
Abstract
Healthcare data is the most sensitive information for processing through machine learning and cloud computing in the various healthcare organizations. Electronic Health Record (EHR) manipulation are now on the rise, and we need to focus on using the data generated by the healthcare applications. Many sensitive data are associated with various health care domains, particularly neurology and cardiology. Previous approaches, such as manual data records, had significant disadvantages, and hence disease prediction based on the above records was found ineffective resulting with improper diagnosis on the patients. These data records require special attention, and current frameworks focused on these areas must implement sophisticated technologies to predict specific patterns. To address the above concerns, the proposed work incorporates the integration of Neuro Fuzzy Logistic Regression (NFLR) machine learning algorithm and cloud computing storage management to solve these problems. The usage of cloud storage reduces data duplication while handling the storage of EHRs where the proposed ML algorithm accurately predict the disease. In the proposed research, the features are extracted using a specific algorithm –Self-organizing Clustering (SOC) which forms a clustered data with highest weight. To select the maximum number of features, and to predict the disease risk factors, the S2NO algorithm and NFLR algorithms are used in this work. Further, the database storage estimation with fuzzy rules, logistic analysis, and other benefits such as experimental learning of different ML tools, data privacy constraints related to healthcare are considered in this paper.
Keywords
Introduction
Cloud and machine learning investigate a lot of clinical information stay testing because of the absence of relevant information and the executive’s methods to help receptive information examination and examination. Medical services information is high-layered. A patient record contains many credits, most in freestyle fields. This information should be cleaned and changed to make forecasts. Find motivators for continuously examining the most complicated medical services datasets.
Machine Learning (ML) procedures are right now impacting many fields. Exceptionally directed businesses, for example, medical services and money, have severe consistency and information administration approaches for information sharing. Propels in medical services information the executives and examination have opened up new skylines for medical services suppliers, including practical therapies, the capacity to differentiate medical care extortion, and early diseases recognition.
A large number of clinical datasets is a complex process. Nowadays, it’s fundamental to provide specialists with more data to come to better conclusions about a patient’s determination and treatment choices while grasping every person’s expected result and expense. Machine learning is being utilized in numerous settings in medical services. ML in medical care empowers us to break down various interest data, suggest choices, give ideal gamble scores and exact asset portions, and has numerous applications. The worth of ML in medical services lies in its capacity to handle gigantic informational collections past the compass of people and dependably decipher the examination of this information into clinical experiences that help clinicians plan and convey therapies, at last prompting improved results and lower costs.
Medical data is comparable in scale and nature to the cloud, hence the medical cloud. Compared to other industries, the healthcare industry has lagged in adopting cloud technologies, and stakeholders must quickly explore developments to address changing clinical and clinical landscapes. Many medical use cases are suitable for embedding cloud technology. Healthcare cloud analytics is creating many exciting avenues for various healthcare businesses, including diagnostics and medicine, clinical decision support and population health management. The success of the medical cloud depends on the efficient collection and storage of large amounts of heterogeneous data obtained from various sources and in-depth analysis.
Clinical Medical data introduce many uncertain-ties into clinical decision-making due to several areas, such as inaccurate laboratory measurements and incomplete understanding of features mechanisms, such as uncertainty in the normal range of results with reduced duplication data. Machine learning and cloud-based Neuro-Fuzzy Logistic Regression (NFLR) can be used as classifiers in certain types of diseases or the selection process of patients in determining prediction ratios based on ML algorithms and creating a fuzzy-based decision support system. This study is a descriptive study that explores and describes the use of NFLR in health care.
Contribution of this research
Initially collecting data for preprocessing, remove irrelevant data from the original dataset. Next, the extracted features based on Self-Organizing Clustering is used to extract the most weighted features from the analysed textural data for classification. Then, selecting features based on Social Spider Neural Optimization (S2NO) used for analysis, can detect the maximum number of features. Finally, the classification uses Neuro-Fuzzy Logistic Regression (NFLR) to predict dis-eases’ risk factors and evaluate data storage using machine learning and a cloud data-base. It can estimate the data storage based on fuzzy rules using the logistic analysis with a low computation time.
Related work
The health care process departs a Patient Treatment Pathway (PTT). It is depicted as a succession of reliant clinical occasions connected with a more effective longitudinal treatment and treatment data framework [1]. The dynamic of where critical patients is discharged is an exceptionally emotional and complex interaction that relies on the ICU care team, patient and caregiver preferences, property requirements, staffing, and bed availability. Correct dynamics of release behavior aid in care arrangements and can be used as surrogates for beneficial stage results after primary disease [2]. However, existing ML arrangements depend on rich, physically named EMRs preparing information for predictive results [3].
Intelligent data retrieval and classification models enable disease research and even prediction of unusual health conditions. Convolutional Neural Network (CNN) models are used to predict such anomalies. CNN models can accurately extract prognostic knowledge from unstructured medical records [4].
It has developed a cloud-based Intelligent Remote Patient Monitoring (IRPM) framework. This framework adopts sophisticated risk stratification based on machine learning-based predictions but reduces functions that rely on commonly used physiological indicators in-hospital and out-of-hospital acquired variants [5]. Disease forecasting can benefit stakeholders like governments and health insurance companies. Identify patients with disease or health conditions at risk [6].
However, it is very complicated for doctors to make accurate predictions based on the symptoms. Accurate prediction of the disease is a tough challenge [7]. Every healthcare application needs to process data in different forms. Data type, data size, and security are essential for data mining. Big data refers to specific characteristics, such as volume, velocity, value, accuracy, and variability [8]. Hospitals and other medical facilities offer expensive heart treatment and surgery. Therefore, early detection of heart disease can help people worldwide to take necessary measures before it becomes severe [9].
The study analyzed the accurate performance of each person’s health. The study implementing ma-chine learning techniques in medical information to solve the personalization problem of medical information [10]. Recognize high-risk people by catching complex examples in truthful information and incorporating information missing model digging and understandable models for the clinically material expectation. The intravenous immunoglobulin opposition created multi-step strategies to address the in-adequacy of clinical data and the absence of interpretability of ML models [11]. Heart disease prognosis is one of the most complex tasks in medicine. Therefore, there is a need to develop a decision sup-port system for diagnosing cardiovascular disease in patients [12].
