
Abstract
The sudden COVID-19 epidemic has caused consumers to gradually switch to online shopping, the increasing number of online consumer reviews (OCR) on Web 2.0 sites has made it difficult for consumers and merchants to make decisions by analyzing OCR. Much of the current literature on ranking products based on OCR ignores neutral reviews in OCR, evaluates mostly given criteria and ignores consumers’ own purchasing preferences, or ranks based on star ratings alone. This study aims to propose a new decision support framework for the evaluation and selection of alternative products based on OCR. The decision support framework mainly includes three parts: 1) Data preprocessing: using Python to capture online consumer comments for data cleaning and preprocessing, and extracting key features as evaluation criteria; 2) Sentiment analysis: using Naive Bayes to analyze the sentiment of OCR, and using intuitionistic fuzzy sets to describe the emotion score; 3) Benchmark analysis: a new IFMBWM-DEA model considering the preference of decision makers is proposed to calculate the efficiency score of alternative schemes and rank them according to the efficiency score. Then, the OCR of 15 laptops crawled from JD.com platform is used to prove the usefulness and applicability of the proposed decision support framework in two aspects: on the one hand, the comparison of whether the preference of decision makers is considered, and on the other hand, the comparison with the existing ranking methods. The comparison also proves that the proposed method is more realistic, the recommendations are more scientific and the complexity of the decision is reduced.
Keywords
Introduction
Since the COVID-19 epidemic, the epidemic lockdown and isolation measures have driven consumers into the internet market and accelerated the digital transformation of e-commerce. The share of e-commerce in global retail trade increased from 14% in 2019 to about 17% in 2020. People’s shopping destinations have also gradually shifted from offline physical stores to online consumption platforms. However, due to the virtual nature of the network, it is difficult to guarantee the quality of goods. With the support of Web 2.0 technology, the emergence of a large number of OCRs on e-commerce platforms [1]. Consumers are more likely to use OCR to make a purchase decision that best suits their preferences than product information provided by the merchant [2, 3]. By using OCR, the instability of online shopping can be reduced, which also has high reference value for consumers to make purchase decisions. Enterprises also receive genuine feedback from consumers via OCR, utilize various types of available data to better understand consumer preferences and demands [4], and formulate corresponding measures to improve brand value [5, 6].
Despite the fact that many websites now give quantitative criteria for product assessment, understanding things through OCR is still suggested because to the subjectivity and unpredictability of customer evaluations. According to the 48th statistical report on China’s Internet Development released by China Internet Network Information Center (CNNIC) 1 in Beijing in August 2021, in the first half of 2021 alone, China’s online retail sales have reached 6113.3 billion yuan. The explosive growth of big data has also brought unprecedented challenges to OCR’s data mining. Because of the vast number of OCRs updated every day, customers spend a lot of time reading, this makes it difficult for them to effectively use OCR to make purchase decisions [7]. How quickly and effectively information can be extracted from OCR plays an important role in the decision making of consumers and merchants [8]. As a result, it is vital to develop a method to assist consumers in making purchasing decisions using OCR [9]. Through literature review, it is found that the research on ranking products by OCR generally includes two parts: 1) Analyzing and studying OCR, 2) Product ranking methods.
The first part is the process of analyzing and studying OCR, namely Sentiment Analysis (SA). As OCR is unstructured textual data, it is difficult to use it directly for decision analysis, so it is important to transform OCR into data that can be used for analysis [10]. The SA of OCR text is a process of analyzing, processing, summarizing and reasoning subjective text with emotional color, aiming at extracting structured opinions from unstructured text [11]. SA methods are mainly divided into sentiment dictionary-based SA methods [8, 11–14] and machine learning-based sentiment analysis methods [15–17]. However, sentiment dictionary-based SA methods cannot consider sentiment words in a context-specific setting and require constant updating of the sentiment dictionary to improve accuracy [18]. Therefore, in this paper, we use the plain Bayesian (NB) method of machine learning-based SA methods for OCR sentiment analysis, which is not only simple, but also fast, accurate and reliable [19]. The most important research content of SA is to judge the polarity of emotions, that is, to judge whether the views in the text are positive, negative or neutral [20]. However, in the existing studies, neutral emotions are often ignored [16, 21–27], which will lead to a lack of valuable information in the decision-making process. In fact, consumers’ neutral comments indicate that they are hesitant and uncertain about the product, and this information cannot be ignored [28]. The results of SA are usually expressed in the form of real numbers, triangular fuzzy numbers, intuitionistic fuzzy numbers and interval intuitionistic fuzzy numbers. In order to comprehensively consider the positive, neutral and negative emotions in OCR, nothing is more appropriate than Intuitive Fuzzy Set (IFS) theory, IFS can describe and characterize the fuzzy nature of the objective world more precisely [29].
The second section deals with product ranking methods. Commonly used ranking methods are TOPSIS, VIKOR, TODIM, PROMETHEE II. and other integrated product ranking methods [9]. Table 1 shows the main recent studies that have used OCR to rank products. Despite the significant impact of these studies, gaps in the research can be expressed as follows: some of the literature on ranking products based on OCR is based on star ratings alone [30, 31]; review criteria are given by experts based on previous experience; most rank products based on previous OCR and then make recommendations to consumers, ignoring consumers’ own purchase preferences; and the decision-making process that partially takes into account consumer preferences is again too complex and not easy to operate.
