
Abstract
Transfer learning (TL) is further investigated in computer intelligence and artificial intelligence. Many TL methodologies have been suggested and applied to figure out the problem of practical applications, such as in natural language processing, classification models for COVID-19 disease, Alzheimer’s disease detection, etc. FTL (fuzzy transfer learning) is an extension of TL that uses a fuzzy system to pertain to the vagueness and uncertainty parameters in TL, allowing the discovery of predicates and their evaluation of unclear data. Because of the system’s increasing complexity, FTL is often utilized to further infer proper results without constructing the knowledge base and environment from scratch. Further, the uncertainty and vagueness in the daily data can arise and modify the process. It has been of great interest to design an FTL model that can handle the periodicity data with fast processing time and reasonable accuracy. This paper proposes a novel model to capture data related to periodical phenomena and enhance the quality of the existing inference process. The model performs knowledge transfer in the absence of reference or predictive information. An experimental stage on the UCI and real-life dataset compares our proposed model against the related methods regarding the number of rules, computing time, and accuracy. The experimental results validated the advantages and suitability of the proposed FTL model.
Keywords
Introduction
Many researchers have delighted in studying transfer learning (TL) and its applications to real-life problems as the meaning of transferring knowledge of source data compatible with the target data [1]. In several real-life situations, the accuracy and generalizability of machine learning technologies are ineffective and unsuitable for data shortage environments [2]. This is the reason and motivation for increasing the research on the TL method and its real-life applications to enhance learning tasks in case of a shortage of knowledge [3, 4]. Due to their remarkable effectiveness in transferring knowledge between domains, TL is widely applied in a lot of fields, such as text classification [5], computer and vision processing [6, 7], medical diagnosis [8], object detection [9] and stock market forecasting [10].
Although TL displays an upward trend, the uncertainty and vague factors in TL problems are still a considerable limitation in the learning and construction of TL models [10]. To overcome these issues, Jethro and Simon [11] introduced the fuzzy transfer learning (FTL) model, which is a framework for hybrid TL with fuzzy theory to deal with this matter. The fuzzy set (FS) theory has become a standard and powerful tool to seize the ambiguity related to imprecise or uncertain data. Extended FSs have been used in many papers to describe real-life problems where the data is ambiguous and inaccurate [12], square-root FS (SR-FS)[13], etc. It is due to the fact that in the case of lacking knowledge or insufficient information, data often has a high grade of hesitation, so utilizing the FTL would bring more information about the degree of membership of each attribute that has high importance to the outcomes. In this regard, FTL is considered an efficient tool for drawing the outputs with uncertainty.
However, imprecise in our daily lives and the uncertain of real-life data arise simultaneously as changes in the process (periodicity) of the data. None of the current theories may account for partial ignorance of the data during a given period. They are inadequate to account for the information that detail contains imprecise factors with periodicity, leading to loss of information. To cope with periodic factors in data, Ramot et al. [14] complemented the phase term to capture the temporal and periodical phenomena, which led to the conceptualization of the complex fuzzy set (CFS). The ANCFIS model (Adaptive neuro complex fuzzy inference system) [15] was proposed with some extensions such as the Randomized and Fast ANCFIS [16, 17]. The Mamdani Complex Fuzzy Inference System (MCFIS) [18] was recently introduced with a specific inference structure. Next, two extensions, the MCFIS with Rule Reduction [19] and MCFIS with Fuzzy Knowledge Graph [20], have been designed to improve the training and testing process in MCFIS. To the best of my knowledge, the above models are the most typical complex fuzzy inference system (CFIS) that deals with periodical data in knowledge systems. Despite these advancements in FTL and CFIS systems, there are still some issues that have not been resolved, as follows: These FTL systems mainly solve the problem of missing data in the target domain or partially labeled target domain without considering the periodical factor to build the system for the target domain. The ignorance of the periodic phenomenon in the TL problems has weakened the application scope of the current works. Most current FTL systems only combine TL with the traditional fuzzy logic. There is little work that is based on the extended fuzzy set, especially the complex fuzzy set. Although the MCFIS model provides an essential representation of uncertainty and periodicity. The primary disadvantage is that it restricts the rule base by generating complex fuzzy rules without learning. Other studies are not complex systems because they mainly focused on amplitude factors and ignored the phase terms, which leads to a loss of information in the inference process.
The shortcomings in the remaining systems above are the primary motivation that led to implementing the model in this research, which may have multiple options to look at an actual situation more effectively. As a result, this article proposes a complex fuzzy transfer learning (CFTL) using the inference capabilities of models based on the complex fuzzy rules to improve the remaining CFIS system’s performance that can handle the ambiguous, uncertain information and periodic factors in the TL problems. TL can be combined with other fuzzy theories to describe the uncertainty and ambiguity in TL problems. However, in the case of data having a periodic factor, the CFS is the best choice in this situation. This is the first work to deal with the TL problem in CFIS.
Specifically, Propose the CFTL model, a combination of FTL and MCFIS, with the aim to enhance the classical FTL for dealing with uncertainty, inconsistency, periodicity, and cyclic phenomena in complex decision-making problems. Introduce the CFTL model that consists of four steps: Adjusting the source domain; Selecting subsets in the destination domain; Rules adaption; and Aggregating rules for final adaptive rules. Propose a novel definition of firing and candidate rules to choose the most significant ones in the rule base and reduce the complexity time. Prove the capability of the proposed CFTL model in handling knowledge transfer problems when having a shortage of information in the target domain through experiment scenarios. Demonstrate our proposed model’s effectiveness through experiments performed on the UCI and real decision-making data sets regarding the accuracy, the number of rules, and time-consuming.
The nature of the proposed CFTL model lies in the inference mechanism according to the Mamdani fuzzy inference model, which is similar to that of the MCFIS system. The
Section 2 provides the relevant works. The preliminaries, which include the fundamental definitions of the TL, CFS, and MCFIS model, are represented in Section 3. Section 4 investigates the new complex fuzzy transfer learning that combines FTL and MCFIS. Section 5 compares the results of our suggested model with existing MCFIS techniques on different datasets regarding the number of rules, accuracy, and estimated time. To conclude, the last part must outline this research’s future work.
Related works
Transfer learning (TL) has grown into an attractive structure to deal with the lack of information and shortage of data. TL aims to take advantage of previous knowledge to reinforce learning new but similar problems. There is an actual reliance between the level of reality in learning a task and the quantity of potential information. If there is too little knowledge in the destination field, only a limited amount of data can be obtained, leading to a costly level of ambiguity. Thus, in this situation, a fuzzy system has been considered an excellent solution to resolve ambiguity and tension in the target domain.
Jethro and Simon [11, 21] opened an FTL framework based on a fuzzy inference system for the tagged target task from the appropriate source field and untagged data from a target task. The works of Deng et al. [22–24] came up with a series of TL methods utilizing a classical TSK fuzzy model. They progressed innovative fuzzy systems to define two advanced objective functions. Also, their techniques have been involved in recognizing electroencephalogram signals in situations where data is in short supply.
Behbood et al. [25] introduced a fuzzy refinement domain adjustment to forecast the long-term bank bankruptcy in source and target fields with divergent data distributions. Liu et al. [26] concentrated on the domain adjustment problem in unsupervised heterogeneous areas and produced a novel TL model via unlimited fuzzy feature combination. A geodesic flow el was introduced for delivering knowledge by rebuilding source and target range features.