Indeed, even after disappointing customary treatment, non-adherence to dialysis treatment is related to expanded dreariness and mortality [13]. AI is a part of artificial intelligence (AI), generally utilized in information science. There is incredible potential in wellbeing-related information examination for computerized illness expectations. AI strategies, DBSCAN, K-Means, and Affinity Propagation, contrast their expectation exactness and computational complexity [14].
Cloud Digital transformation in medical services is of expanding significance to the two scholastics and experts in the field. An examination question surveys how different partners can execute computerized innovations for board and business purposes [15]. Advances in Machine Learning (ML), quicker processors, and the accessibility of wellbeing informatics information have added too many papers characterizing ML projects in wellbeing. ML calculations are making outstanding commitments to disease prediction [16].
For such diagnostic purposes, identify more accurate machine learning classifiers. Several machine learning algorithms were used to compare their performance and accuracy in predicting heart disease [17]. Data mining is the current trend in obtaining diagnostic results. The medical care industry gathers much-unexploited information to uncover stowed away data for viable determination and independent direction [18].
The following is a reconstruction algorithm for predicting Disease Probability Threshold. It is widely used to obtain a website’s hyperlink weights [19]. A privacy-preserving clinical decision support system (hereafter referred to as Peneus) using a Naïve Bayes (NB) classifier is calculated for subcontracted cloud computing environments. It allows for personalized training of NB classifiers using patient health information. This allows the prediction of a patient’s (undiagnosed) disease based on symptoms through a single round of communication [20].
All users have different information stored on separate servers like medical information, bank account information and user registration information. Our data is encrypted and stored on our servers. The critical question is how much data is securely stored on the various servers. Such questions are in the minds of users and co-operatives [21].
Examined databases of computed tomography colonography (CTC) screening trials at several hospitals. Shortly, cloud computing technology will make these network databases available—developed Associative Multiple Databases (AMD) to handle various CTC databases [22]. The extreme difficulties presented by a quickly maturing populace and the predominance of cardiovascular illness high-light the requirement for functional arrangements that help more precise and reasonable clinical findings and treatment. Ongoing advances in distributed computing have affected the plan of many clouds based clinical benefits [23].
However, building and managing solutions with multiple applications operated by various users in different environments (edge, fog, cloud) represent a complex challenge facing healthcare organizations when dealing with large healthcare repositories while meeting Non-Functional Requirements (NFR) [24].
An essential test with this blend is the distinction in nature of administration controls among cluster and streaming figuring. Stream handling is dormancy delicate, while cluster handling can be an asset serious [25]. Since the quantity of new malignant growths is so high, this question merits further re-view. In any case, there is no systematic audit of cloud applications or execution in disease care services. [26].
In this case, medical data can be easily compromised, so only authorized doctors can access the data. Before outsourcing, the information is usually encrypted, and the associated key is sent to the authorized physician [27]. Predictive performance depends on the efficient representation of multidimensional time series EHR data. Existing solutions typically focus on temporal features or intrinsic relationships between clinical event variables or extract information from both in two separate phases.
In ref [28], the study produced a less predictive performance to analysis the health. Likewise, the particular region under the bend (AUC) is stressed as a proportion of sickness and an important forecast in clinical examination. Nonetheless, AUC’s job has not been depicted unequivocally [29]. Choice emotional-ly supportive networks (DSS) have been created, given their capability to develop medical services further. Nonetheless, the absence of a typical clinical technique brings about unfortunate administration of clinical assets and execution of protective medicine [30].
Materials and method
ML and cloud-based healthcare providers must have the proper infrastructure to build and analyze clouds using neuro-fuzzy logistic regression (NFLR) and predict data using machine learning. Effective management, analysis and interpretation of the cloud could be a game changer by opening up new avenues in modern medicine. The powerful integration of biomedical and healthcare data enables modern organizations to revolutionize clinical care and personalize healthcare data.
Figure 1 is described cloud, and Machine Learning based Neuro-Fuzzy Logistic Regression (NFLR) for analyzing datasets based on logical rules. Selecting the features based on the nearest threshold values based on Social Spider Neural Optimization (S2NO) and classification using NFLR reduces the computation time with data storage and predicting the data. And Initially, Using Preprocessing reduces the un-wanted data and extracts the features from the dataset using Self Organizing Clustering with maximum weights of features.
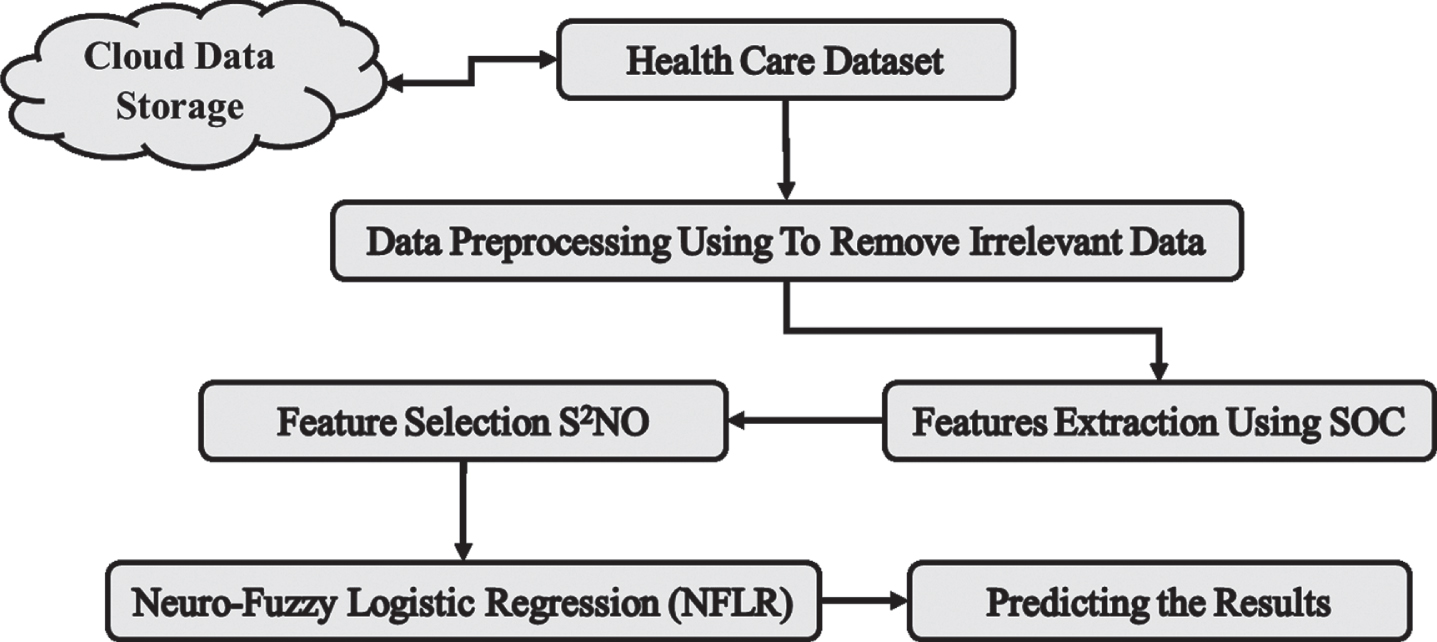
Block diagram for proposed method.
