
Abstract
This paper modifies the original Teaching-Learning-based Optimization (TLBO) algorithm to present a novel Group-Individual Multi-Mode Cooperative Teaching-Learning-based Optimization (CTLBO) algorithm. This algorithm introduces a new preparation phase before the teaching and learning phases and applies multiple teacher-learner cooperation strategies in teaching and learning processes. In the preparation phase, teacher-learner interaction and teacher self-learning mechanism are applied. In the teaching phase, class-teaching and performance-based group-teaching operators are applied. In the learning phase, neighbor learning, student self-learning and team-learning strategies are mixed together to form three operators. Experiments indicate that CTLBO has significant improvement in accuracy and convergence ability compared with original TLBO in solving large scale problems and outperforms other compared variants of TLBO in literature and other 9 meta-heuristic algorithms. A large-scale industrial engineering problem—warehouse materials inventory optimization problem is taken as application case, comparison results show that CTLBO can effectively solve the large-scale real problem with 1000 decision variables, while the accuracies of TLBO and other meta-heuristic algorithm are far lower than CLTBO, revealing that CTLBO can far outperform other algorithms. CTLBO is an excellent algorithm for solving large scale complex optimization issues.
Keywords
Introduction
Intelligent optimization algorithms are some special techniques for overcoming the shortcomings of traditional OR (operations research) methods, and usually are applied to solve large, complex engineering and science problems. It is reported that more than 200 types of intelligent algorithms have been developed [1] in the last three decades.
Teaching-Leaning-based Optimization (TLBO) algorithm is one kind of population-based human-inspired optimization algorithms, it imitates the human knowledge spreading by teaching and learning behaviors [2]. Since its emergence, TLBO has been attracting more and more attentions. Compared with other algorithms, TLBO seems to be a rising star amongst a number of metaheuristics with its excellent performance [3]. Due to its some advantages, such as simple concept, rapid convergence, TLBO has been widely applied in solving single and multi-objective optimization issues in the fields of operations research, manufacturing system, mechanical and electrical engineering, civil engineering, electronics and control engineering, pattern recognition and image processing [4]. However, TLBO also has some shortcomings and limitations. For example, the algorithm also exists premature phenomena when solving complex optimizations problems. it still possible to be trapped in the local convergence phenomena [19]. Meanwhile, TLBO in fact does not really consider the multiple learning mechanisms in real-world, for example self-learning, individual difference in learning ability, etc. [13]. Therefore, in order to overcome these disadvantages of TLBO, some authors also have improved this algorithm by improving its teaching and learning mechanisms or mixing it with other algorithms to form hybrid TLBO algorithms. In most improved versions of TLBO, the main efforts have been made to improve the intrinsic search mechanism. These efforts mainly lie in two aspects: improving the teaching mechanism and improving the learning mechanism.
In the original TLBO, leaners update knowledge based on the teacher’s and the mean knowledge of the class. Zou et al. [5] improved TLBO by revising the teaching phase operator of the individual position update using the principle of PSO. Similarly, Shukla et al. [6] improved TLBO in the teaching phase, each learner’s knowledge update comes from the teacher and his own old knowledge. Tong et al. [7] improved TLBO as SLTLBO algorithm, in the teaching phase, learners improve their knowledge by learning from the difference between the teacher and the worst learner, Zou et al. [8] also improved the TLBO by introducing differential evolution (DE) operator into the teaching phase to increase the diversity of the new population. Tsai [9] improved TLBO algorithm as CTLBO, in the teaching phase of this algorithm, eight teaching strategies are constructed, in which, learner’s knowledge update is related to the difference between the teacher and the mean, or the difference between selected two learners. Wu et al. [10] proposed an improved TLBO algorithm (DI-TLBO), in the teaching phase, depending on a random number, a leaner gains knowledge from the teacher or from a randomly selected learner. Since original TLBO algorithm has only one teacher, so some authors introduced multiple teachers to enhance the algorithm search ability. Rao et al. [11], Vitayasak and Pongcharoen [12] adopted a multi-teacher concept to modify the teaching phase in TLBO algorithm. Ma et al. [13], Zhang and Jin [14] introduced group teaching strategy in TLBO teaching phase.
In the improvement of learning phase, there are also some literatures. Chen et al. [15] improved the learning phase by two strategies, the first strategy is to introduce a probability to decide whether a student learns from others or learns from the teacher and neighbors, and the second strategy is to introduce self-learning. Zou et al. [16] improved the TLBO as a new two-level hierarchical multi-swarm cooperative TLBO. Ji et al. [17] improved TLBO as I-TLBO, using historical population experience in self-feedback phase to improve learners’ results. Shao et al. [18] also improved the learning phase by changing the learning mechanism from neighborhood learning to mixed mechanism combing neighborhood learning with learning from the teacher. Zou et al. [8] improved the learning phase of TLBO, in which, learner’ knowledge update comes from learning from the teacher, neighbors and self-learning. Shukla et al. [6] also improved TLBO in the learning phase, differing from original TLBO only has learning from one neighbor, the improved version randomly selects three neighbors, learner’s knowledge update comes from other two neighbors. Similarly, Tsai [9] improved TLBO in learning phase by introducing four search strategies, in which, a learner updates knowledge based on the mutation with his(her) neighborhood or the mutation of other two randomly selected learners. Wu et al. [10] also improved TLBO in the learning phase; depending on a random number, a leaner gains knowledge from one randomly selected learner or randomly selected two learners. Xu et al. [19] proposed an improved TLBO algorithm as DOLTLBO, which employs a dynamic opposite learning strategy to overcome the algorithm drawback—premature convergence phenomenon.
