
Abstract
Tabular data is a widely used data form in many fields such as product marketing. In some cases, the domain shift between source and target domain of tabular data may occur with the changing of collection conditions such as time. The extant methods on tabular data mainly consist of neural-network-based methods and tree-based methods. They both meet challenges induced by domain shift on tabular data. First, neural-network-based methods are lack of effective mechanism to extract the features of tabular data and the performance may not be higher than tree-based models. Second, tree-based methods are lack of effective feature representations to model the associations between source domain and target domain. To improve the performance of tree-based methods for domain shift, a novel pseudo-label based domain adaptation method is proposed for the tree-based method called Xgboost. The proposed method consists of pseudo-label generation and selection strategies. The pseudo-label generation strategy can control the effects of pseudo-labels on Xgboost in a more flexible way by setting proper values of pseudo-labels. The pseudo-label selection strategy can select the pseudo-labels with high confidences under a consistency condition based on the outputs of Xgboost. The quality of pseudo-labels for the data in target domain is improved and so does the performance of Xgboost trained by the data in both source domain and target domain. In the experiment, several UCI datasets and 5G terminal datasets are used to show that the proposed methods can effectively improve the performance of Xgboost.
Introduction
Tabular data has been widely used in many fields such as finance, marketing and engineering. There are mainly two categories of methods for the tasks on tabular data: tree-based methods and neural-network-based methods. Tree-based methods aim to construct decision rules with tree structures. GBDT [7], XGB [2], Lightgbm[14] and Catboost [23] are the representative tree-based methods. Neural-network-based methods mainly focus on learning the feature representations and extracting effective features of tabular data via different modes structures. For example in [3, 9], wide&deep structures are proposed to extract sufficient information by fusing linear models and deep neural networks. In [8, 28], more effective feature embeddings are modeled by transformer blocks to improve the model performance. Until now, almost all the methods for tabular data focus on typical tasks. But for the scenes such as precision marketing, there may be distribution discrepancy between the source and target domain which is called domain shift. The domain shift may make models trained in source domain have performance degradation in target domain. These methods on tabular data are lack of effective mechanisms for scenes where domain drift occurs. So it is necessary to study domain adaptation mechanisms on tabular data and make models learn adaptively to overcome the performance degradation induced by the domain drift of source domain and target domain.
Extant domain adaptation methods mainly focus on the fields of CV [19], NLP [4, 10]. There are few domain adaptation methods focusing on tabular data or tree-based methods. Until now, domain adaptation methods can be divided into three categories: feature adaption, instance adaption and model adaptation. Feature adaption aims to construct invariant feature space between source domain and target domain. The ways of constructing invariant feature spaces are based on distribution discrepancies measure by the criterions in [13, 27] or the neural networks in [22]. Instance based domain adaptation methods aim to reweigh the data in source domain and the models are trained with the data in target domain. For example in [34], the cross-domain diagnostic problems in PHM are solved by instance-level weighted adversarial learning. Instance based domain adaptation methods work under the assumption that the conditional distributions of source and target domain are nearly identical, and some data in source domain can be available in target domain during reweighing such as in [20]. Model adaptation aims to modify the parameters to get better performance on target domain. For example in [35], a constrained optimization of feature normalization statistics in pre-trained source models is proposed. It is constructed by a small support set in target domain to achieve better performance.
It is necessary to study domain adaptation strategies for tree-based models. On tabular data, tree-based models have advantage over neural-network-based models on the performance of accuracy, stability and time complexity in some cases. On the other hand, most domain adaptation strategies in CV and NLP are not suitable for tree-based models on tabular data. Feature adaptation can not keep tabular structures of tabular data in invariant feature space which may lead to performance degradation of tree-based models. For instance adaptation, there are not proper reweighing strategies based on the structures of trees. For model adaptation, most methods depend on the feature space constructed by neural networks and can not be applied directly to tree structures.
Pseudo-label is a promising way to make an effective domain adaptation strategy for tree-based models. This is because the generation of pseudo-labels can depend only on the outputs of models without the constraints of model structures. Until now, most neural-network-based pseudo-label strategies focus on the regularization of neural networks with some properties, such as consistency of different model structures [16] or the consistency of class center for the data in source and target domain [30]. The pseudo-label strategies mainly depend on entropy minimization for soft pseudo-labels or the pre-defined threshold for hard pseudo-labels. There are some drawbacks of extant pseudo-label strategies on tree-based methods: The regularization of entropy minimization as soft pseudo-labels is through parameterized optimization which is not suitable for tree-based methods. This is because tree structures can not be constructed by end-to-end parametric optimization during training. The effectiveness of entropy minimization or the threshold for hard pseudo-label is not guaranteed on tree-based methods which will be discussed in this paper and may lead to performance degradation.