References for ranking products based on OCR
References for ranking products based on OCR
Data envelopment analysis (DEA) is a non-parametric method for measuring the efficiency of decision-making units (DMUs). DEA is a relatively common method for ranking DMUs or alternatives and has become a popular decision-making technique [32, 33]. There are also studies combining DEA and PROMETHEE to rank DMUs [34] and combining DEA and VIKOR to rank suppliers [35]. However, these studies were conducted in a deterministic setting and due to the complexity of decision making, there is a need to extend the DEA decision making approach in an uncertain setting, Muhammad Akram et al. extended DEA to Fermatean fuzzy sets to solve multi-objective transport problems [36]. Traditional DEA models are unable to take into account the uncertainty of input and output data and have no restrictions on the weights of inputs and outputs, which makes it impossible to distinguish and compare effective DMUs [37]. Researchers have proposed four approaches including general weight, weight restriction, ensuring area and taper ratio [38]. Weight restriction is a powerful method for incorporating decision maker preferences into DEA, and Hu et al. propose a method for ranking units by mixing AHP and DEA in a fuzzy setting [39]. The best-worst method (BWM) has a lower number of pairwise comparisons than AHP and yields more consistent and reliable final weights [40]. There are also few studies that have applied DEA to ranking products based on OCR.
In view of the above problems, this paper develops a decision support framework in an intuitionistic fuzzy environment and proposes a new method for ranking alternative products based on OCR that takes into account the preferences of decision makers. The method is easy to operate and provides reasonable ranking results to maximize the reference value of OCR. The main contributions of this study are as follows: Extracting key attributes from OCR as evaluation indicators is more objective and in line with the actual situation; Considering positive, neutral and negative emotional orientations, IFS are used to express the results of SA; A new IFMBWM-DEA model is proposed, which takes into account the preferences of decision makers and reduces the flexibility of weight; Through numerical experiments, the effectiveness and applicability of the proposed model are verified by using 101405 online reviews of 15 laptops captured from JD.com.
The rest of this article is as follows. Section 2 is the preliminary knowledge. Section 3 describes the decision support framework proposed in this paper. Section 4 is a numerical experiment, a case study of ranking 15 kinds of notebook computers. Section 5 is a summary, emphasizing the main contributions of this paper, the limitations of the research and future work.
renewcommand theequation thesection.arabic equation
Concepts of IFS and IFMPR
And satisfying that 0 ⩽ μ A (x) + ν A (x) ⩽1, x ∈ X, π A (x) =1 - μ A (x) - ν A (x) , x ∈ X, which denotes the hesitancy or uncertainty of the element x ∈ X to the set A. The ordered pair (μ A (x) , ν A (x)) is called an intuitionistic fuzzy value (IFV).
Where (ρ D (x) , σ D (x)) is the intuitionistic multipliers number (IMN), ρ D (x) and σ D (x) are the membership and non-membership of each element x respectively, and satisfy 1/9 ⩽ ρ D (x) , σ D (x) ⩽9, ρ D (x) σ D (x) ⩽ 1, ∀ x ∈ X, ρ D (x) and σ D (x) are represented by Saaty’s scale (see Table 1).
The following operation rules are also met:
Summary of IFMBW [56]
The steps of Intuitionistic fuzzy multiplicative best-worst method (IFMBWM) are described as follows:
Saaty’s scale 1–9
Saaty’s scale 1–9
The standard intuitionistic fuzzy multiplication optimal weight vector can be easily obtained by solving models 2.1 and 2.2:
DEA is a typical nonparametric linear programming performance evaluation model. The concept of single input and single output engineering efficiency is extended to the effectiveness evaluation of the same DMU with multiple inputs and outputs, which greatly enriches the production function theory and its application technology in microeconomics. At the same time, subjective factors are avoided, algorithms are simplified the advantages of reducing errors cannot be underestimated. To judge whether the decision-making unit is DEA effective is essentially to judge whether the decision-making unit falls on the production frontier of the production possibility set. The production frontier is the Pareto surface of linear multi-objective programming, which is composed of the effective part of data envelopment surface. Generally, DEA models are divided into output oriented and input-oriented models. The output-oriented DEA model maximizes the output of a given number of input factors, and the output-oriented DEA model minimizes the input factors required for a given output level. Suppose there are n DMUs to be evaluated, and each DMU has m input and n output. In more precise form, the input-oriented DEA-CCR model is as follows [57]:
Where, x
ij
, y
ij
respectively represents the i
th
input and r
th
output of the evaluated j
th
DMU, and w1, ⋯ , w
m
, wm+1, ⋯ , wm+s respectively represents the weight of the input and output. Moreover, x
ij
, y
ij
are known parameters and w
i
are unknown variables. The efficiency score of the DMU to be evaluated is expressed as
renewcommand theequation thesection.arabic equation
This study introduces a comprehensive decision-support framework in an intuitionistic fuzzy environment to rank alternative merchandises through online consumer reviews for decision makers to make better purchasing decisions.
The decision-support framework proposed in this paper is divided into three predominant components, including data pre-processing, sentiment analysis (SA) and benchmark analysis, of which are shown in Fig. 1. The process and essential role of each component will be depicted in detail below.
