
Abstract
This paper proposes a robust autoencoder with Wasserstein distance metric to extract the linear separability features from the input data. To minimize the difference between the reconstructed feature space and the original feature space, using Wasserstein distance realizes a homeomorphic transformation of the original feature space, i.e., the so-called the reconstruction of feature space. The autoencoder is used for features extraction of linear separability in the reconstructed feature space. Experiment results on real datasets show that the proposed method reaches up 0.9777 and 0.7112 on the low-dimensional and high-dimensional datasets in extracted accuracies, respectively, and also outperforms competitors. Results also confirm that compared with feature metric-based methods and deep network architectures-based method, the linear separabilities of those features extracted by distance metric-based methods win over them. More importantly, the linear separabilities of those features obtained by evaluating distance similarity of the data are better than those obtained by evaluating feature importance of data. We also demonstrate that the data distribution in the feature space reconstructed by a homeomorphic transformation can be closer to the original data distribution.
Introduction
Feature extraction aims at seeking the valuable features from the data through filtering redundant information [1, 2]. Many factors can affect feature extraction, such as data dimension, data distribution, etc. From the perspective of data dimension, feature extraction becomes more and more difficulty as the dimension increases, since the data is sparse distribution upon a high-dimensional space, it is hard to afford sufficient information. However, feature extraction relies on the data information. Form the view of data distribution, usually, the data distribution is unknown and complex, which bring challenges for extracted approaches. Additional, linear separability of those extracted features are used for an evaluated metric aiming at the results of feature extraction [3]. Therefore, feature extraction of the data is a tough work.
Recently, some efforts have been proposed for feature extraction, such as distance metric-based methods, feature metric-based methods, and deep network architectures-based methods. As follows,
Distance metric-based methods. The distance between the data has many types, such as, Mahalanobis distance, Wasserstein distance, Bhattacharyya distance, etc., but such methods adopt the manner of assessing the similarity between the data by the distance between the data. Through changing the distance between the data, the linear separability between features can be increased, i.e., the margins between features can be enlarged. For instance, the [4] proposed the intrinsic semi-supervised metric learning (ISSML) with a distance metric. Similarly, the [5] proposed the information-theoretic metric learning is (ITML) by employing a distance metric. And the [6] et al proposed a deep extraction method using Mahalanobis distance. Results show that the m-AE in [6] has greater advantages than the ISSML in [4] and the ITML in [5] in the linear separability of the extracted features. However, there are still issues in them, for instance, iterative optimization issues need to be addressed during feature extraction, furthermore, feature extraction significantly relies on parameter for them. In fact, distance metric-based methods may suffer from the dear calculation cost because of calculating distances between the data. Feature metric-based methods. Such methods fully consider feature subsets of the data, and calculate feature subsets to achieve feature extraction. In terms of extracted accuracy, such methods indeed gain more since relative important features can be discovered via observing feature subsets. For instance, the [7] proposed a feature selection method with k-means through calculating a cluster of each feature subset, and fully utilizes feature relevance in the process of feature extraction. Unfortunately, calculating a cluster of each feature subset spends dear, particularly, calculation cost hardly affords for high dimensionality data or big scale data. In addition, also including LLE (locally linear embedding) [8], multi-manifold discriminant (MMD) isometric feature mapping [8], ISOMAP-KL [9]. The methods in [7–9] rely on eigen decomposition, but eigen decomposition suffers from the embarrassment of being helpless when encountering singular matrices. Because of measuring feature relevance or importance, feature metric-based methods are favored when tending to extracted accuracy, while it is difficult for them to take into account the linear separability of extracted features. More difficult, how feature relevance or importance is assessed. Deep network architecture-based methods. Usually, feature extraction can be considered to be dimension reduction of the data, so in this regard, deep network architecture-based methods have outstanding ascendency. One of classic representatives in such methods is an autoencoder architecture(AE)-based method, which is a dimension reduction method for the unknown meaningful insights [10], such as Logic-Oriented and Granular Logic Autoencoders in [11], providing the interpretable results, and Denoising Autoencoder [12], filtering noise hidden in the data, and the Sparse Autoencoder (SAE) [13], as well as, the Stacked Sparse Autoencoder (SSAE) [14]. These features extracted by these autoencoders have limitation in linear separability, since these loss functions in these autoencoders think more about extracted precision instead of considering the margins between the extracted features, so that the linear separabilities of features extracted by them are poor.