The Electronic Medical Records database contains all patient registration data. Data for each case included clinical data obtained from the patient’s medical records and signals from bedside monitors and routine measurements. Standard UCI repository data set of EHR analysis in 90 attributes of 6000 records used for training and testing dataset.
This includes the physical and emotional health of the patient, the time at which data is collected, the level of communication skills used by the health care provider, access to previous records, and the potential for future diagnosis. All data should be complete and error-free. Record access refers to the speed with which health record data is retrieved. It refers to the usefulness of records, including how current they are and how relevant they are to particular needs. Indi-cates the completeness of recorded data, ensuring there are no missing values.
Cloud and ML for health care data
The first benefit of an EHR is that it gives healthcare professionals better access to a patient’s complete medical history. Machine learning and the cloud represent vast amounts of data that cannot be managed by traditional software or web-based plat-forms. It goes beyond the storage, processing and analytics capabilities traditionally used. Machine learning algorithms can rapidly process large data sets to provide valuable insights that improve healthcare delivery. The industry has lagged in using this technology but is now catching up quickly to deliver preventative and prescriptive healthcaresolutions.
Increasingly, concerns in the healthcare industry will analyze massive data sets and identify patterns that can provide valuable insights from existing patient data to make accurate diagnoses and provide better patient care.
Cloud computing for data storage and data duplication
Data reduction storage, backup, recovery and archiving are designed to reduce your storage footprint by compressing locally replicated data. Data reduction is an effective way to reduce data volume, re-duce storage requirements, and reduce the cost and risk of data protection.
The reduction helps save space and costs for data requiring large amounts of storage. Figure 2 illustrates the optimized cloud storage which is used to identify the duplicate files.
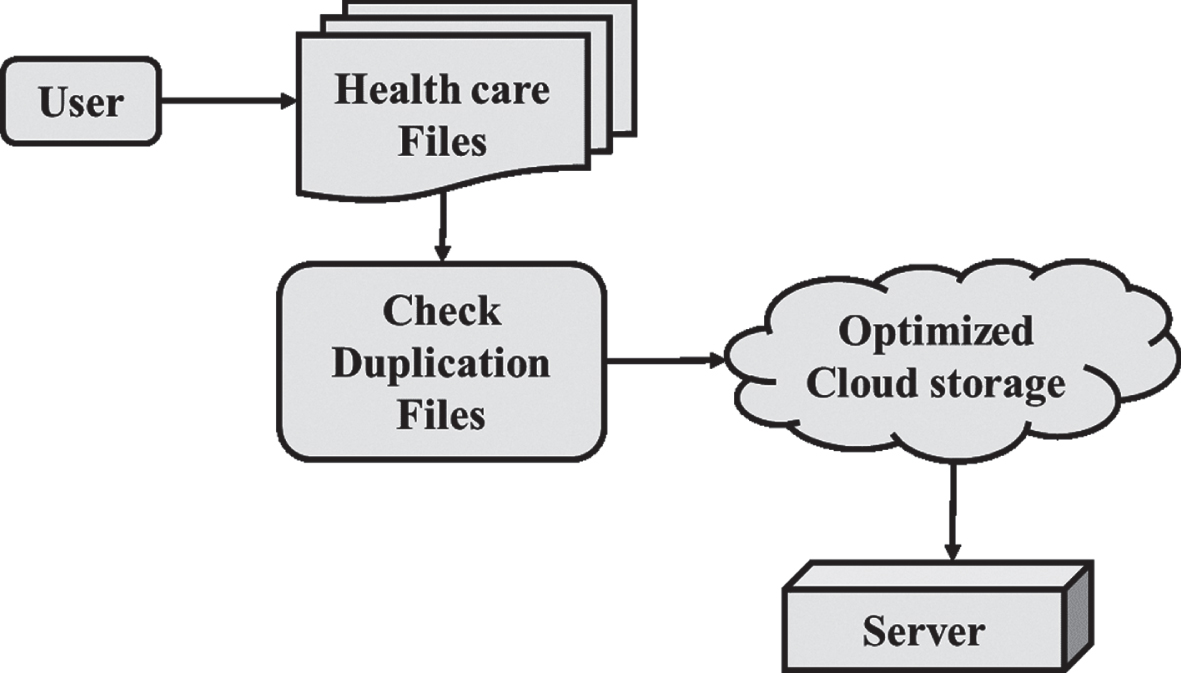
Cloud data flow duplication.
To ensure data quality, machine learning provides one of the critical steps known as data preprocessing. Data preprocessing is an essential step in ML, and its main objective is to provide processed data to im-prove prediction accuracy. This incomplete data requires a data preparation phase to clean and pre-pare the data for further analysis. This step usually takes a lot of time and should be done carefully to improve the overall model performance. Data pre-processing tasks include specific processes such as data preparation, aggregation, cleaning, normalization, scaling, and data reduction techniques that re-duce complexity and noise using features such as feature selection.
Data cleaning
Data from real-world problems is rarely clean and complete. This is particularly true in medicine. The data cleaning/refinement step deals with missing values, errors, and changes in the dataset.
Discarding the missing values
The most common method is rejection, but this method is impractical. The results will be biased if many values are missing in the training data. If a few values are missing in the dataset, the rest of the analysis should not introduce inference bias.
Extracting features based on self-organizing clustering (SOC)
In this stage identifying weight factors of features for analysis the best features of disease risk level. The proposed Self-Organizing Clustering (SOC) is a neural network designed to visualize data by reducing dimensionality by mapping high-dimensional data onto low-dimensional data using self-organizing neural networks. Self-Organizing Clustering (SOC) algorithms treat a vector of weights for each cluster unit, serving as a model for the associated input pat-tern. SOC assumes a cluster topology and uses unsupervised input targets or unsupervised training data.