Some works have expanded the domain transformation capability of fuzzy rule-based models [27]. Almost all algorithms are expressed on two distinctive sides, with the data in the source and target field being inhomogeneous [28] and heterogeneous areas [29] separately. Based on the TSK model, Li et al. [30] recommended a multi-view TL for epilepsy EEG detection by taking advantage of the interpretability and fuzzy inference skills of the TSK fuzzy model. Motivated by the impression of transferring knowledge, Shanoli and Samarjit [10] introduced a time series forecasting technique on stock market data in which FTL is applied to transferring knowledge and adapting rules.
Despite FTL handling the ambiguous and uncertain elements in TL problems, we need to cope with uncertainty, inconsistency, periodicity, and cyclic behaviors. Referring to the complex issues in the real-life data, CFS [31] is a suitable solution for this situation by representing these factors by the phase element in CFS. Some researchers studied CFS theories and developed a model based on CFS for real applications to increase the capability to apply in real-life applications,
Selvacharan et al. [18] announced the MCFIS to deal with multi-attribute decision-making problems. Then in [19], an improved version with the rule base redundant was presented using some complex fuzzy similarity measure. Another version of MCFIS that is delighted by the improvement in the testing phase was denoted MCFIS-FKG [20] in which the authors developed a fuzzy knowledge graph to present the complex fuzzy rules based on linguistic labels and their associations in this study.
Besides, several other studies have introduced models based on complex fuzzy sets. They applied it to real-life problems such as time series prediction [17, 32], complex fuzzy logic system [18–20, 33], multi-target prediction [34–36], signal detection [37, 38]. The review of related works demonstrates that CFIS has gained popularity and has played an important role in recent years. Using CFIS implied good interpretation ability and strong learning ability.
Preliminaries
As mentioned in Section 1, some fundamental concepts strongly relate to transfer learning, complex fuzzy theories, and the complex fuzzy reference system used in this study. In particular, the definitions of transfer learning, CFS, and Mamdani Complex FIS are given as follows.
Transfer learning
TL takes advantage of training a new model by working with a pre-learned model. This section represents the notions and definitions of transfer learning that will be used throughout the whole paper.
The output is the predicted conditional distributions of instances in machine learning:
In practice, a domain consists of both labeled and unlabeled instances. For example, a source domain ζ O and a learning task E O for the source domain are usually observed via the instance-label pairs, that is, ζ O ={ (l, w) |l i ∈ L O }; w k ∈ W O ; i = 1, . . . , m i O ; and k = 1, . . . , m k O . The same with the target domain, which consists of several unlabeled samples and/or a few labeled samples.
As discussed in section 1, there are some kinds of TL. In this study, the FTL approach uses an Inductive TL that the source and destination domain feature has similar dimensions and dissimilar disposals. For inductive TL, the data is only partly available from the destination field, while some valuable data from the source field is available.
(i) The complement of H is:
(iii) The intersection of two CFSs H and M (denote H ∩ M)
Due to its simplicity and flexibility in an approximate nonlinear dynamic system, the MCFIS [18] is the promising fuzzy system for handling data that have periodic and vague phenomena. MCFIS consists of the following steps:
Let
Step 1: Set a rulebase set of complex fuzzy rules (CFRs)
For all u,v:
(i) (u, v) ∈ {1, 2, …, m}, with 1 ≤ u, 1 < u, 2 < … < u, m u ≤ m
(ii) μ
H
u,v
(lu,v)= ϑ
H
u,v
(lu,v) ejϖ
H
u,v
(lu,v), with
(v) Ou,v = or IFF Nu,v= S0, S0 is S-norm
Step 2: Step 2: Fuzzification, using the Gaussian fuzzy function to fuzzify the inputs:
Step 3: Determine the firing strength of a CFR by combining the fuzzified inputs corresponding to CFRs.
This step determine the firing strength ω u for each CFR by function: ω u = τ u e jξ
Step 4: Compute the CFR’s outcome by combining the CFR’s rule strength and the output membership function. In MCFIS, the value of the CFRs’ outcome is received using the Mamdani implication.
Step 5: Aggregation. In this step, all the CFRs’s outputs are combined as follows:
A defuzzified output result w
op
= Φ (D) is obtained using function:
Although TL algorithms have made further progress due to the evolution of artificial intelligence, their lack of ability to be interpreted is very dubious. Some research has concentrated on enhancing fuzzy models to deal with imprecision, vagueness, ambiguity, and uncertainty. Nevertheless, most FTL studies can only deal with phenomena that are not periodic or seasonal.
On the other aspect, The theory of CFS has contributed to an adequate theoretical foundation for many practical mechanisms, specifically decision-making support systems. The MCFIS model was suggested as an efficient inference tool for dealing with issues with uncertain, periodic, and seasonal components. This issue is the primary motivation for introducing a complex fuzzy transfer learning framework that combines FTL and MCFIS. Before presenting the details of our proposed framework, some new definitions are introduced as follows.
New definitions
This section shows some definitions of our proposed CFTL model below.
The complex fuzzy rule (CFR) is the firing rule on the data t when: The output of the rule is the same as the output of the t
th
data. The firing strength of the rule is larger than the given threshold value ɛ A complex fuzzy rule is called a candidate rule for the data t if it satisfies: The output of the rule is the same as the label of the datarow k For each firing amplitude that (F
A
≥ ɛ) then For each firing amplitude that (F
A
< ɛ) then (F
P
≥ β)
where ɛ, α, β ∈ [0, 1] are the given parameters.
CFR2 : If X1 is 0.56ej0.07 and X2 is 0.92ej0.05 and X3 is 0.81ej0.004 and X4 is 0.86ej0.016 then y1
CFR3 : If X1 is 0.89ej0.011 and X2 is 0.69ej0.02 and X3 is 0.98ej0.003 and X4 is 0.43ej0.2 then y1
CFR4 : If X1 is 0.87ej0.07 and X2 is 0.80ej0.02 and X3 is 0.83ej0.07 and X4 is 0.53ej0.08 then y2
According to the firing rule and candidate rule (see Definition 10), with ɛ ≥ 0.8, α ≥ 0.75, β ≥ 0.05, we have: the 1 st rule is a firing rule on the t th data record; the 2 nd rule is a candidate rule; the 3 rd rule does not satisfy the conditions of firing or candidate rule; and the 4 th rule satisfies the firing or candidate condition.
