
Abstract
Bayesian decision models use probability theory as a commonly technique to handling uncertainty and arise in a variety of important practical applications for estimation and prediction as well as offering decision support. But the deficiencies mainly manifest in the two aspects: First, it is often difficult to avoid subjective judgment in the process of quantization of priori probabilities. Second, applying point-valued probabilities in Bayesian decision making is insufficient to capture non-stochastically stable information. Soft set theory as an emerging mathematical tool for dealing with uncertainty has yielded fruitful results. One of the key concepts involved in the theory named soft probability which is as an immediate measurement over a statistical base can be capable of dealing with various types of stochastic phenomena including not stochastically stable phenomena, has been recently introduced to represent statistical characteristics of a given sample in a more natural and direct manner. Motivated by the work, this paper proposes a hybrid methodology that integrates soft probability and Bayesian decision theory to provide decision support when stochastically stable samples and exact values of probabilities are not available. According to the fact that soft probability is as a special case of interval probability which is mathematically proved in the paper, thus the proposed methodology is thereby consistent with Bayesian decision model with interval probability. In order to demonstrate the proof of concept, the proposed methodology has been applied to a numerical case study regarding medical diagnosis.
Introduction
Bayesian decision making theory has been developed and refined over many decades into a powerful and practical tool. This is due in part to the importance of applications, like economic decisions [1], management science [2], pattern recognition [3] and medical diagnosis [4], that require the rational results of decision making. It is also due to the method with a solid theoretical foundation which facilitates a common-sense interpretation of action and inference under uncertainty. In general, Bayesian decision models consist of two key components, i.e., the Bayes rule and the cost function. Combining the two components, one ends up an associated rule from observations to decision [5]. It is important to note that Bayesian decision models based on traditional probabilities are required to ascertain the subjective probabilities and the related prior distribution using the prior information. But inadequacies lie in that on the one hand it is hardly to estimate point-valued probabilities due to partially known information, especially for non-stochastically stable samples. On the other hand the acquisition of probability assignment frequently depends on subjective judgment which may affect the consistency of the posterior estimations. To overcome the defects, Yager and Kreinovich [6] suggested that due to the large uncertainties in the database a more realistic case of intervally known probabilities instead of exact values can be available, and discussed the decision making techniques in case of interval probabilities. Weichselberger [7] axiomatized the concept of interval probabilities, as well as a discussion on the basic operations, and studied the Bayes rule under the condition of interval probabilities. Guo and Tanaka [8] investigated the newsvendor problem under the decision criteria with interval probabilities. But how to gain the interval-valued probabilities objectively from prior information database is of paramount importance and till now a computational challenge.
Soft set theory [9] was conceived in 1999 as a general mathematical technique to handle with uncertain or imprecise information arising in economics, engineering and environment etc. As the initiator, Molodtsov elaborated his view that the classic uncertain theories such as fuzzy set theory [10], intuitionistic fuzzy set theory [11], rough set theory [12] are sometimes incapable of capturing uncertainties in these domains which present in various types. The reason is possibly the inadequacy of the parametrization tools of these theories. To avoid this drawback, Molodtsov introduced the concept of soft set which uses adequate parametrization such as words and sentences, real numbers, functions, mappings. And explained its advantages for describing uncertainties, as well as providing some potential applications in several directions including game theory, operations research, soft analysis, etc. Later, the same author published a detailed survey of soft set theory [13]. With the formation and development of soft set theory, its applications boom in recent years and have spread to decision making [14–17], optimization [18], clustering [19], rule mining [20], medical diagnosis [21, 22], systems of soft encryption and decryption [23], assessment [24, 25], etc.
