sampling technique-based methods include under-sampling techniques and oversampling techniques, where under-sampling techniques are to balance the minority class by reducing the number of majority class instances. The principle is to discard majority class instances with random manners so as to balance the number between the majority class and the minority class [8], however, random discarding may disrupt the distribution of the data. To reduce the classification loss caused by random discarding, the [9] used clustering method to extract features of the data, and then the classifier is trained by these extracted features, unfortunately, there is still the possibility to loss data features. The [10] selected majority class samples and minority class samples by calculating sample sensitivity. The [11] used the neighborhood density to estimate the number of classified samples. These methods in [10] and [11] compensate for the classification loss caused by random discarding, but they still do not focus on minority classes. Unlike under-sampling techniques, oversampling techniques are to balance class distributions by replicating minority class instances until they can reach the number of majority class instances. For example, these oversampling techniques in [12–15] achieve ideal classification results, but they can only learn on specific decision regions of the replicated data, which limit the learning ability of classifiers. Machine learning-based methods. A typical representation is SVM (Support Vector Machine). Indeed, SVM has an outstanding advantage, i.e., it is the only solution once the optimal solution is obtained. Unfortunately, SVM-based architectures suffer from the problem of being only able to learn on specific decision regions [16]. To address this, therefore, the improved models based on SVM architectures are proposed, e.g., TPMSVM [17], THSVM [18] and VTHSVM [18]. These improved models based on SVM architectures have achieved great success in classification ability, whereas, for nonlinear cases they have to reconstruct the optimization problem by considering the surface generated by the kernel [19], increasing calculation complexity, meanwhile, difficult maintaining the precision of solutions. In addition, neural network architectures-based methods are also commonly used for classification of imbalanced data, such as feedback neural network methods. It is easy to fall into a local optimal solution using the gradient descent method in neural networks, so that using neural network structures (in the case of without optimizing them) does not easily gain ideal classification results. By constructing the loss function (can be considered as an optimization), Lee [20] et al improves the classification ability to neural networks
The motivation of this paper is to implement binary classification for imbalanced data. Here, this paper proposes a novel twin-support vector machines method to achieve it. The thought of the method is to construct two support vector machines on imbalanced data, of which one finds majority classes and the other finds minority classes. Furthermore, the kernel is derived to enhance the learning ability of the two support vector machines.
Methodology
Preliminary
For a binary classification task, SVM gains the maximum classification margin by using hyperplanes. Given dataset D = {(x1, y1) , . . . , (x
i
, y
i
)},
Where b is bias and w is weight.
Where α
i
> 0 is the Lagrange multiplier. Equation (2) can be converted into a dual quadratic programming
Where φ () is a mapping function. κ (x
i
, x
j
) = φ (x
i
)
To describe the proposed method in detail, some definitions and lemmas are given in advance.
Model implementation
Using Equation (1) creates two support vector machines H(+) and H(-) to find majority classes and minority classes, respectively. The proposed model, namely TW-SVM, is given in Equations (5)
Equations (5) can be converted by introducing Lagrange multiplier α
i
> 0 and α
j
> 0. As follows
Where
Using Equation (3) converts Equations (9) into kernel function form, having that
The decision function of TW-SVM is given in Equation (12), where ||||2 is norm-2.
For an unknown point x, it is calculated using decision function F(x) in Equation (12). According to the calculated results of F(x), it can be determined whether an unknown point x should be classified to the majority class or the minority class. For instance, if point x is closer to support vector machine H(+) in Equation (10), point x is classified to the majority class. Similarly, if point x is closer to support vector machine H(-) in Equation (11), point x should be classified into the minority class.
Algorithm 1. Training of the model
The learning ability of TW-SVM depends on the kernel κ (,) in Equations (11), which is used to separate the majority class and the minority class. Here, the kernel κ (,) is derived according to Mercer theorem. (Please see Lemma 1 in Section 3.1). Mercer theorem has demonstrated that any semi-positive definite symmetric function can be used as a kernel function. Therefore, a positive definite kernel (please see Lemma 2 in Section 3.2) is considered through calculating the cumulative distribution function [25], as follows
Where γ1, γ2 are the non-negative kernel parameters.