In this paper, a novel pseudo-label based domain adaptation method is proposed for Xgboost on tabular data. We analyze the drawbacks of entropy minimization and generate more effective pseudo-labels only by the outputs of Xgboost. We also propose a simple but effective method to select pseudo-labels with high confidence scores under a consistency condition. Our main contributions are shown as follows: A soft pseudo-label generation method is proposed to optimize the performance of Xgboost in target domain. Compared with entropy minimization, the proposed method can control the value of pseudo-label in a more flexible way according to the outputs of Xgboost. A consistency condition of pseudo-label selection is proposed to measure the confidence scores of pseudo-labels. It consists of two criterions. The first criterion selects the samples which lie in the center region of each class. The second one selects the samples which have stable outputs on Xgboost models with similar parameter values. The first one is a trivial criterion for each pseudo-label selection strategy and the second one is novel and proposed by us.
Related work
Proposed methods
In this section, the details of the proposed methods are introduced. The proposed method consists of two parts: pseudo-label generation and pseudo-label selection. First, the drawbacks of hard pseudo-label and entropy minimization as soft pseudo-label are analyzed for the tree-based method Xgboost. Then the proposed pseudo-label generation strategy is introduced to overcome the drawbacks of Xgboost. Finally, a pseudo-label selection strategy is proposed to select the pseudo-labels with high confidence scores in novel uncertainty-aware framework. Before introducing our work, let us introduce some basic notations and concepts.
Let
Given a sample
Pseudo-label generation with entropy minimization
In this section, a soft pseudo-label generation method is proposed to control the effect of generated pseudo-labels on the performance of Xgboost. Since the form of pseudo-label can be divided into hard pseudo-label and soft pseudo-label, we will analyze the drawbacks of hard pseudo-label and entropy minimization as soft pseudo-label before introducing the proposed method.
In [31, 36], the form of hard pseudo-label is defined as follows:
For entropy minimization as soft pseudo-label, the pseudo-label generator
From the drawbacks of entropy minimization, the entropy of model output should be minimized in a more flexible way by adjusting the scope where
Given a set of hyper-parameters
In this section, the pseudo-labels with high confidence are selected. Given a sample
There are two criterions to characterize the confidence of sample If If
Now, let us see the implementation details of these criterions.
For the first conterion, selecting the samples such that the distance between
Given a set
Given a sample
Pseudo-label based domain adaptation method
In this section, the framework of the proposed method is presented. The method mainly consists of three parts: training Xgboost, pseudo-label generation and pseudo-label selection. The frame of the proposed method is shown in Fig. 1:
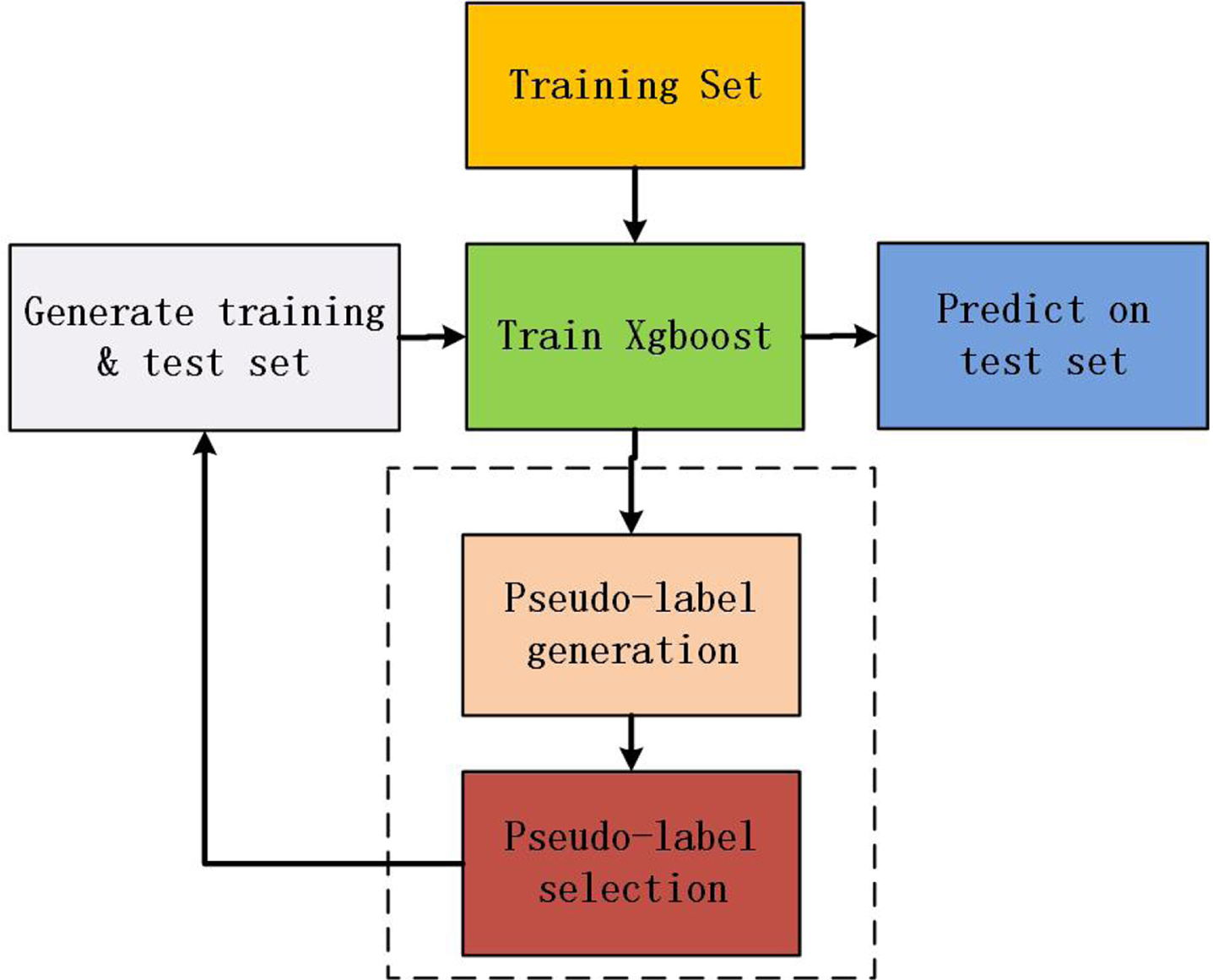
The frame of the proposed method.
