
Abstract
Embedding similarity-based methods obtained good results in unsupervised anomaly detection (AD). This kind of method usually used feature vectors from a model pre-trained by ImageNet to calculate scores by measuring the similarity between test samples and normal samples. Ultimately, anomalous regions are localized based on the scores obtained. However, this strategy may lead to a lack of sufficient adaptability of the extracted features to the detection of anomalous patterns for industrial anomaly detection tasks. To alleviate this problem, we design a novel anomaly detection framework, MFFA, which includes a pseudo sample generation (PSG) block, a local-global feature fusion perception (LGFFP) block and an anomaly map compensation (AMC) block. The PSG block can make the pre-trained model more suitable for real-world anomaly detection tasks by combining the CutPaste augmentation. The LGFFP block aggregates shallow and deep features on different patches and inputs them to CaiT (Class-attention in image Transformers) to guide self-attention, effectively interacting local and global information between different patches, and the AMC block can compensate each other for the two anomaly maps generated by the nearest neighbor search and multivariate Gaussian fitting, improving the accuracy of anomaly detection and localization. In experiments, MVTec AD dataset is used to verify the generalization ability of the proposed method in various real-world applications. It achieves over 99.1% AUROCs in detection and 98.4% AUROCs in localization, respectively.
Introduction
Anomaly detection (AD), as a critical task usually refers to identifying and localizing anomalies with limited, even no, prior knowledge of abnormality. However, anomalies are very rare events under real-world application scenarios, and usually there is no prior information about anomalies, only with a large number of normal samples. Therefore, an unsupervised anomaly detection task is proposed which is usually estimated in a one-class learning setting.
Unsupervised anomaly detection approaches assume that the training dataset does not usually have anomalous samples, but provide a set of normal samples for reference, which can be used when the number of normal samples is much larger than anomalous ones. These methods are well suited for cases where it is difficult to collect anomalous data, such as medical and industrial applications [1, 2].
In computer vision field, anomaly detection refers to giving an anomaly score to the whole image. While anomaly localization is a more complex task, it assigns an anomaly score to each pixel or each patch of pixels to output an anomaly map. Thus, anomaly localization can produce more precise and interpretable results.
In anomaly detection and localization, there are basically two categorized methods which are reconstruction-based methods [3–5] and embedding similarity-based methods [6–9]. However, for anomalous images, reconstruction-based methods may sometimes produce low data reconstruction errors too, which leads to the failure of anomaly detection. Recently, embedding similarity-based methods got more promising performance, which used feature vectors from a model pre-trained by ImageNet to calculate scores by measuring the similarity between test samples and normal samples to detect anomalous regions. Compared with reconstruction-based methods, embedding similarity-based methods are not only simple and explicable, but also have outstanding performance.
However, embedding similarity-based methods still have two limitations for real-world applications. On the one hand, these methods usually require the use of extra data, such as ImageNet, to pre-train a model. This strategy may cause that models pre-trained by ImageNet lack adaptability for the detection of anomalous tiny spatial irregularities. On the other hand, previous studies used straightforward summation or concatenation for shallow and deep features of the network. However, such feature fusion approach cannot sufficiently utilize local and global information between different patches to perceive various anomalous patterns more accurately. Recently, CFA [10] made a related attempt by adding an additional patch descriptor after the pre-trained network and obtaining target-oriented features through hyper-sphere loss, thus alleviating the lack of adaptability. However, this obviously makes the network more difficult to train. Our goal is to keep the original structure without adding additional components to alleviate this problem.
Given the shortcomings of existing methods, we propose a novel anomaly detection framework named MFFA, which includes a pseudo sample generation (PSG) block, a local-global feature fusion perception (LGFFP) block, and an anomaly map compensation (AMC) block, respectively. It optimizes previous studies from the aspects of network, feature and anomaly map. Firstly, to improve the adaptability of the model to the detection of anomalous patterns and learn more essential representation from industrial datasets, we propose a PSG block that constructs a classification task with CutPaste augmentation to fine-tune the original pre-trained model, which can encourage the model sufficiently learn spatial irregularities of anomalous samples augmented by CutPaste, thus making the model more suitable for industrial anomaly detection tasks. Secondly, to better realize the local and global information interaction between different patches, we propose a LGFFP block. LGFFP block feeds the aggregated shallow and deep features to CaiT for guiding the self-attention between patches, thus helping the information interaction and fusion between different patches. Finally, our proposed AMC block uses pixel-level multiplication to compensate each other for the two anomaly maps generated by nearest neighbor search and multivariate Gaussian fitting, respectively, thus enhancing the response of anomaly map to anomalous regions and reducing the false positives of anomaly map to normal regions.
The contributions of our method can be summarized as follows. We propose a PSG block, which uses anomalous samples created by CutPaste to make the model learn the spatial irregularities unique to the anomalous pattern, so as to reduce the overestimation of the normality of anomalous features. We propose a LGFFP block, which guides the self-attention between patches, makes the multi-scale features between different patches fully be interacted and fused to increase the perception of anomalous areas. We propose an AMC block, which makes full use of the advantages of the NNS and Gaussian methods to generate a more robust anomalous segmentation map.
The remainder of this paper is organized as follows. We first review the related works in Section 2 and describe the general framework and key components of our method in Section 3. In Section 4, ablation studies are conducted, and experimental results are analyzed. Section 5 presents our conclusion.
Related works
Reconstruction-based methods
Reconstruction-based methods are widely used for anomaly detection and localization. They encoded or reconstructed normal images using neural network architectures like Autoencoder (AE) [3, 11–13], Transformer [14], Variational Autoencoder (VAE) [15–18] or Generative Adversarial Networks (GAN) [4, 20]. These methods relied on the hypothesis that generative models trained on normal samples only could successfully reconstruct normal regions, but failed for anomalous regions [12, 21]. To localize anomalies, reconstruction-based methods took the pixel-wise reconstruction error or the structural similarity index [22] as the anomaly score [11]. Recently, InTra [14] proposed a Transformer model with masked patches which tried to improve performances by using global attentions. Although reconstruction-based methods are very intuitive and interpretable, their performance is limited by the fact that they may produce low data reconstruction errors for anomalous images.
Embedding similarity-based methods
Embedding similarity-based methods used feature vectors from a model pre-trained by ImageNet to calculate scores by measuring the similarity between test samples and normal samples to detect anomalous regions [6–9, 23]. Patch-SVDD [23] extended Support Vector Data Description(SVDD) to the patch levels. The anomaly score was measured by using the Nearest Neighbor Search(NNS) based on the distance between an embedding vector from a test image and each embedding vector from training images. Patch-SVDD greatly improves the fine-grained detection of anomalies. PaDiM [6] proposed a patch-based approach that preserved the coordination from image space to feature maps, which is simple and effective and does not require much reasoning time. SPADE [8] also achieved good performance by using the K-NN algorithm on a set of normal embedding vectors at test time. Memory bank [9] and parameters of multivariate Gaussian distributions [7] were also constructed or fitted by features of normal images, so as to better record the general pattern of normal samples.