In addition, the Matern52 kernel in [41] is also considered, which is a continuous positive definite kernel, as following
Where φ
k
, γ2 are kernel parameter and kernel radius, respectively. k1, k2 and k3 are a constant. The Matern52 kernel can allow the radius to be warping concave and non-decreasing so that more areas with small radii can be observed [25, 26]. This implies that those local regions containing minority classes can be better explored. Consequently, the kernel κ (,) of TW-SVM consists of κ
cdf
in Equation (13) and κMatern52 in Equation (14), as follows
κ cdf and κMatern52 are a positive definite kernel. According to a well-known closure property of p.d (please see Lemma 3 in Section 3.1), the derived kernel κ (,) is a positive definite kernel.
Algorithm 1 displays the training of TW-SVM. Inputting training set Train_set, the TW-SVM outputs the training accuracy TrainAcc(qmax) and the learned majority class labels {P+1, …, P+1} and minority class labels {N-1, …, N-1} once it is well trained. For each point x i in Train_set, it is calculated by using F (x i ) in Equation (12), and then according to the calculated result of F (x i ), i.e., R (x i , q), point x i is classified into the corresponding classes, illustrated in the procedure between Step 3 and Step 15. The process between Step 6 and Step 9 shows that if R (x i , q) is closer to H(+) in Equation (10), point x i is classified into majority classes and gains a majority class label {P+1}. Otherwise, point x i should be classified into minority classes and gains a minority class label {P+1}, illustrated in the procedure between Step 10 and Step 14. Thereafter, the training accuracy TrainAcc(q) is obtained in Step 16. Whole procedure between Step 1 and Step 17 shows that TW-SVM is iteratively trained until it convergences. Finally, TW-SVM sends out the maximum training accuracy and the learned class labels, illustrated in Step 18 and Step 19.
Experiments
Datasets
To test the proposed TW-SVM, two imbalanced datasets were synthesized, as shown in Table 1. For the two synthesized imbalanced datasets S1, S2, the imbalanced ratio (IR) of majority classes and minority classes is 5 : 1. For dataset S1, it contains 300 training points and 300 testing points. These points in majority classes and in minority classes were randomly generated using the normal distribution (N(0, 0.1)), (N(0, 0.5)), respectively, and the overlap of these two classes is less than 30%, illustrated in Fig. 1(a). As for dataset S2, it contains 350 training points and 350 testing points. These points in majority classes and in minority classes were generated by the mixture of Gaussian distribution, and the overlap of these two classes reaches about 90%, as shown in Fig. 1(b).
Synthetic datasets
Synthetic datasets
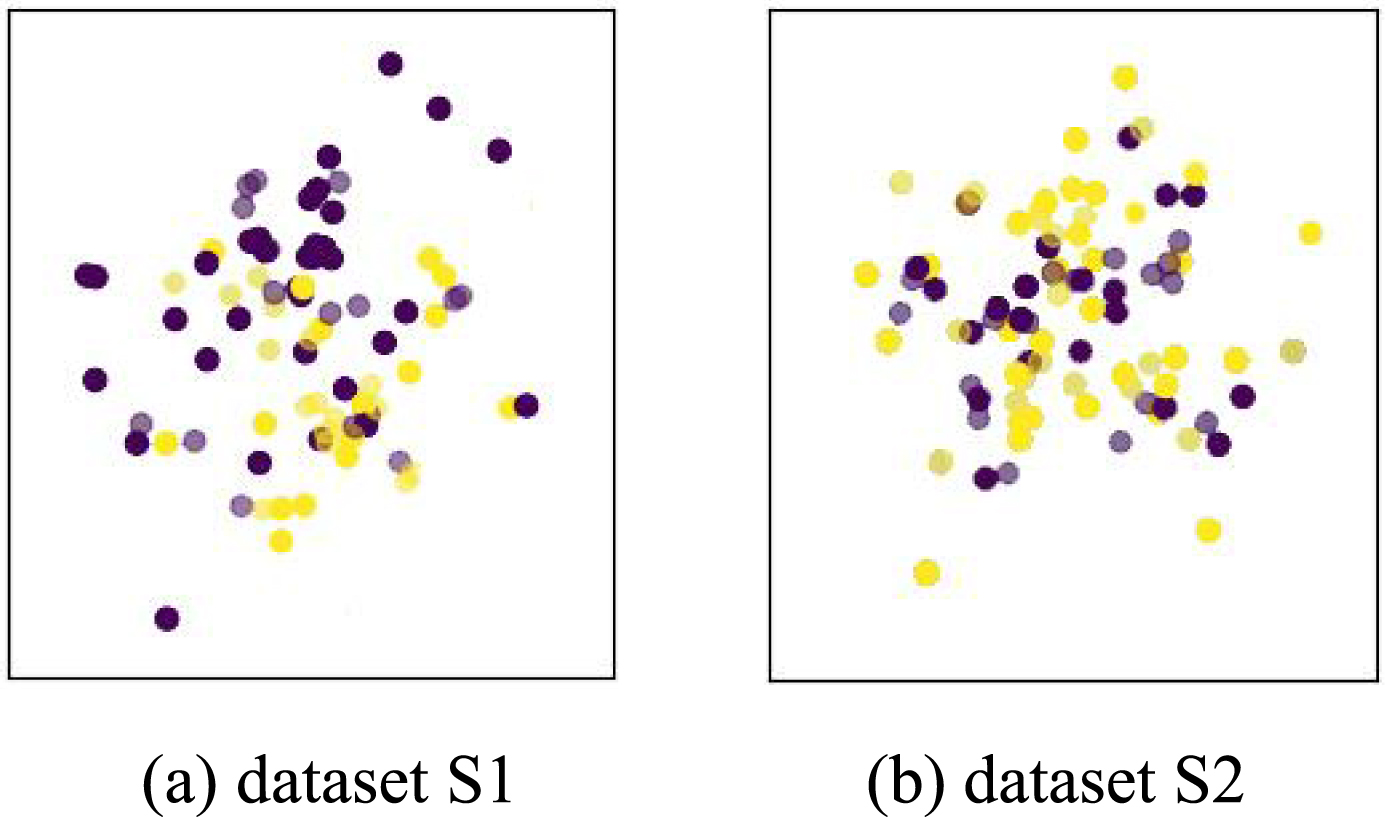
Synthetic datasets. Yellow circles are marked as majority class points. Purple circles are marked as minority class points.
To further test the model, eight UCI datasets used in classification tasks were selected from the perspective of different data dimensions and imbalanced ratio, and the detailed descriptions are given in Table 2.
UCI datasets
The proposed TW-SVM is a model based on SVM architectures, to have fairness, so the three models based on SVM architectures are used as comparisons, i.e., TPMSVM [19], THSVM [20] and VTHSVM [20], and the defaults parameters of competing models in the corresponding literature were used. The corresponding algorithms of the four models were implemented by using Python on Tensorflow framework in Linux system, and the experiments were run using the same setting.
In terms of assessment metrics, Accuracy is used as an evaluation metric for the classification ability of the four models, as follows
Where TP, TN, FP, FN are the number of true positive, false negative, false positive and false negative, respectively. F1-score is also used as an evaluation metric, as follows
To compare the ability to find minority classes for the four models, Sensitive metric is used, as follows
Results on the synthetic datasets
Results in Fig. 2 show that TW-SVM outperforms TPMSVM, THSVM and NHSVM in classification performance. On synthetic datasets S1 and S2, the classification accuracies of TW-SVM are 95.12% and 91.33%, respectively. It can be seen that TW-SVM has clear classification advantages on the two synthetic datasets. Moreover, TW-SVM also wins over the competitors on F1-score metric. While for Sensitive metric, results in Fig. 3 show that the ability of TW-SVM to find minority classes is better than that of the three competitors. This implies that TW-SVM is more adaptable to be suitable for binary classification on complex imbalanced datasets.