Weight updating
All neighbor weights of the SOC node (all neighbors in this Implementation) are according to the weight update rule.
S(N) is a learning rate decrease with the computation time, the Implementation of each value-based.
Wfa(N) is a weight-based feature for the number of iterations.
w(N) is an overall iteration based on weights of features.
A and B include string-based and feature vector-based pattern representations as input variables, data structures, and particular instances. After introducing SOC, we describe some experiments demonstrating its feasibility in weight-basedclustering.
Feature selection based Social Spider Neural Optimization (S2NO)
After weight analysis, in this stage select the best features using S2NO technique. The S2NO is based on spider behavior to identify disease risk factor. The proposed Social Spider Neural Optimization (S2NO) treats the pursuit space as an aggregate cobweb, with every competitor arrangement in the multitude ad-dressing a spider. Every insect gets weight in light of the wellness worth of the solution. S2NO technology solves the problem of data clustering. The performance parameters range probabilities and random variables that affect the clustering and outcome of the distance measurement function.
More critical than a randomly generated value, female spiders can change the status of attracting the best spiders in the world, and the best spiders are the highest values.
gooda is for fitness of the ath spider position, aɛ... . N and the best and worst are respectively.
Wc –max.weights.
Wx,y –weights variables.
The exchange of information or data evaluating the best and worst for whole values.
Δ, ρ, and rand are random numbers between [0, 1] and Ax,y is the iteration number
fsxw is feature selection based on maximum weights
Fn –number of features random weights.
fs –selected features, the individual represents the nearest spider, and its weight is Higher than Fn, the best spider on the public web.
Classification using Neuro-Fuzzy Logistic Regression (NFLR)
An element order model to examine clinical in-formation for infection by Neuro-Fuzzy Logistic Regression (NFLR). First place, the model proposes a fuzzy technique to create enrollment esteems that handle the vulnerability. For fuzzy development, the quantity of elements is contrasted with the first in-formation included and extended to compare sensible registration worth to determine the vulnerability issues.
Dx –selected features.
Fx1, Fx2, Fx3 ... Fxn –fuzzy values.
Finally, based on the three linguistic fuzzy variables, low, medium, and high, all features of the input pattern are transformed into corresponding fuzzy membership values.
Steps for Neuro-Fuzzy Logistic Regression (NFLR)
Input: Health care dataset
Output: Classification Testing data values
Begin
For x←1 to N
For each training data (T)
Set the fixed values for logistic regression to
xq← [yx –D(1|py)] / [([D(1|py). yx –D(1|py)]
Initialize the weights of instance py to [D(1|py). yx -D(1|py)]
Finalize x.f(y) to the data with class weights values (Wx)
NFLR←Classification decision based on fuzzy rules
Assigning the data from the weights.
Find the most significant values and then return the optimal solution
Classify the maximum values
Stop
Were,
xq Fixed features
x.f(y)is feature variables
py is instance values
D is Assigning data values,
Logistic regression models estimate p for linear combinations of independent variables to determine the actual class labels.
Figure 3 describes that Inputs x and y are outputs, A1, B1, A2, B2 is input values. The NFLR model has layers, each with specific tasks using data. The logistic data takes x and y and computes the result for each.

Neuro-fuzzy model.
The Experimental results proposed using Python are made based on the simulation parameters. The proposed method Neuro-Fuzzy Logistic Regression (NFLR) performance will be analyzed and compared with Convolution Neural Network (CNN), Graph Neural Network (GNN), K-Nearest Neighbor (KNN) and Random Forest Regression (RFR) through this simulation, such as the precision, recall, data storage, sensitivity, specificity, accuracy, Time complexity compared in terms of metrics.
Table 1 describes the proposed simulation parameters based on the health care dataset. They are using python language to prove the predicting results. The collected dataset records are 6000; Training data is 4000, and testing data is 1000.
Simulation proposed parameters
Simulation proposed parameters
Confusion Matrix (CM): It is used to find the Accuracy, precision, recall performance based on true positive, true negative, false negative and false positive values.
TP (True Positive): A practice example where the real class is positive and assumes positive. They are truly positive.
FP (False Positive): The samples are negative, and the learning algorithm classifies them as positive.
TN (True Negative): If the actual class of training samples is negative, then we consider it negative. They may be termed as true negatives.
FN (False Negative): These models are specific, yet the learning calculation characterizes them as negative.
Table 2 and Fig. 4. Defines the analysis of accuracy performance produced by various approaches.