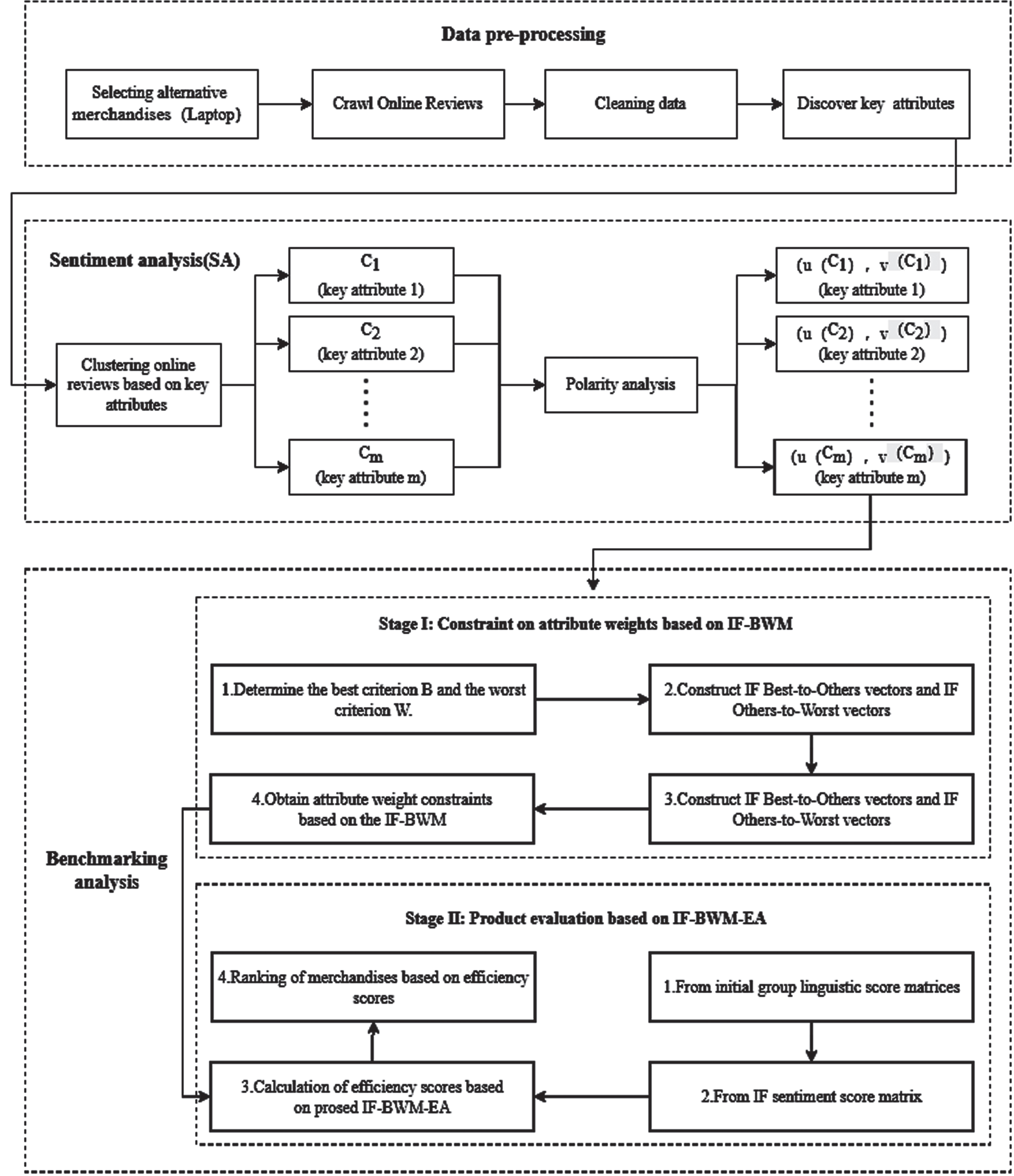
Decision-support framework for merchandises evaluation.
1) Data pre-processing:
Online consumer reviews of merchandises were crawled from the Jindong platform using python, data cleaning and pre-processing were performed on the crawled data, and then key features were extracted as evaluation indicators for judging the ranking of alternative merchandises.
2) Sentiment analysis (SA):
The cleaned online review sentences were clustered into the extracted key attribute groups, and then sentiment analysis of online reviews was conducted based on Naive Bayesian (NB), using intuitionistic fuzzy sets to describe the positive, neutral and negative sentiment scores of online consumer reviews, and constructing an intuitionistic fuzzy decision matrix based on the key features.
3) Benchmark analysis:
The proposed IFMBWM-DEA model is used to calculate the efficiency scores of the alternative solutions and then rank the alternative products according to their efficiency scores.
Crawl online reviews
Although many online shopping websites additionally supply quantitative standards such as positive rating and star rating about products (Fig. 2 shows an example of a product review crawled from the Jindong platform), it is recommended to recognize the specifics of merchandise based totally on online consumer reviews due to the subjective and variable nature of their quantification leading to polarized opinions. This paper uses python to crawl online consumer review data from JD.COM (www.jd.com) for 15 laptops of different brands (Dell, Acer, Huawei, HP and Lenovo) and different price points (below 5000, 5000 to 10000, noted as A = {A1, A2, . . . , An}, to obtain good, medium and bad reviews respectively 100 pages (Jindong has a restriction that only the first 100 pages can be viewed at most, less than that all are obtained). The crawled online comment data is stored in xls format for easy import of data by computer programs.