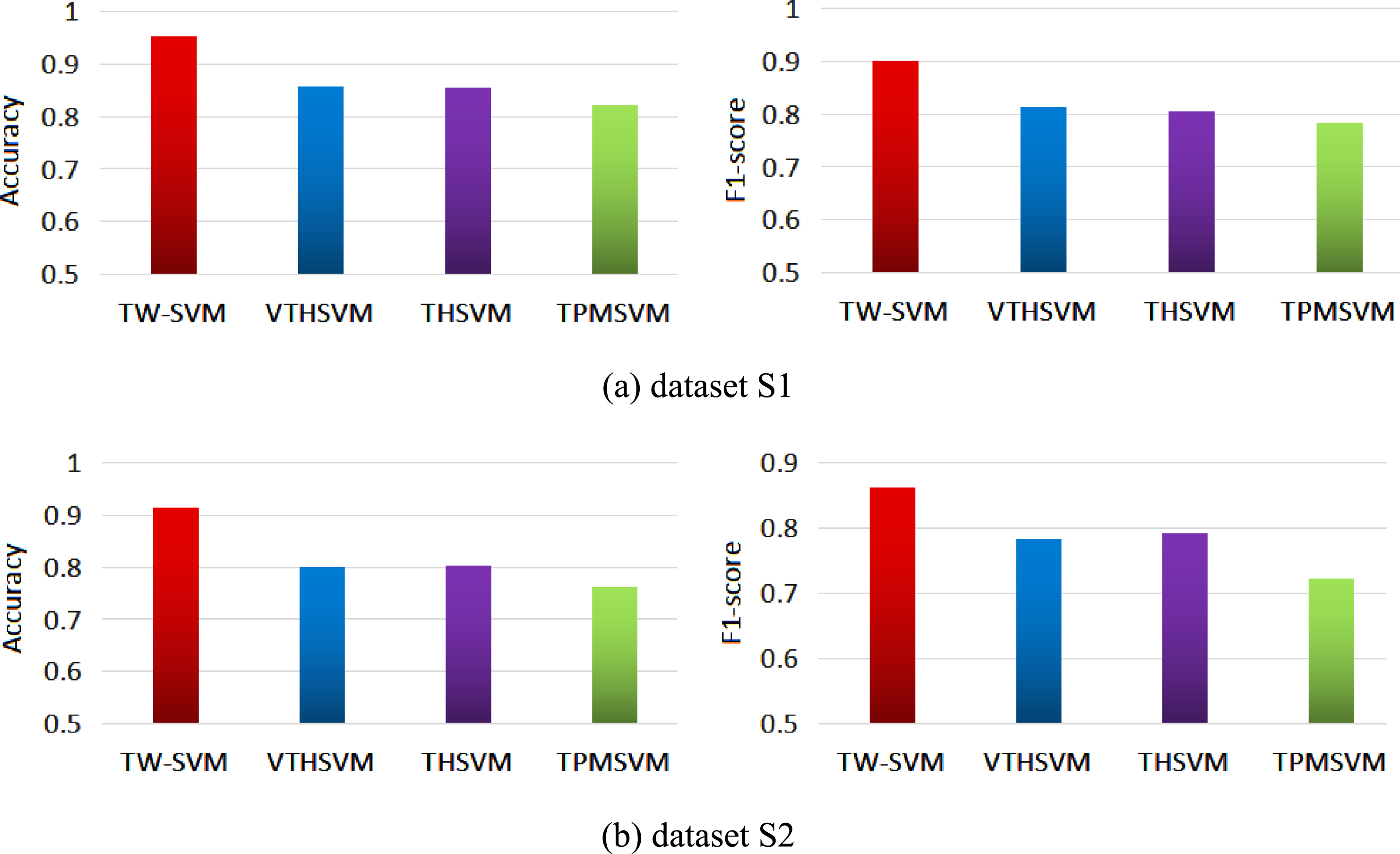
Classification performance. Using Accuracy and F1-socre metrics evaluate the four models.