Our method is similar to the aforementioned approaches, which also uses the feature vectors of the pre-trained model and combines K-NN with multivariate Gaussian distributions to detect the anomaly. However, the MFFA framework combines and optimizes previous studies from the aspects of network, feature and anomaly map to achieve more accurate anomaly detection results.
Self-supervised learning
Self-supervised learning has been significantly developed over the past few years, which reduces dependency on labeled data and enables unsupervised semantic extraction. Representation learning is the core problem of Self-Supervised Learning in computer vision. Many methods have been proposed to learn the representation of images without labels, such as [24–26]. These methods helped models learning useful representation by training with a pretext task from unlabeled data.
In recent researches, data augmentation strategy was also widely used in anomaly detection, which transformed unsupervised tasks into supervised learning tasks [27–30] by adding pseudo-anomalies to the provided normal samples. For example, CutPaste [27] generated pseudo-anomalies by pasting small patches onto normal images and trained a model to detect these anomalous regions. DRÆM [30] jointly discriminatively learned the appropriate distance measure automatically over the joint original and reconstructed space using the simulated anomalies to produce accurate anomaly segmentation maps. MemSeg [31] proposed a memory-based segmentation network, which introduced simulated anomalies and memory samples to segment anomalies from the perspective of differences and commonalities. MSPBA [32] proposed a multi-scale patch-based representation learning method, which designed a novel loss function to extract critical and representative information from normal images by combining SVDD, rotation prediction and K-means ideas. However, these approaches were prone to bias towards pseudo-anomalies and failed to detect a large variety of anomaly types.
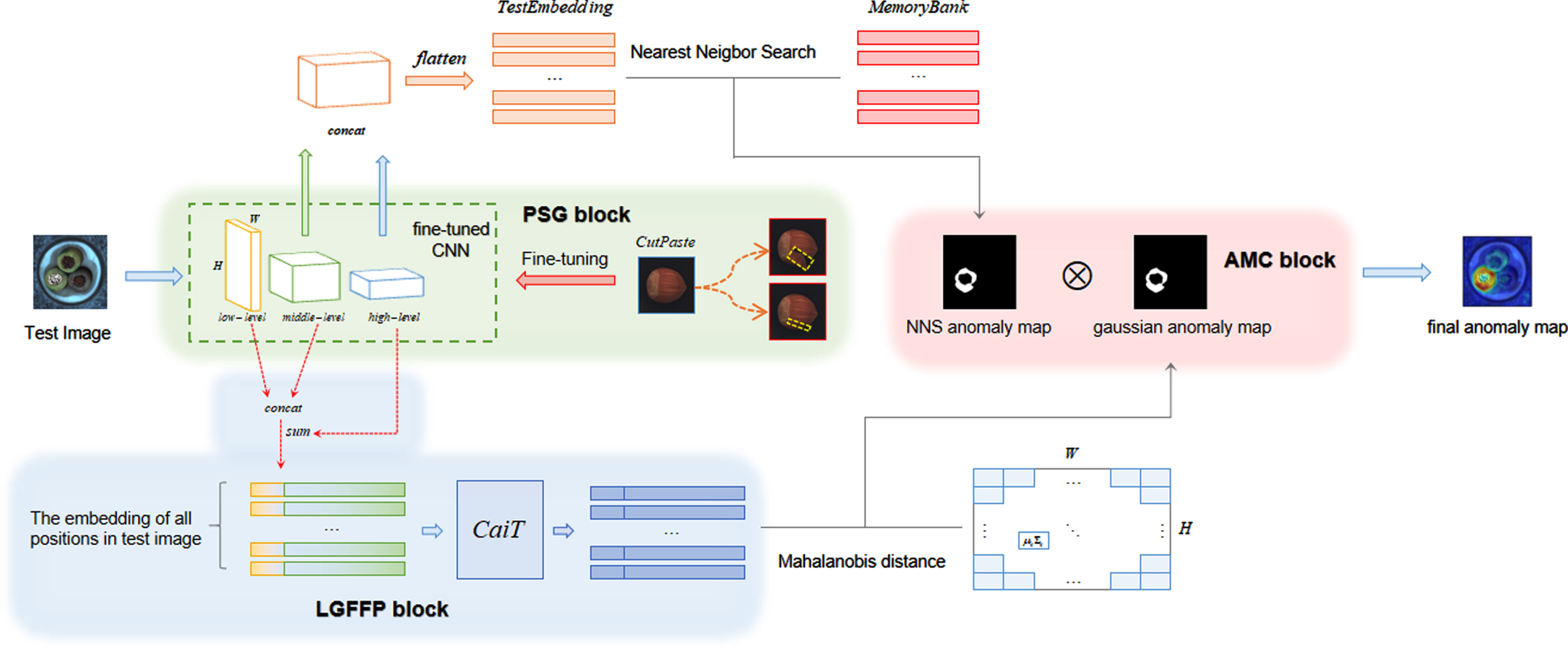
Inference process of the proposed method. The NNS anomaly map is generated by the nearest neighbor search between the test embeddings and the memory bank, and the Gaussian anomaly map is generated by the Mahalanobis distance between the embedding of each patch in test image and the learned distribution parameters. Finally, the final anomaly map is generated through the AMC block.
Overall architecture
In this section, we present our novel framework, MFFA, as shown in Fig. 1.
We first design a PSG block that constructs a classification task using CutPaste augmentation to fine-tune the original pre-trained model and make the model sufficiently learn spatial irregularities of anomalous samples augmented by CutPaste. After that, we design a LGFFP block to feed the aggregated shallow and deep features to CaiT for guiding the self-attention between different patches to effectively perceive various anomalous patterns. Then, the anomaly detection process is divided into two parts: one is used to detect anomalies in local patches, and the other is used to capture patch correlations from different semantic levels for reducing false positives. Using the Nearest Neighbor Search on the testing embeddings can better detect the responsive anomalies in local patches, and fitting multivariate Gaussian distribution for each patch of the training images can better summarize the information carried by the normal image features at each patch to learn the correlation. Finally, we design an AMC block to compensate the two anomaly maps with each other by pixel-level multiplication, which can enhance the response of anomaly map to anomalous regions and reduce the false positives of anomaly map to normal region.