He et al. [20] improved TLBO as chaotic teaching-learning based optimization with Levy flight (CTLBO). Dong et al. [21] also improved TLBO by introducing a two phases kriging-assisted optimization framework to alternately conduct local and global search. Similarly, Dong et al. [22] proposed another surrogate-assisted teaching and learning based optimization algorithm. Mittal et al. [23] improved TLBO by introducing a learning enthusiasm factor to enhance the exploration and exploitation ability, meanwhile, opposition-based learning, local neighborhood search techniques are also applied in the algorithm. Cheng and Prayogo [24] proposed an improved TLBO algorithm—fuzzy adaptive teaching learning optimization (FATLBO). Vitayasak and Pongcharoen [12] proposed a modified TLBO in which single teacher and multiple teachers are employed. Some authors introduced self-learning mechanism learning phase, for example, Rao and Patel [25], Yang et al. [26], Chen et al. [15], Ge et al. [27], Zou et al. [16], Chen et al.[28].
Although many authors have taken different efforts to improve TLBO to enhance its optimization ability, shortcomings also exist. Firstly, all improved algorithms continue to adopt the basic two-phase mechanism—teaching and learning, all improvement are conducted to improve these two phases. Secondly, most of those improved algorithms are only applied in small and small-medium sized cases, seldom applied to large size real problems. In this paper, we develop a new improved version of TLBO–multi-mode group-individual cooperative teaching-learning-based optimization (CTLBO), which applies multiple models of cooperation strategies in teaching and learning processes. CTLBO has several innovative contributions. Firstly, this algorithm introduces a new phase–preparation phase, while original TLBO and other variants of TLBO have only two phases-teaching and learning phases. In the preparation phase, a cooperation strategy between the teacher and students is introduced, then, a teacher self-learning strategy is first put forward in this paper, while all other variants of TLBO only employ self-learning mechanism in the learning phase. Secondly, in the teaching phase, in addition to the application of cooperation strategy in the class-teaching operator, this paper proposes a new performance-based multi-group teaching strategy. Thirdly, in the learning phase, a new cooperation mechanism mixed with neighbor learning, team-learning and self-learning is proposed. Multiple experiments show that this new algorithm reveals a significant performance improvement compared with original TLBO and other improved versions of TLBO, also, it has best performance compared with other 9 meta-heuristic algorithms. At last, in order to validate the effectiveness and feasibility of the CTLBO algorithm in solving large scale complex problems, a real case of hub warehouse materials inventory optimization issue of one automobile assembly factory is applied. The result shows that significant advantage of CTLBO compared with other meta-heuristic algorithms.
The remainder of this paper is organized as follows: the next section introduces the basic principle and algorithm description of TLBO, Section 3 develops the CTLBO algorithm, Section 4 conducts the experiment of numerical examples. Section 5 is the applications of algorithms in real world problems. Section 6 is the conclusions of the paper.
The Original TLBO algorithm
TLBO algorithm imitates the teaching and learning process in a class, the best solution is taken as the teacher, and other solutions are considered as learners(students). Simply, TLBO is divided into two phases, the first phase is called teaching phase, the second phase is called learning phase.
Suppose the optimization problem is min F = f (X), a population of learners composed of the teacher and students in a class represent a group optimization agents, each agent searches one optimization result, F
i
. The number of the optimization agent is i = 1, . . . , NP, the decision dimension (number of variables) is j = 1, . . . , D (equal to the number of “subjects” of teaching in the class), the iteration number of the algorithm is t = 1, . . . , T
max
. The position of i
th
learner (includes the teacher and students) is presented as vector X
i
= [xi, 1, xi, 2, ⋯ , xi, D] ∘ then total leaners’ positions construct a matrix as:
The first search optimization phase of TLBO is teaching phase. In this phase, learners update their knowledge from the teacher and the mean state of the class is written as
After finishing the teaching phase, TLBO enters the second phase—learning phase. In this phase, learners update their knowledge by interacting with other learners, this process is finished by neighbor learning mechanism. A learner randomly selects a neighbor to learn and update his(her) knowledge (solution position). This procedure can be expressed as:
We improve the original TBLO by introducing multi-mode group-individual cooperation mechanism, enhancing the convergence and global search ability of the algorithm. This new algorithm is composed of three phases—preparation phase, teaching phase and learning phase.
Preparation phase
In this phase, we design two operators, the first one is called TLI (teacher-learner interaction) operator which initiates the cooperation between the teacher and students; the second one is called teacher self-learning (TSL) operator which reflects the teacher learns knowledge from her history experience.
(1) Teacher-learner interaction (TLI operator)
A TLI operator is a modified particle swarm algorithm module which has two equations, velocity and position equations. The velocity update equation is described as the following equation (5).
The second equation is called position update which is addition of the original position and the velocity, the position update is described as
(2) Teacher self-learning (TSL operator)
As best as we known, the original TLBO and all other variants of TLBO have not applied self-learning mechanism in teaching phase. In this paper, we employ a teacher self-learning mechanism to enhance the “knowledge” of the teacher. Our teacher self-learning mechanism includes three selective channels. The first channel is call incentive weighted summation, the second channel is called incentive weighted summation with Levy flight exploitation, and the third channel is called random incentive difference. During iteration, three selection switch doors are determined by a random number.