As an important branch of soft set theory, soft probability takes the advantage of adequate parametric tools so as to provide a totally different way of investigating random phenomena with limited samples. It has been successfully applied to some fields like financial portfolio control [26], credit scoring classification [27]. In contrast with the axiomatic definition in the classical probability theory, the main characteristics of soft probability embody that which directly depends on the statistics information and can be seen as an via immediate measurements over the sample base, as well as taking a parametric family of intervals as its values. It is completely data-driven and adapting of not only stochastically stable information but also non-stochastically stable information with small samples. For these reasons, the main aim of this paper is proposed a Bayesian decision model in the framework of soft probability, which can reduce subjectivity in traditional Bayesian decision making and significantly expand the scope of applications.
The remainder of the paper is organized as follows: Section 2 sketches some related background knowledge for preparation. Section 3 presents the method of Bayesian decision making based on soft probabilities, together with the corresponding implement algorithm. A numerical example is employed to illustrate the feasibility and effectiveness of the proposed algorithm in Section 4. Section 5 summarizes several main features of Bayesian risk model with soft probabilities in comparing with the traditional Bayesian decision method. Section 6 concludes the whole paper with a summary and outlook for further research.
Preliminaries
Soft probability
Generally speaking, all phenomena can be divided into three categories. The first one is called deterministic phenomenon with definite regularity. Namely, this kind of phenomenon is under certain conditions, will lead to certain results. Both the second and third categories are classed as the random phenomenon with the condition that results appeared uncertain when facing the certain situations, in which the second one is stochastically stable phenomenon satisfying the large sample statistical laws, the third one as the remaining phenomena existing widely in reality is not stochastically stable that cannot be characterized by classical probability theory.
Soft probability theory initiated by Molodtsov [26] abandons the axiomatic design of classical probability theory and general purposes of calculating the exact probability of the event. Instead, it defines directly over a statistical base, and the value of it is a parametric family of interval numbers, instead of a single point value. As new statistical data appears and the number of sample sequences increases, then these intervals become narrower such that it will be described the phenomenon more accurately. Due to the advantages of without restriction on parametrization tools and totally depending on the investigated sequential samples, soft probability can be capable of handling with any events including not stochastically stable events, in contrast to the classical probability which may be only captured stochastically stable events. Subsequent some basic knowledge regarding soft probability is recalled in brief. Molodtsov [9] first originated the concept of soft set as a new tool to express uncertain information as follows.
A soft set (F, E) in essence can be interpreted as a parameterized family of subsets of the set U. For each &z.epsi; ∈ E, the set F (&z.epsi;) consists of &z.epsi;-elements or &z.epsi;-approximate elements (solutions, points, etc.). It is worth noting that both Zadeh’s fuzzy set and Pawlak’s rough set can be treated as a special case of soft set, respectively. The notion of soft mapping raised by Molodtsov, as a natural generalization of soft set, is a fundamental tool for constructing soft sets.
On the basis of soft mapping, Molodtsov [26] puts forward a new concept of soft probability for dealing with any random events including not stochastically stable events. Suppose that Ω denotes a set of possible outcomes. The outcome of each trial associates with an element of the set Ω. Let R be the set of real numbers. A soft random function denoted by f is any bounded real-valued function over Ω, and the set of f is expressed as
A sample
It can be easily seen that soft probability is a parametric family of subintervals of the initial set R. These intervals that determined directly by all sample sizes and all statistical base sizes, provide bounds for the average values of the functions, as well as give a detailed description of average values. With no confusion soft probability is a direct measurement on a statistical base. If the event is stochastically stable, with the increase of sample size, the intervals will tend to be narrow with a large trust degree. If the event is not stochastically stable, with limited sample size, the intervals will be appeared a wide range. And it provides dynamic descriptions of random events when new statistical data appear. These characteristics makes it very convenient to handle with any types of events, including not stochastically stable case.
Connections between soft probability and interval probability
The main purpose of the current section is to explore connections between soft probability and interval probability. In many instances, the exact values of the probabilities are not easily available due to non-stochastically stable information. Instead, it is customary to employ the intervals of possible values of probabilities. Interval probability adopts an interval number to express the probability measure in order to capture fuzziness and incompleteness in a relatively simple manner.