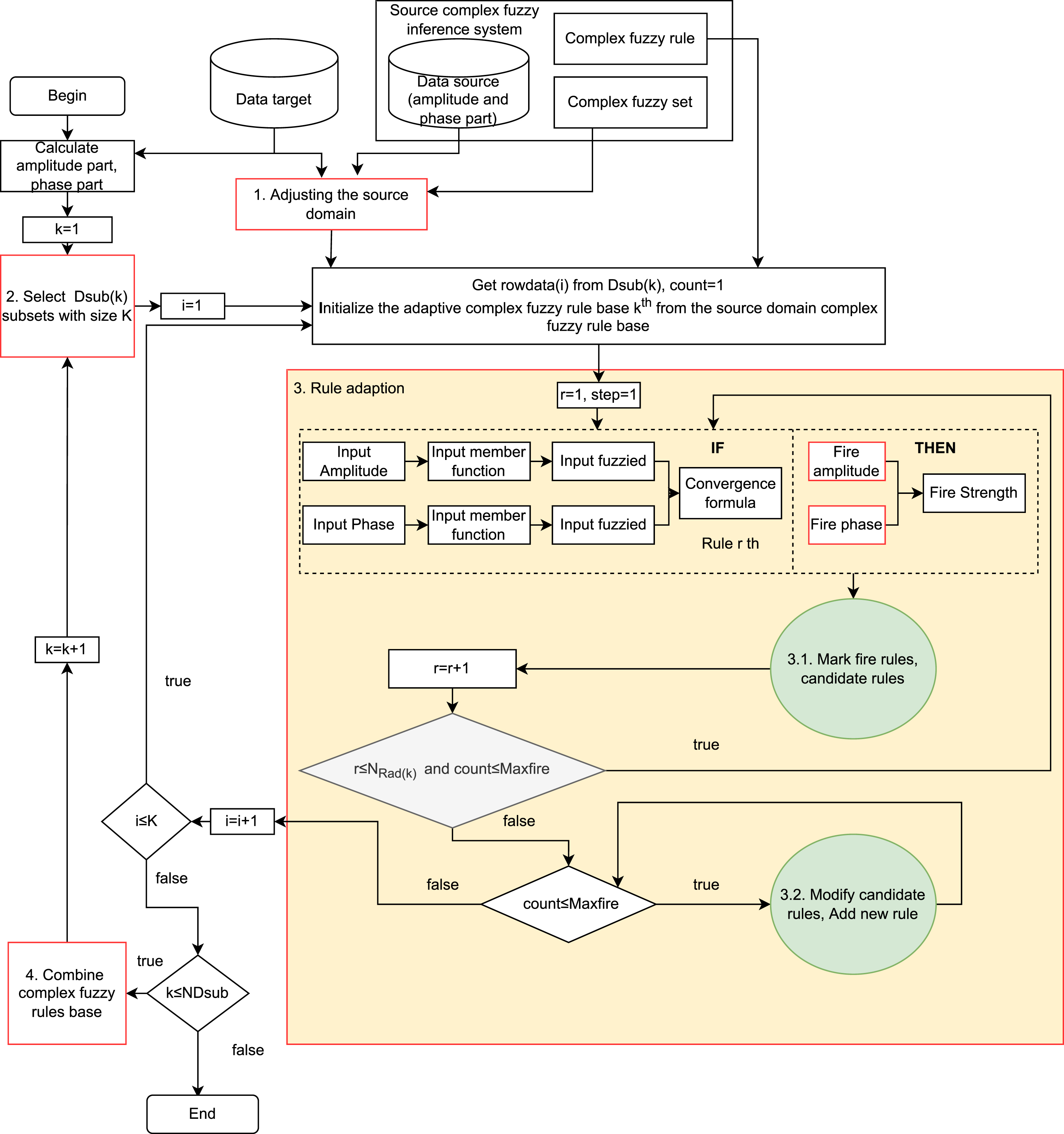
Proposed complex fuzzy transfer learning model.
Based on the notions in Section 4.1, this section defines the new complex fuzzy transfer learning (denote CFTL) model. The proposed CFTL framework is designed as a knowledge transfer framework in which the source and destination domains are relative (Definition 7). In this work, the source and destination domains tasks have the same dimension with different distributions. CFTL strives to bridge knowledge gaps throughout the learning process and adapt learning from one context to another. The change of context can be caused by a domain change, a lack of information, a situation, etc. The proposed CFTL may transfer knowledge from one space to another to enhance the processing time to produce the new rule base with acceptable predictive quality.
However, the first issue is deciding whether to transfer knowledge to support the prediction task in the target domain. To solve this issue, we propose a measure of similarity between the two domains (see Definition 8) by comparing the values of the standard deviation of each field in the two domains. If the value of the similarity measure is relatively high or not close to one, two domains have high similarity. Otherwise, the two domains are not related to each other. The FTL used in this case will improve the task’s outcomes in the target parts.
Relying on the complex fuzzy rule (CFR) and CFS received from MCFIS, the proposed CFTL adapts complex fuzzy concepts to the target domain. The adaptive process uses the knowledge gained from previous information (in the source region) to improve the task in the target region. This model allows adaptation of the individual components of MCFIS to account for alterations in the data. Changes and alterations from one situation to another are taken over by changing the CFS domain and adjusting to the CFRs.
The design of CFTL (Fig 1) consists of 4 stages. First, a domain adjustment procedure alters CFSs information within the source domain to match the target domain. Next, a process to select Dsub(k) subsets based on data labels and attribute fields in the destination is introduced. The number of Dsub(k) subsets, known as N Dsub , is sufficient for the target domain’s data size. Then, the data records within each sub-group are adjusted to adapt rules; each Dsub(k) subset will generate a set of adaptive CFRs, denoting Rad(k). A method for marking the firing and candidate rules is used in the adapting procedure to decrease the number of rules that need modifying or adding. Finally, adaptive CFRs are combined and produce the final adaptive rules- Rad(Final), which is the rule base for inference in the target domain.
The CFTL is executed according to the following steps in Algorithm 1 and described the detail in the below subsection.
1: Adjusting the source domain;
2: k=1;
3: N d = η * N ψ ;{N Ψ is the number of datarows
3: in Target Data)}
4: N Dsub = N d /K;{ the number of Dsub(k)}
5:
6: R ad (k)← CFS rule base;
7: Select subset Dsub(k) from Target Data;
8:
9: Adapting R ad (k) with t;
10: k=k+1;
11: Combining adaptive CFR R ad (1), R ad (2),...,
R ad (N d ) to produce R ad (Final);
Adjusting the source domain
Because of the different data statistical distribution in source and target domains, this section offers an adjustment method to transform the source domain appropriately to the target domain. The domain of input/output in the source or target field is the interval, which implies the universe of discourse of CFS. Each data interval is split into equal or unequal divisions if necessary. Lastly, each division is determined by the corresponding centroid of the cluster.
To adjust the source input domains to fit the target input domains, we need to alter the source input intervals to the target input intervals. The amplitude and phase components between the source domain and target current are compared. The source’s boundaries will extend or narrow due to the data from the target intervals. Each amplitude and phase component in the target input is compared with the amplitude and phase intervals in the source domain, respectively. If it is smaller than the left boundary, the left border is narrowed; otherwise, the right edge is extended if it is greater than the right boundary. Furthermore, the results obtain a set of centroids in the new cluster that adapts to the target input.
It is not easy to pinpoint a specific method to achieve the best results. Choosing an appropriate strategy for adjusting source data is issue-based and depends on the datasets. The overall algorithm for matching source data to fit the target data is given in Algorithm 2.
1: Calculate the left and right boundary values of each attribute’s range in the source domain and the target domain
2:
3: Calculate deviation value of right boundary value for each cluster of attribute i (dr)
4: Calculate deviation value of left boundary for each cluster of attribute i (dl)
5:
6:
7: Calculate C ij =C ij +dr;
8:
9: Calculate C ij =C ij -dr;
10:
11: Calculate C ij =C ij -dl;
12:
13: Calculate C ij =C ij +dl;
Selection of Dsub(k) subsets
Selecting the subsets of target data is essential to reduce the useless information of target samples required in the rule-editing process. Moreover, each subset (denote Dsub(k) with the size K) is disjoint.
If the data in the target field is not included in the source dataset, the Dsub(k) subset with the size K can be selected from this target dataset. The number of Dsub(k) subsets is due to the size K of each subgroup. In our proposed model, assume the total records in the target part is N E , the entire samples for Dsub is N d , then N d < < N E . N d will divide into N Dsub , with each Dsub having the size K or satisfying N Dsub =N d /K. The smaller the size K, the larger the number of Dsub(k) sets and the greater the number of adaptive rule sets generated. It led to more feature characteristics that must be learned and much more computational time.