(left) The process of CutPaste augmentation. Cut a small rectangular area of variable sizes and aspect ratios from a normal training image.Then, rotate or jitter pixel values in the patch. Finally, paste the patch back to the image at a random position. Particularly, CutPaste-Scar uses a scar-like (more long-thin) rectangular box. (right) The process of constructing a classification task. In this process, the pre-trained CNN is fine-tuned.
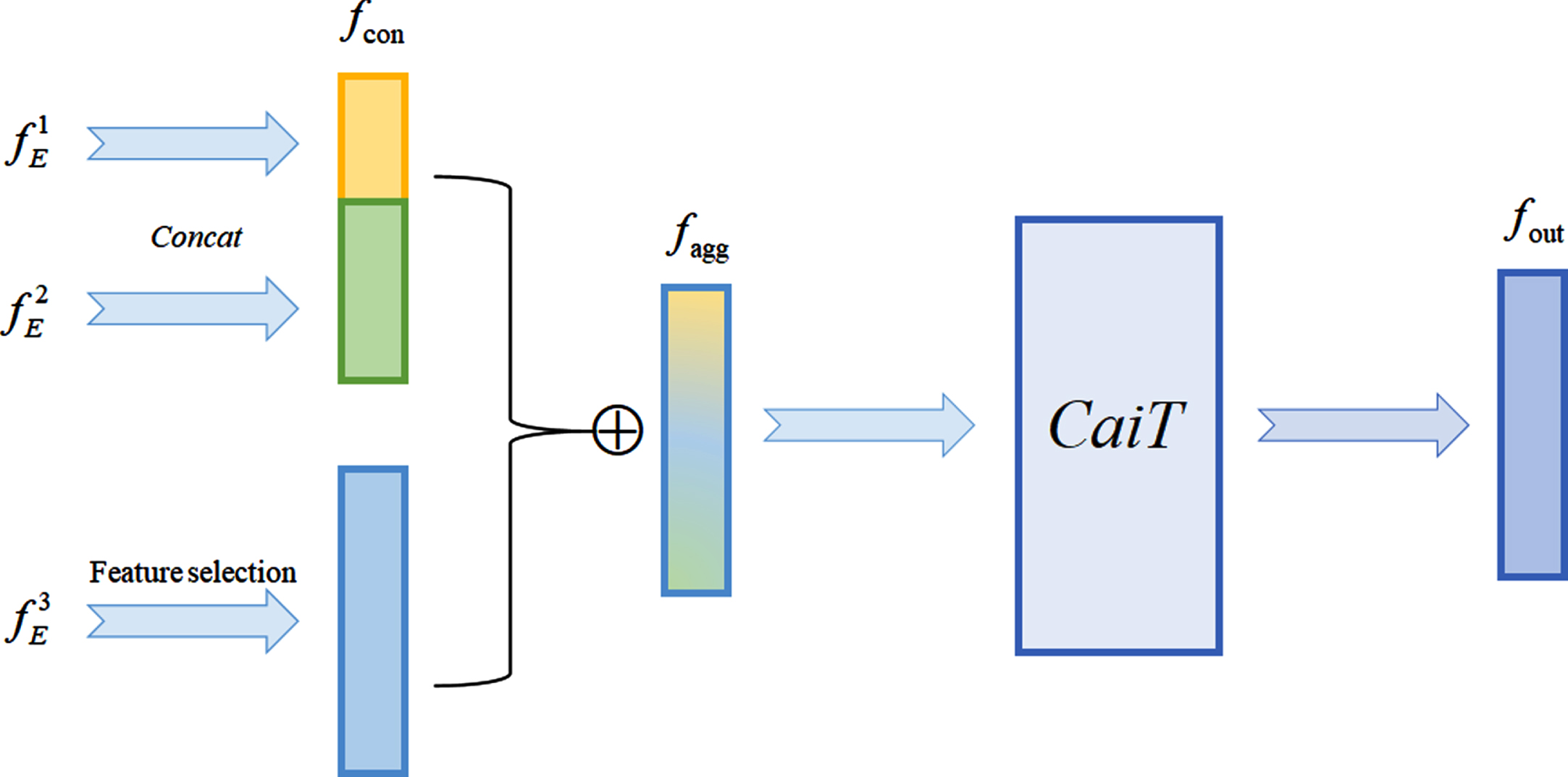
Structure of the LGFFP block. We first concatenate the features of the first two layers of the network, and then directly add the processed feature of the third layer to the concatenated feature to match the dimension of the transformer block of CaiT and aggregate local and global information. Subsequently, the aggregated feature is input into the transformer block of pre-trained CaiT to sufficiently interact information between different patches, and finally the output feature is obtained.
Embedding similarity-based methods usually require the use of additional data, such as ImageNet, to pre-train a model, which may lead to a lack of sufficient adaptability of the features extracted by the model. Because the model pre-trained by ImageNet cannot effectively detect the tiny spatial irregularities of anomalies.
Hence, to improve the generalization ability of the model and learn more information from industrial datasets, following [27, 33], we formulate a pretext task of self-supervised learning and propose a PSG block that constructs a classification task using CutPaste augmentation to fine-tune the original pre-trained model. The PSG block can encourage the model sufficiently learn spatial irregularities of pseudo samples generated by CutPaste, thus making features extracted by the model more suitable for industrial anomaly detection tasks.
Figure 2(left) shows the process of CutPaste augmentation. Following [27], we adopt the same data augmentation strategy: first, cut a small rectangular area of variable sizes and aspect ratios from a normal training image. Then, rotate or jitter pixel values in the patch. Finally, paste the patch back to the image at a random location. Noting that CutPaste-Scar uses a scar-like (more long-thin) rectangular box to fit smaller anomalies, we don’t need to completely simulate the real anomaly, just as a rough approximation. Figure 2(right) depicts the process of constructing classification tasks to fine-tune the model. The images of Normal, CutPaste, and CutPaste-Scar are input into the pre-trained CNN for classification, and in this process of classification, the CNN is fine-tuned. Then the CNN is applied to the training and inference process.
Local-global feature fusion perception block
Embedding similarity-based methods usually used straightforward summation or concatenation for shallow and deep features of the network. However, we believe that this straightforward operation cannot sufficiently utilize local and global information between different patches. To alleviate this problem and perceive various anomalous patterns, we propose a LGFFP block. The LGFFP block feeds the aggregated shallow and deep features to CaiT [34] for guiding the self-attention between patches, thus allowing full interaction of local and global information between different patches, as shown in Fig. 3. CaiT is a typical variant of ViT [35], whose performance does not saturate early with the increase of depth.