(i) Channel I: incentive weighted summation
In this channel, the self-learned knowledge of the teacher is updated from the historical knowledge of the whole class including students and himself. We introduce an incentive factor for the knowledge update; thus, the self-learned knowledge of the teacher is calculated as follows.
Finally, the self-learned knowledge update of the teacher by the channel I is set as follows.
Substitute Δ1 of equation (7) into (8), the final knowledge update equation is as follows:
(ii) Channel II: incentive weighted summation with Levy flight exploitation
In order to increase the exploitation ability of teacher self-learning process, we employ a Levy flight operator added to self-learning process of the teacher. Levy flight is one kind non-Gaussian stochastic walk process whose step length is a Levy flight distribution. The Levy flight distribution is as follows (Chegini et al. [29]):
In this paper, the computation method of Levy flight is set as Heidari et al. [39], i.e.,
Then, after adding a Levy flight process to the first channel update equation, the knowledge update equation of the second channel is as follows:
The ultimately self-learned knowledge of the teacher in the second channel is set as follows.
(iii) Channel III: incentive weighted difference
This channel is called incentive weighted difference operator, the basic idea is that the teacher self learns to increase her(his) knowledge from historical experience by adding new knowledge from the weighted difference of her(his) historical knowledge, so the update equation of the channel III is described as follows.
Combining above three scenarios, the knowledge update of the teacher self-learning operator is described as follows.
In this paper, by experiment, we set r1 = 0.5, r2 = 0.75. The principle of teacher self-learning process is described in Fig. 1.

Principle of teacher self-learning operator.
In this phase, there are two operators. The first operator is called modified class teaching operator (MCT), it is a modified teaching operator based on the original TLBO. The second operator is called performance-based group teaching operator (PBGT), this is one of our innovative operators in this algorithm.
(1) Modified class-teaching operator (MCT)
In the original TLBO algorithm, during teaching process, all learners accept the teacher’s knowledge in the class. in order to utilize the global and local information of population, this algorithm modifies the teaching operator of the original TLBO, proposes a new teaching operator as follows.
(2) Performance-based group teaching (PBGT operator)
The second operator of teaching phase is called performance-based group teaching, group teaching technique has been employed by other authors, for example, Zou et al. [16]. Unlike others, the grouping method of our group teaching technique is based on performance; this idea is shown in Fig. 2.
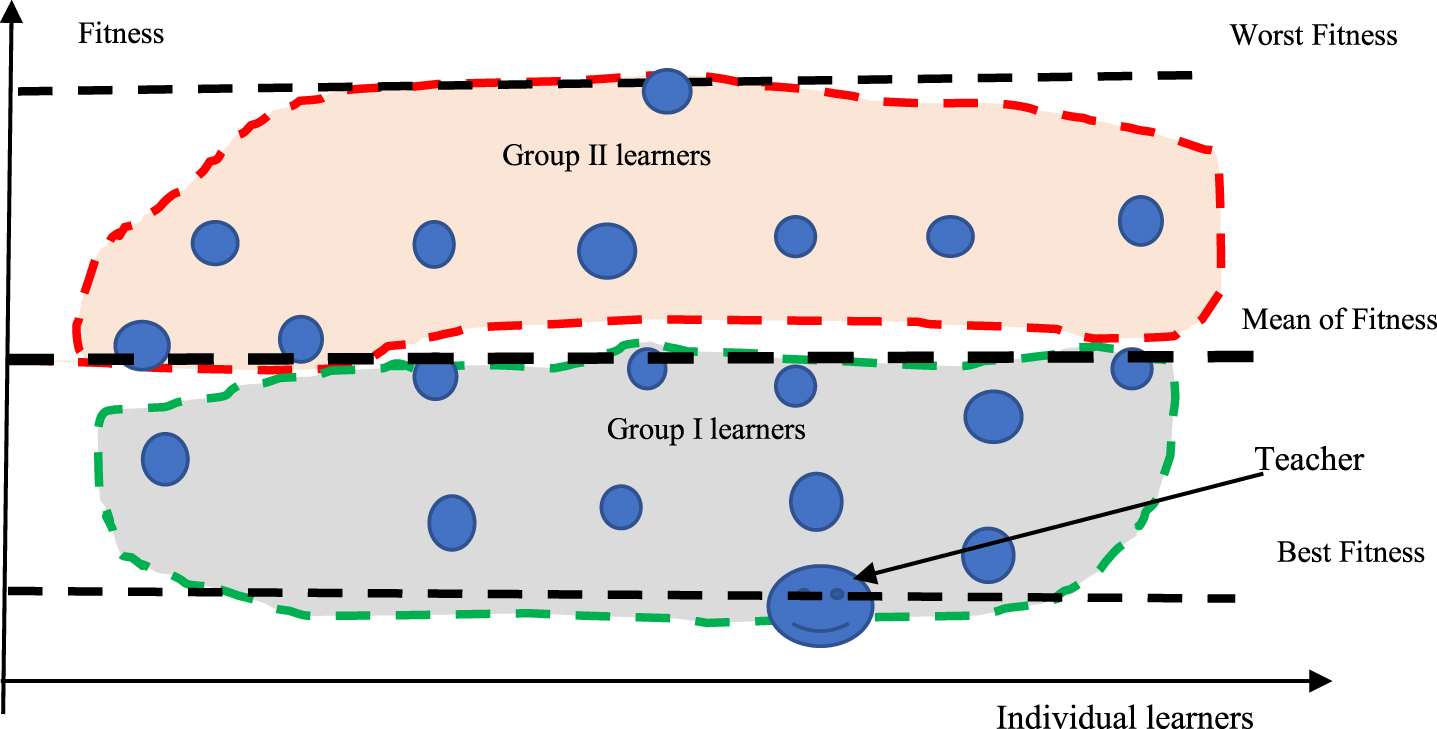
Grouping method based on performance (for min objective).