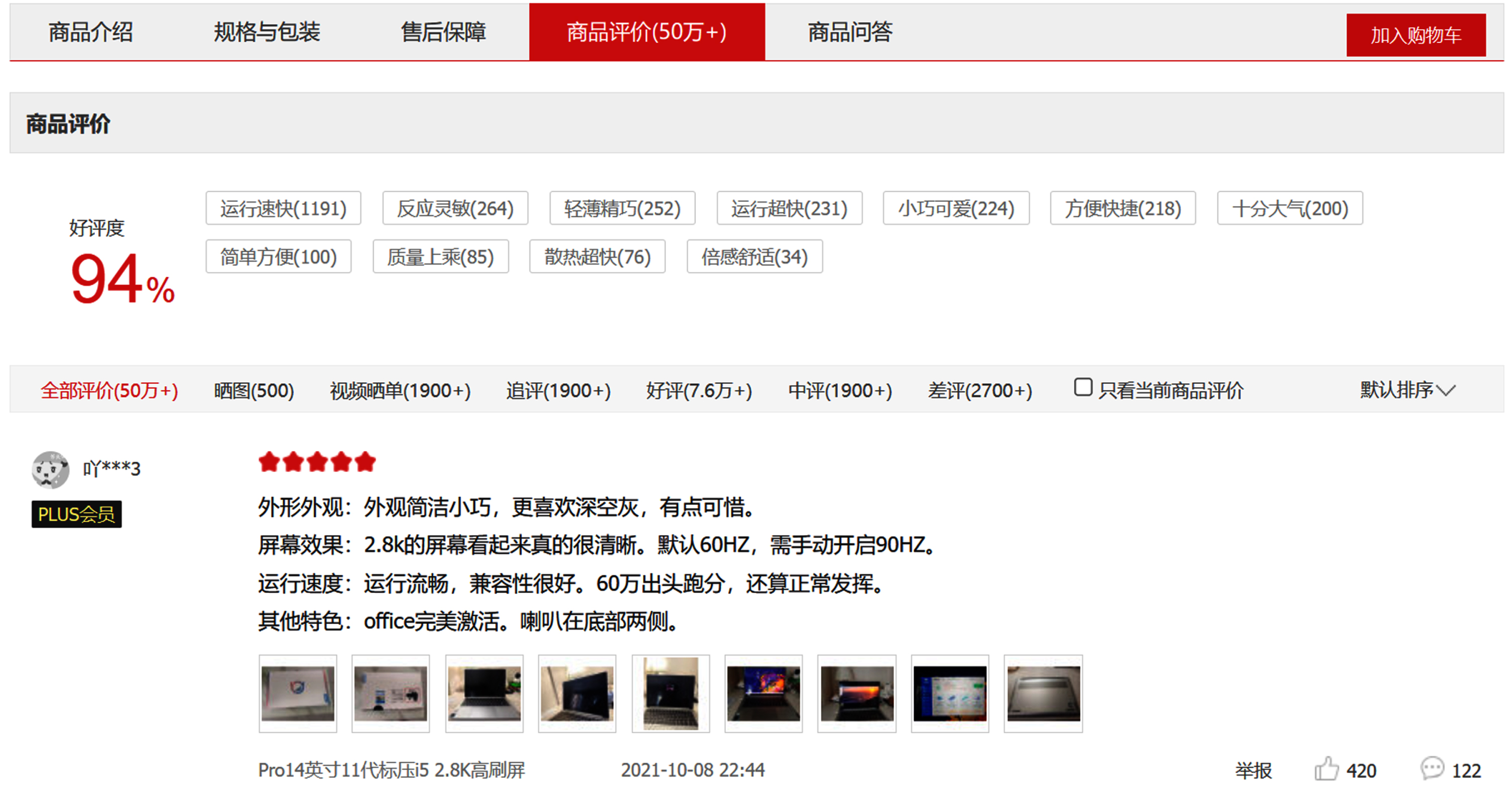
Example of a product review crawled from JD.COM.
The data pre-processing is the first task of sentiment analysis, and is the subsequent step in textual content mining, which directly affects the accuracy of subsequent feature extraction and sentiment analysis. The following are the steps of data pre-processing.
Data cleaning: this is essentially a massive re-examination and verification of data, removing duplicate information and correcting incorrect data to ensure consistency and improve data availability.
data, etc., to make sure consistency and increase the availability of data.
Tagging: Using the jieba Chinese splitting program (A statistically based approach to phrase splitting, with support for manually adding relevant specialist words to improve the lexicon and enhance the quality of the split), precise slice and dice of sentences throughout the text using exact patterns.
Deactivation: Deactivators are words that don’t convey any meaning and are useless for text mining, and commonly encompass conjunctions, prepositions, pronouns, punctuation, logical characters and special characters. In this paper, we refer to the HIT deactivation lexicon to effectively remove invalid words from the text and reduce the noise data generated throughout the word separation process.