Rule adaption
As shown in Fig. 1, each selected Dsub(k) subset will be used to produce the adaptive CFR (denote Rad(k)) through a CFR adjustment. The CFR adjustment is based on the MCFIS’s inference mechanism, using the source’s CFRs as the initial rule base. The exhaustive rule base is checked out iteratively to identify the most used rules with greater fire rule value corresponding, which shows greater ability within the target domain.
Each data record in the Dsub subset puts into a CFR adaption that adjusts or adds CFRs. The Maxfire parameter, called the learning rate parameter, the number of adaptive rules for each record depends on this parameter.
With our proposed model, we randomly selected N d data instead of taking the entire target domain data to generate the rule. It means N d data will represent the entire N E data. Suppose that a data record generated a rule, then for N E data, N E rule is generated. Whereas N d is used to represent N E to help create the target domain rule base. Thus, with N d data after maximal adaptation will generate N E rules and each record should adapt to generate N E /N d rules. This is the basic idea for determining Maxfire when adapting the rule base.
The detailed steps of CFR adaption are given in Algorithm 3.
1: r=1;{the initial 1 st rule}
2: count=1;{the number of fire rules}
3:
4: Calculate fire rule values (Definition 9);
5:
6: count=count+1;
7:
8:
9: Push the r th rule in Edit_list
10:
11: Push the r th rule in Add_list
12: r=r+1;
13:
14: Choose rule from Edit_list
15: Modify rule (amplitude part);
16: count=count+1;
17: Update rule in set rule R ad (k);
18:
19: Choose rule from Add_list
20: Modify rule (amplitude part and phase part);
21: count=count+1;
22: Addition rule in set rule R ad (k);

Mark fire rules, candidate rules.
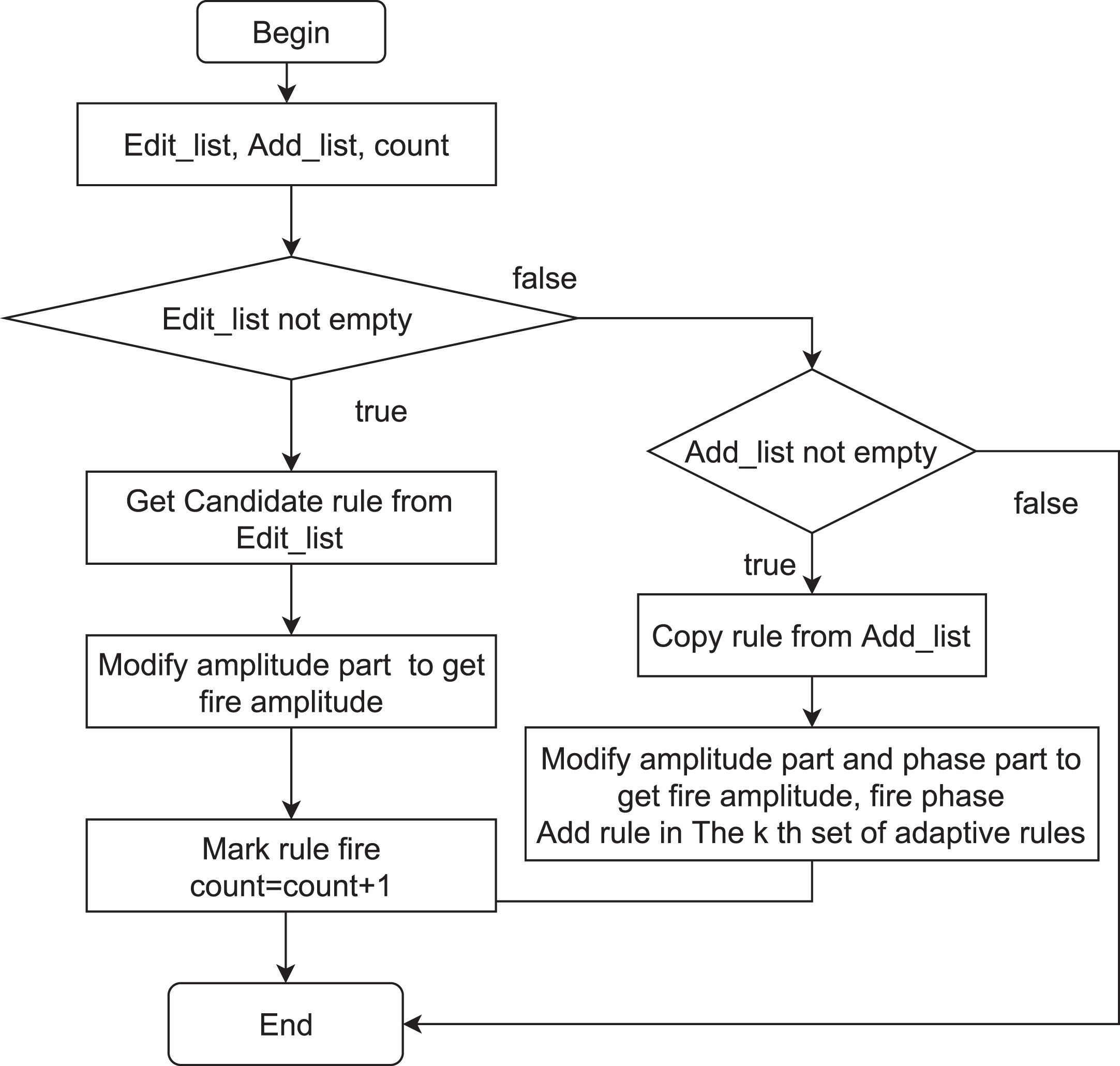
The process of modifying and adding rules.
4.2.3.1. Determine firing rules and candidate rules. The task of this stage is to mark the firing or candidate rules to point out whether the rule is suitable for the testing data. The determination of the firing rule is based on summing the rule strength in amplitude and phase elements. Furthermore, the candidate rule is defined by the rule’s phase terms slighter than the given threshold β. To determine whether the firing rule or candidate rule, rule must be checked with the conditions in Definitions (9) and (10). It is marked as a firing rule if it satisfies the requirement in Definition (9). Otherwise, we consider the conditions of Definition (10) when the rule is marked as a candidate rule or not. A list of candidate rules on the rules queues to modify is called Edit_list. Non-fire and non-candidate rules are evaluated and supplemented to the Add_list due to the firing amplitude, firing phase, and firing rule value to support adding rules. The emphasis in those definitions is on using phase components to determine fire and candidate rules. Note that modifying and adding rules will occur if the number of fire rules has not reached the given Maxfire rate.
4.2.3.2. The process of modifying and adding rules. The process of editing rules will occur when the number of firing rules has not reached the given Maxfire value. Some rules from the Edit_list will modify to adapt to input data, which means changing the rule to firing rule. The editing process will alter each data point where the fire amplitude < ɛ. After each displacement, the firing amplitude, firing phase, and firing rule value are recalculated. Whenever the firing rule value ≥ɛ, the process of editing the rule stops, and the rule is marked as the fire rule.
If the whole exhausted Edit_list has been examined and the number of fire rules has not reached the Maxfire, the modifier and addition rule value for adding new rules will be executed. If the rule is in the Add_list with a priority order, we adjust the amplitude and phase parts to obtain fire rules. Then we replace this rule’s output with the label of record and supplement the fire rule value. Finally, the rule is marked fire rule. Adding rules continues to execute until the number of fire rules reaches Maxfire. The detailed steps of the rule editing process are presented in Fig. 3.