The interval P (A) = [L (A) , U (A)] ⊆ [0, 1] for There exists a probability function p (·) satisfying L (A) ≤ p (A) ≤ U (A) for Let a set of probability functions denoted by If it implies
Note that an interval probability P (A) = [L (A) , U (A)] can be interpreted as a measure of belief, in which L (A) measures the extent to which it is certainly believed that A is true or dependable. 1 - U (A) measures the extent to which it is certainly believed that A is false or undependable. The difference U (A) - L (A) measures the extent of uncertainty of belief in the truth or dependability of A. Five special cases can be derived straightforwardly from the above definition as follows:
L (∅) =0, U (Ω) =1.
P (A) = [0, 0] indicates a belief that A is certainly false or not dependable.
P (A) = [1, 1] indicates a belief that A is certainly true or dependable.
P (A) = [0, 1] indicates a belief that A is unknown.
For a detailed survey of interval probabilities and their properties, see [7]. The following proposition establishes a connection between internal probability and soft probability.
A review of Bayesian decision theory
In current section some fundamental knowledge regarding Bayesian decision theory are recalled for preparation. Informally, a Bayesian decision making is used to select the optimal alternative based on the loss function and the posterior condition probabilities in which the latters are calculated by using Bayes rule on priori probabilities and conditional probabilities. one starts by providing the framework process of the algorithm based on Bayesian decision modeling as the following Fig. 1.
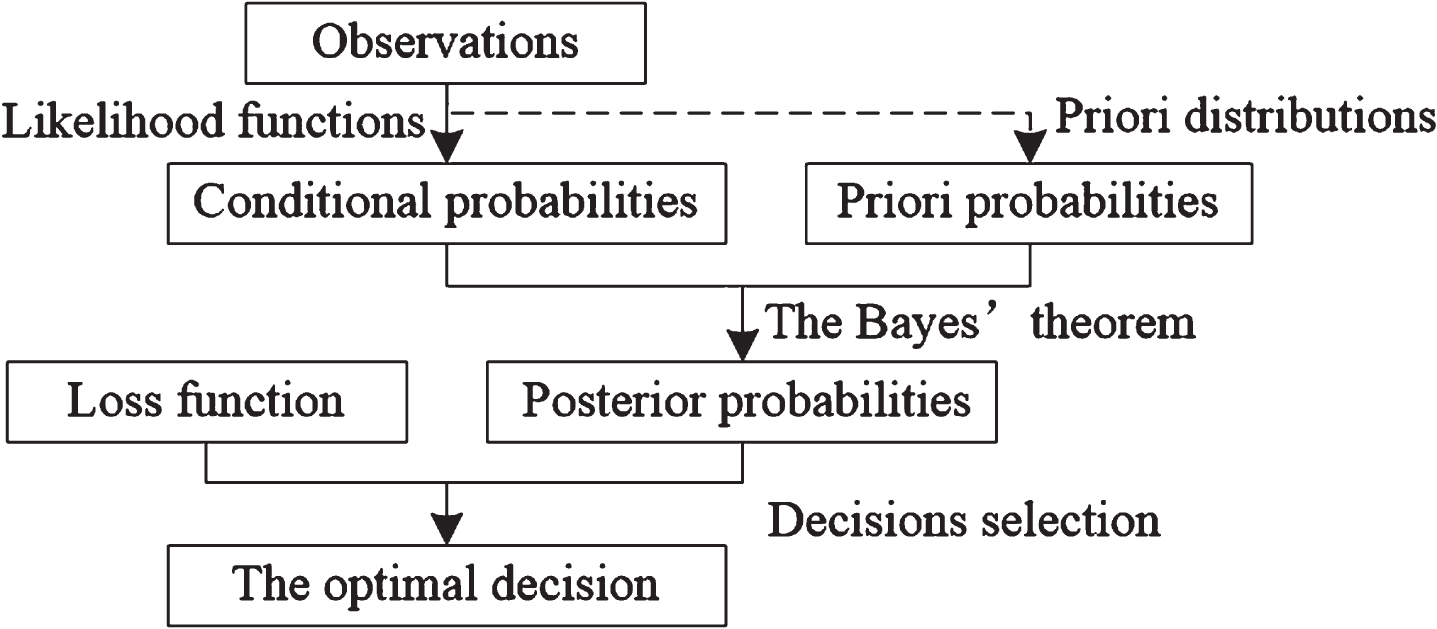
The schematic flow of Bayesian decision making.