To match the dimension of CaiT, we first concatenate the features of the first two layers of the network, denoted by
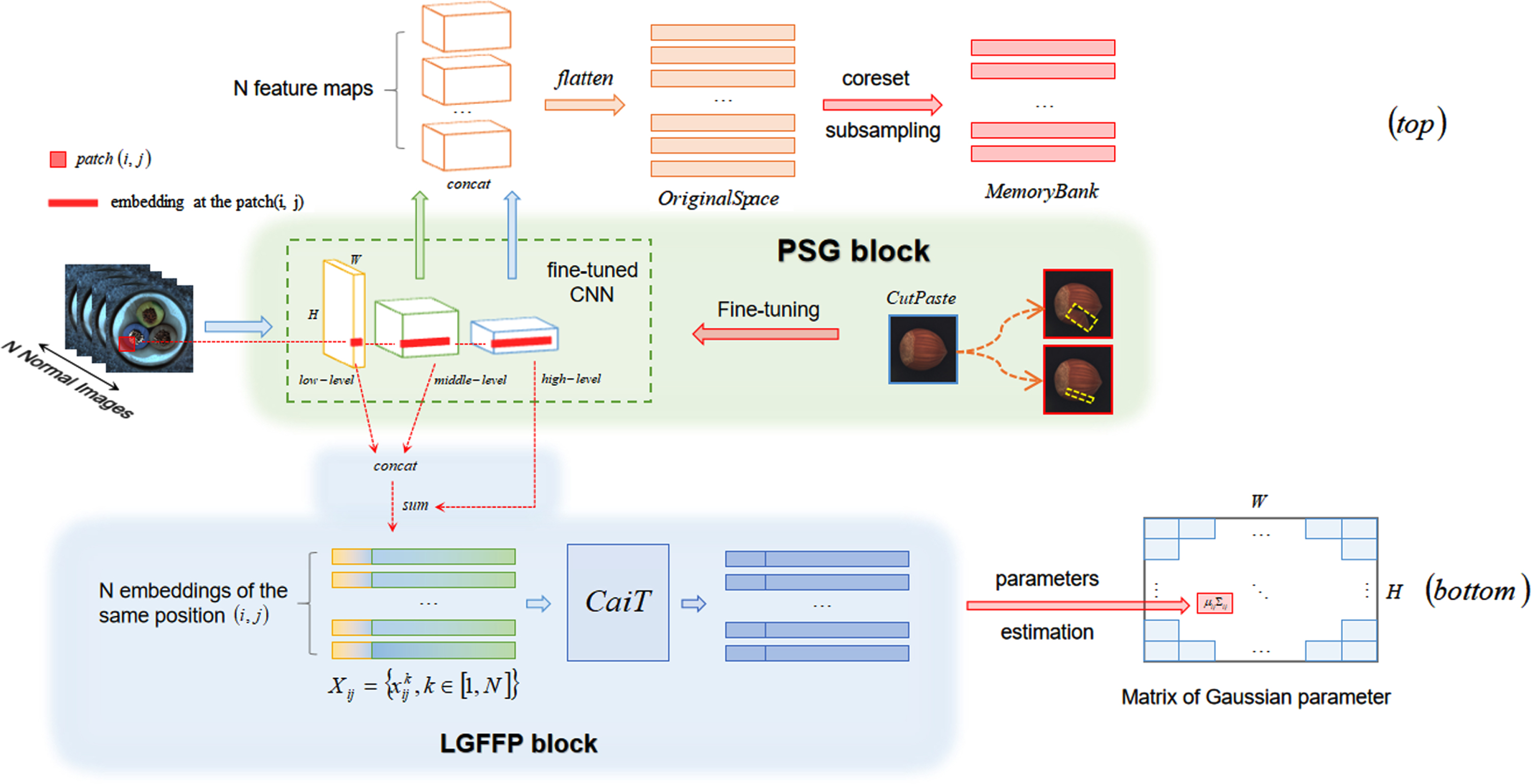
The training process of the proposed method. (top) Corset sub-sampling is used to construct a memory bank for the inference process. (bottom) The multivariate Gaussian distribution is fitted for each patch of the training images to construct the parameter matrix for the inference process.
The training process of the proposed method is divided into two parts: memory bank based nearest neighbor search and patch distribution modeling.
Figure 4 shows the nearest neighbor search method we used. Following [6, 8], we also use the pre-trained model but fine-tune it by the PSG block. To avoid features that are too generic or too biased towards the task of natural image classification, we select the middle-level and high-level features of the network and concatenate them.
At the same time, average pooling is applied to the obtained concatenated feature maps to enlarge the size of receptive fields and the robustness to small spatial deviations.
Then we flatten all concatenated feature maps and adopt the coreset sub-sampling mechanism in [9, 36–38] to select representative features to form a memory bank, thus reducing memory consumption and inference time while retaining performance.
Conceptually, coreset selection aims to find a subset S ⊂ A such that problem solutions over A can be approximated by those computed over S more closely and more quickly. Here we use minimax facility localization coreset selection to ensure that the feature coverage in the memory bank is roughly similar to the original feature space.
To further reduce coreset selection time, before selection, we reduce the feature dimension of the original feature space by random linear projections. Subsequently, the coreset selection process is as follows: firstly, a feature is randomly selected from the original space as the initial coreset element. Then, for each feature in the original space, find its nearest neighbor in the coreset in turn, and add the feature of the original space farthest from the nearest neighbor to the coreset, expanding the coreset iteratively until the number of coreset meets the condition. The final goal is to iteratively approximate:
Where M B denotes the memory bank, and M denotes the original feature space.
Equation 1 is intuitively interpreted as minimizing the maximum distance between the elements of the original space and the nearest neighbor in the memory bank. Following the method in [9], we solve for M B . We believe that using the Nearest Neighbor Search on the testing embeddings can better detect the responsive anomalies in local patches.
Meanwhile, we also use PaDiM which was proposed for modeling the patch distribution, as illustrated in Fig. 4. But, in this process, we get the patch embedding vectors generated by the CNN fine-tuned with the PSG block.
During the training process, each patch of the training images is associated with its spatially corresponding embedding vectors in the fine-tuned CNN feature maps. Embedding vectors from different layers are then fused to get embedding vectors at different semantic levels. As feature maps have a lower resolution than the input image, many pixels have the same embeddings. Hence, the input image can be divided into a grid of (i, j) ∈ [1, W] × [1, H] positions where W × H is the resolution of the largest feature map. Finally, each patch position (i, j) in this grid is associated with an embedding vector x ij computed as described above.
Since the generated patch embedding vector x ij may contain redundant information, random feature selection is adopted to reduce the complexity of training and testing time.