A roust autoencoder with Wasserstein distance is proposed to obtain those features of linear separability. The linear separabilities of features obtained by evaluating distance similarity between the data are better than these obtained by evaluating feature importance between the data. The data distribution in the feature space reconstructed by a homeomorphic transformation can be closer to these in the original space.
Methodology
Reconstruction of feature space
To reconstruct the feature space, here, we need to introduce a transformation both feature spaces. The [3] interprets the transformation from a feature space to another one from the point of view of probability distribution, as follows.
The [3]. Given a convex region
It can be drawn from the [3] that using the optimal mass transmission map can yield a homeomorphic transformation from a feature space to itself, that is, implementing a transformation of a feature space. Hence, the original feature space can be reconstructed through seeking the optimal mass transmission map, which is equivalent to perform a homeomorphic transformation on the original feature space. Next, we seek the optimal mass transmission map.
Lemma 1 indicates that seeking the optimal mass transportation map is equivalent to calculating Brenier’s potential. The [16] and [17] indicate that Brenier’s potential can be calculated by Kantorovich’s potential. Kantorovich’s potential can be calculated by Wasserstein distance [18]. The [19] demonstrates that when X and Y obey Gaussian distribution, respectively, i.e., X ∼ N (m1, Σ1), Y ∼ N (m2, Σ2), Wasserstein distance can be calculated, as follows
Where x ∈ X. t (x) is the transfer function. tr[] is the trace of a matrix. Equation (1) can realize a homeomorphic transformation of the original feature space, i.e., the so-called the reconstruction of feature space. Regarding the mathematical proof of Equation (1), please refer to [19].
Consequently, using Equation (1) can reconstruct the original feature space, i.e., obtaining the reconstructed feature space.
Based on the advantages of autoencoders, here, this paper designs an autoencoder with multiple-hidden layers with Wasserstein distance, namely AE-WD, and the architecture of AE-WD is as follows.
Input layer is used to map the input data. Output layers outputs the reconstructed instances.
Hidden layers. Coding hidden layers and decoding hidden layers are described, respectively. In coding hidden layers, the input and the output of the m-th hidden layer in the i-th iteration are denoted as C (in ; m ; i), C (out ; m ; i), respectively. They are calculated using Equations (2) and (3).
As for decoding hidden layers, correspondingly, the input and the output of the n-th hidden layer in the i-th iteration are given in Equation (4) and Equation (5).
Where
The loss function of AE -WD is given in Equation (6)
Where x is the input. z is the reconstructed input. W g (x, z) is the Wasserstein distance in Equation (1).
The hyper parameters of AE-WD are given, as follows,
Optimizer. Adam not only deals with sparse gradients, but also can provide different adaptive learning rates for different hyper parameters. Therefore, Adam is used for the optimizer of the model. Activation function. Compare with other activation functions, the probability of gradient vanishing caused by activation function Sigmoid and tanh is relatively high. While for ReLu, the phenomenon of gradient vanishing is partially alleviated so that gradient vanishing does not appear in the positive interval. As such, ReLu is used as the activation function of AE-WD. Iteration epochs. To converge the model, iteration epochs are dynamically adjusted through observing training accuracy. Number of neurons. Given that data dimension and data volume of the input data, we adopt a certain range to configure the number of neurons to reduce the risk of over-fitting, and then use cross-validation to determine the value of neurons.