Briefly, the Bayesian decision process can be formalized with the help of some related concepts and terminologies. Suppose that D called the decision space, denote the space of all possible decisions d that could be chosen by a decision maker (abbreviated as DM), let Θ be the space of all possible states of nature θ. Assign λ to a function called loss function, where λ (d, θ) represents loss quantity when the DM adopts decision d under the specific state θ. For simplicity assume that D = {d1, …, d m } and Θ = {θ1, …, θ n } are finite of respective dimensions m and n. Thereby eventually the losses {λ (d i , θ j ) = λ ij |i = 1, … , m ; j = 1, …, n } can be constructed a m × n matrix form called the decision-loss table that can be expressed as below.
The Bayesian modeling framework for choosing a good decision is to pick a decision whose associated expected loss to the DM is minimized. Let X be a vector called the feature vector in which entries are the observation values that describing the states in Θ. With a given trial, the DM obtains a concrete observation X. Given the priori probability of each state θ j written by P (θ j ) and the conditional probability of X given θ j written by P (X|θ j ), then the posterior probability is calculated by using Bayes’ rule
Where P (X) is computed by applying the law of total probability
With regard to a certain feature vector X, then the Bayes risk of choosing decision d i denoted by R (d i | X) is the expected loss value of λ (d i , θ j ) with respect to the posterior distribution derived by the following style
The smaller risk value R (d i | X), the better alternative d i will be. A decision d∗ ∈ D which minimizes R (d i | X) is called a Bayes decision.
The algorithm of Bayesian decision making consists of several typical steps introduced as below:
Step 1: Address the set of initial states and the set of decisions.
Step 2: Prepare decision-loss table [λ (d i , θ j )] as follows
Step 3: Given a certain feature vector X, according to the priori probability P (θ j ) and the conditional probability θ j given X denoted by P (X|θ j ), calculate the posterior probability P (θ j |X)
Step 4: In accordance with the posterior probability P (θ
j
|X) and decision-loss matrix [λ (d
i
, θ
j
)], the Bayes risk by taking d
i
denoted by R (d
i
| X) is formulated as
Our goal in this section is to rigorously integrate with soft probability and Bayesian decision rule, to present the methodology with which to copy with multiple attribute decision making where the input arguments are interval values instead of possible point values. The proposed model has the characteristics of soft probability and Bayes risk, and it is therefore named as soft probability based Bayes risk model. It is worth noting that they are natural generalizations of the method of risk-minimum Bayesian decision.
Consider a typical multiple attribute decision making problem, which contains m decision alternatives d i , i = 1, 2, …, m and n states θ j , j = 1, 2, …, n. Let X1, …, X s be a set of attributes or features. Assign a feature vector X to be a complete assignation of attributes for depicting each state, denoted by X = x, where x = {X1 = x1, …, X s = x s }, i.e., a vector x is uniquely corresponding to a certain state θ ∈ Θ. In addition, these states evaluate the alternatives by using of decision-loss matrix [λ (d i , θ j )], where λ (d i , θ j ) represents the value loss of of adopting alternative d i when meets with real state θ j that determines in advance. Note that the priori probability P (θ j ) and the conditional probability P (X|θ j ) are soft probabilities which are expressed by real subintervals of [0, 1]. The main goal is to choose the optimal decision with minimum Bayes risk. Subsequent the detailed procedure of the proposed method is illustrated as the following steps.