Analysis of accuracy
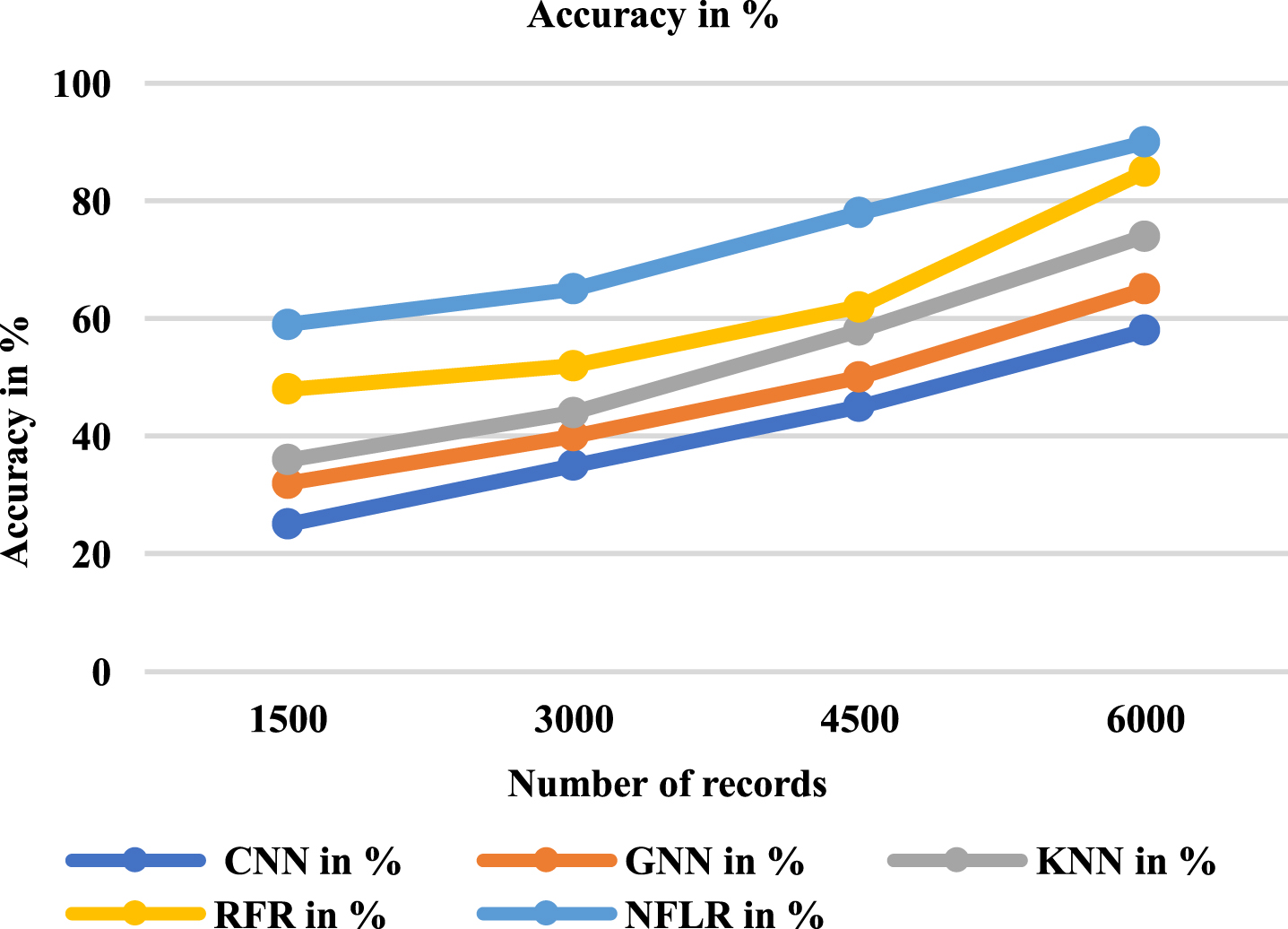
Analysis of the accuracy range.
The proposed method Neuro-Fuzzy Logistic Regression (NFLR) is 90% accuracy compared with Convolution Neural Network (CNN) is 58%, Graph Neural Network (GNN) is 65%, K-Nearest Neighbor (KNN) is 74%, and Random Forest Regression (RFR) is 85%.
Figure 5 and Table 3 illustrates the precision performance compared with other methods in percent-age. The proposed method Neuro-Fuzzy Logistic Regression (NFLR) is 87% precision value compared with Convolution Neural Network (CNN) is 60%, Graph Neural Network (GNN) is 69%, K-Nearest Neighbor (KNN) is 75%, and Random Forest Regression (RFR) is 84%.
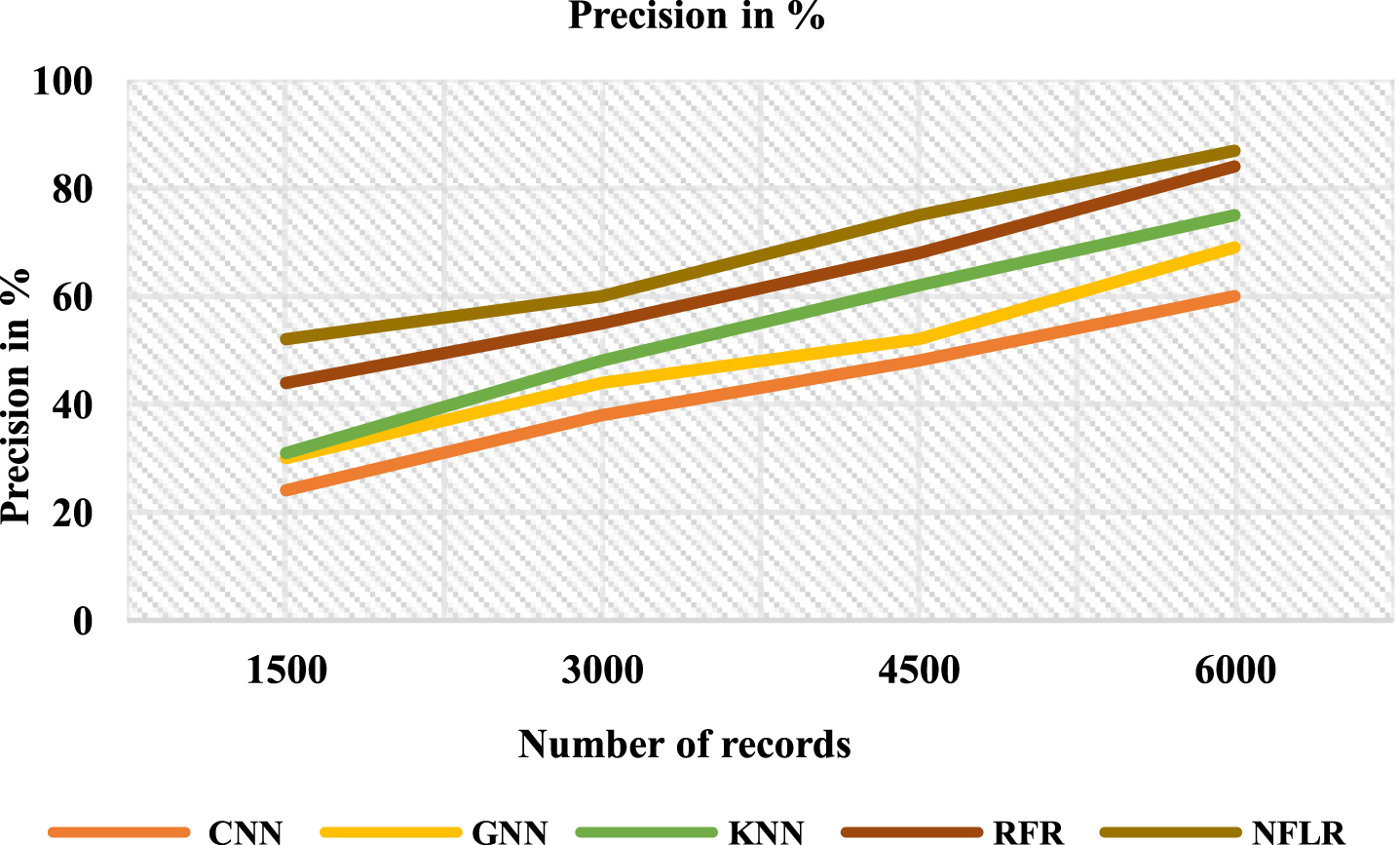
Analysis of the precision ratio.