To learn the normal image characteristics at position (i, j), we first computes the set of patch embedding vectors at (i, j),
where the regularisation term λI makes the sample covariance matrix Σ ij full rank and reversible. Finally, each patch is associated with a multivariate Gaussian distribution as shown in Fig. 4 by the matrix of Gaussian parameters.
We believe that fitting multivariate Gaussian distribution for each patch of the training images can effectively reduce the false positives caused by the nearest neighbor search method, because it considers the correlation of multiple patches at the same localization.
In the inference process, our method generates two anomaly maps as shown in Fig. 1. The first is the NNS anomaly map M NNS generated by the nearest neighbor search, and the second is the gaussian anomaly map M gaussian generated by the Mahalanobis distance [39].
The NNS anomaly map M
NNS
is generated by the nearest neighbor search between the test embeddings and the memory bank to capture the anomalies in the local patch. The embedding sets of test images and memory bank denote
Finally, we resize AL (j) (j = 1, ⋯ , n) to the same size as the original image to obtain the NNS anomaly map M NNS .
Another anomaly map M
gaussian
is obtained by using the Mahalanobis distance Maha (x
ij
) to give an anomaly score to the patch in position (i, j) of a test image. Maha (x
ij
) can be interpreted as the distance between the test patch embedding x
ij
and learned distribution
Thus, the matrix of Mahalanobis distances
can be calculated and adjusted to the same size as the original image to obtain the gaussian anomaly map M gaussian .
Finally, we propose an AMC block to compensate each other for the above two anomaly maps. The final anomaly map M final is constructed by pixel-wise multiplication of two anomaly maps to enhance the response of anomaly map to anomalous regions and reduce the false positives of anomaly map to normal regions.
Where ⨂ denotes pixel-wise multiplication. The image-level anomaly score is defined as the maximum value of the final anomaly map M final .
Dataset description
Our proposed method is evaluated on the MVTec AD [11], which is commonly used for anomaly detection and localization in industrial fields. It contains 15 real-world categories for anomaly detection, with 5 classes of textures and 10 classes of objects. The training set consists of 3629 images without anomalies, while the testing set has both anomalous and normal images, 1725 in total. Each class has multiple anomalies for testing. In addition, it also provides pixel-level annotations for anomalous test images.
Ablation study on the complementarity of the AMC block for the Nearest Neighbor Search and the multivariate Gaussian distribution
Ablation study on the complementarity of the AMC block for the Nearest Neighbor Search and the multivariate Gaussian distribution
Ablation study on baseline(NNS+Gaussian), the PSG block and the LGFFP block
Anomaly localization results on BTAD datasets. We compare our method with VT-ADL, FastFlow, and convolutional auto encoders trained with MSE-loss and MSE+SSIM loss
All images in MVTec are resized to a specific resolution (e.g. 256 × 256). Following the convention in prior works, anomaly detection and localization are performed on one category at a time. In this experiment, we adopt WideResNet50 as the backbone of our method. The training process of the proposed method is divided into two parts. Firstly, a memory bank for the inference process is constructed by using corset sub-sampling. Secondly, the multivariate Gaussian distribution is fitted for each patch of the training images to construct the parameter matrix for the inference process.
In the memory bank construction part, we choose the layer 2 and layer 3 features of backbone and the coreset compression rate is 0.01.
Comparison of detection and localization results with state-of-the-art methods on the MVTec AD(AUROC). For each category with images of 256 × 256 resolution, the highest AUROC value is in bold
Comparison of detection and localization results with state-of-the-art methods on the MVTec AD(AUROC). For each category with images of 256 × 256 resolution, the highest AUROC value is in bold
In the multivariate Gaussian distribution fitting part, we choose the features of the first three layers of backbone, where the dimension of the third layer feature after random feature selection is 768. For CaiT, we select the first 11 transformer blocks. In the patch distribution modeling, to reduce the redundancy of patch embedding vectors, the dimension of random feature selection we used is 570. The hyperparameter λ in the covariance estimation is set to 0.01.
For the whole model training, for each class we use the same hyperparameters. We use the SGD optimizer with the momentum of 0.9, weight decay of 0.00003, and the batch size is 32. We then fine-tune the model 64 epochs with the learning rate of 0.0003.
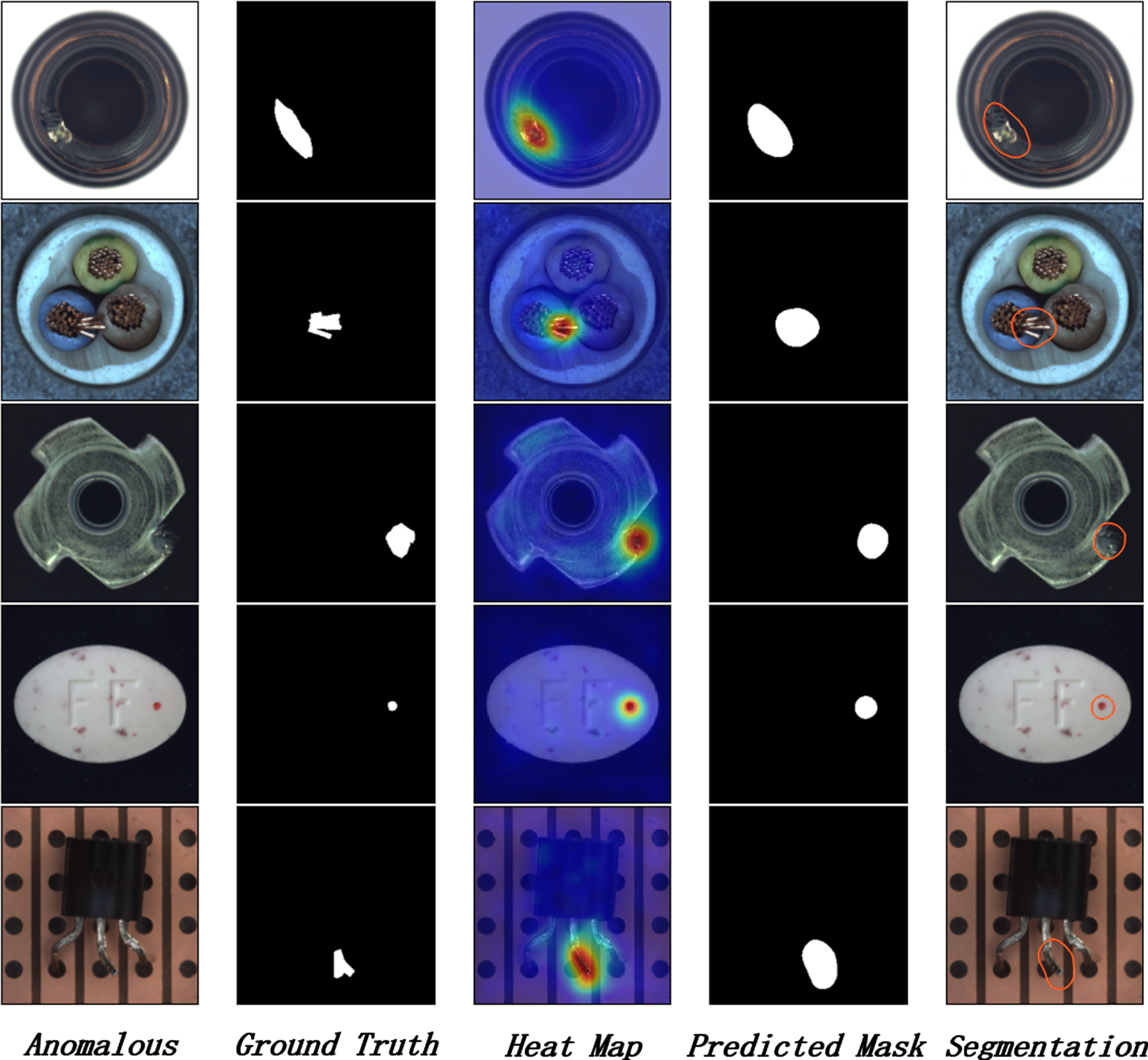
Anomaly detection examples from MVTec AD. Columns from left to right represent anomalous images, ground truth, predicted heat map, predicted mask, and segmentation results. Even tiny or inconspicuous anomalies can have strong responses.