Lexical annotation: The nature of words in online reviews is determined as well as annotated in conjunction with the contextual background, classifying words as adjectives, nouns, verbs, etc. For example, the Chinese sentence “the laptop runs very smoothly” is split and labelled as “laptop/n, runs/v, very/d, smooth/a”, where “n”, “v”, “d” and “a” are expressed as “noun”, “verb”, “adverb” and “adjective”. Correct lexical labelling will bring a great deal of convenience to the subsequent work. The nouns will give an idea of the product features that consumers are concerned about, and the adjectives will give an idea of the user’s emotional inclination towards the product.
Extraction of key features
The purpose of this step is to identify key features of alternative merchandises based on online consumer reviews (each OCR reflects a different consumer preference). Term Frequency-Inverse Document Frequency (TF-IDF) provides the statistical information needed to assess the importance of words based on document and text frequency The required statistical information is provided, so candidate keywords in online reviews are selected by calculating the TF-IDF value corresponding to each review. Using word2vec, the word vector weights were trained, after which the top 200 words with the highest frequency were obtained by splitting the words and removing those that didn’t meet the criteria. The word vectors of the acquired words were then clustered using the K-means clustering algorithm (Algorithm 1) to extract the key features and create normalized labels.
Sentiment analysis (SA)
As Web 2.0 continues to evolve, the number of OCR has increased dramatically. the impact of OCRs on purchase decisions between consumers is also increasing, and researchers are increasingly using SA to aid their decision-making process. SA is the fine-grained study of people’s opinions, sentiments, emotions and attitudes, and context mining of text is used to identify and extract subjective information from textual data. The aim of this section is to calculate a sentiment score for each feature of each product; note that here the sentiment score is denoted as IFV. Most current research on online reviews only considers positive and negative reviews, and there is a lack of research on neutral reviews, which can lead to a loss of information for decision making. This is because neutral OCRs can also be used to avoid retaliation from sellers, but are not necessarily objective. Therefore, this paper considers a combination of positive, neutral and negative emotions in OCR, enabling consumers to make faster and more accurate purchase decisions; helping merchants to further upgrade their products.
This section contains three parts, 1. Clustering of OCR based on key attribute; 2. Sentiment analysis of OCR using Naive Bayes; 3. Building an IF decision matrix based on key attribute.
Clustering of OCR based on key attribute
The pattern matching function “match” in the R programminglanguage (https://stat.ethz.ch/R-manual/R-devel/library/base/html/match.html)was applied to the clustered sentences and the OCR were clustered according to key feature sub-products using Algorithm 2.
Sentiment analysis of OCR using Naive Bayes
Naive Bayes (NB) is a machine learning method that belongs to supervised learning. Weighted Naive Bayes is an extension of NB in which attributes have different weights. The process of sentiment analysis consists of first transforming the vector, then training the classifier, dividing the dataset into a training set and a test set in an 80% :20% ratio in order to prevent overfitting of the model, and finally performing predictive classification. In this paper, the pysenti library (which utilizes weighted NB) is used to assign weights to the sentiment polarity of each sentiment word in conjunction with the sentence structure, and then weighted summation is used to obtain the sentiment polarity score of the text.
NB probabilistic classification technique based on Bayes’ theorem assumes that the attributes are independent of each other and don’t interfere with each other. The prior probability of the data is calculated using the training set text with category labels, and then the probability of the test set text belonging to a particular category is found based on Bayes’ theorem, as shown in the following formula.
Where C
i
(i = 1, 2, . . . , m) indicates that the data are classified into categories, which in this paper are set at three categories, positive, neutral and negative;X denotes the set of attributes, with X = {x1, x2, . . . , x
n
}, indicating a total of one attribute, which corresponds to the number of feature words in the text data; if P (C
i
|X) = max {P (C
j
|X)} (i ≠ j), the category of the unknown sample is judged to be category C
i
. P (C
i
) represents the probability of occurrence of C
i
category in the training set, which can be obtained by calculating the proportion of the number of C
i
category N
i
to the total sample size N, P (C
i
) = N
i
/N. P (X|C
i
) can be calculated from the prior probability of occurrence of each attribute under a category in the training text, as different attributes are assumed to be independent of each other in Naive Bayesian, thus P (X|C
i
) expressed as
Since the above equation has the same denominator
Since the assumption of conditional independence rarely holds in reality, an extension of the Naive Bayes is needed to relax the conditional independence assumption, one way of doing this is to weight the attributes differently and the resulting model is called a weighted Naive Bayes. The definition of a Weighted Naive Bayes (WNB) is as follows.
Let C = {C1, C2, . . . , C
n
} be a set of extracted key attributes and A = {A1, A2, . . . , A
m
} be the set of alternative merchandises. Since IFSs can be used to represent the uncertainty of information related to the emotions expressed (satisfaction, dissatisfaction and hesitation), so that the data from section 4.2.2, after classification according to a Weighted Naive Bayesian categorization, is used to represent the performance scores of the different attribute of the alternative merchandises in terms of the IFS α
ij
= (μ
ij
, ν
ij
), where, μ
ij
, ν
ij
denote the affiliation and non- affiliation of the i
th
merchandises in the A set based on the j
th
attribute in the C set, and π
ij
represents the hesitancy, π
ij
= 1 - μ
ij
- ν
ij
. The formula to calculate these indicators can be as follows [9].