After obtaining the set of adaptive CFRs Rad(1), Rad(2), …., Rad(k), they will be aggregated by removing the same CFRs and weak CFRs to obtain the final set of adaptive CFRs (named Rad(Final)) as the CFRs for the target data.
Complexity analysis
The computational complexity of the proposed model is calculated as follows:
(1) The computational complexity of Adjusting the source domain:
- Determine the left and right boundaries of each attribute of the source and destination domains: O (n O . (N ψ + N O ))
- Shift the centroid vector for each attribute: O (n c . n O ) ⇒O (n O (N ψ + N O + n c )) ≈ O (n O . N ψ )
(2) The computational complexity of processing Selection of Dsub(k) subset with K datarows and Rule adoption with N Rad rules:
- The computational complexity of Selection of Dsub(k) subsets: O (N ψ )
- Computational Complexity of Mamdani Complex fuzzy inference system: O (n O . n c )
- Computational complexity of marking fire law and candidate law: O (10)
- Computational complexity of rule editing and rule addition with maxfire defined according to the description 4.2.3.2. is small:
O (n
O
+ maxfire . n
O
)
- The Computational complexity of combining complex fuzzy rules base:
Finally, the computational complexity of the proposed model is calculated:
where:
n O : Number of attributes in Source Data
n c : Number of clusters
K: Number of data rows in each Dsub(k) subsetmaxfire: Rate of rule fire
N ψ : Number of data rows in Target Data
N O : Number of data rows in Source Data
N Rad : Number of Rules in the adaptive CFRs
N Dsub : Number of Dsub subset
Experimental results
This section aims to appraise the efficient achievement of the proposed CFTL for resolving the complex problem if the rule base is small or partial compared to the latest data.
Experimental datasets and environment
Experimental dataset
Experimental dataset
We have executed the models using the Lenovo laptop with a Core i7 processor for operation in Python. The proposed CFTL is estimated on Benchmark UCI and real-life data by comparing it with the related method. The experimental datasets used in the evaluation consist of two types, UCI medical datasets and real-life medical datasets with two label outputs. There are three datasets (Breast Cancer, Diabetes, and Bank loan) from the UCI Machine Learning Repository [41] and real-life medical data (Liver disease) from Thainguyen Hospital. The detail of experimental datasets is visually described in Table 1.
To figure out the learning potential of CFTL to enhance the rule base in case of knowledge leverage in the target domain of the existing method in the CFS environment, the evaluated results on three validity indicators: the computational time, the accuracy, and the number of rules. Moreover, we have planned two scenarios for experimentation (detailed in Fig. 4) to compare them to the related method-MCFIS. Scenario 1 is used to evaluate the MCFIS’s performance. Scenario 2 aims to validate the reasoning ability of the CFTL in cases of knowledge leverage. In our experiments, the datasets are split into two parts by the Hold-out cross-validation, including the training part (80%) and testing part (20%).
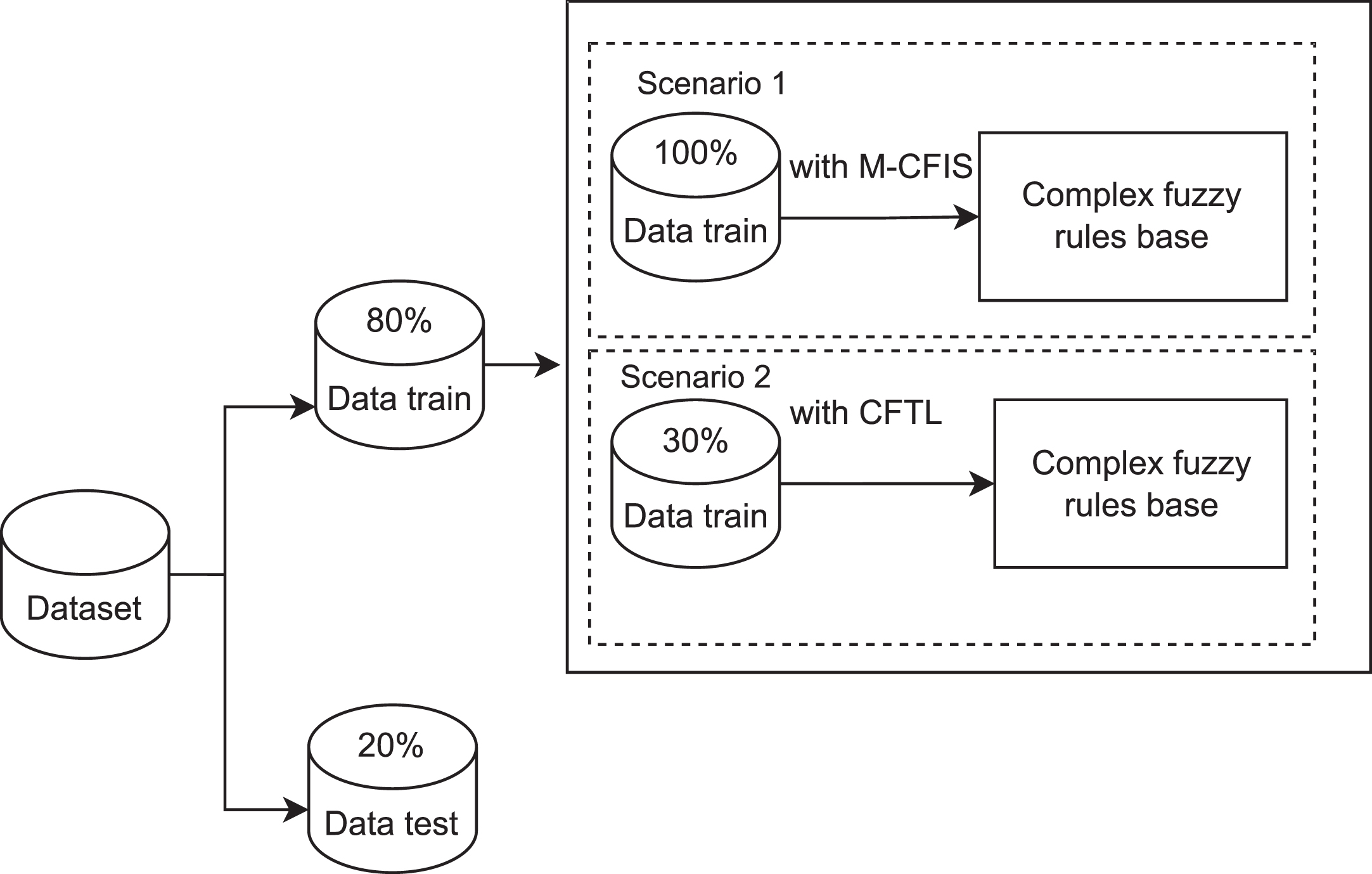
Experimental scenarios.
In the first scenario, the CFS rule-generated mechanism in MCFIS is used for all training data but only 30% of training data in the second scenario. In the second scenario, 30% of training data is split into two parts: 10% data for generating rules using the MCFIS mechanism, and the remaining training data (20%) is used as the Dsub dataset that is used in CFTL. Finally, the set of CFRs results obtained in two scenarios are evaluated on the testing data on three comparison criteria: time-consuming, accuracy, and number of rules. Furthermore, each experiment was repeated twenty times with the learning parameters 4.