Analysis of precision
Table 4 and Fig. 6 describe recall as a measure of the percentage of patients with a true error rate in which the algorithm makes a false diagnosis. The proposed method Neuro-Fuzzy Logistic Regression (NFLR) is 85% recall values compared with Convolution Neural Network (CNN) is 59%, Graph Neural Network (GNN) is 68%, K-Nearest Neighbor (KNN) is 71%, and Random Forest Regression (RFR) is 82%.
Analysis of recall
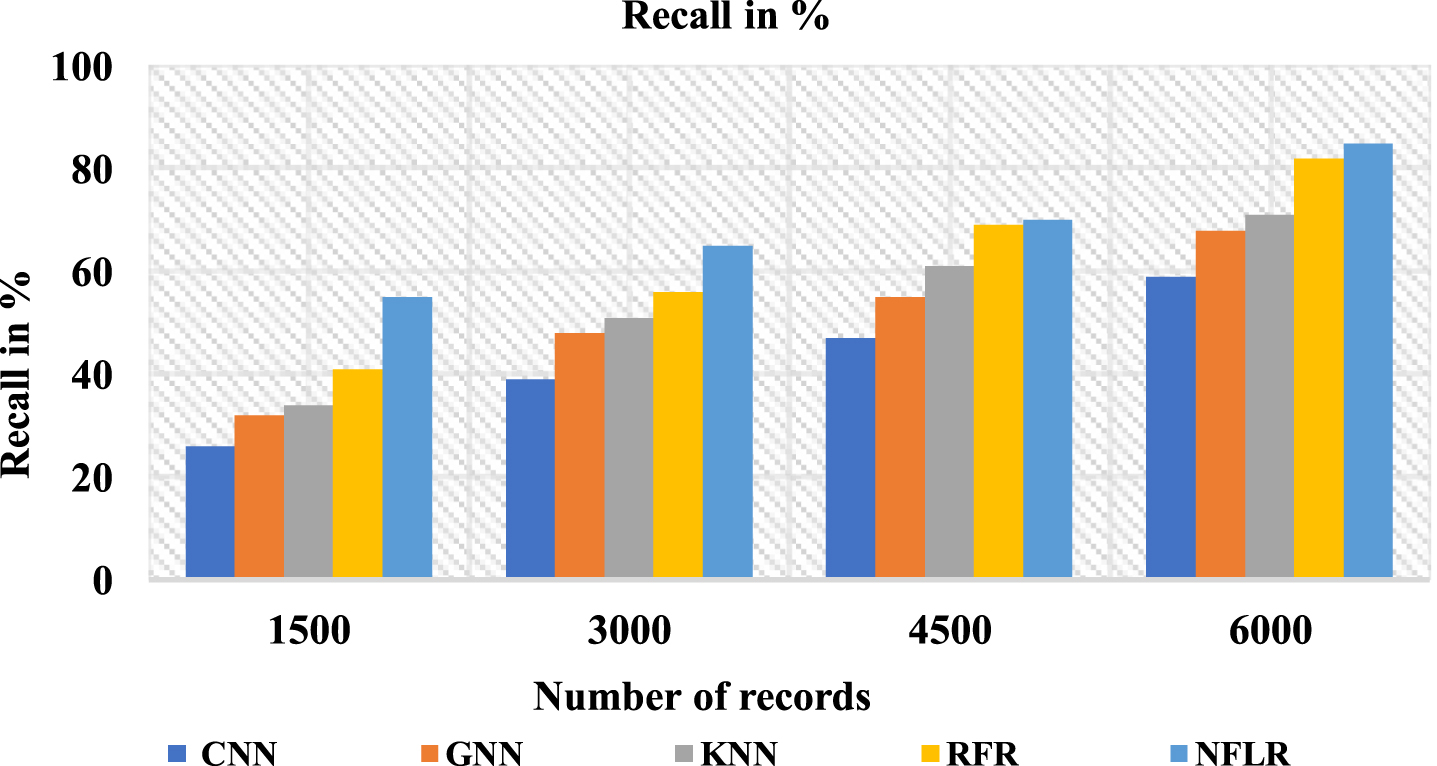
Analysis of the recall ratio.
Table 5 and Fig. 7 describe sensitivity as a measure of the number of false patients detected by the algorithm as an error rate. The proposed method Neuro-Fuzzy Logistic Regression (NFLR) is 89% recall values compared with Convolution Neural Network (CNN) is 60%, Graph Neural Network (GNN) is 65%, K-Nearest Neighbor (KNN) is 70%, and Random Forest Regression (RFR) is 84%.
Analysis of the sensitivity performance

Analysis of the sensitivity ratio.
Table 6 and Fig. 8 describe it as an essential indicator of the proportion of patients for which the model predicts incorrect data. The proposed method Neuro-Fuzzy Logistic Regression (NFLR) is 88% recall values compared with Convolution Neural Network (CNN) is 58%, Graph Neural Network (GNN) is 67%, K-Nearest Neighbor (KNN) is 72%, and Random Forest Regression (RFR) is 80%.