According to the characteristic of intuitionistic fuzzy sets, μ
ij
, ν
ij
∈ [0, 1], and μ
ij
+ ν
ij
+ π
ij
= 1, denote the number of reviews in the OCR, where
In the decision-making process in real life, it is very important to consider the preferences of decision makers. Decision makers’ preferences are usually hesitant and uncertain. Therefore, in order to reduce the flexibility of the traditional DEA model DMU in choosing weights in the intuitionistic fuzzy environment, this paper uses the method of weight restriction to incorporate decision makers’ preferences into the DEA model. A new integrated IFMBWM-DEA model is proposed, which comprehensively considers the positive, neutral and negative online comments of online consumers, making the ranking of alternatives more objective in the intuitionistic fuzzy environment.
Since the IFMBWM model (2.1) and model (2.2) are nonlinear minimum models, which may produce multiple optimal solutions [58], we consider the following corresponding linear models (3.7) and (3.8) of BWM.
The equality constraints
Where,
The first objective function and the first constraint belong to DEA model; The second objective function and the third and fourth constraints are about inputs in BWM; The third objective function and the fifth and sixth constraints belong to the output in BWM; Equality constraints
By solving the model (3.11), we can get the first part of the optimal weight of intuitionistic fuzzy multiplication
The efficiency obtained from the solution is also an intuitionistic fuzzy number. According to definition 2.4, compare the efficiency and rank the products.
renewcommand theequation thesection.arabic equation
We will apply the proposed decision support framework to a case study, using Python from JD.Com (www.jd.com) captured the online consumer review data of 15 notebook computers, including Dell Lingyue 5000, Dell’s magazine 5515, Dell’s magazine G15, Acer shadow knight, Acer Feifan S3, Acer predator, Huawei mate book 14s 2021, Huawei mate Book D15, Huawei mate Book x Pro 2021, HP shadow wizard, HP star 15, HP war 99, Lenovo Xiaoxin air 14 2021, Lenovo Savior y9000k 2021 Lenovo Savior y9000p, the set of replaceable goods is represented as, and Table 3 shows the 101405 data sets of crawled online consumer comments after data cleaning.
The number of OCRs clustered into key attributes
The number of OCRs clustered into key attributes
Preprocess the online consumer comment data after data cleaning. After Chinese word segmentation, deactivation words and part of speech tagging, TF-IDF algorithm is used to extract candidate keywords in online consumer comments, and the TOP200 words with the highest frequency are reserved. After removing unqualified words, K-means clustering algorithm is used to calculate the best category attribution based on the similarity between points and create normalized labels, The K-means clustering diagram is shown in Fig. 1 below. It can be seen from Fig. 3 that when k = 6, the clustering effect is better. Therefore, words with similar meanings are classified into the same group, and a total of six key attributes are clustered, namely after-sales service, quality, logistics, price, appearance and gifts. The key attributes are shown in table.
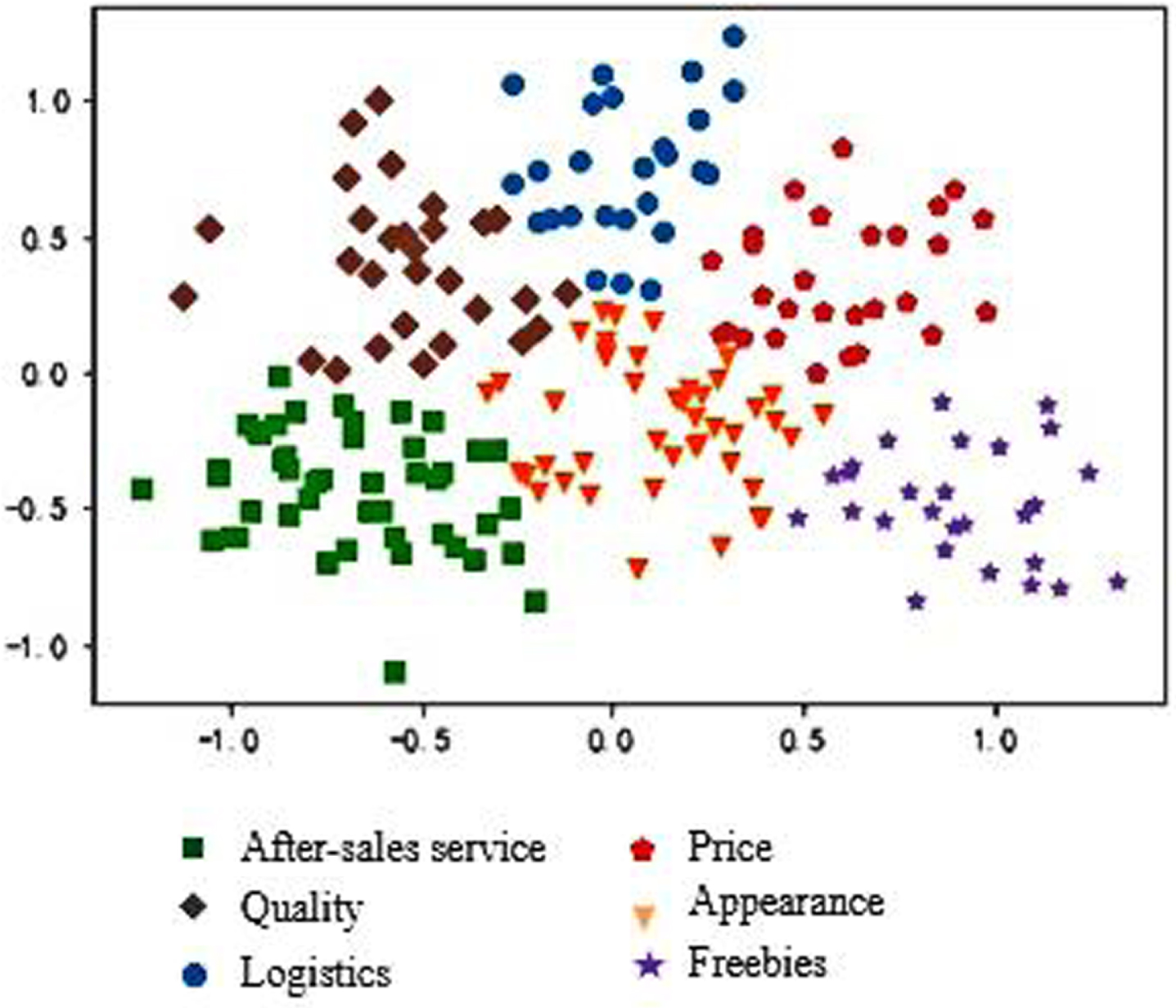
K-means clustering diagram when k = 6.