After carrying out the experiments, the obtained results of four datasets corresponding to two scenarios are presented in Figs. 5 to 8 , respectively. The experimental results in each figure are presented according to the following structure: the left side of the figure shows the detailed results corresponding to 20 experimental runs, and the right side of the figure is the average result.
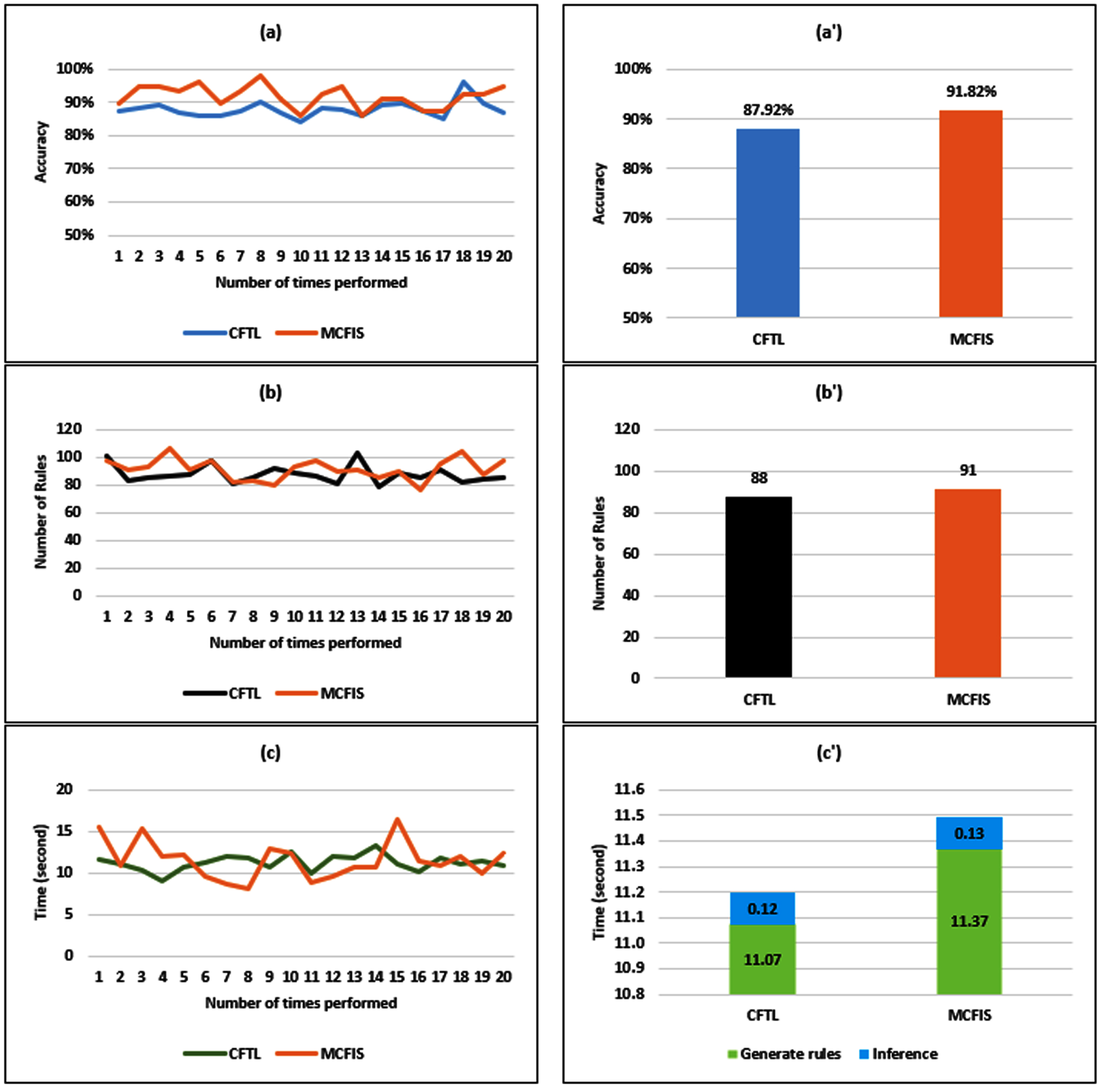
Results on the Diabetes dataset: (a) Accuracy; (a’) Average accuracy; (b) Number of rules; (b’) Average number of rules; (c) Time; (c’) Average time.
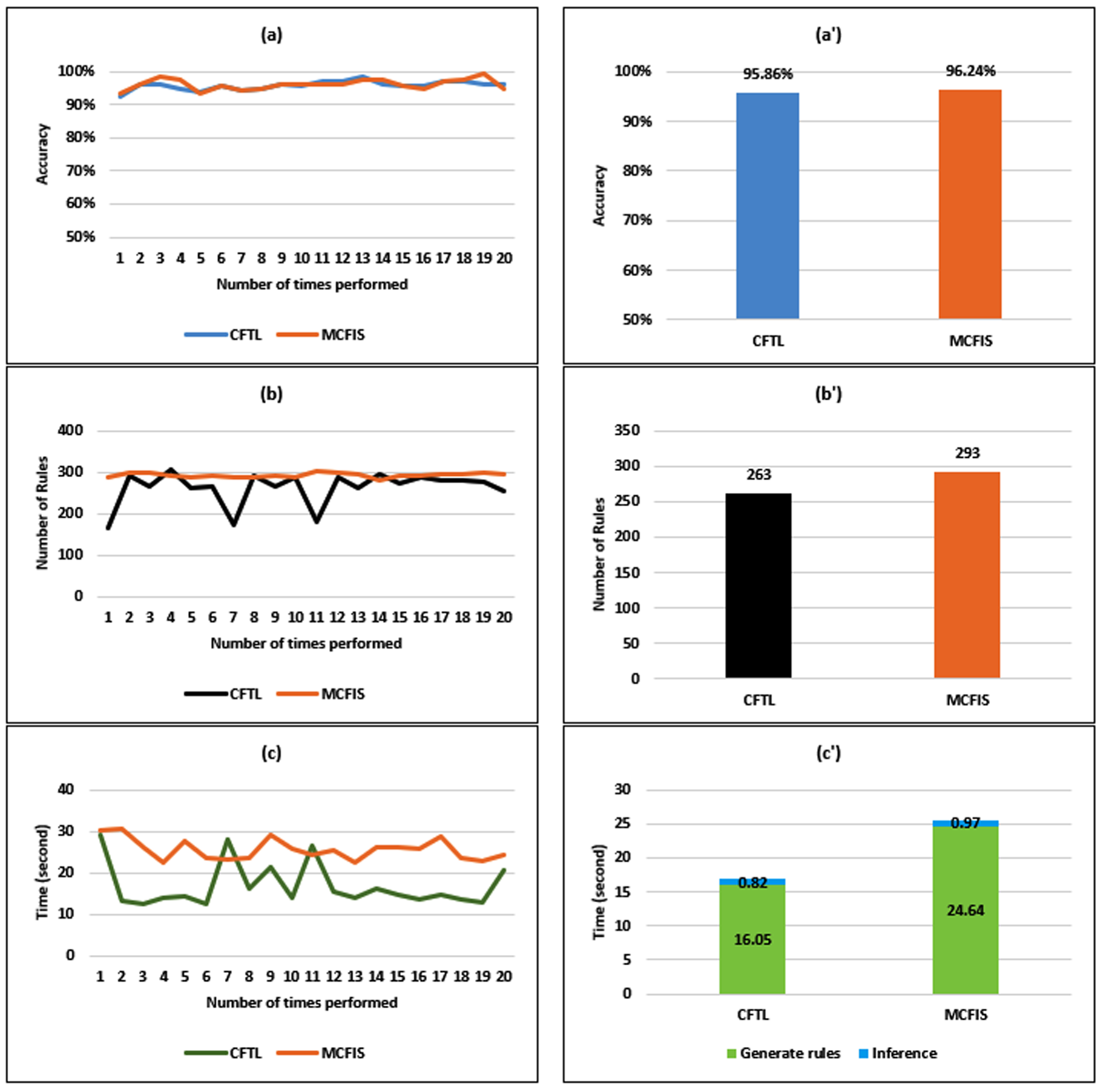
Results on the Breast-Cancer dataset: (a) Accuracy; (a’) Average accuracy; (b) Number of rules; (b’) Average number of rules; (c) Time; (c’) Average time.