In Fig. 2, we divide the class students into two groups: G (I) = {i : |Fitness best ⩽ Fitness i < Fitness mean }, and G (II) = {i : |Fitness mean ⩽ Fitness i ⩽ Fitness worst }.
Based on the grouping results, the teaching operators are described as follows.
For learners of group I after teaching process, the basic idea of this operator is that their knowledge level should look up to the teacher, but for learners of group II, their knowledge level should look up to the mean level.
In this paper, we divide the learning phase into two steps, the first step is called multi-point neighbor learning (MPNL), this operator changes the two-neighbor learning strategy of the original TLBO to a three-neighbor learning strategy. The second step is a mixed self-learning operator (MSL) composed of two selective operators depending a random, i.e., mixed learning of self-learning and inter-learning (MLSI), mixed learning of self-learning and team learning (MLST).
(1) Multi-point neighbor learning operator (MPNL)
In this operator, the way of a learner gains knowledge has two choices depending on a random number. If the random number is larger than a given number, the learner gains knowledge from interaction with a random selected neighbor, otherwise, she(he) will gain knowledge from interaction with other two randomly selected neighbors.
Randomly select a neighbor of individual learner i, XPartner(i) ≠ i. Update the solution of individual i as follows.
Randomly select two neighbors
If
In addition to the multi-point learning mechanism, two self-learning operators are also developed in learning phase, i.e., MLSI (mixed learning of self-learning with inter-learning) and MLSI (mixed learning of self-learning with team-learning).
First: calculate the mean solution of learner i during the last three iterations before current iteration t using the following equation:
Above self-learning operators are executed when the iteration is larger than 3, i.e. t > 3. The pseudo code of CTLBO algorithm is described in the followings.
In order to illustrate the effectiveness of CTLBO algorithm, two sets of experiments are conducted. The first set of experiments validate the improvement effect of CTLBO by comparing with the original version of TLBO. The second set of experiments illustrate the advantage of CTLBO by comparing it with other 9 state-of-the-art algorithms in solving 30 general benchmark functions.
During experiments in this paper, all algorithms are coded in MATLAB and tested in Windows 10 on a PC with Core (TM) i7-7500U CPU 2.70 GHz, 8GB RAM.
Improvement effect validation of CTLBO
In this section, we conduct four experiments to illustrate the advantage of CTLBO. Experiment A is to compare CTLBO with original TLBO, the other three experiments–B, C, and D, are to compare CTLBO with other versions of improved TLBO reported in literature.
Experiment A–comparison with original TLBO
(1) Benchmark functions
In this section, 15 benchmark functions are selected as comparison base. Those functions are very representative and most of them have been widely tested in other research literature, which have generalized comparison value for algorithm research. Those 15 functions are divided into two groups: (1) 6 unimodal functions: Dixon-price, Quartic, Rosenbrock, Sphere, Sum-squares, Zakharov, and (2) 9 multimodal functions: Ackley, Alpine, Exponential, Generalized-Penalized function 1 (Generalized), Griewank, Michalewics, Rastrigin, Schwefel, and Shaffer7. The detail function characteristics: function expressions, solution ranges, optimal solutions are listed in Appendix A. In order to compare the algorithm stability and effectiveness in solving different scale problems, we conduct experiments with different dimensions for five scales: Dim = 100, 300, 1000, 3000, 5000 for all functions. The algorithm parameters for TLBO and CTLBO are set as: the population size = 50, the maximal iteration = 500. For all functions, the two algorithms run 30 times.
(2) Results and analysis
We compare all functions with “mean”, “standard deviation (STD)” for each function and dimension. Results are listed as Table 1. From the results of Table 1, CTLBO algorithm can obtain significant improvement in all benchmark functions.
Experiment A-Comparison of CTLBO with TLBO on high dimensional general functions (population size = 50, iteration 500)
Experiment A-Comparison of CTLBO with TLBO on high dimensional general functions (population size = 50, iteration 500)
For the accuracy (best solutions and average solutions), CTLBO are far better than TLBO on all 15 benchmark functions. Based on the results of Table 1, we find for CTLBO, there are 8 functions have 100% (percent rate 53% of all functions) to obtain 100% optimal solution for all dimensions, but TLBO has only one function (6%) can 100% obtain optimal for all dimension. For the stability, except for three functions: Dixon-price, Michalewics and Schwefel, all other 13 functions, CLTBO can outperform TLBO. Based on the results of Table 1, we can summarize the following conclusion: CTLBO can obtain improvement effect for all benchmark functions than TLBO on best and average solutions.
On the other hand, from the comparison of different dimensional functions, Fig. 3 shows the comparison results of selected functions. It can be seen that for different functions, with the increase of dimension, the accuracy of CTLBO can remain relative stable, but TLBO accuracy deteriorates fast with the increase of dimension. Therefore, we can summarize that for large scale optimization problems, with the increase of dimensions, for most benchmark functions, accuracies of TLBO will fast deteriorate, while CTLBO can remain high accuracies for all high dimensional functions. This reveals that CTLBO can more effectively solve large scale problems than TLBO.