The purpose of this section is to calculate the emotion score of key attributes of replaceable products, w- here the emotion score is expressed by IFVs. This paper considers both positive and negative online consumer comments, so that potential consumers can make purchase decisions more quickly and accurately; It is also very helpful for merchants to further upgrade their products and plan publicity. First, the “match” function in R language is used to cluster the online consumer comments of alternative products according to the key attributes. The results of the number of OCRs clustered into the key attributes are shown in Table 3.
Then the preprocessed word vector is transformed, the classifier is trained, and then the weighted naive Bayes is used to give weight to the emotional polarity of each emotional word in combination with the sentence structure, and then the weighted sum is used to obtain the emotional polarity score of online consumer comments. The polarity results of emotional analysis are shown in Table 4, where POS, neu and neg respectively represent the number of online consumer comments with positive, neutral and negative emotional polarity.
The results of emotional polarity
The results of emotional polarity
Finally, the performance scores of key features are constructed into intuitionistic fuzzy numbers. First, convert the data in Table 4 into intuitionistic fuzzy numbers (such as Eqs. (3.4), (3.5) and (3.6) in section 3.2.3.), and then take the performance scores obtained according to the key features as the output in the DEA model. At the same time, because DEA model requires that decision-making units must have input variables, all decision-making units are given the same virtual input variables
Output of IFMBWM-DEA model
First, we invite experts to use Saaty’s scale to compare the key attributes C = {C1, C2, . . . , C6} extracted from online consumer reviews, and obtain the preference relationship matrix A of the consistency of intuitionistic fuzzy multiplication. The preference of intuitionistic fuzzy multiplication for virtual input is (1, 1).
According to the algorithm for sorting standards proposed by [56], the outgoing degrees of all standard nodes can be calculated,
The optimal weights of IFMBWM-DEA
The optimal weights of IFMBWM-DEA
The efficiency score and ranking results of alternative products can be obtained by substituting the obtained optimal weight into Eq. (4.12), as shown in Table 7 below.
Summary of information obtained from DEA and IFMBWM-DEA models
renewcommand theequation thesection.arabic equation
In order to prove the effectiveness of the proposed method, two aspects are compared in this section, one is the comparison between considering the preference of decision makers and not considering the preference of decision makers, and the other is the comparison between the proposed method and other existing ranking methods.
Comparison of whether or not to consider the preferences of decision makers
In order to verify whether the proposed consideration of the preference of decision makers will have an effect on the ranking of alternatives, we in contrast the DEA methods of whether to pay attention to the preference of decision makers. In order to save space, only the final results are displayed. The results are shown in Table 7.
It can be viewed from Table 7 that the ranking results of these two methods are obviously different. This is mainly due to the fact considering the preference of decision makers, the weight of attributes will have an effect on the dominance of alternative products, and then affect the final ranking of alternative products. In short, thinking about the preference of decision makers will affect the final ranking of alternative products by influencing the weight of attributes.
Comparison between the proposed method and other existing methods
The proposed IFMBWM-DEA is compared with IF-VIKOR [61] and IF-TOPSIS [62] methods.
(1) Comparison with the IF-TOPSIS method
The IF-TOPSIS product ranking method focuses on normalizing the original data matrix, determining the weight coefficients of the attributes based on expert recommendations, then calculating the weighted Euclidean distance and proximity between the alternative product and the best or worst solution, and ranking the alternative products based on proximity. The attribute weights are w = [0.15, 0.25, 0.1, 0.2, 0.15, 0.05, 0.1], and the steps of the IF-TOPSIS method are as follows.
The laptop’s positive ideal solution (PIS) A and negative ideal solution (NIS) A+– are defined as follows.
The results of the IF-TOPSIS method, which calculates the positive and negative ideal distances and similar proximity of the substitutable products, are shown in the Table 8 for the 15 laptops.
The ranking result calculated by the IF-TOPSIS method
The ranking result calculated by the IF-TOPSIS method
(2) Comparison with the IF-VIKOR method
IF-VIKOR is a MCDM based on ideal point trade-off ranking, characterized by the ability to combine maximizing group utility and minimizing individual regret to achieve a preferred choice of finite decision options. Based on the data in Table 5, group utility and individual regret are determined, and then the group utility value and the trade-off value are solved for; the smaller the trade-off value, the better the alternative. the steps of the IF-VIKOR method are as follows.