The statistics of image-level anomaly scores with and non CaiT for all categories. The x-axis indicates anomaly score from 0 to 1 and y-axis is count.
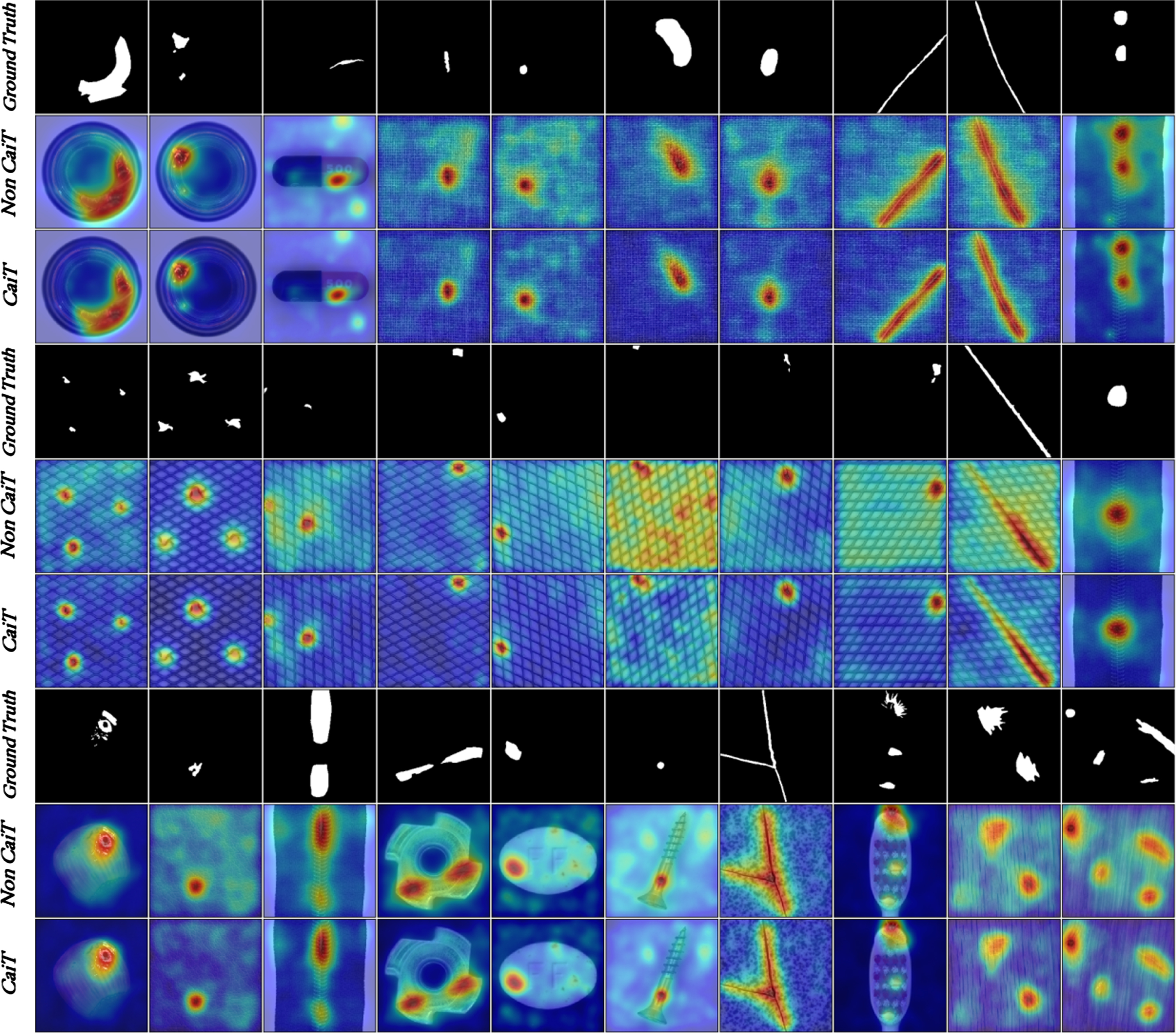
Visualization of anomaly segmentation heat maps with and non CaiT.