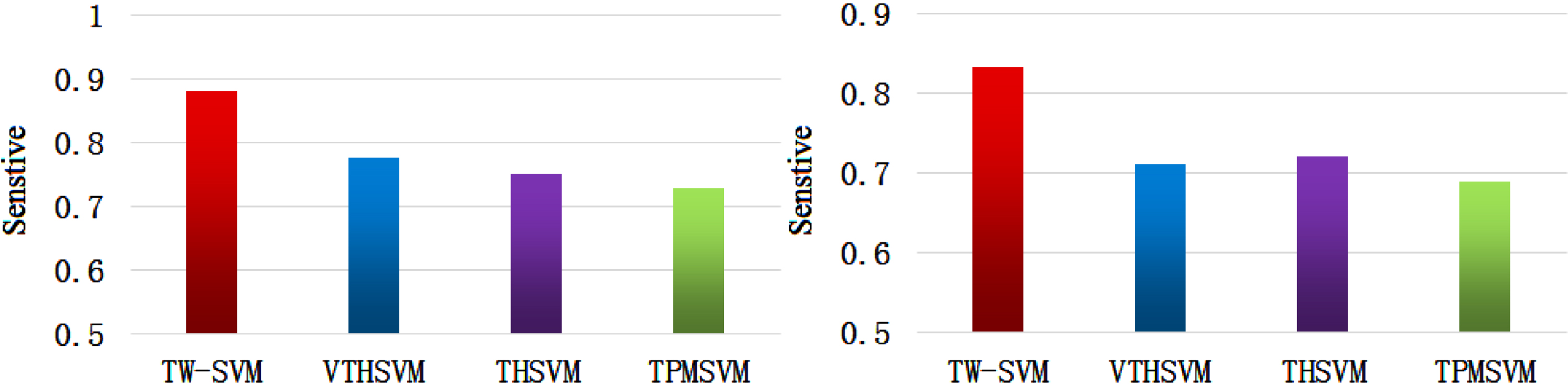
Comparisons of finding minority classes. Using Sensitive metric evaluates the four models.
Figure 4 visualized these classification results. On synthetic dataset S1 and S2, TW-SVM gains desired classification results, meanwhile, also learns advanced classification boundaries. Together, these results gained by TW-SVM on datasets S1 and S2 outperform these gotten by the three competing methods.
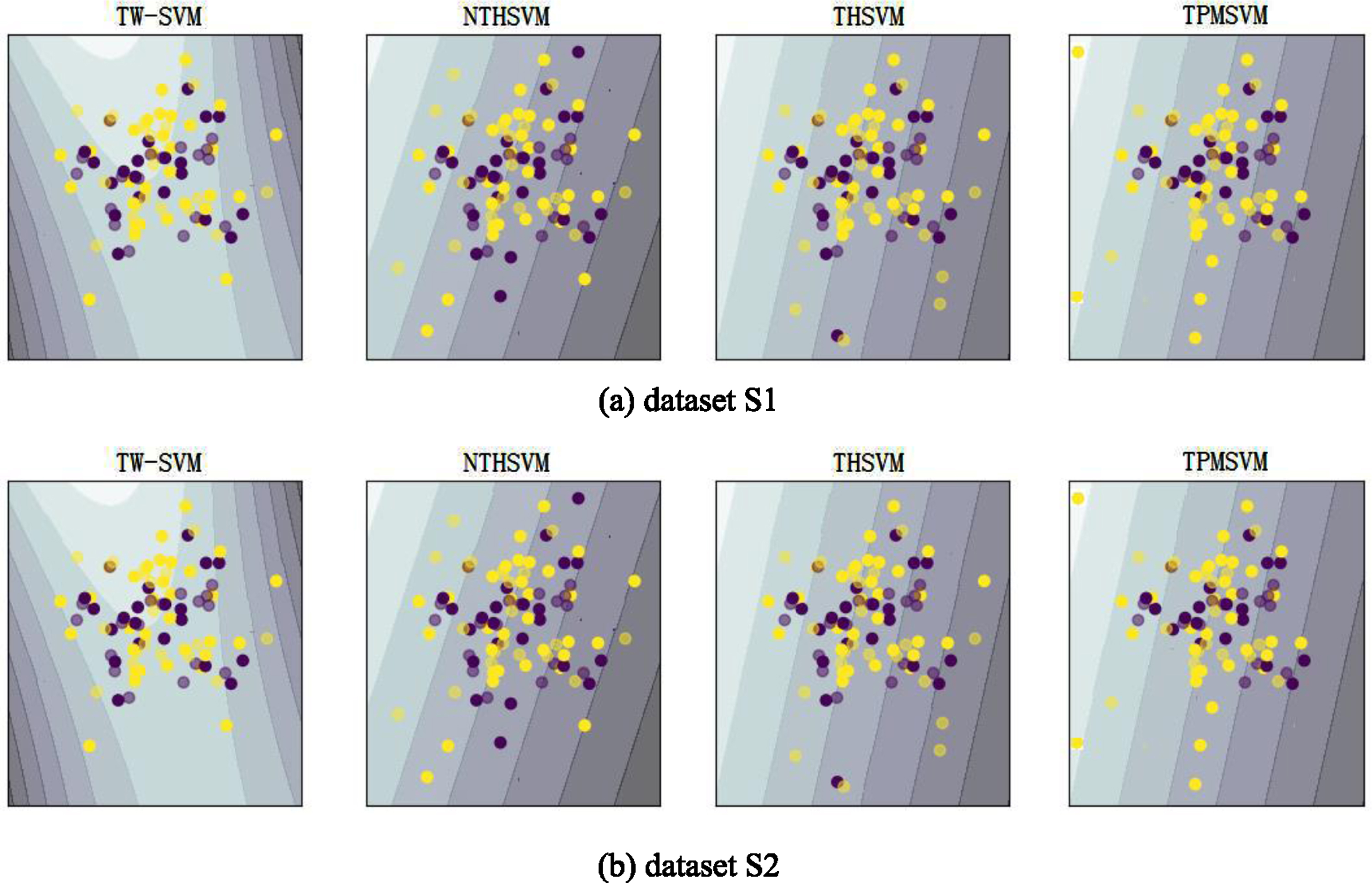
Visualization of classification results. Yellow circles are marked as majority class points. Purple circles are marked as minority class points. Black lines are the boundaries learned by the four models.
To eliminate the effects of randomness, we run 100 times on these eight real datasets, independently, the average is taken. Results in Table 3 show that TW-SVM gains advanced classification results on seven datasets, except for dataset Spect. Particularly, on highly imbalanced ratio dataset Energy (i.e., IR = 15 : 1), our TW-SVM has outstanding advantage over the three competitors. Certainly, on high-dimensional datasets Musk (dimension = 166) and Sonar (dimension = 66), our TW-SVM also wins over the three competitors. Unfortunately, on dataset Spect, the classification results obtained by the three competitors are better than these by TW-SVM, but the advantages are not significant. Overall, the classification ability of our TW-SVM is better than that of the competing TPMSVM, THSVM and NHSVM on imbalanced datasets.
Classification results on UCI datasets. The best results are highlighted using bold
Classification results on UCI datasets. The best results are highlighted using bold
Conclusion
This paper proposes twin-support vector machines for binary classification to imbalanced data. The principle is that by constructing two support vector machines H(+) and H(-), the SVM H(+) learns majority class points and is as far away as possible from minority class points. Similarly, the SVM H(-) also adopts this learning manner. To improve the ability to find minority classes, the kernel was derived for the two support vector machines. Results show that the proposed method is superior to the mainstream classification methods in terms of classification ability and finding minority classes for imbalanced datasets. Results also show that those classifiers-based twin architectures have more advantages than those classifiers-based single architecture. Although the complexity of imbalanced data distribution has negative effects on classification results, those advanced classification results can be gained and those desired boundaries are also learned through optimizing the kernel. In future work, we will look at exploring binary classification methods for imbalanced data while noise disturbs.
Footnotes
Acknowledgments
This work was supported by the Science and Technology Research Program of Chongqing Municipal Education Commission under Grant KJQN20190240.
Declarations
Competing interests
The authors have no conflicts of this article.
Contributions
Jingyi Li proposed the thought and wrote the original manuscript. Shiwei Chao designed and performed the experiments. Jingyi Li and Shiwei Chao analyzed the experimental results