Analysis of the specificity
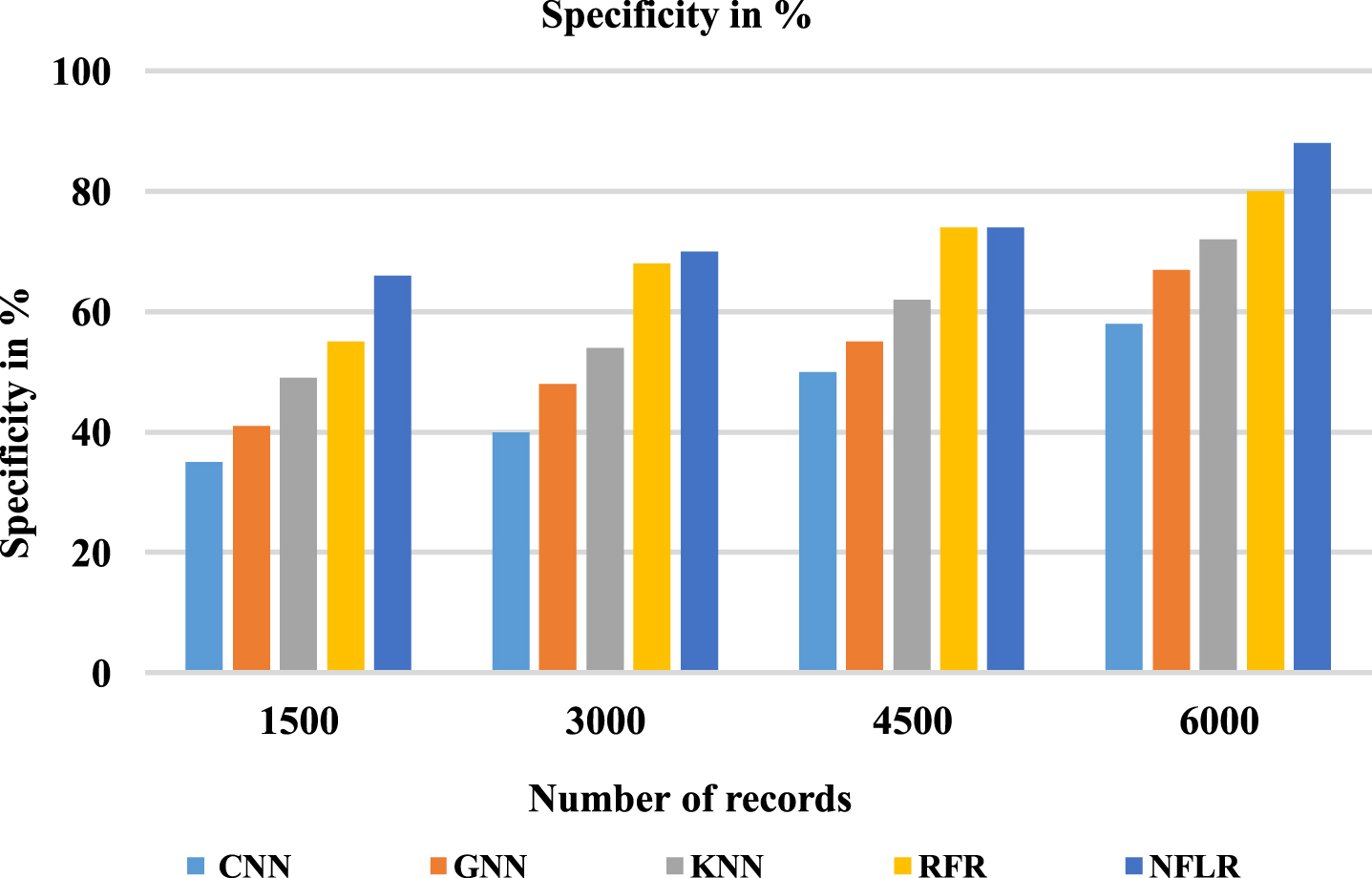
Analysis of the specificity ratio.
Figure 9 and Table 7 defines the analysis of the medical data storage that indicates patient data stored in the cloud. The Proposed method takes less storage performance than the previous method. The proposed method Neuro-Fuzzy Logistic Regression (NFLR) is 55% Storage values compared with Convolution Neural Network (CNN) is 74%, Graph Neural Net-work (GNN) is 70%, K-Nearest Neighbor (KNN) is 65%, and Random Forest Regression (RFR) is 60%.
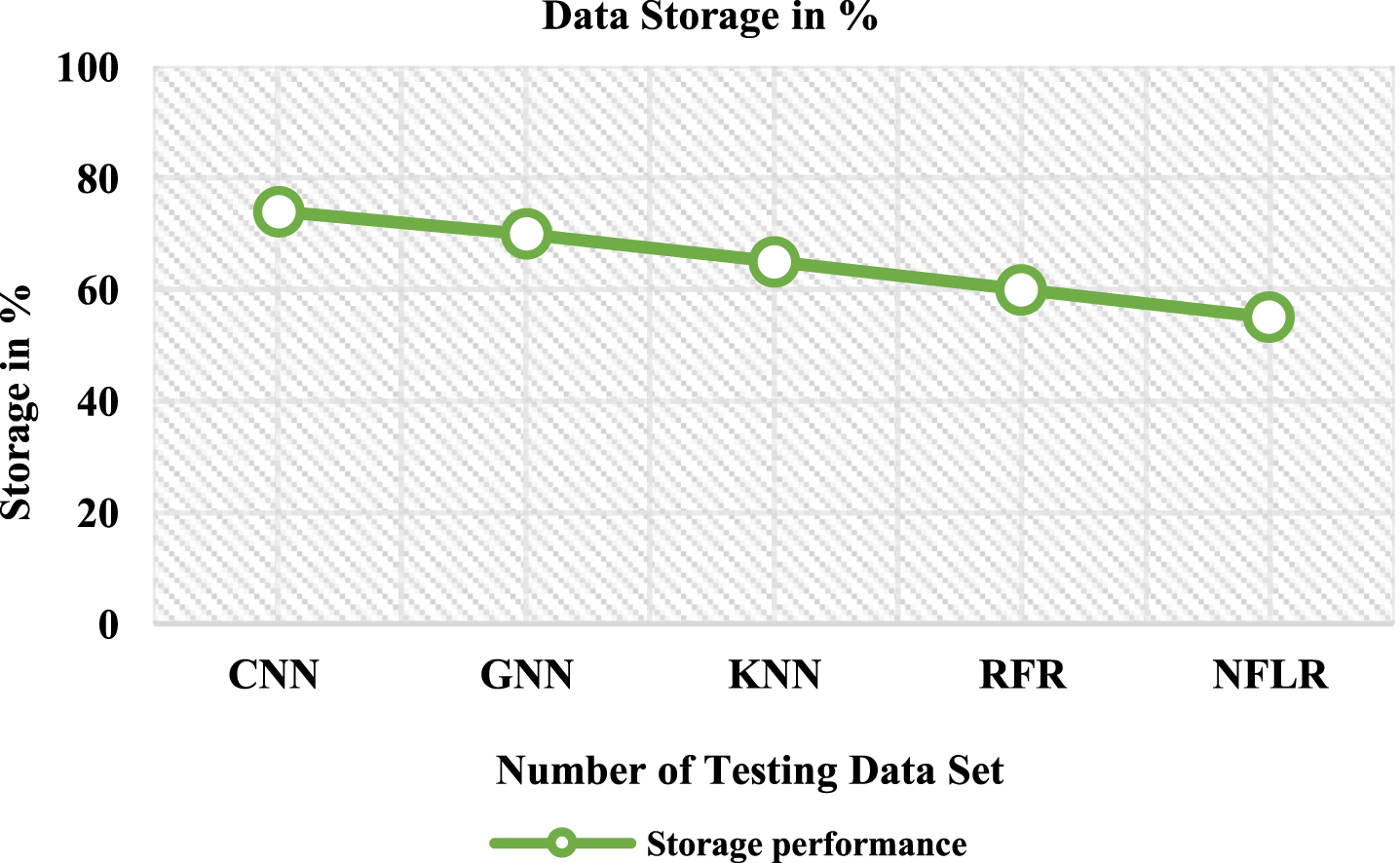
Analysis of the data storage.