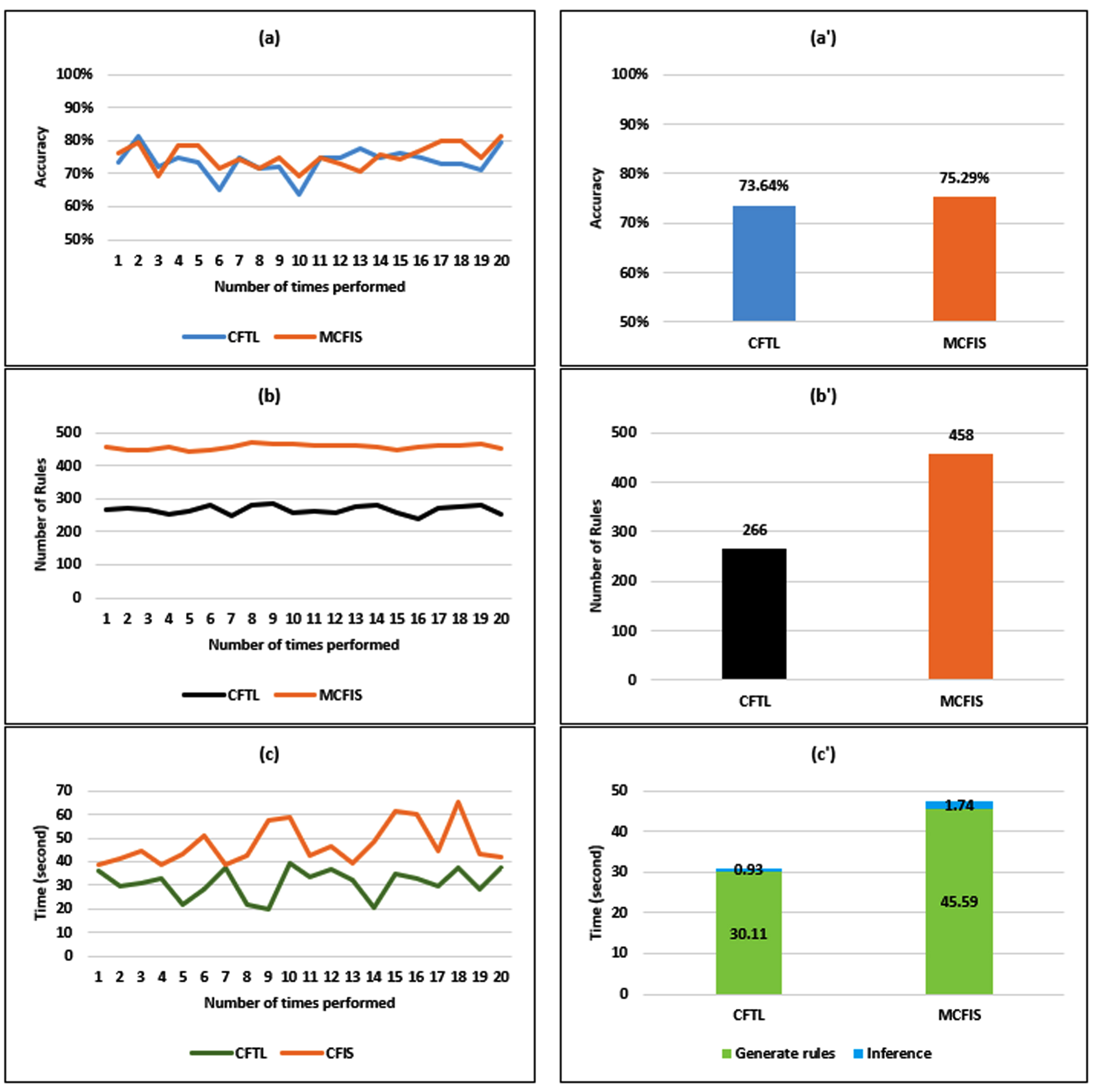
Results on the Bankloan dataset: (a) Accuracy; (a’) Average accuracy; (b) Number of rules; (b’) Average number of rules; (c) Time; (c’) Average time.
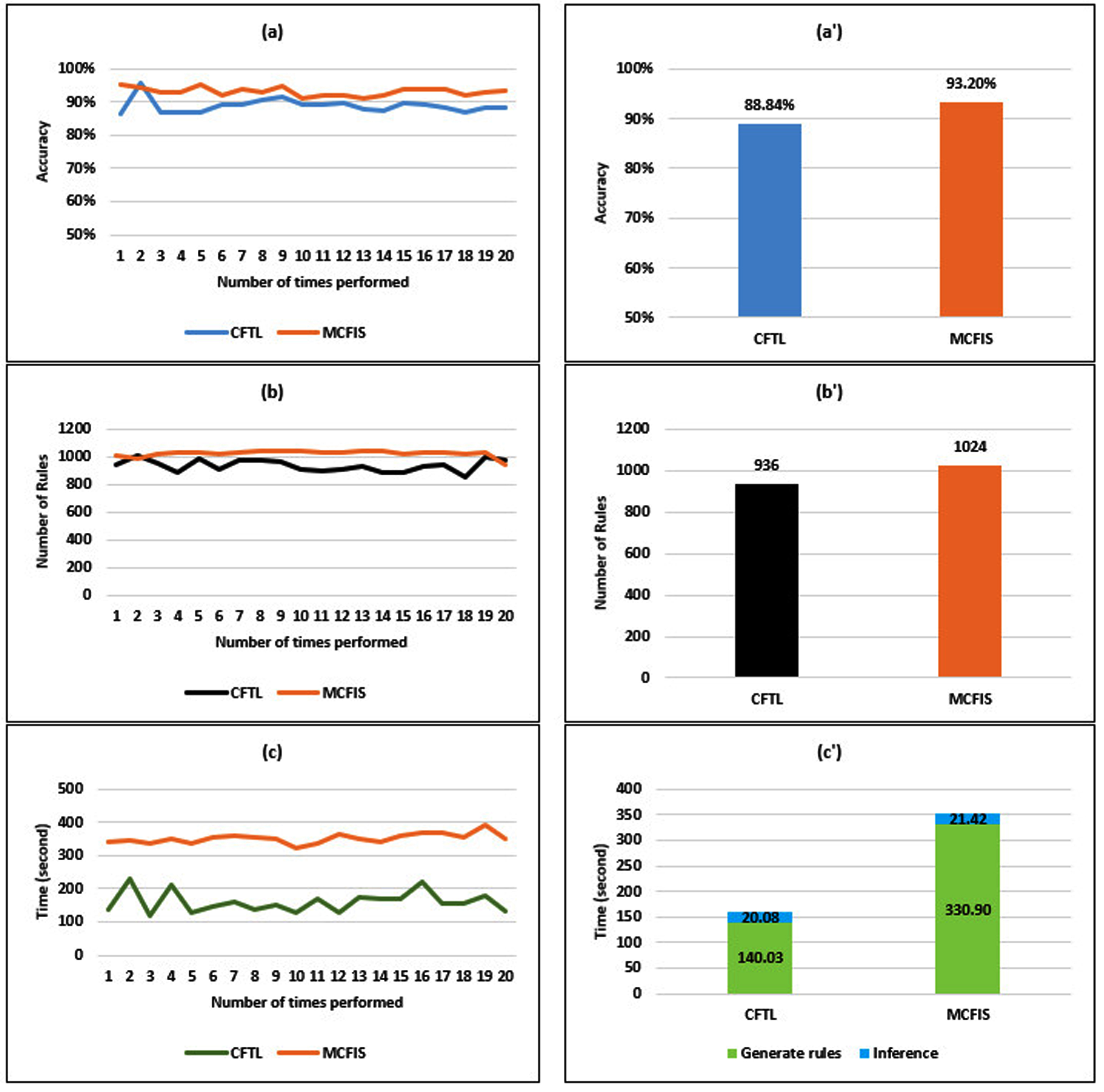
Results on the Liver dataset: (a) Accuracy; (a’) Average accuracy; (b) Number of rules; (b’) Average number of rules; (c) Time; (c’) Average time.