The algorithm of the model contains two Algorithm 1 and Algorithm 2. Algorithm 1 displays the cross-validation of parameters, including the number of hidden layers K, the number of neurons N. In Step 2, we randomly selected 80% from the training set to train the model. The overall process is performed five times, independently, i.e., five cross-validation, and then the testing set is used for the validate of the trained model, i.e., parameter validation. Through observing the testing accuracy, the optimal parameter value are obtained, illustrated in the procedure in Step 3 to Step 18. The procedure of Step 6 to Step 14 verifies the number of hidden layers to obtain the optimal value Opt(K).The procedure of Step 15 to Step 18 is the the number of neurons to obtain the optimal value Opt(N).
Algorithm 2 displays the training of the model. The procedure of Step 1 to Step 7 shows the training of the model. During the training, loss function is iteratively calculated, and then the training is terminated until the model converges, thereafter, the current training accuracy is saved. In Step 8 to Step 10, the maximum training accuracy in the tmax-th training is sent out, and the trained model in the tmax-th training is final saved.
Datasets and evaluation metrics
Four benchmark datasets with different dimensionality were selected, which are widely used in machine learning tasks. In addition, we selected six high-dimensional datasets. (The ten datasets cited by http://www.ics.uci.edu/mlearn/MLRepository.html). Table 1 presents the details regarding the ten datasets. The Receiver operating characteristic curve (ROC) and corresponding area under curve (AUC) are used as evaluation metrics.
The ten datasets
The ten datasets
Competing models are considered from two aspects, of which one aspect opts for distance metric-based methods ISSML [4], ITML [5] and m-AE [6]. Another aspect applies feature metric-based methods as a comparison, including MMD [8]. Furthermore, autoencoder architecture-based models were also used as a comparison, e.g., SAE [13].
Certainly, to further compare the effects of the distance metric on the performance of AE-WD, we also developed a benchmark model with AE-WD as a reference, namely B-AE. Noting that the B-AE model has the same structure and parameters with AE-WD model but without Wasserstein distance.
The corresponding algorithms of these above models were implemented by Python on Tensorflow framework. Unless otherwise stated, these algorithms were run on the same GPU and apply the same experiment configuration.
Experiment description
We carried out three groups of experiments to verify the performance of the proposed method.
Experiment 1. This purpose is to verify the robustness of AE-WD. The ability of feature extraction to the model depends on the scale of hidden layers and neurons, so the number of hidden layers K and neurons N were verified, i.e., let K and N be set in the range of {1, 2, 3, 4, 5, 10, 15, 20}, {10, 20, 30, 50, 100, 200}, respectively.
Experiment 2. The experiment aims at comparing the linear separability of features extracted by AE-WD with these extracted by competing models. Therefore, they were run on the four benchmark datasets, and then the results were compared.
Experiment 3. The ablation experiments were also designed, aiming at proving distance metrics to be beneficial for features extraction of linearly separability.
We used five cross-folding during testing to eliminate random effects on experiment results. Two datasets originated from the four benchmark datasets were randomly selected as the training set, and then the testing was performed on these four datasets, respectively. The overall process was repeated five times, independently, the average of five testing results was used as a measurement.
Result and discussion
Testing on robustness
Results in Fig. 1 (a) show that the proposed AE-WD and the benchmark model B-AE improves along with the increasing of K in performance, and the performance remains stable when K reaches a certain scale, i.e., K = 2. This implies that AE-WD and B-AE are robust on all considered case. Figure 1 (b) shows that AE-WD and B-AE gain the greatest accuracy when N is equal to 30. Clearly, the accuracy of both starts to decline once N value exceeds 30. One reason is that over-fitting phenomenon is induced using too many neurons. Therefore, let K and N be equal to 2, 30 in subsequent experiments, respectively.