In the above equation, w i are the weights of the attributes of the integrated intuitionistic fuzzy decision matrix, and λ (0 ⩽ λ ⩽ 1) are the compromise coefficients. In the article, λ = 0.5,a compromise and balance approach are taken.
Based on the above steps of the IF-VIKOR method, the group utility value, individual regret value and compromise value of the alternative products were calculated and the results of the ranking of the 15 laptops are shown in the Table 9.
The ranking result calculated by the IF-VIKOR method
Comparing the results of ranking products using the DEA method in section 5.1, we can see that whether decision preferences are considered has a significant impact on consumers making purchase decisions. The results of ranking products by IF-TOPSIS, IF-VIKOR in section 5.2 can be seen in Fig. 4, the results of ranking products by the IFMBWM-DEA method are not identical to those of the IF-TOPSIS and IF-VIKOR methods. So we checked the correlation between the proposed method and the other MCDM methods using the Spearman correlation coefficient, which checks the relationship between the rankings obtained from the different MCDM methods, and the calculated results are shown in Table 10. It can be seen from Table 10 that although the ranking results are not identical, there is a high correlation coefficient.

Ranking results.
Spearman coefficients for IFMBWM-DEA and other ranking methods results
*p < 0.05; **p < 0.01.
The reason for the incomplete consistency of the ranking results between these methods is because that the proposed method considers consumers’ own purchase preference situations. The IF-TOPSIS and IF-VOKOR methods assume that consumers are perfectly rational when purchasing laptops, but are not perfectly rational in the actual purchase decision process [63]. Therefore, the OCR-based method of product ranking is more reasonable.
Although many websites now provide quantitative benchmarks for ranking products, it is still recommended that consumers make their purchase decisions through OCR. In contrast, the method proposed in this paper extracts key attributes from OCR as evaluation indicators, integrates positive, neutral and negative sentiment orientations, and considers the decision maker’s own preferences, making it more objective and realistic and simplifying the decision-making process.
With the explosive growth of massive amounts of data, the number of online consumer reviews is also increasing, and more and more attention is being paid to how these reviews can be used to aid decision-making. This study proposes an IFMBWM-DEA method that considers decision maker preferences and solves the proposed bi-objective model using a minimum-maximum approach. The method makes full use of IFS theory, SA, IFMBWM and DEA to deal with the ranking of substitutable products and has the following advantages in practical application.
(1) Most of the existing studies that rank alternative products based on OCR assess them on the basis of a few established criteria based on past experience. This may lead to insufficient consideration of substitutable products and increase the risk of decision making. Therefore, this paper constructs evaluation indicators by extracting the attributes that consumers care about from OCR, which is more in line with objective reality.
(2) Transforming the massive amount of OCR text information into data that can be used for decision analysis, the neutral sentiment in OCR has been neglected in previous studies, which may lead to the loss of decision information. In this paper, we use IFs to integrate positive, neutral and negative emotions in OCR.
(3) The combination of the consumer’s own preferences and OCR together determines the optimal weighting of key attributes. In this paper, we use BWM to consider decision maker preferences and combine it with DEA to rank alternative products, making the final ranking results more reasonable.
(4) Compared to previous methods of ranking alternative products based on OCR, the decision-making process is greatly simplified, making it easier for consumers to make purchase decisions through OCR.
Currently, OCR has been used in different scenarios in real life. The method proposed in this paper is not only applicable to ranking alternative products based on OCR in E-commerce to assist consumers in making purchase decisions, but also provides a low-cost and time-efficient source of information for merchants to make management decisions, and can be applied to other scenarios with similar processes. In the tourism industry, it can be used to explore the desires of travelers, explore and recommend the image of tourist destinations, improve and recommend hotel services, and evaluate and recommend restaurant satisfaction. In the medical industry, the current practice of medical management based on the Internet has improved the unbalanced allocation of medical service resources, allowing for hospital recommendations, doctor service quality evaluation and recommendations. In the film and television industry, in the context of social networking, it can be used for movie recommendations and box office forecasting.
It should be noted that this study has some limitations. Firstly, only text-based OCRs are recognized in the SA process, and the method could be improved to recognize more forms of OCRs such as emojis and videos, etc. Secondly, the method proposed in this paper only serves individual potential consumers and does not consider group decision making, the model could be extended to group decision making problems to deal with more real-world problems. In future research, we can further investigate and extend our proposed model by drawing on the novel approach to solving fractional DEA proposed by Muhammad Akram et al. in their study of Fractional transportation problems under interval-valued Fermatean fuzzy sets [64]. In this paper, we use IFs to describe uncertainty, and Robust Optimization methods are also a very effective tool for dealing with uncertainty [65–67]. In the future, we also can extend Robust Optimization methods to this DEA problem driven by online reviews and use them to assist decision makers in making effective decisions.
Footnotes
Acknowledgments
The work is supported by a research grant from the National Natural Science Foundation of China (No. 72171123, No. 72171149), National Social Science Foundation of China (No. 21ZDA105)
COVID-19 and e-commerce: a global review | UNCTAD