Calculating conditional soft probabilities
In Bayesian theory, the conditional probabilities are assumed as known point values. But when the problem is modeled by soft probabilities, not all the conditional probabilities are need to be known in advance. It is possible to approximate the unknown conditional probabilities by applying the definition of soft probability and historical bases with priori information.
Given the priori information that there exists a series of historical data {x
tj
} (t = 1, 2, …, T) for each attribute X
η
(η = 1, 2, …, s) and {θ
t
} (t = 1, 2, …, T) for taking value in the states space Θ = {θ1, θ2, …, θ
s
}, respectively. Where x
tj
is a binary value of 1 or 0 with respect to attribute X
j
at time t, namely meets or not meets the attribute X
j
. In what follows a historic database denoted by Base
T
= (Base1, Base2, …, Base
T
) consists of T records Base
t
, each contains basic data with regard to the
Given a state θ
j
∈ Θ, one can define an indicator function χ as follows
Therefore, one can obtain the basic data related to decision making consists of attributes and states denoted by
Ascertaining joints and posterior soft probabilities
Let X = (X1, X2, …, X
s
) be independent, jointly distributed random vectors by assuming independence among attributes, i.e., under the Naive Bayes assumption, the joint soft probabilities of attributes {X
η
= x
η
| Θ = θ
j
} (η = 1, 2, …, s) are calculated as follows
Bayes risk minimization
Bayesian decision making associates a loss function λ (d
i
, θ
j
) to measure the loss of classifying the alternative θ
t
to class θ
j
. Given the feature vector X = x and the loss function λ (d
i
, θ
j
), then the Bayes risk of adopting alternative d
i
with respect to x is defined as
p (a ≥ b) + p (b ≥ a) =1;
If p (a ≥ b) = p (b ≥ a), then p (a ≥ b) = p (b ≥ a) =1/2;
If a U ≤ b L , then p (a ≥ b) =0, if b U ≤ a L , then p (a ≥ b) =1;
If p (a ≥ b) ≥1/2 and p (b ≥ c) ≥1/2, then p (a ≥ c) ≥1/2.
(2) It can be straightforward obtained according to (1).
(3) If a
U
≤ b
L
, due to the fact that S (a) + S (b) = a
U
- a
L
+ b
U
- b
L
≥ 0, then
(4) It is easily proved that the equivalent form for p (a ≥ b) ≥1/2 is satisfying a U + a L ≥ b U + b L . At the same reason, the equivalent form for p (b ≥ c) ≥1/2 is satisfying b U + b L ≥ c U + c L . Consequently, a U + a L ≥ c U + c L , hence it can be concluded that p (a ≥ c) ≥1/2. This completes the proof.
Thus, we can compare Bayes risk under different decision by means of possible degrees of interval numbers. The possible degree of the pairwise comparisons judgment matrix is therefore established as follows
Take d
j
∗
∈ {d1, d2, …, d
m
} such that p
ij
∗
≥ 1/2 for ∀d
i
∈ {d1, d2, …, d
m
}. Equivalently, it satisfies the form
Step 1: Input the set of decision alternatives D = {d1, d2, …, d m } and a finite state space Θ = {θ1, θ2, …, θ n }, as well as a set of attributes X = {X1, X2, …, X s } for characterizing each state;
Step 2: Quantify the consequences of choosing each decision d i ∈ D for each possible outcome θ j ∈ Θ. Namely derive the losses {λ (d i , θ j ) = λ ij } (i = 1, 2, …, m, j = 1, 2, …, n) which can be specified as an m × n decision-loss matrix [λ ij ] mn
Step 3: With the help of the states data of the time series and attributes data with respect to each state contained in the priori information, one establishes a historic database Base T = (Base1, Base2, …, Base T ). Assign the statistical starting point l and the size of sample k, denote the pair E = (l, k);
Step 4: Construct the soft mapping (μ, E) according to Definition 3, where μ is a pair functional denoted by
Step 6: Measure the Bayes risk associated with each d i , denoted by R (d i |x) (i = 1, 2, …, m). By using of interval number ranking principle, rank all decision alternatives and select the optimal decision by minimizing the Bayes risk.