Figure 5 depicts the experimental results of the proposed model and MCFIS on the Diabetes dataset. As shown in Fig. 5(a) and 5(a’), it is clear that the accuracy of the proposed model is lower than that of the MCFIS model. But in several times performed, the accuracy of CFTL is higher than those of MCFIS. This result is caused by the total dataset being small, with only 390 records. So leading Dsub is also tiny, and the knowledge for training and testing is limited. Figures 5(b) and 5(b’) show the number of rules between the two models. It can be seen that the number of rules of CFTL is a little smaller than that of MCFIS (only three rules lower on average). This result is understandable because it is suitable for the two models’ corresponding accuracy. However, the consuming time of CFTL is slightly smaller than that of MCFIS in the rule-generating process and the same for the inference process. Experimental results comparing the two models on the Diabetes dataset show that there is not much difference between CFTL and MCFIS. One of the reasons for this result is that the number of records in the dataset is too small.
Experimental results on the Breast-Cancer dataset are presented in Fig. 6. The accuracy results in Fig. 6(a) and 6(a’) of MCFIS are slightly higher than that of CFTL. This value is only 95.86% on the CFTL model and 96.24% on the MCFIS model. Thus, the accuracy of the two models can be assumed equivalent. Nevertheless, the average quantity of rules in Fig. 6(b’) of CFTL is 262, which is 30 rules less than the result of MCFIS. Thus, the rule base of CFTL has fewer rules than MCFIS. Further, the time consumption of CFTL is 35% lower than that of MCFIS (Figures 6(c) and 6(c’)). On average, the total time of generating rules is 16.05 and 24.64, corresponding to CFTL and MCFIS, while the accuracy value is the same. These results prove that the experimental results with CTFL are significantly better in the Breast-Cancer dataset. For the Breast-Cancer dataset with a large number of records, the CFTL model has clearly shown its superiority in terms of execution time. The computation time in each time performed is almost always much shorter than that of MCFIS and has nearly the same accuracy. In addition, with the experimental times that CFTL has a higher running time than MCFIS, it corresponds to times when the number of rules is more and the accuracy of CFTL in those times is higher than that of MCFIS.
On the Bank loan dataset, the results of the performance comparison between CFTL and MCFIS are presented in Fig. 7. Providing similarity to the Breast cancer dataset, there is not much difference in the accuracy indicator between (i.e., CFTL-73.64% and MCFIS –75.29%). Especially in Fig. 7(b’) and 7(c’), the number of rules and the implementation time of MCFIS is significantly higher than that of CFTL. The number of rules of CFTL is reduced by 42% compared with MCFIS (i.e., 266 rules and 458 rules responding as in Fig. 7(b’)). And the ratio of the computation time of MCFIS and CFTL (on average) is 1.72 times higher. Similarly, CFTL works better on the dataset with a large number of records. This can be presented through the experimental results obtained regarding the number of rules and the execution time of the two models, which are quite different. With CFTL, the results are much more efficient than with the MCFIS.
The accuracy, the number of rules, and the implementation time of CFTL and MCFIS on the real-life dataset are demonstrated in Fig. 8 with similar characteristics as in the previous figure. As shown in Fig. 8(a’), the value of validity indices obtained from CFTL is quite lower than that of MCFIS. The values corresponding to CFTL and MCFIS are 88.84% and 93.2% on average. However, similar to the previous Breast cancer and Bank loan datasets, the number of rules of CFTL is much lower than MCFIS (i.e., on average, 936 rules and 1024 rules resp. as in Fig. 8 (b’)). Significantly, the computational time of CFTL is 2.38 times decreasing on average (resp. 140.03s and 330.9s). This result confirms that the proposed CFTL model improves much in terms of time and the number of rules for the datasets with a large number of records and attributes. Moreover, the proposed CFTL works effectively in case shortage of knowledge in the target field.
In summary, the experimental results on both types of data: standard data and actual data, also show the effectiveness and significance regarding execution time and the number of rules of the proposed CFTL model over the MCFIS model. First, to get this result, selecting the data set for the rule adjustment process, the proposed model selects only the DSUB set, not the entire training data. Secondly, the method of determining fire rules, candidate rules, and editing rules also helps the CFTL system to be improved faster than MCFIS. Although the accuracy of the proposed CFTL model is still limited depending on the selection of data set Dsub(i), the difference is not too significant, i.e., ± 5% compared to the method MCFIS.
In this paper, we proposed the CFTL- a new Fuzzy Transfer Learning model on the Complex Fuzzy Inference System (CFIS) to reduce the construction time through learning the knowledge from the related domain. The system selected data for the domain for rule adaptation. The number of selected data is much less than the data set in the target domain to decrease the computational time. In the domain adaptation, we also use the linear mapping method to obtain the target domain data, which is adapted to the source domain interval. In particular, the rule adjustment, in which the phase factor is used to select suitable rules for the editing and addition process, quickly selects the rules that are suitable for the target domain data as well as generates create new rules from the process of modifying or adding rules.
Experimental results on the UCI and the real-life data sets have shown that the CFTL system brings the desired results in situations where it is necessary to build a target domain CFIS with rather large data with limited time by using the complex fuzzy inference system of the available similar domain (source domain). However, the accuracy of the model is still not high, thus, future studies will continue to add other stages to improve the accuracy of the model, as well as change some parameters to fit the other model in real-life applications. The proposed model combines the complex fuzzy concept with transfer learning to apply to data sets with periodic and time factors. In future research, the model can be extended to many different types of data and other extended FS theories, such as intuitionistic FS, Pythagorean FS, (3,2) FS, SR-fuzzy set)...
Footnotes
Acknowledgments
Luong Thi Hong Lan, ID VNU.2021.TTS.10, thanks The Development Foundation of Vietnam National University, Hanoi for sponsoring this research.