In the process of training Xgboost, the training and testing set are formed. Xgboost model is trained on training set. In the part of pseudo-label generation, the proposed methods predict the testing set and generate pseudo-labels by (3) or (4). In the part of pseudo-label selection, the samples with high confidence scores are selected and form new training set with the original training set. After a few epoches, the proposed method is terminated and predict the whole testing set as the final results. The details of the proposed method are shown in Algorithm 1.
Xgboost models, parameters S0 of proposed
Xgboost model, ɛ1, ɛ2, ɛ3, a, b, c, d,
D
L
, Train Xgboost for parameters Train Xgboost model with parameters S
j
and dataset
Compute the average Go to Step 2. Compute the pseudo-labels of Go to Step 3. Set index Define set Ω : =∅ and .
Go to Step 4. Define training set Determine whether to be terminated. IF epoch <nmax epoch:= epoch + 1 Go to Step 1
Train Xgboost with parameters S0 on training set
In this section, the performance of domain adaptation strategy is compared with other neural-network-based methods, tree-based methods and some baseline variants for ablation study on several UCI datasets and 5G terminal purchase prediction dataset(i.e. 5G terminal dataset). The environment is offered by the nine day artificial intelligence platform.
For both UCI datasets and 5G terminal datasets, the methods to be compared are Logistic, MLP, Catboost, Tabnet [1], Saint [26]. The details of these models are shown as follows:
Logistic regression: logistic regression is a linear model which is optimized by Adams and the maximal epoch is set to be 30. MLP: MLP is denoted as the fully-connected neural network with two dense layer of dimension 10, 10. Catboost: Catboost is a tree-based method which is implemented by Catboost package. Tabnet: Tabnet is a nerual-network-based method in AAAI 2021. Using official implementation with website: https://github.com/\\ dreamquark-ai/tabnet. All the parameters of Tabnet are set to be default. Saint: Saint is a nerual-network-based method whose official implementation is at the website https://github.com/somepago/saint. All parameters but batchsize are set to be default. Since the sizes of higgs and 5G terminal datasets are large, the values of batchsize are set to be 2560 and the experimental results are based on the outputs within acceptable time on these datasets.
The experimental results show that the proposed method can effectively improve the performance of Xgboost on tabular data.
Results on UCI datasets
In this section, the experimental results are shown on UCI datasets. The UCI datasets include adult, bank and higgs. The task for such datasets is binary classification. Adult dataset aims to predict whether income exceeds $50000 based on census data. Bank dataset is used to predict if the client will subscribe a term deposit. Higgs dataset distinguishs between a signal process which produces higgs bosons and a background process. The statistical descriptions are shown in Table 1.
Statistical details of UCI datasets
Statistical details of UCI datasets
Since the datasets of bank and higgs are not divided into training sets and testing sets, 80% samples are randomly chosen from the whole dataset as training set and the others are testing set.