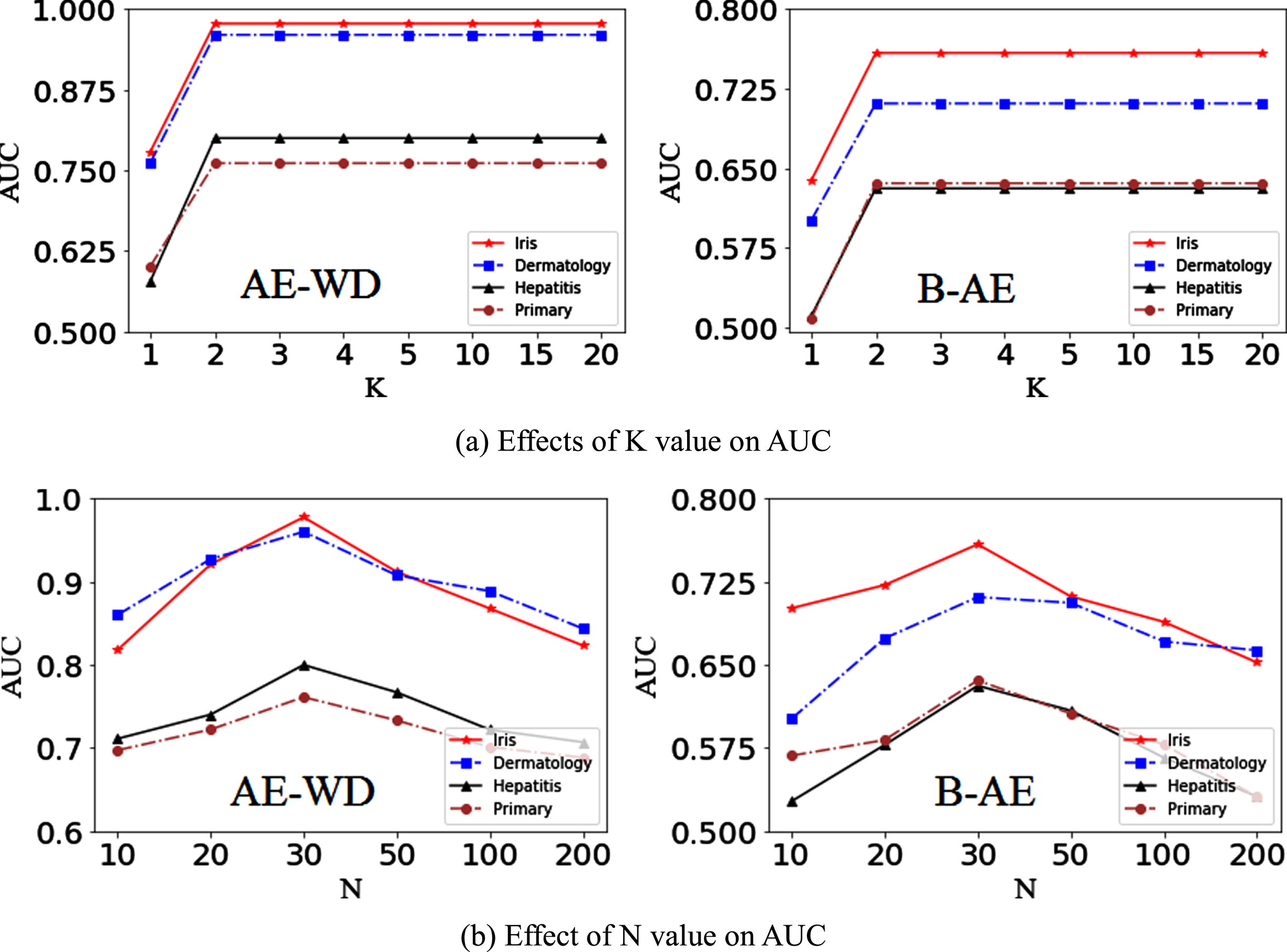
Tested results for K and N value on the benchmark datasets. (a) displays effects of hidden-layer scale on accuracies. (b) displays effects of neuron scale on the accuracies.
The extracted accuracies in Table 2 show that our AE-WD model outperforms competing models and benchmark model on seven datasets, including three benchmark datasets and four high-dimensional datasets. Especially, AE-WD has outstanding advantages on the four high-dimensional dataset Arrhythmia, Madelon, SECOM and ISOLET. However, Competitors m-AE, ISSML, ITML win competitor MMD on most datasets. Figure 2 shows that there are no significant differences between our AE-WD and the competitors. Hence, our AE-WD has outstanding advantages in terms of the extracted accuracy for all considered instances.