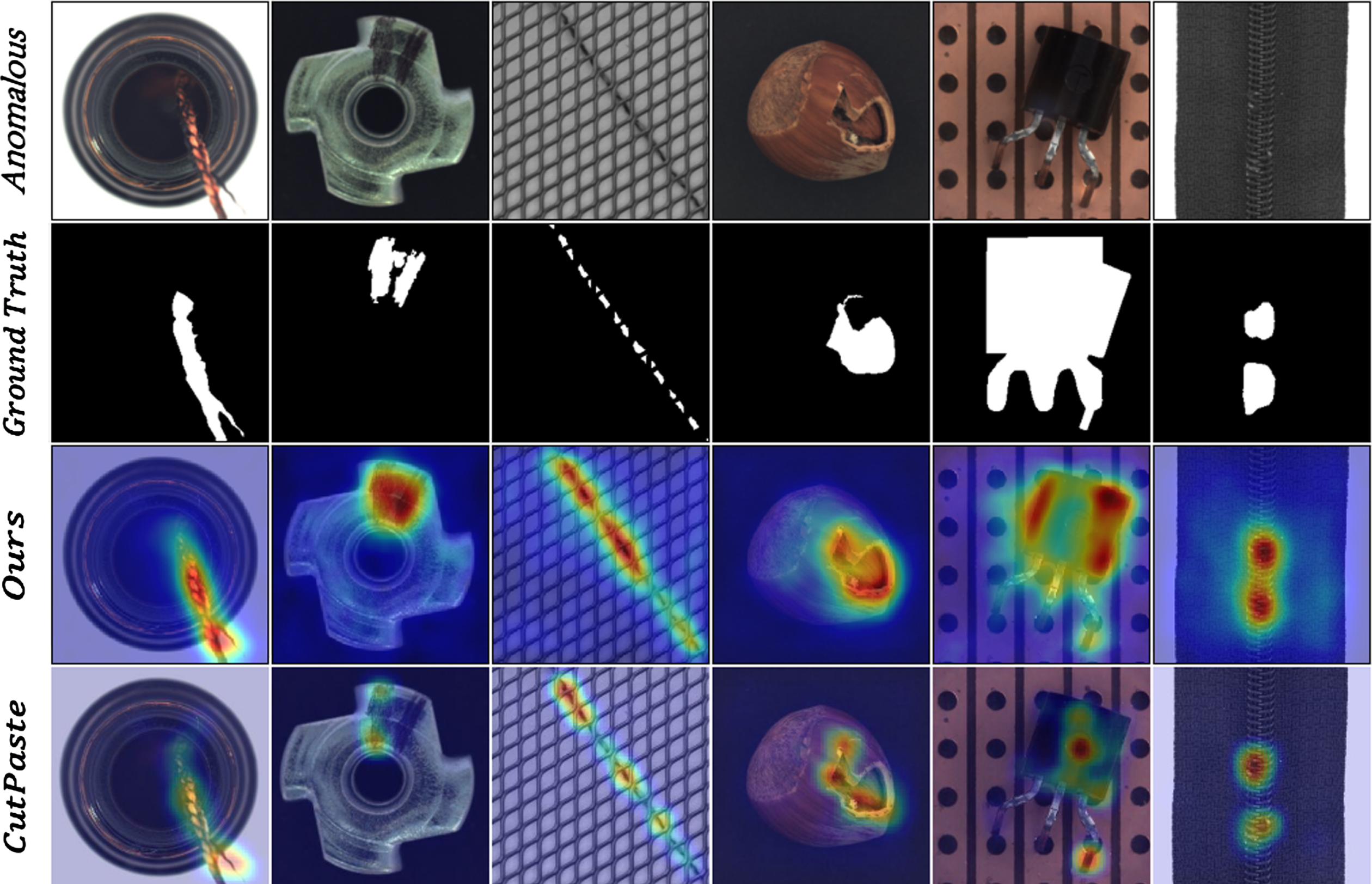
Visualization on large or structural anomalies. From left to right are: bottle, metal nut, grid, hazelnut, transistor and zipper.

Visualization on tiny or inconspicuous anomalies. From left to right are: carpet, tile, wood, cable, pill, toothbrush and screw.
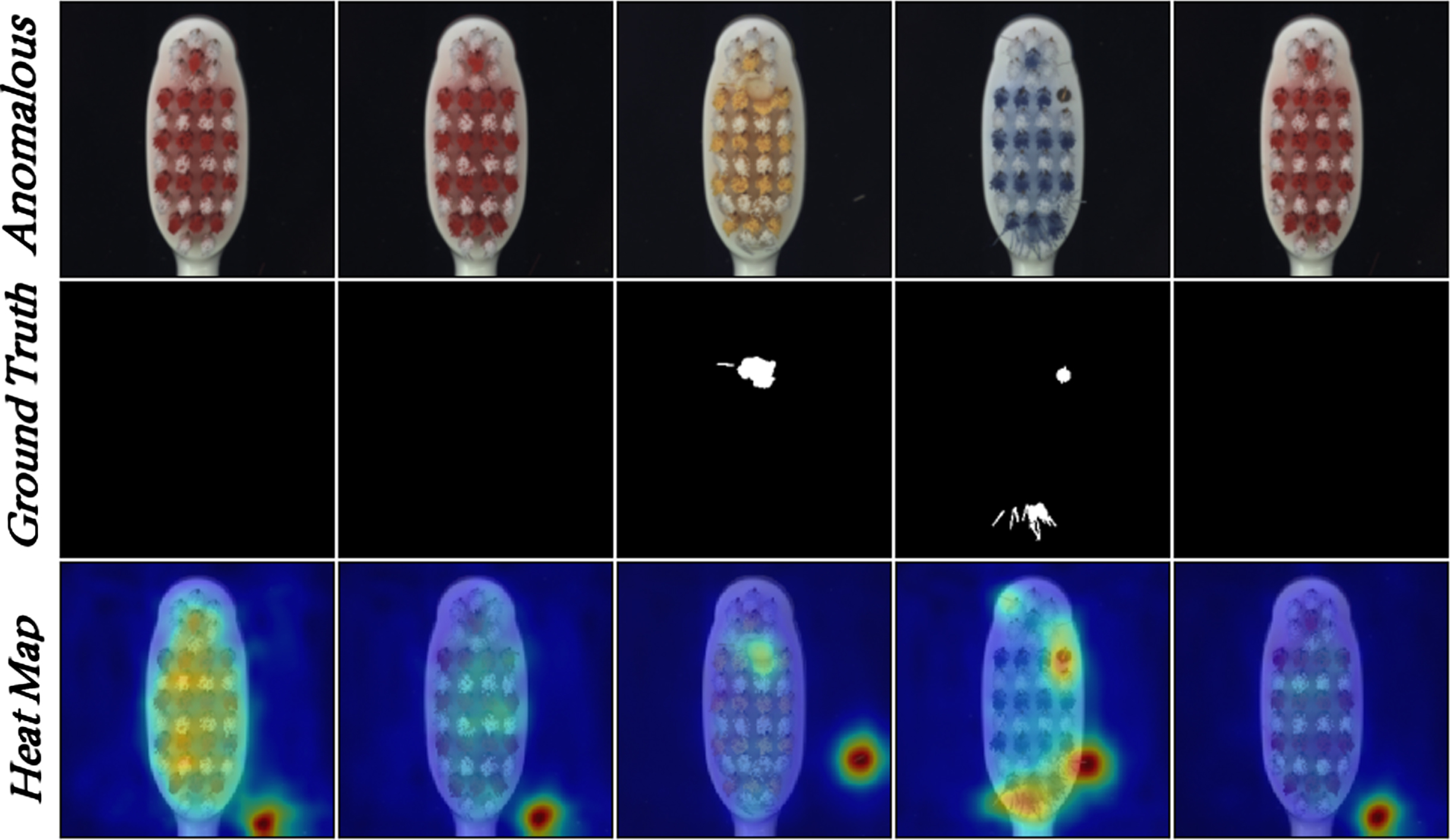
Failure cases of our method in the toothbrush category. Our method incorrectly localizes noisy regions and does not detect actual anomaly regions.