The flowchart of the algorithm above is shown in Fig. 2 as follows.
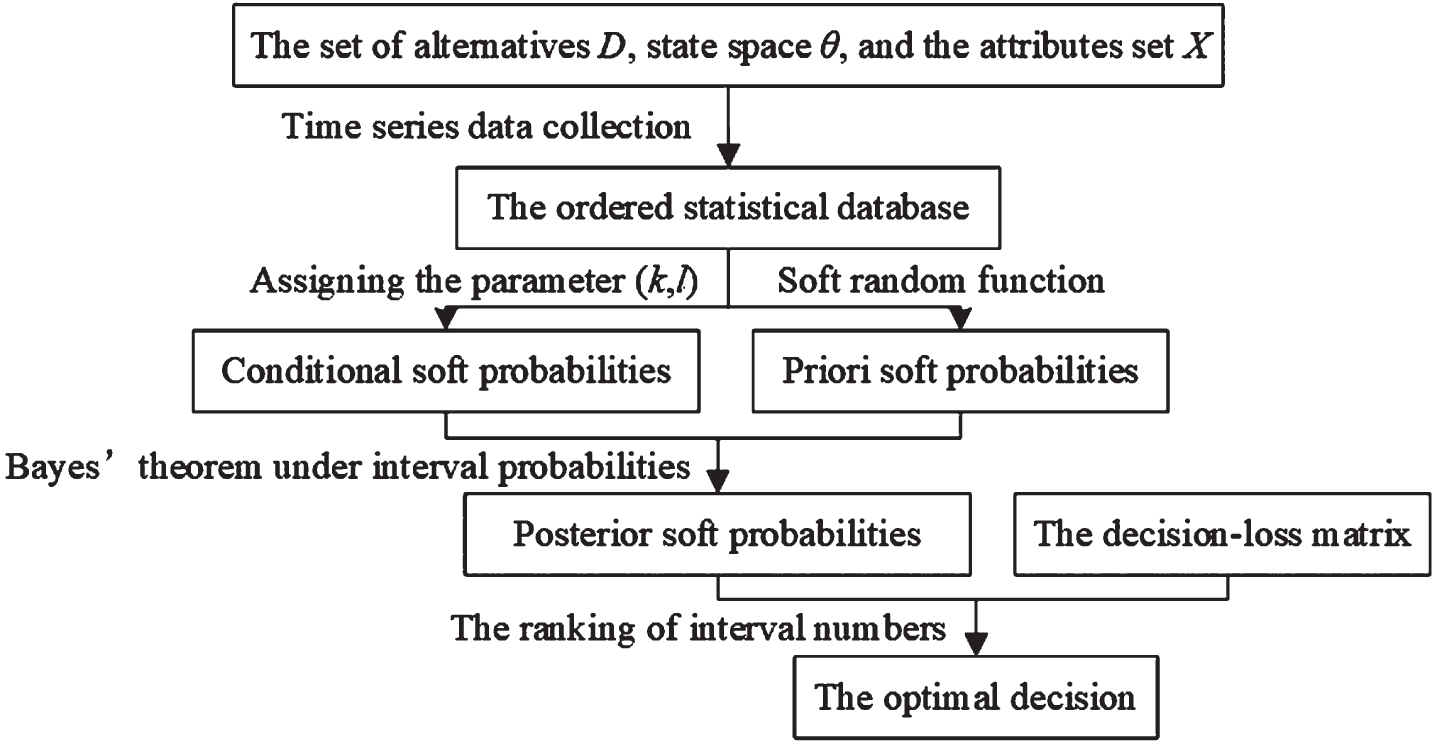
The flowchart of Bayesian decision making with soft probabilities.
In order to test validity and effectiveness of the proposed method, an illustrative example is given as follows.