Table 8 and Fig. 10 depicts the time complexity to predict health risk factor based on the cloud. The proposed method Neuro-Fuzzy Logistic Regression (NFLR) is 25 sec time complexity values compared with Convolution Neural Network (CNN) is 54 sec, Graph Neural Network (GNN) is 50 sec, K-Nearest Neighbor (KNN) is 47 sec and Random Forest Regression (RFR) is 35 sec.
Analysis of the data storage
Analysis of the time complexity
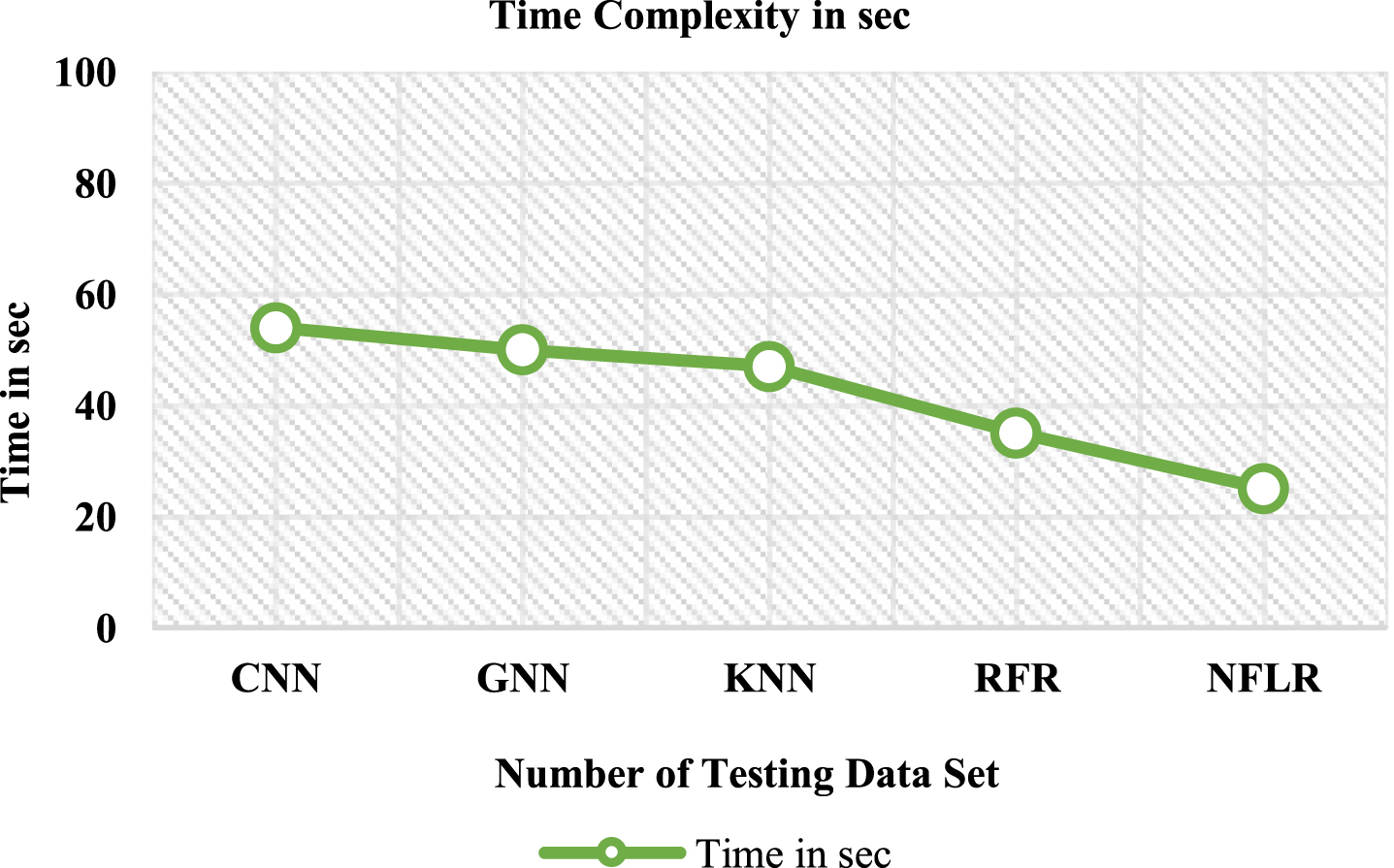
Analysis of the time complexity.
Cloud applications in healthcare are revolutionizing the industry by providing better monitoring of patient health data. In addition, information technology can reduce the costs associated with clinical diagnosis. Here we will first briefly introduce the concept of the cloud and its main applications. Additionally, significant research has been done using the cloud in the healthcare sector and learning to design and propose Neuro-Fuzzy Logistic Regression (NFLR) for healthcare models. Neuro-Fuzzy Logistic Regression (NFLR) handles a wide variety of data sources. It can implement new nature-inspired ML techniques to work on the precision of this logical structure. Finally, the work can be extended to examine the effect of Neuro-Fuzzy Logistic Regression (NFLR) data on the overall performance of this system. In the proposed method, NFLR is analysis the precision is 87%, recall is 85%, sensitivity is 89%, specificity is 88%, accuracy is 90%, data storage is 55%, and time complexity is 25 sec better than previous results.