In the inference process, a Gaussian filter with σ = 4 is used to smooth the anomaly score map.
Ablation study
We conduct several experiments to analyze our method. First, we investigate the complementarity of the AMC block for the Nearest Neighbor Search and the multivariate Gaussian distribution and report the numerical results in Table 1.
We take the Nearest Neighbor Search (NNS) and the multivariate Gaussian distribution (Gaussian) as two baselines and use the network features mentioned in the experimental details. NNS can better detect the responsive anomalies in local patches, but it doesn’t consider the correlations between normal patterns, which may lead to false positives. While Gaussian learns the correlation between multiple patches at the same location, so it is more accurate in anomaly localization, but it is not as strong as NNS in response to local anomalies. Meanwhile, Gaussian is less robust to unaligned categories, and NNS can better compensate for this disadvantage. The AMC block combines the above strategies to achieve more accurate anomaly detection and localization results.
Besides, we also explore the effectiveness of the PSG block and the LGFFP block for anomaly detection and show the results in Table 2. We take the above combination (NNS+Gaussian) as the baseline and gradually add two components. From the results it can be seen that combining these components helps to improve the accuracy of anomaly detection and localization. After the addition of LGFFP block, the performance of both detection and localization is improved, which indicates that the guidance of self-attention is beneficial to increase the perception of anomalous areas. It is worth noting that the entire image is classified directly in PSG block, no fine-grained manipulation is done. Therefore, only the performance of detection is improved, while the performance of localization remains stable.
Comparison with the state-of-the-art methods
For anomaly detection and localization, we take the area under the receiver operating characteristic(AUROC) as the evaluation metric, and the results are shown in Table 3. Comparison baselines include Patch-SVDD [23], SPADE [8], PaDiM [6], CutPaste [27], Reverse Distillation [42].
The average results show that our approach exceeds state-of-the-art methods by 0.6% in anomaly detection and 0.6% in anomaly localization, reaching 99.1% AUROCs and 98.4% AUROCs respectively. For textures and objects, our approach surpasses state-of-the-art methods in both anomaly detection and localization, 99.7%/97.7% and 98.9%/98.7% AUROCs, respectively. Figure 5 shows examples of anomaly maps produced by our method, which is used to localize anomalies in images from the MVTec AD dataset.
Discussions
We analyze the effect of CaiT in the LGFFP block on the fitting of multivariate Gaussian distributions in terms of both detection and localization.
For the detection aspect, we visualize the statistics of image-level anomaly scores with and non CaiT, respectively, as shown in Fig. 6. The non-overlap distribution of normal (blue) and anomaly (red) indicates strong AD ability. For most categories, the distribution of anomaly scores does not change much. But for grid, leather, Metal Nut, toothbrush, and wood, using CaiT widens the difference between normal and anomaly scores, bringing the scores closer to the right category.
For the localization aspect, we visualize anomaly segmentation heat maps with and non CaiT, respectively, as shown in Fig. 7. CaiT pays attention to the information between different patches, thereby increasing the perception of anomalous areas.
To investigate the robustness of our method to various types of anomalies, we also classify the anomaly types into two categories: large or structural anomalies and tiny or inconspicuous anomalies, and qualitatively evaluate the performance by the visualizations in Figs. 8 and 9. Compared to CutPaste using the same augmentation strategy, our method produces a more significant response to the anomaly region.
Inference speed and simulation platform
The MFFA proposed in this paper is performed under the deep learning development framework of PyTorch, with NVIDIA Tesla P100-SXM2-16GB for GPU acceleration, Intel(R) Xeon(R) Gold 6248R CPU. We calculate the time consumption of PaDiM [6] and SPADE [8] in the inference phase, and the inference time for one image is 0.339s and 0.359s for these two models, respectively, while the time to process one image is 0.356s for MFFA, which is similar to their inference speed.
Limitations
Although our method shows better performance on average AUROC, it is less effective in specific categories. The detection results of toothbrush show that its performance is lower than the state-of-the-art methods. For this category, images have a lot of dots as noises. Our method focuses more on detecting these noises and weakens the detection of actual anomalies. We guess that this may be caused by the randomness of the CutPaste argumentation strategy, which makes the model learn the irregularities of noise. As shown in Fig. 10, our method localizes the noisy regions, but this is not the true anomaly region.
Detection and localization on other datasets
To demonstrate the generality of our method, we also evaluate our method on another dataset, BTAD [40], which has 3 categories of industrial products with 2540 images. The training set contains only normal images, while the testing set is a mixture of normal and anomalous images. Under the measure of pixel-level AUROC, we compare the results of our method with the results of FastFLow [41] and three methods reported in VT-ADL [40]: auto encoder with mean square error, automatic encoder with SSIM loss and VT-ADL. The comparison results are shown in Table 4. We can observe that our method achieves 98% pixel-level AUROC, which is higher than the best performance of FastFlow.
Conclusion and future work
We design a novel anomaly detection framework, MFFA, which optimizes previous studies from the aspects of network, feature and anomaly map. The improvements can be summarized as follows: firstly, the PSG block encourages the model to sufficiently learn spatial irregularities of generated pseudo samples, thus improving the adaptability of the model to the detection of anomalous patterns for industrial anomaly detection tasks. Secondly, the LGFFP block pays more attention to the local and global information between different patches, thus increasing the perception of anomalous areas. Lastly, the AMC block combines the advantages of memory bank based nearest neighbor search and patch distribution modeling to achieve more accurate anomaly detection results. Our experimental results show superior anomaly detection and localization performance on the real-world datasets. It achieves over 99.1% AUROCs in detection and 98.4% AUROCs in localization, respectively.
Despite the considerable performance achieved by our method, there are still some room for improvement such as the classification in PSG blocks not being generalized to a fine-grained level. In our future work, we will further extend PSG block to the patch level to improve the performance of anomaly localization.
CRediT authorship contribution statement
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Footnotes
Acknowledgment
This work was supported in part by the National Natural Science Foundation of China under Grants U1903127, and in part by the TaiShan Industrial Experts Programme under Grant tscy20200303