Generally in medical diagnosis a patient suffering from a disease may have multiple visible symptoms. And it is also important to note that there exists certain symptoms which may be in common to more than one disease leading to diagnostic dilemma. Doctors always detect clinical manifestations based on analysis of historical diagnosis information to find the most probable disease. In addition, the possibilities of misdiagnosis exist in same cases, and wrong judgement usually leads to different consequences or losses. As a consequence, it can be formulated as a Bayesian decision problem, and the above proposed approach brings much convenience to deal with the existing uncertainty in the process of medical diagnosis.
Now consider a medical diagnosis problem with four symptoms such as headache, chest pain, cough and fever which have more or less contribution in two diseases such as flu or pneumonia. Here denotes the set of attributes as X = {x1 =“headache”,x2 =“chest pain”,x3 =“cough”,x4 =“fever”}, and denotes the set of states as Θ = {θ1=F, θ2=P}. For simplicity here F and P represent flu and pneumonia, respectively. There already exist ten patients {u1, u2, …, u10} which were diagnosed successively and thus a cases statistical base was established as shown in Table 1.
The tabular representation of cases statistical base
The tabular representation of cases statistical base
In Table 1, if a patient u t has a symptom x η , then x tη = 1, else x tη = 0.
Suppose a new patient u11 who is suffering a disease that has the symptoms consisting of headache, cough and fever. Now the problem is how a doctor detects the actual disease with the priori knowledge on the basis of cases statistical base and the exhibited symptoms among the two diseases for that patient. Apply the proposed method to detect which disease that is most consistent with symptoms. The investigative procedures are addressed as follows.
Step 1: In the decision making, we consider the two classes of diagnostic decisions, i.e., diagnose the illness as flu (abbre. d f ) or diagnose the illness as pneumonia (abbre. d p ), these two categories constitute a decision space denoted by D = {d f , d p }. We consider the set of states Θ = {θ1=F,θ2=P} as a state space and the set of attributes which contains a diagnosis parameter system, denoted by X = {x1 =“headache”, x2 =“chest pain”, x3 =“cough”, x4 =“fever”}.
Step 2: Determine the loss function λ (d
i
, θ
j
) that measures the loss of classifying patient u
t
into class d
i
knowing that the state is θ
j
. It is worthwhile to note that different loss function will yield different decision loss. Due to the fact that “0-1” model is the commonly used loss function, and it can effectively assess the correctness of decision making. Therefore, with the aid of “0-1” model, the decision-loss matrix [λ (d
i
, θ
j
)] (i = 1, 2 ; j = 1, 2) is expressed as follows
Step 4: Construct a soft mapping (μ, E) by Definition 3, thereby the priori soft probability of suffering flu and suffering pneumonia are calculated respectively as follows
The conditional soft probability with respect to flu or pneumonia
Step 5: Given the new patient u11 with observed symptoms of headache, cough and fever, written by x∗ = (x1 = 1, x2 = 0, x3 = 1, x4 = 1). In order to obtain the posterior soft probabilities, a straightforward computation of joint soft probabilities of attributes based on the attribute independence assumption shows that
Increasing the initial statistical scale l would effectively reduce the interval width of priori soft probability and make the results of decisions more accurate. For instance, let l = 4, one can obtain
Be noted that, in the example above, the patients u2 and u9 exhibit exactly the same symptoms with total different diagnosis results. Actually such situation is very common in medical diagnosis problems due to the fact that certain common symptoms may be linked to more than one disease. In this case, it is necessary to evaluating the possibility of suffering from alternative diseases on the basis of historical statistical database. Take into account the new patient u11 who is suffering a disease that has the same symptoms with patients u2 and u9. In the same respect, let k = 1, l = 4, by applying the algorithm above one will have
The ranking of interval Bayesian risk is calculated as follows: p (R (d1|x∗) ≥ R (d2|x∗)) = 0.375 < 0.5, i.e. R (d1|x∗) < R (d2|x∗). That means u11 should be diagnosed as flu based on the available information. The essential reason for this result is that priori soft probability
It worth noting that the historical statistical database only contains 10 samples in this illustration. The limited sample size may, to some extent, has restricted the results obtained by using Bayesian risk model with soft probabilities, causing the diagnosis accuracy is naturally not high. However, with the increase of the sample size, the interval values of soft probabilities will become narrower. As a result, the accuracy of diagnostic results will graduallyincrease.