Fitnesses of CTLBO vs TLBO for selected functions on different dimensions.
Experiment B–comparison of CTLBO with other variants of TLBO
Experiment B–comparison of CTLBO with other variants of TLBO
Note: The algorithm parameters of CTLBO are set as Zuo et al. [8]), population size = 50, FEs = 300000. D = 30dimensions.
In this experiment, the average ranks for all compared algorithms are: CTLBO = 1, DRLTLBO = 1.7, I-TLBO=3, NSTLBO = 2.5, ETLBO = 2.7, TLBO =2.6. according to ranks, the sequence of comparison advantages of these algorithms is: CTLBO (1) ≻ DRLTLBO (1.7) ≻ NSLTLBO (2.5) ≻ TLBO (2.6) ≻ ETLBO (2.7). Furthermore, from this experiment, we know the success rate of 100% obtaining optimal solution for CTLBO is 80%. NSTLBO is 50%, DRTLBO, TBLO, ETLBO are 40%, I-TLBO is 20%
Experiment C–comparison of CTLBO with other variants of TLBO
Note: The algorithm parameters of CTLBO are set as Xu et al. [19]. Population size = 100, FES = 300, 000. D = 30dimension.
From this experiment, the total average ranks: CTLBO = 1, DOLTLBO = 2.18, OTLBO = 3, MTLBO = 5.55, ETLBO = 5.18, SLTLBO = 4.09. According to order of ranks, the sequence of comparison advantage is:
Furthermore, from this experiment, we know the success rate of 100% obtaining optimal solution for CTLBO is 72%.; all other algorithms are 0%.
Experiment D–comparison of CTLBO with other variants of TLBO
Note: The algorithm parameters of CTLBO are set as Wu et al. [10]. Population size = 30, FES = 300, 000. D = 30dimension.
From this experiment, the total average ranks: CTLBO = 1.22, DI-TLBO=1.7, I-TLBO=2.3, ITLBO = 2.67, LETLBO = 2.22. according to order of ranks, the sequence of comparison advantage is:
Furthermore, from this experiment, we know the success rate of 100% obtaining optimal solution for CTLBO is 67%. LETLBO is 56%, I-TLBO and DI-TLBO are 44%, ITLBO is 33%.
Based on results of Experiment B, C, and D, we can see that CTLBO can have outstanding performance compared with other improved versions of TLBO algorithm in accuracy and stability.
In order to generalize our conclusion, we extend to compare CTLBO with other state-of-the-art algorithms in solving more general functions to further verify the effectiveness of our CTLBO algorithm.
Compared algorithms and benchmark functions
(1) compared algorithms
Since there are many nature-inspired algorithms have been developed during last decades, also new algorithms will emerge in future, so we cannot compare with too many algorithms. As nature inspired optimization algorithms are grouped into four types [30, 31]: (i) evolutionary algorithms, (ii) physics-based algorithms, (iii) swarm-based algorithms, and (iv) human-based algorithms, so we will select some typical algorithms from those four types of algorithms to make comparison. After analysis, finally 8 state-of-the-art algorithms are taken as compared algorithms, which represent different progression of meta-heuristic algorithms from 1990-2020, they are described in Appendix B. Since swarm-based algorithms are most fast developed and most widely applied algorithms, which account for the majority of total nature-inspired algorithms [31, 32]. Other three types of algorithms, relatively speaking, are not so widely applied, so we only select one algorithm respectively for them respectively.
(2) Benchmark functions
Referring to literature, we decide to adopt 30 test functions for our test, this can cover most of the literature test functions, which is listed in Appendix A. Those are standard comparison functions and most of them are widely adopted by other researchers in algorithm research.
Results and analysis
Al algorithms are run for 30 time for each function, the population size = 50, maximal iteration times = 500, these two parameters are the same for all algorithms. Other algorithm parameters for each algorithm are set as the algorithm original parameters by algorithm developers which are shown in Appendix B. The results are listed as Table 5. From the results of Table 6, based on the mean solution rank, the overall rank of our CTLBO is at No.1. Meanwhile, among all 30 functions, there are 19 functions, CTLBO can accurately find the optimal solutions, accounting for 63%. Other algorithms, the best one is HHO, by which only 6 functions can be found optimal solutions, accounting for 20%. Based on this result, we can see that CTLBO has very high accuracy compared with other 9 benchmark algorithms, it shows powerful exploration and exploitation ability, verifying the effectiveness of our improvement strategies.
Results of general test functions for compared algorithms.
Results of general test functions for compared algorithms.
Wilcoxon signed-rank test for comparing CTLBO with other compared algorithms
+:CTLBO superior to the compared algorithm, -:CTLBO inferior to the compared algorithm,=:CTLBO with no significant difference with the compared algorithm, w: number of “+”, l: number of “ –”, t:number of “=”.
Algorithm convergence ability reflects the efficiency of an algorithm, if an algorithm has higher convergence ability, then it means that this algorithm can faster find the best solution at shorter time. In this experiment, we select 8 functions from the 30 functions to show the convergence curves of all 10 algorithms. The results show that, except for the function F20 (Schewefel), for all the 8 functions, CTLBO has the fastest convergence speed than all the other algorithms. The results are shown in Fig. 4.