The proposed method is named as Xgbours. The baseline methods consist of xgb1, xgb2, xgb3 and Xgbpseudo. The details of these models are shown as follows: xgb1,xgb2,xgb3: xgb1,xgb2 and xgb3 are general implementations of Xgboost with different key parameters. Xgbpseudo: Xgbpseudo is the implementation of Xgboost model where pseudo-label generation is applied but pseudo-label selection is not applied during training. Xgbours: Xgbours is the implementation of Xgboost model where both pseudo-label generation and pseudo-label selection are applied during training.
The common parameters of these models are shown in Table \ref paraUCI, where Num.E represents the number of trees and Wei.ps represents the weights of positive samples.
Parameters of Xgboost on UCI datasets
For UCI datasets, the precision of binary classification is measured for each method. All models output the probability of positive class and negative class as binary classification. Since training set and testing set are randomly selected from the whole dataset, the results may be different among the choices. All of them are shown in Table 3.
The accuracy(%) of classification for UCI datasets\label resultUCI
The experimental results of Table 3 show that after domain adaptation, the proposed method can achieve better performance than the baseline methods. Both pseudo-label generation and selection method can improve the performance of Xgboost on all datasets. The effects of pseudo-label generation method are more significant than that of pseudo-label selection method. The proposed method Xgbours has advantage over Adult and Higgs compared with Tabnet and Saint. But for Bank, Xgbours is not better than Saint in accuracy.
In 5G terminal purchase prediction, the mobile company needs to determine the people who purchase 5G terminals in next month from the crowd target database by binary classification. The people with 5G terminal purchase behaviors are labeled as positive samples, and the people without 5G terminal purchase behaviors are labeled as negative samples.
The dataset is collected from a city for the precision marketing of 5G mobile terminals. It is monthly data where the features of people behaviours are collected in current month, and the labels are whether purchase behaviors occur in next month. When purchase behavior occurs for a person, the label is set to be 1, otherwise 0. The number of samples for each month is from 4.5 million to 5.5 million. The dimension of the features is 49, including numerical features such as age and traffic statistical indicators, and discrete features such as terminal brand.
In this paper, five labeled datasets are constructed from August to December in 2021. Set the data of current month to be training set, and the data of next month to be testing set. In testing phase, the model outputs the probabilities of positive samples for testing set and select the top 200000 largest samples. The proportion of positive samples in 200000 samples is used as the measure for the performance. Define Num.P and Num.N to be the number of positive samples and negative samples respectively and Ratio to be the proportion of positive samples in the datasets. The statistical details of 5G terminal datasets are shown in Table 4.
Statistical details of 5G terminal datasets
Statistical details of 5G terminal datasets
The baseline methods are xgb1, xgb2, xgb3, xgb4, xgb5. To estimate the performance upper-bound for different months, xgb1 is also trained by testing set and returns the precision of top 200000 largest samples in testing set. The key parameters of all Xgboost models are shown in Table 5, where Num.E represents the number of trees and Wei.ps represents the weight of positive samples.
Parameters of Xgboost on 5G terminal datasets
The proposed method is names as Xgbours and selects Xgboost with the largest value of max-depth. This is because the number of data with pseudo-labels is large, Xgboost with smaller max-depth is prone to be under-fitting. The detailed results are shown in Table 6, where 08-09 refers to the data in August as training set, the data in September as testing set.
The precision(%) of top 200000 people on 5G terminal dataset
The results in Table 6 show that the proposed method Xgbours achieves better performance than Xgboost baseline methods in all datasets. The pseudo-label generation method can improve the performance of Xgboost baseline methods. The performance of pseudo-label selection method depends on the selection of hyper-parameters such as ɛ3. In 5G terminal datasets, each ɛ3 is defined as 90 quantile for the distribution of the scores computed by the criterions. If ɛ3 in 09 - 10 are specially selected as 99 quantile for the distribution of the scores computed by the criterions, the precision of Xgbours will be 9.240, which is higher than that of Xgbpseudo shown in Table 6.
Compared with neural-netowk-based methods, Xgbours has small preponderance in the accuracy. One the other hand, the running time of Xgbours is smaller than that for Tabnet and Saint. For Xgbours, less than 10 minutes are needed for each dataset. For Saint, more than 2 hours per epoch is needed in our platform.
In this paper, a novel domain adaptation strategy is proposed to improve the performance of tree-based model Xgboost on tabular data. The strategy consists of pseudo-label generation and pseudo-label selection for testing data and forms more labeled data to train Xgboost. Hence, Xgboost can learn more effective features on test data. The experimental results show that the strategy can improve the performance of Xgboost not only on UCI data, but also on the scene of 5G terminal purchase prediction where the features of users change dynamic among different months. Since the accuracy of pseudo-labels has large effect on the performance of such methods, how to generate more effective pseudo-labels on tabular data is an important study direction in future.