Note that the proposed method integrates soft probabilities and the traditional Bayes risk model. The interval value of soft probability could be obtained automatically based on soft random function, and it has the ability of dealing with not stochastically stable information with limited samples. In comparing Bayes risk model, the proposed model typically has the advantage of less restrictions and wider application scenarios but the disadvantage of being more difficult to understand and compute. The key features of the proposed model can be concluded asfollows:
Unlike classical Bayes risk model, in which the priori probability is calculated based on prior distribution, or subjective experience, and is only applicable to stochastically stable phenomena. The proposed model does not require prior distribution information, and the priori soft probability can be seen as an objective probability that is directly relying on the statistical base and completely data driven. This makes it a more adequate formalism for application scenarios where the information is stochastically stable or not stochastically stable, and there is no limit on the samplesize.
The results of Bayesian decision can be dynamic adjusted when new statistical data appear. The soft probability will be a sufficiently narrow interval if the sample size is large enough. This leads to a more accurate posterior probability, thus the performance of Bayesian decision with soft probabilities performs more accurate with the increase in the amount of samples. Meanwhile, the formalism of the corresponding algorithm can be implemented easily in practice.
Soft probability takes a subinterval of [0, 1] as its value, it satisfies the axiomatic definition of interval probability, and can be seen as a special form of interval probability. Therefore, Bayesian decision model with soft probabilities is naturally compatible with the mature Bayesian decision model with interval probabilities. Furthermore, due to the fact that soft probability gives a detailed description of bounds for the average values for all sample sizes and all statistical base sizes, which makes Bayesian decision under soft probability is more suitable for dealing with the actual situations, especially not stochastically stable phenomena.
Concluding remarks
Decision making coping with practical problems is often under the condition of time series data that requires extraction of the statistical regulation from a set of samples regarding alternatives and their characteristics. These assessments are generally performed with uncertainty based on stochastically stable information. The classic Bayesian decision model can be considered as a powerful technique to handle uncertainty in a logical and consistent manner in decision making. But inadequacy lies in that the involved traditional probabilities can not portray non-stochastically stable scenarios which may mislead the decision process to an inaccurate decision. To avoid the drawback, this paper proposes a novel Bayesian model in the framework of soft probabilities. Note that soft probability which is proved as a special case of interval probability, is defined via immediate measurements over a statistical base and dynamic changes when new statistical data appear. It readily provides a more straightforward and natural representation to reflect non-stochastically stability and not merely stochastically stability which both lie widely in the actual problems. And thus an algorithmic scheme for implement employing the aforementioned method has been proposed. An illustrative example about medical diagnosis demonstrates the reasonability and efficiency of this method. The suggested methodology can also extend to deal with various selections and ranking problems existing in different domains as a general uncertain decision analysis method under the ordered priori information.
It is worth mentioning that the proposed method as an assembly of soft probability and Bayesian decision, has a relatively complicated process which requires a large amount of calculation and time consumption, and fits in with mainly time series data. A possible future work will concentrate on other common Bayesian decision criteria such as minimax decision criterion and the tradeoff between two types of error rate. Also, if more than one decision criterion are employed in the same Bayesian decision making under soft probabilities, a detailed discussion of ranking results based on different decision criteria and identification of optimal choice are of interest.
Acknowledgments
The research in this paper has been supported by the Scientific Research Foundation for Advanced Talents of Chongqing Technology and Business University under Grant No. 2153014. The author wishes to extend the heartily thanks to the referees for their careful reading and valuable suggestions.