Convergence curves of selected functions for compared algorithms.
From the results of Fig. 4, we can see that, compared with all other 8 algorithms, for almost all functions, CTLBO is the highest efficient algorithm with highest convergence speed, it can fast converge to find best solutions.
From the Table 5, it is obvious, that standard deviations (STD value) of CTLBO for all functions are lowest, except for three functions (Function 5, 12, and 20), the overall rank is No.1.
Wilcoxon’s Signed-rank test analysis
In above analysis, we have based on the results of Table 5 intuitively obtained the advantage of CTLBO comparing it with other algorithms, in order to prove that the results are statistically significant, a non-parametric Wilcoxon’s signed-rank test usually is needed [14, 33]. Table 6 presents the Wilcoxon signed-rank test results with significant level α=0.05. In Table 3, the “H” is marked as “1”, which means that there is significant difference between CTLBO and the compared algorithm; “H” is marked as “0”, which indicates that there is no significant difference between CTLBO and the compared algorithm. “S” is marked as “+”, which implies that the CTLBO is superior to the compared algorithm. “S” is marked “=”, which means that CTLBO has the same performance with the compared algorithm. The last column of the table under heading “w/l/t” represents the win, lose, and tie counts of the CTLBO over the compared algorithms.
From Table 6, we can see that, CTLBO can surpass ABC, Bat, GA, GSA, PSO on all 30 benchmark functions. CTLBO outperforms CHOA on all functions except F24. For F24, CHOA can obtain 29 times optimal solutions in 30 runs (29 : 1), CTLBO can obtain 100% optimal solutions (30 : 0), so statistically, there is no significant difference on this function. The comparison result of CTLBO with WOA is 25/0/5, means that CLTBO surpass WOA on 25 of 30 functions, and there are 5 functions has no significant difference (i.e., F9, F16, F20, F24, F29). For the function F24 and F29, both WOA and CTLBO can obtain 100% optimal solutions (all equal 0). For Function F16, WOA obtains 29 of 30 optimal solutions (29 : 1), CTLBO obtains 100% optimal solutions (30 : 0). For function F9, WOA obtains 26 of 30 optimal solutions (26 : 0), CTLBO obtains 100% optimal solutions (30 : 0). The comparison result of CTLBO with TLBO is 28/0/2, means that CTLBO surpasses TLBO on 28 functions, and there is no significant difference on 2 functions (F9 and F24). For F9 and F24, both CTLBO and TLBO can obtain 100% optimal solutions. The comparison result of CTLBO with HHO is 22/1/7, means that CTLBO surpasses HHO on 22 functions, worse than HHO on 1 function (F20), and there is no significant difference on 7 functions (F1, F7, F9, F10, F16, F24, F29). Among these 7 functions, there are 6 functions (F1, F7, F9, F16, F24, F29), both CTLBO and HHO can obtain 100% optimal solutions.
Application
This is a real case of materials inventory optimization issue of an automobile assembly factory of one automobile company. In order to reduce logistics cost, the assembly factory outsources all her logistics business including materials inbound and product outbound logistics to a TPL (Third-Party Logistics) company. The logistics network of this company is shown in Fig. 5.

Logistics network of the automobile assembly factory.
The TPL company applies JIT (Just-In-Time) and hub supply mechanism to drive the materials supply chain from suppliers, all suppliers transport their materials according to the production planning of the car assembly factory and deliver materials to the hub warehouse near the assembly factory. Since the variety number of the materials of the car manufacturing is very big, the supply chain is very complex and long, materials are delivered every day from several hundreds of suppliers from oversea and domestic regions through different transportation modes, e.g., airplanes, trains, ships, and trucks. How to control and reduce the materials inventory cost of the hub warehouse becomes the big problem faced by the TPL company recently. Therefore, in this paper, we formulate the optimization issue of the ordering and delivery of materials of the hub warehouse. The scale of the model is very big since the decision variables can be from several hundreds to several thousands, depending on the number of materials, in this paper, we apply our CTLBO algorithm to solve the problem, and validate its effectiveness and advantage compared with TLBO and other algorithms.
Assuming each material is supplied by one supplier, the order quantity of material i is Q
i
, the demand of material i is D
i
, holding cost and stockout cost of per unit of material i is H
i
and CS
i
, The lead time of material i is L
i
, it is assumed that the demand of each material is 1 : 1 relationship with the product, that is producing one car needs one material i. Since the product demand is random, so the demand of material i is also random. We assume the demand of each type of cars follows a normal distribution, so each material’s demand is also assumed as normal distribution. Based on this assumption, the safety stock of material i is set as:
When knowing the service level, then, z i = F-1 (SL i ) , F-1 is the reverse function of the normal distribution.
The amount of stockout of material i during one replenishment cycle time can be calculated as [35]:
In order to reduce inventory cost, the manufacturer implements a JIT production strategy, requiring suppliers reduce the variance of lead time, as much as possible on time to deliver materials to the manufacturer’s factory. The manufacturer gives an on-time delivery time for material i as L oi , an upper limit and a lower limit of the delivery time as [L Li , Lu i ] . According to the JIT delivery requirement, if the delivery time of the supplier of material i deviates from the L oi , the manufacturer will penalize the supplier. In this paper, we propose a computation method for estimating the penalty cost of non-on time delivery. We assume the penalty cost of being delay or earlier to the delivery time is a convex function of lead time L i which is shown in Fig. 6.