Extracted accuracies. The best accuracy for each dataset is shown in bold. Distance metric-based models are marked as the symbol +. Feature metric-based models are marked as the symbol = . These models without both metrics are marked as the symbol×
Extracted accuracies. The best accuracy for each dataset is shown in bold. Distance metric-based models are marked as the symbol +. Feature metric-based models are marked as the symbol = . These models without both metrics are marked as the symbol×

Statistical test results. (a) shows the test results that significance level is equal to 0.05. (b) displays the test results that significance level is equal to 0.1.
To further compare AE-WD with competitors, these extracted features on the four benchmark datasets were projected onto 2-dimensional space using principle component analysis (PCA), and then the projected results were visualized in Fig. 3. The visualized results in Fig. 3 show that it is the best for the margins between different types of features extracted by AE-WD, which means that AE-WD is a winner for the linear separabilities of the extracted features.

Visualization of the extracted features on the four benchmark datasets. Distance metric-based models are marked as the symbol+. Feature metric-based models are marked as the symbol = . The models without the both metrics are marked as the symbol×. The results of comparison method are cited the [6].
Results on ablation experiments in Fig. 4 indicate that distance metric-based models, e.g., AE-WD m-AE, ISSML and ITML, win over feature metric-based models and deep network architecture-based models in extracted accuracies. Together, these results confirm that distance metric-based models have more outstanding advantages than feature metric-based models and deep network architecture-based models in terms of the linear separabilities of features extraction.

Results on ablation experiment. Distance metric-based models are marked as the symbol +. Feature metric-based models are marked as the symbol = . The models without the both metrics are marked as the symbol×. (a) displays comparisons between distance metric-based models and the models without the both metrics. (b) displays comparisons of distance metric-based models and feature metric-based models.
The proposed AE-WD gains advantages in feature extraction of linear separabilities, which is because Wasserstein distance in Equation(1) can minimize the difference between the original feature space and the reconstructed feature space. In fact, we performed a homeomorphic transformation on the original feature space, resulting in the so-called reconstructed feature space. Then, in the reconstructed feature space, the autoencoder gains the desired linear separable features, meanwhile, calculating loss function L f in Equation(6) and using Equation(1) maximizes the classification distance between the extracted different types of features.
Certainly, the proposed AE-WD also has limitations. Due to the extracted ability of AE-WD relies on the reconstructed feature space, Wasserstein distance determines the extracted results for features, i.e., qualities of linear separability. In applications, the calculation of Wasserstein distance is very complex and difficult, so that for large-scale or high-dimensional data, the model might spend more to converge when it is trained, while this does not imply that the model cannot converge.
Distance metric-based methods are evaluated by calculating distance similarity between the data, however, feature metric-based methods are evaluated by obtaining feature importance of the data. Especially, for large-scale or high-dimensional data, the former is more suitable for feature extraction of linear separability than the latter since the calculation of the latter suffers from more difficult. Currently, there are no standard or unified feature importance assessment methods. In addition, autoencoders show excellent capabilities for feature extraction, whereas, they show poorly in feature extraction of linear separability. To address the deficiency, it is recommended that distance metrics are introduced into autoencoders, besides Wasserstein distance metric in the [3] and the [20], also considering Bhattacharyya distance metric in [21].
Conclusion
This paper proposes a robust autoencoder with Wasserstein distance for feature extraction of linear separability. Using Wasserstein distance can minimize the difference between the original feature space and the reconstructed feature space. Those features of linearly separability are obtained by using the autoencoder in the reconstructed feature space. Results show that the proposed method wins over the competitors. We demonstrate that the linear separabilities of features obtained by evaluating distance similarity between the data are better than these obtained by evaluating feature importance between the data, and the former is easier to implement than the latter. We also indicate that using the manner of a homeomorphic transformation can reconstruct feature space well, which allows the data distribution in the reconstructed feature space to be closer to the original data distribution. In future work, we will devote more efforts into the feature extraction of linear separability.
Competing interests
The authors declare no conflict of interest.