Penalty cost pf delivery function curve.
The penalty cost of delivery can be formulated as a two-power function of delivery time, i.e.,
In Equation (38) the first item of the first brace is the ordering cost where C
oi
is the ordering cost of each time; the second item of the first brace is the sum of holding cost of cycle inventory Q
i
/2 and safety inventory SS
i
, the second item of Equation (38) is the penalty cost of delivery. The third item of Equation (38) is the stockout cost. Considering the warehouse has capacity constraint, Cap, and the service level constraints of inventory control, the inventory service level of material i is SL
i
. then the optimization model is formulated as follows.
The decision variables are order quantity Q i and delivery lead time L i for material i.
Since the complexity of the model, we cannot prove the optimality of the model, but we can numerically illustrate the objective function is a convex function of order quantity Q and lead time L, meaning that the problem has optimization solution. Using the data given in the computation example of Table 7, we show the 3-dimension diagram of total cost in Fig. 7. It shows the objective function is convex function of the order quantity Q and lead time L.
Parameters data for case I

3D diagram of objective function with stockout cost.
Although the objective function has optimal solution, solving this problem is a tough problem. This is a multiple constraints complex nonlinear programming problem. Since the objective function (39) contains the square root function and two-power function of L i and the constraint (40) contains a normal distribution function of decision variable Q i , it is impossible to solve it and obtain closed-form solution. When there are many materials, for example in this company, there are several hundreds of materials, meaning there are several hundreds, even more than one thousand decision variables, Therefore, it cannot be solved using traditional nonlinear programming method.
We first test the model applying small scale scenario with 20 materials, which has 40 decision variables. In this case, we assume the model parameters as Table 7.
In this case, we assume the parameters as: the number of materials n = 500, that is, there are 500 suppliers. Parameters of the model are generated randomly. The demand of each material is D
i
∈ [0, 5000]unit/month, standard deviation is σ
i
∈ [300, 700] unit/month, stockout cost CS
i
∈ [2, 5] $ /unit, holding cost
In order to evaluate the effectiveness and advantage of CTLBO, we test the model with two scenarios, i.e., small scale case I and large-scale case II, applying CTLBO and other compared algorithms: ABC, Bat, CHOA, GA, GSA, PSO, WOA, TLBO. The results are listed in Table 8. The population size of each algorithm is 50, iteration times is 500, each algorithm run 10 times.
Comparison of algorithm application in the case
From the Table 8, we know that for both the small- and large-scale cases, CTLBO can obtain the best performance in best solutions, means and worst solutions; CTLBO is far better than other compared algorithms; furthermore, it can be seen that ABC, Bat, GA, GSA, PSO almost are ineffective for solving this problem, since their solutions are far away from the results of CTLBO, the total costs of these algorithms are too high. Among other compared algorithms, HHO can be seen as effective algorithm, its result is next to the CTLBO. Figure 10 is the diagram of the means of objective function values (total costs of the hub warehouse) obtain by different algorithms. From Table 8, it is seen that TLBO is effective in solving small scale problem, but for large scale problem, its accuracy is far lower than CTLBO.
Figure 8 are the convergence curves of different algorithms. From Fig. 8, it is clear that for both the small- and large-scale cases, the convergence speeds of CTLBO is the fastest, then HHO is the second while TLBO is the third. It is also shown that, for all other algorithms, HHO is powerful algorithm following CTLBO and TLBO and with higher convergence speed than other algorithms for both small and large scales’ problems. CHOA has good performance in small scale scenario, but has worst performance in large scale scenario.

Convergence curves for the application example (Case II).
In this paper, we propose a new improved version of TLOB, i.e., CTBLO. This new algorithm combines multiple group-individual cooperative teaching and learning strategies. The CTLBO includes three phases: the first phase is called preparation phase, which a new phase proposed by this paper, it includes two operators—teacher self-learning and teacher-learner interaction. In the teaching phase, two operators are applied, the first operator is a modified class-teaching operator, in which, a student updates his(her) knowledge based on three teaching results: class-teaching (TCT), individual-teaching (TIT), and classmate teaching assisting (CTA). The second operator of the teaching phase is called performance-based group teaching operator (PBGT). This is an innovative group teaching method proposed by this paper, it divides the class into two groups—the first group consists of students whose performances are over the mean level of the class, the second group consists of students whose performances are under the mean performance of the class. The knowledge update mechanisms of these two group students are different. The third phase is learning phase, which includes two step and three operators, the first step is a neighbor-learning operator, the second step is composed of two mixed self-learning operators, i.e., the operator of mixed learning of self-learning with inter-learning and the operator of mixed learning of self-learning with team-learning. The test experiment of comparing with original TLBO algorithm shows that CTLBO has notable improvement effect in solving all kinds of scales problems, from small to large and super large (from 30 dimensions to 5000 dimensions). The test experiment of comparing with other variants of TLBO show that CTLBO has significant advantage which can obtain high accuracy than other variants of TLBO. The test experiment with other 8 typical meta-heuristic algorithms in solving 30 general functions shows that CTLBO has significant advantage than other meta-algorithms, it can obtain highest performance for mean solutions, convergence speed and stability. In order to validate the effectiveness and feasibility of CTLBO in solving large scale complex industrial engineering optimization problems, we take the warehouse materials inventory optimization issue of an automobile assembly factory as an application case, compare CTLBO with other meta-heuristic algorithms. This is first application in solving large scale constrained industrial engineering problems in literature. The result shows the significant advantage of CTLBO in solving large scale constrained optimization problems.
Based on this paper, several open directions can be followed in future. First, further optimize the configuration structure of the operators of CTLBO to form more other variants. Second, improve the computation method of the operators of CTLBO to increase the accuracy of the algorithm. Third, further apply CTLBO to solve other complex real problems, such as mixed integer programming with more constraints and multi-objective optimization problems.
Footnotes
Acknowledgement
This paper is founded by the National Natural Science Foundation of China (71772191).
Appendix A
Table A Benchmark functions—general test functions
| Name | Function expression | Type | Solution space | Optimal solution |
| Ackey | Multi-modal | [-32, 32] | F1*(0, 0 ... , 0)=0 | |
| Alpine | Multi-modal | [-10, 10] | F2*(0, 0 ... , 0)=0 | |
| Bent Cigar | Unimodal | [-100, 100] | F3*(0, 0 ... , 0)=0 | |
| Csendes | , | Multi-modal | [-600, 600] | F4*(0, 0 ... , 0)=0 |
| Dixon-price | Unimodal | [-10, 10] | ||
| Easom | multi-modal | [-100, 100] | F6*(π, …, π)=-1 | |
| Exponential | Multi-modal | [-600, 600] | F7*(0, 0..., 0)=-1 | |
| Generalized penalized function No.1 | Where: a = 10, k = 100, m = 4 | Multi-modal | [-50, 50] | F8*(-1, -1 ... . -1)=0 |
| Griewank | Multi-modal | [-600, 600] | F9*(0, 0 ... , 0)=0 | |
| HappyCat | Multi-modal | [-100, 100] | F10*(0, 0 ... , 0)=0 | |
| Levy | Where: | Multi-modal | [-10, 10] | F11*(1, 1 ... , 1)=0 |
| Michalewics | Multi-modal | [0, π] | d=30F12*=-29.7 | |
| Pathological | Multi-modal | [-100, 100] | F13*(0, 0 ... , 0)=0 | |
| Quardirc | Unimodal | [-100, 100] | F14*(0, 0 ... , 0)=0 | |
| Quartic | Unimodal | [-1, 28, 1.28] | F15*(0, 0 ... , 0)=0 | |
| Rastrigin | Multi-modal | [-5.12, 5.12] | F16*(0, 0 ... , 0)=0 | |
| RHE | Unimodal | [-100, 100] | F17*(0, 0 ... , 0)=0 | |
| Rosenbrock | Unimodal | [-30, 30] | F18*(1, 1 ... , 1)=0 | |
| Salomon | Multi-modal | [-100, 100] | F19*(0, 0..., 0)=0 | |
| Schwefel | Multi-modal | [-500, 500] | F20*(420.9687, 420.9687 ... , 420.9687)=0 | |
| Schwefel2.22 | Unimodal | [-10, 10] | F21*(0, 0..., 0)=0 | |
| Shaffer7 | Multi-modal | [-100, 100] | F22*(0, 0 ... , 0)=0 | |
| Sphere | Unimodal | [-100, 100] | F23*(0, 0 ... , 0)=0 | |
| Step | Unimodal | [-100, 100] | F24*(0, 0 ... , 0)=0 | |
| Styblinski-Tang | Multi-modal | [-5, 5] | F25*(-2. 903534, -2. 903534 ... , -2.903534)=-39.16599*d | |
| Sum-squares | Uni-modal | [-10, 10] | F26*(0, 0 ... , 0)=0 | |
| Trid | Unimodal | [-d2, d2] | X*=unknown For d = 30, F27*=-4.9300e+03 | |
| Xin_She_Yang | Multi-modal | [-2π, 2π] | F28*(0, 0 ... , 0)=0 | |
| Weiertrass | Multi-modal | [-0.9, 0.9] | F29*(0, 0..., 0)=0 | |
| Zakharov | Unimodal | [-5, 10] | F30*(0, 0..., 0)=0 |
Appendix B
Parameter settings of the compared algorithms
| Algorithm name | Description | Parameters | Reference |
| PSO | Particle Swarm Optimization | Popsize = 50, iteration 500 personal learning factor C1 = 1.5, social learning factor C2 = 1.5, inertia weight w = 0.8 | Eberhart and Kennedy [36] |
| ABC | Artificial Bee Colony | Popsize = 50, iteration = 500 employed foragers (EF)=1/Popsize | Basturk and Karaboga [37] |
| Bat | Bat Algorithm | Popsize = 50, iteration = 500 Loudness A0 = 0.5, Pulse rate r0 = 0.2, Frequency maximumQmax = 2, Frequency minimumQmin = 0.5 | Yang et al [38] |
| WOA | Whale Optimization Algorithm | Popsize = 50, iteration = 500 | Mirjalili and Lewis [30] |
| HHO | Harris Hawks optimization | Popsize = 50, iteration = 500 | Heidari et al. [39] |
| CHOA | Chimp Optimization Algorithm | Popsize = 50, iteration = 500 | Khishe and Mosavi [40] |
| GA | Genetic Algorithm | Popsize = 50, iteration = 500Pc = 0.85, Pm = 0.01, Er = 0.05; | Holland [41] |
| GSA | Gravitational Search Algorithm | Popsize = 50, iteration = 500 G0=100, α = 20 | Rashedi et al. [42] |